D Programação - Guia Rápido
A linguagem de programação D é uma linguagem de programação de sistema multiparadigma orientada a objetos desenvolvida por Walter Bright da Digital Mars. Seu desenvolvimento começou em 1999 e foi lançado pela primeira vez em 2001. A versão principal de D (1.0) foi lançada em 2007. Atualmente, temos a versão D2 de D.
D é uma linguagem com sintaxe no estilo C e usa tipagem estática. Existem muitos recursos de C e C ++ em D, mas também existem alguns recursos dessas linguagens que não estão incluídos em D. Algumas das adições notáveis a D incluem,
- Teste de unidade
- Módulos verdadeiros
- Coleta de lixo
- Matrizes de primeira classe
- Livre e aberto
- Matrizes associativas
- Matrizes dinâmicas
- Classes internas
- Closures
- Funções anônimas
- Avaliação preguiçosa
- Closures
Paradigmas múltiplos
D é uma linguagem de programação de paradigma múltiplo. Os múltiplos paradigmas incluem,
- Imperative
- Orientado a Objeto
- Metaprogramação
- Functional
- Concurrent
Exemplo
import std.stdio;
void main(string[] args) {
writeln("Hello World!");
}Aprendizagem D
A coisa mais importante a fazer ao aprender D é focar nos conceitos e não se perder nos detalhes técnicos da linguagem.
O objetivo de aprender uma linguagem de programação é se tornar um programador melhor; isto é, para se tornar mais eficaz no projeto e implementação de novos sistemas e na manutenção dos antigos.
Escopo de D
A programação D tem alguns recursos interessantes e o site oficial de programação D afirma que D é conveniente, poderoso e eficiente. A programação em D adiciona muitos recursos na linguagem central que a linguagem C forneceu na forma de bibliotecas padrão, como array redimensionável e função de string. D é uma excelente segunda linguagem para programadores intermediários a avançados. D é melhor para lidar com a memória e gerenciar os ponteiros que geralmente causam problemas em C ++.
A programação D destina-se principalmente a novos programas que convertem os programas existentes. Ele fornece teste e verificação integrados, um ideal para novos projetos grandes que serão escritos com milhões de linhas de código por grandes equipes.
Configuração de ambiente local para D
Se você ainda deseja configurar seu ambiente para a linguagem de programação D, você precisa dos dois softwares a seguir disponíveis em seu computador: (a) Editor de Texto, (b) Compilador D.
Editor de Texto para Programação D
Isso será usado para digitar seu programa. Exemplos de poucos editores incluem o bloco de notas do Windows, o comando Editar do sistema operacional, Brief, Epsilon, EMACS e vim ou vi.
O nome e a versão do editor de texto podem variar em diferentes sistemas operacionais. Por exemplo, o Bloco de notas será usado no Windows e o vim ou vi pode ser usado no Windows, bem como no Linux ou UNIX.
Os arquivos que você cria com seu editor são chamados de arquivos-fonte e contêm o código-fonte do programa. Os arquivos de origem dos programas em D são nomeados com a extensão ".d"
Antes de iniciar sua programação, certifique-se de ter um editor de texto instalado e de ter experiência suficiente para escrever um programa de computador, salvá-lo em um arquivo, compilá-lo e finalmente executá-lo.
O Compilador D
A maioria das implementações de D atuais compilam diretamente no código de máquina para uma execução eficiente.
Temos vários compiladores D disponíveis e inclui o seguinte.
DMD - O compilador Digital Mars D é o compilador D oficial de Walter Bright.
GDC - Um front-end para o back-end GCC, construído usando o código-fonte do compilador DMD aberto.
LDC - Um compilador baseado no front-end DMD que usa LLVM como back-end do compilador.
Os diferentes compiladores acima podem ser baixados do D downloads
Estaremos usando a versão D 2 e recomendamos não baixar D1.
Vamos ter um programa helloWorld.d como segue. Vamos usar isso como o primeiro programa que rodamos na plataforma de sua escolha.
import std.stdio;
void main(string[] args) {
writeln("Hello World!");
}Podemos ver a seguinte saída.
$ hello worldInstalação de D no Windows
Baixe o instalador do Windows .
Execute o executável baixado para instalar o D, o que pode ser feito seguindo as instruções na tela.
Agora podemos construir e executar um arquivo de anúncio, diga helloWorld.d, alternando para a pasta que contém o arquivo usando cd e, em seguida, seguindo as seguintes etapas -
C:\DProgramming> DMD helloWorld.d
C:\DProgramming> helloWorldPodemos ver a seguinte saída.
hello worldC: \ DProgramming é a pasta que estou usando para salvar minhas amostras. Você pode alterá-lo para a pasta onde salvou os programas D.
Instalação de D no Ubuntu / Debian
Baixe o instalador debian .
Execute o executável baixado para instalar o D, o que pode ser feito seguindo as instruções na tela.
Agora podemos construir e executar um arquivo de anúncio, diga helloWorld.d, alternando para a pasta que contém o arquivo usando cd e, em seguida, seguindo as seguintes etapas -
$ dmd helloWorld.d
$ ./helloWorldPodemos ver a seguinte saída.
$ hello worldInstalação de D no Mac OS X
Baixe o instalador do Mac .
Execute o executável baixado para instalar o D, o que pode ser feito seguindo as instruções na tela.
Agora podemos construir e executar um arquivo de anúncio, diga helloWorld.d, alternando para a pasta que contém o arquivo usando cd e, em seguida, seguindo as seguintes etapas -
$ dmd helloWorld.d $ ./helloWorldPodemos ver a seguinte saída.
$ hello worldInstalação de D no Fedora
Baixe o instalador do fedora .
Execute o executável baixado para instalar o D, o que pode ser feito seguindo as instruções na tela.
Agora podemos construir e executar um arquivo de anúncio, diga helloWorld.d, alternando para a pasta que contém o arquivo usando cd e, em seguida, seguindo as seguintes etapas -
$ dmd helloWorld.d
$ ./helloWorldPodemos ver a seguinte saída.
$ hello worldInstalação de D no OpenSUSE
Baixe o instalador do OpenSUSE .
Execute o executável baixado para instalar o D, o que pode ser feito seguindo as instruções na tela.
Agora podemos construir e executar um arquivo de anúncio, diga helloWorld.d, alternando para a pasta que contém o arquivo usando cd e, em seguida, seguindo as seguintes etapas -
$ dmd helloWorld.d $ ./helloWorldPodemos ver a seguinte saída.
$ hello worldD IDE
Na maioria dos casos, temos suporte IDE para D na forma de plug-ins. Isso inclui,
O plug - in Visual D é um plug-in para o Visual Studio 2005-13
DDT é um plugin do eclipse que fornece autocompletar código e depuração com GDB.
Completação de código Mono-D , refatoração com suporte a dmd / ldc / gdc. Ele fez parte do GSoC 2012.
Code Blocks é um IDE multiplataforma que suporta a criação, destaque e depuração de projetos em D.
D é bastante simples de aprender e vamos começar a criar nosso primeiro programa em D!
Primeiro Programa D
Vamos escrever um programa em D simples. Todos os arquivos D terão extensão .d. Portanto, coloque o seguinte código-fonte em um arquivo test.d.
import std.stdio;
/* My first program in D */
void main(string[] args) {
writeln("test!");
}Supondo que o ambiente D esteja configurado corretamente, vamos executar a programação usando -
$ dmd test.d
$ ./testPodemos ver a seguinte saída.
testVamos agora ver a estrutura básica do programa em D, de modo que seja fácil para você entender os blocos de construção básicos da linguagem de programação D.
Importar em D
Bibliotecas que são coleções de partes de programa reutilizáveis podem ser disponibilizadas para nosso projeto com a ajuda do import. Aqui, importamos a biblioteca IO padrão que fornece as operações básicas de E / S. writeln que é usado no programa acima é uma função na biblioteca padrão de D. Ele é usado para imprimir uma linha de texto. O conteúdo da biblioteca em D é agrupado em módulos, com base nos tipos de tarefas que pretendem realizar. O único módulo que este programa usa é std.stdio, que lida com a entrada e saída de dados.
Função principal
A função principal é o início do programa e determina a ordem de execução e como outras seções do programa devem ser executadas.
Tokens em D
O programa AD consiste em vários tokens e um token pode ser uma palavra-chave, um identificador, uma constante, um literal de string ou um símbolo. Por exemplo, a seguinte instrução D consiste em quatro tokens -
writeln("test!");Os tokens individuais são -
writeln (
"test!"
)
;Comentários
Os comentários são como texto de suporte em seu programa em D e são ignorados pelo compilador. O comentário de várias linhas começa com / * e termina com os caracteres * / conforme mostrado abaixo -
/* My first program in D */Um único comentário é escrito usando // no início do comentário.
// my first program in DIdentificadores
Identificador AD é um nome usado para identificar uma variável, função ou qualquer outro item definido pelo usuário. Um identificador começa com uma letra de A a Z ou a a z ou um sublinhado _ seguido por zero ou mais letras, sublinhados e dígitos (0 a 9).
D não permite caracteres de pontuação como @, $ e% nos identificadores. D é umcase sensitivelinguagem de programação. Portanto, Manpower e manpower são dois identificadores diferentes em D. Aqui estão alguns exemplos de identificadores aceitáveis -
mohd zara abc move_name a_123
myname50 _temp j a23b9 retValPalavras-chave
A lista a seguir mostra algumas das palavras reservadas em D. Essas palavras reservadas não podem ser usadas como constantes ou variáveis ou quaisquer outros nomes de identificador.
| abstrato | apelido | alinhar | asm |
| afirmar | auto | corpo | bool |
| byte | caso | fundida | pegar |
| Caracteres | classe | const | continuar |
| dchar | depurar | padrão | delegar |
| descontinuada | Faz | em dobro | outro |
| enum | exportar | externo | falso |
| final | finalmente | flutuador | para |
| para cada | função | vamos para | E se |
| importar | dentro | entrada | int |
| interface | invariante | é | grandes |
| macro | mixin | módulo | Novo |
| nulo | Fora | sobrepor | pacote |
| pragma | privado | protegido | público |
| real | ref | Retorna | escopo |
| baixo | estático | estrutura | super |
| interruptor | sincronizado | modelo | esta |
| lançar | verdadeiro | experimentar | typeid |
| tipo de | ubyte | uint | Ulong |
| União | teste de unidade | ushort | versão |
| vazio | wchar | enquanto | com |
Espaço em branco em D
Uma linha contendo apenas espaços em branco, possivelmente com um comentário, é conhecida como linha em branco, e um compilador de D a ignora totalmente.
Espaço em branco é o termo usado em D para descrever espaços em branco, tabulações, caracteres de nova linha e comentários. O espaço em branco separa uma parte de uma instrução de outra e permite ao intérprete identificar onde um elemento em uma instrução, como int, termina e o próximo elemento começa. Portanto, na seguinte declaração -
local ageDeve haver pelo menos um caractere de espaço em branco (geralmente um espaço) entre local e idade para que o intérprete seja capaz de distingui-los. Por outro lado, na seguinte declaração
int fruit = apples + oranges //get the total fruitsNenhum caractere de espaço em branco é necessário entre frutas e =, ou entre = e maçãs, embora você seja livre para incluir alguns se desejar para fins de legibilidade.
Uma variável nada mais é que um nome dado a uma área de armazenamento que nossos programas podem manipular. Cada variável em D tem um tipo específico, que determina o tamanho e o layout da memória da variável; a faixa de valores que podem ser armazenados nessa memória; e o conjunto de operações que podem ser aplicadas à variável.
O nome de uma variável pode ser composto de letras, dígitos e o caractere de sublinhado. Deve começar com uma letra ou um sublinhado. Letras maiúsculas e minúsculas são distintas porque D faz distinção entre maiúsculas e minúsculas. Com base nos tipos básicos explicados no capítulo anterior, haverá os seguintes tipos básicos de variáveis -
| Sr. Não. | Tipo e descrição |
|---|---|
| 1 | char Normalmente, um único octeto (um byte). Este é um tipo inteiro. |
| 2 | int O tamanho mais natural do inteiro para a máquina. |
| 3 | float Um valor de ponto flutuante de precisão única. |
| 4 | double Um valor de ponto flutuante de precisão dupla. |
| 5 | void Representa a ausência de tipo. |
A linguagem de programação D também permite definir vários outros tipos de variáveis, como Enumeration, Pointer, Array, Structure, Union, etc., que abordaremos nos capítulos subsequentes. Para este capítulo, vamos estudar apenas os tipos básicos de variáveis.
Definição de Variável em D
Uma definição de variável informa ao compilador onde e quanto espaço deve ser criado para a variável. Uma definição de variável especifica um tipo de dados e contém uma lista de uma ou mais variáveis desse tipo da seguinte forma -
type variable_list;Aqui, type deve ser um tipo de dados D válido, incluindo char, wchar, int, float, double, bool ou qualquer objeto definido pelo usuário, etc., e variable_listpode consistir em um ou mais nomes de identificadores separados por vírgulas. Algumas declarações válidas são mostradas aqui -
int i, j, k;
char c, ch;
float f, salary;
double d;A linha int i, j, k;ambos declaram e definem as variáveis i, j e k; que instrui o compilador a criar variáveis chamadas i, j e k do tipo int.
As variáveis podem ser inicializadas (atribuídas a um valor inicial) em sua declaração. O inicializador consiste em um sinal de igual seguido por uma expressão constante da seguinte maneira -
type variable_name = value;Exemplos
extern int d = 3, f = 5; // declaration of d and f.
int d = 3, f = 5; // definition and initializing d and f.
byte z = 22; // definition and initializes z.
char x = 'x'; // the variable x has the value 'x'.Quando uma variável é declarada em D, ela é sempre definida como seu 'inicializador padrão', que pode ser acessado manualmente como T.init Onde T é o tipo (por exemplo, int.init) O inicializador padrão para tipos inteiros é 0, para booleanos falso e para números de ponto flutuante NaN.
Declaração de variável em D
Uma declaração de variável fornece garantia ao compilador de que existe uma variável com o tipo e nome fornecidos para que o compilador prossiga para a compilação posterior sem precisar de detalhes completos sobre a variável. Uma declaração de variável tem seu significado apenas no momento da compilação, o compilador precisa da declaração da variável real no momento da vinculação do programa.
Exemplo
Tente o exemplo a seguir, onde as variáveis foram declaradas no início do programa, mas são definidas e inicializadas dentro da função principal -
import std.stdio;
int a = 10, b = 10;
int c;
float f;
int main () {
writeln("Value of a is : ", a);
/* variable re definition: */
int a, b;
int c;
float f;
/* Initialization */
a = 30;
b = 40;
writeln("Value of a is : ", a);
c = a + b;
writeln("Value of c is : ", c);
f = 70.0/3.0;
writeln("Value of f is : ", f);
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Value of a is : 10
Value of a is : 30
Value of c is : 70
Value of f is : 23.3333Lvalues e Rvalues em D
Existem dois tipos de expressões em D -
lvalue - Uma expressão que é um lvalue pode aparecer como o lado esquerdo ou direito de uma atribuição.
rvalue - Uma expressão que é um rvalue pode aparecer no lado direito, mas não no lado esquerdo de uma atribuição.
As variáveis são lvalues e, portanto, podem aparecer no lado esquerdo de uma atribuição. Literais numéricos são rvalues e, portanto, não podem ser atribuídos e não podem aparecer no lado esquerdo. A seguinte declaração é válida -
int g = 20;Mas o seguinte não é uma declaração válida e geraria um erro em tempo de compilação -
10 = 20;Na linguagem de programação D, os tipos de dados referem-se a um sistema extenso usado para declarar variáveis ou funções de diferentes tipos. O tipo de uma variável determina quanto espaço ela ocupa no armazenamento e como o padrão de bits armazenado é interpretado.
Os tipos em D podem ser classificados da seguinte forma -
| Sr. Não. | Tipos e descrição |
|---|---|
| 1 | Basic Types Eles são tipos aritméticos e consistem em três tipos: (a) inteiro, (b) ponto flutuante e (c) caractere. |
| 2 | Enumerated types Eles são novamente tipos aritméticos. Eles são usados para definir variáveis que só podem ser atribuídas a certos valores inteiros discretos em todo o programa. |
| 3 | The type void O especificador de tipo void indica que nenhum valor está disponível. |
| 4 | Derived types Eles incluem (a) tipos de ponteiro, (b) tipos de matriz, (c) tipos de estrutura, (d) tipos de união e (e) tipos de função. |
Os tipos de matriz e tipos de estrutura são chamados coletivamente de tipos agregados. O tipo de uma função especifica o tipo do valor de retorno da função. Veremos os tipos básicos na seção seguinte, enquanto outros tipos serão abordados nos próximos capítulos.
Tipos inteiros
A tabela a seguir fornece listas de tipos inteiros padrão com seus tamanhos de armazenamento e intervalos de valores -
| Tipo | Tamanho de armazenamento | Faixa de valor |
|---|---|---|
| bool | 1 byte | falso ou verdadeiro |
| byte | 1 byte | -128 a 127 |
| ubyte | 1 byte | 0 a 255 |
| int | 4 bytes | -2.147.483.648 a 2.147.483.647 |
| uint | 4 bytes | 0 a 4.294.967.295 |
| baixo | 2 bytes | -32.768 a 32.767 |
| ushort | 2 bytes | 0 a 65.535 |
| grandes | 8 bytes | -9223372036854775808 a 9223372036854775807 |
| Ulong | 8 bytes | 0 a 18446744073709551615 |
Para obter o tamanho exato de um tipo ou variável, você pode usar o sizeofoperador. O tipo de expressão . (Sizeof) produz o tamanho de armazenamento do objeto ou tipo em bytes. O exemplo a seguir obtém o tamanho do tipo int em qualquer máquina -
import std.stdio;
int main() {
writeln("Length in bytes: ", ulong.sizeof);
return 0;
}Quando você compila e executa o programa acima, ele produz o seguinte resultado -
Length in bytes: 8Tipos de ponto flutuante
A tabela a seguir menciona tipos de ponto flutuante padrão com tamanhos de armazenamento, intervalos de valor e sua finalidade -
| Tipo | Tamanho de armazenamento | Faixa de valor | Objetivo |
|---|---|---|---|
| flutuador | 4 bytes | 1.17549e-38 a 3.40282e + 38 | 6 casas decimais |
| em dobro | 8 bytes | 2.22507e-308 a 1.79769e + 308 | 15 casas decimais |
| real | 10 bytes | 3.3621e-4932 a 1.18973e + 4932 | o maior tipo de ponto flutuante que o hardware suporta ou duplo; o que for maior |
| flutuar | 4 bytes | 1.17549e-38i a 3.40282e + 38i | tipo de valor imaginário de flutuação |
| duplo | 8 bytes | 2.22507e-308i a 1.79769e + 308i | tipo de valor imaginário duplo |
| ireal | 10 bytes | 3.3621e-4932 a 1.18973e + 4932 | tipo de valor imaginário real |
| flutuar | 8 bytes | 1.17549e-38 + 1.17549e-38i a 3.40282e + 38 + 3.40282e + 38i | tipo de número complexo feito de dois carros alegóricos |
| duplo | 16 bytes | 2.22507e-308 + 2.22507e-308i a 1.79769e + 308 + 1.79769e + 308i | tipo de número complexo feito de duas duplas |
| creal | 20 bytes | 3.3621e-4932 + 3.3621e-4932i a 1.18973e + 4932 + 1.18973e + 4932i | tipo de número complexo feito de dois reais |
O exemplo a seguir imprime o espaço de armazenamento ocupado por um tipo float e seus valores de intervalo -
import std.stdio;
int main() {
writeln("Length in bytes: ", float.sizeof);
return 0;
}Quando você compila e executa o programa acima, ele produz o seguinte resultado no Linux -
Length in bytes: 4Tipos de personagem
A tabela a seguir lista os tipos de caracteres padrão com tamanhos de armazenamento e sua finalidade.
| Tipo | Tamanho de armazenamento | Objetivo |
|---|---|---|
| Caracteres | 1 byte | Unidade de código UTF-8 |
| wchar | 2 bytes | Unidade de código UTF-16 |
| dchar | 4 bytes | Unidade de código UTF-32 e ponto de código Unicode |
O exemplo a seguir imprime o espaço de armazenamento ocupado por um tipo char.
import std.stdio;
int main() {
writeln("Length in bytes: ", char.sizeof);
return 0;
}Quando você compila e executa o programa acima, ele produz o seguinte resultado -
Length in bytes: 1O tipo vazio
O tipo void especifica que nenhum valor está disponível. É usado em dois tipos de situações -
| Sr. Não. | Tipos e descrição |
|---|---|
| 1 | Function returns as void Existem várias funções em D que não retornam valor ou você pode dizer que retornam nulas. Uma função sem valor de retorno tem o tipo de retorno nulo. Por exemplo,void exit (int status); |
| 2 | Function arguments as void Existem várias funções em D que não aceitam nenhum parâmetro. Uma função sem parâmetro pode ser aceita como nula. Por exemplo,int rand(void); |
O tipo de vazio pode não ser compreendido por você neste ponto, então vamos prosseguir e abordaremos esses conceitos nos próximos capítulos.
Uma enumeração é usada para definir valores constantes nomeados. Um tipo enumerado é declarado usando oenum palavra-chave.
A sintaxe enum
A forma mais simples de uma definição de enum é a seguinte -
enum enum_name {
enumeration list
}Onde,
O enum_name especifica o nome do tipo de enumeração.
A lista de enumeração é uma lista de identificadores separados por vírgulas.
Cada um dos símbolos na lista de enumeração representa um valor inteiro, um maior do que o símbolo que o precede. Por padrão, o valor do primeiro símbolo de enumeração é 0. Por exemplo -
enum Days { sun, mon, tue, wed, thu, fri, sat };Exemplo
O exemplo a seguir demonstra o uso da variável enum -
import std.stdio;
enum Days { sun, mon, tue, wed, thu, fri, sat };
int main(string[] args) {
Days day;
day = Days.mon;
writefln("Current Day: %d", day);
writefln("Friday : %d", Days.fri);
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Current Day: 1
Friday : 5No programa acima, podemos ver como uma enumeração pode ser usada. Inicialmente, criamos uma variável chamada dia de nossa enumeração definida pelo usuário Dias. Em seguida, definimos como mon usando o operador ponto. Precisamos usar o método writefln para imprimir o valor de mon que foi armazenado. Você também precisa especificar o tipo. É do tipo inteiro, portanto usamos% d para impressão.
Propriedades de Enums Nomeados
O exemplo acima usa um nome Dias para a enumeração e é chamado de enums nomeados. Esses enums nomeados têm as seguintes propriedades -
Init - Inicializa o primeiro valor da enumeração.
min - Retorna o menor valor de enumeração.
max - Retorna o maior valor de enumeração.
sizeof - Retorna o tamanho do armazenamento para enumeração.
Vamos modificar o exemplo anterior para fazer uso das propriedades.
import std.stdio;
// Initialized sun with value 1
enum Days { sun = 1, mon, tue, wed, thu, fri, sat };
int main(string[] args) {
writefln("Min : %d", Days.min);
writefln("Max : %d", Days.max);
writefln("Size of: %d", Days.sizeof);
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Min : 1
Max : 7
Size of: 4Enum anônimo
A enumeração sem nome é chamada de enum anônimo. Um exemplo paraanonymous enum é fornecido abaixo.
import std.stdio;
// Initialized sun with value 1
enum { sun , mon, tue, wed, thu, fri, sat };
int main(string[] args) {
writefln("Sunday : %d", sun);
writefln("Monday : %d", mon);
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Sunday : 0
Monday : 1Enums anônimos funcionam da mesma forma que enums nomeados, mas não têm as propriedades max, min e sizeof.
Enum com sintaxe de tipo de base
A sintaxe para enumeração com tipo base é mostrada abaixo.
enum :baseType {
enumeration list
}Alguns dos tipos básicos incluem long, int e string. Um exemplo usando long é mostrado abaixo.
import std.stdio;
enum : string {
A = "hello",
B = "world",
}
int main(string[] args) {
writefln("A : %s", A);
writefln("B : %s", B);
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
A : hello
B : worldMais recursos
A enumeração em D fornece recursos como inicialização de vários valores em uma enumeração com vários tipos. Um exemplo é mostrado abaixo.
import std.stdio;
enum {
A = 1.2f, // A is 1.2f of type float
B, // B is 2.2f of type float
int C = 3, // C is 3 of type int
D // D is 4 of type int
}
int main(string[] args) {
writefln("A : %f", A);
writefln("B : %f", B);
writefln("C : %d", C);
writefln("D : %d", D);
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
A : 1.200000
B : 2.200000
C : 3
D : 4Valores constantes digitados no programa como parte do código-fonte são chamados literals.
Literais podem ser de qualquer um dos tipos de dados básicos e podem ser divididos em números inteiros, números de ponto flutuante, caracteres, strings e valores booleanos.
Novamente, literais são tratados como variáveis regulares, exceto que seus valores não podem ser modificados após sua definição.
Literais inteiros
Um literal inteiro pode ser um dos seguintes tipos -
Decimal usa a representação de número normal com o primeiro dígito não pode ser 0, pois esse dígito é reservado para indicar o sistema octal. Isso não inclui 0 por si só: 0 é zero.
Octal usa 0 como prefixo do número.
Binary usa 0b ou 0B como prefixo.
Hexadecimal usa 0x ou 0X como prefixo.
Um literal inteiro também pode ter um sufixo que é uma combinação de U e L, para sem sinal e longo, respectivamente. O sufixo pode ser maiúsculo ou minúsculo e pode estar em qualquer ordem.
Quando você não usa um sufixo, o próprio compilador escolhe entre int, uint, long e ulong com base na magnitude do valor.
Aqui estão alguns exemplos de literais inteiros -
212 // Legal
215u // Legal
0xFeeL // Legal
078 // Illegal: 8 is not an octal digit
032UU // Illegal: cannot repeat a suffixA seguir estão outros exemplos de vários tipos de literais inteiros -
85 // decimal
0213 // octal
0x4b // hexadecimal
30 // int
30u // unsigned int
30l // long
30ul // unsigned long
0b001 // binaryLiterais de ponto flutuante
Os literais de ponto flutuante podem ser especificados no sistema decimal como em 1.568 ou no sistema hexadecimal como em 0x91.bc.
No sistema decimal, um expoente pode ser representado adicionando o caractere e ou E e um número depois disso. Por exemplo, 2,3e4 significa "2,3 vezes 10 elevado a 4". Um caractere “+” pode ser especificado antes do valor do expoente, mas não tem efeito. Por exemplo, 2.3e4 e 2.3e + 4 são iguais.
O caractere “-” adicionado antes do valor do expoente muda o significado para ser "dividido por 10 à potência de". Por exemplo, 2,3e-2 significa "2,3 dividido por 10 elevado a 2".
No sistema hexadecimal, o valor começa com 0x ou 0X. O expoente é especificado por p ou P em vez de e ou E. O expoente não significa "10 à potência de", mas "2 à potência de". Por exemplo, o P4 em 0xabc.defP4 significa "abc.de vezes 2 elevado a 4".
Aqui estão alguns exemplos de literais de ponto flutuante -
3.14159 // Legal
314159E-5L // Legal
510E // Illegal: incomplete exponent
210f // Illegal: no decimal or exponent
.e55 // Illegal: missing integer or fraction
0xabc.defP4 // Legal Hexa decimal with exponent
0xabc.defe4 // Legal Hexa decimal without exponent.Por padrão, o tipo de literal de ponto flutuante é duplo. O f e F significam float, e o especificador L significa real.
Literais booleanos
Existem dois literais booleanos e fazem parte das palavras-chave D padrão -
Um valor de true representando verdadeiro.
Um valor de false representando falso.
Você não deve considerar o valor de verdadeiro igual a 1 e o valor de falso igual a 0.
Literais de caracteres
Literais de caracteres são colocados entre aspas simples.
Um literal de caractere pode ser um caractere simples (por exemplo, 'x'), uma sequência de escape (por exemplo, '\ t'), um caractere ASCII (por exemplo, '\ x21'), um caractere Unicode (por exemplo, '\ u011e') ou como caractere nomeado (por exemplo, '\ ©', '\ ♥', '\ €').
Existem certos caracteres em D quando eles são precedidos por uma barra invertida, eles têm um significado especial e são usados para representar como nova linha (\ n) ou tabulação (\ t). Aqui, você tem uma lista de alguns desses códigos de sequência de escape -
| Sequência de fuga | Significado |
|---|---|
| \\ | \ personagem |
| \ ' | ' personagem |
| \ " | " personagem |
| \? | ? personagem |
| \uma | Alerta ou sino |
| \ b | Backspace |
| \ f | Feed de formulário |
| \ n | Nova linha |
| \ r | Retorno de carruagem |
| \ t | Aba horizontal |
| \ v | Aba vertical |
O exemplo a seguir mostra alguns caracteres de sequência de escape -
import std.stdio;
int main(string[] args) {
writefln("Hello\tWorld%c\n",'\x21');
writefln("Have a good day%c",'\x21');
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Hello World!
Have a good day!Literais de string
Literais de string são colocados entre aspas duplas. Uma string contém caracteres semelhantes aos literais de caracteres: caracteres simples, sequências de escape e caracteres universais.
Você pode quebrar uma linha longa em várias linhas usando literais de string e separá-los usando espaços em branco.
Aqui estão alguns exemplos de literais de string -
import std.stdio;
int main(string[] args) {
writeln(q"MY_DELIMITER
Hello World
Have a good day
MY_DELIMITER");
writefln("Have a good day%c",'\x21');
auto str = q{int value = 20; ++value;};
writeln(str);
}No exemplo acima, você pode encontrar o uso de q "MY_DELIMITER MY_DELIMITER" para representar caracteres de várias linhas. Além disso, você pode ver q {} para representar a própria instrução da linguagem D.
Um operador é um símbolo que informa ao compilador para executar manipulações matemáticas ou lógicas específicas. A linguagem D é rica em operadores integrados e fornece os seguintes tipos de operadores -
- Operadores aritméticos
- Operadores Relacionais
- Operadores lógicos
- Operadores bit a bit
- Operadores de atribuição
- Operadores diversos
Este capítulo explica os operadores aritméticos, relacionais, lógicos, bit a bit, atribuição e outros, um por um.
Operadores aritméticos
A tabela a seguir mostra todos os operadores aritméticos suportados pela linguagem D. Assumir variávelA contém 10 e variável B detém 20 então -
Mostrar exemplos
| Operador | Descrição | Exemplo |
|---|---|---|
| + | Ele adiciona dois operandos. | A + B dá 30 |
| - | Ele subtrai o segundo operando do primeiro. | A - B dá -10 |
| * | Ele multiplica ambos os operandos. | A * B dá 200 |
| / | Ele divide numerador por denumerador. | B / A dá 2 |
| % | Ele retorna o resto de uma divisão inteira. | B% A dá 0 |
| ++ | O operador de incremento aumenta o valor inteiro em um. | A ++ dá 11 |
| - | O operador de decrementos diminui o valor inteiro em um. | A-- dá 9 |
Operadores Relacionais
A tabela a seguir mostra todos os operadores relacionais suportados pela linguagem D. Assumir variávelA contém 10 e variável B contém 20, então -
Mostrar exemplos
| Operador | Descrição | Exemplo |
|---|---|---|
| == | Verifica se os valores dos dois operandos são iguais ou não, se sim a condição torna-se verdadeira. | (A == B) não é verdade. |
| ! = | Verifica se os valores de dois operandos são iguais ou não, se os valores não são iguais, a condição se torna verdadeira. | (A! = B) é verdade. |
| > | Verifica se o valor do operando esquerdo é maior que o valor do operando direito, se sim então a condição torna-se verdadeira. | (A> B) não é verdade. |
| < | Verifica se o valor do operando esquerdo é menor que o valor do operando direito; se sim, a condição torna-se verdadeira. | (A <B) é verdade. |
| > = | Verifica se o valor do operando esquerdo é maior ou igual ao valor do operando direito, se sim a condição torna-se verdadeira. | (A> = B) não é verdade. |
| <= | Verifica se o valor do operando esquerdo é menor ou igual ao valor do operando direito; em caso afirmativo, a condição torna-se verdadeira. | (A <= B) é verdadeiro. |
Operadores lógicos
A tabela a seguir mostra todos os operadores lógicos suportados pela linguagem D. Assumir variávelA detém 1 e variável B segura 0, então -
Mostrar exemplos
| Operador | Descrição | Exemplo |
|---|---|---|
| && | É chamado de operador lógico AND. Se ambos os operandos forem diferentes de zero, a condição se torna verdadeira. | (A && B) é falso. |
| || | É denominado Operador OR lógico. Se qualquer um dos dois operandos for diferente de zero, a condição se torna verdadeira. | (A || B) é verdade. |
| ! | É denominado Operador NOT lógico. Use para reverter o estado lógico de seu operando. Se uma condição for verdadeira, o operador NOT lógico tornará falso. | ! (A && B) é verdade. |
Operadores bit a bit
Operadores bit a bit funcionam em bits e realizam operações bit a bit. As tabelas de verdade para &, | e ^ são as seguintes -
| p | q | p & q | p | q | p ^ q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
Suponha que A = 60; e B = 13. No formato binário serão os seguintes -
A = 0011 1100
B = 0000 1101
-----------------
A&B = 0000 1100
A | B = 0011 1101
A ^ B = 0011 0001
~ A = 1100 0011
Os operadores bit a bit suportados pela linguagem D estão listados na tabela a seguir. Suponha que a variável A tenha 60 e a variável B tenha 13, então -
Mostrar exemplos
| Operador | Descrição | Exemplo |
|---|---|---|
| E | O operador Binário AND copia um bit para o resultado se ele existir em ambos os operandos. | (A e B) resultará em 12, significa 0000 1100. |
| | | O operador binário OR copia um bit se ele existir em qualquer operando. | (A | B) dá 61. Significa 0011 1101. |
| ^ | O operador binário XOR copia o bit se estiver definido em um operando, mas não em ambos. | (A ^ B) dá 49. Significa 0011 0001 |
| ~ | O operador de complemento binários é unário e tem o efeito de 'inverter' bits. | (~ A) dá -61. Significa 1100 0011 na forma de complemento de 2. |
| << | Operador binário de deslocamento à esquerda. O valor dos operandos à esquerda é movido para a esquerda pelo número de bits especificado pelo operando à direita. | A << 2 dá 240. Significa 1111 0000 |
| >> | Operador binário de deslocamento à direita. O valor dos operandos à esquerda é movido para a direita pelo número de bits especificado pelo operando à direita. | A >> 2 dá 15. Significa 0000 1111. |
Operadores de atribuição
Os seguintes operadores de atribuição são suportados pela linguagem D -
Mostrar exemplos
| Operador | Descrição | Exemplo |
|---|---|---|
| = | É um operador de atribuição simples. Ele atribui valores de operandos do lado direito para operando do lado esquerdo | C = A + B atribui valor de A + B em C |
| + = | É adicionar e operador de atribuição. Ele adiciona o operando direito ao operando esquerdo e atribui o resultado ao operando esquerdo | C + = A é equivalente a C = C + A |
| - = | É subtrair E o operador de atribuição. Ele subtrai o operando direito do operando esquerdo e atribui o resultado ao operando esquerdo. | C - = A é equivalente a C = C - A |
| * = | É o operador de atribuição de multiplicação AND. Ele multiplica o operando direito pelo operando esquerdo e atribui o resultado ao operando esquerdo. | C * = A é equivalente a C = C * A |
| / = | É o operador de divisão AND atribuição. Ele divide o operando esquerdo com o operando direito e atribui o resultado ao operando esquerdo. | C / = A é equivalente a C = C / A |
| % = | É o módulo E o operador de atribuição. Leva o módulo usando dois operandos e atribui o resultado ao operando esquerdo. | C% = A é equivalente a C = C% A |
| << = | É deslocamento para a esquerda e operador de atribuição. | C << = 2 é igual a C = C << 2 |
| >> = | É o operador de deslocamento e atribuição à direita. | C >> = 2 é igual a C = C >> 2 |
| & = | É um operador de atribuição AND bit a bit. | C & = 2 é igual a C = C & 2 |
| ^ = | É um operador de atribuição e OR exclusivo bit a bit. | C ^ = 2 é igual a C = C ^ 2 |
| | = | É OR inclusivo bit a bit e operador de atribuição | C | = 2 é igual a C = C | 2 |
Operadores diversos - tamanho e ternário
Existem alguns outros operadores importantes, incluindo sizeof e ? : suportado por D Language.
Mostrar exemplos
| Operador | Descrição | Exemplo |
|---|---|---|
| tamanho de() | Retorna o tamanho de uma variável. | sizeof (a), onde a é inteiro, retorna 4. |
| E | Retorna o endereço de uma variável. | &uma; fornece o endereço real da variável. |
| * | Ponteiro para uma variável. | *uma; dá um ponteiro para uma variável. |
| ? : | Expressão Condicional | Se a condição for verdadeira, valor X: Caso contrário, valor Y. |
Precedência de operadores em D
A precedência do operador determina o agrupamento de termos em uma expressão. Isso afeta como uma expressão é avaliada. Certos operadores têm precedência sobre outros.
Por exemplo, o operador de multiplicação tem precedência mais alta do que o operador de adição.
Vamos considerar uma expressão
x = 7 + 3 * 2.
Aqui, x é atribuído a 13, não a 20. A razão simples é que o operador * tem precedência maior do que +, portanto, 3 * 2 é calculado primeiro e, em seguida, o resultado é adicionado a 7.
Aqui, os operadores com a precedência mais alta aparecem na parte superior da tabela, aqueles com a mais baixa aparecem na parte inferior. Em uma expressão, os operadores de precedência mais alta são avaliados primeiro.
Mostrar exemplos
| Categoria | Operador | Associatividade |
|---|---|---|
| Postfix | () [] ->. ++ - - | Da esquerda para direita |
| Unário | + -! ~ ++ - - (tipo) * & sizeof | Direita para esquerda |
| Multiplicativo | * /% | Da esquerda para direita |
| Aditivo | + - | Da esquerda para direita |
| Mudança | << >> | Da esquerda para direita |
| Relacional | <<=>> = | Da esquerda para direita |
| Igualdade | ==! = | Da esquerda para direita |
| E bit a bit | E | Da esquerda para direita |
| XOR bit a bit | ^ | Da esquerda para direita |
| OR bit a bit | | | Da esquerda para direita |
| E lógico | && | Da esquerda para direita |
| OR lógico | || | Da esquerda para direita |
| Condicional | ?: | Direita para esquerda |
| Tarefa | = + = - = * = / =% = >> = << = & = ^ = | = | Direita para esquerda |
| Vírgula | , | Da esquerda para direita |
Pode haver uma situação em que você precise executar um bloco de código várias vezes. Em geral, as instruções são executadas sequencialmente: a primeira instrução em uma função é executada primeiro, seguida pela segunda e assim por diante.
As linguagens de programação fornecem várias estruturas de controle que permitem caminhos de execução mais complicados.
Uma instrução de loop executa uma instrução ou grupo de instruções várias vezes. A seguinte forma geral de uma instrução de loop é usada principalmente nas linguagens de programação -

A linguagem de programação D fornece os seguintes tipos de loop para lidar com os requisitos de loop. Clique nos links a seguir para verificar seus detalhes.
| Sr. Não. | Tipo de Loop e Descrição |
|---|---|
| 1 | loop while Ele repete uma declaração ou grupo de declarações enquanto uma determinada condição for verdadeira. Ele testa a condição antes de executar o corpo do loop. |
| 2 | para loop Ele executa uma sequência de instruções várias vezes e abrevia o código que gerencia a variável de loop. |
| 3 | fazer ... loop while Como uma instrução while, exceto que testa a condição no final do corpo do loop. |
| 4 | loops aninhados Você pode usar um ou mais loops dentro de qualquer outro loop while, for ou do..while. |
Declarações de controle de loop
As instruções de controle de loop alteram a execução de sua sequência normal. Quando a execução deixa um escopo, todos os objetos automáticos que foram criados nesse escopo são destruídos.
D suporta as seguintes instruções de controle -
| Sr. Não. | Declaração de controle e descrição |
|---|---|
| 1 | declaração de quebra Encerra o loop ou a instrução switch e transfere a execução para a instrução imediatamente após o loop ou switch. |
| 2 | continuar declaração Faz com que o loop pule o restante de seu corpo e teste novamente sua condição imediatamente antes de reiterar. |
The Infinite Loop
Um loop se torna um loop infinito se uma condição nunca se torna falsa. oforloop é tradicionalmente usado para esse propósito. Como nenhuma das três expressões que formam o loop for é necessária, você pode fazer um loop infinito deixando a expressão condicional vazia.
import std.stdio;
int main () {
for( ; ; ) {
writefln("This loop will run forever.");
}
return 0;
}Quando a expressão condicional está ausente, ela é considerada verdadeira. Você pode ter uma expressão de inicialização e incremento, mas os programadores de D usam mais comumente a construção for (;;) para significar um loop infinito.
NOTE - Você pode encerrar um loop infinito pressionando as teclas Ctrl + C.
As estruturas de tomada de decisão contêm condições a serem avaliadas junto com os dois conjuntos de instruções a serem executados. Um conjunto de instruções é executado se a condição for verdadeira e outro conjunto de instruções é executado se a condição for falsa.
A seguir está a forma geral de uma estrutura típica de tomada de decisão encontrada na maioria das linguagens de programação -
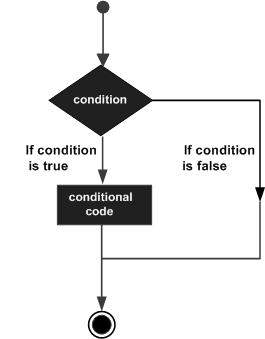
A linguagem de programação D assume qualquer non-zero e non-null valores como true, e se for zero ou null, então é assumido como false valor.
A linguagem de programação D fornece os seguintes tipos de declarações de tomada de decisão.
| Sr. Não. | Declaração e descrição |
|---|---|
| 1 | declaração if A if statement consiste em uma expressão booleana seguida por uma ou mais instruções. |
| 2 | declaração if ... else A if statement pode ser seguido por um opcional else statement, que é executado quando a expressão booleana é falsa. |
| 3 | declarações if aninhadas Você pode usar um if ou else if declaração dentro de outra if ou else if afirmações). |
| 4 | declaração switch UMA switch instrução permite que uma variável seja testada quanto à igualdade em relação a uma lista de valores. |
| 5 | instruções switch aninhadas Você pode usar um switch declaração dentro de outra switch afirmações). |
O ? : Operador em D
Nós cobrimos conditional operator ? : no capítulo anterior, que pode ser usado para substituir if...elseafirmações. Tem a seguinte forma geral
Exp1 ? Exp2 : Exp3;Onde Exp1, Exp2 e Exp3 são expressões. Observe o uso e a localização do cólon.
O valor de um? expressão é determinada da seguinte forma -
Exp1 é avaliado. Se for verdade, então Exp2 é avaliado e se torna o valor de todo? expressão.
Se Exp1 for falso, então Exp3 é avaliado e seu valor se torna o valor da expressão.
Este capítulo descreve as funções usadas na programação D.
Definição de Função em D
Uma definição de função básica consiste em um cabeçalho e um corpo de função.
Sintaxe
return_type function_name( parameter list ) {
body of the function
}Aqui estão todas as partes de uma função -
Return Type- Uma função pode retornar um valor. oreturn_typeé o tipo de dados do valor que a função retorna. Algumas funções realizam as operações desejadas sem retornar um valor. Neste caso, o return_type é a palavra-chavevoid.
Function Name- Este é o nome real da função. O nome da função e a lista de parâmetros juntos constituem a assinatura da função.
Parameters- Um parâmetro é como um espaço reservado. Quando uma função é chamada, você passa um valor para o parâmetro. Esse valor é conhecido como parâmetro ou argumento real. A lista de parâmetros se refere ao tipo, ordem e número dos parâmetros de uma função. Os parâmetros são opcionais; ou seja, uma função pode não conter parâmetros.
Function Body - O corpo da função contém uma coleção de instruções que definem o que a função faz.
Chamando uma função
Você pode chamar uma função da seguinte maneira -
function_name(parameter_values)Tipos de função em D
A programação em D oferece suporte a uma ampla gama de funções e elas estão listadas abaixo.
- Funções puras
- Funções do Nothrow
- Funções Ref
- Funções Automáticas
- Funções Variadicas
- Funções Inout
- Funções de propriedade
As várias funções são explicadas a seguir.
Funções puras
Funções puras são funções que não podem acessar o estado global ou estático, mutável, exceto por meio de seus argumentos. Isso pode permitir otimizações com base no fato de que uma função pura tem garantia de não alterar nada que não seja passado a ela, e nos casos em que o compilador pode garantir que uma função pura não pode alterar seus argumentos, pode permitir pureza funcional completa, que ou seja, a garantia de que a função sempre retornará o mesmo resultado para os mesmos argumentos).
import std.stdio;
int x = 10;
immutable int y = 30;
const int* p;
pure int purefunc(int i,const char* q,immutable int* s) {
//writeln("Simple print"); //cannot call impure function 'writeln'
debug writeln("in foo()"); // ok, impure code allowed in debug statement
// x = i; // error, modifying global state
// i = x; // error, reading mutable global state
// i = *p; // error, reading const global state
i = y; // ok, reading immutable global state
auto myvar = new int; // Can use the new expression:
return i;
}
void main() {
writeln("Value returned from pure function : ",purefunc(x,null,null));
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Value returned from pure function : 30Funções do Nothrow
As funções do Nothrow não lançam nenhuma exceção derivada da classe Exception. As funções do Nothrow são covariantes com as de arremesso.
Nothrow garante que uma função não emita nenhuma exceção.
import std.stdio;
int add(int a, int b) nothrow {
//writeln("adding"); This will fail because writeln may throw
int result;
try {
writeln("adding"); // compiles
result = a + b;
} catch (Exception error) { // catches all exceptions
}
return result;
}
void main() {
writeln("Added value is ", add(10,20));
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
adding
Added value is 30Funções Ref
As funções Ref permitem que as funções retornem por referência. Isso é análogo aos parâmetros da função ref.
import std.stdio;
ref int greater(ref int first, ref int second) {
return (first > second) ? first : second;
}
void main() {
int a = 1;
int b = 2;
greater(a, b) += 10;
writefln("a: %s, b: %s", a, b);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
a: 1, b: 12Funções Automáticas
As funções automáticas podem retornar valores de qualquer tipo. Não há restrição sobre o tipo a ser retornado. Um exemplo simples para a função de tipo automático é fornecido abaixo.
import std.stdio;
auto add(int first, double second) {
double result = first + second;
return result;
}
void main() {
int a = 1;
double b = 2.5;
writeln("add(a,b) = ", add(a, b));
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
add(a,b) = 3.5Funções Variadicas
Funções variadiac são aquelas funções nas quais o número de parâmetros para uma função é determinado em tempo de execução. Em C, há uma limitação de ter pelo menos um parâmetro. Mas na programação D, não existe essa limitação. Um exemplo simples é mostrado abaixo.
import std.stdio;
import core.vararg;
void printargs(int x, ...) {
for (int i = 0; i < _arguments.length; i++) {
write(_arguments[i]);
if (_arguments[i] == typeid(int)) {
int j = va_arg!(int)(_argptr);
writefln("\t%d", j);
} else if (_arguments[i] == typeid(long)) {
long j = va_arg!(long)(_argptr);
writefln("\t%d", j);
} else if (_arguments[i] == typeid(double)) {
double d = va_arg!(double)(_argptr);
writefln("\t%g", d);
}
}
}
void main() {
printargs(1, 2, 3L, 4.5);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
int 2
long 3
double 4.5Funções Inout
O inout pode ser usado para parâmetros e tipos de retorno de funções. É como um modelo para mutável, const e imutável. O atributo de mutabilidade é deduzido do parâmetro. Significa que inout transfere o atributo de mutabilidade deduzido para o tipo de retorno. Um exemplo simples mostrando como a mutabilidade é alterada é mostrado abaixo.
import std.stdio;
inout(char)[] qoutedWord(inout(char)[] phrase) {
return '"' ~ phrase ~ '"';
}
void main() {
char[] a = "test a".dup;
a = qoutedWord(a);
writeln(typeof(qoutedWord(a)).stringof," ", a);
const(char)[] b = "test b";
b = qoutedWord(b);
writeln(typeof(qoutedWord(b)).stringof," ", b);
immutable(char)[] c = "test c";
c = qoutedWord(c);
writeln(typeof(qoutedWord(c)).stringof," ", c);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
char[] "test a"
const(char)[] "test b"
string "test c"Funções de propriedade
As propriedades permitem o uso de funções de membro como variáveis de membro. Ele usa a palavra-chave @property. As propriedades são vinculadas a funções relacionadas que retornam valores com base no requisito. Um exemplo simples de propriedade é mostrado abaixo.
import std.stdio;
struct Rectangle {
double width;
double height;
double area() const @property {
return width*height;
}
void area(double newArea) @property {
auto multiplier = newArea / area;
width *= multiplier;
writeln("Value set!");
}
}
void main() {
auto rectangle = Rectangle(20,10);
writeln("The area is ", rectangle.area);
rectangle.area(300);
writeln("Modified width is ", rectangle.width);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
The area is 200
Value set!
Modified width is 30Os personagens são os blocos de construção das cordas. Qualquer símbolo de um sistema de escrita é chamado de caractere: letras do alfabeto, numerais, sinais de pontuação, o caractere de espaço, etc. É confuso, os blocos de construção dos próprios caracteres são chamados de caracteres também.
O valor inteiro da minúscula a é 97 e o valor inteiro do numeral 1 é 49. Esses valores foram atribuídos apenas por convenções quando a tabela ASCII foi projetada.
A tabela a seguir menciona os tipos de caracteres padrão com seus tamanhos e propósitos de armazenamento.
Os caracteres são representados pelo tipo char, que pode conter apenas 256 valores distintos. Se você está familiarizado com o tipo char de outras linguagens, você já deve saber que ele não é grande o suficiente para suportar os símbolos de muitos sistemas de escrita.
| Tipo | Tamanho de armazenamento | Objetivo |
|---|---|---|
| Caracteres | 1 byte | Unidade de código UTF-8 |
| wchar | 2 bytes | Unidade de código UTF-16 |
| dchar | 4 bytes | Unidade de código UTF-32 e ponto de código Unicode |
Algumas funções úteis de caractere estão listadas abaixo -
isLower - determina se é um caractere minúsculo?
isUpper - Determina se um caractere maiúsculo?
isAlpha - Determina se um caractere alfanumérico Unicode (geralmente, uma letra ou um numeral)?
isWhite - determina se é um caractere de espaço em branco?
toLower - Produz as letras minúsculas do caractere fornecido.
toUpper - Produz as letras maiúsculas do caractere fornecido.
import std.stdio;
import std.uni;
void main() {
writeln("Is ğ lowercase? ", isLower('ğ'));
writeln("Is Ş lowercase? ", isLower('Ş'));
writeln("Is İ uppercase? ", isUpper('İ'));
writeln("Is ç uppercase? ", isUpper('ç'));
writeln("Is z alphanumeric? ", isAlpha('z'));
writeln("Is new-line whitespace? ", isWhite('\n'));
writeln("Is underline whitespace? ", isWhite('_'));
writeln("The lowercase of Ğ: ", toLower('Ğ'));
writeln("The lowercase of İ: ", toLower('İ'));
writeln("The uppercase of ş: ", toUpper('ş'));
writeln("The uppercase of ı: ", toUpper('ı'));
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Is ğ lowercase? true
Is Ş lowercase? false
Is İ uppercase? true
Is ç uppercase? false
Is z alphanumeric? true
Is new-line whitespace? true
Is underline whitespace? false
The lowercase of Ğ: ğ
The lowercase of İ: i
The uppercase of ş: Ş
The uppercase of ı: ILendo caracteres em D
Podemos ler caracteres usando readf como mostrado abaixo.
readf(" %s", &letter);Como a programação em D suporta Unicode, para ler caracteres Unicode, precisamos ler duas vezes e escrever duas vezes para obter o resultado esperado. Isso não funciona no compilador online. O exemplo é mostrado abaixo.
import std.stdio;
void main() {
char firstCode;
char secondCode;
write("Please enter a letter: ");
readf(" %s", &firstCode);
readf(" %s", &secondCode);
writeln("The letter that has been read: ", firstCode, secondCode);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Please enter a letter: ğ
The letter that has been read: ğD fornece os seguintes dois tipos de representações de string -
- Matriz de caracteres
- String de linguagem principal
Matriz de personagens
Podemos representar a matriz de caracteres em uma das duas formas, conforme mostrado abaixo. A primeira forma fornece o tamanho diretamente e a segunda forma usa o método dup que cria uma cópia gravável da string "Bom dia".
char[9] greeting1 = "Hello all";
char[] greeting2 = "Good morning".dup;Exemplo
Aqui está um exemplo simples usando os formulários de matriz de caracteres simples acima.
import std.stdio;
void main(string[] args) {
char[9] greeting1 = "Hello all";
writefln("%s",greeting1);
char[] greeting2 = "Good morning".dup;
writefln("%s",greeting2);
}Quando o código acima é compilado e executado, ele produz um resultado como o seguinte -
Hello all
Good morningString principal da linguagem
Strings são integrados à linguagem central de D. Essas strings são interoperáveis com a matriz de caracteres mostrada acima. O exemplo a seguir mostra uma representação de string simples.
string greeting1 = "Hello all";Exemplo
import std.stdio;
void main(string[] args) {
string greeting1 = "Hello all";
writefln("%s",greeting1);
char[] greeting2 = "Good morning".dup;
writefln("%s",greeting2);
string greeting3 = greeting1;
writefln("%s",greeting3);
}Quando o código acima é compilado e executado, ele produz um resultado como o seguinte -
Hello all
Good morning
Hello allString Concatenation
A concatenação de strings na programação em D usa o símbolo til (~).
Exemplo
import std.stdio;
void main(string[] args) {
string greeting1 = "Good";
char[] greeting2 = "morning".dup;
char[] greeting3 = greeting1~" "~greeting2;
writefln("%s",greeting3);
string greeting4 = "morning";
string greeting5 = greeting1~" "~greeting4;
writefln("%s",greeting5);
}Quando o código acima é compilado e executado, ele produz um resultado como o seguinte -
Good morning
Good morningComprimento da corda
O comprimento da string em bytes pode ser recuperado com a ajuda da função length.
Exemplo
import std.stdio;
void main(string[] args) {
string greeting1 = "Good";
writefln("Length of string greeting1 is %d",greeting1.length);
char[] greeting2 = "morning".dup;
writefln("Length of string greeting2 is %d",greeting2.length);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Length of string greeting1 is 4
Length of string greeting2 is 7Comparação de cordas
A comparação de strings é bastante fácil na programação D. Você pode usar os operadores ==, <e> para comparações de strings.
Exemplo
import std.stdio;
void main() {
string s1 = "Hello";
string s2 = "World";
string s3 = "World";
if (s2 == s3) {
writeln("s2: ",s2," and S3: ",s3, " are the same!");
}
if (s1 < s2) {
writeln("'", s1, "' comes before '", s2, "'.");
} else {
writeln("'", s2, "' comes before '", s1, "'.");
}
}Quando o código acima é compilado e executado, ele produz um resultado como o seguinte -
s2: World and S3: World are the same!
'Hello' comes before 'World'.Substituindo Strings
Podemos substituir strings usando a string [].
Exemplo
import std.stdio;
import std.string;
void main() {
char[] s1 = "hello world ".dup;
char[] s2 = "sample".dup;
s1[6..12] = s2[0..6];
writeln(s1);
}Quando o código acima é compilado e executado, ele produz um resultado como o seguinte -
hello sampleMétodos de Índice
Os métodos de índice para localização de uma substring na string, incluindo indexOf e lastIndexOf, são explicados no exemplo a seguir.
Exemplo
import std.stdio;
import std.string;
void main() {
char[] s1 = "hello World ".dup;
writeln("indexOf of llo in hello is ",std.string.indexOf(s1,"llo"));
writeln(s1);
writeln("lastIndexOf of O in hello is " ,std.string.lastIndexOf(s1,"O",CaseSensitive.no));
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
indexOf.of llo in hello is 2
hello World
lastIndexOf of O in hello is 7Manuseio de casos
Os métodos usados para alterar os casos são mostrados no exemplo a seguir.
Exemplo
import std.stdio;
import std.string;
void main() {
char[] s1 = "hello World ".dup;
writeln("Capitalized string of s1 is ",capitalize(s1));
writeln("Uppercase string of s1 is ",toUpper(s1));
writeln("Lowercase string of s1 is ",toLower(s1));
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Capitalized string of s1 is Hello world
Uppercase string of s1 is HELLO WORLD
Lowercase string of s1 is hello worldPersonagens restritivos
Os caracteres restritos em strings são mostrados no exemplo a seguir.
Exemplo
import std.stdio;
import std.string;
void main() {
string s = "H123Hello1";
string result = munch(s, "0123456789H");
writeln("Restrict trailing characters:",result);
result = squeeze(s, "0123456789H");
writeln("Restrict leading characters:",result);
s = " Hello World ";
writeln("Stripping leading and trailing whitespace:",strip(s));
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Restrict trailing characters:H123H
Restrict leading characters:ello1
Stripping leading and trailing whitespace:Hello WorldA linguagem de programação D fornece uma estrutura de dados, chamada arrays, que armazena uma coleção sequencial de tamanho fixo de elementos do mesmo tipo. Uma matriz é usada para armazenar uma coleção de dados. Freqüentemente, é mais útil pensar em um array como uma coleção de variáveis do mesmo tipo.
Em vez de declarar variáveis individuais, como número0, número1, ... e número99, você declara uma variável de matriz, como números e usa números [0], números [1] e ..., números [99] para representar variáveis individuais. Um elemento específico em uma matriz é acessado por um índice.
Todos os arrays consistem em locais de memória contíguos. O endereço mais baixo corresponde ao primeiro elemento e o endereço mais alto ao último elemento.
Declaração de matrizes
Para declarar uma matriz na linguagem de programação D, o programador especifica o tipo dos elementos e o número de elementos exigidos por uma matriz da seguinte maneira -
type arrayName [ arraySize ];Isso é chamado de matriz de dimensão única. O arraySize deve ser uma constante inteira maior que zero e o tipo pode ser qualquer tipo de dados de linguagem de programação D válido. Por exemplo, para declarar uma matriz de 10 elementos chamada balance do tipo double, use esta instrução -
double balance[10];Inicializando matrizes
Você pode inicializar os elementos da matriz da linguagem de programação D um por um ou usando uma única instrução da seguinte maneira
double balance[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];O número de valores entre colchetes [] no lado direito não pode ser maior do que o número de elementos que você declara para a matriz entre colchetes []. O exemplo a seguir atribui um único elemento da matriz -
Se você omitir o tamanho do array, um array grande o suficiente para conter a inicialização é criado. Portanto, se você escrever
double balance[] = [1000.0, 2.0, 3.4, 17.0, 50.0];em seguida, você criará exatamente o mesmo array que no exemplo anterior.
balance[4] = 50.0;A instrução acima atribui ao elemento número 5 na matriz um valor de 50,0. O array com o 4º índice será o 5º, ou seja, o último elemento, porque todos os arrays têm 0 como o índice do primeiro elemento, também chamado de índice base. A seguinte representação pictórica mostra a mesma matriz que discutimos acima -

Acessando Elementos de Matriz
Um elemento é acessado indexando o nome da matriz. Isso é feito colocando o índice do elemento entre colchetes após o nome da matriz. Por exemplo -
double salary = balance[9];A declaração acima leva 10 th elemento da matriz e atribui o valor para a variável de vencimento . O exemplo a seguir implementa declaração, atribuição e acesso a matrizes -
import std.stdio;
void main() {
int n[ 10 ]; // n is an array of 10 integers
// initialize elements of array n to 0
for ( int i = 0; i < 10; i++ ) {
n[ i ] = i + 100; // set element at location i to i + 100
}
writeln("Element \t Value");
// output each array element's value
for ( int j = 0; j < 10; j++ ) {
writeln(j," \t ",n[j]);
}
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Element Value
0 100
1 101
2 102
3 103
4 104
5 105
6 106
7 107
8 108
9 109Matrizes estáticas versus matrizes dinâmicas
Se o comprimento de um array for especificado durante a gravação do programa, esse array é um array estático. Quando o comprimento pode mudar durante a execução do programa, esse array é um array dinâmico.
Definir matrizes dinâmicas é mais simples do que definir matrizes de comprimento fixo porque omitir o comprimento cria uma matriz dinâmica -
int[] dynamicArray;Propriedades da matriz
Aqui estão as propriedades dos arrays -
| Sr. Não. | Descrição da Propriedade |
|---|---|
| 1 | .init Array estático retorna um literal de array com cada elemento do literal sendo a propriedade .init do tipo de elemento do array. |
| 2 | .sizeof A matriz estática retorna o comprimento da matriz multiplicado pelo número de bytes por elemento da matriz, enquanto as matrizes dinâmicas retornam o tamanho da referência da matriz dinâmica, que é 8 em compilações de 32 bits e 16 em compilações de 64 bits. |
| 3 | .length Matriz estática retorna o número de elementos na matriz, enquanto matrizes dinâmicas são usadas para obter / definir o número de elementos na matriz. O comprimento é do tipo size_t. |
| 4 | .ptr Retorna um ponteiro para o primeiro elemento da matriz. |
| 5 | .dup Crie uma matriz dinâmica do mesmo tamanho e copie o conteúdo da matriz nela. |
| 6 | .idup Crie uma matriz dinâmica do mesmo tamanho e copie o conteúdo da matriz nela. A cópia foi digitada como imutável. |
| 7 | .reverse Inverte no lugar a ordem dos elementos na matriz. Retorna a matriz. |
| 8 | .sort Classifica no local a ordem dos elementos na matriz. Retorna a matriz. |
Exemplo
O exemplo a seguir explica as várias propriedades de uma matriz -
import std.stdio;
void main() {
int n[ 5 ]; // n is an array of 5 integers
// initialize elements of array n to 0
for ( int i = 0; i < 5; i++ ) {
n[ i ] = i + 100; // set element at location i to i + 100
}
writeln("Initialized value:",n.init);
writeln("Length: ",n.length);
writeln("Size of: ",n.sizeof);
writeln("Pointer:",n.ptr);
writeln("Duplicate Array: ",n.dup);
writeln("iDuplicate Array: ",n.idup);
n = n.reverse.dup;
writeln("Reversed Array: ",n);
writeln("Sorted Array: ",n.sort);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Initialized value:[0, 0, 0, 0, 0]
Length: 5
Size of: 20
Pointer:7FFF5A373920
Duplicate Array: [100, 101, 102, 103, 104]
iDuplicate Array: [100, 101, 102, 103, 104]
Reversed Array: [104, 103, 102, 101, 100]
Sorted Array: [100, 101, 102, 103, 104]Matrizes multidimensionais em D
A programação em D permite arrays multidimensionais. Aqui está a forma geral de uma declaração de array multidimensional -
type name[size1][size2]...[sizeN];Exemplo
A declaração a seguir cria um 5 tridimensional. 10 4 matriz de inteiros -
int threedim[5][10][4];Matrizes bidimensionais em D
A forma mais simples da matriz multidimensional é a matriz bidimensional. Um array bidimensional é, em essência, uma lista de arrays unidimensionais. Para declarar uma matriz de inteiro bidimensional de tamanho [x, y], você escreveria a sintaxe da seguinte maneira -
type arrayName [ x ][ y ];Onde type pode ser qualquer tipo de dados de programação D válido e arrayName será um identificador de programação D válido.
Onde tipo pode ser qualquer tipo de dados de programação D válido e arrayName é um identificador de programação D válido.
Uma matriz bidimensional pode ser considerada uma tabela, que possui x número de linhas e y número de colunas. Uma matriz bidimensionala contendo três linhas e quatro colunas pode ser mostrado como abaixo -
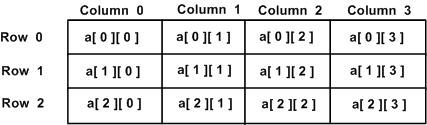
Assim, cada elemento na matriz a é identificado por um elemento como a[ i ][ j ], Onde a é o nome da matriz, e i e j são os subscritos que identificam exclusivamente cada elemento em a.
Inicializando matrizes bidimensionais
As matrizes multidimensionais podem ser inicializadas especificando valores entre colchetes para cada linha. A seguinte matriz possui 3 linhas e cada linha possui 4 colunas.
int a[3][4] = [
[0, 1, 2, 3] , /* initializers for row indexed by 0 */
[4, 5, 6, 7] , /* initializers for row indexed by 1 */
[8, 9, 10, 11] /* initializers for row indexed by 2 */
];As chaves aninhadas, que indicam a linha pretendida, são opcionais. A inicialização a seguir é equivalente ao exemplo anterior -
int a[3][4] = [0,1,2,3,4,5,6,7,8,9,10,11];Acessando Elementos de Matriz Bidimensional
Um elemento na matriz bidimensional é acessado usando os subscritos, significa índice de linha e índice de coluna da matriz. Por exemplo
int val = a[2][3];A declaração acima pega o 4º elemento da 3ª linha do array. Você pode verificar isso no digrama acima.
import std.stdio;
void main () {
// an array with 5 rows and 2 columns.
int a[5][2] = [ [0,0], [1,2], [2,4], [3,6],[4,8]];
// output each array element's value
for ( int i = 0; i < 5; i++ ) for ( int j = 0; j < 2; j++ ) {
writeln( "a[" , i , "][" , j , "]: ",a[i][j]);
}
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
a[0][0]: 0
a[0][1]: 0
a[1][0]: 1
a[1][1]: 2
a[2][0]: 2
a[2][1]: 4
a[3][0]: 3
a[3][1]: 6
a[4][0]: 4
a[4][1]: 8Operações de array comuns em D
Aqui estão várias operações realizadas nos arrays -
Fatiamento de matriz
Freqüentemente, usamos parte de uma matriz, e fatiar a matriz costuma ser bastante útil. Um exemplo simples de divisão de matriz é mostrado abaixo.
import std.stdio;
void main () {
// an array with 5 elements.
double a[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];
double[] b;
b = a[1..3];
writeln(b);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
[2, 3.4]Cópia de matriz
Também usamos cópia de array. Um exemplo simples de cópia de array é mostrado abaixo.
import std.stdio;
void main () {
// an array with 5 elements.
double a[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];
double b[5];
writeln("Array a:",a);
writeln("Array b:",b);
b[] = a; // the 5 elements of a[5] are copied into b[5]
writeln("Array b:",b);
b[] = a[]; // the 5 elements of a[3] are copied into b[5]
writeln("Array b:",b);
b[1..2] = a[0..1]; // same as b[1] = a[0]
writeln("Array b:",b);
b[0..2] = a[1..3]; // same as b[0] = a[1], b[1] = a[2]
writeln("Array b:",b);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Array a:[1000, 2, 3.4, 17, 50]
Array b:[nan, nan, nan, nan, nan]
Array b:[1000, 2, 3.4, 17, 50]
Array b:[1000, 2, 3.4, 17, 50]
Array b:[1000, 1000, 3.4, 17, 50]
Array b:[2, 3.4, 3.4, 17, 50]Configuração de matriz
Um exemplo simples para definir o valor em uma matriz é mostrado abaixo.
import std.stdio;
void main () {
// an array with 5 elements.
double a[5];
a[] = 5;
writeln("Array a:",a);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Array a:[5, 5, 5, 5, 5]Array Concatenation
Um exemplo simples de concatenação de duas matrizes é mostrado abaixo.
import std.stdio;
void main () {
// an array with 5 elements.
double a[5] = 5;
double b[5] = 10;
double [] c;
c = a~b;
writeln("Array c: ",c);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Array c: [5, 5, 5, 5, 5, 10, 10, 10, 10, 10]As matrizes associativas têm um índice que não é necessariamente um número inteiro e podem ser preenchidas de forma esparsa. O índice de uma matriz associativa é chamado deKey, e seu tipo é chamado de KeyType.
Os arrays associativos são declarados colocando o KeyType dentro de [] de uma declaração de array. Um exemplo simples de array associativo é mostrado abaixo.
import std.stdio;
void main () {
int[string] e; // associative array b of ints that are
e["test"] = 3;
writeln(e["test"]);
string[string] f;
f["test"] = "Tuts";
writeln(f["test"]);
writeln(f);
f.remove("test");
writeln(f);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
3
Tuts
["test":"Tuts"]
[]Inicializando Matriz Associativa
Uma inicialização simples de matriz associativa é mostrada abaixo.
import std.stdio;
void main () {
int[string] days =
[ "Monday" : 0,
"Tuesday" : 1,
"Wednesday" : 2,
"Thursday" : 3,
"Friday" : 4,
"Saturday" : 5,
"Sunday" : 6 ];
writeln(days["Tuesday"]);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
1Propriedades da Matriz Associativa
Aqui estão as propriedades de uma matriz associativa -
| Sr. Não. | Descrição da Propriedade |
|---|---|
| 1 | .sizeof Retorna o tamanho da referência ao array associativo; é 4 em compilações de 32 bits e 8 em compilações de 64 bits. |
| 2 | .length Retorna o número de valores na matriz associativa. Ao contrário dos arrays dinâmicos, é somente leitura. |
| 3 | .dup Crie uma nova matriz associativa do mesmo tamanho e copie o conteúdo da matriz associativa nela. |
| 4 | .keys Retorna a matriz dinâmica, cujos elementos são as chaves da matriz associativa. |
| 5 | .values Retorna a matriz dinâmica, cujos elementos são os valores da matriz associativa. |
| 6 | .rehash Reorganiza a matriz associativa no local para que as pesquisas sejam mais eficientes. O rehash é eficaz quando, por exemplo, o programa termina de carregar uma tabela de símbolos e agora precisa de pesquisas rápidas nela. Retorna uma referência à matriz reorganizada. |
| 7 | .byKey() Retorna um delegado adequado para uso como um Aggregate para um ForeachStatement que irá iterar sobre as chaves da matriz associativa. |
| 8 | .byValue() Retorna um delegado adequado para uso como um Aggregate para um ForeachStatement que irá iterar sobre os valores da matriz associativa. |
| 9 | .get(Key key, lazy Value defVal) Procura a chave; se existir, retorna o valor correspondente, então avalia e retorna defVal. |
| 10 | .remove(Key key) Remove um objeto para a chave. |
Exemplo
Um exemplo de uso das propriedades acima é mostrado abaixo.
import std.stdio;
void main () {
int[string] array1;
array1["test"] = 3;
array1["test2"] = 20;
writeln("sizeof: ",array1.sizeof);
writeln("length: ",array1.length);
writeln("dup: ",array1.dup);
array1.rehash;
writeln("rehashed: ",array1);
writeln("keys: ",array1.keys);
writeln("values: ",array1.values);
foreach (key; array1.byKey) {
writeln("by key: ",key);
}
foreach (value; array1.byValue) {
writeln("by value ",value);
}
writeln("get value for key test: ",array1.get("test",10));
writeln("get value for key test3: ",array1.get("test3",10));
array1.remove("test");
writeln(array1);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
sizeof: 8
length: 2
dup: ["test":3, "test2":20]
rehashed: ["test":3, "test2":20]
keys: ["test", "test2"]
values: [3, 20]
by key: test
by key: test2
by value 3
by value 20
get value for key test: 3
get value for key test3: 10
["test2":20]Os ponteiros de programação em D são fáceis e divertidos de aprender. Algumas tarefas de programação em D são realizadas mais facilmente com ponteiros, e outras tarefas de programação em D, como alocação de memória dinâmica, não podem ser realizadas sem eles. Um ponteiro simples é mostrado abaixo.
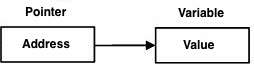
Em vez de apontar diretamente para a variável, o ponteiro aponta para o endereço da variável. Como você sabe, cada variável é um local da memória e cada local da memória tem seu endereço definido, que pode ser acessado usando o operador E comercial (&) que denota um endereço na memória. Considere o seguinte, que imprime o endereço das variáveis definidas -
import std.stdio;
void main () {
int var1;
writeln("Address of var1 variable: ",&var1);
char var2[10];
writeln("Address of var2 variable: ",&var2);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Address of var1 variable: 7FFF52691928
Address of var2 variable: 7FFF52691930O que são ponteiros?
UMA pointeré uma variável cujo valor é o endereço de outra variável. Como qualquer variável ou constante, você deve declarar um ponteiro antes de trabalhar com ele. A forma geral de uma declaração de variável de ponteiro é -
type *var-name;Aqui, typeé o tipo base do ponteiro; deve ser um tipo de programação válido evar-nameé o nome da variável de ponteiro. O asterisco que você usou para declarar um ponteiro é o mesmo asterisco que você usa para a multiplicação. Contudo; nesta declaração, o asterisco está sendo usado para designar uma variável como um ponteiro. A seguir estão as declarações de ponteiro válidas -
int *ip; // pointer to an integer
double *dp; // pointer to a double
float *fp; // pointer to a float
char *ch // pointer to characterO tipo de dados real do valor de todos os ponteiros, seja inteiro, flutuante, caractere ou outro, é o mesmo, um número hexadecimal longo que representa um endereço de memória. A única diferença entre ponteiros de diferentes tipos de dados é o tipo de dados da variável ou constante para a qual o ponteiro aponta.
Usando ponteiros na programação D
Existem algumas operações importantes, quando usamos os ponteiros com muita freqüência.
nós definimos variáveis de ponteiro
atribuir o endereço de uma variável a um ponteiro
finalmente acesse o valor no endereço disponível na variável de ponteiro.
Isso é feito usando o operador unário *que retorna o valor da variável localizada no endereço especificado por seu operando. O exemplo a seguir faz uso dessas operações -
import std.stdio;
void main () {
int var = 20; // actual variable declaration.
int *ip; // pointer variable
ip = &var; // store address of var in pointer variable
writeln("Value of var variable: ",var);
writeln("Address stored in ip variable: ",ip);
writeln("Value of *ip variable: ",*ip);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Value of var variable: 20
Address stored in ip variable: 7FFF5FB7E930
Value of *ip variable: 20Ponteiros nulos
É sempre uma boa prática atribuir o ponteiro NULL a uma variável de ponteiro, caso você não tenha o endereço exato a ser atribuído. Isso é feito no momento da declaração da variável. Um ponteiro atribuído a nulo é chamado denull ponteiro.
O ponteiro nulo é uma constante com valor zero definido em várias bibliotecas padrão, incluindo iostream. Considere o seguinte programa -
import std.stdio;
void main () {
int *ptr = null;
writeln("The value of ptr is " , ptr) ;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
The value of ptr is nullNa maioria dos sistemas operacionais, os programas não têm permissão para acessar a memória no endereço 0 porque essa memória é reservada pelo sistema operacional. Contudo; o endereço de memória 0 tem um significado especial; ele sinaliza que o ponteiro não se destina a apontar para um local de memória acessível.
Por convenção, se um ponteiro contém o valor nulo (zero), ele não aponta para nada. Para verificar se há um ponteiro nulo, você pode usar uma instrução if da seguinte maneira -
if(ptr) // succeeds if p is not null
if(!ptr) // succeeds if p is nullPortanto, se todos os ponteiros não usados receberem o valor nulo e você evitar o uso de um ponteiro nulo, poderá evitar o uso incorreto acidental de um ponteiro não inicializado. Muitas vezes, as variáveis não inicializadas contêm alguns valores inúteis e torna-se difícil depurar o programa.
Pointer Arithmetic
Existem quatro operadores aritméticos que podem ser usados em ponteiros: ++, -, + e -
Para entender a aritmética de ponteiros, vamos considerar um ponteiro inteiro chamado ptr, que aponta para o endereço 1000. Assumindo inteiros de 32 bits, vamos realizar a seguinte operação aritmática no ponteiro -
ptr++então o ptrirá apontar para a localização 1004 porque cada vez que ptr é incrementado, ele aponta para o próximo inteiro. Esta operação moverá o ponteiro para o próximo local da memória sem afetar o valor real no local da memória.
E se ptr aponta para um caractere cujo endereço é 1000, a operação acima aponta para o local 1001 porque o próximo caractere estará disponível em 1001.
Incrementando um Ponteiro
Preferimos usar um ponteiro em nosso programa em vez de um array porque o ponteiro da variável pode ser incrementado, ao contrário do nome do array que não pode ser incrementado porque é um ponteiro constante. O programa a seguir incrementa o ponteiro variável para acessar cada elemento sucessivo da matriz -
import std.stdio;
const int MAX = 3;
void main () {
int var[MAX] = [10, 100, 200];
int *ptr = &var[0];
for (int i = 0; i < MAX; i++, ptr++) {
writeln("Address of var[" , i , "] = ",ptr);
writeln("Value of var[" , i , "] = ",*ptr);
}
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Address of var[0] = 18FDBC
Value of var[0] = 10
Address of var[1] = 18FDC0
Value of var[1] = 100
Address of var[2] = 18FDC4
Value of var[2] = 200Ponteiros vs Array
Ponteiros e arrays estão fortemente relacionados. No entanto, ponteiros e matrizes não são completamente intercambiáveis. Por exemplo, considere o seguinte programa -
import std.stdio;
const int MAX = 3;
void main () {
int var[MAX] = [10, 100, 200];
int *ptr = &var[0];
var.ptr[2] = 290;
ptr[0] = 220;
for (int i = 0; i < MAX; i++, ptr++) {
writeln("Address of var[" , i , "] = ",ptr);
writeln("Value of var[" , i , "] = ",*ptr);
}
}No programa acima, você pode ver var.ptr [2] para definir o segundo elemento e ptr [0] que é usado para definir o elemento zero. O operador de incremento pode ser usado com ptr, mas não com var.
Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Address of var[0] = 18FDBC
Value of var[0] = 220
Address of var[1] = 18FDC0
Value of var[1] = 100
Address of var[2] = 18FDC4
Value of var[2] = 290Ponteiro para Ponteiro
Um ponteiro para um ponteiro é uma forma de múltiplas vias indiretas ou uma cadeia de ponteiros. Normalmente, um ponteiro contém o endereço de uma variável. Quando definimos um ponteiro para um ponteiro, o primeiro ponteiro contém o endereço do segundo ponteiro, que aponta para a localização que contém o valor real, conforme mostrado abaixo.

Uma variável que é um ponteiro para um ponteiro deve ser declarada como tal. Isso é feito colocando um asterisco adicional na frente de seu nome. Por exemplo, a seguir está a sintaxe para declarar um ponteiro para um ponteiro do tipo int -
int **var;Quando um valor de destino é indiretamente apontado por um ponteiro para um ponteiro, o acesso a esse valor requer que o operador asterisco seja aplicado duas vezes, conforme mostrado abaixo no exemplo -
import std.stdio;
const int MAX = 3;
void main () {
int var = 3000;
writeln("Value of var :" , var);
int *ptr = &var;
writeln("Value available at *ptr :" ,*ptr);
int **pptr = &ptr;
writeln("Value available at **pptr :",**pptr);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Value of var :3000
Value available at *ptr :3000
Value available at **pptr :3000Passando Ponteiro para Funções
D permite que você passe um ponteiro para uma função. Para fazer isso, ele simplesmente declara o parâmetro da função como um tipo de ponteiro.
O exemplo simples a seguir passa um ponteiro para uma função.
import std.stdio;
void main () {
// an int array with 5 elements.
int balance[5] = [1000, 2, 3, 17, 50];
double avg;
avg = getAverage( &balance[0], 5 ) ;
writeln("Average is :" , avg);
}
double getAverage(int *arr, int size) {
int i;
double avg, sum = 0;
for (i = 0; i < size; ++i) {
sum += arr[i];
}
avg = sum/size;
return avg;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Average is :214.4Return Pointer from Functions
Considere a seguinte função, que retorna 10 números usando um ponteiro, significa o endereço do primeiro elemento da matriz.
import std.stdio;
void main () {
int *p = getNumber();
for ( int i = 0; i < 10; i++ ) {
writeln("*(p + " , i , ") : ",*(p + i));
}
}
int * getNumber( ) {
static int r [10];
for (int i = 0; i < 10; ++i) {
r[i] = i;
}
return &r[0];
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
*(p + 0) : 0
*(p + 1) : 1
*(p + 2) : 2
*(p + 3) : 3
*(p + 4) : 4
*(p + 5) : 5
*(p + 6) : 6
*(p + 7) : 7
*(p + 8) : 8
*(p + 9) : 9Ponteiro para uma matriz
Um nome de array é um ponteiro constante para o primeiro elemento do array. Portanto, na declaração -
double balance[50];balanceé um ponteiro para & balance [0], que é o endereço do primeiro elemento do array balance. Assim, o seguinte fragmento de programa atribuip o endereço do primeiro elemento de balance -
double *p;
double balance[10];
p = balance;É legal usar nomes de array como ponteiros constantes e vice-versa. Portanto, * (saldo + 4) é uma forma legítima de acessar os dados em saldo [4].
Depois de armazenar o endereço do primeiro elemento em p, você pode acessar os elementos do array usando * p, * (p + 1), * (p + 2) e assim por diante. O exemplo a seguir mostra todos os conceitos discutidos acima -
import std.stdio;
void main () {
// an array with 5 elements.
double balance[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];
double *p;
p = &balance[0];
// output each array element's value
writeln("Array values using pointer " );
for ( int i = 0; i < 5; i++ ) {
writeln( "*(p + ", i, ") : ", *(p + i));
}
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Array values using pointer
*(p + 0) : 1000
*(p + 1) : 2
*(p + 2) : 3.4
*(p + 3) : 17
*(p + 4) : 50Tuplas são usadas para combinar vários valores como um único objeto. Tuplas contém uma sequência de elementos. Os elementos podem ser tipos, expressões ou aliases. O número e os elementos de uma tupla são fixos em tempo de compilação e não podem ser alterados em tempo de execução.
As tuplas têm características tanto de estruturas quanto de matrizes. Os elementos da tupla podem ser de diferentes tipos, como estruturas. Os elementos podem ser acessados por meio de indexação como matrizes. Eles são implementados como um recurso de biblioteca pelo modelo Tuple do módulo std.typecons. Tuple faz uso de TypeTuple do módulo std.typetuple para algumas de suas operações.
Tupla usando tupla ()
Tuplas podem ser construídas pela função tupla (). Os membros de uma tupla são acessados por valores de índice. Um exemplo é mostrado abaixo.
Exemplo
import std.stdio;
import std.typecons;
void main() {
auto myTuple = tuple(1, "Tuts");
writeln(myTuple);
writeln(myTuple[0]);
writeln(myTuple[1]);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Tuple!(int, string)(1, "Tuts")
1
TutsTupla usando modelo de tupla
A tupla também pode ser construída diretamente pelo modelo Tupla em vez da função tupla (). O tipo e o nome de cada membro são especificados como dois parâmetros de modelo consecutivos. É possível acessar os membros por propriedades quando criados usando modelos.
import std.stdio;
import std.typecons;
void main() {
auto myTuple = Tuple!(int, "id",string, "value")(1, "Tuts");
writeln(myTuple);
writeln("by index 0 : ", myTuple[0]);
writeln("by .id : ", myTuple.id);
writeln("by index 1 : ", myTuple[1]);
writeln("by .value ", myTuple.value);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado
Tuple!(int, "id", string, "value")(1, "Tuts")
by index 0 : 1
by .id : 1
by index 1 : Tuts
by .value TutsExpandindo parâmetros de propriedade e função
Os membros da Tupla podem ser expandidos pela propriedade .expand ou por fracionamento. Este valor expandido / fatiado pode ser passado como lista de argumentos de função. Um exemplo é mostrado abaixo.
Exemplo
import std.stdio;
import std.typecons;
void method1(int a, string b, float c, char d) {
writeln("method 1 ",a,"\t",b,"\t",c,"\t",d);
}
void method2(int a, float b, char c) {
writeln("method 2 ",a,"\t",b,"\t",c);
}
void main() {
auto myTuple = tuple(5, "my string", 3.3, 'r');
writeln("method1 call 1");
method1(myTuple[]);
writeln("method1 call 2");
method1(myTuple.expand);
writeln("method2 call 1");
method2(myTuple[0], myTuple[$-2..$]);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
method1 call 1
method 1 5 my string 3.3 r
method1 call 2
method 1 5 my string 3.3 r
method2 call 1
method 2 5 3.3 rTypeTuple
TypeTuple é definido no módulo std.typetuple. Uma lista de valores e tipos separados por vírgulas. Um exemplo simples usando TypeTuple é fornecido abaixo. TypeTuple é usado para criar lista de argumentos, lista de modelos e lista literal de array.
import std.stdio;
import std.typecons;
import std.typetuple;
alias TypeTuple!(int, long) TL;
void method1(int a, string b, float c, char d) {
writeln("method 1 ",a,"\t",b,"\t",c,"\t",d);
}
void method2(TL tl) {
writeln(tl[0],"\t", tl[1] );
}
void main() {
auto arguments = TypeTuple!(5, "my string", 3.3,'r');
method1(arguments);
method2(5, 6L);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
method 1 5 my string 3.3 r
5 6o structure é ainda outro tipo de dados definido pelo usuário disponível na programação D, que permite combinar itens de dados de diferentes tipos.
As estruturas são usadas para representar um registro. Suponha que você queira manter o controle de seus livros em uma biblioteca. Você pode querer rastrear os seguintes atributos sobre cada livro -
- Title
- Author
- Subject
- ID do livro
Definindo uma Estrutura
Para definir uma estrutura, você deve usar o structdeclaração. A instrução struct define um novo tipo de dados, com mais de um membro para seu programa. O formato da instrução de estrutura é este -
struct [structure tag] {
member definition;
member definition;
...
member definition;
} [one or more structure variables];o structure tagé opcional e cada definição de membro é uma definição de variável normal, como int i; ou flutuar f; ou qualquer outra definição de variável válida. No final da definição da estrutura antes do ponto e vírgula, você pode especificar uma ou mais variáveis de estrutura que são opcionais. Esta é a maneira como você declararia a estrutura de livros -
struct Books {
char [] title;
char [] author;
char [] subject;
int book_id;
};Acessando membros da estrutura
Para acessar qualquer membro de uma estrutura, você usa o member access operator (.). O operador de acesso de membro é codificado como um período entre o nome da variável de estrutura e o membro da estrutura que desejamos acessar. Você usariastructpalavra-chave para definir variáveis do tipo de estrutura. O exemplo a seguir explica o uso da estrutura -
import std.stdio;
struct Books {
char [] title;
char [] author;
char [] subject;
int book_id;
};
void main( ) {
Books Book1; /* Declare Book1 of type Book */
Books Book2; /* Declare Book2 of type Book */
/* book 1 specification */
Book1.title = "D Programming".dup;
Book1.author = "Raj".dup;
Book1.subject = "D Programming Tutorial".dup;
Book1.book_id = 6495407;
/* book 2 specification */
Book2.title = "D Programming".dup;
Book2.author = "Raj".dup;
Book2.subject = "D Programming Tutorial".dup;
Book2.book_id = 6495700;
/* print Book1 info */
writeln( "Book 1 title : ", Book1.title);
writeln( "Book 1 author : ", Book1.author);
writeln( "Book 1 subject : ", Book1.subject);
writeln( "Book 1 book_id : ", Book1.book_id);
/* print Book2 info */
writeln( "Book 2 title : ", Book2.title);
writeln( "Book 2 author : ", Book2.author);
writeln( "Book 2 subject : ", Book2.subject);
writeln( "Book 2 book_id : ", Book2.book_id);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Book 1 title : D Programming
Book 1 author : Raj
Book 1 subject : D Programming Tutorial
Book 1 book_id : 6495407
Book 2 title : D Programming
Book 2 author : Raj
Book 2 subject : D Programming Tutorial
Book 2 book_id : 6495700Estruturas como argumentos de função
Você pode passar uma estrutura como um argumento de função de maneira muito semelhante à que passa qualquer outra variável ou ponteiro. Você acessaria as variáveis de estrutura da mesma forma que acessou no exemplo acima -
import std.stdio;
struct Books {
char [] title;
char [] author;
char [] subject;
int book_id;
};
void main( ) {
Books Book1; /* Declare Book1 of type Book */
Books Book2; /* Declare Book2 of type Book */
/* book 1 specification */
Book1.title = "D Programming".dup;
Book1.author = "Raj".dup;
Book1.subject = "D Programming Tutorial".dup;
Book1.book_id = 6495407;
/* book 2 specification */
Book2.title = "D Programming".dup;
Book2.author = "Raj".dup;
Book2.subject = "D Programming Tutorial".dup;
Book2.book_id = 6495700;
/* print Book1 info */
printBook( Book1 );
/* Print Book2 info */
printBook( Book2 );
}
void printBook( Books book ) {
writeln( "Book title : ", book.title);
writeln( "Book author : ", book.author);
writeln( "Book subject : ", book.subject);
writeln( "Book book_id : ", book.book_id);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495407
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495700Inicialização de estruturas
As estruturas podem ser inicializadas em duas formas, uma usando o construtor e outra usando o formato {}. Um exemplo é mostrado abaixo.
Exemplo
import std.stdio;
struct Books {
char [] title;
char [] subject = "Empty".dup;
int book_id = -1;
char [] author = "Raj".dup;
};
void main( ) {
Books Book1 = Books("D Programming".dup, "D Programming Tutorial".dup, 6495407 );
printBook( Book1 );
Books Book2 = Books("D Programming".dup,
"D Programming Tutorial".dup, 6495407,"Raj".dup );
printBook( Book2 );
Books Book3 = {title:"Obj C programming".dup, book_id : 1001};
printBook( Book3 );
}
void printBook( Books book ) {
writeln( "Book title : ", book.title);
writeln( "Book author : ", book.author);
writeln( "Book subject : ", book.subject);
writeln( "Book book_id : ", book.book_id);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495407
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495407
Book title : Obj C programming
Book author : Raj
Book subject : Empty
Book book_id : 1001Membros estáticos
Variáveis estáticas são inicializadas apenas uma vez. Por exemplo, para ter ids únicos para os livros, podemos tornar o book_id como estático e incrementar o id do livro. Um exemplo é mostrado abaixo.
Exemplo
import std.stdio;
struct Books {
char [] title;
char [] subject = "Empty".dup;
int book_id;
char [] author = "Raj".dup;
static int id = 1000;
};
void main( ) {
Books Book1 = Books("D Programming".dup, "D Programming Tutorial".dup,++Books.id );
printBook( Book1 );
Books Book2 = Books("D Programming".dup, "D Programming Tutorial".dup,++Books.id);
printBook( Book2 );
Books Book3 = {title:"Obj C programming".dup, book_id:++Books.id};
printBook( Book3 );
}
void printBook( Books book ) {
writeln( "Book title : ", book.title);
writeln( "Book author : ", book.author);
writeln( "Book subject : ", book.subject);
writeln( "Book book_id : ", book.book_id);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 1001
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 1002
Book title : Obj C programming
Book author : Raj
Book subject : Empty
Book book_id : 1003UMA unioné um tipo de dados especial disponível em D que permite armazenar diferentes tipos de dados no mesmo local da memória. Você pode definir uma união com muitos membros, mas apenas um membro pode conter um valor a qualquer momento. As uniões fornecem uma maneira eficiente de usar o mesmo local de memória para vários fins.
Definindo uma União em D
Para definir uma união, você deve usar a instrução união de maneira muito semelhante à que fez ao definir a estrutura. A declaração de união define um novo tipo de dados, com mais de um membro para seu programa. O formato da declaração sindical é o seguinte -
union [union tag] {
member definition;
member definition;
...
member definition;
} [one or more union variables];o union tagé opcional e cada definição de membro é uma definição de variável normal, como int i; ou flutuar f; ou qualquer outra definição de variável válida. No final da definição da união, antes do ponto e vírgula final, você pode especificar uma ou mais variáveis de união, mas é opcional. Aqui está a maneira que você definiria um tipo de união chamado Data, que tem três membrosi, f, e str -
union Data {
int i;
float f;
char str[20];
} data;Uma variável de Datatype pode armazenar um inteiro, um número de ponto flutuante ou uma string de caracteres. Isso significa que uma única variável (mesmo local de memória) pode ser usada para armazenar vários tipos de dados. Você pode usar quaisquer tipos de dados integrados ou definidos pelo usuário dentro de uma união com base em seus requisitos.
A memória ocupada por um sindicato será grande o suficiente para conter o maior membro do sindicato. Por exemplo, no exemplo acima, o tipo de dados ocupará 20 bytes de espaço de memória porque este é o espaço máximo que pode ser ocupado por uma sequência de caracteres. O exemplo a seguir exibe o tamanho total da memória ocupada pela união acima -
import std.stdio;
union Data {
int i;
float f;
char str[20];
};
int main( ) {
Data data;
writeln( "Memory size occupied by data : ", data.sizeof);
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Memory size occupied by data : 20Acessando Sócios Sindicais
Para acessar qualquer membro de um sindicato, usamos o member access operator (.). O operador de acesso de membro é codificado como um período entre o nome da variável de união e o membro de união que desejamos acessar. Você usaria a palavra-chave união para definir variáveis do tipo união.
Exemplo
O exemplo a seguir explica o uso de união -
import std.stdio;
union Data {
int i;
float f;
char str[13];
};
void main( ) {
Data data;
data.i = 10;
data.f = 220.5;
data.str = "D Programming".dup;
writeln( "size of : ", data.sizeof);
writeln( "data.i : ", data.i);
writeln( "data.f : ", data.f);
writeln( "data.str : ", data.str);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
size of : 16
data.i : 1917853764
data.f : 4.12236e+30
data.str : D ProgrammingAqui, você pode ver que os valores de i e f membros da união foram corrompidos porque o valor final atribuído à variável ocupou o local da memória e esta é a razão que o valor de str membro está sendo impresso muito bem.
Agora vamos dar uma olhada no mesmo exemplo mais uma vez, onde usaremos uma variável por vez, que é o objetivo principal de ter união -
Exemplo Modificado
import std.stdio;
union Data {
int i;
float f;
char str[13];
};
void main( ) {
Data data;
writeln( "size of : ", data.sizeof);
data.i = 10;
writeln( "data.i : ", data.i);
data.f = 220.5;
writeln( "data.f : ", data.f);
data.str = "D Programming".dup;
writeln( "data.str : ", data.str);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
size of : 16
data.i : 10
data.f : 220.5
data.str : D ProgrammingAqui, todos os membros estão sendo impressos muito bem porque um membro está sendo usado por vez.
Os intervalos são uma abstração do acesso ao elemento. Essa abstração permite o uso de um grande número de algoritmos sobre um grande número de tipos de contêineres. Os intervalos enfatizam como os elementos do contêiner são acessados, ao contrário de como os contêineres são implementados. Intervalos é um conceito muito simples que se baseia em se um tipo define determinados conjuntos de funções de membro.
Os intervalos são parte integrante das fatias de D. D's por acaso são implementações do intervalo mais poderoso RandomAccessRange, e há muitos recursos de intervalo em Phobos. Muitos algoritmos de Phobos retornam objetos de alcance temporário. Por exemplo, filter () escolhe elementos maiores que 10 no código a seguir, na verdade retorna um objeto de intervalo, não uma matriz.
Intervalos de números
Intervalos numéricos são comumente usados e esses intervalos são do tipo int. Alguns exemplos para intervalos de números são mostrados abaixo -
// Example 1
foreach (value; 3..7)
// Example 2
int[] slice = array[5..10];Fobos
Intervalos relacionados a structs e interfaces de classe são intervalos de phobos. Phobos é o runtime oficial e a biblioteca padrão que vem com o compilador da linguagem D.
Existem vários tipos de intervalos, que incluem -
- InputRange
- ForwardRange
- BidirectionalRange
- RandomAccessRange
- OutputRange
InputRange
O intervalo mais simples é o intervalo de entrada. As outras faixas trazem mais requisitos além da faixa em que se baseiam. Existem três funções que InputRange requer -
empty- especifica se o intervalo está vazio; ele deve retornar verdadeiro quando o intervalo for considerado vazio; caso contrário, false.
front - Fornece acesso ao elemento no início do intervalo.
popFront() - Encurta o intervalo desde o início, removendo o primeiro elemento.
Exemplo
import std.stdio;
import std.string;
struct Student {
string name;
int number;
string toString() const {
return format("%s(%s)", name, number);
}
}
struct School {
Student[] students;
}
struct StudentRange {
Student[] students;
this(School school) {
this.students = school.students;
}
@property bool empty() const {
return students.length == 0;
}
@property ref Student front() {
return students[0];
}
void popFront() {
students = students[1 .. $];
}
}
void main() {
auto school = School([ Student("Raj", 1), Student("John", 2), Student("Ram", 3)]);
auto range = StudentRange(school);
writeln(range);
writeln(school.students.length);
writeln(range.front);
range.popFront;
writeln(range.empty);
writeln(range);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
[Raj(1), John(2), Ram(3)]
3
Raj(1)
false
[John(2), Ram(3)]ForwardRange
ForwardRange requer adicionalmente a parte da função de membro de salvamento das outras três funções de InputRange e retorna uma cópia do intervalo quando a função de salvamento é chamada.
import std.array;
import std.stdio;
import std.string;
import std.range;
struct FibonacciSeries {
int first = 0;
int second = 1;
enum empty = false; // infinite range
@property int front() const {
return first;
}
void popFront() {
int third = first + second;
first = second;
second = third;
}
@property FibonacciSeries save() const {
return this;
}
}
void report(T)(const dchar[] title, const ref T range) {
writefln("%s: %s", title, range.take(5));
}
void main() {
auto range = FibonacciSeries();
report("Original range", range);
range.popFrontN(2);
report("After removing two elements", range);
auto theCopy = range.save;
report("The copy", theCopy);
range.popFrontN(3);
report("After removing three more elements", range);
report("The copy", theCopy);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Original range: [0, 1, 1, 2, 3]
After removing two elements: [1, 2, 3, 5, 8]
The copy: [1, 2, 3, 5, 8]
After removing three more elements: [5, 8, 13, 21, 34]
The copy: [1, 2, 3, 5, 8]BidirectionalRange
BidirectionalRange também fornece duas funções de membro sobre as funções de membro de ForwardRange. A função posterior, semelhante à anterior, permite o acesso ao último elemento da gama. A função popBack é semelhante à função popFront e remove o último elemento do intervalo.
Exemplo
import std.array;
import std.stdio;
import std.string;
struct Reversed {
int[] range;
this(int[] range) {
this.range = range;
}
@property bool empty() const {
return range.empty;
}
@property int front() const {
return range.back; // reverse
}
@property int back() const {
return range.front; // reverse
}
void popFront() {
range.popBack();
}
void popBack() {
range.popFront();
}
}
void main() {
writeln(Reversed([ 1, 2, 3]));
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
[3, 2, 1]Infinite RandomAccessRange
opIndex () é adicionalmente necessário quando comparado ao ForwardRange. Além disso, o valor de uma função vazia deve ser conhecido no momento da compilação como falso. Um exemplo simples é explicado com intervalo de quadrados é mostrado abaixo.
import std.array;
import std.stdio;
import std.string;
import std.range;
import std.algorithm;
class SquaresRange {
int first;
this(int first = 0) {
this.first = first;
}
enum empty = false;
@property int front() const {
return opIndex(0);
}
void popFront() {
++first;
}
@property SquaresRange save() const {
return new SquaresRange(first);
}
int opIndex(size_t index) const {
/* This function operates at constant time */
immutable integerValue = first + cast(int)index;
return integerValue * integerValue;
}
}
bool are_lastTwoDigitsSame(int value) {
/* Must have at least two digits */
if (value < 10) {
return false;
}
/* Last two digits must be divisible by 11 */
immutable lastTwoDigits = value % 100;
return (lastTwoDigits % 11) == 0;
}
void main() {
auto squares = new SquaresRange();
writeln(squares[5]);
writeln(squares[10]);
squares.popFrontN(5);
writeln(squares[0]);
writeln(squares.take(50).filter!are_lastTwoDigitsSame);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
25
100
25
[100, 144, 400, 900, 1444, 1600, 2500]Finite RandomAccessRange
opIndex () e comprimento são adicionalmente necessários quando comparados ao intervalo bidirecional. Isso é explicado com a ajuda de um exemplo detalhado que usa a série Fibonacci e o exemplo de intervalo de quadrados usado anteriormente. Este exemplo funciona bem no compilador D normal, mas não funciona no compilador online.
Exemplo
import std.array;
import std.stdio;
import std.string;
import std.range;
import std.algorithm;
struct FibonacciSeries {
int first = 0;
int second = 1;
enum empty = false; // infinite range
@property int front() const {
return first;
}
void popFront() {
int third = first + second;
first = second;
second = third;
}
@property FibonacciSeries save() const {
return this;
}
}
void report(T)(const dchar[] title, const ref T range) {
writefln("%40s: %s", title, range.take(5));
}
class SquaresRange {
int first;
this(int first = 0) {
this.first = first;
}
enum empty = false;
@property int front() const {
return opIndex(0);
}
void popFront() {
++first;
}
@property SquaresRange save() const {
return new SquaresRange(first);
}
int opIndex(size_t index) const {
/* This function operates at constant time */
immutable integerValue = first + cast(int)index;
return integerValue * integerValue;
}
}
bool are_lastTwoDigitsSame(int value) {
/* Must have at least two digits */
if (value < 10) {
return false;
}
/* Last two digits must be divisible by 11 */
immutable lastTwoDigits = value % 100;
return (lastTwoDigits % 11) == 0;
}
struct Together {
const(int)[][] slices;
this(const(int)[][] slices ...) {
this.slices = slices.dup;
clearFront();
clearBack();
}
private void clearFront() {
while (!slices.empty && slices.front.empty) {
slices.popFront();
}
}
private void clearBack() {
while (!slices.empty && slices.back.empty) {
slices.popBack();
}
}
@property bool empty() const {
return slices.empty;
}
@property int front() const {
return slices.front.front;
}
void popFront() {
slices.front.popFront();
clearFront();
}
@property Together save() const {
return Together(slices.dup);
}
@property int back() const {
return slices.back.back;
}
void popBack() {
slices.back.popBack();
clearBack();
}
@property size_t length() const {
return reduce!((a, b) => a + b.length)(size_t.init, slices);
}
int opIndex(size_t index) const {
/* Save the index for the error message */
immutable originalIndex = index;
foreach (slice; slices) {
if (slice.length > index) {
return slice[index];
} else {
index -= slice.length;
}
}
throw new Exception(
format("Invalid index: %s (length: %s)", originalIndex, this.length));
}
}
void main() {
auto range = Together(FibonacciSeries().take(10).array, [ 777, 888 ],
(new SquaresRange()).take(5).array);
writeln(range.save);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 777, 888, 0, 1, 4, 9, 16]OutputRange
OutputRange representa a saída do elemento transmitido, semelhante ao envio de caracteres para o stdout. OutputRange requer suporte para a operação put (range, element). put () é uma função definida no módulo std.range. Ele determina as capacidades do intervalo e do elemento em tempo de compilação e usa o método mais apropriado para usar na saída dos elementos. Um exemplo simples é mostrado abaixo.
import std.algorithm;
import std.stdio;
struct MultiFile {
string delimiter;
File[] files;
this(string delimiter, string[] fileNames ...) {
this.delimiter = delimiter;
/* stdout is always included */
this.files ~= stdout;
/* A File object for each file name */
foreach (fileName; fileNames) {
this.files ~= File(fileName, "w");
}
}
void put(T)(T element) {
foreach (file; files) {
file.write(element, delimiter);
}
}
}
void main() {
auto output = MultiFile("\n", "output_0", "output_1");
copy([ 1, 2, 3], output);
copy([ "red", "blue", "green" ], output);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
[1, 2, 3]
["red", "blue", "green"]Alias, como o nome se refere, fornece um nome alternativo para nomes existentes. A sintaxe do alias é mostrada abaixo.
alias new_name = existing_name;A seguir está a sintaxe mais antiga, apenas no caso de você consultar alguns exemplos de formato mais antigos. É fortemente desencorajado o uso disso.
alias existing_name new_name;Há também outra sintaxe que é usada com expressão e é fornecida a seguir, na qual podemos usar diretamente o nome do alias em vez da expressão.
alias expression alias_name ;Como você deve saber, um typedef adiciona a capacidade de criar novos tipos. Alias pode fazer o trabalho de um typedef e ainda mais. Um exemplo simples para usar alias é mostrado abaixo, que usa o cabeçalho std.conv que fornece a capacidade de conversão de tipo.
import std.stdio;
import std.conv:to;
alias to!(string) toString;
void main() {
int a = 10;
string s = "Test"~toString(a);
writeln(s);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Test10No exemplo acima, em vez de usar to! String (a), atribuímos a ele o nome de alias toString, tornando-o mais conveniente e simples de entender.
Alias para uma tupla
Vejamos outro exemplo onde podemos definir um nome alternativo para uma tupla.
import std.stdio;
import std.typetuple;
alias TypeTuple!(int, long) TL;
void method1(TL tl) {
writeln(tl[0],"\t", tl[1] );
}
void main() {
method1(5, 6L);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
5 6No exemplo acima, o tipo tupla é atribuído à variável alias e simplifica a definição do método e o acesso às variáveis. Esse tipo de acesso é ainda mais útil quando tentamos reutilizar tuplas desse tipo.
Alias para tipos de dados
Muitas vezes, podemos definir tipos de dados comuns que precisam ser usados em todo o aplicativo. Quando vários programadores codificam um aplicativo, podem ser casos em que uma pessoa usa int, outra double e assim por diante. Para evitar tais conflitos, costumamos usar tipos para tipos de dados. Um exemplo simples é mostrado abaixo.
Exemplo
import std.stdio;
alias int myAppNumber;
alias string myAppString;
void main() {
myAppNumber i = 10;
myAppString s = "TestString";
writeln(i,s);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
10TestStringAlias para variáveis de classe
Freqüentemente, há um requisito em que precisamos acessar as variáveis de membro da superclasse na subclasse, isso pode ser possível com um alias, possivelmente com um nome diferente.
Caso você seja novo no conceito de classes e herança, dê uma olhada no tutorial sobre classes e herança antes de começar esta seção.
Exemplo
Um exemplo simples é mostrado abaixo.
import std.stdio;
class Shape {
int area;
}
class Square : Shape {
string name() const @property {
return "Square";
}
alias Shape.area squareArea;
}
void main() {
auto square = new Square;
square.squareArea = 42;
writeln(square.name);
writeln(square.squareArea);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Square
42Alias This
Alias, fornece a capacidade de conversões automáticas de tipos definidos pelo usuário. A sintaxe é mostrada abaixo, onde o alias das palavras-chave e isso são escritos em qualquer um dos lados da variável de membro ou função de membro.
alias member_variable_or_member_function this;Exemplo
Um exemplo é mostrado abaixo para mostrar o poder do alias this.
import std.stdio;
struct Rectangle {
long length;
long breadth;
double value() const @property {
return cast(double) length * breadth;
}
alias value this;
}
double volume(double rectangle, double height) {
return rectangle * height;
}
void main() {
auto rectangle = Rectangle(2, 3);
writeln(volume(rectangle, 5));
}No exemplo acima, você pode ver que o retângulo de estrutura é convertido em valor duplo com a ajuda do apelido deste método.
Quando o código acima é compilado e executado, ele produz o seguinte resultado -
30Mixins são estruturas que permitem a mistura do código gerado no código-fonte. Mixins podem ser dos seguintes tipos -
- Mixins de corda
- Mixins de modelo
- Mixin de namespaces
Mixins de corda
D tem a capacidade de inserir código como string, desde que essa string seja conhecida no momento da compilação. A sintaxe dos mixins de string é mostrada abaixo -
mixin (compile_time_generated_string)Exemplo
Um exemplo simples para mixins de cordas é mostrado abaixo.
import std.stdio;
void main() {
mixin(`writeln("Hello World!");`);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Hello World!Aqui está outro exemplo onde podemos passar a string em tempo de compilação para que os mixins possam usar as funções para reutilizar o código. É mostrado abaixo.
import std.stdio;
string print(string s) {
return `writeln("` ~ s ~ `");`;
}
void main() {
mixin (print("str1"));
mixin (print("str2"));
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
str1
str2Mixins de modelo
Os modelos de D definem padrões de código comuns, para o compilador gerar instâncias reais desse padrão. Os modelos podem gerar funções, estruturas, uniões, classes, interfaces e qualquer outro código D legal. A sintaxe dos mixins de template é mostrada abaixo.
mixin a_template!(template_parameters)Um exemplo simples para mixins de string é mostrado abaixo, onde criamos um template com a classe Department e um mixin instanciando um template e, portanto, tornando as funções setName e printNames disponíveis para a escola de estrutura.
Exemplo
import std.stdio;
template Department(T, size_t count) {
T[count] names;
void setName(size_t index, T name) {
names[index] = name;
}
void printNames() {
writeln("The names");
foreach (i, name; names) {
writeln(i," : ", name);
}
}
}
struct College {
mixin Department!(string, 2);
}
void main() {
auto college = College();
college.setName(0, "name1");
college.setName(1, "name2");
college.printNames();
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
The names
0 : name1
1 : name2Mixin Name Spaces
Os espaços de nomes do Mixin são usados para evitar ambiguidades nos mixins de template. Por exemplo, pode haver duas variáveis, uma definida explicitamente em principal e a outra é misturada. Quando um nome misturado é igual a um nome que está no escopo circundante, então o nome que está no escopo circundante obtém usava. Este exemplo é mostrado abaixo.
Exemplo
import std.stdio;
template Person() {
string name;
void print() {
writeln(name);
}
}
void main() {
string name;
mixin Person a;
name = "name 1";
writeln(name);
a.name = "name 2";
print();
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
name 1
name 2Módulos são os blocos de construção de D. Eles são baseados em um conceito simples. Cada arquivo de origem é um módulo. Conseqüentemente, os arquivos individuais nos quais escrevemos os programas são módulos individuais. Por padrão, o nome de um módulo é igual ao nome do arquivo sem a extensão .d.
Quando especificado explicitamente, o nome do módulo é definido pela palavra-chave do módulo, que deve aparecer como a primeira linha sem comentário no arquivo de origem. Por exemplo, suponha que o nome de um arquivo de origem seja "funcionário.d". Em seguida, o nome do módulo é especificado pela palavra-chave do módulo seguida por funcionário . É como mostrado abaixo.
module employee;
class Employee {
// Class definition goes here.
}A linha do módulo é opcional. Quando não especificado, é igual ao nome do arquivo sem a extensão .d.
Nomes de arquivos e módulos
D suporta Unicode no código-fonte e nomes de módulo. No entanto, o suporte Unicode de sistemas de arquivos varia. Por exemplo, embora a maioria dos sistemas de arquivos Linux suporte Unicode, os nomes dos arquivos nos sistemas de arquivos Windows podem não distinguir entre letras maiúsculas e minúsculas. Além disso, a maioria dos sistemas de arquivos limita os caracteres que podem ser usados em nomes de arquivos e diretórios. Por motivos de portabilidade, recomendo que você use apenas letras ASCII minúsculas nos nomes dos arquivos. Por exemplo, "funcionário.d" seria um nome de arquivo adequado para uma classe chamada funcionário.
Assim, o nome do módulo também consistiria em letras ASCII -
module employee; // Module name consisting of ASCII letters
class eëmployëë { }Pacotes D
Uma combinação de módulos relacionados é chamada de pacote. Os pacotes D também têm um conceito simples: os arquivos-fonte que estão dentro do mesmo diretório são considerados como pertencendo ao mesmo pacote. O nome do diretório se torna o nome do pacote, que também deve ser especificado como as primeiras partes dos nomes dos módulos.
Por exemplo, se "funcionário.d" e "escritório.d" estiverem dentro do diretório "empresa", a especificação do nome do diretório junto com o nome do módulo os tornará parte do mesmo pacote -
module company.employee;
class Employee { }Da mesma forma, para o módulo de escritório -
module company.office;
class Office { }Como os nomes dos pacotes correspondem aos nomes dos diretórios, os nomes dos pacotes dos módulos mais profundos do que um nível de diretório devem refletir essa hierarquia. Por exemplo, se o diretório "empresa" incluiu um diretório "filial", o nome de um módulo dentro desse diretório também incluiria a filial.
module company.branch.employee;Usando Módulos em Programas
A palavra-chave import, que temos usado em quase todos os programas até agora, é para a introdução de um módulo ao módulo atual -
import std.stdio;O nome do módulo também pode conter o nome do pacote. Por exemplo, o std. a parte acima indica que stdio é um módulo que faz parte do pacote std.
Localizações de Módulos
O compilador encontra os arquivos do módulo convertendo os nomes do pacote e do módulo diretamente em nomes de diretório e arquivo.
Por exemplo, os dois módulos funcionário e escritório estariam localizados como "empresa / funcionário.d" e "animal / escritório.d", respectivamente (ou "empresa \ funcionário.d" e "empresa \ escritório.d", dependendo de o sistema de arquivos) para company.employee e company.office.
Nomes de módulos longos e curtos
Os nomes que são usados no programa podem ser escritos com os nomes dos módulos e pacotes conforme mostrado abaixo.
import company.employee;
auto employee0 = Employee();
auto employee1 = company.employee.Employee();Os nomes longos normalmente não são necessários, mas às vezes há conflitos de nomes. Por exemplo, ao se referir a um nome que aparece em mais de um módulo, o compilador não pode decidir a qual deles se refere. O programa a seguir está soletrando os nomes longos para distinguir entre duas estruturas de funcionários separadas que são definidas em dois módulos separados: empresa e faculdade. .
O primeiro módulo de funcionário na pasta company é o seguinte.
module company.employee;
import std.stdio;
class Employee {
public:
string str;
void print() {
writeln("Company Employee: ",str);
}
}O segundo módulo de funcionário na faculdade de pasta é o seguinte.
module college.employee;
import std.stdio;
class Employee {
public:
string str;
void print() {
writeln("College Employee: ",str);
}
}O módulo principal em hello.d deve ser salvo na pasta que contém as pastas da faculdade e da empresa. É o seguinte.
import company.employee;
import college.employee;
import std.stdio;
void main() {
auto myemployee1 = new company.employee.Employee();
myemployee1.str = "emp1";
myemployee1.print();
auto myemployee2 = new college.employee.Employee();
myemployee2.str = "emp2";
myemployee2.print();
}A palavra-chave import não é suficiente para tornar os módulos partes do programa. Ele simplesmente disponibiliza os recursos de um módulo dentro do módulo atual. Isso é necessário apenas para compilar o código.
Para que o programa acima seja construído, "empresa / funcionário.d" e "faculdade / funcionário.d" também devem ser especificados na linha de compilação.
Quando o código acima é compilado e executado, ele produz o seguinte resultado -
$ dmd hello.d company/employee.d college/employee.d -ofhello.amx
$ ./hello.amx
Company Employee: emp1
College Employee: emp2Os modelos são a base da programação genérica, que envolve escrever código de uma maneira independente de qualquer tipo específico.
Um modelo é um projeto ou fórmula para criar uma classe ou função genérica.
Os modelos são o recurso que permite descrever o código como um padrão, para que o compilador gere o código do programa automaticamente. Partes do código-fonte podem ser deixadas para o compilador para serem preenchidas até que essa parte seja realmente usada no programa. O compilador preenche as partes ausentes.
Template de Função
Definir uma função como um modelo é deixar um ou mais dos tipos que ela usa como não especificado, a ser deduzido posteriormente pelo compilador. Os tipos que não foram especificados são definidos na lista de parâmetros do modelo, que fica entre o nome da função e a lista de parâmetros da função. Por esse motivo, os modelos de função têm duas listas de parâmetros -
- lista de parâmetros de modelo
- lista de parâmetros de função
import std.stdio;
void print(T)(T value) {
writefln("%s", value);
}
void main() {
print(42);
print(1.2);
print("test");
}Se compilarmos e executarmos o código acima, isso produzirá o seguinte resultado -
42
1.2
testModelo de função com vários parâmetros de tipo
Pode haver vários tipos de parâmetros. Eles são mostrados no exemplo a seguir.
import std.stdio;
void print(T1, T2)(T1 value1, T2 value2) {
writefln(" %s %s", value1, value2);
}
void main() {
print(42, "Test");
print(1.2, 33);
}Se compilarmos e executarmos o código acima, isso produzirá o seguinte resultado -
42 Test
1.2 33Modelos de classes
Assim como podemos definir modelos de função, também podemos definir modelos de classe. O exemplo a seguir define a classe Stack e implementa métodos genéricos para enviar e retirar os elementos da pilha.
import std.stdio;
import std.string;
class Stack(T) {
private:
T[] elements;
public:
void push(T element) {
elements ~= element;
}
void pop() {
--elements.length;
}
T top() const @property {
return elements[$ - 1];
}
size_t length() const @property {
return elements.length;
}
}
void main() {
auto stack = new Stack!string;
stack.push("Test1");
stack.push("Test2");
writeln(stack.top);
writeln(stack.length);
stack.pop;
writeln(stack.top);
writeln(stack.length);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Test2
2
Test1
1Freqüentemente, usamos variáveis que são mutáveis, mas pode haver muitas ocasiões em que a mutabilidade não é necessária. Variáveis imutáveis podem ser usadas em tais casos. Alguns exemplos são fornecidos abaixo, onde variáveis imutáveis podem ser usadas.
No caso de constantes matemáticas, como pi, que nunca mudam.
No caso de arrays onde queremos reter valores e não há requisitos de mutação.
A imutabilidade permite entender se as variáveis são imutáveis ou mutáveis garantindo que certas operações não alterem certas variáveis. Também reduz o risco de certos tipos de erros de programa. O conceito de imutabilidade de D é representado pelas palavras-chave const e immutable. Embora as duas palavras tenham um significado semelhante, suas responsabilidades nos programas são diferentes e, às vezes, incompatíveis.
O conceito de imutabilidade de D é representado pelas palavras-chave const e immutable. Embora as duas palavras tenham um significado semelhante, suas responsabilidades nos programas são diferentes e, às vezes, incompatíveis.
Tipos de variáveis imutáveis em D
Existem três tipos de variáveis de definição que nunca podem sofrer mutação.
- constantes enum
- variáveis imutáveis
- variáveis const
enum Constants in D
As constantes enum possibilitam relacionar valores constantes a nomes significativos. Um exemplo simples é mostrado abaixo.
Exemplo
import std.stdio;
enum Day{
Sunday = 1,
Monday,
Tuesday,
Wednesday,
Thursday,
Friday,
Saturday
}
void main() {
Day day;
day = Day.Sunday;
if (day == Day.Sunday) {
writeln("The day is Sunday");
}
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
The day is SundayVariáveis imutáveis em D
Variáveis imutáveis podem ser determinadas durante a execução do programa. Ele apenas direciona o compilador para que após a inicialização, ele se torne imutável. Um exemplo simples é mostrado abaixo.
Exemplo
import std.stdio;
import std.random;
void main() {
int min = 1;
int max = 10;
immutable number = uniform(min, max + 1);
// cannot modify immutable expression number
// number = 34;
typeof(number) value = 100;
writeln(typeof(number).stringof, number);
writeln(typeof(value).stringof, value);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
immutable(int)4
immutable(int)100Você pode ver no exemplo acima como é possível transferir o tipo de dados para outra variável e usar stringof durante a impressão.
Variáveis Const em D
Variáveis Const não podem ser modificadas de forma semelhante a imutáveis. variáveis imutáveis podem ser passadas para funções como seus parâmetros imutáveis e, portanto, é recomendado usar imutável em vez de const. O mesmo exemplo usado anteriormente é modificado para const conforme mostrado abaixo.
Exemplo
import std.stdio;
import std.random;
void main() {
int min = 1;
int max = 10;
const number = uniform(min, max + 1);
// cannot modify const expression number|
// number = 34;
typeof(number) value = 100;
writeln(typeof(number).stringof, number);
writeln(typeof(value).stringof, value);
}Se compilarmos e executarmos o código acima, isso produzirá o seguinte resultado -
const(int)7
const(int)100Parâmetros imutáveis em D
const apaga as informações sobre se a variável original é mutável ou imutável e, portanto, usar imutável faz com que ela passe para outras funções com o tipo original retido. Um exemplo simples é mostrado abaixo.
Exemplo
import std.stdio;
void print(immutable int[] array) {
foreach (i, element; array) {
writefln("%s: %s", i, element);
}
}
void main() {
immutable int[] array = [ 1, 2 ];
print(array);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
0: 1
1: 2Os arquivos são representados pela estrutura File do módulo std.stdio. Um arquivo representa uma seqüência de bytes, não importa se é um arquivo de texto ou binário.
A linguagem de programação D fornece acesso a funções de alto nível, bem como chamadas de baixo nível (nível do sistema operacional) para manipular arquivos em seus dispositivos de armazenamento.
Abrindo arquivos em D
Os fluxos de entrada e saída padrão stdin e stdout já estão abertos quando os programas começam a ser executados. Eles estão prontos para serem usados. Por outro lado, os arquivos devem primeiro ser abertos especificando o nome do arquivo e os direitos de acesso necessários.
File file = File(filepath, "mode");Aqui, filename é uma string literal, que você usa para nomear o arquivo e acessar mode pode ter um dos seguintes valores -
| Sr. Não. | Modo e descrição |
|---|---|
| 1 | r Abre um arquivo de texto existente para fins de leitura. |
| 2 | w Abre um arquivo de texto para escrita; se não existir, um novo arquivo será criado. Aqui, o seu programa começará a escrever o conteúdo desde o início do arquivo. |
| 3 | a Abre um arquivo de texto para gravação em modo de acréscimo; se ele não existir, um novo arquivo será criado. Aqui, seu programa começará a anexar conteúdo ao conteúdo do arquivo existente. |
| 4 | r+ Abre um arquivo de texto para leitura e escrita. |
| 5 | w+ Abre um arquivo de texto para leitura e escrita. Ele primeiro trunca o arquivo para comprimento zero se ele existir, caso contrário, crie o arquivo se ele não existir. |
| 6 | a+ Abre um arquivo de texto para leitura e escrita. Ele cria o arquivo se ele não existir. A leitura começará do início, mas a escrita só pode ser anexada. |
Fechando um arquivo em D
Para fechar um arquivo, use a função file.close () onde o arquivo contém a referência do arquivo. O protótipo desta função é -
file.close();Qualquer arquivo que foi aberto por um programa deve ser fechado quando o programa terminar de usar esse arquivo. Na maioria dos casos, os arquivos não precisam ser fechados explicitamente; eles são fechados automaticamente quando os objetos File são encerrados.
Escrevendo um arquivo em D
file.writeln é usado para gravar em um arquivo aberto.
file.writeln("hello");import std.stdio;
import std.file;
void main() {
File file = File("test.txt", "w");
file.writeln("hello");
file.close();
}Quando o código acima é compilado e executado, ele cria um novo arquivo test.txt no diretório em que foi iniciado (no diretório de trabalho do programa).
Lendo um arquivo em D
O método a seguir lê uma única linha de um arquivo -
string s = file.readln();Um exemplo completo de leitura e gravação é mostrado abaixo.
import std.stdio;
import std.file;
void main() {
File file = File("test.txt", "w");
file.writeln("hello");
file.close();
file = File("test.txt", "r");
string s = file.readln();
writeln(s);
file.close();
}Quando o código acima é compilado e executado, ele lê o arquivo criado na seção anterior e produz o seguinte resultado -
helloAqui está outro exemplo para ler o arquivo até o final do arquivo.
import std.stdio;
import std.string;
void main() {
File file = File("test.txt", "w");
file.writeln("hello");
file.writeln("world");
file.close();
file = File("test.txt", "r");
while (!file.eof()) {
string line = chomp(file.readln());
writeln("line -", line);
}
}Quando o código acima é compilado e executado, ele lê o arquivo criado na seção anterior e produz o seguinte resultado -
line -hello
line -world
line -Você pode ver no exemplo acima uma terceira linha vazia, pois writeln a leva para a próxima linha assim que for executada.
Simultaneidade é fazer um programa rodar em vários threads ao mesmo tempo. Um exemplo de programa simultâneo é um servidor da Web respondendo a vários clientes ao mesmo tempo. A simultaneidade é fácil com a passagem de mensagens, mas muito difícil de escrever se forem baseadas no compartilhamento de dados.
Os dados transmitidos entre threads são chamados de mensagens. As mensagens podem ser compostas de qualquer tipo e qualquer número de variáveis. Cada tópico tem um id, que é usado para especificar os destinatários das mensagens. Qualquer thread que inicia outro thread é chamado de proprietário do novo thread.
Iniciando Threads em D
A função spawn () pega um ponteiro como parâmetro e inicia um novo thread a partir dessa função. Todas as operações realizadas por essa função, incluindo outras funções que ela pode chamar, seriam executadas no novo encadeamento. O proprietário e o trabalhador começam a executar separadamente, como se fossem programas independentes.
Exemplo
import std.stdio;
import std.stdio;
import std.concurrency;
import core.thread;
void worker(int a) {
foreach (i; 0 .. 4) {
Thread.sleep(1);
writeln("Worker Thread ",a + i);
}
}
void main() {
foreach (i; 1 .. 4) {
Thread.sleep(2);
writeln("Main Thread ",i);
spawn(≈worker, i * 5);
}
writeln("main is done.");
}Quando o código acima é compilado e executado, ele lê o arquivo criado na seção anterior e produz o seguinte resultado -
Main Thread 1
Worker Thread 5
Main Thread 2
Worker Thread 6
Worker Thread 10
Main Thread 3
main is done.
Worker Thread 7
Worker Thread 11
Worker Thread 15
Worker Thread 8
Worker Thread 12
Worker Thread 16
Worker Thread 13
Worker Thread 17
Worker Thread 18Identificadores de thread em D
A variável thisTid disponível globalmente no nível do módulo é sempre o id do segmento atual. Além disso, você pode receber o threadId quando o spawn for chamado. Um exemplo é mostrado abaixo.
Exemplo
import std.stdio;
import std.concurrency;
void printTid(string tag) {
writefln("%s: %s, address: %s", tag, thisTid, &thisTid);
}
void worker() {
printTid("Worker");
}
void main() {
Tid myWorker = spawn(&worker);
printTid("Owner ");
writeln(myWorker);
}Quando o código acima é compilado e executado, ele lê o arquivo criado na seção anterior e produz o seguinte resultado -
Owner : Tid(std.concurrency.MessageBox), address: 10C71A59C
Worker: Tid(std.concurrency.MessageBox), address: 10C71A59C
Tid(std.concurrency.MessageBox)Passagem de mensagens em D
A função send () envia mensagens e a função receiveOnly () espera por uma mensagem de um tipo específico. Existem outras funções chamadas prioritySend (), receive () e receiveTimeout (), que são explicadas posteriormente.
O proprietário no programa a seguir envia a seu trabalhador uma mensagem do tipo int e aguarda uma mensagem do trabalhador do tipo double. Os threads continuam enviando mensagens para frente e para trás até que o proprietário envie um int negativo. Um exemplo é mostrado abaixo.
Exemplo
import std.stdio;
import std.concurrency;
import core.thread;
import std.conv;
void workerFunc(Tid tid) {
int value = 0;
while (value >= 0) {
value = receiveOnly!int();
auto result = to!double(value) * 5; tid.send(result);
}
}
void main() {
Tid worker = spawn(&workerFunc,thisTid);
foreach (value; 5 .. 10) {
worker.send(value);
auto result = receiveOnly!double();
writefln("sent: %s, received: %s", value, result);
}
worker.send(-1);
}Quando o código acima é compilado e executado, ele lê o arquivo criado na seção anterior e produz o seguinte resultado -
sent: 5, received: 25
sent: 6, received: 30
sent: 7, received: 35
sent: 8, received: 40
sent: 9, received: 45Passagem de mensagem com espera em D
Um exemplo simples com a mensagem passando com espera é mostrado abaixo.
import std.stdio;
import std.concurrency;
import core.thread;
import std.conv;
void workerFunc(Tid tid) {
Thread.sleep(dur!("msecs")( 500 ),);
tid.send("hello");
}
void main() {
spawn(&workerFunc,thisTid);
writeln("Waiting for a message");
bool received = false;
while (!received) {
received = receiveTimeout(dur!("msecs")( 100 ), (string message) {
writeln("received: ", message);
});
if (!received) {
writeln("... no message yet");
}
}
}Quando o código acima é compilado e executado, ele lê o arquivo criado na seção anterior e produz o seguinte resultado -
Waiting for a message
... no message yet
... no message yet
... no message yet
... no message yet
received: helloUma exceção é um problema que surge durante a execução de um programa. A exceção AD é uma resposta a uma circunstância excepcional que surge durante a execução de um programa, como uma tentativa de divisão por zero.
As exceções fornecem uma maneira de transferir o controle de uma parte de um programa para outra. O tratamento de exceções D é baseado em três palavras-chavetry, catch, e throw.
throw- Um programa lança uma exceção quando um problema aparece. Isso é feito usando umthrow palavra-chave.
catch- Um programa captura uma exceção com um manipulador de exceção no local de um programa onde você deseja manipular o problema. ocatch palavra-chave indica a captura de uma exceção.
try - A tryblock identifica um bloco de código para o qual determinadas exceções são ativadas. Ele é seguido por um ou mais blocos catch.
Assumindo que um bloco levantará uma exceção, um método captura uma exceção usando uma combinação de try e catchpalavras-chave. Um bloco try / catch é colocado em torno do código que pode gerar uma exceção. O código dentro de um bloco try / catch é referido como código protegido, e a sintaxe para usar try / catch se parece com a seguinte -
try {
// protected code
}
catch( ExceptionName e1 ) {
// catch block
}
catch( ExceptionName e2 ) {
// catch block
}
catch( ExceptionName eN ) {
// catch block
}Você pode listar vários catch declarações para capturar diferentes tipos de exceções no caso de seu try block levanta mais de uma exceção em diferentes situações.
Lançando exceções em D
As exceções podem ser lançadas em qualquer lugar dentro de um bloco de código usando throwafirmações. O operando das instruções de lançamento determina um tipo para a exceção e pode ser qualquer expressão e o tipo do resultado da expressão determina o tipo de exceção lançada.
O exemplo a seguir lança uma exceção quando ocorre a divisão por zero -
Exemplo
double division(int a, int b) {
if( b == 0 ) {
throw new Exception("Division by zero condition!");
}
return (a/b);
}Capturando exceções em D
o catch bloco seguindo o trybloco captura qualquer exceção. Você pode especificar o tipo de exceção que deseja capturar e isso é determinado pela declaração de exceção que aparece entre parênteses após a palavra-chave catch.
try {
// protected code
}
catch( ExceptionName e ) {
// code to handle ExceptionName exception
}O código acima captura uma exceção de ExceptionNametipo. Se você quiser especificar que um bloco catch deve lidar com qualquer tipo de exceção que é lançada em um bloco try, você deve colocar reticências, ..., entre os parênteses envolvendo a declaração de exceção da seguinte maneira -
try {
// protected code
}
catch(...) {
// code to handle any exception
}O exemplo a seguir lança uma exceção de divisão por zero. Ele está preso no bloco de captura.
import std.stdio;
import std.string;
string division(int a, int b) {
string result = "";
try {
if( b == 0 ) {
throw new Exception("Cannot divide by zero!");
} else {
result = format("%s",a/b);
}
} catch (Exception e) {
result = e.msg;
}
return result;
}
void main () {
int x = 50;
int y = 0;
writeln(division(x, y));
y = 10;
writeln(division(x, y));
}Quando o código acima é compilado e executado, ele lê o arquivo criado na seção anterior e produz o seguinte resultado -
Cannot divide by zero!
5A programação de contrato na programação D se concentra em fornecer um meio simples e compreensível de tratamento de erros. A programação de contrato em D é implementada por três tipos de blocos de código -
- bloqueio corporal
- em bloco
- fora do bloco
Bloco corporal em D
O bloco de corpo contém o código de funcionalidade real de execução. Os blocos de entrada e saída são opcionais, enquanto o bloco do corpo é obrigatório. Uma sintaxe simples é mostrada abaixo.
return_type function_name(function_params)
in {
// in block
}
out (result) {
// in block
}
body {
// actual function block
}No Bloco para Pré-condições em D
Em bloco é para pré-condições simples que verificam se os parâmetros de entrada são aceitáveis e dentro da faixa que pode ser manipulada pelo código. Um benefício de um bloco interno é que todas as condições de entrada podem ser mantidas juntas e separadas do corpo real da função. Uma pré-condição simples para validar a senha para seu comprimento mínimo é mostrada abaixo.
import std.stdio;
import std.string;
bool isValid(string password)
in {
assert(password.length>=5);
}
body {
// other conditions
return true;
}
void main() {
writeln(isValid("password"));
}Quando o código acima é compilado e executado, ele lê o arquivo criado na seção anterior e produz o seguinte resultado -
trueBlocos de saída para pós-condições em D
O bloco de saída cuida dos valores de retorno da função. Ele valida se o valor de retorno está na faixa esperada. Um exemplo simples contendo entrada e saída é mostrado abaixo, que converte meses, ano em uma forma de idade decimal combinada.
import std.stdio;
import std.string;
double getAge(double months,double years)
in {
assert(months >= 0);
assert(months <= 12);
}
out (result) {
assert(result>=years);
}
body {
return years + months/12;
}
void main () {
writeln(getAge(10,12));
}Quando o código acima é compilado e executado, ele lê o arquivo criado na seção anterior e produz o seguinte resultado -
12.8333Compilação condicional é o processo de selecionar qual código compilar e qual código não compilar, semelhante a #if / #else / #endif em C e C ++. Qualquer instrução que não seja compilada ainda deve ser sintaticamente correta.
A compilação condicional envolve verificações de condições que podem ser avaliadas em tempo de compilação. Instruções condicionais de tempo de execução como if, for, while não são recursos de compilação condicional. Os seguintes recursos de D são destinados à compilação condicional -
- debug
- version
- estático se
Declaração de depuração em D
A depuração é útil durante o desenvolvimento do programa. As expressões e instruções marcadas como depuração são compiladas no programa apenas quando a opção do compilador -debug está ativada.
debug a_conditionally_compiled_expression;
debug {
// ... conditionally compiled code ...
} else {
// ... code that is compiled otherwise ...
}A cláusula else é opcional. A expressão única e o bloco de código acima são compilados apenas quando a opção -debug do compilador está habilitada.
Em vez de serem totalmente removidas, as linhas podem ser marcadas como depuração.
debug writefln("%s debug only statement", value);Essas linhas são incluídas no programa apenas quando a opção -debug do compilador está ativada.
dmd test.d -oftest -w -debugDeclaração de depuração (tag) em D
As instruções de depuração podem receber nomes (tags) para serem incluídas no programa seletivamente.
debug(mytag) writefln("%s not found", value);Essas linhas são incluídas no programa apenas quando a opção -debug do compilador está ativada.
dmd test.d -oftest -w -debug = mytagOs blocos de depuração também podem ter tags.
debug(mytag) {
//
}É possível habilitar mais de uma tag de depuração por vez.
dmd test.d -oftest -w -debug = mytag1 -debug = mytag2Declaração de depuração (nível) em D
Às vezes, é mais útil associar instruções de depuração por níveis numéricos. Níveis crescentes podem fornecer informações mais detalhadas.
import std.stdio;
void myFunction() {
debug(1) writeln("debug1");
debug(2) writeln("debug2");
}
void main() {
myFunction();
}As expressões de depuração e os blocos que são menores ou iguais ao nível especificado seriam compilados.
$ dmd test.d -oftest -w -debug = 1 $ ./test
debug1Declarações de versão (tag) e versão (nível) em D
A versão é semelhante à depuração e é usada da mesma maneira. A cláusula else é opcional. Embora a versão funcione essencialmente da mesma forma que a depuração, ter palavras-chave separadas ajuda a distinguir seus usos não relacionados. Tal como acontece com a depuração, mais de uma versão pode ser habilitada.
import std.stdio;
void myFunction() {
version(1) writeln("version1");
version(2) writeln("version2");
}
void main() {
myFunction();
}As expressões de depuração e os blocos que são menores ou iguais ao nível especificado seriam compilados.
$ dmd test.d -oftest -w -version = 1 $ ./test
version1Estático se
If estático é o equivalente em tempo de compilação da instrução if. Assim como a instrução if, if static pega uma expressão lógica e a avalia. Ao contrário da instrução if, estático if não é sobre o fluxo de execução; em vez disso, determina se um trecho de código deve ser incluído no programa ou não.
A expressão if não está relacionada ao operador is que vimos anteriormente, tanto sintaticamente quanto semanticamente. Ele é avaliado em tempo de compilação. Ele produz um valor int, 0 ou 1; dependendo da expressão especificada entre parênteses. Embora a expressão que ele assume não seja uma expressão lógica, a própria expressão é usada como uma expressão lógica de tempo de compilação. É especialmente útil em restrições estáticas se condicionais e de modelo.
import std.stdio;
enum Days {
sun,
mon,
tue,
wed,
thu,
fri,
sat
};
void myFunction(T)(T mytemplate) {
static if (is (T == class)) {
writeln("This is a class type");
} else static if (is (T == enum)) {
writeln("This is an enum type");
}
}
void main() {
Days day;
myFunction(day);
}Quando compilarmos e executarmos, obteremos alguma saída como segue.
This is an enum typeAs classes são o recurso central da programação em D que oferece suporte à programação orientada a objetos e costumam ser chamadas de tipos definidos pelo usuário.
Uma classe é usada para especificar a forma de um objeto e combina representação de dados e métodos para manipular esses dados em um pacote organizado. Os dados e funções dentro de uma classe são chamados de membros da classe.
Definições de classe D
Ao definir uma classe, você define um blueprint para um tipo de dados. Na verdade, isso não define nenhum dado, mas define o que significa o nome da classe, ou seja, em que consistirá um objeto da classe e quais operações podem ser executadas nesse objeto.
Uma definição de classe começa com a palavra-chave classseguido pelo nome da classe; e o corpo da classe, delimitado por um par de chaves. Uma definição de classe deve ser seguida por um ponto e vírgula ou uma lista de declarações. Por exemplo, definimos o tipo de dados Box usando a palavra-chaveclass como segue -
class Box {
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
}A palavra-chave publicdetermina os atributos de acesso dos membros da classe que o seguem. Um membro público pode ser acessado de fora da classe em qualquer lugar dentro do escopo do objeto de classe. Você também pode especificar os membros de uma classe comoprivate ou protected que discutiremos em uma subseção.
Definindo Objetos D
Uma classe fornece os projetos para objetos, portanto, basicamente, um objeto é criado a partir de uma classe. Você declara objetos de uma classe exatamente com o mesmo tipo de declaração que declara variáveis de tipos básicos. As seguintes declarações declaram dois objetos da classe Box -
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type BoxAmbos os objetos Box1 e Box2 têm sua própria cópia de membros de dados.
Acessando os Membros de Dados
Os membros de dados públicos de objetos de uma classe podem ser acessados usando o operador de acesso direto ao membro (.). Vamos tentar o seguinte exemplo para deixar as coisas claras -
import std.stdio;
class Box {
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
}
void main() {
Box box1 = new Box(); // Declare Box1 of type Box
Box box2 = new Box(); // Declare Box2 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
box1.height = 5.0;
box1.length = 6.0;
box1.breadth = 7.0;
// box 2 specification
box2.height = 10.0;
box2.length = 12.0;
box2.breadth = 13.0;
// volume of box 1
volume = box1.height * box1.length * box1.breadth;
writeln("Volume of Box1 : ",volume);
// volume of box 2
volume = box2.height * box2.length * box2.breadth;
writeln("Volume of Box2 : ", volume);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Volume of Box1 : 210
Volume of Box2 : 1560É importante observar que membros privados e protegidos não podem ser acessados diretamente usando o operador de acesso direto ao membro (.). Em breve, você aprenderá como membros privados e protegidos podem ser acessados.
Classes e objetos em D
Até agora, você tem uma ideia muito básica sobre classes e objetos D. Existem outros conceitos interessantes relacionados a classes e objetos D que discutiremos em várias subseções listadas abaixo -
| Sr. Não. | Conceito e descrição |
|---|---|
| 1 | Funções de membro de classe Uma função de membro de uma classe é uma função que tem sua definição ou seu protótipo dentro da definição de classe como qualquer outra variável. |
| 2 | Modificadores de acesso de classe Um membro da classe pode ser definido como público, privado ou protegido. Por padrão, os membros seriam considerados privados. |
| 3 | Construtor e destruidor Um construtor de classe é uma função especial em uma classe que é chamada quando um novo objeto da classe é criado. Um destruidor também é uma função especial que é chamada quando o objeto criado é excluído. |
| 4 | O ponteiro this em D Cada objeto tem um ponteiro especial this que aponta para o próprio objeto. |
| 5 | Ponteiro para classes D Um ponteiro para uma classe é feito exatamente da mesma maneira que um ponteiro para uma estrutura. Na verdade, uma classe é apenas uma estrutura com funções. |
| 6 | Membros estáticos de uma classe Os membros de dados e membros de função de uma classe podem ser declarados como estáticos. |
Um dos conceitos mais importantes na programação orientada a objetos é a herança. A herança permite definir uma classe em termos de outra classe, o que torna mais fácil criar e manter um aplicativo. Isso também fornece uma oportunidade de reutilizar a funcionalidade do código e tempo de implementação rápido.
Ao criar uma classe, em vez de escrever membros de dados e funções de membro completamente novos, o programador pode designar que a nova classe deve herdar os membros de uma classe existente. Esta classe existente é chamada debase classe, e a nova classe é chamada de derived classe.
A ideia de herança implementa o é um relacionamento. Por exemplo, mamífero IS-A animal, cão IS-A mamífero, portanto cão IS-A animal também e assim por diante.
Classes básicas e classes derivadas em D
Uma classe pode ser derivada de mais de uma classe, o que significa que pode herdar dados e funções de várias classes base. Para definir uma classe derivada, usamos uma lista de derivação de classe para especificar a (s) classe (s) base. Uma lista de derivação de classe nomeia uma ou mais classes base e tem a forma -
class derived-class: base-classConsidere uma classe base Shape e sua classe derivada Rectangle como segue -
import std.stdio;
// Base class
class Shape {
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
}
// Derived class
class Rectangle: Shape {
public:
int getArea() {
return (width * height);
}
}
void main() {
Rectangle Rect = new Rectangle();
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
writeln("Total area: ", Rect.getArea());
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Total area: 35Controle de acesso e herança
Uma classe derivada pode acessar todos os membros não privados de sua classe base. Portanto, os membros da classe base que não devem ser acessíveis às funções de membro das classes derivadas devem ser declarados privados na classe base.
Uma classe derivada herda todos os métodos da classe base com as seguintes exceções -
- Construtores, destruidores e construtores de cópia da classe base.
- Operadores sobrecarregados da classe base.
Herança multinível
A herança pode ser de vários níveis e é mostrada no exemplo a seguir.
import std.stdio;
// Base class
class Shape {
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
}
// Derived class
class Rectangle: Shape {
public:
int getArea() {
return (width * height);
}
}
class Square: Rectangle {
this(int side) {
this.setWidth(side);
this.setHeight(side);
}
}
void main() {
Square square = new Square(13);
// Print the area of the object.
writeln("Total area: ", square.getArea());
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Total area: 169D permite que você especifique mais de uma definição para um function nome ou um operator no mesmo escopo, que é chamado function overloading e operator overloading respectivamente.
Uma declaração sobrecarregada é uma declaração que foi declarada com o mesmo nome de uma declaração anterior no mesmo escopo, exceto que ambas as declarações têm argumentos diferentes e definição (implementação) obviamente diferente.
Quando você liga para um sobrecarregado function ou operator, o compilador determina a definição mais apropriada a ser usada, comparando os tipos de argumento usados para chamar a função ou operador com os tipos de parâmetro especificados nas definições. O processo de seleção da função ou operador sobrecarregado mais apropriado é chamadooverload resolution..
Sobrecarga de função
Você pode ter várias definições para o mesmo nome de função no mesmo escopo. A definição da função deve diferir uma da outra pelos tipos e / ou número de argumentos na lista de argumentos. Você não pode sobrecarregar as declarações de função que diferem apenas pelo tipo de retorno.
Exemplo
O exemplo a seguir usa a mesma função print() para imprimir diferentes tipos de dados -
import std.stdio;
import std.string;
class printData {
public:
void print(int i) {
writeln("Printing int: ",i);
}
void print(double f) {
writeln("Printing float: ",f );
}
void print(string s) {
writeln("Printing string: ",s);
}
};
void main() {
printData pd = new printData();
// Call print to print integer
pd.print(5);
// Call print to print float
pd.print(500.263);
// Call print to print character
pd.print("Hello D");
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Printing int: 5
Printing float: 500.263
Printing string: Hello DSobrecarga do operador
Você pode redefinir ou sobrecarregar a maioria dos operadores integrados disponíveis em D. Assim, um programador também pode usar operadores com tipos definidos pelo usuário.
Os operadores podem ser sobrecarregados usando a string op seguida por Add, Sub e assim por diante, com base no operador que está sendo sobrecarregado. Podemos sobrecarregar o operador + para adicionar duas caixas conforme mostrado abaixo.
Box opAdd(Box b) {
Box box = new Box();
box.length = this.length + b.length;
box.breadth = this.breadth + b.breadth;
box.height = this.height + b.height;
return box;
}O exemplo a seguir mostra o conceito de sobrecarga de operador usando uma função de membro. Aqui, um objeto é passado como um argumento cujas propriedades são acessadas usando este objeto. O objeto que chama este operador pode ser acessado usandothis operador conforme explicado abaixo -
import std.stdio;
class Box {
public:
double getVolume() {
return length * breadth * height;
}
void setLength( double len ) {
length = len;
}
void setBreadth( double bre ) {
breadth = bre;
}
void setHeight( double hei ) {
height = hei;
}
Box opAdd(Box b) {
Box box = new Box();
box.length = this.length + b.length;
box.breadth = this.breadth + b.breadth;
box.height = this.height + b.height;
return box;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
// Main function for the program
void main( ) {
Box box1 = new Box(); // Declare box1 of type Box
Box box2 = new Box(); // Declare box2 of type Box
Box box3 = new Box(); // Declare box3 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
box1.setLength(6.0);
box1.setBreadth(7.0);
box1.setHeight(5.0);
// box 2 specification
box2.setLength(12.0);
box2.setBreadth(13.0);
box2.setHeight(10.0);
// volume of box 1
volume = box1.getVolume();
writeln("Volume of Box1 : ", volume);
// volume of box 2
volume = box2.getVolume();
writeln("Volume of Box2 : ", volume);
// Add two object as follows:
box3 = box1 + box2;
// volume of box 3
volume = box3.getVolume();
writeln("Volume of Box3 : ", volume);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Volume of Box1 : 210
Volume of Box2 : 1560
Volume of Box3 : 5400Tipos de sobrecarga do operador
Basicamente, existem três tipos de sobrecarga do operador, conforme listado abaixo.
| Sr. Não. | Tipos de sobrecarga |
|---|---|
| 1 | Sobrecarga de operadores unários |
| 2 | Sobrecarga de operadores binários |
| 3 | Sobrecarga de operadores de comparação |
Todos os programas D são compostos dos seguintes dois elementos fundamentais -
Program statements (code) - Esta é a parte de um programa que executa ações e são chamadas de funções.
Program data - São as informações do programa que são afetadas pelas funções do programa.
Encapsulamento é um conceito de Programação Orientada a Objetos que vincula dados e funções que manipulam os dados juntos, e que mantém ambos protegidos contra interferências externas e uso indevido. O encapsulamento de dados levou ao importante conceito OOP dedata hiding.
Data encapsulation é um mecanismo de agrupar os dados e as funções que os usam e data abstraction é um mecanismo de expor apenas as interfaces e ocultar os detalhes de implementação do usuário.
D suporta as propriedades de encapsulamento e ocultação de dados por meio da criação de tipos definidos pelo usuário, chamados classes. Já estudamos que uma classe pode conterprivate, protegido e publicmembros. Por padrão, todos os itens definidos em uma classe são privados. Por exemplo -
class Box {
public:
double getVolume() {
return length * breadth * height;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};As variáveis comprimento, largura e altura são private. Isso significa que eles podem ser acessados apenas por outros membros da classe Box, e não por qualquer outra parte de seu programa. Esta é uma forma de o encapsulamento ser alcançado.
Para fazer partes de uma classe public (ou seja, acessível a outras partes do seu programa), você deve declará-los após o publicpalavra-chave. Todas as variáveis ou funções definidas após o especificador público são acessíveis por todas as outras funções em seu programa.
Tornar uma classe amiga de outra expõe os detalhes de implementação e reduz o encapsulamento. É ideal manter o máximo possível de detalhes de cada classe ocultos de todas as outras classes.
Encapsulamento de dados em D
Qualquer programa em D onde você implementa uma classe com membros públicos e privados é um exemplo de encapsulamento e abstração de dados. Considere o seguinte exemplo -
Exemplo
import std.stdio;
class Adder {
public:
// constructor
this(int i = 0) {
total = i;
}
// interface to outside world
void addNum(int number) {
total += number;
}
// interface to outside world
int getTotal() {
return total;
};
private:
// hidden data from outside world
int total;
}
void main( ) {
Adder a = new Adder();
a.addNum(10);
a.addNum(20);
a.addNum(30);
writeln("Total ",a.getTotal());
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Total 60Acima da classe soma os números e retorna a soma. Os membros públicosaddNum e getTotalsão as interfaces para o mundo exterior e um usuário precisa conhecê-las para usar a classe. O total de membros privados é algo que está escondido do mundo exterior, mas é necessário para que a classe funcione corretamente.
Estratégia de projeto de classe em D
A maioria de nós aprendeu por meio de experiências amargas a tornar os alunos privados por padrão, a menos que realmente precisemos expô-los. Isso é bomencapsulation.
Essa sabedoria é aplicada com mais frequência aos membros de dados, mas se aplica igualmente a todos os membros, incluindo funções virtuais.
Uma interface é uma forma de forçar as classes que herdam dela a implementar certas funções ou variáveis. As funções não devem ser implementadas em uma interface porque são sempre implementadas nas classes que herdam da interface.
Uma interface é criada usando a palavra-chave interface em vez da palavra-chave class, embora as duas sejam semelhantes em vários aspectos. Quando você deseja herdar de uma interface e a classe já herda de outra classe, você precisa separar o nome da classe e o nome da interface com uma vírgula.
Vejamos um exemplo simples que explica o uso de uma interface.
Exemplo
import std.stdio;
// Base class
interface Shape {
public:
void setWidth(int w);
void setHeight(int h);
}
// Derived class
class Rectangle: Shape {
int width;
int height;
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
int getArea() {
return (width * height);
}
}
void main() {
Rectangle Rect = new Rectangle();
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
writeln("Total area: ", Rect.getArea());
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Total area: 35Interface com funções finais e estáticas em D
Uma interface pode ter um método final e estático para o qual as definições devem ser incluídas na própria interface. Essas funções não podem ser substituídas pela classe derivada. Um exemplo simples é mostrado abaixo.
Exemplo
import std.stdio;
// Base class
interface Shape {
public:
void setWidth(int w);
void setHeight(int h);
static void myfunction1() {
writeln("This is a static method");
}
final void myfunction2() {
writeln("This is a final method");
}
}
// Derived class
class Rectangle: Shape {
int width;
int height;
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
int getArea() {
return (width * height);
}
}
void main() {
Rectangle rect = new Rectangle();
rect.setWidth(5);
rect.setHeight(7);
// Print the area of the object.
writeln("Total area: ", rect.getArea());
rect.myfunction1();
rect.myfunction2();
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Total area: 35
This is a static method
This is a final methodAbstração se refere à capacidade de tornar uma classe abstrata em OOP. Uma classe abstrata é aquela que não pode ser instanciada. Todas as outras funcionalidades da classe ainda existem e seus campos, métodos e construtores são todos acessados da mesma maneira. Você simplesmente não pode criar uma instância da classe abstrata.
Se uma classe for abstrata e não puder ser instanciada, a classe não terá muito uso, a menos que seja uma subclasse. Normalmente é assim que as classes abstratas surgem durante a fase de design. Uma classe pai contém a funcionalidade comum de uma coleção de classes filho, mas a própria classe pai é muito abstrata para ser usada sozinha.
Usando a classe abstrata em D
Use o abstractpalavra-chave para declarar um resumo de classe. A palavra-chave aparece na declaração da classe em algum lugar antes da palavra-chave da classe. O seguinte mostra um exemplo de como uma classe abstrata pode ser herdada e usada.
Exemplo
import std.stdio;
import std.string;
import std.datetime;
abstract class Person {
int birthYear, birthDay, birthMonth;
string name;
int getAge() {
SysTime sysTime = Clock.currTime();
return sysTime.year - birthYear;
}
}
class Employee : Person {
int empID;
}
void main() {
Employee emp = new Employee();
emp.empID = 101;
emp.birthYear = 1980;
emp.birthDay = 10;
emp.birthMonth = 10;
emp.name = "Emp1";
writeln(emp.name);
writeln(emp.getAge);
}Quando compilamos e executamos o programa acima, obteremos a seguinte saída.
Emp1
37Funções Abstratas
Semelhante às funções, as classes também podem ser abstratas. A implementação de tal função não é fornecida em sua classe, mas deve ser fornecida na classe que herda a classe com função abstrata. O exemplo acima é atualizado com a função abstrata.
Exemplo
import std.stdio;
import std.string;
import std.datetime;
abstract class Person {
int birthYear, birthDay, birthMonth;
string name;
int getAge() {
SysTime sysTime = Clock.currTime();
return sysTime.year - birthYear;
}
abstract void print();
}
class Employee : Person {
int empID;
override void print() {
writeln("The employee details are as follows:");
writeln("Emp ID: ", this.empID);
writeln("Emp Name: ", this.name);
writeln("Age: ",this.getAge);
}
}
void main() {
Employee emp = new Employee();
emp.empID = 101;
emp.birthYear = 1980;
emp.birthDay = 10;
emp.birthMonth = 10;
emp.name = "Emp1";
emp.print();
}Quando compilamos e executamos o programa acima, obteremos a seguinte saída.
The employee details are as follows:
Emp ID: 101
Emp Name: Emp1
Age: 37