Algoritmos de Clustering - Clustering Hierárquico
Introdução ao clustering hierárquico
O clustering hierárquico é outro algoritmo de aprendizagem não supervisionado que é usado para agrupar os pontos de dados não rotulados com características semelhantes. Os algoritmos de agrupamento hierárquico se enquadram nas duas categorias a seguir -
Agglomerative hierarchical algorithms- Em algoritmos hierárquicos aglomerativos, cada ponto de dados é tratado como um único cluster e, em seguida, mescla ou aglomera sucessivamente (abordagem de baixo para cima) os pares de clusters. A hierarquia dos clusters é representada como um dendrograma ou estrutura de árvore.
Divisive hierarchical algorithms - Por outro lado, em algoritmos hierárquicos divisivos, todos os pontos de dados são tratados como um grande cluster e o processo de agrupamento envolve a divisão (abordagem de cima para baixo) de um grande cluster em vários pequenos clusters.
Etapas para realizar o clustering hierárquico aglomerativo
Vamos explicar o agrupamento hierárquico mais usado e importante, isto é, aglomerativo. As etapas para realizar o mesmo são as seguintes -
Step 1- Trate cada ponto de dados como um único cluster. Portanto, teremos, digamos, K clusters no início. O número de pontos de dados também será K no início.
Step 2- Agora, nesta etapa, precisamos formar um grande cluster unindo dois pontos de dados do armário. Isso resultará em um total de grupos K-1.
Step 3- Agora, para formar mais clusters, precisamos juntar dois clusters de armário. Isso resultará em um total de clusters K-2.
Step 4 - Agora, para formar um grande cluster, repita as três etapas acima até que K se torne 0, ou seja, não há mais pontos de dados para juntar.
Step 5 - Por fim, depois de fazer um único grande cluster, os dendrogramas serão usados para dividir em vários clusters dependendo do problema.
Papel dos dendrogramas no agrupamento hierárquico aglomerativo
Como discutimos na última etapa, o papel do dendrograma começa assim que o grande aglomerado é formado. O dendrograma será usado para dividir os clusters em vários grupos de pontos de dados relacionados, dependendo do nosso problema. Pode ser entendido com a ajuda do seguinte exemplo -
Exemplo 1
Para entender, vamos começar importando as bibliotecas necessárias da seguinte maneira -
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as npA seguir, iremos traçar os pontos de dados que tomamos para este exemplo -
X = np.array([[7,8],[12,20],[17,19],[26,15],[32,37],[87,75],[73,85], [62,80],[73,60],[87,96],])
labels = range(1, 11)
plt.figure(figsize=(10, 7))
plt.subplots_adjust(bottom=0.1)
plt.scatter(X[:,0],X[:,1], label='True Position')
for label, x, y in zip(labels, X[:, 0], X[:, 1]):
plt.annotate(label,xy=(x, y), xytext=(-3, 3),textcoords='offset points', ha='right', va='bottom')
plt.show()
No diagrama acima, é muito fácil ver que temos dois clusters em pontos de dados de fora, mas nos dados do mundo real, pode haver milhares de clusters. A seguir, iremos traçar os dendrogramas de nossos pontos de dados usando a biblioteca Scipy -
from scipy.cluster.hierarchy import dendrogram, linkage
from matplotlib import pyplot as plt
linked = linkage(X, 'single')
labelList = range(1, 11)
plt.figure(figsize=(10, 7))
dendrogram(linked, orientation='top',labels=labelList, distance_sort='descending',show_leaf_counts=True)
plt.show()
Agora, uma vez que o grande aglomerado é formado, a distância vertical mais longa é selecionada. Uma linha vertical é então desenhada através dele, conforme mostrado no diagrama a seguir. Como a linha horizontal cruza a linha azul em dois pontos, o número de clusters seria dois.

Em seguida, precisamos importar a classe para clustering e chamar seu método fit_predict para prever o cluster. Estamos importando a classe AgglomerativeClustering da biblioteca sklearn.cluster -
from sklearn.cluster import AgglomerativeClustering
cluster = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward')
cluster.fit_predict(X)Em seguida, plote o cluster com a ajuda do seguinte código -
plt.scatter(X[:,0],X[:,1], c=cluster.labels_, cmap='rainbow')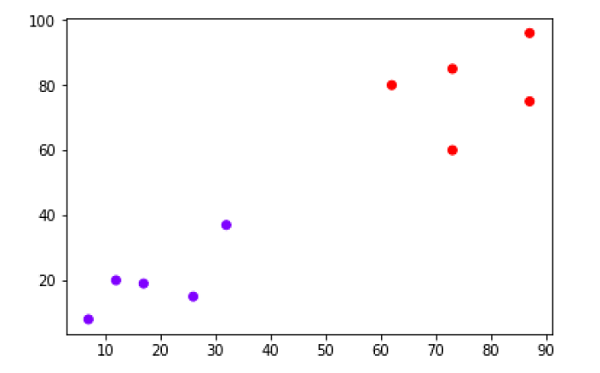
O diagrama acima mostra os dois clusters de nossos pontos de dados.
Exemplo 2
Como entendemos o conceito de dendrogramas a partir do exemplo simples discutido acima, vamos passar para outro exemplo em que estamos criando clusters do ponto de dados no Conjunto de Dados de Diabetes Indiano Pima usando clustering hierárquico -
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
import numpy as np
from pandas import read_csv
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=headernames)
array = data.values
X = array[:,0:8]
Y = array[:,8]
data.shape
(768, 9)
data.head()| Sim. Não. | preg | Plas | Pres | pele | teste | massa | pedi | era | classe |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33,6 | 0,627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26,6 | 0,351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23,3 | 0,672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28,1 | 0,167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43,1 | 2.288 | 33 | 1 |
patient_data = data.iloc[:, 3:5].values
import scipy.cluster.hierarchy as shc
plt.figure(figsize=(10, 7))
plt.title("Patient Dendograms")
dend = shc.dendrogram(shc.linkage(data, method='ward'))
from sklearn.cluster import AgglomerativeClustering
cluster = AgglomerativeClustering(n_clusters=4, affinity='euclidean', linkage='ward')
cluster.fit_predict(patient_data)
plt.figure(figsize=(10, 7))
plt.scatter(patient_data[:,0], patient_data[:,1], c=cluster.labels_, cmap='rainbow')