Mahout - Meio Ambiente
Este capítulo ensina como configurar o mahout. Java e Hadoop são os pré-requisitos do mahout. Abaixo, estão as etapas para baixar e instalar o Java, Hadoop e Mahout.
Configuração de pré-instalação
Antes de instalar o Hadoop no ambiente Linux, precisamos configurar o Linux usando ssh(Capsula segura). Siga as etapas mencionadas abaixo para configurar o ambiente Linux.
Criação de um usuário
É recomendável criar um usuário separado para Hadoop para isolar o sistema de arquivos Hadoop do sistema de arquivos Unix. Siga as etapas abaixo para criar um usuário:
Abra o root usando o comando “su”.
- Crie um usuário a partir da conta root usando o comando “useradd username”.
Agora você pode abrir uma conta de usuário existente usando o comando “su username”.
Abra o terminal Linux e digite os seguintes comandos para criar um usuário.
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdConfiguração e geração de chave SSH
A configuração do SSH é necessária para executar diferentes operações em um cluster, como iniciar, parar e operações de shell daemon distribuído. Para autenticar diferentes usuários do Hadoop, é necessário fornecer um par de chaves pública / privada para um usuário do Hadoop e compartilhá-lo com diferentes usuários.
Os comandos a seguir são usados para gerar um par de valores de chave usando SSH, copiar as chaves públicas do formulário id_rsa.pub para authorized_keys e fornecer permissões de proprietário, leitura e gravação para o arquivo authorized_keys respectivamente.
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keysVerificando ssh
ssh localhostInstalando Java
Java é o principal pré-requisito para Hadoop e HBase. Em primeiro lugar, você deve verificar a existência de Java em seu sistema usando “java -version”. A sintaxe do comando da versão Java é fornecida a seguir.
$ java -versionEle deve produzir a seguinte saída.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Se você não tiver o Java instalado em seu sistema, siga as etapas abaixo para instalar o Java.
Step 1
Baixe o java (JDK <versão mais recente> - X64.tar.gz) visitando o seguinte link: Oracle
Então jdk-7u71-linux-x64.tar.gz is downloaded em seu sistema.
Step 2
Geralmente, você encontra o arquivo Java baixado na pasta Downloads. Verifique e extraia ojdk-7u71-linux-x64.gz arquivo usando os seguintes comandos.
$ cd Downloads/
$ ls
jdk-7u71-linux-x64.gz
$ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzStep 3
Para disponibilizar o Java para todos os usuários, você precisa movê-lo para o local “/ usr / local /”. Abra o root e digite os seguintes comandos.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitStep 4
Para configurar PATH e JAVA_HOME variáveis, adicione os seguintes comandos para ~/.bashrc file.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH= $PATH:$JAVA_HOME/binAgora, verifique o java -version comando do terminal como explicado acima.
Baixando Hadoop
Depois de instalar o Java, você precisa instalar o Hadoop inicialmente. Verifique a existência do Hadoop usando o comando “Hadoop version” conforme mostrado abaixo.
hadoop versionEle deve produzir a seguinte saída:
Hadoop 2.6.0
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /home/hadoop/hadoop/share/hadoop/common/hadoopcommon-2.6.0.jarSe o seu sistema não conseguir localizar o Hadoop, faça download do Hadoop e instale-o no sistema. Siga os comandos fornecidos abaixo para fazer isso.
Faça download e extraia o hadoop-2.6.0 do apache software Foundation usando os comandos a seguir.
$ su
password:
# cd /usr/local
# wget http://mirrors.advancedhosters.com/apache/hadoop/common/hadoop-
2.6.0/hadoop-2.6.0-src.tar.gz
# tar xzf hadoop-2.6.0-src.tar.gz
# mv hadoop-2.6.0/* hadoop/
# exitInstalando Hadoop
Instale o Hadoop em qualquer um dos modos necessários. Aqui, estamos demonstrando as funcionalidades do HBase no modo pseudo-distribuído, portanto, instale o Hadoop no modo pseudo-distribuído.
Siga as etapas abaixo para instalar Hadoop 2.4.1 em seu sistema.
Etapa 1: Configurando o Hadoop
Você pode definir variáveis de ambiente Hadoop anexando os seguintes comandos a ~/.bashrc Arquivo.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOMEAgora, aplique todas as alterações no sistema em execução no momento.
$ source ~/.bashrcEtapa 2: configuração do Hadoop
Você pode encontrar todos os arquivos de configuração do Hadoop no local “$ HADOOP_HOME / etc / hadoop”. É necessário fazer alterações nesses arquivos de configuração de acordo com sua infraestrutura Hadoop.
$ cd $HADOOP_HOME/etc/hadoopPara desenvolver programas Hadoop em Java, você precisa redefinir as variáveis de ambiente Java em hadoop-env.sh arquivo substituindo JAVA_HOME valor com a localização do Java em seu sistema.
export JAVA_HOME=/usr/local/jdk1.7.0_71A seguir está a lista de arquivos que você deve editar para configurar o Hadoop.
core-site.xml
o core-site.xml arquivo contém informações como o número da porta usado para a instância do Hadoop, memória alocada para o sistema de arquivos, limite de memória para armazenamento de dados e o tamanho dos buffers de leitura / gravação.
Abra core-site.xml e adicione a seguinte propriedade entre as tags <configuration>, </configuration>:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xm
o hdfs-site.xmlarquivo contém informações como o valor dos dados de replicação, caminho do namenode e caminhos do datanode de seus sistemas de arquivos locais. Significa o local onde você deseja armazenar a infraestrutura do Hadoop.
Vamos supor os seguintes dados:
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeAbra este arquivo e adicione as seguintes propriedades entre as marcas <configuration>, </configuration> neste arquivo.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note:No arquivo acima, todos os valores das propriedades são definidos pelo usuário. Você pode fazer alterações de acordo com sua infraestrutura Hadoop.
mapred-site.xml
Este arquivo é usado para configurar o yarn no Hadoop. Abra o arquivo mapred-site.xml e adicione a seguinte propriedade entre as marcas <configuration>, </configuration> neste arquivo.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Este arquivo é usado para especificar qual estrutura MapReduce estamos usando. Por padrão, o Hadoop contém um modelo de mapred-site.xml. Em primeiro lugar, é necessário copiar o arquivo demapred-site.xml.template para mapred-site.xml arquivo usando o seguinte comando.
$ cp mapred-site.xml.template mapred-site.xmlAbrir mapred-site.xml arquivo e adicione as seguintes propriedades entre as marcas <configuration>, </configuration> neste arquivo.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Verificando a instalação do Hadoop
As etapas a seguir são usadas para verificar a instalação do Hadoop.
Etapa 1: configuração do nó de nome
Configure o namenode usando o comando “hdfs namenode -format” da seguinte forma:
$ cd ~
$ hdfs namenode -formatO resultado esperado é o seguinte:
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain
1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Etapa 2: verificar Hadoop dfs
O seguinte comando é usado para iniciar o dfs. Este comando inicia seu sistema de arquivos Hadoop.
$ start-dfs.shA saída esperada é a seguinte:
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Etapa 3: Verificando o script do Yarn
O seguinte comando é usado para iniciar o script do yarn. Executar este comando iniciará seus demônios do fio.
$ start-yarn.shA saída esperada é a seguinte:
starting yarn daemons
starting resource manager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn-
hadoop-resourcemanager-localhost.out
localhost: starting node manager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-nodemanager-localhost.outEtapa 4: Acessando o Hadoop no navegador
O número da porta padrão para acessar o hadoop é 50070. Use a seguinte URL para obter serviços Hadoop em seu navegador.
http://localhost:50070/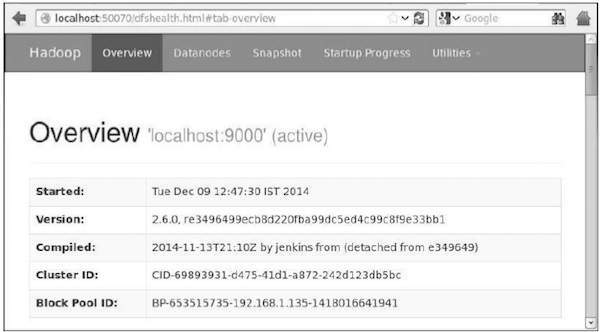
Etapa 5: verificar todos os aplicativos do cluster
O número da porta padrão para acessar todos os aplicativos do cluster é 8088. Use a seguinte URL para visitar este serviço.
http://localhost:8088/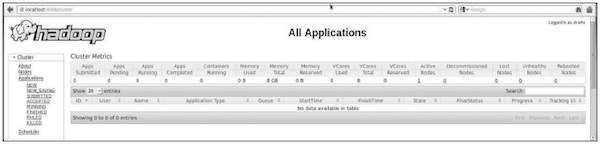
Baixando Mahout
O Mahout está disponível no site Mahout . Baixe o Mahout no link fornecido no site. Aqui está a imagem do site.

Passo 1
Baixe o Apache mahout do link http://mirror.nexcess.net/apache/mahout/ usando o seguinte comando.
[Hadoop@localhost ~]$ wget
http://mirror.nexcess.net/apache/mahout/0.9/mahout-distribution-0.9.tar.gzEntão mahout-distribution-0.9.tar.gz será baixado em seu sistema.
Passo 2
Navegue pela pasta onde mahout-distribution-0.9.tar.gz é armazenado e extrai o arquivo jar baixado conforme mostrado abaixo.
[Hadoop@localhost ~]$ tar zxvf mahout-distribution-0.9.tar.gzRepositório Maven
A seguir está o pom.xml para construir o Apache Mahout usando Eclipse.
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-core</artifactId>
<version>0.9</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-math</artifactId>
<version>${mahout.version}</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-integration</artifactId>
<version>${mahout.version}</version>
</dependency>