Mahout - Aprendizado de Máquina
Apache Mahout é uma biblioteca de aprendizado de máquina altamente escalonável que permite aos desenvolvedores usar algoritmos otimizados. Mahout implementa técnicas populares de aprendizado de máquina, como recomendação, classificação e armazenamento em cluster. Portanto, é prudente ter uma breve seção sobre aprendizado de máquina antes de prosseguirmos.
O que é aprendizado de máquina?
O aprendizado de máquina é um ramo da ciência que lida com a programação de sistemas de forma que eles aprendam e melhorem automaticamente com a experiência. Aqui, aprender significa reconhecer e compreender os dados de entrada e tomar decisões sábias com base nos dados fornecidos.
É muito difícil atender a todas as decisões com base em todas as entradas possíveis. Para resolver este problema, algoritmos são desenvolvidos. Esses algoritmos constroem conhecimento a partir de dados específicos e experiências anteriores com os princípios da estatística, teoria da probabilidade, lógica, otimização combinatória, busca, aprendizado por reforço e teoria de controle.
Os algoritmos desenvolvidos formam a base de vários aplicativos, como:
- Processamento de visão
- Processamento de linguagem
- Previsão (por exemplo, tendências do mercado de ações)
- Reconhecimento de padrões
- Games
- Mineração de dados
- Sistemas especializados
- Robotics
O aprendizado de máquina é uma área vasta e está muito além do escopo deste tutorial para cobrir todos os seus recursos. Existem várias maneiras de implementar técnicas de aprendizado de máquina, mas as mais comumente usadas sãosupervised e unsupervised learning.
Aprendizagem Supervisionada
A aprendizagem supervisionada trata de aprender uma função a partir dos dados de treinamento disponíveis. Um algoritmo de aprendizado supervisionado analisa os dados de treinamento e produz uma função inferida, que pode ser usada para mapear novos exemplos. Exemplos comuns de aprendizagem supervisionada incluem:
- classificando e-mails como spam,
- rotular páginas da web com base em seu conteúdo e
- reconhecimento de voz.
Existem muitos algoritmos de aprendizagem supervisionada, como redes neurais, Support Vector Machines (SVMs) e classificadores Naive Bayes. Mahout implementa classificador Naive Bayes.
Aprendizagem Não Supervisionada
O aprendizado não supervisionado dá sentido a dados não rotulados sem ter nenhum conjunto de dados predefinido para seu treinamento. O aprendizado não supervisionado é uma ferramenta extremamente poderosa para analisar os dados disponíveis e procurar padrões e tendências. É mais comumente usado para agrupar entradas semelhantes em grupos lógicos. As abordagens comuns para a aprendizagem não supervisionada incluem:
- k-means
- mapas auto-organizáveis e
- agrupamento hierárquico
Recomendação
A recomendação é uma técnica popular que fornece recomendações aproximadas com base nas informações do usuário, como compras anteriores, cliques e classificações.
A Amazon usa essa técnica para exibir uma lista de itens recomendados nos quais você pode estar interessado, extraindo informações de suas ações anteriores. Existem motores de recomendação que funcionam por trás do Amazon para capturar o comportamento do usuário e recomendar itens selecionados com base em suas ações anteriores.
O Facebook usa a técnica de recomendação para identificar e recomendar a “lista de pessoas que você talvez conheça”.

Classificação
Classificação, também conhecida como categorization, é uma técnica de aprendizado de máquina que usa dados conhecidos para determinar como os novos dados devem ser classificados em um conjunto de categorias existentes. A classificação é uma forma de aprendizagem supervisionada.
Provedores de serviços de correio, como Yahoo! e o Gmail usa essa técnica para decidir se um novo e-mail deve ser classificado como spam. O algoritmo de categorização se treina analisando os hábitos do usuário de marcar determinados e-mails como spam. Com base nisso, o classificador decide se uma futura correspondência deve ser depositada em sua caixa de entrada ou na pasta de spams.
O aplicativo iTunes usa classificação para preparar listas de reprodução.
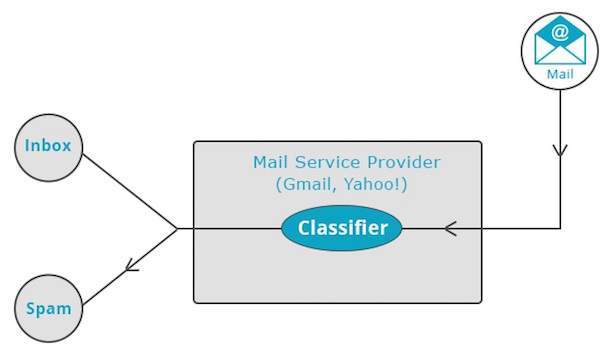
Clustering
O armazenamento em cluster é usado para formar grupos ou clusters de dados semelhantes com base em características comuns. O agrupamento é uma forma de aprendizagem não supervisionada.
Mecanismos de busca como Google e Yahoo! use técnicas de agrupamento para agrupar dados com características semelhantes.
Os grupos de notícias usam técnicas de agrupamento para agrupar vários artigos com base em tópicos relacionados.
O mecanismo de armazenamento em cluster analisa os dados de entrada completamente e, com base nas características dos dados, ele decidirá em qual cluster deve ser agrupado. Dê uma olhada no exemplo a seguir.
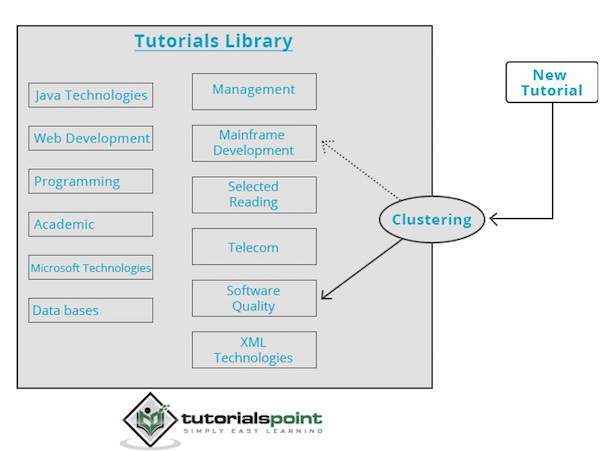
Nossa biblioteca de tutoriais contém tópicos sobre vários assuntos. Quando recebemos um novo tutorial no TutorialsPoint, ele é processado por um mecanismo de clustering que decide, com base em seu conteúdo, onde deve ser agrupado.