Mahout - Guia Rápido
Estamos vivendo em uma época em que as informações estão disponíveis em abundância. A sobrecarga de informações atingiu tais alturas que às vezes fica difícil gerenciar nossas pequenas caixas de correio! Imagine o volume de dados e registros que alguns dos sites populares (como Facebook, Twitter e Youtube) precisam coletar e gerenciar diariamente. Não é incomum, mesmo que sites menos conhecidos, recebam grandes quantidades de informações em massa.
Normalmente recorremos a algoritmos de mineração de dados para analisar dados em massa para identificar tendências e tirar conclusões. No entanto, nenhum algoritmo de mineração de dados pode ser eficiente o suficiente para processar conjuntos de dados muito grandes e fornecer resultados em tempo rápido, a menos que as tarefas computacionais sejam executadas em várias máquinas distribuídas pela nuvem.
Agora temos novas estruturas que nos permitem dividir uma tarefa de computação em vários segmentos e executar cada segmento em uma máquina diferente. Mahout é uma estrutura de mineração de dados que normalmente é executada em conjunto com a infraestrutura do Hadoop em seu segundo plano para gerenciar grandes volumes de dados.
O que é Apache Mahout?
Um mahout é aquele que dirige um elefante como seu mestre. O nome vem de sua associação com o Apache Hadoop, que usa um elefante como logotipo.
Hadoop é uma estrutura de código aberto da Apache que permite armazenar e processar big data em um ambiente distribuído entre clusters de computadores usando modelos de programação simples.
Apache Mahouté um projeto de código aberto usado principalmente para criar algoritmos de aprendizado de máquina escalonáveis. Ele implementa técnicas populares de aprendizado de máquina, como:
- Recommendation
- Classification
- Clustering
O Apache Mahout começou como um subprojeto do Lucene do Apache em 2008. Em 2010, o Mahout se tornou um projeto de nível superior do Apache.
Características do Mahout
Os recursos primitivos do Apache Mahout estão listados abaixo.
Os algoritmos do Mahout são escritos sobre o Hadoop, portanto, funcionam bem em ambiente distribuído. Mahout usa a biblioteca Apache Hadoop para escalar com eficiência na nuvem.
O Mahout oferece ao codificador uma estrutura pronta para uso para realizar tarefas de mineração de dados em grandes volumes de dados.
O Mahout permite que os aplicativos analisem grandes conjuntos de dados com eficácia e rapidez.
Inclui várias implementações de clustering habilitadas para MapReduce, como k-means, fuzzy k-means, Canopy, Dirichlet e Mean-Shift.
Suporta implementações de classificação Distributed Naive Bayes e Complementary Naive Bayes.
Vem com recursos de função de aptidão distribuída para programação evolutiva.
Inclui bibliotecas de matriz e vetor.
Aplicações de Mahout
Empresas como Adobe, Facebook, LinkedIn, Foursquare, Twitter e Yahoo usam o Mahout internamente.
O Foursquare ajuda você a descobrir lugares, comida e entretenimento disponíveis em uma área específica. Ele usa o mecanismo de recomendação do Mahout.
O Twitter usa Mahout para modelagem de interesse do usuário.
Yahoo! usa Mahout para mineração de padrões.
Apache Mahout é uma biblioteca de aprendizado de máquina altamente escalonável que permite aos desenvolvedores usar algoritmos otimizados. Mahout implementa técnicas populares de aprendizado de máquina, como recomendação, classificação e armazenamento em cluster. Portanto, é prudente ter uma breve seção sobre aprendizado de máquina antes de prosseguirmos.
O que é aprendizado de máquina?
O aprendizado de máquina é um ramo da ciência que lida com a programação de sistemas de forma que eles aprendam e melhorem automaticamente com a experiência. Aqui, aprender significa reconhecer e compreender os dados de entrada e tomar decisões sábias com base nos dados fornecidos.
É muito difícil atender a todas as decisões com base em todas as entradas possíveis. Para resolver este problema, algoritmos são desenvolvidos. Esses algoritmos constroem conhecimento a partir de dados específicos e experiências anteriores com os princípios da estatística, teoria da probabilidade, lógica, otimização combinatória, busca, aprendizado por reforço e teoria de controle.
Os algoritmos desenvolvidos formam a base de vários aplicativos, como:
- Processamento de visão
- Processamento de linguagem
- Previsão (por exemplo, tendências do mercado de ações)
- Reconhecimento de padrões
- Games
- Mineração de dados
- Sistemas especializados
- Robotics
O aprendizado de máquina é uma área vasta e está muito além do escopo deste tutorial para cobrir todos os seus recursos. Existem várias maneiras de implementar técnicas de aprendizado de máquina, mas as mais comumente usadas sãosupervised e unsupervised learning.
Aprendizagem Supervisionada
A aprendizagem supervisionada trata de aprender uma função a partir dos dados de treinamento disponíveis. Um algoritmo de aprendizado supervisionado analisa os dados de treinamento e produz uma função inferida, que pode ser usada para mapear novos exemplos. Exemplos comuns de aprendizagem supervisionada incluem:
- classificando e-mails como spam,
- rotular páginas da web com base em seu conteúdo e
- reconhecimento de voz.
Existem muitos algoritmos de aprendizagem supervisionada, como redes neurais, Support Vector Machines (SVMs) e classificadores Naive Bayes. Mahout implementa classificador Naive Bayes.
Aprendizagem Não Supervisionada
O aprendizado não supervisionado dá sentido a dados não rotulados sem ter nenhum conjunto de dados predefinido para seu treinamento. O aprendizado não supervisionado é uma ferramenta extremamente poderosa para analisar os dados disponíveis e procurar padrões e tendências. É mais comumente usado para agrupar entradas semelhantes em grupos lógicos. As abordagens comuns para a aprendizagem não supervisionada incluem:
- k-means
- mapas auto-organizáveis e
- agrupamento hierárquico
Recomendação
A recomendação é uma técnica popular que fornece recomendações aproximadas com base nas informações do usuário, como compras anteriores, cliques e classificações.
A Amazon usa essa técnica para exibir uma lista de itens recomendados nos quais você pode estar interessado, extraindo informações de suas ações anteriores. Existem motores de recomendação que funcionam por trás do Amazon para capturar o comportamento do usuário e recomendar itens selecionados com base em suas ações anteriores.
O Facebook usa a técnica de recomendação para identificar e recomendar a “lista de pessoas que você talvez conheça”.

Classificação
Classificação, também conhecida como categorization, é uma técnica de aprendizado de máquina que usa dados conhecidos para determinar como os novos dados devem ser classificados em um conjunto de categorias existentes. A classificação é uma forma de aprendizagem supervisionada.
Provedores de serviços de correio, como Yahoo! e o Gmail usa essa técnica para decidir se um novo e-mail deve ser classificado como spam. O algoritmo de categorização se treina analisando os hábitos do usuário de marcar determinados e-mails como spam. Com base nisso, o classificador decide se uma futura correspondência deve ser depositada em sua caixa de entrada ou na pasta de spams.
O aplicativo iTunes usa classificação para preparar listas de reprodução.
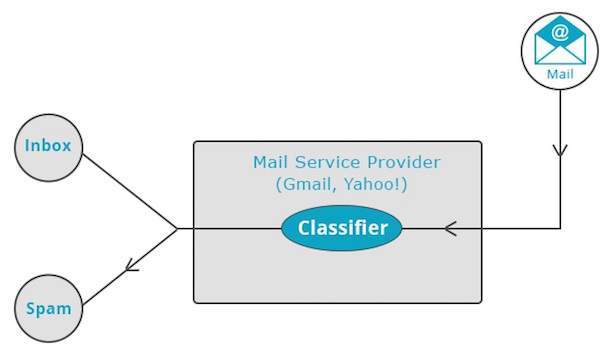
Clustering
O armazenamento em cluster é usado para formar grupos ou clusters de dados semelhantes com base em características comuns. O agrupamento é uma forma de aprendizagem não supervisionada.
Mecanismos de busca como Google e Yahoo! use técnicas de agrupamento para agrupar dados com características semelhantes.
Os grupos de notícias usam técnicas de agrupamento para agrupar vários artigos com base em tópicos relacionados.
O mecanismo de armazenamento em cluster analisa os dados de entrada completamente e, com base nas características dos dados, ele decidirá em qual cluster deve ser agrupado. Dê uma olhada no exemplo a seguir.
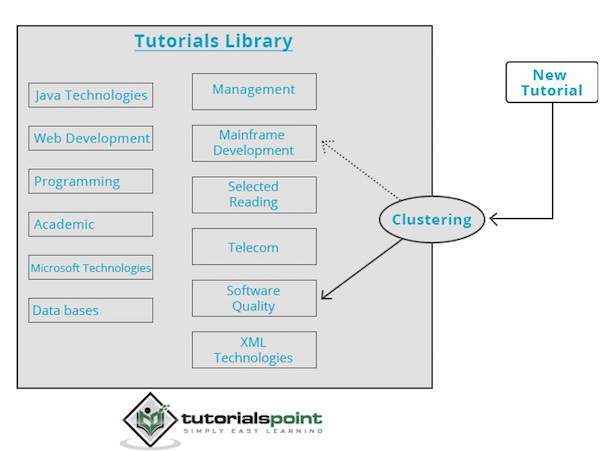
Nossa biblioteca de tutoriais contém tópicos sobre vários assuntos. Quando recebemos um novo tutorial no TutorialsPoint, ele é processado por um mecanismo de clustering que decide, com base em seu conteúdo, onde deve ser agrupado.
Este capítulo ensina como configurar o mahout. Java e Hadoop são os pré-requisitos do mahout. Abaixo, estão as etapas para baixar e instalar Java, Hadoop e Mahout.
Configuração de pré-instalação
Antes de instalar o Hadoop no ambiente Linux, precisamos configurar o Linux usando ssh(Capsula segura). Siga as etapas mencionadas abaixo para configurar o ambiente Linux.
Criação de um usuário
É recomendável criar um usuário separado para Hadoop para isolar o sistema de arquivos Hadoop do sistema de arquivos Unix. Siga as etapas abaixo para criar um usuário:
Abra o root usando o comando “su”.
- Crie um usuário a partir da conta root usando o comando “useradd username”.
Agora você pode abrir uma conta de usuário existente usando o comando “su username”.
Abra o terminal Linux e digite os seguintes comandos para criar um usuário.
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdConfiguração e geração de chave SSH
A configuração do SSH é necessária para executar diferentes operações em um cluster, como iniciar, parar e operações de shell daemon distribuído. Para autenticar diferentes usuários do Hadoop, é necessário fornecer um par de chaves pública / privada para um usuário do Hadoop e compartilhá-lo com diferentes usuários.
Os comandos a seguir são usados para gerar um par de valores de chave usando SSH, copiar as chaves públicas do formulário id_rsa.pub para authorized_keys e fornecer permissões de proprietário, leitura e gravação para o arquivo authorized_keys respectivamente.
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keysVerificando ssh
ssh localhostInstalando Java
Java é o principal pré-requisito para Hadoop e HBase. Em primeiro lugar, você deve verificar a existência de Java em seu sistema usando “java -version”. A sintaxe do comando da versão Java é fornecida a seguir.
$ java -versionEle deve produzir a seguinte saída.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Se você não tiver o Java instalado em seu sistema, siga as etapas fornecidas a seguir para instalar o Java.
Step 1
Baixe o java (JDK <versão mais recente> - X64.tar.gz) visitando o seguinte link: Oracle
Então jdk-7u71-linux-x64.tar.gz is downloaded em seu sistema.
Step 2
Geralmente, você encontra o arquivo Java baixado na pasta Downloads. Verifique e extraia ojdk-7u71-linux-x64.gz arquivo usando os seguintes comandos.
$ cd Downloads/
$ ls
jdk-7u71-linux-x64.gz
$ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzStep 3
Para disponibilizar o Java para todos os usuários, você precisa movê-lo para o local “/ usr / local /”. Abra o root e digite os seguintes comandos.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitStep 4
Para configurar PATH e JAVA_HOME variáveis, adicione os seguintes comandos para ~/.bashrc file.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH= $PATH:$JAVA_HOME/binAgora, verifique o java -version comando do terminal como explicado acima.
Baixando Hadoop
Depois de instalar o Java, você precisa instalar o Hadoop inicialmente. Verifique a existência do Hadoop usando o comando “Hadoop version” conforme mostrado abaixo.
hadoop versionEle deve produzir a seguinte saída:
Hadoop 2.6.0
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /home/hadoop/hadoop/share/hadoop/common/hadoopcommon-2.6.0.jarSe o seu sistema não conseguir localizar o Hadoop, faça download do Hadoop e instale-o no sistema. Siga os comandos fornecidos abaixo para fazer isso.
Faça download e extraia o hadoop-2.6.0 do apache software Foundation usando os comandos a seguir.
$ su
password:
# cd /usr/local
# wget http://mirrors.advancedhosters.com/apache/hadoop/common/hadoop-
2.6.0/hadoop-2.6.0-src.tar.gz
# tar xzf hadoop-2.6.0-src.tar.gz
# mv hadoop-2.6.0/* hadoop/
# exitInstalando o Hadoop
Instale o Hadoop em qualquer um dos modos necessários. Aqui, estamos demonstrando as funcionalidades do HBase no modo pseudo-distribuído, portanto, instale o Hadoop no modo pseudo-distribuído.
Siga as etapas abaixo para instalar Hadoop 2.4.1 em seu sistema.
Etapa 1: Configurando o Hadoop
Você pode definir variáveis de ambiente Hadoop, anexando os seguintes comandos a ~/.bashrc Arquivo.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOMEAgora, aplique todas as alterações no sistema em execução no momento.
$ source ~/.bashrcEtapa 2: configuração do Hadoop
Você pode encontrar todos os arquivos de configuração do Hadoop no local “$ HADOOP_HOME / etc / hadoop”. É necessário fazer alterações nesses arquivos de configuração de acordo com sua infraestrutura Hadoop.
$ cd $HADOOP_HOME/etc/hadoopPara desenvolver programas Hadoop em Java, você precisa redefinir as variáveis de ambiente Java em hadoop-env.sh arquivo substituindo JAVA_HOME valor com a localização do Java em seu sistema.
export JAVA_HOME=/usr/local/jdk1.7.0_71A seguir está a lista de arquivos que você deve editar para configurar o Hadoop.
core-site.xml
o core-site.xml arquivo contém informações como o número da porta usado para a instância do Hadoop, memória alocada para o sistema de arquivos, limite de memória para armazenamento de dados e o tamanho dos buffers de leitura / gravação.
Abra core-site.xml e adicione a seguinte propriedade entre as tags <configuration>, </configuration>:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xm
o hdfs-site.xmlarquivo contém informações como o valor dos dados de replicação, caminho do namenode e caminhos do datanode de seus sistemas de arquivos locais. Significa o local onde você deseja armazenar a infraestrutura do Hadoop.
Vamos supor os seguintes dados:
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeAbra este arquivo e adicione as seguintes propriedades entre as marcas <configuration>, </configuration> neste arquivo.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note:No arquivo acima, todos os valores das propriedades são definidos pelo usuário. Você pode fazer alterações de acordo com sua infraestrutura Hadoop.
mapred-site.xml
Este arquivo é usado para configurar o yarn no Hadoop. Abra o arquivo mapred-site.xml e adicione a seguinte propriedade entre as marcas <configuration>, </configuration> neste arquivo.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Este arquivo é usado para especificar qual estrutura MapReduce estamos usando. Por padrão, o Hadoop contém um modelo de mapred-site.xml. Em primeiro lugar, é necessário copiar o arquivo demapred-site.xml.template para mapred-site.xml arquivo usando o seguinte comando.
$ cp mapred-site.xml.template mapred-site.xmlAbrir mapred-site.xml arquivo e adicione as seguintes propriedades entre as marcas <configuration>, </configuration> neste arquivo.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Verificando a instalação do Hadoop
As etapas a seguir são usadas para verificar a instalação do Hadoop.
Etapa 1: configuração do nó de nome
Configure o namenode usando o comando “hdfs namenode -format” da seguinte forma:
$ cd ~
$ hdfs namenode -formatO resultado esperado é o seguinte:
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain
1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Etapa 2: verificar Hadoop dfs
O seguinte comando é usado para iniciar o dfs. Este comando inicia seu sistema de arquivos Hadoop.
$ start-dfs.shA saída esperada é a seguinte:
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Etapa 3: Verificando o script do Yarn
O seguinte comando é usado para iniciar o script do yarn. Executar este comando iniciará seus demônios do fio.
$ start-yarn.shA saída esperada é a seguinte:
starting yarn daemons
starting resource manager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn-
hadoop-resourcemanager-localhost.out
localhost: starting node manager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-nodemanager-localhost.outEtapa 4: Acessando o Hadoop no navegador
O número da porta padrão para acessar o hadoop é 50070. Use a seguinte URL para obter serviços Hadoop em seu navegador.
http://localhost:50070/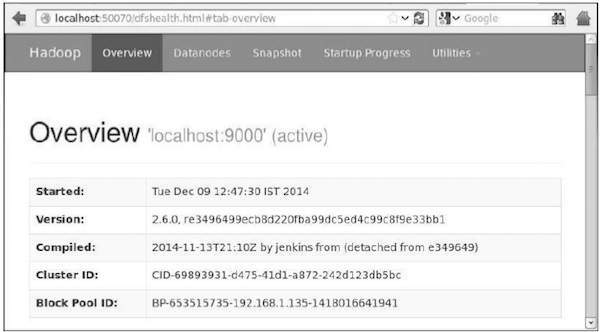
Etapa 5: verificar todos os aplicativos do cluster
O número da porta padrão para acessar todos os aplicativos do cluster é 8088. Use a seguinte URL para visitar este serviço.
http://localhost:8088/
Baixando Mahout
O Mahout está disponível no site Mahout . Baixe o Mahout no link fornecido no site. Aqui está a imagem do site.

Passo 1
Baixe o Apache mahout do link http://mirror.nexcess.net/apache/mahout/ usando o seguinte comando.
[Hadoop@localhost ~]$ wget
http://mirror.nexcess.net/apache/mahout/0.9/mahout-distribution-0.9.tar.gzEntão mahout-distribution-0.9.tar.gz será baixado em seu sistema.
Passo 2
Navegue pela pasta onde mahout-distribution-0.9.tar.gz é armazenado e extrai o arquivo jar baixado conforme mostrado abaixo.
[Hadoop@localhost ~]$ tar zxvf mahout-distribution-0.9.tar.gzRepositório Maven
A seguir está o pom.xml para construir o Apache Mahout usando Eclipse.
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-core</artifactId>
<version>0.9</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-math</artifactId>
<version>${mahout.version}</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-integration</artifactId>
<version>${mahout.version}</version>
</dependency>Este capítulo cobre a técnica popular de aprendizado de máquina chamada recommendation, seus mecanismos e como escrever um aplicativo que implementa a recomendação do Mahout.
Recomendação
Você já se perguntou como a Amazon surge com uma lista de itens recomendados para chamar sua atenção para um produto específico no qual você possa estar interessado!
Suponha que você queira comprar o livro “Mahout in Action” da Amazon:
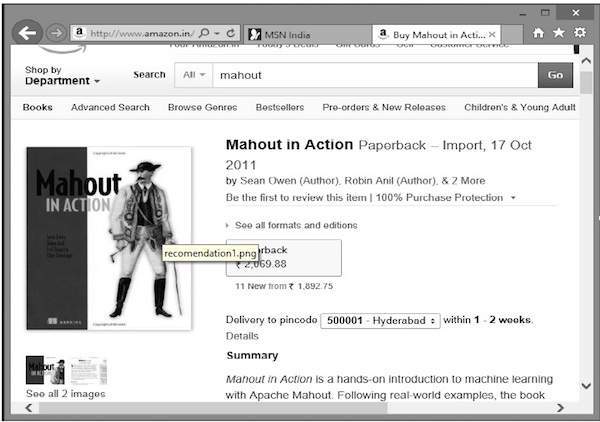
Junto com o produto selecionado, a Amazon também exibe uma lista de itens recomendados relacionados, conforme mostrado abaixo.

Essas listas de recomendações são produzidas com a ajuda de recommender engines. O Mahout fornece mecanismos de recomendação de vários tipos, como:
- recomendadores baseados no usuário,
- recomendadores baseados em itens e
- vários outros algoritmos.
Mecanismo de recomendação Mahout
Mahout tem um mecanismo de recomendação não distribuído e não baseado em Hadoop. Você deve passar um documento de texto com as preferências do usuário para os itens. E a saída desse mecanismo seriam as preferências estimadas de um determinado usuário para outros itens.
Exemplo
Considere um site que vende bens de consumo, como celulares, gadgets e seus acessórios. Se quisermos implementar os recursos do Mahout em tal site, podemos construir um mecanismo de recomendação. Este mecanismo analisa os dados de compra anteriores dos usuários e recomenda novos produtos com base nisso.
Os componentes fornecidos pelo Mahout para construir um mecanismo de recomendação são os seguintes:
- DataModel
- UserSimilarity
- ItemSimilarity
- UserNeighborhood
- Recommender
A partir do armazenamento de dados, o modelo de dados é preparado e passado como uma entrada para o mecanismo de recomendação. O mecanismo de recomendação gera as recomendações para um determinado usuário. A seguir está a arquitetura do mecanismo de recomendação.
Arquitetura do motor de recomendação

Construindo um Recomendador usando Mahout
Aqui estão as etapas para desenvolver um recomendador simples:
Etapa 1: Criar objeto DataModel
O construtor de PearsonCorrelationSimilarityA classe requer um objeto de modelo de dados, que contém um arquivo que contém os detalhes de Usuários, Itens e Preferências de um produto. Aqui está o arquivo de modelo de dados de amostra:
1,00,1.0
1,01,2.0
1,02,5.0
1,03,5.0
1,04,5.0
2,00,1.0
2,01,2.0
2,05,5.0
2,06,4.5
2,02,5.0
3,01,2.5
3,02,5.0
3,03,4.0
3,04,3.0
4,00,5.0
4,01,5.0
4,02,5.0
4,03,0.0o DataModelobjeto requer o objeto de arquivo, que contém o caminho do arquivo de entrada. Crie oDataModel objeto como mostrado abaixo.
DataModel datamodel = new FileDataModel(new File("input file"));Etapa 2: Criar objeto UserSimilarity
Crio UserSimilarity objeto usando PearsonCorrelationSimilarity classe como mostrado abaixo:
UserSimilarity similarity = new PearsonCorrelationSimilarity(datamodel);Passo 3: Crie o objeto UserNeighborhood
Este objeto calcula uma "vizinhança" de usuários como um determinado usuário. Existem dois tipos de vizinhança:
NearestNUserNeighborhood- Esta classe calcula uma vizinhança que consiste nos n usuários mais próximos de um determinado usuário. "Mais próximo" é definido pela semelhança de usuário fornecida.
ThresholdUserNeighborhood- Esta classe calcula uma vizinhança que consiste em todos os usuários cuja semelhança com o usuário determinado atende ou excede um determinado limite. Similaridade é definida por UserSimilarity fornecida.
Aqui estamos usando ThresholdUserNeighborhood e defina o limite de preferência para 3,0.
UserNeighborhood neighborhood = new ThresholdUserNeighborhood(3.0, similarity, model);Etapa 4: Criar objeto de recomendação
Crio UserbasedRecomenderobjeto. Passe todos os objetos criados acima para seu construtor, conforme mostrado abaixo.
UserBasedRecommender recommender = new GenericUserBasedRecommender(model, neighborhood, similarity);Etapa 5: Recomendar itens a um usuário
Recomende produtos a um usuário usando o método recommend () de Recommenderinterface. Este método requer dois parâmetros. O primeiro representa o id do usuário para o qual devemos enviar as recomendações, e o segundo representa o número de recomendações a serem enviadas. Aqui está o uso derecommender() método:
List<RecommendedItem> recommendations = recommender.recommend(2, 3);
for (RecommendedItem recommendation : recommendations) {
System.out.println(recommendation);
}Example Program
Abaixo está um exemplo de programa para definir recomendações. Prepare as recomendações para o usuário com ID de usuário 2.
import java.io.File;
import java.util.List;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.ThresholdUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.UserBasedRecommender;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
public class Recommender {
public static void main(String args[]){
try{
//Creating data model
DataModel datamodel = new FileDataModel(new File("data")); //data
//Creating UserSimilarity object.
UserSimilarity usersimilarity = new PearsonCorrelationSimilarity(datamodel);
//Creating UserNeighbourHHood object.
UserNeighborhood userneighborhood = new ThresholdUserNeighborhood(3.0, usersimilarity, datamodel);
//Create UserRecomender
UserBasedRecommender recommender = new GenericUserBasedRecommender(datamodel, userneighborhood, usersimilarity);
List<RecommendedItem> recommendations = recommender.recommend(2, 3);
for (RecommendedItem recommendation : recommendations) {
System.out.println(recommendation);
}
}catch(Exception e){}
}
}Compile o programa usando os seguintes comandos:
javac Recommender.java
java RecommenderEle deve produzir a seguinte saída:
RecommendedItem [item:3, value:4.5]
RecommendedItem [item:4, value:4.0]Clustering é o procedimento para organizar elementos ou itens de uma determinada coleção em grupos com base na similaridade entre os itens. Por exemplo, os aplicativos relacionados à publicação de notícias online agrupam seus artigos de notícias usando clustering.
Aplicações de Clustering
O clustering é amplamente utilizado em muitas aplicações, como pesquisa de mercado, reconhecimento de padrões, análise de dados e processamento de imagens.
O agrupamento pode ajudar os profissionais de marketing a descobrir grupos distintos em sua base de clientes. E eles podem caracterizar seus grupos de clientes com base nos padrões de compra.
No campo da biologia, pode ser usado para derivar taxonomias de plantas e animais, categorizar genes com funcionalidade semelhante e obter informações sobre as estruturas inerentes às populações.
O agrupamento ajuda na identificação de áreas de uso da terra semelhantes em um banco de dados de observação da Terra.
O clustering também ajuda a classificar documentos na web para descoberta de informações.
O clustering é usado em aplicativos de detecção de outliers, como detecção de fraude de cartão de crédito.
Como uma função de mineração de dados, a Análise de Cluster serve como uma ferramenta para obter uma visão sobre a distribuição de dados para observar as características de cada cluster.
Usando o Mahout, podemos agrupar um determinado conjunto de dados. As etapas necessárias são as seguintes:
Algorithm Você precisa selecionar um algoritmo de clustering adequado para agrupar os elementos de um cluster.
Similarity and Dissimilarity Você precisa ter uma regra em vigor para verificar a similaridade entre os elementos recém-encontrados e os elementos nos grupos.
Stopping Condition Uma condição de parada é necessária para definir o ponto onde nenhum clustering é necessário.
Procedimento de Clustering
Para agrupar os dados fornecidos, você precisa -
Inicie o servidor Hadoop. Crie os diretórios necessários para armazenar arquivos no Hadoop File System. (Crie diretórios para arquivo de entrada, arquivo de sequência e saída em cluster no caso de dossel).
Copie o arquivo de entrada para o sistema de arquivos Hadoop do sistema de arquivos Unix.
Prepare o arquivo de sequência a partir dos dados de entrada.
Execute qualquer um dos algoritmos de clustering disponíveis.
Obtenha os dados agrupados.
Iniciando Hadoop
O Mahout funciona com o Hadoop, portanto, certifique-se de que o servidor Hadoop esteja instalado e funcionando.
$ cd HADOOP_HOME/bin
$ start-all.shPreparando diretórios de arquivos de entrada
Crie diretórios no sistema de arquivos Hadoop para armazenar o arquivo de entrada, arquivos de sequência e dados em cluster usando o seguinte comando:
$ hadoop fs -p mkdir /mahout_data
$ hadoop fs -p mkdir /clustered_data
$ hadoop fs -p mkdir /mahout_seqVocê pode verificar se o diretório é criado usando a interface da web hadoop no seguinte URL - http://localhost:50070/
Ele fornece a saída conforme mostrado abaixo:
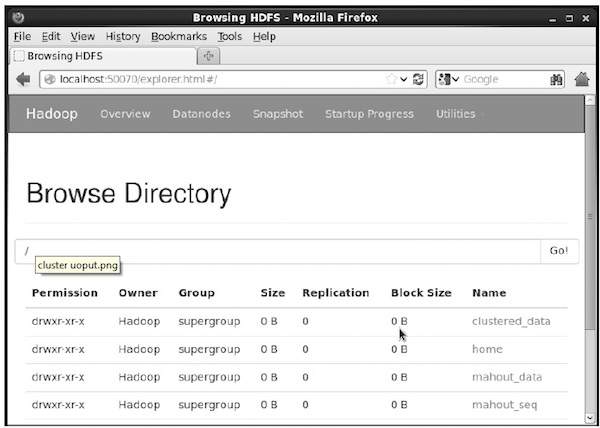
Copiando arquivo de entrada para HDFS
Agora, copie o arquivo de dados de entrada do sistema de arquivos Linux para o diretório mahout_data no Hadoop File System, conforme mostrado abaixo. Suponha que seu arquivo de entrada seja mydata.txt e esteja no diretório / home / Hadoop / data /.
$ hadoop fs -put /home/Hadoop/data/mydata.txt /mahout_data/Preparando o Arquivo de Sequência
O Mahout fornece um utilitário para converter o arquivo de entrada fornecido em um formato de arquivo de sequência. Este utilitário requer dois parâmetros.
- O diretório do arquivo de entrada onde residem os dados originais.
- O diretório do arquivo de saída onde os dados agrupados devem ser armazenados.
A seguir está o prompt de ajuda do mahout seqdirectory Utilitário.
Step 1:Navegue até o diretório inicial do Mahout. Você pode obter ajuda do utilitário conforme mostrado abaixo:
[Hadoop@localhost bin]$ ./mahout seqdirectory --help
Job-Specific Options:
--input (-i) input Path to job input directory.
--output (-o) output The directory pathname for output.
--overwrite (-ow) If present, overwrite the output directoryGere o arquivo de sequência usando o utilitário usando a seguinte sintaxe:
mahout seqdirectory -i <input file path> -o <output directory>Example
mahout seqdirectory
-i hdfs://localhost:9000/mahout_seq/
-o hdfs://localhost:9000/clustered_data/Algoritmos de clustering
Mahout suporta dois algoritmos principais para clustering, a saber:
- Agrupamento de canopy
- Agrupamento K-means
Clustering Canopy
O clustering Canopy é uma técnica simples e rápida usada pelo Mahout para fins de clustering. Os objetos serão tratados como pontos em um espaço simples. Essa técnica é frequentemente usada como uma etapa inicial em outras técnicas de agrupamento, como agrupamento k-means. Você pode executar um trabalho Canopy usando a seguinte sintaxe:
mahout canopy -i <input vectors directory>
-o <output directory>
-t1 <threshold value 1>
-t2 <threshold value 2>O trabalho do Canopy requer um diretório de arquivo de entrada com o arquivo de sequência e um diretório de saída onde os dados agrupados devem ser armazenados.
Example
mahout canopy -i hdfs://localhost:9000/mahout_seq/mydata.seq
-o hdfs://localhost:9000/clustered_data
-t1 20
-t2 30Você obterá os dados agrupados gerados no diretório de saída fornecido.
Clustering K-means
O agrupamento K-means é um algoritmo de agrupamento importante. O algoritmo de agrupamento k em k-means representa o número de clusters em que os dados devem ser divididos. Por exemplo, o valor k especificado para este algoritmo é selecionado como 3, o algoritmo irá dividir os dados em 3 clusters.
Cada objeto será representado como vetor no espaço. Inicialmente k pontos serão escolhidos pelo algoritmo de forma aleatória e tratados como centros, todos os objetos mais próximos de cada centro são agrupados. Existem vários algoritmos para medida de distância e o usuário deve escolher o desejado.
Creating Vector Files
Ao contrário do algoritmo Canopy, o algoritmo k-means requer arquivos vetoriais como entrada, portanto, você deve criar arquivos vetoriais.
Para gerar arquivos vetoriais a partir do formato de arquivo de sequência, o Mahout fornece o seq2parse Utilitário.
Abaixo estão algumas das opções de seq2parseUtilitário. Crie arquivos vetoriais usando essas opções.
$MAHOUT_HOME/bin/mahout seq2sparse
--analyzerName (-a) analyzerName The class name of the analyzer
--chunkSize (-chunk) chunkSize The chunkSize in MegaBytes.
--output (-o) output The directory pathname for o/p
--input (-i) input Path to job input directory.Após criar os vetores, prossiga com o algoritmo k-means. A sintaxe para executar o trabalho k-means é a seguinte:
mahout kmeans -i <input vectors directory>
-c <input clusters directory>
-o <output working directory>
-dm <Distance Measure technique>
-x <maximum number of iterations>
-k <number of initial clusters>O trabalho de cluster K-means requer um diretório de vetores de entrada, diretório de clusters de saída, medida de distância, número máximo de iterações a serem realizadas e um valor inteiro que representa o número de clusters em que os dados de entrada devem ser divididos.
O que é classificação?
Classificação é uma técnica de aprendizado de máquina que usa dados conhecidos para determinar como os novos dados devem ser classificados em um conjunto de categorias existentes. Por exemplo,
O aplicativo iTunes usa classificação para preparar listas de reprodução.
Provedores de serviços de correio, como Yahoo! e o Gmail usa essa técnica para decidir se um novo e-mail deve ser classificado como spam. O algoritmo de categorização se treina analisando os hábitos do usuário de marcar determinados e-mails como spam. Com base nisso, o classificador decide se uma futura correspondência deve ser depositada em sua caixa de entrada ou na pasta de spams.
Como funciona a classificação
Ao classificar um determinado conjunto de dados, o sistema classificador executa as seguintes ações:
- Inicialmente, um novo modelo de dados é preparado usando qualquer um dos algoritmos de aprendizagem.
- Em seguida, o modelo de dados preparado é testado.
- Depois disso, esse modelo de dados é usado para avaliar os novos dados e determinar sua classe.
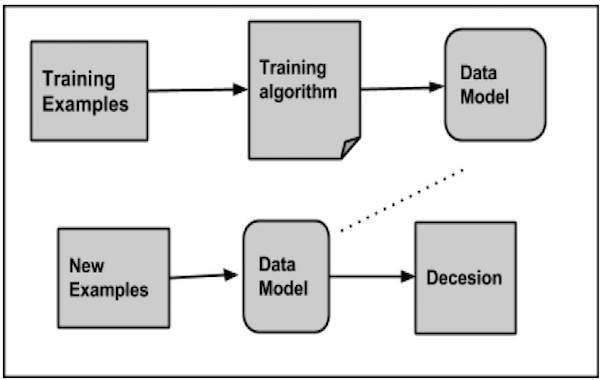
Aplicações de Classificação
Credit card fraud detection- O mecanismo de classificação é usado para prever fraudes de cartão de crédito. Usando informações históricas de fraudes anteriores, o classificador pode prever quais transações futuras podem se transformar em fraudes.
Spam e-mails - Dependendo das características dos e-mails de spam anteriores, o classificador determina se um e-mail recém-encontrado deve ser enviado para a pasta de spam.
Classificador Naive Bayes
Mahout usa o algoritmo classificador Naive Bayes. Ele usa duas implementações:
- Classificação distribuída de Naive Bayes
- Classificação complementar Naive Bayes
Naive Bayes é uma técnica simples para construir classificadores. Não é um único algoritmo para treinar esses classificadores, mas uma família de algoritmos. Um classificador Bayes constrói modelos para classificar as instâncias do problema. Essas classificações são feitas com base nos dados disponíveis.
Uma vantagem do Bayes ingênuo é que ele requer apenas uma pequena quantidade de dados de treinamento para estimar os parâmetros necessários para a classificação.
Para alguns tipos de modelos de probabilidade, os classificadores Bayes ingênuos podem ser treinados de forma muito eficiente em um ambiente de aprendizado supervisionado.
Apesar de suas suposições simplificadas demais, os classificadores Bayes ingênuos funcionaram muito bem em muitas situações complexas do mundo real.
Procedimento de Classificação
As seguintes etapas devem ser seguidas para implementar a Classificação:
- Gere dados de exemplo
- Crie arquivos de sequência a partir de dados
- Converter arquivos de sequência em vetores
- Treine os vetores
- Teste os vetores
Etapa 1: gerar dados de exemplo
Gere ou baixe os dados a serem classificados. Por exemplo, você pode obter o 20 newsgroups dados de exemplo do seguinte link: http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz
Crie um diretório para armazenar dados de entrada. Baixe o exemplo conforme mostrado abaixo.
$ mkdir classification_example
$ cd classification_example
$tar xzvf 20news-bydate.tar.gz
wget http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gzEtapa 2: criar arquivos de sequência
Crie um arquivo de sequência a partir do exemplo usando seqdirectoryUtilitário. A sintaxe para gerar a sequência é fornecida a seguir:
mahout seqdirectory -i <input file path> -o <output directory>Etapa 3: converter arquivos de sequência em vetores
Crie arquivos vetoriais a partir de arquivos de sequência usando seq2parseUtilitário. As opções de seq2parse utilitários são fornecidos abaixo:
$MAHOUT_HOME/bin/mahout seq2sparse
--analyzerName (-a) analyzerName The class name of the analyzer
--chunkSize (-chunk) chunkSize The chunkSize in MegaBytes.
--output (-o) output The directory pathname for o/p
--input (-i) input Path to job input directory.Etapa 4: treinar os vetores
Treine os vetores gerados usando o trainnbUtilitário. As opções para usartrainnb utilitários são fornecidos abaixo:
mahout trainnb
-i ${PATH_TO_TFIDF_VECTORS}
-el
-o ${PATH_TO_MODEL}/model
-li ${PATH_TO_MODEL}/labelindex
-ow
-cEtapa 5: teste os vetores
Teste os vetores usando testnbUtilitário. As opções para usartestnb utilitários são fornecidos abaixo:
mahout testnb
-i ${PATH_TO_TFIDF_TEST_VECTORS}
-m ${PATH_TO_MODEL}/model
-l ${PATH_TO_MODEL}/labelindex
-ow
-o ${PATH_TO_OUTPUT}
-c
-seq