CNTK - Rede Neural Recorrente
Agora, vamos entender como construir uma Rede Neural Recorrente (RNN) em CNTK.
Introdução
Aprendemos como classificar imagens com uma rede neural, e é uma das tarefas icônicas do aprendizado profundo. Mas, outra área onde as redes neurais se destacam e muitas pesquisas estão acontecendo são as Redes Neurais Recorrentes (RNN). Aqui, vamos saber o que é RNN e como ele pode ser usado em cenários onde precisamos lidar com dados de série temporal.
O que é Rede Neural Recorrente?
Redes neurais recorrentes (RNNs) podem ser definidas como a raça especial de NNs que são capazes de raciocinar ao longo do tempo. Os RNNs são usados principalmente em cenários, nos quais precisamos lidar com valores que mudam com o tempo, ou seja, dados de séries temporais. Para entendê-lo de uma maneira melhor, vamos fazer uma pequena comparação entre redes neurais regulares e redes neurais recorrentes -
Como sabemos que, em uma rede neural regular, podemos fornecer apenas uma entrada. Isso o limita a resultados em apenas uma previsão. Para dar um exemplo, podemos fazer o trabalho de tradução de texto usando redes neurais regulares.
Por outro lado, em redes neurais recorrentes, podemos fornecer uma sequência de amostras que resultam em uma única previsão. Em outras palavras, usando RNNs, podemos prever uma sequência de saída com base em uma sequência de entrada. Por exemplo, houve alguns experimentos bem-sucedidos com RNN em tarefas de tradução.
Usos da rede neural recorrente
Os RNNs podem ser usados de várias maneiras. Alguns deles são os seguintes -
Prevendo uma única saída
Antes de mergulhar nas etapas, para saber como o RNN pode prever uma única saída com base em uma sequência, vamos ver como é um RNN básico -

Como podemos no diagrama acima, RNN contém uma conexão de loopback para a entrada e sempre que alimentamos uma sequência de valores, ele processará cada elemento na sequência como etapas de tempo.
Além disso, por causa da conexão de loopback, o RNN pode combinar a saída gerada com a entrada para o próximo elemento na sequência. Desta forma, o RNN construirá uma memória sobre toda a sequência que pode ser usada para fazer uma previsão.
Para fazer a previsão com RNN, podemos realizar as seguintes etapas−
Primeiro, para criar um estado inicial oculto, precisamos alimentar o primeiro elemento da sequência de entrada.
Depois disso, para produzir um estado oculto atualizado, precisamos pegar o estado oculto inicial e combiná-lo com o segundo elemento na sequência de entrada.
Por fim, para produzir o estado oculto final e prever a saída para o RNN, precisamos pegar o elemento final na sequência de entrada.
Dessa forma, com a ajuda dessa conexão de loopback, podemos ensinar um RNN a reconhecer padrões que acontecem com o tempo.
Prevendo uma sequência
O modelo básico, discutido acima, de RNN pode ser estendido para outros casos de uso também. Por exemplo, podemos usá-lo para prever uma sequência de valores com base em uma única entrada. Neste cenário, para fazer a previsão com RNN, podemos realizar as seguintes etapas -
Primeiro, para criar um estado inicial oculto e prever o primeiro elemento na sequência de saída, precisamos alimentar uma amostra de entrada na rede neural.
Depois disso, para produzir um estado oculto atualizado e o segundo elemento na sequência de saída, precisamos combinar o estado oculto inicial com a mesma amostra.
Por fim, para atualizar o estado oculto mais uma vez e prever o elemento final na sequência de saída, alimentamos a amostra outra vez.
Prever sequências
Como vimos, como prever um único valor com base em uma sequência e como prever uma sequência com base em um único valor. Agora vamos ver como podemos prever sequências para sequências. Neste cenário, para fazer a previsão com RNN, podemos realizar as seguintes etapas -
Primeiro, para criar um estado inicial oculto e prever o primeiro elemento na sequência de saída, precisamos pegar o primeiro elemento na sequência de entrada.
Depois disso, para atualizar o estado oculto e prever o segundo elemento na sequência de saída, precisamos assumir o estado oculto inicial.
Por fim, para prever o elemento final na sequência de saída, precisamos pegar o estado oculto atualizado e o elemento final na sequência de entrada.
Trabalho de RNN
Para entender o funcionamento das redes neurais recorrentes (RNNs), precisamos primeiro entender como as camadas recorrentes na rede funcionam. Portanto, primeiro vamos discutir como podemos prever a saída com uma camada recorrente padrão.
Previsão de saída com camada RNN padrão
Como discutimos anteriormente, também uma camada básica em RNN é bastante diferente de uma camada regular em uma rede neural. Na seção anterior, também demonstramos no diagrama a arquitetura básica do RNN. A fim de atualizar o estado oculto para a sequência passo a passo da primeira vez, podemos usar a seguinte fórmula -

Na equação acima, calculamos o novo estado oculto calculando o produto escalar entre o estado oculto inicial e um conjunto de pesos.
Agora, para a próxima etapa, o estado oculto para a etapa de tempo atual é usado como o estado oculto inicial para a próxima etapa de tempo na sequência. É por isso que, para atualizar o estado oculto pela segunda etapa, podemos repetir os cálculos realizados na etapa inicial da seguinte forma -
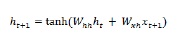
Em seguida, podemos repetir o processo de atualização do estado oculto para a terceira e última etapa na sequência, conforme abaixo -

E quando tivermos processado todas as etapas acima na sequência, podemos calcular a saída da seguinte forma -

Para a fórmula acima, usamos um terceiro conjunto de pesos e o estado oculto da etapa de tempo final.
Unidades Recorrentes Avançadas
O principal problema com a camada recorrente básica é o problema do gradiente de desaparecimento e, devido a isso, ela não é muito boa para aprender correlações de longo prazo. Em palavras simples, a camada recorrente básica não lida muito bem com sequências longas. Essa é a razão pela qual alguns outros tipos de camadas recorrentes que são muito mais adequados para trabalhar com sequências mais longas são os seguintes -
Memória de longo-curto prazo (LSTM)

As redes de memória de longo-curto prazo (LSTMs) foram introduzidas por Hochreiter & Schmidhuber. Resolveu o problema de obter uma camada básica recorrente para lembrar coisas por um longo tempo. A arquitetura do LSTM é fornecida acima no diagrama. Como podemos ver, ele possui neurônios de entrada, células de memória e neurônios de saída. A fim de combater o problema do gradiente de desaparecimento, as redes de memória de longo-curto prazo usam uma célula de memória explícita (armazena os valores anteriores) e as seguintes portas -
Forget gate- Como o nome indica, diz à célula de memória para esquecer os valores anteriores. A célula de memória armazena os valores até que o portão, ou seja, 'esqueça o portão', diga para esquecê-los.
Input gate- Como o nome indica, adiciona coisas novas à célula.
Output gate- Como o nome indica, a porta de saída decide quando passar os vetores da célula para o próximo estado oculto.
Unidades recorrentes bloqueadas (GRUs)

Gradient recurrent units(GRUs) é uma pequena variação da rede LSTMs. Ele tem uma porta a menos e os fios são ligeiramente diferentes dos LSTMs. Sua arquitetura é mostrada no diagrama acima. Possui neurônios de entrada, células de memória com portas e neurônios de saída. A rede de unidades recorrentes bloqueadas tem as duas portas a seguir -
Update gate- Isso determina as duas coisas a seguir−
Qual quantidade de informação deve ser mantida do último estado?
Que quantidade de informações deve ser permitida da camada anterior?
Reset gate- A funcionalidade da porta de reset é muito parecida com a da porta de esquecimento da rede LSTMs. A única diferença é que ele está localizado de forma ligeiramente diferente.
Em contraste com a rede de memória de longo prazo, as redes de Gated Recurrent Unit são ligeiramente mais rápidas e fáceis de operar.
Criando estrutura RNN
Antes de começarmos, fazendo previsões sobre a saída de qualquer uma de nossas fontes de dados, precisamos primeiro construir RNN e construir RNN é exatamente o mesmo que tínhamos construído rede neural regular na seção anterior. A seguir está o código para construir um -
from cntk.losses import squared_error
from cntk.io import CTFDeserializer, MinibatchSource, INFINITELY_REPEAT, StreamDefs, StreamDef
from cntk.learners import adam
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
BATCH_SIZE = 14 * 10
EPOCH_SIZE = 12434
EPOCHS = 10Estaqueamento de camadas múltiplas
Também podemos empilhar várias camadas recorrentes no CNTK. Por exemplo, podemos usar a seguinte combinação de camadas−
from cntk import sequence, default_options, input_variable
from cntk.layers import Recurrence, LSTM, Dropout, Dense, Sequential, Fold
features = sequence.input_variable(1)
with default_options(initial_state = 0.1):
model = Sequential([
Fold(LSTM(15)),
Dense(1)
])(features)
target = input_variable(1, dynamic_axes=model.dynamic_axes)Como podemos ver no código acima, temos as duas maneiras a seguir nas quais podemos modelar RNN em CNTK -
Primeiro, se quisermos apenas a saída final de uma camada recorrente, podemos usar o Fold camada em combinação com uma camada recorrente, como GRU, LSTM ou mesmo RNNStep.
Em segundo lugar, como uma forma alternativa, também podemos usar o Recurrence quadra.
Treinamento RNN com dados de série temporal
Depois de construir o modelo, vamos ver como podemos treinar RNN em CNTK -
from cntk import Function
@Function
def criterion_factory(z, t):
loss = squared_error(z, t)
metric = squared_error(z, t)
return loss, metric
loss = criterion_factory(model, target)
learner = adam(model.parameters, lr=0.005, momentum=0.9)Agora, para carregar os dados no processo de treinamento, devemos desserializar as sequências de um conjunto de arquivos CTF. O código a seguir tem ocreate_datasource , que é uma função de utilidade útil para criar a fonte de dados de treinamento e teste.
target_stream = StreamDef(field='target', shape=1, is_sparse=False)
features_stream = StreamDef(field='features', shape=1, is_sparse=False)
deserializer = CTFDeserializer(filename, StreamDefs(features=features_stream, target=target_stream))
datasource = MinibatchSource(deserializer, randomize=True, max_sweeps=sweeps)
return datasource
train_datasource = create_datasource('Training data filename.ctf')#we need to provide the location of training file we created from our dataset.
test_datasource = create_datasource('Test filename.ctf', sweeps=1) #we need to provide the location of testing file we created from our dataset.Agora, como configuramos as fontes de dados, o modelo e a função de perda, podemos iniciar o processo de treinamento. É bastante semelhante ao que fizemos nas seções anteriores com redes neurais básicas.
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
target: train_datasource.streams.target
}
history = loss.train(
train_datasource,
epoch_size=EPOCH_SIZE,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config],
minibatch_size=BATCH_SIZE,
max_epochs=EPOCHS
)Obteremos uma saída semelhante à seguinte -
Output−
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.005
0.4 0.4 0.4 0.4 19
0.4 0.4 0.4 0.4 59
0.452 0.495 0.452 0.495 129
[…]Validando o modelo
Na verdade, redefinir com um RNN é bastante semelhante a fazer previsões com qualquer outro modelo CNK. A única diferença é que precisamos fornecer sequências em vez de amostras únicas.
Agora, como nosso RNN finalmente concluiu o treinamento, podemos validar o modelo testando-o usando algumas sequências de amostras como segue -
import pickle
with open('test_samples.pkl', 'rb') as test_file:
test_samples = pickle.load(test_file)
model(test_samples) * NORMALIZEOutput−
array([[ 8081.7905],
[16597.693 ],
[13335.17 ],
...,
[11275.804 ],
[15621.697 ],
[16875.555 ]], dtype=float32)