Transferidor - Guia rápido
Este capítulo fornece uma introdução ao Protractor, onde você aprenderá sobre a origem desta estrutura de teste e porque você deve escolher isso, o funcionamento e as limitações desta ferramenta.
O que é transferidor?
Protractor é uma estrutura de teste ponta a ponta de código aberto para aplicativos Angular e AngularJS. Ele foi construído pelo Google no topo do WebDriver. Ele também serve como um substituto para a estrutura de teste AngularJS E2E existente chamada “Angular Scenario Runner”.
Ele também funciona como um integrador de solução que combina tecnologias poderosas como NodeJS, Selenium, Jasmine, WebDriver, Cucumber, Mocha etc. Junto com o teste de aplicativo AngularJS, ele também escreve testes de regressão automatizados para aplicativos web normais. Ele nos permite testar nosso aplicativo como um usuário real, porque executa o teste usando um navegador real.
O diagrama a seguir dará uma breve visão geral do Transferidor -
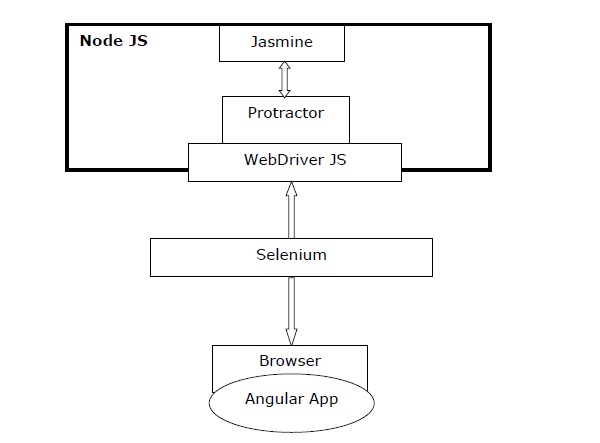
Observe que no diagrama acima, temos -
Protractor - Conforme discutido anteriormente, é um wrapper sobre WebDriver JS especialmente projetado para aplicativos angulares.
Jasmine- É basicamente uma estrutura de desenvolvimento orientada por comportamento para testar o código JavaScript. Podemos escrever os testes facilmente com Jasmine.
WebDriver JS - É uma implementação de vínculos Node JS para selenium 2.0 / WebDriver.
Selenium - Simplesmente automatiza o navegador.
Origem
Como dito anteriormente, o Protractor é um substituto para a estrutura de teste AngularJS E2E existente chamada “Angular Scenario Runner”. Basicamente, a origem do Transferidor começa com o final do Scenario Runner. Uma questão que surge aqui é por que precisamos construir o Protractor? Para entender isso, primeiro precisamos verificar seu antecessor - Scenario Runner.
Início do Transferidor
Julie Ralph, a principal contribuidora para o desenvolvimento do Protractor, teve a seguinte experiência com o Angular Scenario Runner em outro projeto do Google. Isso se tornou ainda mais a motivação para construir o Transferidor, especialmente para preencher as lacunas -
“Tentamos usar o Scenario Runner e descobrimos que ele realmente não conseguia fazer as coisas que precisávamos testar. Precisávamos testar coisas como fazer login. Sua página de login não é uma página Angular, e o Scenario Runner não conseguiu lidar com isso. E não conseguia lidar com coisas como pop-ups e várias janelas, navegar no histórico do navegador e coisas assim. ”
A maior vantagem para o Transferidor foi a maturidade do projeto Selenium e ele envolve seus métodos para que possa ser facilmente usado para projetos angulares. O design do Protractor é construído de tal forma que testa todas as camadas, como IU da web, serviços de back-end, camada de persistência e assim por diante de um aplicativo.
Por que transferidor?
Como sabemos, quase todos os aplicativos estão usando JavaScript para desenvolvimento. A tarefa dos testadores se torna difícil quando o JavaScript aumenta de tamanho e se torna complexo para os aplicativos devido ao número crescente dos próprios aplicativos. Na maioria das vezes torna-se muito difícil capturar os elementos da web em aplicativos AngularJS, usa sintaxe HTML estendida para expressar componentes de aplicativos da web, usando JUnit ou Selenium WebDriver.
A questão aqui é porque o Selenium Web Driver não consegue encontrar os elementos da web AngularJS? A razão é porque os aplicativos AngularJS têm alguns atributos HTML estendidos, como ng-repetidor, ng-controlador e ng-model, etc., que não estão incluídos nos localizadores Selenium.
Aqui, a importância do Protractor passa a existir porque o Protractor na parte superior do Selenium pode manipular e controlar esses elementos HTML estendidos em aplicativos da web AngularJS. É por isso que podemos dizer que a maioria dos frameworks se concentra na realização de testes de unidade para aplicativos AngularJS, o Protractor usado para fazer testes da funcionalidade real de um aplicativo.
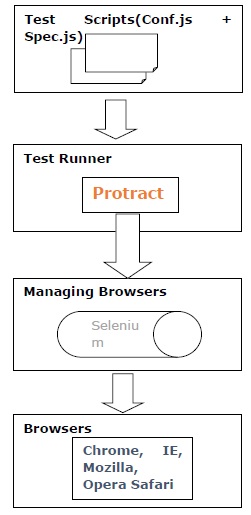
Trabalho do transferidor
Protractor, a estrutura de teste, funciona em conjunto com o Selenium para fornecer uma infraestrutura de teste automatizada para simular a interação de um usuário com um aplicativo AngularJS que está sendo executado em um navegador ou dispositivo móvel.
O funcionamento do Transferidor pode ser compreendido com a ajuda das seguintes etapas -
Step 1- Na primeira etapa, precisamos escrever os testes. Isso pode ser feito com a ajuda de Jasmim ou Mocha ou Pepino.
Step 2- Agora, precisamos executar o teste que pode ser feito com a ajuda do Transferidor. Também é chamado de executor de teste.
Step 3 - Nesta etapa, o servidor Selenium ajudará a gerenciar os navegadores.
Step 4 - Por fim, as APIs do navegador são chamadas com a ajuda do Selenium WebDriver.
Vantagens
Esta estrutura de teste ponta a ponta de código aberto oferece as seguintes vantagens -
Uma ferramenta de código aberto, o Protractor é muito fácil de instalar e configurar.
Funciona bem com a estrutura Jasmine para criar o teste.
Suporta desenvolvimento orientado a testes (TDD).
Contém esperas automáticas, o que significa que não precisamos adicionar esperas e suspensões explicitamente ao nosso teste.
Oferece todas as vantagens do Selenium WebDriver.
Suporta testes paralelos em vários navegadores.
Oferece o benefício de sincronização automática.
Possui excelente velocidade de teste.
Limitações
Esta estrutura de teste ponta a ponta de código aberto possui as seguintes limitações -
Não descobre quaisquer verticais na automação do navegador porque é um wrapper para WebDriver JS.
O conhecimento de JavaScript é essencial para o usuário, pois está disponível apenas para JavaScript.
Fornece apenas teste de front-end porque é uma ferramenta de teste orientada pela IU.
Como o conhecimento de JavaScript é essencial para trabalhar com o Protractor, neste capítulo, vamos entender os conceitos de teste de JavaScript em detalhes.
Teste e automação de JavaScript
JavaScript é a linguagem de script interpretada e digitada dinamicamente mais popular, mas a tarefa mais desafiadora é testar o código. É porque, ao contrário de outras linguagens compiladas como JAVA e C ++, não há etapas de compilação em JavaScript que podem ajudar o testador a descobrir os erros. Além disso, o teste baseado em navegador consome muito tempo; portanto, há uma necessidade de ferramentas que suportem testes automatizados para JavaScript.
Conceitos de teste automatizado
É sempre uma boa prática escrever o teste porque torna o código melhor; o problema com o teste manual é que ele consome um pouco de tempo e está sujeito a erros. O processo de teste manual também é muito enfadonho para o programador, pois eles precisam repetir o processo, escrever especificações de teste, alterar o código e atualizar o navegador várias vezes. Além disso, o teste manual também retarda o processo de desenvolvimento.
Pelos motivos acima, é sempre útil ter algumas ferramentas que possam automatizar esses testes e ajudar os programadores a se livrar dessas etapas repetitivas e enfadonhas. O que um desenvolvedor deve fazer para automatizar o processo de teste?
Basicamente, um desenvolvedor pode implementar o conjunto de ferramentas no CLI (Command Line Interpreter) ou no IDE de desenvolvimento (Integrated development environment). Em seguida, esses testes serão executados continuamente em um processo separado, mesmo sem a entrada do desenvolvedor. O teste automatizado de JavaScript também não é novo e muitas ferramentas como Karma, Protractor, CasperJS etc. foram desenvolvidas.
Tipos de teste para JavaScript
Pode haver testes diferentes para finalidades diferentes. Por exemplo, alguns testes são escritos para verificar o comportamento das funções em um programa, enquanto outros são escritos para testar o fluxo de um módulo ou recurso. Assim, temos os seguintes dois tipos de teste -
Teste de Unidade
O teste é feito na menor parte testável do programa, chamada unidade. A unidade é testada basicamente de forma isolada sem qualquer tipo de dependência daquela unidade das outras partes. No caso do JavaScript, o método ou função individual que tem um comportamento específico pode ser uma unidade de código e essas unidades de código devem ser testadas de forma isolada.
Uma das vantagens do teste de unidade é que o teste das unidades pode ser feito em qualquer ordem porque as unidades são independentes umas das outras. Outra vantagem do teste de unidade que realmente conta é que ele pode executar o teste a qualquer momento da seguinte forma -
- Desde o início do processo de desenvolvimento.
- Depois de concluir o desenvolvimento de qualquer módulo / recurso.
- Depois de modificar qualquer módulo / recurso.
- Depois de adicionar qualquer novo recurso no aplicativo existente.
Para o teste de unidade automatizado de aplicativos JavaScript, podemos escolher entre muitas ferramentas de teste e estruturas, como Mocha, Jasmine e QUnit.
Teste de ponta a ponta
Pode ser definido como a metodologia de teste usada para testar se o fluxo do aplicativo do início ao fim (de uma extremidade a outra) está funcionando bem de acordo com o design.
O teste de ponta a ponta também é chamado de teste de função / fluxo. Ao contrário do teste de unidade, o teste de ponta a ponta testa como os componentes individuais funcionam juntos como um aplicativo. Esta é a principal diferença entre o teste de unidade e o teste de ponta a ponta.
Por exemplo, suponha que se temos um módulo de registro em que o usuário precisa fornecer algumas informações válidas para concluir o registro, o teste E2E para esse módulo específico seguirá as seguintes etapas para concluir o teste -
- Primeiro, ele irá carregar / compilar o formulário ou módulo.
- Agora, ele obterá o DOM (modelo de objeto de documento) dos elementos do formulário.
- Em seguida, acione o evento click do botão enviar para verificar se está funcionando ou não.
- Agora, para fins de validação, colete o valor dos campos de entrada.
- Em seguida, os campos de entrada devem ser validados.
- Para fins de teste, chame uma API falsa para armazenar os dados.
Cada etapa dá seus próprios resultados que serão comparados com o conjunto de resultados esperado.
Agora, a questão que se coloca é, embora este tipo de teste E2E ou funcional também possa ser executado manualmente, por que precisamos de automação para isso? O principal motivo é que a automação tornará esse processo de teste fácil. Algumas das ferramentas disponíveis que podem ser facilmente integradas com qualquer aplicativo, para isso, são Selenium, PhantomJS e Protractor.
Ferramentas e frameworks de teste
Temos várias ferramentas de teste e estruturas para teste Angular. A seguir estão algumas das ferramentas e estruturas conhecidas -
Carma
Karma, criado por Vojta Jina, é um executor de testes. Originalmente, esse projeto foi chamado de Testacular. Não é uma estrutura de teste, o que significa que nos dá a capacidade de executar testes de unidade JavaScript de maneira fácil e automática em navegadores reais. O Karma foi construído para AngularJS porque antes do Karma não havia ferramenta de teste automatizada para desenvolvedores de JavaScript baseados na web. Por outro lado, com a automação fornecida pelo Karma, os desenvolvedores podem executar um único comando simples e determinar se um conjunto de testes inteiro foi aprovado ou reprovado.
Prós de usar Karma
A seguir estão alguns prós do uso do Karma em comparação com o processo manual -
- Automatiza testes em vários navegadores e também em dispositivos.
- Monitora arquivos em busca de erros e os corrige.
- Fornece suporte e documentação online.
- Facilita a integração com um servidor de integração contínua.
Contras do uso de Karma
A seguir estão alguns contras do uso de Karma -
A principal desvantagem de usar o Karma é que ele requer uma ferramenta adicional para configurar e manter.
Se você estiver usando o executor de teste Karma com Jasmine, haverá menos documentação disponível para encontrar informações sobre como configurar seu CSS no caso de ter vários ids para um elemento.
Jasmim
Jasmine, uma estrutura de desenvolvimento orientada por comportamento para testar código JavaScript, é desenvolvida no Pivotal Labs. Antes do desenvolvimento ativo da estrutura Jasmine, uma estrutura de teste de unidade semelhante chamada JsUnit também foi desenvolvida pela Pivotal Labs, que possui um executor de teste embutido. Os testes de navegadores podem ser executados por meio de testes Jasmine incluindo o arquivo SpecRunner.html ou usando-o também como um executor de teste de linha de comando. Também pode ser usado com ou sem Karma.
Prós de usar Jasmine
A seguir estão alguns prós do uso do Jasmine -
Uma estrutura independente de navegador, plataforma e linguagem.
Oferece suporte ao desenvolvimento orientado a testes (TDD) junto com o desenvolvimento orientado a comportamento.
Possui integração padrão com Karma.
Sintaxe fácil de entender.
Fornece spies de teste, falsificações e funcionalidades de passagem que auxiliam no teste como funções adicionais.
Contras do uso de Jasmine
O seguinte é um contra de usar Jasmine -
Os testes devem ser retornados pelo usuário à medida que mudam, porque não há recurso de observação de arquivos disponível no Jasmine durante a execução do teste.
Mocha
Mocha, escrito para aplicativos Node.js, é uma estrutura de teste, mas também oferece suporte a testes de navegador. É bem parecido com o Jasmine, mas a principal diferença entre eles é que o Mocha precisa de algum plug-in e biblioteca porque não pode ser executado sozinho como uma estrutura de teste. Por outro lado, Jasmine é independente. No entanto, o Mocha é mais flexível do que o Jasmine.
Prós de usar Mocha
A seguir estão alguns prós do uso do Mocha -
- O Mocha é muito fácil de instalar e configurar.
- Documentação simples e amigável.
- Contém plug-ins com vários projetos de nó.
Contras de usar Mocha
A seguir estão alguns contras do uso do Mocha -
- Ele precisa de módulos separados para afirmações, espiões etc.
- Também requer configuração adicional para uso com o Karma.
QUnit
O QUint, originalmente desenvolvido por John Resig em 2008 como parte do jQuery, é um conjunto de testes de unidade JavaScript poderoso e fácil de usar. Ele pode ser usado para testar qualquer código JavaScript genérico. Embora se concentre em testar o JavaScript no navegador, é muito conveniente para ser usado pelo desenvolvedor.
Prós de usar QUnit
A seguir estão alguns prós do uso do QUnit -
- Fácil de instalar e configurar.
- Documentação simples e amigável.
Contras de usar QUnit
O seguinte é um contra de usar QUnit -
- Ele foi desenvolvido principalmente para jQuery e, portanto, não é tão bom para uso com outros frameworks.
Selênio
Selenium, originalmente desenvolvido por Jason Huggins em 2004 como uma ferramenta interna da ThoughtWorks, é uma ferramenta de automação de teste de código aberto. Selenium se define como “Selenium automatiza navegadores. É isso aí!". Automação de navegadores significa que os desenvolvedores podem interagir com os navegadores muito facilmente.
Prós de usar Selenium
A seguir estão alguns prós do uso de selênio -
- Contém um grande conjunto de recursos.
- Suporta testes distribuídos.
- Possui suporte SaaS por meio de serviços como Sauce Labs.
- Fácil de usar com documentações simples e ricos recursos disponíveis.
Contras do uso de selênio
A seguir estão alguns contras do uso de Selenium -
- A principal desvantagem do uso do Selenium é que ele deve ser executado como um processo separado.
- A configuração é um pouco complicada, pois o desenvolvedor precisa seguir várias etapas.
Nos capítulos anteriores, aprendemos o básico do Transferidor. Neste capítulo, vamos aprender como instalá-lo e configurá-lo.
Pré-requisitos
Precisamos satisfazer os seguintes pré-requisitos antes de instalar o Protractor em seu computador -
Node.js
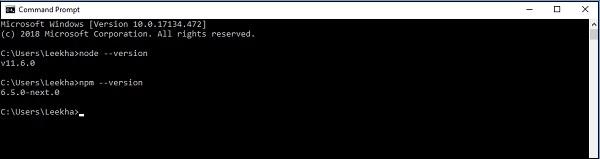
Protractor é um módulo Node.js, portanto, o pré-requisito muito importante é que devemos ter o Node.js instalado em nosso computador. Vamos instalar o pacote Protractor usando npm (um gerenciador de pacotes JavaScript), que vem com o Node.js.
Para instalar o Node.js, siga o link oficial - https://nodejs.org/en/download/. Depois de instalar o Node.js, você pode verificar a versão do Node.js e do npm escrevendo o comandonode --version e npm --version no prompt de comando conforme mostrado abaixo -
cromada
O Google Chrome, um navegador desenvolvido pelo Google, será usado para executar testes de ponta a ponta no Protractor sem a necessidade de um servidor Selenium. Você pode baixar o Chrome clicando no link -https://www.google.com/chrome/.
Selenium WebDriver para Chrome
Essa ferramenta é fornecida com o módulo Protractor npm e nos permite interagir com aplicativos da web.
Instalando o Transferidor
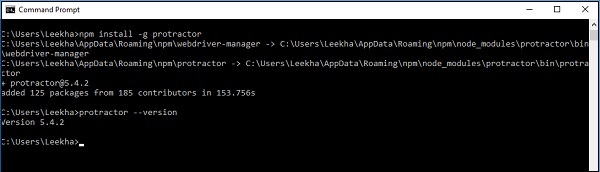
Depois de instalar o Node.js em nosso computador, podemos instalar o Protractor com a ajuda do seguinte comando -
npm install -g protractorAssim que o transferidor for instalado com sucesso, podemos verificar sua versão escrevendo protractor --version comando no prompt de comando como mostrado abaixo -
Instalando WebDriver para Chrome
Depois de instalar o Protractor, precisamos instalar o Selenium WebDriver para Chrome. Ele pode ser instalado com a ajuda do seguinte comando -
webdriver-manager updateO comando acima criará um diretório Selenium que contém o driver do Chrome necessário usado no projeto.
Confirmando instalação e configuração
Podemos confirmar a instalação e configuração do Protractor alterando ligeiramente o conf.js fornecido no exemplo após a instalação do Protractor. Você pode encontrar este arquivo conf.js no diretório raiznode_modules/Protractor/example.
Para isso, primeiro crie um novo arquivo chamado testingconfig.js no mesmo diretório, ou seja node_modules/Protractor/example.
Agora, no arquivo conf.js, no parâmetro de declaração do arquivo de origem, escreva testingconfig.js.
Em seguida, salve e feche todos os arquivos e abra o prompt de comando. Execute o arquivo conf.js conforme mostrado na captura de tela fornecida abaixo.
A configuração e instalação do Protractor são bem-sucedidas se você obtiver a saída conforme mostrado abaixo -
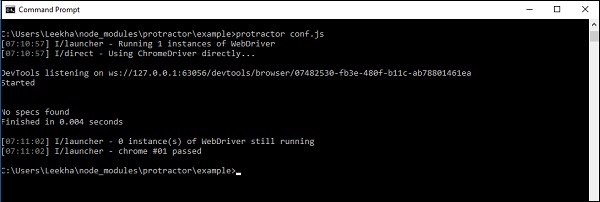
A saída acima mostra que não há especificação porque fornecemos o arquivo vazio no parâmetro de declaração do arquivo de origem no arquivo conf.js. Mas pela saída acima, podemos ver que o transferidor e o WebDriver estão sendo executados com sucesso.
Problemas na instalação e configuração
Ao instalar e configurar o Protractor e WebDriver, podemos encontrar os seguintes problemas comuns -
Selenium não instalado corretamente
É o problema mais comum durante a instalação do WebDriver. Esse problema surge se você não atualizar o WebDriver. Observe que devemos atualizar o WebDriver, caso contrário, não poderíamos fazer referência à instalação do Protractor.
Não foi possível encontrar testes
Outro problema comum é que depois de executar o Protractor, ele mostra que não foi possível encontrar testes. Para isso, devemos ter certeza de que os caminhos relativos, nomes de arquivos ou extensões estão corretos. Também precisamos escrever o arquivo conf.js com muito cuidado porque ele começa com o próprio arquivo de configuração.
Conforme discutido anteriormente, o Protractor é uma estrutura de teste ponta a ponta de código aberto para aplicativos Angular e AngularJS. É um programa Node.js. Por outro lado, Selenium é uma estrutura de automação de navegador que inclui o Selenium Server, as APIs WebDriver e os drivers de navegador WebDriver.
Transferidor com Selênio
Se falarmos sobre a conjunção de Transferidor e Selenium, o Protractor pode trabalhar com o servidor Selenium para fornecer uma infraestrutura de teste automatizada. A infraestrutura pode simular a interação do usuário com um aplicativo angular que está sendo executado em um navegador ou em um dispositivo móvel. A conjunção de Transferidor e Selênio pode ser dividida em três partições, a saber, teste, servidor e navegador, conforme mostrado no diagrama a seguir -

Processos Selenium WebDriver
Como vimos no diagrama acima, um teste usando Selenium WebDriver envolve os três processos a seguir -
- Os scripts de teste
- O servidor
- O navegador
Nesta seção, vamos discutir a comunicação entre esses três processos.
Comunicação entre Scripts de Teste e Servidor
A comunicação entre os dois primeiros processos - os scripts de teste e o servidor depende do funcionamento do Selenium Server. Em outras palavras, podemos dizer que a forma como o servidor Selenium está rodando dará forma ao processo de comunicação entre os scripts de teste e o servidor.
O servidor Selenium pode ser executado localmente em nossa máquina como um servidor Selenium autônomo (selenium-server-standalone.jar) ou pode ser executado remotamente por meio de um serviço (Sauce Labs). No caso do servidor Selenium autônomo, haveria uma comunicação http entre o Node.js e o servidor selenium.
Comunicação entre o servidor e o navegador
Como sabemos que o servidor é responsável por encaminhar comandos para o navegador após interpretar os mesmos a partir dos scripts de teste. É por isso que o servidor e o navegador também requerem um meio de comunicação e aqui a comunicação é feita com a ajuda deJSON WebDriver Wire Protocol. O navegador ampliado com o driver do navegador que é usado para interpretar os comandos.
O conceito acima sobre os processos do Selenium WebDriver e sua comunicação pode ser compreendido com a ajuda do diagrama a seguir -

Ao trabalhar com o Protractor, o primeiro processo, ou seja, o script de teste é executado usando Node.js, mas antes de executar qualquer ação no navegador, ele enviará um comando extra para certificar-se de que o aplicativo sendo testado está estabilizado.
Configurando o Selenium Server
O Selenium Server atua como um servidor proxy entre o nosso script de teste e o driver do navegador. Basicamente, ele encaminha o comando do nosso script de teste para o WebDriver e retorna as respostas do WebDriver para o nosso script de teste. Existem as seguintes opções para configurar o servidor Selenium que estão incluídas noconf.js arquivo do script de teste -
Servidor Selenium autônomo
Se quisermos executar o servidor em nossa máquina local, precisamos instalar o servidor selenium autônomo. O pré-requisito para instalar o servidor selenium autônomo é o JDK (Java Development Kit). Devemos ter o JDK instalado em nossa máquina local. Podemos verificar executando o seguinte comando na linha de comando -
java -versionAgora, temos a opção de instalar e iniciar o Selenium Server manualmente ou a partir do script de teste.
Instalando e iniciando o servidor Selenium manualmente
Para instalar e iniciar o servidor Selenium manualmente, precisamos usar a ferramenta de linha de comando WebDriver-Manager que vem com o Protractor. As etapas para instalar e iniciar o servidor Selenium são as seguintes -
Step 1- A primeira etapa é instalar o servidor Selenium e o ChromeDriver. Isso pode ser feito com a ajuda da execução do seguinte comando -
webdriver-manager updateStep 2- Em seguida, precisamos iniciar o servidor. Isso pode ser feito com a ajuda da execução do seguinte comando -
webdriver-manager startStep 3- Por fim, precisamos definir seleniumAddress no arquivo de configuração para o endereço do servidor em execução. O endereço padrão seriahttp://localhost:4444/wd/hub.
Iniciando o servidor Selenium a partir de um script de teste
Para iniciar o servidor Selenium a partir de um script de teste, precisamos definir as seguintes opções em nosso arquivo de configuração -
Location of jar file - Precisamos definir a localização do arquivo jar para o servidor Selenium autônomo no arquivo de configuração definindo seleniumServerJar.
Specifying the port- Também precisamos especificar a porta a ser usada para iniciar o servidor Selenium autônomo. Ele pode ser especificado no arquivo de configuração definindo seleniumPort. A porta padrão é 4444.
Array of command line options- Também precisamos definir o conjunto de opções de linha de comando para passar ao servidor. Ele pode ser especificado no arquivo de configuração definindo seleniumArgs. Se você precisa de uma lista completa de conjuntos de comandos, inicie o servidor com o-help bandeira.
Trabalhando com Servidor Selenium Remoto
Outra opção para executar nosso teste é usar o servidor Selenium remotamente. O pré-requisito para usar o servidor remotamente é que devemos ter uma conta com um serviço que hospeda o servidor. Enquanto trabalhamos com o Protractor, temos o suporte integrado para os seguintes serviços de hospedagem do servidor -
TestObject
Para usar TestObject como o servidor Selenium remoto, precisamos definir o testobjectUser, o nome de usuário de nossa conta TestObject e testobjectKey, a chave API de nossa conta TestObject.
BrowserStack
Para usar BrowserStack como o servidor Selenium remoto, precisamos definir o browserstackUser, o nome de usuário de nossa conta BrowserStack e browserstackKey, a chave API de nossa conta BrowserStack.
Laboratórios de molho
Para usar a Sauce Labs como o servidor Selenium remoto, precisamos definir o sauceUser, o nome de usuário de nossa conta da Sauce Labs e SauceKey, a chave API de nossa conta da Sauce Labs.
Kobiton
Para usar o Kobiton como o servidor Selenium remoto, precisamos definir o kobitonUser, o nome de usuário de nossa conta Kobiton e kobitonKey, a chave API de nossa conta Kobiton.
Conectando-se diretamente ao driver do navegador sem usar o servidor Selenium
Mais uma opção para executar nosso teste é conectar-se ao driver do navegador diretamente, sem usar o servidor Selenium. O transferidor pode testar diretamente, sem o uso do Selenium Server, no Chrome e no Firefox, definindo directConnect: true no arquivo de configuração.
Configurando o navegador
Antes de configurar e definir o navegador, precisamos saber quais navegadores são compatíveis com o Protractor. A seguir está a lista de navegadores suportados pelo Protractor -
- ChromeDriver
- FirefoxDriver
- SafariDriver
- IEDriver
- Appium-iOS/Safari
- Appium-Android/Chrome
- Selendroid
- PhantomJS
Para definir e configurar o navegador, precisamos mover para o arquivo de configuração do Protractor porque a configuração do navegador é feita dentro do objeto de recursos do arquivo de configuração.
Configurando o Chrome
Para configurar o navegador Chrome, precisamos definir o objeto de capacidades da seguinte maneira
capabilities: {
'browserName': 'chrome'
}Também podemos adicionar opções específicas do Chrome que estão aninhadas em chromeOptions e sua lista completa pode ser vista em https://sites.google.com/a/chromium.org/chromedriver/capabilities.
Por exemplo, se você deseja adicionar FPS-counter no canto superior direito, então isso pode ser feito da seguinte forma no arquivo de configuração -
capabilities: {
'browserName': 'chrome',
'chromeOptions': {
'args': ['show-fps-counter=true']
}
},Configurando o Firefox
Para configurar o navegador Firefox, precisamos definir o objeto de capacidades da seguinte maneira -
capabilities: {
'browserName': 'firefox'
}Também podemos adicionar opções específicas do Firefox que estão aninhadas no objeto moz: firefoxOptions e sua lista completa pode ser vista em https://github.com/mozilla/geckodriver#firefox-capabilities.
Por exemplo, se você deseja executar seu teste no Firefox em modo de segurança, isso pode ser feito da seguinte forma no arquivo de configuração -
capabilities: {
'browserName': 'firefox',
'moz:firefoxOptions': {
'args': ['—safe-mode']
}
},Configurando outro navegador
Para configurar qualquer outro navegador além do Chrome ou Firefox, precisamos instalar um binário separado do https://docs.seleniumhq.org/download/.
Configurando PhantonJS
Na verdade, o PhantomJS não é mais compatível por causa de seus problemas de travamento. Em vez disso, é recomendável usar o Chrome sem cabeça ou o Firefox sem cabeça. Eles podem ser configurados da seguinte forma -
Para configurar o Chrome sem cabeça, precisamos iniciar o Chrome com o sinalizador –headless da seguinte forma -
capabilities: {
'browserName': 'chrome',
'chromeOptions': {
'args': [“--headless”, “--disable-gpu”, “--window-size=800,600”]
}
},Para configurar o Firefox sem cabeça, precisamos iniciar o Firefox com o –headless sinalizar da seguinte forma -
capabilities: {
'browserName': 'firefox',
'moz:firefoxOptions': {
'args': [“--headless”]
}
},Configurando vários navegadores para teste
Também podemos testar em vários navegadores. Para isso, precisamos usar a opção de configuração multiCapabilities da seguinte forma -
multiCapabilities: [{
'browserName': 'chrome'
},{
'browserName': 'firefox'
}]Qual estrutura?
Duas estruturas de teste BDD (desenvolvimento orientado por comportamento), Jasmine e Mocha, são suportadas pelo Protractor. Ambas as estruturas são baseadas em JavaScript e Node.js. A sintaxe, o relatório e a estrutura, necessários para escrever e gerenciar os testes, são fornecidos por essas estruturas.
A seguir, veremos como podemos instalar vários frameworks -
Estrutura Jasmine
É a estrutura de teste padrão do Protractor. Ao instalar o Protractor, você obterá a versão Jasmine 2.x com ele. Não precisamos instalá-lo separadamente.
Estrutura Mocha
Mocha é outro framework de teste JavaScript basicamente rodando em Node.js. Para usar o Mocha como nossa estrutura de teste, precisamos usar a interface BDD (desenvolvimento orientado por comportamento) e asserções Chai com Chai As Promised. A instalação pode ser feita com a ajuda dos seguintes comandos -
npm install -g mocha
npm install chai
npm install chai-as-promisedComo você pode ver, a opção -g é usada durante a instalação do mocha, é porque instalamos o Protractor globalmente usando a opção -g. Depois de instalá-lo, precisamos solicitar e configurar o Chai dentro de nossos arquivos de teste. Isso pode ser feito da seguinte forma -
var chai = require('chai');
var chaiAsPromised = require('chai-as-promised');
chai.use(chaiAsPromised);
var expect = chai.expect;Depois disso, podemos usar Chai As Promised como tal -
expect(myElement.getText()).to.eventually.equal('some text');Agora, precisamos definir a propriedade do framework como mocha do arquivo de configuração adicionando framework: 'mocha'. As opções como 'repórter' e 'lento' para mocha podem ser adicionadas no arquivo de configuração da seguinte forma -
mochaOpts: {
reporter: "spec", slow: 3000
}Estrutura de pepino
Para usar o Cucumber como nossa estrutura de teste, precisamos integrá-lo ao Protractor com a opção de estrutura custom. A instalação pode ser feita com a ajuda dos seguintes comandos
npm install -g cucumber
npm install --save-dev protractor-cucumber-frameworkComo você pode ver, a opção -g é usada durante a instalação do Cucumber, porque instalamos o Protractor globalmente, ou seja, com a opção -g. Em seguida, precisamos definir a propriedade do framework paracustom do arquivo de configuração adicionando framework: 'custom' e frameworkPath: 'Protractor-cucumber-framework' ao arquivo de configuração chamado cucumberConf.js.
O código de exemplo mostrado abaixo é um arquivo cucumberConf.js básico que pode ser usado para executar arquivos de recurso pepino com o Protractor -
exports.config = {
seleniumAddress: 'http://localhost:4444/wd/hub',
baseUrl: 'https://angularjs.org/',
capabilities: {
browserName:'Firefox'
},
framework: 'custom',
frameworkPath: require.resolve('protractor-cucumber-framework'),
specs: [
'./cucumber/*.feature'
],
// cucumber command line options
cucumberOpts: {
require: ['./cucumber/*.js'],
tags: [],
strict: true,
format: ["pretty"],
'dry-run': false,
compiler: []
},
onPrepare: function () {
browser.manage().window().maximize();
}
};Neste capítulo, vamos entender como escrever o primeiro teste no Protractor.
Arquivos exigidos pelo Transferidor
O Protractor precisa dos dois arquivos a seguir para ser executado -
Especificação ou arquivo de teste
É um dos arquivos importantes para executar o Protractor. Neste arquivo, escreveremos nosso código de teste real. O código de teste é escrito usando a sintaxe de nossa estrutura de teste.
Por exemplo, se estivermos usando Jasmine framework, então o código de teste será escrito usando a sintaxe de Jasmine. Este arquivo conterá todos os fluxos funcionais e afirmações do teste.
Em palavras simples, podemos dizer que este arquivo contém a lógica e os localizadores para interagir com a aplicação.
Exemplo
A seguir está um script simples, TestSpecification.js, tendo o caso de teste para navegar até um URL e verificar o título da página -
//TestSpecification.js
describe('Protractor Demo', function() {
it('to check the page title', function() {
browser.ignoreSynchronization = true;
browser.get('https://www.tutorialspoint.com/tutorialslibrary.htm');
browser.driver.getTitle().then(function(pageTitle) {
expect(pageTitle).toEqual('Free Online Tutorials and Courses');
});
});
});Explicação do código
O código do arquivo de especificação acima pode ser explicado da seguinte forma -
Navegador
É a variável global criada pelo Protractor para lidar com todos os comandos do navegador. É basicamente um wrapper em torno de uma instância do WebDriver. browser.get () é um método Selenium simples que instrui o Protractor a carregar uma página específica.
describe e it- Ambos são as sintaxes do framework de teste Jasmine. o’Describe’ é usado para conter o fluxo de ponta a ponta do nosso caso de teste, enquanto ‘it’contém alguns dos cenários de teste. Podemos ter vários‘it’ blocos em nosso programa de caso de teste.
Expect - É uma afirmação em que comparamos o título da página da web com alguns dados predefinidos.
ignoreSynchronization- É uma tag de navegador que é usada quando tentamos testar sites não angulares. O Protractor espera trabalhar apenas com sites angulares, mas se quisermos trabalhar com sites não angulares, essa tag deve ser definida como“true”.
Arquivo de configuração
Como o nome sugere, este arquivo fornece explicações para todas as opções de configuração do Protractor. Basicamente, diz ao Transferidor o seguinte -
- Onde encontrar os arquivos de teste ou especificações
- Qual navegador escolher
- Qual estrutura de teste usar
- Onde falar com o servidor Selenium
Exemplo
A seguir está o script simples, config.js, tendo o teste
// config.js
exports.config = {
directConnect: true,
// Capabilities to be passed to the webdriver instance.
capabilities: {
'browserName': 'chrome'
},
// Framework to use. Jasmine is recommended.
framework: 'jasmine',
// Spec patterns are relative to the current working directory when
// protractor is called.
specs: ['TestSpecification.js'],Explicação do código
O código do arquivo de configuração acima com três parâmetros básicos, pode ser explicado da seguinte forma -
Parâmetro de Capacidades
Este parâmetro é usado para especificar o nome do navegador. Isso pode ser visto no seguinte bloco de código do arquivo conf.js -
exports.config = {
directConnect: true,
// Capabilities to be passed to the webdriver instance.
capabilities: {
'browserName': 'chrome'
},Como visto acima, o nome do navegador fornecido aqui é 'chrome', que é o navegador padrão do Protractor. Também podemos alterar o nome do navegador.
Parâmetro de Estrutura
Este parâmetro é usado para especificar o nome da estrutura de teste. Isso pode ser visto no seguinte bloco de código do arquivo config.js -
exports.config = {
directConnect: true,
// Framework to use. Jasmine is recommended.
framework: 'jasmine',Aqui estamos usando a estrutura de teste 'jasmim'.
Parâmetro de declaração do arquivo fonte
Este parâmetro é usado para especificar o nome da declaração do arquivo de origem. Isso pode ser visto no seguinte bloco de código do arquivo conf.js -
exports.config = {
directConnect: true,
// Spec patterns are relative to the current working
directory when protractor is called.
specs: ['TsetSpecification.js'],Como visto acima, o nome da declaração do arquivo fonte dado aqui é ‘TestSpecification.js’. É porque, para este exemplo, criamos o arquivo de especificação com o nomeTestSpecification.js.
Executando o código
Como temos um conhecimento básico sobre os arquivos necessários e sua codificação para rodar o Protractor, vamos tentar rodar o exemplo. Podemos seguir as seguintes etapas para executar este exemplo -
Step 1 - Primeiro, abra o prompt de comando.
Step 2 - Em seguida, precisamos ir para o diretório onde salvamos nossos arquivos, ou seja, config.js e TestSpecification.js.
Step 3 - Agora, execute o arquivo config.js executando o comando Protrcator config.js.
A captura de tela mostrada abaixo irá explicar as etapas acima para executar o exemplo -

É visto na captura de tela que o teste foi aprovado.
Agora, suponha que se estamos testando sites não angulares e não colocando a tag ignoreSynchronization como true, depois de executar o código, obteremos o erro “Angular não pôde ser encontrado na página”.
Isso pode ser visto na captura de tela a seguir -

Geração de relatório
Até agora, discutimos sobre os arquivos necessários e sua codificação para a execução de casos de teste. O transferidor também é capaz de gerar o relatório para casos de teste. Para este efeito, suporta Jasmine. JunitXMLReporter pode ser usado para gerar relatórios de execução de teste automaticamente.
Mas antes disso, precisamos instalar o Jasmine reporter com a ajuda do seguinte comando -
npm install -g jasmine-reportersComo você pode ver, a opção -g é usada durante a instalação do Jasmine Reporters, porque instalamos o Protractor globalmente, com a opção -g.
Depois de instalar com sucesso o jasmine-reporters, precisamos adicionar o seguinte código em nosso arquivo config.js usado anteriormente -
onPrepare: function(){ //configure junit xml report
var jasmineReporters = require('jasmine-reporters');
jasmine.getEnv().addReporter(new jasmineReporters.JUnitXmlReporter({
consolidateAll: true,
filePrefix: 'guitest-xmloutput',
savePath: 'test/reports'
}));Agora, nosso novo arquivo config.js seria o seguinte -
// An example configuration file.
exports.config = {
directConnect: true,
// Capabilities to be passed to the webdriver instance.
capabilities: {
'browserName': 'chrome'
},
// Framework to use. Jasmine is recommended.
framework: 'jasmine',
// Spec patterns are relative to the current working directory when
// protractor is called.
specs: ['TestSpecification.js'],
//framework: "jasmine2", //must set it if you use JUnitXmlReporter
onPrepare: function(){ //configure junit xml report
var jasmineReporters = require('jasmine-reporters');
jasmine.getEnv().addReporter(new jasmineReporters.JUnitXmlReporter({
consolidateAll: true,
filePrefix: 'guitest-xmloutput',
savePath: 'reports'
}));
},
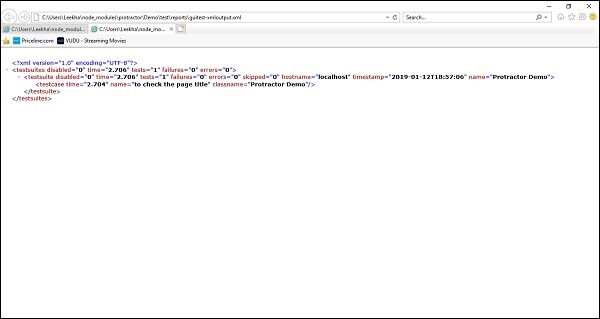
};Depois de executar o arquivo de configuração acima da mesma maneira que executamos anteriormente, ele irá gerar um arquivo XML contendo o relatório no diretório raiz em reportspasta. Se o teste for bem-sucedido, o relatório será semelhante a abaixo -
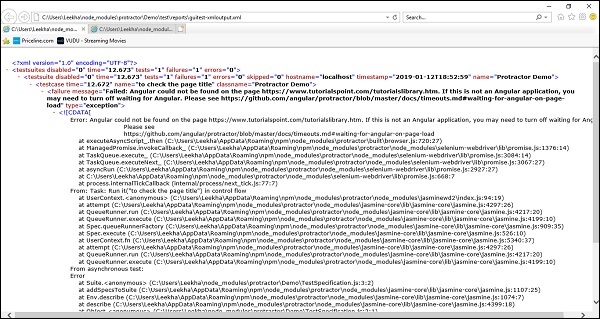
Mas, se o teste falhar, o relatório terá a aparência mostrada abaixo -
Transferidor - Núcleo APIS
Este capítulo permite que você entenda várias APIs principais que são essenciais para o funcionamento do transferidor.
Importância das APIs do Protractor
O Protractor nos fornece uma ampla gama de APIs que são muito importantes para realizar as seguintes ações para obter o estado atual do site -
- Obtendo os elementos DOM da página da web que iremos testar.
- Interagindo com os elementos DOM.
- Atribuindo ações a eles.
- Compartilhando informações com eles.
Para realizar as tarefas acima, é muito importante entender as APIs do Protractor.
Várias APIs do Protractor
Como sabemos, o Protractor é um invólucro em torno do Selenium-WebDriver, que são as ligações WebDriver para Node.js. Transferidor tem as seguintes APIs -
Navegador
É um wrapper em torno de uma instância do WebDriver que é usado para lidar com comandos de nível de navegador, como navegação, informações de toda a página, etc. Por exemplo, o método browser.get carrega uma página.
Elemento
Ele é usado para pesquisar e interagir com o elemento DOM na página que estamos testando. Para isso, requer um parâmetro para localizar o elemento.
Localizadores (por)
É uma coleção de estratégias de localização de elementos. Os elementos, por exemplo, podem ser encontrados pelo seletor CSS, por ID ou por qualquer outro atributo ao qual eles estão vinculados com o modelo ng.
A seguir, discutiremos em detalhes sobre essas APIs e suas funções.
API do navegador
Conforme discutido acima, é um invólucro em torno de uma instância do WebDriver para manipular comandos no nível do navegador. Ele executa várias funções da seguinte forma -
Funções e suas descrições
As funções da API ProtractorBrowser são as seguintes−
browser.angularAppRoot
Esta função da API do navegador define o seletor CSS para um elemento no qual encontraremos o Angular. Normalmente, esta função está em 'body', mas no caso de ser nosso ng-app, está em uma subseção da página; pode ser um subelemento também.
browser.waitForAngularEnabled
Esta função da API do navegador pode ser definida como verdadeira ou falsa. Como o nome sugere, se esta função for definida como falsa, o transferidor não esperará por Angular$http and $tarefas de tempo limite a serem concluídas antes de interagir com o navegador. Também podemos ler o estado atual sem alterá-lo, chamando waitForAngularEnabled () sem passar um valor.
browser.getProcessedConfig
Com a ajuda desta função de APIs do navegador, podemos obter o objeto de configuração processado, incluindo especificações e recursos, que está sendo executado no momento.
browser.forkNewDriverInstance
Como o nome sugere, essa função bifurcará outra instância do navegador para ser usada em testes interativos. Pode ser executado com o fluxo de controle ativado e desativado. O exemplo é dado abaixo para ambos os casos -
Example 1
Corrida browser.forkNewDriverInstance() com fluxo de controle habilitado -
var fork = browser.forkNewDriverInstance();
fork.get(‘page1’);Example 2
Corrida browser.forkNewDriverInstance() com fluxo de controle desativado -
var fork = await browser.forkNewDriverInstance().ready;
await forked.get(‘page1’);browser.restart
Como o nome sugere, ele irá reiniciar o navegador fechando a instância do navegador e criando uma nova. Ele também pode ser executado com o fluxo de controle ativado e desativado. O exemplo é dado abaixo para ambos os casos -
Example 1 - correndo browser.restart() com fluxo de controle habilitado -
browser.get(‘page1’);
browser.restart();
browser.get(‘page2’);Example 2 - correndo browser.forkNewDriverInstance() com fluxo de controle desativado -
await browser.get(‘page1’);
await browser.restart();
await browser.get(‘page2’);browser.restartSync
É semelhante à função browser.restart (). A única diferença é que ele retorna a nova instância do navegador diretamente, em vez de retornar uma promessa de resolução para a nova instância do navegador. Ele só pode ser executado quando o fluxo de controle está ativado.
Example - correndo browser.restartSync() com fluxo de controle habilitado -
browser.get(‘page1’);
browser.restartSync();
browser.get(‘page2’);browser.useAllAngular2AppRoots
Como o nome sugere, ele é compatível apenas com Angular2. Ele pesquisará todos os aplicativos angulares disponíveis na página enquanto encontra elementos ou espera pela estabilidade.
browser.waitForAngular
Esta função de API do navegador instrui o WebDriver a esperar até que o Angular termine a renderização e não tenha $http or $tempo limite de chamadas antes de continuar.
browser.findElement
Como o nome sugere, esta função da API do navegador espera que o Angular termine a renderização antes de pesquisar o elemento.
browser.isElementPresent
Como o nome sugere, essa função de API do navegador testará se o elemento está presente ou não na página.
browser.addMockModule
Ele adicionará um módulo para carregar antes do Angular sempre que o método Protractor.get for chamado.
Example
browser.addMockModule('modName', function() {
angular.module('modName', []).value('foo', 'bar');
});browser.clearMockModules
ao contrário de browser.addMockModule, ele limpará a lista de módulos simulados registrados.
browser.removeMockModule
Como o nome sugere, ele removerá um módulo de simulação de registro. Exemplo: browser.removeMockModule ('modName');
browser.getRegisteredMockModules
Ao lado de browser.clearMockModule, ele obterá a lista de módulos simulados registrados.
browser.get
Podemos usar browser.get () para navegar no navegador até um endereço da web específico e carregar os módulos simulados para essa página antes do carregamento Angular.
Example
browser.get(url);
browser.get('http://localhost:3000');
// This will navigate to the localhost:3000 and will load mock module if neededbrowser.refresh
Como o nome sugere, isso irá recarregar a página atual e carregar módulos de simulação antes do Angular.
browser.navigate
Como o nome sugere, ele é usado para misturar métodos de navegação de volta ao objeto de navegação para que sejam chamados como antes. Exemplo: driver.navigate (). Refresh ().
browser.setLocation
É usado para navegar para outra página usando a navegação in-page.
Example
browser.get('url/ABC');
browser.setLocation('DEF');
expect(browser.getCurrentUrl())
.toBe('url/DEF');Ele irá navegar da página ABC para a página DEF.
browser.debugger
Como o nome sugere, isso deve ser usado com a depuração do transferidor. Essa função basicamente adiciona uma tarefa ao fluxo de controle para pausar o teste e injetar funções auxiliares no navegador para que a depuração possa ser feita no console do navegador.
browser.pause
É usado para depurar testes WebDriver. Podemos usarbrowser.pause() em nosso teste para entrar no depurador do transferidor a partir desse ponto no fluxo de controle.
Example
element(by.id('foo')).click();
browser.pause();
// Execution will stop before the next click action.
element(by.id('bar')).click();browser.controlFlowEnabled
É usado para determinar se o fluxo de controle está habilitado ou não.
Transferidor - Core APIS (CONTD ...)
Neste capítulo, vamos aprender mais algumas APIs básicas do Protractor.
Elements API
O elemento é uma das funções globais expostas pelo transferidor. Esta função pega um localizador e retorna o seguinte -
- ElementFinder, que encontra um único elemento com base no localizador.
- ElementArrayFinder, que encontra uma matriz de elementos com base no localizador.
Ambos os métodos acima suportam encadeamento conforme discutido abaixo.
Funções de encadeamento de ElementArrayFinder e suas descrições
As seguintes são as funções de ElementArrayFinder -
element.all(locator).clone
Como o nome sugere, esta função criará uma cópia superficial do array dos elementos, ou seja, ElementArrayFinder.
element.all(locator).all(locator)
Esta função basicamente retorna um novo ElementArrayFinder que pode estar vazio ou conter os elementos filhos. Pode ser usado para selecionar vários elementos como uma matriz da seguinte maneira
Example
element.all(locator).all(locator)
elementArr.all(by.css(‘.childselector’));
// it will return another ElementFindArray as child element based on child locator.element.all(locator).filter(filterFn)
Como o nome sugere, após aplicar a função de filtro a cada elemento em ElementArrayFinder, ele retorna um novo ElementArrayFinder com todos os elementos que passam pela função de filtro. Ele tem basicamente dois argumentos, o primeiro é ElementFinder e o segundo é o índice. Ele também pode ser usado em objetos de página.
Example
View
<ul class = "items">
<li class = "one">First</li>
<li class = "two">Second</li>
<li class = "three">Third</li>
</ul>Code
element.all(by.css('.items li')).filter(function(elem, index) {
return elem.getText().then(function(text) {
return text === 'Third';
});
}).first().click();element.all(locator).get(index)
Com a ajuda disso, podemos obter um elemento dentro do ElementArrayFinder por índice. Observe que o índice começa em 0 e os índices negativos são quebrados.
Example
View
<ul class = "items">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>Code
let list = element.all(by.css('.items li'));
expect(list.get(0).getText()).toBe('First');
expect(list.get(1).getText()).toBe('Second');element.all(locator).first()
Como o nome sugere, isso obterá o primeiro elemento para ElementArrayFinder. Ele não recuperará o elemento subjacente.
Example
View
<ul class = "items">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>Code
let first = element.all(by.css('.items li')).first();
expect(first.getText()).toBe('First');element.all(locator).last()
Como o nome sugere, isso obterá o último elemento para ElementArrayFinder. Ele não recuperará o elemento subjacente.
Example
View
<ul class = "items">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>Code
let first = element.all(by.css('.items li')).last();
expect(last.getText()).toBe('Third');element.all(locator).all(selector)
É usado para encontrar uma matriz de elementos dentro de um pai quando chamadas para $$ podem ser encadeadas.
Example
View
<div class = "parent">
<ul>
<li class = "one">First</li>
<li class = "two">Second</li>
<li class = "three">Third</li>
</ul>
</div>Code
let items = element(by.css('.parent')).$$('li');element.all(locator).count()
Como o nome sugere, isso contará o número de elementos representados por ElementArrayFinder. Ele não recuperará o elemento subjacente.
Example
View
<ul class = "items">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>Code
let list = element.all(by.css('.items li'));
expect(list.count()).toBe(3);element.all(locator).isPresent()
Ele irá combinar os elementos com o localizador. Ele pode retornar verdadeiro ou falso. Verdadeiro, se houver qualquer elemento presente que corresponda ao localizador e Falso caso contrário.
Example
expect($('.item').isPresent()).toBeTruthy();element.all(locator).locator
Como o nome sugere, ele retornará o localizador mais relevante.
Example
$('#ID1').locator();
// returns by.css('#ID1')
$('#ID1').$('#ID2').locator();
// returns by.css('#ID2')
$$('#ID1').filter(filterFn).get(0).click().locator();
// returns by.css('#ID1')element.all(locator).then(thenFunction)
Ele recuperará os elementos representados pelo ElementArrayFinder.
Example
View
<ul class = "items">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>Code
element.all(by.css('.items li')).then(function(arr) {
expect(arr.length).toEqual(3);
});element.all(locator).each(eachFunction)
Como o nome sugere, ele chamará a função de entrada em cada ElementFinder representado pelo ElementArrayFinder.
Example
View
<ul class = "items">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>Code
element.all(by.css('.items li')).each(function(element, index) {
// It will print First 0, Second 1 and Third 2.
element.getText().then(function (text) {
console.log(index, text);
});
});element.all(locator).map(mapFunction)
Como o nome sugere, ele aplicará uma função de mapa em cada elemento do ElementArrayFinder. É ter dois argumentos. O primeiro seria o ElementFinder e o segundo seria o índice.
Example
View
<ul class = "items">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>Code
let items = element.all(by.css('.items li')).map(function(elm, index) {
return {
index: index,
text: elm.getText(),
class: elm.getAttribute('class')
};
});
expect(items).toEqual([
{index: 0, text: 'First', class: 'one'},
{index: 1, text: 'Second', class: 'two'},
{index: 2, text: 'Third', class: 'three'}
]);element.all(locator).reduce(reduceFn)
Como o nome sugere, ele aplicará uma função de redução contra um acumulador e todos os elementos encontrados usando o localizador. Esta função irá reduzir cada elemento em um único valor.
Example
View
<ul class = "items">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>Code
let value = element.all(by.css('.items li')).reduce(function(acc, elem) {
return elem.getText().then(function(text) {
return acc + text + ' ';
});
}, '');
expect(value).toEqual('First Second Third ');element.all(locator).evaluate
Como o nome sugere, ele avaliará a entrada se está no escopo dos elementos subjacentes atuais ou não.
Example
View
<span class = "foo">{{letiableInScope}}</span>Code
let value =
element.all(by.css('.foo')).evaluate('letiableInScope');element.all(locator).allowAnimations
Como o nome sugere, ele determinará se a animação é permitida nos elementos subjacentes atuais ou não.
Example
element(by.css('body')).allowAnimations(false);Funções de encadeamento de ElementFinder e suas descrições
Funções de encadeamento do ElementFinder e suas descrições -
element(locator).clone
Como o nome sugere, esta função criará uma cópia superficial do ElementFinder.
element(locator).getWebElement()
Ele retornará o WebElement representado por este ElementFinder e um erro de WebDriver será lançado se o elemento não existir.
Example
View
<div class="parent">
some text
</div>Code
// All the four following expressions are equivalent.
$('.parent').getWebElement();
element(by.css('.parent')).getWebElement();
browser.driver.findElement(by.css('.parent'));
browser.findElement(by.css('.parent'));element(locator).all(locator)
Ele encontrará uma matriz de elementos dentro de um pai.
Example
View
<div class = "parent">
<ul>
<li class = "one">First</li>
<li class = "two">Second</li>
<li class = "three">Third</li>
</ul>
</div>Code
let items = element(by.css('.parent')).all(by.tagName('li'));element(locator).element(locator)
Ele encontrará elementos dentro de um pai.
Example
View
<div class = "parent">
<div class = "child">
Child text
<div>{{person.phone}}</div>
</div>
</div>Code
// Calls Chain 2 element.
let child = element(by.css('.parent')).
element(by.css('.child'));
expect(child.getText()).toBe('Child text\n981-000-568');
// Calls Chain 3 element.
let triple = element(by.css('.parent')).
element(by.css('.child')).
element(by.binding('person.phone'));
expect(triple.getText()).toBe('981-000-568');element(locator).all(selector)
Ele encontrará uma matriz de elementos dentro de um pai quando as chamadas para $$ puderem ser encadeadas.
Example
View
<div class = "parent">
<ul>
<li class = "one">First</li>
<li class = "two">Second</li>
<li class = "three">Third</li>
</ul>
</div>Code
let items = element(by.css('.parent')).$$('li'));element(locator).$(locator)
Ele encontrará elementos dentro de um pai quando as chamadas para $ puderem ser encadeadas.
Example
View
<div class = "parent">
<div class = "child">
Child text
<div>{{person.phone}}</div>
</div>
</div>Code
// Calls Chain 2 element.
let child = element(by.css('.parent')).
$('.child')); expect(child.getText()).toBe('Child text\n981-000-568'); // Calls Chain 3 element. let triple = element(by.css('.parent')). $('.child')).
element(by.binding('person.phone'));
expect(triple.getText()).toBe('981-000-568');element(locator).isPresent()
Ele determinará se o elemento é apresentado na página ou não.
Example
View
<span>{{person.name}}</span>Code
expect(element(by.binding('person.name')).isPresent()).toBe(true);
// will check for the existence of element
expect(element(by.binding('notPresent')).isPresent()).toBe(false);
// will check for the non-existence of elementelement(locator).isElementPresent()
É o mesmo que element (localizador) .isPresent (). A única diferença é que ele irá verificar se o elemento identificado pelo sublocator está presente em vez do localizador de elemento atual.
element.all(locator).evaluate
Como o nome sugere, ele avaliará a entrada se está no escopo dos elementos subjacentes atuais ou não.
Example
View
<span id = "foo">{{letiableInScope}}</span>Code
let value = element(by.id('.foo')).evaluate('letiableInScope');element(locator).allowAnimations
Como o nome sugere, ele determinará se a animação é permitida nos elementos subjacentes atuais ou não.
Example
element(by.css('body')).allowAnimations(false);element(locator).equals
Como o nome sugere, ele irá comparar um elemento de igualdade.
Localizadores (por) API
É basicamente uma coleção de estratégias de localizador de elemento que fornece maneiras de encontrar elementos em aplicativos angulares por vinculação, modelo etc.
Functions and their descriptions
As funções da API ProtractorLocators são as seguintes -
by.addLocator(locatorName,fuctionOrScript)
Ele adicionará um localizador a esta instância de ProtrcatorBy que ainda pode ser usado com o elemento (by.locatorName (args)).
Example
View
<button ng-click = "doAddition()">Go!</button>Code
// Adding the custom locator.
by.addLocator('buttonTextSimple',
function(buttonText, opt_parentElement, opt_rootSelector) {
var using = opt_parentElement || document,
buttons = using.querySelectorAll('button');
return Array.prototype.filter.call(buttons, function(button) {
return button.textContent === buttonText;
});
});
element(by.buttonTextSimple('Go!')).click();// Using the custom locator.by.binding
Como o nome sugere, ele encontrará um elemento por vinculação de texto. Uma correspondência parcial será feita para que quaisquer elementos vinculados às variáveis que contêm a string de entrada sejam retornados.
Example
View
<span>{{person.name}}</span>
<span ng-bind = "person.email"></span>Code
var span1 = element(by.binding('person.name'));
expect(span1.getText()).toBe('Foo');
var span2 = element(by.binding('person.email'));
expect(span2.getText()).toBe('[email protected]');by.exactbinding
Como o nome sugere, ele encontrará um elemento por ligação exata.
Example
View
<spangt;{{ person.name }}</spangt;
<span ng-bind = "person-email"gt;</spangt;
<spangt;{{person_phone|uppercase}}</span>Code
expect(element(by.exactBinding('person.name')).isPresent()).toBe(true);
expect(element(by.exactBinding('person-email')).isPresent()).toBe(true);
expect(element(by.exactBinding('person')).isPresent()).toBe(false);
expect(element(by.exactBinding('person_phone')).isPresent()).toBe(true);
expect(element(by.exactBinding('person_phone|uppercase')).isPresent()).toBe(true);
expect(element(by.exactBinding('phone')).isPresent()).toBe(false);by.model(modelName)
Como o nome sugere, ele encontrará um elemento pela expressão do modelo ng.
Example
View
<input type = "text" ng-model = "person.name">Code
var input = element(by.model('person.name'));
input.sendKeys('123');
expect(input.getAttribute('value')).toBe('Foo123');by.buttonText
Como o nome sugere, ele encontrará um botão por texto.
Example
View
<button>Save</button>Code
element(by.buttonText('Save'));by.partialButtonText
Como o nome sugere, ele encontrará um botão por texto parcial.
Example
View
<button>Save my file</button>Code
element(by.partialButtonText('Save'));by.repeater
Como o nome sugere, ele encontrará um elemento dentro de uma repetição de ng.
Example
View
<div ng-repeat = "cat in pets">
<span>{{cat.name}}</span>
<span>{{cat.age}}</span>
<</div>
<div class = "book-img" ng-repeat-start="book in library">
<span>{{$index}}</span>
</div>
<div class = "book-info" ng-repeat-end>
<h4>{{book.name}}</h4>
<p>{{book.blurb}}</p>
</div>Code
var secondCat = element(by.repeater('cat in
pets').row(1)); // It will return the DIV for the second cat.
var firstCatName = element(by.repeater('cat in pets').
row(0).column('cat.name')); // It will return the SPAN for the first cat's name.by.exactRepeater
Como o nome sugere, ele encontrará um elemento por repetidor exato.
Example
View
<li ng-repeat = "person in peopleWithRedHair"></li>
<li ng-repeat = "car in cars | orderBy:year"></li>Code
expect(element(by.exactRepeater('person in
peopleWithRedHair')).isPresent())
.toBe(true);
expect(element(by.exactRepeater('person in
people')).isPresent()).toBe(false);
expect(element(by.exactRepeater('car in cars')).isPresent()).toBe(true);by.cssContainingText
Como o nome sugere, ele encontrará os elementos, contendo a string exata, por CSS
Example
View
<ul>
<li class = "pet">Dog</li>
<li class = "pet">Cat</li>
</ul>Code
var dog = element(by.cssContainingText('.pet', 'Dog'));
// It will return the li for the dog, but not for the cat.by.options(optionsDescriptor)
Como o nome sugere, ele encontrará um elemento pela expressão ng-options.
Example
View
<select ng-model = "color" ng-options = "c for c in colors">
<option value = "0" selected = "selected">red</option>
<option value = "1">green</option>
</select>Code
var allOptions = element.all(by.options('c for c in colors'));
expect(allOptions.count()).toEqual(2);
var firstOption = allOptions.first();
expect(firstOption.getText()).toEqual('red');by.deepCSS(selector)
Como o nome sugere, ele encontrará um elemento por seletor CSS dentro do DOM shadow.
Example
View
<div>
<span id = "outerspan">
<"shadow tree">
<span id = "span1"></span>
<"shadow tree">
<span id = "span2"></span>
</>
</>
</div>Code
var spans = element.all(by.deepCss('span'));
expect(spans.count()).toEqual(3);Transferidor - Objetos
Este capítulo discute em detalhes sobre os objetos no Protractor.
O que são objetos de página?
O objeto de página é um padrão de design que se tornou popular para escrever testes e2e a fim de aprimorar a manutenção do teste e reduzir a duplicação de código. Ele pode ser definido como uma classe orientada a objetos servindo como uma interface para uma página de seu AUT (aplicativo em teste). Mas, antes de mergulhar profundamente nos objetos de página, devemos entender os desafios do teste de IU automatizado e as maneiras de lidar com eles.
Desafios com testes automatizados de IU
A seguir estão alguns desafios comuns com testes automatizados de IU -
Mudanças na interface do usuário
Os problemas muito comuns ao trabalhar com testes de IU são as mudanças que acontecem na IU. Por exemplo, acontece na maioria das vezes que botões ou caixas de texto, etc., geralmente sofrem alterações e criam problemas para o teste de IU.
Falta de suporte DSL (Domain Specific Language)
Outro problema com o teste de IU é a falta de suporte DSL. Com esse problema, fica muito difícil entender o que está sendo testado.
Muita repetição / duplicação de código
O próximo problema comum em testes de IU é que há muita repetição ou duplicação de código. Pode ser entendido com a ajuda das seguintes linhas de código -
element(by.model(‘event.name’)).sendKeys(‘An Event’);
element(by.model(‘event.name’)).sendKeys(‘Module 3’);
element(by.model(‘event.name’));Manutenção difícil
Devido aos desafios acima, torna-se uma dor de cabeça para manutenção. É porque temos que encontrar todas as instâncias, substituir pelo novo nome, seletor e outro código. Também precisamos gastar muito tempo para manter os testes alinhados com a refatoração.
Testes quebrados
Outro desafio nos testes de IU é o surgimento de muitas falhas nos testes.
Maneiras de lidar com desafios
Vimos alguns desafios comuns de teste de IU. Algumas das maneiras de lidar com esses desafios são as seguintes -
Atualizando referências manualmente
A primeira opção para lidar com os desafios acima é atualizar as referências manualmente. O problema com esta opção é que devemos fazer a mudança manual no código, bem como em nossos testes. Isso pode ser feito quando você tem um ou dois arquivos de teste, mas e se você tiver centenas de arquivos de teste em um projeto?
Usando objetos de página
Outra opção para lidar com os desafios acima é usar objetos de página. Um objeto de página é basicamente um JavaScript simples que encapsula as propriedades de um modelo Angular. Por exemplo, o arquivo de especificação a seguir é escrito sem e com objetos de página para entender a diferença -
Without Page Objects
describe('angularjs homepage', function() {
it('should greet the named user', function() {
browser.get('http://www.angularjs.org');
element(by.model('yourName')).sendKeys('Julie');
var greeting = element(by.binding('yourName'));
expect(greeting.getText()).toEqual('Hello Julie!');
});
});With Page Objects
Para escrever o código com Objetos de Página, a primeira coisa que precisamos fazer é criar um Objeto de Página. Portanto, um objeto de página para o exemplo acima poderia ser parecido com este -
var AngularHomepage = function() {
var nameInput = element(by.model('yourName'));
var greeting = element(by.binding('yourName'));
this.get = function() {
browser.get('http://www.angularjs.org');
};
this.setName = function(name) {
nameInput.sendKeys(name);
};
this.getGreetingText = function() {
return greeting.getText();
};
};
module.exports = new AngularHomepage();Usando objetos de página para organizar testes
Vimos o uso de objetos de página no exemplo acima para lidar com os desafios do teste de IU. A seguir, vamos discutir como podemos usá-los para organizar os testes. Para isso, precisamos modificar o script de teste sem modificar a funcionalidade do script de teste.
Exemplo
Para entender esse conceito, estamos pegando o arquivo de configuração acima com objetos de página. Precisamos modificar o script de teste da seguinte forma -
var angularHomepage = require('./AngularHomepage');
describe('angularjs homepage', function() {
it('should greet the named user', function() {
angularHomepage.get();
angularHomepage.setName('Julie');
expect(angularHomepage.getGreetingText()).toEqual
('Hello Julie!');
});
});Aqui, observe que o caminho para o objeto da página será relativo à sua especificação.
Na mesma nota, também podemos separar nosso conjunto de testes em vários conjuntos de testes. O arquivo de configuração pode então ser alterado da seguinte forma
exports.config = {
// The address of a running selenium server.
seleniumAddress: 'http://localhost:4444/wd/hub',
// Capabilities to be passed to the webdriver instance.
capabilities: {
'browserName': 'chrome'
},
// Spec patterns are relative to the location of the spec file. They may
// include glob patterns.
suites: {
homepage: 'tests/e2e/homepage/**/*Spec.js',
search: ['tests/e2e/contact_search/**/*Spec.js',
'tests/e2e/venue_search/**/*Spec.js']
},
// Options to be passed to Jasmine-node.
jasmineNodeOpts: {
showColors: true, // Use colors in the command line report.
}
};Agora, podemos alternar facilmente entre a execução de um ou outro conjunto de testes. O comando a seguir executará apenas a seção da página inicial do teste -
protractor protractor.conf.js --suite homepageDa mesma forma, podemos executar conjuntos específicos de testes com o comando da seguinte maneira -
protractor protractor.conf.js --suite homepage,searchTransferidor - Depuração
Agora que vimos todos os conceitos do Protractor nos capítulos anteriores, vamos entender os conceitos de depuração em detalhes neste capítulo.
Introdução
Os testes ponta a ponta (e2e) são muito difíceis de depurar porque dependem de todo o ecossistema desse aplicativo. Vimos que eles dependem de várias ações ou, particularmente, podemos dizer que de ações anteriores como o login e às vezes dependem da permissão. Outra dificuldade na depuração de testes e2e é sua dependência do WebDriver porque ele age de maneira diferente com diferentes sistemas operacionais e navegadores. Por fim, a depuração de testes e2e também gera longas mensagens de erro e torna difícil separar os problemas relacionados ao navegador e os erros do processo de teste.
Tipos de falha
Pode haver vários motivos para a falha de suítes de teste e a seguir estão alguns tipos de falha bem conhecidos -
Falha do WebDriver
Quando um comando não pode ser concluído, um erro é lançado pelo WebDriver. Por exemplo, um navegador não pode obter o endereço definido ou um elemento não foi encontrado conforme o esperado.
Falha inesperada do WebDriver
Um navegador inesperado e uma falha relacionada ao sistema operacional acontecem quando ele falha ao atualizar o gerenciador de driver da web.
Falha do transferidor para Angular
A falha do Transferidor para Angular ocorre quando o Transferidor não encontrou o Angular na biblioteca como esperado.
Falha do transferidor Angular2
Nesse tipo de falha, o Protractor falhará quando o parâmetro useAllAngular2AppRoots não for encontrado na configuração. Isso acontece porque, sem isso, o processo de teste examinará um único elemento raiz enquanto espera mais de um elemento no processo.
Falha do transferidor por tempo limite
Esse tipo de falha ocorre quando a especificação de teste atinge um loop ou um pool longo e falha em retornar os dados a tempo.
Falha de expectativa
Uma das falhas de teste mais comuns que mostra a aparência de uma falha de expectativa normal.
Por que a depuração é importante no Protractor?
Suponha que, se você escreveu casos de teste e eles falharam, é muito importante saber como depurar esses casos de teste, pois seria muito difícil encontrar o local exato onde o erro ocorreu. Ao trabalhar com o Protractor, você obterá alguns erros longos na fonte da cor vermelha na linha de comando.
Pausando e depurando o teste
As formas de depurar no Protractor são explicadas aqui & miuns;
Método de pausa
Usar o método pause para depurar os casos de teste no Protractor é uma das maneiras mais fáceis. Podemos digitar o seguinte comando no local onde queremos pausar o nosso código de teste & miuns;
browser.pause();Quando os códigos em execução atingirem o comando acima, ele pausará o programa em execução nesse ponto. Depois disso, podemos dar os seguintes comandos de acordo com nossa preferência -
Digite C para seguir em frente
Sempre que um comando se esgota, devemos digitar C para seguir em frente. Se você não digitar C, o teste não executará o código completo e falhará devido ao erro de tempo limite do Jasmine.
Digite repl para entrar no modo interativo
A vantagem do modo interativo é que podemos enviar os comandos WebDriver para o nosso navegador. Se quisermos entrar no modo interativo, digiterepl.
Digite Ctrl-C para sair e continuar os testes
Para sair do teste do estado de pausa e continuar o teste de onde parou, precisamos digitar Ctrl-C.
Exemplo
Neste exemplo, temos o arquivo de especificação abaixo denominado example_debug.js, transferidor tenta identificar um elemento com localizador by.binding('mmmm') mas o URL (https://angularjs.org/ a página não tem nenhum elemento com o localizador especificado.
describe('Suite for protractor debugger',function(){
it('Failing spec',function(){
browser.get("http://angularjs.org");
element(by.model('yourName')).sendKeys('Vijay');
//Element doesn't exist
var welcomeText =
element(by.binding('mmmm')).getText();
expect('Hello '+welcomeText+'!').toEqual('Hello Ram!')
});
});Agora, para executar o teste acima, precisamos adicionar o código browser.pause (), onde você deseja pausar o teste, no arquivo de especificação acima. Será o seguinte -
describe('Suite for protractor debugger',function(){
it('Failing spec',function(){
browser.get("http://angularjs.org");
browser.pause();
element(by.model('yourName')).sendKeys('Vijay');
//Element doesn't exist
var welcomeText =
element(by.binding('mmmm')).getText();
expect('Hello '+welcomeText+'!').toEqual('Hello Ram!')
});
});Mas antes de executar, precisamos fazer algumas mudanças no arquivo de configuração também. Estamos fazendo as seguintes alterações no arquivo de configuração usado anteriormente, denominadoexample_configuration.js no capítulo anterior -
// An example configuration file.
exports.config = {
directConnect: true,
// Capabilities to be passed to the webdriver instance.
capabilities: {
'browserName': 'chrome'
},
// Framework to use. Jasmine is recommended.
framework: 'jasmine',
// Spec patterns are relative to the current working directory when
// protractor is called.
specs: ['example_debug.js'],
allScriptsTimeout: 999999,
jasmineNodeOpts: {
defaultTimeoutInterval: 999999
},
onPrepare: function () {
browser.manage().window().maximize();
browser.manage().timeouts().implicitlyWait(5000);
}
};Agora, execute o seguinte comando -
protractor example_configuration.jsO depurador será iniciado após o comando acima.
Método Depurador
Usar o método pause para depurar os casos de teste no Protractor é um modo um pouco avançado. Podemos digitar o seguinte comando no local em que queremos quebrar nosso código de teste -
browser.debugger();Ele usa o depurador de nó para depurar o código de teste. Para executar o comando acima, devemos digitar o seguinte comando em um prompt de comando separado que foi aberto a partir do local do projeto de teste -
protractor debug protractor.conf.jsNeste método, também precisamos digitar C no terminal para continuar o código de teste. Mas ao contrário do método de pausa, neste método ele deve ser digitado apenas uma vez.
Exemplo
Neste exemplo, estamos usando o mesmo arquivo de especificação denominado bexample_debug.js, usado acima. A única diferença é que em vez debrowser.pause(), precisamos usar browser.debugger()onde queremos quebrar o código de teste. Será o seguinte -
describe('Suite for protractor debugger',function(){
it('Failing spec',function(){
browser.get("http://angularjs.org");
browser.debugger();
element(by.model('yourName')).sendKeys('Vijay');
//Element doesn't exist
var welcomeText = element(by.binding('mmmm')).getText();
expect('Hello '+welcomeText+'!').toEqual('Hello Ram!')
});
});Estamos usando o mesmo arquivo de configuração, example_configuration.js, usado no exemplo acima.
Agora, execute o teste do transferidor com a seguinte opção de linha de comando de depuração
protractor debug example_configuration.jsO depurador será iniciado após o comando acima.
Transferidor - Guia de estilo para transferidor
Neste capítulo, vamos aprender em detalhes sobre o guia de estilo para transferidor.
Introdução
O guia de estilo foi criado por dois engenheiros de software chamados, Carmen Popoviciu, engenheiro de front-end no ING e Andres Dominguez, engenheiro de software do Google. Portanto, este guia de estilo também é chamado de Carmen Popoviciu e guia de estilo do Google para transferidor.
Este guia de estilo pode ser dividido nos seguintes cinco pontos-chave -
- Regras genéricas
- Estrutura do Projeto
- Estratégias de localizador
- Objetos de Página
- Suítes de teste
Regras Genéricas
A seguir estão algumas regras genéricas que devem ser tomadas com cuidado ao usar o transferidor para teste -
Não teste de ponta a ponta o que já foi testado na unidade
Esta é a primeira regra genérica dada por Carmen e Andres. Eles sugeriram que não devemos realizar o teste e2e no código que já foi testado na unidade. A principal razão por trás disso é que os testes de unidade são muito mais rápidos do que os testes e2e. Outra razão é que devemos evitar testes duplicados (não execute os testes unitário e e2e) para economizar nosso tempo.
Use apenas um arquivo de configuração
Outro ponto importante recomendado é que devemos usar apenas um arquivo de configuração. Não crie um arquivo de configuração para cada ambiente que você está testando. Você pode usargrunt-protractor-coverage a fim de configurar diferentes ambientes.
Evite usar lógica em seu teste
Devemos evitar o uso de instruções IF ou loops FOR em nossos casos de teste porque, se fizermos isso, o teste pode passar sem testar nada ou pode ser executado muito lentamente.
Faça o teste independente no nível do arquivo
O transferidor pode executar o teste paralelamente quando o compartilhamento está ativado. Em seguida, esses arquivos são executados em diferentes navegadores à medida que se tornam disponíveis. Carmen e Andres recomendaram tornar o teste independente pelo menos no nível do arquivo porque a ordem em que eles serão executados pelo transferidor é incerta e, além disso, é muito fácil executar um teste isoladamente.
Estrutura do Projeto
Outro ponto importante em relação ao guia de estilo do Transferidor é a estrutura do seu projeto. A seguir está a recomendação sobre a estrutura do projeto -
Teste e2e tateando em uma estrutura sensível
Carmen e Andres recomendaram que devemos agrupar nossos testes e2e em uma estrutura que faça sentido para a estrutura do seu projeto. A razão por trás dessa recomendação é que a localização dos arquivos se tornaria fácil e a estrutura da pasta seria mais legível. Esta etapa também separará os testes e2e dos testes de unidade. Eles recomendaram que o seguinte tipo de estrutura deve ser evitado -
|-- project-folder
|-- app
|-- css
|-- img
|-- partials
home.html
profile.html
contacts.html
|-- js
|-- controllers
|-- directives
|-- services
app.js
...
index.html
|-- test
|-- unit
|-- e2e
home-page.js
home-spec.js
profile-page.js
profile-spec.js
contacts-page.js
contacts-spec.jsPor outro lado, eles recomendaram o seguinte tipo de estrutura -
|-- project-folder
|-- app
|-- css
|-- img
|-- partials
home.html
profile.html
contacts.html
|-- js
|-- controllers
|-- directives
|-- services
app.js
...
index.html
|-- test
|-- unit
|-- e2e
|-- page-objects
home-page.js
profile-page.js
contacts-page.js
home-spec.js
profile-spec.js
contacts-spec.jsEstratégias de localizador
A seguir estão algumas estratégias de localizador que devem ser tomadas com cuidado ao usar o transferidor para teste -
Nunca use XPATH
Esta é a primeira estratégia de localizador recomendada no guia de estilo do transferidor. As razões por trás disso são que o XPath requer muita manutenção porque a marcação está muito facilmente sujeita a alterações. Além disso, as expressões XPath são as mais lentas e muito difíceis de depurar.
Sempre prefira localizadores específicos do transferidor, como by.model e by.binding
Os localizadores específicos do transferidor, como by.model e by.binding, são curtos, específicos e fáceis de ler. Com a ajuda deles, é muito fácil escrever também nosso localizador.
Exemplo
View
<ul class = "red">
<li>{{color.name}}</li>
<li>{{color.shade}}</li>
<li>{{color.code}}</li>
</ul>
<div class = "details">
<div class = "personal">
<input ng-model = "person.name">
</div>
</div>Para o código acima, é recomendado evitar o seguinte -
var nameElement = element.all(by.css('.red li')).get(0);
var personName = element(by.css('.details .personal input'));Por outro lado, recomenda-se o uso do seguinte -
var nameElement = element.all(by.css('.red li')).get(0);
var personName = element(by.css('.details .personal input'));var nameElement = element(by.binding('color.name'));
var personName = element(by.model('person.name'));Quando nenhum localizador de transferidor estiver disponível, é recomendável preferir by.id e by.css.
Sempre evite localizadores de texto para texto alterado com frequência
Devemos ter que evitar localizadores baseados em texto, como by.linkText, by.buttonText e by.cssContaningText porque o texto para botões, links e rótulos mudam frequentemente com o tempo.
Objetos de Página
Conforme discutido anteriormente, os objetos de página encapsulam informações sobre os elementos em nossa página de aplicativo e, devido a isso, nos ajudam a escrever casos de teste mais limpos. Uma vantagem muito útil dos objetos de página é que eles podem ser reutilizados em vários testes e, caso o modelo de nosso aplicativo tenha sido alterado, só precisamos atualizar o objeto de página. A seguir estão algumas recomendações para objetos de página que devem ser cuidados ao usar o transferidor para teste -
Para interagir com a página em teste, use objetos de página
É recomendável usar objetos de página para interagir com a página em teste porque eles podem encapsular informações sobre o elemento na página em teste e também podem ser reutilizados.
Sempre declare o objeto de uma página por arquivo
Devemos definir cada objeto de página em seu próprio arquivo porque ele mantém o código limpo e fica fácil encontrar as coisas.
No final da página, o arquivo de objeto sempre usa um único módulo.
Recomenda-se que cada objeto de página declare uma única classe, de modo que só precisemos exportar uma classe. Por exemplo, o seguinte uso de arquivo objeto deve ser evitado -
var UserProfilePage = function() {};
var UserSettingsPage = function() {};
module.exports = UserPropertiesPage;
module.exports = UserSettingsPage;Mas, por outro lado, é recomendado o uso a seguir -
/** @constructor */
var UserPropertiesPage = function() {};
module.exports = UserPropertiesPage;Declare todos os módulos necessários no topo
Devemos declarar todos os módulos necessários na parte superior do objeto da página porque isso torna as dependências do módulo claras e fáceis de encontrar.
Instancie todos os objetos de página no início do conjunto de testes
Recomenda-se instanciar todos os objetos de página no início da suíte de teste porque isso separará as dependências do código de teste e também tornará as dependências disponíveis para todas as especificações da suíte.
Não use expect () em objetos de página
Não devemos usar expect () em objetos de página, ou seja, não devemos fazer nenhuma asserção em nossos objetos de página porque todas as asserções devem ser feitas em casos de teste.
Outra razão é que o leitor do teste deve ser capaz de entender o comportamento do aplicativo lendo apenas os casos de teste.