AI с Python - пакет NLTK
В этой главе мы узнаем, как начать работу с пакетом Natural Language Toolkit Package.
Предпосылка
Если мы хотим создавать приложения с обработкой естественного языка, изменение контекста усложняет задачу. Фактор контекста влияет на то, как машина понимает конкретное предложение. Следовательно, нам необходимо разрабатывать приложения на естественном языке с использованием подходов машинного обучения, чтобы машина также могла понять, как человек может понять контекст.
Для создания таких приложений мы будем использовать пакет Python под названием NLTK (Natural Language Toolkit Package).
Импорт NLTK
Нам необходимо установить NLTK перед его использованием. Его можно установить с помощью следующей команды -
pip install nltkЧтобы создать пакет conda для NLTK, используйте следующую команду -
conda install -c anaconda nltkТеперь, после установки пакета NLTK, нам нужно импортировать его через командную строку python. Мы можем импортировать его, написав следующую команду в командной строке Python -
>>> import nltkСкачивание данных НЛТК
Теперь после импорта NLTK нам нужно загрузить необходимые данные. Это можно сделать с помощью следующей команды в командной строке Python -
>>> nltk.download()Установка других необходимых пакетов
Для создания приложений обработки естественного языка с помощью NLTK нам необходимо установить необходимые пакеты. Пакеты следующие -
Gensim
Это надежная библиотека семантического моделирования, которая полезна для многих приложений. Мы можем установить его, выполнив следующую команду -
pip install gensimшаблон
Он используется для изготовления gensimпакет работает правильно. Мы можем установить его, выполнив следующую команду
pip install patternКонцепция токенизации, стемминга и лемматизации
В этом разделе мы поймем, что такое токенизация, стемминг и лемматизация.
Токенизация
Это можно определить как процесс разбиения данного текста, то есть последовательности символов, на более мелкие единицы, называемые токенами. Жетонами могут быть слова, числа или знаки препинания. Это также называется сегментацией слов. Ниже приводится простой пример токенизации -
Input - Манго, банан, ананас и яблоко - все это фрукты.
Output -

Процесс разрыва данного текста может быть выполнен с помощью определения границ слова. Окончание слова и начало нового слова называются границами слова. Система письма и типографская структура слов влияют на границы.
В модуле Python NLTK у нас есть разные пакеты, связанные с токенизацией, которые мы можем использовать для разделения текста на токены в соответствии с нашими требованиями. Некоторые из пакетов следующие -
sent_tokenize пакет
Как следует из названия, этот пакет разделит вводимый текст на предложения. Мы можем импортировать этот пакет с помощью следующего кода Python -
from nltk.tokenize import sent_tokenizeword_tokenize пакет
Этот пакет делит вводимый текст на слова. Мы можем импортировать этот пакет с помощью следующего кода Python -
from nltk.tokenize import word_tokenizeПакет WordPunctTokenizer
Этот пакет разделяет вводимый текст на слова и знаки препинания. Мы можем импортировать этот пакет с помощью следующего кода Python -
from nltk.tokenize import WordPuncttokenizerСтемминг
Работая со словами, мы сталкиваемся с множеством вариаций по грамматическим причинам. Концепция вариаций здесь означает, что мы имеем дело с разными формами одних и тех же слов, напримерdemocracy, democratic, а также democratization. Машинам очень необходимо понимать, что эти разные слова имеют одинаковую базовую форму. Таким образом, было бы полезно извлекать базовые формы слов, пока мы анализируем текст.
Мы можем добиться этого, остановив. Таким образом, мы можем сказать, что выделение корней - это эвристический процесс извлечения основных форм слов путем отсечения концов слов.
В модуле Python NLTK у нас есть разные пакеты, связанные со стеммингом. Эти пакеты можно использовать для получения базовых форм слова. Эти пакеты используют алгоритмы. Некоторые из пакетов следующие -
Пакет PorterStemmer
Этот пакет Python использует алгоритм Портера для извлечения базовой формы. Мы можем импортировать этот пакет с помощью следующего кода Python -
from nltk.stem.porter import PorterStemmerНапример, если мы дадим слово ‘writing’ в качестве входных данных для этого стеммера мы получим слово ‘write’ после забоя.
Пакет LancasterStemmer
Этот пакет Python будет использовать алгоритм Ланкастера для извлечения базовой формы. Мы можем импортировать этот пакет с помощью следующего кода Python -
from nltk.stem.lancaster import LancasterStemmerНапример, если мы дадим слово ‘writing’ в качестве входных данных для этого стеммера мы получим слово ‘write’ после забоя.
Пакет SnowballStemmer
Этот пакет Python будет использовать алгоритм снежного кома для извлечения базовой формы. Мы можем импортировать этот пакет с помощью следующего кода Python -
from nltk.stem.snowball import SnowballStemmerНапример, если мы дадим слово ‘writing’ в качестве входных данных для этого стеммера мы получим слово ‘write’ после забоя.
Все эти алгоритмы имеют разную степень строгости. Если мы сравним эти три стеммера, то стеммер Портера наименее строгий, а Ланкастер самый строгий. Стеммер Snowball хорош как с точки зрения скорости, так и с точки зрения строгости.
Лемматизация
Мы также можем извлечь базовую форму слов с помощью лемматизации. В основном он выполняет эту задачу с использованием словарного и морфологического анализа слов, обычно стремясь удалить только флективные окончания. Такая базовая форма любого слова называется леммой.
Основное различие между стеммингом и лемматизацией - это использование словарного запаса и морфологический анализ слов. Еще одно отличие состоит в том, что основание чаще всего сворачивает слова, связанные с словообразованием, тогда как лемматизация обычно сворачивает только различные флективные формы леммы. Например, если мы предоставим слово saw в качестве входного слова, то основание может вернуть слово s, но лемматизация будет пытаться вернуть слово see или saw в зависимости от того, использовался ли токен глаголом или существительным.
В модуле Python NLTK у нас есть следующий пакет, связанный с процессом лемматизации, который мы можем использовать для получения базовых форм слова:
Пакет WordNetLemmatizer
Этот пакет Python извлечет базовую форму слова в зависимости от того, используется ли оно как существительное или как глагол. Мы можем импортировать этот пакет с помощью следующего кода Python -
from nltk.stem import WordNetLemmatizerРазделение на части: разделение данных на фрагменты
Это один из важных процессов обработки естественного языка. Основная задача разбиения на фрагменты - выявление частей речи и коротких фраз, таких как словосочетания с существительными. Мы уже изучили процесс токенизации, создания токенов. Разделение на части - это маркировка этих токенов. Другими словами, разбиение на части покажет нам структуру предложения.
В следующем разделе мы узнаем о различных типах разбиения на части.
Типы фрагментов
Есть два типа разбиения на части. Типы следующие -
Разбивать
В этом процессе фрагментов объект, вещи и т. Д. Становятся более общими, а язык становится более абстрактным. Шансов на согласие больше. В этом процессе мы уменьшаем масштаб. Например, если мы разберем вопрос, «для чего нужны автомобили»? Мы можем получить ответ «транспорт».
Дробление
В этом процессе фрагментации объект, вещи и т. Д. Становятся более конкретными, и язык становится более проникнутым. Более глубокая структура будет исследована при разделении на части. В этом процессе мы увеличиваем масштаб. Например, если мы разберем вопрос «Расскажите конкретно об автомобиле»? Мы получим более мелкие детали об автомобиле.
Example
В этом примере мы сделаем фрагменты существительных и фраз, категорию фрагментов, которые найдут фрагменты словосочетаний существительных в предложении, используя модуль NLTK в Python -
Follow these steps in python for implementing noun phrase chunking −
Step 1- На этом этапе нам нужно определить грамматику для разбиения на части. Он будет состоять из правил, которым мы должны следовать.
Step 2- На этом этапе нам нужно создать парсер чанков. Он проанализирует грамматику и выдаст результат.
Step 3 - На этом последнем шаге вывод создается в формате дерева.
Давайте импортируем необходимый пакет NLTK следующим образом -
import nltkТеперь нам нужно определить предложение. Здесь DT означает определитель, VBP означает глагол, JJ означает прилагательное, IN означает предлог, а NN означает существительное.
sentence=[("a","DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]Теперь нам нужно дать грамматику. Здесь мы дадим грамматику в виде регулярного выражения.
grammar = "NP:{<DT>?<JJ>*<NN>}"Нам нужно определить синтаксический анализатор, который будет анализировать грамматику.
parser_chunking = nltk.RegexpParser(grammar)Синтаксический анализатор анализирует предложение следующим образом -
parser_chunking.parse(sentence)Далее нам нужно получить результат. Вывод генерируется в простой переменной с именемoutput_chunk.
Output_chunk = parser_chunking.parse(sentence)После выполнения следующего кода мы можем нарисовать наш вывод в виде дерева.
output.draw()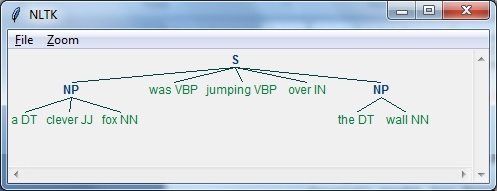
Модель мешка слов (BoW)
Bag of Word (BoW), модель обработки естественного языка, в основном используется для извлечения функций из текста, чтобы текст можно было использовать в моделировании, например в алгоритмах машинного обучения.
Теперь возникает вопрос, зачем нам нужно извлекать черты из текста. Это связано с тем, что алгоритмы машинного обучения не могут работать с необработанными данными, и им нужны числовые данные, чтобы они могли извлекать из них значимую информацию. Преобразование текстовых данных в числовые данные называется извлечением признаков или кодированием признаков.
Как это работает
Это очень простой подход к извлечению функций из текста. Предположим, у нас есть текстовый документ, и мы хотим преобразовать его в числовые данные или сказать, что хотим извлечь из него функции, тогда, прежде всего, эта модель извлекает словарь из всех слов в документе. Затем, используя матрицу терминов документа, он построит модель. Таким образом, BoW представляет документ только как набор слов. Любая информация о порядке или структуре слов в документе удаляется.
Понятие матрицы терминов документа
Алгоритм BoW строит модель, используя матрицу терминов документа. Как следует из названия, матрица терминов документа - это матрица различных количеств слов, которые встречаются в документе. С помощью этой матрицы текстовый документ можно представить как взвешенную комбинацию различных слов. Устанавливая порог и выбирая более значимые слова, мы можем построить гистограмму всех слов в документах, которые можно использовать в качестве вектора признаков. Ниже приведен пример для понимания концепции матрицы терминов документа.
Example
Предположим, у нас есть следующие два предложения -
Sentence 1 - Мы используем модель «Мешок слов».
Sentence 2 - Модель Bag of Words используется для извлечения функций.
Теперь, рассматривая эти два предложения, мы получаем следующие 13 различных слов:
- we
- are
- using
- the
- bag
- of
- words
- model
- is
- used
- for
- extracting
- features
Теперь нам нужно построить гистограмму для каждого предложения, используя количество слов в каждом предложении -
Sentence 1 - [1,1,1,1,1,1,1,1,0,0,0,0,0]
Sentence 2 - [0,0,0,1,1,1,1,1,1,1,1,1,1]
Таким образом, у нас есть извлеченные векторы признаков. Каждый вектор признаков 13-мерный, потому что у нас есть 13 различных слов.
Понятие статистики
Концепция статистики называется TermFrequency-Inverse Document Frequency (tf-idf). В документе важно каждое слово. Статистика помогает нам понять важность каждого слова.
Срок действия (тс)
Это показатель того, как часто каждое слово появляется в документе. Его можно получить, разделив количество каждого слова на общее количество слов в данном документе.
Обратная частота документов (idf)
Это мера того, насколько уникально слово для этого документа в данном наборе документов. Для вычисления idf и формулирования вектора отличительных признаков нам нужно уменьшить веса часто встречающихся слов, таких как the, и взвесить редкие слова.
Построение модели мешка слов в NLTK
В этом разделе мы определим набор строк с помощью CountVectorizer для создания векторов из этих предложений.
Импортируем необходимый пакет -
from sklearn.feature_extraction.text import CountVectorizerТеперь определите набор предложений.
Sentences = ['We are using the Bag of Word model', 'Bag of Word model is
used for extracting the features.']
vectorizer_count = CountVectorizer()
features_text = vectorizer.fit_transform(Sentences).todense()
print(vectorizer.vocabulary_)Приведенная выше программа генерирует выходные данные, как показано ниже. Это показывает, что у нас есть 13 различных слов в двух приведенных выше предложениях -
{'we': 11, 'are': 0, 'using': 10, 'the': 8, 'bag': 1, 'of': 7,
'word': 12, 'model': 6, 'is': 5, 'used': 9, 'for': 4, 'extracting': 2, 'features': 3}Это векторы функций (текст в числовую форму), которые можно использовать для машинного обучения.
Решаю задачи
В этом разделе мы решим несколько связанных проблем.
Категория Прогноз
В комплекте документов важны не только слова, но и категория слов; к какой категории текста относится конкретное слово. Например, мы хотим предсказать, принадлежит ли данное предложение категории электронная почта, новости, спорт, компьютер и т. Д. В следующем примере мы собираемся использовать tf-idf, чтобы сформулировать вектор признаков для поиска категории документов. Мы будем использовать данные из набора данных 20 групп новостей sklearn.
Нам нужно импортировать необходимые пакеты -
from sklearn.datasets import fetch_20newsgroups
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizerОпределите карту категорий. Мы используем пять различных категорий: религия, автомобили, спорт, электроника и космос.
category_map = {'talk.religion.misc':'Religion','rec.autos''Autos',
'rec.sport.hockey':'Hockey','sci.electronics':'Electronics', 'sci.space': 'Space'}Создать обучающий набор -
training_data = fetch_20newsgroups(subset = 'train',
categories = category_map.keys(), shuffle = True, random_state = 5)Создайте векторизатор подсчета и извлеките количество терминов -
vectorizer_count = CountVectorizer()
train_tc = vectorizer_count.fit_transform(training_data.data)
print("\nDimensions of training data:", train_tc.shape)Трансформатор tf-idf создается следующим образом -
tfidf = TfidfTransformer()
train_tfidf = tfidf.fit_transform(train_tc)Теперь определите тестовые данные -
input_data = [
'Discovery was a space shuttle',
'Hindu, Christian, Sikh all are religions',
'We must have to drive safely',
'Puck is a disk made of rubber',
'Television, Microwave, Refrigrated all uses electricity'
]Приведенные выше данные помогут нам обучить полиномиальный наивный байесовский классификатор -
classifier = MultinomialNB().fit(train_tfidf, training_data.target)Преобразуйте входные данные с помощью векторизатора счета -
input_tc = vectorizer_count.transform(input_data)Теперь мы преобразуем векторизованные данные с помощью преобразователя tfidf -
input_tfidf = tfidf.transform(input_tc)Мы будем прогнозировать выходные категории -
predictions = classifier.predict(input_tfidf)Вывод генерируется следующим образом -
for sent, category in zip(input_data, predictions):
print('\nInput Data:', sent, '\n Category:', \
category_map[training_data.target_names[category]])Предиктор категории генерирует следующий вывод -
Dimensions of training data: (2755, 39297)
Input Data: Discovery was a space shuttle
Category: Space
Input Data: Hindu, Christian, Sikh all are religions
Category: Religion
Input Data: We must have to drive safely
Category: Autos
Input Data: Puck is a disk made of rubber
Category: Hockey
Input Data: Television, Microwave, Refrigrated all uses electricity
Category: ElectronicsПоиск пола
В этой постановке задачи классификатор будет обучен определять пол (мужской или женский) по именам. Нам нужно использовать эвристику, чтобы построить вектор признаков и обучить классификатор. Мы будем использовать помеченные данные из пакета scikit-learn. Ниже приведен код Python для создания средства поиска пола.
Импортируем необходимые пакеты -
import random
from nltk import NaiveBayesClassifier
from nltk.classify import accuracy as nltk_accuracy
from nltk.corpus import namesТеперь нам нужно извлечь последние N букв из входного слова. Эти буквы будут действовать как особенности -
def extract_features(word, N = 2):
last_n_letters = word[-N:]
return {'feature': last_n_letters.lower()}
if __name__=='__main__':Создайте данные обучения, используя помеченные имена (мужские и женские), доступные в NLTK -
male_list = [(name, 'male') for name in names.words('male.txt')]
female_list = [(name, 'female') for name in names.words('female.txt')]
data = (male_list + female_list)
random.seed(5)
random.shuffle(data)Теперь тестовые данные будут созданы следующим образом -
namesInput = ['Rajesh', 'Gaurav', 'Swati', 'Shubha']Определите количество образцов, используемых для обучения и тестирования, с помощью следующего кода
train_sample = int(0.8 * len(data))Теперь нам нужно перебрать разную длину, чтобы можно было сравнить точность -
for i in range(1, 6):
print('\nNumber of end letters:', i)
features = [(extract_features(n, i), gender) for (n, gender) in data]
train_data, test_data = features[:train_sample],
features[train_sample:]
classifier = NaiveBayesClassifier.train(train_data)Точность классификатора можно вычислить следующим образом:
accuracy_classifier = round(100 * nltk_accuracy(classifier, test_data), 2)
print('Accuracy = ' + str(accuracy_classifier) + '%')Теперь мы можем предсказать результат -
for name in namesInput:
print(name, '==>', classifier.classify(extract_features(name, i)))Вышеупомянутая программа сгенерирует следующий вывод -
Number of end letters: 1
Accuracy = 74.7%
Rajesh -> female
Gaurav -> male
Swati -> female
Shubha -> female
Number of end letters: 2
Accuracy = 78.79%
Rajesh -> male
Gaurav -> male
Swati -> female
Shubha -> female
Number of end letters: 3
Accuracy = 77.22%
Rajesh -> male
Gaurav -> female
Swati -> female
Shubha -> female
Number of end letters: 4
Accuracy = 69.98%
Rajesh -> female
Gaurav -> female
Swati -> female
Shubha -> female
Number of end letters: 5
Accuracy = 64.63%
Rajesh -> female
Gaurav -> female
Swati -> female
Shubha -> femaleВ приведенном выше выводе мы видим, что точность максимального количества конечных букв равна двум, и она уменьшается по мере увеличения количества конечных букв.
Тематическое моделирование: выявление закономерностей в текстовых данных
Мы знаем, что обычно документы сгруппированы по темам. Иногда нам нужно определить закономерности в тексте, которые соответствуют определенной теме. Техника выполнения этого называется тематическим моделированием. Другими словами, мы можем сказать, что тематическое моделирование - это метод выявления абстрактных тем или скрытой структуры в данном наборе документов.
Мы можем использовать технику тематического моделирования в следующих сценариях -
Текстовая классификация
С помощью тематического моделирования можно улучшить классификацию, поскольку она группирует похожие слова вместе, а не использует каждое слово отдельно как функцию.
Рекомендательные системы
С помощью тематического моделирования мы можем построить рекомендательные системы, используя меры сходства.
Алгоритмы тематического моделирования
Тематическое моделирование может быть реализовано с помощью алгоритмов. Алгоритмы следующие -
Скрытое распределение Дирихле (LDA)
Этот алгоритм является наиболее популярным для тематического моделирования. Он использует вероятностные графические модели для реализации тематического моделирования. Нам нужно импортировать пакет gensim в Python для использования алгоритма LDA.
Скрытый семантический анализ (LDA) или скрытое семантическое индексирование (LSI)
Этот алгоритм основан на линейной алгебре. В основном он использует концепцию SVD (разложение по сингулярным значениям) в матрице терминов документа.
Неотрицательная матричная факторизация (NMF)
Он также основан на линейной алгебре.
Все вышеупомянутые алгоритмы тематического моделирования будут иметь number of topics как параметр, Document-Word Matrix как вход и WTM (Word Topic Matrix) & TDM (Topic Document Matrix) как выход.