AI с Python - контролируемое обучение: классификация
В этой главе мы сосредоточимся на реализации контролируемого обучения - классификации.
Методика классификации или модель пытается получить какой-то вывод из наблюдаемых значений. В задаче классификации у нас есть категоризированные выходные данные, такие как «черный» или «белый» или «обучающий» и «не обучающий». При построении модели классификации нам нужен обучающий набор данных, содержащий точки данных и соответствующие метки. Например, если мы хотим проверить, является ли изображение автомобилем или нет. Чтобы проверить это, мы построим обучающий набор данных, в котором два класса связаны с «автомобилем» и «без машины». Затем нам нужно обучить модель, используя обучающие образцы. Модели классификации в основном используются при распознавании лиц, идентификации спама и т. Д.
Шаги по созданию классификатора на Python
Для создания классификатора на Python мы собираемся использовать Python 3 и Scikit-learn, инструмент для машинного обучения. Выполните следующие шаги, чтобы создать классификатор в Python -
Шаг 1 - Импортируйте Scikit-learn
Это будет самый первый шаг к созданию классификатора на Python. На этом этапе мы установим пакет Python под названием Scikit-learn, который является одним из лучших модулей машинного обучения в Python. Следующая команда поможет нам импортировать пакет -
Import SklearnШаг 2 - Импортируйте набор данных Scikit-learn
На этом этапе мы можем начать работу с набором данных для нашей модели машинного обучения. Здесь мы будем использоватьthe Диагностическая база данных рака молочной железы Висконсина. Набор данных включает различную информацию об опухолях рака груди, а также классификационные меткиmalignant или benign. Набор данных содержит 569 экземпляров или данных о 569 опухолях и включает информацию о 30 атрибутах или характеристиках, таких как радиус опухоли, текстура, гладкость и площадь. С помощью следующей команды мы можем импортировать набор данных рака молочной железы Scikit-learn -
from sklearn.datasets import load_breast_cancerТеперь следующая команда загрузит набор данных.
data = load_breast_cancer()Ниже приведен список важных словарных ключей -
- Имена классификационных ярлыков (target_names)
- Фактические метки (цель)
- Имена атрибутов / функций (имена объектов)
- Атрибут (данные)
Теперь с помощью следующей команды мы можем создавать новые переменные для каждого важного набора информации и назначать данные. Другими словами, мы можем организовать данные с помощью следующих команд -
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']Теперь, чтобы было понятнее, мы можем распечатать метки классов, метку первого экземпляра данных, имена наших функций и значение функции с помощью следующих команд:
print(label_names)Приведенная выше команда напечатает имена классов, которые являются злокачественными и доброкачественными соответственно. Это показано как результат ниже -
['malignant' 'benign']Теперь команда ниже покажет, что они сопоставлены с двоичными значениями 0 и 1. Здесь 0 представляет злокачественный рак, а 1 представляет доброкачественный рак. Вы получите следующий вывод -
print(labels[0])
0Две приведенные ниже команды произведут имена и значения функций.
print(feature_names[0])
mean radius
print(features[0])
[ 1.79900000e+01 1.03800000e+01 1.22800000e+02 1.00100000e+03
1.18400000e-01 2.77600000e-01 3.00100000e-01 1.47100000e-01
2.41900000e-01 7.87100000e-02 1.09500000e+00 9.05300000e-01
8.58900000e+00 1.53400000e+02 6.39900000e-03 4.90400000e-02
5.37300000e-02 1.58700000e-02 3.00300000e-02 6.19300000e-03
2.53800000e+01 1.73300000e+01 1.84600000e+02 2.01900000e+03
1.62200000e-01 6.65600000e-01 7.11900000e-01 2.65400000e-01
4.60100000e-01 1.18900000e-01]Из приведенного выше вывода мы видим, что первый экземпляр данных - это злокачественная опухоль, радиус которой составляет 1,7990000e + 01.
Шаг 3 - Организация данных в наборы
На этом этапе мы разделим наши данные на две части, а именно на обучающий набор и тестовый набор. Разделение данных на эти наборы очень важно, потому что мы должны протестировать нашу модель на невидимых данных. Для разделения данных на наборы в sklearn есть функция, называемаяtrain_test_split()функция. С помощью следующих команд мы можем разделить данные на эти наборы:
from sklearn.model_selection import train_test_splitПриведенная выше команда импортирует train_test_splitфункция из sklearn, а команда ниже разделит данные на данные для обучения и тестирования. В приведенном ниже примере мы используем 40% данных для тестирования, а оставшиеся данные будут использоваться для обучения модели.
train, test, train_labels, test_labels = train_test_split(features,labels,test_size = 0.40, random_state = 42)Шаг 4 - Построение модели
На этом этапе мы будем строить нашу модель. Мы собираемся использовать алгоритм Наивного Байеса для построения модели. Следующие команды могут использоваться для построения модели -
from sklearn.naive_bayes import GaussianNBПриведенная выше команда импортирует модуль GaussianNB. Теперь следующая команда поможет вам инициализировать модель.
gnb = GaussianNB()Мы обучим модель, подогнав ее к данным с помощью gnb.fit ().
model = gnb.fit(train, train_labels)Шаг 5 - Оценка модели и ее точности
На этом этапе мы собираемся оценить модель, сделав прогнозы на наших тестовых данных. Тогда мы и выясним его точность. Для прогнозов мы будем использовать функцию predic (). Следующая команда поможет вам в этом -
preds = gnb.predict(test)
print(preds)
[1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1
0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0
0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0
0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0
1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0
1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0
1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0
1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1]Вышеупомянутые серии из 0 и 1 представляют собой прогнозируемые значения для классов опухолей - злокачественных и доброкачественных.
Теперь, сравнивая два массива, а именно test_labels а также preds, мы можем узнать точность нашей модели. Мы собираемся использоватьaccuracy_score()функция для определения точности. Рассмотрим для этого следующую команду -
from sklearn.metrics import accuracy_score
print(accuracy_score(test_labels,preds))
0.951754385965Результат показывает, что классификатор NaïveBayes имеет точность 95,17%.
Таким образом, с помощью описанных выше шагов мы можем построить наш классификатор на Python.
Построение классификатора на Python
В этом разделе мы узнаем, как создать классификатор на Python.
Наивный байесовский классификатор
Наивный Байес - это метод классификации, используемый для построения классификатора с использованием теоремы Байеса. Предполагается, что предикторы независимы. Проще говоря, он предполагает, что наличие определенной функции в классе не связано с наличием какой-либо другой функции. Для создания наивного байесовского классификатора нам нужно использовать библиотеку Python под названием scikit learn. Существует три типа наивных байесовских моделей:Gaussian, Multinomial and Bernoulli в пакете scikit learn.
Чтобы построить наивную модель классификатора Байесовского машинного обучения, нам понадобится следующий & минус
Набор данных
Мы собираемся использовать набор данных под названием Breast Cancer Wisconsin Diagnostic Database. Набор данных включает различную информацию об опухолях рака груди, а также классификационные меткиmalignant или benign. Набор данных содержит 569 экземпляров или данных о 569 опухолях и включает информацию о 30 атрибутах или характеристиках, таких как радиус опухоли, текстура, гладкость и площадь. Мы можем импортировать этот набор данных из пакета sklearn.
Наивная байесовская модель
Для построения наивного байесовского классификатора нам нужна наивная байесовская модель. Как говорилось ранее, существует три типа наивных байесовских моделей, названныхGaussian, Multinomial а также Bernoulliв пакете scikit learn. Здесь, в следующем примере, мы собираемся использовать гауссовскую наивную байесовскую модель.
Используя вышеизложенное, мы собираемся построить наивную байесовскую модель машинного обучения, чтобы использовать информацию об опухоли, чтобы предсказать, является ли опухоль злокачественной или доброкачественной.
Для начала нам нужно установить модуль sklearn. Это можно сделать с помощью следующей команды -
Import SklearnТеперь нам нужно импортировать набор данных под названием «Диагностическая база данных рака груди, штат Висконсин».
from sklearn.datasets import load_breast_cancerТеперь следующая команда загрузит набор данных.
data = load_breast_cancer()Данные могут быть организованы следующим образом -
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']Теперь, чтобы было понятнее, мы можем распечатать метки классов, метку первого экземпляра данных, имена наших функций и значение функции с помощью следующих команд:
print(label_names)Приведенная выше команда напечатает имена классов, которые являются злокачественными и доброкачественными соответственно. Это показано как результат ниже -
['malignant' 'benign']Теперь приведенная ниже команда покажет, что они сопоставлены с двоичными значениями 0 и 1. Здесь 0 представляет злокачественный рак, а 1 представляет доброкачественный рак. Это показано как результат ниже -
print(labels[0])
0Следующие две команды произведут имена и значения функций.
print(feature_names[0])
mean radius
print(features[0])
[ 1.79900000e+01 1.03800000e+01 1.22800000e+02 1.00100000e+03
1.18400000e-01 2.77600000e-01 3.00100000e-01 1.47100000e-01
2.41900000e-01 7.87100000e-02 1.09500000e+00 9.05300000e-01
8.58900000e+00 1.53400000e+02 6.39900000e-03 4.90400000e-02
5.37300000e-02 1.58700000e-02 3.00300000e-02 6.19300000e-03
2.53800000e+01 1.73300000e+01 1.84600000e+02 2.01900000e+03
1.62200000e-01 6.65600000e-01 7.11900000e-01 2.65400000e-01
4.60100000e-01 1.18900000e-01]Из вышеприведенного вывода мы видим, что первый экземпляр данных - это злокачественная опухоль, основной радиус которой составляет 1,7990000e + 01.
Для тестирования нашей модели на невидимых данных нам необходимо разделить наши данные на данные обучения и тестирования. Это можно сделать с помощью следующего кода -
from sklearn.model_selection import train_test_splitПриведенная выше команда импортирует train_test_splitфункция из sklearn, а команда ниже разделит данные на данные для обучения и тестирования. В приведенном ниже примере мы используем 40% данных для тестирования, а данные напоминания будут использоваться для обучения модели.
train, test, train_labels, test_labels =
train_test_split(features,labels,test_size = 0.40, random_state = 42)Теперь мы строим модель с помощью следующих команд -
from sklearn.naive_bayes import GaussianNBПриведенная выше команда импортирует GaussianNBмодуль. Теперь с помощью приведенной ниже команды нам нужно инициализировать модель.
gnb = GaussianNB()Мы обучим модель, подогнав ее под данные, используя gnb.fit().
model = gnb.fit(train, train_labels)Теперь оцените модель, сделав прогноз на основе тестовых данных, и это можно сделать следующим образом:
preds = gnb.predict(test)
print(preds)
[1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1
0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0
0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0
0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0
1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0
1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0
1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0
1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1]Вышеупомянутые серии из 0 и 1 являются прогнозируемыми значениями для классов опухолей, т.е. злокачественных и доброкачественных.
Теперь, сравнивая два массива, а именно test_labels а также preds, мы можем узнать точность нашей модели. Мы собираемся использоватьaccuracy_score()функция для определения точности. Рассмотрим следующую команду -
from sklearn.metrics import accuracy_score
print(accuracy_score(test_labels,preds))
0.951754385965Результат показывает, что классификатор NaïveBayes имеет точность 95,17%.
Это был классификатор машинного обучения, основанный на модели Naïve Bayse Gaussian.
Машины опорных векторов (SVM)
По сути, машина опорных векторов (SVM) - это управляемый алгоритм машинного обучения, который можно использовать как для регрессии, так и для классификации. Основная концепция SVM состоит в том, чтобы отобразить каждый элемент данных как точку в n-мерном пространстве, где значение каждой функции является значением конкретной координаты. Здесь n функций, которые у нас будут. Ниже приводится простое графическое представление, чтобы понять концепцию SVM.
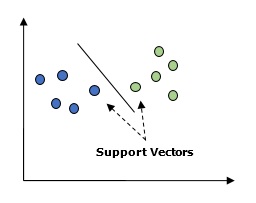
На диаграмме выше у нас есть две особенности. Следовательно, нам сначала нужно построить эти две переменные в двумерном пространстве, где каждая точка имеет две координаты, называемые опорными векторами. Линия разделяет данные на две разные классифицированные группы. Эта строка будет классификатором.
Здесь мы собираемся создать классификатор SVM, используя scikit-learn и набор данных iris. Библиотека Scikitlearn имеетsklearn.svmмодуль и предоставляет sklearn.svm.svc для классификации. Классификатор SVM для прогнозирования класса ириса на основе 4 признаков показан ниже.
Набор данных
Мы будем использовать набор данных iris, который содержит 3 класса по 50 экземпляров каждый, где каждый класс относится к типу растения ириса. Каждый экземпляр имеет четыре характеристики, а именно длину чашелистика, ширину чашелистика, длину лепестка и ширину лепестка. Классификатор SVM для прогнозирования класса ириса на основе 4 признаков показан ниже.
Ядро
Это метод, используемый SVM. В основном это функции, которые берут входное пространство низкой размерности и преобразуют ее в пространство более высокой размерности. Он превращает неразрывную проблему в разделимую проблему. Функция ядра может быть любой из линейной, полиномиальной, rbf и сигмоидной. В этом примере мы будем использовать линейное ядро.
Давайте теперь импортируем следующие пакеты -
import pandas as pd
import numpy as np
from sklearn import svm, datasets
import matplotlib.pyplot as pltТеперь загрузите входные данные -
iris = datasets.load_iris()Мы берем первые две функции -
X = iris.data[:, :2]
y = iris.targetМы построим границы машины опорных векторов с исходными данными. Мы создаем сетку для построения.
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = (x_max / x_min)/100
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
X_plot = np.c_[xx.ravel(), yy.ravel()]Нам нужно указать значение параметра регуляризации.
C = 1.0Нам нужно создать объект классификатора SVM.
Svc_classifier = svm_classifier.SVC(kernel='linear',
C=C, decision_function_shape = 'ovr').fit(X, y)
Z = svc_classifier.predict(X_plot)
Z = Z.reshape(xx.shape)
plt.figure(figsize = (15, 5))
plt.subplot(121)
plt.contourf(xx, yy, Z, cmap = plt.cm.tab10, alpha = 0.3)
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = plt.cm.Set1)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('SVC with linear kernel')
Логистическая регрессия
По сути, модель логистической регрессии является одним из членов семейства алгоритмов контролируемой классификации. Логистическая регрессия измеряет взаимосвязь между зависимыми и независимыми переменными путем оценки вероятностей с помощью логистической функции.
Здесь, если мы говорим о зависимых и независимых переменных, тогда зависимая переменная - это переменная целевого класса, которую мы собираемся прогнозировать, а с другой стороны, независимые переменные - это функции, которые мы собираемся использовать для прогнозирования целевого класса.
В логистической регрессии оценка вероятностей означает прогнозирование вероятности возникновения события. Например, владелец магазина хотел бы предсказать, что покупатель, вошедший в магазин, купит игровую приставку (например) или нет. У покупателя будет много характеристик - пол, возраст и т. Д., Которые будут наблюдаться владельцем магазина, чтобы предсказать вероятность появления, т. Е. Покупка игровой приставки или нет. Логистическая функция - это сигмовидная кривая, которая используется для построения функции с различными параметрами.
Предпосылки
Перед построением классификатора с использованием логистической регрессии нам необходимо установить пакет Tkinter в нашей системе. Его можно установить изhttps://docs.python.org/2/library/tkinter.html.
Теперь с помощью кода, приведенного ниже, мы можем создать классификатор с использованием логистической регрессии -
Сначала мы импортируем несколько пакетов -
import numpy as np
from sklearn import linear_model
import matplotlib.pyplot as pltТеперь нам нужно определить образцы данных, которые можно сделать следующим образом:
X = np.array([[2, 4.8], [2.9, 4.7], [2.5, 5], [3.2, 5.5], [6, 5], [7.6, 4],
[3.2, 0.9], [2.9, 1.9],[2.4, 3.5], [0.5, 3.4], [1, 4], [0.9, 5.9]])
y = np.array([0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3])Затем нам нужно создать классификатор логистической регрессии, что можно сделать следующим образом:
Classifier_LR = linear_model.LogisticRegression(solver = 'liblinear', C = 75)И последнее, но не менее важное: нам нужно обучить этот классификатор -
Classifier_LR.fit(X, y)Теперь, как мы можем визуализировать результат? Это можно сделать, создав функцию с именем Logistic_visualize () -
Def Logistic_visualize(Classifier_LR, X, y):
min_x, max_x = X[:, 0].min() - 1.0, X[:, 0].max() + 1.0
min_y, max_y = X[:, 1].min() - 1.0, X[:, 1].max() + 1.0В приведенной выше строке мы определили минимальное и максимальное значения X и Y, которые будут использоваться в сетке сетки. Кроме того, мы определим размер шага для построения сетки сетки.
mesh_step_size = 0.02Давайте определим сетку сетки значений X и Y следующим образом:
x_vals, y_vals = np.meshgrid(np.arange(min_x, max_x, mesh_step_size),
np.arange(min_y, max_y, mesh_step_size))С помощью следующего кода мы можем запустить классификатор в сетке сетки -
output = classifier.predict(np.c_[x_vals.ravel(), y_vals.ravel()])
output = output.reshape(x_vals.shape)
plt.figure()
plt.pcolormesh(x_vals, y_vals, output, cmap = plt.cm.gray)
plt.scatter(X[:, 0], X[:, 1], c = y, s = 75, edgecolors = 'black',
linewidth=1, cmap = plt.cm.Paired)В следующей строке кода будут указаны границы графика.
plt.xlim(x_vals.min(), x_vals.max())
plt.ylim(y_vals.min(), y_vals.max())
plt.xticks((np.arange(int(X[:, 0].min() - 1), int(X[:, 0].max() + 1), 1.0)))
plt.yticks((np.arange(int(X[:, 1].min() - 1), int(X[:, 1].max() + 1), 1.0)))
plt.show()Теперь, после запуска кода, мы получим следующий вывод, классификатор логистической регрессии -

Классификатор дерева решений
Дерево решений - это, по сути, блок-схема двоичного дерева, где каждый узел разбивает группу наблюдений в соответствии с некоторой переменной признака.
Здесь мы строим классификатор дерева решений для прогнозирования мужского или женского пола. Мы возьмем очень небольшой набор данных из 19 образцов. Эти образцы будут состоять из двух характеристик - «рост» и «длина волос».
Предпосылка
Для построения следующего классификатора нам необходимо установить pydotplus а также graphviz. По сути, graphviz - это инструмент для рисования графики с использованием точечных файлов иpydotplusявляется модулем языка точек Graphviz. Его можно установить с помощью диспетчера пакетов или pip.
Теперь мы можем построить классификатор дерева решений с помощью следующего кода Python:
Для начала давайте импортируем некоторые важные библиотеки следующим образом:
import pydotplus
from sklearn import tree
from sklearn.datasets import load_iris
from sklearn.metrics import classification_report
from sklearn import cross_validation
import collectionsТеперь нам нужно предоставить набор данных следующим образом:
X = [[165,19],[175,32],[136,35],[174,65],[141,28],[176,15],[131,32],
[166,6],[128,32],[179,10],[136,34],[186,2],[126,25],[176,28],[112,38],
[169,9],[171,36],[116,25],[196,25]]
Y = ['Man','Woman','Woman','Man','Woman','Man','Woman','Man','Woman',
'Man','Woman','Man','Woman','Woman','Woman','Man','Woman','Woman','Man']
data_feature_names = ['height','length of hair']
X_train, X_test, Y_train, Y_test = cross_validation.train_test_split
(X, Y, test_size=0.40, random_state=5)После предоставления набора данных нам нужно подогнать модель, что можно сделать следующим образом:
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X,Y)Прогнозирование можно сделать с помощью следующего кода Python -
prediction = clf.predict([[133,37]])
print(prediction)Мы можем визуализировать дерево решений с помощью следующего кода Python -
dot_data = tree.export_graphviz(clf,feature_names = data_feature_names,
out_file = None,filled = True,rounded = True)
graph = pydotplus.graph_from_dot_data(dot_data)
colors = ('orange', 'yellow')
edges = collections.defaultdict(list)
for edge in graph.get_edge_list():
edges[edge.get_source()].append(int(edge.get_destination()))
for edge in edges: edges[edge].sort()
for i in range(2):dest = graph.get_node(str(edges[edge][i]))[0]
dest.set_fillcolor(colors[i])
graph.write_png('Decisiontree16.png')Это даст прогноз для приведенного выше кода как [‘Woman’] и создайте следующее дерево решений -

Мы можем изменить значения функций в прогнозе, чтобы проверить его.
Классификатор случайного леса
Как мы знаем, ансамблевые методы - это методы, которые объединяют модели машинного обучения в более мощную модель машинного обучения. Случайный лес, набор деревьев решений, является одним из них. Это лучше, чем одно дерево решений, потому что, сохраняя возможности прогнозирования, оно может уменьшить чрезмерную подгонку за счет усреднения результатов. Здесь мы собираемся реализовать модель случайного леса в наборе данных scikit learn Cancer.
Импортируйте необходимые пакеты -
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
import matplotlib.pyplot as plt
import numpy as npТеперь нам нужно предоставить набор данных, что можно сделать следующим образом & минус
cancer = load_breast_cancer()
X_train, X_test, y_train,
y_test = train_test_split(cancer.data, cancer.target, random_state = 0)После предоставления набора данных нам нужно подогнать модель, что можно сделать следующим образом:
forest = RandomForestClassifier(n_estimators = 50, random_state = 0)
forest.fit(X_train,y_train)Теперь получите точность как для обучения, так и для подмножества тестирования: если мы увеличим количество оценщиков, то точность подмножества тестирования также повысится.
print('Accuracy on the training subset:(:.3f)',format(forest.score(X_train,y_train)))
print('Accuracy on the training subset:(:.3f)',format(forest.score(X_test,y_test)))Выход
Accuracy on the training subset:(:.3f) 1.0
Accuracy on the training subset:(:.3f) 0.965034965034965Теперь, как и дерево решений, случайный лес имеет feature_importanceмодуль, который обеспечит лучшее представление о весе функции, чем дерево решений. Его можно построить и визуализировать следующим образом:
n_features = cancer.data.shape[1]
plt.barh(range(n_features),forest.feature_importances_, align='center')
plt.yticks(np.arange(n_features),cancer.feature_names)
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.show()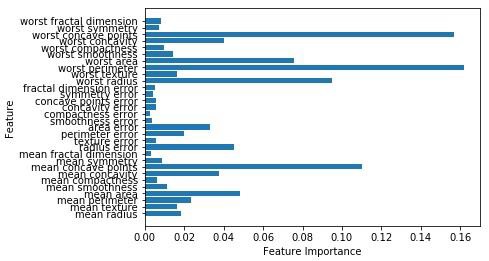
Производительность классификатора
После реализации алгоритма машинного обучения нам нужно выяснить, насколько эффективна модель. Критерии измерения эффективности могут быть основаны на наборах данных и метрике. Для оценки различных алгоритмов машинного обучения мы можем использовать разные показатели производительности. Например, предположим, что если классификатор используется для различения изображений разных объектов, мы можем использовать такие показатели эффективности классификации, как средняя точность, AUC и т. Д. В том или ином смысле метрика, которую мы выбираем для оценки нашей модели машинного обучения, очень важно, потому что выбор метрик влияет на то, как измеряется и сравнивается производительность алгоритма машинного обучения. Ниже приведены некоторые показатели -
Матрица путаницы
В основном он используется для задач классификации, где на выходе могут быть два или более типов классов. Это самый простой способ измерить эффективность классификатора. Матрица неточностей - это, по сути, таблица с двумя измерениями, а именно «Фактическая» и «Прогнозируемая». Оба измерения имеют «Истинные положительные результаты (TP)», «Истинные отрицательные результаты (TN)», «Ложные положительные результаты (FP)», «Ложные отрицательные результаты (FN)».
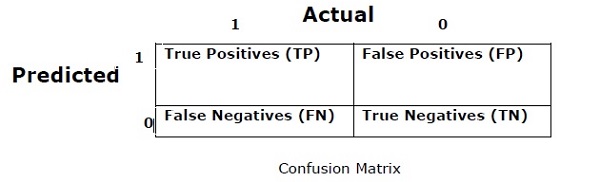
В приведенной выше матрице путаницы 1 соответствует положительному классу, а 0 - отрицательному классу.
Ниже приведены термины, связанные с матрицей путаницы.
True Positives − TP - это случаи, когда фактический класс точки данных был 1, а прогнозируемый - также 1.
True Negatives − TN - это случаи, когда фактический класс точки данных был 0, а прогнозируемый также равен 0.
False Positives − FP - это случаи, когда фактический класс точки данных был равен 0, а прогнозируемый также равен 1.
False Negatives − FN - это случаи, когда фактический класс точки данных был 1, а прогнозируемый также 0.
Точность
Сама матрица неточностей не является показателем эффективности как таковая, но почти все матрицы эффективности основаны на матрице неточностей. Одно из них - точность. В задачах классификации это может быть определено как количество правильных прогнозов, сделанных моделью по всем видам сделанных прогнозов. Формула для расчета точности следующая:
$$ Точность = \ frac {TP + TN} {TP + FP + FN + TN} $$
Точность
Он в основном используется при поиске документов. Это может быть определено как количество верных документов. Ниже приведена формула для расчета точности -
$$ Точность = \ frac {TP} {TP + FP} $$
Отзыв или чувствительность
Это можно определить как количество положительных результатов, которые дает модель. Ниже приведена формула для расчета отзыва / чувствительности модели.
$$ Recall = \ frac {TP} {TP + FN} $$
Специфика
Его можно определить как количество негативов, возвращаемых моделью. Напоминание с точностью до наоборот. Ниже приводится формула для расчета специфики модели -
$$ Специфика = \ frac {TN} {TN + FP} $$
Проблема дисбаланса классов
Несбалансированность классов - это сценарий, при котором количество наблюдений, принадлежащих к одному классу, значительно меньше, чем количество наблюдений, принадлежащих другим классам. Например, эта проблема проявляется в сценарии, когда нам необходимо идентифицировать редкие заболевания, мошеннические транзакции в банке и т. Д.
Пример несбалансированных классов
Давайте рассмотрим пример набора данных обнаружения мошенничества, чтобы понять концепцию несбалансированного класса -
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%Решение
Balancing the classes’действует как решение несбалансированных классов. Основная цель уравновешивания классов состоит в том, чтобы либо увеличить частоту класса меньшинства, либо уменьшить частоту класса большинства. Ниже приведены подходы к решению проблемы классов дисбаланса.
Повторная выборка
Повторная выборка - это серия методов, используемых для восстановления наборов данных выборки - как обучающих, так и тестовых. Повторная выборка сделана для повышения точности модели. Ниже приведены некоторые методы повторной выборки -
Random Under-Sampling- Этот метод направлен на сбалансированное распределение классов путем случайного исключения примеров большинства классов. Это делается до тех пор, пока экземпляры классов большинства и меньшинства не будут сбалансированы.
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%В этом случае мы берем 10% образцов без замены из случаев, не связанных с мошенничеством, а затем объединяем их с экземплярами мошенничества -
Не мошеннические наблюдения после случайной выборки = 10% от 4950 = 495
Общее количество наблюдений после их объединения с мошенническими наблюдениями = 50 + 495 = 545
Следовательно, теперь частота событий для нового набора данных после недостаточной выборки = 9%.
Основное преимущество этого метода заключается в том, что он может сократить время выполнения и улучшить хранение. Но с другой стороны, он может отбросить полезную информацию, уменьшив при этом количество обучающих выборок данных.
Random Over-Sampling - Этот метод направлен на сбалансированное распределение классов за счет увеличения количества экземпляров в классе меньшинства путем их репликации.
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%В случае, если мы реплицируем 50 мошеннических наблюдений 30 раз, то мошеннические наблюдения после репликации наблюдений класса меньшинства составят 1500. И тогда общее количество наблюдений в новых данных после передискретизации будет 4950 + 1500 = 6450. Следовательно, частота событий для нового набора данных будет 1500/6450 = 23%.
Главное преимущество этого метода в том, что не будет потери полезной информации. Но с другой стороны, он имеет повышенные шансы переобучения, потому что он воспроизводит события класса меньшинства.
Ансамблевые техники
Эта методология в основном используется для модификации существующих алгоритмов классификации, чтобы сделать их подходящими для несбалансированных наборов данных. В этом подходе мы создаем несколько двухэтапных классификаторов из исходных данных, а затем объединяем их прогнозы. Классификатор случайных лесов является примером классификатора на основе ансамбля.