AI с Python - Распознавание речи
В этой главе мы узнаем о распознавании речи с использованием ИИ с Python.
Речь - это самое основное средство общения взрослых людей. Основная цель обработки речи - обеспечить взаимодействие человека и машины.
Система обработки речи имеет в основном три задачи:
First, распознавание речи, которое позволяет машине улавливать слова, фразы и предложения, которые мы произносим
Second, обработка естественного языка, позволяющая машине понимать, о чем мы говорим, и
Third, синтез речи, чтобы машина могла говорить.
В этой главе основное внимание уделяется speech recognition, процесс понимания слов, которые говорят люди. Помните, что речевые сигналы фиксируются с помощью микрофона, а затем они должны быть поняты системой.
Создание распознавателя речи
Распознавание речи или автоматическое распознавание речи (ASR) находится в центре внимания таких проектов ИИ, как робототехника. Без ASR невозможно представить когнитивного робота, взаимодействующего с человеком. Однако создать распознаватель речи непросто.
Трудности в разработке системы распознавания речи
Разработка качественной системы распознавания речи - действительно сложная задача. Сложность технологии распознавания речи можно в общих чертах охарактеризовать по ряду аспектов, как обсуждается ниже:
Size of the vocabulary- Размер словарного запаса влияет на легкость разработки ASR. Для лучшего понимания рассмотрите следующие объемы словарного запаса.
Небольшой словарный запас состоит из 2-100 слов, например, как в системе голосового меню.
Словарь среднего размера состоит из нескольких сотен или тысяч слов, например, как в задаче поиска в базе данных.
Большой словарный запас состоит из нескольких десятков тысяч слов, как в общем задании на диктовку.
Channel characteristics- Качество канала также является важным параметром. Например, человеческая речь имеет широкую полосу пропускания с полным частотным диапазоном, тогда как телефонная речь состоит из узкой полосы пропускания с ограниченным частотным диапазоном. Учтите, что в последнем случае сложнее.
Speaking mode- Простота разработки ASR также зависит от режима разговора, то есть от того, идет ли речь в режиме изолированного слова, в режиме связного слова или в режиме непрерывной речи. Обратите внимание, что непрерывную речь труднее распознать.
Speaking style- Прочитанная речь может быть формальной или спонтанной и разговорной с повседневным стилем. Последних распознать сложнее.
Speaker dependency- Речь может быть зависимой от говорящего, адаптивной или независимой. Сложнее всего построить независимый динамик.
Type of noise- Шум - еще один фактор, который следует учитывать при разработке ASR. Отношение сигнал / шум может быть в различных диапазонах, в зависимости от акустической среды, в которой наблюдается меньше фонового шума или больше -
Если отношение сигнал / шум больше 30 дБ, это считается высоким диапазоном.
Если отношение сигнал / шум находится в пределах от 30 до 10 дБ, это считается средним SNR.
Если отношение сигнал / шум меньше 10 дБ, это считается низким диапазоном.
Microphone characteristics- Качество микрофона может быть хорошим, средним или ниже среднего. Также может варьироваться расстояние между ртом и микрофоном. Эти факторы также следует учитывать для систем распознавания.
Учтите, что чем больше словарный запас, тем труднее выполнять распознавание.
Например, тип фонового шума, такой как стационарный, нечеловеческий шум, фоновая речь и перекрестные помехи от других ораторов, также усложняет проблему.
Несмотря на эти трудности, исследователи много работали над различными аспектами речи, такими как понимание речевого сигнала, говорящего и определение акцентов.
Вам нужно будет выполнить следующие шаги, чтобы создать распознаватель речи -
Визуализация аудиосигналов - чтение из файла и работа с ним
Это первый шаг в построении системы распознавания речи, поскольку он дает понимание того, как структурирован звуковой сигнал. Некоторые общие шаги, которые можно выполнить для работы со звуковыми сигналами, следующие:
Запись
Когда вам нужно прочитать аудиосигнал из файла, сначала запишите его с помощью микрофона.
Отбор проб
При записи с микрофона сигналы сохраняются в оцифрованном виде. Но чтобы работать с этим, машине они нужны в дискретной числовой форме. Следовательно, мы должны выполнить выборку на определенной частоте и преобразовать сигнал в дискретную числовую форму. Выбор высокой частоты для выборки подразумевает, что когда люди слушают сигнал, они воспринимают его как непрерывный звуковой сигнал.
пример
В следующем примере показан пошаговый подход к анализу аудиосигнала с использованием Python, который хранится в файле. Частота этого аудиосигнала составляет 44 100 Гц.
Импортируйте необходимые пакеты, как показано здесь -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfileТеперь прочтите сохраненный аудиофайл. Он вернет два значения: частоту дискретизации и звуковой сигнал. Укажите путь к аудиофайлу, в котором он хранится, как показано здесь -
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")Отобразите параметры, такие как частота дискретизации аудиосигнала, тип данных сигнала и его продолжительность, используя показанные команды -
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0] /
float(frequency_sampling), 2), 'seconds')Этот шаг включает в себя нормализацию сигнала, как показано ниже -
audio_signal = audio_signal / np.power(2, 15)На этом этапе мы извлекаем первые 100 значений из этого сигнала для визуализации. Для этого используйте следующие команды -
audio_signal = audio_signal [:100]
time_axis = 1000 * np.arange(0, len(signal), 1) / float(frequency_sampling)Теперь визуализируйте сигнал, используя команды, приведенные ниже -
plt.plot(time_axis, signal, color='blue')
plt.xlabel('Time (milliseconds)')
plt.ylabel('Amplitude')
plt.title('Input audio signal')
plt.show()Вы сможете увидеть выходной график и данные, извлеченные для вышеуказанного аудиосигнала, как показано на изображении здесь.

Signal shape: (132300,)
Signal Datatype: int16
Signal duration: 3.0 secondsХарактеристика аудиосигнала: преобразование в частотную область
Характеристика аудиосигнала включает преобразование сигнала временной области в частотную область и понимание его частотных компонентов с помощью. Это важный шаг, потому что он дает много информации о сигнале. Вы можете использовать математический инструмент, такой как преобразование Фурье, для выполнения этого преобразования.
пример
В следующем примере показано, шаг за шагом, как охарактеризовать сигнал с помощью Python, который хранится в файле. Обратите внимание, что здесь мы используем математический инструмент преобразования Фурье, чтобы преобразовать его в частотную область.
Импортируйте необходимые пакеты, как показано здесь -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfileТеперь прочтите сохраненный аудиофайл. Он вернет два значения: частоту дискретизации и звуковой сигнал. Укажите путь к аудиофайлу, в котором он хранится, как показано в команде здесь -
frequency_sampling, audio_signal = wavfile.read("/Users/admin/sample.wav")На этом шаге мы отобразим такие параметры, как частота дискретизации аудиосигнала, тип данных сигнала и его продолжительность, используя команды, приведенные ниже -
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0] /
float(frequency_sampling), 2), 'seconds')На этом этапе нам нужно нормализовать сигнал, как показано в следующей команде -
audio_signal = audio_signal / np.power(2, 15)Этот шаг включает извлечение длины и половинной длины сигнала. Для этого используйте следующие команды -
length_signal = len(audio_signal)
half_length = np.ceil((length_signal + 1) / 2.0).astype(np.int)Теперь нам нужно применить математические инструменты для преобразования в частотную область. Здесь мы используем преобразование Фурье.
signal_frequency = np.fft.fft(audio_signal)Теперь сделайте нормализацию сигнала частотной области и возведите его в квадрат -
signal_frequency = abs(signal_frequency[0:half_length]) / length_signal
signal_frequency **= 2Затем извлеките длину и половину длины преобразованного по частоте сигнала -
len_fts = len(signal_frequency)Обратите внимание, что преобразованный сигнал Фурье должен быть настроен как для четного, так и для нечетного случая.
if length_signal % 2:
signal_frequency[1:len_fts] *= 2
else:
signal_frequency[1:len_fts-1] *= 2Теперь извлеките мощность в децибалах (дБ) -
signal_power = 10 * np.log10(signal_frequency)Отрегулируйте частоту в кГц для оси X -
x_axis = np.arange(0, len_half, 1) * (frequency_sampling / length_signal) / 1000.0Теперь представьте себе характеристику сигнала следующим образом -
plt.figure()
plt.plot(x_axis, signal_power, color='black')
plt.xlabel('Frequency (kHz)')
plt.ylabel('Signal power (dB)')
plt.show()Вы можете наблюдать выходной график приведенного выше кода, как показано на изображении ниже -

Генерация монотонного аудиосигнала
Два шага, которые вы видели до сих пор, важны для изучения сигналов. Теперь этот шаг будет полезен, если вы хотите сгенерировать аудиосигнал с некоторыми предопределенными параметрами. Обратите внимание, что этот шаг сохранит аудиосигнал в выходном файле.
пример
В следующем примере мы собираемся сгенерировать монотонный сигнал с помощью Python, который будет сохранен в файле. Для этого вам нужно будет предпринять следующие шаги -
Импортируйте необходимые пакеты, как показано -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io.wavfile import writeУкажите файл, в котором должен быть сохранен выходной файл
output_file = 'audio_signal_generated.wav'Теперь укажите параметры по вашему выбору, как показано -
duration = 4 # in seconds
frequency_sampling = 44100 # in Hz
frequency_tone = 784
min_val = -4 * np.pi
max_val = 4 * np.piНа этом этапе мы можем сгенерировать аудиосигнал, как показано -
t = np.linspace(min_val, max_val, duration * frequency_sampling)
audio_signal = np.sin(2 * np.pi * tone_freq * t)Теперь сохраните аудиофайл в выходном файле -
write(output_file, frequency_sampling, signal_scaled)Извлеките первые 100 значений для нашего графика, как показано -
audio_signal = audio_signal[:100]
time_axis = 1000 * np.arange(0, len(signal), 1) / float(sampling_freq)Теперь визуализируйте сгенерированный звуковой сигнал следующим образом -
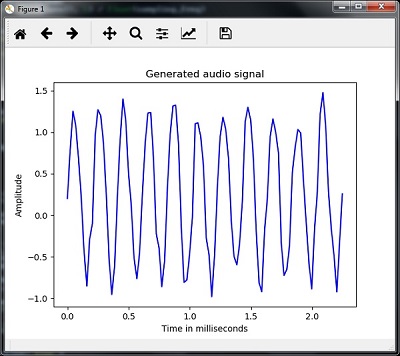
plt.plot(time_axis, signal, color='blue')
plt.xlabel('Time in milliseconds')
plt.ylabel('Amplitude')
plt.title('Generated audio signal')
plt.show()Вы можете наблюдать сюжет, как показано на рисунке, приведенном здесь -
Извлечение функций из речи
Это наиболее важный шаг в создании распознавателя речи, потому что после преобразования речевого сигнала в частотную область мы должны преобразовать его в пригодную для использования форму вектора признаков. Для этой цели мы можем использовать различные методы извлечения функций, такие как MFCC, PLP, PLP-RASTA и т. Д.
пример
В следующем примере мы собираемся извлекать функции из сигнала, шаг за шагом, используя Python, используя технику MFCC.
Импортируйте необходимые пакеты, как показано здесь -
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
from python_speech_features import mfcc, logfbankТеперь прочтите сохраненный аудиофайл. Он вернет два значения - частоту дискретизации и звуковой сигнал. Укажите путь к аудиофайлу, в котором он хранится.
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")Обратите внимание, что здесь мы берем на анализ первые 15000 проб.
audio_signal = audio_signal[:15000]Используйте методы MFCC и выполните следующую команду, чтобы извлечь функции MFCC:
features_mfcc = mfcc(audio_signal, frequency_sampling)Теперь распечатайте параметры MFCC, как показано -
print('\nMFCC:\nNumber of windows =', features_mfcc.shape[0])
print('Length of each feature =', features_mfcc.shape[1])Теперь постройте и визуализируйте функции MFCC, используя команды, приведенные ниже -
features_mfcc = features_mfcc.T
plt.matshow(features_mfcc)
plt.title('MFCC')На этом этапе мы работаем с функциями банка фильтров, как показано -
Извлеките функции банка фильтров -
filterbank_features = logfbank(audio_signal, frequency_sampling)Теперь распечатайте параметры набора фильтров.
print('\nFilter bank:\nNumber of windows =', filterbank_features.shape[0])
print('Length of each feature =', filterbank_features.shape[1])Теперь постройте и визуализируйте функции банка фильтров.
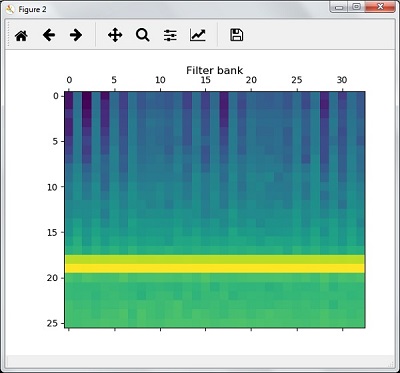
filterbank_features = filterbank_features.T
plt.matshow(filterbank_features)
plt.title('Filter bank')
plt.show()В результате описанных выше шагов вы можете наблюдать следующие выходные данные: Рисунок 1 для MFCC и Рисунок 2 для банка фильтров.

Распознавание произнесенных слов
Распознавание речи означает, что когда люди говорят, машина их понимает. Здесь мы используем Google Speech API в Python, чтобы это произошло. Для этого нам нужно установить следующие пакеты -
Pyaudio - Его можно установить с помощью pip install Pyaudio команда.
SpeechRecognition - Этот пакет можно установить с помощью pip install SpeechRecognition.
Google-Speech-API - Его можно установить с помощью команды pip install google-api-python-client.
пример
Обратите внимание на следующий пример, чтобы понять распознавание произносимых слов -
Импортируйте необходимые пакеты, как показано -
import speech_recognition as srСоздайте объект, как показано ниже -
recording = sr.Recognizer()Теперь Microphone() модуль примет голос как вход -
with sr.Microphone() as source: recording.adjust_for_ambient_noise(source)
print("Please Say something:")
audio = recording.listen(source)Теперь API Google распознает голос и выдаст результат.
try:
print("You said: \n" + recording.recognize_google(audio))
except Exception as e:
print(e)Вы можете увидеть следующий результат -
Please Say Something:
You said:Например, если вы сказали tutorialspoint.com, то система распознает его правильно следующим образом -
tutorialspoint.com