Python Web Scraping - Работа с текстом
В предыдущей главе мы увидели, как работать с видео и изображениями, которые мы получаем как часть веб-скрапинга. В этой главе мы займемся анализом текста с помощью библиотеки Python и узнаем об этом подробно.
Введение
Вы можете выполнить анализ текста с помощью библиотеки Python под названием Natural Language Tool Kit (NLTK). Прежде чем переходить к концепциям NLTK, давайте поймем связь между анализом текста и парсингом веб-страниц.
Анализ слов в тексте может помочь нам узнать, какие слова важны, какие слова необычны, как слова сгруппированы. Этот анализ упрощает задачу очистки веб-страниц.
Начало работы с NLTK
Набор инструментов для естественного языка (NLTK) - это набор библиотек Python, который разработан специально для идентификации и маркировки частей речи, встречающихся в тексте на естественном языке, таком как английский.
Установка NLTK
Вы можете использовать следующую команду для установки NLTK в Python -
pip install nltkЕсли вы используете Anaconda, то пакет conda для NLTK можно создать с помощью следующей команды -
conda install -c anaconda nltkСкачивание данных НЛТК
После установки NLTK мы должны загрузить предустановленные текстовые репозитории. Но перед загрузкой репозиториев текстовых пресетов нам нужно импортировать NLTK с помощьюimport команда следующим образом -
mport nltkТеперь с помощью следующей команды можно загрузить данные NLTK -
nltk.download()Установка всех доступных пакетов NLTK займет некоторое время, но всегда рекомендуется устанавливать все пакеты.
Установка других необходимых пакетов
Нам также нужны другие пакеты Python, например gensim и pattern для анализа текста, а также для создания приложений обработки естественного языка с помощью NLTK.
gensim- Надежная библиотека семантического моделирования, полезная для многих приложений. Его можно установить с помощью следующей команды -
pip install gensimpattern - Используется для изготовления gensimпакет работает правильно. Его можно установить с помощью следующей команды -
pip install patternТокенизация
Процесс разбиения данного текста на более мелкие единицы, называемые токенами, называется токенизацией. Эти токены могут быть словами, числами или знаками препинания. Его еще называютword segmentation.
пример

Модуль NLTK предоставляет разные пакеты для токенизации. Мы можем использовать эти пакеты в соответствии с нашими требованиями. Некоторые из пакетов описаны здесь -
sent_tokenize package- Этот пакет разделит вводимый текст на предложения. Вы можете использовать следующую команду для импорта этого пакета -
from nltk.tokenize import sent_tokenizeword_tokenize package- Этот пакет разделит вводимый текст на слова. Вы можете использовать следующую команду для импорта этого пакета -
from nltk.tokenize import word_tokenizeWordPunctTokenizer package- Этот пакет разделит вводимый текст, а также знаки препинания на слова. Вы можете использовать следующую команду для импорта этого пакета -
from nltk.tokenize import WordPuncttokenizerСтемминг
В любом языке есть разные формы слов. Язык включает множество вариаций по грамматическим причинам. Например, рассмотрим словаdemocracy, democratic, и democratization. Для машинного обучения, а также для проектов по парсингу веб-страниц важно, чтобы машины понимали, что эти разные слова имеют одинаковую базовую форму. Следовательно, мы можем сказать, что может быть полезно извлекать базовые формы слов при анализе текста.
Это может быть достигнуто путем выделения корней, которое можно определить как эвристический процесс извлечения основных форм слов путем отсечения концов слов.
Модуль NLTK предоставляет различные пакеты для стемминга. Мы можем использовать эти пакеты в соответствии с нашими требованиями. Некоторые из этих пакетов описаны здесь -
PorterStemmer package- Алгоритм Портера используется этим пакетом Python для извлечения базовой формы. Вы можете использовать следующую команду для импорта этого пакета -
from nltk.stem.porter import PorterStemmerНапример, после слова ‘writing’ в качестве входных данных для этого стеммера на выходе будет слово ‘write’ после забоя.
LancasterStemmer package- Этот пакет стемминга Python использует алгоритм Ланкастера для извлечения базовой формы. Вы можете использовать следующую команду для импорта этого пакета -
from nltk.stem.lancaster import LancasterStemmerНапример, после слова ‘writing’ в качестве входных данных для этого стеммера на выходе будет слово ‘writ’ после забоя.
SnowballStemmer package- Алгоритм Snowball используется этим пакетом Python для извлечения базовой формы. Вы можете использовать следующую команду для импорта этого пакета -
from nltk.stem.snowball import SnowballStemmerНапример, после подачи слова «запись» в качестве входных данных для этого стеммера, на выходе будет слово «запись» после стемминга.
Лемматизация
Другой способ извлечения базовой формы слов - лемматизация, обычно направленная на удаление флективных окончаний с помощью словарного и морфологического анализа. Базовая форма любого слова после лемматизации называется леммой.
Модуль NLTK предоставляет следующие пакеты для лемматизации -
WordNetLemmatizer package- Он будет извлекать базовую форму слова в зависимости от того, используется ли оно как существительное или как глагол. Вы можете использовать следующую команду для импорта этого пакета -
from nltk.stem import WordNetLemmatizerРазбивка
Разделение на части, что означает разделение данных на небольшие фрагменты, является одним из важных процессов обработки естественного языка для определения частей речи и коротких фраз, таких как фразы существительных. Разделение на части - это маркировка токенов. Мы можем получить структуру предложения с помощью процесса разбиения на части.
пример
В этом примере мы собираемся реализовать разбиение существительного и фраз с помощью модуля Python NLTK. NP chunking - это категория разбиения на фрагменты, при которой в предложении встречаются фрагменты словосочетаний.
Шаги по разделению именных фраз
Нам нужно выполнить шаги, приведенные ниже, для реализации фрагментации именных фраз:
Шаг 1 - Определение грамматики фрагментов
На первом этапе мы определим грамматику для разбиения на части. Он будет состоять из правил, которым мы должны следовать.
Шаг 2 - Создание парсера фрагментов
Теперь мы создадим парсер чанков. Он проанализирует грамматику и выдаст результат.
Шаг 3 - Вывод
На этом последнем шаге вывод будет произведен в формате дерева.
Во-первых, нам нужно импортировать пакет NLTK следующим образом:
import nltkДалее нам нужно определить предложение. Здесь DT: определитель, VBP: глагол, JJ: прилагательное, IN: предлог и NN: существительное.
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]Далее мы даем грамматику в виде регулярного выражения.
grammar = "NP:{<DT>?<JJ>*<NN>}"Теперь в следующей строке кода будет определен синтаксический анализатор для анализа грамматики.
parser_chunking = nltk.RegexpParser(grammar)Теперь синтаксический анализатор проанализирует предложение.
parser_chunking.parse(sentence)Затем мы передаем наш результат в переменную.
Output = parser_chunking.parse(sentence)С помощью следующего кода мы можем нарисовать наш вывод в виде дерева, как показано ниже.
output.draw()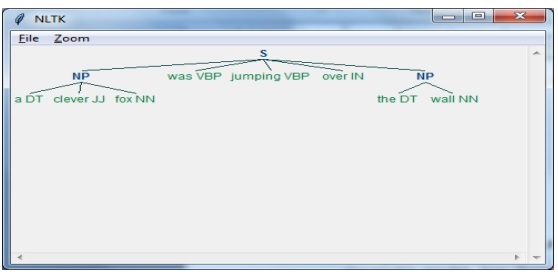
Модель Bag of Word (BoW) Извлечение и преобразование текста в числовую форму
Bag of Word (BoW), полезная модель в обработке естественного языка, в основном используется для извлечения функций из текста. После извлечения функций из текста его можно использовать при моделировании в алгоритмах машинного обучения, поскольку необработанные данные нельзя использовать в приложениях машинного обучения.
Работа модели BoW
Первоначально модель извлекает словарь из всех слов в документе. Позже, используя матрицу терминов документа, он построит модель. Таким образом, модель BoW представляет документ только как набор слов, а порядок или структура отбрасываются.
пример
Предположим, у нас есть следующие два предложения -
Sentence1 - Это пример модели Bag of Words.
Sentence2 - Мы можем извлекать особенности, используя модель Bag of Words.
Теперь, рассматривая эти два предложения, мы получаем следующие 14 различных слов:
- This
- is
- an
- example
- bag
- of
- words
- model
- we
- can
- extract
- features
- by
- using
Построение модели мешка слов в NLTK
Давайте посмотрим на следующий скрипт Python, который построит модель BoW в NLTK.
Сначала импортируйте следующий пакет -
from sklearn.feature_extraction.text import CountVectorizerЗатем определите набор предложений -
Sentences=['This is an example of Bag of Words model.', ' We can extract
features by using Bag of Words model.']
vector_count = CountVectorizer()
features_text = vector_count.fit_transform(Sentences).todense()
print(vector_count.vocabulary_)Вывод
Это показывает, что у нас есть 14 различных слов в двух приведенных выше предложениях -
{
'this': 10, 'is': 7, 'an': 0, 'example': 4, 'of': 9,
'bag': 1, 'words': 13, 'model': 8, 'we': 12, 'can': 3,
'extract': 5, 'features': 6, 'by': 2, 'using':11
}Тематическое моделирование: выявление закономерностей в текстовых данных
Как правило, документы сгруппированы по темам, а тематическое моделирование - это метод определения закономерностей в тексте, соответствующих определенной теме. Другими словами, тематическое моделирование используется для выявления абстрактных тем или скрытой структуры в заданном наборе документов.
Вы можете использовать тематическое моделирование в следующих сценариях -
Текстовая классификация
Классификацию можно улучшить с помощью тематического моделирования, поскольку оно группирует похожие слова вместе, а не использует каждое слово отдельно как функцию.
Рекомендательные системы
Мы можем создавать рекомендательные системы, используя меры сходства.
Алгоритмы тематического моделирования
Мы можем реализовать тематическое моделирование, используя следующие алгоритмы:
Latent Dirichlet Allocation(LDA) - Это один из самых популярных алгоритмов, использующий вероятностные графические модели для реализации тематического моделирования.
Latent Semantic Analysis(LDA) or Latent Semantic Indexing(LSI) - Он основан на линейной алгебре и использует концепцию SVD (сингулярное разложение) в матрице терминов документа.
Non-Negative Matrix Factorization (NMF) - Он также основан на линейной алгебре, как и LDA.
Вышеупомянутые алгоритмы будут иметь следующие элементы -
- Количество тем: Параметр
- Матрица документа-слова: ввод
- WTM (матрица тем Word) и TDM (матрица тематических документов): вывод