Python Web Scraping - Краткое руководство
Веб-скрапинг - это автоматический процесс извлечения информации из Интернета. Эта глава даст вам подробное представление о парсинге веб-страниц, его сравнении со сканированием веб-страниц и о том, почему вам следует выбрать парсинг веб-страниц. Вы также узнаете о компонентах и работе парсера.
Что такое парсинг?
Словарное значение слова «Утилизация» подразумевает получение чего-либо из Интернета. Здесь возникают два вопроса: что мы можем получить из Интернета и как это получить.
Ответ на первый вопрос: ‘data’. Данные необходимы любому программисту, и основным требованием каждого программного проекта является большой объем полезных данных.
Ответ на второй вопрос немного сложен, потому что есть много способов получить данные. Как правило, мы можем получать данные из базы данных или файла данных и из других источников. Но что, если нам нужен большой объем данных, доступных в Интернете? Один из способов получить такие данные - это вручную выполнить поиск (щелкнув мышью в веб-браузере) и сохранить (скопировать и вставить в электронную таблицу или файл) необходимые данные. Этот метод довольно утомителен и требует много времени. Другой способ получить такие данные - использоватьweb scraping.
Web scraping, также называется web data mining или же web harvesting, представляет собой процесс создания агента, который может автоматически извлекать, анализировать, загружать и систематизировать полезную информацию из Интернета. Другими словами, мы можем сказать, что вместо того, чтобы вручную сохранять данные с веб-сайтов, программное обеспечение для очистки веб-страниц автоматически загружает и извлекает данные с нескольких веб-сайтов в соответствии с нашими требованиями.
Происхождение веб-парсинга
Происхождение веб-скрейпинга - это удаление экрана, которое использовалось для интеграции не веб-приложений или собственных приложений Windows. Первоначально очистка экрана использовалась до широкого использования Всемирной паутины (WWW), но она не могла масштабироваться в расширенном масштабе. Это сделало необходимым автоматизировать метод очистки экрана и технику, называемую‘Web Scraping’ возникла.
Веб-сканирование против веб-скрапинга
Термины «Веб-сканирование» и «Скребок» часто используются как синонимы, поскольку их основная концепция заключается в извлечении данных. Однако они отличаются друг от друга. Мы можем понять основное отличие из их определений.
Веб-сканирование в основном используется для индексации информации на странице с помощью ботов, известных как сканеры. Его еще называютindexing. С другой стороны, веб-парсинг - это автоматический способ извлечения информации с помощью ботов, известных как парсеры. Его еще называютdata extraction.
Чтобы понять разницу между этими двумя терминами, давайте посмотрим на таблицу сравнения, приведенную ниже -
| Веб-сканирование | Веб-парсинг |
|---|---|
| Относится к загрузке и хранению содержимого большого количества веб-сайтов. | Относится к извлечению отдельных элементов данных с веб-сайта с использованием специфичной для сайта структуры. |
| В основном делается в больших масштабах. | Может быть реализован в любом масштабе. |
| Предоставляет общую информацию. | Предоставляет конкретную информацию. |
| Используется основными поисковыми системами, такими как Google, Bing, Yahoo. Googlebot является примером поискового робота. | Информация, извлеченная с помощью веб-скрейпинга, может быть использована для копирования на каком-либо другом веб-сайте или может использоваться для анализа данных. Например, элементами данных могут быть имена, адрес, цена и т. Д. |
Использование веб-скрапинга
Использование и причины использования веб-скрапинга безграничны, как и использование всемирной паутины. Веб-скребки могут делать все, например, заказывать еду в Интернете, сканировать веб-сайт онлайн-покупок для вас, покупать билеты на матч, когда они становятся доступны, и т. Д. Точно так же, как это может делать человек. Здесь обсуждаются некоторые из важных применений парсинга веб-страниц -
E-commerce Websites - Веб-парсеры могут собирать данные, специально относящиеся к цене конкретного продукта, с различных веб-сайтов электронной коммерции для их сравнения.
Content Aggregators - Веб-скрапинг широко используется агрегаторами контента, такими как агрегаторы новостей и агрегаторы вакансий, для предоставления обновленных данных своим пользователям.
Marketing and Sales Campaigns - Веб-парсеры могут использоваться для получения данных, таких как электронные письма, номер телефона и т. Д., Для продаж и маркетинговых кампаний.
Search Engine Optimization (SEO) - Веб-скрапинг широко используется инструментами SEO, такими как SEMRush, Majestic и т. Д., Чтобы сообщить бизнесу, как они ранжируются по ключевым словам поиска, которые для них важны.
Data for Machine Learning Projects - Получение данных для проектов машинного обучения зависит от парсинга веб-страниц.
Data for Research - Исследователи могут собирать полезные данные для исследовательской работы, экономя свое время с помощью этого автоматизированного процесса.
Компоненты веб-парсера
Веб-парсер состоит из следующих компонентов -
Модуль веб-сканера
Очень необходимый компонент веб-парсера, модуль веб-сканера, используется для навигации по целевому веб-сайту, выполняя HTTP или HTTPS-запросы к URL-адресам. Сканер загружает неструктурированные данные (содержимое HTML) и передает их экстрактору, следующему модулю.
Экстрактор
Экстрактор обрабатывает полученный HTML-контент и извлекает данные в полуструктурированный формат. Он также называется модулем синтаксического анализатора и для его работы использует различные методы синтаксического анализа, такие как регулярное выражение, анализ HTML, анализ DOM или искусственный интеллект.
Модуль преобразования и очистки данных
Извлеченные выше данные не подходят для готового использования. Он должен пройти через какой-то модуль очистки, чтобы мы могли его использовать. Для этой цели можно использовать такие методы, как манипуляции со строками или регулярные выражения. Обратите внимание, что извлечение и преобразование также можно выполнить за один шаг.
Модуль хранения
После извлечения данных нам необходимо сохранить их в соответствии с нашим требованием. Модуль хранения будет выводить данные в стандартном формате, который может быть сохранен в базе данных или в формате JSON или CSV.
Работа веб-парсера
Веб-скребок можно определить как программное обеспечение или сценарий, используемый для загрузки содержимого нескольких веб-страниц и извлечения из него данных.
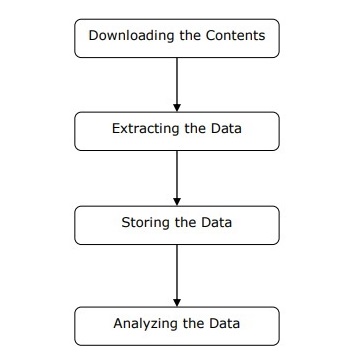
Мы можем понять работу веб-парсера, выполнив простые шаги, как показано на диаграмме, приведенной выше.
Шаг 1. Загрузка содержимого с веб-страниц
На этом этапе веб-парсер загрузит запрошенное содержимое с нескольких веб-страниц.
Шаг 2: извлечение данных
Данные на веб-сайтах представлены в формате HTML и в основном неструктурированы. Следовательно, на этом этапе веб-парсер проанализирует и извлечет структурированные данные из загруженного содержимого.
Шаг 3: Хранение данных
Здесь веб-парсер будет хранить и сохранять извлеченные данные в любом формате, таком как CSV, JSON или в базе данных.
Шаг 4: Анализ данных
После успешного выполнения всех этих шагов веб-скребок проанализирует полученные таким образом данные.
В первой главе мы узнали, что такое парсинг веб-страниц. В этой главе давайте посмотрим, как реализовать парсинг веб-страниц с помощью Python.
Почему Python для веб-парсинга?
Python - популярный инструмент для реализации парсинга веб-страниц. Язык программирования Python также используется для других полезных проектов, связанных с кибербезопасностью, тестированием на проникновение, а также с приложениями цифровой криминалистики. Используя базовое программирование Python, парсинг веб-страниц может выполняться без использования каких-либо сторонних инструментов.
Язык программирования Python набирает огромную популярность, и причины, по которым Python хорошо подходит для проектов парсинга веб-страниц, следующие:
Простота синтаксиса
Python имеет простейшую структуру по сравнению с другими языками программирования. Эта функция Python упрощает тестирование, и разработчик может больше сосредоточиться на программировании.
Встроенные модули
Еще одна причина использования Python для парсинга веб-страниц - это как встроенные, так и внешние полезные библиотеки, которыми он обладает. Мы можем выполнить множество реализаций, связанных со сканированием веб-страниц, используя Python в качестве основы для программирования.
Язык программирования с открытым исходным кодом
Python пользуется огромной поддержкой сообщества, потому что это язык программирования с открытым исходным кодом.
Широкий спектр приложений
Python можно использовать для различных задач программирования, от небольших сценариев оболочки до корпоративных веб-приложений.
Установка Python
Дистрибутив Python доступен для таких платформ, как Windows, MAC и Unix / Linux. Для установки Python нам нужно загрузить только двоичный код, применимый к нашей платформе. Но в случае, если двоичный код для нашей платформы недоступен, у нас должен быть компилятор C, чтобы исходный код можно было скомпилировать вручную.
Мы можем установить Python на различные платформы следующим образом:
Установка Python в Unix и Linux
Для установки Python на машины Unix / Linux вам необходимо выполнить следующие шаги:
Step 1 - Перейти по ссылке https://www.python.org/downloads/
Step 2 - Загрузите заархивированный исходный код, доступный для Unix / Linux по ссылке выше.
Step 3 - Извлеките файлы на свой компьютер.
Step 4 - Используйте следующие команды для завершения установки -
run ./configure script
make
make installВы можете найти установленный Python в стандартном месте /usr/local/bin и его библиотеки в /usr/local/lib/pythonXX, где XX - версия Python.
Установка Python в Windows
Для установки Python на машины с Windows вам необходимо выполнить следующие шаги:
Step 1 - Перейти по ссылке https://www.python.org/downloads/
Step 2 - Загрузите установщик Windows python-XYZ.msi файл, где XYZ - это версия, которую нам нужно установить.
Step 3 - Теперь сохраните файл установщика на локальном компьютере и запустите файл MSI.
Step 4 - Наконец, запустите загруженный файл, чтобы вызвать мастер установки Python.
Установка Python на Macintosh
Мы должны использовать Homebrew для установки Python 3 в Mac OS X. Homebrew прост в установке и представляет собой отличный установщик пакетов.
Homebrew также можно установить с помощью следующей команды -
$ ruby -e "$(curl -fsSL
https://raw.githubusercontent.com/Homebrew/install/master/install)"Для обновления диспетчера пакетов мы можем использовать следующую команду -
$ brew updateС помощью следующей команды мы можем установить Python3 на нашу машину MAC -
$ brew install python3Настройка пути
Вы можете использовать следующие инструкции для настройки пути в различных средах -
Настройка пути в Unix / Linux
Используйте следующие команды для настройки путей с использованием различных командных оболочек -
Для оболочки csh
setenv PATH "$PATH:/usr/local/bin/python".Для оболочки bash (Linux)
ATH="$PATH:/usr/local/bin/python".Для оболочки sh или ksh
PATH="$PATH:/usr/local/bin/python".Настройка пути в Windows
Для установки пути в Windows мы можем использовать путь %path%;C:\Python в командной строке и нажмите Enter.
Запуск Python
Мы можем запустить Python любым из следующих трех способов:
Интерактивный переводчик
Операционная система, такая как UNIX и DOS, которая предоставляет интерпретатор командной строки или оболочку, может использоваться для запуска Python.
Мы можем начать кодирование в интерактивном интерпретаторе следующим образом:
Step 1 - Войти python в командной строке.
Step 2 - Тогда мы можем сразу приступить к написанию кода в интерактивном интерпретаторе.
$python # Unix/Linux
or
python% # Unix/Linux
or
C:> python # Windows/DOSСкрипт из командной строки
Мы можем выполнить сценарий Python в командной строке, вызвав интерпретатор. Это можно понять следующим образом -
$python script.py # Unix/Linux
or
python% script.py # Unix/Linux
or
C: >python script.py # Windows/DOSИнтегрированная среда разработки
Мы также можем запускать Python из среды графического интерфейса, если в системе есть приложение с графическим интерфейсом, поддерживающее Python. Некоторые IDE, которые поддерживают Python на различных платформах, приведены ниже -
IDE for UNIX - UNIX для Python имеет IDLE IDE.
IDE for Windows - В Windows есть PythonWin IDE с графическим интерфейсом.
IDE for Macintosh - Macintosh имеет IDLE IDE, которую можно загрузить в виде файлов MacBinary или BinHex'd с основного веб-сайта.
В этой главе давайте изучим различные модули Python, которые мы можем использовать для парсинга веб-страниц.
Среды разработки Python с использованием virtualenv
Virtualenv - это инструмент для создания изолированных сред Python. С помощью virtualenv мы можем создать папку, содержащую все необходимые исполняемые файлы для использования пакетов, которые требуются нашему проекту Python. Это также позволяет нам добавлять и изменять модули Python без доступа к глобальной установке.
Вы можете использовать следующую команду для установки virtualenv -
(base) D:\ProgramData>pip install virtualenv
Collecting virtualenv
Downloading
https://files.pythonhosted.org/packages/b6/30/96a02b2287098b23b875bc8c2f58071c3
5d2efe84f747b64d523721dc2b5/virtualenv-16.0.0-py2.py3-none-any.whl
(1.9MB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 1.9MB 86kB/s
Installing collected packages: virtualenv
Successfully installed virtualenv-16.0.0Теперь нам нужно создать каталог, который будет представлять проект с помощью следующей команды -
(base) D:\ProgramData>mkdir webscrapТеперь войдите в этот каталог с помощью следующей команды -
(base) D:\ProgramData>cd webscrapТеперь нам нужно инициализировать папку виртуальной среды по нашему выбору следующим образом:
(base) D:\ProgramData\webscrap>virtualenv websc
Using base prefix 'd:\\programdata'
New python executable in D:\ProgramData\webscrap\websc\Scripts\python.exe
Installing setuptools, pip, wheel...done.Теперь активируйте виртуальную среду с помощью приведенной ниже команды. После успешной активации вы увидите его название в скобках слева.
(base) D:\ProgramData\webscrap>websc\scripts\activateМы можем установить любой модуль в этой среде следующим образом:
(websc) (base) D:\ProgramData\webscrap>pip install requests
Collecting requests
Downloading
https://files.pythonhosted.org/packages/65/47/7e02164a2a3db50ed6d8a6ab1d6d60b69
c4c3fdf57a284257925dfc12bda/requests-2.19.1-py2.py3-none-any.whl (9
1kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 148kB/s
Collecting chardet<3.1.0,>=3.0.2 (from requests)
Downloading
https://files.pythonhosted.org/packages/bc/a9/01ffebfb562e4274b6487b4bb1ddec7ca
55ec7510b22e4c51f14098443b8/chardet-3.0.4-py2.py3-none-any.whl (133
kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 143kB 369kB/s
Collecting certifi>=2017.4.17 (from requests)
Downloading
https://files.pythonhosted.org/packages/df/f7/04fee6ac349e915b82171f8e23cee6364
4d83663b34c539f7a09aed18f9e/certifi-2018.8.24-py2.py3-none-any.whl
(147kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 153kB 527kB/s
Collecting urllib3<1.24,>=1.21.1 (from requests)
Downloading
https://files.pythonhosted.org/packages/bd/c9/6fdd990019071a4a32a5e7cb78a1d92c5
3851ef4f56f62a3486e6a7d8ffb/urllib3-1.23-py2.py3-none-any.whl (133k
B)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 143kB 517kB/s
Collecting idna<2.8,>=2.5 (from requests)
Downloading
https://files.pythonhosted.org/packages/4b/2a/0276479a4b3caeb8a8c1af2f8e4355746
a97fab05a372e4a2c6a6b876165/idna-2.7-py2.py3-none-any.whl (58kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 61kB 339kB/s
Installing collected packages: chardet, certifi, urllib3, idna, requests
Successfully installed certifi-2018.8.24 chardet-3.0.4 idna-2.7 requests-2.19.1
urllib3-1.23Для деактивации виртуальной среды мы можем использовать следующую команду -
(websc) (base) D:\ProgramData\webscrap>deactivate
(base) D:\ProgramData\webscrap>Вы можете видеть, что (websc) отключен.
Модули Python для парсинга веб-страниц
Веб-скрапинг - это процесс создания агента, который может автоматически извлекать, анализировать, загружать и систематизировать полезную информацию из Интернета. Другими словами, вместо того, чтобы вручную сохранять данные с веб-сайтов, программное обеспечение для парсинга автоматически загружает и извлекает данные с нескольких веб-сайтов в соответствии с нашими требованиями.
В этом разделе мы собираемся обсудить полезные библиотеки Python для парсинга веб-страниц.
Запросы
Это простая библиотека для очистки веб-страниц на Python. Это эффективная HTTP-библиотека, используемая для доступа к веб-страницам. С помощьюRequests, мы можем получить необработанный HTML-код веб-страниц, который затем может быть проанализирован для получения данных. Перед использованиемrequests, давайте разберемся с его установкой.
Установка запросов
Мы можем установить его либо в нашей виртуальной среде, либо в глобальной установке. С помощьюpip команду, мы можем легко установить ее следующим образом -
(base) D:\ProgramData> pip install requests
Collecting requests
Using cached
https://files.pythonhosted.org/packages/65/47/7e02164a2a3db50ed6d8a6ab1d6d60b69
c4c3fdf57a284257925dfc12bda/requests-2.19.1-py2.py3-none-any.whl
Requirement already satisfied: idna<2.8,>=2.5 in d:\programdata\lib\sitepackages
(from requests) (2.6)
Requirement already satisfied: urllib3<1.24,>=1.21.1 in
d:\programdata\lib\site-packages (from requests) (1.22)
Requirement already satisfied: certifi>=2017.4.17 in d:\programdata\lib\sitepackages
(from requests) (2018.1.18)
Requirement already satisfied: chardet<3.1.0,>=3.0.2 in
d:\programdata\lib\site-packages (from requests) (3.0.4)
Installing collected packages: requests
Successfully installed requests-2.19.1пример
В этом примере мы выполняем HTTP-запрос GET для веб-страницы. Для этого нам нужно сначала импортировать библиотеку запросов следующим образом:
In [1]: import requestsВ этой следующей строке кода мы используем запросы для создания HTTP-запросов GET для URL-адреса: https://authoraditiagarwal.com/ сделав запрос GET.
In [2]: r = requests.get('https://authoraditiagarwal.com/')Теперь мы можем получить контент, используя .text имущество следующим образом -
In [5]: r.text[:200]Обратите внимание, что в следующем выводе мы получили первые 200 символов.
Out[5]: '<!DOCTYPE html>\n<html lang="en-US"\n\titemscope
\n\titemtype="http://schema.org/WebSite" \n\tprefix="og: http://ogp.me/ns#"
>\n<head>\n\t<meta charset
="UTF-8" />\n\t<meta http-equiv="X-UA-Compatible" content="IE'Urllib3
Это еще одна библиотека Python, которую можно использовать для извлечения данных из URL-адресов, похожих на requestsбиблиотека. Вы можете узнать больше об этом в технической документации на сайтеhttps://urllib3.readthedocs.io/en/latest/.
Установка Urllib3
Используя pip команда, мы можем установить urllib3 либо в нашей виртуальной среде, либо в глобальной установке.
(base) D:\ProgramData>pip install urllib3
Collecting urllib3
Using cached
https://files.pythonhosted.org/packages/bd/c9/6fdd990019071a4a32a5e7cb78a1d92c5
3851ef4f56f62a3486e6a7d8ffb/urllib3-1.23-py2.py3-none-any.whl
Installing collected packages: urllib3
Successfully installed urllib3-1.23Пример: парсинг с использованием Urllib3 и BeautifulSoup
В следующем примере мы очищаем веб-страницу с помощью Urllib3 и BeautifulSoup. Мы используемUrllib3на месте библиотеки запросов на получение необработанных данных (HTML) с веб-страницы. Затем мы используемBeautifulSoup для анализа этих HTML-данных.
import urllib3
from bs4 import BeautifulSoup
http = urllib3.PoolManager()
r = http.request('GET', 'https://authoraditiagarwal.com')
soup = BeautifulSoup(r.data, 'lxml')
print (soup.title)
print (soup.title.text)Это результат, который вы увидите, когда запустите этот код -
<title>Learn and Grow with Aditi Agarwal</title>
Learn and Grow with Aditi AgarwalСелен
Это пакет автоматического тестирования с открытым исходным кодом для веб-приложений в различных браузерах и платформах. Это не отдельный инструмент, а набор программ. У нас есть привязки селена для Python, Java, C #, Ruby и JavaScript. Здесь мы собираемся выполнить парсинг веб-страниц с использованием селена и его привязок к Python. Вы можете узнать больше о Selenium с Java по ссылке Selenium .
Привязки Selenium Python предоставляют удобный API для доступа к Selenium WebDrivers, таким как Firefox, IE, Chrome, Remote и т. Д. Текущие поддерживаемые версии Python - 2.7, 3.5 и выше.
Установка Selenium
Используя pip команда, мы можем установить urllib3 либо в нашей виртуальной среде, либо в глобальной установке.
pip install seleniumПоскольку селену требуется драйвер для взаимодействия с выбранным браузером, нам необходимо его загрузить. В следующей таблице показаны различные браузеры и их ссылки для их загрузки.
Chrome |
https://sites.google.com/a/chromium.org/ |
Edge |
https://developer.microsoft.com/ |
Firefox |
https://github.com/ |
Safari |
https://webkit.org/ |
пример
В этом примере показан парсинг веб-страниц с использованием селена. Его также можно использовать для тестирования, которое называется тестированием на селен.
После загрузки конкретного драйвера для указанной версии браузера нам нужно заняться программированием на Python.
Во-первых, нужно импортировать webdriver из селена следующим образом -
from selenium import webdriverТеперь укажите путь к веб-драйверу, который мы загрузили в соответствии с нашим требованием -
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
browser = webdriver.Chrome(executable_path = path)Теперь укажите URL-адрес, который мы хотим открыть в этом веб-браузере, который теперь контролируется нашим скриптом Python.
browser.get('https://authoraditiagarwal.com/leadershipmanagement')Мы также можем очистить определенный элемент, указав xpath, как указано в lxml.
browser.find_element_by_xpath('/html/body').click()Вы можете проверить браузер, управляемый скриптом Python, на предмет вывода.
Scrapy
Scrapy - это быстрая структура веб-сканирования с открытым исходным кодом, написанная на Python, используемая для извлечения данных с веб-страницы с помощью селекторов на основе XPath. Scrapy был впервые выпущен 26 июня 2008 года под лицензией BSD, а в июне 2015 года была выпущена веха 1.0. Он предоставляет нам все инструменты, необходимые для извлечения, обработки и структурирования данных с веб-сайтов.
Установка Scrapy
Используя pip команда, мы можем установить urllib3 либо в нашей виртуальной среде, либо в глобальной установке.
pip install scrapyДля более детального изучения Scrapy вы можете перейти по ссылке Scrapy
С помощью Python мы можем очищать любой веб-сайт или отдельные элементы веб-страницы, но знаете ли вы, законно это или нет? Прежде чем выполнять парсинг любого веб-сайта, мы должны знать о законности парсинга. В этой главе будут объяснены концепции, связанные с законностью парсинга веб-страниц.
Введение
Как правило, если вы собираетесь использовать очищенные данные в личных целях, проблем может не быть. Но если вы собираетесь повторно опубликовать эти данные, то перед тем, как сделать то же самое, вам следует сделать запрос на загрузку владельцу или провести небольшое исследование политики, а также данных, которые вы собираетесь очистить.
Перед очисткой требуется исследование
Если вы настраиваете веб-сайт для извлечения данных с него, нам необходимо понимать его масштаб и структуру. Ниже приведены некоторые файлы, которые нам необходимо проанализировать перед запуском парсинга веб-страниц.
Анализируем robots.txt
На самом деле большинство издателей позволяют программистам в той или иной степени сканировать свои веб-сайты. В другом смысле издатели хотят, чтобы сканировались определенные части веб-сайтов. Чтобы определить это, веб-сайты должны установить некоторые правила, определяющие, какие части можно сканировать, а какие нет. Такие правила определены в файле с именемrobots.txt.
robots.txt- это удобочитаемый файл, используемый для определения частей веб-сайта, которые сканеры могут или не могут сканировать. Стандартного формата файла robots.txt не существует, и издатели веб-сайта могут вносить изменения в соответствии со своими потребностями. Мы можем проверить файл robots.txt для конкретного веб-сайта, указав косую черту и robots.txt после URL-адреса этого веб-сайта. Например, если мы хотим проверить его на Google.com, нам нужно ввестиhttps://www.google.com/robots.txt и мы получим примерно следующее -
User-agent: *
Disallow: /search
Allow: /search/about
Allow: /search/static
Allow: /search/howsearchworks
Disallow: /sdch
Disallow: /groups
Disallow: /index.html?
Disallow: /?
Allow: /?hl=
Disallow: /?hl=*&
Allow: /?hl=*&gws_rd=ssl$
and so on……..Некоторые из наиболее распространенных правил, которые определены в файле robots.txt веб-сайта, следующие:
User-agent: BadCrawler
Disallow: /Вышеупомянутое правило означает, что файл robots.txt запрашивает у сканера BadCrawler пользовательский агент не сканировать их сайт.
User-agent: *
Crawl-delay: 5
Disallow: /trapВышеупомянутое правило означает, что файл robots.txt задерживает поисковый робот на 5 секунд между запросами на загрузку для всех пользовательских агентов, чтобы избежать перегрузки сервера. В/traplink будет пытаться заблокировать вредоносных поисковых роботов, которые переходят по запрещенным ссылкам. Есть еще много правил, которые могут быть определены издателем веб-сайта в соответствии со своими требованиями. Некоторые из них обсуждаются здесь -
Анализ файлов Sitemap
Что вы должны делать, если хотите сканировать веб-сайт в поисках обновленной информации? Вы будете сканировать каждую веб-страницу для получения этой обновленной информации, но это увеличит трафик сервера этого конкретного веб-сайта. Вот почему веб-сайты предоставляют файлы карты сайта, чтобы помочь сканерам найти обновленный контент без необходимости сканировать каждую веб-страницу. Стандарт Sitemap определен наhttp://www.sitemaps.org/protocol.html.
Содержание файла Sitemap
Ниже приводится содержимое файла карты сайта https://www.microsoft.com/robots.txt что обнаружено в файле robot.txt -
Sitemap: https://www.microsoft.com/en-us/explore/msft_sitemap_index.xml
Sitemap: https://www.microsoft.com/learning/sitemap.xml
Sitemap: https://www.microsoft.com/en-us/licensing/sitemap.xml
Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml
Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8
Sitemap: https://www.microsoft.com/store/collections.xml
Sitemap: https://www.microsoft.com/store/productdetailpages.index.xml
Sitemap: https://www.microsoft.com/en-us/store/locations/store-locationssitemap.xmlПриведенный выше контент показывает, что карта сайта перечисляет URL-адреса на веб-сайте и, кроме того, позволяет веб-мастеру указать некоторую дополнительную информацию, такую как дата последнего обновления, изменение содержимого, важность URL-адреса по отношению к другим и т.д. о каждом URL-адресе.
Какой размер веб-сайта?
Влияет ли размер веб-сайта, т. Е. Количество веб-страниц на то, как мы сканируем? Конечно да. Поскольку, если у нас будет меньшее количество веб-страниц для сканирования, эффективность не будет серьезной проблемой, но предположим, что если наш веб-сайт имеет миллионы веб-страниц, например Microsoft.com, то последовательная загрузка каждой веб-страницы займет несколько месяцев и тогда эффективность будет серьезной проблемой.
Проверка размера веб-сайта
Проверяя размер результатов поискового робота Google, мы можем оценить размер веб-сайта. Наш результат можно отфильтровать с помощью ключевого словаsiteпри поиске в Google. Например, оценивая размерhttps://authoraditiagarwal.com/ приведено ниже -
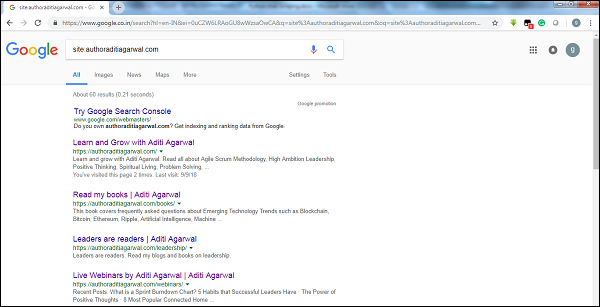
Вы можете увидеть, что есть около 60 результатов, что означает, что это небольшой веб-сайт, и сканирование не приведет к снижению эффективности.
Какая технология используется на сайте?
Еще один важный вопрос: влияет ли технология, используемая на веб-сайте, на способ сканирования? Да, влияет. Но как мы можем проверить технологию, используемую веб-сайтом? Существует библиотека Python с именемbuiltwith с помощью которых мы можем узнать о технологиях, используемых на веб-сайте.
пример
В этом примере мы собираемся проверить технологию, используемую на сайте. https://authoraditiagarwal.com с помощью библиотеки Python builtwith. Но перед использованием этой библиотеки нам необходимо установить ее следующим образом:
(base) D:\ProgramData>pip install builtwith
Collecting builtwith
Downloading
https://files.pythonhosted.org/packages/9b/b8/4a320be83bb3c9c1b3ac3f9469a5d66e0
2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz
Requirement already satisfied: six in d:\programdata\lib\site-packages (from
builtwith) (1.10.0)
Building wheels for collected packages: builtwith
Running setup.py bdist_wheel for builtwith ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b
f926764a924873e0304f10b2524
Successfully built builtwith
Installing collected packages: builtwith
Successfully installed builtwith-1.3.3Теперь, с помощью следующей простой строки кодов, мы можем проверить технологию, используемую конкретным веб-сайтом -
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}Кто владелец сайта?
Владелец веб-сайта также имеет значение, потому что, если известно, что владелец блокирует поисковые роботы, они должны быть осторожны при извлечении данных с веб-сайта. Существует протокол с именемWhois с помощью которого мы можем узнать о владельце сайта.
пример
В этом примере мы собираемся проверить владельца веб-сайта, скажем, microsoft.com, с помощью Whois. Но перед использованием этой библиотеки нам необходимо установить ее следующим образом:
(base) D:\ProgramData>pip install python-whois
Collecting python-whois
Downloading
https://files.pythonhosted.org/packages/63/8a/8ed58b8b28b6200ce1cdfe4e4f3bbc8b8
5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s
Requirement already satisfied: future in d:\programdata\lib\site-packages (from
python-whois) (0.16.0)
Building wheels for collected packages: python-whois
Running setup.py bdist_wheel for python-whois ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b
4dcc81ab212a3d5e52ab32dc531
Successfully built python-whois
Installing collected packages: python-whois
Successfully installed python-whois-0.7.0Теперь, с помощью следующей простой строки кодов, мы можем проверить технологию, используемую конкретным веб-сайтом -
In [1]: import whois
In [2]: print (whois.whois('microsoft.com'))
{
"domain_name": [
"MICROSOFT.COM",
"microsoft.com"
],
-------
"name_servers": [
"NS1.MSFT.NET",
"NS2.MSFT.NET",
"NS3.MSFT.NET",
"NS4.MSFT.NET",
"ns3.msft.net",
"ns1.msft.net",
"ns4.msft.net",
"ns2.msft.net"
],
"emails": [
"[email protected]",
"[email protected]",
"[email protected]",
"[email protected]"
],
}Анализировать веб-страницу означает понимать ее структуру. Теперь возникает вопрос, почему это важно для парсинга веб-страниц? В этой главе давайте разберемся в этом подробнее.
Анализ веб-страницы
Анализ веб-страницы важен, потому что без анализа мы не можем знать, в какой форме мы собираемся получать данные (структурированные или неструктурированные) с этой веб-страницы после извлечения. Мы можем проводить анализ веб-страниц следующими способами:
Просмотр источника страницы
Это способ понять, как устроена веб-страница, изучив ее исходный код. Чтобы реализовать это, нам нужно щелкнуть страницу правой кнопкой мыши, а затем выбратьView page sourceвариант. Затем мы получим интересующие нас данные с этой веб-страницы в форме HTML. Но главное беспокойство вызывают пробелы и форматирование, которое нам сложно форматировать.
Проверка источника страницы с помощью параметра «Проверить элемент»
Это еще один способ анализа веб-страницы. Но разница в том, что это решит проблему форматирования и пробелов в исходном коде веб-страницы. Вы можете реализовать это, щелкнув правой кнопкой мыши и выбравInspect или же Inspect elementвариант из меню. Он предоставит информацию о конкретной области или элементе этой веб-страницы.
Различные способы извлечения данных с веб-страницы
Следующие методы в основном используются для извлечения данных с веб-страницы:
Регулярное выражение
Это узкоспециализированный язык программирования, встроенный в Python. Мы можем использовать это черезreмодуль Python. Его также называют RE или регулярными выражениями или шаблонами регулярных выражений. С помощью регулярных выражений мы можем указать некоторые правила для возможного набора строк, которым мы хотим сопоставить данные.
Если вы хотите узнать больше о регулярных выражениях в целом, перейдите по ссылке https://www.tutorialspoint.com/automata_theory/regular_expressions.htmа если вы хотите узнать больше о модуле re или регулярном выражении в Python, вы можете перейти по ссылке https://www.tutorialspoint.com/python/python_reg_expressions.htm .
пример
В следующем примере мы собираемся извлечь данные об Индии из http://example.webscraping.com после сопоставления содержимого <td> с помощью регулярного выражения.
import re
import urllib.request
response =
urllib.request.urlopen('http://example.webscraping.com/places/default/view/India-102')
html = response.read()
text = html.decode()
re.findall('<td class="w2p_fw">(.*?)</td>',text)Вывод
Соответствующий вывод будет таким, как показано здесь -
[
'<img src="/places/static/images/flags/in.png" />',
'3,287,590 square kilometres',
'1,173,108,018',
'IN',
'India',
'New Delhi',
'<a href="/places/default/continent/AS">AS</a>',
'.in',
'INR',
'Rupee',
'91',
'######',
'^(\\d{6})$',
'enIN,hi,bn,te,mr,ta,ur,gu,kn,ml,or,pa,as,bh,sat,ks,ne,sd,kok,doi,mni,sit,sa,fr,lus,inc',
'<div>
<a href="/places/default/iso/CN">CN </a>
<a href="/places/default/iso/NP">NP </a>
<a href="/places/default/iso/MM">MM </a>
<a href="/places/default/iso/BT">BT </a>
<a href="/places/default/iso/PK">PK </a>
<a href="/places/default/iso/BD">BD </a>
</div>'
]Обратите внимание, что в приведенном выше выводе вы можете увидеть подробную информацию о стране Индия, используя регулярное выражение.
Красивый суп
Предположим, мы хотим собрать все гиперссылки с веб-страницы, тогда мы можем использовать синтаксический анализатор под названием BeautifulSoup, который можно узнать более подробно на https://www.crummy.com/software/BeautifulSoup/bs4/doc/.Проще говоря, BeautifulSoup - это библиотека Python для извлечения данных из файлов HTML и XML. Его можно использовать с запросами, потому что ему нужен ввод (документ или URL-адрес) для создания объекта супа, поскольку он не может получить веб-страницу самостоятельно. Вы можете использовать следующий сценарий Python для сбора заголовка веб-страницы и гиперссылок.
Установка Beautiful Soup
Используя pip команда, мы можем установить beautifulsoup либо в нашей виртуальной среде, либо в глобальной установке.
(base) D:\ProgramData>pip install bs4
Collecting bs4
Downloading
https://files.pythonhosted.org/packages/10/ed/7e8b97591f6f456174139ec089c769f89
a94a1a4025fe967691de971f314/bs4-0.0.1.tar.gz
Requirement already satisfied: beautifulsoup4 in d:\programdata\lib\sitepackages
(from bs4) (4.6.0)
Building wheels for collected packages: bs4
Running setup.py bdist_wheel for bs4 ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\a0\b0\b2\4f80b9456b87abedbc0bf2d
52235414c3467d8889be38dd472
Successfully built bs4
Installing collected packages: bs4
Successfully installed bs4-0.0.1пример
Обратите внимание, что в этом примере мы расширяем приведенный выше пример, реализованный с помощью модуля python запросов. мы используемr.text для создания объекта супа, который в дальнейшем будет использоваться для получения таких деталей, как заголовок веб-страницы.
Во-первых, нам нужно импортировать необходимые модули Python -
import requests
from bs4 import BeautifulSoupВ этой следующей строке кода мы используем запросы для создания HTTP-запросов GET для URL-адреса: https://authoraditiagarwal.com/ сделав запрос GET.
r = requests.get('https://authoraditiagarwal.com/')Теперь нам нужно создать объект Soup следующим образом:
soup = BeautifulSoup(r.text, 'lxml')
print (soup.title)
print (soup.title.text)Вывод
Соответствующий вывод будет таким, как показано здесь -
<title>Learn and Grow with Aditi Agarwal</title>
Learn and Grow with Aditi AgarwalLxml
Еще одна библиотека Python, которую мы собираемся обсудить для веб-парсинга, - это lxml. Это высокопроизводительная библиотека синтаксического анализа HTML и XML. Это сравнительно быстро и просто. Вы можете прочитать об этом подробнее наhttps://lxml.de/.
Установка lxml
Используя команду pip, мы можем установить lxml либо в нашей виртуальной среде, либо в глобальной установке.
(base) D:\ProgramData>pip install lxml
Collecting lxml
Downloading
https://files.pythonhosted.org/packages/b9/55/bcc78c70e8ba30f51b5495eb0e
3e949aa06e4a2de55b3de53dc9fa9653fa/lxml-4.2.5-cp36-cp36m-win_amd64.whl
(3.
6MB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 3.6MB 64kB/s
Installing collected packages: lxml
Successfully installed lxml-4.2.5Пример: извлечение данных с использованием lxml и запросов
В следующем примере мы очищаем определенный элемент веб-страницы от authoraditiagarwal.com с помощью lxml и запросов -
Во-первых, нам нужно импортировать запросы и html из библиотеки lxml следующим образом:
import requests
from lxml import htmlТеперь нам нужно указать URL-адрес веб-страницы, которую нужно удалить.
url = 'https://authoraditiagarwal.com/leadershipmanagement/'Теперь нам нужно указать путь (Xpath) к конкретному элементу этой веб-страницы -
path = '//*[@id="panel-836-0-0-1"]/div/div/p[1]'
response = requests.get(url)
byte_string = response.content
source_code = html.fromstring(byte_string)
tree = source_code.xpath(path)
print(tree[0].text_content())Вывод
Соответствующий вывод будет таким, как показано здесь -
The Sprint Burndown or the Iteration Burndown chart is a powerful tool to communicate
daily progress to the stakeholders. It tracks the completion of work for a given sprint
or an iteration. The horizontal axis represents the days within a Sprint. The vertical
axis represents the hours remaining to complete the committed work.В предыдущих главах мы узнали об извлечении данных с веб-страниц или о парсинге веб-страниц с помощью различных модулей Python. В этой главе давайте рассмотрим различные методы обработки данных, которые были очищены.
Введение
Чтобы обработать данные, которые были очищены, мы должны хранить данные на нашем локальном компьютере в определенном формате, таком как электронная таблица (CSV), JSON или иногда в базах данных, таких как MySQL.
Обработка данных CSV и JSON
Во-первых, мы собираемся записать информацию после захвата с веб-страницы в файл CSV или электронную таблицу. Давайте сначала разберемся с простым примером, в котором мы сначала будем собирать информацию, используяBeautifulSoup модуль, как это было ранее, а затем, используя модуль Python CSV, мы запишем эту текстовую информацию в файл CSV.
Во-первых, нам нужно импортировать необходимые библиотеки Python следующим образом:
import requests
from bs4 import BeautifulSoup
import csvВ этой следующей строке кода мы используем запросы для создания HTTP-запросов GET для URL-адреса: https://authoraditiagarwal.com/ сделав запрос GET.
r = requests.get('https://authoraditiagarwal.com/')Теперь нам нужно создать объект Soup следующим образом:
soup = BeautifulSoup(r.text, 'lxml')Теперь, с помощью следующих строк кода, мы запишем полученные данные в файл CSV с именем dataprocessing.csv.
f = csv.writer(open(' dataprocessing.csv ','w'))
f.writerow(['Title'])
f.writerow([soup.title.text])После запуска этого сценария текстовая информация или название веб-страницы будут сохранены в вышеупомянутом файле CSV на вашем локальном компьютере.
Точно так же мы можем сохранить собранную информацию в файле JSON. Ниже приведен простой для понимания скрипт Python для выполнения того же самого, в котором мы захватываем ту же информацию, что и в предыдущем скрипте Python, но на этот раз полученная информация сохраняется в JSONfile.txt с помощью модуля JSON Python.
import requests
from bs4 import BeautifulSoup
import csv
import json
r = requests.get('https://authoraditiagarwal.com/')
soup = BeautifulSoup(r.text, 'lxml')
y = json.dumps(soup.title.text)
with open('JSONFile.txt', 'wt') as outfile:
json.dump(y, outfile)После запуска этого сценария полученная информация, то есть заголовок веб-страницы, будет сохранена в вышеупомянутом текстовом файле на вашем локальном компьютере.
Обработка данных с использованием AWS S3
Иногда нам может потребоваться сохранить очищенные данные в нашем локальном хранилище для архивирования. Но что, если нам нужно хранить и анализировать эти данные в массовом масштабе? Ответ - облачный сервис хранения под названием Amazon S3 или AWS S3 (Simple Storage Service). По сути, AWS S3 - это объектное хранилище, которое создано для хранения и извлечения любого объема данных из любого места.
Мы можем выполнить следующие шаги для хранения данных в AWS S3:
Step 1- Сначала нам нужна учетная запись AWS, которая предоставит нам секретные ключи для использования в нашем скрипте Python при хранении данных. Он создаст корзину S3, в которой мы сможем хранить наши данные.
Step 2 - Далее нам нужно установить boto3Библиотека Python для доступа к ведру S3. Его можно установить с помощью следующей команды -
pip install boto3Step 3 - Затем мы можем использовать следующий скрипт Python для очистки данных с веб-страницы и сохранения их в корзине AWS S3.
Во-первых, нам нужно импортировать библиотеки Python для парсинга, здесь мы работаем с requests, и boto3 сохранение данных в ведро S3.
import requests
import boto3Теперь мы можем очистить данные с нашего URL.
data = requests.get("Enter the URL").textТеперь для хранения данных в корзине S3 нам нужно создать клиента S3 следующим образом:
s3 = boto3.client('s3')
bucket_name = "our-content"Следующая строка кода создаст корзину S3 следующим образом:
s3.create_bucket(Bucket = bucket_name, ACL = 'public-read')
s3.put_object(Bucket = bucket_name, Key = '', Body = data, ACL = "public-read")Теперь вы можете проверить корзину с именем our-content из своей учетной записи AWS.
Обработка данных с использованием MySQL
Давайте узнаем, как обрабатывать данные с помощью MySQL. Если вы хотите узнать о MySQL, то можете перейти по ссылкеhttps://www.tutorialspoint.com/mysql/.
С помощью следующих шагов мы можем очистить и обработать данные в таблице MySQL:
Step 1- Во-первых, с помощью MySQL нам нужно создать базу данных и таблицу, в которой мы хотим сохранить наши очищенные данные. Например, мы создаем таблицу со следующим запросом -
CREATE TABLE Scrap_pages (id BIGINT(7) NOT NULL AUTO_INCREMENT,
title VARCHAR(200), content VARCHAR(10000),PRIMARY KEY(id));Step 2- Далее нам нужно разобраться с Unicode. Обратите внимание, что MySQL по умолчанию не поддерживает Unicode. Нам нужно включить эту функцию с помощью следующих команд, которые изменят набор символов по умолчанию для базы данных, для таблицы и для обоих столбцов:
ALTER DATABASE scrap CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
ALTER TABLE Scrap_pages CONVERT TO CHARACTER SET utf8mb4 COLLATE
utf8mb4_unicode_ci;
ALTER TABLE Scrap_pages CHANGE title title VARCHAR(200) CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;
ALTER TABLE pages CHANGE content content VARCHAR(10000) CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;Step 3- Теперь интегрируйте MySQL с Python. Для этого нам понадобится PyMySQL, который можно установить с помощью следующей команды
pip install PyMySQLStep 4- Теперь наша база данных с именем Scrap, созданная ранее, готова сохранить данные после извлечения из Интернета в таблицу с именем Scrap_pages. В нашем примере мы собираемся очистить данные из Википедии, и они будут сохранены в нашей базе данных.
Во-первых, нам нужно импортировать необходимые модули Python.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import pymysql
import reТеперь установите соединение, которое интегрирует с Python.
conn = pymysql.connect(host='127.0.0.1',user='root', passwd = None, db = 'mysql',
charset = 'utf8')
cur = conn.cursor()
cur.execute("USE scrap")
random.seed(datetime.datetime.now())
def store(title, content):
cur.execute('INSERT INTO scrap_pages (title, content) VALUES ''("%s","%s")', (title, content))
cur.connection.commit()Теперь подключитесь к Википедии и получите данные из нее.
def getLinks(articleUrl):
html = urlopen('http://en.wikipedia.org'+articleUrl)
bs = BeautifulSoup(html, 'html.parser')
title = bs.find('h1').get_text()
content = bs.find('div', {'id':'mw-content-text'}).find('p').get_text()
store(title, content)
return bs.find('div', {'id':'bodyContent'}).findAll('a',href=re.compile('^(/wiki/)((?!:).)*$'))
links = getLinks('/wiki/Kevin_Bacon')
try:
while len(links) > 0:
newArticle = links[random.randint(0, len(links)-1)].attrs['href']
print(newArticle)
links = getLinks(newArticle)Наконец, нам нужно закрыть курсор и соединение.
finally:
cur.close()
conn.close()Это сохранит данные, собранные из Википедии, в таблицу с именем scrap_pages. Если вы знакомы с MySQL и веб-парсингом, то приведенный выше код будет несложно понять.
Обработка данных с использованием PostgreSQL
PostgreSQL, разработанный командой добровольцев со всего мира, представляет собой систему управления реляционными базами данных с открытым исходным кодом (RDMS). Процесс обработки очищенных данных с помощью PostgreSQL аналогичен процессу MySQL. Произойдет два изменения: во-первых, команды будут отличаться от MySQL, а во-вторых, здесь мы будем использоватьpsycopg2 Библиотека Python для интеграции с Python.
Если вы не знакомы с PostgreSQL, вы можете изучить его на https://www.tutorialspoint.com/postgresql/. И с помощью следующей команды мы можем установить библиотеку Python psycopg2 -
pip install psycopg2Веб-скрапинг обычно включает загрузку, хранение и обработку веб-мультимедийного контента. В этой главе давайте разберемся, как обрабатывать контент, загруженный из Интернета.
Введение
Интернет-медиа-контент, который мы получаем во время парсинга, может быть изображениями, аудио- и видеофайлами в форме не веб-страниц, а также файлов данных. Но можем ли мы доверять загруженным данным, особенно в отношении расширения данных, которые мы собираемся загружать и хранить в памяти нашего компьютера? Поэтому важно знать, какие данные мы собираемся хранить локально.
Получение медиаконтента с веб-страницы
В этом разделе мы узнаем, как мы можем загрузить медиа-контент, который правильно представляет тип медиа на основе информации с веб-сервера. Мы можем сделать это с помощью Pythonrequests модуль, как мы делали в предыдущей главе.
Во-первых, нам нужно импортировать необходимые модули Python следующим образом:
import requestsТеперь укажите URL-адрес медиа-контента, который мы хотим загрузить и сохранить локально.
url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg"Используйте следующий код для создания объекта ответа HTTP.
r = requests.get(url)С помощью следующей строки кода мы можем сохранить полученный контент как файл .png.
with open("ThinkBig.png",'wb') as f:
f.write(r.content)После запуска вышеуказанного скрипта Python мы получим файл с именем ThinkBig.png, в котором будет загруженное изображение.
Извлечение имени файла из URL
После загрузки содержимого с веб-сайта мы также хотим сохранить его в файле с именем файла, указанным в URL-адресе. Но мы также можем проверить, существуют ли дополнительные фрагменты в URL. Для этого нам нужно найти фактическое имя файла из URL-адреса.
С помощью следующего скрипта Python, используя urlparse, мы можем извлечь имя файла из URL -
import urllib3
import os
url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg"
a = urlparse(url)
a.pathВы можете наблюдать результат, как показано ниже -
'/wp-content/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg'
os.path.basename(a.path)Вы можете наблюдать результат, как показано ниже -
'MetaSlider_ThinkBig-1080x180.jpg'Как только вы запустите вышеуказанный скрипт, мы получим имя файла из URL.
Информация о типе контента из URL
При извлечении содержимого с веб-сервера с помощью запроса GET мы также можем проверить информацию, предоставленную веб-сервером. С помощью следующего скрипта Python мы можем определить, что означает веб-сервер с типом контента -
Во-первых, нам нужно импортировать необходимые модули Python следующим образом:
import requestsТеперь нам нужно предоставить URL-адрес медиа-контента, который мы хотим загрузить и сохранить локально.
url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg"Следующая строка кода создаст объект ответа HTTP.
r = requests.get(url, allow_redirects=True)Теперь мы можем узнать, какую информацию о контенте может предоставить веб-сервер.
for headers in r.headers: print(headers)Вы можете наблюдать результат, как показано ниже -
Date
Server
Upgrade
Connection
Last-Modified
Accept-Ranges
Content-Length
Keep-Alive
Content-TypeС помощью следующей строки кода мы можем получить конкретную информацию о типе контента, скажем, тип контента -
print (r.headers.get('content-type'))Вы можете наблюдать результат, как показано ниже -
image/jpegС помощью следующей строки кода мы можем получить конкретную информацию о типе контента, скажем, EType -
print (r.headers.get('ETag'))Вы можете наблюдать результат, как показано ниже -
NoneСоблюдайте следующую команду -
print (r.headers.get('content-length'))Вы можете наблюдать результат, как показано ниже -
12636С помощью следующей строки кода мы можем получить конкретную информацию о типе контента, скажем, Сервер -
print (r.headers.get('Server'))Вы можете наблюдать результат, как показано ниже -
ApacheСоздание эскизов для изображений
Миниатюра - это очень маленькое описание или представление. Пользователь может захотеть сохранить только эскиз большого изображения или сохранить как изображение, так и эскиз. В этом разделе мы собираемся создать миниатюру изображения с именемThinkBig.png загружен в предыдущем разделе «Получение медиа-контента с веб-страницы».
Для этого скрипта Python нам нужно установить библиотеку Python с именем Pillow, ответвление библиотеки изображений Python, имеющее полезные функции для управления изображениями. Его можно установить с помощью следующей команды -
pip install pillowСледующий сценарий Python создаст миниатюру изображения и сохранит ее в текущем каталоге, добавив к файлу миниатюр префикс Th_
import glob
from PIL import Image
for infile in glob.glob("ThinkBig.png"):
img = Image.open(infile)
img.thumbnail((128, 128), Image.ANTIALIAS)
if infile[0:2] != "Th_":
img.save("Th_" + infile, "png")Приведенный выше код очень легко понять, и вы можете проверить файл эскиза в текущем каталоге.
Скриншот с веб-сайта
При парсинге веб-страниц очень распространенная задача - сделать снимок экрана веб-сайта. Для реализации этого мы будем использовать селен и webdriver. Следующий скрипт Python сделает снимок экрана с веб-сайта и сохранит его в текущем каталоге.
From selenium import webdriver
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
browser = webdriver.Chrome(executable_path = path)
browser.get('https://tutorialspoint.com/')
screenshot = browser.save_screenshot('screenshot.png')
browser.quitВы можете наблюдать результат, как показано ниже -
DevTools listening on ws://127.0.0.1:1456/devtools/browser/488ed704-9f1b-44f0-
a571-892dc4c90eb7
<bound method WebDriver.quit of <selenium.webdriver.chrome.webdriver.WebDriver
(session="37e8e440e2f7807ef41ca7aa20ce7c97")>>После запуска скрипта вы можете проверить текущий каталог на наличие screenshot.png файл.
Создание эскизов для видео
Предположим, мы загрузили видео с веб-сайта и хотим создать для них эскизы, чтобы можно было щелкнуть конкретное видео на основе его эскиза. Для создания миниатюр видео нам понадобится простой инструмент под названиемffmpeg который можно скачать с www.ffmpeg.org. После загрузки нам необходимо установить его в соответствии со спецификациями нашей ОС.
Следующий скрипт Python сгенерирует эскиз видео и сохранит его в нашем локальном каталоге -
import subprocess
video_MP4_file = “C:\Users\gaurav\desktop\solar.mp4
thumbnail_image_file = 'thumbnail_solar_video.jpg'
subprocess.call(['ffmpeg', '-i', video_MP4_file, '-ss', '00:00:20.000', '-
vframes', '1', thumbnail_image_file, "-y"])После запуска приведенного выше сценария мы получим эскиз с именем thumbnail_solar_video.jpg сохранены в нашем локальном каталоге.
Копирование видео MP4 в MP3
Предположим, вы загрузили какой-то видеофайл с веб-сайта, но вам нужен только звук из этого файла для вашей цели, тогда это можно сделать на Python с помощью библиотеки Python под названием moviepy который можно установить с помощью следующей команды -
pip install moviepyТеперь, после успешной установки moviepy с помощью следующего скрипта, мы можем конвертировать MP4 в MP3.
import moviepy.editor as mp
clip = mp.VideoFileClip(r"C:\Users\gaurav\Desktop\1234.mp4")
clip.audio.write_audiofile("movie_audio.mp3")Вы можете наблюдать результат, как показано ниже -
[MoviePy] Writing audio in movie_audio.mp3
100%|¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦
¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 674/674 [00:01<00:00,
476.30it/s]
[MoviePy] Done.Приведенный выше сценарий сохранит аудиофайл MP3 в локальном каталоге.
В предыдущей главе мы увидели, как работать с видео и изображениями, которые мы получаем как часть веб-скрапинга. В этой главе мы рассмотрим анализ текста с помощью библиотеки Python и узнаем об этом подробно.
Введение
Вы можете выполнить анализ текста с помощью библиотеки Python под названием Natural Language Tool Kit (NLTK). Прежде чем перейти к концепциям NLTK, давайте поймем связь между анализом текста и парсингом веб-страниц.
Анализ слов в тексте может помочь нам узнать, какие слова важны, какие слова необычны, как слова сгруппированы. Этот анализ упрощает задачу очистки веб-страниц.
Начало работы с NLTK
Инструментарий естественного языка (NLTK) - это набор библиотек Python, который разработан специально для идентификации и пометки частей речи, встречающихся в тексте на естественном языке, таком как английский.
Установка NLTK
Вы можете использовать следующую команду для установки NLTK в Python -
pip install nltkЕсли вы используете Anaconda, то пакет conda для NLTK можно создать с помощью следующей команды -
conda install -c anaconda nltkСкачивание данных НЛТК
После установки NLTK мы должны загрузить предустановленные текстовые репозитории. Но перед загрузкой репозиториев текстовых пресетов нам нужно импортировать NLTK с помощьюimport команда следующим образом -
mport nltkТеперь с помощью следующей команды можно загрузить данные NLTK -
nltk.download()Установка всех доступных пакетов NLTK займет некоторое время, но всегда рекомендуется устанавливать все пакеты.
Установка других необходимых пакетов
Нам также нужны другие пакеты Python, например gensim и pattern для анализа текста, а также для создания приложений обработки естественного языка с помощью NLTK.
gensim- Надежная библиотека семантического моделирования, полезная для многих приложений. Его можно установить с помощью следующей команды -
pip install gensimpattern - Используется для изготовления gensimпакет работает правильно. Его можно установить с помощью следующей команды -
pip install patternТокенизация
Процесс разбиения данного текста на более мелкие единицы, называемые токенами, называется токенизацией. Эти токены могут быть словами, числами или знаками препинания. Его еще называютword segmentation.
пример

Модуль NLTK предоставляет разные пакеты для токенизации. Мы можем использовать эти пакеты в соответствии с нашими требованиями. Некоторые из пакетов описаны здесь -
sent_tokenize package- Этот пакет разделит вводимый текст на предложения. Вы можете использовать следующую команду для импорта этого пакета -
from nltk.tokenize import sent_tokenizeword_tokenize package- Этот пакет разделит вводимый текст на слова. Вы можете использовать следующую команду для импорта этого пакета -
from nltk.tokenize import word_tokenizeWordPunctTokenizer package- Этот пакет разделит вводимый текст и знаки препинания на слова. Вы можете использовать следующую команду для импорта этого пакета -
from nltk.tokenize import WordPuncttokenizerСтемминг
В любом языке есть разные формы слов. Язык включает множество вариаций по грамматическим причинам. Например, рассмотрим словаdemocracy, democratic, и democratization. Для машинного обучения, а также для проектов по парсингу веб-страниц важно, чтобы машины понимали, что эти разные слова имеют одинаковую базовую форму. Следовательно, мы можем сказать, что может быть полезно извлекать базовые формы слов при анализе текста.
Это может быть достигнуто путем выделения корней, которое можно определить как эвристический процесс извлечения основных форм слов путем отсечения концов слов.
Модуль NLTK предоставляет различные пакеты для стемминга. Мы можем использовать эти пакеты в соответствии с нашими требованиями. Некоторые из этих пакетов описаны здесь -
PorterStemmer package- Алгоритм Портера используется этим пакетом Python для извлечения базовой формы. Вы можете использовать следующую команду для импорта этого пакета -
from nltk.stem.porter import PorterStemmerНапример, после слова ‘writing’ в качестве входных данных для этого стеммера на выходе будет слово ‘write’ после забоя.
LancasterStemmer package- Алгоритм Ланкастера используется этим пакетом Python для извлечения базовой формы. Вы можете использовать следующую команду для импорта этого пакета -
from nltk.stem.lancaster import LancasterStemmerНапример, после слова ‘writing’ в качестве входных данных для этого стеммера на выходе будет слово ‘writ’ после забоя.
SnowballStemmer package- Алгоритм Snowball используется этим пакетом Python для извлечения базовой формы. Вы можете использовать следующую команду для импорта этого пакета -
from nltk.stem.snowball import SnowballStemmerНапример, после подачи слова «запись» в качестве входных данных для этого стеммера на выходе будет слово «запись» после стемминга.
Лемматизация
Другой способ извлечь базовую форму слов - это лемматизация, обычно направленная на удаление флективных окончаний с помощью словарного и морфологического анализа. Базовая форма любого слова после лемматизации называется леммой.
Модуль NLTK предоставляет следующие пакеты для лемматизации -
WordNetLemmatizer package- Он будет извлекать базовую форму слова в зависимости от того, используется ли оно как существительное или как глагол. Вы можете использовать следующую команду для импорта этого пакета -
from nltk.stem import WordNetLemmatizerРазбивка
Разделение на части, что означает разделение данных на небольшие фрагменты, является одним из важных процессов обработки естественного языка для идентификации частей речи и коротких фраз, таких как словосочетания с существительными. Разделение на части - это маркировка токенов. Мы можем получить структуру предложения с помощью процесса разбиения на части.
пример
В этом примере мы собираемся реализовать фрагментирование существительных и фраз с помощью модуля NLTK Python. NP chunking - это категория разбиения на фрагменты, при которой в предложении встречаются фрагменты словосочетаний.
Шаги по разделению именных фраз
Нам нужно выполнить шаги, указанные ниже, для реализации фрагментации именных фраз:
Шаг 1 - Определение грамматики фрагментов
На первом этапе мы определим грамматику для разбиения на части. Он будет состоять из правил, которым мы должны следовать.
Шаг 2 - Создание парсера фрагментов
Теперь мы создадим парсер чанков. Он проанализирует грамматику и выдаст результат.
Шаг 3 - Вывод
На этом последнем шаге вывод будет произведен в формате дерева.
Во-первых, нам нужно импортировать пакет NLTK следующим образом:
import nltkДалее нам нужно определить предложение. Здесь DT: определитель, VBP: глагол, JJ: прилагательное, IN: предлог и NN: существительное.
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]Далее мы даем грамматику в виде регулярного выражения.
grammar = "NP:{<DT>?<JJ>*<NN>}"Теперь в следующей строке кода будет определен синтаксический анализатор для анализа грамматики.
parser_chunking = nltk.RegexpParser(grammar)Теперь парсер проанализирует предложение.
parser_chunking.parse(sentence)Затем мы передаем наш результат в переменную.
Output = parser_chunking.parse(sentence)С помощью следующего кода мы можем нарисовать наш вывод в виде дерева, как показано ниже.
output.draw()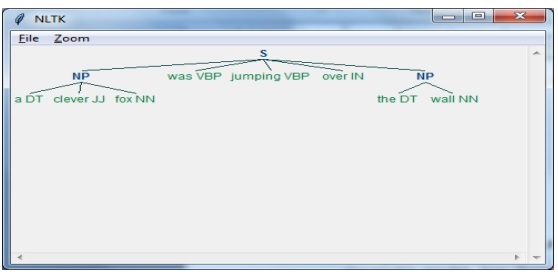
Модель Bag of Word (BoW) Извлечение и преобразование текста в числовую форму
Bag of Word (BoW), полезная модель в обработке естественного языка, в основном используется для извлечения функций из текста. После извлечения функций из текста его можно использовать при моделировании в алгоритмах машинного обучения, поскольку необработанные данные нельзя использовать в приложениях машинного обучения.
Работа модели BoW
Первоначально модель извлекает словарь из всех слов в документе. Позже, используя матрицу терминов документа, он построит модель. Таким образом, модель BoW представляет документ только как набор слов, а порядок или структура отбрасываются.
пример
Предположим, у нас есть следующие два предложения -
Sentence1 - Это пример модели Bag of Words.
Sentence2 - Мы можем извлекать особенности, используя модель Bag of Words.
Теперь, рассматривая эти два предложения, мы получаем следующие 14 различных слов:
- This
- is
- an
- example
- bag
- of
- words
- model
- we
- can
- extract
- features
- by
- using
Построение модели мешка слов в NLTK
Давайте посмотрим на следующий скрипт Python, который построит модель BoW в NLTK.
Сначала импортируйте следующий пакет -
from sklearn.feature_extraction.text import CountVectorizerЗатем определите набор предложений -
Sentences=['This is an example of Bag of Words model.', ' We can extract
features by using Bag of Words model.']
vector_count = CountVectorizer()
features_text = vector_count.fit_transform(Sentences).todense()
print(vector_count.vocabulary_)Вывод
Это показывает, что у нас есть 14 различных слов в двух приведенных выше предложениях -
{
'this': 10, 'is': 7, 'an': 0, 'example': 4, 'of': 9,
'bag': 1, 'words': 13, 'model': 8, 'we': 12, 'can': 3,
'extract': 5, 'features': 6, 'by': 2, 'using':11
}Тематическое моделирование: выявление закономерностей в текстовых данных
Как правило, документы сгруппированы по темам, а тематическое моделирование - это метод выявления закономерностей в тексте, соответствующих определенной теме. Другими словами, тематическое моделирование используется для выявления абстрактных тем или скрытой структуры в заданном наборе документов.
Вы можете использовать тематическое моделирование в следующих сценариях -
Текстовая классификация
Классификацию можно улучшить с помощью тематического моделирования, поскольку оно группирует похожие слова вместе, а не использует каждое слово отдельно как функцию.
Рекомендательные системы
Мы можем создавать рекомендательные системы, используя меры сходства.
Алгоритмы тематического моделирования
Мы можем реализовать тематическое моделирование, используя следующие алгоритмы:
Latent Dirichlet Allocation(LDA) - Это один из самых популярных алгоритмов, использующий вероятностные графические модели для реализации тематического моделирования.
Latent Semantic Analysis(LDA) or Latent Semantic Indexing(LSI) - Он основан на линейной алгебре и использует концепцию SVD (сингулярное разложение) в матрице терминов документа.
Non-Negative Matrix Factorization (NMF) - Он также основан на линейной алгебре, как и LDA.
Вышеупомянутые алгоритмы будут иметь следующие элементы -
- Количество тем: Параметр
- Матрица документа-слова: ввод
- WTM (матрица тем Word) и TDM (матрица тематических документов): вывод
Введение
Парсинг веб-страниц - сложная задача, и сложность возрастает, если веб-сайт является динамическим. Согласно Глобальному аудиту веб-доступности Организации Объединенных Наций, более 70% веб-сайтов являются динамическими по своей природе, и они полагаются на JavaScript для выполнения своих функций.
Пример динамического веб-сайта
Давайте посмотрим на пример динамического веб-сайта и узнаем, почему его сложно очистить. Здесь мы собираемся взять пример поиска с веб-сайта с именемhttp://example.webscraping.com/places/default/search.Но как мы можем сказать, что этот сайт носит динамический характер? Об этом можно судить по выводам следующего скрипта Python, который попытается очистить данные с вышеупомянутой веб-страницы -
import re
import urllib.request
response = urllib.request.urlopen('http://example.webscraping.com/places/default/search')
html = response.read()
text = html.decode()
re.findall('(.*?)',text)Вывод
[ ]Приведенный выше вывод показывает, что пример скребка не смог извлечь информацию, потому что элемент <div>, который мы пытаемся найти, пуст.
Подходы к извлечению данных с динамических веб-сайтов
Мы видели, что парсер не может очистить информацию с динамического веб-сайта, потому что данные загружаются динамически с помощью JavaScript. В таких случаях мы можем использовать следующие два метода для извлечения данных с динамических сайтов, зависящих от JavaScript:
- Обратный инжиниринг JavaScript
- Рендеринг JavaScript
Обратный инжиниринг JavaScript
Был бы полезен процесс, называемый обратным проектированием, который позволяет нам понять, как данные динамически загружаются веб-страницами.
Для этого нам нужно щелкнуть inspect elementвкладка для указанного URL. Далее мы нажмемNETWORK вкладка, чтобы найти все запросы, сделанные для этой веб-страницы, включая search.json с путем /ajax. Вместо доступа к данным AJAX из браузера или через вкладку NETWORK, мы можем сделать это также с помощью следующего скрипта Python -
import requests
url=requests.get('http://example.webscraping.com/ajax/search.json?page=0&page_size=10&search_term=a')
url.json()пример
Приведенный выше скрипт позволяет нам получить доступ к ответу JSON с помощью метода Python json. Точно так же мы можем загрузить необработанный строковый ответ и, используя метод python json.loads, мы также можем загрузить его. Мы делаем это с помощью следующего скрипта Python. Он будет в основном очищать все страны, выполняя поиск по букве алфавита «а», а затем повторяя полученные страницы ответов JSON.
import requests
import string
PAGE_SIZE = 15
url = 'http://example.webscraping.com/ajax/' + 'search.json?page={}&page_size={}&search_term=a'
countries = set()
for letter in string.ascii_lowercase:
print('Searching with %s' % letter)
page = 0
while True:
response = requests.get(url.format(page, PAGE_SIZE, letter))
data = response.json()
print('adding %d records from the page %d' %(len(data.get('records')),page))
for record in data.get('records'):countries.add(record['country'])
page += 1
if page >= data['num_pages']:
break
with open('countries.txt', 'w') as countries_file:
countries_file.write('n'.join(sorted(countries)))После запуска приведенного выше сценария мы получим следующий вывод, и записи будут сохранены в файле с именем country.txt.
Вывод
Searching with a
adding 15 records from the page 0
adding 15 records from the page 1
...Рендеринг JavaScript
В предыдущем разделе мы провели обратный инжиниринг на веб-странице, чтобы узнать, как работает API и как мы можем использовать его для получения результатов в одном запросе. Однако при выполнении обратного проектирования мы можем столкнуться со следующими трудностями:
Иногда веб-сайты могут быть очень сложными. Например, если веб-сайт создан с помощью расширенного инструмента браузера, такого как Google Web Toolkit (GWT), то полученный код JS будет сгенерирован машиной, его будет сложно понять и перепроектировать.
Некоторые структуры более высокого уровня, такие как React.js может затруднить обратное проектирование, абстрагируя уже сложную логику JavaScript.
Решением вышеупомянутых трудностей является использование механизма рендеринга браузера, который анализирует HTML, применяет форматирование CSS и выполняет JavaScript для отображения веб-страницы.
пример
В этом примере для рендеринга Java Script мы будем использовать знакомый Python-модуль Selenium. Следующий код Python будет отображать веб-страницу с помощью Selenium -
Во-первых, нам нужно импортировать webdriver из селена следующим образом:
from selenium import webdriverТеперь укажите путь к веб-драйверу, который мы загрузили в соответствии с нашим требованием -
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
driver = webdriver.Chrome(executable_path = path)Теперь укажите URL-адрес, который мы хотим открыть в этом веб-браузере, который теперь контролируется нашим скриптом Python.
driver.get('http://example.webscraping.com/search')Теперь мы можем использовать идентификатор панели инструментов поиска для установки элемента для выбора.
driver.find_element_by_id('search_term').send_keys('.')Затем мы можем использовать java-скрипт, чтобы установить содержимое поля выбора следующим образом:
js = "document.getElementById('page_size').options[1].text = '100';"
driver.execute_script(js)Следующая строка кода показывает, что поиск готов для нажатия на веб-странице -
driver.find_element_by_id('search').click()Следующая строка кода показывает, что он будет ждать 45 секунд для завершения запроса AJAX.
driver.implicitly_wait(45)Теперь для выбора ссылок на страны мы можем использовать селектор CSS следующим образом:
links = driver.find_elements_by_css_selector('#results a')Теперь текст каждой ссылки можно извлечь для создания списка стран -
countries = [link.text for link in links]
print(countries)
driver.close()В предыдущей главе мы видели парсинг динамических веб-сайтов. В этой главе давайте разберемся со сканированием веб-сайтов, которые работают с вводом данных пользователем, то есть веб-сайтов на основе форм.
Введение
В наши дни WWW (World Wide Web) движется в сторону социальных сетей, а также контента, создаваемого пользователями. Возникает вопрос, как мы можем получить доступ к такой информации, которая выходит за рамки экрана входа в систему? Для этого нам нужно разобраться с формами и логинами.
В предыдущих главах мы работали с методом HTTP GET для запроса информации, но в этой главе мы будем работать с методом HTTP POST, который отправляет информацию на веб-сервер для хранения и анализа.
Взаимодействие с формами входа
Работая в Интернете, вы должны много раз взаимодействовать с формами входа. Они могут быть очень простыми, например, включать в себя только несколько полей HTML, кнопку отправки и страницу действия, или они могут быть сложными и иметь некоторые дополнительные поля, такие как электронная почта, оставить сообщение вместе с капчей по соображениям безопасности.
В этом разделе мы рассмотрим простую форму отправки с помощью библиотеки запросов Python.
Во-первых, нам нужно импортировать библиотеку запросов следующим образом:
import requestsТеперь нам нужно предоставить информацию для полей формы входа.
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}В следующей строке кода нам нужно указать URL-адрес, по которому будет происходить действие формы.
r = requests.post(“enter the URL”, data = parameters)
print(r.text)После запуска скрипта он вернет содержимое страницы, на которой произошло действие.
Предположим, если вы хотите отправить любое изображение с формой, это очень просто с помощью requests.post (). Вы можете понять это с помощью следующего скрипта Python -
import requests
file = {‘Uploadfile’: open(’C:\Usres\desktop\123.png’,‘rb’)}
r = requests.post(“enter the URL”, files = file)
print(r.text)Загрузка файлов cookie с веб-сервера
Файл cookie, иногда называемый веб-файлом cookie или Интернет-файлом cookie, представляет собой небольшой фрагмент данных, отправляемый с веб-сайта, и наш компьютер сохраняет его в файле, расположенном внутри нашего веб-браузера.
В контексте работы с формами входа файлы cookie могут быть двух типов. Первый, который мы рассмотрели в предыдущем разделе, позволяет нам отправлять информацию на веб-сайт, а второй позволяет нам оставаться в состоянии постоянного входа в систему на протяжении всего нашего посещения веб-сайта. Для форм второго типа веб-сайты используют файлы cookie, чтобы отслеживать, кто вошел в систему, а кто нет.
Что делают куки?
В наши дни большинство веб-сайтов используют файлы cookie для отслеживания. Мы можем понять работу файлов cookie с помощью следующих шагов -
Step 1- Во-первых, сайт аутентифицирует наши учетные данные и сохраняет их в файле cookie нашего браузера. Этот файл cookie обычно содержит генерируемый сервером токен, время ожидания и информацию для отслеживания.
Step 2- Затем веб-сайт будет использовать файл cookie в качестве доказательства аутентификации. Эта аутентификация всегда отображается всякий раз, когда мы посещаем веб-сайт.
Файлы cookie очень проблематичны для веб-парсеров, потому что, если веб-парсеры не отслеживают файлы cookie, отправленная форма отправляется обратно, и на следующей странице кажется, что они никогда не входили в систему. Очень легко отслеживать файлы cookie с помощью Python requests библиотека, как показано ниже -
import requests
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}
r = requests.post(“enter the URL”, data = parameters)В приведенной выше строке кода URL-адрес будет страницей, которая будет действовать как процессор для формы входа.
print(‘The cookie is:’)
print(r.cookies.get_dict())
print(r.text)После запуска вышеуказанного скрипта мы получим файлы cookie из результата последнего запроса.
Есть еще одна проблема с файлами cookie: иногда веб-сайты часто изменяют файлы cookie без предупреждения. С такой ситуацией можно справитьсяrequests.Session() следующим образом -
import requests
session = requests.Session()
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}
r = session.post(“enter the URL”, data = parameters)В приведенной выше строке кода URL-адрес будет страницей, которая будет действовать как процессор для формы входа.
print(‘The cookie is:’)
print(r.cookies.get_dict())
print(r.text)Обратите внимание, что вы можете легко понять разницу между сценарием с сеансом и без него.
Автоматизация форм с помощью Python
В этом разделе мы собираемся иметь дело с модулем Python под названием Mechanize, который сократит нашу работу и автоматизирует процесс заполнения форм.
Модуль механизации
Модуль Mechanize предоставляет нам высокоуровневый интерфейс для взаимодействия с формами. Перед тем, как начать использовать его, нам нужно установить его с помощью следующей команды -
pip install mechanizeОбратите внимание, что это будет работать только в Python 2.x.
пример
В этом примере мы собираемся автоматизировать процесс заполнения формы входа, имеющей два поля, а именно адрес электронной почты и пароль -
import mechanize
brwsr = mechanize.Browser()
brwsr.open(Enter the URL of login)
brwsr.select_form(nr = 0)
brwsr['email'] = ‘Enter email’
brwsr['password'] = ‘Enter password’
response = brwsr.submit()
brwsr.submit()Приведенный выше код очень легко понять. Сначала мы импортировали модуль механизации. Затем был создан объект браузера Mechanize. Затем мы перешли к URL-адресу входа и выбрали форму. После этого имена и значения передаются непосредственно объекту браузера.
В этой главе давайте разберемся, как выполнять парсинг веб-страниц и обрабатывать CAPTCHA, которая используется для тестирования пользователя на человека или робота.
Что такое CAPTCHA?
Полная форма CAPTCHA: Completely Automated Public Turing test to tell Computers and Humans Apart, что явно предполагает, что это тест, чтобы определить, является ли пользователь человеком или нет.
CAPTCHA - это искаженное изображение, которое обычно нелегко обнаружить компьютерной программой, но человеку каким-то образом удается его понять. Большинство веб-сайтов используют CAPTCHA для предотвращения взаимодействия ботов.
Загрузка CAPTCHA с помощью Python
Предположим, мы хотим зарегистрироваться на веб-сайте и есть форма с CAPTCHA, тогда перед загрузкой изображения CAPTCHA нам нужно знать о конкретной информации, требуемой формой. С помощью следующего скрипта Python мы сможем понять требования к форме регистрационной формы на веб-сайте с именемhttp://example.webscrapping.com.
import lxml.html
import urllib.request as urllib2
import pprint
import http.cookiejar as cookielib
def form_parsing(html):
tree = lxml.html.fromstring(html)
data = {}
for e in tree.cssselect('form input'):
if e.get('name'):
data[e.get('name')] = e.get('value')
return data
REGISTER_URL = '<a target="_blank" rel="nofollow"
href="http://example.webscraping.com/user/register">http://example.webscraping.com/user/register'</a>
ckj = cookielib.CookieJar()
browser = urllib2.build_opener(urllib2.HTTPCookieProcessor(ckj))
html = browser.open(
'<a target="_blank" rel="nofollow"
href="http://example.webscraping.com/places/default/user/register?_next">
http://example.webscraping.com/places/default/user/register?_next</a> = /places/default/index'
).read()
form = form_parsing(html)
pprint.pprint(form)В приведенном выше скрипте Python сначала мы определили функцию, которая будет анализировать форму с помощью модуля lxml python, а затем она распечатает требования к форме следующим образом:
{
'_formkey': '5e306d73-5774-4146-a94e-3541f22c95ab',
'_formname': 'register',
'_next': '/places/default/index',
'email': '',
'first_name': '',
'last_name': '',
'password': '',
'password_two': '',
'recaptcha_response_field': None
}Вы можете проверить из приведенного выше вывода, что вся информация, кроме recpatcha_response_fieldпонятны и понятны. Теперь возникает вопрос, как мы можем обработать эту сложную информацию и загрузить CAPTCHA. Это можно сделать с помощью библиотеки Python Pillow следующим образом:
Подушка Python Package
Pillow - это ответвление библиотеки изображений Python, имеющее полезные функции для управления изображениями. Его можно установить с помощью следующей команды -
pip install pillowВ следующем примере мы будем использовать его для загрузки CAPTCHA -
from io import BytesIO
import lxml.html
from PIL import Image
def load_captcha(html):
tree = lxml.html.fromstring(html)
img_data = tree.cssselect('div#recaptcha img')[0].get('src')
img_data = img_data.partition(',')[-1]
binary_img_data = img_data.decode('base64')
file_like = BytesIO(binary_img_data)
img = Image.open(file_like)
return imgВышеупомянутый скрипт python использует pillowpython и определение функции для загрузки изображения CAPTCHA. Он должен использоваться с функцией с именемform_parser()который определен в предыдущем скрипте для получения информации о регистрационной форме. Этот скрипт сохранит изображение CAPTCHA в удобном формате, который в дальнейшем может быть извлечен как строка.
OCR: извлечение текста из изображения с помощью Python
После загрузки CAPTCHA в удобном формате, мы можем извлечь ее с помощью оптического распознавания символов (OCR), процесса извлечения текста из изображений. Для этого мы собираемся использовать движок Tesseract OCR с открытым исходным кодом. Его можно установить с помощью следующей команды -
pip install pytesseractпример
Здесь мы расширим вышеуказанный скрипт Python, который загрузил CAPTCHA с помощью пакета Python Pillow, следующим образом:
import pytesseract
img = get_captcha(html)
img.save('captcha_original.png')
gray = img.convert('L')
gray.save('captcha_gray.png')
bw = gray.point(lambda x: 0 if x < 1 else 255, '1')
bw.save('captcha_thresholded.png')Вышеупомянутый скрипт Python будет читать CAPTCHA в черно-белом режиме, который будет понятен и легко передан в tesseract следующим образом:
pytesseract.image_to_string(bw)После запуска приведенного выше сценария мы получим CAPTCHA регистрационной формы в качестве вывода.
В этой главе объясняется, как выполнять тестирование с использованием веб-парсеров в Python.
Введение
В крупных веб-проектах автоматическое тестирование серверной части веб-сайта выполняется регулярно, но тестирование внешнего интерфейса часто пропускается. Основная причина этого в том, что программирование веб-сайтов похоже на сеть различных языков разметки и программирования. Мы можем написать модульный тест для одного языка, но это становится сложной задачей, если взаимодействие осуществляется на другом языке. Вот почему у нас должен быть набор тестов, чтобы убедиться, что наш код работает в соответствии с нашими ожиданиями.
Тестирование с использованием Python
Когда мы говорим о тестировании, это означает модульное тестирование. Прежде чем углубиться в тестирование с помощью Python, мы должны знать о модульном тестировании. Ниже приведены некоторые характеристики модульного тестирования.
По крайней мере, один аспект функциональности компонента будет тестироваться в каждом модульном тесте.
Каждый модульный тест независим и может выполняться независимо.
Модульное тестирование не влияет на успешность или неудачу любого другого теста.
Модульные тесты могут выполняться в любом порядке и должны содержать хотя бы одно утверждение.
Unittest - модуль Python
Модуль Python с именем Unittest для модульного тестирования поставляется со всей стандартной установкой Python. Нам просто нужно импортировать его, а остальное - это задача класса unittest.TestCase, который будет выполнять следующие действия:
Функции SetUp и tearDown предоставляются классом unittest.TestCase. Эти функции могут выполняться до и после каждого модульного теста.
Он также предоставляет операторы assert, позволяющие пройти или не пройти тесты.
Он запускает все функции, которые начинаются с test_, как модульный тест.
пример
В этом примере мы собираемся объединить парсинг веб-страниц с unittest. Мы протестируем страницу Википедии на предмет поиска строки «Python». По сути, он будет выполнять два теста: первый - будет ли титульная страница такой же, как строка поиска, то есть «Python» или нет, а второй тест проверяет, есть ли на странице контентный div.
Сначала мы импортируем необходимые модули Python. Мы используем BeautifulSoup для парсинга веб-страниц и, конечно же, unittest для тестирования.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import unittestТеперь нам нужно определить класс, который будет расширять unittest.TestCase. Глобальный объект bs будет использоваться всеми тестами. Это выполнит функция setUpClass, указанная в unittest. Здесь мы определим две функции: одну для тестирования титульной страницы, а другую для тестирования содержимого страницы.
class Test(unittest.TestCase):
bs = None
def setUpClass():
url = '<a target="_blank" rel="nofollow" href="https://en.wikipedia.org/wiki/Python">https://en.wikipedia.org/wiki/Python'</a>
Test.bs = BeautifulSoup(urlopen(url), 'html.parser')
def test_titleText(self):
pageTitle = Test.bs.find('h1').get_text()
self.assertEqual('Python', pageTitle);
def test_contentExists(self):
content = Test.bs.find('div',{'id':'mw-content-text'})
self.assertIsNotNone(content)
if __name__ == '__main__':
unittest.main()После запуска вышеуказанного скрипта мы получим следующий вывод -
----------------------------------------------------------------------
Ran 2 tests in 2.773s
OK
An exception has occurred, use %tb to see the full traceback.
SystemExit: False
D:\ProgramData\lib\site-packages\IPython\core\interactiveshell.py:2870:
UserWarning: To exit: use 'exit', 'quit', or Ctrl-D.
warn("To exit: use 'exit', 'quit', or Ctrl-D.", stacklevel=1)Тестирование с помощью Selenium
Давайте обсудим, как использовать Python Selenium для тестирования. Это также называется Selenium-тестированием. Оба Pythonunittest и Seleniumне имеют много общего. Мы знаем, что Selenium отправляет стандартные команды Python в разные браузеры, несмотря на различия в дизайне их браузеров. Напомним, что мы уже установили и работали с Selenium в предыдущих главах. Здесь мы создадим тестовые скрипты в Selenium и будем использовать их для автоматизации.
пример
С помощью следующего скрипта Python мы создаем тестовый скрипт для автоматизации страницы входа в Facebook. Вы можете изменить пример для автоматизации других форм и учетных записей по вашему выбору, однако концепция будет такой же.
Сначала для подключения к веб-браузеру мы импортируем webdriver из модуля selenium -
from selenium import webdriverТеперь нам нужно импортировать ключи из модуля селена.
from selenium.webdriver.common.keys import KeysЗатем нам нужно указать имя пользователя и пароль для входа в нашу учетную запись facebook.
user = "[email protected]"
pwd = ""Затем укажите путь к веб-драйверу для Chrome.
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
driver = webdriver.Chrome(executable_path=path)
driver.get("http://www.facebook.com")Теперь мы проверим условия, используя ключевое слово assert.
assert "Facebook" in driver.titleС помощью следующей строки кода мы отправляем значения в раздел электронной почты. Здесь мы ищем его по идентификатору, но мы можем сделать это, выполнив поиск по имени какdriver.find_element_by_name("email").
element = driver.find_element_by_id("email")
element.send_keys(user)С помощью следующей строки кода мы отправляем значения в раздел пароля. Здесь мы ищем его по идентификатору, но мы можем сделать это, выполнив поиск по имени какdriver.find_element_by_name("pass").
element = driver.find_element_by_id("pass")
element.send_keys(pwd)Следующая строка кода используется для нажатия клавиши ввода / входа после ввода значений в поле адреса электронной почты и пароля.
element.send_keys(Keys.RETURN)Теперь закроем браузер.
driver.close()После запуска вышеуказанного скрипта откроется веб-браузер Chrome, и вы увидите, что адрес электронной почты и пароль вставляются и нажимаются на кнопку входа в систему.
Сравнение: unittest или Selenium
Сравнение unittest и selenium затруднено, потому что, если вы хотите работать с большими тестовыми наборами, требуется синтаксическая жесткость unites. С другой стороны, если вы собираетесь протестировать гибкость веб-сайта, то первым выбором будет Selenium test. Но что, если мы сможем объединить их оба. Мы можем импортировать селен в Python unittest и получить лучшее от обоих. Selenium можно использовать для получения информации о веб-сайте, а unittest может оценить, соответствует ли эта информация критериям прохождения теста.
Например, мы переписываем приведенный выше сценарий Python для автоматизации входа в систему Facebook, комбинируя их оба следующим образом:
import unittest
from selenium import webdriver
class InputFormsCheck(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome(r'C:\Users\gaurav\Desktop\chromedriver')
def test_singleInputField(self):
user = "[email protected]"
pwd = ""
pageUrl = "http://www.facebook.com"
driver=self.driver
driver.maximize_window()
driver.get(pageUrl)
assert "Facebook" in driver.title
elem = driver.find_element_by_id("email")
elem.send_keys(user)
elem = driver.find_element_by_id("pass")
elem.send_keys(pwd)
elem.send_keys(Keys.RETURN)
def tearDown(self):
self.driver.close()
if __name__ == "__main__":
unittest.main()