Scikit Learn - API-интерфейс оценщика
В этой главе мы узнаем о Estimator API(интерфейс прикладного программирования). Давайте начнем с понимания, что такое API-интерфейс оценщика.
Что такое API-интерфейс оценщика
Это один из основных API, реализованных Scikit-learn. Он обеспечивает согласованный интерфейс для широкого спектра приложений машинного обучения, поэтому все алгоритмы машинного обучения в Scikit-Learn реализованы через API-интерфейс Estimator. Объект, который учится на данных (соответствует данным), является оценщиком. Его можно использовать с любым из алгоритмов, таких как классификация, регрессия, кластеризация, или даже с преобразователем, который извлекает полезные функции из необработанных данных.
Для подгонки данных все объекты оценщика предоставляют метод подбора, который принимает набор данных, показанный ниже:
estimator.fit(data)Затем все параметры оценщика могут быть установлены следующим образом, когда он создается соответствующим атрибутом.
estimator = Estimator (param1=1, param2=2)
estimator.param1Результатом выше будет 1.
После того, как данные подобраны с помощью оценщика, параметры оцениваются на основе имеющихся данных. Теперь все предполагаемые параметры будут атрибутами объекта оценки, оканчивающимися нижним подчеркиванием следующим образом:
estimator.estimated_param_Использование API-интерфейса оценщика
Основные виды использования оценщиков следующие:
Оценка и расшифровка модели
Объект оценщика используется для оценки и расшифровки модели. Кроме того, модель оценивается как детерминированная функция следующего:
Параметры, предусмотренные при строительстве объекта.
Глобальное случайное состояние (numpy.random), если для параметра random_state оценщика установлено значение none.
Любые данные, переданные последнему вызову fit, fit_transform, or fit_predict.
Любые данные, передаваемые в последовательности обращений к partial_fit.
Отображение непрямоугольного представления данных в прямоугольные данные
Он отображает непрямоугольное представление данных в прямоугольные данные. Проще говоря, он принимает входные данные, где каждый образец не представлен как объект, подобный массиву, фиксированной длины, и создает подобный массиву объект функций для каждого образца.
Различие между керном и удаленными образцами
Он моделирует различие между керном и удаленными образцами, используя следующие методы:
fit
fit_predict, если трансдуктивный
предсказать, если индуктивный
Руководящие принципы
При разработке Scikit-Learn API необходимо учитывать следующие руководящие принципы:
Последовательность
Этот принцип гласит, что все объекты должны иметь общий интерфейс, созданный из ограниченного набора методов. Документация также должна быть согласованной.
Ограниченная иерархия объектов
Этот руководящий принцип гласит:
Алгоритмы должны быть представлены классами Python
Наборы данных должны быть представлены в стандартном формате, таком как массивы NumPy, Pandas DataFrames, разреженная матрица SciPy.
Имена параметров должны использовать стандартные строки Python.
Сочинение
Как мы знаем, алгоритмы машинного обучения можно выразить как последовательность многих фундаментальных алгоритмов. Scikit-learn использует эти фундаментальные алгоритмы всякий раз, когда это необходимо.
Разумные настройки по умолчанию
В соответствии с этим принципом библиотека Scikit-learn определяет соответствующее значение по умолчанию, когда модели машинного обучения требуют параметров, задаваемых пользователем.
Осмотр
В соответствии с этим руководящим принципом каждое указанное значение параметра отображается как публичные атрибуты.
Шаги по использованию API-интерфейса оценщика
Ниже приведены шаги по использованию API оценки Scikit-Learn.
Шаг 1. Выберите класс модели
На этом первом этапе нам нужно выбрать класс модели. Это можно сделать, импортировав соответствующий класс оценщика из Scikit-learn.
Шаг 2: Выберите гиперпараметры модели
На этом этапе нам нужно выбрать гиперпараметры модели классов. Это можно сделать, создав экземпляр класса с желаемыми значениями.
Шаг 3. Упорядочение данных
Затем нам нужно организовать данные в матрицу функций (X) и целевой вектор (y).
Шаг 4: установка модели
Теперь нам нужно подогнать модель под ваши данные. Это можно сделать, вызвав метод fit () экземпляра модели.
Шаг 5: Применение модели
После подбора модели мы можем применить ее к новым данным. Для обучения с учителем используйтеpredict()метод прогнозирования меток для неизвестных данных. В то время как для обучения без учителя используйтеpredict() или же transform() для вывода свойств данных.
Пример контролируемого обучения
Здесь, в качестве примера этого процесса, мы используем общий случай подгонки линии к данным (x, y), т.е. simple linear regression.
Во-первых, нам нужно загрузить набор данных, мы используем набор данных iris -
пример
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shapeВывод
(150, 4)пример
y_iris = iris['species']
y_iris.shapeВывод
(150,)пример
Теперь для этого примера регрессии мы собираемся использовать следующие образцы данных -
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);Вывод
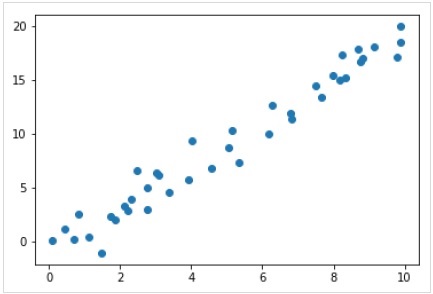
Итак, у нас есть приведенные выше данные для нашего примера линейной регрессии.
Теперь, имея эти данные, мы можем применить вышеупомянутые шаги.
Выберите класс модели
Здесь, чтобы вычислить простую модель линейной регрессии, нам нужно импортировать класс линейной регрессии следующим образом:
from sklearn.linear_model import LinearRegressionВыберите гиперпараметры модели
После того, как мы выбрали класс модели, нам нужно сделать некоторые важные выборы, которые часто представлены как гиперпараметры, или параметры, которые должны быть установлены до того, как модель будет соответствовать данным. Здесь, для этого примера линейной регрессии, мы хотели бы подогнать точку пересечения с помощьюfit_intercept гиперпараметр следующим образом -
Example
model = LinearRegression(fit_intercept = True)
modelOutput
LinearRegression(copy_X = True, fit_intercept = True, n_jobs = None, normalize = False)Организация данных
Теперь, когда мы знаем, что наша целевая переменная y в правильной форме, т.е. длина n_samplesмассив 1-D. Но нам нужно изменить форму матрицы функций.X сделать матрицу размера [n_samples, n_features]. Это можно сделать следующим образом -
Example
X = x[:, np.newaxis]
X.shapeOutput
(40, 1)Примерка модели
После того, как мы упорядочим данные, пора подобрать модель, то есть применить нашу модель к данным. Это можно сделать с помощьюfit() метод следующим образом -
Example
model.fit(X, y)Output
LinearRegression(copy_X = True, fit_intercept = True, n_jobs = None,normalize = False)В Scikit-learn fit() В конце процесса есть подчеркивания.
В этом примере параметр ниже показывает наклон простой линейной аппроксимации данных -
Example
model.coef_Output
array([1.99839352])Параметр ниже представляет собой точку пересечения простого линейного соответствия данным -
Example
model.intercept_Output
-0.9895459457775022Применение модели к новым данным
После обучения модели мы можем применить ее к новым данным. Поскольку основной задачей машинного обучения с учителем является оценка модели на основе новых данных, которые не входят в обучающий набор. Это можно сделать с помощьюpredict() метод следующим образом -
Example
xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
yfit = model.predict(Xfit)
plt.scatter(x, y)
plt.plot(xfit, yfit);Output
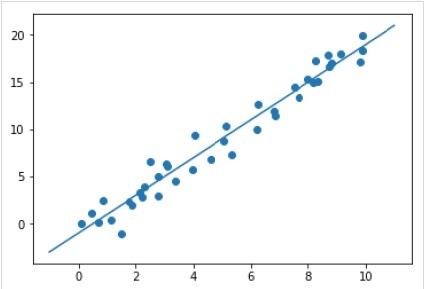
Полный рабочий / исполняемый пример
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model
X = x[:, np.newaxis]
X.shape
model.fit(X, y)
model.coef_
model.intercept_
xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
yfit = model.predict(Xfit)
plt.scatter(x, y)
plt.plot(xfit, yfit);Пример неконтролируемого обучения
Здесь, в качестве примера этого процесса, мы берем общий случай уменьшения размерности набора данных Iris, чтобы нам было легче его визуализировать. В этом примере мы собираемся использовать анализ главных компонентов (PCA), метод быстрого линейного уменьшения размерности.
Как и в приведенном выше примере, мы можем загрузить и построить случайные данные из набора данных iris. После этого мы можем выполнить следующие шаги:
Выберите класс модели
from sklearn.decomposition import PCAВыберите гиперпараметры модели
Example
model = PCA(n_components=2)
modelOutput
PCA(copy = True, iterated_power = 'auto', n_components = 2, random_state = None,
svd_solver = 'auto', tol = 0.0, whiten = False)Примерка модели
Example
model.fit(X_iris)Output
PCA(copy = True, iterated_power = 'auto', n_components = 2, random_state = None,
svd_solver = 'auto', tol = 0.0, whiten = False)Преобразуйте данные в двумерные
Example
X_2D = model.transform(X_iris)Теперь мы можем построить результат следующим образом:
Output
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot("PCA1", "PCA2", hue = 'species', data = iris, fit_reg = False);Output
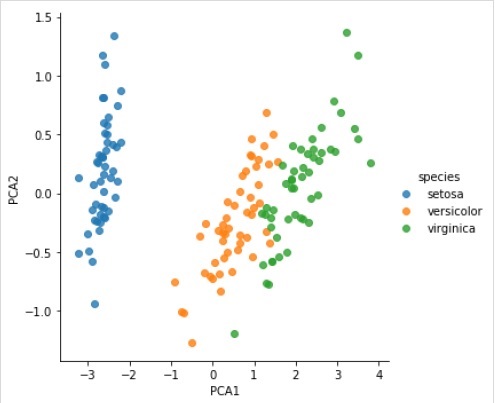
Полный рабочий / исполняемый пример
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);
from sklearn.decomposition import PCA
model = PCA(n_components=2)
model
model.fit(X_iris)
X_2D = model.transform(X_iris)
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot("PCA1", "PCA2", hue='species', data=iris, fit_reg=False);