SQLAlchemy - Краткое руководство
SQLAlchemy - популярный набор инструментов SQL и Object Relational Mapper. Это написано вPythonи предоставляет разработчику приложений полную мощность и гибкость SQL. Этоopen source и cross-platform software выпущен под лицензией MIT.
SQLAlchemy известна своим объектно-реляционным преобразователем (ORM), с помощью которого классы могут быть сопоставлены с базой данных, что позволяет с самого начала разрабатывать объектную модель и схему базы данных совершенно независимым образом.
Поскольку размер и производительность баз данных SQL начинают иметь значение, они становятся менее похожими на коллекции объектов. С другой стороны, когда абстракция в коллекциях объектов начинает иметь значение, они ведут себя не так, как таблицы и строки. SQLAlchemy стремится учесть оба этих принципа.
По этой причине он принял data mapper pattern (like Hibernate) rather than the active record pattern used by a number of other ORMs. Базы данных и SQL будут рассматриваться с другой точки зрения с помощью SQLAlchemy.
Майкл Байер - оригинальный автор SQLAlchemy. Его первоначальная версия была выпущена в феврале 2006 года. Последняя версия под номером 1.2.7 была выпущена совсем недавно, в апреле 2018 года.
Что такое ORM?
ORM (Object Relational Mapping) - это метод программирования для преобразования данных между несовместимыми системами типов в объектно-ориентированных языках программирования. Обычно система типов, используемая в объектно-ориентированном (OO) языке, таком как Python, содержит нескалярные типы. Они не могут быть выражены как примитивные типы, такие как целые числа и строки. Следовательно, объектно-ориентированный программист должен преобразовывать объекты в скалярные данные для взаимодействия с серверной базой данных. Однако типы данных в большинстве продуктов баз данных, таких как Oracle, MySQL и т. Д., Являются первичными.
В системе ORM каждый класс отображается в таблицу в базовой базе данных. Вместо того, чтобы самостоятельно писать утомительный код взаимодействия с базой данных, ORM позаботится об этих проблемах за вас, а вы можете сосредоточиться на программировании логики системы.
SQLAlchemy - Настройка среды
Давайте обсудим настройку среды, необходимую для использования SQLAlchemy.
Для установки SQLAlchemy необходима любая версия Python выше 2.7. Самый простой способ установить - использовать диспетчер пакетов Python,pip. Эта утилита входит в стандартный дистрибутив Python.
pip install sqlalchemyИспользуя указанную выше команду, мы можем загрузить latest released versionSQLAlchemy с python.org и установите его в свою систему.
В случае распространения Python в виде анаконды, SQLAlchemy может быть установлен из conda terminal используя следующую команду -
conda install -c anaconda sqlalchemyТакже можно установить SQLAlchemy из исходного кода ниже -
python setup.py installSQLAlchemy разработан для работы с реализацией DBAPI, созданной для конкретной базы данных. Он использует систему диалектов для связи с различными типами реализаций DBAPI и базами данных. Все диалекты требуют, чтобы был установлен соответствующий драйвер DBAPI.
Следующие диалекты включены -
- Firebird
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- SQLite
- Sybase
Чтобы проверить, правильно ли установлен SQLAlchemy, и узнать его версию, введите следующую команду в командной строке Python:
>>> import sqlalchemy
>>>sqlalchemy.__version__
'1.2.7'Ядро SQLAlchemy включает SQL rendering engine, DBAPI integration, transaction integration, и schema description services. Ядро SQLAlchemy использует язык выражений SQL, который предоставляетschema-centric usage парадигма, тогда как SQLAlchemy ORM - это domain-centric mode of usage.
Язык выражений SQL представляет собой систему представления структур и выражений реляционной базы данных с использованием конструкций Python. Он представляет собой систему представления примитивных конструкций реляционной базы данных напрямую, без мнения, что в отличие от ORM, которое представляет высокоуровневый и абстрактный шаблон использования, который сам по себе является примером прикладного использования языка выражений.
Язык выражений - один из основных компонентов SQLAlchemy. Это позволяет программисту указывать операторы SQL в коде Python и напрямую использовать его в более сложных запросах. Язык выражений не зависит от серверной части и всесторонне охватывает все аспекты необработанного SQL. Он ближе к чистому SQL, чем любой другой компонент SQLAlchemy.
Expression Language напрямую представляет примитивные конструкции реляционной базы данных. Поскольку ORM основан на языке Expression, типичное приложение базы данных Python может перекрывать их использование. Приложение может использовать только язык выражений, хотя оно должно определить свою собственную систему перевода концепций приложения в отдельные запросы к базе данных.
Выражения языка Expression будут переведены в соответствующие необработанные SQL-запросы механизмом SQLAlchemy. Теперь мы узнаем, как создать движок и с его помощью выполнять различные SQL-запросы.
В предыдущей главе мы обсудили язык выражений в SQLAlchemy. Теперь перейдем к шагам, связанным с подключением к базе данных.
Класс двигателя подключает Pool and Dialect together предоставить источник базы данных connectivity and behavior. Объект класса Engine создается с использованиемcreate_engine() функция.
Функция create_engine () принимает базу данных как один аргумент. База данных не требуется нигде определять. Стандартная форма вызова должна отправлять URL-адрес в качестве первого позиционного аргумента, обычно это строка, указывающая диалект базы данных и аргументы подключения. Используя приведенный ниже код, мы можем создать базу данных.
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///college.db', echo = True)Для MySQL databaseиспользуйте следующую команду -
engine = create_engine("mysql://user:pwd@localhost/college",echo = True)Чтобы особо упомянуть DB-API для подключения URL string принимает следующий вид -
dialect[+driver]://user:password@host/dbnameНапример, если вы используете PyMySQL driver with MySQLиспользуйте следующую команду -
mysql+pymysql://<username>:<password>@<host>/<dbname>В echo flag- это ярлык для настройки ведения журнала SQLAlchemy, который выполняется с помощью стандартного модуля ведения журнала Python. В следующих главах мы изучим все сгенерированные SQL-запросы. Чтобы скрыть подробный вывод, установите для атрибута echo значениеNone. Другие аргументы функции create_engine () могут зависеть от диалекта.
Функция create_engine () возвращает Engine object. Некоторые важные методы класса Engine:
| Sr.No. | Метод и описание |
|---|---|
| 1 | connect() Возвращает объект подключения |
| 2 | execute() Выполняет конструкцию оператора SQL |
| 3 | begin() Возвращает диспетчер контекста, доставляющий соединение с установленной транзакцией. После успешной операции транзакция фиксируется, в противном случае выполняется откат |
| 4 | dispose() Удаляет пул соединений, используемый Engine |
| 5 | driver() Имя драйвера диалекта, используемого движком |
| 6 | table_names() Возвращает список всех имен таблиц, доступных в базе данных |
| 7 | transaction() Выполняет заданную функцию в границах транзакции |
Давайте теперь обсудим, как использовать функцию создания таблицы.
Язык выражений SQL строит свои выражения для столбцов таблицы. SQLAlchemy Column объект представляетcolumn в таблице базы данных, которая, в свою очередь, представлена Tableobject. Метаданные содержат определения таблиц и связанных объектов, таких как индекс, представление, триггеры и т. Д.
Следовательно, объект класса MetaData из SQLAlchemy Metadata представляет собой набор объектов Table и связанных с ними конструкций схемы. Он содержит коллекцию объектов Table, а также дополнительную привязку к Engine или Connection.
from sqlalchemy import MetaData
meta = MetaData()Конструктор класса MetaData может иметь параметры привязки и схемы, которые по умолчанию None.
Затем мы определяем все наши таблицы в указанном выше каталоге метаданных, используя the Table construct, который напоминает обычный оператор SQL CREATE TABLE.
Объект класса Table представляет соответствующую таблицу в базе данных. Конструктор принимает следующие параметры -
| имя | Название таблицы |
|---|---|
| Метаданные | Объект MetaData, который будет содержать эту таблицу |
| Столбец (и) | Один или несколько объектов класса столбца |
Объект столбца представляет собой column в database table. Конструктор принимает имя, тип и другие параметры, такие как primary_key, autoincrement и другие ограничения.
SQLAlchemy сопоставляет данные Python с определенными в нем наилучшими общими типами данных столбцов. Некоторые из общих типов данных -
- BigInteger
- Boolean
- Date
- DateTime
- Float
- Integer
- Numeric
- SmallInteger
- String
- Text
- Time
Чтобы создать students table в базе данных колледжа используйте следующий фрагмент -
from sqlalchemy import Table, Column, Integer, String, MetaData
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)Функция create_all () использует объект движка для создания всех определенных объектов таблицы и сохраняет информацию в метаданных.
meta.create_all(engine)Ниже приведен полный код, который создаст базу данных SQLite College.db с таблицей студентов в ней.
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
meta.create_all(engine)Поскольку атрибут echo функции create_engine () имеет значение True, консоль отобразит фактический запрос SQL для создания таблицы следующим образом:
CREATE TABLE students (
id INTEGER NOT NULL,
name VARCHAR,
lastname VARCHAR,
PRIMARY KEY (id)
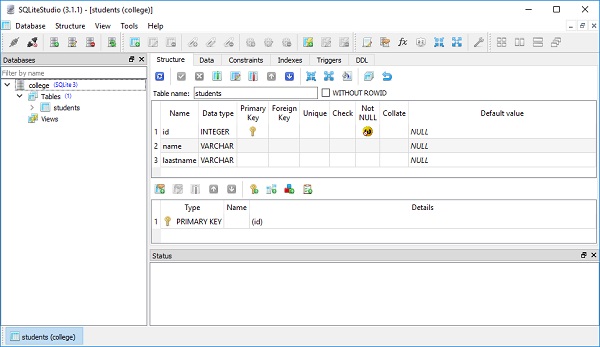
)College.db будет создан в текущем рабочем каталоге. Чтобы проверить, создана ли таблица студентов, вы можете открыть базу данных с помощью любого инструмента с графическим интерфейсом SQLite, такого какSQLiteStudio.
На изображении ниже показана таблица студентов, созданная в базе данных -
В этой главе мы кратко сосредоточимся на выражениях SQL и их функциях.
Выражения SQL создаются с использованием соответствующих методов относительно объекта целевой таблицы. Например, оператор INSERT создается путем выполнения метода insert () следующим образом:
ins = students.insert()Результатом вышеуказанного метода является объект вставки, который можно проверить с помощью str()функция. В приведенном ниже коде вставляются такие данные, как идентификатор студента, имя, фамилия.
'INSERT INTO students (id, name, lastname) VALUES (:id, :name, :lastname)'Можно вставить значение в определенное поле, values()метод для вставки объекта. Код для того же приведен ниже -
>>> ins = users.insert().values(name = 'Karan')
>>> str(ins)
'INSERT INTO users (name) VALUES (:name)'SQL, отображаемый на консоли Python, не показывает фактическое значение (в данном случае «Karan»). Вместо этого SQLALchemy генерирует параметр связывания, который отображается в скомпилированной форме оператора.
ins.compile().params
{'name': 'Karan'}Точно так же такие методы, как update(), delete() и select()создать выражения UPDATE, DELETE и SELECT соответственно. Мы узнаем о них в следующих главах.
В предыдущей главе мы изучили выражения SQL. В этой главе мы рассмотрим выполнение этих выражений.
Чтобы выполнить полученные выражения SQL, мы должны obtain a connection object representing an actively checked out DBAPI connection resource а потом feed the expression object как показано в коде ниже.
conn = engine.connect()Следующий объект insert () может использоваться для метода execute () -
ins = students.insert().values(name = 'Ravi', lastname = 'Kapoor')
result = conn.execute(ins)Консоль показывает результат выполнения выражения SQL, как показано ниже -
INSERT INTO students (name, lastname) VALUES (?, ?)
('Ravi', 'Kapoor')
COMMITНиже приведен весь фрагмент, который показывает выполнение запроса INSERT с использованием основного метода SQLAlchemy.
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
ins = students.insert()
ins = students.insert().values(name = 'Ravi', lastname = 'Kapoor')
conn = engine.connect()
result = conn.execute(ins)Результат можно проверить, открыв базу данных с помощью SQLite Studio, как показано на скриншоте ниже -

Переменная результата известна как ResultProxy. object. Он аналогичен объекту курсора DBAPI. Мы можем получить информацию о значениях первичных ключей, которые были сгенерированы из нашего оператора, используяResultProxy.inserted_primary_key как показано ниже -
result.inserted_primary_key
[1]Чтобы выполнить множество вставок с использованием метода DBAPI execute many (), мы можем отправить список словарей, каждый из которых содержит отдельный набор параметров для вставки.
conn.execute(students.insert(), [
{'name':'Rajiv', 'lastname' : 'Khanna'},
{'name':'Komal','lastname' : 'Bhandari'},
{'name':'Abdul','lastname' : 'Sattar'},
{'name':'Priya','lastname' : 'Rajhans'},
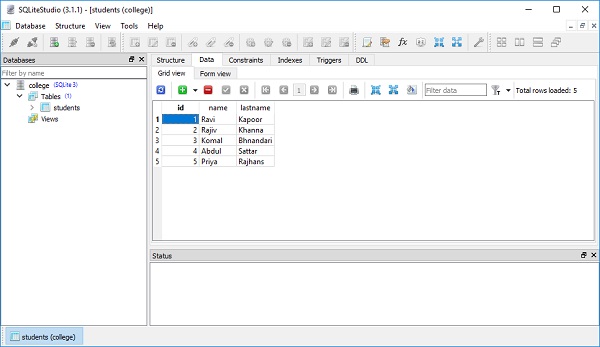
])Это отражено в представлении данных таблицы, как показано на следующем рисунке -
В этой главе мы обсудим концепцию выбора строк в объекте таблицы.
Метод select () объекта таблицы позволяет нам construct SELECT expression.
s = students.select()Объект выбора преобразуется в SELECT query by str(s) function как показано ниже -
'SELECT students.id, students.name, students.lastname FROM students'Мы можем использовать этот объект выбора в качестве параметра для метода execute () объекта подключения, как показано в приведенном ниже коде -
result = conn.execute(s)Когда приведенный выше оператор выполняется, оболочка Python повторяет следующее эквивалентное выражение SQL:
SELECT students.id, students.name, students.lastname
FROM studentsРезультирующая переменная является эквивалентом курсора в DBAPI. Теперь мы можем получать записи, используяfetchone() method.
row = result.fetchone()Все выбранные строки в таблице можно распечатать с помощью for loop как указано ниже -
for row in result:
print (row)Полный код для печати всех строк из таблицы студентов показан ниже -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
s = students.select()
conn = engine.connect()
result = conn.execute(s)
for row in result:
print (row)Вывод, показанный в оболочке Python, выглядит следующим образом:
(1, 'Ravi', 'Kapoor')
(2, 'Rajiv', 'Khanna')
(3, 'Komal', 'Bhandari')
(4, 'Abdul', 'Sattar')
(5, 'Priya', 'Rajhans')Предложение WHERE запроса SELECT можно применить с помощью Select.where(). Например, если мы хотим отображать строки с id> 2
s = students.select().where(students.c.id>2)
result = conn.execute(s)
for row in result:
print (row)Вот c attribute is an alias for column. Следующий вывод будет отображаться в оболочке -
(3, 'Komal', 'Bhandari')
(4, 'Abdul', 'Sattar')
(5, 'Priya', 'Rajhans')Здесь мы должны отметить, что объект select также можно получить с помощью функции select () в модуле sqlalchemy.sql. Функция select () требует в качестве аргумента объект таблицы.
from sqlalchemy.sql import select
s = select([users])
result = conn.execute(s)SQLAlchemy позволяет вам просто использовать строки в тех случаях, когда SQL уже известен и нет сильной необходимости в выражении поддержки динамических функций. Конструкция text () используется для составления текстового оператора, который передается в базу данных в основном без изменений.
Создает новый TextClause, представляющий текстовую строку SQL напрямую, как показано в приведенном ниже коде -
from sqlalchemy import text
t = text("SELECT * FROM students")
result = connection.execute(t)Преимущества text() предоставляет над простой строкой -
- бэкэнд-нейтральная поддержка параметров привязки
- параметры выполнения для каждого оператора
- поведение при вводе столбца результатов
Функция text () требует привязанных параметров в указанном формате двоеточия. Они согласованы независимо от серверной части базы данных. Чтобы отправить значения для параметров, мы передаем их в метод execute () в качестве дополнительных аргументов.
В следующем примере используются связанные параметры в текстовом SQL -
from sqlalchemy.sql import text
s = text("select students.name, students.lastname from students where students.name between :x and :y")
conn.execute(s, x = 'A', y = 'L').fetchall()Функция text () создает выражение SQL следующим образом:
select students.name, students.lastname from students where students.name between ? and ?Значения x = 'A' и y = 'L' передаются как параметры. Результат - список строк с именами между 'A' и 'L' -
[('Komal', 'Bhandari'), ('Abdul', 'Sattar')]Конструкция text () поддерживает предварительно установленные связанные значения с помощью метода TextClause.bindparams (). Параметры также могут быть явно введены следующим образом:
stmt = text("SELECT * FROM students WHERE students.name BETWEEN :x AND :y")
stmt = stmt.bindparams(
bindparam("x", type_= String),
bindparam("y", type_= String)
)
result = conn.execute(stmt, {"x": "A", "y": "L"})
The text() function also be produces fragments of SQL within a select() object that
accepts text() objects as an arguments. The “geometry” of the statement is provided by
select() construct , and the textual content by text() construct. We can build a statement
without the need to refer to any pre-established Table metadata.
from sqlalchemy.sql import select
s = select([text("students.name, students.lastname from students")]).where(text("students.name between :x and :y"))
conn.execute(s, x = 'A', y = 'L').fetchall()Вы также можете использовать and_() функция для объединения нескольких условий в предложении WHERE, созданном с помощью функции text ().
from sqlalchemy import and_
from sqlalchemy.sql import select
s = select([text("* from students")]) \
.where(
and_(
text("students.name between :x and :y"),
text("students.id>2")
)
)
conn.execute(s, x = 'A', y = 'L').fetchall()Приведенный выше код выбирает строки с именами между «A» и «L» с идентификатором больше 2. Результат кода приведен ниже -
[(3, 'Komal', 'Bhandari'), (4, 'Abdul', 'Sattar')]Псевдоним в SQL соответствует «переименованной» версии таблицы или оператора SELECT, который возникает каждый раз, когда вы произносите «SELECT * FROM table1 AS a». AS создает новое имя для таблицы. Псевдонимы позволяют ссылаться на любую таблицу или подзапрос по уникальному имени.
В случае таблицы это позволяет несколько раз называть одну и ту же таблицу в предложении FROM. Он предоставляет родительское имя для столбцов, представленных оператором, позволяя ссылаться на них относительно этого имени.
В SQLAlchemy любую конструкцию Table, select () или другой выбираемый объект можно превратить в псевдоним с помощью From Clause.alias(), который создает конструкцию Alias. Функция alias () в модуле sqlalchemy.sql представляет псевдоним, который обычно применяется к любой таблице или подвыборке в операторе SQL с использованием ключевого слова AS.
from sqlalchemy.sql import alias
st = students.alias("a")Этот псевдоним теперь можно использовать в конструкции select () для ссылки на таблицу студентов -
s = select([st]).where(st.c.id>2)Это переводится в выражение SQL следующим образом:
SELECT a.id, a.name, a.lastname FROM students AS a WHERE a.id > 2Теперь мы можем выполнить этот SQL-запрос с помощью метода execute () объекта подключения. Полный код выглядит следующим образом -
from sqlalchemy.sql import alias, select
st = students.alias("a")
s = select([st]).where(st.c.id > 2)
conn.execute(s).fetchall()Когда приведенная выше строка кода выполняется, она генерирует следующий вывод:
[(3, 'Komal', 'Bhandari'), (4, 'Abdul', 'Sattar'), (5, 'Priya', 'Rajhans')]В update() Метод для объекта целевой таблицы создает эквивалентное выражение UPDATE SQL.
table.update().where(conditions).values(SET expressions)В values()для результирующего объекта обновления используется для определения условий SET для UPDATE. Если оставить значение None, условия SET определяются на основе тех параметров, которые передаются в оператор во время выполнения и / или компиляции оператора.
Предложение where - это необязательное выражение, описывающее условие WHERE оператора UPDATE.
Следующий фрагмент кода изменяет значение столбца 'lastname' с 'Khanna' на 'Kapoor' в таблице студентов.
stmt = students.update().where(students.c.lastname == 'Khanna').values(lastname = 'Kapoor')Объект stmt - это объект обновления, который переводится в -
'UPDATE students SET lastname = :lastname WHERE students.lastname = :lastname_1'Связанный параметр lastname_1 будет заменен, когда execute()вызывается метод. Полный код обновления приведен ниже -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students',
meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn = engine.connect()
stmt=students.update().where(students.c.lastname=='Khanna').values(lastname='Kapoor')
conn.execute(stmt)
s = students.select()
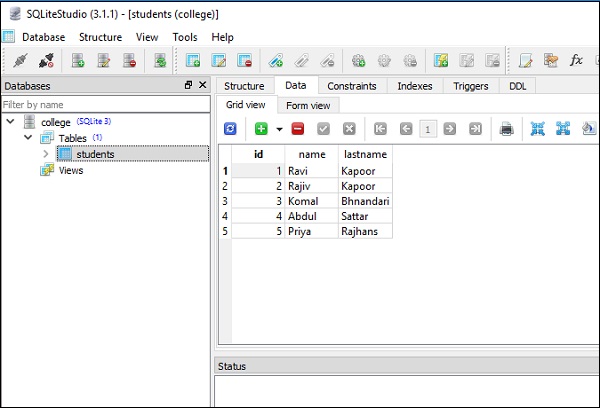
conn.execute(s).fetchall()Приведенный выше код отображает следующий вывод со второй строкой, показывающей эффект операции обновления, как на приведенном снимке экрана -
[
(1, 'Ravi', 'Kapoor'),
(2, 'Rajiv', 'Kapoor'),
(3, 'Komal', 'Bhandari'),
(4, 'Abdul', 'Sattar'),
(5, 'Priya', 'Rajhans')
]
Обратите внимание, что аналогичная функциональность также может быть достигнута с помощью update() функция в модуле sqlalchemy.sql.expression, как показано ниже -
from sqlalchemy.sql.expression import update
stmt = update(students).where(students.c.lastname == 'Khanna').values(lastname = 'Kapoor')В предыдущей главе мы поняли, что такое Updateвыражение делает. Следующее выражение, которое мы собираемся изучить, этоDelete.
Операция удаления может быть достигнута путем запуска метода delete () для объекта целевой таблицы, как указано в следующем заявлении:
stmt = students.delete()В случае таблицы студентов, приведенная выше строка кода создает выражение SQL следующим образом:
'DELETE FROM students'Однако это приведет к удалению всех строк в таблице студентов. Обычно запрос DELETE связан с логическим выражением, указанным в предложении WHERE. В следующем заявлении показано, где параметр -
stmt = students.delete().where(students.c.id > 2)Результирующее выражение SQL будет иметь связанный параметр, который будет заменен во время выполнения при выполнении оператора.
'DELETE FROM students WHERE students.id > :id_1'В следующем примере кода из таблицы студентов будут удалены эти строки с фамилией «Ханна» -
from sqlalchemy.sql.expression import update
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn = engine.connect()
stmt = students.delete().where(students.c.lastname == 'Khanna')
conn.execute(stmt)
s = students.select()
conn.execute(s).fetchall()Чтобы проверить результат, обновите представление данных таблицы студентов в SQLiteStudio.
Одна из важных функций СУБД - установление связи между таблицами. Операции SQL, такие как SELECT, UPDATE и DELETE, могут выполняться над связанными таблицами. В этом разделе описываются эти операции с использованием SQLAlchemy.
Для этого в нашей базе данных SQLite (college.db) созданы две таблицы. Таблица студентов имеет ту же структуру, что и в предыдущем разделе; тогда как в таблице адресов естьst_id столбец, который сопоставлен с id column in students table с использованием ограничения внешнего ключа.
Следующий код создаст две таблицы в College.db -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey
engine = create_engine('sqlite:///college.db', echo=True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer, ForeignKey('students.id')),
Column('postal_add', String),
Column('email_add', String))
meta.create_all(engine)Приведенный выше код будет преобразован в запросы CREATE TABLE для студентов и таблицу адресов, как показано ниже -
CREATE TABLE students (
id INTEGER NOT NULL,
name VARCHAR,
lastname VARCHAR,
PRIMARY KEY (id)
)
CREATE TABLE addresses (
id INTEGER NOT NULL,
st_id INTEGER,
postal_add VARCHAR,
email_add VARCHAR,
PRIMARY KEY (id),
FOREIGN KEY(st_id) REFERENCES students (id)
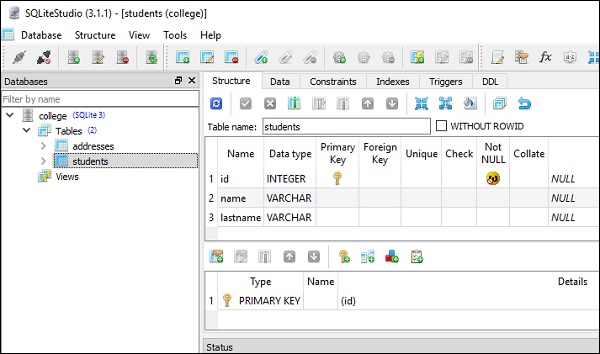
)Следующие снимки экрана очень четко представляют приведенный выше код -
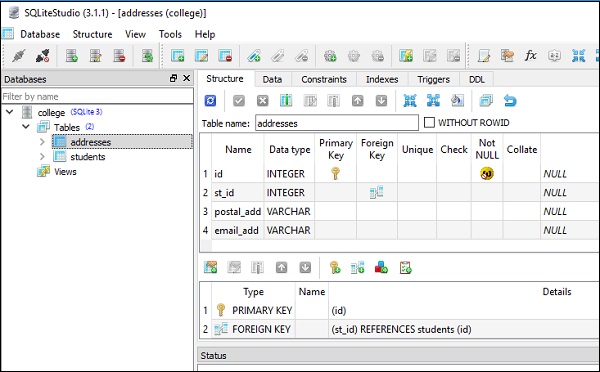
Эти таблицы заполняются данными путем выполнения insert() methodобъектов таблицы. Чтобы вставить 5 строк в таблицу студентов, вы можете использовать приведенный ниже код -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn.execute(students.insert(), [
{'name':'Ravi', 'lastname':'Kapoor'},
{'name':'Rajiv', 'lastname' : 'Khanna'},
{'name':'Komal','lastname' : 'Bhandari'},
{'name':'Abdul','lastname' : 'Sattar'},
{'name':'Priya','lastname' : 'Rajhans'},
])Rows добавляются в таблицу адресов с помощью следующего кода -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer),
Column('postal_add', String),
Column('email_add', String)
)
conn.execute(addresses.insert(), [
{'st_id':1, 'postal_add':'Shivajinagar Pune', 'email_add':'[email protected]'},
{'st_id':1, 'postal_add':'ChurchGate Mumbai', 'email_add':'[email protected]'},
{'st_id':3, 'postal_add':'Jubilee Hills Hyderabad', 'email_add':'[email protected]'},
{'st_id':5, 'postal_add':'MG Road Bangaluru', 'email_add':'[email protected]'},
{'st_id':2, 'postal_add':'Cannought Place new Delhi', 'email_add':'[email protected]'},
])Обратите внимание, что столбец st_id в таблице адресов относится к столбцу id в таблице студентов. Теперь мы можем использовать это отношение для извлечения данных из обеих таблиц. Мы хотим получитьname и lastname из таблицы студентов, соответствующей st_id в таблице адресов.
from sqlalchemy.sql import select
s = select([students, addresses]).where(students.c.id == addresses.c.st_id)
result = conn.execute(s)
for row in result:
print (row)Выбранные объекты будут эффективно преобразованы в следующее выражение SQL, объединяющее две таблицы по общему отношению:
SELECT students.id,
students.name,
students.lastname,
addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM students, addresses
WHERE students.id = addresses.st_idЭто приведет к извлечению соответствующих данных из обеих таблиц следующим образом:
(1, 'Ravi', 'Kapoor', 1, 1, 'Shivajinagar Pune', '[email protected]')
(1, 'Ravi', 'Kapoor', 2, 1, 'ChurchGate Mumbai', '[email protected]')
(3, 'Komal', 'Bhandari', 3, 3, 'Jubilee Hills Hyderabad', '[email protected]')
(5, 'Priya', 'Rajhans', 4, 5, 'MG Road Bangaluru', '[email protected]')
(2, 'Rajiv', 'Khanna', 5, 2, 'Cannought Place new Delhi', '[email protected]')В предыдущей главе мы обсудили, как использовать несколько таблиц. Итак, мы продвигаемся дальше и узнаемmultiple table updates в этой главе.
Используя объект таблицы SQLAlchemy, в предложении WHERE метода update () можно указать несколько таблиц. PostgreSQL и Microsoft SQL Server поддерживают операторы UPDATE, которые относятся к нескольким таблицам. Это реализует“UPDATE FROM”синтаксис, который обновляет одну таблицу за раз. Однако на дополнительные таблицы можно напрямую ссылаться в дополнительном предложении «FROM» в предложении WHERE. Следующие строки кода объясняют концепциюmultiple table updates ясно.
stmt = students.update().\
values({
students.c.name:'xyz',
addresses.c.email_add:'[email protected]'
}).\
where(students.c.id == addresses.c.id)Объект обновления эквивалентен следующему запросу UPDATE -
UPDATE students
SET email_add = :addresses_email_add, name = :name
FROM addresses
WHERE students.id = addresses.idЧто касается диалекта MySQL, несколько таблиц могут быть встроены в один оператор UPDATE, разделенный запятой, как указано ниже:
stmt = students.update().\
values(name = 'xyz').\
where(students.c.id == addresses.c.id)Следующий код изображает результирующий запрос UPDATE -
'UPDATE students SET name = :name
FROM addresses
WHERE students.id = addresses.id'Однако диалект SQLite не поддерживает критерии с несколькими таблицами в UPDATE и показывает следующую ошибку:
NotImplementedError: This backend does not support multiple-table criteria within UPDATEЗапрос UPDATE необработанного SQL имеет предложение SET. Он отображается конструкцией update () с использованием порядка столбцов, заданного в исходном объекте Table. Следовательно, конкретный оператор UPDATE с определенными столбцами будет отображаться каждый раз одинаково. Поскольку сами параметры передаются методу Update.values () как ключи словаря Python, другой фиксированный порядок недоступен.
В некоторых случаях важен порядок отображения параметров в предложении SET. В MySQL предоставление обновлений значений столбцов основано на обновлениях значений других столбцов.
Результат следующего заявления -
UPDATE table1 SET x = y + 10, y = 20будет иметь другой результат, чем -
UPDATE table1 SET y = 20, x = y + 10Предложение SET в MySQL оценивается для каждого значения, а не для каждой строки. Для этогоpreserve_parameter_orderиспользуется. Список Python из двух кортежей дается как аргумент дляUpdate.values() метод -
stmt = table1.update(preserve_parameter_order = True).\
values([(table1.c.y, 20), (table1.c.x, table1.c.y + 10)])Объект List похож на словарь, за исключением того, что он упорядочен. Это гарантирует, что сначала будет отображаться предложение SET столбца «y», а затем предложение SET столбца «x».
В этой главе мы рассмотрим выражение Multiple Table Deletes, которое похоже на использование функции Multiple Table Updates.
В предложении WHERE оператора DELETE во многих диалектах СУБД можно указать несколько таблиц. Для PG и MySQL используется синтаксис DELETE USING; а для SQL Server выражение «DELETE FROM» относится к нескольким таблицам. SQLAlchemydelete() конструкция поддерживает оба этих режима неявно, указав несколько таблиц в предложении WHERE следующим образом:
stmt = users.delete().\
where(users.c.id == addresses.c.id).\
where(addresses.c.email_address.startswith('xyz%'))
conn.execute(stmt)На бэкэнде PostgreSQL результирующий SQL из приведенного выше оператора будет отображаться как -
DELETE FROM users USING addresses
WHERE users.id = addresses.id
AND (addresses.email_address LIKE %(email_address_1)s || '%%')Если этот метод используется с базой данных, которая не поддерживает такое поведение, компилятор вызовет NotImplementedError.
В этой главе мы узнаем, как использовать объединения в SQLAlchemy.
Эффект объединения достигается простым размещением двух таблиц либо в columns clause или where clauseконструкции select (). Теперь мы используем методы join () и externaljoin ().
Метод join () возвращает объект соединения от одного объекта таблицы к другому.
join(right, onclause = None, isouter = False, full = False)Функции параметров, упомянутых в приведенном выше коде, следующие:
right- правая часть стыка; это любой объект таблицы
onclause- выражение SQL, представляющее предложение ON соединения. Если оставить значение Нет, он пытается объединить две таблицы на основе отношения внешнего ключа.
isouter - если True, отображает LEFT OUTER JOIN вместо JOIN
full - если True, отображает FULL OUTER JOIN вместо LEFT OUTER JOIN
Например, следующее использование метода join () автоматически приведет к объединению на основе внешнего ключа.
>>> print(students.join(addresses))Это эквивалентно следующему выражению SQL -
students JOIN addresses ON students.id = addresses.st_idВы можете явно указать критерии присоединения следующим образом:
j = students.join(addresses, students.c.id == addresses.c.st_id)Если мы теперь построим приведенную ниже конструкцию select, используя это соединение как -
stmt = select([students]).select_from(j)Это приведет к следующему выражению SQL -
SELECT students.id, students.name, students.lastname
FROM students JOIN addresses ON students.id = addresses.st_idЕсли этот оператор выполняется с использованием механизма представления соединений, будут отображаться данные, принадлежащие выбранным столбцам. Полный код выглядит следующим образом -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer,ForeignKey('students.id')),
Column('postal_add', String),
Column('email_add', String)
)
from sqlalchemy import join
from sqlalchemy.sql import select
j = students.join(addresses, students.c.id == addresses.c.st_id)
stmt = select([students]).select_from(j)
result = conn.execute(stmt)
result.fetchall()Ниже приводится вывод приведенного выше кода -
[
(1, 'Ravi', 'Kapoor'),
(1, 'Ravi', 'Kapoor'),
(3, 'Komal', 'Bhandari'),
(5, 'Priya', 'Rajhans'),
(2, 'Rajiv', 'Khanna')
]Конъюнкции - это функции в модуле SQLAlchemy, которые реализуют операторы отношения, используемые в предложении WHERE выражений SQL. Операторы AND, OR, NOT и т. Д. Используются для формирования составного выражения, объединяющего два отдельных логических выражения. Простой пример использования AND в операторе SELECT выглядит следующим образом:
SELECT * from EMPLOYEE WHERE salary>10000 AND age>30Функции SQLAlchemy and_ (), or_ () и not_ () соответственно реализуют операторы AND, OR и NOT.
and_ () функция
Он создает соединение выражений, соединенных оператором AND. Пример приведен ниже для лучшего понимания -
from sqlalchemy import and_
print(
and_(
students.c.name == 'Ravi',
students.c.id <3
)
)Это означает -
students.name = :name_1 AND students.id < :id_1Чтобы использовать and_ () в конструкции select () в таблице студентов, используйте следующую строку кода -
stmt = select([students]).where(and_(students.c.name == 'Ravi', students.c.id <3))Будет построен оператор SELECT следующего характера -
SELECT students.id,
students.name,
students.lastname
FROM students
WHERE students.name = :name_1 AND students.id < :id_1Полный код, который отображает вывод вышеуказанного запроса SELECT, выглядит следующим образом:
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey, select
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
from sqlalchemy import and_, or_
stmt = select([students]).where(and_(students.c.name == 'Ravi', students.c.id <3))
result = conn.execute(stmt)
print (result.fetchall())Следующая строка будет выбрана при условии, что таблица студентов заполнена данными, использованными в предыдущем примере -
[(1, 'Ravi', 'Kapoor')]or_ () функция
Он производит соединение выражений, соединенных оператором OR. Мы заменим объект stmt в приведенном выше примере на следующий, используя or_ ()
stmt = select([students]).where(or_(students.c.name == 'Ravi', students.c.id <3))Что будет эффективно эквивалентно следующему запросу SELECT -
SELECT students.id,
students.name,
students.lastname
FROM students
WHERE students.name = :name_1
OR students.id < :id_1После того, как вы сделаете замену и запустите приведенный выше код, результатом будут две строки, попадающие в условие ИЛИ -
[(1, 'Ravi', 'Kapoor'),
(2, 'Rajiv', 'Khanna')]функция asc ()
Он создает предложение ORDER BY по возрастанию. Функция принимает столбец, чтобы применить функцию в качестве параметра.
from sqlalchemy import asc
stmt = select([students]).order_by(asc(students.c.name))Оператор реализует следующее выражение SQL -
SELECT students.id,
students.name,
students.lastname
FROM students
ORDER BY students.name ASCВ следующем коде перечислены все записи в таблице студентов в порядке возрастания столбца имени -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey, select
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
from sqlalchemy import asc
stmt = select([students]).order_by(asc(students.c.name))
result = conn.execute(stmt)
for row in result:
print (row)Приведенный выше код дает следующий результат -
(4, 'Abdul', 'Sattar')
(3, 'Komal', 'Bhandari')
(5, 'Priya', 'Rajhans')
(2, 'Rajiv', 'Khanna')
(1, 'Ravi', 'Kapoor')функция desc ()
Аналогичным образом функция desc () создает убывающее предложение ORDER BY следующим образом:
from sqlalchemy import desc
stmt = select([students]).order_by(desc(students.c.lastname))Эквивалентное выражение SQL -
SELECT students.id,
students.name,
students.lastname
FROM students
ORDER BY students.lastname DESCИ вывод для приведенных выше строк кода -
(4, 'Abdul', 'Sattar')
(5, 'Priya', 'Rajhans')
(2, 'Rajiv', 'Khanna')
(1, 'Ravi', 'Kapoor')
(3, 'Komal', 'Bhandari')между () функция
Он создает предложение предиката BETWEEN. Обычно это используется для проверки того, попадает ли значение определенного столбца в диапазон. Например, следующий код выбирает строки, для которых столбец id находится между 2 и 4 -
from sqlalchemy import between
stmt = select([students]).where(between(students.c.id,2,4))
print (stmt)Результирующее выражение SQL похоже -
SELECT students.id,
students.name,
students.lastname
FROM students
WHERE students.id
BETWEEN :id_1 AND :id_2и результат следующий -
(2, 'Rajiv', 'Khanna')
(3, 'Komal', 'Bhandari')
(4, 'Abdul', 'Sattar')В этой главе обсуждаются некоторые важные функции, используемые в SQLAlchemy.
Стандартный SQL рекомендовал множество функций, которые реализованы на большинстве диалектов. Они возвращают единственное значение на основе переданных ему аргументов. Некоторые функции SQL принимают столбцы в качестве аргументов, тогда как некоторые являются общими.Thefunc keyword in SQLAlchemy API is used to generate these functions.
В SQL now () - это общая функция. Следующие инструкции отображают функцию now () с использованием func -
from sqlalchemy.sql import func
result = conn.execute(select([func.now()]))
print (result.fetchone())Пример результата приведенного выше кода может быть таким, как показано ниже -
(datetime.datetime(2018, 6, 16, 6, 4, 40),)С другой стороны, функция count (), которая возвращает количество строк, выбранных из таблицы, отображается следующим образом: func -
from sqlalchemy.sql import func
result = conn.execute(select([func.count(students.c.id)]))
print (result.fetchone())Из приведенного выше кода будет извлечено количество строк в таблице студентов.
Некоторые встроенные функции SQL демонстрируются с использованием таблицы Employee со следующими данными:
| Я БЫ | имя | Метки |
|---|---|---|
| 1 | Камаль | 56 |
| 2 | Фернандес | 85 |
| 3 | Сунил | 62 |
| 4 | Бхаскар | 76 |
Функция max () реализована следующим образом: func из SQLAlchemy, что приведет к 85, общим максимальным полученным оценкам -
from sqlalchemy.sql import func
result = conn.execute(select([func.max(employee.c.marks)]))
print (result.fetchone())Точно так же функция min (), которая вернет 56, минимальных оценок, будет отображаться следующим кодом:
from sqlalchemy.sql import func
result = conn.execute(select([func.min(employee.c.marks)]))
print (result.fetchone())Итак, функция AVG () также может быть реализована с помощью приведенного ниже кода -
from sqlalchemy.sql import func
result = conn.execute(select([func.avg(employee.c.marks)]))
print (result.fetchone())
Functions are normally used in the columns clause of a select statement.
They can also be given label as well as a type. A label to function allows the result
to be targeted in a result row based on a string name, and a type is required when
you need result-set processing to occur.from sqlalchemy.sql import func
result = conn.execute(select([func.max(students.c.lastname).label('Name')]))
print (result.fetchone())В предыдущей главе мы узнали о различных функциях, таких как max (), min (), count () и т. Д., Здесь мы узнаем об операциях над наборами и их использовании.
Операции над множествами, такие как UNION и INTERSECT, поддерживаются стандартным SQL и большей частью его диалекта. SQLAlchemy реализует их с помощью следующих функций:
союз ()
При объединении результатов двух или более операторов SELECT UNION удаляет дубликаты из набора результатов. Количество столбцов и тип данных должны быть одинаковыми в обеих таблицах.
Функция union () возвращает объект CompoundSelect из нескольких таблиц. Следующий пример демонстрирует его использование -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, union
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer),
Column('postal_add', String),
Column('email_add', String)
)
u = union(addresses.select().where(addresses.c.email_add.like('%@gmail.com addresses.select().where(addresses.c.email_add.like('%@yahoo.com'))))
result = conn.execute(u)
result.fetchall()Конструкция union преобразуется в следующее выражение SQL -
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? UNION SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ?Из нашей таблицы адресов следующие строки представляют операцию объединения -
[
(1, 1, 'Shivajinagar Pune', '[email protected]'),
(2, 1, 'ChurchGate Mumbai', '[email protected]'),
(3, 3, 'Jubilee Hills Hyderabad', '[email protected]'),
(4, 5, 'MG Road Bangaluru', '[email protected]')
]union_all ()
Операция UNION ALL не может удалить дубликаты и не может отсортировать данные в наборе результатов. Например, в приведенном выше запросе UNION заменяется на UNION ALL, чтобы увидеть эффект.
u = union_all(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.email_add.like('%@yahoo.com')))Соответствующее выражение SQL выглядит следующим образом -
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? UNION ALL SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ?Кроме_()
SQL EXCEPTПредложение / оператор используется для объединения двух операторов SELECT и возврата строк из первого оператора SELECT, которые не возвращаются вторым оператором SELECT. Функция except_ () генерирует выражение SELECT с предложением EXCEPT.
В следующем примере функция except_ () возвращает только те записи из таблицы адресов, у которых есть «gmail.com» в поле email_add, но исключает те, которые содержат «Pune» как часть поля postal_add.
u = except_(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.postal_add.like('%Pune')))Результатом приведенного выше кода является следующее выражение SQL -
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? EXCEPT SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.postal_add LIKE ?Предполагая, что таблица адресов содержит данные, использованные в более ранних примерах, она отобразит следующий вывод:
[(2, 1, 'ChurchGate Mumbai', '[email protected]'),
(3, 3, 'Jubilee Hills Hyderabad', '[email protected]')]пересечь ()
Используя оператор INTERSECT, SQL отображает общие строки из обоих операторов SELECT. Это поведение реализует функция crossct ().
В следующих примерах две конструкции SELECT являются параметрами для функции intersect (). Один возвращает строки, содержащие «gmail.com» как часть столбца email_add, а другой возвращает строки, содержащие «Pune» как часть столбца postal_add. Результатом будут общие строки из обоих наборов результатов.
u = intersect(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.postal_add.like('%Pune')))По сути, это эквивалентно следующему оператору SQL -
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? INTERSECT SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.postal_add LIKE ?Два связанных параметра «% gmail.com» и «% Pune» создают одну строку из исходных данных в таблице адресов, как показано ниже -
[(1, 1, 'Shivajinagar Pune', '[email protected]')]Основная цель API объектно-реляционного сопоставления SQLAlchemy состоит в том, чтобы облегчить связывание определенных пользователем классов Python с таблицами базы данных, а объекты этих классов - со строками в соответствующих таблицах. Изменения состояний объектов и строк синхронно согласовываются друг с другом. SQLAlchemy позволяет выражать запросы к базе данных в терминах определяемых пользователем классов и их определенных отношений.
ORM построен на языке выражений SQL. Это высокоуровневый и абстрактный шаблон использования. Фактически, ORM - это прикладное использование языка выражений.
Хотя успешное приложение может быть создано исключительно с использованием объектно-реляционного сопоставителя, иногда приложение, созданное с помощью ORM, может напрямую использовать язык выражений там, где требуются определенные взаимодействия с базой данных.
Объявить сопоставление
Прежде всего, функция create_engine () вызывается для установки объекта движка, который впоследствии используется для выполнения операций SQL. Функция имеет два аргумента: один - это имя базы данных, а другой - параметр эха, если задано значение True, будет создан журнал активности. Если его не существует, база данных будет создана. В следующем примере создается база данных SQLite.
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)Механизм устанавливает реальное соединение DBAPI с базой данных, когда вызывается такой метод, как Engine.execute () или Engine.connect (). Затем он используется для создания SQLORM, который напрямую не использует движок; вместо этого он используется ORM за кулисами.
В случае ORM процесс настройки начинается с описания таблиц базы данных, а затем с определения классов, которые будут сопоставлены с этими таблицами. В SQLAlchemy эти две задачи выполняются вместе. Это делается с помощью декларативной системы; созданные классы включают директивы для описания фактической таблицы базы данных, на которую они отображаются.
Базовый класс хранит каталог классов и сопоставленных таблиц в декларативной системе. Это называется декларативным базовым классом. Обычно в обычно импортируемом модуле будет только один экземпляр этой базы. Функция declarative_base () используется для создания базового класса. Эта функция определена в модуле sqlalchemy.ext.declarative.
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()После объявления базового класса любое количество сопоставленных классов может быть определено в его терминах. Следующий код определяет класс клиента. Он содержит таблицу, с которой нужно сопоставить, а также имена и типы данных столбцов в ней.
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)Класс в Declarative должен иметь __tablename__ атрибут и хотя бы один Columnкоторый является частью первичного ключа. Декларативная заменяет всеColumn объекты со специальными средствами доступа Python, известными как descriptors. Этот процесс известен как инструментарий, который предоставляет средства для обращения к таблице в контексте SQL и позволяет сохранять и загружать значения столбцов из базы данных.
Этот сопоставленный класс, как и обычный класс Python, имеет атрибуты и методы в соответствии с требованиями.
Информация о классе в декларативной системе называется метаданными таблицы. SQLAlchemy использует объект Table для представления этой информации для конкретной таблицы, созданной Declarative. Объект Table создается в соответствии со спецификациями и связывается с классом путем создания объекта Mapper. Этот объект сопоставления не используется напрямую, но используется внутри как интерфейс между сопоставленным классом и таблицей.
Каждый объект Table является членом более крупной коллекции, известной как MetaData, и этот объект доступен с помощью .metadataатрибут декларативного базового класса. ВMetaData.create_all()метод заключается в передаче нашего движка в качестве источника подключения к базе данных. Для всех таблиц, которые еще не были созданы, он отправляет операторы CREATE TABLE в базу данных.
Base.metadata.create_all(engine)Полный сценарий для создания базы данных и таблицы, а также для сопоставления класса Python приведен ниже -
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key=True)
name = Column(String)
address = Column(String)
email = Column(String)
Base.metadata.create_all(engine)При выполнении консоль Python будет эхом после выполнения выражения SQL -
CREATE TABLE customers (
id INTEGER NOT NULL,
name VARCHAR,
address VARCHAR,
email VARCHAR,
PRIMARY KEY (id)
)Если мы откроем Sales.db с помощью графического инструмента SQLiteStudio, внутри него будет показана таблица клиентов с вышеупомянутой структурой.

Чтобы взаимодействовать с базой данных, нам нужно получить ее дескриптор. Объект сеанса - это дескриптор базы данных. Класс сеанса определяется с помощью sessionmaker () - настраиваемого фабричного метода сеанса, который привязан к объекту движка, созданному ранее.
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)Затем объект сеанса настраивается с использованием конструктора по умолчанию следующим образом:
session = Session()Некоторые из часто требуемых методов класса сеанса перечислены ниже -
| Sr.No. | Метод и описание |
|---|---|
| 1 | begin() начинает транзакцию в этом сеансе |
| 2 | add() помещает объект в сеанс. Его состояние сохраняется в базе данных при следующей операции очистки. |
| 3 | add_all() добавляет в сессию коллекцию объектов |
| 4 | commit() очищает все элементы и любую текущую транзакцию |
| 5 | delete() отмечает транзакцию как удаленную |
| 6 | execute() выполняет выражение SQL |
| 7 | expire() помечает атрибуты экземпляра как устаревшие |
| 8 | flush() сбрасывает все изменения объекта в базу данных |
| 9 | invalidate() закрывает сеанс, используя аннулирование соединения |
| 10 | rollback() откатывает текущую транзакцию в процессе |
| 11 | close() Закрывает текущий сеанс, очищая все элементы и завершая любую текущую транзакцию |
В предыдущих главах SQLAlchemy ORM мы узнали, как объявлять сопоставление и создавать сеансы. В этой главе мы узнаем, как добавлять объекты в таблицу.
Мы объявили класс Customer, который был сопоставлен с таблицей клиентов. Мы должны объявить объект этого класса и постоянно добавлять его в таблицу с помощью метода add () объекта сеанса.
c1 = Sales(name = 'Ravi Kumar', address = 'Station Road Nanded', email = '[email protected]')
session.add(c1)Обратите внимание, что эта транзакция ожидается, пока она не будет сброшена с помощью метода commit ().
session.commit()Ниже приведен полный сценарий для добавления записи в таблицу клиентов.
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key=True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
c1 = Customers(name = 'Ravi Kumar', address = 'Station Road Nanded', email = '[email protected]')
session.add(c1)
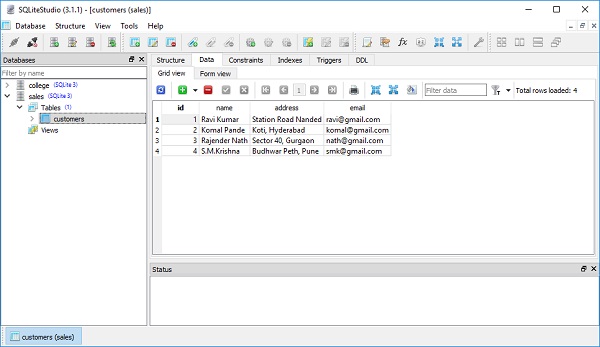
session.commit()Чтобы добавить несколько записей, мы можем использовать add_all() метод сеансового класса.
session.add_all([
Customers(name = 'Komal Pande', address = 'Koti, Hyderabad', email = '[email protected]'),
Customers(name = 'Rajender Nath', address = 'Sector 40, Gurgaon', email = '[email protected]'),
Customers(name = 'S.M.Krishna', address = 'Budhwar Peth, Pune', email = '[email protected]')]
)
session.commit()Табличное представление SQLiteStudio показывает, что записи постоянно добавляются в таблицу клиентов. На следующем изображении показан результат -
Все операторы SELECT, сгенерированные SQLAlchemy ORM, создаются объектом Query. Он предоставляет генеративный интерфейс, поэтому последовательные вызовы возвращают новый объект Query, копию первого с дополнительными критериями и параметрами, связанными с ним.
Объекты запроса изначально создаются с помощью метода query () сеанса следующим образом:
q = session.query(mapped class)Следующее утверждение также эквивалентно приведенному выше утверждению -
q = Query(mappedClass, session)У объекта запроса есть метод all (), который возвращает набор результатов в виде списка объектов. Если мы выполним это на столе наших клиентов -
result = session.query(Customers).all()Этот оператор фактически эквивалентен следующему выражению SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customersОбойти объект результата можно с помощью цикла For, как показано ниже, чтобы получить все записи в базовой таблице клиентов. Вот полный код для отображения всех записей в таблице клиентов:
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
result = session.query(Customers).all()
for row in result:
print ("Name: ",row.name, "Address:",row.address, "Email:",row.email)Консоль Python показывает список записей, как показано ниже -
Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
Name: Komal Pande Address: Koti, Hyderabad Email: [email protected]
Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]У объекта Query также есть следующие полезные методы -
| Sr.No. | Метод и описание |
|---|---|
| 1 | add_columns() Он добавляет одно или несколько выражений столбцов в список возвращаемых столбцов результатов. |
| 2 | add_entity() Он добавляет сопоставленную сущность в список возвращаемых столбцов результатов. |
| 3 | count() Он возвращает количество строк, которые должен вернуть этот запрос. |
| 4 | delete() Он выполняет запрос массового удаления. Удаляет строки, соответствующие этому запросу, из базы данных. |
| 5 | distinct() Он применяет к запросу предложение DISTINCT и возвращает вновь полученный запрос. |
| 6 | filter() Он применяет данный критерий фильтрации к копии этого запроса, используя выражения SQL. |
| 7 | first() Он возвращает первый результат этого запроса или None, если результат не содержит ни одной строки. |
| 8 | get() Он возвращает экземпляр, основанный на заданном идентификаторе первичного ключа, обеспечивая прямой доступ к карте идентификаторов сеанса-владельца. |
| 9 | group_by() Он применяет к запросу один или несколько критериев GROUP BY и возвращает вновь полученный запрос. |
| 10 | join() Он создает SQL JOIN в соответствии с критерием этого объекта Query и применяется генеративно, возвращая вновь полученный запрос. |
| 11 | one() Он возвращает ровно один результат или вызывает исключение. |
| 12 | order_by() Он применяет к запросу один или несколько критериев ORDER BY и возвращает вновь полученный запрос. |
| 13 | update() Он выполняет запрос массового обновления и обновляет строки, соответствующие этому запросу, в базе данных. |
В этой главе мы увидим, как изменить или обновить таблицу желаемыми значениями.
Чтобы изменить данные определенного атрибута любого объекта, мы должны присвоить ему новое значение и зафиксировать изменения, чтобы сделать изменение постоянным.
Давайте возьмем объект из таблицы, у которой идентификатор первичного ключа, в нашей таблице Customers с ID = 2. Мы можем использовать метод сеанса get () следующим образом:
x = session.query(Customers).get(2)Мы можем отобразить содержимое выбранного объекта с помощью приведенного ниже кода -
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)Из нашей таблицы клиентов должен отображаться следующий вывод -
Name: Komal Pande Address: Koti, Hyderabad Email: [email protected]Теперь нам нужно обновить поле адреса, присвоив новое значение, как указано ниже -
x.address = 'Banjara Hills Secunderabad'
session.commit()Изменение будет постоянно отражаться в базе данных. Теперь мы получаем объект, соответствующий первой строке в таблице, используяfirst() method следующим образом -
x = session.query(Customers).first()Это выполнит следующее выражение SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
LIMIT ? OFFSET ?Связанные параметры будут иметь значение LIMIT = 1 и OFFSET = 0 соответственно, что означает, что будет выбрана первая строка.
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)Теперь вывод для приведенного выше кода, отображающего первую строку, выглядит следующим образом:
Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]Теперь измените атрибут имени и отобразите содержимое, используя приведенный ниже код -
x.name = 'Ravi Shrivastava'
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)Вывод приведенного выше кода -
Name: Ravi Shrivastava Address: Station Road Nanded Email: [email protected]Несмотря на то, что изменение отображается, оно не фиксируется. Вы можете сохранить прежнее постоянное положение, используяrollback() method с кодом ниже.
session.rollback()
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)Будет отображено исходное содержимое первой записи.
Для массовых обновлений мы будем использовать метод update () объекта Query. Давайте попробуем дать приставку «Мистер». для имени в каждой строке (кроме ID = 2). Соответствующий оператор update () выглядит следующим образом:
session.query(Customers).filter(Customers.id! = 2).
update({Customers.name:"Mr."+Customers.name}, synchronize_session = False)The update() method requires two parameters as follows −
Словарь ключей и значений, в котором ключ является атрибутом, который необходимо обновить, а значение - новым содержимым атрибута.
Атрибут synchronize_session, указывающий на стратегию обновления атрибутов в сеансе. Допустимые значения - false: если сеанс не синхронизируется, fetch: выполняет запрос выбора перед обновлением, чтобы найти объекты, которые соответствуют запросу на обновление; и оценивать: оценивать критерии объектов в сеансе.
В трех из 4 строк таблицы будет стоять префикс «Мистер». Однако изменения не фиксируются и, следовательно, не будут отражены в табличном представлении SQLiteStudio. Он будет обновлен только после фиксации сеанса.
В этой главе мы обсудим, как применять фильтр, а также некоторые операции фильтра вместе с их кодами.
Набор результатов, представленный объектом Query, может быть подвергнут определенным критериям с помощью метода filter (). Общее использование метода фильтрации следующее -
session.query(class).filter(criteria)В следующем примере набор результатов, полученный запросом SELECT для таблицы Customers, фильтруется по условию (ID> 2) -
result = session.query(Customers).filter(Customers.id>2)Этот оператор будет переведен в следующее выражение SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id > ?Поскольку привязанный параметр (?) Задан как 2, будут отображаться только те строки, у которых столбец ID> 2. Полный код приведен ниже -
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
result = session.query(Customers).filter(Customers.id>2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)Вывод, отображаемый в консоли Python, выглядит следующим образом:
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]Теперь мы изучим операции фильтра с их соответствующими кодами и выходными данными.
Равно
Обычно используется оператор ==, который применяет критерии для проверки равенства.
result = session.query(Customers).filter(Customers.id == 2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)SQLAlchemy отправит следующее выражение SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id = ?Вывод для приведенного выше кода выглядит следующим образом:
ID: 2 Name: Komal Pande Address: Banjara Hills Secunderabad Email: [email protected]Не равно
Оператор, используемый для неравенства, -! =, И он обеспечивает критерий неравенства.
result = session.query(Customers).filter(Customers.id! = 2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)Результирующее выражение SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id != ?Вывод для приведенных выше строк кода следующий:
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]подобно
Сам метод like () создает критерии LIKE для предложения WHERE в выражении SELECT.
result = session.query(Customers).filter(Customers.name.like('Ra%'))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)Вышеупомянутый код SQLAlchemy эквивалентен следующему выражению SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name LIKE ?И вывод для приведенного выше кода -
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]В
Этот оператор проверяет, принадлежит ли значение столбца к набору элементов в списке. Это обеспечивается методом in_ ().
result = session.query(Customers).filter(Customers.id.in_([1,3]))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)Здесь выражение SQL, оцениваемое механизмом SQLite, будет следующим:
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id IN (?, ?)Вывод для приведенного выше кода выглядит следующим образом:
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]И
Это соединение порождается либо putting multiple commas separated criteria in the filter or using and_() method как указано ниже -
result = session.query(Customers).filter(Customers.id>2, Customers.name.like('Ra%'))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)from sqlalchemy import and_
result = session.query(Customers).filter(and_(Customers.id>2, Customers.name.like('Ra%')))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)Оба вышеуказанных подхода приводят к аналогичному выражению SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id > ? AND customers.name LIKE ?Вывод для приведенных выше строк кода -
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]ИЛИ ЖЕ
Это соединение реализуется or_() method.
from sqlalchemy import or_
result = session.query(Customers).filter(or_(Customers.id>2, Customers.name.like('Ra%')))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)В результате движок SQLite получает следующее эквивалентное выражение SQL:
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id > ? OR customers.name LIKE ?Вывод для приведенного выше кода выглядит следующим образом:
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]Есть несколько методов объекта Query, которые немедленно выдают SQL и возвращают значение, содержащее загруженные результаты базы данных.
Вот краткое изложение списка возврата и скаляров -
все()
Он возвращает список. Ниже приведена строка кода для функции all ().
session.query(Customers).all()Консоль Python отображает следующее выражение SQL:
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customersпервый()
Он применяет ограничение в единицу и возвращает первый результат в виде скаляра.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
LIMIT ? OFFSET ?Граничные параметры для LIMIT равны 1, а для OFFSET - 0.
один()
Эта команда полностью извлекает все строки, и если в результате не присутствует ровно одна идентификация объекта или составная строка, возникает ошибка.
session.query(Customers).one()При обнаружении нескольких строк -
MultipleResultsFound: Multiple rows were found for one()Если строк не найдено -
NoResultFound: No row was found for one()Метод one () полезен для систем, которые рассчитывают по-разному обрабатывать «элементы не найдены» и «обнаружено несколько элементов».
скаляр ()
Он вызывает метод one () и в случае успеха возвращает первый столбец строки следующим образом:
session.query(Customers).filter(Customers.id == 3).scalar()Это генерирует следующий оператор SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id = ?Ранее текстовый SQL с использованием функции text () объяснялся с точки зрения основного языка выражений SQLAlchemy. Теперь обсудим это с точки зрения ORM.
Литеральные строки можно гибко использовать с объектом Query, указав их использование с помощью конструкции text (). Большинство применимых методов принимают это. Например, filter () и order_by ().
В приведенном ниже примере метод filter () переводит строку «id <3» в WHERE id <3
from sqlalchemy import text
for cust in session.query(Customers).filter(text("id<3")):
print(cust.name)Сгенерированное необработанное выражение SQL показывает преобразование фильтра в предложение WHERE с кодом, показанным ниже -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE id<3Из нашего образца данных в таблице клиентов будут выбраны две строки, и столбец имени будет напечатан следующим образом:
Ravi Kumar
Komal PandeЧтобы указать параметры привязки с помощью строкового SQL, используйте двоеточие, а для указания значений используйте метод params ().
cust = session.query(Customers).filter(text("id = :value")).params(value = 1).one()Эффективный SQL, отображаемый на консоли Python, будет таким, как указано ниже -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE id = ?Чтобы использовать полностью строковый оператор, конструкцию text (), представляющую полный оператор, можно передать в from_statement ().
session.query(Customers).from_statement(text("SELECT * FROM customers")).all()Результатом приведенного выше кода будет базовый оператор SELECT, как показано ниже -
SELECT * FROM customersОчевидно, что будут выбраны все записи в таблице клиентов.
Конструкция text () позволяет нам позиционно связать ее текстовый SQL с выражениями столбцов Core или ORM. Мы можем добиться этого, передав выражения столбцов в качестве позиционных аргументов методу TextClause.columns ().
stmt = text("SELECT name, id, name, address, email FROM customers")
stmt = stmt.columns(Customers.id, Customers.name)
session.query(Customers.id, Customers.name).from_statement(stmt).all()Столбцы id и name всех строк будут выбраны, даже если механизм SQLite выполняет следующее выражение, сгенерированное вышеуказанным кодом, показывает все столбцы в методе text () -
SELECT name, id, name, address, email FROM customersЭтот сеанс описывает создание другой таблицы, которая связана с уже существующей в нашей базе данных. Таблица клиентов содержит основные данные клиентов. Теперь нам нужно создать таблицу счетов, в которой может быть любое количество счетов, принадлежащих клиенту. Это случай отношений "один ко многим".
Используя декларативно, мы определяем эту таблицу вместе с ее сопоставленным классом Invoices, как указано ниже -
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
class Invoice(Base):
__tablename__ = 'invoices'
id = Column(Integer, primary_key = True)
custid = Column(Integer, ForeignKey('customers.id'))
invno = Column(Integer)
amount = Column(Integer)
customer = relationship("Customer", back_populates = "invoices")
Customer.invoices = relationship("Invoice", order_by = Invoice.id, back_populates = "customer")
Base.metadata.create_all(engine)Это отправит запрос CREATE TABLE в механизм SQLite, как показано ниже -
CREATE TABLE invoices (
id INTEGER NOT NULL,
custid INTEGER,
invno INTEGER,
amount INTEGER,
PRIMARY KEY (id),
FOREIGN KEY(custid) REFERENCES customers (id)
)Проверить создание новой таблицы в sales.db можно с помощью инструмента SQLiteStudio.
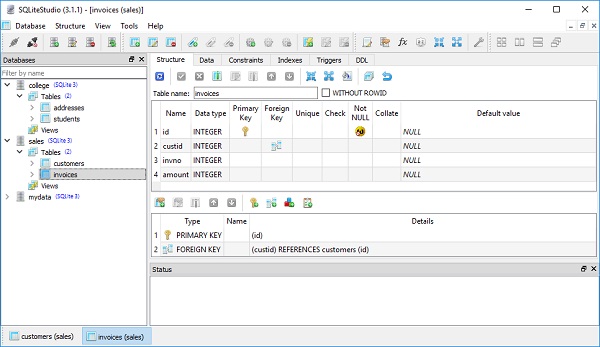
Класс Invoices применяет конструкцию ForeignKey к атрибуту custid. Эта директива указывает, что значения в этом столбце должны быть ограничены значениями, присутствующими в столбце id в таблице клиентов. Это ключевая особенность реляционных баз данных и «клей», который преобразует несвязанный набор таблиц, чтобы иметь богатые перекрывающиеся отношения.
Вторая директива, известная как Relationship (), сообщает ORM, что класс Invoice должен быть связан с классом Customer с помощью атрибута Invoice.customer. Отношение () использует отношения внешнего ключа между двумя таблицами, чтобы определить характер этой связи, определяя, что она много к одному.
Дополнительная директива Relations () помещается в сопоставленный класс Customer под атрибутом Customer.invoices. Параметр Relationship.back_populate назначается для ссылки на дополнительные имена атрибутов, так что каждая взаимосвязь () может принимать разумное решение о том же отношении, выраженном в обратном порядке. С одной стороны, Invoices.customer относится к экземпляру Invoices, а с другой стороны, Customer.invoices относится к списку экземпляров Customers.
Функция отношения является частью API отношений пакета ORM SQLAlchemy. Он обеспечивает связь между двумя отображенными классами. Это соответствует родительско-дочерним или ассоциативным отношениям таблицы.
Ниже приведены основные найденные паттерны взаимоотношений.
Один ко многим
Отношение «один ко многим» относится к родителю с помощью внешнего ключа в дочерней таблице. Relationship () затем указывается для родительского элемента, как ссылка на коллекцию элементов, представленных дочерним элементом. Параметр Relationship.back_populate используется для установления двунаправленного отношения в режиме «один ко многим», где «обратная» сторона - это многие к одному.
Многие к одному
С другой стороны, отношение «многие к одному» помещает внешний ключ в родительскую таблицу для ссылки на дочерний элемент. Relationship () объявляется в родительском элементе, где будет создан новый атрибут скалярного хранения. Здесь снова параметр Relations.back_populate используется для двунаправленного поведения.
Один к одному
Отношения «один к одному» по сути своей являются двусторонними отношениями. Флаг списка пользователей указывает размещение скалярного атрибута вместо коллекции на стороне «многие» отношения. Чтобы преобразовать отношение «один ко многим» в тип отношения «один к одному», установите для параметра uselist значение false.
Многие ко многим
Отношение «многие ко многим» устанавливается путем добавления таблицы ассоциаций, связанной с двумя классами, путем определения атрибутов с их внешними ключами. На это указывает вторичный аргумент функции Relationship (). Обычно в таблице используется объект MetaData, связанный с декларативным базовым классом, так что директивы ForeignKey могут найти удаленные таблицы, с которыми можно установить связь. Параметр Relationship.back_populate для каждой связи () устанавливает двунаправленную связь. Обе стороны отношений содержат коллекцию.
В этой главе мы сосредоточимся на связанных объектах в SQLAlchemy ORM.
Теперь, когда мы создаем объект Customer, будет представлена пустая коллекция счетов в форме списка Python.
c1 = Customer(name = "Gopal Krishna", address = "Bank Street Hydarebad", email = "[email protected]")Атрибут invoices c1.invoices будет пустым списком. Мы можем назначить элементы в списке как -
c1.invoices = [Invoice(invno = 10, amount = 15000), Invoice(invno = 14, amount = 3850)]Давайте зафиксируем этот объект в базе данных, используя объект Session следующим образом:
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
session.add(c1)
session.commit()Это автоматически создаст запросы INSERT для таблиц клиентов и счетов-фактур -
INSERT INTO customers (name, address, email) VALUES (?, ?, ?)
('Gopal Krishna', 'Bank Street Hydarebad', '[email protected]')
INSERT INTO invoices (custid, invno, amount) VALUES (?, ?, ?)
(2, 10, 15000)
INSERT INTO invoices (custid, invno, amount) VALUES (?, ?, ?)
(2, 14, 3850)Давайте теперь посмотрим на содержимое таблицы клиентов и таблицы счетов-фактур в табличном представлении SQLiteStudio -

Вы можете создать объект Customer, предоставив сопоставленный атрибут счетов-фактур в самом конструкторе, используя следующую команду:
c2 = [
Customer(
name = "Govind Pant",
address = "Gulmandi Aurangabad",
email = "[email protected]",
invoices = [Invoice(invno = 3, amount = 10000),
Invoice(invno = 4, amount = 5000)]
)
]Или список объектов, которые нужно добавить с помощью функции add_all () объекта сеанса, как показано ниже -
rows = [
Customer(
name = "Govind Kala",
address = "Gulmandi Aurangabad",
email = "[email protected]",
invoices = [Invoice(invno = 7, amount = 12000), Invoice(invno = 8, amount = 18500)]),
Customer(
name = "Abdul Rahman",
address = "Rohtak",
email = "[email protected]",
invoices = [Invoice(invno = 9, amount = 15000),
Invoice(invno = 11, amount = 6000)
])
]
session.add_all(rows)
session.commit()Теперь, когда у нас есть две таблицы, мы увидим, как создавать запросы к обеим таблицам одновременно. Чтобы создать простое неявное соединение между Customer и Invoice, мы можем использовать Query.filter () для приравнивания связанных столбцов вместе. Ниже мы загружаем сущности Customer и Invoice одновременно, используя этот метод -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
for c, i in session.query(Customer, Invoice).filter(Customer.id == Invoice.custid).all():
print ("ID: {} Name: {} Invoice No: {} Amount: {}".format(c.id,c.name, i.invno, i.amount))Выражение SQL, выдаваемое SQLAlchemy, выглядит следующим образом:
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email, invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM customers, invoices
WHERE customers.id = invoices.custidИ результат приведенных выше строк кода выглядит следующим образом:
ID: 2 Name: Gopal Krishna Invoice No: 10 Amount: 15000
ID: 2 Name: Gopal Krishna Invoice No: 14 Amount: 3850
ID: 3 Name: Govind Pant Invoice No: 3 Amount: 10000
ID: 3 Name: Govind Pant Invoice No: 4 Amount: 5000
ID: 4 Name: Govind Kala Invoice No: 7 Amount: 12000
ID: 4 Name: Govind Kala Invoice No: 8 Amount: 8500
ID: 5 Name: Abdul Rahman Invoice No: 9 Amount: 15000
ID: 5 Name: Abdul Rahman Invoice No: 11 Amount: 6000Фактический синтаксис SQL JOIN легко достигается с помощью метода Query.join () следующим образом:
session.query(Customer).join(Invoice).filter(Invoice.amount == 8500).all()Выражение SQL для соединения будет отображаться на консоли -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers JOIN invoices ON customers.id = invoices.custid
WHERE invoices.amount = ?Мы можем перебирать результат, используя цикл for -
result = session.query(Customer).join(Invoice).filter(Invoice.amount == 8500)
for row in result:
for inv in row.invoices:
print (row.id, row.name, inv.invno, inv.amount)С 8500 в качестве параметра привязки отображается следующий вывод -
4 Govind Kala 8 8500Query.join () знает, как соединяться между этими таблицами, потому что между ними есть только один внешний ключ. Если внешних ключей не было или было больше, Query.join () работает лучше, если используется одна из следующих форм:
| query.join (счет-фактура, id == Address.custid) | явное условие |
| query.join (Customer.invoices) | указать отношение слева направо |
| query.join (счет-фактура, Customer.invoices) | то же самое, с явной целью |
| query.join ('счета-фактуры') | то же самое, используя строку |
Аналогично доступна функция outerjoin () для левого внешнего соединения.
query.outerjoin(Customer.invoices)Метод subquery () создает выражение SQL, представляющее инструкцию SELECT, встроенную в псевдоним.
from sqlalchemy.sql import func
stmt = session.query(
Invoice.custid, func.count('*').label('invoice_count')
).group_by(Invoice.custid).subquery()Объект stmt будет содержать инструкцию SQL, как показано ниже -
SELECT invoices.custid, count(:count_1) AS invoice_count FROM invoices GROUP BY invoices.custidКогда у нас есть оператор, он ведет себя как конструкция Table. Столбцы в заявлении доступны через атрибут c, как показано в приведенном ниже коде:
for u, count in session.query(Customer, stmt.c.invoice_count).outerjoin(stmt, Customer.id == stmt.c.custid).order_by(Customer.id):
print(u.name, count)Вышеупомянутый цикл for отображает количество счетов-фактур по имени следующим образом:
Arjun Pandit None
Gopal Krishna 2
Govind Pant 2
Govind Kala 2
Abdul Rahman 2В этой главе мы обсудим операторы, которые строятся на отношениях.
__eq __ ()
Вышеупомянутый оператор представляет собой сравнение «многие к одному». Строка кода для этого оператора показана ниже -
s = session.query(Customer).filter(Invoice.invno.__eq__(12))Эквивалентный SQL-запрос для приведенной выше строки кода -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers, invoices
WHERE invoices.invno = ?__ne __ ()
Этот оператор является сравнением «многие к одному не равно». Строка кода для этого оператора показана ниже -
s = session.query(Customer).filter(Invoice.custid.__ne__(2))Эквивалентный SQL-запрос для приведенной выше строки кода приведен ниже -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers, invoices
WHERE invoices.custid != ?содержит()
Этот оператор используется для коллекций типа "один ко многим", и ниже приведен код для contains () -
s = session.query(Invoice).filter(Invoice.invno.contains([3,4,5]))Эквивалентный SQL-запрос для приведенной выше строки кода -
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE (invoices.invno LIKE '%' + ? || '%')Любые()
Оператор any () используется для коллекций, как показано ниже -
s = session.query(Customer).filter(Customer.invoices.any(Invoice.invno==11))Эквивалентный запрос SQL для приведенной выше строки кода показан ниже -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE EXISTS (
SELECT 1
FROM invoices
WHERE customers.id = invoices.custid
AND invoices.invno = ?)имеет ()
Этот оператор используется для скалярных ссылок следующим образом:
s = session.query(Invoice).filter(Invoice.customer.has(name = 'Arjun Pandit'))Эквивалентный SQL-запрос для приведенной выше строки кода -
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE EXISTS (
SELECT 1
FROM customers
WHERE customers.id = invoices.custid
AND customers.name = ?)Жадная нагрузка снижает количество запросов. SQLAlchemy предлагает функции активной загрузки, вызываемые через параметры запроса, которые дают дополнительные инструкции для запроса. Эти параметры определяют, как загружать различные атрибуты с помощью метода Query.options ().
Загрузка подзапроса
Мы хотим, чтобы счета Customer.invoices загружались быстро. Параметр orm.subqueryload () дает второй оператор SELECT, который полностью загружает коллекции, связанные с только что загруженными результатами. Имя «подзапрос» приводит к тому, что оператор SELECT создается напрямую с помощью повторно используемого запроса и встраивается в качестве подзапроса в запрос SELECT для связанной таблицы.
from sqlalchemy.orm import subqueryload
c1 = session.query(Customer).options(subqueryload(Customer.invoices)).filter_by(name = 'Govind Pant').one()Это приводит к следующим двум выражениям SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?
('Govind Pant',)
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount, anon_1.customers_id
AS anon_1_customers_id
FROM (
SELECT customers.id
AS customers_id
FROM customers
WHERE customers.name = ?)
AS anon_1
JOIN invoices
ON anon_1.customers_id = invoices.custid
ORDER BY anon_1.customers_id, invoices.id 2018-06-25 18:24:47,479
INFO sqlalchemy.engine.base.Engine ('Govind Pant',)Чтобы получить доступ к данным из двух таблиц, мы можем использовать следующую программу -
print (c1.name, c1.address, c1.email)
for x in c1.invoices:
print ("Invoice no : {}, Amount : {}".format(x.invno, x.amount))Результат вышеупомянутой программы выглядит следующим образом -
Govind Pant Gulmandi Aurangabad [email protected]
Invoice no : 3, Amount : 10000
Invoice no : 4, Amount : 5000Присоединенная нагрузка
Другая функция называется orm.joinedload (). Это испускает LEFT OUTER JOIN. Ведущий объект, а также связанный объект или коллекция загружаются за один шаг.
from sqlalchemy.orm import joinedload
c1 = session.query(Customer).options(joinedload(Customer.invoices)).filter_by(name='Govind Pant').one()Это испускает следующее выражение, дающее тот же результат, что и выше -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email, invoices_1.id
AS invoices_1_id, invoices_1.custid
AS invoices_1_custid, invoices_1.invno
AS invoices_1_invno, invoices_1.amount
AS invoices_1_amount
FROM customers
LEFT OUTER JOIN invoices
AS invoices_1
ON customers.id = invoices_1.custid
WHERE customers.name = ? ORDER BY invoices_1.id
('Govind Pant',)OUTER JOIN привело к появлению двух строк, но возвращает один экземпляр Customer. Это связано с тем, что Query применяет к возвращаемым объектам стратегию «уникальности», основанную на идентичности объекта. Совместная активная загрузка может применяться без влияния на результаты запроса.
Subqueryload () больше подходит для загрузки связанных коллекций, в то время как connectedload () лучше подходит для отношений «многие к одному».
Операцию удаления для одной таблицы легко выполнить. Все, что вам нужно сделать, это удалить объект сопоставленного класса из сеанса и зафиксировать действие. Однако операция удаления нескольких связанных таблиц немного сложна.
В нашей базе данных sales.db классы «Клиент» и «Счет-фактура» сопоставляются с таблицей «Клиент» и «Счет-фактура» с помощью отношений «один ко многим». Мы попробуем удалить объект «Клиент» и увидим результат.
В качестве краткой справки ниже приведены определения классов Customer и Invoice.
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
class Invoice(Base):
__tablename__ = 'invoices'
id = Column(Integer, primary_key = True)
custid = Column(Integer, ForeignKey('customers.id'))
invno = Column(Integer)
amount = Column(Integer)
customer = relationship("Customer", back_populates = "invoices")
Customer.invoices = relationship("Invoice", order_by = Invoice.id, back_populates = "customer")Мы настраиваем сеанс и получаем объект Customer, запрашивая его с первичным идентификатором, используя следующую программу -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
session = Session()
x = session.query(Customer).get(2)В нашей примерной таблице x.name означает «Гопал Кришна». Удалим этот x из сеанса и посчитаем появление этого имени.
session.delete(x)
session.query(Customer).filter_by(name = 'Gopal Krishna').count()Результирующее выражение SQL вернет 0.
SELECT count(*)
AS count_1
FROM (
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?)
AS anon_1('Gopal Krishna',) 0Однако связанные объекты Invoice x все еще существуют. Это можно проверить с помощью следующего кода -
session.query(Invoice).filter(Invoice.invno.in_([10,14])).count()Здесь 10 и 14 - номера счетов, принадлежащих клиенту Гопалу Кришне. Результатом вышеуказанного запроса является 2, что означает, что связанные объекты не были удалены.
SELECT count(*)
AS count_1
FROM (
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE invoices.invno IN (?, ?))
AS anon_1(10, 14) 2Это потому, что SQLAlchemy не предполагает удаления каскада; мы должны дать команду на его удаление.
Чтобы изменить поведение, мы настраиваем параметры каскада для отношения User.addresses. Давайте закроем текущий сеанс, воспользуемся новой declarative_base () и повторно объявим класс User, добавив отношения адресов, включая каскадную конфигурацию.
Атрибут cascade в функции отношения представляет собой список правил каскада, разделенных запятыми, который определяет, как операции сеанса должны «каскадироваться» от родителя к потомку. По умолчанию это False, что означает «сохранить-обновить, объединить».
Доступные каскады следующие:
- save-update
- merge
- expunge
- delete
- delete-orphan
- refresh-expire
Часто используется опция «all, delete-orphan», чтобы указать, что связанные объекты должны следовать вместе с родительским объектом во всех случаях и удаляться при отключении.
Следовательно, повторно объявленный класс Customer показан ниже -
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
invoices = relationship(
"Invoice",
order_by = Invoice.id,
back_populates = "customer",
cascade = "all,
delete, delete-orphan"
)Давайте удалим клиента с именем Гопал Кришна, используя приведенную ниже программу, и посмотрим количество связанных с ним объектов счета-фактуры -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
x = session.query(Customer).get(2)
session.delete(x)
session.query(Customer).filter_by(name = 'Gopal Krishna').count()
session.query(Invoice).filter(Invoice.invno.in_([10,14])).count()Счетчик теперь равен 0 со следующим SQL, выпущенным вышеуказанным скриптом -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id = ?
(2,)
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE ? = invoices.custid
ORDER BY invoices.id (2,)
DELETE FROM invoices
WHERE invoices.id = ? ((1,), (2,))
DELETE FROM customers
WHERE customers.id = ? (2,)
SELECT count(*)
AS count_1
FROM (
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?)
AS anon_1('Gopal Krishna',)
SELECT count(*)
AS count_1
FROM (
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE invoices.invno IN (?, ?))
AS anon_1(10, 14)
0Many to Many relationshipмежду двумя таблицами достигается путем добавления таблицы ассоциаций, в которой есть два внешних ключа - по одному от первичного ключа каждой таблицы. Более того, классы, отображаемые в две таблицы, имеют атрибут с набором объектов других ассоциативных таблиц, назначенный как вторичный атрибут функции Relationship ().
Для этого создадим базу данных SQLite (mycollege.db) с двумя таблицами - отдел и сотрудник. Здесь мы предполагаем, что сотрудник является частью более чем одного отдела, а в отделе более одного сотрудника. Это составляет отношение "многие ко многим".
Определение классов сотрудников и отделов, сопоставленных с таблицей отделов и сотрудников, выглядит следующим образом:
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///mycollege.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Department(Base):
__tablename__ = 'department'
id = Column(Integer, primary_key = True)
name = Column(String)
employees = relationship('Employee', secondary = 'link')
class Employee(Base):
__tablename__ = 'employee'
id = Column(Integer, primary_key = True)
name = Column(String)
departments = relationship(Department,secondary='link')Теперь мы определяем класс Link. Он связан с таблицей ссылок и содержит атрибуты Department_id и employee_id, соответственно ссылающиеся на первичные ключи таблицы отдела и сотрудника.
class Link(Base):
__tablename__ = 'link'
department_id = Column(
Integer,
ForeignKey('department.id'),
primary_key = True)
employee_id = Column(
Integer,
ForeignKey('employee.id'),
primary_key = True)Здесь мы должны отметить, что у класса Department есть атрибут сотрудников, связанный с классом Employee. Вторичному атрибуту функции отношений в качестве значения присваивается ссылка.
Точно так же класс Employee имеет атрибут отделов, связанный с классом отдела. Вторичному атрибуту функции отношений в качестве значения присваивается ссылка.
Все эти три таблицы создаются при выполнении следующего оператора:
Base.metadata.create_all(engine)Консоль Python генерирует следующие запросы CREATE TABLE -
CREATE TABLE department (
id INTEGER NOT NULL,
name VARCHAR,
PRIMARY KEY (id)
)
CREATE TABLE employee (
id INTEGER NOT NULL,
name VARCHAR,
PRIMARY KEY (id)
)
CREATE TABLE link (
department_id INTEGER NOT NULL,
employee_id INTEGER NOT NULL,
PRIMARY KEY (department_id, employee_id),
FOREIGN KEY(department_id) REFERENCES department (id),
FOREIGN KEY(employee_id) REFERENCES employee (id)
)Мы можем проверить это, открыв mycollege.db с помощью SQLiteStudio, как показано на скриншотах, приведенных ниже -
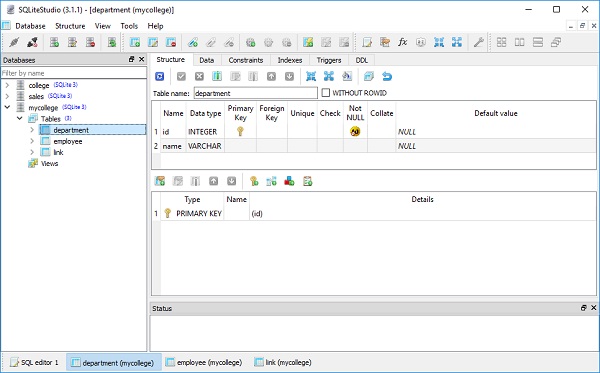
Затем мы создаем три объекта класса Department и три объекта класса Employee, как показано ниже -
d1 = Department(name = "Accounts")
d2 = Department(name = "Sales")
d3 = Department(name = "Marketing")
e1 = Employee(name = "John")
e2 = Employee(name = "Tony")
e3 = Employee(name = "Graham")Каждая таблица имеет атрибут коллекции, имеющий метод append (). Мы можем добавить объекты Employee в коллекцию Employees объекта Department. Точно так же мы можем добавить объекты отдела в атрибут коллекции отделов объектов Employee.
e1.departments.append(d1)
e2.departments.append(d3)
d1.employees.append(e3)
d2.employees.append(e2)
d3.employees.append(e1)
e3.departments.append(d2)Все, что нам нужно сделать сейчас, это настроить объект сеанса, добавить к нему все объекты и зафиксировать изменения, как показано ниже -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
session.add(e1)
session.add(e2)
session.add(d1)
session.add(d2)
session.add(d3)
session.add(e3)
session.commit()Следующие операторы SQL будут выведены на консоль Python -
INSERT INTO department (name) VALUES (?) ('Accounts',)
INSERT INTO department (name) VALUES (?) ('Sales',)
INSERT INTO department (name) VALUES (?) ('Marketing',)
INSERT INTO employee (name) VALUES (?) ('John',)
INSERT INTO employee (name) VALUES (?) ('Graham',)
INSERT INTO employee (name) VALUES (?) ('Tony',)
INSERT INTO link (department_id, employee_id) VALUES (?, ?) ((1, 2), (3, 1), (2, 3))
INSERT INTO link (department_id, employee_id) VALUES (?, ?) ((1, 1), (2, 2), (3, 3))Чтобы проверить эффект вышеуказанных операций, используйте SQLiteStudio и просмотрите данные в таблицах отделов, сотрудников и ссылок -
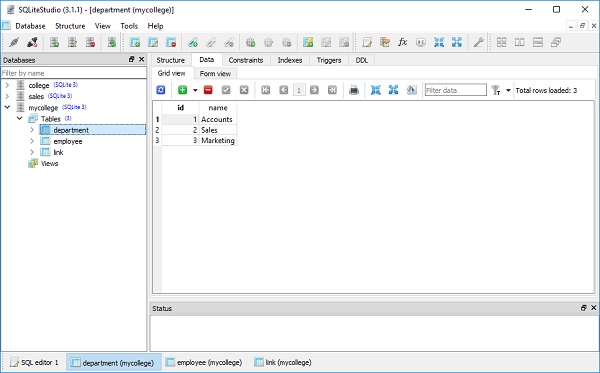
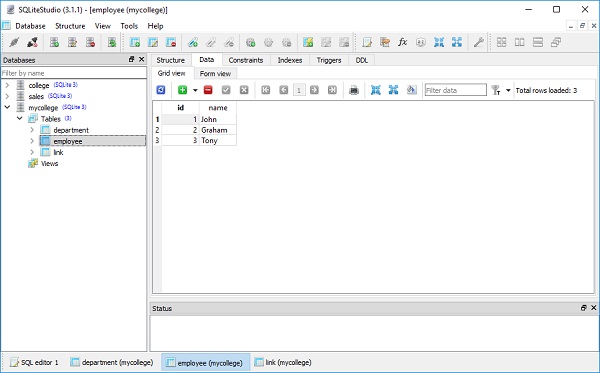
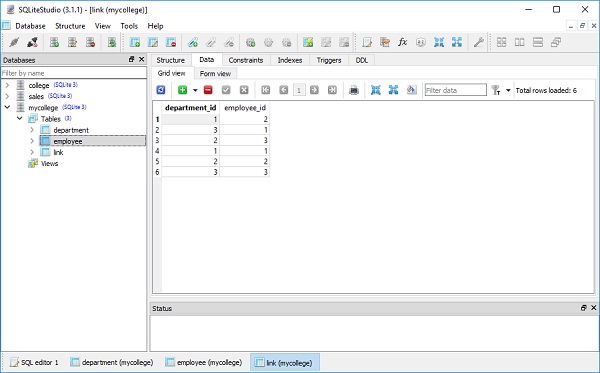
Чтобы отобразить данные, запустите следующий оператор запроса -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
for x in session.query( Department, Employee).filter(Link.department_id == Department.id,
Link.employee_id == Employee.id).order_by(Link.department_id).all():
print ("Department: {} Name: {}".format(x.Department.name, x.Employee.name))Согласно данным, заполненным в нашем примере, вывод будет отображаться, как показано ниже -
Department: Accounts Name: John
Department: Accounts Name: Graham
Department: Sales Name: Graham
Department: Sales Name: Tony
Department: Marketing Name: John
Department: Marketing Name: TonySQLAlchemy использует систему диалектов для связи с различными типами баз данных. Каждая база данных имеет соответствующую оболочку DBAPI. Все диалекты требуют, чтобы был установлен соответствующий драйвер DBAPI.
Следующие диалекты включены в SQLAlchemy API -
- Firebird
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- SQL
- Sybase
Объект Engine на основе URL создается функцией create_engine (). Эти URL-адреса могут включать имя пользователя, пароль, имя хоста и имя базы данных. Для дополнительной настройки могут быть необязательные ключевые аргументы. В некоторых случаях допускается путь к файлу, а в других «имя источника данных» заменяет части «хост» и «база данных». Типичная форма URL-адреса базы данных выглядит следующим образом:
dialect+driver://username:password@host:port/databasePostgreSQL
Диалект PostgreSQL использует psycopg2как DBAPI по умолчанию. pg8000 также доступен в качестве замены на чистом Python, как показано ниже:
# default
engine = create_engine('postgresql://scott:tiger@localhost/mydatabase')
# psycopg2
engine = create_engine('postgresql+psycopg2://scott:tiger@localhost/mydatabase')
# pg8000
engine = create_engine('postgresql+pg8000://scott:tiger@localhost/mydatabase')MySQL
Диалект MySQL использует mysql-pythonкак DBAPI по умолчанию. Доступно множество MySQL DBAPI, например MySQL-connector-python, как показано ниже:
# default
engine = create_engine('mysql://scott:tiger@localhost/foo')
# mysql-python
engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo')
# MySQL-connector-python
engine = create_engine('mysql+mysqlconnector://scott:tiger@localhost/foo')Oracle
Диалект Oracle использует cx_oracle в качестве DBAPI по умолчанию:
engine = create_engine('oracle://scott:[email protected]:1521/sidname')
engine = create_engine('oracle+cx_oracle://scott:tiger@tnsname')Microsoft SQL Server
Диалект SQL Server использует pyodbcкак DBAPI по умолчанию. pymssql также доступен.
# pyodbc
engine = create_engine('mssql+pyodbc://scott:tiger@mydsn')
# pymssql
engine = create_engine('mssql+pymssql://scott:tiger@hostname:port/dbname')SQLite
SQLite подключается к файловым базам данных с помощью встроенного модуля Python. sqlite3по умолчанию. Поскольку SQLite подключается к локальным файлам, формат URL-адреса немного отличается. «Файловая» часть URL-адреса - это имя файла базы данных. Для относительного пути к файлу требуется три слэша, как показано ниже -
engine = create_engine('sqlite:///foo.db')А для абсолютного пути к файлу за тремя косыми чертами следует абсолютный путь, как указано ниже -
engine = create_engine('sqlite:///C:\\path\\to\\foo.db')Чтобы использовать базу данных SQLite: memory:, укажите пустой URL-адрес, как указано ниже -
engine = create_engine('sqlite://')Заключение
В первой части этого руководства мы узнали, как использовать язык выражений для выполнения операторов SQL. Язык выражений встраивает конструкции SQL в код Python. Во второй части мы обсудили возможность отображения объектных отношений в SQLAlchemy. ORM API сопоставляет таблицы SQL с классами Python.