Apache Flink - สถาปัตยกรรม
Apache Flink ทำงานบนสถาปัตยกรรม Kappa สถาปัตยกรรม Kappa มีโปรเซสเซอร์เดียว - สตรีมซึ่งถือว่าอินพุตทั้งหมดเป็นสตรีมและเอ็นจิ้นการสตรีมประมวลผลข้อมูลแบบเรียลไทม์ ข้อมูลแบทช์ในสถาปัตยกรรมคัปปาเป็นกรณีพิเศษของการสตรีม
แผนภาพต่อไปนี้แสดงไฟล์ Apache Flink Architecture.
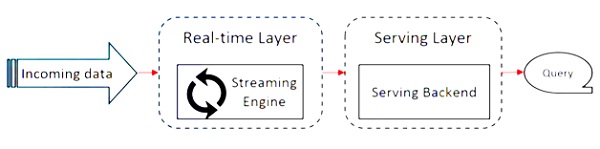
แนวคิดหลักในสถาปัตยกรรม Kappa คือการจัดการข้อมูลทั้งแบบแบทช์และแบบเรียลไทม์ผ่านระบบประมวลผลแบบสตรีมเดียว
เฟรมเวิร์กข้อมูลขนาดใหญ่ส่วนใหญ่ทำงานบนสถาปัตยกรรม Lambda ซึ่งมีโปรเซสเซอร์แยกต่างหากสำหรับข้อมูลแบตช์และสตรีม ในสถาปัตยกรรมแลมบ์ดาคุณมีโค้ดเบสแยกกันสำหรับการดูแบตช์และสตรีม สำหรับการสืบค้นและรับผลลัพธ์จำเป็นต้องผสานโค้ดเบส การไม่ดูแลฐานข้อมูล / มุมมองที่แยกจากกันและการรวมเข้าด้วยกันเป็นความเจ็บปวด แต่สถาปัตยกรรม Kappa ช่วยแก้ปัญหานี้ได้เนื่องจากมีเพียงมุมมองเดียว - แบบเรียลไทม์ดังนั้นจึงไม่จำเป็นต้องรวมโค้ดเบสเข้าด้วยกัน
นั่นไม่ได้หมายความว่าสถาปัตยกรรม Kappa จะเข้ามาแทนที่สถาปัตยกรรม Lambda โดยสมบูรณ์ขึ้นอยู่กับกรณีการใช้งานและแอปพลิเคชันที่ตัดสินใจว่าสถาปัตยกรรมใดจะดีกว่า
แผนภาพต่อไปนี้แสดงสถาปัตยกรรมการดำเนินงานของ Apache Flink

โปรแกรม
เป็นโค้ดส่วนหนึ่งที่คุณเรียกใช้บน Flink Cluster
ลูกค้า
มีหน้าที่รับโค้ด (โปรแกรม) และสร้างกราฟกระแสข้อมูลงานจากนั้นส่งต่อไปยัง JobManager นอกจากนี้ยังดึงผลลัพธ์ของงาน
JobManager
หลังจากได้รับ Job Dataflow Graph จาก Client แล้วจะมีหน้าที่สร้างกราฟการดำเนินการ จะมอบหมายงานให้กับ TaskManagers ในคลัสเตอร์และดูแลการดำเนินการของงาน
ผู้จัดการงาน
มีหน้าที่รับผิดชอบในการดำเนินงานทั้งหมดที่ได้รับมอบหมายจาก JobManager TaskManagers ทั้งหมดรันงานในสล็อตแยกต่างหากในความขนานที่ระบุ มีหน้าที่ส่งสถานะของงานไปยัง JobManager
คุณสมบัติของ Apache Flink
คุณสมบัติของ Apache Flink มีดังต่อไปนี้ -
มีโปรเซสเซอร์สตรีมมิ่งซึ่งสามารถรันได้ทั้งโปรแกรมแบตช์และสตรีม
สามารถประมวลผลข้อมูลด้วยความเร็วที่รวดเร็ว
API พร้อมใช้งานใน Java, Scala และ Python
จัดเตรียม API สำหรับการดำเนินการทั่วไปทั้งหมดซึ่งง่ายมากสำหรับโปรแกรมเมอร์ที่จะใช้
ประมวลผลข้อมูลด้วยเวลาแฝงต่ำ (นาโนวินาที) และปริมาณงานสูง
ยอมรับความผิดได้ หากโหนดแอปพลิเคชันหรือฮาร์ดแวร์ล้มเหลวจะไม่มีผลต่อคลัสเตอร์
สามารถทำงานร่วมกับ Apache Hadoop, Apache MapReduce, Apache Spark, HBase และเครื่องมือข้อมูลขนาดใหญ่อื่น ๆ ได้อย่างง่ายดาย
การจัดการในหน่วยความจำสามารถปรับแต่งเพื่อการคำนวณที่ดีขึ้น
สามารถปรับขนาดได้สูงและสามารถปรับขนาดได้ไม่เกินหลายพันโหนดในคลัสเตอร์
Windowing มีความยืดหยุ่นมากใน Apache Flink
ให้การประมวลผลกราฟการเรียนรู้ของเครื่องไลบรารีการประมวลผลเหตุการณ์ที่ซับซ้อน