Apache Flink - คู่มือฉบับย่อ
ความก้าวหน้าของข้อมูลในช่วง 10 ปีที่ผ่านมามีมากมายมหาศาล สิ่งนี้ทำให้เกิดคำว่า 'Big Data' ไม่มีขนาดข้อมูลคงที่ซึ่งคุณสามารถเรียกได้ว่าเป็นข้อมูลขนาดใหญ่ ข้อมูลใด ๆ ที่ระบบดั้งเดิม (RDBMS) ของคุณไม่สามารถจัดการได้คือ Big Data ข้อมูลขนาดใหญ่นี้สามารถอยู่ในรูปแบบที่มีโครงสร้างกึ่งโครงสร้างหรือไม่มีโครงสร้าง ในขั้นต้นข้อมูลมีสามมิติ ได้แก่ Volume, Velocity, Variety ตอนนี้มิติได้ไปไกลกว่าแค่สาม Vs ตอนนี้เราได้เพิ่ม Vs อื่น ๆ - ความจริงความถูกต้องช่องโหว่มูลค่าความแปรปรวนและอื่น ๆ
Big Data นำไปสู่การเกิดขึ้นของเครื่องมือและเฟรมเวิร์กมากมายที่ช่วยในการจัดเก็บและประมวลผลข้อมูล มีกรอบข้อมูลขนาดใหญ่ที่เป็นที่นิยมอยู่สองสามตัวเช่น Hadoop, Spark, Hive, Pig, Storm และ Zookeeper นอกจากนี้ยังเปิดโอกาสให้สร้างผลิตภัณฑ์ Next Gen ในหลายโดเมนเช่น Healthcare, Finance, Retail, E-Commerce และอื่น ๆ
ไม่ว่าจะเป็น MNC หรือสตาร์ทอัพทุกคนต่างก็ใช้ประโยชน์จาก Big Data เพื่อจัดเก็บและประมวลผลและตัดสินใจอย่างชาญฉลาด
ในแง่ของข้อมูลขนาดใหญ่มีสองประเภทของการประมวลผล -
- การประมวลผลแบทช์
- การประมวลผลแบบเรียลไทม์
การประมวลผลตามข้อมูลที่รวบรวมในช่วงเวลาหนึ่งเรียกว่าการประมวลผลแบบกลุ่ม ตัวอย่างเช่นผู้จัดการธนาคารต้องการประมวลผลข้อมูลหนึ่งเดือนที่ผ่านมา (เก็บรวบรวมเมื่อเวลาผ่านไป) เพื่อทราบจำนวนเช็คที่ถูกยกเลิกใน 1 เดือนที่ผ่านมา
การประมวลผลตามข้อมูลทันทีเพื่อให้ได้ผลลัพธ์ทันทีเรียกว่าการประมวลผลแบบเรียลไทม์ ตัวอย่างเช่นผู้จัดการธนาคารได้รับการแจ้งเตือนการฉ้อโกงทันทีหลังจากเกิดธุรกรรมการฉ้อโกง (ผลลัพธ์ทันที)
ตารางด้านล่างแสดงความแตกต่างระหว่างการประมวลผลแบบเป็นกลุ่มและแบบเรียลไทม์ -
| การประมวลผลแบทช์ | การประมวลผลแบบเรียลไทม์ |
|---|---|
ไฟล์คงที่ |
สตรีมเหตุการณ์ |
ประมวลผลเป็นระยะ ๆ เป็นนาทีชั่วโมงวันและอื่น ๆ |
ดำเนินการทันที นาโนวินาที |
ข้อมูลที่ผ่านมาในการจัดเก็บดิสก์ |
ในหน่วยความจำ |
ตัวอย่าง - การสร้างบิล |
ตัวอย่าง - การแจ้งเตือนธุรกรรม ATM |
ทุกวันนี้การประมวลผลแบบเรียลไทม์ถูกนำมาใช้มากในทุกองค์กร ใช้กรณีต่างๆเช่นการตรวจจับการฉ้อโกงการแจ้งเตือนแบบเรียลไทม์ในการดูแลสุขภาพและการแจ้งเตือนการโจมตีเครือข่ายต้องการการประมวลผลข้อมูลทันทีแบบเรียลไทม์ ความล่าช้าแม้เพียงไม่กี่มิลลิวินาทีอาจส่งผลกระทบอย่างมาก
เครื่องมือที่เหมาะสำหรับกรณีการใช้งานแบบเรียลไทม์เช่นนี้คือเครื่องมือที่สามารถป้อนข้อมูลเป็นสตรีมและไม่ใช่แบทช์ Apache Flink เป็นเครื่องมือประมวลผลแบบเรียลไทม์
Apache Flink เป็นกรอบการประมวลผลแบบเรียลไทม์ซึ่งสามารถประมวลผลข้อมูลสตรีมมิ่ง เป็นกรอบการประมวลผลสตรีมโอเพ่นซอร์สสำหรับแอปพลิเคชันแบบเรียลไทม์ที่มีประสิทธิภาพสูงปรับขนาดได้และแม่นยำ มีรูปแบบการสตรีมที่แท้จริงและไม่ใช้ข้อมูลอินพุตเป็นแบตช์หรือไมโครแบทช์
Apache Flink ก่อตั้งโดย บริษัท Data Artisans และได้รับการพัฒนาภายใต้ Apache License โดย Apache Flink Community ชุมชนนี้มีผู้ร่วมให้ข้อมูลมากกว่า 479 คนและจนถึงขณะนี้มากกว่า 15,000 คน
ระบบนิเวศบน Apache Flink
แผนภาพด้านล่างแสดงชั้นต่างๆของ Apache Flink Ecosystem -

การจัดเก็บ
Apache Flink มีตัวเลือกมากมายสำหรับการอ่าน / เขียนข้อมูล ด้านล่างนี้คือรายการพื้นที่เก็บข้อมูลพื้นฐาน -
- HDFS (ระบบไฟล์แบบกระจาย Hadoop)
- ระบบไฟล์ในเครื่อง
- S3
- RDBMS (MySQL, Oracle, MS SQL ฯลฯ )
- MongoDB
- HBase
- อาปาเช่คาฟคา
- Apache Flume
ปรับใช้
คุณสามารถปรับใช้ Apache Fink ในโหมดโลคัลโหมดคลัสเตอร์หรือบนคลาวด์ โหมดคลัสเตอร์สามารถเป็นแบบสแตนด์อโลน, YARN, MESOS
บนคลาวด์สามารถปรับใช้ Flink บน AWS หรือ GCP ได้
เคอร์เนล
นี่คือเลเยอร์รันไทม์ซึ่งจัดเตรียมการประมวลผลแบบกระจายความทนทานต่อข้อผิดพลาดความน่าเชื่อถือความสามารถในการประมวลผลซ้ำแบบเนทีฟและอื่น ๆ
API และไลบรารี
นี่คือเลเยอร์บนสุดและชั้นที่สำคัญที่สุดของ Apache Flink มี Dataset API ซึ่งดูแลการประมวลผลชุดงานและ Datastream API ซึ่งดูแลการประมวลผลสตรีม มีไลบรารีอื่น ๆ เช่น Flink ML (สำหรับการเรียนรู้ของเครื่อง), Gelly (สำหรับการประมวลผลกราฟ), ตารางสำหรับ SQL เลเยอร์นี้มอบความสามารถที่หลากหลายให้กับ Apache Flink
Apache Flink ทำงานบนสถาปัตยกรรม Kappa สถาปัตยกรรม Kappa มีโปรเซสเซอร์เดียว - สตรีมซึ่งถือว่าอินพุตทั้งหมดเป็นสตรีมและเอ็นจิ้นการสตรีมประมวลผลข้อมูลแบบเรียลไทม์ ข้อมูลแบทช์ในสถาปัตยกรรมคัปปาเป็นกรณีพิเศษของการสตรีม
แผนภาพต่อไปนี้แสดงไฟล์ Apache Flink Architecture.
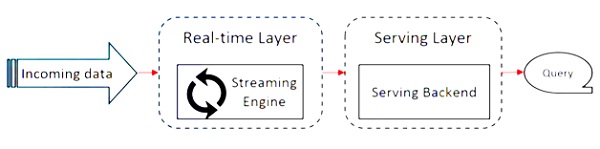
แนวคิดหลักในสถาปัตยกรรม Kappa คือการจัดการข้อมูลทั้งแบบแบทช์และแบบเรียลไทม์ผ่านระบบประมวลผลแบบสตรีมเดียว
เฟรมเวิร์กข้อมูลขนาดใหญ่ส่วนใหญ่ทำงานบนสถาปัตยกรรม Lambda ซึ่งมีโปรเซสเซอร์แยกต่างหากสำหรับข้อมูลแบตช์และสตรีม ในสถาปัตยกรรมแลมบ์ดาคุณมีโค้ดเบสแยกกันสำหรับการดูแบตช์และสตรีม สำหรับการสืบค้นและรับผลลัพธ์จำเป็นต้องผสานโค้ดเบส การไม่ดูแลฐานข้อมูล / มุมมองที่แยกจากกันและการรวมเข้าด้วยกันเป็นความเจ็บปวด แต่สถาปัตยกรรม Kappa ช่วยแก้ปัญหานี้ได้เนื่องจากมีเพียงมุมมองเดียว - แบบเรียลไทม์ดังนั้นจึงไม่จำเป็นต้องรวมโค้ดเบสเข้าด้วยกัน
นั่นไม่ได้หมายความว่าสถาปัตยกรรม Kappa จะเข้ามาแทนที่สถาปัตยกรรม Lambda โดยสมบูรณ์ขึ้นอยู่กับกรณีการใช้งานและแอปพลิเคชันที่ตัดสินใจว่าสถาปัตยกรรมใดจะดีกว่า
แผนภาพต่อไปนี้แสดงสถาปัตยกรรมการดำเนินงานของ Apache Flink

โปรแกรม
เป็นโค้ดส่วนหนึ่งที่คุณเรียกใช้บน Flink Cluster
ลูกค้า
มีหน้าที่รับโค้ด (โปรแกรม) และสร้างกราฟกระแสข้อมูลงานจากนั้นส่งต่อไปยัง JobManager นอกจากนี้ยังดึงผลลัพธ์ของงาน
JobManager
หลังจากได้รับ Job Dataflow Graph จาก Client แล้วจะมีหน้าที่สร้างกราฟการดำเนินการ จะมอบหมายงานให้กับ TaskManagers ในคลัสเตอร์และดูแลการดำเนินการของงาน
ผู้จัดการงาน
มีหน้าที่รับผิดชอบในการดำเนินงานทั้งหมดที่ได้รับมอบหมายจาก JobManager TaskManagers ทั้งหมดรันงานในสล็อตแยกต่างหากในความขนานที่ระบุ มีหน้าที่ส่งสถานะของงานไปยัง JobManager
คุณสมบัติของ Apache Flink
คุณสมบัติของ Apache Flink มีดังต่อไปนี้ -
มีโปรเซสเซอร์สตรีมมิ่งซึ่งสามารถรันได้ทั้งโปรแกรมแบตช์และสตรีม
สามารถประมวลผลข้อมูลด้วยความเร็วที่รวดเร็ว
API พร้อมใช้งานใน Java, Scala และ Python
จัดเตรียม API สำหรับการดำเนินการทั่วไปทั้งหมดซึ่งง่ายมากสำหรับโปรแกรมเมอร์ที่จะใช้
ประมวลผลข้อมูลด้วยเวลาแฝงต่ำ (นาโนวินาที) และปริมาณงานสูง
ยอมรับความผิดได้ หากโหนดแอปพลิเคชันหรือฮาร์ดแวร์ล้มเหลวจะไม่มีผลต่อคลัสเตอร์
สามารถทำงานร่วมกับ Apache Hadoop, Apache MapReduce, Apache Spark, HBase และเครื่องมือข้อมูลขนาดใหญ่อื่น ๆ ได้อย่างง่ายดาย
การจัดการในหน่วยความจำสามารถปรับแต่งเพื่อการคำนวณที่ดีขึ้น
สามารถปรับขนาดได้สูงและสามารถปรับขนาดได้ไม่เกินหลายพันโหนดในคลัสเตอร์
Windowing มีความยืดหยุ่นมากใน Apache Flink
ให้การประมวลผลกราฟการเรียนรู้ของเครื่องไลบรารีการประมวลผลเหตุการณ์ที่ซับซ้อน
ต่อไปนี้เป็นข้อกำหนดของระบบในการดาวน์โหลดและทำงานบน Apache Flink -
ระบบปฏิบัติการที่แนะนำ
- Microsoft Windows 10
- Ubuntu 16.04 LTS
- Apple macOS 10.13 / High Sierra
ความต้องการหน่วยความจำ
- หน่วยความจำ - ขั้นต่ำ 4 GB แนะนำ 8 GB
- พื้นที่จัดเก็บ - 30 GB
Note - Java 8 ต้องพร้อมใช้งานพร้อมกับตัวแปรสภาพแวดล้อมที่กำหนดไว้แล้ว
ก่อนเริ่มต้นด้วยการตั้งค่า / การติดตั้ง Apache Flink ให้เราตรวจสอบว่าเราติดตั้ง Java 8 ในระบบของเราหรือไม่
Java - เวอร์ชัน

ตอนนี้เราจะดำเนินการต่อโดยดาวน์โหลด Apache Flink
wget http://mirrors.estointernet.in/apache/flink/flink-1.7.1/flink-1.7.1-bin-scala_2.11.tgz
ตอนนี้คลายการบีบอัดไฟล์ tar
tar -xzf flink-1.7.1-bin-scala_2.11.tgz
ไปที่โฮมไดเร็กทอรีของ Flink
cd flink-1.7.1/เริ่ม Flink Cluster
./bin/start-cluster.sh
เปิดเบราว์เซอร์ Mozilla และไปที่ URL ด้านล่างมันจะเปิด Flink Web Dashboard
http://localhost:8081
นี่คือลักษณะของส่วนติดต่อผู้ใช้ของ Apache Flink Dashboard

ขณะนี้คลัสเตอร์ Flink พร้อมทำงานแล้ว
Flink มีชุด API ที่สมบูรณ์ซึ่งนักพัฒนาสามารถทำการเปลี่ยนแปลงได้ทั้งข้อมูลแบทช์และแบบเรียลไทม์ การเปลี่ยนแปลงที่หลากหลายรวมถึงการทำแผนที่การกรองการเรียงลำดับการเข้าร่วมการจัดกลุ่มและการรวมกลุ่ม การแปลงเหล่านี้โดย Apache Flink ดำเนินการกับข้อมูลแบบกระจาย ให้เราพูดคุยเกี่ยวกับข้อเสนอ APIs Apache Flink ที่แตกต่างกัน
API ชุดข้อมูล
Dataset API ใน Apache Flink ใช้เพื่อดำเนินการกับข้อมูลเป็นกลุ่มในช่วงเวลาหนึ่ง API นี้สามารถใช้ได้ใน Java, Scala และ Python สามารถใช้การเปลี่ยนแปลงประเภทต่างๆในชุดข้อมูลเช่นการกรองการทำแผนที่การรวมการรวมและการจัดกลุ่ม
ชุดข้อมูลถูกสร้างขึ้นจากแหล่งที่มาเช่นไฟล์ในเครื่องหรือโดยการอ่านไฟล์จากแหล่งที่มาเฉพาะและข้อมูลผลลัพธ์สามารถเขียนบนซิงก์ต่างๆเช่นไฟล์แบบกระจายหรือเทอร์มินัลบรรทัดคำสั่ง API นี้รองรับทั้งภาษาโปรแกรม Java และ Scala
นี่คือโปรแกรม Wordcount ของ Dataset API -
public class WordCountProg {
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> text = env.fromElements(
"Hello",
"My Dataset API Flink Program");
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
wordCounts.print();
}
public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}DataStream API
API นี้ใช้สำหรับจัดการข้อมูลในสตรีมแบบต่อเนื่อง คุณสามารถดำเนินการต่างๆเช่นการกรองการทำแผนที่การกำหนดหน้าต่างการรวมข้อมูลสตรีม มีแหล่งข้อมูลต่างๆในสตรีมข้อมูลนี้เช่นคิวข้อความไฟล์ซ็อกเก็ตสตรีมและข้อมูลผลลัพธ์สามารถเขียนบนซิงก์ต่างๆเช่นเทอร์มินัลบรรทัดคำสั่ง ทั้งภาษาโปรแกรม Java และ Scala รองรับ API นี้
นี่คือโปรแกรม Wordcount แบบสตรีมของ DataStream API ซึ่งคุณมีสตรีมจำนวนคำอย่างต่อเนื่องและข้อมูลจะถูกจัดกลุ่มในหน้าต่างที่สอง
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class WindowWordCountProg {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("localhost", 9999)
.flatMap(new Splitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
dataStream.print();
env.execute("Streaming WordCount Example");
}
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}Table API เป็น API เชิงสัมพันธ์ที่มี SQL เหมือนกับภาษานิพจน์ API นี้ทำได้ทั้งการประมวลผลแบบแบตช์และสตรีม สามารถฝังกับ Java และ Scala Dataset และ Datastream API ได้ คุณสามารถสร้างตารางจากชุดข้อมูลและ Datastreams ที่มีอยู่หรือจากแหล่งข้อมูลภายนอก ด้วย API เชิงสัมพันธ์นี้คุณสามารถดำเนินการต่างๆเช่นเข้าร่วมรวมเลือกและกรอง ไม่ว่าอินพุตจะเป็นแบตช์หรือสตรีมความหมายของแบบสอบถามจะยังคงเหมือนเดิม
นี่คือตัวอย่างโปรแกรม Table API -
// for batch programs use ExecutionEnvironment instead of StreamExecutionEnvironment
val env = StreamExecutionEnvironment.getExecutionEnvironment
// create a TableEnvironment
val tableEnv = TableEnvironment.getTableEnvironment(env)
// register a Table
tableEnv.registerTable("table1", ...) // or
tableEnv.registerTableSource("table2", ...) // or
tableEnv.registerExternalCatalog("extCat", ...)
// register an output Table
tableEnv.registerTableSink("outputTable", ...);
// create a Table from a Table API query
val tapiResult = tableEnv.scan("table1").select(...)
// Create a Table from a SQL query
val sqlResult = tableEnv.sqlQuery("SELECT ... FROM table2 ...")
// emit a Table API result Table to a TableSink, same for SQL result
tapiResult.insertInto("outputTable")
// execute
env.execute()ในบทนี้เราจะเรียนรู้วิธีสร้างแอปพลิเคชัน Flink
เปิด Eclipse IDE คลิกที่ New Project และเลือก Java Project

ตั้งชื่อโครงการและคลิกที่ Finish

ตอนนี้คลิกที่ Finish ตามที่แสดงในภาพหน้าจอต่อไปนี้
ตอนนี้คลิกขวาที่ src และไปที่ New >> Class

ตั้งชื่อชั้นเรียนแล้วคลิกที่ Finish

คัดลอกและวางโค้ดด้านล่างในตัวแก้ไข
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.util.Collector;
public class WordCount {
// *************************************************************************
// PROGRAM
// *************************************************************************
public static void main(String[] args) throws Exception {
final ParameterTool params = ParameterTool.fromArgs(args);
// set up the execution environment
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// make parameters available in the web interface
env.getConfig().setGlobalJobParameters(params);
// get input data
DataSet<String> text = env.readTextFile(params.get("input"));
DataSet<Tuple2<String, Integer>> counts =
// split up the lines in pairs (2-tuples) containing: (word,1)
text.flatMap(new Tokenizer())
// group by the tuple field "0" and sum up tuple field "1"
.groupBy(0)
.sum(1);
// emit result
if (params.has("output")) {
counts.writeAsCsv(params.get("output"), "\n", " ");
// execute program
env.execute("WordCount Example");
} else {
System.out.println("Printing result to stdout. Use --output to specify output path.");
counts.print();
}
}
// *************************************************************************
// USER FUNCTIONS
// *************************************************************************
public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// normalize and split the line
String[] tokens = value.toLowerCase().split("\\W+");
// emit the pairs
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
}คุณจะได้รับข้อผิดพลาดมากมายในตัวแก้ไขเนื่องจากต้องเพิ่มไลบรารี Flink ในโปรเจ็กต์นี้

คลิกขวาที่โปรเจ็กต์ >> Build Path >> Configure Build Path
เลือกแท็บ Libraries และคลิกที่ Add External JARs

ไปที่ไดเรกทอรี lib ของ Flink เลือกไลบรารีทั้งหมด 4 ไลบรารีแล้วคลิกตกลง
ไปที่แท็บ Order and Export เลือกไลบรารีทั้งหมดแล้วคลิกตกลง
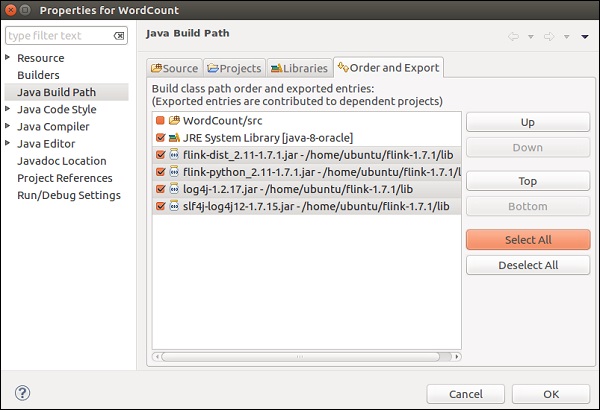
คุณจะเห็นว่าไม่มีข้อผิดพลาดอีกต่อไป
ตอนนี้ให้เราส่งออกแอปพลิเคชันนี้ คลิกขวาที่โครงการและคลิกที่ส่งออก

เลือกไฟล์ JAR แล้วคลิกถัดไป

ระบุเส้นทางปลายทางแล้วคลิกถัดไป

คลิกที่ถัดไป>
คลิกที่ Browse เลือกคลาสหลัก (WordCount) แล้วคลิก Finish

Note - คลิกตกลงในกรณีที่คุณได้รับคำเตือน
เรียกใช้คำสั่งด้านล่าง มันจะเรียกใช้แอปพลิเคชัน Flink ที่คุณเพิ่งสร้างขึ้น
./bin/flink run /home/ubuntu/wordcount.jar --input README.txt --output /home/ubuntu/output
ในบทนี้เราจะเรียนรู้วิธีเรียกใช้โปรแกรม Flink
ให้เราเรียกใช้ตัวอย่าง Flink wordcount บนคลัสเตอร์ Flink
ไปที่โฮมไดเร็กทอรีของ Flink และเรียกใช้คำสั่งด้านล่างในเทอร์มินัล
bin/flink run examples/batch/WordCount.jar -input README.txt -output /home/ubuntu/flink-1.7.1/output.txt
ไปที่แดชบอร์ด Flink คุณจะสามารถดูงานที่เสร็จสมบูรณ์พร้อมรายละเอียด

หากคุณคลิกที่งานที่เสร็จสมบูรณ์คุณจะเห็นภาพรวมโดยละเอียดของงาน

ในการตรวจสอบผลลัพธ์ของโปรแกรม wordcount ให้รันคำสั่งด้านล่างในเทอร์มินัล
cat output.txt
ในบทนี้เราจะเรียนรู้เกี่ยวกับไลบรารีต่างๆของ Apache Flink
การประมวลผลเหตุการณ์ที่ซับซ้อน (CEP)
FlinkCEP เป็น API ใน Apache Flink ซึ่งวิเคราะห์รูปแบบเหตุการณ์บนข้อมูลสตรีมมิ่งแบบต่อเนื่อง เหตุการณ์เหล่านี้ใกล้เคียงกับเวลาจริงซึ่งมีทรูพุตสูงและเวลาแฝงต่ำ API นี้ใช้กับข้อมูลเซนเซอร์เป็นส่วนใหญ่ซึ่งมาในแบบเรียลไทม์และมีความซับซ้อนในการประมวลผล
CEP วิเคราะห์รูปแบบของอินพุตสตรีมและให้ผลลัพธ์เร็ว ๆ นี้ มีความสามารถในการแจ้งเตือนแบบเรียลไทม์และการแจ้งเตือนในกรณีที่รูปแบบเหตุการณ์มีความซับซ้อน FlinkCEP สามารถเชื่อมต่อกับแหล่งอินพุตประเภทต่างๆและวิเคราะห์รูปแบบในนั้น
นี่คือลักษณะของสถาปัตยกรรมตัวอย่างที่มี CEP -

ข้อมูลเซ็นเซอร์จะมาจากแหล่งต่างๆ Kafka จะทำหน้าที่เป็นกรอบการส่งข้อความแบบกระจายซึ่งจะกระจายสตรีมไปยัง Apache Flink และ FlinkCEP จะวิเคราะห์รูปแบบเหตุการณ์ที่ซับซ้อน
คุณสามารถเขียนโปรแกรมใน Apache Flink สำหรับการประมวลผลเหตุการณ์ที่ซับซ้อนโดยใช้ Pattern API ช่วยให้คุณสามารถตัดสินใจรูปแบบเหตุการณ์ที่จะตรวจจับจากข้อมูลสตรีมแบบต่อเนื่อง ด้านล่างนี้คือรูปแบบ CEP ที่ใช้บ่อยที่สุด -
เริ่ม
ใช้เพื่อกำหนดสถานะเริ่มต้น โปรแกรมต่อไปนี้แสดงให้เห็นว่ามีการกำหนดไว้อย่างไรในโปรแกรม Flink -
Pattern<Event, ?> next = start.next("next");ที่ไหน
ใช้เพื่อกำหนดเงื่อนไขตัวกรองในสถานะปัจจุบัน
patternState.where(new FilterFunction <Event>() {
@Override
public boolean filter(Event value) throws Exception {
}
});ต่อไป
ใช้เพื่อผนวกสถานะรูปแบบใหม่และเหตุการณ์การจับคู่ที่จำเป็นเพื่อส่งผ่านรูปแบบก่อนหน้า
Pattern<Event, ?> next = start.next("next");ติดตามโดย
ใช้เพื่อต่อท้ายสถานะรูปแบบใหม่ แต่ที่นี่เหตุการณ์อื่นอาจเกิดขึ้น b / w สองเหตุการณ์ที่ตรงกัน
Pattern<Event, ?> followedBy = start.followedBy("next");เกลลี่
Graph API ของ Apache Flink คือ Gelly Gelly ใช้ในการวิเคราะห์กราฟบนแอพพลิเคชั่น Flink โดยใช้ชุดวิธีการและยูทิลิตี้ คุณสามารถวิเคราะห์กราฟขนาดใหญ่โดยใช้ Apache Flink API แบบกระจายด้วย Gelly มีไลบรารีกราฟอื่น ๆ เช่น Apache Giraph เพื่อจุดประสงค์เดียวกัน แต่เนื่องจาก Gelly ใช้กับ Apache Flink จึงใช้ API เดียว สิ่งนี้มีประโยชน์มากจากมุมมองของการพัฒนาและการดำเนินงาน
ให้เราเรียกใช้ตัวอย่างโดยใช้ Apache Flink API - Gelly
ประการแรกคุณต้องคัดลอกไฟล์ Gelly jar 2 ไฟล์จากไดเร็กทอรี opt ของ Apache Flink ไปยังไดเร็กทอรี lib จากนั้นเรียกใช้ขวดตัวอย่าง flink-gelly
cp opt/flink-gelly* lib/
./bin/flink run examples/gelly/flink-gelly-examples_*.jar
ตอนนี้ให้เราเรียกใช้ตัวอย่างเพจแรงก์
เพจแรงก์คำนวณคะแนนต่อจุดยอดซึ่งเป็นผลรวมของคะแนนเพจแรงก์ที่ส่งผ่านขอบ คะแนนของจุดยอดแต่ละจุดจะถูกแบ่งเท่า ๆ กันระหว่างขอบนอก จุดยอดที่มีคะแนนสูงจะเชื่อมโยงกับจุดยอดอื่น ๆ ที่มีคะแนนสูง
ผลลัพธ์ประกอบด้วยจุดยอด ID และคะแนนเพจแรงก์
usage: flink run examples/flink-gelly-examples_<version>.jar --algorithm PageRank [algorithm options] --input <input> [input options] --output <output> [output options]
./bin/flink run examples/gelly/flink-gelly-examples_*.jar --algorithm PageRank --input CycleGraph --vertex_count 2 --output Print
ไลบรารี Machine Learning ของ Apache Flink เรียกว่า FlinkML เนื่องจากการใช้แมชชีนเลิร์นนิงเพิ่มขึ้นอย่างทวีคูณในช่วง 5 ปีที่ผ่านมาชุมชน Flink จึงตัดสินใจเพิ่ม APO การเรียนรู้ของเครื่องนี้ในระบบนิเวศ รายชื่อผู้ร่วมให้ข้อมูลและอัลกอริทึมเพิ่มขึ้นใน FlinkML API นี้ยังไม่ได้เป็นส่วนหนึ่งของการแจกแจงแบบไบนารี
นี่คือตัวอย่างของการถดถอยเชิงเส้นโดยใช้ FlinkML -
// LabeledVector is a feature vector with a label (class or real value)
val trainingData: DataSet[LabeledVector] = ...
val testingData: DataSet[Vector] = ...
// Alternatively, a Splitter is used to break up a DataSet into training and testing data.
val dataSet: DataSet[LabeledVector] = ...
val trainTestData: DataSet[TrainTestDataSet] = Splitter.trainTestSplit(dataSet)
val trainingData: DataSet[LabeledVector] = trainTestData.training
val testingData: DataSet[Vector] = trainTestData.testing.map(lv => lv.vector)
val mlr = MultipleLinearRegression()
.setStepsize(1.0)
.setIterations(100)
.setConvergenceThreshold(0.001)
mlr.fit(trainingData)
// The fitted model can now be used to make predictions
val predictions: DataSet[LabeledVector] = mlr.predict(testingData)ข้างใน flink-1.7.1/examples/batch/เส้นทางคุณจะพบไฟล์ KMeans.jar ให้เราเรียกใช้ตัวอย่าง FlinkML ตัวอย่างนี้
โปรแกรมตัวอย่างนี้ทำงานโดยใช้จุดเริ่มต้นและชุดข้อมูลเซนทรอยด์
./bin/flink run examples/batch/KMeans.jar --output Print
ในบทนี้เราจะเข้าใจกรณีทดสอบบางส่วนใน Apache Flink
Apache Flink - Bouygues Telecom
Bouygues Telecom เป็นองค์กรโทรคมนาคมที่ใหญ่ที่สุดแห่งหนึ่งในฝรั่งเศส มีผู้ใช้บริการโทรศัพท์มือถือ 11+ ล้านรายและลูกค้าคงที่มากกว่า 2.5 ล้านราย Bouygues ได้ยินเกี่ยวกับ Apache Flink เป็นครั้งแรกในการประชุมกลุ่ม Hadoop ซึ่งจัดขึ้นที่ปารีส ตั้งแต่นั้นมาพวกเขาใช้ Flink สำหรับการใช้งานหลายกรณี พวกเขาประมวลผลข้อความหลายพันล้านข้อความในหนึ่งวันแบบเรียลไทม์ผ่าน Apache Flink
นี่คือสิ่งที่ Bouygues พูดเกี่ยวกับ Apache Flink: "เราจบลงด้วย Flink เพราะระบบรองรับการสตรีมที่แท้จริง - ทั้งในระดับ API และในระดับรันไทม์ทำให้เรามีความสามารถในการตั้งโปรแกรมและเวลาแฝงต่ำที่เรากำลังมองหานอกจากนี้ เราสามารถทำให้ระบบของเราทำงานด้วย Flink ได้ในเวลาอันสั้นเมื่อเทียบกับโซลูชันอื่น ๆ ซึ่งส่งผลให้มีทรัพยากรสำหรับนักพัฒนาที่มีอยู่มากขึ้นสำหรับการขยายตรรกะทางธุรกิจในระบบ "
ที่ Bouygues ประสบการณ์ของลูกค้าเป็นสิ่งสำคัญสูงสุด พวกเขาวิเคราะห์ข้อมูลแบบเรียลไทม์เพื่อให้ข้อมูลเชิงลึกแก่วิศวกรด้านล่าง -
ประสบการณ์ของลูกค้าแบบเรียลไทม์ผ่านเครือข่ายของพวกเขา
สิ่งที่เกิดขึ้นทั่วโลกบนเครือข่าย
การประเมินและการดำเนินงานของเครือข่าย
พวกเขาสร้างระบบที่เรียกว่า LUX (Logged User Experience) ซึ่งประมวลผลข้อมูลบันทึกขนาดใหญ่จากอุปกรณ์เครือข่ายพร้อมการอ้างอิงข้อมูลภายในเพื่อให้ตัวบ่งชี้คุณภาพของประสบการณ์ซึ่งจะบันทึกประสบการณ์ของลูกค้าและสร้างฟังก์ชันที่น่าตกใจเพื่อตรวจจับความล้มเหลวในการใช้ข้อมูลภายใน 60 วินาที.
เพื่อให้บรรลุเป้าหมายนี้พวกเขาต้องการเฟรมเวิร์กที่สามารถรับข้อมูลจำนวนมากแบบเรียลไทม์ติดตั้งง่ายและมีชุด API มากมายสำหรับการประมวลผลข้อมูลที่สตรีม Apache Flink เหมาะอย่างยิ่งสำหรับ Bouygues Telecom
Apache Flink - อาลีบาบา
อาลีบาบาเป็น บริษัท ค้าปลีกอีคอมเมิร์ซที่ใหญ่ที่สุดในโลกโดยมีรายได้ 394 พันล้านดอลลาร์ในปี 2558 การค้นหาของอาลีบาบาเป็นจุดเริ่มต้นของลูกค้าทั้งหมดซึ่งจะแสดงการค้นหาทั้งหมดและแนะนำตามนั้น
Alibaba ใช้ Apache Flink ในเครื่องมือค้นหาเพื่อแสดงผลแบบเรียลไทม์ด้วยความแม่นยำและความเกี่ยวข้องสูงสุดสำหรับผู้ใช้แต่ละราย
อาลีบาบากำลังมองหากรอบการทำงานซึ่งก็คือ -
คล่องตัวมากในการบำรุงรักษาโค้ดเบสเดียวสำหรับกระบวนการโครงสร้างพื้นฐานการค้นหาทั้งหมด
ให้เวลาแฝงต่ำสำหรับการเปลี่ยนแปลงความพร้อมใช้งานของผลิตภัณฑ์บนเว็บไซต์
สอดคล้องและคุ้มค่า
Apache Flink มีคุณสมบัติตรงตามข้อกำหนดข้างต้นทั้งหมด พวกเขาต้องการเฟรมเวิร์กซึ่งมีกลไกการประมวลผลเดียวและสามารถประมวลผลทั้งแบตช์และสตรีมข้อมูลด้วยเอ็นจิ้นเดียวกันและนั่นคือสิ่งที่ Apache Flink ทำ
นอกจากนี้ยังใช้ Blink ซึ่งเป็นเวอร์ชันแยกสำหรับ Flink เพื่อตอบสนองความต้องการเฉพาะบางประการสำหรับการค้นหาของพวกเขา พวกเขายังใช้ Table API ของ Apache Flink ซึ่งมีการปรับปรุงเล็กน้อยสำหรับการค้นหา
นี่คือสิ่งที่อาลีบาบาพูดเกี่ยวกับ apache Flink: " เมื่อมองย้อนกลับไปไม่ต้องสงสัยเลยว่าเป็นปีที่ยิ่งใหญ่สำหรับ Blink และ Flink ที่ Alibaba ไม่มีใครคิดว่าเราจะก้าวหน้ามากขนาดนี้ใน 1 ปีและเรารู้สึกขอบคุณทุกคน ผู้คนที่ช่วยเหลือเราในชุมชน Flink ได้รับการพิสูจน์แล้วว่าทำงานในระดับที่ใหญ่มากเรามีความมุ่งมั่นมากขึ้นที่จะทำงานร่วมกับชุมชนต่อไปเพื่อขับเคลื่อน Flink ไปข้างหน้า! "
นี่คือตารางที่ครอบคลุมซึ่งแสดงการเปรียบเทียบระหว่างกรอบข้อมูลขนาดใหญ่ที่ได้รับความนิยมสูงสุดสามกรอบ ได้แก่ Apache Flink, Apache Spark และ Apache Hadoop
| Apache Hadoop | Apache Spark | Apache Flink | |
|---|---|---|---|
Year of Origin |
พ.ศ. 2548 | 2552 | 2552 |
Place of Origin |
MapReduce (Google) Hadoop (Yahoo) | มหาวิทยาลัยแคลิฟอร์เนียเบิร์กลีย์ | มหาวิทยาลัยเทคนิคแห่งเบอร์ลิน |
Data Processing Engine |
แบทช์ | แบทช์ | กระแส |
Processing Speed |
ช้ากว่า Spark และ Flink | เร็วกว่า Hadoop 100 เท่า | เร็วกว่าประกายไฟ |
Programming Languages |
Java, C, C ++, Ruby, Groovy, Perl, Python | Java, Scala, python และ R | Java และ Scala |
Programming Model |
MapReduce | ชุดข้อมูลแบบกระจายที่ยืดหยุ่น (RDD) | กระแสข้อมูล Cyclic |
Data Transfer |
แบทช์ | แบทช์ | ท่อและแบทช์ |
Memory Management |
ตามดิสก์ | JVM จัดการ | มีการจัดการที่ใช้งานอยู่ |
Latency |
ต่ำ | ปานกลาง | ต่ำ |
Throughput |
ปานกลาง | สูง | สูง |
Optimization |
คู่มือ | คู่มือ | อัตโนมัติ |
API |
ระดับต่ำ | ระดับสูง | ระดับสูง |
Streaming Support |
NA | Spark Streaming | Flink Streaming |
SQL Support |
รังอิมพาลา | SparkSQL | ตาราง API และ SQL |
Graph Support |
NA | GraphX | เกลลี่ |
Machine Learning Support |
NA | SparkML | FlinkML |
ตารางเปรียบเทียบที่เราเห็นในบทที่แล้วสรุปตัวชี้ได้สวยมาก Apache Flink เป็นเฟรมเวิร์กที่เหมาะสมที่สุดสำหรับการประมวลผลแบบเรียลไทม์และกรณีการใช้งาน ระบบเอนจิ้นเดียวมีเอกลักษณ์เฉพาะซึ่งสามารถประมวลผลทั้งแบทช์และสตรีมข้อมูลด้วย API ที่แตกต่างกันเช่น Dataset และ DataStream
ไม่ได้หมายความว่า Hadoop และ Spark ไม่อยู่ในเกมการเลือกเฟรมเวิร์กข้อมูลขนาดใหญ่ที่เหมาะสมที่สุดนั้นขึ้นอยู่กับและแตกต่างกันไปในแต่ละกรณีการใช้งาน อาจมีกรณีการใช้งานหลายกรณีที่อาจใช้ Hadoop และ Flink หรือ Spark และ Flink ร่วมกันได้
อย่างไรก็ตาม Flink เป็นเฟรมเวิร์กที่ดีที่สุดสำหรับการประมวลผลแบบเรียลไทม์ในปัจจุบัน การเติบโตของ Apache Flink นั้นน่าทึ่งมากและจำนวนผู้มีส่วนร่วมในชุมชนก็เพิ่มขึ้นทุกวัน
แฮปปี้วูบวาบ!