AI กับ Python - การเรียนรู้ภายใต้การดูแล: การถดถอย
การถดถอยเป็นเครื่องมือทางสถิติและการเรียนรู้ของเครื่องจักรที่สำคัญที่สุดอย่างหนึ่ง เราคงไม่ผิดหากจะบอกว่าเส้นทางของการเรียนรู้ของเครื่องเริ่มต้นจากการถดถอย อาจถูกกำหนดให้เป็นเทคนิคพาราเมตริกที่ช่วยให้เราสามารถตัดสินใจโดยอาศัยข้อมูลหรือกล่าวอีกนัยหนึ่งช่วยให้เราทำการคาดการณ์จากข้อมูลโดยเรียนรู้ความสัมพันธ์ระหว่างตัวแปรอินพุตและเอาต์พุต ที่นี่ตัวแปรเอาต์พุตขึ้นอยู่กับตัวแปรอินพุตคือจำนวนจริงที่มีมูลค่าต่อเนื่อง ในการถดถอยความสัมพันธ์ระหว่างตัวแปรอินพุตและเอาต์พุตมีความสำคัญและช่วยให้เราเข้าใจว่าค่าของตัวแปรเอาต์พุตเปลี่ยนแปลงไปอย่างไรเมื่อมีการเปลี่ยนแปลงตัวแปรอินพุต การถดถอยมักใช้ในการทำนายราคาเศรษฐศาสตร์การเปลี่ยนแปลงและอื่น ๆ
การสร้าง Regressors ใน Python
ในส่วนนี้เราจะได้เรียนรู้วิธีการสร้างตัวถอยหลังแบบเดี่ยวและแบบหลายตัวแปร
Linear Regressor / ตัวควบคุมตัวแปรเดียว
ให้เราสำคัญแพ็คเกจที่จำเป็นบางอย่าง -
import numpy as np
from sklearn import linear_model
import sklearn.metrics as sm
import matplotlib.pyplot as pltตอนนี้เราจำเป็นต้องให้ข้อมูลอินพุตและเราได้บันทึกข้อมูลของเราไว้ในไฟล์ชื่อ linear.txt
input = 'D:/ProgramData/linear.txt'เราจำเป็นต้องโหลดข้อมูลนี้โดยใช้ไฟล์ np.loadtxt ฟังก์ชัน
input_data = np.loadtxt(input, delimiter=',')
X, y = input_data[:, :-1], input_data[:, -1]ขั้นตอนต่อไปคือการฝึกโมเดล ให้เราฝึกอบรมและทดสอบตัวอย่าง
training_samples = int(0.6 * len(X))
testing_samples = len(X) - num_training
X_train, y_train = X[:training_samples], y[:training_samples]
X_test, y_test = X[training_samples:], y[training_samples:]ตอนนี้เราต้องสร้างวัตถุตัวถอยหลังเชิงเส้น
reg_linear = linear_model.LinearRegression()ฝึกวัตถุด้วยตัวอย่างการฝึกอบรม
reg_linear.fit(X_train, y_train)เราจำเป็นต้องทำการคาดคะเนด้วยข้อมูลการทดสอบ
y_test_pred = reg_linear.predict(X_test)ตอนนี้วางแผนและแสดงภาพข้อมูล
plt.scatter(X_test, y_test, color = 'red')
plt.plot(X_test, y_test_pred, color = 'black', linewidth = 2)
plt.xticks(())
plt.yticks(())
plt.show()เอาต์พุต
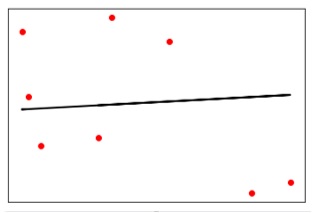
ตอนนี้เราสามารถคำนวณประสิทธิภาพของการถดถอยเชิงเส้นได้ดังนี้ -
print("Performance of Linear regressor:")
print("Mean absolute error =", round(sm.mean_absolute_error(y_test, y_test_pred), 2))
print("Mean squared error =", round(sm.mean_squared_error(y_test, y_test_pred), 2))
print("Median absolute error =", round(sm.median_absolute_error(y_test, y_test_pred), 2))
print("Explain variance score =", round(sm.explained_variance_score(y_test, y_test_pred),
2))
print("R2 score =", round(sm.r2_score(y_test, y_test_pred), 2))เอาต์พุต
ประสิทธิภาพของ Linear Regressor -
Mean absolute error = 1.78
Mean squared error = 3.89
Median absolute error = 2.01
Explain variance score = -0.09
R2 score = -0.09ในโค้ดด้านบนเราได้ใช้ข้อมูลขนาดเล็กนี้ หากคุณต้องการชุดข้อมูลขนาดใหญ่คุณสามารถใช้ sklearn.dataset เพื่อนำเข้าชุดข้อมูลที่ใหญ่ขึ้น
2,4.82.9,4.72.5,53.2,5.56,57.6,43.2,0.92.9,1.92.4,
3.50.5,3.41,40.9,5.91.2,2.583.2,5.65.1,1.54.5,
1.22.3,6.32.1,2.8Regressor หลายตัวแปร
ขั้นแรกให้เรานำเข้าแพ็คเกจที่จำเป็นบางอย่าง -
import numpy as np
from sklearn import linear_model
import sklearn.metrics as sm
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeaturesตอนนี้เราจำเป็นต้องให้ข้อมูลอินพุตและเราได้บันทึกข้อมูลของเราไว้ในไฟล์ชื่อ linear.txt
input = 'D:/ProgramData/Mul_linear.txt'เราจะโหลดข้อมูลนี้โดยใช้ไฟล์ np.loadtxt ฟังก์ชัน
input_data = np.loadtxt(input, delimiter=',')
X, y = input_data[:, :-1], input_data[:, -1]ขั้นตอนต่อไปคือการฝึกโมเดล เราจะให้การฝึกอบรมและการทดสอบตัวอย่าง
training_samples = int(0.6 * len(X))
testing_samples = len(X) - num_training
X_train, y_train = X[:training_samples], y[:training_samples]
X_test, y_test = X[training_samples:], y[training_samples:]ตอนนี้เราต้องสร้างวัตถุตัวถอยหลังเชิงเส้น
reg_linear_mul = linear_model.LinearRegression()ฝึกวัตถุด้วยตัวอย่างการฝึกอบรม
reg_linear_mul.fit(X_train, y_train)ในที่สุดเราต้องทำการคาดการณ์ด้วยข้อมูลการทดสอบ
y_test_pred = reg_linear_mul.predict(X_test)
print("Performance of Linear regressor:")
print("Mean absolute error =", round(sm.mean_absolute_error(y_test, y_test_pred), 2))
print("Mean squared error =", round(sm.mean_squared_error(y_test, y_test_pred), 2))
print("Median absolute error =", round(sm.median_absolute_error(y_test, y_test_pred), 2))
print("Explain variance score =", round(sm.explained_variance_score(y_test, y_test_pred), 2))
print("R2 score =", round(sm.r2_score(y_test, y_test_pred), 2))เอาต์พุต
ประสิทธิภาพของ Linear Regressor -
Mean absolute error = 0.6
Mean squared error = 0.65
Median absolute error = 0.41
Explain variance score = 0.34
R2 score = 0.33ตอนนี้เราจะสร้างพหุนามดีกรี 10 และฝึกตัวถอยหลัง เราจะจัดเตรียมจุดข้อมูลตัวอย่าง
polynomial = PolynomialFeatures(degree = 10)
X_train_transformed = polynomial.fit_transform(X_train)
datapoint = [[2.23, 1.35, 1.12]]
poly_datapoint = polynomial.fit_transform(datapoint)
poly_linear_model = linear_model.LinearRegression()
poly_linear_model.fit(X_train_transformed, y_train)
print("\nLinear regression:\n", reg_linear_mul.predict(datapoint))
print("\nPolynomial regression:\n", poly_linear_model.predict(poly_datapoint))เอาต์พุต
การถดถอยเชิงเส้น -
[2.40170462]การถดถอยพหุนาม -
[1.8697225]ในโค้ดด้านบนเราได้ใช้ข้อมูลขนาดเล็กนี้ หากคุณต้องการชุดข้อมูลขนาดใหญ่คุณสามารถใช้ sklearn.dataset เพื่อนำเข้าชุดข้อมูลที่ใหญ่ขึ้น
2,4.8,1.2,3.22.9,4.7,1.5,3.62.5,5,2.8,23.2,5.5,3.5,2.16,5,
2,3.27.6,4,1.2,3.23.2,0.9,2.3,1.42.9,1.9,2.3,1.22.4,3.5,
2.8,3.60.5,3.4,1.8,2.91,4,3,2.50.9,5.9,5.6,0.81.2,2.58,
3.45,1.233.2,5.6,2,3.25.1,1.5,1.2,1.34.5,1.2,4.1,2.32.3,
6.3,2.5,3.22.1,2.8,1.2,3.6