XML DOM - คู่มือฉบับย่อ
Dเอกสาร Oขงเบ้ง Model (DOM) เป็นมาตรฐาน W3C กำหนดมาตรฐานสำหรับการเข้าถึงเอกสารเช่น HTML และ XML
คำจำกัดความของ DOM ที่W3Cวางไว้คือ -
Document Object Model (DOM) คืออินเทอร์เฟซโปรแกรมประยุกต์ (API) สำหรับเอกสาร HTML และ XML เป็นการกำหนดโครงสร้างทางตรรกะของเอกสารและวิธีการเข้าถึงและจัดการเอกสาร
DOM กำหนดอ็อบเจ็กต์และคุณสมบัติและวิธีการ (อินเทอร์เฟซ) เพื่อเข้าถึงองค์ประกอบ XML ทั้งหมด แบ่งออกเป็น 3 ส่วน / ระดับที่แตกต่างกัน -
Core DOM - แบบจำลองมาตรฐานสำหรับเอกสารที่มีโครงสร้าง
XML DOM - รูปแบบมาตรฐานสำหรับเอกสาร XML
HTML DOM - รูปแบบมาตรฐานสำหรับเอกสาร HTML
XML DOM เป็นโมเดลออบเจ็กต์มาตรฐานสำหรับ XML เอกสาร XML มีลำดับชั้นของหน่วยงานในการให้ข้อมูลที่เรียกว่าโหนด ; DOM เป็นอินเทอร์เฟซการเขียนโปรแกรมมาตรฐานสำหรับการอธิบายโหนดเหล่านั้นและความสัมพันธ์ระหว่างโหนด
เนื่องจาก XML DOM ยังมี API ที่ช่วยให้นักพัฒนาสามารถเพิ่มแก้ไขย้ายหรือลบโหนด ณ จุดใดก็ได้บนต้นไม้เพื่อสร้างแอปพลิเคชัน
ต่อไปนี้เป็นแผนภาพสำหรับโครงสร้าง DOM แผนภาพแสดงให้เห็นว่า parser ประเมินเอกสาร XML เป็นโครงสร้าง DOM โดยการข้ามผ่านแต่ละโหนด
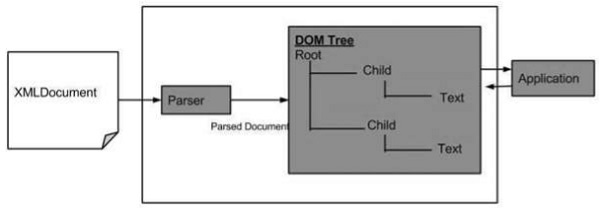
ข้อดีของ XML DOM
ต่อไปนี้เป็นข้อดีของ XML DOM
XML DOM เป็นภาษาและแพลตฟอร์มที่เป็นอิสระ
XML DOM คือ traversable - ข้อมูลใน XML DOM ถูกจัดเรียงตามลำดับชั้นซึ่งช่วยให้นักพัฒนาสามารถนำทางไปรอบ ๆ ลำดับชั้นเพื่อค้นหาข้อมูลเฉพาะ
XML DOM คือ modifiable - มันเป็นแบบไดนามิกในธรรมชาติที่ทำให้นักพัฒนามีขอบเขตในการเพิ่มแก้ไขย้ายหรือลบโหนด ณ จุดใดก็ได้บนต้นไม้
ข้อเสียของ XML DOM
มันใช้หน่วยความจำมากขึ้น (ถ้าโครงสร้าง XML มีขนาดใหญ่) เนื่องจากโปรแกรมที่เขียนครั้งเดียวจะยังคงอยู่ในหน่วยความจำตลอดเวลาจนกว่าและเว้นแต่จะถูกลบออกอย่างชัดเจน
เนื่องจากการใช้งานหน่วยความจำที่กว้างขวางความเร็วในการทำงานเมื่อเทียบกับ SAX จึงช้ากว่า
ตอนนี้เรารู้แล้วว่า DOM หมายถึงอะไรมาดูกันว่าโครงสร้าง DOM คืออะไร เอกสาร DOM คือชุดของโหนดหรือส่วนของข้อมูลที่จัดระเบียบตามลำดับชั้น บางชนิดของโหนดอาจมีเด็กโหนดประเภทต่างๆและอื่น ๆ เป็นโหนดใบที่ไม่สามารถมีอะไรภายใต้พวกเขาในโครงสร้างเอกสาร ต่อไปนี้เป็นรายการประเภทโหนดที่มีรายการประเภทโหนดที่อาจมีเป็นลูก -
Document - องค์ประกอบ (สูงสุดหนึ่งรายการ), การประมวลผลคำแนะนำ, ความคิดเห็น, ประเภทเอกสาร (สูงสุดหนึ่งรายการ)
DocumentFragment - องค์ประกอบการประมวลผลคำแนะนำข้อคิดเห็นข้อความ CDATASection EntityReference
EntityReference - องค์ประกอบการประมวลผลคำแนะนำข้อคิดเห็นข้อความ CDATASection EntityReference
Element - องค์ประกอบข้อความข้อคิดเห็นการประมวลผลคำสั่ง CDATASection EntityReference
Attr - ข้อความ EntityReference
ProcessingInstruction - ไม่มีลูก
Comment - ไม่มีลูก
Text - ไม่มีลูก
CDATASection - ไม่มีลูก
Entity - องค์ประกอบการประมวลผลคำแนะนำข้อคิดเห็นข้อความ CDATASection EntityReference
Notation - ไม่มีลูก
ตัวอย่าง
พิจารณาการเป็นตัวแทน DOM ของเอกสาร XML ต่อไปนี้ node.xml.
<?xml version = "1.0"?>
<Company>
<Employee category = "technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
</Employee>
<Employee category = "non-technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
</Employee>
</Company>Document Object Model ของเอกสาร XML ด้านบนจะเป็นดังนี้ -

จากผังงานข้างต้นเราสามารถอนุมานได้ -
โหนดวัตถุสามารถมีได้เพียงหนึ่งผู้ปกครองโหนดวัตถุ สิ่งนี้ครอบครองตำแหน่งเหนือโหนดทั้งหมด นี่มันเป็นบริษัท
โหนดแม่สามารถมีหลายโหนดเรียกว่าเด็กโหนด โหนดลูกเหล่านี้สามารถมีโหนดเพิ่มเติมที่เรียกว่าโหนดแอตทริบิวต์ ในตัวอย่างข้างต้นเรามีสองแอตทริบิวต์โหนดเทคนิคและไม่ใช่เทคนิค แอตทริบิวต์โหนดไม่จริงลูกของโหนดองค์ประกอบ แต่ยังคงเกี่ยวข้องกับมัน
โหนดลูกเหล่านี้สามารถมีโหนดลูกได้หลายโหนด ข้อความภายในโหนดเรียกว่าโหนดข้อความ
โหนดอ็อบเจ็กต์ในระดับเดียวกันถูกเรียกว่าเป็นพี่น้องกัน
DOM ระบุ -
อ็อบเจ็กต์เพื่อแสดงอินเตอร์เฟสและจัดการกับเอกสาร
ความสัมพันธ์ระหว่างวัตถุและส่วนต่อประสาน
ในบทนี้เราจะศึกษาเกี่ยวกับ XML DOM โหนด XML DOM ทุกตัวมีข้อมูลในหน่วยลำดับชั้นที่เรียกว่าโหนดและ DOM จะอธิบายโหนดเหล่านี้และความสัมพันธ์ระหว่างโหนดเหล่านี้
ประเภทโหนด
ผังงานต่อไปนี้แสดงประเภทโหนดทั้งหมด -
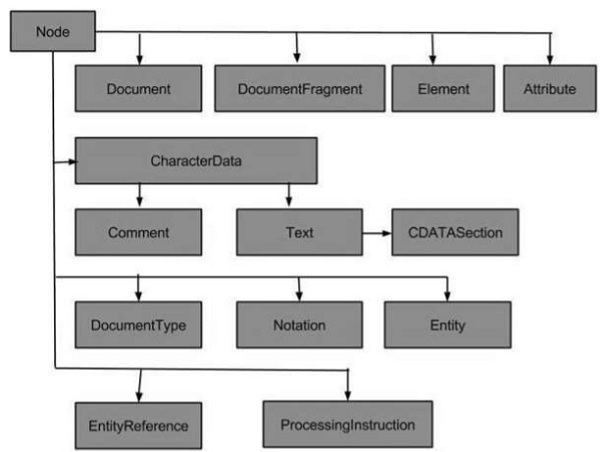
ประเภทของโหนดที่พบบ่อยที่สุดใน XML ได้แก่ -
Document Node- โครงสร้างเอกสาร XML ที่สมบูรณ์แบบเป็นโหนดเอกสาร
Element Node- องค์ประกอบ XML ทุกคนเป็นโหนดองค์ประกอบ นอกจากนี้ยังเป็นโหนดประเภทเดียวที่สามารถมีแอตทริบิวต์ได้
Attribute Node- แต่ละแอตทริบิวต์ถือว่าเป็นโหนดแอตทริบิวต์ มีข้อมูลเกี่ยวกับโหนดองค์ประกอบ แต่ไม่ถือว่าเป็นลูกขององค์ประกอบ
Text Node- ตำราเอกสารถือเป็นโหนดข้อความ อาจประกอบด้วยข้อมูลเพิ่มเติมหรือเพียงช่องว่าง
โหนดบางประเภทที่ไม่ค่อยพบบ่อย ได้แก่ -
CData Node- โหนดนี้มีข้อมูลที่ไม่ควรวิเคราะห์โดยตัวแยกวิเคราะห์ แต่ควรส่งต่อเป็นข้อความธรรมดา
Comment Node - โหนดนี้มีข้อมูลเกี่ยวกับข้อมูลและโดยปกติแอปพลิเคชันจะไม่สนใจ
Processing Instructions Node - โหนดนี้มีข้อมูลที่มุ่งเป้าไปที่แอปพลิเคชันโดยเฉพาะ
Document Fragments Node
Entities Node
Entity reference nodes
Notations Node
ในบทนี้เราจะศึกษาเกี่ยวกับ XML DOM Node Tree ในเอกสาร XML ข้อมูลจะถูกเก็บรักษาตามโครงสร้างลำดับชั้น โครงสร้างลำดับชั้นนี้เรียกว่าโหนดต้นไม้ ลำดับชั้นนี้ช่วยให้นักพัฒนาสามารถนำทางไปรอบ ๆ ต้นไม้เพื่อค้นหาข้อมูลเฉพาะดังนั้นโหนดจึงได้รับอนุญาตให้เข้าถึง จากนั้นสามารถอัพเดตเนื้อหาของโหนดเหล่านี้ได้
โครงสร้างของโหนดทรีเริ่มต้นด้วยองค์ประกอบรากและกระจายออกไปยังองค์ประกอบลูกจนถึงระดับต่ำสุด
ตัวอย่าง
ตัวอย่างต่อไปนี้แสดงให้เห็นถึงเอกสาร XML อย่างง่ายซึ่งโครงสร้างของโหนดเป็นโครงสร้างดังแสดงในแผนภาพด้านล่าง -
<?xml version = "1.0"?>
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
</Employee>
</Company>ดังที่เห็นได้จากตัวอย่างข้างต้นซึ่งมีการแสดงภาพ (ของ DOM) ดังที่แสดงด้านล่าง -
โหนดบนสุดของทรีเรียกว่า root. rootโหนดคือ <บริษัท > ซึ่งจะมีสองโหนดของ <Employee> โหนดเหล่านี้เรียกว่าโหนดลูก
โหนดลูก <Employee> ของโหนดราก <บริษัท > ในทางกลับกันประกอบด้วยโหนดลูกของตัวเอง (<FirstName>, <LastName>, <ContactNo>)
ทั้งสองโหนดลูก <ลูกจ้าง> มีเทคนิคค่าแอตทริบิวต์และไม่ใช่ทางด้านเทคนิคจะเรียกว่าเป็นต่อมน้ำแอตทริบิวต์
ข้อความที่อยู่ในทุกโหนดเรียกว่าโหนดข้อความ
XML DOM - วิธีการ
DOM เป็น API มีอินเทอร์เฟซที่แสดงข้อมูลประเภทต่างๆที่สามารถพบได้ในเอกสาร XML เช่นองค์ประกอบและข้อความ อินเทอร์เฟซเหล่านี้รวมถึงวิธีการและคุณสมบัติที่จำเป็นในการทำงานกับอ็อบเจ็กต์เหล่านี้ คุณสมบัติกำหนดลักษณะของโหนดในขณะที่เมธอดให้วิธีจัดการกับโหนด
ตารางต่อไปนี้แสดงรายการคลาส DOM และอินเทอร์เฟซ -
| ส. | อินเทอร์เฟซและคำอธิบาย |
|---|---|
| 1 | DOMImplementation มีวิธีการหลายวิธีสำหรับการดำเนินการที่ไม่ขึ้นกับอินสแตนซ์เฉพาะใด ๆ ของโมเดลอ็อบเจ็กต์เอกสาร |
| 2 | DocumentFragment เป็นอ็อบเจ็กต์เอกสาร "น้ำหนักเบา" หรือ "น้อยที่สุด" และ (ในฐานะซูเปอร์คลาสของเอกสาร) ยึดโครงสร้าง XML / HTML ในเอกสารที่มีคุณสมบัติครบถ้วน |
| 3 | Document แสดงถึงโหนดระดับบนสุดของเอกสาร XML ซึ่งให้การเข้าถึงโหนดทั้งหมดในเอกสารรวมถึงองค์ประกอบรูท |
| 4 | Node แสดงถึงโหนด XML |
| 5 | NodeList แสดงรายการวัตถุโหนดแบบอ่านอย่างเดียว |
| 6 | NamedNodeMap แสดงถึงคอลเลกชันของโหนดที่สามารถเข้าถึงได้โดยใช้ชื่อ |
| 7 | Data ขยายNodeด้วยชุดแอตทริบิวต์และวิธีการเข้าถึงข้อมูลอักขระใน DOM |
| 8 | Attribute แสดงถึงแอตทริบิวต์ในออบเจ็กต์ Element |
| 9 | Element แสดงถึงโหนดองค์ประกอบ มาจากโหนด |
| 10 | Text แสดงถึงโหนดข้อความ มาจาก CharacterData |
| 11 | Comment แสดงถึงโหนดความคิดเห็น มาจาก CharacterData |
| 12 | ProcessingInstruction แสดงถึง "คำสั่งการประมวลผล" ใช้ใน XML เพื่อเก็บข้อมูลเฉพาะของโปรเซสเซอร์ในข้อความของเอกสาร |
| 13 | CDATA Section เป็นตัวแทนของส่วน CDATA มาจากข้อความ |
| 14 | Entity แสดงถึงเอนทิตี มาจากโหนด |
| 15 | EntityReference สิ่งนี้แสดงถึงการอ้างอิงเอนทิตีในแผนภูมิ มาจากโหนด |
เราจะพูดถึงวิธีการและคุณสมบัติของอินเทอร์เฟซข้างต้นในแต่ละบท
ในบทนี้เราจะศึกษาเกี่ยวกับ XML โหลดและแยก
เพื่ออธิบายอินเตอร์เฟสที่จัดเตรียมโดย API W3C ใช้ภาษานามธรรมที่เรียกว่า Interface Definition Language (IDL) ข้อดีของการใช้ IDL คือผู้พัฒนาเรียนรู้วิธีใช้ DOM กับภาษาโปรดของตนและสามารถเปลี่ยนไปใช้ภาษาอื่นได้อย่างง่ายดาย
ข้อเสียคือเนื่องจากเป็นนามธรรมนักพัฒนาเว็บจึงไม่สามารถใช้ IDL ได้โดยตรง เนื่องจากความแตกต่างระหว่างภาษาการเขียนโปรแกรมจึงจำเป็นต้องมีการแมป - หรือการเชื่อมโยงระหว่างอินเทอร์เฟซนามธรรมกับภาษาที่เป็นรูปธรรม DOM ได้รับการแมปกับภาษาโปรแกรมเช่น Javascript, JScript, Java, C, C ++, PLSQL, Python และ Perl
ในส่วนและบทต่อไปนี้เราจะใช้ Javascript เป็นภาษาโปรแกรมของเราเพื่อโหลดไฟล์ XML
Parser
โปรแกรมแยกวิเคราะห์เป็นแอปพลิเคชันซอฟต์แวร์ที่ออกแบบมาเพื่อวิเคราะห์เอกสารในกรณีของเอกสาร XML และดำเนินการบางอย่างกับข้อมูลโดยเฉพาะ ตัวแยกวิเคราะห์ที่ใช้ DOM บางตัวแสดงอยู่ในตารางต่อไปนี้ -
| ส. เลขที่ | Parser & Description |
|---|---|
| 1 | JAXP Java API ของ Sun Microsystem สำหรับการแยกวิเคราะห์ XML (JAXP) |
| 2 | XML4J ตัวแยกวิเคราะห์ XML ของ IBM สำหรับ Java (XML4J) |
| 3 | msxml ตัวแยกวิเคราะห์ XML ของ Microsoft (msxml) เวอร์ชัน 2.0 มีอยู่แล้วใน Internet Explorer 5.5 |
| 4 | 4DOM 4DOM เป็นตัวแยกวิเคราะห์สำหรับภาษาโปรแกรม Python |
| 5 | XML::DOM XML :: DOM เป็นโมดูล Perl สำหรับจัดการเอกสาร XML โดยใช้ Perl |
| 6 | Xerces Xerces Java Parser ของ Apache |
ใน API แบบต้นไม้เช่น DOM ตัวแยกวิเคราะห์ข้ามไฟล์ XML และสร้างวัตถุ DOM ที่เกี่ยวข้อง จากนั้นคุณสามารถสำรวจโครงสร้าง DOM ไปมาได้
กำลังโหลดและแยกวิเคราะห์ XML
ขณะโหลดเอกสาร XML เนื้อหา XML สามารถมีได้สองรูปแบบ -
- โดยตรงเป็นไฟล์ XML
- เป็นสตริง XML
เนื้อหาเป็นไฟล์ XML
ตัวอย่างต่อไปนี้สาธิตวิธีการโหลดข้อมูล XML ( node.xml ) โดยใช้ Ajax และ Javascript เมื่อได้รับเนื้อหา XML เป็นไฟล์ XML ที่นี่ฟังก์ชัน Ajax รับเนื้อหาของไฟล์ xml และเก็บไว้ใน XML DOM เมื่อสร้างวัตถุ DOM แล้วจะมีการแยกวิเคราะห์
<!DOCTYPE html>
<html>
<body>
<div>
<b>FirstName:</b> <span id = "FirstName"></span><br>
<b>LastName:</b> <span id = "LastName"></span><br>
<b>ContactNo:</b> <span id = "ContactNo"></span><br>
<b>Email:</b> <span id = "Email"></span>
</div>
<script>
//if browser supports XMLHttpRequest
if (window.XMLHttpRequest) { // Create an instance of XMLHttpRequest object.
code for IE7+, Firefox, Chrome, Opera, Safari xmlhttp = new XMLHttpRequest();
} else { // code for IE6, IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
// sets and sends the request for calling "node.xml"
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
// sets and returns the content as XML DOM
xmlDoc = xmlhttp.responseXML;
//parsing the DOM object
document.getElementById("FirstName").innerHTML =
xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0].nodeValue;
document.getElementById("LastName").innerHTML =
xmlDoc.getElementsByTagName("LastName")[0].childNodes[0].nodeValue;
document.getElementById("ContactNo").innerHTML =
xmlDoc.getElementsByTagName("ContactNo")[0].childNodes[0].nodeValue;
document.getElementById("Email").innerHTML =
xmlDoc.getElementsByTagName("Email")[0].childNodes[0].nodeValue;
</script>
</body>
</html>node.xml
<Company>
<Employee category = "Technical" id = "firstelement">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>[email protected]</Email>
</Employee>
</Company>รายละเอียดของโค้ดส่วนใหญ่อยู่ในโค้ดสคริปต์
Internet Explorer ใช้ActiveXObject ( "Microsoft.XMLHTTP")ในการสร้างตัวอย่างของวัตถุ XMLHttpRequest เป็นเบราว์เซอร์อื่น ๆ ใช้XMLHttpRequest ()วิธีการ
responseXMLแปลง XML เนื้อหาโดยตรงใน DOM XML
เมื่อเนื้อหา XML ถูกแปลงเป็น JavaScript XML DOM คุณสามารถเข้าถึงองค์ประกอบ XML ใดก็ได้โดยใช้เมธอด JS DOM และคุณสมบัติ เราได้ใช้คุณสมบัติ DOM เช่นเมธอดchildNodes , nodeValueและ DOM เช่น getElementsById (ID), getElementsByTagName (tags_name)
การดำเนินการ
บันทึกไฟล์นี้เป็น loadingexample.html และเปิดในเบราว์เซอร์ของคุณ คุณจะได้รับผลลัพธ์ต่อไปนี้ -

เนื้อหาเป็นสตริง XML
ตัวอย่างต่อไปนี้สาธิตวิธีโหลดข้อมูล XML โดยใช้ Ajax และ Javascript เมื่อรับเนื้อหา XML เป็นไฟล์ XML ที่นี่ฟังก์ชั่น Ajax รับเนื้อหาของไฟล์ xml และเก็บไว้ใน XML DOM เมื่อสร้างวัตถุ DOM แล้วจะมีการแยกวิเคราะห์
<!DOCTYPE html>
<html>
<head>
<script>
// loads the xml string in a dom object
function loadXMLString(t) { // for non IE browsers
if (window.DOMParser) {
// create an instance for xml dom object parser = new DOMParser();
xmlDoc = parser.parseFromString(t,"text/xml");
}
// code for IE
else { // create an instance for xml dom object
xmlDoc = new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.async = false;
xmlDoc.loadXML(t);
}
return xmlDoc;
}
</script>
</head>
<body>
<script>
// a variable with the string
var text = "<Employee>";
text = text+"<FirstName>Tanmay</FirstName>";
text = text+"<LastName>Patil</LastName>";
text = text+"<ContactNo>1234567890</ContactNo>";
text = text+"<Email>[email protected]</Email>";
text = text+"</Employee>";
// calls the loadXMLString() with "text" function and store the xml dom in a variable
var xmlDoc = loadXMLString(text);
//parsing the DOM object
y = xmlDoc.documentElement.childNodes;
for (i = 0;i<y.length;i++) {
document.write(y[i].childNodes[0].nodeValue);
document.write("<br>");
}
</script>
</body>
</html>รายละเอียดของโค้ดส่วนใหญ่อยู่ในโค้ดสคริปต์
Internet Explorer ใช้ActiveXObject ( "Microsoft.XMLDOM")ในการโหลดข้อมูล XML เป็นวัตถุ DOM เป็นเบราว์เซอร์อื่น ๆ ใช้DOMParser ()ฟังก์ชั่นและparseFromString (ข้อความ 'ข้อความ / XML)วิธีการ
ข้อความตัวแปรจะต้องมีสตริงที่มีเนื้อหา XML
เมื่อเนื้อหา XML ถูกแปลงเป็น JavaScript XML DOM คุณสามารถเข้าถึงองค์ประกอบ XML ใดก็ได้โดยใช้เมธอด JS DOM และคุณสมบัติ เราได้ใช้คุณสมบัติ DOM เช่นchildNodes , nodeValue
การดำเนินการ
บันทึกไฟล์นี้เป็น loadingexample.html และเปิดในเบราว์เซอร์ของคุณ คุณจะเห็นผลลัพธ์ต่อไปนี้ -

ตอนนี้เราได้เห็นว่าเนื้อหา XML แปลงเป็น JavaScript XML DOM ได้อย่างไรตอนนี้คุณสามารถเข้าถึงองค์ประกอบ XML ใดก็ได้โดยใช้วิธี XML DOM
ในบทนี้เราจะพูดถึง XML DOM Traversing เราได้ศึกษาในบทที่แล้วว่าจะโหลดเอกสาร XML และแยกวิเคราะห์วัตถุ DOM ที่ได้รับมาอย่างไร ออบเจ็กต์ DOM ที่แยกวิเคราะห์นี้สามารถข้ามผ่านได้ การข้ามผ่านเป็นกระบวนการที่การวนซ้ำเกิดขึ้นอย่างเป็นระบบโดยการข้ามแต่ละองค์ประกอบทีละขั้นตอนในโหนดทรี
ตัวอย่าง
ตัวอย่างต่อไปนี้ (traverse_example.htm) แสดงให้เห็นถึงการข้ามผ่าน DOM ที่นี่เราสำรวจผ่านโหนดลูกของ <Employee> แต่ละองค์ประกอบ
<!DOCTYPE html>
<html>
<style>
table,th,td {
border:1px solid black;
border-collapse:collapse
}
</style>
<body>
<div id = "ajax_xml"></div>
<script>
//if browser supports XMLHttpRequest
if (window.XMLHttpRequest) {// Create an instance of XMLHttpRequest object.
code for IE7+, Firefox, Chrome, Opera, Safari
var xmlhttp = new XMLHttpRequest();
} else {// code for IE6, IE5
var xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
// sets and sends the request for calling "node.xml"
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
// sets and returns the content as XML DOM
var xml_dom = xmlhttp.responseXML;
// this variable stores the code of the html table
var html_tab = '<table id = "id_tabel" align = "center">
<tr>
<th>Employee Category</th>
<th>FirstName</th>
<th>LastName</th>
<th>ContactNo</th>
<th>Email</th>
</tr>';
var arr_employees = xml_dom.getElementsByTagName("Employee");
// traverses the "arr_employees" array
for(var i = 0; i<arr_employees.length; i++) {
var employee_cat = arr_employees[i].getAttribute('category');
// gets the value of 'category' element of current "Element" tag
// gets the value of first child-node of 'FirstName'
// element of current "Employee" tag
var employee_firstName =
arr_employees[i].getElementsByTagName('FirstName')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'LastName'
// element of current "Employee" tag
var employee_lastName =
arr_employees[i].getElementsByTagName('LastName')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'ContactNo'
// element of current "Employee" tag
var employee_contactno =
arr_employees[i].getElementsByTagName('ContactNo')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'Email'
// element of current "Employee" tag
var employee_email =
arr_employees[i].getElementsByTagName('Email')[0].childNodes[0].nodeValue;
// adds the values in the html table
html_tab += '<tr>
<td>'+ employee_cat+ '</td>
<td>'+ employee_firstName+ '</td>
<td>'+ employee_lastName+ '</td>
<td>'+ employee_contactno+ '</td>
<td>'+ employee_email+ '</td>
</tr>';
}
html_tab += '</table>';
// adds the html table in a html tag, with id = "ajax_xml"
document.getElementById('ajax_xml').innerHTML = html_tab;
</script>
</body>
</html>นี้จะโหลดรหัสnode.xml
เนื้อหา XML ถูกแปลงเป็นวัตถุ JavaScript XML DOM
ได้รับอาร์เรย์ขององค์ประกอบ (พร้อมแท็ก Element) โดยใช้เมธอด getElementsByTagName ()
จากนั้นเราจะสำรวจอาร์เรย์นี้และแสดงค่าโหนดลูกในตาราง
การดำเนินการ
บันทึกไฟล์นี้เป็นtraverse_example.htmlบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และ node.xml ควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) คุณจะได้รับผลลัพธ์ต่อไปนี้ -

จนถึงตอนนี้เราได้ศึกษาโครงสร้าง DOM วิธีโหลดและแยกวิเคราะห์วัตถุ XML DOM และสำรวจผ่านวัตถุ DOM ที่นี่เราจะดูว่าเราสามารถนำทางระหว่างโหนดในวัตถุ DOM ได้อย่างไร XML DOM ประกอบด้วยคุณสมบัติต่างๆของโหนดซึ่งช่วยให้เรานำทางผ่านโหนดต่างๆเช่น -
- parentNode
- childNodes
- firstChild
- lastChild
- nextSibling
- previousSibling
ต่อไปนี้เป็นแผนภาพของโหนดทรีที่แสดงความสัมพันธ์กับโหนดอื่น ๆ
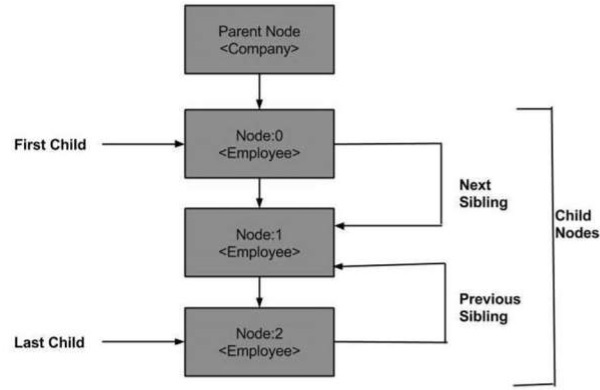
DOM - โหนดหลัก
คุณสมบัตินี้ระบุโหนดพาเรนต์เป็นอ็อบเจ็กต์โหนด
ตัวอย่าง
ตัวอย่างต่อไปนี้ ( navigation_example.htm ) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM จากนั้นวัตถุ DOM จะถูกนำทางไปยังโหนดแม่ผ่านโหนดลูก -
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
var y = xmlDoc.getElementsByTagName("Employee")[0];
document.write(y.parentNode.nodeName);
</script>
</body>
</html>ในขณะที่คุณสามารถเห็นในตัวอย่างข้างต้นโหนดเด็กพนักงานนำทางไปยังโหนดแม่ของมัน
การดำเนินการ
บันทึกแฟ้มนี้เป็นnavigate_example.htmlบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และnode.xmlควรจะอยู่ในเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) ในการส่งออกที่เราได้รับโหนดแม่ของพนักงานเช่นบริษัท
ลูกคนแรก
คุณสมบัตินี้เป็นประเภทNodeและแสดงถึงชื่อลูกคนแรกที่มีอยู่ใน NodeList
ตัวอย่าง
ตัวอย่างต่อไปนี้ (first_node_example.htm) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM จากนั้นไปที่โหนดลูกแรกที่มีอยู่ในอ็อบเจ็กต์ DOM
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_firstChild(p) {
a = p.firstChild;
while (a.nodeType != 1) {
a = a.nextSibling;
}
return a;
}
var firstchild = get_firstChild(xmlDoc.getElementsByTagName("Employee")[0]);
document.write(firstchild.nodeName);
</script>
</body>
</html>ฟังก์ชันget_firstChild (p)ใช้เพื่อหลีกเลี่ยงโหนดว่าง ช่วยในการรับองค์ประกอบ firstChild จากรายการโหนด
x = get_firstChild(xmlDoc.getElementsByTagName("Employee")[0])เรียกโหนดลูกคนแรกสำหรับชื่อแท็กของพนักงาน
การดำเนินการ
บันทึกไฟล์นี้เป็นfirst_node_example.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และnode.xmlควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) ในการส่งออกที่เราได้รับโหนดลูกคนแรกของพนักงานเช่นFirstName
ลูกคนสุดท้อง
คุณสมบัตินี้เป็นประเภทNodeและแสดงถึงนามสกุลลูกที่มีอยู่ใน NodeList
ตัวอย่าง
ตัวอย่างต่อไปนี้ (last_node_example.htm) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM จากนั้นไปที่โหนดลูกสุดท้ายที่มีอยู่ในอ็อบเจ็กต์ xml DOM
<!DOCTYPE html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_lastChild(p) {
a = p.lastChild;
while (a.nodeType != 1){
a = a.previousSibling;
}
return a;
}
var lastchild = get_lastChild(xmlDoc.getElementsByTagName("Employee")[0]);
document.write(lastchild.nodeName);
</script>
</body>
</html>การดำเนินการ
บันทึกไฟล์นี้เป็นlast_node_example.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และ node.xml ควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) ในการส่งออกเราได้รับเด็กโหนดสุดท้ายของพนักงานเช่นอีเมล์
ถัดไปพี่น้อง
คุณสมบัตินี้เป็นประเภทNodeและแสดงถึงลูกถัดไปนั่นคือพี่น้องถัดไปขององค์ประกอบลูกที่ระบุที่มีอยู่ใน NodeList
ตัวอย่าง
ตัวอย่างต่อไปนี้ (nextSibling_example.htm) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM ซึ่งนำทางไปยังโหนดถัดไปที่มีอยู่ในเอกสาร xml ทันที
<!DOCTYPE html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
}
else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_nextSibling(p) {
a = p.nextSibling;
while (a.nodeType != 1) {
a = a.nextSibling;
}
return a;
}
var nextsibling = get_nextSibling(xmlDoc.getElementsByTagName("FirstName")[0]);
document.write(nextsibling.nodeName);
</script>
</body>
</html>การดำเนินการ
บันทึกไฟล์นี้เป็นnextSibling_example.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และ node.xml ควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) ในการส่งออกที่เราได้รับโหนดพี่น้องต่อไปของFirstName,เช่นนามสกุล
ก่อนหน้าพี่น้อง
คุณสมบัตินี้เป็นประเภทNodeและแสดงถึงชายด์ก่อนหน้านั่นคือพี่น้องก่อนหน้าขององค์ประกอบลูกที่ระบุที่มีอยู่ใน NodeList
ตัวอย่าง
ตัวอย่างต่อไปนี้ (previoussibling_example.htm) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM จากนั้นนำทางไปยังโหนดก่อนหน้าของโหนดลูกสุดท้ายที่มีอยู่ในเอกสาร xml
<!DOCTYPE html>
<body>
<script>
if (window.XMLHttpRequest)
{
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_previousSibling(p) {
a = p.previousSibling;
while (a.nodeType != 1) {
a = a.previousSibling;
}
return a;
}
prevsibling = get_previousSibling(xmlDoc.getElementsByTagName("Email")[0]);
document.write(prevsibling.nodeName);
</script>
</body>
</html>การดำเนินการ
บันทึกไฟล์นี้เป็นprevioussibling_example.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และnode.xmlควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) ในการส่งออกที่เราได้รับโหนดพี่น้องก่อนหน้าของอีเมล์คือContactNo
ในบทนี้เราจะศึกษาเกี่ยวกับวิธีการเข้าถึงโหนด XML DOM ซึ่งถือเป็นหน่วยข้อมูลของเอกสาร XML โครงสร้างโหนดของ XML DOM ช่วยให้นักพัฒนาสามารถนำทางไปรอบ ๆ ต้นไม้เพื่อค้นหาข้อมูลเฉพาะและเข้าถึงข้อมูลพร้อมกัน
การเข้าถึงโหนด
ต่อไปนี้เป็นสามวิธีที่คุณสามารถเข้าถึงโหนด -
โดยใช้ไฟล์ getElementsByTagName () วิธี
โดยการวนซ้ำหรือข้ามผ่านโหนดต้นไม้
โดยการนำทางโหนดทรีโดยใช้ความสัมพันธ์ของโหนด
getElementsByTagName ()
วิธีนี้อนุญาตให้เข้าถึงข้อมูลของโหนดโดยระบุชื่อโหนด นอกจากนี้ยังอนุญาตให้เข้าถึงข้อมูลของรายการโหนดและความยาวรายการโหนด
ไวยากรณ์
เมธอด getElementByTagName () มีไวยากรณ์ต่อไปนี้ -
node.getElementByTagName("tagname");ที่ไหน
โหนด - คือโหนดเอกสาร
tagname - เก็บชื่อของโหนดที่มีค่าที่คุณต้องการได้รับ
ตัวอย่าง
ต่อไปนี้เป็นโปรแกรมง่ายๆที่แสดงการใช้เมธอด getElementByTagName
<!DOCTYPE html>
<html>
<body>
<div>
<b>FirstName:</b> <span id = "FirstName"></span><br>
<b>LastName:</b> <span id = "LastName"></span><br>
<b>Category:</b> <span id = "Employee"></span><br>
</div>
<script>
if (window.XMLHttpRequest) {// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp = new XMLHttpRequest();
} else {// code for IE6, IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
document.getElementById("FirstName").innerHTML =
xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0].nodeValue;
document.getElementById("LastName").innerHTML =
xmlDoc.getElementsByTagName("LastName")[0].childNodes[0].nodeValue;
document.getElementById("Employee").innerHTML =
xmlDoc.getElementsByTagName("Employee")[0].attributes[0].nodeValue;
</script>
</body>
</html>ในตัวอย่างข้างต้นเราจะเข้าถึงข้อมูลของโหนดที่FirstName , นามสกุลและลูกจ้าง
xmlDoc.getElementsByTagName ("FirstName") [0] .childNodes [0] .nodeValue; บรรทัดนี้เข้าถึงค่าสำหรับโหนดลูกFirstNameโดยใช้เมธอด getElementByTagName ()
xmlDoc.getElementsByTagName ("พนักงาน") [0] .attributes [0] .nodeValue; บรรทัดนี้เข้าถึงค่าแอ็ตทริบิวต์ของโหนดEmployee getElementByTagName () เมธอด
การข้ามผ่านโหนด
สิ่งนี้ครอบคลุมในบทDOM Traversingพร้อมตัวอย่าง
การนำทางผ่านโหนด
สิ่งนี้ครอบคลุมในบทDOM Navigationพร้อมตัวอย่าง
ในบทนี้เราจะศึกษาเกี่ยวกับวิธีรับค่าโหนดของอ็อบเจ็กต์ XML DOM เอกสาร XML มีลำดับชั้นของหน่วยข้อมูลที่เรียกว่าโหนด อ็อบเจ็กต์โหนดมีคุณสมบัติnodeValueซึ่งส่งคืนค่าขององค์ประกอบ
ในส่วนต่อไปนี้เราจะพูดถึง -
รับค่าโหนดขององค์ประกอบ
รับค่าแอตทริบิวต์ของโหนด
node.xmlใช้ในทุกตัวอย่างต่อไปนี้จะเป็นด้านล่าง -
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>[email protected]</Email>
</Employee>
</Company>รับค่าโหนด
เมธอดgetElementsByTagName ()ส่งคืนNodeListขององค์ประกอบทั้งหมดตามลำดับเอกสารด้วยชื่อแท็กที่กำหนด
ตัวอย่าง
ตัวอย่างต่อไปนี้ (getnode_example.htm) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM และแยกค่าโหนดของโหนดลูกFirstname (ดัชนีที่ 0) -
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else{
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
x = xmlDoc.getElementsByTagName('FirstName')[0]
y = x.childNodes[0];
document.write(y.nodeValue);
</script>
</body>
</html>การดำเนินการ
บันทึกไฟล์นี้เป็นgetnode_example.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และ node.xml ควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) ในการส่งออกเราได้รับค่าโหนดเป็นTanmay
รับค่าคุณสมบัติ
แอตทริบิวต์เป็นส่วนหนึ่งขององค์ประกอบโหนด XML องค์ประกอบโหนดสามารถมีแอตทริบิวต์ที่ไม่ซ้ำกันได้หลายรายการ แอตทริบิวต์ให้ข้อมูลเพิ่มเติมเกี่ยวกับองค์ประกอบโหนด XML เพื่อให้แม่นยำยิ่งขึ้นพวกเขากำหนดคุณสมบัติขององค์ประกอบโหนด แอตทริบิวต์ XML คือคู่ชื่อ - ค่าเสมอ ค่าของแอตทริบิวต์นี้เรียกว่าโหนดแอตทริบิวต์
getAttribute ()วิธีการดึงค่าแอตทริบิวต์ตามชื่อธาตุ
ตัวอย่าง
ตัวอย่างต่อไปนี้ (get_attribute_example.htm) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM และแยกค่าแอ็ตทริบิวต์ของประเภทพนักงาน (ดัชนีที่ 2) -
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
x = xmlDoc.getElementsByTagName('Employee')[2];
document.write(x.getAttribute('category'));
</script>
</body>
</html>การดำเนินการ
บันทึกไฟล์นี้เป็นget_attribute_example.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และ node.xml ควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) ในการส่งออกที่เราได้รับค่าแอตทริบิวต์เป็นการบริหารจัดการ
ในบทนี้เราจะศึกษาเกี่ยวกับวิธีการเปลี่ยนค่าของโหนดในอ็อบเจ็กต์ XML DOM ค่าโหนดสามารถเปลี่ยนแปลงได้ดังนี้ -
var value = node.nodeValue;ถ้าโหนดเป็นแอตทริบิวต์แล้วค่าตัวแปรจะเป็นค่าของแอตทริบิวต์นั้น ถ้าโหนดเป็นโหนดข้อความจะเป็นเนื้อหาข้อความ ถ้าโหนดเป็นองค์ประกอบมันจะเป็นโมฆะ
ส่วนต่อไปนี้จะสาธิตการตั้งค่าโหนดสำหรับโหนดแต่ละประเภท (แอตทริบิวต์โหนดข้อความและองค์ประกอบ)
node.xmlใช้ในทุกตัวอย่างต่อไปนี้จะเป็นด้านล่าง -
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>[email protected]</Email>
</Employee>
</Company>เปลี่ยนค่าของโหนดข้อความ
เมื่อเราพูดว่าค่าการเปลี่ยนแปลงขององค์ประกอบโหนดเราหมายถึงการแก้ไขเนื้อหาข้อความขององค์ประกอบ (ซึ่งเรียกอีกอย่างว่าโหนดข้อความ ) ตัวอย่างต่อไปนี้สาธิตวิธีการเปลี่ยนโหนดข้อความขององค์ประกอบ
ตัวอย่าง
ตัวอย่างต่อไปนี้ (set_text_node_example.htm) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM และเปลี่ยนค่าของโหนดข้อความขององค์ประกอบ ในกรณีนี้อีเมลของพนักงานแต่ละคนไปที่[email protected]แล้วพิมพ์ค่า
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("Email");
for(i = 0;i<x.length;i++) {
x[i].childNodes[0].nodeValue = "[email protected]";
document.write(i+');
document.write(x[i].childNodes[0].nodeValue);
document.write('<br>');
}
</script>
</body>
</html>การดำเนินการ
บันทึกไฟล์นี้เป็นset_text_node_example.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และnode.xmlควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) คุณจะได้รับผลลัพธ์ต่อไปนี้ -
0) [email protected]
1) [email protected]
2) [email protected]เปลี่ยนค่าของโหนดแอตทริบิวต์
ตัวอย่างต่อไปนี้สาธิตวิธีการเปลี่ยนโหนดแอตทริบิวต์ขององค์ประกอบ
ตัวอย่าง
ตัวอย่างต่อไปนี้ (set_attribute_example.htm) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM และเปลี่ยนค่าของโหนดแอ็ตทริบิวต์ขององค์ประกอบ ในกรณีนี้ประเภทของพนักงานแต่ละคนถึงadmin-0, admin-1, admin-2ตามลำดับและพิมพ์ค่า
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("Employee");
for(i = 0 ;i<x.length;i++){
newcategory = x[i].getAttributeNode('category');
newcategory.nodeValue = "admin-"+i;
document.write(i+');
document.write(x[i].getAttributeNode('category').nodeValue);
document.write('<br>');
}
</script>
</body>
</html>การดำเนินการ
บันทึกไฟล์นี้เป็นset_node_attribute_example.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และnode.xmlควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) ผลลัพธ์จะเป็นดังนี้ -
0) admin-0
1) admin-1
2) admin-2ในบทนี้เราจะพูดถึงวิธีการสร้างโหนดใหม่โดยใช้สองวิธีของวัตถุเอกสาร วิธีการเหล่านี้ให้ขอบเขตที่จะสร้างใหม่โหนดองค์ประกอบโหนดข้อความแสดงความคิดเห็นโหนด CDATA โหนดส่วนและโหนดแอตทริบิวต์ หากโหนดที่สร้างขึ้นใหม่มีอยู่แล้วในออบเจ็กต์องค์ประกอบโหนดใหม่จะถูกแทนที่ ส่วนต่อไปนี้แสดงให้เห็นถึงสิ่งนี้พร้อมตัวอย่าง
สร้างโหนดองค์ประกอบใหม่
เมธอดcreateElement ()สร้างโหนดองค์ประกอบใหม่ หากโหนดองค์ประกอบที่สร้างขึ้นใหม่มีอยู่ในออบเจ็กต์องค์ประกอบจะถูกแทนที่ด้วยโหนดใหม่
ไวยากรณ์
ไวยากรณ์ที่จะใช้เมธอดcreateElement ()มีดังนี้ -
var_name = xmldoc.createElement("tagname");ที่ไหน
var_name - คือชื่อตัวแปรที่ผู้ใช้กำหนดซึ่งเป็นชื่อขององค์ประกอบใหม่
("tagname") - คือชื่อของโหนดองค์ประกอบใหม่ที่จะสร้าง
ตัวอย่าง
ตัวอย่างต่อไปนี้ (createnewelement_example.htm) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM และสร้างโหนดองค์ประกอบใหม่PhoneNoในเอกสาร XML
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
new_element = xmlDoc.createElement("PhoneNo");
x = xmlDoc.getElementsByTagName("FirstName")[0];
x.appendChild(new_element);
document.write(x.getElementsByTagName("PhoneNo")[0].nodeName);
</script>
</body>
</html>new_element = xmlDoc.createElement ("PhoneNo"); สร้างโหนดองค์ประกอบใหม่ <PhoneNo>
x.appendChild (new_element); xถือชื่อของโหนดลูกที่ระบุ <FirstName> ซึ่งต่อท้ายโหนดองค์ประกอบใหม่
การดำเนินการ
บันทึกไฟล์นี้เป็นcreatenewelement_example.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และnode.xmlควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) ในการส่งออกที่เราได้รับค่าแอตทริบิวต์เป็นPhoneNo
สร้างโหนดข้อความใหม่
เมธอดcreateTextNode ()สร้างโหนดข้อความใหม่
ไวยากรณ์
ไวยากรณ์ที่จะใช้createTextNode ()มีดังนี้ -
var_name = xmldoc.createTextNode("tagname");ที่ไหน
var_name - เป็นชื่อตัวแปรที่ผู้ใช้กำหนดซึ่งเก็บชื่อของโหนดข้อความใหม่
("tagname") - ภายในวงเล็บคือชื่อของโหนดข้อความใหม่ที่จะสร้าง
ตัวอย่าง
ตัวอย่างต่อไปนี้ (createtextnode_example.htm) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM และสร้างโหนดข้อความใหม่ Im โหนดข้อความใหม่ในเอกสาร XML
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_e = xmlDoc.createElement("PhoneNo");
create_t = xmlDoc.createTextNode("Im new text node");
create_e.appendChild(create_t);
x = xmlDoc.getElementsByTagName("Employee")[0];
x.appendChild(create_e);
document.write(" PhoneNO: ");
document.write(x.getElementsByTagName("PhoneNo")[0].childNodes[0].nodeValue);
</script>
</body>
</html>รายละเอียดของโค้ดด้านบนมีดังต่อไปนี้ -
create_e = xmlDoc.createElement ("PhoneNo"); สร้างองค์ประกอบใหม่ < PhoneNo >
create_t = xmlDoc.createTextNode ("ฉันโหนดข้อความใหม่"); สร้างโหนดข้อความใหม่"อิ่มโหนดข้อความใหม่"
x.appendChild (create_e); โหนดข้อความ"Im new text node"ต่อท้ายองค์ประกอบ < PhoneNo >
document.write (x.getElementsByTagName ("PhoneNo") [0] .childNodes [0] .nodeValue); เขียนค่าโหนดข้อความใหม่ให้กับองค์ประกอบ <PhoneNo>
การดำเนินการ
บันทึกไฟล์นี้เป็นcreatetextnode_example.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และ node.xml ควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) ในการส่งออกที่เราได้รับค่าแอตทริบิวต์เป็นเช่นPhoneNO: อิ่มโหนดข้อความใหม่
สร้างโหนดความคิดเห็นใหม่
เมธอดcreateComment ()สร้างโหนดข้อคิดเห็นใหม่ โหนดข้อคิดเห็นรวมอยู่ในโปรแกรมเพื่อให้เข้าใจการทำงานของโค้ดได้ง่าย
ไวยากรณ์
ไวยากรณ์ที่จะใช้createComment ()มีดังนี้ -
var_name = xmldoc.createComment("tagname");ที่ไหน
var_name - คือชื่อตัวแปรที่ผู้ใช้กำหนดเองซึ่งมีชื่อของโหนดข้อคิดเห็นใหม่
("tagname") - คือชื่อของโหนดข้อคิดเห็นใหม่ที่จะสร้างขึ้น
ตัวอย่าง
ตัวอย่างต่อไปนี้ (createcommentnode_example.htm) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM และสร้างโหนดข้อคิดเห็นใหม่"Company is the parent node"ในเอกสาร XML
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
}
else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_comment = xmlDoc.createComment("Company is the parent node");
x = xmlDoc.getElementsByTagName("Company")[0];
x.appendChild(create_comment);
document.write(x.lastChild.nodeValue);
</script>
</body>
</html>ในตัวอย่างข้างต้น -
create_comment = xmlDoc.createComment ("บริษัท คือโหนดหลัก") creates a specified comment line.
x.appendChild (create_comment)ในบรรทัดนี้'x'ถือชื่อขององค์ประกอบ <บริษัท > ซึ่งต่อท้ายบรรทัดความคิดเห็น
การดำเนินการ
บันทึกไฟล์นี้เป็นcreatecommentnode_example.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และnode.xmlควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) ในการส่งออกที่เราได้รับค่าแอตทริบิวต์เป็นบริษัท เป็นโหนดแม่
สร้างโหนดส่วน CDATAใหม่
เมธอดcreateCDATASection ()สร้างโหนดส่วน CDATA ใหม่ หากโหนดส่วน CDATA ที่สร้างขึ้นใหม่มีอยู่ในออบเจ็กต์องค์ประกอบจะถูกแทนที่ด้วยโหนดใหม่
ไวยากรณ์
ไวยากรณ์ที่จะใช้createCDATASection ()มีดังนี้ -
var_name = xmldoc.createCDATASection("tagname");ที่ไหน
var_name - คือชื่อตัวแปรที่ผู้ใช้กำหนดเองซึ่งเก็บชื่อของโหนดส่วน CDATA ใหม่
("tagname") - คือชื่อของโหนดส่วน CDATA ใหม่ที่จะสร้างขึ้น
ตัวอย่าง
ตัวอย่างต่อไปนี้ (createcdatanode_example.htm) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM และสร้างโหนดส่วน CDATA ใหม่"Create CDATA Example"ในเอกสาร XML
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
}
else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_CDATA = xmlDoc.createCDATASection("Create CDATA Example");
x = xmlDoc.getElementsByTagName("Employee")[0];
x.appendChild(create_CDATA);
document.write(x.lastChild.nodeValue);
</script>
</body>
</html>ในตัวอย่างข้างต้น -
create_CDATA = xmlDoc.createCDATASection ("สร้างตัวอย่าง CDATA")สร้างโหนดส่วน CDATA ใหม่"สร้างตัวอย่าง CDATA"
x.appendChild (create_CDATA)ที่นี่xถือองค์ประกอบที่ระบุ <Employee> ที่ทำดัชนีไว้ที่ 0 ซึ่งค่าโหนด CDATA ถูกต่อท้าย
การดำเนินการ
บันทึกไฟล์นี้เป็นcreatecdatanode_example.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และ node.xml ควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) ในการส่งออกที่เราได้รับค่าแอตทริบิวต์เป็นสร้างตัวอย่าง CDATA
สร้างโหนดแอตทริบิวต์ใหม่
เพื่อสร้างโหนดแอตทริบิวต์ใหม่วิธีการsetAttributeNode ()ถูกนำมาใช้ หากโหนดแอตทริบิวต์ที่สร้างขึ้นใหม่มีอยู่ในออบเจ็กต์องค์ประกอบโหนดใหม่จะถูกแทนที่
ไวยากรณ์
ไวยากรณ์ที่จะใช้เมธอดcreateElement ()มีดังนี้ -
var_name = xmldoc.createAttribute("tagname");ที่ไหน
var_name - คือชื่อตัวแปรที่ผู้ใช้กำหนดเองซึ่งมีชื่อของโหนดแอตทริบิวต์ใหม่
("tagname") - คือชื่อของโหนดแอตทริบิวต์ใหม่ที่จะสร้าง
ตัวอย่าง
ตัวอย่างต่อไปนี้ (createattributenode_example.htm) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM และสร้างส่วนโหนดแอ็ตทริบิวต์ใหม่ในเอกสาร XML
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_a = xmlDoc.createAttribute("section");
create_a.nodeValue = "A";
x = xmlDoc.getElementsByTagName("Employee");
x[0].setAttributeNode(create_a);
document.write("New Attribute: ");
document.write(x[0].getAttribute("section"));
</script>
</body>
</html>ในตัวอย่างข้างต้น -
create_a = xmlDoc.createAttribute ("Category")สร้างแอตทริบิวต์ด้วยชื่อ <section>
create_a.nodeValue = "Management"สร้างค่า"A"สำหรับแอตทริบิวต์ <section>
x [0] .setAttributeNode (create_a)ค่าแอ็ตทริบิวต์นี้ถูกตั้งค่าเป็นองค์ประกอบโหนด <Employee> ที่ทำดัชนีไว้ที่ 0
ในบทนี้เราจะพูดถึงโหนดขององค์ประกอบที่มีอยู่ มันให้วิธีการ -
ผนวกโหนดลูกใหม่ก่อนหรือหลังโหนดลูกที่มีอยู่
แทรกข้อมูลภายในโหนดข้อความ
เพิ่มโหนดแอตทริบิวต์
สามารถใช้วิธีการต่อไปนี้เพื่อเพิ่ม / ผนวกโหนดเข้ากับองค์ประกอบใน DOM -
- appendChild()
- insertBefore()
- insertData()
appendChild ()
เมธอด appendChild () เพิ่มโหนดลูกใหม่หลังโหนดลูกที่มีอยู่
ไวยากรณ์
ไวยากรณ์ของ appendChild () วิธีการมีดังนี้ -
Node appendChild(Node newChild) throws DOMExceptionที่ไหน
newChild - เป็นโหนดที่จะเพิ่ม
วิธีนี้ส่งคืนโหนดที่เพิ่ม
ตัวอย่าง
ตัวอย่างต่อไปนี้ (appendchildnode_example.htm) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM และผนวกPhoneNoลูกใหม่เข้ากับองค์ประกอบ <FirstName>
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_e = xmlDoc.createElement("PhoneNo");
x = xmlDoc.getElementsByTagName("FirstName")[0];
x.appendChild(create_e);
document.write(x.getElementsByTagName("PhoneNo")[0].nodeName);
</script>
</body>
</html>ในตัวอย่างข้างต้น -
โดยใช้วิธีการ createElement () จากองค์ประกอบใหม่PhoneNoจะถูกสร้างขึ้น
องค์ประกอบใหม่PhoneNoถูกเพิ่มเข้าไปในองค์ประกอบFirstNameโดยใช้เมธอด appendChild ()
การดำเนินการ
บันทึกไฟล์นี้เป็นappendchildnode_example.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และ node.xml ควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) ในการส่งออกที่เราได้รับค่าแอตทริบิวต์เป็นPhoneNo
แทรกก่อน ()
เมธอดinsertBefore ()แทรกโหนดลูกใหม่ก่อนโหนดลูกที่ระบุ
ไวยากรณ์
ไวยากรณ์ของวิธีการ insertBefore () มีดังนี้ -
Node insertBefore(Node newChild, Node refChild) throws DOMExceptionที่ไหน
newChild - เป็นโหนดที่จะแทรก
refChild - คือโหนดอ้างอิงกล่าวคือโหนดก่อนที่จะต้องแทรกโหนดใหม่
วิธีนี้ส่งคืนโหนดที่กำลังแทรก
ตัวอย่าง
ตัวอย่างต่อไปนี้ (insertnodebefore_example.htm) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM และแทรกอีเมลลูกใหม่ก่อนองค์ประกอบที่ระบุ <Email>
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_e = xmlDoc.createElement("Email");
x = xmlDoc.documentElement;
y = xmlDoc.getElementsByTagName("Email");
document.write("No of Email elements before inserting was: " + y.length);
document.write("<br>");
x.insertBefore(create_e,y[3]);
y=xmlDoc.getElementsByTagName("Email");
document.write("No of Email elements after inserting is: " + y.length);
</script>
</body>
</html>ในตัวอย่างข้างต้น -
โดยใช้เมธอด createElement () อีเมลองค์ประกอบใหม่จะถูกสร้างขึ้น
องค์ประกอบใหม่อีเมลถูกเพิ่มก่อนองค์ประกอบอีเมลโดยใช้เมธอด insertBefore ()
y.lengthให้จำนวนองค์ประกอบทั้งหมดที่เพิ่มก่อนและหลังองค์ประกอบใหม่
การดำเนินการ
บันทึกไฟล์นี้เป็นinsertnodebefore_example.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และ node.xml ควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) เราจะได้รับผลลัพธ์ต่อไปนี้ -
No of Email elements before inserting was: 3
No of Email elements after inserting is: 4insertData ()
เมธอด insertData () แทรกสตริงที่ออฟเซ็ตหน่วย 16 บิตที่ระบุ
ไวยากรณ์
insertData () มีไวยากรณ์ต่อไปนี้ -
void insertData(int offset, java.lang.String arg) throws DOMExceptionที่ไหน
offset - คือออฟเซ็ตอักขระที่จะแทรก
arg - เป็นคำสำคัญในการแทรกข้อมูล มันใส่ค่าออฟเซ็ตและสตริงสองพารามิเตอร์ภายในวงเล็บคั่นด้วยลูกน้ำ
ตัวอย่าง
ตัวอย่างต่อไปนี้ (addtext_example.htm) แยกวิเคราะห์เอกสาร XML (" node.xml ") ลงในอ็อบเจ็กต์ XML DOM และแทรกข้อมูลใหม่MiddleNameที่ตำแหน่งที่ระบุไปยังอิลิเมนต์ <FirstName>
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0];
document.write(x.nodeValue);
x.insertData(6,"MiddleName");
document.write("<br>");
document.write(x.nodeValue);
</script>
</body>
</html>x.insertData(6,"MiddleName");- ที่นี่xถือชื่อของลูกที่ระบุเช่น <FirstName> จากนั้นเราจะแทรกข้อมูล"MiddleName"ไปยังโหนดข้อความนี้โดยเริ่มจากตำแหน่งที่ 6
การดำเนินการ
บันทึกไฟล์นี้เป็นaddtext_example.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และ node.xml ควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) เราจะได้รับสิ่งต่อไปนี้ในผลลัพธ์ -
Tanmay
TanmayMiddleNameในบทนี้เราจะศึกษาเกี่ยวกับการดำเนินการแทนที่โหนดในอ็อบเจ็กต์ XML DOM ดังที่เราทราบทุกอย่างใน DOM นั้นได้รับการดูแลในหน่วยข้อมูลตามลำดับชั้นที่เรียกว่าโหนดและโหนดแทนที่เป็นอีกวิธีหนึ่งในการอัปเดตโหนดที่ระบุเหล่านี้หรือโหนดข้อความ
ต่อไปนี้เป็นสองวิธีในการแทนที่โหนด
- replaceChild()
- replaceData()
แทนที่เด็ก ()
เมธอดreplaceChild ()แทนที่โหนดที่ระบุด้วยโหนดใหม่
ไวยากรณ์
insertData () มีไวยากรณ์ต่อไปนี้ -
Node replaceChild(Node newChild, Node oldChild) throws DOMExceptionที่ไหน
newChild - คือโหนดใหม่ที่จะใส่ในรายการลูก
oldChild - คือโหนดที่ถูกแทนที่ในรายการ
วิธีนี้ส่งคืนโหนดที่ถูกแทนที่
ตัวอย่าง
ตัวอย่างต่อไปนี้ (replacenode_example.htm) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM และแทนที่โหนดที่ระบุ <FirstName> ด้วยโหนดใหม่ <Name>
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.documentElement;
z = xmlDoc.getElementsByTagName("FirstName");
document.write("<b>Content of FirstName element before replace operation</b><br>");
for (i=0;i<z.length;i++) {
document.write(z[i].childNodes[0].nodeValue);
document.write("<br>");
}
//create a Employee element, FirstName element and a text node
newNode = xmlDoc.createElement("Employee");
newTitle = xmlDoc.createElement("Name");
newText = xmlDoc.createTextNode("MS Dhoni");
//add the text node to the title node,
newTitle.appendChild(newText);
//add the title node to the book node
newNode.appendChild(newTitle);
y = xmlDoc.getElementsByTagName("Employee")[0]
//replace the first book node with the new node
x.replaceChild(newNode,y);
z = xmlDoc.getElementsByTagName("FirstName");
document.write("<b>Content of FirstName element after replace operation</b><br>");
for (i = 0;i<z.length;i++) {
document.write(z[i].childNodes[0].nodeValue);
document.write("<br>");
}
</script>
</body>
</html>การดำเนินการ
บันทึกไฟล์นี้เป็น replacenode_example.htm บนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และ node.xml ควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) เราจะได้ผลลัพธ์ตามที่แสดงด้านล่าง -
Content of FirstName element before replace operation
Tanmay
Taniya
Tanisha
Content of FirstName element after replace operation
Taniya
Tanishaแทนที่ข้อมูล ()
เมธอด replaceData () แทนที่อักขระที่เริ่มต้นที่ออฟเซ็ตหน่วย 16 บิตที่ระบุด้วยสตริงที่ระบุ
ไวยากรณ์
replaceData () มีไวยากรณ์ต่อไปนี้ -
void replaceData(int offset, int count, java.lang.String arg) throws DOMExceptionที่ไหน
offset - คือค่าชดเชยที่จะเริ่มแทนที่
count - คือจำนวนหน่วย 16 บิตที่จะแทนที่ หากผลรวมของออฟเซ็ตและจำนวนเกินความยาวหน่วย 16 บิตทั้งหมดที่อยู่ท้ายข้อมูลจะถูกแทนที่
arg - DOMStringซึ่งต้องเปลี่ยนช่วง
ตัวอย่าง
ตัวอย่างต่อไปนี้ (แทนที่ata_example.htm ) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM และแทนที่
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("ContactNo")[0].childNodes[0];
document.write("<b>ContactNo before replace operation:</b> "+x.nodeValue);
x.replaceData(1,5,"9999999");
document.write("<br>");
document.write("<b>ContactNo after replace operation:</b> "+x.nodeValue);
</script>
</body>
</html>ในตัวอย่างข้างต้น -
x.replaceData (2,3, "999"); - ที่นี่xถือข้อความขององค์ประกอบที่ระบุ <ContactNo> ซึ่งข้อความจะถูกแทนที่ด้วยข้อความใหม่"9999999"เริ่มต้นจากตำแหน่ง1จนถึงความยาวของ5
การดำเนินการ
บันทึกไฟล์นี้เป็นแทนที่ ata_example.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และ node.xml ควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) เราจะได้ผลลัพธ์ตามที่แสดงด้านล่าง -
ContactNo before replace operation: 1234567890
ContactNo after replace operation: 199999997890ในบทนี้เราจะศึกษาเกี่ยวกับ DOM XML ลบโหนดการดำเนินงาน การดำเนินการลบโหนดจะลบโหนดที่ระบุออกจากเอกสาร การดำเนินการนี้สามารถนำไปใช้เพื่อลบโหนดเช่นโหนดข้อความโหนดองค์ประกอบหรือโหนดแอตทริบิวต์
ต่อไปนี้เป็นวิธีการที่ใช้สำหรับการลบโหนด -
removeChild()
removeAttribute()
RemoveChild ()
เมธอดremoveChild ()จะลบโหนดลูกที่ระบุโดยoldChildออกจากรายการเด็กและส่งคืน การลบโหนดลูกจะเท่ากับการลบโหนดข้อความ ดังนั้นการลบโหนดลูกจะลบโหนดข้อความที่เกี่ยวข้อง
ไวยากรณ์
ไวยากรณ์ที่จะใช้ removeChild () มีดังนี้ -
Node removeChild(Node oldChild) throws DOMExceptionที่ไหน
oldChild - คือโหนดที่ถูกลบออก
วิธีนี้ส่งคืนโหนดที่ถูกลบออก
ตัวอย่าง - ลบโหนดปัจจุบัน
ตัวอย่างต่อไปนี้ (removecurrentnode_example.htm) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM และลบโหนดที่ระบุ <ContactNo> ออกจากโหนดหลัก
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
document.write("<b>Before remove operation, total ContactNo elements: </b>");
document.write(xmlDoc.getElementsByTagName("ContactNo").length);
document.write("<br>");
x = xmlDoc.getElementsByTagName("ContactNo")[0];
x.parentNode.removeChild(x);
document.write("<b>After remove operation, total ContactNo elements: </b>");
document.write(xmlDoc.getElementsByTagName("ContactNo").length);
</script>
</body>
</html>ในตัวอย่างข้างต้น -
x = xmlDoc.getElementsByTagName ("ContactNo") [0]ได้รับองค์ประกอบ <ContactNo> ที่จัดทำดัชนีที่ 0
x.parentNode.removeChild (x); ลบองค์ประกอบ <ContactNo> ที่ทำดัชนีที่ 0 จากโหนดแม่
การดำเนินการ
บันทึกไฟล์นี้เป็นremovecurrentnode_example.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และ node.xml ควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) เราได้ผลลัพธ์ดังต่อไปนี้ -
Before remove operation, total ContactNo elements: 3
After remove operation, total ContactNo elements: 2ตัวอย่าง - ลบโหนดข้อความ
ตัวอย่างต่อไปนี้ (removetextNode_example.htm) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM และลบโหนดลูกที่ระบุ <FirstName>
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("FirstName")[0];
document.write("<b>Text node of child node before removal is:</b> ");
document.write(x.childNodes.length);
document.write("<br>");
y = x.childNodes[0];
x.removeChild(y);
document.write("<b>Text node of child node after removal is:</b> ");
document.write(x.childNodes.length);
</script>
</body>
</html>ในตัวอย่างข้างต้น -
x = xmlDoc.getElementsByTagName ("ชื่อแรก") [0]; - รับองค์ประกอบแรก <FirstName> เป็นxดัชนีที่ 0
y = x.childNodes [0]; - ในบรรทัดนี้yถือโหนดลูกที่จะลบ
x.removeChild (y); - ลบโหนดลูกที่ระบุ
การดำเนินการ
บันทึกไฟล์นี้เป็นremovetextNode_example.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และ node.xml ควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) เราได้ผลลัพธ์ดังต่อไปนี้ -
Text node of child node before removal is: 1
Text node of child node after removal is: 0removeAttribute ()
วิธี removeAttribute () ลบแอตทริบิวต์ขององค์ประกอบตามชื่อ
ไวยากรณ์
ไวยากรณ์ที่จะใช้removeAttribute ()มีดังนี้ -
void removeAttribute(java.lang.String name) throws DOMExceptionที่ไหน
ชื่อ - คือชื่อของแอตทริบิวต์ที่จะลบ
ตัวอย่าง
ตัวอย่างต่อไปนี้ (removeelementattribute_example.htm) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM และลบโหนดแอ็ตทริบิวต์ที่ระบุ
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName('Employee');
document.write(x[1].getAttribute('category'));
document.write("<br>");
x[1].removeAttribute('category');
document.write(x[1].getAttribute('category'));
</script>
</body>
</html>ในตัวอย่างข้างต้น -
document.write (x [1] .getAttribute ('หมวดหมู่')); - ค่าของประเภทแอตทริบิวต์ที่จัดทำดัชนีที่ตำแหน่งที่ 1 จะถูกเรียกใช้
x [1] .removeAttribute ('หมวดหมู่'); - ลบค่าแอตทริบิวต์
การดำเนินการ
บันทึกไฟล์นี้เป็นremoveelementattribute_example.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และ node.xml ควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) เราได้ผลลัพธ์ดังต่อไปนี้ -
Non-Technical
nullในบทนี้เราจะอธิบายการดำเนินการClone Nodeบนวัตถุ XML DOM การดำเนินการ Clone node ใช้เพื่อสร้างสำเนาของโหนดที่ระบุ cloneNode ()ใช้สำหรับการดำเนินการนี้
cloneNode ()
วิธีนี้ส่งคืนโหนดที่ซ้ำกันกล่าวคือทำหน้าที่เป็นตัวสร้างสำเนาทั่วไปสำหรับโหนด โหนดที่ซ้ำกันไม่มีพาเรนต์ (parentNode เป็น null) และไม่มีข้อมูลผู้ใช้
ไวยากรณ์
cloneNode ()วิธีการมีไวยากรณ์ต่อไป -
Node cloneNode(boolean deep)ลึก - หากเป็นจริงให้โคลนทรีย่อยซ้ำภายใต้โหนดที่ระบุ หากเป็นเท็จให้โคลนเฉพาะโหนดเท่านั้น (และแอตทริบิวต์หากเป็นองค์ประกอบ)
วิธีนี้ส่งคืนโหนดที่ซ้ำกัน
ตัวอย่าง
ตัวอย่างต่อไปนี้ (clonenode_example.htm) แยกวิเคราะห์เอกสาร XML ( node.xml ) ลงในอ็อบเจ็กต์ XML DOM และสร้างสำเนาลึกขององค์ประกอบEmployeeแรก
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName('Employee')[0];
clone_node = x.cloneNode(true);
xmlDoc.documentElement.appendChild(clone_node);
firstname = xmlDoc.getElementsByTagName("FirstName");
lastname = xmlDoc.getElementsByTagName("LastName");
contact = xmlDoc.getElementsByTagName("ContactNo");
email = xmlDoc.getElementsByTagName("Email");
for (i = 0;i < firstname.length;i++) {
document.write(firstname[i].childNodes[0].nodeValue+'
'+lastname[i].childNodes[0].nodeValue+',
'+contact[i].childNodes[0].nodeValue+', '+email[i].childNodes[0].nodeValue);
document.write("<br>");
}
</script>
</body>
</html>ขณะที่คุณสามารถเห็นในตัวอย่างข้างต้นเราได้ตั้งcloneNode ()พระรามที่จะเป็นจริง ดังนั้นองค์ประกอบย่อยแต่ละองค์ประกอบภายใต้องค์ประกอบของพนักงานจะถูกคัดลอกหรือโคลน
การดำเนินการ
บันทึกไฟล์นี้เป็นclonenode_example.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และ node.xml ควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) เราจะได้ผลลัพธ์ตามที่แสดงด้านล่าง -
Tanmay Patil, 1234567890, [email protected]
Taniya Mishra, 1234667898, [email protected]
Tanisha Sharma, 1234562350, [email protected]
Tanmay Patil, 1234567890, [email protected]คุณจะสังเกตเห็นว่าองค์ประกอบพนักงานแรกถูกโคลนอย่างสมบูรณ์
อินเทอร์เฟซโหนดเป็นประเภทข้อมูลหลักสำหรับ Document Object Model ทั้งหมด โหนดถูกใช้เพื่อแสดงองค์ประกอบ XML เดียวในโครงสร้างเอกสารทั้งหมด
โหนดสามารถเป็นประเภทใดก็ได้ที่เป็นโหนดแอตทริบิวต์โหนดข้อความหรือโหนดอื่น ๆ แอตทริบิวต์nodeName, nodeValueและแอตทริบิวต์รวมอยู่เป็นกลไกในการรับข้อมูลโหนดโดยไม่ต้องแคสต์ลงไปยังอินเตอร์เฟสที่ได้รับเฉพาะ
คุณลักษณะ
ตารางต่อไปนี้แสดงรายการคุณลักษณะของวัตถุโหนด -
| แอตทริบิวต์ | ประเภท | คำอธิบาย |
|---|---|---|
| คุณลักษณะ | ชื่อโหนดแผนที่ | เป็นประเภทNamedNodeMapที่มีแอตทริบิวต์ของโหนดนี้ (ถ้าเป็นองค์ประกอบ) หรือเป็นโมฆะ สิ่งนี้ถูกลบออก ดูรายละเอียด |
| baseURI | DOMString | ใช้เพื่อระบุ URI ฐานสัมบูรณ์ของโหนด |
| childNodes | NodeList | เป็นNodeListที่มีลูกทั้งหมดของโหนดนี้ หากไม่มีลูกนี่คือNodeListที่ไม่มีโหนด |
| firstChild | โหนด | ระบุลูกคนแรกของโหนด |
| ลูกคนสุดท้อง | โหนด | ระบุลูกสุดท้ายของโหนด |
| localName | DOMString | ใช้เพื่อระบุชื่อของส่วนโลคัลของโหนด สิ่งนี้ถูกลบออก โปรดดูรายละเอียด |
| namespaceURI | DOMString | ระบุ URI เนมสเปซของโหนด สิ่งนี้ถูกลบออก ดูรายละเอียด |
| ต่อไป | โหนด | ส่งคืนโหนดทันทีตามโหนดนี้ หากไม่มีโหนดดังกล่าวจะส่งคืนค่าว่าง |
| nodeName | DOMString | ชื่อของโหนดนี้ขึ้นอยู่กับประเภทของโหนด |
| nodeType | สั้นไม่ได้ลงนาม | เป็นรหัสที่แสดงถึงประเภทของวัตถุที่อยู่เบื้องหลัง |
| nodeValue | DOMString | ใช้เพื่อระบุค่าของโหนดขึ้นอยู่กับประเภทของโหนด |
| ownerDocument | เอกสาร | ระบุวัตถุเอกสารที่เกี่ยวข้องกับโหนด |
| parentNode | โหนด | คุณสมบัตินี้ระบุโหนดหลักของโหนด |
| คำนำหน้า | DOMString | คุณสมบัตินี้ส่งคืนคำนำหน้าเนมสเปซของโหนด สิ่งนี้ถูกลบออก ดูรายละเอียด |
| ก่อนหน้า | โหนด | สิ่งนี้ระบุโหนดที่อยู่ข้างหน้าโหนดปัจจุบันทันที |
| textContent | DOMString | สิ่งนี้ระบุเนื้อหาที่เป็นข้อความของโหนด |
ประเภทโหนด
เราได้ระบุประเภทโหนดไว้ด้านล่าง -
- ELEMENT_NODE
- ATTRIBUTE_NODE
- ENTITY_NODE
- ENTITY_REFERENCE_NODE
- DOCUMENT_FRAGMENT_NODE
- TEXT_NODE
- CDATA_SECTION_NODE
- COMMENT_NODE
- PROCESSING_INSTRUCTION_NODE
- DOCUMENT_NODE
- DOCUMENT_TYPE_NODE
- NOTATION_NODE
วิธีการ
ตารางด้านล่างแสดงวิธีการของ Node Object ต่างๆ -
| ส. | วิธีการและคำอธิบาย |
|---|---|
| 1 | appendChild (โหนด newChild) วิธีนี้จะเพิ่มโหนดหลังโหนดลูกสุดท้ายของโหนดองค์ประกอบที่ระบุ ส่งคืนโหนดที่เพิ่ม |
| 2 | cloneNode (บูลีนลึก) วิธีนี้ใช้เพื่อสร้างโหนดที่ซ้ำกันเมื่อถูกแทนที่ในคลาสที่ได้รับ มันส่งคืนโหนดที่ซ้ำกัน |
| 3 | CompareDocumentPosition (โหนดอื่น ๆ ) วิธีนี้ใช้เพื่อเปรียบเทียบตำแหน่งของโหนดปัจจุบันกับโหนดที่ระบุตามลำดับเอกสาร ส่งคืนค่าย่อที่ไม่ได้ลงชื่อว่าโหนดอยู่ในตำแหน่งที่ค่อนข้างตรงกับโหนดอ้างอิงอย่างไร |
| 4 | getFeature(DOMString feature, DOMString version) ส่งคืนวัตถุ DOM ที่ใช้ API เฉพาะของคุณลักษณะและเวอร์ชันที่ระบุถ้ามีหรือว่างหากไม่มีวัตถุ สิ่งนี้ถูกลบออก โปรดดูรายละเอียด |
| 5 | getUserData(DOMString key) ดึงวัตถุที่เกี่ยวข้องกับคีย์บนโหนดนี้ วัตถุต้องถูกตั้งค่าเป็นโหนดนี้ก่อนโดยเรียกใช้ setUserData ด้วยคีย์เดียวกัน ส่งคืน DOMUserData ที่เชื่อมโยงกับคีย์ที่กำหนดบนโหนดนี้หรือค่าว่างถ้าไม่มี สิ่งนี้ถูกลบออก โปรดดูรายละเอียด |
| 6 | hasAttributes() ส่งกลับว่าโหนดนี้ (ถ้าเป็นองค์ประกอบ) มีแอตทริบิวต์หรือไม่ ผลตอบแทนจริงถ้าแอตทริบิวต์ใด ๆ ที่มีอยู่ในโหนดที่ระบุผลตอบแทนอื่น ๆที่เป็นเท็จ สิ่งนี้ถูกลบออก โปรดดูรายละเอียด |
| 7 | hasChildNodes () ส่งคืนว่าโหนดนี้มีชายด์หรือไม่ วิธีการนี้จะส่งกลับจริงถ้าโหนดปัจจุบันมีโหนดลูกมิฉะนั้นเท็จ |
| 8 | insertBefore (โหนด newChild, โหนด refChild) วิธีนี้ใช้เพื่อแทรกโหนดใหม่เป็นชายด์ของโหนดนี้โดยตรงก่อนชายด์ที่มีอยู่ของโหนดนี้ ส่งคืนโหนดที่ถูกแทรก |
| 9 | isDefaultNamespace (DOMString namespaceURI) เมธอดนี้ยอมรับเนมสเปซ URI เป็นอาร์กิวเมนต์และส่งคืนบูลีนที่มีค่าเป็นจริงหากเนมสเปซเป็นเนมสเปซเริ่มต้นบนโหนดที่กำหนดหรือเป็นเท็จถ้าไม่ใช่ |
| 10 | isEqualNode (โหนด arg) วิธีนี้จะทดสอบว่าสองโหนดเท่ากันหรือไม่ ส่งคืนจริงถ้าโหนดเท่ากันมิฉะนั้นจะเป็นเท็จ |
| 11 | isSameNode(Node other) วิธีนี้จะคืนค่าว่าโหนดปัจจุบันเป็นโหนดเดียวกับโหนดที่กำหนดหรือไม่ ส่งคืนค่าจริงหากโหนดเหมือนกันมิฉะนั้นจะเป็นเท็จ สิ่งนี้ถูกลบออก โปรดดูรายละเอียด |
| 12 | isSupported(DOMString feature, DOMString version) วิธีนี้ส่งคืนว่าโมดูล DOM ที่ระบุได้รับการสนับสนุนโดยโหนดปัจจุบันหรือไม่ ส่งคืนค่าจริงหากคุณลักษณะที่ระบุได้รับการสนับสนุนบนโหนดนี้มิฉะนั้นจะเป็นเท็จ สิ่งนี้ถูกลบออก โปรดดูรายละเอียด |
| 13 | lookupNamespaceURI (คำนำหน้า DOMString) เมธอดนี้รับ URI ของเนมสเปซที่เชื่อมโยงกับคำนำหน้าเนมสเปซ |
| 14 | lookupPrefix (DOMString namespaceURI) วิธีนี้ส่งคืนคำนำหน้าที่ใกล้เคียงที่สุดที่กำหนดไว้ในเนมสเปซปัจจุบันสำหรับเนมสเปซ URI ส่งคืนคำนำหน้าเนมสเปซที่เกี่ยวข้องหากพบหรือว่างหากไม่พบ |
| 15 | ทำให้ปกติ () Normalization จะเพิ่มโหนดข้อความทั้งหมดรวมถึงโหนดแอตทริบิวต์ซึ่งกำหนดรูปแบบปกติโดยที่โครงสร้างของโหนดซึ่งประกอบด้วยองค์ประกอบข้อคิดเห็นคำแนะนำการประมวลผลส่วน CDATA และการอ้างอิงเอนทิตีแยกโหนดข้อความกล่าวคือไม่มีโหนดข้อความที่อยู่ติดกันหรือโหนดข้อความว่าง |
| 16 | removeChild (โหนด oldChild) วิธีนี้ใช้เพื่อลบโหนดลูกที่ระบุออกจากโหนดปัจจุบัน สิ่งนี้ส่งคืนโหนดที่ถูกลบออก |
| 17 | replaceChild (โหนด newChild โหนด oldChild) วิธีนี้ใช้เพื่อแทนที่โหนดลูกเก่าด้วยโหนดใหม่ สิ่งนี้ส่งคืนโหนดที่ถูกแทนที่ |
| 18 | setUserData(DOMString key, DOMUserData data, UserDataHandler handler) วิธีนี้เชื่อมโยงวัตถุกับคีย์บนโหนดนี้ สามารถดึงอ็อบเจ็กต์จากโหนดนี้ได้ในภายหลังโดยเรียกgetUserDataด้วยคีย์เดียวกัน สิ่งนี้ส่งคืนDOMUserDataก่อนหน้านี้ที่เชื่อมโยงกับคีย์ที่กำหนดบนโหนดนี้ สิ่งนี้ถูกลบออก โปรดดูรายละเอียด |
วัตถุ NodeList ระบุสิ่งที่เป็นนามธรรมของคอลเลกชันที่เรียงลำดับของโหนด รายการใน NodeList สามารถเข้าถึงได้ผ่านดัชนีอินทิกรัลโดยเริ่มจาก 0
คุณลักษณะ
ตารางต่อไปนี้แสดงรายการคุณลักษณะของวัตถุ NodeList -
| แอตทริบิวต์ | ประเภท | คำอธิบาย |
|---|---|---|
| ความยาว | ไม่ได้ลงนามยาว | ให้จำนวนโหนดในรายการโหนด |
วิธีการ
ต่อไปนี้เป็นวิธีเดียวของอ็อบเจ็กต์ NodeList
| ส. | วิธีการและคำอธิบาย |
|---|---|
| 1 | สิ่งของ() ส่งคืนดัชนี th รายการในคอลเลกชัน หากดัชนีมากกว่าหรือเท่ากับจำนวนโหนดในรายการสิ่งนี้จะส่งกลับค่า null |
NamedNodeMapวัตถุถูกนำมาใช้เพื่อเป็นตัวแทนของคอลเลกชันของโหนดที่สามารถเข้าถึงได้โดยใช้ชื่อ
คุณลักษณะ
ตารางต่อไปนี้แสดงรายการคุณสมบัติของวัตถุ NamedNodeMap
| แอตทริบิวต์ | ประเภท | คำอธิบาย |
|---|---|---|
| ความยาว | ไม่ได้ลงนามยาว | มันให้จำนวนโหนดในแผนที่นี้ ช่วงของดัชนีโหนดลูกที่ถูกต้องคือ 0 ถึงความยาว -1 |
วิธีการ
ตารางต่อไปนี้แสดงวิธีการของอ็อบเจ็กต์NamedNodeMap
| ส. | วิธีการและคำอธิบาย |
|---|---|
| 1 | getNamedItem () ดึงโหนดที่ระบุโดยชื่อ |
| 2 | getNamedItemNS () ดึงโหนดที่ระบุโดยชื่อโลคัลและเนมสเปซ URI |
| 3 | สิ่งของ () ส่งคืนดัชนี th รายการในแผนที่ หากดัชนีมีค่ามากกว่าหรือเท่ากับจำนวนโหนดในแผนที่นี้จะส่งกลับค่า null |
| 4 | removeNamedItem () ลบโหนดที่ระบุโดยชื่อ |
| 5 | removeNamedItemNS () ลบโหนดที่ระบุโดยชื่อโลคัลและเนมสเปซ URI |
| 6 | setNamedItem () เพิ่มโหนดโดยใช้แอตทริบิวต์ nodeName ถ้าโหนดที่มีชื่อนั้นมีอยู่แล้วในแผนที่นี้โหนดใหม่จะถูกแทนที่ |
| 7 | setNamedItemNS () เพิ่มโหนดใช้ของnamespaceURIและLOCALNAME ถ้าโหนดที่มีเนมสเปซ URI และชื่อโลคัลนั้นมีอยู่แล้วในแผนที่นี้โหนดใหม่จะถูกแทนที่ การแทนที่โหนดด้วยตัวเองจะไม่มีผล |
DOMImplementationวัตถุให้จำนวนของวิธีการสำหรับการดำเนินการที่เป็นอิสระของอินสแตนซ์ในด้านของรูปแบบวัตถุเอกสาร
วิธีการ
ตารางต่อไปนี้แสดงวิธีการของวัตถุDOMImplementation -
| ส. | วิธีการและคำอธิบาย |
|---|---|
| 1 | createDocument (namespaceURI, qualifiedName, doctype) สร้างวัตถุ DOM Document ตามประเภทที่ระบุด้วยองค์ประกอบเอกสาร |
| 2 | createDocumentType (qualificationName, publicId, systemId) สร้างโหนดDocumentType ที่ว่างเปล่า |
| 3 | getFeature(feature, version) เมธอดนี้ส่งคืนอ็อบเจ็กต์พิเศษที่ใช้ API เฉพาะของคุณลักษณะและเวอร์ชันที่ระบุ สิ่งนี้ถูกลบออก โปรดดูรายละเอียด |
| 4 | hasFeature (คุณลักษณะเวอร์ชัน) วิธีนี้จะทดสอบว่าการใช้งาน DOM ใช้คุณลักษณะและเวอร์ชันเฉพาะหรือไม่ |
DocumentTypeวัตถุเป็นกุญแจสำคัญในการเข้าถึงข้อมูลของเอกสารและในเอกสารแอตทริบิวต์ประเภทเอกสารที่สามารถมีทั้งค่า Null หรือค่าวัตถุ DocumentType อ็อบเจ็กต์ DocumentType เหล่านี้ทำหน้าที่เป็นส่วนต่อประสานกับเอนทิตีที่อธิบายไว้สำหรับเอกสาร XML
คุณลักษณะ
ตารางต่อไปนี้แสดงรายการคุณลักษณะของวัตถุDocumentType -
| แอตทริบิวต์ | ประเภท | คำอธิบาย |
|---|---|---|
| ชื่อ | DOMString | จะส่งคืนชื่อของ DTD ซึ่งเขียนทันทีถัดจากคีย์เวิร์ด! DOCTYPE |
| เอนทิตี | ชื่อโหนดแผนที่ | ส่งคืนอ็อบเจ็กต์ NamedNodeMap ที่มีเอนทิตีทั่วไปทั้งภายนอกและภายในที่ประกาศใน DTD |
| สัญกรณ์ | ชื่อโหนดแผนที่ | ส่งคืน NamedNodeMap ที่มีสัญกรณ์ที่ประกาศใน DTD |
| internalSubset | DOMString | จะคืนค่าส่วนย่อยภายในเป็นสตริงหรือค่าว่างถ้าไม่มี สิ่งนี้ถูกลบออก โปรดดูรายละเอียด |
| publicId | DOMString | ส่งคืนตัวระบุสาธารณะของส่วนย่อยภายนอก |
| systemId | DOMString | ส่งคืนตัวระบุระบบของชุดย่อยภายนอก นี่อาจเป็น URI แบบสัมบูรณ์หรือไม่ก็ได้ |
วิธีการ
DocumentTypeสืบทอดเมธอดจากพาเรนต์โหนดและใช้อินเทอร์เฟซChildNode
การประมวลผลคำแนะนำจะให้ข้อมูลเฉพาะแอปพลิเคชันซึ่งโดยทั่วไปรวมอยู่ในส่วน prolog ของเอกสาร XML
คำสั่งการประมวลผล (PI) สามารถใช้เพื่อส่งผ่านข้อมูลไปยังแอปพลิเคชัน PI สามารถปรากฏที่ใดก็ได้ในเอกสารนอกมาร์กอัป โดยสามารถปรากฏใน prolog รวมถึงข้อกำหนดประเภทเอกสาร (DTD) ในเนื้อหาที่เป็นข้อความหรือหลังเอกสาร
PI เริ่มต้นด้วยแท็กพิเศษ <? และลงท้ายด้วย ?>. การประมวลผลเนื้อหาจะสิ้นสุดทันทีหลังจากสตริง?> พบ
คุณลักษณะ
ตารางต่อไปนี้แสดงรายการคุณลักษณะของวัตถุProcessingInstruction -
| แอตทริบิวต์ | ประเภท | คำอธิบาย |
|---|---|---|
| ข้อมูล | DOMString | เป็นอักขระที่อธิบายข้อมูลเพื่อให้แอปพลิเคชันประมวลผลทันทีก่อนหน้า?> |
| เป้าหมาย | DOMString | สิ่งนี้ระบุแอปพลิเคชันที่คำสั่งหรือข้อมูลถูกนำไป |
อินเทอร์เฟซเอนทิตีแสดงถึงเอนทิตีที่รู้จักไม่ว่าจะแยกวิเคราะห์หรือไม่ได้แยกวิเคราะห์ในเอกสาร XML NodeNameแอตทริบิวต์ที่สืบทอดมาจากโหนดมีชื่อของกิจการ
อ็อบเจ็กต์เอนทิตีไม่มีโหนดพาเรนต์และโหนดตัวต่อทั้งหมดเป็นแบบอ่านอย่างเดียว
คุณลักษณะ
ตารางต่อไปนี้แสดงรายการคุณลักษณะของวัตถุเอนทิตี -
| แอตทริบิวต์ | ประเภท | คำอธิบาย |
|---|---|---|
| inputEncoding | DOMString | สิ่งนี้ระบุการเข้ารหัสที่ใช้โดยเอนทิตีแยกวิเคราะห์ภายนอก ค่าเป็นโมฆะถ้าเป็นเอนทิตีจากส่วนย่อยภายในหรือไม่ทราบ |
| notationName | DOMString | สำหรับเอนทิตีที่ไม่ได้แยกวิเคราะห์จะให้ชื่อของสัญกรณ์และค่าของมันเป็นค่าว่างสำหรับเอนทิตีที่แยกวิเคราะห์ |
| publicId | DOMString | ให้ชื่อของตัวระบุสาธารณะที่เชื่อมโยงกับเอนทิตี |
| systemId | DOMString | ให้ชื่อของตัวระบุระบบที่เกี่ยวข้องกับเอนทิตี |
| xml การเข้ารหัส | DOMString | จะให้การเข้ารหัส xml รวมเป็นส่วนหนึ่งของการประกาศข้อความสำหรับเอนทิตีที่แยกวิเคราะห์ภายนอกเป็นโมฆะ |
| xmlVersion | DOMString | จะให้เวอร์ชัน xml รวมเป็นส่วนหนึ่งของการประกาศข้อความสำหรับเอนทิตีที่แยกวิเคราะห์ภายนอกเป็นโมฆะ |
EntityReferenceวัตถุอ้างอิงนิติบุคคลทั่วไปที่จะแทรกเข้าไปในเอกสาร XML ให้ขอบเขตที่จะเปลี่ยนข้อความ EntityReference Object ไม่ทำงานสำหรับเอนทิตีที่กำหนดไว้ล่วงหน้าเนื่องจากถือว่าถูกขยายโดยตัวประมวลผล HTML หรือ XML
อินเตอร์เฟซนี้ไม่ได้มีคุณสมบัติหรือวิธีการของตัวเอง แต่สืบทอดจากโหนด
ในบทนี้เราจะศึกษาเกี่ยวกับ XML DOM โน้ตวัตถุ คุณสมบัติออบเจ็กต์สัญกรณ์จัดเตรียมขอบเขตในการจดจำรูปแบบขององค์ประกอบที่มีแอตทริบิวต์สัญกรณ์คำสั่งการประมวลผลเฉพาะหรือข้อมูลที่ไม่ใช่ XML คุณสมบัติและวิธีการของ Node Object สามารถทำได้บน Notation Object เนื่องจากถือว่าเป็น Node ด้วย
วัตถุนี้สืบทอดวิธีการและคุณสมบัติจากโหนด มันNodeNameเป็นชื่อสัญกรณ์ ไม่มีผู้ปกครอง
คุณลักษณะ
ตารางต่อไปนี้แสดงรายการคุณลักษณะของวัตถุสัญกรณ์ -
| แอตทริบิวต์ | ประเภท | คำอธิบาย |
|---|---|---|
| publicID | DOMString | มันให้ชื่อของตัวระบุสาธารณะที่เกี่ยวข้องกับสัญกรณ์ |
| systemID | DOMString | ให้ชื่อของตัวระบุระบบที่เกี่ยวข้องกับสัญกรณ์ |
องค์ประกอบ XML สามารถกำหนดให้เป็นแบบเอกสารสำเร็จรูปของ XML องค์ประกอบสามารถทำงานเป็นคอนเทนเนอร์เพื่อเก็บข้อความองค์ประกอบแอตทริบิวต์วัตถุสื่อหรือสิ่งเหล่านี้ทั้งหมด เมื่อใดก็ตามที่ parser แยกวิเคราะห์เอกสาร XML เทียบกับความสมบูรณ์แบบตัววิเคราะห์จะนำทางผ่านโหนดองค์ประกอบ โหนดองค์ประกอบมีข้อความอยู่ภายในซึ่งเรียกว่าโหนดข้อความ
ออบเจ็กต์องค์ประกอบสืบทอดคุณสมบัติและวิธีการของวัตถุโหนดเป็นวัตถุองค์ประกอบถือเป็นโหนด นอกเหนือจากคุณสมบัติและวิธีการอ็อบเจ็กต์โหนดแล้วยังมีคุณสมบัติและวิธีการดังต่อไปนี้
คุณสมบัติ
ตารางต่อไปนี้แสดงรายการคุณลักษณะของวัตถุองค์ประกอบ -
| แอตทริบิวต์ | ประเภท | คำอธิบาย |
|---|---|---|
| tagName | DOMString | ให้ชื่อของแท็กสำหรับองค์ประกอบที่ระบุ |
| schemaTypeInfo | TypeInfo | แสดงถึงข้อมูลประเภทที่เกี่ยวข้องกับองค์ประกอบนี้ สิ่งนี้ถูกลบออก โปรดดูรายละเอียด |
วิธีการ
ตารางด้านล่างแสดงวิธีการของ Element Object -
| วิธีการ | ประเภท | คำอธิบาย |
|---|---|---|
| getAttribute () | DOMString | ดึงค่าของแอตทริบิวต์หากมีอยู่สำหรับองค์ประกอบที่ระบุ |
| getAttributeNS () | DOMString | ดึงค่าแอ็ตทริบิวต์ตามชื่อโลคัลและเนมสเปซ URI |
| getAttributeNode () | Attr | ดึงชื่อของโหนดแอตทริบิวต์จากองค์ประกอบปัจจุบัน |
| getAttributeNodeNS () | Attr | ดึงโหนด Attr ตามชื่อโลคัลและเนมสเปซ URI |
| getElementsByTagName () | NodeList | ส่งคืน NodeList ขององค์ประกอบที่สืบทอดมาทั้งหมดพร้อมชื่อแท็กที่กำหนดตามลำดับเอกสาร |
| getElementsByTagNameNS () | NodeList | ส่งคืน NodeList ขององค์ประกอบที่สืบทอดมาทั้งหมดพร้อมด้วยชื่อท้องถิ่นที่กำหนดและ URI เนมสเปซตามลำดับเอกสาร |
| hasAttribute () | บูลีน | ส่งคืนจริงเมื่อระบุแอตทริบิวต์ที่มีชื่อที่กำหนดไว้ในองค์ประกอบนี้หรือมีค่าเริ่มต้นเป็นเท็จ |
| hasAttributeNS () | บูลีน | ส่งคืนจริงเมื่อแอตทริบิวต์ที่มีชื่อโลคัลและเนมสเปซ URI ระบุไว้ในองค์ประกอบนี้หรือมีค่าดีฟอลต์เป็นเท็จ |
| removeAttribute () | ไม่มีค่าส่งคืน | ลบแอตทริบิวต์ตามชื่อ |
| removeAttributeNS | ไม่มีค่าส่งคืน | ลบแอตทริบิวต์ตามชื่อโลคัลและเนมสเปซ URI |
| removeAttributeNode () | Attr | โหนดแอตทริบิวต์ที่ระบุถูกลบออกจากองค์ประกอบ |
| setAttribute () | ไม่มีค่าส่งคืน | ตั้งค่าแอตทริบิวต์ใหม่ให้กับองค์ประกอบที่มีอยู่ |
| setAttributeNS () | ไม่มีค่าส่งคืน | เพิ่มแอตทริบิวต์ใหม่ หากแอ็ตทริบิวต์ที่มีชื่อโลคัลและเนมสเปซ URI เดียวกันมีอยู่แล้วในองค์ประกอบคำนำหน้าจะเปลี่ยนเป็นส่วนนำหน้าของชื่อคุณสมบัติและค่าของมันจะเปลี่ยนเป็นพารามิเตอร์ค่า |
| setAttributeNode () | Attr | ตั้งค่าโหนดแอ็ตทริบิวต์ใหม่ให้กับองค์ประกอบที่มีอยู่ |
| setAttributeNodeNS | Attr | เพิ่มแอตทริบิวต์ใหม่ ถ้าแอตทริบิวต์ที่มีชื่อโลคัลนั้นและเนมสเปซ URI นั้นมีอยู่แล้วในองค์ประกอบนั้นจะถูกแทนที่ด้วยชื่อใหม่ |
| setIdAttribute | ไม่มีค่าส่งคืน | หากพารามิเตอร์ isId เป็นจริงเมธอดนี้จะประกาศแอ็ตทริบิวต์ที่ระบุเป็นแอ็ตทริบิวต์ ID ที่ผู้ใช้กำหนด สิ่งนี้ถูกลบออก โปรดดูรายละเอียด |
| setIdAttributeNS | ไม่มีค่าส่งคืน | หากพารามิเตอร์ isId เป็นจริงเมธอดนี้จะประกาศแอ็ตทริบิวต์ที่ระบุเป็นแอ็ตทริบิวต์ ID ที่ผู้ใช้กำหนด สิ่งนี้ถูกลบออก โปรดดูรายละเอียด |
อินเตอร์เฟสAttrแสดงถึงแอตทริบิวต์ในออบเจ็กต์ Element โดยทั่วไปค่าที่อนุญาตสำหรับแอตทริบิวต์จะถูกกำหนดในสคีมาที่เกี่ยวข้องกับเอกสาร อ็อบเจ็กต์Attrไม่ถือว่าเป็นส่วนหนึ่งของแผนผังเอกสารเนื่องจากไม่ใช่โหนดลูกขององค์ประกอบที่อธิบาย ดังนั้นสำหรับโหนดเด็กparentNode , previousSiblingและnextSiblingค่าแอตทริบิวต์เป็นโมฆะ
คุณลักษณะ
ตารางต่อไปนี้แสดงรายการคุณลักษณะของวัตถุแอตทริบิวต์ -
| แอตทริบิวต์ | ประเภท | คำอธิบาย |
|---|---|---|
| ชื่อ | DOMString | สิ่งนี้ทำให้ชื่อของแอตทริบิวต์ |
| ระบุ | บูลีน | เป็นค่าบูลีนที่คืนค่าจริงหากค่าแอตทริบิวต์มีอยู่ในเอกสาร |
| มูลค่า | DOMString | ส่งคืนค่าของแอตทริบิวต์ |
| ownerElement | ธาตุ | จะให้โหนดที่เชื่อมโยงแอตทริบิวต์หรือ null หากไม่ได้ใช้แอตทริบิวต์ |
| isId | บูลีน | จะส่งคืนว่าแอตทริบิวต์เป็นที่ทราบกันดีว่าเป็นประเภท ID (กล่าวคือมีตัวระบุสำหรับองค์ประกอบเจ้าของ) หรือไม่ |
ในบทนี้เราจะศึกษาเกี่ยวกับ XML DOM CDATASection วัตถุ ข้อความที่อยู่ในเอกสาร XML จะถูกแยกวิเคราะห์หรือไม่แยกวิเคราะห์ขึ้นอยู่กับสิ่งที่ประกาศ ถ้าข้อความถูกประกาศว่าเป็น Parse Character Data (PCDATA) จะถูกแยกวิเคราะห์โดย parser เพื่อแปลงเอกสาร XML เป็น XML DOM Object ในทางกลับกันถ้าข้อความถูกประกาศว่าเป็นข้อมูลอักขระที่ไม่ได้แยกวิเคราะห์ (CDATA) ข้อความภายในจะไม่ถูกแยกวิเคราะห์โดยตัวแยกวิเคราะห์ XML สิ่งเหล่านี้ไม่ถือเป็นมาร์กอัปและจะไม่ขยายเอนทิตี
วัตถุประสงค์ของการใช้อ็อบเจ็กต์ CDATASection คือการหลีกเลี่ยงบล็อกของข้อความที่มีอักขระที่อาจถือเป็นมาร์กอัป "]]>"นี่เป็นตัวคั่นเดียวที่ได้รับการยอมรับในส่วน CDATA ซึ่งสิ้นสุดส่วน CDATA
แอตทริบิวต์ CharacterData.data เก็บข้อความที่อยู่ในส่วน CDATA อินเทอร์เฟซนี้สืบทอดอินเตอร์เฟสCharatcterDataผ่านอินเทอร์เฟซข้อความ
ไม่มีวิธีการและแอ็ตทริบิวต์ที่กำหนดไว้สำหรับอ็อบเจ็กต์ CDATASection ใช้เฉพาะอินเทอร์เฟซ ข้อความโดยตรงเท่านั้น
ในบทนี้เราจะศึกษาเกี่ยวกับวัตถุแสดงความคิดเห็น ข้อคิดเห็นจะถูกเพิ่มเป็นบันทึกย่อหรือบรรทัดเพื่อทำความเข้าใจวัตถุประสงค์ของโค้ด XML ความคิดเห็นสามารถใช้เพื่อรวมลิงค์ข้อมูลและข้อกำหนดที่เกี่ยวข้อง สิ่งเหล่านี้อาจปรากฏที่ใดก็ได้ในโค้ด XML
อินเทอร์เฟซความคิดเห็นสืบทอดอินเทอร์เฟซCharacterData ที่แสดงเนื้อหาของข้อคิดเห็น
ไวยากรณ์
ความคิดเห็น XML มีไวยากรณ์ต่อไปนี้ -
<!-------Your comment----->ความคิดเห็นเริ่มต้นด้วย <! - และลงท้ายด้วย -> คุณสามารถเพิ่มบันทึกข้อความเป็นข้อคิดเห็นระหว่างอักขระ คุณต้องไม่ซ้อนความคิดเห็นหนึ่งไว้ในความคิดเห็นอื่น
ไม่มีวิธีการและแอตทริบิวต์ที่กำหนดไว้สำหรับออบเจ็กต์ข้อคิดเห็น มันสืบทอดบรรดาแม่ CharacterDataและทางอ้อมของผู้ โหนด
อ็อบเจ็กต์ XMLHttpRequest สร้างสื่อระหว่างฝั่งไคลเอ็นต์และฝั่งเซิร์ฟเวอร์ของเว็บเพจที่สามารถใช้โดยภาษาสคริปต์ต่างๆเช่น JavaScript, JScript, VBScript และเว็บเบราว์เซอร์อื่น ๆ เพื่อถ่ายโอนและจัดการข้อมูล XML
ด้วยอ็อบเจ็กต์ XMLHttpRequest เป็นไปได้ที่จะอัปเดตส่วนของเว็บเพจโดยไม่ต้องโหลดซ้ำทั้งเพจขอและรับข้อมูลจากเซิร์ฟเวอร์หลังจากโหลดเพจแล้วและส่งข้อมูลไปยังเซิร์ฟเวอร์
ไวยากรณ์
อ็อบเจ็กต์ XMLHttpRequest สามารถติดตั้งได้ดังนี้ -
xmlhttp = new XMLHttpRequest();ในการจัดการเบราว์เซอร์ทั้งหมดรวมถึง IE5 และ IE6 ให้ตรวจสอบว่าเบราว์เซอร์รองรับวัตถุ XMLHttpRequest ดังต่อไปนี้หรือไม่ -
if(window.XMLHttpRequest) // for Firefox, IE7+, Opera, Safari, ... {
xmlHttp = new XMLHttpRequest();
} else if(window.ActiveXObject) // for Internet Explorer 5 or 6 {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}ตัวอย่างการโหลดไฟล์ XML โดยใช้อ็อบเจ็กต์ XMLHttpRequest สามารถอ้างอิงได้ที่นี่
วิธีการ
ตารางต่อไปนี้แสดงวิธีการของวัตถุ XMLHttpRequest -
| ส. | วิธีการและคำอธิบาย |
|---|---|
| 1 | abort() ยุติคำขอปัจจุบันที่ทำ |
| 2 | getAllResponseHeaders() ส่งคืนส่วนหัวของการตอบกลับทั้งหมดเป็นสตริงหรือค่าว่างหากไม่ได้รับการตอบกลับ |
| 3 | getResponseHeader() ส่งคืนสตริงที่มีข้อความของส่วนหัวที่ระบุหรือเป็นค่าว่างหากยังไม่ได้รับการตอบกลับหรือไม่มีส่วนหัวในการตอบกลับ |
| 4 | open(method,url,async,uname,pswd) ใช้ในการผันคำกริยาด้วยวิธี Send เพื่อส่งคำขอไปยังเซิร์ฟเวอร์ วิธีการเปิดระบุพารามิเตอร์ต่อไปนี้ -
|
| 5 | send(string) ใช้เพื่อส่งคำขอที่ทำงานในการผันคำกริยาด้วยวิธีเปิด |
| 6 | setRequestHeader() ส่วนหัวมีคู่ป้ายกำกับ / ค่าที่ส่งคำขอ |
คุณลักษณะ
ตารางต่อไปนี้แสดงรายการแอตทริบิวต์ของวัตถุ XMLHttpRequest -
| ส. | คุณสมบัติและคำอธิบาย |
|---|---|
| 1 | onreadystatechange เป็นคุณสมบัติตามเหตุการณ์ซึ่งตั้งค่าไว้ในทุกการเปลี่ยนแปลงสถานะ |
| 2 | readyState สิ่งนี้อธิบายสถานะปัจจุบันของอ็อบเจ็กต์ XMLHttpRequest คุณสมบัติ readyState มีอยู่ห้าสถานะ -
|
| 3 | responseText คุณสมบัตินี้ใช้เมื่อการตอบสนองจากเซิร์ฟเวอร์เป็นไฟล์ข้อความ |
| 4 | responseXML คุณสมบัตินี้ถูกใช้เมื่อการตอบสนองจากเซิร์ฟเวอร์เป็นไฟล์ XML |
| 5 | status ให้สถานะของอ็อบเจ็กต์คำขอ Http เป็นตัวเลข ตัวอย่างเช่น "404" หรือ "200" |
| 6 | statusText ให้สถานะของอ็อบเจ็กต์คำขอ Http เป็นสตริง ตัวอย่างเช่น "ไม่พบ" หรือ "ตกลง" |
ตัวอย่าง
เนื้อหาnode.xmlมีดังต่อไปนี้ -
<?xml version = "1.0"?>
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>[email protected]</Email>
</Employee>
</Company>ดึงข้อมูลเฉพาะของไฟล์ทรัพยากร
ตัวอย่างต่อไปนี้แสดงให้เห็นถึงวิธีการที่จะดึงข้อมูลที่เฉพาะเจาะจงของไฟล์ทรัพยากรโดยใช้วิธีการgetResponseHeader ()และทรัพย์สินREADSTATE
<!DOCTYPE html>
<html>
<head>
<meta http-equiv = "content-type" content = "text/html; charset = iso-8859-2" />
<script>
function loadXMLDoc() {
var xmlHttp = null;
if(window.XMLHttpRequest) // for Firefox, IE7+, Opera, Safari, ... {
xmlHttp = new XMLHttpRequest();
}
else if(window.ActiveXObject) // for Internet Explorer 5 or 6 {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}
return xmlHttp;
}
function makerequest(serverPage, myDiv) {
var request = loadXMLDoc();
request.open("GET", serverPage);
request.send(null);
request.onreadystatechange = function() {
if (request.readyState == 4) {
document.getElementById(myDiv).innerHTML = request.getResponseHeader("Content-length");
}
}
}
</script>
</head>
<body>
<button type = "button" onclick="makerequest('/dom/node.xml', 'ID')">Click me to get the specific ResponseHeader</button>
<div id = "ID">Specific header information is returned.</div>
</body>
</html>การดำเนินการ
บันทึกไฟล์นี้เป็นelementattribute_removeAttributeNS.htmบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และ node_ns.xml ควรอยู่บนพา ธ เดียวกันในเซิร์ฟเวอร์ของคุณ) เราจะได้ผลลัพธ์ตามที่แสดงด้านล่าง -
Before removing the attributeNS: en
After removing the attributeNS: nullดึงข้อมูลส่วนหัวของไฟล์ทรัพยากร
ตัวอย่างต่อไปนี้สาธิตวิธีการดึงข้อมูลส่วนหัวของไฟล์รีซอร์สโดยใช้เมธอด getAllResponseHeaders() โดยใช้ทรัพย์สิน readyState.
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="content-type" content="text/html; charset=iso-8859-2" />
<script>
function loadXMLDoc() {
var xmlHttp = null;
if(window.XMLHttpRequest) // for Firefox, IE7+, Opera, Safari, ... {
xmlHttp = new XMLHttpRequest();
} else if(window.ActiveXObject) // for Internet Explorer 5 or 6 {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}
return xmlHttp;
}
function makerequest(serverPage, myDiv) {
var request = loadXMLDoc();
request.open("GET", serverPage);
request.send(null);
request.onreadystatechange = function() {
if (request.readyState == 4) {
document.getElementById(myDiv).innerHTML = request.getAllResponseHeaders();
}
}
}
</script>
</head>
<body>
<button type = "button" onclick = "makerequest('/dom/node.xml', 'ID')">
Click me to load the AllResponseHeaders</button>
<div id = "ID"></div>
</body>
</html>การดำเนินการ
บันทึกไฟล์นี้เป็นhttp_allheader.htmlบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และ node.xml ควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) เราจะได้ผลลัพธ์ตามที่แสดงด้านล่าง (ขึ้นอยู่กับเบราว์เซอร์) -
Date: Sat, 27 Sep 2014 07:48:07 GMT Server: Apache Last-Modified:
Wed, 03 Sep 2014 06:35:30 GMT Etag: "464bf9-2af-50223713b8a60" Accept-Ranges: bytes Vary: Accept-Encoding,User-Agent
Content-Encoding: gzip Content-Length: 256 Content-Type: text/xmlDOMExceptionแสดงให้เห็นถึงสิ่งที่เกิดขึ้นเหตุการณ์ที่ผิดปกติเมื่อมีวิธีการหรือทรัพย์สินที่ถูกนำมาใช้
คุณสมบัติ
ตารางด้านล่างแสดงคุณสมบัติของวัตถุ DOMException
| ส. | คุณสมบัติและคำอธิบาย |
|---|---|
| 1 | name ส่งคืน DOMString ที่มีหนึ่งในสตริงที่เกี่ยวข้องกับค่าคงที่ของข้อผิดพลาด (ดังที่เห็นในตารางด้านล่าง) |
ประเภทข้อผิดพลาด
| ส. | ประเภทและคำอธิบาย |
|---|---|
| 1 | IndexSizeError ดัชนีไม่อยู่ในช่วงที่อนุญาต ตัวอย่างเช่นสิ่งนี้สามารถโยนได้โดยวัตถุ Range (ค่ารหัสเดิม: 1 และชื่อค่าคงที่เดิม: INDEX_SIZE_ERR) |
| 2 | HierarchyRequestError ลำดับชั้นของโหนดทรีไม่ถูกต้อง (ค่ารหัสเดิม: 3 และชื่อคงที่เดิม: HIERARCHY_REQUEST_ERR) |
| 3 | WrongDocumentError วัตถุอยู่ในเอกสารที่ไม่ถูกต้อง (ค่ารหัสเดิม: 4 และชื่อค่าคงที่เดิม: WRONG_DOCUMENT_ERR) |
| 4 | InvalidCharacterError สตริงมีอักขระที่ไม่ถูกต้อง (ค่ารหัสเดิม: 5 และชื่อค่าคงที่เดิม: INVALID_CHARACTER_ERR) |
| 5 | NoModificationAllowedError ไม่สามารถแก้ไขวัตถุได้ (ค่ารหัสเดิม: 7 และชื่อค่าคงที่เดิม: NO_MODIFICATION_ALLOWED_ERR) |
| 6 | NotFoundError ไม่พบวัตถุที่นี่ (ค่ารหัสเดิม: 8 และชื่อค่าคงที่เดิม: NOT_FOUND_ERR) |
| 7 | NotSupportedError ไม่รองรับการดำเนินการนี้ (ค่ารหัสเดิม: 9 และชื่อค่าคงที่เดิม: NOT_SUPPORTED_ERR) |
| 8 | InvalidStateError วัตถุอยู่ในสถานะไม่ถูกต้อง (ค่ารหัสเดิม: 11 และชื่อค่าคงที่เดิม: INVALID_STATE_ERR) |
| 9 | SyntaxError สตริงไม่ตรงกับรูปแบบที่คาดไว้ (ค่ารหัสเดิม: 12 และชื่อค่าคงที่เดิม: SYNTAX_ERR) |
| 10 | InvalidModificationError ไม่สามารถแก้ไขวัตถุด้วยวิธีนี้ (ค่ารหัสเดิม: 13 และชื่อค่าคงที่เดิม: INVALID_MODIFICATION_ERR) |
| 11 | NamespaceError Namespaces ไม่อนุญาตการดำเนินการใน XML (ค่ารหัสเดิม: 14 และชื่อค่าคงที่เดิม: NAMESPACE_ERR) |
| 12 | InvalidAccessError วัตถุไม่สนับสนุนการดำเนินการหรืออาร์กิวเมนต์ (ค่ารหัสเดิม: 15 และชื่อค่าคงที่เดิม: INVALID_ACCESS_ERR) |
| 13 | TypeMismatchError ประเภทของวัตถุไม่ตรงกับประเภทที่คาดไว้ (ค่ารหัสเดิม: 17 และชื่อค่าคงที่เดิม: TYPE_MISMATCH_ERR) ค่านี้เลิกใช้แล้วข้อยกเว้นของ JavaScript TypeError จะถูกยกขึ้นแทน DOMException ด้วยค่านี้ |
| 14 | SecurityError การดำเนินการไม่ปลอดภัย (ค่ารหัสเดิม: 18 และชื่อค่าคงที่เดิม: SECURITY_ERR) |
| 15 | NetworkError เกิดข้อผิดพลาดของเครือข่าย (ค่ารหัสเดิม: 19 และชื่อค่าคงที่เดิม: NETWORK_ERR) |
| 16 | AbortError การดำเนินการถูกยกเลิก (ค่ารหัสเดิม: 20 และชื่อค่าคงที่เดิม: ABORT_ERR) |
| 17 | URLMismatchError URL ที่ระบุไม่ตรงกับ URL อื่น (ค่ารหัสเดิม: 21 และชื่อคงเดิม: URL_MISMATCH_ERR) |
| 18 | QuotaExceededError เกินโควต้าแล้ว (ค่ารหัสเดิม: 22 และชื่อค่าคงที่เดิม: QUOTA_EXCEEDED_ERR) |
| 19 | TimeoutError หมดเวลาการดำเนินการ (ค่ารหัสเดิม: 23 และชื่อค่าคงที่เดิม: TIMEOUT_ERR) |
| 20 | InvalidNodeTypeError โหนดไม่ถูกต้องหรือมีบรรพบุรุษที่ไม่ถูกต้องสำหรับการดำเนินการนี้ (ค่ารหัสเดิม: 24 และชื่อค่าคงที่เดิม: INVALID_NODE_TYPE_ERR) |
| 21 | DataCloneError ไม่สามารถโคลนวัตถุได้ (ค่ารหัสเดิม: 25 และชื่อค่าคงที่เดิม: DATA_CLONE_ERR) |
| 22 | EncodingError การดำเนินการเข้ารหัสเป็นการเข้ารหัสหรือถอดรหัสล้มเหลว (ไม่มีค่ารหัสเดิมและชื่อค่าคงที่) |
| 23 | NotReadableError การดำเนินการอ่านอินพุต / เอาต์พุตล้มเหลว (ไม่มีค่ารหัสเดิมและชื่อค่าคงที่) |
ตัวอย่าง
ตัวอย่างต่อไปนี้แสดงให้เห็นว่าการใช้เอกสาร XML ที่มีรูปแบบไม่ถูกต้องทำให้เกิด DOMException ได้อย่างไร
เนื้อหาerror.xmlมีดังต่อไปนี้ -
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?>
<Company id = "companyid">
<Employee category = "Technical" id = "firstelement" type = "text/html">
<FirstName>Tanmay</first>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>[email protected]</Email>
</Employee>
</Company>ตัวอย่างต่อไปนี้แสดงให้เห็นถึงการใช้แอตทริบิวต์ชื่อ -
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
try {
xmlDoc = loadXMLDoc("/dom/error.xml");
var node = xmlDoc.getElementsByTagName("to").item(0);
var refnode = node.nextSibling;
var newnode = xmlDoc.createTextNode('That is why you fail.');
node.insertBefore(newnode, refnode);
} catch(err) {
document.write(err.name);
}
</script>
</body>
</html>การดำเนินการ
บันทึกไฟล์นี้เป็นdomexcption_name.htmlบนเส้นทางเซิร์ฟเวอร์ (ไฟล์นี้และ error.xml ควรอยู่บนเส้นทางเดียวกันในเซิร์ฟเวอร์ของคุณ) เราจะได้ผลลัพธ์ตามที่แสดงด้านล่าง -
TypeError