Keras - คู่มือฉบับย่อ
Keras - บทนำ
การเรียนรู้เชิงลึกเป็นหนึ่งในสาขาย่อยที่สำคัญของกรอบการเรียนรู้ของเครื่อง การเรียนรู้ของเครื่องเป็นการศึกษาการออกแบบอัลกอริทึมซึ่งได้รับแรงบันดาลใจจากแบบจำลองของสมองมนุษย์ การเรียนรู้เชิงลึกกำลังเป็นที่นิยมมากขึ้นในสาขาวิทยาศาสตร์ข้อมูลเช่นหุ่นยนต์ปัญญาประดิษฐ์ (AI) การจดจำเสียงและวิดีโอและการจดจำภาพ โครงข่ายประสาทเทียมเป็นหัวใจหลักของวิธีการเรียนรู้เชิงลึก การเรียนรู้เชิงลึกได้รับการสนับสนุนโดยไลบรารีต่างๆเช่น Theano, TensorFlow, Caffe, Mxnet เป็นต้น Keras เป็นหนึ่งในไลบรารี python ที่มีประสิทธิภาพและใช้งานง่ายที่สุดซึ่งสร้างขึ้นจากไลบรารีการเรียนรู้เชิงลึกยอดนิยมเช่น TensorFlow, Theano เป็นต้น สำหรับการสร้างแบบจำลองการเรียนรู้เชิงลึก
ภาพรวมของ Keras
Keras ทำงานบนไลบรารีเครื่องโอเพนซอร์สเช่น TensorFlow, Theano หรือ Cognitive Toolkit (CNTK) Theano เป็นไลบรารี python ที่ใช้สำหรับงานคำนวณตัวเลขอย่างรวดเร็ว TensorFlow เป็นห้องสมุดคณิตศาสตร์เชิงสัญลักษณ์ที่มีชื่อเสียงที่สุดที่ใช้ในการสร้างเครือข่ายประสาทเทียมและแบบจำลองการเรียนรู้เชิงลึก TensorFlow มีความยืดหยุ่นมากและประโยชน์หลักคือคอมพิวเตอร์แบบกระจาย CNTK เป็นกรอบการเรียนรู้เชิงลึกที่พัฒนาโดย Microsoft ใช้ไลบรารีเช่น Python, C #, C ++ หรือชุดเครื่องมือแมชชีนเลิร์นนิงแบบสแตนด์อโลน Theano และ TensorFlow เป็นไลบรารีที่ทรงพลังมาก แต่เข้าใจยากสำหรับการสร้างเครือข่ายประสาทเทียม
Keras ขึ้นอยู่กับโครงสร้างที่เรียบง่ายซึ่งเป็นวิธีที่ง่ายและสะอาดในการสร้างแบบจำลองการเรียนรู้เชิงลึกโดยใช้ TensorFlow หรือ Theano Keras ออกแบบมาเพื่อกำหนดโมเดลการเรียนรู้เชิงลึกอย่างรวดเร็ว Keras เป็นตัวเลือกที่ดีที่สุดสำหรับแอปพลิเคชันการเรียนรู้เชิงลึก
คุณสมบัติ
Keras ใช้ประโยชน์จากเทคนิคการเพิ่มประสิทธิภาพต่างๆเพื่อทำให้ API เครือข่ายประสาทเทียมระดับสูงง่ายขึ้นและมีประสิทธิภาพมากขึ้น รองรับคุณสมบัติดังต่อไปนี้ -
API ที่สอดคล้องง่ายและขยายได้
โครงสร้างน้อยที่สุด - ง่ายต่อการบรรลุผลโดยไม่ต้องหรูหราใด ๆ
รองรับหลายแพลตฟอร์มและแบ็กเอนด์
เป็นเฟรมเวิร์กที่เป็นมิตรกับผู้ใช้ซึ่งทำงานได้ทั้งบน CPU และ GPU
ความสามารถในการคำนวณที่ปรับขนาดได้สูง
สิทธิประโยชน์
Keras เป็นเฟรมเวิร์กแบบไดนามิกที่ทรงพลังและมีข้อดีดังต่อไปนี้ -
การสนับสนุนชุมชนที่ใหญ่ขึ้น
ง่ายต่อการทดสอบ
Keras Neural Network เขียนด้วย Python ซึ่งทำให้สิ่งต่างๆง่ายขึ้น
Keras รองรับทั้ง Convolution และเครือข่ายที่เกิดซ้ำ
แบบจำลองการเรียนรู้เชิงลึกเป็นส่วนประกอบที่ไม่ต่อเนื่องดังนั้นคุณจึงสามารถรวมเข้าด้วยกันได้หลายวิธี
Keras - การติดตั้ง
บทนี้จะอธิบายเกี่ยวกับวิธีการติดตั้ง Keras บนเครื่องของคุณ ก่อนที่จะย้ายไปติดตั้งให้เราทำตามข้อกำหนดพื้นฐานของ Keras
ข้อกำหนดเบื้องต้น
คุณต้องปฏิบัติตามข้อกำหนดต่อไปนี้ -
- ระบบปฏิบัติการทุกประเภท (Windows, Linux หรือ Mac)
- Python เวอร์ชัน 3.5 ขึ้นไป
Python
Keras เป็นไลบรารีเครือข่ายประสาทเทียมที่ใช้ python ดังนั้นจึงต้องติดตั้ง python ในเครื่องของคุณ หาก python ได้รับการติดตั้งอย่างถูกต้องบนเครื่องของคุณให้เปิดเทอร์มินัลและพิมพ์ python คุณจะเห็นการตอบสนองที่คล้ายกันตามที่ระบุไว้ด้านล่าง
Python 3.6.5 (v3.6.5:f59c0932b4, Mar 28 2018, 17:00:18)
[MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>ณ ตอนนี้เวอร์ชันล่าสุดคือ '3.7.2' หากไม่ได้ติดตั้ง Python ให้ไปที่ลิงก์ python อย่างเป็นทางการ - www.python.orgและดาวน์โหลดเวอร์ชันล่าสุดตามระบบปฏิบัติการของคุณและติดตั้งลงในระบบของคุณทันที
ขั้นตอนการติดตั้ง Keras
การติดตั้ง Keras นั้นค่อนข้างง่าย ทำตามขั้นตอนด้านล่างเพื่อติดตั้ง Keras บนระบบของคุณอย่างถูกต้อง
ขั้นตอนที่ 1: สร้างสภาพแวดล้อมเสมือนจริง
Virtualenvใช้เพื่อจัดการแพ็คเกจ Python สำหรับโครงการต่างๆ สิ่งนี้จะเป็นประโยชน์ในการหลีกเลี่ยงการทำลายแพ็คเกจที่ติดตั้งในสภาพแวดล้อมอื่น ๆ ดังนั้นขอแนะนำให้ใช้สภาพแวดล้อมเสมือนในขณะที่พัฒนาแอปพลิเคชัน Python เสมอ
Linux/Mac OS
ผู้ใช้ Linux หรือ mac OS ไปที่ไดเร็กทอรีรูทโปรเจ็กต์ของคุณและพิมพ์คำสั่งด้านล่างเพื่อสร้างสภาพแวดล้อมเสมือน
python3 -m venv kerasenvหลังจากดำเนินการคำสั่งข้างต้นแล้วไดเร็กทอรี“ kerasenv” จะถูกสร้างขึ้นด้วยไฟล์ bin,lib and include folders ในตำแหน่งการติดตั้งของคุณ
Windows
ผู้ใช้ Windows สามารถใช้คำสั่งด้านล่าง
py -m venv kerasขั้นตอนที่ 2: เปิดใช้งานสภาพแวดล้อม
ขั้นตอนนี้จะกำหนดค่าไฟล์ปฏิบัติการ python และ pip ในเชลล์พา ธ ของคุณ
Linux/Mac OS
ตอนนี้เราได้สร้างสภาพแวดล้อมเสมือนจริงชื่อ“ kerasvenv” ย้ายไปที่โฟลเดอร์และพิมพ์คำสั่งด้านล่าง
$ cd kerasvenv kerasvenv $ source bin/activateWindows
ผู้ใช้ Windows ย้ายเข้าไปในโฟลเดอร์“ kerasenv” และพิมพ์คำสั่งด้านล่าง
.\env\Scripts\activateขั้นตอนที่ 3: ไลบรารี Python
Keras ขึ้นอยู่กับไลบรารี python ต่อไปนี้
- Numpy
- Pandas
- Scikit-learn
- Matplotlib
- Scipy
- Seaborn
หวังว่าคุณได้ติดตั้งไลบรารีข้างต้นทั้งหมดในระบบของคุณแล้ว หากไม่ได้ติดตั้งไลบรารีเหล่านี้ให้ใช้คำสั่งด้านล่างเพื่อติดตั้งทีละรายการ
numpy
pip install numpyคุณจะเห็นคำตอบต่อไปนี้
Collecting numpy
Downloading
https://files.pythonhosted.org/packages/cf/a4/d5387a74204542a60ad1baa84cd2d3353c330e59be8cf2d47c0b11d3cde8/
numpy-3.1.1-cp36-cp36m-macosx_10_6_intel.
macosx_10_9_intel.macosx_10_9_x86_64.
macosx_10_10_intel.macosx_10_10_x86_64.whl (14.4MB)
|████████████████████████████████| 14.4MB 2.8MB/spandas
pip install pandasเราจะเห็นคำตอบต่อไปนี้
Collecting pandas
Downloading
https://files.pythonhosted.org/packages/cf/a4/d5387a74204542a60ad1baa84cd2d3353c330e59be8cf2d47c0b11d3cde8/
pandas-3.1.1-cp36-cp36m-macosx_10_6_intel.
macosx_10_9_intel.macosx_10_9_x86_64.
macosx_10_10_intel.macosx_10_10_x86_64.whl (14.4MB)
|████████████████████████████████| 14.4MB 2.8MB/smatplotlib
pip install matplotlibเราจะเห็นคำตอบต่อไปนี้
Collecting matplotlib
Downloading
https://files.pythonhosted.org/packages/cf/a4/d5387a74204542a60ad1baa84cd2d3353c330e59be8cf2d47c0b11d3cde8/
matplotlib-3.1.1-cp36-cp36m-macosx_10_6_intel.
macosx_10_9_intel.macosx_10_9_x86_64.
macosx_10_10_intel.macosx_10_10_x86_64.whl (14.4MB)
|████████████████████████████████| 14.4MB 2.8MB/sscipy
pip install scipyเราจะเห็นคำตอบต่อไปนี้
Collecting scipy
Downloading
https://files.pythonhosted.org/packages/cf/a4/d5387a74204542a60ad1baa84cd2d3353c330e59be8cf2d47c0b11d3cde8
/scipy-3.1.1-cp36-cp36m-macosx_10_6_intel.
macosx_10_9_intel.macosx_10_9_x86_64.
macosx_10_10_intel.macosx_10_10_x86_64.whl (14.4MB)
|████████████████████████████████| 14.4MB 2.8MB/sscikit-learn
เป็นไลบรารีการเรียนรู้ของเครื่องโอเพนซอร์ส ใช้สำหรับการจำแนกประเภทการถดถอยและอัลกอริทึมการจัดกลุ่ม ก่อนที่จะย้ายไปติดตั้งต้องมีสิ่งต่อไปนี้ -
- Python เวอร์ชัน 3.5 ขึ้นไป
- NumPy เวอร์ชัน 1.11.0 หรือสูงกว่า
- SciPy เวอร์ชัน 0.17.0 หรือสูงกว่า
- joblib 0.11 หรือสูงกว่า
ตอนนี้เราติดตั้ง scikit-learn โดยใช้คำสั่งด้านล่าง -
pip install -U scikit-learnSeaborn
Seaborn เป็นห้องสมุดที่น่าทึ่งที่ช่วยให้คุณเห็นภาพข้อมูลของคุณได้อย่างง่ายดาย ใช้คำสั่งด้านล่างเพื่อติดตั้ง -
pip pip install seaborninstall -U scikit-learnคุณจะเห็นข้อความคล้ายกับที่ระบุไว้ด้านล่าง -
Collecting seaborn
Downloading
https://files.pythonhosted.org/packages/a8/76/220ba4420459d9c4c9c9587c6ce607bf56c25b3d3d2de62056efe482dadc
/seaborn-0.9.0-py3-none-any.whl (208kB) 100%
|████████████████████████████████| 215kB 4.0MB/s
Requirement already satisfied: numpy> = 1.9.3 in
./lib/python3.7/site-packages (from seaborn) (1.17.0)
Collecting pandas> = 0.15.2 (from seaborn)
Downloading
https://files.pythonhosted.org/packages/39/b7/441375a152f3f9929ff8bc2915218ff1a063a59d7137ae0546db616749f9/
pandas-0.25.0-cp37-cp37m-macosx_10_9_x86_64.
macosx_10_10_x86_64.whl (10.1MB) 100%
|████████████████████████████████| 10.1MB 1.8MB/s
Requirement already satisfied: scipy>=0.14.0 in
./lib/python3.7/site-packages (from seaborn) (1.3.0)
Collecting matplotlib> = 1.4.3 (from seaborn)
Downloading
https://files.pythonhosted.org/packages/c3/8b/af9e0984f
5c0df06d3fab0bf396eb09cbf05f8452de4e9502b182f59c33b/
matplotlib-3.1.1-cp37-cp37m-macosx_10_6_intel.
macosx_10_9_intel.macosx_10_9_x86_64
.macosx_10_10_intel.macosx_10_10_x86_64.whl (14.4MB) 100%
|████████████████████████████████| 14.4MB 1.4MB/s
......................................
......................................
Successfully installed cycler-0.10.0 kiwisolver-1.1.0
matplotlib-3.1.1 pandas-0.25.0 pyparsing-2.4.2
python-dateutil-2.8.0 pytz-2019.2 seaborn-0.9.0การติดตั้ง Keras โดยใช้ Python
ณ ตอนนี้เราได้ทำตามข้อกำหนดพื้นฐานสำหรับการติดตั้ง Kera เรียบร้อยแล้ว ตอนนี้ติดตั้ง Keras โดยใช้ขั้นตอนเดียวกับที่ระบุด้านล่าง -
pip install kerasออกจากสภาพแวดล้อมเสมือนจริง
หลังจากเสร็จสิ้นการเปลี่ยนแปลงทั้งหมดในโครงการของคุณแล้วเพียงแค่เรียกใช้คำสั่งด้านล่างเพื่อออกจากสภาพแวดล้อม -
deactivateเมฆอนาคอนดา
เราเชื่อว่าคุณได้ติดตั้ง anaconda cloud บนเครื่องของคุณแล้ว หากไม่ได้ติดตั้ง anaconda ให้ไปที่ลิงค์อย่างเป็นทางการwww.anaconda.com/distributionและเลือกดาวน์โหลดตามระบบปฏิบัติการของคุณ
สร้างสภาพแวดล้อม conda ใหม่
เปิดพรอมต์ anaconda ซึ่งจะเป็นการเปิดสภาพแวดล้อมของ Anaconda พื้นฐาน ให้เราสร้างสภาพแวดล้อม conda ใหม่ กระบวนการนี้คล้ายกับ Virtualenv พิมพ์คำสั่งด้านล่างใน conda terminal ของคุณ -
conda create --name PythonCPUหากต้องการคุณสามารถสร้างและติดตั้งโมดูลโดยใช้ GPU ได้เช่นกัน ในบทช่วยสอนนี้เราทำตามคำแนะนำของ CPU
เปิดใช้งานสภาพแวดล้อม conda
ในการเปิดใช้งานสภาพแวดล้อมให้ใช้คำสั่งด้านล่าง -
activate PythonCPUติดตั้ง spyder
Spyder เป็น IDE สำหรับเรียกใช้งานแอปพลิเคชัน python ให้เราติดตั้ง IDE นี้ในสภาพแวดล้อม conda ของเราโดยใช้คำสั่งด้านล่าง -
conda install spyderติดตั้งไลบรารี python
เรารู้จัก python libraries numpy, pandas และอื่น ๆ แล้วซึ่งจำเป็นสำหรับ keras คุณสามารถติดตั้งโมดูลทั้งหมดโดยใช้ไวยากรณ์ด้านล่าง -
Syntax
conda install -c anaconda <module-name>ตัวอย่างเช่นคุณต้องการติดตั้งแพนด้า -
conda install -c anaconda pandasเช่นเดียวกับวิธีการเดียวกันลองติดตั้งโมดูลที่เหลือด้วยตัวเอง
ติดตั้ง Keras
ตอนนี้ทุกอย่างดูดีดังนั้นคุณสามารถเริ่มการติดตั้ง keras โดยใช้คำสั่งด้านล่าง -
conda install -c anaconda kerasเปิดตัว spyder
สุดท้ายเปิด spyder ใน conda terminal ของคุณโดยใช้คำสั่งด้านล่าง -
spyderเพื่อให้แน่ใจว่าทุกอย่างได้รับการติดตั้งอย่างถูกต้องให้นำเข้าโมดูลทั้งหมดมันจะเพิ่มทุกอย่างและหากมีอะไรผิดพลาดคุณจะได้รับ module not found ข้อความผิดพลาด.
Keras - การกำหนดค่าแบ็กเอนด์
บทนี้อธิบายรายละเอียดการใช้งานแบ็กเอนด์ Keras TensorFlow และ Theano ให้เราดำเนินการตามแต่ละขั้นตอน
TensorFlow
TensorFlow เป็นไลบรารีแมชชีนเลิร์นนิงแบบโอเพนซอร์สที่ใช้สำหรับงานคำนวณเชิงตัวเลขที่พัฒนาโดย Google Keras เป็น API ระดับสูงที่สร้างขึ้นจาก TensorFlow หรือ Theano เรารู้วิธีติดตั้ง TensorFlow โดยใช้ pip แล้ว
หากไม่ได้ติดตั้งคุณสามารถติดตั้งโดยใช้คำสั่งด้านล่าง -
pip install TensorFlowเมื่อเรารัน keras แล้วเราจะเห็นไฟล์คอนฟิกูเรชันอยู่ที่โฮมไดเร็กทอรีของคุณภายในและไปที่. keras / keras.json
keras.json
{
"image_data_format": "channels_last",
"epsilon": 1e-07, "floatx": "float32", "backend": "tensorflow"
}ที่นี่
image_data_format แทนรูปแบบข้อมูล
epsilonแทนค่าคงที่เป็นตัวเลข ใช้เพื่อหลีกเลี่ยงDivideByZero ข้อผิดพลาด
floatx แทนชนิดข้อมูลเริ่มต้น float32. คุณยังสามารถเปลี่ยนเป็นfloat16 หรือ float64 โดยใช้ set_floatx() วิธี.
image_data_format แทนรูปแบบข้อมูล
สมมติว่าถ้าไฟล์ไม่ได้สร้างขึ้นให้ย้ายไปที่ตำแหน่งและสร้างโดยใช้ขั้นตอนด้านล่าง -
> cd home
> mkdir .keras
> vi keras.jsonจำไว้ว่าคุณควรระบุ. keras เป็นชื่อโฟลเดอร์และเพิ่มการกำหนดค่าข้างต้นในไฟล์ keras.json เราสามารถดำเนินการบางอย่างที่กำหนดไว้ล่วงหน้าเพื่อทราบฟังก์ชันแบ็กเอนด์
ธีโน
Theano เป็นไลบรารีการเรียนรู้เชิงลึกแบบโอเพนซอร์สที่ช่วยให้คุณประเมินอาร์เรย์หลายมิติได้อย่างมีประสิทธิภาพ เราสามารถติดตั้งได้อย่างง่ายดายโดยใช้คำสั่งด้านล่าง -
pip install theanoโดยค่าเริ่มต้น keras จะใช้แบ็กเอนด์ TensorFlow หากคุณต้องการเปลี่ยนการกำหนดค่าแบ็กเอนด์จาก TensorFlow เป็น Theano เพียงแค่เปลี่ยน backend = theano ในไฟล์ keras.json มีอธิบายไว้ด้านล่าง -
keras.json
{
"image_data_format": "channels_last",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "theano"
}ตอนนี้บันทึกไฟล์ของคุณรีสตาร์ทเทอร์มินัลและเริ่ม keras แบ็กเอนด์ของคุณจะเปลี่ยนไป
>>> import keras as k
using theano backend.Keras - ภาพรวมของการเรียนรู้เชิงลึก
การเรียนรู้เชิงลึกเป็นส่วนย่อยของการเรียนรู้ของเครื่องที่กำลังพัฒนา การเรียนรู้เชิงลึกเกี่ยวข้องกับการวิเคราะห์อินพุตทีละชั้นโดยแต่ละชั้นจะดึงข้อมูลระดับที่สูงขึ้นเกี่ยวกับอินพุต
ให้เราใช้สถานการณ์ง่ายๆในการวิเคราะห์ภาพ สมมติว่าภาพอินพุตของคุณแบ่งออกเป็นตารางสี่เหลี่ยมพิกเซล ตอนนี้เลเยอร์แรกเป็นนามธรรมพิกเซล ชั้นที่สองเข้าใจขอบในภาพ ชั้นถัดไปสร้างโหนดจากขอบ จากนั้นถัดไปจะค้นหากิ่งก้านจากโหนด ในที่สุดเลเยอร์เอาต์พุตจะตรวจจับวัตถุเต็ม ที่นี่กระบวนการแยกคุณลักษณะจะเริ่มจากเอาต์พุตของเลเยอร์หนึ่งไปยังอินพุตของเลเยอร์ถัดไปที่ตามมา
ด้วยการใช้วิธีนี้เราสามารถประมวลผลคุณสมบัติจำนวนมากซึ่งทำให้การเรียนรู้เชิงลึกเป็นเครื่องมือที่ทรงพลังมาก อัลกอริทึมการเรียนรู้เชิงลึกยังมีประโยชน์สำหรับการวิเคราะห์ข้อมูลที่ไม่มีโครงสร้าง ให้เราเรียนรู้พื้นฐานของการเรียนรู้เชิงลึกในบทนี้
โครงข่ายประสาทเทียม
แนวทางหลักของการเรียนรู้เชิงลึกที่ได้รับความนิยมมากที่สุดคือการใช้ "โครงข่ายประสาทเทียม" (ANN) พวกเขาได้รับแรงบันดาลใจจากแบบจำลองของสมองมนุษย์ซึ่งเป็นอวัยวะที่ซับซ้อนที่สุดในร่างกายของเรา สมองของมนุษย์ประกอบด้วยเซลล์เล็ก ๆ มากกว่า 90 พันล้านเซลล์ที่เรียกว่า "เซลล์ประสาท" เซลล์ประสาทเชื่อมต่อระหว่างกันผ่านใยประสาทที่เรียกว่า“ แอกซอน” และ“ เดนไดรต์” บทบาทหลักของแอกซอนคือการส่งข้อมูลจากเซลล์ประสาทหนึ่งไปยังอีกเซลล์หนึ่งซึ่งเชื่อมต่ออยู่
ในทำนองเดียวกันบทบาทหลักของเดนไดรต์คือการรับข้อมูลที่ส่งโดยแอกซอนของเซลล์ประสาทอื่นที่เชื่อมต่ออยู่ เซลล์ประสาทแต่ละเซลล์ประมวลผลข้อมูลขนาดเล็กแล้วส่งผลลัพธ์ไปยังเซลล์ประสาทอื่นและกระบวนการนี้จะดำเนินต่อไป นี่เป็นวิธีการพื้นฐานที่สมองของมนุษย์ใช้ในการประมวลผลข้อมูลจำนวนมากเช่นคำพูดภาพ ฯลฯ และดึงข้อมูลที่เป็นประโยชน์ออกมา
จากแบบจำลองนี้เครือข่ายประสาทเทียม (ANN) แรกถูกคิดค้นโดยนักจิตวิทยา Frank Rosenblattในปีพ. ศ. 2501 ANN ประกอบด้วยหลายโหนดซึ่งคล้ายกับเซลล์ประสาท โหนดเชื่อมต่อกันอย่างแน่นหนาและจัดเป็นชั้นต่างๆที่ซ่อนอยู่ เลเยอร์อินพุตรับข้อมูลอินพุตและข้อมูลจะผ่านเลเยอร์ที่ซ่อนอยู่อย่างน้อยหนึ่งเลเยอร์ตามลำดับและในที่สุดเลเยอร์เอาต์พุตจะทำนายสิ่งที่เป็นประโยชน์เกี่ยวกับข้อมูลอินพุต ตัวอย่างเช่นอินพุตอาจเป็นรูปภาพและผลลัพธ์อาจเป็นสิ่งที่ระบุในภาพพูดว่า“ แมว”
เซลล์ประสาทเดี่ยว (เรียกว่า perceptron ใน ANN) สามารถแสดงได้ดังนี้ -
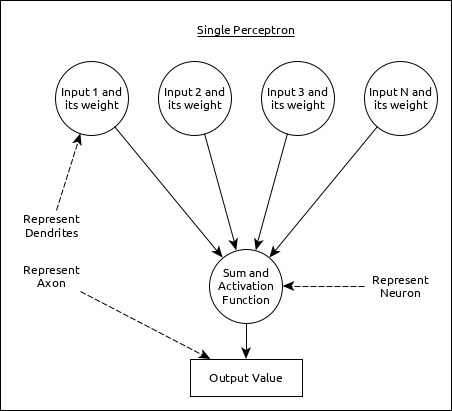
ที่นี่
การป้อนข้อมูลหลายรายการพร้อมกับน้ำหนักหมายถึงเดนไดรต์
ผลรวมของอินพุตพร้อมกับฟังก์ชันกระตุ้นแสดงถึงเซลล์ประสาท Sum อันที่จริงหมายถึงค่าที่คำนวณของอินพุตและฟังก์ชันการเปิดใช้งานทั้งหมดแสดงถึงฟังก์ชันซึ่งแก้ไขไฟล์ Sum ค่าเป็น 0, 1 หรือ 0 ถึง 1
เอาต์พุตจริงแสดงถึงแอกซอนและเซลล์ประสาทจะได้รับเอาต์พุตในชั้นถัดไป
ให้เราทำความเข้าใจโครงข่ายประสาทเทียมประเภทต่างๆในส่วนนี้
Perceptron หลายชั้น
Multi-Layer perceptron เป็นรูปแบบที่ง่ายที่สุดของ ANN ประกอบด้วยเลเยอร์อินพุตเดียวเลเยอร์ที่ซ่อนอยู่อย่างน้อยหนึ่งเลเยอร์และสุดท้ายเป็นเลเยอร์เอาต์พุต เลเยอร์ประกอบด้วยคอลเลกชันของเพอร์เซปตรอน ชั้นอินพุตเป็นคุณสมบัติอย่างน้อยหนึ่งอย่างของข้อมูลอินพุต ทุกชั้นที่ซ่อนอยู่ประกอบด้วยเซลล์ประสาทอย่างน้อยหนึ่งเซลล์และประมวลผลลักษณะบางอย่างของคุณลักษณะและส่งข้อมูลที่ประมวลผลไปยังชั้นที่ซ่อนถัดไป กระบวนการเลเยอร์เอาต์พุตรับข้อมูลจากเลเยอร์สุดท้ายที่ซ่อนอยู่และส่งผลลัพธ์ออกมาในที่สุด

Convolutional Neural Network (CNN)
Convolutional neural network เป็นหนึ่งใน ANN ที่ได้รับความนิยมมากที่สุด มีการใช้กันอย่างแพร่หลายในด้านการจดจำรูปภาพและวิดีโอ มันขึ้นอยู่กับแนวคิดของ Convolution ซึ่งเป็นแนวคิดทางคณิตศาสตร์ มันเกือบจะคล้ายกับ Perceptron หลายชั้นยกเว้นว่ามันมีชุดของชั้น Convolution และชั้นรวมกันก่อนชั้นเซลล์ประสาทที่ซ่อนอยู่อย่างเต็มที่ มีสามชั้นที่สำคัญ -
Convolution layer - เป็นหน่วยการสร้างหลักและทำงานด้านการคำนวณตามฟังก์ชัน Convolution
Pooling layer - จัดเรียงถัดจากเลเยอร์คอนโวลูชั่นและใช้เพื่อลดขนาดของอินพุตโดยลบข้อมูลที่ไม่จำเป็นออกเพื่อให้สามารถคำนวณได้เร็วขึ้น
Fully connected layer - จัดเรียงให้อยู่ถัดจากชุดของเลเยอร์การแปลงและการรวมกลุ่มและจำแนกข้อมูลเข้าเป็นหมวดหมู่ต่างๆ
CNN ธรรมดาสามารถแสดงได้ดังต่อไปนี้ -

ที่นี่
มีการใช้ Convolution และ pooling layer 2 ชุดและรับและประมวลผลอินพุต (เช่นรูปภาพ)
ใช้เลเยอร์เดียวที่เชื่อมต่ออย่างสมบูรณ์และใช้เพื่อส่งออกข้อมูล (เช่นการจำแนกประเภทของภาพ)
โครงข่ายประสาทที่เกิดซ้ำ (RNN)
Recurrent Neural Networks (RNN) มีประโยชน์ในการแก้ไขข้อบกพร่องใน ANN รุ่นอื่น ๆ ANN ส่วนใหญ่จำขั้นตอนจากสถานการณ์ก่อนหน้าไม่ได้และเรียนรู้ที่จะตัดสินใจตามบริบทในการฝึกอบรม ในขณะเดียวกัน RNN จัดเก็บข้อมูลในอดีตและการตัดสินใจทั้งหมดนำมาจากสิ่งที่ได้เรียนรู้จากอดีต
แนวทางนี้มีประโยชน์ในการจำแนกภาพเป็นหลัก บางครั้งเราอาจต้องมองไปในอนาคตเพื่อแก้ไขอดีต ในกรณีนี้ RNN แบบสองทิศทางจะเป็นประโยชน์ในการเรียนรู้จากอดีตและทำนายอนาคต ตัวอย่างเช่นเรามีตัวอย่างที่เขียนด้วยลายมือในหลายอินพุต สมมติว่าเรามีความสับสนในอินพุตหนึ่งจากนั้นเราต้องตรวจสอบข้อมูลอื่น ๆ อีกครั้งเพื่อรับรู้บริบทที่ถูกต้องซึ่งใช้เวลาในการตัดสินใจจากอดีต
ขั้นตอนการทำงานของ ANN
ให้เราทำความเข้าใจขั้นตอนต่างๆของการเรียนรู้เชิงลึกก่อนแล้วเรียนรู้ว่า Keras ช่วยในกระบวนการเรียนรู้เชิงลึกได้อย่างไร
รวบรวมข้อมูลที่จำเป็น
การเรียนรู้เชิงลึกต้องใช้ข้อมูลอินพุตจำนวนมากเพื่อให้เรียนรู้และทำนายผลลัพธ์ได้สำเร็จ ดังนั้นก่อนอื่นให้รวบรวมข้อมูลให้ได้มากที่สุด
วิเคราะห์ข้อมูล
วิเคราะห์ข้อมูลและรับความเข้าใจที่ดีเกี่ยวกับข้อมูล จำเป็นต้องมีความเข้าใจที่ดีขึ้นเกี่ยวกับข้อมูลเพื่อเลือกอัลกอริทึม ANN ที่ถูกต้อง
เลือกอัลกอริทึม (แบบจำลอง)
เลือกอัลกอริทึมที่เหมาะสมที่สุดสำหรับประเภทของกระบวนการเรียนรู้ (เช่นการจัดประเภทรูปภาพการประมวลผลข้อความ ฯลฯ ) และข้อมูลอินพุตที่มี อัลกอริทึมแสดงโดยModelใน Keras อัลกอริทึมประกอบด้วยเลเยอร์อย่างน้อยหนึ่งเลเยอร์ แต่ละเลเยอร์ใน ANN สามารถแสดงด้วยKeras Layer ใน Keras
Prepare data - ประมวลผลกรองและเลือกเฉพาะข้อมูลที่ต้องการจากข้อมูล
Split data- แยกข้อมูลออกเป็นชุดข้อมูลการฝึกอบรมและการทดสอบ ข้อมูลการทดสอบจะถูกใช้เพื่อประเมินการคาดคะเนของอัลกอริทึม / โมเดล (เมื่อเครื่องเรียนรู้) และเพื่อตรวจสอบประสิทธิภาพของกระบวนการเรียนรู้
Compile the model- รวบรวมอัลกอริทึม / แบบจำลองเพื่อให้สามารถใช้ต่อไปเพื่อเรียนรู้โดยการฝึกอบรมและในที่สุดก็ทำการทำนาย ขั้นตอนนี้ต้องการให้เราเลือกฟังก์ชันการสูญเสียและเครื่องมือเพิ่มประสิทธิภาพ ฟังก์ชันการสูญเสียและเครื่องมือเพิ่มประสิทธิภาพใช้ในขั้นตอนการเรียนรู้เพื่อค้นหาข้อผิดพลาด (ค่าเบี่ยงเบนจากผลลัพธ์จริง) และทำการปรับให้เหมาะสมเพื่อให้ข้อผิดพลาดลดลง
Fit the model - ขั้นตอนการเรียนรู้จริงจะทำในระยะนี้โดยใช้ชุดข้อมูลการฝึกอบรม
Predict result for unknown value - ทำนายผลลัพธ์สำหรับข้อมูลอินพุตที่ไม่รู้จัก (นอกเหนือจากข้อมูลการฝึกอบรมและการทดสอบที่มีอยู่)
Evaluate model - ประเมินแบบจำลองโดยการทำนายผลลัพธ์สำหรับข้อมูลการทดสอบและเปรียบเทียบการคาดการณ์กับผลลัพธ์จริงของข้อมูลการทดสอบ
Freeze, Modify or choose new algorithm- ตรวจสอบว่าการประเมินรูปแบบสำเร็จหรือไม่ ถ้าใช่ให้บันทึกอัลกอริทึมเพื่อใช้ในการทำนายในอนาคต ถ้าไม่เช่นนั้นให้แก้ไขหรือเลือกอัลกอริทึม / โมเดลใหม่และสุดท้ายฝึกทำนายและประเมินโมเดลอีกครั้ง ทำซ้ำขั้นตอนจนกว่าจะพบอัลกอริทึม (แบบจำลอง) ที่ดีที่สุด
ขั้นตอนข้างต้นสามารถแสดงได้โดยใช้ผังงานด้านล่าง -

Keras - การเรียนรู้เชิงลึก
Keras จัดเตรียมเฟรมเวิร์กที่สมบูรณ์เพื่อสร้างเครือข่ายประสาทประเภทใดก็ได้ Keras เป็นนวัตกรรมใหม่และง่ายต่อการเรียนรู้ สนับสนุนเครือข่ายประสาทเทียมอย่างง่ายไปจนถึงแบบจำลองเครือข่ายประสาทเทียมที่มีขนาดใหญ่และซับซ้อน ให้เราเข้าใจสถาปัตยกรรมของ Keras framework และวิธีที่ Keras ช่วยในการเรียนรู้เชิงลึกในบทนี้
สถาปัตยกรรมของ Keras
Keras API สามารถแบ่งออกเป็นสามประเภทหลัก -
- Model
- Layer
- โมดูลหลัก
ใน Keras ทุก ANN จะแสดงด้วย Keras Models. ในทางกลับกัน Keras Model ทุกตัวเป็นองค์ประกอบของKeras Layers และแสดงถึงเลเยอร์ ANN เช่นอินพุต, เลเยอร์ที่ซ่อนอยู่, เลเยอร์เอาต์พุต, เลเยอร์คอนโวลูชั่น, เลเยอร์พูลเป็นต้น, โมเดล Keras และการเข้าถึงเลเยอร์ Keras modules สำหรับฟังก์ชันการเปิดใช้งานฟังก์ชันการสูญเสียฟังก์ชันการทำให้เป็นมาตรฐาน ฯลฯ การใช้โมเดล Keras, Keras Layer และโมดูล Keras อัลกอริทึม ANN ใด ๆ (CNN, RNN ฯลฯ ) สามารถแสดงได้อย่างเรียบง่ายและมีประสิทธิภาพ
แผนภาพต่อไปนี้แสดงถึงความสัมพันธ์ระหว่างโมเดลเลเยอร์และโมดูลแกน -

ให้เราดูภาพรวมของโมเดล Keras เลเยอร์ Keras และโมดูล Keras
รุ่น
Keras Models มีสองประเภทดังที่กล่าวไว้ด้านล่าง -
Sequential Model- แบบจำลองตามลำดับนั้นเป็นองค์ประกอบเชิงเส้นของ Keras Layers แบบจำลองต่อเนื่องเป็นเรื่องง่ายน้อยที่สุดและมีความสามารถในการแสดงโครงข่ายประสาทเทียมที่มีอยู่เกือบทั้งหมด
แบบจำลองตามลำดับอย่างง่ายมีดังนี้ -
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,)))ที่ไหน
Line 1 การนำเข้า Sequential โมเดลจากโมเดล Keras
Line 2 การนำเข้า Dense เลเยอร์และ Activation โมดูล
Line 4 สร้างแบบจำลองตามลำดับใหม่โดยใช้ Sequential API
Line 5 เพิ่มเลเยอร์หนาแน่น (Dense API) ด้วย relu การเปิดใช้งาน (โดยใช้โมดูลการเปิดใช้งาน)
Sequential แบบจำลองเปิดเผย Modelคลาสเพื่อสร้างโมเดลที่กำหนดเองด้วย เราสามารถใช้แนวคิดการแบ่งประเภทย่อยเพื่อสร้างแบบจำลองที่ซับซ้อนของเราเอง
Functional API - Functional API โดยพื้นฐานแล้วจะใช้เพื่อสร้างโมเดลที่ซับซ้อน
ชั้น
เลเยอร์ Keras แต่ละชั้นในแบบจำลอง Keras แสดงถึงเลเยอร์ที่เกี่ยวข้อง (ชั้นอินพุตชั้นที่ซ่อนอยู่และชั้นเอาต์พุต) ในแบบจำลองเครือข่ายประสาทเทียมที่เสนอจริง Keras มีเลเยอร์ที่สร้างไว้ล่วงหน้าจำนวนมากเพื่อให้สามารถสร้างเครือข่ายประสาทเทียมที่ซับซ้อนได้อย่างง่ายดาย เลเยอร์ Keras ที่สำคัญบางส่วนมีการระบุไว้ด้านล่าง
- เลเยอร์หลัก
- เลเยอร์ Convolution
- เลเยอร์พูล
- เลเยอร์ที่เกิดซ้ำ
รหัส python อย่างง่ายเพื่อแสดงรูปแบบเครือข่ายประสาทโดยใช้ sequential โมเดลมีดังนี้ -
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation = 'relu')) model.add(Dropout(0.2))
model.add(Dense(num_classes, activation = 'softmax'))ที่ไหน
Line 1 การนำเข้า Sequential โมเดลจากโมเดล Keras
Line 2 การนำเข้า Dense เลเยอร์และ Activation โมดูล
Line 4 สร้างแบบจำลองตามลำดับใหม่โดยใช้ Sequential API
Line 5 เพิ่มเลเยอร์หนาแน่น (Dense API) ด้วย relu การเปิดใช้งาน (โดยใช้โมดูลการเปิดใช้งาน)
Line 6 เพิ่มเลเยอร์กลางคัน (Dropout API) เพื่อจัดการกับความเหมาะสมมากเกินไป
Line 7 เพิ่มเลเยอร์หนาแน่น (Dense API) ด้วย relu การเปิดใช้งาน (โดยใช้โมดูลการเปิดใช้งาน)
Line 8 เพิ่มเลเยอร์กลางคัน (Dropout API) อีกชั้นเพื่อจัดการกับความเหมาะสมที่มากเกินไป
Line 9 เพิ่มเลเยอร์หนาแน่นขั้นสุดท้าย (Dense API) ด้วย softmax การเปิดใช้งาน (โดยใช้โมดูลการเปิดใช้งาน)
Keras ยังมีตัวเลือกในการสร้างเลเยอร์ที่กำหนดเอง สามารถสร้างเลเยอร์ที่กำหนดเองได้โดยการแบ่งประเภทย่อยของไฟล์Keras.Layer คลาสและคล้ายกับโมเดล Keras ย่อย
โมดูลหลัก
Keras ยังมีฟังก์ชันที่เกี่ยวข้องกับเครือข่ายประสาทเทียมในตัวมากมายเพื่อสร้างโมเดล Keras และเลเยอร์ Keras อย่างถูกต้อง บางส่วนของฟังก์ชั่นมีดังนี้ -
Activations module - ฟังก์ชั่นการเปิดใช้งานเป็นแนวคิดที่สำคัญใน ANN และโมดูลการเปิดใช้งานมีฟังก์ชันการเปิดใช้งานมากมายเช่น softmax, relu ฯลฯ
Loss module - โมดูลการสูญเสียมีฟังก์ชันการสูญเสียเช่น mean_squared_error, mean_absolute_error, poisson เป็นต้น
Optimizer module - โมดูลเครื่องมือเพิ่มประสิทธิภาพให้ฟังก์ชันเครื่องมือเพิ่มประสิทธิภาพเช่น adam, sgd ฯลฯ
Regularizers - โมดูล Regularizer มีฟังก์ชันต่างๆเช่น L1 regularizer, L2 regularizer เป็นต้น
ให้เราเรียนรู้โมดูล Keras โดยละเอียดในบทต่อไป
Keras - โมดูล
ดังที่เราได้เรียนรู้ไปก่อนหน้านี้โมดูล Keras ประกอบด้วยคลาสฟังก์ชันและตัวแปรที่กำหนดไว้ล่วงหน้าซึ่งมีประโยชน์สำหรับอัลกอริทึมการเรียนรู้เชิงลึก ให้เราเรียนรู้โมดูลที่ Keras ให้ไว้ในบทนี้
โมดูลที่มี
ก่อนอื่นให้เราดูรายการโมดูลที่มีอยู่ใน Keras
Initializers- แสดงรายการฟังก์ชัน initializers เราสามารถเรียนรู้ได้ในรายละเอียดใน Keras ชั้นบท ระหว่างขั้นตอนการสร้างโมเดลของการเรียนรู้ของเครื่อง
Regularizers- แสดงรายการของฟังก์ชัน Regularizers เราสามารถเรียนรู้รายละเอียดได้ในบทKeras Layers
Constraints- แสดงรายการฟังก์ชันข้อ จำกัด เราสามารถเรียนรู้รายละเอียดได้ในบทKeras Layers
Activations- แสดงรายการฟังก์ชันตัวกระตุ้น เราสามารถเรียนรู้รายละเอียดได้ในบทKeras Layers
Losses- แสดงรายการฟังก์ชันการสูญเสีย เราสามารถเรียนรู้รายละเอียดได้ในบทการฝึกโมเดล
Metrics- แสดงรายการฟังก์ชันเมตริก เราสามารถเรียนรู้รายละเอียดได้ในบทการฝึกโมเดล
Optimizers- แสดงรายการฟังก์ชันเพิ่มประสิทธิภาพ เราสามารถเรียนรู้รายละเอียดได้ในบทการฝึกโมเดล
Callback- แสดงรายการฟังก์ชันการโทรกลับ เราสามารถใช้ในระหว่างขั้นตอนการฝึกเพื่อพิมพ์ข้อมูลระดับกลางและหยุดการฝึกอบรมได้ (EarlyStopping วิธีการ) ขึ้นอยู่กับเงื่อนไขบางประการ
Text processing- มีฟังก์ชันในการแปลงข้อความเป็นอาร์เรย์ NumPy ที่เหมาะสำหรับการเรียนรู้ของเครื่อง เราสามารถใช้ในขั้นตอนการเตรียมข้อมูลของการเรียนรู้ของเครื่อง
Image processing- มีฟังก์ชันในการแปลงรูปภาพเป็นอาร์เรย์ NumPy ที่เหมาะสำหรับการเรียนรู้ของเครื่อง เราสามารถใช้ในขั้นตอนการเตรียมข้อมูลของการเรียนรู้ของเครื่อง
Sequence processing- จัดเตรียมฟังก์ชันในการสร้างข้อมูลตามเวลาจากข้อมูลอินพุตที่กำหนด เราสามารถใช้ในขั้นตอนการเตรียมข้อมูลของการเรียนรู้ของเครื่อง
Backend- ให้การทำงานของห้องสมุดแบ็กเอนด์เช่นTensorFlowและTheano
Utilities - มีฟังก์ชันยูทิลิตี้มากมายที่เป็นประโยชน์ในการเรียนรู้เชิงลึก
ให้เราดู backend โมดูลและ utils แบบจำลองในบทนี้
โมดูลแบ็กเอนด์
backend moduleใช้สำหรับการดำเนินการแบ็กเอนด์ keras โดยค่าเริ่มต้น Keras จะทำงานที่ด้านบนของแบ็กเอนด์ TensorFlow หากต้องการคุณสามารถเปลี่ยนไปใช้แบ็กเอนด์อื่น ๆ เช่น Theano หรือ CNTK การกำหนดค่าแบ็กเอนด์เริ่มต้นถูกกำหนดไว้ภายในไดเร็กทอรีรากของคุณภายใต้ไฟล์. keras / keras.json
สามารถนำเข้าโมดูลแบ็กเอนด์ Keras ได้โดยใช้โค้ดด้านล่าง
>>> from keras import backend as kหากเรากำลังใช้TensorFlowแบ็กเอนด์เริ่มต้นฟังก์ชันด้านล่างจะส่งคืนข้อมูลตามTensorFlowตามที่ระบุด้านล่าง -
>>> k.backend()
'tensorflow'
>>> k.epsilon()
1e-07
>>> k.image_data_format()
'channels_last'
>>> k.floatx()
'float32'ให้เราเข้าใจฟังก์ชั่นแบ็กเอนด์ที่สำคัญบางอย่างที่ใช้สำหรับการวิเคราะห์ข้อมูลโดยสังเขป -
get_uid ()
เป็นตัวระบุสำหรับกราฟเริ่มต้น มีการกำหนดไว้ด้านล่าง -
>>> k.get_uid(prefix='')
1
>>> k.get_uid(prefix='') 2reset_uids
ใช้รีเซ็ตค่า uid
>>> k.reset_uids()ตอนนี้เรียกใช้get_uid ()อีกครั้ง สิ่งนี้จะถูกรีเซ็ตและเปลี่ยนอีกครั้งเป็น 1
>>> k.get_uid(prefix='')
1ตัวยึด
มันถูกใช้ในการสร้างตัวยึดตำแหน่งเทนเซอร์ ตัวยึดที่เรียบง่ายเพื่อยึดรูปร่าง 3 มิติดังแสดงด้านล่าง -
>>> data = k.placeholder(shape = (1,3,3))
>>> data
<tf.Tensor 'Placeholder_9:0' shape = (1, 3, 3) dtype = float32>
If you use int_shape(), it will show the shape.
>>> k.int_shape(data) (1, 3, 3)จุด
ใช้ในการคูณสองเทนเซอร์ พิจารณา a และ b เป็นสองเทนเซอร์และ c จะเป็นผลลัพธ์ของการคูณของ ab สมมติว่ารูปร่างคือ (4,2) และรูปร่าง b คือ (2,3) มีการกำหนดไว้ด้านล่าง
>>> a = k.placeholder(shape = (4,2))
>>> b = k.placeholder(shape = (2,3))
>>> c = k.dot(a,b)
>>> c
<tf.Tensor 'MatMul_3:0' shape = (4, 3) dtype = float32>
>>>คน
ใช้เพื่อเริ่มต้นทั้งหมดเป็นไฟล์ one มูลค่า.
>>> res = k.ones(shape = (2,2))
#print the value
>>> k.eval(res)
array([[1., 1.], [1., 1.]], dtype = float32)batch_dot
มันถูกใช้เพื่อดำเนินการผลคูณของข้อมูลสองชุดในแบทช์ มิติข้อมูลอินพุตต้องเป็น 2 หรือสูงกว่า ดังแสดงด้านล่าง -
>>> a_batch = k.ones(shape = (2,3))
>>> b_batch = k.ones(shape = (3,2))
>>> c_batch = k.batch_dot(a_batch,b_batch)
>>> c_batch
<tf.Tensor 'ExpandDims:0' shape = (2, 1) dtype = float32>ตัวแปร
ใช้เพื่อเริ่มต้นตัวแปร ให้เราดำเนินการเปลี่ยนอย่างง่ายในตัวแปรนี้
>>> data = k.variable([[10,20,30,40],[50,60,70,80]])
#variable initialized here
>>> result = k.transpose(data)
>>> print(result)
Tensor("transpose_6:0", shape = (4, 2), dtype = float32)
>>> print(k.eval(result))
[[10. 50.]
[20. 60.]
[30. 70.]
[40. 80.]]หากคุณต้องการเข้าถึงจาก numpy -
>>> data = np.array([[10,20,30,40],[50,60,70,80]])
>>> print(np.transpose(data))
[[10 50]
[20 60]
[30 70]
[40 80]]
>>> res = k.variable(value = data)
>>> print(res)
<tf.Variable 'Variable_7:0' shape = (2, 4) dtype = float32_ref>is_sparse (เทนเซอร์)
ใช้ตรวจสอบว่าเทนเซอร์เบาบางหรือไม่
>>> a = k.placeholder((2, 2), sparse=True)
>>> print(a) SparseTensor(indices =
Tensor("Placeholder_8:0",
shape = (?, 2), dtype = int64),
values = Tensor("Placeholder_7:0", shape = (?,),
dtype = float32), dense_shape = Tensor("Const:0", shape = (2,), dtype = int64))
>>> print(k.is_sparse(a)) Trueto_dense ()
ใช้เพื่อแปลงกระจัดกระจายเป็นหนาแน่น
>>> b = k.to_dense(a)
>>> print(b) Tensor("SparseToDense:0", shape = (2, 2), dtype = float32)
>>> print(k.is_sparse(b)) Falserandom_uniform_variable
ใช้เพื่อเริ่มต้นโดยใช้ไฟล์ uniform distribution แนวคิด.
k.random_uniform_variable(shape, mean, scale)ที่นี่
shape - หมายถึงแถวและคอลัมน์ในรูปแบบของ tuples
mean - ค่าเฉลี่ยของการกระจายสม่ำเสมอ
scale - ค่าเบี่ยงเบนมาตรฐานของการกระจายสม่ำเสมอ
ให้เราดูตัวอย่างการใช้งานด้านล่าง -
>>> a = k.random_uniform_variable(shape = (2, 3), low=0, high = 1)
>>> b = k. random_uniform_variable(shape = (3,2), low = 0, high = 1)
>>> c = k.dot(a, b)
>>> k.int_shape(c)
(2, 2)โมดูลยูทิลิตี้
utilsมีฟังก์ชันยูทิลิตี้ที่เป็นประโยชน์สำหรับการเรียนรู้เชิงลึก วิธีการบางอย่างที่มีให้โดยไฟล์utils โมดูลมีดังนี้ -
HDF5Matrix
ใช้เพื่อแสดงข้อมูลอินพุตในรูปแบบ HDF5
from keras.utils import HDF5Matrix data = HDF5Matrix('data.hdf5', 'data')to_categorical
ใช้เพื่อแปลงเวกเตอร์คลาสเป็นเมทริกซ์คลาสไบนารี
>>> from keras.utils import to_categorical
>>> labels = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> to_categorical(labels)
array([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]], dtype = float32)
>>> from keras.utils import normalize
>>> normalize([1, 2, 3, 4, 5])
array([[0.13483997, 0.26967994, 0.40451992, 0.53935989, 0.67419986]])print_summary
ใช้เพื่อพิมพ์ข้อมูลสรุปของโมเดล
from keras.utils import print_summary print_summary(model)plot_model
ใช้เพื่อสร้างการแสดงโมเดลในรูปแบบจุดและบันทึกลงในไฟล์
from keras.utils import plot_model
plot_model(model,to_file = 'image.png')นี้ plot_model จะสร้างภาพเพื่อทำความเข้าใจประสิทธิภาพของโมเดล
Keras - เลเยอร์
ดังที่ได้เรียนไปก่อนหน้านี้เลเยอร์ Keras เป็นส่วนประกอบหลักของโมเดล Keras แต่ละเลเยอร์จะรับข้อมูลอินพุตทำการคำนวณบางอย่างและสุดท้ายส่งออกข้อมูลที่แปลงแล้ว เอาต์พุตของเลเยอร์หนึ่งจะไหลไปยังเลเยอร์ถัดไปเป็นอินพุต ให้เราเรียนรู้รายละเอียดทั้งหมดเกี่ยวกับเลเยอร์ในบทนี้
บทนำ
ต้องการเลเยอร์ Keras shape of the input (input_shape) เพื่อทำความเข้าใจโครงสร้างของข้อมูลอินพุต initializerเพื่อกำหนดน้ำหนักสำหรับแต่ละอินพุตและในที่สุดตัวกระตุ้นจะแปลงเอาต์พุตเพื่อให้ไม่เป็นเชิงเส้น ในระหว่างนั้นข้อ จำกัด จะ จำกัด และระบุช่วงที่น้ำหนักของข้อมูลอินพุตที่จะสร้างขึ้นและตัวควบคุมจะพยายามเพิ่มประสิทธิภาพเลเยอร์ (และโมเดล) โดยการใช้บทลงโทษกับน้ำหนักแบบไดนามิกในระหว่างขั้นตอนการเพิ่มประสิทธิภาพ
สรุปได้ว่าเลเยอร์ Keras ต้องการรายละเอียดขั้นต่ำด้านล่างเพื่อสร้างเลเยอร์ที่สมบูรณ์
- รูปร่างของข้อมูลอินพุต
- จำนวนเซลล์ประสาท / หน่วยในชั้น
- Initializers
- Regularizers
- Constraints
- Activations
ให้เราเข้าใจแนวคิดพื้นฐานในบทถัดไป ก่อนที่จะทำความเข้าใจแนวคิดพื้นฐานให้เราสร้างเลเยอร์ Keras อย่างง่ายโดยใช้ Sequential model API เพื่อรับแนวคิดว่าโมเดลและเลเยอร์ของ Keras ทำงานอย่างไร
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
from keras import regularizers
from keras import constraints
model = Sequential()
model.add(Dense(32, input_shape=(16,), kernel_initializer = 'he_uniform',
kernel_regularizer = None, kernel_constraint = 'MaxNorm', activation = 'relu'))
model.add(Dense(16, activation = 'relu'))
model.add(Dense(8))ที่ไหน
Line 1-5 นำเข้าโมดูลที่จำเป็น
Line 7 สร้างโมเดลใหม่โดยใช้ Sequential API
Line 9 สร้างไฟล์ Dense เลเยอร์และเพิ่มลงในโมเดล Denseเป็นชั้นเริ่มต้นที่ Keras จัดเตรียมไว้ซึ่งยอมรับจำนวนเซลล์ประสาทหรือหน่วย (32) เป็นพารามิเตอร์ที่ต้องการ หากเลเยอร์เป็นเลเยอร์แรกเราจำเป็นต้องจัดเตรียมInput Shape, (16,)เช่นกัน. มิฉะนั้นเอาต์พุตของเลเยอร์ก่อนหน้าจะถูกใช้เป็นอินพุตของเลเยอร์ถัดไป พารามิเตอร์อื่น ๆ ทั้งหมดเป็นทางเลือก
พารามิเตอร์แรกแสดงถึงจำนวนหน่วย (เซลล์ประสาท)
input_shape แสดงถึงรูปร่างของข้อมูลอินพุต
kernel_initializer เป็นตัวแทนของ initializer ที่จะใช้ he_uniform ฟังก์ชันถูกกำหนดเป็นค่า
kernel_regularizer แทน regularizerที่จะใช้ ไม่มีการตั้งค่าเป็นค่า
kernel_constraint แสดงถึงข้อ จำกัด ที่จะใช้ MaxNorm ฟังก์ชันถูกกำหนดเป็นค่า
activationแสดงถึงการเปิดใช้งานที่จะใช้ ฟังก์ชัน relu ถูกตั้งค่าเป็นค่า
Line 10 สร้างวินาที Dense ชั้นที่มี 16 หน่วยและชุด relu เป็นฟังก์ชันการเปิดใช้งาน
Line 11 สร้างเลเยอร์ Dense ขั้นสุดท้ายด้วย 8 หน่วย
แนวคิดพื้นฐานของเลเยอร์
ให้เราเข้าใจแนวคิดพื้นฐานของเลเยอร์รวมถึงวิธีที่ Keras สนับสนุนแนวคิดแต่ละอย่าง
รูปร่างอินพุต
ในแมชชีนเลิร์นนิงข้อมูลอินพุตทุกประเภทเช่นข้อความรูปภาพหรือวิดีโอจะถูกแปลงเป็นอาร์เรย์ของตัวเลขก่อนแล้วจึงป้อนเข้าในอัลกอริทึม ตัวเลขอินพุตอาจเป็นอาร์เรย์มิติเดียวอาร์เรย์สองมิติ (เมทริกซ์) หรืออาร์เรย์หลายมิติ เราสามารถระบุข้อมูลมิติโดยใช้shapeทูเพิลของจำนวนเต็ม ตัวอย่างเช่น,(4,2) แสดงเมทริกซ์ด้วยสี่แถวและสองคอลัมน์
>>> import numpy as np
>>> shape = (4, 2)
>>> input = np.zeros(shape)
>>> print(input)
[
[0. 0.]
[0. 0.]
[0. 0.]
[0. 0.]
]
>>>ในทำนองเดียวกัน (3,4,2) เมทริกซ์สามมิติที่มีเมทริกซ์ 4x2 สามคอลเลกชัน (สองแถวและสี่คอลัมน์)
>>> import numpy as np
>>> shape = (3, 4, 2)
>>> input = np.zeros(shape)
>>> print(input)
[
[[0. 0.] [0. 0.] [0. 0.] [0. 0.]]
[[0. 0.] [0. 0.] [0. 0.] [0. 0.]]
[[0. 0.] [0. 0.] [0. 0.] [0. 0.]]
]
>>>ในการสร้างเลเยอร์แรกของโมเดล (หรือชั้นอินพุตของโมเดล) ควรระบุรูปร่างของข้อมูลอินพุต
ตัวเริ่มต้น
ใน Machine Learning น้ำหนักจะถูกกำหนดให้กับข้อมูลอินพุตทั้งหมด Initializersโมดูลมีฟังก์ชันที่แตกต่างกันเพื่อกำหนดน้ำหนักเริ่มต้นเหล่านี้ บางส่วนของKeras Initializer ฟังก์ชั่นมีดังนี้ -
เลขศูนย์
สร้าง 0 สำหรับข้อมูลอินพุตทั้งหมด
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.Zeros()
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))ที่ไหน kernel_initializer เป็นตัวแทนของ initializer สำหรับเคอร์เนลของโมเดล
คน
สร้าง 1 สำหรับข้อมูลอินพุตทั้งหมด
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.Ones()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))คงที่
สร้างค่าคงที่ (พูดว่า 5) ระบุโดยผู้ใช้สำหรับข้อมูลอินพุตทั้งหมด
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.Constant(value = 0) model.add(
Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init)
)ที่ไหน value แทนค่าคงที่
สุ่ม
สร้างค่าโดยใช้การกระจายปกติของข้อมูลอินพุต
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.RandomNormal(mean=0.0,
stddev = 0.05, seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))ที่ไหน
mean แสดงถึงค่าเฉลี่ยของค่าสุ่มที่จะสร้าง
stddev แทนค่าเบี่ยงเบนมาตรฐานของค่าสุ่มที่จะสร้าง
seed แทนค่าเพื่อสร้างตัวเลขสุ่ม
RandomUniform
สร้างค่าโดยใช้การกระจายข้อมูลอินพุตอย่างสม่ำเสมอ
from keras import initializers
my_init = initializers.RandomUniform(minval = -0.05, maxval = 0.05, seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))ที่ไหน
minval แสดงขอบเขตล่างของค่าสุ่มที่จะสร้าง
maxval แสดงขอบเขตบนของค่าสุ่มที่จะสร้าง
ปกติ
สร้างค่าโดยใช้การแจกแจงข้อมูลอินพุตแบบปกติที่ถูกตัดทอน
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.TruncatedNormal(mean = 0.0, stddev = 0.05, seed = None
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))ความแปรปรวน
สร้างค่าตามรูปร่างอินพุตและรูปร่างเอาต์พุตของเลเยอร์พร้อมกับมาตราส่วนที่ระบุ
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.VarianceScaling(
scale = 1.0, mode = 'fan_in', distribution = 'normal', seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
skernel_initializer = my_init))ที่ไหน
scale แสดงถึงปัจจัยการปรับขนาด
mode เป็นตัวแทนของคนใดคนหนึ่ง fan_in, fan_out และ fan_avg ค่า
distribution เป็นตัวแทนของ normal หรือ uniform
ความแปรปรวน
พบไฟล์ stddev ค่าสำหรับการแจกแจงปกติโดยใช้สูตรด้านล่างจากนั้นหาน้ำหนักโดยใช้การแจกแจงปกติ
stddev = sqrt(scale / n)ที่ไหน n แทน,
จำนวนหน่วยอินพุตสำหรับโหมด = fan_in
จำนวนหน่วยออกสำหรับโหมด = fan_out
จำนวนหน่วยอินพุตและเอาต์พุตโดยเฉลี่ยสำหรับโหมด = fan_avg
ในทำนองเดียวกันพบขีด จำกัดสำหรับการแจกแจงแบบสม่ำเสมอโดยใช้สูตรด้านล่างจากนั้นหาน้ำหนักโดยใช้การแจกแจงแบบสม่ำเสมอ
limit = sqrt(3 * scale / n)lecun_normal
สร้างค่าโดยใช้การแจกแจงแบบปกติของข้อมูลอินพุต
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.RandomUniform(minval = -0.05, maxval = 0.05, seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))พบไฟล์ stddev โดยใช้สูตรด้านล่างแล้วใช้การแจกแจงแบบปกติ
stddev = sqrt(1 / fan_in)ที่ไหน fan_in แทนจำนวนหน่วยอินพุต
lecun_uniform
สร้างค่าโดยใช้การกระจายข้อมูลอินพุตที่สม่ำเสมอของ lecun
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.lecun_uniform(seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))พบไฟล์ limit ใช้สูตรด้านล่างแล้วใช้การกระจายสม่ำเสมอ
limit = sqrt(3 / fan_in)ที่ไหน
fan_in แสดงถึงจำนวนหน่วยอินพุต
fan_out แสดงถึงจำนวนหน่วยเอาต์พุต
glorot_normal
สร้างค่าโดยใช้การกระจายข้อมูลอินพุตแบบปกติของ glorot
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.glorot_normal(seed=None) model.add(
Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init)
)พบไฟล์ stddev โดยใช้สูตรด้านล่างแล้วใช้การแจกแจงแบบปกติ
stddev = sqrt(2 / (fan_in + fan_out))ที่ไหน
fan_in แสดงถึงจำนวนหน่วยอินพุต
fan_out แสดงถึงจำนวนหน่วยเอาต์พุต
glorot_uniform
สร้างมูลค่าโดยใช้การกระจายข้อมูลอินพุตที่สม่ำเสมอของ glorot
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.glorot_uniform(seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))พบไฟล์ limit ใช้สูตรด้านล่างแล้วใช้การกระจายสม่ำเสมอ
limit = sqrt(6 / (fan_in + fan_out))ที่ไหน
fan_in แทนจำนวนหน่วยอินพุต
fan_out แสดงถึงจำนวนหน่วยเอาต์พุต
he_normal
สร้างมูลค่าโดยใช้การกระจายข้อมูลอินพุตตามปกติ
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.RandomUniform(minval = -0.05, maxval = 0.05, seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))พบstddevโดยใช้สูตรด้านล่างจากนั้นใช้การแจกแจงแบบปกติ
stddev = sqrt(2 / fan_in)ที่ไหน fan_in แทนจำนวนหน่วยอินพุต
he_uniform
สร้างมูลค่าโดยใช้การกระจายข้อมูลอินพุตอย่างสม่ำเสมอ
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.he_normal(seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))พบไฟล์ limit ใช้สูตรด้านล่างแล้วใช้การกระจายสม่ำเสมอ
limit = sqrt(6 / fan_in)ที่ไหน fan_in แทนจำนวนหน่วยอินพุต
มุมฉาก
สร้างเมทริกซ์มุมฉากแบบสุ่ม
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.Orthogonal(gain = 1.0, seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))ที่ไหน gain แทนตัวคูณการคูณของเมทริกซ์
เอกลักษณ์
สร้างเมทริกซ์เอกลักษณ์
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.Identity(gain = 1.0) model.add(
Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init)
)ข้อ จำกัด
ในแมชชีนเลิร์นนิงจะมีการกำหนดข้อ จำกัด ให้กับพารามิเตอร์ (น้ำหนัก) ในระหว่างขั้นตอนการเพิ่มประสิทธิภาพ <> โมดูลข้อ จำกัด มีฟังก์ชันต่างๆในการตั้งค่าข้อ จำกัด บนเลเยอร์ ฟังก์ชันข้อ จำกัด บางประการมีดังนี้
NonNeg
จำกัด น้ำหนักให้ไม่เป็นลบ
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.Identity(gain = 1.0) model.add(
Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init)
)ที่ไหน kernel_constraint แสดงถึงข้อ จำกัด ที่จะใช้ในเลเยอร์
UnitNorm
จำกัด น้ำหนักให้เป็นบรรทัดฐานของหน่วย
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import constraints
my_constrain = constraints.UnitNorm(axis = 0)
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_constraint = my_constrain))MaxNorm
จำกัด น้ำหนักให้เป็นบรรทัดฐานน้อยกว่าหรือเท่ากับค่าที่กำหนด
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import constraints
my_constrain = constraints.MaxNorm(max_value = 2, axis = 0)
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_constraint = my_constrain))ที่ไหน
max_value แสดงขอบเขตบน
แกนแสดงถึงมิติที่จะใช้ข้อ จำกัด เช่นใน Shape (2,3,4) แกน 0 หมายถึงมิติแรก 1 หมายถึงมิติที่สองและ 2 หมายถึงมิติที่สาม
MinMaxNorm
จำกัด น้ำหนักให้เป็นบรรทัดฐานระหว่างค่าต่ำสุดและค่าสูงสุดที่ระบุ
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import constraints
my_constrain = constraints.MinMaxNorm(min_value = 0.0, max_value = 1.0, rate = 1.0, axis = 0)
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_constraint = my_constrain))ที่ไหน rate แสดงถึงอัตราที่ใช้ข้อ จำกัด ด้านน้ำหนัก
Regularizers
ในแมชชีนเลิร์นนิงจะใช้ตัวควบคุมปกติในขั้นตอนการเพิ่มประสิทธิภาพ ใช้บทลงโทษบางอย่างกับพารามิเตอร์เลเยอร์ระหว่างการปรับให้เหมาะสม โมดูลการทำให้เป็นมาตรฐาน Keras มีฟังก์ชันด้านล่างเพื่อกำหนดบทลงโทษบนเลเยอร์ การทำให้เป็นมาตรฐานใช้ต่อชั้นเท่านั้น
L1 Regularizer
ให้การทำให้เป็นมาตรฐานตาม L1
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import regularizers
my_regularizer = regularizers.l1(0.)
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_regularizer = my_regularizer))ที่ไหน kernel_regularizer แสดงถึงอัตราที่ใช้ข้อ จำกัด ด้านน้ำหนัก
L2 Regularizer
ให้การกำหนดมาตรฐานตาม L2
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import regularizers
my_regularizer = regularizers.l2(0.)
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_regularizer = my_regularizer))L1 และ L2 Regularizer
มีทั้งการกำหนดมาตรฐานตาม L1 และ L2
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import regularizers
my_regularizer = regularizers.l2(0.)
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_regularizer = my_regularizer))การเปิดใช้งาน
ในการเรียนรู้ของเครื่องฟังก์ชันการเปิดใช้งานเป็นฟังก์ชันพิเศษที่ใช้เพื่อค้นหาว่าเซลล์ประสาทเฉพาะถูกเปิดใช้งานหรือไม่ โดยพื้นฐานแล้วฟังก์ชั่นการกระตุ้นจะทำการเปลี่ยนแปลงข้อมูลอินพุตแบบไม่เชิงเส้นและทำให้เซลล์ประสาทเรียนรู้ได้ดีขึ้น ผลลัพธ์ของเซลล์ประสาทขึ้นอยู่กับฟังก์ชันการกระตุ้น
ในขณะที่คุณนึกถึงแนวคิดของการรับรู้เดี่ยวผลลัพธ์ของ perceptron (เซลล์ประสาท) เป็นเพียงผลจากฟังก์ชันกระตุ้นซึ่งยอมรับการรวมของอินพุตทั้งหมดคูณด้วยน้ำหนักที่สอดคล้องกันบวกอคติโดยรวมหากมี
result = Activation(SUMOF(input * weight) + bias)ดังนั้นฟังก์ชันการเปิดใช้งานจึงมีบทบาทสำคัญในการเรียนรู้โมเดลที่ประสบความสำเร็จ Keras มีฟังก์ชันการเปิดใช้งานจำนวนมากในโมดูลการเปิดใช้งาน ให้เราเรียนรู้การเปิดใช้งานทั้งหมดที่มีอยู่ในโมดูล
เชิงเส้น
ใช้ฟังก์ชัน Linear ไม่ทำอะไรเลย
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'linear', input_shape = (784,)))ที่ไหน activationหมายถึงฟังก์ชันการเปิดใช้งานของเลเยอร์ สามารถระบุได้ง่ายๆด้วยชื่อของฟังก์ชันและเลเยอร์จะใช้ตัวกระตุ้นที่เกี่ยวข้อง
elu
ใช้หน่วยเชิงเส้นเอกซ์โปเนนเชียล
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'elu', input_shape = (784,)))Selu
ใช้หน่วยเชิงเส้นเลขชี้กำลังที่ปรับขนาด
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'selu', input_shape = (784,)))relu
ใช้ Rectified Linear Unit
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,)))ซอฟต์แม็กซ์
ใช้ฟังก์ชัน Softmax
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'softmax', input_shape = (784,)))ซอฟท์พลัส
ใช้ฟังก์ชัน Softplus
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'softplus', input_shape = (784,)))softsign
ใช้ฟังก์ชัน Softsign
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'softsign', input_shape = (784,)))Tanh
ใช้ฟังก์ชันไฮเพอร์โบลิกแทนเจนต์
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'tanh', input_shape = (784,)))ซิกมอยด์
ใช้ฟังก์ชัน Sigmoid
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'sigmoid', input_shape = (784,)))hard_sigmoid
ใช้ฟังก์ชัน Hard Sigmoid
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'hard_sigmoid', input_shape = (784,)))เลขชี้กำลัง
ใช้ฟังก์ชันเอกซ์โพเนนเชียล
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'exponential', input_shape = (784,)))| ซีเนียร์ No | เลเยอร์และคำอธิบาย |
|---|---|
| 1 | เลเยอร์หนาแน่น Dense layer เป็นชั้นเครือข่ายประสาทเทียมที่เชื่อมต่อกันอย่างลึกซึ้งปกติ |
| 2 | เลเยอร์กลางคัน Dropout เป็นแนวคิดที่สำคัญอย่างหนึ่งในการเรียนรู้ของเครื่อง |
| 3 | แบนเลเยอร์ Flatten ใช้เพื่อทำให้อินพุตแบนราบ |
| 4 | ปรับรูปร่างเลเยอร์ Reshape ใช้เพื่อเปลี่ยนรูปร่างของอินพุต |
| 5 | ชั้นอนุญาต Permute ยังใช้เพื่อเปลี่ยนรูปร่างของอินพุตโดยใช้รูปแบบ |
| 6 | RepeatVector เลเยอร์ RepeatVector ใช้เพื่อป้อนข้อมูลซ้ำสำหรับจำนวนชุด n ครั้ง |
| 7 | แลมบ์ดาเลเยอร์ Lambda ใช้เพื่อแปลงข้อมูลอินพุตโดยใช้นิพจน์หรือฟังก์ชัน |
| 8 | เลเยอร์ Convolution Keras มีจำนวนมากของชั้นสำหรับการสร้างบิดตาม ANN นิยมเรียกกันว่าเป็นบิดโครงข่ายประสาทเทียม (ซีเอ็นเอ็น) |
| 9 | การรวมเลเยอร์ ใช้เพื่อดำเนินการรวมสูงสุดกับข้อมูลชั่วคราว |
| 10 | เลเยอร์ที่เชื่อมต่อภายใน เลเยอร์ที่เชื่อมต่อภายในนั้นคล้ายกับเลเยอร์ Conv1D แต่ความแตกต่างคือน้ำหนักของเลเยอร์ Conv1D จะถูกแชร์ แต่ที่นี่จะไม่แชร์น้ำหนัก |
| 11 | ผสานเลเยอร์ ใช้เพื่อรวมรายการอินพุต |
| 12 | การฝังเลเยอร์ ดำเนินการฝังในชั้นอินพุต |
Keras - เลเยอร์ที่กำหนดเอง
Keras อนุญาตให้สร้างเลเยอร์ที่กำหนดเองของเราเอง เมื่อสร้างเลเยอร์ใหม่แล้วจะสามารถใช้งานได้ในทุกรุ่นโดยไม่มีข้อ จำกัด ให้เราเรียนรู้วิธีสร้างเลเยอร์ใหม่ในบทนี้
Keras เป็นฐาน layerclass, Layer ซึ่งสามารถย่อยเพื่อสร้าง Layer ที่เรากำหนดเองได้ ให้เราสร้างเลเยอร์ง่ายๆซึ่งจะหาน้ำหนักตามการแจกแจงปกติจากนั้นทำการคำนวณพื้นฐานเพื่อหาผลรวมของผลคูณของข้อมูลเข้าและน้ำหนักระหว่างการฝึก
ขั้นตอนที่ 1: นำเข้าโมดูลที่จำเป็น
ขั้นแรกให้เรานำเข้าโมดูลที่จำเป็น -
from keras import backend as K
from keras.layers import Layerที่นี่
backend ใช้เพื่อเข้าถึงไฟล์ dot ฟังก์ชัน
Layer เป็นคลาสพื้นฐานและเราจะแบ่งคลาสย่อยเพื่อสร้างเลเยอร์ของเรา
ขั้นตอนที่ 2: กำหนดคลาสเลเยอร์
ให้เราสร้างคลาสใหม่ MyCustomLayer โดยการแบ่งประเภทย่อย Layer class -
class MyCustomLayer(Layer):
...ขั้นตอนที่ 3: เริ่มต้นคลาสเลเยอร์
ให้เราเริ่มต้นคลาสใหม่ของเราตามที่ระบุด้านล่าง -
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(MyCustomLayer, self).__init__(**kwargs)ที่นี่
Line 2 ตั้งค่ามิติข้อมูลเอาต์พุต
Line 3 เรียกฐานหรือชั้นซุปเปอร์ init ฟังก์ชัน
ขั้นตอนที่ 4: ใช้วิธีการสร้าง
buildเป็นวิธีการหลักและมีจุดประสงค์เดียวคือการสร้างเลเยอร์อย่างถูกต้อง มันสามารถทำอะไรก็ได้ที่เกี่ยวข้องกับการทำงานภายในของเลเยอร์ เมื่อฟังก์ชันที่กำหนดเองเสร็จสิ้นเราสามารถเรียกใช้คลาสพื้นฐานได้buildฟังก์ชัน ประเพณีของเราbuild ฟังก์ชั่นมีดังนี้ -
def build(self, input_shape):
self.kernel = self.add_weight(name = 'kernel',
shape = (input_shape[1], self.output_dim),
initializer = 'normal', trainable = True)
super(MyCustomLayer, self).build(input_shape)ที่นี่
Line 1 กำหนด build วิธีการด้วยอาร์กิวเมนต์เดียว input_shape. รูปร่างของข้อมูลอินพุตถูกอ้างอิงโดย input_shape
Line 2สร้างน้ำหนักที่สอดคล้องกับรูปร่างอินพุตและตั้งค่าในเคอร์เนล เป็นฟังก์ชันที่กำหนดเองของเลเยอร์ สร้างน้ำหนักโดยใช้ตัวเริ่มต้น 'ปกติ'
Line 6 เรียกคลาสพื้นฐาน build วิธี.
ขั้นตอนที่ 5: ใช้วิธีการโทร
call วิธีการทำงานที่แน่นอนของเลเยอร์ในระหว่างกระบวนการฝึกอบรม
ประเพณีของเรา call วิธีการมีดังนี้
def call(self, input_data):
return K.dot(input_data, self.kernel)ที่นี่
Line 1 กำหนด call วิธีการด้วยอาร์กิวเมนต์เดียว input_data. input_data คือข้อมูลอินพุตสำหรับเลเยอร์ของเรา
Line 2 ส่งคืนผลิตภัณฑ์ดอทของข้อมูลอินพุต input_data และเคอร์เนลของเลเยอร์ของเรา self.kernel
ขั้นตอนที่ 6: ใช้เมธอด compute_output_shape
def compute_output_shape(self, input_shape): return (input_shape[0], self.output_dim)ที่นี่
Line 1 กำหนด compute_output_shape วิธีการด้วยอาร์กิวเมนต์เดียว input_shape
Line 2 คำนวณรูปร่างผลลัพธ์โดยใช้รูปร่างของข้อมูลอินพุตและชุดมิติข้อมูลเอาต์พุตขณะเริ่มต้นเลเยอร์
การใช้งาน build, call และ compute_output_shapeเสร็จสิ้นการสร้างเลเยอร์ที่กำหนดเอง รหัสสุดท้ายและสมบูรณ์มีดังนี้
from keras import backend as K from keras.layers import Layer
class MyCustomLayer(Layer):
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(MyCustomLayer, self).__init__(**kwargs)
def build(self, input_shape): self.kernel =
self.add_weight(name = 'kernel',
shape = (input_shape[1], self.output_dim),
initializer = 'normal', trainable = True)
super(MyCustomLayer, self).build(input_shape) #
Be sure to call this at the end
def call(self, input_data): return K.dot(input_data, self.kernel)
def compute_output_shape(self, input_shape): return (input_shape[0], self.output_dim)ใช้เลเยอร์ที่กำหนดเองของเรา
ให้เราสร้างโมเดลง่ายๆโดยใช้เลเยอร์ที่กำหนดเองตามที่ระบุด้านล่าง -
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(MyCustomLayer(32, input_shape = (16,)))
model.add(Dense(8, activation = 'softmax')) model.summary()ที่นี่
ของเรา MyCustomLayer ถูกเพิ่มเข้าไปในโมเดลโดยใช้ 32 หน่วยและ (16,) เป็นรูปทรงอินพุต
การเรียกใช้แอปพลิเคชันจะพิมพ์สรุปโมเดลดังต่อไปนี้ -
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param
#================================================================
my_custom_layer_1 (MyCustomL (None, 32) 512
_________________________________________________________________
dense_1 (Dense) (None, 8) 264
=================================================================
Total params: 776
Trainable params: 776
Non-trainable params: 0
_________________________________________________________________Keras - โมเดล
ดังที่ได้เรียนไปก่อนหน้านี้โมเดล Keras แสดงถึงแบบจำลองเครือข่ายประสาทเทียมที่แท้จริง Keras มีสองโหมดในการสร้างโมเดลคือSequential API ที่เรียบง่ายและใช้งานง่ายตลอดจนFunctional API ที่ยืดหยุ่นและทันสมัยมากขึ้น ให้เราเรียนรู้ตอนนี้เพื่อสร้างโมเดลโดยใช้ทั้งSequentialและFunctional API ในบทนี้
ตามลำดับ
แนวคิดหลักของ Sequential APIเป็นเพียงการจัดชั้น Keras ตามลำดับและอื่น ๆ จะเรียกว่าลำดับ API ANN ส่วนใหญ่ยังมีเลเยอร์ตามลำดับและข้อมูลจะไหลจากเลเยอร์หนึ่งไปยังอีกเลเยอร์หนึ่งตามลำดับที่กำหนดจนกว่าข้อมูลจะมาถึงเลเยอร์เอาต์พุตในที่สุด
สามารถสร้างแบบจำลอง ANN ได้เพียงแค่โทร Sequential() API ตามที่ระบุด้านล่าง -
from keras.models import Sequential
model = Sequential()เพิ่มเลเยอร์
ในการเพิ่มเลเยอร์เพียงแค่สร้างเลเยอร์โดยใช้ Keras Layer API จากนั้นส่งเลเยอร์ผ่านฟังก์ชัน add () ตามที่ระบุด้านล่าง -
from keras.models import Sequential
model = Sequential()
input_layer = Dense(32, input_shape=(8,)) model.add(input_layer)
hidden_layer = Dense(64, activation='relu'); model.add(hidden_layer)
output_layer = Dense(8)
model.add(output_layer)ที่นี่เราได้สร้างเลเยอร์อินพุตหนึ่งเลเยอร์ซ่อนหนึ่งเลเยอร์และเลเยอร์เอาต์พุตหนึ่งเลเยอร์
เข้าถึงโมเดล
Keras มีวิธีการไม่กี่วิธีในการรับข้อมูลโมเดลเช่นเลเยอร์ข้อมูลอินพุตและข้อมูลเอาต์พุต มีดังนี้ -
model.layers - ส่งคืนเลเยอร์ทั้งหมดของโมเดลตามรายการ
>>> layers = model.layers
>>> layers
[
<keras.layers.core.Dense object at 0x000002C8C888B8D0>,
<keras.layers.core.Dense object at 0x000002C8C888B7B8>
<keras.layers.core.Dense object at 0x 000002C8C888B898>
]model.inputs - ส่งคืนค่าเทนเซอร์อินพุตทั้งหมดของโมเดลเป็นรายการ
>>> inputs = model.inputs
>>> inputs
[<tf.Tensor 'dense_13_input:0' shape=(?, 8) dtype=float32>]model.outputs - ส่งคืนค่าเทนเซอร์เอาท์พุตทั้งหมดของโมเดลดังรายการ
>>> outputs = model.outputs
>>> outputs
<tf.Tensor 'dense_15/BiasAdd:0' shape=(?, 8) dtype=float32>]model.get_weights - ส่งคืนน้ำหนักทั้งหมดเป็นอาร์เรย์ NumPy
model.set_weights(weight_numpy_array) - ตั้งค่าน้ำหนักของแบบจำลอง
ทำให้โมเดลเป็นอนุกรม
Keras จัดเตรียมวิธีการทำให้โมเดลเป็นอนุกรมเป็นวัตถุเช่นเดียวกับ json และโหลดอีกครั้งในภายหลัง มีดังนี้ -
get_config() - เปลี่ยนโมเดลเป็นวัตถุ
config = model.get_config()from_config() - ยอมรับออบเจ็กต์การกำหนดค่าโมเดลเป็นอาร์กิวเมนต์และสร้างโมเดลตามนั้น
new_model = Sequential.from_config(config)to_json() - ส่งคืนโมเดลเป็นวัตถุ json
>>> json_string = model.to_json()
>>> json_string '{"class_name": "Sequential", "config":
{"name": "sequential_10", "layers":
[{"class_name": "Dense", "config":
{"name": "dense_13", "trainable": true, "batch_input_shape":
[null, 8], "dtype": "float32", "units": 32, "activation": "linear",
"use_bias": true, "kernel_initializer":
{"class_name": "Vari anceScaling", "config":
{"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}},
"bias_initializer": {"class_name": "Zeros", "conf
ig": {}}, "kernel_regularizer": null, "bias_regularizer": null,
"activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}},
{" class_name": "Dense", "config": {"name": "dense_14", "trainable": true,
"dtype": "float32", "units": 64, "activation": "relu", "use_bias": true,
"kern el_initializer": {"class_name": "VarianceScaling", "config":
{"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}},
"bias_initia lizer": {"class_name": "Zeros",
"config": {}}, "kernel_regularizer": null, "bias_regularizer": null,
"activity_regularizer": null, "kernel_constraint" : null, "bias_constraint": null}},
{"class_name": "Dense", "config": {"name": "dense_15", "trainable": true,
"dtype": "float32", "units": 8, "activation": "linear", "use_bias": true,
"kernel_initializer": {"class_name": "VarianceScaling", "config":
{"scale": 1.0, "mode": "fan_avg", "distribution": " uniform", "seed": null}},
"bias_initializer": {"class_name": "Zeros", "config": {}},
"kernel_regularizer": null, "bias_regularizer": null, "activity_r egularizer":
null, "kernel_constraint": null, "bias_constraint":
null}}]}, "keras_version": "2.2.5", "backend": "tensorflow"}'
>>>model_from_json() - ยอมรับการเป็นตัวแทนของโมเดล json และสร้างโมเดลใหม่
from keras.models import model_from_json
new_model = model_from_json(json_string)to_yaml() - ส่งคืนโมเดลเป็นสตริง yaml
>>> yaml_string = model.to_yaml()
>>> yaml_string 'backend: tensorflow\nclass_name:
Sequential\nconfig:\n layers:\n - class_name: Dense\n config:\n
activation: linear\n activity_regular izer: null\n batch_input_shape:
!!python/tuple\n - null\n - 8\n bias_constraint: null\n bias_initializer:\n
class_name : Zeros\n config: {}\n bias_regularizer: null\n dtype:
float32\n kernel_constraint: null\n
kernel_initializer:\n cla ss_name: VarianceScaling\n config:\n
distribution: uniform\n mode: fan_avg\n
scale: 1.0\n seed: null\n kernel_regularizer: null\n name: dense_13\n
trainable: true\n units: 32\n
use_bias: true\n - class_name: Dense\n config:\n activation: relu\n activity_regularizer: null\n
bias_constraint: null\n bias_initializer:\n class_name: Zeros\n
config : {}\n bias_regularizer: null\n dtype: float32\n
kernel_constraint: null\n kernel_initializer:\n class_name: VarianceScalin g\n
config:\n distribution: uniform\n mode: fan_avg\n scale: 1.0\n
seed: null\n kernel_regularizer: nu ll\n name: dense_14\n trainable: true\n
units: 64\n use_bias: true\n - class_name: Dense\n config:\n
activation: linear\n activity_regularizer: null\n
bias_constraint: null\n bias_initializer:\n
class_name: Zeros\n config: {}\n bias_regu larizer: null\n
dtype: float32\n kernel_constraint: null\n
kernel_initializer:\n class_name: VarianceScaling\n config:\n
distribution: uniform\n mode: fan_avg\n
scale: 1.0\n seed: null\n kernel_regularizer: null\n name: dense _15\n
trainable: true\n units: 8\n
use_bias: true\n name: sequential_10\nkeras_version: 2.2.5\n'
>>>model_from_yaml() - ยอมรับการเป็นตัวแทนของ yaml ของโมเดลและสร้างโมเดลใหม่
from keras.models import model_from_yaml
new_model = model_from_yaml(yaml_string)สรุปโมเดล
การทำความเข้าใจโมเดลเป็นขั้นตอนที่สำคัญมากในการนำไปใช้เพื่อการฝึกอบรมและการทำนายอย่างเหมาะสม Keras มีวิธีการง่ายๆสรุปเพื่อรับข้อมูลทั้งหมดเกี่ยวกับโมเดลและเลเยอร์
สรุปโมเดลที่สร้างในส่วนก่อนหน้ามีดังนี้ -
>>> model.summary() Model: "sequential_10"
_________________________________________________________________
Layer (type) Output Shape Param
#================================================================
dense_13 (Dense) (None, 32) 288
_________________________________________________________________
dense_14 (Dense) (None, 64) 2112
_________________________________________________________________
dense_15 (Dense) (None, 8) 520
=================================================================
Total params: 2,920
Trainable params: 2,920
Non-trainable params: 0
_________________________________________________________________
>>>ฝึกและทำนายแบบจำลอง
แบบจำลองมีฟังก์ชันสำหรับการฝึกอบรมการประเมินผลและการทำนาย มีดังนี้ -
compile - กำหนดค่ากระบวนการเรียนรู้ของแบบจำลอง
fit - ฝึกโมเดลโดยใช้ข้อมูลการฝึกอบรม
evaluate - ประเมินแบบจำลองโดยใช้ข้อมูลการทดสอบ
predict - ทำนายผลลัพธ์สำหรับการป้อนข้อมูลใหม่
API การทำงาน
Sequential API ใช้ในการสร้างโมเดลทีละชั้น Functional API เป็นอีกทางเลือกหนึ่งในการสร้างโมเดลที่ซับซ้อนมากขึ้น รูปแบบการทำงานคุณสามารถกำหนดอินพุตหรือเอาต์พุตหลายรายการที่แชร์เลเยอร์ได้ ขั้นแรกเราสร้างอินสแตนซ์สำหรับโมเดลและเชื่อมต่อกับเลเยอร์เพื่อเข้าถึงอินพุตและเอาต์พุตไปยังโมเดล ส่วนนี้จะอธิบายเกี่ยวกับโมเดลการทำงานโดยสังเขป
สร้างแบบจำลอง
นำเข้าเลเยอร์อินพุตโดยใช้โมดูลด้านล่าง -
>>> from keras.layers import Inputตอนนี้สร้างเลเยอร์อินพุตที่ระบุรูปร่างมิติข้อมูลอินพุตสำหรับโมเดลโดยใช้โค้ดด้านล่าง -
>>> data = Input(shape=(2,3))กำหนดเลเยอร์สำหรับอินพุตโดยใช้โมดูลด้านล่าง -
>>> from keras.layers import Denseเพิ่มเลเยอร์หนาแน่นสำหรับอินพุตโดยใช้บรรทัดด้านล่างของโค้ด -
>>> layer = Dense(2)(data)
>>> print(layer)
Tensor("dense_1/add:0", shape =(?, 2, 2), dtype = float32)กำหนดโมเดลโดยใช้โมดูลด้านล่าง -
from keras.models import Modelสร้างแบบจำลองในลักษณะการทำงานโดยระบุทั้งชั้นอินพุตและเอาต์พุต -
model = Model(inputs = data, outputs = layer)โค้ดที่สมบูรณ์ในการสร้างโมเดลอย่างง่ายแสดงอยู่ด้านล่าง -
from keras.layers import Input
from keras.models import Model
from keras.layers import Dense
data = Input(shape=(2,3))
layer = Dense(2)(data) model =
Model(inputs=data,outputs=layer) model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, 2, 3) 0
_________________________________________________________________
dense_2 (Dense) (None, 2, 2) 8
=================================================================
Total params: 8
Trainable params: 8
Non-trainable params: 0
_________________________________________________________________Keras - การรวบรวมโมเดล
ก่อนหน้านี้เราได้ศึกษาพื้นฐานเกี่ยวกับวิธีสร้างโมเดลโดยใช้ Sequential และ Functional API บทนี้จะอธิบายเกี่ยวกับวิธีการรวบรวมแบบจำลอง การรวบรวมเป็นขั้นตอนสุดท้ายในการสร้างแบบจำลอง เมื่อรวบรวมเสร็จแล้วเราสามารถไปยังขั้นตอนการฝึกอบรมได้
ให้เราเรียนรู้แนวคิดบางประการที่จำเป็นเพื่อให้เข้าใจกระบวนการรวบรวมได้ดีขึ้น
การสูญเสีย
ในการเรียนรู้ของเครื่อง Lossฟังก์ชันใช้เพื่อค้นหาข้อผิดพลาดหรือความเบี่ยงเบนในกระบวนการเรียนรู้ Keras ต้องการฟังก์ชันการสูญเสียระหว่างกระบวนการคอมไพล์โมเดล
Keras มีฟังก์ชันการสูญเสียค่อนข้างน้อยในไฟล์ losses โมดูลและมีดังนี้ -
- mean_squared_error
- mean_absolute_error
- mean_absolute_percentage_error
- mean_squared_logarithmic_error
- squared_hinge
- hinge
- categorical_hinge
- logcosh
- huber_loss
- categorical_crossentropy
- sparse_categorical_crossentropy
- binary_crossentropy
- kullback_leibler_divergence
- poisson
- cosine_proximity
- is_categorical_crossentropy
ฟังก์ชันการสูญเสียทั้งหมดข้างต้นยอมรับสองอาร์กิวเมนต์ -
y_true - ฉลากที่แท้จริงเป็นเทนเซอร์
y_pred - การทำนายที่มีรูปร่างเหมือนกับ y_true
นำเข้าโมดูลการสูญเสียก่อนใช้ฟังก์ชันการสูญเสียตามที่ระบุด้านล่าง -
from keras import lossesเครื่องมือเพิ่มประสิทธิภาพ
ในการเรียนรู้ของเครื่อง Optimizationเป็นกระบวนการสำคัญที่เพิ่มประสิทธิภาพน้ำหนักอินพุตโดยการเปรียบเทียบการคาดคะเนและฟังก์ชันการสูญเสีย Keras มีเครื่องมือเพิ่มประสิทธิภาพบางอย่างเป็นโมดูลเครื่องมือเพิ่มประสิทธิภาพและมีดังนี้:
SGD - เครื่องมือเพิ่มประสิทธิภาพการไล่ระดับสีแบบสุ่ม
keras.optimizers.SGD(learning_rate = 0.01, momentum = 0.0, nesterov = False)RMSprop - เครื่องมือเพิ่มประสิทธิภาพ RMSProp
keras.optimizers.RMSprop(learning_rate = 0.001, rho = 0.9)Adagrad - เครื่องมือเพิ่มประสิทธิภาพ Adagrad
keras.optimizers.Adagrad(learning_rate = 0.01)Adadelta - เครื่องมือเพิ่มประสิทธิภาพ Adadelta
keras.optimizers.Adadelta(learning_rate = 1.0, rho = 0.95)Adam - เครื่องมือเพิ่มประสิทธิภาพ Adam
keras.optimizers.Adam(
learning_rate = 0.001, beta_1 = 0.9, beta_2 = 0.999, amsgrad = False
)Adamax - เครื่องมือเพิ่มประสิทธิภาพ Adamax จาก Adam
keras.optimizers.Adamax(learning_rate = 0.002, beta_1 = 0.9, beta_2 = 0.999)Nadam - เครื่องมือเพิ่มประสิทธิภาพ Nesterov Adam
keras.optimizers.Nadam(learning_rate = 0.002, beta_1 = 0.9, beta_2 = 0.999)นำเข้าโมดูลเครื่องมือเพิ่มประสิทธิภาพก่อนใช้เครื่องมือเพิ่มประสิทธิภาพตามที่ระบุด้านล่าง -
from keras import optimizersเมตริก
ในการเรียนรู้ของเครื่อง Metricsใช้ในการประเมินประสิทธิภาพของโมเดลของคุณ คล้ายกับฟังก์ชันการสูญเสีย แต่ไม่ได้ใช้ในกระบวนการฝึกอบรม Keras ให้เมตริกค่อนข้างน้อยเป็นโมดูลmetrics และมีดังต่อไปนี้
- accuracy
- binary_accuracy
- categorical_accuracy
- sparse_categorical_accuracy
- top_k_categorical_accuracy
- sparse_top_k_categorical_accuracy
- cosine_proximity
- clone_metric
เช่นเดียวกับฟังก์ชันการสูญเสียเมตริกยังยอมรับอาร์กิวเมนต์ด้านล่างสองข้อด้วย -
y_true - ฉลากที่แท้จริงเป็นเทนเซอร์
y_pred - การทำนายที่มีรูปร่างเหมือนกับ y_true
นำเข้าโมดูลเมตริกก่อนใช้เมตริกตามที่ระบุด้านล่าง -
from keras import metricsรวบรวมโมเดล
Keras model มีวิธีการ compile()เพื่อรวบรวมโมเดล อาร์กิวเมนต์และค่าเริ่มต้นของcompile() วิธีการมีดังนี้
compile(
optimizer,
loss = None,
metrics = None,
loss_weights = None,
sample_weight_mode = None,
weighted_metrics = None,
target_tensors = None
)ข้อโต้แย้งที่สำคัญมีดังนี้ -
- ฟังก์ชั่นการสูญเสีย
- Optimizer
- metrics
โค้ดตัวอย่างในการคอมไพล์โหมดมีดังนี้ -
from keras import losses
from keras import optimizers
from keras import metrics
model.compile(loss = 'mean_squared_error',
optimizer = 'sgd', metrics = [metrics.categorical_accuracy])ที่ไหน
ฟังก์ชันการสูญเสียถูกตั้งค่าเป็น mean_squared_error
เครื่องมือเพิ่มประสิทธิภาพถูกตั้งค่าเป็น sgd
เมตริกถูกตั้งค่าเป็น metrics.categorical_accuracy
การฝึกโมเดล
โมเดลได้รับการฝึกฝนโดยอาร์เรย์ NumPy โดยใช้ไฟล์ fit(). วัตถุประสงค์หลักของฟังก์ชัน Fit นี้ใช้เพื่อประเมินโมเดลของคุณในการฝึกซ้อม นอกจากนี้ยังสามารถใช้สำหรับประสิทธิภาพของโมเดลกราฟ มีไวยากรณ์ต่อไปนี้ -
model.fit(X, y, epochs = , batch_size = )ที่นี่
X, y - เป็นทูเพิลในการประเมินข้อมูลของคุณ
epochs - ไม่จำเป็นต้องประเมินโมเดลในระหว่างการฝึกอบรม
batch_size - อินสแตนซ์การฝึกอบรม
ให้เรายกตัวอย่างง่ายๆของข้อมูลสุ่มจำนวนมากเพื่อใช้แนวคิดนี้
สร้างข้อมูล
ให้เราสร้างข้อมูลแบบสุ่มโดยใช้ numpy สำหรับ x และ y ด้วยความช่วยเหลือของคำสั่งที่กล่าวถึงด้านล่าง -
import numpy as np
x_train = np.random.random((100,4,8))
y_train = np.random.random((100,10))ตอนนี้สร้างข้อมูลการตรวจสอบแบบสุ่ม
x_val = np.random.random((100,4,8))
y_val = np.random.random((100,10))สร้างแบบจำลอง
ให้เราสร้างแบบจำลองตามลำดับอย่างง่าย -
from keras.models import Sequential model = Sequential()เพิ่มเลเยอร์
สร้างเลเยอร์เพื่อเพิ่มโมเดล -
from keras.layers import LSTM, Dense
# add a sequence of vectors of dimension 16
model.add(LSTM(16, return_sequences = True))
model.add(Dense(10, activation = 'softmax'))รวบรวมโมเดล
ตอนนี้มีการกำหนดโมเดลแล้ว คุณสามารถรวบรวมโดยใช้คำสั่งด้านล่าง -
model.compile(
loss = 'categorical_crossentropy', optimizer = 'sgd', metrics = ['accuracy']
)ใช้พอดี ()
ตอนนี้เราใช้ฟังก์ชันfit ()เพื่อฝึกอบรมข้อมูลของเรา -
model.fit(x_train, y_train, batch_size = 32, epochs = 5, validation_data = (x_val, y_val))สร้าง Multi-Layer Perceptron ANN
เราได้เรียนรู้การสร้างรวบรวมและฝึกโมเดล Keras
ให้เราใช้การเรียนรู้ของเราและสร้าง ANN ตาม MPL อย่างง่าย
โมดูลชุดข้อมูล
ก่อนสร้างแบบจำลองเราต้องเลือกปัญหาต้องรวบรวมข้อมูลที่ต้องการและแปลงข้อมูลเป็นอาร์เรย์ NumPy เมื่อรวบรวมข้อมูลแล้วเราสามารถเตรียมแบบจำลองและฝึกอบรมได้โดยใช้ข้อมูลที่รวบรวมได้ การรวบรวมข้อมูลเป็นหนึ่งในขั้นตอนที่ยากที่สุดของการเรียนรู้ของเครื่อง Keras มีโมดูลพิเศษชุดข้อมูลสำหรับดาวน์โหลดข้อมูลการเรียนรู้ของเครื่องออนไลน์เพื่อวัตถุประสงค์ในการฝึกอบรม ดึงข้อมูลจากเซิร์ฟเวอร์ออนไลน์ประมวลผลข้อมูลและส่งคืนข้อมูลเป็นการฝึกอบรมและชุดทดสอบ ให้เราตรวจสอบข้อมูลที่มาจากโมดูลชุดข้อมูล Keras ข้อมูลที่มีอยู่ในโมดูลมีดังนี้
- CIFAR10 small image classification
- CIFAR100 small image classification
- IMDB Movie reviews sentiment classification
- Reuters newswire topics classification
- MNIST database of handwritten digits
- Fashion-MNIST database of fashion articles
- Boston housing price regression dataset
Let us use the MNIST database of handwritten digits (or minst) as our input. minst is a collection of 60,000, 28x28 grayscale images. It contains 10 digits. It also contains 10,000 test images.
Below code can be used to load the dataset −
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()where
Line 1 imports minst from the keras dataset module.
Line 3 calls the load_data function, which will fetch the data from online server and return the data as 2 tuples, First tuple, (x_train, y_train) represent the training data with shape, (number_sample, 28, 28) and its digit label with shape, (number_samples, ). Second tuple, (x_test, y_test) represent test data with same shape.
Other dataset can also be fetched using similar API and every API returns similar data as well except the shape of the data. The shape of the data depends on the type of data.
Create a model
Let us choose a simple multi-layer perceptron (MLP) as represented below and try to create the model using Keras.

The core features of the model are as follows −
Input layer consists of 784 values (28 x 28 = 784).
First hidden layer, Dense consists of 512 neurons and ‘relu’ activation function.
Second hidden layer, Dropout has 0.2 as its value.
Third hidden layer, again Dense consists of 512 neurons and ‘relu’ activation function.
Fourth hidden layer, Dropout has 0.2 as its value.
Fifth and final layer consists of 10 neurons and ‘softmax’ activation function.
Use categorical_crossentropy as loss function.
Use RMSprop() as Optimizer.
Use accuracy as metrics.
Use 128 as batch size.
Use 20 as epochs.
Step 1 − Import the modules
Let us import the necessary modules.
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
import numpy as npStep 2 − Load data
Let us import the mnist dataset.
(x_train, y_train), (x_test, y_test) = mnist.load_data()Step 3 − Process the data
Let us change the dataset according to our model, so that it can be feed into our model.
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)Where
reshape is used to reshape the input from (28, 28) tuple to (784, )
to_categorical is used to convert vector to binary matrix
Step 4 − Create the model
Let us create the actual model.
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation = 'relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation = 'softmax'))Step 5 − Compile the model
Let us compile the model using selected loss function, optimizer and metrics.
model.compile(loss = 'categorical_crossentropy',
optimizer = RMSprop(),
metrics = ['accuracy'])Step 6 − Train the model
Let us train the model using fit() method.
history = model.fit(
x_train, y_train,
batch_size = 128,
epochs = 20,
verbose = 1,
validation_data = (x_test, y_test)
)Final thoughts
We have created the model, loaded the data and also trained the data to the model. We still need to evaluate the model and predict output for unknown input, which we learn in upcoming chapter.
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
import numpy as np
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
model = Sequential()
model.add(Dense(512, activation='relu', input_shape = (784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation = 'relu')) model.add(Dropout(0.2))
model.add(Dense(10, activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy',
optimizer = RMSprop(),
metrics = ['accuracy'])
history = model.fit(x_train, y_train,
batch_size = 128, epochs = 20, verbose = 1, validation_data = (x_test, y_test))Executing the application will give the below content as output −
Train on 60000 samples, validate on 10000 samples Epoch 1/20
60000/60000 [==============================] - 7s 118us/step - loss: 0.2453
- acc: 0.9236 - val_loss: 0.1004 - val_acc: 0.9675 Epoch 2/20
60000/60000 [==============================] - 7s 110us/step - loss: 0.1023
- acc: 0.9693 - val_loss: 0.0797 - val_acc: 0.9761 Epoch 3/20
60000/60000 [==============================] - 7s 110us/step - loss: 0.0744
- acc: 0.9770 - val_loss: 0.0727 - val_acc: 0.9791 Epoch 4/20
60000/60000 [==============================] - 7s 110us/step - loss: 0.0599
- acc: 0.9823 - val_loss: 0.0704 - val_acc: 0.9801 Epoch 5/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0504
- acc: 0.9853 - val_loss: 0.0714 - val_acc: 0.9817 Epoch 6/20
60000/60000 [==============================] - 7s 111us/step - loss: 0.0438
- acc: 0.9868 - val_loss: 0.0845 - val_acc: 0.9809 Epoch 7/20
60000/60000 [==============================] - 7s 114us/step - loss: 0.0391
- acc: 0.9887 - val_loss: 0.0823 - val_acc: 0.9802 Epoch 8/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0364
- acc: 0.9892 - val_loss: 0.0818 - val_acc: 0.9830 Epoch 9/20
60000/60000 [==============================] - 7s 113us/step - loss: 0.0308
- acc: 0.9905 - val_loss: 0.0833 - val_acc: 0.9829 Epoch 10/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0289
- acc: 0.9917 - val_loss: 0.0947 - val_acc: 0.9815 Epoch 11/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0279
- acc: 0.9921 - val_loss: 0.0818 - val_acc: 0.9831 Epoch 12/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0260
- acc: 0.9927 - val_loss: 0.0945 - val_acc: 0.9819 Epoch 13/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0257
- acc: 0.9931 - val_loss: 0.0952 - val_acc: 0.9836 Epoch 14/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0229
- acc: 0.9937 - val_loss: 0.0924 - val_acc: 0.9832 Epoch 15/20
60000/60000 [==============================] - 7s 115us/step - loss: 0.0235
- acc: 0.9937 - val_loss: 0.1004 - val_acc: 0.9823 Epoch 16/20
60000/60000 [==============================] - 7s 113us/step - loss: 0.0214
- acc: 0.9941 - val_loss: 0.0991 - val_acc: 0.9847 Epoch 17/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0219
- acc: 0.9943 - val_loss: 0.1044 - val_acc: 0.9837 Epoch 18/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0190
- acc: 0.9952 - val_loss: 0.1129 - val_acc: 0.9836 Epoch 19/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0197
- acc: 0.9953 - val_loss: 0.0981 - val_acc: 0.9841 Epoch 20/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0198
- acc: 0.9950 - val_loss: 0.1215 - val_acc: 0.9828Keras - Model Evaluation and Model Prediction
This chapter deals with the model evaluation and model prediction in Keras.
Let us begin by understanding the model evaluation.
Model Evaluation
Evaluation is a process during development of the model to check whether the model is best fit for the given problem and corresponding data. Keras model provides a function, evaluate which does the evaluation of the model. It has three main arguments,
- Test data
- Test data label
- verbose - true or false
Let us evaluate the model, which we created in the previous chapter using test data.
score = model.evaluate(x_test, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])Executing the above code will output the below information.
0The test accuracy is 98.28%. We have created a best model to identify the handwriting digits. On the positive side, we can still scope to improve our model.
Model Prediction
Prediction is the final step and our expected outcome of the model generation. Keras provides a method, predict to get the prediction of the trained model. The signature of the predict method is as follows,
predict(
x,
batch_size = None,
verbose = 0,
steps = None,
callbacks = None,
max_queue_size = 10,
workers = 1,
use_multiprocessing = False
)Here, all arguments are optional except the first argument, which refers the unknown input data. The shape should be maintained to get the proper prediction.
Let us do prediction for our MPL model created in previous chapter using below code −
pred = model.predict(x_test)
pred = np.argmax(pred, axis = 1)[:5]
label = np.argmax(y_test,axis = 1)[:5]
print(pred)
print(label)Here,
Line 1 call the predict function using test data.
Line 2 gets the first five prediction
Line 3 gets the first five labels of the test data.
Line 5 - 6 prints the prediction and actual label.
The output of the above application is as follows −
[7 2 1 0 4]
[7 2 1 0 4]The output of both array is identical and it indicate that our model predicts correctly the first five images.
Keras - Convolution Neural Network
Let us modify the model from MPL to Convolution Neural Network (CNN) for our earlier digit identification problem.
CNN can be represented as below −
The core features of the model are as follows −
Input layer consists of (1, 8, 28) values.
First layer, Conv2D consists of 32 filters and ‘relu’ activation function with kernel size, (3,3).
Second layer, Conv2D consists of 64 filters and ‘relu’ activation function with kernel size, (3,3).
Thrid layer, MaxPooling has pool size of (2, 2).
Fifth layer, Flatten is used to flatten all its input into single dimension.
Sixth layer, Dense consists of 128 neurons and ‘relu’ activation function.
Seventh layer, Dropout has 0.5 as its value.
Eighth and final layer consists of 10 neurons and ‘softmax’ activation function.
Use categorical_crossentropy as loss function.
Use Adadelta() as Optimizer.
Use accuracy as metrics.
Use 128 as batch size.
Use 20 as epochs.
Step 1 − Import the modules
Let us import the necessary modules.
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
import numpy as npStep 2 − Load data
Let us import the mnist dataset.
(x_train, y_train), (x_test, y_test) = mnist.load_data()Step 3 − Process the data
Let us change the dataset according to our model, so that it can be feed into our model.
img_rows, img_cols = 28, 28
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)The data processing is similar to MPL model except the shape of the input data and image format configuration.
Step 4 − Create the model
Let us create tha actual model.
model = Sequential()
model.add(Conv2D(32, kernel_size = (3, 3),
activation = 'relu', input_shape = input_shape))
model.add(Conv2D(64, (3, 3), activation = 'relu'))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Dropout(0.25)) model.add(Flatten())
model.add(Dense(128, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation = 'softmax'))Step 5 − Compile the model
Let us compile the model using selected loss function, optimizer and metrics.
model.compile(loss = keras.losses.categorical_crossentropy,
optimizer = keras.optimizers.Adadelta(), metrics = ['accuracy'])Step 6 − Train the model
Let us train the model using fit() method.
model.fit(
x_train, y_train,
batch_size = 128,
epochs = 12,
verbose = 1,
validation_data = (x_test, y_test)
)Executing the application will output the below information −
Train on 60000 samples, validate on 10000 samples Epoch 1/12
60000/60000 [==============================] - 84s 1ms/step - loss: 0.2687
- acc: 0.9173 - val_loss: 0.0549 - val_acc: 0.9827 Epoch 2/12
60000/60000 [==============================] - 86s 1ms/step - loss: 0.0899
- acc: 0.9737 - val_loss: 0.0452 - val_acc: 0.9845 Epoch 3/12
60000/60000 [==============================] - 83s 1ms/step - loss: 0.0666
- acc: 0.9804 - val_loss: 0.0362 - val_acc: 0.9879 Epoch 4/12
60000/60000 [==============================] - 81s 1ms/step - loss: 0.0564
- acc: 0.9830 - val_loss: 0.0336 - val_acc: 0.9890 Epoch 5/12
60000/60000 [==============================] - 86s 1ms/step - loss: 0.0472
- acc: 0.9861 - val_loss: 0.0312 - val_acc: 0.9901 Epoch 6/12
60000/60000 [==============================] - 83s 1ms/step - loss: 0.0414
- acc: 0.9877 - val_loss: 0.0306 - val_acc: 0.9902 Epoch 7/12
60000/60000 [==============================] - 89s 1ms/step - loss: 0.0375
-acc: 0.9883 - val_loss: 0.0281 - val_acc: 0.9906 Epoch 8/12
60000/60000 [==============================] - 91s 2ms/step - loss: 0.0339
- acc: 0.9893 - val_loss: 0.0280 - val_acc: 0.9912 Epoch 9/12
60000/60000 [==============================] - 89s 1ms/step - loss: 0.0325
- acc: 0.9901 - val_loss: 0.0260 - val_acc: 0.9909 Epoch 10/12
60000/60000 [==============================] - 89s 1ms/step - loss: 0.0284
- acc: 0.9910 - val_loss: 0.0250 - val_acc: 0.9919 Epoch 11/12
60000/60000 [==============================] - 86s 1ms/step - loss: 0.0287
- acc: 0.9907 - val_loss: 0.0264 - val_acc: 0.9916 Epoch 12/12
60000/60000 [==============================] - 86s 1ms/step - loss: 0.0265
- acc: 0.9920 - val_loss: 0.0249 - val_acc: 0.9922Step 7 − Evaluate the model
Let us evaluate the model using test data.
score = model.evaluate(x_test, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])Executing the above code will output the below information −
Test loss: 0.024936060590433316
Test accuracy: 0.9922The test accuracy is 99.22%. We have created a best model to identify the handwriting digits.
Step 8 − Predict
Finally, predict the digit from images as below −
pred = model.predict(x_test)
pred = np.argmax(pred, axis = 1)[:5]
label = np.argmax(y_test,axis = 1)[:5]
print(pred)
print(label)The output of the above application is as follows −
[7 2 1 0 4]
[7 2 1 0 4]The output of both array is identical and it indicate our model correctly predicts the first five images.
Keras - Regression Prediction using MPL
In this chapter, let us write a simple MPL based ANN to do regression prediction. Till now, we have only done the classification based prediction. Now, we will try to predict the next possible value by analyzing the previous (continuous) values and its influencing factors.
The Regression MPL can be represented as below −

The core features of the model are as follows −
Input layer consists of (13,) values.
First layer, Dense consists of 64 units and ‘relu’ activation function with ‘normal’ kernel initializer.
Second layer, Dense consists of 64 units and ‘relu’ activation function.
Output layer, Dense consists of 1 unit.
Use mse as loss function.
Use RMSprop as Optimizer.
Use accuracy as metrics.
Use 128 as batch size.
Use 500 as epochs.
Step 1 − Import the modules
Let us import the necessary modules.
import keras
from keras.datasets import boston_housing
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import RMSprop
from keras.callbacks import EarlyStopping
from sklearn import preprocessing
from sklearn.preprocessing import scaleStep 2 − Load data
Let us import the Boston housing dataset.
(x_train, y_train), (x_test, y_test) = boston_housing.load_data()Here,
boston_housing is a dataset provided by Keras. It represents a collection of housing information in Boston area, each having 13 features.
Step 3 − Process the data
Let us change the dataset according to our model, so that, we can feed into our model. The data can be changed using below code −
x_train_scaled = preprocessing.scale(x_train)
scaler = preprocessing.StandardScaler().fit(x_train)
x_test_scaled = scaler.transform(x_test)Here, we have normalized the training data using sklearn.preprocessing.scale function. preprocessing.StandardScaler().fit function returns a scalar with the normalized mean and standard deviation of the training data, which we can apply to the test data using scalar.transform function. This will normalize the test data as well with the same setting as that of training data.
Step 4 − Create the model
Let us create the actual model.
model = Sequential()
model.add(Dense(64, kernel_initializer = 'normal', activation = 'relu',
input_shape = (13,)))
model.add(Dense(64, activation = 'relu')) model.add(Dense(1))Step 5 − Compile the model
Let us compile the model using selected loss function, optimizer and metrics.
model.compile(
loss = 'mse',
optimizer = RMSprop(),
metrics = ['mean_absolute_error']
)Step 6 − Train the model
Let us train the model using fit() method.
history = model.fit(
x_train_scaled, y_train,
batch_size=128,
epochs = 500,
verbose = 1,
validation_split = 0.2,
callbacks = [EarlyStopping(monitor = 'val_loss', patience = 20)]
)Here, we have used callback function, EarlyStopping. The purpose of this callback is to monitor the loss value during each epoch and compare it with previous epoch loss value to find the improvement in the training. If there is no improvement for the patience times, then the whole process will be stopped.
Executing the application will give the below information as output −
Train on 323 samples, validate on 81 samples Epoch 1/500 2019-09-24 01:07:03.889046: I
tensorflow/core/platform/cpu_feature_guard.cc:142]
Your CPU supports instructions that this
TensorFlow binary was not co mpiled to use: AVX2 323/323
[==============================] - 0s 515us/step - loss: 562.3129
- mean_absolute_error: 21.8575 - val_loss: 621.6523 - val_mean_absolute_erro
r: 23.1730 Epoch 2/500
323/323 [==============================] - 0s 11us/step - loss: 545.1666
- mean_absolute_error: 21.4887 - val_loss: 605.1341 - val_mean_absolute_error
: 22.8293 Epoch 3/500
323/323 [==============================] - 0s 12us/step - loss: 528.9944
- mean_absolute_error: 21.1328 - val_loss: 588.6594 - val_mean_absolute_error
: 22.4799 Epoch 4/500
323/323 [==============================] - 0s 12us/step - loss: 512.2739
- mean_absolute_error: 20.7658 - val_loss: 570.3772 - val_mean_absolute_error
: 22.0853 Epoch 5/500
323/323 [==============================] - 0s 9us/step - loss: 493.9775
- mean_absolute_error: 20.3506 - val_loss: 550.9548 - val_mean_absolute_error: 21.6547
..........
..........
..........
Epoch 143/500
323/323 [==============================] - 0s 15us/step - loss: 8.1004
- mean_absolute_error: 2.0002 - val_loss: 14.6286 - val_mean_absolute_error:
2. 5904 Epoch 144/500
323/323 [==============================] - 0s 19us/step - loss: 8.0300
- mean_absolute_error: 1.9683 - val_loss: 14.5949 - val_mean_absolute_error:
2. 5843 Epoch 145/500
323/323 [==============================] - 0s 12us/step - loss: 7.8704
- mean_absolute_error: 1.9313 - val_loss: 14.3770 - val_mean_absolute_error: 2. 4996Step 7 − Evaluate the model
Let us evaluate the model using test data.
score = model.evaluate(x_test_scaled, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])Executing the above code will output the below information −
Test loss: 21.928471583946077 Test accuracy: 2.9599233234629914Step 8 − Predict
Finally, predict using test data as below −
prediction = model.predict(x_test_scaled)
print(prediction.flatten())
print(y_test)The output of the above application is as follows −
[ 7.5612316 17.583357 21.09344 31.859276 25.055613 18.673872 26.600405 22.403967 19.060272 22.264952
17.4191 17.00466 15.58924 41.624374 20.220217 18.985565 26.419338 19.837091 19.946192 36.43445
12.278508 16.330965 20.701359 14.345301 21.741161 25.050423 31.046402 27.738455 9.959419 20.93039
20.069063 14.518344 33.20235 24.735163 18.7274 9.148898 15.781284 18.556862 18.692865 26.045074
27.954073 28.106823 15.272034 40.879818 29.33896 23.714525 26.427515 16.483374 22.518442 22.425386
33.94826 18.831465 13.2501955 15.537227 34.639984 27.468002 13.474407 48.134598 34.39617
22.8503124.042334 17.747198 14.7837715 18.187277 23.655672 22.364983 13.858193 22.710032 14.371148
7.1272087 35.960033 28.247292 25.3014 14.477208 25.306196 17.891165 20.193708 23.585173 34.690193
12.200583 20.102983 38.45882 14.741723 14.408362 17.67158 18.418497 21.151712 21.157492 22.693687
29.809034 19.366991 20.072294 25.880817 40.814568 34.64087 19.43741 36.2591 50.73806 26.968863 43.91787
32.54908 20.248306 ] [ 7.2 18.8 19. 27. 22.2 24.5 31.2 22.9 20.5 23.2 18.6 14.5 17.8 50. 20.8 24.3 24.2
19.8 19.1 22.7 12. 10.2 20. 18.5 20.9 23. 27.5 30.1 9.5 22. 21.2 14.1 33.1 23.4 20.1 7.4 15.4 23.8 20.1
24.5 33. 28.4 14.1 46.7 32.5 29.6 28.4 19.8 20.2 25. 35.4 20.3 9.7 14.5 34.9 26.6 7.2 50. 32.4 21.6 29.8
13.1 27.5 21.2 23.1 21.9 13. 23.2 8.1 5.6 21.7 29.6 19.6 7. 26.4 18.9 20.9 28.1 35.4 10.2 24.3 43.1 17.6
15.4 16.2 27.1 21.4 21.5 22.4 25. 16.6 18.6 22. 42.8 35.1 21.5 36. 21.9 24.1 50. 26.7 25. ]The output of both array have around 10-30% difference and it indicate our model predicts with reasonable range.
Keras - Time Series Prediction using LSTM RNN
In this chapter, let us write a simple Long Short Term Memory (LSTM) based RNN to do sequence analysis. A sequence is a set of values where each value corresponds to a particular instance of time. Let us consider a simple example of reading a sentence. Reading and understanding a sentence involves reading the word in the given order and trying to understand each word and its meaning in the given context and finally understanding the sentence in a positive or negative sentiment.
Here, the words are considered as values, and first value corresponds to first word, second value corresponds to second word, etc., and the order will be strictly maintained. Sequence Analysis is used frequently in natural language processing to find the sentiment analysis of the given text.
Let us create a LSTM model to analyze the IMDB movie reviews and find its positive/negative sentiment.
The model for the sequence analysis can be represented as below −
The core features of the model are as follows −
Input layer using Embedding layer with 128 features.
First layer, Dense consists of 128 units with normal dropout and recurrent dropout set to 0.2.
Output layer, Dense consists of 1 unit and ‘sigmoid’ activation function.
Use binary_crossentropy as loss function.
Use adam as Optimizer.
Use accuracy as metrics.
Use 32 as batch size.
Use 15 as epochs.
Use 80 as the maximum length of the word.
Use 2000 as the maximum number of word in a given sentence.
Step 1: Import the modules
Let us import the necessary modules.
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Embedding
from keras.layers import LSTM
from keras.datasets import imdbStep 2: Load data
Let us import the imdb dataset.
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words = 2000)Here,
imdb is a dataset provided by Keras. It represents a collection of movies and its reviews.
num_words represent the maximum number of words in the review.
Step 3: Process the data
Let us change the dataset according to our model, so that it can be fed into our model. The data can be changed using the below code −
x_train = sequence.pad_sequences(x_train, maxlen=80)
x_test = sequence.pad_sequences(x_test, maxlen=80)Here,
sequence.pad_sequences convert the list of input data with shape, (data) into 2D NumPy array of shape (data, timesteps). Basically, it adds timesteps concept into the given data. It generates the timesteps of length, maxlen.
Step 4: Create the model
Let us create the actual model.
model = Sequential()
model.add(Embedding(2000, 128))
model.add(LSTM(128, dropout = 0.2, recurrent_dropout = 0.2))
model.add(Dense(1, activation = 'sigmoid'))Here,
We have used Embedding layer as input layer and then added the LSTM layer. Finally, a Dense layer is used as output layer.
Step 5: Compile the model
Let us compile the model using selected loss function, optimizer and metrics.
model.compile(loss = 'binary_crossentropy',
optimizer = 'adam', metrics = ['accuracy'])Step 6: Train the model
LLet us train the model using fit() method.
model.fit(
x_train, y_train,
batch_size = 32,
epochs = 15,
validation_data = (x_test, y_test)
)Executing the application will output the below information −
Epoch 1/15 2019-09-24 01:19:01.151247: I
tensorflow/core/platform/cpu_feature_guard.cc:142]
Your CPU supports instructions that this
TensorFlow binary was not co mpiled to use: AVX2
25000/25000 [==============================] - 101s 4ms/step - loss: 0.4707
- acc: 0.7716 - val_loss: 0.3769 - val_acc: 0.8349 Epoch 2/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.3058
- acc: 0.8756 - val_loss: 0.3763 - val_acc: 0.8350 Epoch 3/15
25000/25000 [==============================] - 91s 4ms/step - loss: 0.2100
- acc: 0.9178 - val_loss: 0.5065 - val_acc: 0.8110 Epoch 4/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.1394
- acc: 0.9495 - val_loss: 0.6046 - val_acc: 0.8146 Epoch 5/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.0973
- acc: 0.9652 - val_loss: 0.5969 - val_acc: 0.8147 Epoch 6/15
25000/25000 [==============================] - 98s 4ms/step - loss: 0.0759
- acc: 0.9730 - val_loss: 0.6368 - val_acc: 0.8208 Epoch 7/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.0578
- acc: 0.9811 - val_loss: 0.6657 - val_acc: 0.8184 Epoch 8/15
25000/25000 [==============================] - 97s 4ms/step - loss: 0.0448
- acc: 0.9850 - val_loss: 0.7452 - val_acc: 0.8136 Epoch 9/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.0324
- acc: 0.9894 - val_loss: 0.7616 - val_acc: 0.8162Epoch 10/15
25000/25000 [==============================] - 100s 4ms/step - loss: 0.0247
- acc: 0.9922 - val_loss: 0.9654 - val_acc: 0.8148 Epoch 11/15
25000/25000 [==============================] - 99s 4ms/step - loss: 0.0169
- acc: 0.9946 - val_loss: 1.0013 - val_acc: 0.8104 Epoch 12/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.0154
- acc: 0.9948 - val_loss: 1.0316 - val_acc: 0.8100 Epoch 13/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0113
- acc: 0.9963 - val_loss: 1.1138 - val_acc: 0.8108 Epoch 14/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0106
- acc: 0.9971 - val_loss: 1.0538 - val_acc: 0.8102 Epoch 15/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0090
- acc: 0.9972 - val_loss: 1.1453 - val_acc: 0.8129
25000/25000 [==============================] - 10s 390us/stepStep 7 − Evaluate the model
Let us evaluate the model using test data.
score, acc = model.evaluate(x_test, y_test, batch_size = 32)
print('Test score:', score)
print('Test accuracy:', acc)Executing the above code will output the below information −
Test score: 1.145306069601178
Test accuracy: 0.81292Keras - Applications
Keras applications module is used to provide pre-trained model for deep neural networks. Keras models are used for prediction, feature extraction and fine tuning. This chapter explains about Keras applications in detail.
Pre-trained models
Trained model consists of two parts model Architecture and model Weights. Model weights are large file so we have to download and extract the feature from ImageNet database. Some of the popular pre-trained models are listed below,
- ResNet
- VGG16
- MobileNet
- InceptionResNetV2
- InceptionV3
Loading a model
Keras pre-trained models can be easily loaded as specified below −
import keras
import numpy as np
from keras.applications import vgg16, inception_v3, resnet50, mobilenet
#Load the VGG model
vgg_model = vgg16.VGG16(weights = 'imagenet')
#Load the Inception_V3 model
inception_model = inception_v3.InceptionV3(weights = 'imagenet')
#Load the ResNet50 model
resnet_model = resnet50.ResNet50(weights = 'imagenet')
#Load the MobileNet model mobilenet_model = mobilenet.MobileNet(weights = 'imagenet')Once the model is loaded, we can immediately use it for prediction purpose. Let us check each pre-trained model in the upcoming chapters.
Real Time Prediction using ResNet Model
ResNet is a pre-trained model. It is trained using ImageNet. ResNet model weights pre-trained on ImageNet. It has the following syntax −
keras.applications.resnet.ResNet50 (
include_top = True,
weights = 'imagenet',
input_tensor = None,
input_shape = None,
pooling = None,
classes = 1000
)Here,
include_top refers the fully-connected layer at the top of the network.
weights refer pre-training on ImageNet.
input_tensor refers optional Keras tensor to use as image input for the model.
input_shape refers optional shape tuple. The default input size for this model is 224x224.
classes refer optional number of classes to classify images.
Let us understand the model by writing a simple example −
Step 1: import the modules
Let us load the necessary modules as specified below −
>>> import PIL
>>> from keras.preprocessing.image import load_img
>>> from keras.preprocessing.image import img_to_array
>>> from keras.applications.imagenet_utils import decode_predictions
>>> import matplotlib.pyplot as plt
>>> import numpy as np
>>> from keras.applications.resnet50 import ResNet50
>>> from keras.applications import resnet50Step 2: Select an input
Let us choose an input image, Lotus as specified below −
>>> filename = 'banana.jpg'
>>> ## load an image in PIL format
>>> original = load_img(filename, target_size = (224, 224))
>>> print('PIL image size',original.size)
PIL image size (224, 224)
>>> plt.imshow(original)
<matplotlib.image.AxesImage object at 0x1304756d8>
>>> plt.show()Here, we have loaded an image (banana.jpg) and displayed it.
Step 3: Convert images into NumPy array
Let us convert our input, Banana into NumPy array, so that it can be passed into the model for the purpose of prediction.
>>> #convert the PIL image to a numpy array
>>> numpy_image = img_to_array(original)
>>> plt.imshow(np.uint8(numpy_image))
<matplotlib.image.AxesImage object at 0x130475ac8>
>>> print('numpy array size',numpy_image.shape)
numpy array size (224, 224, 3)
>>> # Convert the image / images into batch format
>>> image_batch = np.expand_dims(numpy_image, axis = 0)
>>> print('image batch size', image_batch.shape)
image batch size (1, 224, 224, 3)
>>>Step 4: Model prediction
Let us feed our input into the model to get the predictions
>>> prepare the image for the resnet50 model >>>
>>> processed_image = resnet50.preprocess_input(image_batch.copy())
>>> # create resnet model
>>>resnet_model = resnet50.ResNet50(weights = 'imagenet')
>>> Downloavding data from https://github.com/fchollet/deep-learning-models/releas
es/download/v0.2/resnet50_weights_tf_dim_ordering_tf_kernels.h5
102858752/102853048 [==============================] - 33s 0us/step
>>> # get the predicted probabilities for each class
>>> predictions = resnet_model.predict(processed_image)
>>> # convert the probabilities to class labels
>>> label = decode_predictions(predictions)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/
data/imagenet_class_index.json
40960/35363 [==================================] - 0s 0us/step
>>> print(label)Output
[
[
('n07753592', 'banana', 0.99229723),
('n03532672', 'hook', 0.0014551596),
('n03970156', 'plunger', 0.0010738898),
('n07753113', 'fig', 0.0009359837) ,
('n03109150', 'corkscrew', 0.00028538404)
]
]Here, the model predicted the images as banana correctly.
Keras - Pre-Trained Models
In this chapter, we will learn about the pre-trained models in Keras. Let us begin with VGG16.
VGG16
VGG16 is another pre-trained model. It is also trained using ImageNet. The syntax to load the model is as follows −
keras.applications.vgg16.VGG16(
include_top = True,
weights = 'imagenet',
input_tensor = None,
input_shape = None,
pooling = None,
classes = 1000
)The default input size for this model is 224x224.
MobileNetV2
MobileNetV2 is another pre-trained model. It is also trained uing ImageNet.
The syntax to load the model is as follows −
keras.applications.mobilenet_v2.MobileNetV2 (
input_shape = None,
alpha = 1.0,
include_top = True,
weights = 'imagenet',
input_tensor = None,
pooling = None,
classes = 1000
)Here,
alpha controls the width of the network. If the value is below 1, decreases the number of filters in each layer. If the value is above 1, increases the number of filters in each layer. If alpha = 1, default number of filters from the paper are used at each layer.
The default input size for this model is 224x224.
InceptionResNetV2
InceptionResNetV2 is another pre-trained model. It is also trained using ImageNet. The syntax to load the model is as follows −
keras.applications.inception_resnet_v2.InceptionResNetV2 (
include_top = True,
weights = 'imagenet',
input_tensor = None,
input_shape = None,
pooling = None,
classes = 1000)This model and can be built both with ‘channels_first’ data format (channels, height, width) or ‘channels_last’ data format (height, width, channels).
The default input size for this model is 299x299.
InceptionV3
InceptionV3 is another pre-trained model. It is also trained uing ImageNet. The syntax to load the model is as follows −
keras.applications.inception_v3.InceptionV3 (
include_top = True,
weights = 'imagenet',
input_tensor = None,
input_shape = None,
pooling = None,
classes = 1000
)Here,
The default input size for this model is 299x299.
Conclusion
Keras is very simple, extensible and easy to implement neural network API, which can be used to build deep learning applications with high level abstraction. Keras is an optimal choice for deep leaning models.