Keras - การทำนายอนุกรมเวลาโดยใช้ LSTM RNN
ในบทนี้ให้เราเขียน RNN แบบ Long Short Term Memory (LSTM) เพื่อทำการวิเคราะห์ลำดับ ลำดับคือชุดของค่าที่แต่ละค่าสอดคล้องกับช่วงเวลาเฉพาะ ขอให้เราพิจารณาตัวอย่างง่ายๆในการอ่านประโยค การอ่านและทำความเข้าใจประโยคเกี่ยวข้องกับการอ่านคำตามลำดับที่กำหนดและพยายามเข้าใจแต่ละคำและความหมายในบริบทที่กำหนดและในที่สุดก็เข้าใจประโยคด้วยความรู้สึกเชิงบวกหรือเชิงลบ
ในที่นี้คำถือเป็นค่านิยมและค่าแรกตรงกับคำแรกค่าที่สองสอดคล้องกับคำที่สองเป็นต้นและคำสั่งจะได้รับการดูแลอย่างเคร่งครัด Sequence Analysis มักใช้ในการประมวลผลภาษาธรรมชาติเพื่อค้นหาการวิเคราะห์ความรู้สึกของข้อความที่กำหนด
ให้เราสร้างแบบจำลอง LSTM เพื่อวิเคราะห์บทวิจารณ์ภาพยนตร์ของ IMDB และค้นหาความรู้สึกเชิงบวก / เชิงลบ
โมเดลสำหรับการวิเคราะห์ลำดับสามารถแสดงได้ดังต่อไปนี้ -
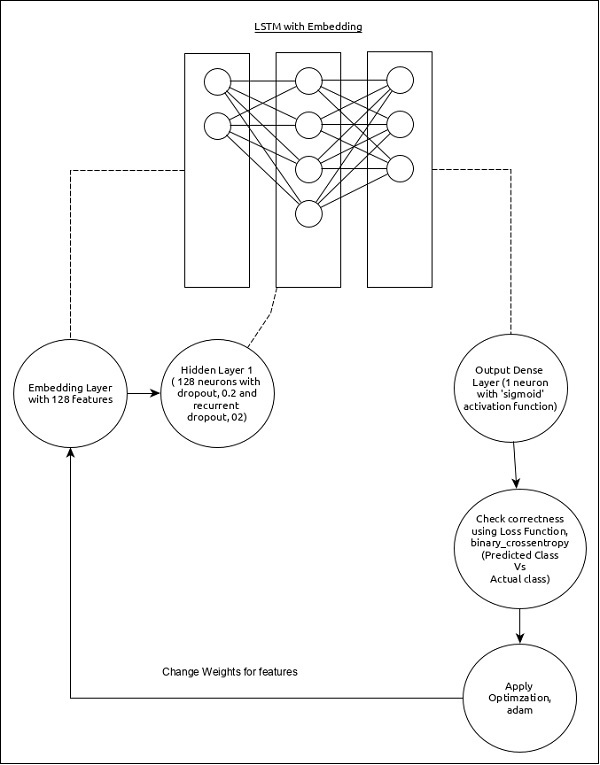
คุณสมบัติหลักของรุ่นมีดังนี้ -
เลเยอร์อินพุตโดยใช้เลเยอร์การฝังที่มีคุณสมบัติ 128 รายการ
ชั้นแรก Dense ประกอบด้วย 128 หน่วยโดยมีการออกกลางคันตามปกติและการออกกลางคันซ้ำตั้งค่าเป็น 0.2
ชั้นเอาต์พุตDenseประกอบด้วย 1 หน่วยและฟังก์ชันการเปิดใช้งาน 'sigmoid'
ใช้ binary_crossentropy เป็นฟังก์ชันการสูญเสีย
ใช้ adam เป็นเครื่องมือเพิ่มประสิทธิภาพ
ใช้ accuracy เป็นเมตริก
ใช้ 32 เป็นขนาดแบทช์
ใช้ 15 เป็นยุค
ใช้ 80 เป็นความยาวสูงสุดของคำ
ใช้ 2000 เป็นจำนวนคำสูงสุดในประโยคที่กำหนด
ขั้นตอนที่ 1: นำเข้าโมดูล
ให้เรานำเข้าโมดูลที่จำเป็น
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Embedding
from keras.layers import LSTM
from keras.datasets import imdbขั้นตอนที่ 2: โหลดข้อมูล
ให้เรานำเข้าชุดข้อมูล imdb
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words = 2000)ที่นี่
imdbเป็นชุดข้อมูลที่ Keras ให้มา เป็นชุดของภาพยนตร์และบทวิจารณ์
num_words แสดงจำนวนคำสูงสุดในบทวิจารณ์
ขั้นตอนที่ 3: ประมวลผลข้อมูล
ให้เราเปลี่ยนชุดข้อมูลตามรุ่นของเราเพื่อให้สามารถป้อนลงในโมเดลของเราได้ ข้อมูลสามารถเปลี่ยนแปลงได้โดยใช้รหัสด้านล่าง -
x_train = sequence.pad_sequences(x_train, maxlen=80)
x_test = sequence.pad_sequences(x_test, maxlen=80)ที่นี่
sequence.pad_sequences แปลงรายการข้อมูลอินพุตที่มีรูปร่าง (data) เป็นอาร์เรย์ 2D NumPy ของรูปร่าง (data, timesteps). โดยทั่วไปจะเพิ่มแนวคิดเวลาลงในข้อมูลที่กำหนด มันสร้างเวลาของความยาวmaxlen.
ขั้นตอนที่ 4: สร้างแบบจำลอง
ให้เราสร้างแบบจำลองจริง
model = Sequential()
model.add(Embedding(2000, 128))
model.add(LSTM(128, dropout = 0.2, recurrent_dropout = 0.2))
model.add(Dense(1, activation = 'sigmoid'))ที่นี่
เราได้ใช้ Embedding layerเป็นเลเยอร์อินพุตจากนั้นเพิ่มเลเยอร์ LSTM สุดท้ายกDense layer ใช้เป็นชั้นเอาต์พุต
ขั้นตอนที่ 5: รวบรวมโมเดล
ให้เรารวบรวมโมเดลโดยใช้ฟังก์ชันการสูญเสียเครื่องมือเพิ่มประสิทธิภาพและเมตริกที่เลือก
model.compile(loss = 'binary_crossentropy',
optimizer = 'adam', metrics = ['accuracy'])ขั้นตอนที่ 6: ฝึกโมเดล
ให้เราฝึกโมเดลโดยใช้ fit() วิธี.
model.fit(
x_train, y_train,
batch_size = 32,
epochs = 15,
validation_data = (x_test, y_test)
)การดำเนินการแอปพลิเคชันจะแสดงข้อมูลด้านล่าง -
Epoch 1/15 2019-09-24 01:19:01.151247: I
tensorflow/core/platform/cpu_feature_guard.cc:142]
Your CPU supports instructions that this
TensorFlow binary was not co mpiled to use: AVX2
25000/25000 [==============================] - 101s 4ms/step - loss: 0.4707
- acc: 0.7716 - val_loss: 0.3769 - val_acc: 0.8349 Epoch 2/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.3058
- acc: 0.8756 - val_loss: 0.3763 - val_acc: 0.8350 Epoch 3/15
25000/25000 [==============================] - 91s 4ms/step - loss: 0.2100
- acc: 0.9178 - val_loss: 0.5065 - val_acc: 0.8110 Epoch 4/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.1394
- acc: 0.9495 - val_loss: 0.6046 - val_acc: 0.8146 Epoch 5/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.0973
- acc: 0.9652 - val_loss: 0.5969 - val_acc: 0.8147 Epoch 6/15
25000/25000 [==============================] - 98s 4ms/step - loss: 0.0759
- acc: 0.9730 - val_loss: 0.6368 - val_acc: 0.8208 Epoch 7/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.0578
- acc: 0.9811 - val_loss: 0.6657 - val_acc: 0.8184 Epoch 8/15
25000/25000 [==============================] - 97s 4ms/step - loss: 0.0448
- acc: 0.9850 - val_loss: 0.7452 - val_acc: 0.8136 Epoch 9/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.0324
- acc: 0.9894 - val_loss: 0.7616 - val_acc: 0.8162Epoch 10/15
25000/25000 [==============================] - 100s 4ms/step - loss: 0.0247
- acc: 0.9922 - val_loss: 0.9654 - val_acc: 0.8148 Epoch 11/15
25000/25000 [==============================] - 99s 4ms/step - loss: 0.0169
- acc: 0.9946 - val_loss: 1.0013 - val_acc: 0.8104 Epoch 12/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.0154
- acc: 0.9948 - val_loss: 1.0316 - val_acc: 0.8100 Epoch 13/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0113
- acc: 0.9963 - val_loss: 1.1138 - val_acc: 0.8108 Epoch 14/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0106
- acc: 0.9971 - val_loss: 1.0538 - val_acc: 0.8102 Epoch 15/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0090
- acc: 0.9972 - val_loss: 1.1453 - val_acc: 0.8129
25000/25000 [==============================] - 10s 390us/stepขั้นตอนที่ 7 - ประเมินโมเดล
ให้เราประเมินแบบจำลองโดยใช้ข้อมูลการทดสอบ
score, acc = model.evaluate(x_test, y_test, batch_size = 32)
print('Test score:', score)
print('Test accuracy:', acc)การดำเนินการโค้ดด้านบนจะแสดงข้อมูลด้านล่าง -
Test score: 1.145306069601178
Test accuracy: 0.81292