อัลกอริทึมการจำแนก - โครงสร้างการตัดสินใจ
ข้อมูลเบื้องต้นเกี่ยวกับแผนผังการตัดสินใจ
โดยทั่วไปแล้วการวิเคราะห์แผนผังการตัดสินใจเป็นเครื่องมือสร้างแบบจำลองเชิงคาดการณ์ที่สามารถนำไปใช้ในหลาย ๆ ด้าน แผนผังการตัดสินใจสามารถสร้างขึ้นโดยวิธีอัลกอริทึมที่สามารถแยกชุดข้อมูลในรูปแบบต่างๆตามเงื่อนไขที่แตกต่างกัน มัดการตัดสินใจเป็นอัลกอริทึมที่ทรงพลังที่สุดซึ่งอยู่ภายใต้หมวดหมู่ของอัลกอริทึมภายใต้การดูแล
สามารถใช้สำหรับทั้งการจำแนกประเภทและงานการถดถอย เอนทิตีหลักสองอย่างของทรีคือโหนดการตัดสินใจซึ่งข้อมูลจะถูกแยกและออกจากจุดที่เราได้ผลลัพธ์ ตัวอย่างของต้นไม้ไบนารีสำหรับทำนายว่าบุคคลนั้นเหมาะสมหรือไม่เหมาะสมโดยให้ข้อมูลต่างๆเช่นอายุพฤติกรรมการกินและพฤติกรรมการออกกำลังกายมีดังต่อไปนี้ -
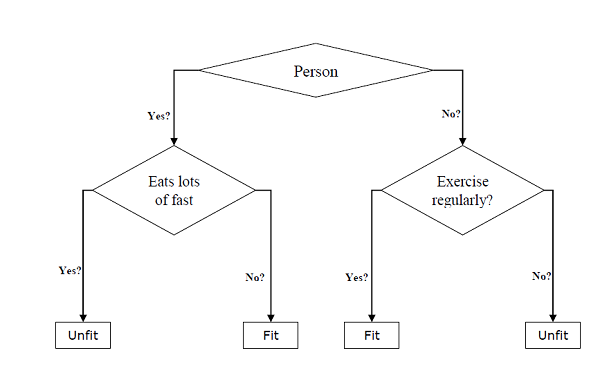
ในแผนผังการตัดสินใจข้างต้นคำถามคือโหนดการตัดสินใจและผลลัพธ์สุดท้ายคือใบไม้ เรามีแผนผังการตัดสินใจสองประเภทดังต่อไปนี้ -
Classification decision trees- ในโครงสร้างการตัดสินใจประเภทนี้ตัวแปรการตัดสินใจเป็นแบบเด็ดขาด แผนผังการตัดสินใจข้างต้นเป็นตัวอย่างของแผนผังการตัดสินใจจำแนกประเภท
Regression decision trees - ในโครงสร้างการตัดสินใจแบบนี้ตัวแปรการตัดสินใจจะต่อเนื่อง
การใช้อัลกอริทึมแผนผังการตัดสินใจ
ดัชนี Gini
เป็นชื่อของฟังก์ชันต้นทุนที่ใช้ในการประเมินการแยกไบนารีในชุดข้อมูลและทำงานร่วมกับตัวแปรเป้าหมายประเภท "ความสำเร็จ" หรือ "ความล้มเหลว"
ค่าดัชนี Gini สูงขึ้นความเป็นเนื้อเดียวกันจะสูงขึ้น ค่าดัชนี Gini ที่สมบูรณ์แบบคือ 0 และแย่ที่สุดคือ 0.5 (สำหรับปัญหา 2 คลาส) ดัชนี Gini สำหรับการแยกสามารถคำนวณได้ด้วยความช่วยเหลือของขั้นตอนต่อไปนี้ -
ขั้นแรกให้คำนวณดัชนี Gini สำหรับโหนดย่อยโดยใช้สูตร p ^ 2 + q ^ 2 ซึ่งเป็นผลรวมของกำลังสองของความน่าจะเป็นสำหรับความสำเร็จและความล้มเหลว
จากนั้นคำนวณดัชนี Gini สำหรับการแยกโดยใช้คะแนน Gini แบบถ่วงน้ำหนักของแต่ละโหนดของการแยกนั้น
อัลกอริทึม Classification and Regression Tree (CART) ใช้วิธี Gini เพื่อสร้างการแยกไบนารี
แยกการสร้าง
โดยทั่วไปการแบ่งจะรวมแอตทริบิวต์ในชุดข้อมูลและค่า เราสามารถสร้างการแยกในชุดข้อมูลด้วยความช่วยเหลือของสามส่วนต่อไปนี้ -
Part1: Calculating Gini Score - เราเพิ่งพูดถึงส่วนนี้ในหัวข้อก่อนหน้านี้
Part2: Splitting a dataset- อาจกำหนดเป็นการแยกชุดข้อมูลออกเป็นสองรายการของแถวที่มีดัชนีของแอตทริบิวต์และค่าแยกของแอตทริบิวต์นั้น หลังจากได้ทั้งสองกลุ่ม - ขวาและซ้ายจากชุดข้อมูลเราสามารถคำนวณมูลค่าของการแบ่งโดยใช้คะแนน Gini ที่คำนวณในส่วนแรก ค่าแยกจะเป็นตัวตัดสินว่าแอตทริบิวต์จะอยู่ในกลุ่มใด
Part3: Evaluating all splits- ส่วนถัดไปหลังจากการค้นหาคะแนน Gini และการแยกชุดข้อมูลคือการประเมินการแยกทั้งหมด เพื่อจุดประสงค์นี้อันดับแรกเราต้องตรวจสอบทุกค่าที่เกี่ยวข้องกับแต่ละแอตทริบิวต์เป็นตัวแบ่งตัวเลือก จากนั้นเราต้องหาการแยกที่ดีที่สุดโดยการประเมินต้นทุนของการแยก การแยกที่ดีที่สุดจะถูกใช้เป็นโหนดในแผนผังการตัดสินใจ
การสร้างต้นไม้
ดังที่เราทราบว่าต้นไม้มีโหนดรูทและโหนดเทอร์มินัล หลังจากสร้างโหนดรูทแล้วเราสามารถสร้างทรีได้โดยทำตามสองส่วน -
ส่วนที่ 1: การสร้างโหนดเทอร์มินัล
ในขณะที่สร้างโหนดเทอร์มินัลของทรีการตัดสินใจประเด็นสำคัญอย่างหนึ่งคือการตัดสินใจว่าจะหยุดการเติบโตของต้นไม้หรือสร้างโหนดเทอร์มินัลต่อไป สามารถทำได้โดยใช้สองเกณฑ์คือความลึกของต้นไม้สูงสุดและบันทึกโหนดขั้นต่ำดังนี้ -
Maximum Tree Depth- ตามชื่อแนะนำนี่คือจำนวนโหนดสูงสุดในทรีหลังโหนดรูท เราต้องหยุดการเพิ่มโหนดเทอร์มินัลเมื่อต้นไม้ถึงระดับความลึกสูงสุดเช่นเมื่อต้นไม้มีจำนวนโหนดเทอร์มินัลสูงสุด
Minimum Node Records- อาจกำหนดเป็นจำนวนขั้นต่ำของรูปแบบการฝึกอบรมที่โหนดหนึ่ง ๆ รับผิดชอบ เราต้องหยุดการเพิ่มโหนดเทอร์มินัลเมื่อทรีมาถึงที่ระเบียนโหนดขั้นต่ำเหล่านี้หรือต่ำกว่าขั้นต่ำนี้
โหนดเทอร์มินัลใช้ในการทำนายขั้นสุดท้าย
Part2: การแยกซ้ำ
ตามที่เราเข้าใจเกี่ยวกับเวลาที่จะสร้างโหนดเทอร์มินัลตอนนี้เราสามารถเริ่มสร้างต้นไม้ของเราได้ การแยกซ้ำเป็นวิธีการสร้างต้นไม้ ในวิธีนี้เมื่อสร้างโหนดแล้วเราสามารถสร้างโหนดลูก (โหนดที่เพิ่มไปยังโหนดที่มีอยู่) ซ้ำในแต่ละกลุ่มข้อมูลซึ่งสร้างขึ้นโดยการแยกชุดข้อมูลโดยเรียกใช้ฟังก์ชันเดียวกันซ้ำแล้วซ้ำอีก
คาดการณ์
หลังจากสร้างแผนผังการตัดสินใจแล้วเราจำเป็นต้องคาดเดาเกี่ยวกับมัน โดยทั่วไปการคาดการณ์เกี่ยวข้องกับการนำทางโครงสร้างการตัดสินใจด้วยแถวข้อมูลที่จัดเตรียมไว้โดยเฉพาะ
เราสามารถคาดคะเนได้โดยใช้ฟังก์ชันเรียกซ้ำดังที่กล่าวมาข้างต้น รูทีนการทำนายเดียวกันจะถูกเรียกอีกครั้งโดยใช้โหนดซ้ายหรือโหนดขวาของลูก
สมมติฐาน
ต่อไปนี้เป็นสมมติฐานบางส่วนที่เราสร้างขึ้นในขณะที่สร้างแผนผังการตัดสินใจ -
ในขณะเตรียมทรีการตัดสินใจชุดการฝึกจะเป็นเสมือนรูทโหนด
ลักษณนามทรีการตัดสินใจต้องการให้ค่าคุณลักษณะเป็นหมวดหมู่ ในกรณีที่คุณต้องการใช้ค่าต่อเนื่องจะต้องแยกออกก่อนสร้างแบบจำลอง
ตามค่าของแอตทริบิวต์ระเบียนจะกระจายแบบวนซ้ำ
วิธีการทางสถิติจะใช้เพื่อวางแอตทริบิวต์ที่ตำแหน่งโหนดใด ๆ เช่นโหนดรูทหรือโหนดภายใน
การใช้งานใน Python
ตัวอย่าง
ในตัวอย่างต่อไปนี้เราจะนำ Decision Tree ลักษณนามมาใช้กับ Pima Indian Diabetes -
ขั้นแรกเริ่มต้นด้วยการนำเข้าแพ็คเกจ python ที่จำเป็น -
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_splitจากนั้นดาวน์โหลดชุดข้อมูลม่านตาจากเว็บลิงค์ดังต่อไปนี้ -
col_names = ['pregnant', 'glucose', 'bp', 'skin', 'insulin', 'bmi', 'pedigree', 'age', 'label']
pima = pd.read_csv(r"C:\pima-indians-diabetes.csv", header=None, names=col_names)
pima.head()pregnant glucose bp skin insulin bmi pedigree age label
0 6 148 72 35 0 33.6 0.627 50 1
1 1 85 66 29 0 26.6 0.351 31 0
2 8 183 64 0 0 23.3 0.672 32 1
3 1 89 66 23 94 28.1 0.167 21 0
4 0 137 40 35 168 43.1 2.288 33 1ตอนนี้แยกชุดข้อมูลออกเป็นคุณสมบัติและตัวแปรเป้าหมายดังนี้ -
feature_cols = ['pregnant', 'insulin', 'bmi', 'age','glucose','bp','pedigree']
X = pima[feature_cols] # Features
y = pima.label # Target variableต่อไปเราจะแบ่งข้อมูลออกเป็นส่วนรถไฟและการทดสอบ รหัสต่อไปนี้จะแบ่งชุดข้อมูลออกเป็นข้อมูลการฝึกอบรม 70% และข้อมูลการทดสอบ 30% -
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)จากนั้นฝึกโมเดลด้วยความช่วยเหลือของคลาส DecisionTreeClassifier ของ sklearn ดังต่อไปนี้ -
clf = DecisionTreeClassifier()
clf = clf.fit(X_train,y_train)ในที่สุดเราต้องทำการทำนาย สามารถทำได้ด้วยความช่วยเหลือของสคริปต์ต่อไปนี้ -
y_pred = clf.predict(X_test)ต่อไปเราจะได้รับคะแนนความแม่นยำเมทริกซ์ความสับสนและรายงานการจำแนกดังนี้ -
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
result = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(result)
result1 = classification_report(y_test, y_pred)
print("Classification Report:",)
print (result1)
result2 = accuracy_score(y_test,y_pred)
print("Accuracy:",result2)เอาต์พุต
Confusion Matrix:
[[116 30]
[ 46 39]]
Classification Report:
precision recall f1-score support
0 0.72 0.79 0.75 146
1 0.57 0.46 0.51 85
micro avg 0.67 0.67 0.67 231
macro avg 0.64 0.63 0.63 231
weighted avg 0.66 0.67 0.66 231
Accuracy: 0.670995670995671การแสดงแผนผังการตัดสินใจ
แผนภูมิการตัดสินใจข้างต้นสามารถมองเห็นได้ด้วยความช่วยเหลือของรหัสต่อไปนี้ -
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
from IPython.display import Image
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data,
filled=True, rounded=True,
special_characters=True,feature_names = feature_cols,class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('Pima_diabetes_Tree.png')
Image(graph.create_png())