อัลกอริทึมการถดถอย - การถดถอยเชิงเส้น
บทนำสู่ Linear Regression
การถดถอยเชิงเส้นอาจถูกกำหนดให้เป็นแบบจำลองทางสถิติที่วิเคราะห์ความสัมพันธ์เชิงเส้นระหว่างตัวแปรตามกับตัวแปรอิสระที่กำหนด ความสัมพันธ์เชิงเส้นระหว่างตัวแปรหมายความว่าเมื่อค่าของตัวแปรอิสระหนึ่งตัวขึ้นไปจะเปลี่ยนไป (เพิ่มขึ้นหรือลดลง) ค่าของตัวแปรตามก็จะเปลี่ยนตามไปด้วย (เพิ่มขึ้นหรือลดลง)
ในทางคณิตศาสตร์ความสัมพันธ์สามารถแสดงได้ด้วยความช่วยเหลือของสมการต่อไปนี้ -
Y = mX + b
ที่นี่ Y คือตัวแปรตามที่เราพยายามทำนาย
Xคือตัวแปรตามที่เราใช้ในการทำนาย
mคือ slop ของเส้นถดถอยซึ่งแสดงถึงเอฟเฟกต์ X ที่มีต่อ Y
bคือค่าคงที่หรือที่เรียกว่า Y-intercept ถ้า X = 0 Y จะเท่ากับ b
นอกจากนี้ความสัมพันธ์เชิงเส้นสามารถเป็นบวกหรือลบได้ตามที่อธิบายไว้ด้านล่าง -
ความสัมพันธ์เชิงเส้นเชิงบวก
ความสัมพันธ์เชิงเส้นจะถูกเรียกว่าเป็นบวกหากทั้งตัวแปรอิสระและตัวแปรตามเพิ่มขึ้น สามารถเข้าใจได้ด้วยความช่วยเหลือของกราฟต่อไปนี้ -

ความสัมพันธ์เชิงเส้นเชิงลบ
ความสัมพันธ์เชิงเส้นจะถูกเรียกว่าเป็นบวกหากเพิ่มขึ้นอย่างอิสระและตัวแปรตามลดลง สามารถเข้าใจได้ด้วยความช่วยเหลือของกราฟต่อไปนี้ -

ประเภทของการถดถอยเชิงเส้น
การถดถอยเชิงเส้นมีสองประเภทต่อไปนี้ -
- การถดถอยเชิงเส้นอย่างง่าย
- การถดถอยเชิงเส้นหลาย ๆ
การถดถอยเชิงเส้นอย่างง่าย (SLR)
เป็นเวอร์ชันพื้นฐานที่สุดของการถดถอยเชิงเส้นซึ่งทำนายการตอบสนองโดยใช้คุณลักษณะเดียว สมมติฐานใน SLR คือตัวแปรทั้งสองมีความสัมพันธ์กันเชิงเส้น
การใช้งาน Python
เราสามารถใช้ SLR ใน Python ได้สองวิธีวิธีหนึ่งคือการให้ชุดข้อมูลของคุณเองและอื่น ๆ คือการใช้ชุดข้อมูลจากไลบรารี scikit-learn python
Example 1 - ในตัวอย่างการใช้งาน Python ต่อไปนี้เรากำลังใช้ชุดข้อมูลของเราเอง
ขั้นแรกเราจะเริ่มต้นด้วยการนำเข้าแพ็คเกจที่จำเป็นดังนี้ -
%matplotlib inline
import numpy as np
import matplotlib.pyplot as pltจากนั้นกำหนดฟังก์ชันที่จะคำนวณค่าที่สำคัญสำหรับ SLR -
def coef_estimation(x, y):บรรทัดสคริปต์ต่อไปนี้จะให้จำนวนการสังเกต n -
n = np.size(x)ค่าเฉลี่ยของเวกเตอร์ x และ y สามารถคำนวณได้ดังนี้ -
m_x, m_y = np.mean(x), np.mean(y)เราสามารถหา cross-deviation และ deviation เกี่ยวกับ x ได้ดังนี้ -
SS_xy = np.sum(y*x) - n*m_y*m_x
SS_xx = np.sum(x*x) - n*m_x*m_xถัดไปค่าสัมประสิทธิ์การถดถอยเช่น b สามารถคำนวณได้ดังนี้ -
b_1 = SS_xy / SS_xx
b_0 = m_y - b_1*m_x
return(b_0, b_1)ต่อไปเราต้องกำหนดฟังก์ชันที่จะพล็อตเส้นการถดถอยและทำนายเวกเตอร์การตอบสนอง -
def plot_regression_line(x, y, b):บรรทัดสคริปต์ต่อไปนี้จะพล็อตจุดจริงเป็น scatter plot -
plt.scatter(x, y, color = "m", marker = "o", s = 30)บรรทัดสคริปต์ต่อไปนี้จะทำนายเวกเตอร์การตอบสนอง -
y_pred = b[0] + b[1]*xบรรทัดสคริปต์ต่อไปนี้จะพล็อตเส้นการถดถอยและจะใส่ป้ายกำกับไว้ -
plt.plot(x, y_pred, color = "g")
plt.xlabel('x')
plt.ylabel('y')
plt.show()ในที่สุดเราต้องกำหนดฟังก์ชัน main () เพื่อให้ชุดข้อมูลและเรียกใช้ฟังก์ชันที่เรากำหนดไว้ข้างต้น -
def main():
x = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
y = np.array([100, 300, 350, 500, 750, 800, 850, 900, 1050, 1250])
b = coef_estimation(x, y)
print("Estimated coefficients:\nb_0 = {} \nb_1 = {}".format(b[0], b[1]))
plot_regression_line(x, y, b)
if __name__ == "__main__":
main()เอาต์พุต
Estimated coefficients:
b_0 = 154.5454545454545
b_1 = 117.87878787878788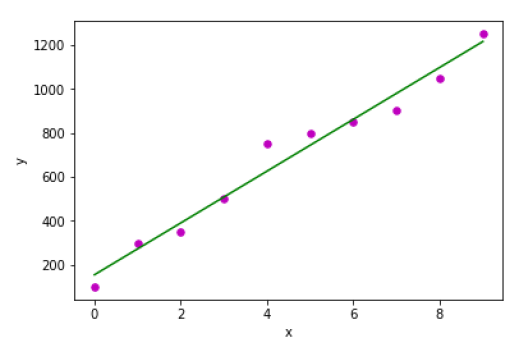
Example 2 - ในตัวอย่างการใช้งาน Python ต่อไปนี้เรากำลังใช้ชุดข้อมูลเบาหวานจาก scikit-learn
ขั้นแรกเราจะเริ่มต้นด้วยการนำเข้าแพ็คเกจที่จำเป็นดังนี้ -
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_scoreต่อไปเราจะโหลดชุดข้อมูลเบาหวานและสร้างวัตถุ -
diabetes = datasets.load_diabetes()ในขณะที่เราใช้ SLR เราจะใช้คุณลักษณะเดียวดังต่อไปนี้ -
X = diabetes.data[:, np.newaxis, 2]ต่อไปเราต้องแบ่งข้อมูลออกเป็นชุดการฝึกอบรมและการทดสอบดังนี้ -
X_train = X[:-30]
X_test = X[-30:]ต่อไปเราต้องแบ่งเป้าหมายออกเป็นชุดฝึกและชุดทดสอบดังนี้ -
y_train = diabetes.target[:-30]
y_test = diabetes.target[-30:]ตอนนี้ในการฝึกโมเดลเราจำเป็นต้องสร้างวัตถุถดถอยเชิงเส้นดังนี้ -
regr = linear_model.LinearRegression()จากนั้นฝึกโมเดลโดยใช้ชุดฝึกดังนี้ -
regr.fit(X_train, y_train)จากนั้นทำการคาดคะเนโดยใช้ชุดการทดสอบดังนี้ -
y_pred = regr.predict(X_test)ต่อไปเราจะพิมพ์ค่าสัมประสิทธิ์บางอย่างเช่น MSE คะแนนความแปรปรวนเป็นต้นดังต่อไปนี้ -
print('Coefficients: \n', regr.coef_)
print("Mean squared error: %.2f" % mean_squared_error(y_test, y_pred))
print('Variance score: %.2f' % r2_score(y_test, y_pred))ตอนนี้พล็อตผลลัพธ์ดังนี้ -
plt.scatter(X_test, y_test, color='blue')
plt.plot(X_test, y_pred, color='red', linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()เอาต์พุต
Coefficients:
[941.43097333]
Mean squared error: 3035.06
Variance score: 0.41
การถดถอยเชิงเส้นหลายเส้น (MLR)
มันเป็นส่วนขยายของการถดถอยเชิงเส้นอย่างง่ายที่ทำนายการตอบสนองโดยใช้คุณสมบัติสองอย่างขึ้นไป ในทางคณิตศาสตร์เราสามารถอธิบายได้ดังนี้ -
พิจารณาชุดข้อมูลที่มีข้อสังเกต n คุณสมบัติ p คือตัวแปรอิสระและ y เป็นหนึ่งการตอบสนองเช่นตัวแปรตามเส้นการถดถอยสำหรับคุณลักษณะ p สามารถคำนวณได้ดังนี้ -
$$ h (x_ {i}) = b_ {0} + b_ {1} x_ {i1} + b_ {2} x_ {i2} + ... + b_ {p} x_ {ip} $$ในที่นี้ h (x i ) คือค่าตอบสนองที่คาดการณ์ไว้และ b 0 , b 1 , b 2 …, b pคือสัมประสิทธิ์การถดถอย
แบบจำลองการถดถอยเชิงเส้นหลายตัวมักจะมีข้อผิดพลาดในข้อมูลที่เรียกว่าข้อผิดพลาดที่เหลือซึ่งจะเปลี่ยนแปลงการคำนวณดังนี้ -
$$ h (x_ {i}) = b_ {0} + b_ {1} x_ {i1} + b_ {2} x_ {i2} + ... + b_ {p} x_ {ip} + e_ {i} $$เรายังสามารถเขียนสมการข้างต้นได้ดังนี้ -
$$ y_ {i} = h (x_ {i}) + e_ {i} \: หรือ \: e_ {i} = y_ {i} - h (x_ {i}) $$การใช้งาน Python
ในตัวอย่างนี้เราจะใช้ชุดข้อมูลที่อยู่อาศัยของบอสตันจาก scikit learn -
ขั้นแรกเราจะเริ่มต้นด้วยการนำเข้าแพ็คเกจที่จำเป็นดังนี้ -
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model, metricsจากนั้นโหลดชุดข้อมูลดังนี้ -
boston = datasets.load_boston(return_X_y=False)บรรทัดสคริปต์ต่อไปนี้จะกำหนดคุณสมบัติเมทริกซ์ X และเวกเตอร์การตอบสนอง Y -
X = boston.data
y = boston.targetจากนั้นแยกชุดข้อมูลออกเป็นชุดการฝึกอบรมและชุดทดสอบดังนี้ -
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.7, random_state=1)ตัวอย่าง
ตอนนี้สร้างวัตถุถดถอยเชิงเส้นและฝึกโมเดลดังนี้ -
reg = linear_model.LinearRegression()
reg.fit(X_train, y_train)
print('Coefficients: \n', reg.coef_)
print('Variance score: {}'.format(reg.score(X_test, y_test)))
plt.style.use('fivethirtyeight')
plt.scatter(reg.predict(X_train), reg.predict(X_train) - y_train,
color = "green", s = 10, label = 'Train data')
plt.scatter(reg.predict(X_test), reg.predict(X_test) - y_test,
color = "blue", s = 10, label = 'Test data')
plt.hlines(y = 0, xmin = 0, xmax = 50, linewidth = 2)
plt.legend(loc = 'upper right')
plt.title("Residual errors")
plt.show()เอาต์พุต
Coefficients:
[
-1.16358797e-01 6.44549228e-02 1.65416147e-01 1.45101654e+00
-1.77862563e+01 2.80392779e+00 4.61905315e-02 -1.13518865e+00
3.31725870e-01 -1.01196059e-02 -9.94812678e-01 9.18522056e-03
-7.92395217e-01
]
Variance score: 0.709454060230326
สมมติฐาน
ต่อไปนี้เป็นสมมติฐานบางประการเกี่ยวกับชุดข้อมูลที่สร้างโดยแบบจำลองการถดถอยเชิงเส้น -
Multi-collinearity- แบบจำลองการถดถอยเชิงเส้นจะถือว่าข้อมูลมีความคลาดเคลื่อนน้อยมากหรือไม่มีเลย โดยทั่วไปแล้วความเรียงหลายอย่างเกิดขึ้นเมื่อตัวแปรอิสระหรือคุณลักษณะมีการพึ่งพากัน
Auto-correlation- ข้อสันนิษฐานอีกประการหนึ่งแบบจำลองการถดถอยเชิงเส้นสันนิษฐานว่ามีความสัมพันธ์อัตโนมัติน้อยมากหรือไม่มีเลยในข้อมูล โดยทั่วไปความสัมพันธ์อัตโนมัติเกิดขึ้นเมื่อมีการพึ่งพาระหว่างข้อผิดพลาดที่เหลือ
Relationship between variables - แบบจำลองการถดถอยเชิงเส้นจะถือว่าความสัมพันธ์ระหว่างตัวแปรตอบสนองและคุณลักษณะต้องเป็นเชิงเส้น