อัลกอริทึมการทำคลัสเตอร์ - การทำคลัสเตอร์ตามลำดับชั้น
ข้อมูลเบื้องต้นเกี่ยวกับการจัดกลุ่มตามลำดับชั้น
การจัดกลุ่มตามลำดับชั้นเป็นอีกหนึ่งอัลกอริทึมการเรียนรู้ที่ไม่ได้รับการดูแลซึ่งใช้เพื่อจัดกลุ่มจุดข้อมูลที่ไม่มีป้ายกำกับที่มีลักษณะคล้ายคลึงกัน อัลกอริธึมการจัดกลุ่มตามลำดับชั้นแบ่งออกเป็นสองประเภทต่อไปนี้ -
Agglomerative hierarchical algorithms- ในอัลกอริธึมลำดับชั้นแบบ agglomerative จุดข้อมูลแต่ละจุดจะถือว่าเป็นคลัสเตอร์เดียวจากนั้นจึงรวมหรือรวมกลุ่มกันอย่างต่อเนื่อง (แนวทางจากล่างขึ้นบน) ลำดับชั้นของคลัสเตอร์แสดงเป็น dendrogram หรือโครงสร้างต้นไม้
Divisive hierarchical algorithms - ในทางกลับกันในอัลกอริธึมแบบลำดับชั้นแบบแบ่งจุดข้อมูลทั้งหมดจะถือว่าเป็นคลัสเตอร์ใหญ่กลุ่มเดียวและกระบวนการจัดกลุ่มเกี่ยวข้องกับการแบ่ง (วิธีการจากบนลงล่าง) คลัสเตอร์ใหญ่กลุ่มหนึ่งออกเป็นคลัสเตอร์เล็ก ๆ
ขั้นตอนในการทำคลัสเตอร์แบบลำดับชั้นแบบ Agglomerative
เราจะอธิบายการจัดกลุ่มตามลำดับชั้นที่ใช้มากที่สุดและมีความสำคัญเช่น agglomerative ขั้นตอนในการดำเนินการเดียวกันมีดังนี้ -
Step 1- ถือว่าแต่ละจุดข้อมูลเป็นคลัสเตอร์เดียว ดังนั้นเราจะมีกลุ่ม K พูดตั้งแต่เริ่มต้น จำนวนจุดข้อมูลจะเป็น K เมื่อเริ่มต้น
Step 2- ตอนนี้ในขั้นตอนนี้เราจำเป็นต้องสร้างคลัสเตอร์ขนาดใหญ่โดยการรวมจุดข้อมูลตู้เสื้อผ้าสองจุด ซึ่งจะส่งผลให้มีคลัสเตอร์ K-1 ทั้งหมด
Step 3- ตอนนี้ในการสร้างกลุ่มเพิ่มเติมเราจำเป็นต้องเข้าร่วมกลุ่มตู้เสื้อผ้าสองกลุ่ม ซึ่งจะส่งผลให้คลัสเตอร์ K-2 ทั้งหมด
Step 4 - ตอนนี้ในการสร้างคลัสเตอร์ขนาดใหญ่หนึ่งกลุ่มให้ทำซ้ำสามขั้นตอนข้างต้นจนกว่า K จะกลายเป็น 0 เช่นไม่มีจุดข้อมูลให้เข้าร่วมอีกต่อไป
Step 5 - ในที่สุดหลังจากสร้างคลัสเตอร์ขนาดใหญ่ 1 กลุ่มแล้ว dendrograms จะถูกใช้เพื่อแบ่งออกเป็นหลายคลัสเตอร์ขึ้นอยู่กับปัญหา
บทบาทของ Dendrograms ใน Agglomerative Hierarchical Clustering
ดังที่เราได้กล่าวไว้ในขั้นตอนสุดท้ายบทบาทของ dendrogram จะเริ่มต้นเมื่อมีการสร้างคลัสเตอร์ขนาดใหญ่ Dendrogram จะถูกใช้เพื่อแบ่งคลัสเตอร์ออกเป็นหลาย ๆ จุดข้อมูลที่เกี่ยวข้องขึ้นอยู่กับปัญหาของเรา สามารถเข้าใจได้ด้วยความช่วยเหลือของตัวอย่างต่อไปนี้ -
ตัวอย่าง 1
เพื่อทำความเข้าใจให้เราเริ่มต้นด้วยการนำเข้าไลบรารีที่จำเป็นดังต่อไปนี้ -
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as npต่อไปเราจะพล็อตจุดข้อมูลที่เรานำมาใช้สำหรับตัวอย่างนี้ -
X = np.array([[7,8],[12,20],[17,19],[26,15],[32,37],[87,75],[73,85], [62,80],[73,60],[87,96],])
labels = range(1, 11)
plt.figure(figsize=(10, 7))
plt.subplots_adjust(bottom=0.1)
plt.scatter(X[:,0],X[:,1], label='True Position')
for label, x, y in zip(labels, X[:, 0], X[:, 1]):
plt.annotate(label,xy=(x, y), xytext=(-3, 3),textcoords='offset points', ha='right', va='bottom')
plt.show()
จากแผนภาพด้านบนเป็นเรื่องง่ายมากที่จะเห็นว่าเรามีสองกลุ่มในจุดข้อมูลออก แต่ในข้อมูลจริงอาจมีได้หลายพันคลัสเตอร์ ต่อไปเราจะวางแผน dendrograms ของ datapoints ของเราโดยใช้ Scipy library -
from scipy.cluster.hierarchy import dendrogram, linkage
from matplotlib import pyplot as plt
linked = linkage(X, 'single')
labelList = range(1, 11)
plt.figure(figsize=(10, 7))
dendrogram(linked, orientation='top',labels=labelList, distance_sort='descending',show_leaf_counts=True)
plt.show()
ตอนนี้เมื่อสร้างคลัสเตอร์ขนาดใหญ่แล้วระยะทางแนวตั้งที่ยาวที่สุดจะถูกเลือก จากนั้นเส้นแนวตั้งจะลากผ่านดังที่แสดงในแผนภาพต่อไปนี้ เมื่อเส้นแนวนอนตัดกับเส้นสีน้ำเงินที่จุดสองจุดจำนวนคลัสเตอร์จะเป็นสอง

ต่อไปเราต้องนำเข้าคลาสสำหรับการทำคลัสเตอร์และเรียกเมธอด fit_predict เพื่อทำนายคลัสเตอร์ เรากำลังนำเข้าคลาส AgglomerativeClustering ของไลบรารี sklearn.cluster -
from sklearn.cluster import AgglomerativeClustering
cluster = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward')
cluster.fit_predict(X)จากนั้นลงจุดคลัสเตอร์ด้วยความช่วยเหลือของรหัสต่อไปนี้ -
plt.scatter(X[:,0],X[:,1], c=cluster.labels_, cmap='rainbow')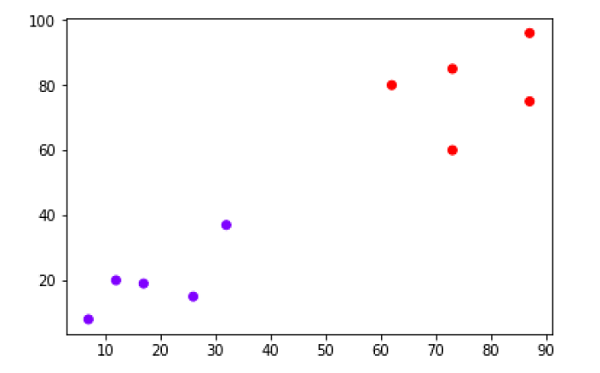
แผนภาพด้านบนแสดงทั้งสองคลัสเตอร์จากจุดข้อมูลของเรา
ตัวอย่าง 2
ตามที่เราเข้าใจแนวคิดของ dendrograms จากตัวอย่างง่ายๆที่กล่าวถึงข้างต้นให้เราไปยังอีกตัวอย่างหนึ่งซึ่งเรากำลังสร้างกลุ่มของจุดข้อมูลในชุดข้อมูลโรคเบาหวานอินเดีย Pima โดยใช้การจัดกลุ่มตามลำดับชั้น -
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
import numpy as np
from pandas import read_csv
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=headernames)
array = data.values
X = array[:,0:8]
Y = array[:,8]
data.shape
(768, 9)
data.head()| slno. | preg | พลาส | ปธน | ผิวหนัง | ทดสอบ | มวล | Pedi | อายุ | ชั้นเรียน |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
patient_data = data.iloc[:, 3:5].values
import scipy.cluster.hierarchy as shc
plt.figure(figsize=(10, 7))
plt.title("Patient Dendograms")
dend = shc.dendrogram(shc.linkage(data, method='ward'))
from sklearn.cluster import AgglomerativeClustering
cluster = AgglomerativeClustering(n_clusters=4, affinity='euclidean', linkage='ward')
cluster.fit_predict(patient_data)
plt.figure(figsize=(10, 7))
plt.scatter(patient_data[:,0], patient_data[:,1], c=cluster.labels_, cmap='rainbow')