การประมวลผลวาทกรรมภาษาธรรมชาติ
ปัญหาที่ยากที่สุดของ AI คือการประมวลผลภาษาธรรมชาติด้วยคอมพิวเตอร์หรืออีกนัยหนึ่งการประมวลผลภาษาธรรมชาติเป็นปัญหาที่ยากที่สุดของปัญญาประดิษฐ์ หากเราพูดถึงปัญหาที่สำคัญใน NLP ปัญหาสำคัญอย่างหนึ่งใน NLP คือการประมวลผลวาทกรรม - การสร้างทฤษฎีและแบบจำลองของคำพูดที่รวมกันเป็นรูปเป็นร่างcoherent discourse. จริงๆแล้วภาษามักประกอบด้วยกลุ่มประโยคที่เรียงต่อกันมีโครงสร้างและสอดคล้องกันมากกว่าประโยคที่แยกออกมาและไม่เกี่ยวข้องกันเช่นภาพยนตร์ กลุ่มประโยคที่เชื่อมโยงกันเหล่านี้เรียกว่าวาทกรรม
แนวคิดของการเชื่อมโยงกัน
การเชื่อมโยงกันและโครงสร้างของวาทกรรมมีความเชื่อมโยงกันในหลาย ๆ ด้าน การเชื่อมโยงกันพร้อมกับคุณสมบัติของข้อความที่ดีถูกใช้เพื่อประเมินคุณภาพผลลัพธ์ของระบบการสร้างภาษาธรรมชาติ คำถามที่เกิดขึ้นที่นี่คือข้อความที่สอดคล้องกันหมายความว่าอย่างไร? สมมติว่าเรารวบรวมประโยคหนึ่งจากหนังสือพิมพ์ทุกหน้าแล้วจะเป็นวาทกรรมหรือไม่? แน่นอนไม่ใช่ เป็นเพราะประโยคเหล่านี้ไม่แสดงความเชื่อมโยงกัน วาทกรรมที่สอดคล้องกันต้องมีคุณสมบัติดังต่อไปนี้ -
ความสัมพันธ์เชื่อมโยงระหว่างคำพูด
วาทกรรมจะสอดคล้องกันหากมีการเชื่อมโยงที่มีความหมายระหว่างคำพูดของมัน คุณสมบัตินี้เรียกว่าความสัมพันธ์เชื่อมโยงกัน ตัวอย่างเช่นต้องมีคำอธิบายบางอย่างเพื่อแสดงความเชื่อมโยงระหว่างคำพูด
ความสัมพันธ์ระหว่างเอนทิตี
คุณสมบัติอีกประการหนึ่งที่ทำให้วาทกรรมสอดคล้องกันคือต้องมีความสัมพันธ์บางอย่างกับเอนทิตี การเชื่อมโยงกันแบบนี้เรียกว่าการเชื่อมโยงตามเอนทิตี
โครงสร้างวาทกรรม
คำถามสำคัญเกี่ยวกับวาทกรรมคือวาทกรรมต้องมีโครงสร้างแบบไหน คำตอบสำหรับคำถามนี้ขึ้นอยู่กับการแบ่งกลุ่มที่เราใช้กับวาทกรรม การแบ่งส่วนของวาทกรรมอาจถูกกำหนดเป็นการกำหนดประเภทของโครงสร้างสำหรับวาทกรรมขนาดใหญ่ มันค่อนข้างยากที่จะใช้การแบ่งส่วนของวาทกรรม แต่มันสำคัญมากสำหรับinformation retrieval, text summarization and information extraction ประเภทของการใช้งาน
อัลกอริทึมสำหรับการแบ่งกลุ่มวาทกรรม
ในส่วนนี้เราจะเรียนรู้เกี่ยวกับอัลกอริทึมสำหรับการแบ่งส่วนวาทกรรม อัลกอริทึมอธิบายไว้ด้านล่าง -
การแบ่งกลุ่มวาทกรรมที่ไม่ได้รับการดูแล
ชั้นของการแบ่งกลุ่มวาทกรรมที่ไม่ได้รับการดูแลมักแสดงเป็นการแบ่งส่วนเชิงเส้น เราสามารถเข้าใจงานของการแบ่งส่วนเชิงเส้นด้วยความช่วยเหลือของตัวอย่าง ในตัวอย่างมีภารกิจในการแบ่งส่วนข้อความเป็นหน่วยหลายย่อหน้า หน่วยแสดงข้อความของข้อความต้นฉบับ อัลกอริทึมเหล่านี้ขึ้นอยู่กับการทำงานร่วมกันซึ่งอาจกำหนดได้ว่าเป็นการใช้อุปกรณ์ทางภาษาบางอย่างเพื่อผูกหน่วยข้อความเข้าด้วยกัน ในทางกลับกันคำศัพท์ที่เชื่อมโยงกันคือความสัมพันธ์ที่บ่งบอกโดยความสัมพันธ์ระหว่างคำสองคำหรือมากกว่าในสองหน่วยเช่นการใช้คำพ้องความหมาย
การแบ่งกลุ่มวาทกรรมภายใต้การดูแล
วิธีการก่อนหน้านี้ไม่มีขอบเขตส่วนที่ติดป้ายกำกับด้วยมือ ในทางกลับกันการแบ่งกลุ่มวาทกรรมภายใต้การดูแลจำเป็นต้องมีข้อมูลการฝึกอบรมที่มีป้ายกำกับขอบเขต มันง่ายมากที่จะได้รับสิ่งเดียวกัน ในการแบ่งกลุ่มวาทกรรมภายใต้การดูแลเครื่องหมายวาทกรรมหรือคำพูดมีบทบาทสำคัญ Discourse marker หรือ cue word คือคำหรือวลีที่ทำหน้าที่ส่งสัญญาณโครงสร้างวาทกรรม เครื่องหมายวาทกรรมเหล่านี้เป็นเครื่องหมายเฉพาะโดเมน
การเชื่อมโยงกันของข้อความ
การทำซ้ำคำศัพท์เป็นวิธีการค้นหาโครงสร้างในวาทกรรม แต่ไม่เป็นไปตามข้อกำหนดของการเป็นวาทกรรมที่สอดคล้องกัน เพื่อให้บรรลุวาทกรรมที่สอดคล้องกันเราต้องมุ่งเน้นไปที่ความสัมพันธ์เชื่อมโยงกันโดยเฉพาะ ดังที่เราทราบว่าความสัมพันธ์การเชื่อมโยงกันกำหนดความเชื่อมโยงที่เป็นไปได้ระหว่างคำพูดในวาทกรรม เฮ็บบ์ได้เสนอความสัมพันธ์เช่นนี้ดังนี้ -
เราใช้เวลาสองเทอม S0 และ S1 เพื่อแสดงความหมายของสองประโยคที่เกี่ยวข้อง -
ผลลัพธ์
อนุมานได้ว่ารัฐยืนยันตามระยะ S0 อาจทำให้รัฐถูกกล่าวหาโดย S1. ตัวอย่างเช่นข้อความสองข้อความแสดงผลลัพธ์ความสัมพันธ์: Ram ถูกไฟไหม้ ผิวหนังของเขาไหม้
คำอธิบาย
มันอนุมานได้ว่ารัฐยืนยันโดย S1 อาจทำให้รัฐถูกกล่าวหาโดย S0. ตัวอย่างเช่นข้อความสองข้อความแสดงความสัมพันธ์ - รามต่อสู้กับเพื่อนของชยัม เขาเมา
ขนาน
มันอนุมาน p (a1, a2, …) จากการยืนยันของ S0 และ p (b1, b2, …) จากการยืนยัน S1. ที่นี่ ai และ bi คล้ายกันสำหรับ i ทั้งหมด ตัวอย่างเช่นสองคำสั่งขนานกัน - Ram ต้องการรถ ชยัมต้องการเงิน
ความประณีต
มันอนุมานประพจน์ P เดียวกันจากทั้งสองการยืนยัน - S0 และ S1ตัวอย่างเช่นสองข้อความแสดงความสัมพันธ์โดยละเอียด: รามมาจากจั ณ ฑีครห์ Shyam มาจาก Kerala
โอกาส
มันเกิดขึ้นเมื่อสามารถอนุมานการเปลี่ยนแปลงของสถานะได้จากการยืนยันของ S0สถานะสุดท้ายที่สามารถอนุมานได้ S1และในทางกลับกัน. ตัวอย่างเช่นข้อความสองข้อความแสดงโอกาสความสัมพันธ์: รามหยิบหนังสือขึ้นมา เขามอบให้ชยัม
การสร้างโครงสร้างวาทกรรมตามลำดับชั้น
การเชื่อมโยงกันของวาทกรรมทั้งหมดสามารถพิจารณาได้จากโครงสร้างลำดับชั้นระหว่างความสัมพันธ์แบบเชื่อมโยงกัน ตัวอย่างเช่นข้อความต่อไปนี้สามารถแสดงเป็นโครงสร้างลำดับชั้น -
S1 - รามไปที่ธนาคารเพื่อฝากเงิน
S2 - จากนั้นเขาก็นั่งรถไฟไปที่ร้านขายผ้าของ Shyam
S3 - เขาต้องการซื้อเสื้อผ้า
S4 - เขาไม่มีเสื้อผ้าใหม่สำหรับปาร์ตี้
S5 - เขาอยากคุยกับชยัมเกี่ยวกับสุขภาพของเขาด้วย
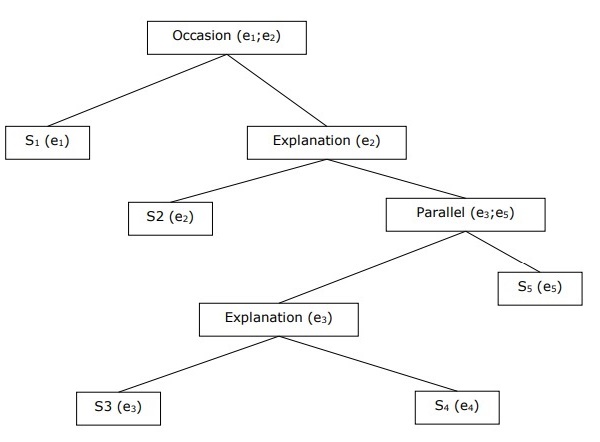
ความละเอียดอ้างอิง
การตีความประโยคจากวาทกรรมใด ๆ เป็นงานที่สำคัญอีกอย่างหนึ่งและเพื่อให้บรรลุเป้าหมายนี้เราจำเป็นต้องรู้ว่าใครหรือหน่วยงานใดที่กำลังพูดถึง ที่นี่การอ้างอิงการตีความเป็นองค์ประกอบสำคัญReferenceอาจถูกกำหนดให้เป็นนิพจน์ทางภาษาเพื่อแสดงถึงเอนทิตีหรือบุคคล ยกตัวอย่างเช่นในทางเดิน, Ram , ผู้จัดการของธนาคารเอบีซีเห็นของเขาเพื่อนยัมที่ร้าน เขาไปพบเขาสำนวนภาษาศาสตร์เช่นรามเขาเขาอ้างอิง
ในบันทึกเดียวกัน reference resolution อาจถูกกำหนดให้เป็นภารกิจในการพิจารณาว่าเอนทิตีใดถูกอ้างถึงโดยนิพจน์ทางภาษาศาสตร์
คำศัพท์ที่ใช้ในการแก้ปัญหาการอ้างอิง
เราใช้คำศัพท์ต่อไปนี้ในการแก้ปัญหาอ้างอิง -
Referring expression- นิพจน์ภาษาธรรมชาติที่ใช้ในการอ้างอิงเรียกว่านิพจน์อ้างอิง ตัวอย่างเช่นข้อความที่ใช้ข้างต้นเป็นนิพจน์อ้างอิง
Referent- เป็นเอนทิตีที่อ้างถึง ตัวอย่างเช่นในตัวอย่างสุดท้ายที่กำหนด Ram เป็นตัวอ้างอิง
Corefer- เมื่อใช้สองนิพจน์เพื่ออ้างถึงเอนทิตีเดียวกันจะเรียกว่าคอร์เฟอร์ ตัวอย่างเช่น,Ram และ he เป็น corefers
Antecedent- คำนี้มีใบอนุญาตให้ใช้คำอื่นได้ ตัวอย่างเช่น,Ram เป็นค่าก่อนหน้าของการอ้างอิง he.
Anaphora & Anaphoric- อาจหมายถึงการอ้างอิงถึงเอนทิตีที่ได้รับการแนะนำก่อนหน้านี้ในประโยค และนิพจน์อ้างอิงเรียกว่า anaphoric
Discourse model - แบบจำลองที่มีการนำเสนอของเอนทิตีที่ถูกอ้างถึงในวาทกรรมและความสัมพันธ์ที่พวกเขามีส่วนร่วม
ประเภทของนิพจน์อ้างอิง
ตอนนี้ให้เราดูนิพจน์การอ้างอิงประเภทต่างๆ นิพจน์การอ้างอิงห้าประเภทได้อธิบายไว้ด้านล่าง -
วลีคำนามไม่แน่นอน
การอ้างอิงแบบนี้แสดงถึงเอนทิตีที่ใหม่สำหรับผู้ฟังในบริบทของวาทกรรม ตัวอย่างเช่น - ในประโยคที่ Ram ไปรอบ ๆ วันหนึ่งเพื่อนำอาหารมาให้เขา - บางส่วนเป็นข้อมูลอ้างอิงที่ไม่มีกำหนด
วลีคำนามที่แน่นอน
ตรงข้ามกับข้างต้นการอ้างอิงประเภทนี้แสดงถึงเอนทิตีที่ไม่ใหม่หรือระบุตัวตนได้ให้ผู้ฟังเข้าสู่บริบทของวาทกรรม ตัวอย่างเช่นในประโยค - ฉันเคยอ่าน The Times of India - The Times of India เป็นการอ้างอิงที่ชัดเจน
สรรพนาม
มันเป็นรูปแบบของการอ้างอิงที่แน่นอน ตัวอย่างเช่นรามหัวเราะดังที่สุดเท่าที่จะทำได้ คำhe แสดงถึงนิพจน์ที่อ้างถึงสรรพนาม
การสาธิต
สิ่งเหล่านี้แสดงให้เห็นและมีพฤติกรรมที่แตกต่างจากคำสรรพนามที่เรียบง่าย ตัวอย่างเช่นนี่และนั่นคือคำสรรพนามที่แสดงให้เห็น
ชื่อ
เป็นนิพจน์อ้างอิงประเภทที่ง่ายที่สุด อาจเป็นชื่อบุคคลองค์กรและสถานที่ได้ด้วย ตัวอย่างเช่นในตัวอย่างข้างต้น Ram เป็นนิพจน์การตัดสินชื่อ
งานการแก้ปัญหาการอ้างอิง
งานการแก้ปัญหาการอ้างอิงสองงานได้อธิบายไว้ด้านล่าง
ความละเอียดของ Coreference
เป็นหน้าที่ในการค้นหานิพจน์อ้างอิงในข้อความที่อ้างถึงเอนทิตีเดียวกัน พูดง่ายๆคือเป็นหน้าที่ในการค้นหานิพจน์ของคอร์เฟอร์ ชุดของนิพจน์ coreferring เรียกว่า coreference chain ตัวอย่างเช่น - เขาหัวหน้าผู้จัดการและเขา - สิ่งเหล่านี้หมายถึงนิพจน์ในข้อความแรกที่ให้ไว้เป็นตัวอย่าง
ข้อ จำกัด เกี่ยวกับความละเอียดของ Coreference
ในภาษาอังกฤษปัญหาหลักสำหรับการแก้ปัญหาแกนกลางคือสรรพนาม เหตุผลที่อยู่เบื้องหลังนี้คือคำสรรพนามมีประโยชน์มากมาย ตัวอย่างเช่นสามารถอ้างถึงเขาและเธอได้มาก สรรพนามยังหมายถึงสิ่งที่ไม่ได้หมายถึงสิ่งที่เฉพาะเจาะจง ตัวอย่างเช่นฝนตก มันดีจริงๆ.
ความละเอียด Anaphora Pronominal
ซึ่งแตกต่างจากความละเอียดของ coreference การแก้ปัญหา anaphora แบบสรรพนามอาจถูกกำหนดให้เป็นภารกิจในการค้นหาคำนำหน้าสำหรับคำสรรพนามเดียว ตัวอย่างเช่นสรรพนามเป็นของเขาและงานของการแก้ปัญหา anaphora สรรพนามคือการค้นหาคำว่า Ram เนื่องจาก Ram เป็นคำก่อนหน้า