การประมวลผลภาษาธรรมชาติ - บทนำ
ภาษาเป็นวิธีการสื่อสารด้วยความช่วยเหลือซึ่งเราสามารถพูดอ่านเขียนได้ ตัวอย่างเช่นเราคิดว่าเราตัดสินใจวางแผนและอื่น ๆ ด้วยภาษาที่เป็นธรรมชาติ แม่นยำในคำพูด อย่างไรก็ตามคำถามใหญ่ที่ทำให้เราต้องเผชิญในยุค AI นี้คือเราสามารถสื่อสารในลักษณะเดียวกันกับคอมพิวเตอร์ได้หรือไม่ กล่าวอีกนัยหนึ่งมนุษย์สามารถสื่อสารกับคอมพิวเตอร์ด้วยภาษาธรรมชาติได้หรือไม่? เป็นความท้าทายสำหรับเราในการพัฒนาแอปพลิเคชัน NLP เนื่องจากคอมพิวเตอร์ต้องการข้อมูลที่มีโครงสร้าง แต่คำพูดของมนุษย์ไม่มีโครงสร้างและมักมีความคลุมเครือ
ในแง่นี้เราสามารถพูดได้ว่า Natural Language Processing (NLP) เป็นสาขาย่อยของวิทยาการคอมพิวเตอร์โดยเฉพาะปัญญาประดิษฐ์ (AI) ที่เกี่ยวข้องกับการทำให้คอมพิวเตอร์เข้าใจและประมวลผลภาษาของมนุษย์ ในทางเทคนิคงานหลักของ NLP คือการเขียนโปรแกรมคอมพิวเตอร์เพื่อวิเคราะห์และประมวลผลข้อมูลภาษาธรรมชาติจำนวนมาก
ประวัติ NLP
เราได้แบ่งประวัติของ NLP ออกเป็นสี่ขั้นตอน ระยะมีความกังวลและสไตล์ที่แตกต่างกัน
ระยะแรก (ระยะการแปลด้วยเครื่อง) - ปลายทศวรรษที่ 1940 ถึงปลายทศวรรษที่ 1960
งานที่ทำในระยะนี้มุ่งเน้นไปที่การแปลด้วยเครื่อง (MT) เป็นหลัก ระยะนี้เป็นช่วงของความกระตือรือร้นและการมองโลกในแง่ดี
ตอนนี้ให้เราดูทั้งหมดที่เฟสแรกมีอยู่ -
การวิจัยเกี่ยวกับ NLP เริ่มต้นในต้นปี 1950 หลังจากการสอบสวนของ Booth & Richens และบันทึกข้อตกลงของ Weaver เกี่ยวกับการแปลด้วยเครื่องในปีพ. ศ. 2492
ปี 1954 เป็นปีที่มีการทดลองแบบ จำกัด เกี่ยวกับการแปลอัตโนมัติจากภาษารัสเซียเป็นภาษาอังกฤษในการทดลองของ Georgetown-IBM
ในปีเดียวกันการตีพิมพ์วารสาร MT (Machine Translation) เริ่มต้นขึ้น
การประชุมระหว่างประเทศครั้งแรกเกี่ยวกับการแปลด้วยเครื่อง (MT) จัดขึ้นในปี พ.ศ. 2495 และครั้งที่สองจัดขึ้นในปี พ.ศ. 2499
ในปีพ. ศ. 2504 งานที่นำเสนอในการประชุมนานาชาติ Teddington เรื่องการแปลภาษาและการวิเคราะห์ภาษาประยุกต์เป็นประเด็นสำคัญของขั้นตอนนี้
ระยะที่สอง (ระยะที่มีอิทธิพลของ AI) - ปลายทศวรรษที่ 1960 ถึงปลายทศวรรษ 1970
ในระยะนี้งานที่ทำนั้นเกี่ยวข้องกับความรู้ทางโลกเป็นหลักและมีบทบาทในการสร้างและจัดการการแสดงความหมาย นั่นคือเหตุผลที่ระยะนี้เรียกอีกอย่างว่าเฟสปรุงแต่ง AI
เฟสมีดังต่อไปนี้ -
ในช่วงต้นปีพ. ศ. 2504 งานนี้ได้เริ่มต้นขึ้นเกี่ยวกับปัญหาในการจัดการและสร้างข้อมูลหรือฐานความรู้ งานนี้ได้รับอิทธิพลจาก AI
ในปีเดียวกันนี้ยังมีการพัฒนาระบบตอบคำถาม BASEBALL ข้อมูลเข้าสู่ระบบนี้ถูก จำกัด และการประมวลผลภาษาที่เกี่ยวข้องเป็นเรื่องง่าย
มีการอธิบายระบบขั้นสูงมากใน Minsky (1968) ระบบนี้เมื่อเปรียบเทียบกับระบบตอบคำถาม BASEBALL ได้รับการยอมรับและจัดเตรียมไว้สำหรับความจำเป็นในการอนุมานบนฐานความรู้ในการตีความและตอบสนองต่อการป้อนข้อมูลภาษา
เฟสที่สาม (Grammatico-logical Phase) - ปลายทศวรรษ 1970 ถึงปลายทศวรรษ 1980
เฟสนี้สามารถอธิบายได้ว่าเป็นเฟสไวยากรณ์ - ตรรกะ เนื่องจากความล้มเหลวของการสร้างระบบในทางปฏิบัติในช่วงสุดท้ายนักวิจัยจึงหันไปใช้ตรรกะในการแสดงความรู้และการให้เหตุผลใน AI
ระยะที่สามมีดังต่อไปนี้ -
แนวทางไวยากรณ์ - ตรรกะในช่วงปลายทศวรรษช่วยให้เรามีตัวประมวลผลประโยคที่มีวัตถุประสงค์ทั่วไปที่มีประสิทธิภาพเช่น Core Language Engine ของ SRI และทฤษฎีการเป็นตัวแทนของวาทกรรมซึ่งนำเสนอวิธีการจัดการกับวาทกรรมที่ขยายออกไปมากขึ้น
ในขั้นตอนนี้เรามีทรัพยากรและเครื่องมือที่ใช้ได้จริงเช่นตัวแยกวิเคราะห์เช่น Alvey Natural Language Tools พร้อมกับระบบปฏิบัติการและเชิงพาณิชย์อื่น ๆ เช่นสำหรับการสืบค้นฐานข้อมูล
งานเกี่ยวกับศัพท์ในปี 1980 ยังชี้ไปในทิศทางของวิธีแกรมมาติโก - ตรรกะ
ระยะที่สี่ (Lexical & Corpus Phase) - ทศวรรษที่ 1990
เราสามารถอธิบายสิ่งนี้เป็นเฟสศัพท์ & คลังข้อมูล ขั้นตอนนี้มีการใช้คำศัพท์เกี่ยวกับไวยากรณ์ที่ปรากฏในช่วงปลายทศวรรษ 1980 และกลายเป็นอิทธิพลที่เพิ่มขึ้น มีการปฏิวัติการประมวลผลภาษาธรรมชาติในทศวรรษนี้ด้วยการนำอัลกอริทึมการเรียนรู้ของเครื่องมาใช้สำหรับการประมวลผลภาษา
การศึกษาภาษามนุษย์
ภาษาเป็นองค์ประกอบที่สำคัญสำหรับชีวิตมนุษย์และยังเป็นลักษณะพื้นฐานที่สุดของพฤติกรรมของเรา เราสามารถสัมผัสได้ในสองรูปแบบส่วนใหญ่คือเขียนและพูด ในรูปแบบที่เป็นลายลักษณ์อักษรเป็นการส่งต่อความรู้ของเราจากรุ่นหนึ่งไปยังรุ่นต่อไป ในรูปแบบการพูดมันเป็นสื่อหลักสำหรับมนุษย์ในการประสานงานซึ่งกันและกันในพฤติกรรมประจำวันของพวกเขา ภาษาได้รับการศึกษาในสาขาวิชาการต่างๆ ระเบียบวินัยแต่ละข้อมีชุดปัญหาของตัวเองและชุดวิธีแก้ไขเพื่อจัดการกับปัญหาเหล่านั้น
พิจารณาตารางต่อไปนี้เพื่อทำความเข้าใจสิ่งนี้ -
| วินัย | ปัญหา | เครื่องมือ |
|---|---|---|
นักภาษาศาสตร์ |
วลีและประโยคสามารถสร้างขึ้นด้วยคำได้อย่างไร? อะไรเป็นตัวยับยั้งความหมายที่เป็นไปได้ของประโยค? |
สัญชาตญาณเกี่ยวกับรูปร่างที่ดีและความหมาย แบบจำลองโครงสร้างทางคณิตศาสตร์ ตัวอย่างเช่นความหมายเชิงทฤษฎีแบบจำลองทฤษฎีภาษาที่เป็นทางการ |
นักจิตวิทยา |
มนุษย์สามารถระบุโครงสร้างของประโยคได้อย่างไร? ความหมายของคำสามารถระบุได้อย่างไร? ความเข้าใจเกิดขึ้นเมื่อใด |
เทคนิคการทดลองส่วนใหญ่สำหรับการวัดประสิทธิภาพของมนุษย์ การวิเคราะห์ทางสถิติของการสังเกต |
นักปรัชญา |
คำและประโยคได้รับความหมายอย่างไร? วัตถุถูกระบุด้วยคำพูดอย่างไร? มันหมายความว่าอะไร? |
การโต้แย้งภาษาธรรมชาติโดยใช้สัญชาตญาณ แบบจำลองทางคณิตศาสตร์เช่นตรรกะและทฤษฎีแบบจำลอง |
นักภาษาศาสตร์เชิงคำนวณ |
เราจะระบุโครงสร้างของประโยคได้อย่างไร ความรู้และเหตุผลสามารถจำลองได้อย่างไร? เราจะใช้ภาษาเพื่อทำงานบางอย่างให้สำเร็จได้อย่างไร? |
อัลกอริทึม โครงสร้างข้อมูล แบบจำลองทางการของการแสดงและการให้เหตุผล เทคนิค AI เช่นวิธีการค้นหาและการเป็นตัวแทน |
ความคลุมเครือและความไม่แน่นอนในภาษา
ความคลุมเครือโดยทั่วไปใช้ในการประมวลผลภาษาธรรมชาติสามารถเรียกได้ว่าเป็นความสามารถในการเข้าใจได้มากกว่าหนึ่งวิธี พูดง่ายๆก็คือเราสามารถพูดได้ว่าความคลุมเครือคือความสามารถในการเข้าใจได้มากกว่าหนึ่งวิธี ภาษาธรรมชาติมีความคลุมเครือมาก NLP มีความคลุมเครือประเภทต่อไปนี้ -
ความคลุมเครือของคำศัพท์
ความไม่ชัดเจนของคำเดียวเรียกว่าความไม่ชัดเจนของศัพท์ ตัวอย่างเช่นการรักษาคำsilver เป็นคำนามคำคุณศัพท์หรือคำกริยา
ความไม่ชัดเจนของไวยากรณ์
ความคลุมเครือประเภทนี้เกิดขึ้นเมื่อมีการแยกวิเคราะห์ประโยคในรูปแบบต่างๆ ตัวอย่างเช่นประโยค“ ชายเห็นหญิงสาวด้วยกล้องโทรทรรศน์” มีความคลุมเครือว่าชายคนนั้นเห็นหญิงสาวถือกล้องโทรทรรศน์หรือเขาเห็นเธอผ่านกล้องโทรทรรศน์ของเขา
ความไม่ชัดเจนของความหมาย
ความคลุมเครือแบบนี้เกิดขึ้นเมื่อความหมายของคำพูดนั้นสามารถตีความผิดได้ กล่าวอีกนัยหนึ่งความคลุมเครือทางความหมายเกิดขึ้นเมื่อประโยคมีคำหรือวลีที่คลุมเครือ ตัวอย่างเช่นประโยค“ รถชนเสาในขณะที่กำลังเคลื่อนที่” มีความหมายไม่ชัดเจนเนื่องจากการตีความอาจเป็น“ รถขณะเคลื่อนที่ชนเสา” และ“ รถชนเสาขณะที่เสากำลังเคลื่อนที่”
Anaphoric Ambiguity
ความคลุมเครือแบบนี้เกิดขึ้นเนื่องจากการใช้เอนทิตี anaphora ในวาทกรรม ตัวอย่างเช่นม้าวิ่งขึ้นเขา มันชันมาก ไม่นานมันก็เหนื่อย ในที่นี้การอ้างอิงเชิงอนาล็อกของ "มัน" ในสองสถานการณ์ทำให้เกิดความคลุมเครือ
ความคลุมเครือในทางปฏิบัติ
ความคลุมเครือดังกล่าวหมายถึงสถานการณ์ที่บริบทของวลีทำให้เกิดการตีความหลายอย่าง พูดง่ายๆเราสามารถพูดได้ว่าความคลุมเครือในทางปฏิบัติเกิดขึ้นเมื่อข้อความนั้นไม่ได้เจาะจง ตัวอย่างเช่นประโยค“ ฉันชอบคุณเหมือนกัน” สามารถตีความได้หลายแบบเช่นฉันชอบคุณ (เช่นเดียวกับที่คุณชอบฉัน) ฉันชอบคุณ (เหมือนกับที่คนอื่นพูด)
ขั้นตอน NLP
แผนภาพต่อไปนี้แสดงขั้นตอนหรือขั้นตอนเชิงตรรกะในการประมวลผลภาษาธรรมชาติ -
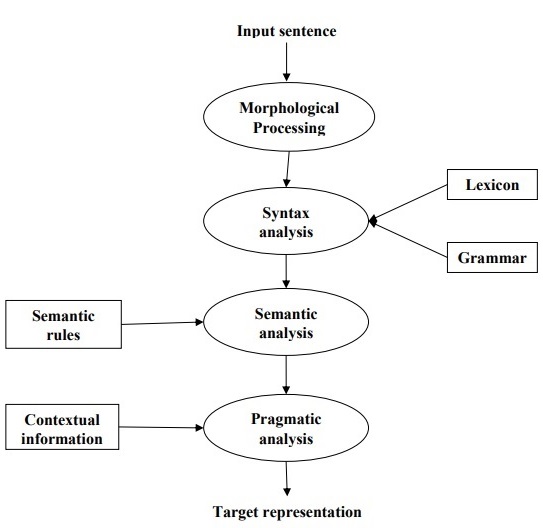
การประมวลผลทางสัณฐานวิทยา
เป็นช่วงแรกของ NLP จุดประสงค์ของขั้นตอนนี้คือการแบ่งส่วนของการป้อนข้อมูลภาษาออกเป็นชุดโทเค็นที่สอดคล้องกับย่อหน้าประโยคและคำ ตัวอย่างเช่นคำเช่น“uneasy” สามารถแบ่งออกเป็นโทเค็นสองคำย่อยเป็น “un-easy”.
การวิเคราะห์ไวยากรณ์
เป็นระยะที่สองของ NLP จุดประสงค์ของระยะนี้มีสองเท่า: เพื่อตรวจสอบว่าประโยคนั้นถูกสร้างขึ้นอย่างถูกต้องหรือไม่และแยกเป็นโครงสร้างที่แสดงความสัมพันธ์ทางวากยสัมพันธ์ระหว่างคำต่างๆ ตัวอย่างเช่นประโยคเช่น“The school goes to the boy” จะถูกปฏิเสธโดยตัววิเคราะห์ไวยากรณ์หรือตัวแยกวิเคราะห์
การวิเคราะห์ความหมาย
เป็นระยะที่สามของ NLP จุดประสงค์ของขั้นตอนนี้คือการดึงความหมายที่แน่นอนหรือคุณสามารถพูดความหมายตามพจนานุกรมจากข้อความ ข้อความถูกตรวจสอบความหมาย ตัวอย่างเช่นตัววิเคราะห์ความหมายจะปฏิเสธประโยคเช่น“ ไอศกรีมร้อน”
การวิเคราะห์เชิงปฏิบัติ
เป็นระยะที่สี่ของ NLP การวิเคราะห์เชิงปฏิบัตินั้นเหมาะกับวัตถุ / เหตุการณ์จริงซึ่งมีอยู่ในบริบทที่กำหนดพร้อมการอ้างอิงวัตถุที่ได้รับในช่วงสุดท้าย (การวิเคราะห์เชิงความหมาย) ตัวอย่างเช่นประโยค“ ใส่กล้วยในตะกร้าบนชั้นวาง” สามารถตีความเชิงความหมายได้สองแบบและตัววิเคราะห์เชิงปฏิบัติจะเลือกระหว่างความเป็นไปได้ทั้งสองนี้