การแยกชิ้นส่วนและข้อมูล
Chunking คืออะไร?
Chunking เป็นหนึ่งในกระบวนการที่สำคัญในการประมวลผลภาษาธรรมชาติใช้เพื่อระบุส่วนของคำพูด (POS) และวลีสั้น ๆ พูดง่ายๆว่าด้วยการแบ่งชิ้นส่วนเราจะได้โครงสร้างของประโยค เรียกอีกอย่างว่าpartial parsing.
รูปแบบก้อนและรอยแตก
Chunk patternsคือรูปแบบของแท็ก part-of-speech (POS) ที่กำหนดประเภทของคำที่ประกอบขึ้นเป็นกลุ่ม เราสามารถกำหนดรูปแบบกลุ่มโดยใช้นิพจน์ทั่วไปที่แก้ไขได้
นอกจากนี้เรายังสามารถกำหนดรูปแบบของคำประเภทที่ไม่ควรอยู่ในกลุ่มคำและคำที่ไม่เรียงกันเหล่านี้เรียกว่า chinks.
ตัวอย่างการใช้งาน
ในตัวอย่างด้านล่างพร้อมกับผลลัพธ์ของการแยกวิเคราะห์ประโยค “the book has many chapters”, มีไวยากรณ์สำหรับวลีคำนามที่รวมทั้งรูปแบบก้อนและแบบบิ่น -
import nltk
sentence = [
("the", "DT"),
("book", "NN"),
("has","VBZ"),
("many","JJ"),
("chapters","NNS")
]
chunker = nltk.RegexpParser(
r'''
NP:{<DT><NN.*><.*>*<NN.*>}
}<VB.*>{
'''
)
chunker.parse(sentence)
Output = chunker.parse(sentence)
Output.draw()เอาต์พุต
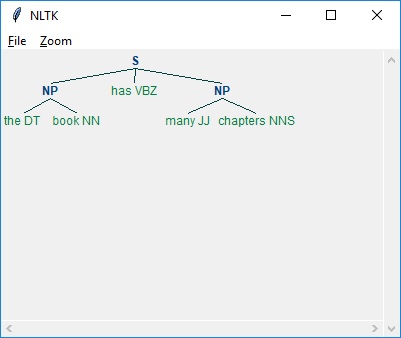
ดังที่เห็นด้านบนรูปแบบในการระบุก้อนคือการใช้วงเล็บปีกกาดังนี้ -
{<DT><NN>}และเพื่อระบุความผิดปกติเราสามารถพลิกวงเล็บปีกกาได้ดังนี้ -
}<VB>{.ตอนนี้สำหรับประเภทวลีหนึ่ง ๆ กฎเหล่านี้สามารถรวมกันเป็นไวยากรณ์ได้
การสกัดข้อมูล
เราได้ดำเนินการผ่าน taggers และ parsers ที่สามารถใช้ในการสร้างเครื่องมือดึงข้อมูล ให้เราดูท่อส่งข้อมูลพื้นฐาน -
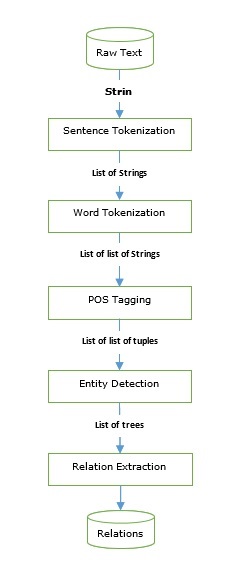
การสกัดข้อมูลมีหลายโปรแกรม ได้แก่ -
- ระบบธุรกิจอัจฉริยะ
- เก็บเกี่ยวต่อ
- การวิเคราะห์สื่อ
- การตรวจจับความรู้สึก
- การค้นหาสิทธิบัตร
- การสแกนอีเมล
การรับรู้ชื่อเอนทิตี (NER)
การจดจำชื่อเอนทิตี (NER) เป็นวิธีการแยกเอนทิตีทั่วไปบางส่วนเช่นชื่อองค์กรสถานที่ตั้ง ฯลฯ ให้เราดูตัวอย่างที่ใช้ขั้นตอนก่อนการประมวลผลทั้งหมดเช่นโทเค็นประโยคการติดแท็ก POS การแบ่งส่วน NER และเป็นไปตามท่อที่ให้ไว้ในรูปด้านบน
ตัวอย่าง
Import nltk
file = open (
# provide here the absolute path for the file of text for which we want NER
)
data_text = file.read()
sentences = nltk.sent_tokenize(data_text)
tokenized_sentences = [nltk.word_tokenize(sentence) for sentence in sentences]
tagged_sentences = [nltk.pos_tag(sentence) for sentence in tokenized_sentences]
for sent in tagged_sentences:
print nltk.ne_chunk(sent)การรับรู้ชื่อเอนทิตี (NER) ที่แก้ไขแล้วบางรายการยังสามารถใช้เพื่อแยกเอนทิตีเช่นชื่อผลิตภัณฑ์เอนทิตีทางการแพทย์ชีวภาพชื่อแบรนด์และอื่น ๆ อีกมากมาย
การแยกความสัมพันธ์
การแยกความสัมพันธ์ซึ่งเป็นอีกหนึ่งการดำเนินการแยกข้อมูลที่ใช้กันทั่วไปคือกระบวนการแยกความสัมพันธ์ที่แตกต่างกันระหว่างเอนทิตีต่างๆ อาจมีความสัมพันธ์ที่แตกต่างกันเช่นการถ่ายทอดทางพันธุกรรมคำพ้องความหมายการเปรียบเทียบ ฯลฯ ซึ่งคำจำกัดความขึ้นอยู่กับความต้องการข้อมูล ตัวอย่างเช่นสมมติว่าหากเราต้องการหางานเขียนหนังสือการประพันธ์จะเป็นความสัมพันธ์ระหว่างชื่อผู้แต่งและชื่อหนังสือ
ตัวอย่าง
ในตัวอย่างต่อไปนี้เราใช้ไปป์ไลน์ IE เดียวกันดังที่แสดงในแผนภาพด้านบนที่เราใช้จนถึง Named-entity relationship (NER) และขยายด้วยรูปแบบความสัมพันธ์ตามแท็ก NER
import nltk
import re
IN = re.compile(r'.*\bin\b(?!\b.+ing)')
for doc in nltk.corpus.ieer.parsed_docs('NYT_19980315'):
for rel in nltk.sem.extract_rels('ORG', 'LOC', doc, corpus = 'ieer',
pattern = IN):
print(nltk.sem.rtuple(rel))เอาต์พุต
[ORG: 'WHYY'] 'in' [LOC: 'Philadelphia']
[ORG: 'McGlashan & Sarrail'] 'firm in' [LOC: 'San Mateo']
[ORG: 'Freedom Forum'] 'in' [LOC: 'Arlington']
[ORG: 'Brookings Institution'] ', the research group in' [LOC: 'Washington']
[ORG: 'Idealab'] ', a self-described business incubator based in' [LOC: 'Los Angeles']
[ORG: 'Open Text'] ', based in' [LOC: 'Waterloo']
[ORG: 'WGBH'] 'in' [LOC: 'Boston']
[ORG: 'Bastille Opera'] 'in' [LOC: 'Paris']
[ORG: 'Omnicom'] 'in' [LOC: 'New York']
[ORG: 'DDB Needham'] 'in' [LOC: 'New York']
[ORG: 'Kaplan Thaler Group'] 'in' [LOC: 'New York']
[ORG: 'BBDO South'] 'in' [LOC: 'Atlanta']
[ORG: 'Georgia-Pacific'] 'in' [LOC: 'Atlanta']ในโค้ดด้านบนเราได้ใช้คลังข้อมูล inbuilt ชื่อ ieer ในคลังข้อมูลนี้ประโยคจะถูกแท็กจนถึงเนมเอนทิตีรีเลชัน (NER) ที่นี่เราจำเป็นต้องระบุรูปแบบความสัมพันธ์ที่เราต้องการและชนิดของ NER ที่เราต้องการให้ความสัมพันธ์กำหนดเท่านั้น ในตัวอย่างของเราเรากำหนดความสัมพันธ์ระหว่างองค์กรและสถานที่ เราแยกการผสมผสานทั้งหมดของรูปแบบเหล่านี้