ชุดเครื่องมือภาษาธรรมชาติ - Unigram Tagger
Unigram Tagger คืออะไร?
ตามความหมายของชื่อ unigram tagger คือแท็กเกอร์ที่ใช้เพียงคำเดียวเป็นบริบทในการกำหนดแท็ก POS (Part-of-Speech) พูดง่ายๆ Unigram Tagger คือแท็กเกอร์ตามบริบทที่มีบริบทเป็นคำเดียวคือ Unigram
มันทำงานอย่างไร?
NLTK จัดเตรียมโมดูลที่ชื่อ UnigramTaggerเพื่อจุดประสงค์นี้. แต่ก่อนที่จะลงลึกในการทำงานให้เราเข้าใจลำดับชั้นด้วยความช่วยเหลือของแผนภาพต่อไปนี้ -
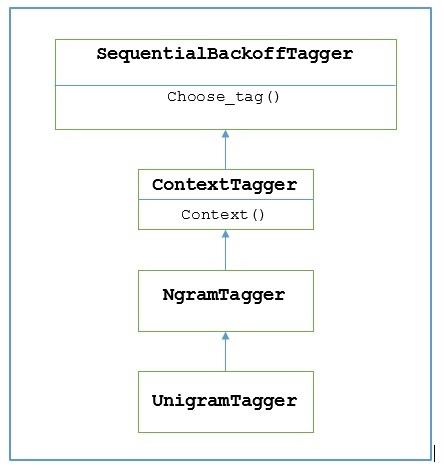
จากแผนภาพด้านบนเป็นที่เข้าใจว่า UnigramTagger สืบทอดมาจาก NgramTagger ซึ่งเป็นคลาสย่อยของ ContextTaggerซึ่งสืบทอดมาจาก SequentialBackoffTagger.
การทำงานของ UnigramTagger อธิบายด้วยความช่วยเหลือของขั้นตอนต่อไปนี้ -
อย่างที่เราเห็น UnigramTagger สืบทอดมาจาก ContextTaggerมันใช้ context()วิธี. นี้context() วิธีการใช้สามอาร์กิวเมนต์เดียวกันกับ choose_tag() วิธี.
ผลของ context()วิธีการจะเป็นโทเค็นคำที่ใช้ในการสร้างแบบจำลองต่อไป เมื่อสร้างแบบจำลองแล้วโทเค็นคำจะถูกใช้เพื่อค้นหาแท็กที่ดีที่สุด
ทางนี้, UnigramTagger จะสร้างแบบจำลองบริบทจากรายการประโยคที่ติดแท็ก
การฝึก Unigram Tagger
NLTK ของ UnigramTaggerสามารถฝึกได้โดยให้รายการประโยคที่ติดแท็กในขณะเริ่มต้น ในตัวอย่างด้านล่างเราจะใช้ประโยคที่ติดแท็กของคลังข้อมูลธนาคารต้นไม้ เราจะใช้ 2500 ประโยคแรกจากคลังข้อมูลนั้น
ตัวอย่าง
ก่อนอื่นให้นำเข้าโมดูล UniframTagger จาก nltk -
from nltk.tag import UnigramTaggerจากนั้นนำเข้าคลังข้อมูลที่คุณต้องการใช้ ที่นี่เรากำลังใช้คลังข้อมูลธนาคารต้นไม้ -
from nltk.corpus import treebankตอนนี้ใช้ประโยคสำหรับการฝึกอบรม เราใช้ 2500 ประโยคแรกเพื่อจุดประสงค์ในการฝึกอบรมและจะแท็ก -
train_sentences = treebank.tagged_sents()[:2500]จากนั้นใช้ UnigramTagger กับประโยคที่ใช้เพื่อการฝึกอบรม -
Uni_tagger = UnigramTagger(train_sentences)ใช้บางประโยคไม่ว่าจะเท่ากับหรือน้อยกว่าที่นำมาเพื่อวัตถุประสงค์ในการฝึกอบรมเช่น 2500 เพื่อการทดสอบ ที่นี่เราใช้ 1,500 คนแรกเพื่อการทดสอบ -
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sents)เอาต์พุต
0.8942306156033808ที่นี่เรามีความแม่นยำประมาณ 89 เปอร์เซ็นต์สำหรับแท็กเกอร์ที่ใช้การค้นหาคำเดียวเพื่อกำหนดแท็ก POS
ตัวอย่างการใช้งานที่สมบูรณ์
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)เอาต์พุต
0.8942306156033808การลบล้างโมเดลบริบท
จากแผนภาพด้านบนแสดงลำดับชั้นสำหรับ UnigramTaggerเรารู้จักแท็กเกอร์ทั้งหมดที่สืบทอดมาจาก ContextTaggerแทนที่จะฝึกด้วยตนเองสามารถใช้แบบจำลองที่สร้างไว้ล่วงหน้า โมเดลที่สร้างไว้ล่วงหน้านี้เป็นเพียงการแมปพจนานุกรม Python ของคีย์บริบทไปยังแท็ก และสำหรับUnigramTaggerคีย์บริบทคือคำแต่ละคำในขณะที่คำอื่น ๆ NgramTagger คลาสย่อยมันจะเป็นทูเปิล
เราสามารถลบล้างโมเดลบริบทนี้ได้โดยส่งโมเดลพื้นฐานอื่นไปยังไฟล์ UnigramTaggerชั้นเรียนแทนที่จะผ่านชุดฝึก ให้เราเข้าใจโดยใช้ตัวอย่างง่ายๆด้านล่าง -
ตัวอย่าง
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
Override_tagger = UnigramTagger(model = {‘Vinken’ : ‘NN’})
Override_tagger.tag(treebank.sents()[0])เอาต์พุต
[
('Pierre', None),
('Vinken', 'NN'),
(',', None),
('61', None),
('years', None),
('old', None),
(',', None),
('will', None),
('join', None),
('the', None),
('board', None),
('as', None),
('a', None),
('nonexecutive', None),
('director', None),
('Nov.', None),
('29', None),
('.', None)
]เนื่องจากโมเดลของเรามี 'Vinken' เป็นคีย์บริบทเพียงอย่างเดียวคุณสามารถสังเกตได้จากผลลัพธ์ด้านบนว่ามีเพียงคำนี้เท่านั้นที่มีแท็กและคำอื่น ๆ ทุกคำไม่มีเป็นแท็ก
การกำหนดเกณฑ์ความถี่ขั้นต่ำ
สำหรับการตัดสินใจว่าแท็กใดมีแนวโน้มมากที่สุดสำหรับบริบทหนึ่ง ๆ ContextTaggerคลาสใช้ความถี่ของการเกิดขึ้น มันจะทำตามค่าเริ่มต้นแม้ว่าคำบริบทและแท็กจะเกิดขึ้นเพียงครั้งเดียว แต่เราสามารถกำหนดเกณฑ์ความถี่ขั้นต่ำได้โดยส่งcutoff ค่า UnigramTaggerชั้นเรียน ในตัวอย่างด้านล่างเรากำลังส่งผ่านค่าคัตออฟในสูตรก่อนหน้าซึ่งเราฝึก UnigramTagger -
ตัวอย่าง
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences, cutoff = 4)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)เอาต์พุต
0.7357651629613641