Stemming & Lemmatization
Stemming คืออะไร?
Stemming เป็นเทคนิคที่ใช้ในการแยกรูปแบบฐานของคำโดยการลบคำติดออกจากคำเหล่านั้น มันก็เหมือนกับการตัดกิ่งก้านของต้นไม้ไปที่ลำต้นของมัน ตัวอย่างเช่นก้านของคำeating, eats, eaten คือ eat.
เครื่องมือค้นหาใช้ Stemming สำหรับการสร้างดัชนีคำ นั่นเป็นเหตุผลที่แทนที่จะจัดเก็บคำทุกรูปแบบเครื่องมือค้นหาสามารถจัดเก็บเฉพาะลำต้นได้ ด้วยวิธีนี้ Stemming จะลดขนาดของดัชนีและเพิ่มความแม่นยำในการดึงข้อมูล
อัลกอริธึม Stemming ต่างๆ
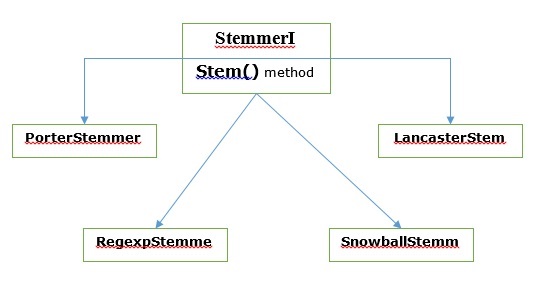
ใน NLTK stemmerI, ที่มี stem()วิธีการอินเทอร์เฟซมีต้นกำเนิดทั้งหมดที่เราจะกล่าวถึงต่อไป ให้เราเข้าใจด้วยแผนภาพต่อไปนี้
ขั้นตอนวิธีการสกัดกั้น Porter
เป็นหนึ่งในอัลกอริธึมการแยกคำที่ใช้กันทั่วไปซึ่งได้รับการออกแบบมาเพื่อลบและแทนที่คำต่อท้ายของคำภาษาอังกฤษที่รู้จักกันดี
ชั้น PorterStemmer
NLTK มี PorterStemmerคลาสด้วยความช่วยเหลือซึ่งเราสามารถใช้อัลกอริธึม Porter Stemmer สำหรับคำที่เราต้องการเรียกได้อย่างง่ายดาย คลาสนี้รู้จักรูปแบบคำปกติและคำต่อท้ายหลายแบบด้วยความช่วยเหลือซึ่งสามารถเปลี่ยนคำที่ป้อนให้เป็นคำสุดท้ายได้ ลำต้นที่เกิดมักเป็นคำสั้น ๆ ที่มีความหมายรากเดียวกัน ให้เราดูตัวอย่าง -
ขั้นแรกเราต้องนำเข้าชุดเครื่องมือภาษาธรรมชาติ (nltk)
import nltkตอนนี้นำเข้าไฟล์ PorterStemmer คลาสเพื่อใช้อัลกอริทึม Porter Stemmer
from nltk.stem import PorterStemmerจากนั้นสร้างอินสแตนซ์ของคลาส Porter Stemmer ดังนี้ -
word_stemmer = PorterStemmer()ตอนนี้ป้อนคำที่คุณต้องการกำเนิด
word_stemmer.stem('writing')เอาต์พุต
'write'word_stemmer.stem('eating')เอาต์พุต
'eat'ตัวอย่างการใช้งานที่สมบูรณ์
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('writing')เอาต์พุต
'write'อัลกอริธึมการสกัดกั้นของ Lancaster
ได้รับการพัฒนาที่มหาวิทยาลัย Lancaster และเป็นอีกหนึ่งอัลกอริธึมการหยุดชะงักที่พบบ่อยมาก
ระดับ LancasterStemmer
NLTK มี LancasterStemmerคลาสด้วยความช่วยเหลือซึ่งเราสามารถใช้อัลกอริทึม Lancaster Stemmer สำหรับคำที่เราต้องการเรียกได้อย่างง่ายดาย ให้เราดูตัวอย่าง -
ขั้นแรกเราต้องนำเข้าชุดเครื่องมือภาษาธรรมชาติ (nltk)
import nltkตอนนี้นำเข้าไฟล์ LancasterStemmer คลาสเพื่อใช้อัลกอริทึม Lancaster Stemmer
from nltk.stem import LancasterStemmerจากนั้นสร้างอินสแตนซ์ของ LancasterStemmer ชั้นเรียนดังนี้ -
Lanc_stemmer = LancasterStemmer()ตอนนี้ป้อนคำที่คุณต้องการกำเนิด
Lanc_stemmer.stem('eats')เอาต์พุต
'eat'ตัวอย่างการใช้งานที่สมบูรณ์
import nltk
from nltk.stem import LancatserStemmer
Lanc_stemmer = LancasterStemmer()
Lanc_stemmer.stem('eats')เอาต์พุต
'eat'อัลกอริธึมการหยุดนิพจน์ทั่วไป
ด้วยความช่วยเหลือของอัลกอริทึมการแยกนี้เราสามารถสร้างสเต็มเมอร์ของเราเองได้
คลาส RegexpStemmer
NLTK มี RegexpStemmerคลาสด้วยความช่วยเหลือซึ่งเราสามารถใช้อัลกอริทึม Regular Expression Stemmer ได้อย่างง่ายดาย โดยทั่วไปจะใช้นิพจน์ทั่วไปเดียวและลบคำนำหน้าหรือคำต่อท้ายที่ตรงกับนิพจน์ ให้เราดูตัวอย่าง -
ขั้นแรกเราต้องนำเข้าชุดเครื่องมือภาษาธรรมชาติ (nltk)
import nltkตอนนี้นำเข้าไฟล์ RegexpStemmer คลาสเพื่อใช้อัลกอริทึม Regular Expression Stemmer
from nltk.stem import RegexpStemmerจากนั้นสร้างอินสแตนซ์ของ RegexpStemmer คลาสและระบุคำต่อท้ายหรือคำนำหน้าที่คุณต้องการลบออกจากคำดังนี้ -
Reg_stemmer = RegexpStemmer(‘ing’)ตอนนี้ป้อนคำที่คุณต้องการกำเนิด
Reg_stemmer.stem('eating')เอาต์พุต
'eat'Reg_stemmer.stem('ingeat')เอาต์พุต
'eat'
Reg_stemmer.stem('eats')เอาต์พุต
'eat'ตัวอย่างการใช้งานที่สมบูรณ์
import nltk
from nltk.stem import RegexpStemmer
Reg_stemmer = RegexpStemmer()
Reg_stemmer.stem('ingeat')เอาต์พุต
'eat'อัลกอริธึมการกำเนิดสโนว์บอล
มันเป็นอีกหนึ่งอัลกอริธึมที่มีประโยชน์มาก
สโนว์บอลคลาส Stemmer
NLTK มี SnowballStemmerคลาสด้วยความช่วยเหลือซึ่งเราสามารถใช้อัลกอริทึม Snowball Stemmer ได้อย่างง่ายดาย รองรับ 15 ภาษาที่ไม่ใช่ภาษาอังกฤษ ในการใช้คลาสนึ่งนี้เราจำเป็นต้องสร้างอินสแตนซ์ที่มีชื่อภาษาที่เราใช้แล้วเรียกเมธอด stem () ให้เราดูตัวอย่าง -
ขั้นแรกเราต้องนำเข้าชุดเครื่องมือภาษาธรรมชาติ (nltk)
import nltkตอนนี้นำเข้าไฟล์ SnowballStemmer คลาสเพื่อใช้อัลกอริทึม Snowball Stemmer
from nltk.stem import SnowballStemmerให้เราดูภาษาที่รองรับ -
SnowballStemmer.languagesเอาต์พุต
(
'arabic',
'danish',
'dutch',
'english',
'finnish',
'french',
'german',
'hungarian',
'italian',
'norwegian',
'porter',
'portuguese',
'romanian',
'russian',
'spanish',
'swedish'
)จากนั้นสร้างอินสแตนซ์ของคลาส SnowballStemmer ด้วยภาษาที่คุณต้องการใช้ ที่นี่เรากำลังสร้างตัวตั้งต้นสำหรับภาษา "ฝรั่งเศส"
French_stemmer = SnowballStemmer(‘french’)ตอนนี้เรียกใช้วิธี stem () และป้อนคำที่คุณต้องการตั้งต้น
French_stemmer.stem (‘Bonjoura’)เอาต์พุต
'bonjour'ตัวอย่างการใช้งานที่สมบูรณ์
import nltk
from nltk.stem import SnowballStemmer
French_stemmer = SnowballStemmer(‘french’)
French_stemmer.stem (‘Bonjoura’)เอาต์พุต
'bonjour'Lemmatization คืออะไร?
เทคนิค Lemmatization ก็เหมือนกับการ Stemming ผลลัพธ์ที่เราจะได้รับหลังจากการทำให้เป็นตัวอักษรเรียกว่า 'เลมมา' ซึ่งเป็นคำรากมากกว่ารากซึ่งเป็นผลลัพธ์ของการสร้างคำ หลังจากสร้างคำศัพท์แล้วเราจะได้คำที่ถูกต้องซึ่งหมายถึงสิ่งเดียวกัน
NLTK ให้ WordNetLemmatizer คลาสซึ่งเป็นกระดาษห่อบาง ๆ รอบ ๆ wordnetคลังข้อมูล คลาสนี้ใช้morphy() ฟังก์ชันไปที่ WordNet CorpusReaderชั้นเรียนเพื่อค้นหาคำหลัก ให้เราเข้าใจด้วยตัวอย่าง -
ตัวอย่าง
ขั้นแรกเราต้องนำเข้าชุดเครื่องมือภาษาธรรมชาติ (nltk)
import nltkตอนนี้นำเข้าไฟล์ WordNetLemmatizer คลาสเพื่อใช้เทคนิคการทำให้เป็นตัวอักษร
from nltk.stem import WordNetLemmatizerจากนั้นสร้างอินสแตนซ์ของ WordNetLemmatizer ชั้นเรียน
lemmatizer = WordNetLemmatizer()ตอนนี้เรียกเมธอด lemmatize () และป้อนคำที่คุณต้องการค้นหา lemma
lemmatizer.lemmatize('eating')เอาต์พุต
'eating'lemmatizer.lemmatize('books')เอาต์พุต
'book'ตัวอย่างการใช้งานที่สมบูรณ์
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize('books')เอาต์พุต
'book'ความแตกต่างระหว่าง Stemming & Lemmatization
ให้เราเข้าใจความแตกต่างระหว่าง Stemming และ Lemmatization ด้วยความช่วยเหลือของตัวอย่างต่อไปนี้ -
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('believes')เอาต์พุต
believimport nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize(' believes ')เอาต์พุต
believผลลัพธ์ของทั้งสองโปรแกรมจะบอกถึงความแตกต่างที่สำคัญระหว่างการสะกดคำและการทำให้เป็นตัวอักษร PorterStemmerคลาสตัด 'es' ออกจากคำ ในทางกลับกัน,WordNetLemmatizerชั้นเรียนพบคำที่ถูกต้อง ในคำง่ายๆเทคนิคการสร้างคำจะดูที่รูปแบบของคำเท่านั้นในขณะที่เทคนิคการสร้างคำอธิบายจะดูที่ความหมายของคำ หมายความว่าหลังจากใช้คำนามเราจะได้คำที่ถูกต้องเสมอ