Python Web Scraping - การจัดการกับข้อความ
ในบทที่แล้วเราได้เห็นวิธีจัดการกับวิดีโอและรูปภาพที่เราได้รับเป็นส่วนหนึ่งของเนื้อหาในการขูดเว็บ ในบทนี้เราจะจัดการกับการวิเคราะห์ข้อความโดยใช้ไลบรารี Python และจะเรียนรู้เกี่ยวกับเรื่องนี้โดยละเอียด
บทนำ
คุณสามารถทำการวิเคราะห์ข้อความโดยใช้ไลบรารี Python ที่เรียกว่า Natural Language Tool Kit (NLTK) ก่อนดำเนินการตามแนวคิดของ NLTK ขอให้เราเข้าใจความสัมพันธ์ระหว่างการวิเคราะห์ข้อความและการคัดลอกเว็บ
การวิเคราะห์คำในข้อความสามารถทำให้เรารู้ว่าคำไหนสำคัญคำไหนผิดปกติมีการจัดกลุ่มคำอย่างไร การวิเคราะห์นี้ช่วยให้งานขูดเว็บง่ายขึ้น
เริ่มต้นกับ NLTK
ชุดเครื่องมือภาษาธรรมชาติ (NLTK) คือชุดของไลบรารี Python ซึ่งออกแบบมาโดยเฉพาะสำหรับการระบุและแท็กส่วนของคำพูดที่พบในข้อความของภาษาธรรมชาติเช่นภาษาอังกฤษ
การติดตั้ง NLTK
คุณสามารถใช้คำสั่งต่อไปนี้เพื่อติดตั้ง NLTK ใน Python -
pip install nltkหากคุณใช้ Anaconda คุณสามารถสร้างแพ็คเกจ conda สำหรับ NLTK ได้โดยใช้คำสั่งต่อไปนี้ -
conda install -c anaconda nltkกำลังดาวน์โหลดข้อมูลของ NLTK
หลังจากติดตั้ง NLTK เราต้องดาวน์โหลดที่เก็บข้อความที่ตั้งไว้ล่วงหน้า แต่ก่อนที่จะดาวน์โหลดที่เก็บข้อความที่ตั้งไว้ล่วงหน้าเราจำเป็นต้องนำเข้า NLTK ด้วยความช่วยเหลือของไฟล์import คำสั่งดังนี้ -
mport nltkตอนนี้ด้วยความช่วยเหลือของคำสั่งต่อไปนี้ข้อมูล NLTK สามารถดาวน์โหลดได้ -
nltk.download()การติดตั้งแพ็คเกจทั้งหมดที่มีของ NLTK จะใช้เวลาพอสมควร แต่ขอแนะนำให้ติดตั้งแพ็คเกจทั้งหมดเสมอ
การติดตั้งแพ็คเกจที่จำเป็นอื่น ๆ
เราต้องการแพ็คเกจ Python อื่น ๆ เช่น gensim และ pattern สำหรับการวิเคราะห์ข้อความและการสร้างแอปพลิเคชันการประมวลผลภาษาธรรมชาติโดยใช้ NLTK
gensim- ไลบรารีการสร้างแบบจำลองความหมายที่แข็งแกร่งซึ่งมีประโยชน์สำหรับแอปพลิเคชันมากมาย สามารถติดตั้งได้โดยคำสั่งต่อไปนี้ -
pip install gensimpattern - ใช้ในการทำ gensimแพคเกจทำงานอย่างถูกต้อง สามารถติดตั้งได้โดยคำสั่งต่อไปนี้ -
pip install patternTokenization
กระบวนการทำลายข้อความที่กำหนดให้เป็นหน่วยเล็ก ๆ ที่เรียกว่าโทเค็นเรียกว่าโทเค็น โทเค็นเหล่านี้อาจเป็นคำตัวเลขหรือเครื่องหมายวรรคตอน เรียกอีกอย่างว่าword segmentation.
ตัวอย่าง

โมดูล NLTK มีแพ็คเกจที่แตกต่างกันสำหรับโทเค็น เราสามารถใช้แพ็คเกจเหล่านี้ได้ตามความต้องการของเรา บางส่วนของแพ็คเกจมีอธิบายไว้ที่นี่ -
sent_tokenize package- แพ็คเกจนี้จะแบ่งข้อความที่ป้อนออกเป็นประโยค คุณสามารถใช้คำสั่งต่อไปนี้เพื่อนำเข้าแพ็คเกจนี้ -
from nltk.tokenize import sent_tokenizeword_tokenize package- แพ็คเกจนี้จะแบ่งข้อความที่ป้อนเป็นคำ คุณสามารถใช้คำสั่งต่อไปนี้เพื่อนำเข้าแพ็คเกจนี้ -
from nltk.tokenize import word_tokenizeWordPunctTokenizer package- แพ็คเกจนี้จะแบ่งข้อความที่ป้อนและเครื่องหมายวรรคตอนออกเป็นคำ คุณสามารถใช้คำสั่งต่อไปนี้เพื่อนำเข้าแพ็คเกจนี้ -
from nltk.tokenize import WordPuncttokenizerStemming
ในภาษาใด ๆ มีคำในรูปแบบต่างๆ ภาษามีรูปแบบต่างๆมากมายเนื่องจากเหตุผลทางไวยากรณ์ ตัวอย่างเช่นพิจารณาคำdemocracy, democraticและ democratization. สำหรับแมชชีนเลิร์นนิงและโปรเจ็กต์การขูดเว็บสิ่งสำคัญคือต้องให้เครื่องจักรเข้าใจว่าคำต่างๆเหล่านี้มีรูปแบบฐานเดียวกัน ดังนั้นเราสามารถพูดได้ว่าการแยกรูปแบบฐานของคำในขณะที่วิเคราะห์ข้อความจะมีประโยชน์
สิ่งนี้สามารถทำได้โดยการแยกส่วนซึ่งอาจนิยามได้ว่าเป็นกระบวนการฮิวริสติกในการแยกรูปแบบฐานของคำโดยการตัดส่วนท้ายของคำออก
โมดูล NLTK มีแพ็คเกจที่แตกต่างกันสำหรับการสกัดกั้น เราสามารถใช้แพ็คเกจเหล่านี้ได้ตามความต้องการของเรา บางส่วนของแพ็คเกจเหล่านี้มีคำอธิบายไว้ที่นี่ -
PorterStemmer package- อัลกอริทึมของ Porter ถูกใช้โดยแพ็คเกจ Python Stemming นี้เพื่อดึงรูปแบบพื้นฐาน คุณสามารถใช้คำสั่งต่อไปนี้เพื่อนำเข้าแพ็คเกจนี้ -
from nltk.stem.porter import PorterStemmerตัวอย่างเช่นหลังจากให้คำ ‘writing’ ในฐานะที่เป็นอินพุตของตัวตั้งต้นนี้ผลลัพธ์จะเป็นคำ ‘write’ หลังจากหยุดชะงัก
LancasterStemmer package- อัลกอริทึมของ Lancaster ใช้โดยแพ็คเกจ Python Stemming นี้เพื่อแยกรูปแบบพื้นฐาน คุณสามารถใช้คำสั่งต่อไปนี้เพื่อนำเข้าแพ็คเกจนี้ -
from nltk.stem.lancaster import LancasterStemmerตัวอย่างเช่นหลังจากให้คำ ‘writing’ ในฐานะที่เป็นอินพุตของสเต็มเมอร์นี้ผลลัพธ์จะเป็นคำ ‘writ’ หลังจากหยุดชะงัก
SnowballStemmer package- อัลกอริทึมของ Snowball ใช้โดยแพ็คเกจ Python Stemming เพื่อแยกรูปแบบพื้นฐาน คุณสามารถใช้คำสั่งต่อไปนี้เพื่อนำเข้าแพ็คเกจนี้ -
from nltk.stem.snowball import SnowballStemmerตัวอย่างเช่นหลังจากให้คำว่า 'เขียน' เป็นอินพุตของตัวเริ่มต้นแล้วผลลัพธ์จะเป็นคำว่า 'เขียน' หลังจากที่กำหนด
Lemmatization
อีกวิธีหนึ่งในการแยกรูปแบบฐานของคำคือการทำให้เป็นตัวอักษรโดยปกติมีจุดมุ่งหมายเพื่อลบคำลงท้ายที่ผันแปรโดยใช้คำศัพท์และการวิเคราะห์ทางสัณฐานวิทยา รูปแบบฐานของคำใด ๆ หลังการทำให้เป็นตัวอักษรเรียกว่า lemma
โมดูล NLTK มีแพ็คเกจต่อไปนี้สำหรับการย่อขนาด -
WordNetLemmatizer package- มันจะดึงรูปแบบฐานของคำขึ้นอยู่กับว่าใช้เป็นคำนามเป็นคำกริยาหรือไม่ คุณสามารถใช้คำสั่งต่อไปนี้เพื่อนำเข้าแพ็คเกจนี้ -
from nltk.stem import WordNetLemmatizerการจัดเป็นกลุ่ม
การจัดกลุ่มซึ่งหมายถึงการแบ่งข้อมูลออกเป็นชิ้นเล็ก ๆ เป็นหนึ่งในกระบวนการที่สำคัญในการประมวลผลภาษาธรรมชาติเพื่อระบุส่วนของคำพูดและวลีสั้น ๆ เช่นวลีคำนาม Chunking คือการทำฉลากของโทเค็น เราสามารถรับโครงสร้างของประโยคด้วยความช่วยเหลือของกระบวนการแยกชิ้นส่วน
ตัวอย่าง
ในตัวอย่างนี้เราจะใช้ Noun-Phrase chunking โดยใช้โมดูล NLTK Python NP chunking เป็นหมวดหมู่ของ chunking ซึ่งจะพบคำนามวลีในประโยค
ขั้นตอนในการใช้การแบ่งวลีคำนาม
เราจำเป็นต้องทำตามขั้นตอนที่ระบุด้านล่างสำหรับการใช้คำนามวลี -
ขั้นตอนที่ 1 - นิยามไวยากรณ์แบบกลุ่ม
ในขั้นตอนแรกเราจะกำหนดไวยากรณ์สำหรับ chunking มันจะประกอบด้วยกฎที่เราต้องปฏิบัติตาม
ขั้นตอนที่ 2 - การสร้างตัวแยกวิเคราะห์แบบก้อน
ตอนนี้เราจะสร้างตัวแยกวิเคราะห์แบบก้อน มันจะแยกวิเคราะห์ไวยากรณ์และให้ผลลัพธ์
ขั้นตอนที่ 3 - ผลลัพธ์
ในขั้นตอนสุดท้ายนี้ผลลัพธ์จะถูกสร้างในรูปแบบต้นไม้
ก่อนอื่นเราต้องนำเข้าแพ็คเกจ NLTK ดังนี้ -
import nltkต่อไปเราต้องกำหนดประโยค ที่นี่ DT: ดีเทอร์มิแนนต์, VBP: คำกริยา, JJ: คำคุณศัพท์, IN: คำบุพบทและ NN: คำนาม
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]ต่อไปเราจะให้ไวยากรณ์ในรูปแบบของนิพจน์ทั่วไป
grammar = "NP:{<DT>?<JJ>*<NN>}"ตอนนี้บรรทัดถัดไปของโค้ดจะกำหนดตัวแยกวิเคราะห์สำหรับการแยกวิเคราะห์ไวยากรณ์
parser_chunking = nltk.RegexpParser(grammar)ตอนนี้โปรแกรมแยกวิเคราะห์จะแยกวิเคราะห์ประโยค
parser_chunking.parse(sentence)ต่อไปเราจะให้ผลลัพธ์ของเราในตัวแปร
Output = parser_chunking.parse(sentence)ด้วยความช่วยเหลือของรหัสต่อไปนี้เราสามารถวาดผลลัพธ์ของเราในรูปแบบของต้นไม้ดังที่แสดงด้านล่าง
output.draw()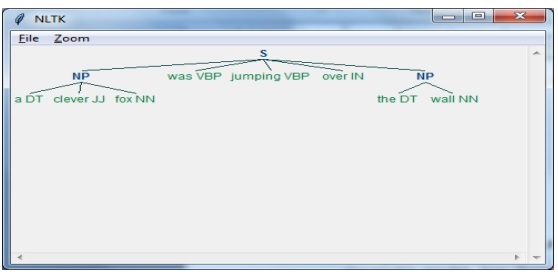
Bag of Word (BoW) Model การแยกและแปลงข้อความเป็นรูปแบบตัวเลข
Bag of Word (BoW) ซึ่งเป็นรูปแบบที่มีประโยชน์ในการประมวลผลภาษาธรรมชาติโดยทั่วไปจะใช้เพื่อแยกคุณสมบัติออกจากข้อความ หลังจากแยกคุณสมบัติออกจากข้อความแล้วจะสามารถใช้ในการสร้างแบบจำลองในอัลกอริทึมการเรียนรู้ของเครื่องเนื่องจากไม่สามารถใช้ข้อมูลดิบในแอปพลิเคชัน ML ได้
การทำงานของ BoW Model
ในขั้นต้นโมเดลจะแยกคำศัพท์จากคำทั้งหมดในเอกสาร ต่อมาโดยใช้เมทริกซ์คำศัพท์ของเอกสารจะสร้างแบบจำลอง ด้วยวิธีนี้แบบจำลอง BoW จะแสดงเอกสารเป็นถุงคำเท่านั้นและคำสั่งหรือโครงสร้างจะถูกทิ้ง
ตัวอย่าง
สมมติว่าเรามีสองประโยคต่อไปนี้ -
Sentence1 - นี่คือตัวอย่างโมเดล Bag of Words
Sentence2 - เราสามารถดึงคุณสมบัติโดยใช้โมเดล Bag of Words
ตอนนี้เมื่อพิจารณาสองประโยคนี้เรามีคำที่แตกต่างกัน 14 คำต่อไปนี้ -
- This
- is
- an
- example
- bag
- of
- words
- model
- we
- can
- extract
- features
- by
- using
การสร้างแบบจำลองถุงคำใน NLTK
ให้เราดูสคริปต์ Python ต่อไปนี้ซึ่งจะสร้างโมเดล BoW ใน NLTK
ขั้นแรกให้นำเข้าแพ็คเกจต่อไปนี้ -
from sklearn.feature_extraction.text import CountVectorizerจากนั้นกำหนดชุดของประโยค -
Sentences=['This is an example of Bag of Words model.', ' We can extract
features by using Bag of Words model.']
vector_count = CountVectorizer()
features_text = vector_count.fit_transform(Sentences).todense()
print(vector_count.vocabulary_)เอาต์พุต
แสดงว่าเรามีคำที่แตกต่างกัน 14 คำในสองประโยคข้างต้น -
{
'this': 10, 'is': 7, 'an': 0, 'example': 4, 'of': 9,
'bag': 1, 'words': 13, 'model': 8, 'we': 12, 'can': 3,
'extract': 5, 'features': 6, 'by': 2, 'using':11
}การสร้างแบบจำลองหัวข้อ: การระบุรูปแบบในข้อมูลข้อความ
โดยทั่วไปเอกสารจะถูกจัดกลุ่มเป็นหัวข้อและการสร้างแบบจำลองหัวข้อเป็นเทคนิคในการระบุรูปแบบในข้อความที่สอดคล้องกับหัวข้อเฉพาะ กล่าวอีกนัยหนึ่งการสร้างแบบจำลองหัวข้อจะใช้เพื่อเปิดเผยธีมนามธรรมหรือโครงสร้างที่ซ่อนอยู่ในชุดเอกสารที่กำหนด
คุณสามารถใช้การสร้างแบบจำลองหัวข้อในสถานการณ์ต่อไปนี้ -
การจัดประเภทข้อความ
การจัดหมวดหมู่สามารถปรับปรุงได้โดยการสร้างแบบจำลองหัวข้อเนื่องจากจัดกลุ่มคำที่คล้ายกันเข้าด้วยกันแทนที่จะใช้คำแต่ละคำแยกกันเป็นคุณลักษณะ
ระบบผู้แนะนำ
เราสามารถสร้างระบบผู้แนะนำโดยใช้มาตรการความคล้ายคลึงกัน
อัลกอริทึมการสร้างแบบจำลองหัวข้อ
เราสามารถใช้การสร้างแบบจำลองหัวข้อโดยใช้อัลกอริทึมต่อไปนี้ -
Latent Dirichlet Allocation(LDA) - เป็นหนึ่งในอัลกอริทึมที่ได้รับความนิยมมากที่สุดที่ใช้โมเดลกราฟิกที่น่าจะเป็นในการใช้การสร้างแบบจำลองหัวข้อ
Latent Semantic Analysis(LDA) or Latent Semantic Indexing(LSI) - ขึ้นอยู่กับ Linear Algebra และใช้แนวคิดของ SVD (Singular Value Decomposition) บนเมทริกซ์คำศัพท์ของเอกสาร
Non-Negative Matrix Factorization (NMF) - มันขึ้นอยู่กับพีชคณิตเชิงเส้นเช่นเดียวกับ LDA
อัลกอริทึมที่กล่าวถึงข้างต้นจะมีองค์ประกอบดังต่อไปนี้ -
- จำนวนหัวข้อ: พารามิเตอร์
- Document-Word Matrix: อินพุต
- WTM (เมทริกซ์หัวข้อของ Word) และ TDM (เมทริกซ์เอกสารหัวข้อ): เอาต์พุต