Python Web Scraping - บทนำ
การขูดเว็บเป็นกระบวนการอัตโนมัติในการดึงข้อมูลจากเว็บ บทนี้จะให้แนวคิดเชิงลึกเกี่ยวกับการขูดเว็บการเปรียบเทียบกับการรวบรวมข้อมูลเว็บและเหตุผลที่คุณควรเลือกใช้การขูดเว็บ คุณจะได้เรียนรู้เกี่ยวกับส่วนประกอบและการทำงานของเครื่องขูดเว็บ
Web Scraping คืออะไร?
ความหมายตามพจนานุกรมของคำว่า 'Scrapping' หมายถึงการได้รับบางสิ่งจากเว็บ คำถามสองข้อนี้เกิดขึ้น: สิ่งที่เราจะได้รับจากเว็บและวิธีรับสิ่งนั้น
คำตอบสำหรับคำถามแรกคือ ‘data’. ข้อมูลเป็นสิ่งที่ขาดไม่ได้สำหรับโปรแกรมเมอร์ทุกคนและความต้องการพื้นฐานของโครงการเขียนโปรแกรมทุกโครงการคือข้อมูลที่มีประโยชน์จำนวนมาก
คำตอบสำหรับคำถามที่สองค่อนข้างยุ่งยากเพราะมีหลายวิธีในการรับข้อมูล โดยทั่วไปเราอาจได้รับข้อมูลจากฐานข้อมูลหรือแฟ้มข้อมูลและแหล่งอื่น ๆ แต่ถ้าเราต้องการข้อมูลจำนวนมากที่มีอยู่ทางออนไลน์ล่ะ? วิธีหนึ่งในการรับข้อมูลประเภทนี้คือการค้นหาด้วยตนเอง (คลิกจากเว็บเบราว์เซอร์) และบันทึก (คัดลอกวางลงในสเปรดชีตหรือไฟล์) ข้อมูลที่ต้องการ วิธีนี้ค่อนข้างน่าเบื่อและใช้เวลานาน อีกวิธีหนึ่งในการรับข้อมูลดังกล่าวคือการใช้web scraping.
Web scrapingเรียกอีกอย่างว่า web data mining หรือ web harvestingคือขั้นตอนการสร้างตัวแทนที่สามารถแยกวิเคราะห์ดาวน์โหลดและจัดระเบียบข้อมูลที่เป็นประโยชน์จากเว็บโดยอัตโนมัติ กล่าวอีกนัยหนึ่งเราสามารถพูดได้ว่าแทนที่จะบันทึกข้อมูลจากเว็บไซต์ด้วยตนเองซอฟต์แวร์คัดลอกเว็บจะโหลดและดึงข้อมูลจากหลายเว็บไซต์โดยอัตโนมัติตามความต้องการของเรา
ที่มาของการขูดเว็บ
ต้นกำเนิดของการขูดเว็บคือการลบหน้าจอซึ่งใช้เพื่อรวมแอปพลิเคชันที่ไม่ใช่เว็บหรือแอปพลิเคชัน Windows ดั้งเดิม เดิมใช้การขูดหน้าจอก่อนการใช้งาน World Wide Web (WWW) อย่างกว้างขวาง แต่ไม่สามารถขยายขนาด WWW ได้ สิ่งนี้ทำให้จำเป็นต้องใช้วิธีการขูดหน้าจอโดยอัตโนมัติและเทคนิคที่เรียกว่า‘Web Scraping’ เกิดขึ้น
การรวบรวมข้อมูลเว็บ v / s การขูดเว็บ
คำว่าการรวบรวมข้อมูลเว็บและการคัดลอกมักใช้สลับกันได้เนื่องจากแนวคิดพื้นฐานของคำเหล่านี้คือการดึงข้อมูล อย่างไรก็ตามพวกเขามีความแตกต่างกัน เราสามารถเข้าใจความแตกต่างพื้นฐานจากคำจำกัดความของพวกเขา
การรวบรวมข้อมูลเว็บโดยทั่วไปจะใช้เพื่อจัดทำดัชนีข้อมูลบนหน้าโดยใช้โปรแกรมรวบรวมข้อมูลบอทหรือที่เรียกว่าโปรแกรมรวบรวมข้อมูล เรียกอีกอย่างว่าindexing. ในทางกลับกันการขูดเว็บเป็นวิธีการอัตโนมัติในการดึงข้อมูลโดยใช้บอทหรือที่ขูด เรียกอีกอย่างว่าdata extraction.
เพื่อทำความเข้าใจความแตกต่างระหว่างสองคำนี้ให้เราดูตารางเปรียบเทียบที่ระบุไว้ในที่นี้ -
| การรวบรวมข้อมูลเว็บ | การขูดเว็บ |
|---|---|
| หมายถึงการดาวน์โหลดและจัดเก็บเนื้อหาของเว็บไซต์จำนวนมาก | หมายถึงการดึงข้อมูลแต่ละองค์ประกอบออกจากเว็บไซต์โดยใช้โครงสร้างเฉพาะไซต์ |
| ส่วนใหญ่ทำในขนาดใหญ่ | สามารถใช้งานได้ทุกขนาด |
| ให้ข้อมูลทั่วไป | ให้ข้อมูลเฉพาะ |
| ใช้โดยเครื่องมือค้นหาหลัก ๆ เช่น Google, Bing, Yahoo Googlebot เป็นตัวอย่างของโปรแกรมรวบรวมข้อมูลเว็บ | ข้อมูลที่ดึงโดยใช้การขูดเว็บสามารถใช้เพื่อทำซ้ำในเว็บไซต์อื่น ๆ หรือสามารถใช้เพื่อทำการวิเคราะห์ข้อมูล ตัวอย่างเช่นองค์ประกอบข้อมูลอาจเป็นชื่อที่อยู่ราคาเป็นต้น |
การใช้งานการขูดเว็บ
การใช้และเหตุผลในการใช้การขูดเว็บนั้นไม่มีที่สิ้นสุดเหมือนกับการใช้งานเวิลด์ไวด์เว็บ เครื่องขูดเว็บสามารถทำอะไรก็ได้เช่นสั่งอาหารออนไลน์สแกนเว็บไซต์ช้อปปิ้งออนไลน์ให้คุณและซื้อตั๋วการแข่งขันทันทีที่มีให้บริการเป็นต้นเช่นเดียวกับที่มนุษย์สามารถทำได้ การใช้งานที่สำคัญบางประการของการขูดเว็บจะกล่าวถึงที่นี่ -
E-commerce Websites - เครื่องขูดเว็บสามารถรวบรวมข้อมูลที่เกี่ยวข้องเป็นพิเศษกับราคาของผลิตภัณฑ์เฉพาะจากเว็บไซต์อีคอมเมิร์ซต่างๆเพื่อเปรียบเทียบ
Content Aggregators - การคัดลอกเว็บถูกใช้อย่างกว้างขวางโดยผู้รวบรวมเนื้อหาเช่นผู้รวบรวมข่าวสารและผู้รวบรวมงานเพื่อให้ข้อมูลที่อัปเดตแก่ผู้ใช้ของตน
Marketing and Sales Campaigns - เครื่องขูดเว็บสามารถใช้เพื่อรับข้อมูลเช่นอีเมลหมายเลขโทรศัพท์ ฯลฯ สำหรับแคมเปญการขายและการตลาด
Search Engine Optimization (SEO) - การขูดเว็บถูกใช้อย่างแพร่หลายโดยเครื่องมือ SEO เช่น SEMRush, Majestic เป็นต้นเพื่อบอกธุรกิจว่าพวกเขาจัดอันดับคำค้นหาที่สำคัญกับพวกเขาอย่างไร
Data for Machine Learning Projects - การดึงข้อมูลสำหรับโครงการแมชชีนเลิร์นนิงขึ้นอยู่กับการขูดเว็บ
Data for Research - นักวิจัยสามารถรวบรวมข้อมูลที่มีประโยชน์เพื่อวัตถุประสงค์ในการทำงานวิจัยโดยประหยัดเวลาด้วยกระบวนการอัตโนมัตินี้
ส่วนประกอบของ Web Scraper
มีดโกนเว็บประกอบด้วยส่วนประกอบต่อไปนี้ -
โมดูลโปรแกรมรวบรวมข้อมูลเว็บ
ส่วนประกอบที่จำเป็นมากของเว็บสแครปเปอร์โมดูลโปรแกรมรวบรวมข้อมูลเว็บใช้เพื่อนำทางไปยังเว็บไซต์เป้าหมายโดยการร้องขอ HTTP หรือ HTTPS ไปยัง URL โปรแกรมรวบรวมข้อมูลจะดาวน์โหลดข้อมูลที่ไม่มีโครงสร้าง (เนื้อหา HTML) และส่งต่อไปยังตัวแยกข้อมูลซึ่งเป็นโมดูลถัดไป
Extractor
ตัวแยกจะประมวลผลเนื้อหา HTML ที่ดึงมาและแยกข้อมูลออกเป็นรูปแบบกึ่งโครงสร้าง สิ่งนี้เรียกว่าเป็นโมดูลตัวแยกวิเคราะห์และใช้เทคนิคการแยกวิเคราะห์ที่แตกต่างกันเช่นนิพจน์ทั่วไปการแยกวิเคราะห์ HTML การแยกวิเคราะห์ DOM หรือปัญญาประดิษฐ์สำหรับการทำงาน
โมดูลการแปลงข้อมูลและการทำความสะอาด
ข้อมูลที่แยกออกมาข้างต้นไม่เหมาะสำหรับการใช้งานพร้อม ต้องผ่านโมดูลทำความสะอาดบางส่วนเพื่อให้เราใช้งานได้ สามารถใช้วิธีการเช่นการจัดการสตริงหรือนิพจน์ทั่วไปเพื่อจุดประสงค์นี้ โปรดทราบว่าการแยกและการแปลงสามารถทำได้ในขั้นตอนเดียวเช่นกัน
โมดูลการจัดเก็บ
หลังจากแยกข้อมูลแล้วเราจำเป็นต้องจัดเก็บข้อมูลตามความต้องการของเรา โมดูลหน่วยเก็บข้อมูลจะส่งออกข้อมูลในรูปแบบมาตรฐานที่สามารถจัดเก็บในฐานข้อมูลหรือรูปแบบ JSON หรือ CSV
การทำงานของ Web Scraper
Web scraper อาจถูกกำหนดให้เป็นซอฟต์แวร์หรือสคริปต์ที่ใช้ในการดาวน์โหลดเนื้อหาของเว็บเพจหลาย ๆ หน้าและดึงข้อมูลออกมา
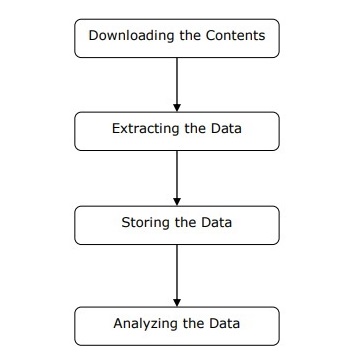
เราสามารถเข้าใจการทำงานของเครื่องขูดเว็บได้ในขั้นตอนง่ายๆดังที่แสดงในแผนภาพด้านบน
ขั้นตอนที่ 1: การดาวน์โหลดเนื้อหาจากหน้าเว็บ
ในขั้นตอนนี้เว็บมีดโกนจะดาวน์โหลดเนื้อหาที่ร้องขอจากหน้าเว็บหลายหน้า
ขั้นตอนที่ 2: การแยกข้อมูล
ข้อมูลบนเว็บไซต์เป็น HTML และส่วนใหญ่ไม่มีโครงสร้าง ดังนั้นในขั้นตอนนี้เครื่องขูดเว็บจะแยกวิเคราะห์และดึงข้อมูลที่มีโครงสร้างออกจากเนื้อหาที่ดาวน์โหลด
ขั้นตอนที่ 3: การจัดเก็บข้อมูล
ที่นี่เว็บสแครปเปอร์จะจัดเก็บและบันทึกข้อมูลที่แยกออกมาในรูปแบบใด ๆ เช่น CSV, JSON หรือในฐานข้อมูล
ขั้นตอนที่ 4: การวิเคราะห์ข้อมูล
หลังจากทำตามขั้นตอนเหล่านี้เรียบร้อยแล้ว Web scraper จะวิเคราะห์ข้อมูลที่ได้รับ