Python Web Scraping - คู่มือฉบับย่อ
การขูดเว็บเป็นกระบวนการอัตโนมัติในการดึงข้อมูลจากเว็บ บทนี้จะให้แนวคิดเชิงลึกเกี่ยวกับการขูดเว็บการเปรียบเทียบกับการรวบรวมข้อมูลเว็บและเหตุผลที่คุณควรเลือกใช้การขูดเว็บ คุณจะได้เรียนรู้เกี่ยวกับส่วนประกอบและการทำงานของเครื่องขูดเว็บ
Web Scraping คืออะไร?
ความหมายตามพจนานุกรมของคำว่า 'Scrapping' หมายถึงการได้รับบางสิ่งจากเว็บ คำถามสองข้อนี้เกิดขึ้น: สิ่งที่เราจะได้รับจากเว็บและวิธีรับสิ่งนั้น
คำตอบสำหรับคำถามแรกคือ ‘data’. ข้อมูลเป็นสิ่งที่ขาดไม่ได้สำหรับโปรแกรมเมอร์ทุกคนและความต้องการพื้นฐานของโครงการเขียนโปรแกรมทุกโครงการคือข้อมูลที่มีประโยชน์จำนวนมาก
คำตอบสำหรับคำถามที่สองค่อนข้างยุ่งยากเพราะมีหลายวิธีในการรับข้อมูล โดยทั่วไปเราอาจได้รับข้อมูลจากฐานข้อมูลหรือแฟ้มข้อมูลและแหล่งอื่น ๆ แต่ถ้าเราต้องการข้อมูลจำนวนมากที่มีอยู่ทางออนไลน์ล่ะ? วิธีหนึ่งในการรับข้อมูลประเภทนี้คือการค้นหาด้วยตนเอง (คลิกจากเว็บเบราว์เซอร์) และบันทึก (คัดลอกวางลงในสเปรดชีตหรือไฟล์) ข้อมูลที่ต้องการ วิธีนี้ค่อนข้างน่าเบื่อและใช้เวลานาน อีกวิธีหนึ่งในการรับข้อมูลดังกล่าวคือการใช้web scraping.
Web scrapingเรียกอีกอย่างว่า web data mining หรือ web harvestingคือขั้นตอนการสร้างตัวแทนที่สามารถแยกวิเคราะห์ดาวน์โหลดและจัดระเบียบข้อมูลที่เป็นประโยชน์จากเว็บโดยอัตโนมัติ กล่าวอีกนัยหนึ่งเราสามารถพูดได้ว่าแทนที่จะบันทึกข้อมูลจากเว็บไซต์ด้วยตนเองซอฟต์แวร์คัดลอกเว็บจะโหลดและดึงข้อมูลจากหลายเว็บไซต์โดยอัตโนมัติตามความต้องการของเรา
ที่มาของการขูดเว็บ
ต้นกำเนิดของการขูดเว็บคือการลบหน้าจอซึ่งใช้เพื่อรวมแอปพลิเคชันที่ไม่ใช่เว็บหรือแอปพลิเคชัน Windows ดั้งเดิม เดิมใช้การขูดหน้าจอก่อนการใช้งาน World Wide Web (WWW) อย่างกว้างขวาง แต่ไม่สามารถขยายขนาด WWW ได้ สิ่งนี้ทำให้จำเป็นต้องใช้วิธีการขูดหน้าจอโดยอัตโนมัติและเทคนิคที่เรียกว่า‘Web Scraping’ เกิดขึ้น
การรวบรวมข้อมูลเว็บ v / s การขูดเว็บ
คำว่า Web Crawling และ Scraping มักใช้แทนกันได้เนื่องจากแนวคิดพื้นฐานของคำเหล่านี้คือการดึงข้อมูล อย่างไรก็ตามพวกเขามีความแตกต่างกัน เราสามารถเข้าใจความแตกต่างพื้นฐานจากคำจำกัดความของพวกเขา
การรวบรวมข้อมูลเว็บโดยทั่วไปจะใช้เพื่อจัดทำดัชนีข้อมูลบนหน้าโดยใช้โปรแกรมรวบรวมข้อมูลบอทหรือที่เรียกว่าโปรแกรมรวบรวมข้อมูล เรียกอีกอย่างว่าindexing. ในทางกลับกันการขูดเว็บเป็นวิธีการอัตโนมัติในการดึงข้อมูลโดยใช้บอทหรือที่ขูด เรียกอีกอย่างว่าdata extraction.
เพื่อทำความเข้าใจความแตกต่างระหว่างสองคำนี้ให้เราดูตารางเปรียบเทียบที่ระบุไว้ในที่นี้ -
| การรวบรวมข้อมูลเว็บ | การขูดเว็บ |
|---|---|
| หมายถึงการดาวน์โหลดและจัดเก็บเนื้อหาของเว็บไซต์จำนวนมาก | หมายถึงการดึงข้อมูลแต่ละองค์ประกอบออกจากเว็บไซต์โดยใช้โครงสร้างเฉพาะไซต์ |
| ส่วนใหญ่ทำในขนาดใหญ่ | สามารถใช้งานได้ทุกขนาด |
| ให้ข้อมูลทั่วไป | ให้ข้อมูลเฉพาะ |
| ใช้โดยเครื่องมือค้นหาหลักเช่น Google, Bing, Yahoo Googlebot เป็นตัวอย่างของโปรแกรมรวบรวมข้อมูลเว็บ | ข้อมูลที่ดึงโดยใช้การขูดเว็บสามารถใช้เพื่อทำซ้ำในเว็บไซต์อื่นหรือใช้ในการวิเคราะห์ข้อมูลก็ได้ ตัวอย่างเช่นองค์ประกอบข้อมูลอาจเป็นชื่อที่อยู่ราคาเป็นต้น |
การใช้งานการขูดเว็บ
การใช้และเหตุผลในการใช้การขูดเว็บนั้นไม่มีที่สิ้นสุดเหมือนกับการใช้งานเวิลด์ไวด์เว็บ เครื่องขูดเว็บสามารถทำอะไรก็ได้เช่นสั่งอาหารออนไลน์สแกนเว็บไซต์ช้อปปิ้งออนไลน์ให้คุณและซื้อตั๋วการแข่งขันทันทีที่มีให้บริการ ฯลฯ เช่นเดียวกับที่มนุษย์สามารถทำได้ การใช้งานที่สำคัญบางประการของการขูดเว็บจะกล่าวถึงที่นี่ -
E-commerce Websites - เครื่องขูดเว็บสามารถรวบรวมข้อมูลที่เกี่ยวข้องเป็นพิเศษกับราคาของผลิตภัณฑ์เฉพาะจากเว็บไซต์อีคอมเมิร์ซต่างๆเพื่อเปรียบเทียบ
Content Aggregators - การขูดเว็บถูกใช้อย่างกว้างขวางโดยผู้รวบรวมเนื้อหาเช่นผู้รวบรวมข่าวสารและผู้รวบรวมงานเพื่อให้ข้อมูลที่อัปเดตแก่ผู้ใช้ของตน
Marketing and Sales Campaigns - เครื่องขูดเว็บสามารถใช้เพื่อรับข้อมูลเช่นอีเมลหมายเลขโทรศัพท์ ฯลฯ สำหรับแคมเปญการขายและการตลาด
Search Engine Optimization (SEO) - การขูดเว็บใช้กันอย่างแพร่หลายโดยเครื่องมือ SEO เช่น SEMRush, Majestic เป็นต้นเพื่อบอกธุรกิจว่าพวกเขาจัดอันดับคำค้นหาที่สำคัญกับพวกเขาอย่างไร
Data for Machine Learning Projects - การดึงข้อมูลสำหรับโครงการแมชชีนเลิร์นนิงขึ้นอยู่กับการขูดเว็บ
Data for Research - นักวิจัยสามารถรวบรวมข้อมูลที่มีประโยชน์เพื่อวัตถุประสงค์ในการทำงานวิจัยโดยประหยัดเวลาด้วยกระบวนการอัตโนมัตินี้
ส่วนประกอบของ Web Scraper
มีดโกนเว็บประกอบด้วยส่วนประกอบต่อไปนี้ -
โมดูลโปรแกรมรวบรวมข้อมูลเว็บ
ส่วนประกอบที่จำเป็นมากของเว็บสแครปเปอร์โมดูลโปรแกรมรวบรวมข้อมูลเว็บใช้เพื่อนำทางไปยังเว็บไซต์เป้าหมายโดยการร้องขอ HTTP หรือ HTTPS ไปยัง URL โปรแกรมรวบรวมข้อมูลจะดาวน์โหลดข้อมูลที่ไม่มีโครงสร้าง (เนื้อหา HTML) และส่งต่อไปยังตัวแยกข้อมูลซึ่งเป็นโมดูลถัดไป
Extractor
ตัวแยกจะประมวลผลเนื้อหา HTML ที่ดึงมาและแยกข้อมูลออกเป็นรูปแบบกึ่งโครงสร้าง สิ่งนี้เรียกว่าเป็นโมดูลตัวแยกวิเคราะห์และใช้เทคนิคการแยกวิเคราะห์ที่แตกต่างกันเช่นนิพจน์ทั่วไปการแยกวิเคราะห์ HTML การแยกวิเคราะห์ DOM หรือปัญญาประดิษฐ์สำหรับการทำงาน
โมดูลการแปลงข้อมูลและการทำความสะอาด
ข้อมูลที่แยกออกมาข้างต้นไม่เหมาะสำหรับการใช้งานแบบสำเร็จรูป ต้องผ่านโมดูลทำความสะอาดบางส่วนจึงจะใช้งานได้ สามารถใช้วิธีการเช่นการจัดการสตริงหรือนิพจน์ทั่วไปเพื่อจุดประสงค์นี้ โปรดทราบว่าการแยกและการแปลงสามารถทำได้ในขั้นตอนเดียวเช่นกัน
โมดูลการจัดเก็บ
หลังจากแยกข้อมูลแล้วเราจำเป็นต้องจัดเก็บข้อมูลตามความต้องการของเรา โมดูลหน่วยเก็บข้อมูลจะส่งออกข้อมูลในรูปแบบมาตรฐานที่สามารถจัดเก็บในฐานข้อมูลหรือรูปแบบ JSON หรือ CSV
การทำงานของ Web Scraper
Web scraper อาจถูกกำหนดให้เป็นซอฟต์แวร์หรือสคริปต์ที่ใช้ในการดาวน์โหลดเนื้อหาของเว็บเพจหลาย ๆ หน้าและดึงข้อมูลออกมา
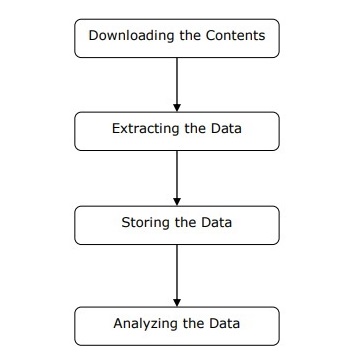
เราสามารถทำความเข้าใจการทำงานของเครื่องขูดเว็บได้ในขั้นตอนง่าย ๆ ดังแสดงในแผนภาพด้านบน
ขั้นตอนที่ 1: การดาวน์โหลดเนื้อหาจากหน้าเว็บ
ในขั้นตอนนี้เว็บมีดโกนจะดาวน์โหลดเนื้อหาที่ร้องขอจากหลายหน้าเว็บ
ขั้นตอนที่ 2: การแยกข้อมูล
ข้อมูลบนเว็บไซต์เป็น HTML และส่วนใหญ่ไม่มีโครงสร้าง ดังนั้นในขั้นตอนนี้เครื่องขูดเว็บจะแยกวิเคราะห์และดึงข้อมูลที่มีโครงสร้างออกจากเนื้อหาที่ดาวน์โหลด
ขั้นตอนที่ 3: การจัดเก็บข้อมูล
ที่นี่เครื่องขูดเว็บจะจัดเก็บและบันทึกข้อมูลที่แยกออกมาในรูปแบบใด ๆ เช่น CSV, JSON หรือในฐานข้อมูล
ขั้นตอนที่ 4: การวิเคราะห์ข้อมูล
หลังจากทำตามขั้นตอนเหล่านี้เรียบร้อยแล้ว Web scraper จะวิเคราะห์ข้อมูลที่ได้รับ
ในบทแรกเราได้เรียนรู้ว่าการขูดเว็บเกี่ยวกับอะไร ในบทนี้ให้เราดูวิธีใช้การขูดเว็บโดยใช้ Python
ทำไมต้อง Python สำหรับการขูดเว็บ
Python เป็นเครื่องมือยอดนิยมสำหรับการใช้งานการขูดเว็บ ภาษาการเขียนโปรแกรม Python ยังใช้สำหรับโครงการที่มีประโยชน์อื่น ๆ ที่เกี่ยวข้องกับความปลอดภัยในโลกไซเบอร์การทดสอบการเจาะและแอปพลิเคชันทางนิติวิทยาศาสตร์ดิจิทัล การใช้การเขียนโปรแกรมพื้นฐานของ Python การขูดเว็บสามารถทำได้โดยไม่ต้องใช้เครื่องมือของบุคคลที่สามอื่น ๆ
ภาษาโปรแกรม Python กำลังได้รับความนิยมอย่างมากและสาเหตุที่ทำให้ Python เหมาะสำหรับโครงการขูดเว็บมีดังต่อไปนี้ -
ความเรียบง่ายของไวยากรณ์
Python มีโครงสร้างที่ง่ายที่สุดเมื่อเทียบกับภาษาโปรแกรมอื่น ๆ คุณลักษณะนี้ของ Python ทำให้การทดสอบง่ายขึ้นและนักพัฒนาสามารถมุ่งเน้นไปที่การเขียนโปรแกรมได้มากขึ้น
โมดูล Inbuilt
อีกเหตุผลหนึ่งในการใช้ Python สำหรับการขูดเว็บคือไลบรารีที่มีประโยชน์ภายในและภายนอกที่มีอยู่ เราสามารถใช้งานได้หลายอย่างที่เกี่ยวข้องกับการขูดเว็บโดยใช้ Python เป็นฐานในการเขียนโปรแกรม
ภาษาโปรแกรมโอเพ่นซอร์ส
Python ได้รับการสนับสนุนอย่างมากจากชุมชนเนื่องจากเป็นภาษาโปรแกรมโอเพ่นซอร์ส
การใช้งานที่หลากหลาย
Python สามารถใช้สำหรับงานการเขียนโปรแกรมต่างๆตั้งแต่เชลล์สคริปต์ขนาดเล็กไปจนถึงเว็บแอปพลิเคชันขององค์กร
การติดตั้ง Python
การแจกจ่าย Python พร้อมใช้งานสำหรับแพลตฟอร์มเช่น Windows, MAC และ Unix / Linux เราจำเป็นต้องดาวน์โหลดเฉพาะรหัสไบนารีที่ใช้กับแพลตฟอร์มของเราเพื่อติดตั้ง Python แต่ในกรณีที่ไม่มีรหัสไบนารีสำหรับแพลตฟอร์มของเราเราต้องมีคอมไพเลอร์ C เพื่อให้สามารถรวบรวมซอร์สโค้ดได้ด้วยตนเอง
เราสามารถติดตั้ง Python บนแพลตฟอร์มต่างๆได้ดังนี้ -
การติดตั้ง Python บน Unix และ Linux
คุณต้องทำตามขั้นตอนด้านล่างเพื่อติดตั้ง Python บนเครื่อง Unix / Linux -
Step 1 - ไปที่ลิงค์ https://www.python.org/downloads/
Step 2 - ดาวน์โหลดซอร์สโค้ดซิปสำหรับ Unix / Linux ที่ลิงค์ด้านบน
Step 3 - แตกไฟล์ลงในคอมพิวเตอร์ของคุณ
Step 4 - ใช้คำสั่งต่อไปนี้เพื่อทำการติดตั้ง -
run ./configure script
make
make installคุณสามารถค้นหา Python ที่ติดตั้งไว้ในตำแหน่งมาตรฐาน /usr/local/bin และห้องสมุดที่ /usr/local/lib/pythonXXโดยที่ XX คือเวอร์ชันของ Python
การติดตั้ง Python บน Windows
คุณต้องทำตามขั้นตอนด้านล่างเพื่อติดตั้ง Python บนเครื่อง Windows -
Step 1 - ไปที่ลิงค์ https://www.python.org/downloads/
Step 2 - ดาวน์โหลดตัวติดตั้ง Windows python-XYZ.msi ไฟล์โดย XYZ เป็นเวอร์ชันที่เราต้องติดตั้ง
Step 3 - ตอนนี้บันทึกไฟล์ตัวติดตั้งลงในเครื่องของคุณและเรียกใช้ไฟล์ MSI
Step 4 - ในที่สุดให้เรียกใช้ไฟล์ที่ดาวน์โหลดมาเพื่อเปิดวิซาร์ดการติดตั้ง Python
การติดตั้ง Python บน Macintosh
เราต้องใช้ Homebrew สำหรับการติดตั้ง Python 3 บน Mac OS X Homebrew นั้นติดตั้งง่ายและเป็นโปรแกรมติดตั้งแพ็คเกจที่ยอดเยี่ยม
นอกจากนี้ยังสามารถติดตั้ง Homebrew ได้โดยใช้คำสั่งต่อไปนี้ -
$ ruby -e "$(curl -fsSL
https://raw.githubusercontent.com/Homebrew/install/master/install)"สำหรับการอัปเดตตัวจัดการแพ็คเกจเราสามารถใช้คำสั่งต่อไปนี้ -
$ brew updateด้วยความช่วยเหลือของคำสั่งต่อไปนี้เราสามารถติดตั้ง Python3 บนเครื่อง MAC ของเรา -
$ brew install python3การตั้งค่า PATH
คุณสามารถใช้คำแนะนำต่อไปนี้เพื่อตั้งค่าเส้นทางบนสภาพแวดล้อมต่างๆ -
การตั้งค่า Path บน Unix / Linux
ใช้คำสั่งต่อไปนี้สำหรับการตั้งค่าพา ธ โดยใช้เชลล์คำสั่งต่างๆ -
สำหรับ csh เชลล์
setenv PATH "$PATH:/usr/local/bin/python".สำหรับ bash shell (Linux)
ATH="$PATH:/usr/local/bin/python".สำหรับ sh หรือ ksh shell
PATH="$PATH:/usr/local/bin/python".การตั้งค่าเส้นทางบน Windows
สำหรับการกำหนด path บน Windows เราสามารถใช้ path %path%;C:\Python ที่พรอมต์คำสั่งจากนั้นกด Enter
กำลังรัน Python
เราสามารถเริ่ม Python โดยใช้สามวิธีต่อไปนี้ -
ล่ามแบบโต้ตอบ
ระบบปฏิบัติการเช่น UNIX และ DOS ที่จัดเตรียมล่ามบรรทัดคำสั่งหรือเชลล์สามารถใช้สำหรับเริ่ม Python
เราสามารถเริ่มเขียนโค้ดในล่ามโต้ตอบได้ดังนี้ -
Step 1 - เข้า python ที่บรรทัดคำสั่ง
Step 2 - จากนั้นเราสามารถเริ่มเขียนโค้ดได้ทันทีในล่ามเชิงโต้ตอบ
$python # Unix/Linux
or
python% # Unix/Linux
or
C:> python # Windows/DOSสคริปต์จากบรรทัดคำสั่ง
เราสามารถเรียกใช้สคริปต์ Python ที่บรรทัดคำสั่งโดยเรียกใช้ตัวแปล สามารถเข้าใจได้ดังนี้ -
$python script.py # Unix/Linux
or
python% script.py # Unix/Linux
or
C: >python script.py # Windows/DOSสภาพแวดล้อมการพัฒนาแบบบูรณาการ
นอกจากนี้เรายังสามารถเรียกใช้ Python จากสภาพแวดล้อม GUI ได้หากระบบมีแอปพลิเคชัน GUI ที่รองรับ Python IDE บางตัวที่รองรับ Python บนแพลตฟอร์มต่างๆได้รับด้านล่าง -
IDE for UNIX - UNIX สำหรับ Python มี IDLE IDE
IDE for Windows - Windows มี PythonWin IDE ซึ่งมี GUI ด้วย
IDE for Macintosh - Macintosh มี IDLE IDE ซึ่งสามารถดาวน์โหลดได้ทั้งไฟล์ MacBinary หรือ BinHex จากเว็บไซต์หลัก
ในบทนี้ให้เราเรียนรู้โมดูล Python ต่างๆที่เราสามารถใช้สำหรับการขูดเว็บ
สภาพแวดล้อมการพัฒนา Python โดยใช้ Virtualenv
Virtualenv เป็นเครื่องมือในการสร้างสภาพแวดล้อม Python ที่แยกได้ ด้วยความช่วยเหลือของ Virtualenv เราสามารถสร้างโฟลเดอร์ที่มีไฟล์ปฏิบัติการที่จำเป็นทั้งหมดเพื่อใช้แพ็คเกจที่โครงการ Python ของเราต้องการ นอกจากนี้ยังช่วยให้เราสามารถเพิ่มและแก้ไขโมดูล Python ได้โดยไม่ต้องเข้าถึงการติดตั้งส่วนกลาง
คุณสามารถใช้คำสั่งต่อไปนี้เพื่อติดตั้ง virtualenv -
(base) D:\ProgramData>pip install virtualenv
Collecting virtualenv
Downloading
https://files.pythonhosted.org/packages/b6/30/96a02b2287098b23b875bc8c2f58071c3
5d2efe84f747b64d523721dc2b5/virtualenv-16.0.0-py2.py3-none-any.whl
(1.9MB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 1.9MB 86kB/s
Installing collected packages: virtualenv
Successfully installed virtualenv-16.0.0ตอนนี้เราต้องสร้างไดเร็กทอรีซึ่งจะเป็นตัวแทนของโครงการด้วยความช่วยเหลือของคำสั่งต่อไปนี้ -
(base) D:\ProgramData>mkdir webscrapตอนนี้เข้าสู่ไดเร็กทอรีนั้นด้วยความช่วยเหลือของคำสั่งต่อไปนี้ -
(base) D:\ProgramData>cd webscrapตอนนี้เราจำเป็นต้องเริ่มต้นโฟลเดอร์สภาพแวดล้อมเสมือนที่เราเลือกดังนี้ -
(base) D:\ProgramData\webscrap>virtualenv websc
Using base prefix 'd:\\programdata'
New python executable in D:\ProgramData\webscrap\websc\Scripts\python.exe
Installing setuptools, pip, wheel...done.ตอนนี้เปิดใช้งานสภาพแวดล้อมเสมือนจริงด้วยคำสั่งที่ระบุด้านล่าง เมื่อเปิดใช้งานสำเร็จคุณจะเห็นชื่อทางด้านซ้ายมือในวงเล็บ
(base) D:\ProgramData\webscrap>websc\scripts\activateเราสามารถติดตั้งโมดูลใดก็ได้ในสภาพแวดล้อมนี้ดังนี้ -
(websc) (base) D:\ProgramData\webscrap>pip install requests
Collecting requests
Downloading
https://files.pythonhosted.org/packages/65/47/7e02164a2a3db50ed6d8a6ab1d6d60b69
c4c3fdf57a284257925dfc12bda/requests-2.19.1-py2.py3-none-any.whl (9
1kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 148kB/s
Collecting chardet<3.1.0,>=3.0.2 (from requests)
Downloading
https://files.pythonhosted.org/packages/bc/a9/01ffebfb562e4274b6487b4bb1ddec7ca
55ec7510b22e4c51f14098443b8/chardet-3.0.4-py2.py3-none-any.whl (133
kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 143kB 369kB/s
Collecting certifi>=2017.4.17 (from requests)
Downloading
https://files.pythonhosted.org/packages/df/f7/04fee6ac349e915b82171f8e23cee6364
4d83663b34c539f7a09aed18f9e/certifi-2018.8.24-py2.py3-none-any.whl
(147kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 153kB 527kB/s
Collecting urllib3<1.24,>=1.21.1 (from requests)
Downloading
https://files.pythonhosted.org/packages/bd/c9/6fdd990019071a4a32a5e7cb78a1d92c5
3851ef4f56f62a3486e6a7d8ffb/urllib3-1.23-py2.py3-none-any.whl (133k
B)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 143kB 517kB/s
Collecting idna<2.8,>=2.5 (from requests)
Downloading
https://files.pythonhosted.org/packages/4b/2a/0276479a4b3caeb8a8c1af2f8e4355746
a97fab05a372e4a2c6a6b876165/idna-2.7-py2.py3-none-any.whl (58kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 61kB 339kB/s
Installing collected packages: chardet, certifi, urllib3, idna, requests
Successfully installed certifi-2018.8.24 chardet-3.0.4 idna-2.7 requests-2.19.1
urllib3-1.23สำหรับการปิดใช้งานสภาพแวดล้อมเสมือนเราสามารถใช้คำสั่งต่อไปนี้ -
(websc) (base) D:\ProgramData\webscrap>deactivate
(base) D:\ProgramData\webscrap>คุณจะเห็นว่า (websc) ถูกปิดใช้งาน
โมดูล Python สำหรับการขูดเว็บ
การขูดเว็บเป็นกระบวนการสร้างตัวแทนซึ่งสามารถแยกวิเคราะห์ดาวน์โหลดและจัดระเบียบข้อมูลที่เป็นประโยชน์จากเว็บโดยอัตโนมัติ กล่าวอีกนัยหนึ่งคือแทนที่จะบันทึกข้อมูลจากเว็บไซต์ด้วยตนเองซอฟต์แวร์ขูดเว็บจะโหลดและดึงข้อมูลจากหลายเว็บไซต์โดยอัตโนมัติตามความต้องการของเรา
ในส่วนนี้เราจะพูดถึงไลบรารี Python ที่มีประโยชน์สำหรับการขูดเว็บ
คำขอ
มันเป็นไลบรารีการขูดเว็บหลามอย่างง่าย เป็นไลบรารี HTTP ที่มีประสิทธิภาพที่ใช้ในการเข้าถึงเว็บเพจ ด้วยความช่วยเหลือของRequestsเราสามารถรับ HTML ดิบของหน้าเว็บซึ่งสามารถแยกวิเคราะห์เพื่อดึงข้อมูลได้ ก่อนใช้requestsให้เราเข้าใจการติดตั้ง
การติดตั้งคำขอ
เราสามารถติดตั้งได้ทั้งในสภาพแวดล้อมเสมือนของเราหรือในการติดตั้งส่วนกลาง ด้วยความช่วยเหลือของpip คำสั่งเราสามารถติดตั้งได้ง่ายๆดังนี้ -
(base) D:\ProgramData> pip install requests
Collecting requests
Using cached
https://files.pythonhosted.org/packages/65/47/7e02164a2a3db50ed6d8a6ab1d6d60b69
c4c3fdf57a284257925dfc12bda/requests-2.19.1-py2.py3-none-any.whl
Requirement already satisfied: idna<2.8,>=2.5 in d:\programdata\lib\sitepackages
(from requests) (2.6)
Requirement already satisfied: urllib3<1.24,>=1.21.1 in
d:\programdata\lib\site-packages (from requests) (1.22)
Requirement already satisfied: certifi>=2017.4.17 in d:\programdata\lib\sitepackages
(from requests) (2018.1.18)
Requirement already satisfied: chardet<3.1.0,>=3.0.2 in
d:\programdata\lib\site-packages (from requests) (3.0.4)
Installing collected packages: requests
Successfully installed requests-2.19.1ตัวอย่าง
ในตัวอย่างนี้เรากำลังสร้างคำขอ GET HTTP สำหรับหน้าเว็บ สำหรับสิ่งนี้เราต้องนำเข้าไลบรารีคำขอก่อนดังนี้ -
In [1]: import requestsในโค้ดบรรทัดต่อไปนี้เราใช้การร้องขอเพื่อส่งคำขอ GET HTTP สำหรับ url: https://authoraditiagarwal.com/ โดยการร้องขอ GET
In [2]: r = requests.get('https://authoraditiagarwal.com/')ตอนนี้เราสามารถดึงเนื้อหาโดยใช้ไฟล์ .text คุณสมบัติดังนี้ -
In [5]: r.text[:200]สังเกตว่าในผลลัพธ์ต่อไปนี้เรามีอักขระ 200 ตัวแรก
Out[5]: '<!DOCTYPE html>\n<html lang="en-US"\n\titemscope
\n\titemtype="http://schema.org/WebSite" \n\tprefix="og: http://ogp.me/ns#"
>\n<head>\n\t<meta charset
="UTF-8" />\n\t<meta http-equiv="X-UA-Compatible" content="IE'Urllib 3
เป็นไลบรารี Python อีกตัวที่สามารถใช้สำหรับดึงข้อมูลจาก URL ที่คล้ายกับไฟล์ requestsห้องสมุด. คุณสามารถอ่านเพิ่มเติมได้ที่เอกสารทางเทคนิคที่https://urllib3.readthedocs.io/en/latest/.
การติดตั้ง Urllib3
ใช้ pip เราสามารถติดตั้ง urllib3 ทั้งในสภาพแวดล้อมเสมือนของเราหรือในการติดตั้งส่วนกลาง
(base) D:\ProgramData>pip install urllib3
Collecting urllib3
Using cached
https://files.pythonhosted.org/packages/bd/c9/6fdd990019071a4a32a5e7cb78a1d92c5
3851ef4f56f62a3486e6a7d8ffb/urllib3-1.23-py2.py3-none-any.whl
Installing collected packages: urllib3
Successfully installed urllib3-1.23ตัวอย่าง: การขูดโดยใช้ Urllib3 และ BeautifulSoup
ในตัวอย่างต่อไปนี้เรากำลังขูดหน้าเว็บโดยใช้ Urllib3 และ BeautifulSoup. เรากำลังใช้Urllib3ที่ตำแหน่งของไลบรารีคำขอสำหรับการรับข้อมูลดิบ (HTML) จากเว็บเพจ จากนั้นเราจะใช้BeautifulSoup สำหรับการแยกวิเคราะห์ข้อมูล HTML นั้น
import urllib3
from bs4 import BeautifulSoup
http = urllib3.PoolManager()
r = http.request('GET', 'https://authoraditiagarwal.com')
soup = BeautifulSoup(r.data, 'lxml')
print (soup.title)
print (soup.title.text)นี่คือผลลัพธ์ที่คุณจะสังเกตเห็นเมื่อคุณเรียกใช้รหัสนี้ -
<title>Learn and Grow with Aditi Agarwal</title>
Learn and Grow with Aditi Agarwalซีลีเนียม
เป็นชุดทดสอบอัตโนมัติแบบโอเพ่นซอร์สสำหรับเว็บแอปพลิเคชันในเบราว์เซอร์และแพลตฟอร์มต่างๆ ไม่ใช่เครื่องมือเดียว แต่เป็นชุดซอฟต์แวร์ เรามีการผูกซีลีเนียมสำหรับ Python, Java, C #, Ruby และ JavaScript ที่นี่เราจะทำการขูดเว็บโดยใช้ซีลีเนียมและการผูก Python คุณสามารถเรียนรู้เพิ่มเติมเกี่ยวกับ Java ซีลีเนียมที่ลิงค์ซีลีเนียม
การผูก Selenium Python มอบ API ที่สะดวกในการเข้าถึง Selenium WebDrivers เช่น Firefox, IE, Chrome, Remote เป็นต้นเวอร์ชัน Python ที่รองรับในปัจจุบันคือ 2.7, 3.5 ขึ้นไป
การติดตั้งซีลีเนียม
ใช้ pip เราสามารถติดตั้ง urllib3 ทั้งในสภาพแวดล้อมเสมือนของเราหรือในการติดตั้งส่วนกลาง
pip install seleniumเนื่องจากซีลีเนียมต้องการไดรเวอร์เพื่อเชื่อมต่อกับเบราว์เซอร์ที่เลือกเราจึงจำเป็นต้องดาวน์โหลด ตารางต่อไปนี้แสดงเบราว์เซอร์ที่แตกต่างกันและลิงก์สำหรับการดาวน์โหลดเดียวกัน
Chrome |
https://sites.google.com/a/chromium.org/ |
Edge |
https://developer.microsoft.com/ |
Firefox |
https://github.com/ |
Safari |
https://webkit.org/ |
ตัวอย่าง
ตัวอย่างนี้แสดงการขูดเว็บโดยใช้ซีลีเนียม นอกจากนี้ยังสามารถใช้สำหรับการทดสอบซึ่งเรียกว่าการทดสอบซีลีเนียม
หลังจากดาวน์โหลดไดรเวอร์เฉพาะสำหรับเบราว์เซอร์เวอร์ชันที่ระบุเราจำเป็นต้องทำการเขียนโปรแกรมใน Python
ขั้นแรกต้องนำเข้า webdriver จากซีลีเนียมดังนี้ -
from selenium import webdriverตอนนี้ให้เส้นทางของโปรแกรมควบคุมเว็บที่เราดาวน์โหลดตามความต้องการของเรา -
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
browser = webdriver.Chrome(executable_path = path)ตอนนี้ให้ระบุ url ที่เราต้องการเปิดในเว็บเบราว์เซอร์นั้นตอนนี้ควบคุมโดยสคริปต์ Python ของเรา
browser.get('https://authoraditiagarwal.com/leadershipmanagement')นอกจากนี้เรายังสามารถขูดองค์ประกอบเฉพาะโดยการจัดเตรียม xpath ตามที่ระบุไว้ใน lxml
browser.find_element_by_xpath('/html/body').click()คุณสามารถตรวจสอบเบราว์เซอร์ที่ควบคุมโดยสคริปต์ Python สำหรับเอาต์พุต
Scrapy
Scrapy เป็นเฟรมเวิร์กการรวบรวมข้อมูลเว็บแบบโอเพนซอร์สที่รวดเร็วซึ่งเขียนด้วย Python ซึ่งใช้ในการดึงข้อมูลจากหน้าเว็บด้วยความช่วยเหลือของตัวเลือกที่ใช้ XPath Scrapy เปิดตัวครั้งแรกเมื่อวันที่ 26 มิถุนายน 2551 ได้รับอนุญาตภายใต้ BSD โดยมีการเปิดตัว 1.0 ในเดือนมิถุนายน 2558 โดยมีเครื่องมือทั้งหมดที่จำเป็นในการดึงประมวลผลและจัดโครงสร้างข้อมูลจากเว็บไซต์
การติดตั้ง Scrapy
ใช้ pip เราสามารถติดตั้ง urllib3 ทั้งในสภาพแวดล้อมเสมือนของเราหรือในการติดตั้งส่วนกลาง
pip install scrapyสำหรับการศึกษารายละเอียดเพิ่มเติมของ Scrapy คุณสามารถไปที่ลิงค์Scrapy
ด้วย Python เราสามารถขูดเว็บไซต์หรือองค์ประกอบเฉพาะของหน้าเว็บ แต่คุณมีความคิดว่าถูกกฎหมายหรือไม่? ก่อนที่จะขูดเว็บไซต์ใด ๆ เราต้องทราบเกี่ยวกับกฎหมายของการขูดเว็บ บทนี้จะอธิบายแนวคิดที่เกี่ยวข้องกับความชอบด้วยกฎหมายของการขูดเว็บ
บทนำ
โดยทั่วไปหากคุณจะใช้ข้อมูลที่คัดลอกมาเพื่อการใช้งานส่วนตัวก็อาจไม่มีปัญหาใด ๆ แต่หากคุณกำลังจะเผยแพร่ข้อมูลนั้นอีกครั้งก่อนที่จะดำเนินการเช่นเดียวกันคุณควรส่งคำขอดาวน์โหลดไปยังเจ้าของหรือทำการค้นคว้าข้อมูลพื้นฐานเกี่ยวกับนโยบายรวมทั้งข้อมูลที่คุณกำลังจะขูด
การวิจัยที่จำเป็นก่อนการขูด
หากคุณกำหนดเป้าหมายเว็บไซต์เพื่อคัดลอกข้อมูลจากเว็บไซต์เราจำเป็นต้องเข้าใจขนาดและโครงสร้างของเว็บไซต์นั้น ต่อไปนี้เป็นไฟล์บางส่วนที่เราต้องวิเคราะห์ก่อนเริ่มการขูดเว็บ
การวิเคราะห์ robots.txt
จริงๆแล้วผู้เผยแพร่โฆษณาส่วนใหญ่อนุญาตให้โปรแกรมเมอร์รวบรวมข้อมูลเว็บไซต์ของตนได้ในระดับหนึ่ง ในอีกแง่หนึ่งผู้เผยแพร่ต้องการให้มีการรวบรวมข้อมูลบางส่วนของเว็บไซต์ ในการกำหนดสิ่งนี้เว็บไซต์ต้องวางกฎเกณฑ์บางประการเพื่อระบุว่าส่วนใดบ้างที่สามารถรวบรวมข้อมูลได้และไม่สามารถรวบรวมข้อมูลได้ กฎดังกล่าวกำหนดไว้ในไฟล์ที่เรียกว่าrobots.txt.
robots.txtเป็นไฟล์ที่มนุษย์สามารถอ่านได้ซึ่งใช้เพื่อระบุส่วนต่างๆของเว็บไซต์ที่อนุญาตให้โปรแกรมรวบรวมข้อมูลและไม่อนุญาตให้ขูด ไม่มีรูปแบบไฟล์ robots.txt มาตรฐานและผู้เผยแพร่เว็บไซต์สามารถทำการแก้ไขได้ตามความต้องการ เราสามารถตรวจสอบไฟล์ robots.txt สำหรับเว็บไซต์ใดเว็บไซต์หนึ่งได้โดยใส่เครื่องหมายทับและ robots.txt หลัง url ของเว็บไซต์นั้น ตัวอย่างเช่นหากเราต้องการตรวจสอบ Google.com เราก็ต้องพิมพ์https://www.google.com/robots.txt และเราจะได้รับสิ่งต่อไปนี้ -
User-agent: *
Disallow: /search
Allow: /search/about
Allow: /search/static
Allow: /search/howsearchworks
Disallow: /sdch
Disallow: /groups
Disallow: /index.html?
Disallow: /?
Allow: /?hl=
Disallow: /?hl=*&
Allow: /?hl=*&gws_rd=ssl$
and so on……..กฎทั่วไปบางส่วนที่กำหนดไว้ในไฟล์ robots.txt ของเว็บไซต์มีดังนี้ -
User-agent: BadCrawler
Disallow: /กฎข้างต้นหมายถึงไฟล์ robots.txt ขอโปรแกรมรวบรวมข้อมูลด้วย BadCrawler ตัวแทนผู้ใช้ไม่ให้รวบรวมข้อมูลเว็บไซต์ของตน
User-agent: *
Crawl-delay: 5
Disallow: /trapกฎข้างต้นหมายความว่าไฟล์ robots.txt จะหน่วงเวลาโปรแกรมรวบรวมข้อมูลเป็นเวลา 5 วินาทีระหว่างคำขอดาวน์โหลดสำหรับ User-agent ทั้งหมดเพื่อหลีกเลี่ยงการทำงานของเซิร์ฟเวอร์ที่ทำงานหนักเกินไป /trapลิงก์จะพยายามบล็อกโปรแกรมรวบรวมข้อมูลที่เป็นอันตรายซึ่งติดตามลิงก์ที่ไม่ได้รับอนุญาต มีกฎอื่น ๆ อีกมากมายที่ผู้เผยแพร่เว็บไซต์สามารถกำหนดได้ตามความต้องการ บางส่วนมีการกล่าวถึงที่นี่ -
การวิเคราะห์ไฟล์แผนผังไซต์
คุณควรทำอย่างไรหากต้องการรวบรวมข้อมูลเว็บไซต์เพื่อดูข้อมูลล่าสุด คุณจะรวบรวมข้อมูลทุกหน้าเว็บเพื่อรับข้อมูลที่อัปเดต แต่จะเพิ่มปริมาณการใช้งานเซิร์ฟเวอร์ของเว็บไซต์นั้น ๆ นั่นคือเหตุผลที่เว็บไซต์มีไฟล์แผนผังเว็บไซต์เพื่อช่วยให้โปรแกรมรวบรวมข้อมูลค้นหาเนื้อหาที่อัปเดตโดยไม่จำเป็นต้องรวบรวมข้อมูลทุกหน้าเว็บ มาตรฐานแผนผังเว็บไซต์กำหนดไว้ที่http://www.sitemaps.org/protocol.html.
เนื้อหาของไฟล์แผนผังไซต์
ต่อไปนี้เป็นเนื้อหาของไฟล์แผนผังเว็บไซต์ของ https://www.microsoft.com/robots.txt ที่ถูกค้นพบในไฟล์ robot.txt -
Sitemap: https://www.microsoft.com/en-us/explore/msft_sitemap_index.xml
Sitemap: https://www.microsoft.com/learning/sitemap.xml
Sitemap: https://www.microsoft.com/en-us/licensing/sitemap.xml
Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml
Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8
Sitemap: https://www.microsoft.com/store/collections.xml
Sitemap: https://www.microsoft.com/store/productdetailpages.index.xml
Sitemap: https://www.microsoft.com/en-us/store/locations/store-locationssitemap.xmlเนื้อหาข้างต้นแสดงให้เห็นว่าแผนผังเว็บไซต์แสดงรายการ URL บนเว็บไซต์และช่วยให้ผู้ดูแลเว็บสามารถระบุข้อมูลเพิ่มเติมบางอย่างเช่นวันที่อัปเดตล่าสุดการเปลี่ยนแปลงเนื้อหาความสำคัญของ URL ที่เกี่ยวข้องกับผู้อื่นเป็นต้นเกี่ยวกับ URL แต่ละรายการ
ขนาดของเว็บไซต์คืออะไร?
ขนาดของเว็บไซต์เช่นจำนวนหน้าเว็บของเว็บไซต์มีผลต่อวิธีการรวบรวมข้อมูลหรือไม่? ใช่แน่นอน เนื่องจากหากเรามีจำนวนหน้าเว็บในการรวบรวมข้อมูลน้อยประสิทธิภาพก็จะไม่ใช่ปัญหาร้ายแรง แต่สมมติว่าหากเว็บไซต์ของเรามีหน้าเว็บหลายล้านหน้าเช่น Microsoft.com การดาวน์โหลดแต่ละหน้าเว็บตามลำดับจะใช้เวลาหลายเดือนและ ประสิทธิภาพจะเป็นปัญหาอย่างมาก
ตรวจสอบขนาดของเว็บไซต์
ด้วยการตรวจสอบขนาดของผลลัพธ์ของโปรแกรมรวบรวมข้อมูลของ Google เราสามารถประมาณขนาดของเว็บไซต์ได้ ผลลัพธ์ของเราสามารถกรองได้โดยใช้คำหลักsiteขณะทำการค้นหาโดย Google ตัวอย่างเช่นการประมาณขนาดของhttps://authoraditiagarwal.com/ ได้รับด้านล่าง -
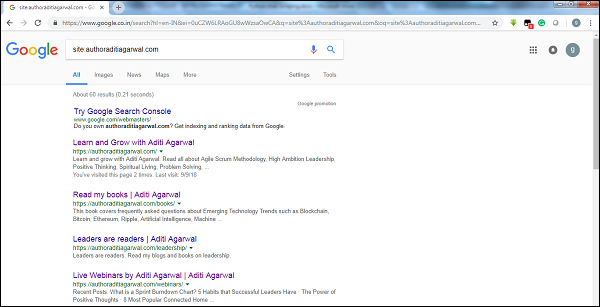
คุณสามารถเห็นผลลัพธ์ประมาณ 60 รายการซึ่งหมายความว่าไม่ใช่เว็บไซต์ขนาดใหญ่และการรวบรวมข้อมูลจะไม่นำไปสู่ปัญหาด้านประสิทธิภาพ
เว็บไซต์ใช้เทคโนโลยีใด
คำถามสำคัญอีกประการหนึ่งคือเทคโนโลยีที่เว็บไซต์ใช้มีผลต่อวิธีการรวบรวมข้อมูลหรือไม่? ใช่มันมีผลต่อ แต่เราจะตรวจสอบเกี่ยวกับเทคโนโลยีที่เว็บไซต์ใช้งานได้อย่างไร? มีไลบรารี Python ชื่อbuiltwith ด้วยความช่วยเหลือซึ่งเราสามารถหาข้อมูลเกี่ยวกับเทคโนโลยีที่เว็บไซต์ใช้
ตัวอย่าง
ในตัวอย่างนี้เราจะตรวจสอบเทคโนโลยีที่ใช้ในเว็บไซต์ https://authoraditiagarwal.com ด้วยความช่วยเหลือของไลบรารี Python builtwith. แต่ก่อนที่จะใช้ไลบรารีนี้เราจำเป็นต้องติดตั้งดังนี้ -
(base) D:\ProgramData>pip install builtwith
Collecting builtwith
Downloading
https://files.pythonhosted.org/packages/9b/b8/4a320be83bb3c9c1b3ac3f9469a5d66e0
2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz
Requirement already satisfied: six in d:\programdata\lib\site-packages (from
builtwith) (1.10.0)
Building wheels for collected packages: builtwith
Running setup.py bdist_wheel for builtwith ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b
f926764a924873e0304f10b2524
Successfully built builtwith
Installing collected packages: builtwith
Successfully installed builtwith-1.3.3ตอนนี้ด้วยความช่วยเหลือของการทำตามบรรทัดรหัสง่ายๆเราสามารถตรวจสอบเทคโนโลยีที่ใช้โดยเว็บไซต์ใดเว็บไซต์หนึ่งได้ -
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}เจ้าของเว็บไซต์คือใคร?
เจ้าของเว็บไซต์ก็มีความสำคัญเช่นกันเนื่องจากหากเจ้าของเป็นที่รู้จักในการบล็อกโปรแกรมรวบรวมข้อมูลโปรแกรมรวบรวมข้อมูลจะต้องระมัดระวังในขณะที่ขูดข้อมูลจากเว็บไซต์ มีโปรโตคอลที่ชื่อWhois ด้วยความช่วยเหลือซึ่งเราสามารถค้นหาเกี่ยวกับเจ้าของเว็บไซต์ได้
ตัวอย่าง
ในตัวอย่างนี้เราจะตรวจสอบเจ้าของเว็บไซต์ว่าmicrosoft.comด้วยความช่วยเหลือของ Whois แต่ก่อนที่จะใช้ไลบรารีนี้เราจำเป็นต้องติดตั้งดังนี้ -
(base) D:\ProgramData>pip install python-whois
Collecting python-whois
Downloading
https://files.pythonhosted.org/packages/63/8a/8ed58b8b28b6200ce1cdfe4e4f3bbc8b8
5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s
Requirement already satisfied: future in d:\programdata\lib\site-packages (from
python-whois) (0.16.0)
Building wheels for collected packages: python-whois
Running setup.py bdist_wheel for python-whois ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b
4dcc81ab212a3d5e52ab32dc531
Successfully built python-whois
Installing collected packages: python-whois
Successfully installed python-whois-0.7.0ตอนนี้ด้วยความช่วยเหลือของการทำตามบรรทัดรหัสง่ายๆเราสามารถตรวจสอบเทคโนโลยีที่ใช้โดยเว็บไซต์ใดเว็บไซต์หนึ่งได้ -
In [1]: import whois
In [2]: print (whois.whois('microsoft.com'))
{
"domain_name": [
"MICROSOFT.COM",
"microsoft.com"
],
-------
"name_servers": [
"NS1.MSFT.NET",
"NS2.MSFT.NET",
"NS3.MSFT.NET",
"NS4.MSFT.NET",
"ns3.msft.net",
"ns1.msft.net",
"ns4.msft.net",
"ns2.msft.net"
],
"emails": [
"[email protected]",
"[email protected]",
"[email protected]",
"[email protected]"
],
}การวิเคราะห์หน้าเว็บหมายถึงการทำความเข้าใจโครงสร้าง ตอนนี้คำถามเกิดขึ้นว่าทำไมการขูดเว็บจึงสำคัญ? ในบทนี้ให้เราเข้าใจโดยละเอียด
การวิเคราะห์หน้าเว็บ
การวิเคราะห์หน้าเว็บมีความสำคัญเนื่องจากหากไม่มีการวิเคราะห์เราจะไม่สามารถทราบได้ว่าเราจะรับข้อมูลจากหน้าเว็บนั้นในรูปแบบใด (ที่มีโครงสร้างหรือไม่มีโครงสร้าง) หลังจากการแยก เราสามารถทำการวิเคราะห์หน้าเว็บได้ด้วยวิธีต่อไปนี้ -
การดูที่มาของเพจ
นี่เป็นวิธีทำความเข้าใจว่าหน้าเว็บมีโครงสร้างอย่างไรโดยการตรวจสอบซอร์สโค้ด ในการดำเนินการนี้เราต้องคลิกขวาที่หน้าจากนั้นต้องเลือกไฟล์View page sourceตัวเลือก จากนั้นเราจะได้รับข้อมูลที่เราสนใจจากหน้าเว็บนั้นในรูปแบบของ HTML แต่ข้อกังวลหลักคือเรื่องช่องว่างและการจัดรูปแบบซึ่งยากสำหรับเราในการจัดรูปแบบ
การตรวจสอบแหล่งที่มาของหน้าโดยคลิกตัวเลือกตรวจสอบองค์ประกอบ
นี่เป็นอีกวิธีหนึ่งในการวิเคราะห์หน้าเว็บ แต่ความแตกต่างคือจะแก้ไขปัญหาการจัดรูปแบบและช่องว่างในซอร์สโค้ดของหน้าเว็บ คุณสามารถดำเนินการได้โดยคลิกขวาจากนั้นเลือกไฟล์Inspect หรือ Inspect elementตัวเลือกจากเมนู จะให้ข้อมูลเกี่ยวกับพื้นที่หรือองค์ประกอบเฉพาะของหน้าเว็บนั้น
วิธีต่างๆในการดึงข้อมูลจากเว็บเพจ
วิธีการต่อไปนี้ส่วนใหญ่ใช้สำหรับการดึงข้อมูลจากหน้าเว็บ -
นิพจน์ทั่วไป
เป็นภาษาโปรแกรมพิเศษที่ฝังอยู่ใน Python เราสามารถใช้มันผ่านreโมดูลของ Python เรียกอีกอย่างว่ารูปแบบ RE หรือ regexes หรือ regex ด้วยความช่วยเหลือของนิพจน์ทั่วไปเราสามารถระบุกฎบางอย่างสำหรับชุดสตริงที่เป็นไปได้ที่เราต้องการจับคู่จากข้อมูล
หากคุณต้องการเรียนรู้เพิ่มเติมเกี่ยวกับนิพจน์ทั่วไปโดยทั่วไปให้ไปที่ลิงก์ https://www.tutorialspoint.com/automata_theory/regular_expressions.htmและหากคุณต้องการทราบข้อมูลเพิ่มเติมเกี่ยวกับโมดูลใหม่หรือการแสดงออกปกติในหลามคุณสามารถทำตามลิงค์ https://www.tutorialspoint.com/python/python_reg_expressions.htm
ตัวอย่าง
ในตัวอย่างต่อไปนี้เราจะดึงข้อมูลเกี่ยวกับอินเดียจาก http://example.webscraping.com หลังจากจับคู่เนื้อหาของ <td> ด้วยความช่วยเหลือของนิพจน์ทั่วไป
import re
import urllib.request
response =
urllib.request.urlopen('http://example.webscraping.com/places/default/view/India-102')
html = response.read()
text = html.decode()
re.findall('<td class="w2p_fw">(.*?)</td>',text)เอาต์พุต
ผลลัพธ์ที่เกี่ยวข้องจะเป็นดังที่แสดงไว้ที่นี่ -
[
'<img src="/places/static/images/flags/in.png" />',
'3,287,590 square kilometres',
'1,173,108,018',
'IN',
'India',
'New Delhi',
'<a href="/places/default/continent/AS">AS</a>',
'.in',
'INR',
'Rupee',
'91',
'######',
'^(\\d{6})$',
'enIN,hi,bn,te,mr,ta,ur,gu,kn,ml,or,pa,as,bh,sat,ks,ne,sd,kok,doi,mni,sit,sa,fr,lus,inc',
'<div>
<a href="/places/default/iso/CN">CN </a>
<a href="/places/default/iso/NP">NP </a>
<a href="/places/default/iso/MM">MM </a>
<a href="/places/default/iso/BT">BT </a>
<a href="/places/default/iso/PK">PK </a>
<a href="/places/default/iso/BD">BD </a>
</div>'
]สังเกตว่าในผลลัพธ์ด้านบนคุณสามารถดูรายละเอียดเกี่ยวกับประเทศอินเดียได้โดยใช้นิพจน์ทั่วไป
ซุปที่สวยงาม
สมมติว่าเราต้องการรวบรวมไฮเปอร์ลิงก์ทั้งหมดจากหน้าเว็บจากนั้นเราสามารถใช้ตัวแยกวิเคราะห์ที่เรียกว่า BeautifulSoup ซึ่งสามารถทราบรายละเอียดเพิ่มเติมได้ที่ https://www.crummy.com/software/BeautifulSoup/bs4/doc/.พูดง่ายๆก็คือ BeautifulSoup เป็นไลบรารี Python สำหรับดึงข้อมูลออกจากไฟล์ HTML และ XML สามารถใช้กับคำขอได้เนื่องจากต้องมีอินพุต (เอกสารหรือ url) เพื่อสร้างออบเจ็กต์ซุปเนื่องจากไม่สามารถดึงหน้าเว็บได้ด้วยตัวเอง คุณสามารถใช้สคริปต์ Python ต่อไปนี้เพื่อรวบรวมชื่อของหน้าเว็บและไฮเปอร์ลิงก์
การติดตั้งซุปที่สวยงาม
ใช้ pip เราสามารถติดตั้ง beautifulsoup ทั้งในสภาพแวดล้อมเสมือนของเราหรือในการติดตั้งส่วนกลาง
(base) D:\ProgramData>pip install bs4
Collecting bs4
Downloading
https://files.pythonhosted.org/packages/10/ed/7e8b97591f6f456174139ec089c769f89
a94a1a4025fe967691de971f314/bs4-0.0.1.tar.gz
Requirement already satisfied: beautifulsoup4 in d:\programdata\lib\sitepackages
(from bs4) (4.6.0)
Building wheels for collected packages: bs4
Running setup.py bdist_wheel for bs4 ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\a0\b0\b2\4f80b9456b87abedbc0bf2d
52235414c3467d8889be38dd472
Successfully built bs4
Installing collected packages: bs4
Successfully installed bs4-0.0.1ตัวอย่าง
โปรดทราบว่าในตัวอย่างนี้เรากำลังขยายตัวอย่างข้างต้นที่นำไปใช้กับโมดูล python ที่ร้องขอ เรากำลังใช้r.text สำหรับการสร้างวัตถุซุปซึ่งจะใช้ในการดึงรายละเอียดเช่นชื่อของหน้าเว็บต่อไป
ขั้นแรกเราต้องนำเข้าโมดูล Python ที่จำเป็น -
import requests
from bs4 import BeautifulSoupในโค้ดบรรทัดต่อไปนี้เราใช้การร้องขอเพื่อส่งคำขอ GET HTTP สำหรับ url: https://authoraditiagarwal.com/ โดยการร้องขอ GET
r = requests.get('https://authoraditiagarwal.com/')ตอนนี้เราต้องสร้างวัตถุซุปดังต่อไปนี้ -
soup = BeautifulSoup(r.text, 'lxml')
print (soup.title)
print (soup.title.text)เอาต์พุต
ผลลัพธ์ที่เกี่ยวข้องจะเป็นดังที่แสดงไว้ที่นี่ -
<title>Learn and Grow with Aditi Agarwal</title>
Learn and Grow with Aditi AgarwalLxml
ไลบรารี Python อื่นที่เราจะพูดถึงสำหรับการขูดเว็บคือ lxml เป็นไลบรารีแยกวิเคราะห์ HTML และ XML ที่มีประสิทธิภาพสูง ค่อนข้างรวดเร็วและตรงไปตรงมา คุณสามารถอ่านเพิ่มเติมได้ที่https://lxml.de/.
การติดตั้ง lxml
ใช้คำสั่ง pip เราสามารถติดตั้ง lxml ทั้งในสภาพแวดล้อมเสมือนของเราหรือในการติดตั้งส่วนกลาง
(base) D:\ProgramData>pip install lxml
Collecting lxml
Downloading
https://files.pythonhosted.org/packages/b9/55/bcc78c70e8ba30f51b5495eb0e
3e949aa06e4a2de55b3de53dc9fa9653fa/lxml-4.2.5-cp36-cp36m-win_amd64.whl
(3.
6MB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 3.6MB 64kB/s
Installing collected packages: lxml
Successfully installed lxml-4.2.5ตัวอย่าง: การแยกข้อมูลโดยใช้ lxml และการร้องขอ
ในตัวอย่างต่อไปนี้เรากำลังคัดลอกองค์ประกอบเฉพาะของหน้าเว็บจาก authoraditiagarwal.com โดยใช้ lxml และคำขอ -
ขั้นแรกเราต้องนำเข้าคำขอและ html จากไลบรารี lxml ดังนี้ -
import requests
from lxml import htmlตอนนี้เราจำเป็นต้องให้ url ของหน้าเว็บเป็นเรื่องที่สนใจ
url = 'https://authoraditiagarwal.com/leadershipmanagement/'ตอนนี้เราจำเป็นต้องระบุเส้นทาง (Xpath) ไปยังองค์ประกอบเฉพาะของหน้าเว็บนั้น -
path = '//*[@id="panel-836-0-0-1"]/div/div/p[1]'
response = requests.get(url)
byte_string = response.content
source_code = html.fromstring(byte_string)
tree = source_code.xpath(path)
print(tree[0].text_content())เอาต์พุต
ผลลัพธ์ที่เกี่ยวข้องจะเป็นดังที่แสดงไว้ที่นี่ -
The Sprint Burndown or the Iteration Burndown chart is a powerful tool to communicate
daily progress to the stakeholders. It tracks the completion of work for a given sprint
or an iteration. The horizontal axis represents the days within a Sprint. The vertical
axis represents the hours remaining to complete the committed work.ในบทก่อนหน้านี้เราได้เรียนรู้เกี่ยวกับการดึงข้อมูลจากหน้าเว็บหรือการขูดเว็บโดยโมดูล Python ต่างๆ ในบทนี้ให้เราดูเทคนิคต่างๆในการประมวลผลข้อมูลที่คัดลอกมา
บทนำ
ในการประมวลผลข้อมูลที่คัดลอกมาเราต้องจัดเก็บข้อมูลในเครื่องของเราในรูปแบบเฉพาะเช่นสเปรดชีต (CSV) JSON หรือบางครั้งในฐานข้อมูลเช่น MySQL
การประมวลผลข้อมูล CSV และ JSON
ขั้นแรกเราจะเขียนข้อมูลหลังจากดึงจากหน้าเว็บลงในไฟล์ CSV หรือสเปรดชีต ก่อนอื่นให้เราทำความเข้าใจผ่านตัวอย่างง่ายๆซึ่งก่อนอื่นเราจะคว้าข้อมูลโดยใช้BeautifulSoup โมดูลดังที่เคยทำก่อนหน้านี้จากนั้นโดยใช้โมดูล Python CSV เราจะเขียนข้อมูลที่เป็นข้อความลงในไฟล์ CSV
ขั้นแรกเราต้องนำเข้าไลบรารี Python ที่จำเป็นดังนี้ -
import requests
from bs4 import BeautifulSoup
import csvในโค้ดบรรทัดต่อไปนี้เราใช้การร้องขอเพื่อส่งคำขอ GET HTTP สำหรับ url: https://authoraditiagarwal.com/ โดยการร้องขอ GET
r = requests.get('https://authoraditiagarwal.com/')ตอนนี้เราต้องสร้างวัตถุซุปดังต่อไปนี้ -
soup = BeautifulSoup(r.text, 'lxml')ตอนนี้ด้วยความช่วยเหลือของโค้ดบรรทัดถัดไปเราจะเขียนข้อมูลที่จับลงในไฟล์ CSV ชื่อ dataprocessing.csv
f = csv.writer(open(' dataprocessing.csv ','w'))
f.writerow(['Title'])
f.writerow([soup.title.text])หลังจากเรียกใช้สคริปต์นี้ข้อมูลที่เป็นข้อความหรือชื่อของหน้าเว็บจะถูกบันทึกไว้ในไฟล์ CSV ที่กล่าวถึงข้างต้นในเครื่องของคุณ
ในทำนองเดียวกันเราสามารถบันทึกข้อมูลที่รวบรวมไว้ในไฟล์ JSON ต่อไปนี้เป็นสคริปต์ Python ที่เข้าใจง่ายสำหรับการทำเช่นเดียวกันกับที่เรากำลังดึงข้อมูลเดียวกันกับที่เราทำในสคริปต์ Python ล่าสุด แต่คราวนี้ข้อมูลที่จับได้จะถูกบันทึกไว้ใน JSONfile.txt โดยใช้โมดูล JSON Python
import requests
from bs4 import BeautifulSoup
import csv
import json
r = requests.get('https://authoraditiagarwal.com/')
soup = BeautifulSoup(r.text, 'lxml')
y = json.dumps(soup.title.text)
with open('JSONFile.txt', 'wt') as outfile:
json.dump(y, outfile)หลังจากเรียกใช้สคริปต์นี้ข้อมูลที่จับได้เช่นชื่อของหน้าเว็บจะถูกบันทึกไว้ในไฟล์ข้อความที่กล่าวถึงข้างต้นในเครื่องของคุณ
การประมวลผลข้อมูลโดยใช้ AWS S3
บางครั้งเราอาจต้องการบันทึกข้อมูลที่คัดลอกไว้ในที่จัดเก็บในตัวเครื่องเพื่อวัตถุประสงค์ในการเก็บถาวร แต่ถ้าเราจำเป็นต้องจัดเก็บและวิเคราะห์ข้อมูลนี้ในปริมาณมากล่ะ? คำตอบคือบริการจัดเก็บข้อมูลบนคลาวด์ชื่อ Amazon S3 หรือ AWS S3 (Simple Storage Service) โดยพื้นฐานแล้ว AWS S3 คือที่เก็บข้อมูลออบเจ็กต์ซึ่งสร้างขึ้นเพื่อจัดเก็บและดึงข้อมูลจำนวนเท่าใดก็ได้จากทุกที่
เราสามารถทำตามขั้นตอนต่อไปนี้สำหรับการจัดเก็บข้อมูลใน AWS S3 -
Step 1- อันดับแรกเราต้องมีบัญชี AWS ซึ่งจะมอบคีย์ลับสำหรับใช้ในสคริปต์ Python ของเราในขณะจัดเก็บข้อมูล มันจะสร้างที่เก็บข้อมูล S3 ซึ่งเราสามารถจัดเก็บข้อมูลของเราได้
Step 2 - ต่อไปเราต้องติดตั้ง boto3ไลบรารี Python สำหรับการเข้าถึงที่เก็บข้อมูล S3 สามารถติดตั้งได้ด้วยความช่วยเหลือของคำสั่งต่อไปนี้ -
pip install boto3Step 3 - ต่อไปเราสามารถใช้สคริปต์ Python ต่อไปนี้สำหรับการขูดข้อมูลจากหน้าเว็บและบันทึกลงในที่เก็บข้อมูล AWS S3
ขั้นแรกเราต้องนำเข้าไลบรารี Python เพื่อทำการขูดที่นี่เรากำลังดำเนินการกับ requestsและ boto3 บันทึกข้อมูลลงในถัง S3
import requests
import boto3ตอนนี้เราสามารถขูดข้อมูลจาก URL ของเราได้แล้ว
data = requests.get("Enter the URL").textตอนนี้สำหรับการจัดเก็บข้อมูลไปยังถัง S3 เราจำเป็นต้องสร้างไคลเอนต์ S3 ดังต่อไปนี้ -
s3 = boto3.client('s3')
bucket_name = "our-content"โค้ดบรรทัดถัดไปจะสร้างบัคเก็ต S3 ดังนี้ -
s3.create_bucket(Bucket = bucket_name, ACL = 'public-read')
s3.put_object(Bucket = bucket_name, Key = '', Body = data, ACL = "public-read")ตอนนี้คุณสามารถตรวจสอบที่เก็บข้อมูลพร้อมตั้งชื่อเนื้อหาของเราจากบัญชี AWS ของคุณ
การประมวลผลข้อมูลโดยใช้ MySQL
ให้เราเรียนรู้วิธีการประมวลผลข้อมูลโดยใช้ MySQL หากคุณต้องการเรียนรู้เกี่ยวกับ MySQL คุณสามารถไปที่ลิงค์https://www.tutorialspoint.com/mysql/.
ด้วยความช่วยเหลือของขั้นตอนต่อไปนี้เราสามารถขูดและประมวลผลข้อมูลลงในตาราง MySQL -
Step 1- ขั้นแรกโดยใช้ MySQL เราต้องสร้างฐานข้อมูลและตารางที่เราต้องการบันทึกข้อมูลที่คัดลอกมา ตัวอย่างเช่นเรากำลังสร้างตารางด้วยแบบสอบถามต่อไปนี้ -
CREATE TABLE Scrap_pages (id BIGINT(7) NOT NULL AUTO_INCREMENT,
title VARCHAR(200), content VARCHAR(10000),PRIMARY KEY(id));Step 2- ต่อไปเราต้องจัดการกับ Unicode โปรดทราบว่า MySQL ไม่จัดการ Unicode ตามค่าเริ่มต้น เราจำเป็นต้องเปิดคุณสมบัตินี้ด้วยความช่วยเหลือของคำสั่งต่อไปนี้ซึ่งจะเปลี่ยนชุดอักขระเริ่มต้นสำหรับฐานข้อมูลสำหรับตารางและสำหรับทั้งสองคอลัมน์ -
ALTER DATABASE scrap CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
ALTER TABLE Scrap_pages CONVERT TO CHARACTER SET utf8mb4 COLLATE
utf8mb4_unicode_ci;
ALTER TABLE Scrap_pages CHANGE title title VARCHAR(200) CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;
ALTER TABLE pages CHANGE content content VARCHAR(10000) CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;Step 3- ตอนนี้รวม MySQL กับ Python สำหรับสิ่งนี้เราจะต้องใช้ PyMySQL ซึ่งสามารถติดตั้งได้ด้วยความช่วยเหลือของคำสั่งต่อไปนี้
pip install PyMySQLStep 4- ตอนนี้ฐานข้อมูลของเราชื่อ Scrap ที่สร้างขึ้นก่อนหน้านี้พร้อมที่จะบันทึกข้อมูลหลังจากคัดลอกจากเว็บลงในตารางชื่อ Scrap_pages ในตัวอย่างของเราเราจะขูดข้อมูลจาก Wikipedia และจะถูกบันทึกลงในฐานข้อมูลของเรา
ขั้นแรกเราต้องนำเข้าโมดูล Python ที่จำเป็น
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import pymysql
import reตอนนี้ทำการเชื่อมต่อซึ่งรวมเข้ากับ Python
conn = pymysql.connect(host='127.0.0.1',user='root', passwd = None, db = 'mysql',
charset = 'utf8')
cur = conn.cursor()
cur.execute("USE scrap")
random.seed(datetime.datetime.now())
def store(title, content):
cur.execute('INSERT INTO scrap_pages (title, content) VALUES ''("%s","%s")', (title, content))
cur.connection.commit()ตอนนี้เชื่อมต่อกับ Wikipedia และรับข้อมูลจากมัน
def getLinks(articleUrl):
html = urlopen('http://en.wikipedia.org'+articleUrl)
bs = BeautifulSoup(html, 'html.parser')
title = bs.find('h1').get_text()
content = bs.find('div', {'id':'mw-content-text'}).find('p').get_text()
store(title, content)
return bs.find('div', {'id':'bodyContent'}).findAll('a',href=re.compile('^(/wiki/)((?!:).)*$'))
links = getLinks('/wiki/Kevin_Bacon')
try:
while len(links) > 0:
newArticle = links[random.randint(0, len(links)-1)].attrs['href']
print(newArticle)
links = getLinks(newArticle)สุดท้ายเราต้องปิดทั้งเคอร์เซอร์และการเชื่อมต่อ
finally:
cur.close()
conn.close()สิ่งนี้จะบันทึกข้อมูลที่รวบรวมจาก Wikipedia ลงในตารางชื่อ scrap_pages หากคุณคุ้นเคยกับ MySQL และการขูดเว็บรหัสข้างต้นจะไม่ยากที่จะเข้าใจ
การประมวลผลข้อมูลโดยใช้ PostgreSQL
PostgreSQL ซึ่งพัฒนาโดยทีมอาสาสมัครทั่วโลกเป็นระบบจัดการฐานข้อมูลเชิงสัมพันธ์แบบโอเพ่นซอร์ส (RDMS) กระบวนการประมวลผลข้อมูลที่คัดลอกโดยใช้ PostgreSQL นั้นคล้ายกับ MySQL จะมีการเปลี่ยนแปลงสองประการ: ประการแรกคำสั่งจะแตกต่างจาก MySQL และประการที่สองเราจะใช้ที่นี่psycopg2 ไลบรารี Python เพื่อดำเนินการรวมกับ Python
หากคุณไม่คุ้นเคยกับ PostgreSQL คุณสามารถเรียนรู้ได้ที่ https://www.tutorialspoint.com/postgresql/. และด้วยความช่วยเหลือของคำสั่งต่อไปนี้เราสามารถติดตั้งไลบรารี psycopg2 Python -
pip install psycopg2การขูดเว็บมักเกี่ยวข้องกับการดาวน์โหลดจัดเก็บและประมวลผลเนื้อหาสื่อบนเว็บ ในบทนี้ให้เราเข้าใจวิธีการประมวลผลเนื้อหาที่ดาวน์โหลดจากเว็บ
บทนำ
เนื้อหาสื่อบนเว็บที่เราได้รับระหว่างการขูดอาจเป็นไฟล์รูปภาพเสียงและวิดีโอในรูปแบบของหน้าเว็บที่ไม่ใช่หน้าเว็บเช่นเดียวกับไฟล์ข้อมูล แต่เราสามารถเชื่อถือข้อมูลที่ดาวน์โหลดโดยเฉพาะในส่วนขยายของข้อมูลที่เรากำลังจะดาวน์โหลดและจัดเก็บไว้ในหน่วยความจำคอมพิวเตอร์ของเราได้หรือไม่? สิ่งนี้ทำให้จำเป็นต้องทราบเกี่ยวกับประเภทของข้อมูลที่เราจะจัดเก็บไว้ในเครื่อง
รับเนื้อหาสื่อจากเว็บเพจ
ในส่วนนี้เราจะเรียนรู้วิธีดาวน์โหลดเนื้อหาสื่อที่แสดงถึงประเภทสื่ออย่างถูกต้องตามข้อมูลจากเว็บเซิร์ฟเวอร์ เราสามารถทำได้ด้วยความช่วยเหลือของ Pythonrequests โมดูลตามที่เราทำในบทที่แล้ว
ขั้นแรกเราต้องนำเข้าโมดูล Python ที่จำเป็นดังต่อไปนี้ -
import requestsตอนนี้ให้ระบุ URL ของเนื้อหาสื่อที่เราต้องการดาวน์โหลดและจัดเก็บไว้ในเครื่อง
url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg"ใช้รหัสต่อไปนี้เพื่อสร้างวัตถุตอบกลับ HTTP
r = requests.get(url)ด้วยความช่วยเหลือของบรรทัดโค้ดต่อไปนี้เราสามารถบันทึกเนื้อหาที่ได้รับเป็นไฟล์. png
with open("ThinkBig.png",'wb') as f:
f.write(r.content)หลังจากเรียกใช้สคริปต์ Python ด้านบนเราจะได้ไฟล์ชื่อ ThinkBig.png ซึ่งจะมีภาพที่ดาวน์โหลดมา
การแยกชื่อไฟล์จาก URL
หลังจากดาวน์โหลดเนื้อหาจากเว็บไซต์เราต้องการบันทึกลงในไฟล์ที่มีชื่อไฟล์ที่พบใน URL แต่เราสามารถตรวจสอบได้ด้วยว่ามีจำนวนชิ้นส่วนเพิ่มเติมใน URL หรือไม่ สำหรับสิ่งนี้เราต้องหาชื่อไฟล์จริงจาก URL
ด้วยความช่วยเหลือของการทำตามสคริปต์ Python โดยใช้ urlparseเราสามารถแยกชื่อไฟล์จาก URL -
import urllib3
import os
url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg"
a = urlparse(url)
a.pathคุณสามารถสังเกตผลลัพธ์ที่แสดงด้านล่าง -
'/wp-content/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg'
os.path.basename(a.path)คุณสามารถสังเกตผลลัพธ์ที่แสดงด้านล่าง -
'MetaSlider_ThinkBig-1080x180.jpg'เมื่อคุณเรียกใช้สคริปต์ข้างต้นเราจะได้ชื่อไฟล์จาก URL
ข้อมูลเกี่ยวกับประเภทของเนื้อหาจาก URL
ในขณะที่ดึงเนื้อหาจากเว็บเซิร์ฟเวอร์ตามคำขอ GET เราสามารถตรวจสอบข้อมูลที่เว็บเซิร์ฟเวอร์ให้มาได้ ด้วยความช่วยเหลือของการทำตามสคริปต์ Python เราสามารถกำหนดความหมายของเว็บเซิร์ฟเวอร์ด้วยประเภทของเนื้อหา -
ขั้นแรกเราต้องนำเข้าโมดูล Python ที่จำเป็นดังต่อไปนี้ -
import requestsตอนนี้เราจำเป็นต้องระบุ URL ของเนื้อหาสื่อที่เราต้องการดาวน์โหลดและจัดเก็บไว้ในเครื่อง
url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg"บรรทัดโค้ดต่อไปนี้จะสร้างอ็อบเจกต์ตอบกลับ HTTP
r = requests.get(url, allow_redirects=True)ตอนนี้เราสามารถรับข้อมูลประเภทเนื้อหาที่เว็บเซิร์ฟเวอร์สามารถให้ได้
for headers in r.headers: print(headers)คุณสามารถสังเกตผลลัพธ์ที่แสดงด้านล่าง -
Date
Server
Upgrade
Connection
Last-Modified
Accept-Ranges
Content-Length
Keep-Alive
Content-Typeด้วยความช่วยเหลือของบรรทัดโค้ดต่อไปนี้เราจะได้รับข้อมูลเฉพาะเกี่ยวกับประเภทเนื้อหาพูดประเภทเนื้อหา -
print (r.headers.get('content-type'))คุณสามารถสังเกตผลลัพธ์ที่แสดงด้านล่าง -
image/jpegด้วยความช่วยเหลือของบรรทัดโค้ดต่อไปนี้เราจะได้รับข้อมูลเฉพาะเกี่ยวกับประเภทเนื้อหากล่าวว่า EType -
print (r.headers.get('ETag'))คุณสามารถสังเกตผลลัพธ์ที่แสดงด้านล่าง -
Noneปฏิบัติตามคำสั่งต่อไปนี้ -
print (r.headers.get('content-length'))คุณสามารถสังเกตผลลัพธ์ที่แสดงด้านล่าง -
12636ด้วยความช่วยเหลือของบรรทัดโค้ดต่อไปนี้เราจะได้รับข้อมูลเฉพาะเกี่ยวกับประเภทเนื้อหาเช่นเซิร์ฟเวอร์ -
print (r.headers.get('Server'))คุณสามารถสังเกตผลลัพธ์ที่แสดงด้านล่าง -
Apacheการสร้างภาพขนาดย่อสำหรับรูปภาพ
ภาพขนาดย่อเป็นคำอธิบายหรือการแสดงที่มีขนาดเล็กมาก ผู้ใช้อาจต้องการบันทึกเฉพาะภาพขนาดย่อของภาพขนาดใหญ่หรือบันทึกทั้งภาพและภาพขนาดย่อ ในส่วนนี้เราจะสร้างภาพขนาดย่อของภาพที่มีชื่อว่าThinkBig.png ดาวน์โหลดในส่วนก่อนหน้า“ การรับเนื้อหาสื่อจากหน้าเว็บ”
สำหรับสคริปต์ Python นี้เราจำเป็นต้องติดตั้งไลบรารี Python ชื่อ Pillow ซึ่งเป็นทางแยกของไลบรารี Python Image ที่มีฟังก์ชันที่มีประโยชน์สำหรับการจัดการรูปภาพ สามารถติดตั้งได้ด้วยความช่วยเหลือของคำสั่งต่อไปนี้ -
pip install pillowสคริปต์ Python ต่อไปนี้จะสร้างรูปขนาดย่อของรูปภาพและจะบันทึกลงในไดเร็กทอรีปัจจุบันโดยนำหน้าไฟล์รูปขนาดย่อด้วย Th_
import glob
from PIL import Image
for infile in glob.glob("ThinkBig.png"):
img = Image.open(infile)
img.thumbnail((128, 128), Image.ANTIALIAS)
if infile[0:2] != "Th_":
img.save("Th_" + infile, "png")โค้ดด้านบนเข้าใจง่ายมากและคุณสามารถตรวจสอบไฟล์ขนาดย่อในไดเร็กทอรีปัจจุบันได้
ภาพหน้าจอจากเว็บไซต์
ในการขูดเว็บงานทั่วไปคือการถ่ายภาพหน้าจอของเว็บไซต์ ในการดำเนินการนี้เราจะใช้ซีลีเนียมและเว็บไดร์เวอร์ สคริปต์ Python ต่อไปนี้จะนำภาพหน้าจอจากเว็บไซต์และจะบันทึกลงในไดเรกทอรีปัจจุบัน
From selenium import webdriver
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
browser = webdriver.Chrome(executable_path = path)
browser.get('https://tutorialspoint.com/')
screenshot = browser.save_screenshot('screenshot.png')
browser.quitคุณสามารถสังเกตผลลัพธ์ที่แสดงด้านล่าง -
DevTools listening on ws://127.0.0.1:1456/devtools/browser/488ed704-9f1b-44f0-
a571-892dc4c90eb7
<bound method WebDriver.quit of <selenium.webdriver.chrome.webdriver.WebDriver
(session="37e8e440e2f7807ef41ca7aa20ce7c97")>>หลังจากรันสคริปต์คุณสามารถตรวจสอบไดเร็กทอรีปัจจุบันของคุณสำหรับ screenshot.png ไฟล์.
การสร้างภาพขนาดย่อสำหรับวิดีโอ
สมมติว่าเราได้ดาวน์โหลดวิดีโอจากเว็บไซต์และต้องการสร้างภาพขนาดย่อสำหรับพวกเขาเพื่อให้สามารถคลิกวิดีโอใดวิดีโอหนึ่งโดยพิจารณาจากภาพขนาดย่อได้ ในการสร้างภาพขนาดย่อสำหรับวิดีโอเราจำเป็นต้องมีเครื่องมือง่ายๆที่เรียกว่าffmpeg ซึ่งสามารถดาวน์โหลดได้จาก www.ffmpeg.org. หลังจากดาวน์โหลดเราจำเป็นต้องติดตั้งตามข้อกำหนดของระบบปฏิบัติการของเรา
สคริปต์ Python ต่อไปนี้จะสร้างภาพขนาดย่อของวิดีโอและจะบันทึกลงในไดเร็กทอรีท้องถิ่นของเรา -
import subprocess
video_MP4_file = “C:\Users\gaurav\desktop\solar.mp4
thumbnail_image_file = 'thumbnail_solar_video.jpg'
subprocess.call(['ffmpeg', '-i', video_MP4_file, '-ss', '00:00:20.000', '-
vframes', '1', thumbnail_image_file, "-y"])หลังจากเรียกใช้สคริปต์ด้านบนเราจะได้รับชื่อภาพขนาดย่อ thumbnail_solar_video.jpg บันทึกไว้ในไดเร็กทอรีท้องถิ่นของเรา
การริปวิดีโอ MP4 เป็น MP3
สมมติว่าคุณดาวน์โหลดไฟล์วิดีโอจากเว็บไซต์ แต่คุณต้องการเพียงเสียงจากไฟล์นั้นเพื่อตอบสนองจุดประสงค์ของคุณจากนั้นสามารถทำได้ใน Python ด้วยความช่วยเหลือของไลบรารี Python ที่เรียกว่า moviepy ซึ่งสามารถติดตั้งได้ด้วยความช่วยเหลือของคำสั่งต่อไปนี้ -
pip install moviepyตอนนี้หลังจากติดตั้ง moviepy สำเร็จด้วยความช่วยเหลือของสคริปต์ต่อไปนี้เราสามารถแปลงและ MP4 เป็น MP3 ได้
import moviepy.editor as mp
clip = mp.VideoFileClip(r"C:\Users\gaurav\Desktop\1234.mp4")
clip.audio.write_audiofile("movie_audio.mp3")คุณสามารถสังเกตผลลัพธ์ที่แสดงด้านล่าง -
[MoviePy] Writing audio in movie_audio.mp3
100%|¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦
¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 674/674 [00:01<00:00,
476.30it/s]
[MoviePy] Done.สคริปต์ข้างต้นจะบันทึกไฟล์ MP3 เสียงในไดเร็กทอรีท้องถิ่น
ในบทที่แล้วเราได้เห็นวิธีจัดการกับวิดีโอและรูปภาพที่เราได้รับมาเป็นส่วนหนึ่งของเนื้อหาในการขูดเว็บ ในบทนี้เราจะจัดการกับการวิเคราะห์ข้อความโดยใช้ไลบรารี Python และจะเรียนรู้เกี่ยวกับเรื่องนี้โดยละเอียด
บทนำ
คุณสามารถทำการวิเคราะห์ข้อความโดยใช้ไลบรารี Python ที่เรียกว่า Natural Language Tool Kit (NLTK) ก่อนที่จะดำเนินการตามแนวคิดของ NLTK ให้เราเข้าใจความสัมพันธ์ระหว่างการวิเคราะห์ข้อความและการคัดลอกเว็บ
การวิเคราะห์คำในข้อความสามารถทำให้เรารู้ว่าคำไหนสำคัญคำไหนผิดปกติมีการจัดกลุ่มคำอย่างไร การวิเคราะห์นี้ช่วยลดความยุ่งยากในการขูดเว็บ
เริ่มต้นกับ NLTK
ชุดเครื่องมือภาษาธรรมชาติ (NLTK) คือชุดของไลบรารี Python ซึ่งออกแบบมาโดยเฉพาะสำหรับการระบุและแท็กส่วนของคำพูดที่พบในข้อความของภาษาธรรมชาติเช่นภาษาอังกฤษ
การติดตั้ง NLTK
คุณสามารถใช้คำสั่งต่อไปนี้เพื่อติดตั้ง NLTK ใน Python -
pip install nltkหากคุณใช้ Anaconda คุณสามารถสร้างแพ็คเกจ conda สำหรับ NLTK ได้โดยใช้คำสั่งต่อไปนี้ -
conda install -c anaconda nltkกำลังดาวน์โหลดข้อมูลของ NLTK
หลังจากติดตั้ง NLTK เราต้องดาวน์โหลดที่เก็บข้อความที่ตั้งไว้ล่วงหน้า แต่ก่อนที่จะดาวน์โหลดที่เก็บข้อความที่ตั้งไว้ล่วงหน้าเราจำเป็นต้องนำเข้า NLTK ด้วยความช่วยเหลือของไฟล์import คำสั่งดังนี้ -
mport nltkตอนนี้ด้วยความช่วยเหลือของคำสั่งต่อไปนี้ข้อมูล NLTK สามารถดาวน์โหลดได้ -
nltk.download()การติดตั้งแพ็คเกจทั้งหมดที่มีของ NLTK จะใช้เวลาสักครู่ แต่ขอแนะนำให้ติดตั้งแพ็คเกจทั้งหมดเสมอ
การติดตั้งแพ็คเกจที่จำเป็นอื่น ๆ
เราต้องการแพ็คเกจ Python อื่น ๆ เช่น gensim และ pattern สำหรับการวิเคราะห์ข้อความและการสร้างแอปพลิเคชันการประมวลผลภาษาธรรมชาติโดยใช้ NLTK
gensim- ไลบรารีการสร้างแบบจำลองความหมายที่แข็งแกร่งซึ่งมีประโยชน์สำหรับแอปพลิเคชันมากมาย สามารถติดตั้งได้โดยคำสั่งต่อไปนี้ -
pip install gensimpattern - ใช้ในการทำ gensimแพคเกจทำงานอย่างถูกต้อง สามารถติดตั้งได้โดยคำสั่งต่อไปนี้ -
pip install patternTokenization
กระบวนการทำลายข้อความที่กำหนดให้เป็นหน่วยเล็ก ๆ ที่เรียกว่าโทเค็นเรียกว่าโทเค็น โทเค็นเหล่านี้อาจเป็นคำตัวเลขหรือเครื่องหมายวรรคตอน เรียกอีกอย่างว่าword segmentation.
ตัวอย่าง

โมดูล NLTK มีแพ็คเกจที่แตกต่างกันสำหรับโทเค็น เราสามารถใช้แพ็คเกจเหล่านี้ได้ตามความต้องการของเรา บางส่วนของแพ็คเกจมีอธิบายไว้ที่นี่ -
sent_tokenize package- แพ็คเกจนี้จะแบ่งข้อความที่ป้อนออกเป็นประโยค คุณสามารถใช้คำสั่งต่อไปนี้เพื่อนำเข้าแพ็คเกจนี้ -
from nltk.tokenize import sent_tokenizeword_tokenize package- แพ็คเกจนี้จะแบ่งข้อความที่ป้อนเป็นคำ คุณสามารถใช้คำสั่งต่อไปนี้เพื่อนำเข้าแพ็คเกจนี้ -
from nltk.tokenize import word_tokenizeWordPunctTokenizer package- แพ็คเกจนี้จะแบ่งข้อความที่ป้อนและเครื่องหมายวรรคตอนออกเป็นคำ คุณสามารถใช้คำสั่งต่อไปนี้เพื่อนำเข้าแพ็คเกจนี้ -
from nltk.tokenize import WordPuncttokenizerStemming
ในภาษาใด ๆ มีคำในรูปแบบต่างๆ ภาษามีรูปแบบต่างๆมากมายเนื่องจากเหตุผลทางไวยากรณ์ ตัวอย่างเช่นพิจารณาคำdemocracy, democraticและ democratization. สำหรับแมชชีนเลิร์นนิงและโปรเจ็กต์การคัดลอกเว็บสิ่งสำคัญคือเครื่องต้องเข้าใจว่าคำต่างๆเหล่านี้มีรูปแบบฐานเดียวกัน ดังนั้นเราสามารถพูดได้ว่าการแยกรูปแบบฐานของคำในขณะที่วิเคราะห์ข้อความจะมีประโยชน์
สิ่งนี้สามารถทำได้โดยการแยกส่วนซึ่งอาจนิยามได้ว่าเป็นกระบวนการฮิวริสติกของการแยกรูปแบบฐานของคำโดยการตัดส่วนท้ายของคำออก
โมดูล NLTK มีแพ็คเกจที่แตกต่างกันสำหรับการสกัดกั้น เราสามารถใช้แพ็คเกจเหล่านี้ได้ตามความต้องการของเรา บางส่วนของแพ็คเกจเหล่านี้มีคำอธิบายไว้ที่นี่ -
PorterStemmer package- อัลกอริทึมของ Porter ถูกใช้โดยแพ็คเกจ Python Stemming นี้เพื่อดึงรูปแบบพื้นฐาน คุณสามารถใช้คำสั่งต่อไปนี้เพื่อนำเข้าแพ็คเกจนี้ -
from nltk.stem.porter import PorterStemmerตัวอย่างเช่นหลังจากให้คำ ‘writing’ ในฐานะที่เป็นอินพุตของตัวตั้งต้นนี้ผลลัพธ์จะเป็นคำ ‘write’ หลังจากหยุดชะงัก
LancasterStemmer package- อัลกอริทึมของ Lancaster ถูกใช้โดยแพ็คเกจ Python Stemming เพื่อดึงรูปแบบพื้นฐาน คุณสามารถใช้คำสั่งต่อไปนี้เพื่อนำเข้าแพ็คเกจนี้ -
from nltk.stem.lancaster import LancasterStemmerตัวอย่างเช่นหลังจากให้คำ ‘writing’ ในฐานะที่เป็นอินพุตของสเต็มเมอร์นี้ผลลัพธ์จะเป็นคำ ‘writ’ หลังจากหยุดชะงัก
SnowballStemmer package- อัลกอริทึมของ Snowball ถูกใช้โดยแพ็คเกจ Python Stemming เพื่อแยกรูปแบบพื้นฐาน คุณสามารถใช้คำสั่งต่อไปนี้เพื่อนำเข้าแพ็คเกจนี้ -
from nltk.stem.snowball import SnowballStemmerตัวอย่างเช่นหลังจากให้คำว่า 'เขียน' เป็นอินพุตให้กับตัวเริ่มต้นแล้วผลลัพธ์จะเป็นคำว่า 'เขียน' หลังจากที่กำหนด
Lemmatization
อีกวิธีหนึ่งในการแยกรูปแบบฐานของคำคือการทำให้เป็นตัวอักษรโดยปกติจะมีจุดมุ่งหมายเพื่อลบคำลงท้ายที่ผันแปรโดยใช้คำศัพท์และการวิเคราะห์ทางสัณฐานวิทยา รูปแบบฐานของคำใด ๆ หลังการทำให้เป็นตัวอักษรเรียกว่า lemma
โมดูล NLTK มีแพ็คเกจต่อไปนี้สำหรับการย่อขนาด -
WordNetLemmatizer package- มันจะดึงรูปแบบฐานของคำขึ้นอยู่กับว่าใช้เป็นคำนามเป็นคำกริยาหรือไม่ คุณสามารถใช้คำสั่งต่อไปนี้เพื่อนำเข้าแพ็คเกจนี้ -
from nltk.stem import WordNetLemmatizerการจัดเป็นกลุ่ม
Chunking ซึ่งหมายถึงการแบ่งข้อมูลออกเป็นชิ้นเล็ก ๆ เป็นกระบวนการที่สำคัญอย่างหนึ่งในการประมวลผลภาษาธรรมชาติเพื่อระบุส่วนของคำพูดและวลีสั้น ๆ เช่นวลีคำนาม Chunking คือการทำฉลากของโทเค็น เราสามารถรับโครงสร้างของประโยคด้วยความช่วยเหลือของกระบวนการแยกชิ้นส่วน
ตัวอย่าง
ในตัวอย่างนี้เราจะใช้ Noun-Phrase chunking โดยใช้โมดูล NLTK Python NP chunking คือหมวดหมู่ของ chunking ซึ่งจะพบคำนามวลีในประโยค
ขั้นตอนในการใช้การแบ่งวลีคำนาม
เราจำเป็นต้องทำตามขั้นตอนที่ระบุด้านล่างสำหรับการใช้คำนามวลี -
ขั้นตอนที่ 1 - นิยามไวยากรณ์แบบกลุ่ม
ในขั้นตอนแรกเราจะกำหนดไวยากรณ์สำหรับ chunking มันจะประกอบด้วยกฎที่เราต้องปฏิบัติตาม
ขั้นตอนที่ 2 - การสร้างตัวแยกวิเคราะห์แบบก้อน
ตอนนี้เราจะสร้างตัวแยกวิเคราะห์แบบก้อน มันจะแยกวิเคราะห์ไวยากรณ์และให้ผลลัพธ์
ขั้นตอนที่ 3 - ผลลัพธ์
ในขั้นตอนสุดท้ายนี้ผลลัพธ์จะถูกสร้างในรูปแบบต้นไม้
ก่อนอื่นเราต้องนำเข้าแพ็คเกจ NLTK ดังนี้ -
import nltkต่อไปเราต้องกำหนดประโยค ที่นี่ DT: ดีเทอร์มิแนนต์ VBP: คำกริยา JJ: คำคุณศัพท์ IN: คำบุพบทและ NN: คำนาม
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]ต่อไปเราจะให้ไวยากรณ์ในรูปแบบของนิพจน์ทั่วไป
grammar = "NP:{<DT>?<JJ>*<NN>}"ตอนนี้บรรทัดถัดไปของโค้ดจะกำหนดตัวแยกวิเคราะห์สำหรับการแยกวิเคราะห์ไวยากรณ์
parser_chunking = nltk.RegexpParser(grammar)ตอนนี้โปรแกรมแยกวิเคราะห์จะแยกวิเคราะห์ประโยค
parser_chunking.parse(sentence)ต่อไปเราจะให้ผลลัพธ์ของเราในตัวแปร
Output = parser_chunking.parse(sentence)ด้วยความช่วยเหลือของรหัสต่อไปนี้เราสามารถวาดผลลัพธ์ของเราในรูปแบบของต้นไม้ดังที่แสดงด้านล่าง
output.draw()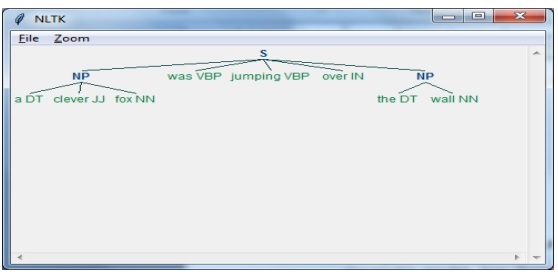
Bag of Word (BoW) Model การแยกและแปลงข้อความเป็นรูปแบบตัวเลข
Bag of Word (BoW) ซึ่งเป็นรูปแบบที่มีประโยชน์ในการประมวลผลภาษาธรรมชาติโดยทั่วไปจะใช้เพื่อแยกคุณสมบัติออกจากข้อความ หลังจากแยกคุณสมบัติออกจากข้อความแล้วสามารถใช้ในการสร้างแบบจำลองในอัลกอริทึมการเรียนรู้ของเครื่องเนื่องจากไม่สามารถใช้ข้อมูลดิบในแอปพลิเคชัน ML ได้
การทำงานของ BoW Model
ในขั้นต้นโมเดลจะแยกคำศัพท์จากคำทั้งหมดในเอกสาร ต่อมาโดยใช้เมทริกซ์คำศัพท์ของเอกสารจะสร้างแบบจำลอง ด้วยวิธีนี้แบบจำลอง BoW จะแสดงเอกสารเป็นถุงคำเท่านั้นและคำสั่งหรือโครงสร้างจะถูกทิ้ง
ตัวอย่าง
สมมติว่าเรามีสองประโยคต่อไปนี้ -
Sentence1 - นี่คือตัวอย่างโมเดล Bag of Words
Sentence2 - เราสามารถดึงคุณสมบัติโดยใช้โมเดล Bag of Words
ตอนนี้เมื่อพิจารณาสองประโยคนี้เรามีคำที่แตกต่างกัน 14 คำต่อไปนี้ -
- This
- is
- an
- example
- bag
- of
- words
- model
- we
- can
- extract
- features
- by
- using
การสร้างแบบจำลองถุงคำใน NLTK
ให้เราดูสคริปต์ Python ต่อไปนี้ซึ่งจะสร้างแบบจำลอง BoW ใน NLTK
ก่อนอื่นให้นำเข้าแพ็คเกจต่อไปนี้ -
from sklearn.feature_extraction.text import CountVectorizerจากนั้นกำหนดชุดของประโยค -
Sentences=['This is an example of Bag of Words model.', ' We can extract
features by using Bag of Words model.']
vector_count = CountVectorizer()
features_text = vector_count.fit_transform(Sentences).todense()
print(vector_count.vocabulary_)เอาต์พุต
แสดงให้เห็นว่าเรามีคำที่แตกต่างกัน 14 คำในสองประโยคข้างต้น -
{
'this': 10, 'is': 7, 'an': 0, 'example': 4, 'of': 9,
'bag': 1, 'words': 13, 'model': 8, 'we': 12, 'can': 3,
'extract': 5, 'features': 6, 'by': 2, 'using':11
}การสร้างแบบจำลองหัวข้อ: การระบุรูปแบบในข้อมูลข้อความ
โดยทั่วไปเอกสารจะถูกจัดกลุ่มเป็นหัวข้อและการสร้างแบบจำลองหัวข้อเป็นเทคนิคในการระบุรูปแบบในข้อความที่สอดคล้องกับหัวข้อใดหัวข้อหนึ่ง กล่าวอีกนัยหนึ่งการสร้างแบบจำลองหัวข้อใช้เพื่อเปิดเผยธีมนามธรรมหรือโครงสร้างที่ซ่อนอยู่ในชุดเอกสารที่กำหนด
คุณสามารถใช้การสร้างแบบจำลองหัวข้อในสถานการณ์ต่อไปนี้ -
การจัดประเภทข้อความ
การจัดหมวดหมู่สามารถปรับปรุงได้โดยการสร้างแบบจำลองหัวข้อเนื่องจากจัดกลุ่มคำที่คล้ายกันเข้าด้วยกันแทนที่จะใช้คำแต่ละคำแยกกันเป็นคุณลักษณะ
ระบบผู้แนะนำ
เราสามารถสร้างระบบผู้แนะนำโดยใช้มาตรการความคล้ายคลึงกัน
อัลกอริทึมการสร้างแบบจำลองหัวข้อ
เราสามารถใช้การสร้างแบบจำลองหัวข้อได้โดยใช้อัลกอริทึมต่อไปนี้ -
Latent Dirichlet Allocation(LDA) - เป็นหนึ่งในอัลกอริทึมที่ได้รับความนิยมมากที่สุดที่ใช้โมเดลกราฟิกที่น่าจะเป็นในการใช้การสร้างแบบจำลองหัวข้อ
Latent Semantic Analysis(LDA) or Latent Semantic Indexing(LSI) - ขึ้นอยู่กับ Linear Algebra และใช้แนวคิดของ SVD (Singular Value Decomposition) บนเมทริกซ์คำศัพท์ของเอกสาร
Non-Negative Matrix Factorization (NMF) - มันขึ้นอยู่กับพีชคณิตเชิงเส้นเช่นเดียวกับ LDA
อัลกอริทึมที่กล่าวถึงข้างต้นจะมีองค์ประกอบดังต่อไปนี้ -
- จำนวนหัวข้อ: พารามิเตอร์
- Document-Word Matrix: อินพุต
- WTM (เมทริกซ์หัวข้อของ Word) และ TDM (เมทริกซ์เอกสารหัวข้อ): เอาต์พุต
บทนำ
การขูดเว็บเป็นงานที่ซับซ้อนและความซับซ้อนจะทวีคูณหากเว็บไซต์เป็นแบบไดนามิก จากการตรวจสอบความสามารถในการเข้าถึงเว็บทั่วโลกขององค์การสหประชาชาติมากกว่า 70% ของเว็บไซต์มีลักษณะที่ไม่หยุดนิ่งและพวกเขาพึ่งพา JavaScript สำหรับฟังก์ชันการทำงานของตน
ตัวอย่างเว็บไซต์แบบไดนามิก
ให้เราดูตัวอย่างของเว็บไซต์แบบไดนามิกและทราบว่าเหตุใดจึงยากที่จะขูด เราจะนำตัวอย่างการค้นหาจากเว็บไซต์ชื่อhttp://example.webscraping.com/places/default/search.แต่เราจะพูดได้อย่างไรว่าเว็บไซต์นี้มีลักษณะไดนามิก สามารถตัดสินได้จากผลลัพธ์ของสคริปต์ Python ต่อไปนี้ซึ่งจะพยายามขูดข้อมูลจากหน้าเว็บที่กล่าวถึงข้างต้น -
import re
import urllib.request
response = urllib.request.urlopen('http://example.webscraping.com/places/default/search')
html = response.read()
text = html.decode()
re.findall('(.*?)',text)เอาต์พุต
[ ]ผลลัพธ์ด้านบนแสดงให้เห็นว่ามีดโกนตัวอย่างไม่สามารถดึงข้อมูลได้เนื่องจากองค์ประกอบ <div> ที่เราพยายามค้นหาว่างเปล่า
แนวทางการขูดข้อมูลจากเว็บไซต์แบบไดนามิก
เราได้เห็นแล้วว่าเครื่องขูดไม่สามารถขูดข้อมูลจากเว็บไซต์แบบไดนามิกได้เนื่องจากข้อมูลถูกโหลดแบบไดนามิกด้วย JavaScript ในกรณีเช่นนี้เราสามารถใช้สองเทคนิคต่อไปนี้ในการดึงข้อมูลจากเว็บไซต์ที่ขึ้นกับ JavaScript แบบไดนามิก -
- JavaScript วิศวกรรมย้อนกลับ
- การแสดงผล JavaScript
JavaScript วิศวกรรมย้อนกลับ
กระบวนการที่เรียกว่าวิศวกรรมย้อนกลับจะมีประโยชน์และช่วยให้เราเข้าใจว่าข้อมูลถูกโหลดแบบไดนามิกโดยหน้าเว็บอย่างไร
ในการดำเนินการนี้เราต้องคลิกไฟล์ inspect elementแท็บสำหรับ URL ที่ระบุ ต่อไปเราจะคลิกNETWORK เพื่อค้นหาคำขอทั้งหมดที่สร้างขึ้นสำหรับหน้าเว็บนั้นรวมถึง search.json ด้วยเส้นทางของ /ajax. แทนที่จะเข้าถึงข้อมูล AJAX จากเบราว์เซอร์หรือผ่านแท็บ NETWORK เราสามารถทำได้ด้วยความช่วยเหลือของการทำตามสคริปต์ Python ด้วย -
import requests
url=requests.get('http://example.webscraping.com/ajax/search.json?page=0&page_size=10&search_term=a')
url.json()ตัวอย่าง
สคริปต์ด้านบนช่วยให้เราเข้าถึงการตอบสนอง JSON โดยใช้วิธี Python json ในทำนองเดียวกันเราสามารถดาวน์โหลดการตอบกลับสตริงดิบและโดยใช้เมธอด json.loads ของ python เราก็สามารถโหลดได้เช่นกัน เรากำลังทำสิ่งนี้ด้วยความช่วยเหลือของการทำตามสคริปต์ Python โดยพื้นฐานแล้วมันจะขูดทุกประเทศโดยค้นหาตัวอักษร 'a' จากนั้นวนซ้ำหน้าผลลัพธ์ของการตอบกลับ JSON
import requests
import string
PAGE_SIZE = 15
url = 'http://example.webscraping.com/ajax/' + 'search.json?page={}&page_size={}&search_term=a'
countries = set()
for letter in string.ascii_lowercase:
print('Searching with %s' % letter)
page = 0
while True:
response = requests.get(url.format(page, PAGE_SIZE, letter))
data = response.json()
print('adding %d records from the page %d' %(len(data.get('records')),page))
for record in data.get('records'):countries.add(record['country'])
page += 1
if page >= data['num_pages']:
break
with open('countries.txt', 'w') as countries_file:
countries_file.write('n'.join(sorted(countries)))หลังจากเรียกใช้สคริปต์ข้างต้นเราจะได้ผลลัพธ์ต่อไปนี้และบันทึกจะถูกบันทึกไว้ในไฟล์ชื่อ countries.txt
เอาต์พุต
Searching with a
adding 15 records from the page 0
adding 15 records from the page 1
...การแสดงผล JavaScript
ในส่วนก่อนหน้านี้เราได้ทำวิศวกรรมย้อนกลับบนหน้าเว็บว่า API ทำงานอย่างไรและเราจะใช้มันเพื่อดึงผลลัพธ์ในคำขอเดียวได้อย่างไร อย่างไรก็ตามเราสามารถเผชิญกับปัญหาต่อไปนี้ได้ในขณะที่ทำวิศวกรรมย้อนกลับ -
บางครั้งเว็บไซต์อาจเป็นเรื่องยากมาก ตัวอย่างเช่นหากเว็บไซต์สร้างด้วยเครื่องมือเบราว์เซอร์ขั้นสูงเช่น Google Web Toolkit (GWT) โค้ด JS ที่ได้จะถูกสร้างขึ้นโดยเครื่องและยากที่จะเข้าใจและทำวิศวกรรมย้อนกลับ
เฟรมเวิร์กระดับสูงบางอย่างเช่น React.js สามารถทำให้วิศวกรรมย้อนกลับเป็นเรื่องยากโดยการสรุปตรรกะ JavaScript ที่ซับซ้อนอยู่แล้ว
วิธีแก้ปัญหาข้างต้นคือการใช้เครื่องมือเรนเดอร์เบราว์เซอร์ที่แยกวิเคราะห์ HTML ใช้การจัดรูปแบบ CSS และเรียกใช้ JavaScript เพื่อแสดงหน้าเว็บ
ตัวอย่าง
ในตัวอย่างนี้สำหรับการแสดงผล Java Script เราจะใช้โมดูล Python Selenium ที่คุ้นเคย รหัส Python ต่อไปนี้จะแสดงหน้าเว็บด้วยความช่วยเหลือของ Selenium -
ขั้นแรกเราต้องนำเข้า webdriver จากซีลีเนียมดังนี้ -
from selenium import webdriverตอนนี้ให้เส้นทางของโปรแกรมควบคุมเว็บที่เราดาวน์โหลดตามความต้องการของเรา -
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
driver = webdriver.Chrome(executable_path = path)ตอนนี้ให้ระบุ url ที่เราต้องการเปิดในเว็บเบราว์เซอร์นั้นตอนนี้ควบคุมโดยสคริปต์ Python ของเรา
driver.get('http://example.webscraping.com/search')ตอนนี้เราสามารถใช้ ID ของกล่องเครื่องมือค้นหาเพื่อตั้งค่าองค์ประกอบเพื่อเลือก
driver.find_element_by_id('search_term').send_keys('.')ต่อไปเราสามารถใช้ java script เพื่อตั้งค่าเนื้อหากล่องเลือกได้ดังนี้ -
js = "document.getElementById('page_size').options[1].text = '100';"
driver.execute_script(js)โค้ดบรรทัดต่อไปนี้แสดงให้เห็นว่าการค้นหาพร้อมที่จะคลิกบนหน้าเว็บ -
driver.find_element_by_id('search').click()โค้ดบรรทัดถัดไปแสดงว่าจะรอ 45 วินาทีเพื่อให้คำขอ AJAX เสร็จสมบูรณ์
driver.implicitly_wait(45)ตอนนี้สำหรับการเลือกลิงค์ประเทศเราสามารถใช้ตัวเลือก CSS ได้ดังนี้ -
links = driver.find_elements_by_css_selector('#results a')ตอนนี้สามารถแยกข้อความของแต่ละลิงค์เพื่อสร้างรายชื่อประเทศ -
countries = [link.text for link in links]
print(countries)
driver.close()ในบทที่แล้วเราได้เห็นการขูดเว็บไซต์แบบไดนามิก ในบทนี้ให้เราทำความเข้าใจเกี่ยวกับการคัดลอกเว็บไซต์ที่ทำงานโดยใช้ปัจจัยการผลิตตามผู้ใช้นั่นคือเว็บไซต์ที่ใช้รูปแบบ
บทนำ
ทุกวันนี้ WWW (เวิลด์ไวด์เว็บ) กำลังก้าวไปสู่โซเชียลมีเดียเช่นเดียวกับเนื้อหาที่ผู้ใช้สร้างขึ้น จึงเกิดคำถามว่าเราจะเข้าถึงข้อมูลประเภทที่อยู่นอกเหนือจากหน้าจอล็อกอินได้อย่างไร? สำหรับสิ่งนี้เราจำเป็นต้องจัดการกับแบบฟอร์มและการเข้าสู่ระบบ
ในบทก่อนหน้านี้เราใช้เมธอด HTTP GET เพื่อขอข้อมูล แต่ในบทนี้เราจะทำงานกับวิธี HTTP POST ที่ส่งข้อมูลไปยังเว็บเซิร์ฟเวอร์เพื่อจัดเก็บและวิเคราะห์
การโต้ตอบกับแบบฟอร์มการเข้าสู่ระบบ
ในขณะที่ทำงานบนอินเทอร์เน็ตคุณต้องโต้ตอบกับแบบฟอร์มการเข้าสู่ระบบหลายครั้ง อาจจะง่ายมากเช่นใส่ช่อง HTML เพียงไม่กี่ช่องปุ่มส่งและหน้าการดำเนินการหรืออาจซับซ้อนและมีช่องเพิ่มเติมเช่นอีเมลฝากข้อความไว้พร้อมกับ captcha เพื่อความปลอดภัย
ในส่วนนี้เราจะจัดการกับแบบฟอร์มการส่งแบบธรรมดาด้วยความช่วยเหลือของไลบรารีคำขอ Python
ขั้นแรกเราต้องนำเข้าไลบรารีคำขอดังนี้ -
import requestsตอนนี้เราจำเป็นต้องให้ข้อมูลสำหรับฟิลด์ของแบบฟอร์มการเข้าสู่ระบบ
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}ในบรรทัดถัดไปของโค้ดเราจำเป็นต้องระบุ URL ที่จะเกิดการทำงานของแบบฟอร์ม
r = requests.post(“enter the URL”, data = parameters)
print(r.text)หลังจากเรียกใช้สคริปต์สคริปต์จะส่งคืนเนื้อหาของหน้าที่มีการดำเนินการเกิดขึ้น
สมมติว่าคุณต้องการส่งภาพใด ๆ พร้อมแบบฟอร์มก็ทำได้ง่ายมากโดยใช้ request.post () คุณสามารถเข้าใจได้ด้วยความช่วยเหลือของการทำตามสคริปต์ Python -
import requests
file = {‘Uploadfile’: open(’C:\Usres\desktop\123.png’,‘rb’)}
r = requests.post(“enter the URL”, files = file)
print(r.text)กำลังโหลดคุกกี้จากเว็บเซิร์ฟเวอร์
คุกกี้บางครั้งเรียกว่าคุกกี้เว็บหรือคุกกี้อินเทอร์เน็ตเป็นข้อมูลชิ้นเล็ก ๆ ที่ส่งมาจากเว็บไซต์และคอมพิวเตอร์ของเราเก็บไว้ในไฟล์ที่อยู่ในเว็บเบราว์เซอร์ของเรา
ในบริบทของการติดต่อกับแบบฟอร์มการเข้าสู่ระบบคุกกี้สามารถมีได้สองประเภท หนึ่งเราจัดการในส่วนก่อนหน้านี้ที่อนุญาตให้เราส่งข้อมูลไปยังเว็บไซต์และอย่างที่สองซึ่งช่วยให้เราอยู่ในสถานะ "เข้าสู่ระบบ" ถาวรตลอดการเยี่ยมชมเว็บไซต์ สำหรับรูปแบบที่สองเว็บไซต์จะใช้คุกกี้เพื่อติดตามว่าใครเข้าสู่ระบบและใครไม่ใช่ใคร
คุกกี้ทำอะไร?
ทุกวันนี้เว็บไซต์ส่วนใหญ่ใช้คุกกี้ในการติดตาม เราสามารถเข้าใจการทำงานของคุกกี้ด้วยความช่วยเหลือของขั้นตอนต่อไปนี้ -
Step 1- ขั้นแรกไซต์จะตรวจสอบข้อมูลรับรองการเข้าสู่ระบบของเราและเก็บไว้ในคุกกี้ของเบราว์เซอร์ของเรา โดยทั่วไปคุกกี้นี้จะมีข้อมูลโทคการหมดเวลาและการติดตามที่สร้างโดยเซิร์ฟเวอร์
Step 2- ต่อไปเว็บไซต์จะใช้คุกกี้เป็นหลักฐานการรับรองความถูกต้อง การรับรองความถูกต้องนี้จะแสดงเสมอทุกครั้งที่เราเยี่ยมชมเว็บไซต์
คุกกี้เป็นปัญหาอย่างมากสำหรับเครื่องขูดเว็บเพราะหากผู้ขูดเว็บไม่ติดตามคุกกี้แบบฟอร์มที่ส่งจะถูกส่งกลับไปและในหน้าถัดไปดูเหมือนว่าพวกเขาไม่เคยเข้าสู่ระบบการติดตามคุกกี้ทำได้ง่ายมากด้วยความช่วยเหลือของ Python requests ไลบรารีดังที่แสดงด้านล่าง -
import requests
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}
r = requests.post(“enter the URL”, data = parameters)ในบรรทัดโค้ดด้านบน URL จะเป็นหน้าที่ทำหน้าที่เป็นตัวประมวลผลสำหรับฟอร์มล็อกอิน
print(‘The cookie is:’)
print(r.cookies.get_dict())
print(r.text)หลังจากเรียกใช้สคริปต์ข้างต้นเราจะดึงคุกกี้จากผลลัพธ์ของคำขอล่าสุด
มีปัญหาอื่นเกี่ยวกับคุกกี้ที่บางครั้งเว็บไซต์มักแก้ไขคุกกี้โดยไม่มีการเตือนล่วงหน้า สถานการณ์แบบนี้สามารถจัดการได้requests.Session() ดังต่อไปนี้ -
import requests
session = requests.Session()
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}
r = session.post(“enter the URL”, data = parameters)ในบรรทัดโค้ดด้านบน URL จะเป็นหน้าที่ทำหน้าที่เป็นตัวประมวลผลสำหรับฟอร์มล็อกอิน
print(‘The cookie is:’)
print(r.cookies.get_dict())
print(r.text)สังเกตว่าคุณสามารถเข้าใจความแตกต่างระหว่างสคริปต์ที่มีเซสชันและไม่มีเซสชันได้อย่างง่ายดาย
สร้างแบบฟอร์มอัตโนมัติด้วย Python
ในส่วนนี้เราจะจัดการกับโมดูล Python ชื่อ Mechanize ซึ่งจะลดงานของเราและทำให้ขั้นตอนการกรอกแบบฟอร์มเป็นไปโดยอัตโนมัติ
กลไกโมดูล
โมดูล Mechanize มอบอินเทอร์เฟซระดับสูงสำหรับการโต้ตอบกับแบบฟอร์ม ก่อนเริ่มใช้งานเราจำเป็นต้องติดตั้งด้วยคำสั่งต่อไปนี้ -
pip install mechanizeโปรดทราบว่ามันจะใช้ได้เฉพาะใน Python 2.x.
ตัวอย่าง
ในตัวอย่างนี้เราจะดำเนินการกรอกแบบฟอร์มเข้าสู่ระบบโดยอัตโนมัติโดยมีสองช่อง ได้แก่ อีเมลและรหัสผ่าน -
import mechanize
brwsr = mechanize.Browser()
brwsr.open(Enter the URL of login)
brwsr.select_form(nr = 0)
brwsr['email'] = ‘Enter email’
brwsr['password'] = ‘Enter password’
response = brwsr.submit()
brwsr.submit()โค้ดด้านบนเข้าใจง่ายมาก ขั้นแรกเรานำเข้าโมดูลเครื่องจักรกล จากนั้นวัตถุเบราว์เซอร์ Mechanize ถูกสร้างขึ้น จากนั้นเราไปที่ URL การเข้าสู่ระบบและเลือกแบบฟอร์ม หลังจากนั้นชื่อและค่าจะถูกส่งไปยังวัตถุเบราว์เซอร์โดยตรง
ในบทนี้ให้เราเข้าใจวิธีการขูดเว็บและการประมวลผล CAPTCHA ที่ใช้สำหรับการทดสอบผู้ใช้สำหรับมนุษย์หรือหุ่นยนต์
CAPTCHA คืออะไร?
CAPTCHA แบบเต็มคือ Completely Automated Public Turing test to tell Computers and Humans Apartซึ่งชี้ให้เห็นอย่างชัดเจนว่าเป็นการทดสอบเพื่อตรวจสอบว่าผู้ใช้เป็นมนุษย์หรือไม่
CAPTCHA เป็นภาพที่บิดเบี้ยวซึ่งโดยปกติแล้วโปรแกรมคอมพิวเตอร์จะตรวจจับได้ไม่ยาก แต่มนุษย์สามารถจัดการเพื่อทำความเข้าใจได้ เว็บไซต์ส่วนใหญ่ใช้ CAPTCHA เพื่อป้องกันไม่ให้บอทโต้ตอบ
กำลังโหลด CAPTCHA ด้วย Python
สมมติว่าเราต้องการลงทะเบียนบนเว็บไซต์และมีแบบฟอร์มที่มี CAPTCHA จากนั้นก่อนที่จะโหลดภาพ CAPTCHA เราจำเป็นต้องทราบเกี่ยวกับข้อมูลเฉพาะที่ต้องการในแบบฟอร์ม ด้วยความช่วยเหลือของสคริปต์ Python ถัดไปเราสามารถเข้าใจข้อกำหนดของแบบฟอร์มการลงทะเบียนบนเว็บไซต์ชื่อhttp://example.webscrapping.com.
import lxml.html
import urllib.request as urllib2
import pprint
import http.cookiejar as cookielib
def form_parsing(html):
tree = lxml.html.fromstring(html)
data = {}
for e in tree.cssselect('form input'):
if e.get('name'):
data[e.get('name')] = e.get('value')
return data
REGISTER_URL = '<a target="_blank" rel="nofollow"
href="http://example.webscraping.com/user/register">http://example.webscraping.com/user/register'</a>
ckj = cookielib.CookieJar()
browser = urllib2.build_opener(urllib2.HTTPCookieProcessor(ckj))
html = browser.open(
'<a target="_blank" rel="nofollow"
href="http://example.webscraping.com/places/default/user/register?_next">
http://example.webscraping.com/places/default/user/register?_next</a> = /places/default/index'
).read()
form = form_parsing(html)
pprint.pprint(form)ในสคริปต์ Python ข้างต้นอันดับแรกเรากำหนดฟังก์ชันที่จะแยกวิเคราะห์ฟอร์มโดยใช้โมดูล lxml python จากนั้นจะพิมพ์ข้อกำหนดของฟอร์มดังนี้ -
{
'_formkey': '5e306d73-5774-4146-a94e-3541f22c95ab',
'_formname': 'register',
'_next': '/places/default/index',
'email': '',
'first_name': '',
'last_name': '',
'password': '',
'password_two': '',
'recaptcha_response_field': None
}คุณสามารถตรวจสอบได้จากผลลัพธ์ด้านบนว่าข้อมูลทั้งหมดยกเว้น recpatcha_response_fieldมีความเข้าใจและตรงไปตรงมา ตอนนี้คำถามเกิดขึ้นว่าเราจะจัดการกับข้อมูลที่ซับซ้อนนี้และดาวน์โหลด CAPTCHA ได้อย่างไร สามารถทำได้ด้วยความช่วยเหลือของ Pillow Python library ดังนี้
แพ็คเกจหมอน Python
หมอนเป็นส่วนแยกของไลบรารีรูปภาพ Python ที่มีฟังก์ชันที่มีประโยชน์สำหรับการจัดการรูปภาพ สามารถติดตั้งได้ด้วยความช่วยเหลือของคำสั่งต่อไปนี้ -
pip install pillowในตัวอย่างถัดไปเราจะใช้สำหรับโหลด CAPTCHA -
from io import BytesIO
import lxml.html
from PIL import Image
def load_captcha(html):
tree = lxml.html.fromstring(html)
img_data = tree.cssselect('div#recaptcha img')[0].get('src')
img_data = img_data.partition(',')[-1]
binary_img_data = img_data.decode('base64')
file_like = BytesIO(binary_img_data)
img = Image.open(file_like)
return imgกำลังใช้สคริปต์ python ข้างต้น pillowแพคเกจ python และกำหนดฟังก์ชันสำหรับการโหลดภาพ CAPTCHA ต้องใช้กับฟังก์ชันที่ชื่อform_parser()ที่กำหนดไว้ในสคริปต์ก่อนหน้าเพื่อรับข้อมูลเกี่ยวกับแบบฟอร์มการลงทะเบียน สคริปต์นี้จะบันทึกภาพ CAPTCHA ในรูปแบบที่มีประโยชน์ซึ่งสามารถแยกออกมาเป็นสตริงได้
OCR: การแยกข้อความจากรูปภาพโดยใช้ Python
หลังจากโหลด CAPTCHA ในรูปแบบที่มีประโยชน์แล้วเราสามารถดึงข้อมูลได้ด้วยความช่วยเหลือของ Optical Character Recognition (OCR) ซึ่งเป็นกระบวนการแยกข้อความออกจากภาพ เพื่อจุดประสงค์นี้เราจะใช้เอ็นจิ้น Tesseract OCR แบบโอเพนซอร์ส สามารถติดตั้งได้ด้วยความช่วยเหลือของคำสั่งต่อไปนี้ -
pip install pytesseractตัวอย่าง
ในที่นี้เราจะขยายสคริปต์ Python ข้างต้นซึ่งโหลด CAPTCHA โดยใช้ Pillow Python Package ดังนี้ -
import pytesseract
img = get_captcha(html)
img.save('captcha_original.png')
gray = img.convert('L')
gray.save('captcha_gray.png')
bw = gray.point(lambda x: 0 if x < 1 else 255, '1')
bw.save('captcha_thresholded.png')สคริปต์ Python ด้านบนจะอ่าน CAPTCHA ในโหมดขาวดำซึ่งจะชัดเจนและส่งผ่านไปยัง tesseract ได้ง่ายดังนี้ -
pytesseract.image_to_string(bw)หลังจากเรียกใช้สคริปต์ข้างต้นเราจะได้รับ CAPTCHA ของแบบฟอร์มการลงทะเบียนเป็นผลลัพธ์
บทนี้จะอธิบายถึงวิธีการทดสอบโดยใช้เครื่องขูดเว็บใน Python
บทนำ
ในโครงการเว็บขนาดใหญ่จะมีการทดสอบแบ็กเอนด์ของเว็บไซต์โดยอัตโนมัติเป็นประจำ แต่การทดสอบส่วนหน้ามักจะข้ามไป เหตุผลหลักที่อยู่เบื้องหลังสิ่งนี้คือการเขียนโปรแกรมของเว็บไซต์ก็เหมือนกับมาร์กอัปและภาษาโปรแกรมต่างๆ เราสามารถเขียน unit test สำหรับภาษาหนึ่งได้ แต่จะกลายเป็นเรื่องที่ท้าทายหากกำลังดำเนินการโต้ตอบในภาษาอื่น นั่นคือเหตุผลที่เราต้องมีชุดการทดสอบเพื่อให้แน่ใจว่าโค้ดของเราทำงานได้ตามที่เราคาดหวัง
การทดสอบโดยใช้ Python
เมื่อเรากำลังพูดถึงการทดสอบหมายถึงการทดสอบหน่วย ก่อนที่จะเจาะลึกการทดสอบด้วย Python เราต้องรู้เกี่ยวกับการทดสอบหน่วย ต่อไปนี้เป็นลักษณะบางประการของการทดสอบหน่วย -
จะมีการทดสอบการทำงานของส่วนประกอบอย่างน้อยหนึ่งด้านในการทดสอบแต่ละหน่วย
การทดสอบแต่ละหน่วยเป็นอิสระและยังสามารถทำงานได้อย่างอิสระ
การทดสอบหน่วยไม่รบกวนความสำเร็จหรือความล้มเหลวของการทดสอบอื่น ๆ
การทดสอบหน่วยสามารถรันในลำดับใดก็ได้และต้องมีการยืนยันอย่างน้อยหนึ่งครั้ง
Unittest - โมดูล Python
โมดูล Python ชื่อ Unittest สำหรับการทดสอบหน่วยมาพร้อมกับการติดตั้ง Python มาตรฐานทั้งหมด เราเพียงแค่ต้องนำเข้าและส่วนที่เหลือเป็นหน้าที่ของคลาส unittest.TestCase ซึ่งจะทำดังต่อไปนี้ -
ฟังก์ชัน SetUp และ tearDown จัดเตรียมโดยคลาส unittest.TestCase ฟังก์ชันเหล่านี้สามารถทำงานก่อนและหลังการทดสอบแต่ละหน่วย
นอกจากนี้ยังมีข้อความยืนยันเพื่อให้การทดสอบผ่านหรือล้มเหลว
เรียกใช้ฟังก์ชันทั้งหมดที่ขึ้นต้นด้วย test_ เป็นการทดสอบหน่วย
ตัวอย่าง
ในตัวอย่างนี้เราจะรวมการขูดเว็บด้วย unittest. เราจะทดสอบหน้า Wikipedia เพื่อค้นหาสตริง 'Python' โดยทั่วไปจะทำการทดสอบสองครั้งโดยสภาพอากาศครั้งแรกหน้าชื่อจะเหมือนกับสตริงการค้นหาเช่น 'Python' หรือไม่และการทดสอบครั้งที่สองทำให้แน่ใจว่าหน้านั้นมี div เนื้อหา
ขั้นแรกเราจะนำเข้าโมดูล Python ที่จำเป็น เราใช้ BeautifulSoup สำหรับการขูดเว็บและแน่นอนที่สุดสำหรับการทดสอบ
from urllib.request import urlopen
from bs4 import BeautifulSoup
import unittestตอนนี้เราต้องกำหนดคลาสซึ่งจะขยาย unittest.TestCase Global object bs จะถูกแชร์ระหว่างการทดสอบทั้งหมด setUpClass ฟังก์ชั่นที่ระบุโดยเฉพาะจะทำให้สำเร็จ ในที่นี้เราจะกำหนดสองฟังก์ชันหนึ่งสำหรับการทดสอบหน้าชื่อเรื่องและอื่น ๆ สำหรับการทดสอบเนื้อหาของเพจ
class Test(unittest.TestCase):
bs = None
def setUpClass():
url = '<a target="_blank" rel="nofollow" href="https://en.wikipedia.org/wiki/Python">https://en.wikipedia.org/wiki/Python'</a>
Test.bs = BeautifulSoup(urlopen(url), 'html.parser')
def test_titleText(self):
pageTitle = Test.bs.find('h1').get_text()
self.assertEqual('Python', pageTitle);
def test_contentExists(self):
content = Test.bs.find('div',{'id':'mw-content-text'})
self.assertIsNotNone(content)
if __name__ == '__main__':
unittest.main()หลังจากเรียกใช้สคริปต์ด้านบนเราจะได้ผลลัพธ์ต่อไปนี้ -
----------------------------------------------------------------------
Ran 2 tests in 2.773s
OK
An exception has occurred, use %tb to see the full traceback.
SystemExit: False
D:\ProgramData\lib\site-packages\IPython\core\interactiveshell.py:2870:
UserWarning: To exit: use 'exit', 'quit', or Ctrl-D.
warn("To exit: use 'exit', 'quit', or Ctrl-D.", stacklevel=1)การทดสอบด้วยซีลีเนียม
ให้เราพูดคุยเกี่ยวกับวิธีใช้ Python Selenium สำหรับการทดสอบ เรียกอีกอย่างว่าการทดสอบซีลีเนียม ทั้ง Pythonunittest และ Seleniumไม่ค่อยมีอะไรเหมือนกัน เราทราบดีว่า Selenium ส่งคำสั่ง Python มาตรฐานไปยังเบราว์เซอร์ต่างๆ จำได้ว่าเราได้ติดตั้งและทำงานร่วมกับซีลีเนียมในบทก่อนหน้านี้แล้ว ที่นี่เราจะสร้างสคริปต์ทดสอบในซีลีเนียมและใช้สำหรับระบบอัตโนมัติ
ตัวอย่าง
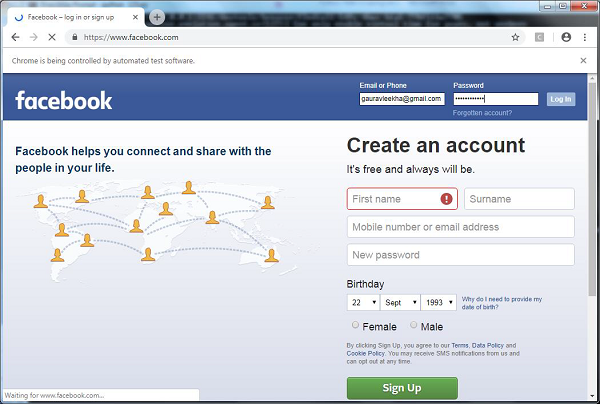
ด้วยความช่วยเหลือของสคริปต์ Python ถัดไปเรากำลังสร้างสคริปต์ทดสอบสำหรับการทำงานอัตโนมัติของหน้าเข้าสู่ระบบ Facebook คุณสามารถปรับเปลี่ยนตัวอย่างสำหรับการทำแบบฟอร์มอื่น ๆ และการเข้าสู่ระบบที่คุณเลือกโดยอัตโนมัติอย่างไรก็ตามแนวคิดจะเหมือนกัน
อันดับแรกสำหรับการเชื่อมต่อกับเว็บเบราว์เซอร์เราจะนำเข้า webdriver จากโมดูลซีลีเนียม -
from selenium import webdriverตอนนี้เราจำเป็นต้องนำเข้าคีย์จากโมดูลซีลีเนียม
from selenium.webdriver.common.keys import Keysต่อไปเราต้องระบุชื่อผู้ใช้และรหัสผ่านเพื่อเข้าสู่บัญชี Facebook ของเรา
user = "[email protected]"
pwd = ""จากนั้นระบุเส้นทางไปยังเว็บไดรเวอร์สำหรับ Chrome
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
driver = webdriver.Chrome(executable_path=path)
driver.get("http://www.facebook.com")ตอนนี้เราจะตรวจสอบเงื่อนไขโดยใช้คำหลักยืนยัน
assert "Facebook" in driver.titleด้วยความช่วยเหลือของบรรทัดรหัสต่อไปนี้เราจะส่งค่าไปยังส่วนอีเมล ที่นี่เรากำลังค้นหาโดยใช้ id ของมัน แต่เราสามารถทำได้โดยค้นหาโดยใช้ชื่อเป็นdriver.find_element_by_name("email").
element = driver.find_element_by_id("email")
element.send_keys(user)ด้วยความช่วยเหลือของบรรทัดรหัสต่อไปนี้เราจะส่งค่าไปยังส่วนรหัสผ่าน ที่นี่เรากำลังค้นหาโดยใช้ id ของมัน แต่เราสามารถทำได้โดยค้นหาโดยใช้ชื่อเป็นdriver.find_element_by_name("pass").
element = driver.find_element_by_id("pass")
element.send_keys(pwd)รหัสบรรทัดถัดไปใช้เพื่อกด enter / login หลังจากใส่ค่าในช่องอีเมลและรหัสผ่าน
element.send_keys(Keys.RETURN)ตอนนี้เราจะปิดเบราว์เซอร์
driver.close()หลังจากเรียกใช้สคริปต์ข้างต้นเว็บเบราว์เซอร์ Chrome จะเปิดขึ้นและคุณสามารถเห็นอีเมลและรหัสผ่านถูกแทรกและคลิกที่ปุ่มเข้าสู่ระบบ
การเปรียบเทียบ: unittest หรือ Selenium
การเปรียบเทียบระหว่าง Unittest และซีลีเนียมเป็นเรื่องยากเพราะถ้าคุณต้องการทำงานกับชุดทดสอบขนาดใหญ่จำเป็นต้องมีความแข็งแกร่งเชิงสังเคราะห์ของการรวม ในทางกลับกันหากคุณกำลังจะทดสอบความยืดหยุ่นของเว็บไซต์การทดสอบซีลีเนียมจะเป็นตัวเลือกแรกของเรา แต่ถ้าเรารวมทั้งสองอย่างเข้าด้วยกันได้ เราสามารถนำเข้าซีลีเนียมเข้าสู่ Python ได้โดยไม่ต้องใช้ความพยายามและรับสิ่งที่ดีที่สุดจากทั้งสองอย่าง ซีลีเนียมสามารถใช้เพื่อรับข้อมูลเกี่ยวกับเว็บไซต์และ unittest สามารถประเมินได้ว่าข้อมูลนั้นตรงตามเกณฑ์ในการผ่านการทดสอบหรือไม่
ตัวอย่างเช่นเราเขียนสคริปต์ Python ด้านบนใหม่สำหรับการเข้าสู่ระบบ Facebook โดยอัตโนมัติโดยรวมทั้งสองอย่างดังนี้ -
import unittest
from selenium import webdriver
class InputFormsCheck(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome(r'C:\Users\gaurav\Desktop\chromedriver')
def test_singleInputField(self):
user = "[email protected]"
pwd = ""
pageUrl = "http://www.facebook.com"
driver=self.driver
driver.maximize_window()
driver.get(pageUrl)
assert "Facebook" in driver.title
elem = driver.find_element_by_id("email")
elem.send_keys(user)
elem = driver.find_element_by_id("pass")
elem.send_keys(pwd)
elem.send_keys(Keys.RETURN)
def tearDown(self):
self.driver.close()
if __name__ == "__main__":
unittest.main()