SAS - คู่มือฉบับย่อ
SAS หมายถึง Statistical Analysis Software. สร้างขึ้นในปี พ.ศ. 2503 โดยสถาบัน SAS ตั้งแต่วันที่ 1 มกราคม พ.ศ. 2503 เป็นต้นมา SAS ถูกนำมาใช้ในการจัดการข้อมูลระบบธุรกิจอัจฉริยะการวิเคราะห์เชิงคาดการณ์การวิเคราะห์เชิงพรรณนาและการกำหนดคำอธิบายเป็นต้นตั้งแต่นั้นมามีการนำขั้นตอนและส่วนประกอบทางสถิติใหม่ ๆ มาใช้ในซอฟต์แวร์
ด้วยการแนะนำ JMP (Jump) สำหรับสถิติ SAS ใช้ประโยชน์จากไฟล์ Graphical user Interfaceซึ่งได้รับการแนะนำโดย Macintosh Jump ใช้สำหรับแอปพลิเคชันเช่น Six Sigma การออกแบบการควบคุมคุณภาพและวิศวกรรมและการวิเคราะห์ทางวิทยาศาสตร์
SAS ไม่ขึ้นอยู่กับแพลตฟอร์มซึ่งหมายความว่าคุณสามารถเรียกใช้ SAS บนระบบปฏิบัติการใดก็ได้ทั้ง Linux หรือ Windows SAS ขับเคลื่อนโดยโปรแกรมเมอร์ SAS ซึ่งใช้ลำดับการดำเนินการหลายลำดับบนชุดข้อมูล SAS เพื่อสร้างรายงานที่เหมาะสมสำหรับการวิเคราะห์ข้อมูล
ในช่วงหลายปีที่ผ่านมา SAS ได้เพิ่มโซลูชันมากมายให้กับกลุ่มผลิตภัณฑ์ มีโซลูชันสำหรับการกำกับดูแลข้อมูลคุณภาพข้อมูลการวิเคราะห์ข้อมูลขนาดใหญ่การขุดข้อความการจัดการการฉ้อโกงวิทยาศาสตร์สุขภาพ ฯลฯ เราสามารถสรุปได้อย่างปลอดภัยว่า SAS มีโซลูชันสำหรับทุกโดเมนธุรกิจ
หากต้องการดูรายการผลิตภัณฑ์ที่มีจำหน่ายอย่างรวดเร็วคุณสามารถเยี่ยมชมส่วนประกอบ SAS
ทำไมเราถึงใช้ SAS
SAS นั้นทำงานบนชุดข้อมูลขนาดใหญ่โดยทั่วไป ด้วยความช่วยเหลือของซอฟต์แวร์ SAS คุณสามารถดำเนินการต่างๆกับข้อมูลเช่น -
- การจัดการข้อมูล
- การวิเคราะห์ทางสถิติ
- การสร้างรายงานด้วยกราฟิกที่สมบูรณ์แบบ
- การวางแผนธุรกิจ
- การวิจัยปฏิบัติการและการบริหารโครงการ
- การปรับปรุงคุณภาพ
- การพัฒนาโปรแกรมประยุกต์
- การดึงข้อมูล
- การแปลงข้อมูล
- การอัปเดตและแก้ไขข้อมูล
หากเราพูดถึงส่วนประกอบของ SAS แสดงว่ามีส่วนประกอบมากกว่า 200 รายการใน SAS
| ซีเนียร์ | ส่วนประกอบ SAS และการใช้งาน |
|---|---|
| 1 | Base SAS เป็นส่วนประกอบหลักที่ประกอบด้วยสิ่งอำนวยความสะดวกในการจัดการข้อมูลและภาษาโปรแกรมสำหรับการวิเคราะห์ข้อมูล นอกจากนี้ยังใช้กันอย่างแพร่หลายมากที่สุด |
| 2 | SAS/GRAPH สร้างกราฟการนำเสนอเพื่อความเข้าใจที่ดีขึ้นและแสดงผลลัพธ์ในรูปแบบที่เหมาะสม |
| 3 | SAS/STAT ทำการวิเคราะห์ทางสถิติด้วยการวิเคราะห์ความแปรปรวนการถดถอยการวิเคราะห์หลายตัวแปรการวิเคราะห์การอยู่รอดและการวิเคราะห์ไซโครเมตริกการวิเคราะห์แบบจำลองแบบผสม |
| 4 | SAS/OR การวิจัยปฏิบัติการ. |
| 5 | SAS/ETS เศรษฐมิติและการวิเคราะห์อนุกรมเวลา |
| 6 | SAS/IML ภาษาเมทริกซ์ CInteractive |
| 7 | SAS/AF สิ่งอำนวยความสะดวกการใช้งาน |
| 8 | SAS/QC ควบคุมคุณภาพ. |
| 9 | SAS/INSIGHT การขุดข้อมูล |
| 10 | SAS/PH การวิเคราะห์การทดลองทางคลินิก |
| 11 | SAS/Enterprise Miner การขุดข้อมูล |
ประเภทของซอฟต์แวร์ SAS
- Windows หรือ PC SAS
- SAS EG (คู่มือสำหรับองค์กร)
- SAS EM (Enterprise Miner เช่นสำหรับการวิเคราะห์เชิงคาดการณ์)
- SAS หมายถึง
- สถิติ SAS
ส่วนใหญ่เราใช้ Window SAS ในองค์กรและในสถาบันฝึกอบรม บางองค์กรใช้ Linux แต่ไม่มีอินเทอร์เฟซผู้ใช้แบบกราฟิกดังนั้นคุณต้องเขียนโค้ดสำหรับทุกแบบสอบถาม แต่ในหน้าต่าง SAS มียูทิลิตี้มากมายที่ช่วยโปรแกรมเมอร์ได้มากและยังช่วยลดเวลาในการเขียนโค้ดอีกด้วย
หน้าต่าง SaS มี 5 ส่วน
| ซีเนียร์ | หน้าต่าง SAS และการใช้งาน |
|---|---|
| 1 | Log Window หน้าต่างบันทึกเป็นเหมือนหน้าต่างการดำเนินการที่เราสามารถตรวจสอบการทำงานของโปรแกรม SAS ในหน้าต่างนี้เราสามารถตรวจสอบข้อผิดพลาดได้ด้วย เป็นสิ่งสำคัญมากในการตรวจสอบทุกครั้งที่หน้าต่างบันทึกหลังจากเรียกใช้โปรแกรม เพื่อให้เรามีความเข้าใจที่ถูกต้องเกี่ยวกับการทำงานของโปรแกรมของเรา |
| 2 | Editor Window
Editor Window เป็นส่วนหนึ่งของ SAS ที่เราเขียนโค้ดทั้งหมด มันเป็นเหมือนสมุดบันทึก |
| 3 | Output Window หน้าต่างผลลัพธ์คือหน้าต่างผลลัพธ์ที่เราสามารถดูผลลัพธ์ของโปรแกรมของเราได้ |
| 4 | Result Window เปรียบเสมือนดัชนีของผลลัพธ์ทั้งหมด โปรแกรมทั้งหมดที่เราเรียกใช้ในหนึ่งเซสชันของ SAS จะแสดงอยู่ที่นั่นและคุณสามารถเปิดผลลัพธ์ได้โดยคลิกที่ผลลัพธ์ผลลัพธ์ แต่จะกล่าวถึงใน SAS เพียงเซสชันเดียวเท่านั้น หากเราปิดซอฟต์แวร์แล้วเปิดขึ้นมาหน้าต่างผลลัพธ์จะว่างเปล่า |
| 5 | Explore Window นี่คือไลบรารีทั้งหมดที่ระบุไว้ คุณยังสามารถเรียกดูไฟล์ที่รองรับ SAS ของระบบได้จากที่นี่ |
ห้องสมุดใน SAS
ไลบรารีเปรียบเสมือนที่เก็บข้อมูลใน SAS คุณสามารถสร้างไลบรารีและบันทึกโปรแกรมที่คล้ายกันทั้งหมดในไลบรารีนั้น SAS ให้ความสะดวกแก่คุณในการสร้างไลบรารีหลาย ๆ ไลบรารี SAS มีความยาวเพียง 8 อักขระ
มีห้องสมุดสองประเภทที่มีอยู่ใน SAS -
| ซีเนียร์ | หน้าต่าง SAS และการใช้งาน |
|---|---|
| 1 | Temporary or Work Library นี่คือไลบรารีเริ่มต้นของ SAS โปรแกรมทั้งหมดที่เราสร้างขึ้นจะถูกเก็บไว้ในไลบรารีงานนี้หากเราไม่ได้กำหนดไลบรารีอื่นให้ คุณสามารถตรวจสอบไลบรารีงานนี้ได้ในหน้าต่างสำรวจ หากคุณสร้างโปรแกรม SAS และไม่ได้กำหนดไลบรารีถาวรใด ๆ ให้กับโปรแกรมนั้นหากคุณสิ้นสุดเซสชันหลังจากนั้นอีกครั้งคุณจะเริ่มซอฟต์แวร์โปรแกรมนี้จะไม่อยู่ในไลบรารีงาน เนื่องจากจะอยู่ในไลบรารีงานเท่านั้นตราบเท่าที่เซสชันนั้นดำเนินไป |
| 2 | Permanent Library นี่คือไลบรารีถาวรของ SAS เราสามารถสร้างไลบรารี SAS ใหม่โดยใช้ยูทิลิตี้ SAS หรือโดยการเขียนโค้ดในหน้าต่างตัวแก้ไข ไลบรารีเหล่านี้ถูกตั้งชื่อเป็นแบบถาวรเนื่องจากหากเราสร้างโปรแกรมใน SAS และบันทึกไว้ในไลบรารีถาวรเหล่านี้จะสามารถใช้ได้ตราบเท่าที่เราต้องการ |
SAS Institute Inc. ได้เปิดตัวไฟล์ SAS University Editionซึ่งดีพอสำหรับการเรียนรู้การเขียนโปรแกรม SAS มีคุณสมบัติทั้งหมดที่คุณต้องเรียนรู้ในการเขียนโปรแกรม BASE SAS ซึ่งจะช่วยให้คุณสามารถเรียนรู้ส่วนประกอบ SAS อื่น ๆ
กระบวนการดาวน์โหลดและติดตั้ง SAS University Edition ตรงไปตรงมามาก มีให้ใช้งานในรูปแบบเครื่องเสมือนที่ต้องทำงานบนสภาพแวดล้อมเสมือนจริง คุณต้องมีซอฟต์แวร์เวอร์ชวลไลเซชันติดตั้งอยู่แล้วในพีซีของคุณก่อนจึงจะสามารถเรียกใช้ซอฟต์แวร์ SAS ได้ ในบทช่วยสอนนี้เราจะใช้VMware. ด้านล่างนี้เป็นรายละเอียดของขั้นตอนในการดาวน์โหลดตั้งค่าสภาพแวดล้อม SAS และตรวจสอบการติดตั้ง
ดาวน์โหลด SAS University Edition
SAS University Editionนี้สามารถดาวน์โหลดได้ที่ URL SAS มหาวิทยาลัยฉบับ โปรดเลื่อนลงเพื่ออ่านข้อกำหนดของระบบก่อนที่คุณจะเริ่มดาวน์โหลด หน้าจอต่อไปนี้จะปรากฏขึ้นเมื่อไปที่ URL นี้
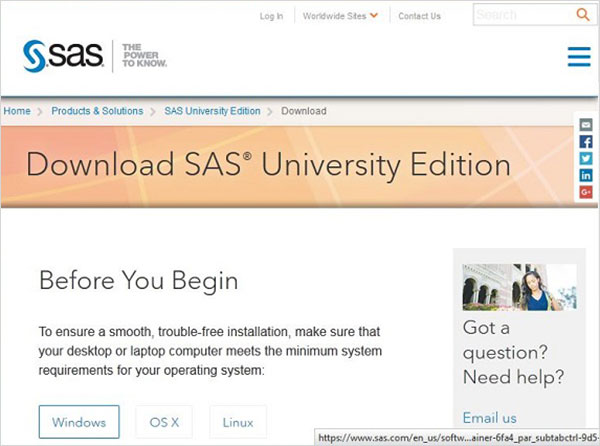
ตั้งค่าซอฟต์แวร์เวอร์ชวลไลเซชัน
เลื่อนลงในหน้าเดียวกันเพื่อค้นหา stpe-1 การติดตั้ง ขั้นตอนนี้ให้ลิงค์เพื่อรับซอฟต์แวร์เวอร์ชวลไลเซชันที่เหมาะกับคุณ ในกรณีที่คุณติดตั้งซอฟต์แวร์เหล่านี้ในระบบของคุณอยู่แล้วคุณสามารถข้ามขั้นตอนนี้ได้

ซอฟต์แวร์การจำลองเสมือนเริ่มต้นอย่างรวดเร็ว
ในกรณีที่คุณยังใหม่กับสภาพแวดล้อมการจำลองเสมือนจริงคุณสามารถทำความคุ้นเคยกับสิ่งนี้ได้โดยอ่านคำแนะนำและวิดีโอต่อไปนี้ที่มีให้ในขั้นตอนที่ 2 คุณสามารถข้ามขั้นตอนนี้ได้อีกครั้งในกรณีที่คุณคุ้นเคยแล้ว

ดาวน์โหลดไฟล์ Zip
ในขั้นตอนที่ 3 คุณสามารถเลือกเวอร์ชันที่เหมาะสมของ SAS University Edition ที่เข้ากันได้กับสภาพแวดล้อมการจำลองเสมือนที่คุณมี ดาวน์โหลดเป็นไฟล์ zip ที่มีชื่อคล้ายกับ unvbasicvapp__9411005__vmx__en__sp0__1.zip
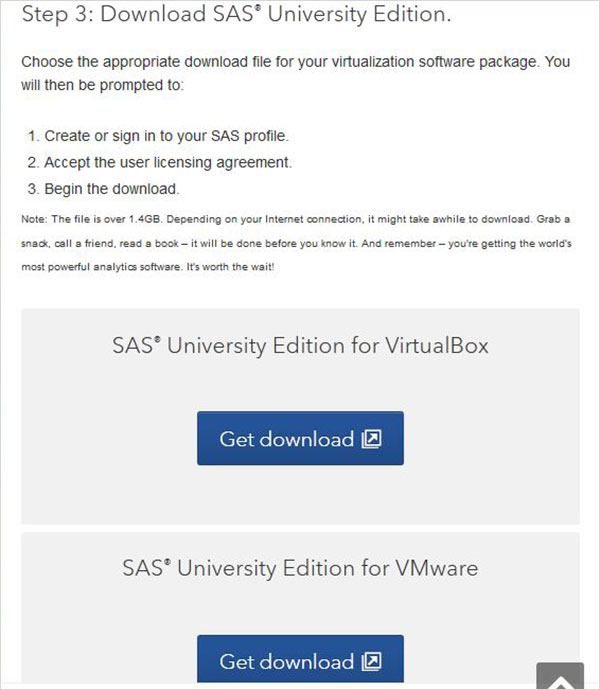
แตกไฟล์ zip
ไฟล์ zip ด้านบนจะต้องแตกไฟล์และจัดเก็บไว้ในไดเร็กทอรีที่เหมาะสม ในกรณีของเราเราได้เลือกไฟล์ zip VMware ซึ่งจะแสดงไฟล์ต่อไปนี้หลังจากคลายซิป
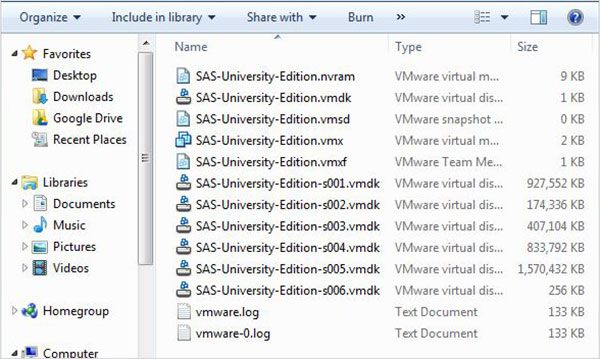
กำลังโหลดเครื่องเสมือน
เริ่มโปรแกรมเล่น VMware (หรือเวิร์กสเตชัน) และเปิดไฟล์ที่ลงท้ายด้วยนามสกุล. vmx หน้าจอด้านล่างจะปรากฏขึ้น โปรดสังเกตการตั้งค่าพื้นฐานเช่นหน่วยความจำและพื้นที่ฮาร์ดดิสก์ที่จัดสรรให้กับ vm
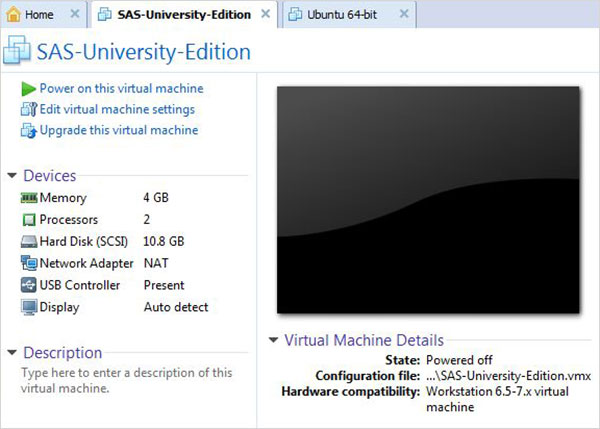
เปิดเครื่องเสมือน
คลิก Power on this virtual machineข้างเครื่องหมายลูกศรสีเขียวเพื่อเริ่มเครื่องเสมือน หน้าจอต่อไปนี้จะปรากฏขึ้น

หน้าจอด้านล่างจะปรากฏขึ้นเมื่อ SAS vm อยู่ในสถานะของการโหลดหลังจากนั้น vm ที่ทำงานอยู่จะแจ้งให้ไปยังตำแหน่ง URL ซึ่งจะเปิดสภาพแวดล้อม SAS
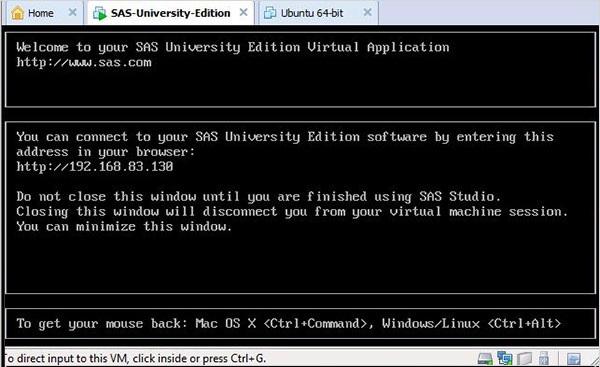
เริ่มต้น SAS studio
เปิดแท็บเบราว์เซอร์ใหม่และโหลด URL ด้านบน (ซึ่งแตกต่างจากพีซีเครื่องหนึ่งไปยังอีกเครื่องหนึ่ง) หน้าจอด้านล่างปรากฏขึ้นเพื่อระบุว่าสภาพแวดล้อม SAS พร้อมแล้ว
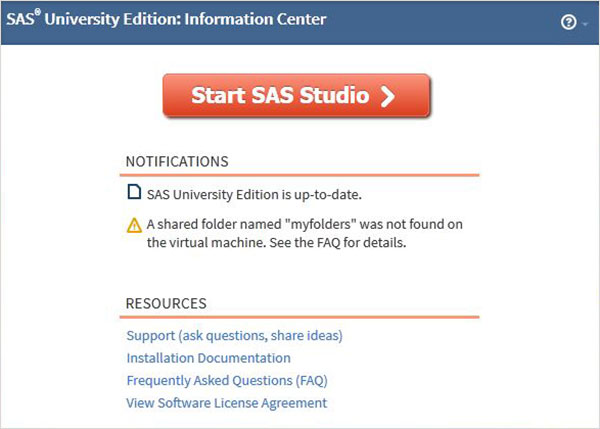
สิ่งแวดล้อม SAS
เมื่อคลิกที่ไฟล์ Start SAS Studio เราได้รับสภาพแวดล้อม SAS ซึ่งโดยค่าเริ่มต้นจะเปิดขึ้นในโหมดโปรแกรมเมอร์ภาพดังที่แสดงด้านล่าง
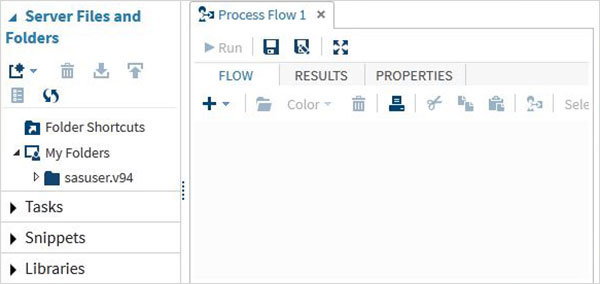
นอกจากนี้เรายังสามารถเปลี่ยนเป็นโหมดโปรแกรมเมอร์ SAS ได้โดยคลิกที่เมนูแบบเลื่อนลง
ตอนนี้เราพร้อมที่จะเขียนโปรแกรม SAS
โปรแกรม SAS ถูกสร้างขึ้นโดยใช้ส่วนต่อประสานผู้ใช้ที่เรียกว่า SAS Studio.
ด้านล่างนี้คือคำอธิบายของหน้าต่างต่างๆและการใช้งาน
หน้าต่างหลักของ SAS
นี่คือหน้าต่างที่คุณเห็นเมื่อเข้าสู่สภาพแวดล้อม SAS ทางด้านซ้ายคือไฟล์Navigation Paneใช้เพื่อนำทางคุณสมบัติการเขียนโปรแกรมต่างๆ ทางด้านขวาคือไฟล์Work Area ซึ่งใช้สำหรับเขียนโค้ดและเรียกใช้งาน

การเติมโค้ดอัตโนมัติ
นี่เป็นคุณสมบัติที่มีประสิทธิภาพมากซึ่งช่วยให้ได้รับไวยากรณ์ที่ถูกต้องของคำหลัก SAS รวมทั้งให้ลิงก์ไปยังเอกสารประกอบสำหรับคำหลักนั้น
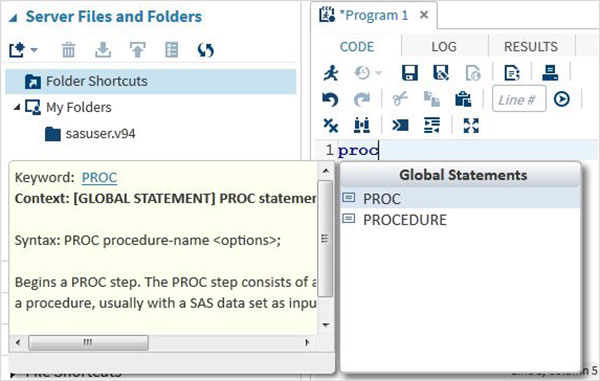
การดำเนินการโปรแกรม
การเรียกใช้โค้ดทำได้โดยการกดไอคอน run ซึ่งเป็นไอคอนแรกจากด้านซ้ายหรือปุ่ม F3
บันทึกโปรแกรม
บันทึกของโค้ดที่เรียกใช้งานอยู่ภายใต้ไฟล์ Logแท็บ อธิบายถึงข้อผิดพลาดคำเตือนหรือหมายเหตุเกี่ยวกับการทำงานของโปรแกรม นี่คือหน้าต่างที่คุณจะได้รับเบาะแสทั้งหมดในการแก้ปัญหารหัสของคุณ
ผลลัพธ์ของโปรแกรม
ผลลัพธ์ของการเรียกใช้โค้ดจะเห็นในแท็บผลลัพธ์ โดยค่าเริ่มต้นจะถูกจัดรูปแบบเป็นตาราง html
แท็บโปรแกรม
พื้นที่การนำทางมีคุณสมบัติในการสร้างและจัดการโปรแกรม นอกจากนี้ยังมีฟังก์ชันที่สร้างไว้ล่วงหน้าเพื่อใช้กับโปรแกรมของคุณ
ไฟล์เซิร์ฟเวอร์และโฟลเดอร์
ภายใต้แท็บนี้เราสามารถสร้างโปรแกรมเพิ่มเติมนำเข้าข้อมูลเพื่อวิเคราะห์และสืบค้นข้อมูลที่มีอยู่ นอกจากนี้ยังสามารถใช้เพื่อสร้างทางลัดโฟลเดอร์
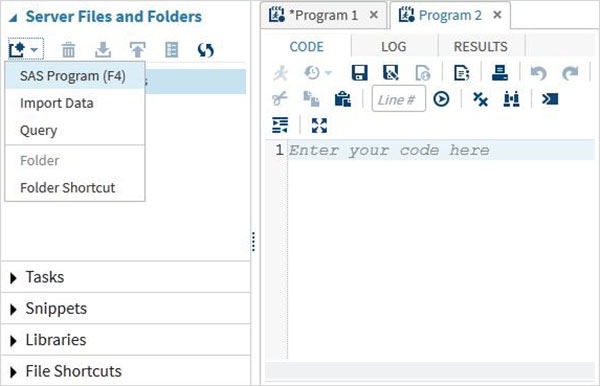
งาน
แท็บ Tasks มีคุณลักษณะในการใช้โปรแกรม SAS ที่สร้างขึ้นโดยการจัดหาเฉพาะตัวแปรอินพุต ตัวอย่างเช่นภายใต้โฟลเดอร์สถิติคุณสามารถค้นหาโปรแกรม SAS เพื่อทำการถดถอยเชิงเส้นได้โดยใส่เฉพาะชื่อชุดข้อมูล SAS และชื่อตัวแปรเท่านั้น
ตัวอย่างข้อมูล
แท็บข้อมูลโค้ดมีคุณสมบัติในการเขียน SAS Macro และสร้างไฟล์จากชุดข้อมูลที่มีอยู่

โปรแกรมไลบรารี
SAS เก็บชุดข้อมูลในไลบรารี SAS ไลบรารีชั่วคราวพร้อมใช้งานสำหรับเซสชันเดียวเท่านั้นและมีชื่อว่า WORK แต่ห้องสมุดถาวรจะพร้อมใช้งานเสมอ
ทางลัดไฟล์
แท็บนี้ใช้เพื่อเข้าถึงไฟล์ที่เก็บไว้นอกสภาพแวดล้อม SAS ทางลัดไปยังไฟล์ดังกล่าวจะถูกเก็บไว้ในแท็บนี้
การเขียนโปรแกรม SAS เกี่ยวข้องกับการสร้าง / อ่านชุดข้อมูลลงในหน่วยความจำก่อนแล้วจึงทำการวิเคราะห์ข้อมูลนี้ เราต้องเข้าใจขั้นตอนการเขียนโปรแกรมเพื่อให้บรรลุสิ่งนี้
โครงสร้างโปรแกรม SAS
แผนภาพด้านล่างแสดงขั้นตอนที่ต้องเขียนตามลำดับที่กำหนดเพื่อสร้างโปรแกรม SAS
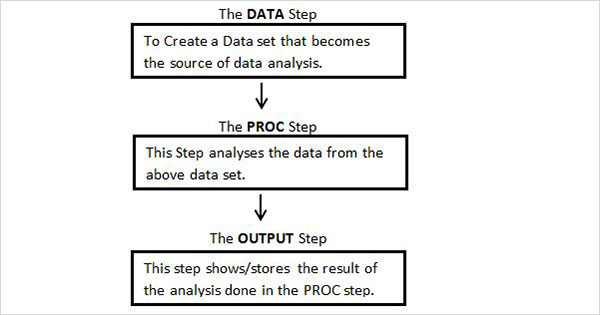
โปรแกรม SAS ทุกโปรแกรมจะต้องมีขั้นตอนเหล่านี้ทั้งหมดเพื่ออ่านข้อมูลอินพุตวิเคราะห์ข้อมูลและให้ผลลัพธ์ของการวิเคราะห์ นอกจากนี้RUN คำสั่งในตอนท้ายของแต่ละขั้นตอนจะต้องดำเนินการตามขั้นตอนนั้นให้เสร็จสิ้น
ขั้นตอนข้อมูล
ขั้นตอนนี้เกี่ยวข้องกับการโหลดชุดข้อมูลที่ต้องการลงในหน่วยความจำ SAS และการระบุตัวแปร (หรือที่เรียกว่าคอลัมน์) ของชุดข้อมูล นอกจากนี้ยังเก็บบันทึก (เรียกอีกอย่างว่าการสังเกตหรือวัตถุ) ไวยากรณ์สำหรับคำสั่ง DATA มีดังต่อไปนี้
ไวยากรณ์
DATA data_set_name; #Name the data set.
INPUT var1,var2,var3; #Define the variables in this data set.
NEW_VAR; #Create new variables.
LABEL; #Assign labels to variables.
DATALINES; #Enter the data.
RUN;ตัวอย่าง
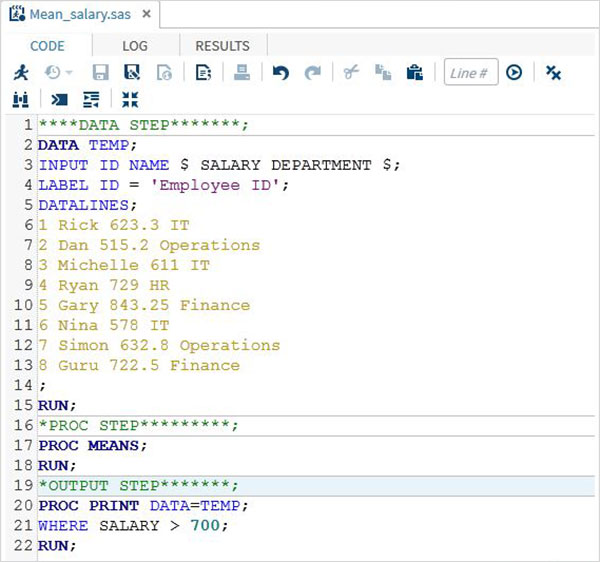
ตัวอย่างด้านล่างแสดงกรณีง่ายๆในการตั้งชื่อชุดข้อมูลกำหนดตัวแปรสร้างตัวแปรใหม่และป้อนข้อมูล ที่นี่ตัวแปรสตริงมี $ ต่อท้ายและไม่มีค่าตัวเลข
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
comm = SALARY*0.25;
LABEL ID = 'Employee ID' comm = 'COMMISION';
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;ขั้นตอนกระบวนการ
ขั้นตอนนี้เกี่ยวข้องกับการเรียกใช้โพรซีเดอร์ในตัว SAS เพื่อวิเคราะห์ข้อมูล
ไวยากรณ์
PROC procedure_name options; #The name of the proc.
RUN;ตัวอย่าง
ตัวอย่างด้านล่างแสดงโดยใช้ไฟล์ MEANS ขั้นตอนการพิมพ์ค่าเฉลี่ยของตัวแปรตัวเลขในชุดข้อมูล
PROC MEANS;
RUN;ขั้นตอน OUTPUT
ข้อมูลจากชุดข้อมูลสามารถแสดงด้วยคำสั่งเอาต์พุตตามเงื่อนไข
ไวยากรณ์
PROC PRINT DATA = data_set;
OPTIONS;
RUN;ตัวอย่าง
ตัวอย่างด้านล่างแสดงโดยใช้ where clause ในเอาต์พุตเพื่อสร้างเร็กคอร์ดเพียงไม่กี่รายการจากชุดข้อมูล
PROC PRINT DATA = TEMP;
WHERE SALARY > 700;
RUN;โปรแกรม SAS ที่สมบูรณ์
ด้านล่างนี้คือรหัสที่สมบูรณ์สำหรับแต่ละขั้นตอนข้างต้น
เอาต์พุตโปรแกรม
RESULTS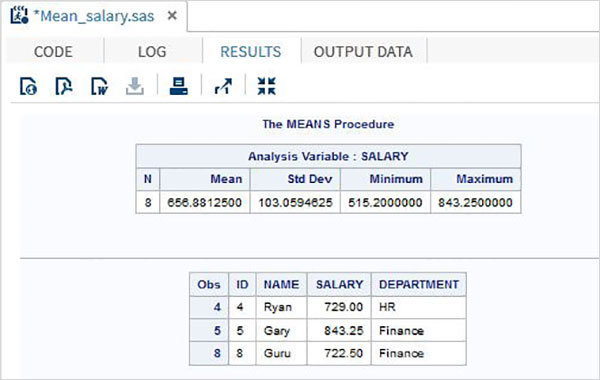
เช่นเดียวกับภาษาโปรแกรมอื่น ๆ ภาษา SAS มีกฎของไวยากรณ์ในการสร้างโปรแกรม SAS
องค์ประกอบทั้งสามของโปรแกรม SAS - คำสั่งตัวแปรและชุดข้อมูลเป็นไปตามกฎด้านล่างในไวยากรณ์
งบ SAS
คำสั่งสามารถเริ่มต้นที่ใดก็ได้และสิ้นสุดที่ใดก็ได้ เครื่องหมายอัฒภาคที่ท้ายบรรทัดสุดท้ายหมายถึงจุดสิ้นสุดของคำสั่ง
คำสั่ง SAS จำนวนมากสามารถอยู่ในบรรทัดเดียวกันโดยแต่ละคำสั่งจะลงท้ายด้วยอัฒภาค
ช่องว่างสามารถใช้เพื่อแยกส่วนประกอบในคำสั่งโปรแกรม SAS
คีย์เวิร์ด SAS ไม่คำนึงถึงขนาดตัวพิมพ์
ทุกโปรแกรม SAS ต้องลงท้ายด้วยคำสั่ง RUN
ชื่อตัวแปร SAS
ตัวแปรใน SAS แสดงคอลัมน์ในชุดข้อมูล SAS ชื่อตัวแปรเป็นไปตามกฎด้านล่าง
มีความยาวได้สูงสุด 32 อักขระ
ไม่สามารถใส่ช่องว่างได้
ต้องขึ้นต้นด้วยตัวอักษร A ถึง Z (ไม่คำนึงถึงขนาดตัวพิมพ์) หรือขีดล่าง (_)
สามารถใส่ตัวเลขได้ แต่ไม่ใช่อักขระตัวแรก
ชื่อตัวแปรไม่คำนึงถึงตัวพิมพ์เล็กและใหญ่
ตัวอย่าง
# Valid Variable Names
REVENUE_YEAR
MaxVal
_Length
# Invalid variable Names
Miles Per Liter #contains Space.
RainfFall% # contains apecial character other than underscore.
90_high # Starts with a number.ชุดข้อมูล SAS
คำสั่ง DATA เป็นการสร้างชุดข้อมูล SAS ใหม่ กฎสำหรับการสร้างชุดข้อมูลมีดังต่อไปนี้
คำเดียวหลังคำสั่ง DATA แสดงชื่อชุดข้อมูลชั่วคราว ซึ่งหมายความว่าชุดข้อมูลจะถูกลบเมื่อสิ้นสุดเซสชัน
ชื่อชุดข้อมูลสามารถนำหน้าด้วยชื่อไลบรารีซึ่งทำให้เป็นชุดข้อมูลถาวร ซึ่งหมายความว่าชุดข้อมูลจะยังคงอยู่หลังจากเซสชันสิ้นสุดลง
หากไม่ใส่ชื่อชุดข้อมูล SAS SAS จะสร้างชุดข้อมูลชั่วคราวโดยใช้ชื่อที่สร้างโดย SAS เช่น - DATA1, DATA2 เป็นต้น
ตัวอย่าง
# Temporary data sets.
DATA TempData;
DATA abc;
DATA newdat;
# Permanent data sets.
DATA LIBRARY1.DATA1
DATA MYLIB.newdat;นามสกุลไฟล์ SAS
โปรแกรม SAS ไฟล์ข้อมูลและผลลัพธ์ของโปรแกรมจะถูกบันทึกด้วยนามสกุลต่างๆใน windows
*.sas - แสดงถึงไฟล์รหัส SAS ซึ่งสามารถแก้ไขได้โดยใช้ SAS Editor หรือโปรแกรมแก้ไขข้อความใด ๆ
*.log - แสดงถึงไฟล์บันทึก SAS ซึ่งมีข้อมูลเช่นข้อผิดพลาดคำเตือนและรายละเอียดชุดข้อมูลสำหรับโปรแกรม SAS ที่ส่งมา
*.mht / *.html − แสดงถึงไฟล์ SAS Results
*.sas7bdat − แสดงถึงไฟล์ข้อมูล SAS ซึ่งมีชุดข้อมูล SAS รวมถึงชื่อตัวแปรป้ายกำกับและผลลัพธ์ของการคำนวณ
ความคิดเห็นใน SAS
ความคิดเห็นในรหัส SAS ระบุไว้สองวิธี ด้านล่างนี้คือสองรูปแบบนี้
* ข้อความ; พิมพ์ความคิดเห็น
ความคิดเห็นในรูปแบบของ *message;ต้องไม่มีอัฒภาคหรือเครื่องหมายคำพูดที่ไม่ตรงกันอยู่ข้างใน นอกจากนี้ไม่ควรมีการอ้างอิงถึงคำสั่งมหภาคใด ๆ ในความคิดเห็นดังกล่าว สามารถขยายได้หลายบรรทัดและมีความยาวเท่าใดก็ได้ .. ต่อไปนี้เป็นตัวอย่างความคิดเห็นบรรทัดเดียว -
* This is comment ;ต่อไปนี้เป็นตัวอย่างความคิดเห็นหลายบรรทัด -
* This is first line of the comment
* This is second line of the comment;/ * ข้อความ * / พิมพ์ความคิดเห็น
ความคิดเห็นในรูปแบบของ /*message*/ถูกใช้บ่อยขึ้นและไม่สามารถซ้อนกันได้ แต่สามารถขยายได้หลายบรรทัดและมีความยาวเท่าใดก็ได้ ต่อไปนี้เป็นตัวอย่างความคิดเห็นบรรทัดเดียว -
/* This is comment */ต่อไปนี้เป็นตัวอย่างความคิดเห็นหลายบรรทัด -
/* This is first line of the comment
* This is second line of the comment */ข้อมูลที่พร้อมใช้งานสำหรับโปรแกรม SAS สำหรับการวิเคราะห์เรียกว่าชุดข้อมูล SAS มันถูกสร้างขึ้นโดยใช้ขั้นตอน DATA SAS สามารถอ่านไฟล์ได้หลากหลายเป็นแหล่งข้อมูลเช่นCSV, Excel, Access, SPSS and also raw data. นอกจากนี้ยังมีแหล่งข้อมูลในตัวมากมายให้ใช้งานได้
ชุดข้อมูลเรียกว่า temporary Data Set หากพวกเขาถูกใช้โดยโปรแกรม SAS แล้วทิ้งไปหลังจากที่เรียกใช้เซสชัน
แต่ถ้าเก็บถาวรเพื่อใช้ในอนาคตจะเรียกว่าก permanent Data set. ชุดข้อมูลถาวรทั้งหมดจะถูกเก็บไว้ในไลบรารีเฉพาะ
ชุดข้อมูล SAS ถูกจัดเก็บในรูปแบบของแถวและคอลัมน์และเรียกอีกอย่างว่าตารางข้อมูล SAS ด้านล่างนี้เราจะเห็นตัวอย่างของชุดข้อมูลถาวรที่สร้างขึ้นและเป็นสีแดงจากแหล่งภายนอก
ชุดข้อมูลในตัว SAS
ชุดข้อมูลเหล่านี้มีอยู่แล้วในซอฟต์แวร์ SAS ที่ติดตั้ง สามารถสำรวจและใช้ในการกำหนดนิพจน์ตัวอย่างสำหรับการวิเคราะห์ข้อมูล หากต้องการสำรวจชุดข้อมูลเหล่านี้ให้ไปที่Libraries -> My Libraries -> SASHELP. ในการขยายเราจะเห็นรายชื่อของชุดข้อมูลในตัวทั้งหมดที่มีอยู่
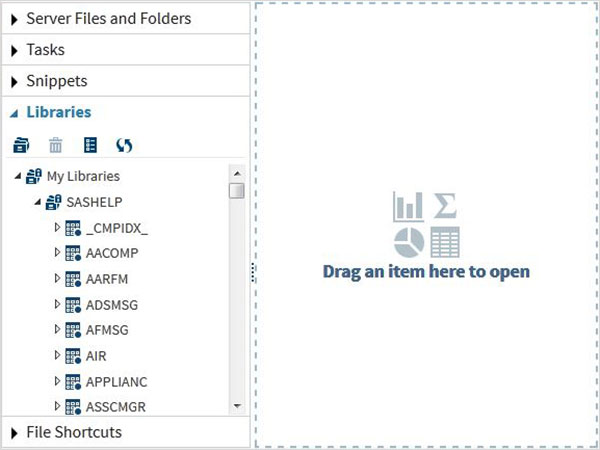
ให้เลื่อนลงเพื่อค้นหาชุดข้อมูลที่ชื่อ CARSการคลิกสองครั้งที่ชุดข้อมูลนี้จะเป็นการเปิดชุดข้อมูลนี้ในบานหน้าต่างด้านขวาซึ่งเราสามารถสำรวจเพิ่มเติมได้นอกจากนี้เรายังสามารถย่อขนาดบานหน้าต่างด้านซ้ายโดยใช้ปุ่มขยายมุมมองที่อยู่ใต้บานหน้าต่างด้านขวา
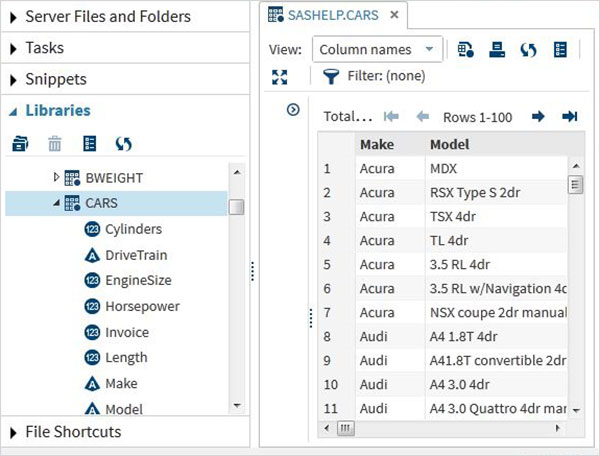
เราสามารถเลื่อนไปทางขวาโดยใช้แถบเลื่อนที่ด้านล่างเพื่อสำรวจคอลัมน์และค่าทั้งหมดในตาราง
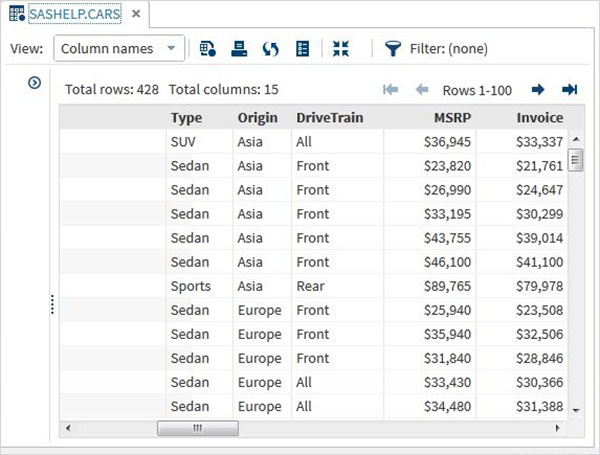
การนำเข้าชุดข้อมูลภายนอก
เราสามารถส่งออกไฟล์ของเราเองเป็นชุดข้อมูลโดยใช้คุณลักษณะการนำเข้าที่มีอยู่ใน SAS Studio แต่ไฟล์เหล่านี้ต้องพร้อมใช้งานในโฟลเดอร์เซิร์ฟเวอร์ SAS ดังนั้นเราต้องอัปโหลดไฟล์แหล่งข้อมูลไปยังโฟลเดอร์ SAS โดยใช้ตัวเลือกอัปโหลดภายใต้ไฟล์Server Files and Folders.
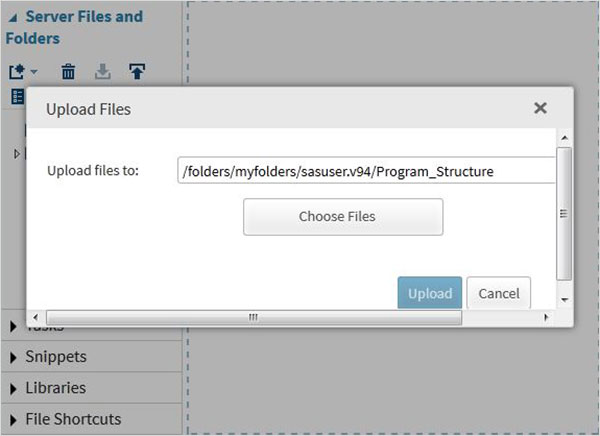
ต่อไปเราจะใช้ไฟล์ด้านบนในโปรแกรม SAS โดยการนำเข้า ในการทำเช่นนี้เราใช้ตัวเลือกTasks -> Utilities -> Import data ดังแสดงด้านล่าง ดับเบิลคลิกที่ปุ่มนำเข้าข้อมูลซึ่งจะเปิดหน้าต่างทางด้านขวาเพื่อเลือกไฟล์สำหรับชุดข้อมูล
คลิกถัดไปที่ Select Filesใต้โปรแกรมนำเข้าข้อมูลในบานหน้าต่างด้านขวา ต่อไปนี้เป็นรายการประเภทไฟล์ที่สามารถนำเข้าได้
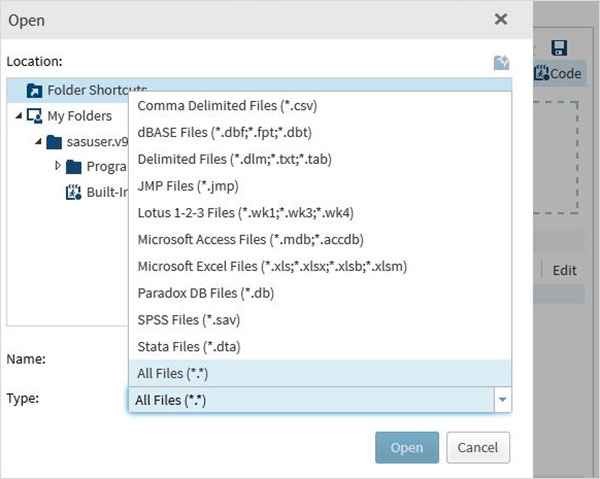
เราเลือกไฟล์ "staff.txt" ที่เก็บไว้ในระบบภายในเครื่องและรับไฟล์ที่นำเข้าตามที่แสดงด้านล่าง
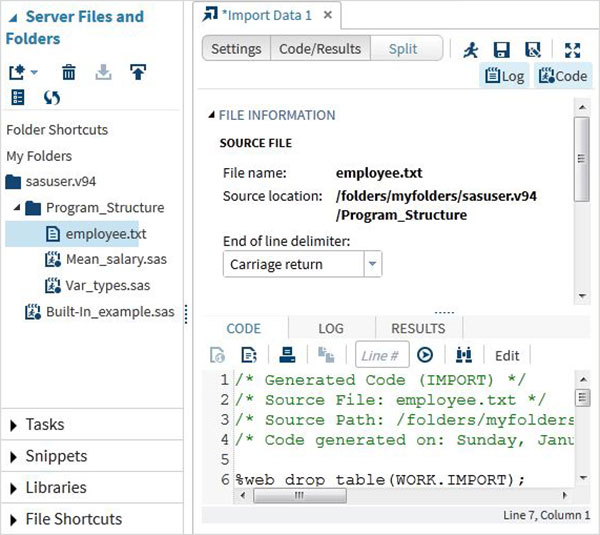
ดูข้อมูลที่นำเข้า
เราสามารถดูข้อมูลที่นำเข้าโดยการเรียกใช้รหัสนำเข้าเริ่มต้นที่สร้างขึ้นโดยใช้ตัวเลือกเรียกใช้
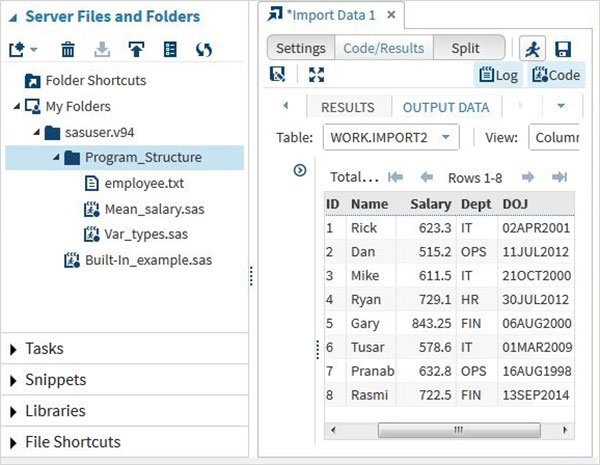
เราสามารถนำเข้าไฟล์ประเภทอื่น ๆ โดยใช้แนวทางเดียวกับข้างต้นและใช้ในโปรแกรม SAS ต่างๆ
ในตัวแปรทั่วไปใน SAS แสดงถึงชื่อคอลัมน์ของตารางข้อมูลที่กำลังวิเคราะห์ แต่ยังสามารถใช้เพื่อวัตถุประสงค์อื่นเช่นใช้เป็นตัวนับในลูปการเขียนโปรแกรม ในบทปัจจุบันเราจะเห็นการใช้ตัวแปร SAS เป็นชื่อคอลัมน์ของชุดข้อมูล SAS
ประเภทตัวแปร SAS
SAS มีตัวแปรสามประเภทดังนี้ -
ตัวแปรตัวเลข
นี่คือประเภทตัวแปรเริ่มต้น ตัวแปรเหล่านี้ใช้ในนิพจน์ทางคณิตศาสตร์
ไวยากรณ์
INPUT VAR1 VAR2 VAR3; #Define numeric variables in the data set.ในไวยากรณ์ข้างต้นคำสั่ง INPUT แสดงการประกาศตัวแปรตัวเลข
ตัวอย่าง
INPUT ID SALARY COMM_PERCENT;ตัวแปรอักขระ
ตัวแปรอักขระใช้สำหรับค่าที่ไม่ได้ใช้ในนิพจน์ทางคณิตศาสตร์ จะถือว่าเป็นข้อความหรือสตริง ตัวแปรจะกลายเป็นตัวแปรอักขระโดยการเพิ่ม $ sing โดยเว้นวรรคท้ายชื่อตัวแปร
ไวยากรณ์
INPUT VAR1 $ VAR2 $ VAR3 $; #Define character variables in the data set.ในไวยากรณ์ข้างต้นคำสั่ง INPUT แสดงการประกาศตัวแปรอักขระ
ตัวอย่าง
INPUT FNAME $ LNAME $ ADDRESS $;ตัวแปรวันที่
ตัวแปรเหล่านี้ถือว่าเป็นวันที่เท่านั้นและจำเป็นต้องอยู่ในรูปแบบวันที่ที่ถูกต้อง ตัวแปรจะกลายเป็นตัวแปรวันที่โดยการเพิ่มรูปแบบวันที่ด้วยช่องว่างที่ท้ายชื่อตัวแปร
ไวยากรณ์
INPUT VAR1 DATE11. VAR2 MMDDYY10. ; #Define date variables in the data set.ในไวยากรณ์ข้างต้นคำสั่ง INPUT แสดงการประกาศตัวแปรวันที่
ตัวอย่าง
INPUT DOB DATE11. START_DATE MMDDYY10. ;การใช้ตัวแปรในโปรแกรม SAS
ตัวแปรข้างต้นใช้ในโปรแกรม SAS ดังแสดงในตัวอย่างด้านล่าง
ตัวอย่าง
โค้ดด้านล่างนี้แสดงวิธีการประกาศและใช้ตัวแปรทั้งสามประเภทในโปรแกรม SAS
DATA TEMP;
INPUT ID NAME $ SALARY DEPT $ DOJ DATE9. ;
FORMAT DOJ DATE9. ;
DATALINES;
1 Rick 623.3 IT 02APR2001
2 Dan 515.2 OPS 11JUL2012
3 Michelle 611 IT 21OCT2000
4 Ryan 729 HR 30JUL2012
5 Gary 843.25 FIN 06AUG2000
6 Tusar 578 IT 01MAR2009
7 Pranab 632.8 OPS 16AUG1998
8 Rasmi 722.5 FIN 13SEP2014
;
PROC PRINT DATA = TEMP;
RUN;ในตัวอย่างข้างต้นตัวแปรอักขระทั้งหมดจะถูกประกาศตามด้วยเครื่องหมาย $ และตัวแปรวันที่จะถูกประกาศตามด้วยรูปแบบวันที่ ผลลัพธ์ของโปรแกรมข้างต้นมีดังต่อไปนี้
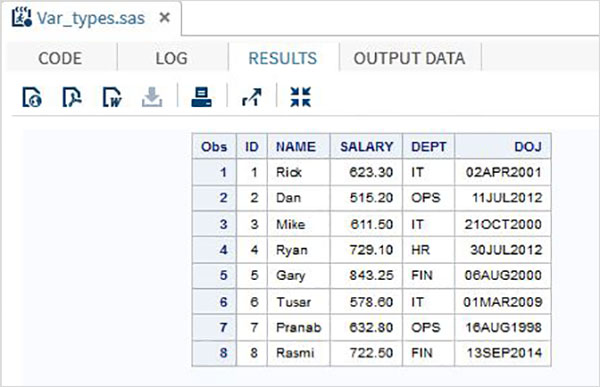
การใช้ตัวแปร
ตัวแปรมีประโยชน์มากในการวิเคราะห์ข้อมูล ใช้ในนิพจน์ที่ใช้การวิเคราะห์ทางสถิติ มาดูตัวอย่างการวิเคราะห์ชุดข้อมูลในตัวที่ชื่อCARS ซึ่งอยู่ภายใต้ Libraries → My Libraries → SASHELP. ดับเบิลคลิกเพื่อสำรวจตัวแปรและประเภทข้อมูล

จากนั้นเราสามารถสร้างสถิติสรุปของตัวแปรเหล่านี้โดยใช้ตัวเลือก Tasks ใน SAS studio ไปที่Tasks -> Statistics -> Summary Statisticsและดับเบิลคลิกเพื่อเปิดหน้าต่างดังที่แสดงด้านล่าง เลือกชุดข้อมูลSASHELP.CARSและเลือกตัวแปรสามตัว ได้แก่ MPG_CITY, MPG_Highway และ Weight ภายใต้ตัวแปรการวิเคราะห์ กดปุ่ม Ctrl ค้างไว้ขณะเลือกตัวแปรโดยคลิก คลิกเรียกใช้

คลิกที่แท็บผลลัพธ์หลังจากขั้นตอนข้างต้น แสดงข้อมูลสรุปทางสถิติของตัวแปรทั้งสามที่เลือก คอลัมน์สุดท้ายระบุจำนวนการสังเกต (บันทึก) ที่ใช้ในการวิเคราะห์
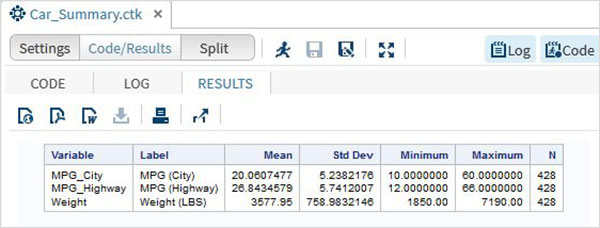
สตริงใน SAS คือค่าที่อยู่ในอัญประกาศคู่หนึ่ง นอกจากนี้ยังมีการประกาศตัวแปรสตริงโดยการเพิ่มช่องว่างและเครื่องหมาย $ ที่ส่วนท้ายของการประกาศตัวแปร SAS มีฟังก์ชันที่มีประสิทธิภาพมากมายในการวิเคราะห์และจัดการสตริง
การประกาศตัวแปรสตริง
เราสามารถประกาศตัวแปรสตริงและค่าได้ดังที่แสดงด้านล่าง ในโค้ดด้านล่างเราจะประกาศตัวแปรอักขระ 2 ตัวที่มีความยาว 6 และ 5 คีย์เวิร์ด LENGTH ใช้สำหรับการประกาศตัวแปรโดยไม่ต้องสร้างการสังเกตหลาย ๆ
data string_examples;
LENGTH string1 $ 6 String2 $ 5;
/*String variables of length 6 and 5 */
String1 = 'Hello';
String2 = 'World';
Joined_strings = String1 ||String2 ;
run;
proc print data = string_examples noobs;
run;ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ซึ่งแสดงชื่อตัวแปรและค่าของตัวแปร
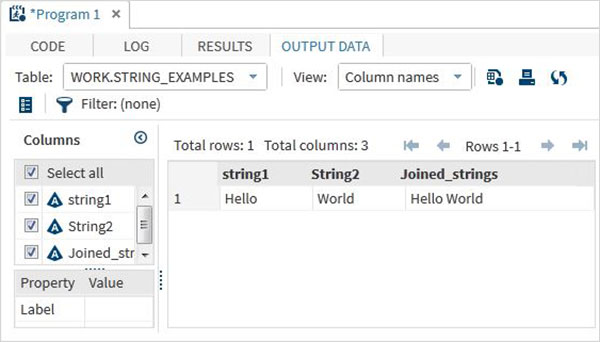
ฟังก์ชันสตริง
ด้านล่างนี้เป็นตัวอย่างของฟังก์ชัน SAS ที่ใช้บ่อย
SUBSTRN
ฟังก์ชันนี้แยกสตริงย่อยโดยใช้ตำแหน่งเริ่มต้นและตำแหน่งสิ้นสุด ในกรณีที่ไม่มีการกล่าวถึงตำแหน่งสิ้นสุดจะดึงอักขระทั้งหมดออกจนจบสตริง
ไวยากรณ์
SUBSTRN('stringval',p1,p2)ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
- stringval คือค่าของตัวแปรสตริง
- p1 คือตำแหน่งเริ่มต้นของการสกัด
- p2 เป็นตำแหน่งสุดท้ายของการสกัด
ตัวอย่าง
data string_examples;
LENGTH string1 $ 6 ;
String1 = 'Hello';
sub_string1 = substrn(String1,2,4) ;
/*Extract from position 2 to 4 */
sub_string2 = substrn(String1,3) ;
/*Extract from position 3 onwards */
run;
proc print data = string_examples noobs;
run;ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ซึ่งแสดงผลลัพธ์ของฟังก์ชัน substrn

TRIMN
ฟังก์ชันนี้จะลบช่องว่างต่อท้ายในรูปแบบสตริง
ไวยากรณ์
TRIMN('stringval')ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
- stringval คือค่าของตัวแปรสตริง
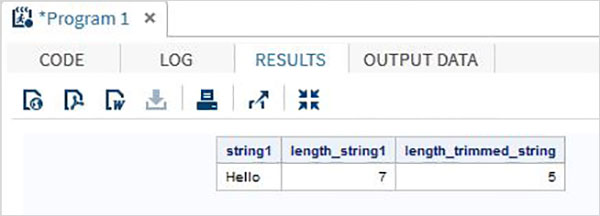
data string_examples;
LENGTH string1 $ 7 ;
String1='Hello ';
length_string1 = lengthc(String1);
length_trimmed_string = lengthc(TRIMN(String1));
run;
proc print data = string_examples noobs;
run;ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ซึ่งแสดงผลลัพธ์ของฟังก์ชัน TRIMN
อาร์เรย์ใน SAS ใช้เพื่อจัดเก็บและดึงข้อมูลชุดของค่าโดยใช้ค่าดัชนี ดัชนีแสดงตำแหน่งในพื้นที่หน่วยความจำที่สงวนไว้
ไวยากรณ์
ใน SAS อาร์เรย์ถูกประกาศโดยใช้ไวยากรณ์ต่อไปนี้ -
ARRAY ARRAY-NAME(SUBSCRIPT) ($) VARIABLE-LIST ARRAY-VALUESในไวยากรณ์ข้างต้น -
ARRAY คือคีย์เวิร์ด SAS เพื่อประกาศอาร์เรย์
ARRAY-NAME คือชื่อของอาร์เรย์ซึ่งเป็นไปตามกฎเดียวกันกับชื่อตัวแปร
SUBSCRIPT คือจำนวนค่าที่อาร์เรย์จะจัดเก็บ
($) เป็นพารามิเตอร์ทางเลือกที่จะใช้เฉพาะในกรณีที่อาร์เรย์จัดเก็บค่าอักขระ
VARIABLE-LIST เป็นรายการทางเลือกของตัวแปรซึ่งเป็นตัวยึดสำหรับค่าอาร์เรย์
ARRAY-VALUESคือค่าจริงที่เก็บไว้ในอาร์เรย์ สามารถประกาศได้ที่นี่หรืออ่านได้จากไฟล์หรือดาตาไลน์
ตัวอย่างของการประกาศอาร์เรย์
อาร์เรย์สามารถประกาศได้หลายวิธีโดยใช้ไวยากรณ์ข้างต้น ด้านล่างนี้คือตัวอย่าง
# Declare an array of length 5 named AGE with values.
ARRAY AGE[5] (12 18 5 62 44);
# Declare an array of length 5 named COUNTRIES with values starting at index 0.
ARRAY COUNTRIES(0:8) A B C D E F G H I;
# Declare an array of length 5 named QUESTS which contain character values.
ARRAY QUESTS(1:5) $ Q1-Q5;
# Declare an array of required length as per the number of values supplied.
ARRAY ANSWER(*) A1-A100;การเข้าถึงค่าอาร์เรย์
ค่าที่เก็บไว้ในอาร์เรย์สามารถเข้าถึงได้โดยใช้ printขั้นตอนดังแสดงด้านล่าง หลังจากประกาศโดยใช้วิธีใดวิธีหนึ่งข้างต้นข้อมูลจะถูกส่งโดยใช้คำสั่ง DATALINES
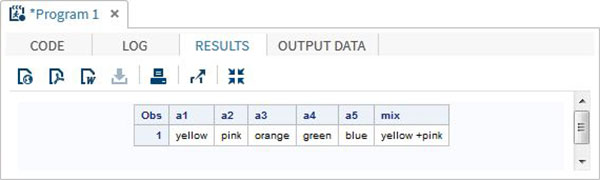
DATA array_example;
INPUT a1 $ a2 $ a3 $ a4 $ a5 $; ARRAY colours(5) $ a1-a5;
mix = a1||'+'||a2;
DATALINES;
yello pink orange green blue
;
RUN;
PROC PRINT DATA = array_example;
RUN;เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
การใช้ตัวดำเนินการ OF
ตัวดำเนินการ OF ถูกใช้ในการวิเคราะห์ข้อมูลในรูปแบบอาร์เรย์เพื่อทำการคำนวณในแถวทั้งหมดของอาร์เรย์ ในตัวอย่างด้านล่างเราใช้ผลรวมและค่าเฉลี่ยของค่าในแต่ละแถว
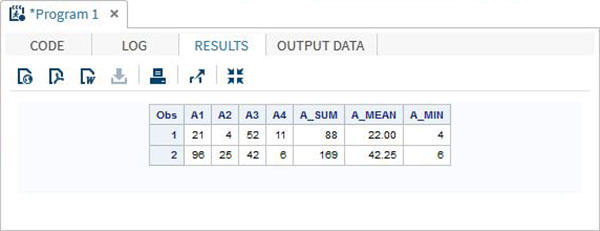
DATA array_example_OF;
INPUT A1 A2 A3 A4;
ARRAY A(4) A1-A4;
A_SUM = SUM(OF A(*));
A_MEAN = MEAN(OF A(*));
A_MIN = MIN(OF A(*));
DATALINES;
21 4 52 11
96 25 42 6
;
RUN;
PROC PRINT DATA = array_example_OF;
RUN;เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
การใช้ตัวดำเนินการ IN
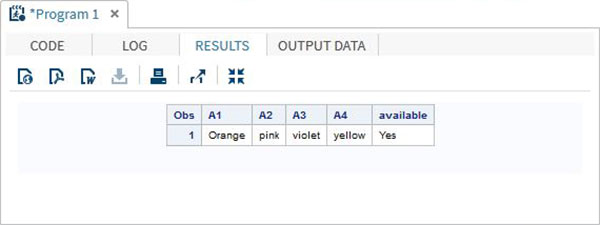
ค่าในอาร์เรย์ยังสามารถเข้าถึงได้โดยใช้ตัวดำเนินการ IN ซึ่งตรวจสอบการมีอยู่ของค่าในแถวของอาร์เรย์ ในตัวอย่างด้านล่างเราตรวจสอบความพร้อมใช้งานของสี "เหลือง" ในข้อมูล ค่านี้คำนึงถึงขนาดตัวพิมพ์
DATA array_in_example;
INPUT A1 $ A2 $ A3 $ A4 $;
ARRAY COLOURS(4) A1-A4;
IF 'yellow' IN COLOURS THEN available = 'Yes';ELSE available = 'No';
DATALINES;
Orange pink violet yellow
;
RUN;
PROC PRINT DATA = array_in_example;
RUN;เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
SAS สามารถจัดการรูปแบบข้อมูลตัวเลขได้หลากหลาย ใช้รูปแบบเหล่านี้ที่ส่วนท้ายของชื่อตัวแปรเพื่อใช้รูปแบบตัวเลขเฉพาะกับข้อมูล SAS ใช้รูปแบบตัวเลขสองประเภท หนึ่งสำหรับการอ่านรูปแบบเฉพาะของข้อมูลตัวเลขที่เรียกว่าinformat และอีกรายการหนึ่งสำหรับการแสดงข้อมูลตัวเลขในรูปแบบเฉพาะที่เรียกว่า output format.
ไวยากรณ์
ไวยากรณ์สำหรับข้อมูลตัวเลขคือ -
Varname Formatnamew.dต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
Varname คือชื่อของตัวแปร
Formatname คือชื่อของชื่อรูปแบบตัวเลขที่ใช้กับตัวแปร
w คือจำนวนคอลัมน์ข้อมูลสูงสุด (รวมถึงตัวเลขหลังทศนิยมและจุดทศนิยมเอง) ที่อนุญาตให้จัดเก็บสำหรับตัวแปร
d คือจำนวนหลักทางขวาของทศนิยม
การอ่านรูปแบบตัวเลข
ด้านล่างนี้คือรายการรูปแบบที่ใช้ในการอ่านข้อมูลลงใน SAS
ป้อนรูปแบบตัวเลข
| รูปแบบ | ใช้ |
|---|---|
| n. | จำนวนคอลัมน์สูงสุด "n" ที่ไม่มีจุดทศนิยม |
| n.p | จำนวนคอลัมน์สูงสุด "n" ที่มีจุดทศนิยม "p" |
| COMMAn.p | จำนวนคอลัมน์สูงสุด "n" ที่มีตำแหน่งทศนิยม "p" ซึ่งจะลบเครื่องหมายลูกน้ำหรือเครื่องหมายดอลลาร์ |
| COMMAn.p | จำนวนคอลัมน์สูงสุด "n" ที่มีตำแหน่งทศนิยม "p" ซึ่งจะลบเครื่องหมายลูกน้ำหรือเครื่องหมายดอลลาร์ |
การแสดงรูปแบบตัวเลข
คล้ายกับการใช้รูปแบบขณะอ่านข้อมูลด้านล่างนี้คือรายการรูปแบบที่ใช้สำหรับแสดงข้อมูลในผลลัพธ์ของโปรแกรม SAS
รูปแบบตัวเลขเอาต์พุต
| รูปแบบ | ใช้ |
|---|---|
| n. | เขียนจำนวนหลัก "n" สูงสุดโดยไม่มีจุดทศนิยม |
| n.p | เขียนจำนวนคอลัมน์สูงสุด "np" ด้วยจุดทศนิยม "p" |
| DOLLARn.p | เขียนจำนวนคอลัมน์สูงสุด "n" โดยมีจุดทศนิยม p เครื่องหมายดอลลาร์นำหน้าและเครื่องหมายจุลภาคที่ตำแหน่งที่พัน |
โปรดทราบ -
หากจำนวนหลักหลังจุดทศนิยมน้อยกว่าตัวระบุรูปแบบzeros will be appended ในตอนท้าย
หากจำนวนหลักหลังจุดทศนิยมมากกว่าตัวระบุรูปแบบตัวเลขสุดท้ายจะเป็น rounded off.
ตัวอย่าง
ตัวอย่างด้านล่างแสดงสถานการณ์ข้างต้น
DATA MYDATA1;
input x 6.; /*maxiiuum width of the data*/
format x 6.3;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA1;
RUN;
DATA MYDATA2;
input x 6.; /*maximum width of the data*/
format x 5.2;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA2;
RUN;
DATA MYDATA3;
input x 6.; /*maximum width of the data*/
format x DOLLAR10.2;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA3;
RUN;เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
# MYDATA1.
Obs x
1 8722.0 # Display 6 columns with zero appended after decimal.
2 93.200 # Display 6 columns with zero appended after decimal.
3 0.112 # No integers before decimal, so display 3 available digits after decimal.
4 15.116 # Display 6 columns with 3 available digits after decimal.
# MYDATA2
Obs x
1 8722 # Display 5 columns. Only 4 are available.
2 93.20 # Display 5 columns with zero appended after decimal.
3 0.11 # Display 5 columns with 2 places after decimal.
4 15.12 # Display 5 columns with 2 places after decimal.
# MYDATA3
Obs x
1 $8,722.00 # Display 10 columns with leading $ sign, comma at thousandth place and zeros appended after decimal.
2 $93.20 # Only 2 integers available before decimal and one available after the decimal. 3 $0.11 # No integers available before decimal and two available after the decimal.
4 $15.12 # Only 2 integers available before decimal and two available after the decimal.ตัวดำเนินการใน SAS เป็นสัญลักษณ์ที่ใช้ในนิพจน์ทางคณิตศาสตร์ตรรกะหรือการเปรียบเทียบ สัญลักษณ์เหล่านี้สร้างขึ้นในภาษา SAS และสามารถรวมตัวดำเนินการหลายตัวในนิพจน์เดียวเพื่อให้ได้ผลลัพธ์สุดท้าย
ด้านล่างนี้คือรายชื่อของตัวดำเนินการประเภท SAS
- ตัวดำเนินการเลขคณิต
- ตัวดำเนินการทางตรรกะ
- ตัวดำเนินการเปรียบเทียบ
- ตัวดำเนินการขั้นต่ำ / สูงสุด
- ตัวดำเนินการเชื่อมต่อ
เราจะดูทีละคน ตัวดำเนินการจะใช้กับตัวแปรที่เป็นส่วนหนึ่งของข้อมูลที่กำลังวิเคราะห์โดยโปรแกรม SAS เสมอ
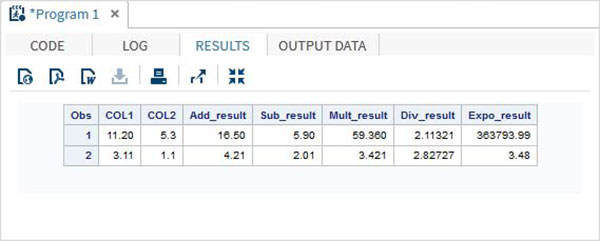
ตัวดำเนินการเลขคณิต
ตารางด้านล่างอธิบายรายละเอียดของตัวดำเนินการเลขคณิต สมมติตัวแปรข้อมูลสองตัวV1 และ V2ด้วยค่า 8 และ 4 ตามลำดับ
| ตัวดำเนินการ | คำอธิบาย | ตัวอย่าง |
|---|---|---|
| + | ส่วนที่เพิ่มเข้าไป | V1 + V2 = 12 |
| - | การลบ | V1-V2 = 4 |
| * | การคูณ | V1 * V2 = 32 |
| / | แผนก | V1 / V2 = 2 |
| ** | การยกกำลัง | V1 ** V2 = 4096 |
ตัวอย่าง
DATA MYDATA1;
input @1 COL1 4.2 @7 COL2 3.1;
Add_result = COL1+COL2;
Sub_result = COL1-COL2;
Mult_result = COL1*COL2;
Div_result = COL1/COL2;
Expo_result = COL1**COL2;
datalines;
11.21 5.3
3.11 11
;
PROC PRINT DATA = MYDATA1;
RUN;ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ต่อไปนี้
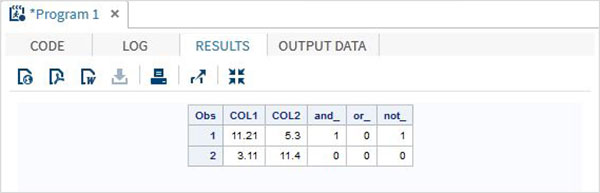
ตัวดำเนินการทางตรรกะ
ตารางด้านล่างนี้อธิบายรายละเอียดของตัวดำเนินการทางตรรกะ ตัวดำเนินการเหล่านี้ประเมินค่าความจริงของนิพจน์ ดังนั้นผลลัพธ์ของตัวดำเนินการทางตรรกะจะเป็น 1 หรือ 0 เสมอสมมติว่าตัวแปรข้อมูลสองตัวV1 และ V2ด้วยค่า 8 และ 4 ตามลำดับ
| ตัวดำเนินการ | คำอธิบาย | ตัวอย่าง |
|---|---|---|
| & | ตัวดำเนินการ AND หากค่าข้อมูลทั้งสองประเมินเป็นจริงผลลัพธ์คือ 1 มิฉะนั้นจะเป็น 0 | (V1> 2 & V2> 3) ให้ 0 |
| | | ตัวดำเนินการหรือ หากค่าข้อมูลใดค่าหนึ่งประเมินเป็นจริงผลลัพธ์คือ 1 มิฉะนั้นจะเป็น 0 | (V1> 9 & V2> 3) คือ 1 |
| ~ | ไม่ใช่ตัวดำเนินการ ผลลัพธ์ของตัวดำเนินการ NOT ในรูปแบบของนิพจน์ที่มีค่าเป็น FALSE หรือค่าที่หายไปคือ 1 มิฉะนั้นจะเป็น 0 | NOT (V1> 3) คือ 1 |
ตัวอย่าง
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1;
and_=(COL1 > 10 & COL2 > 5 );
or_ = (COL1 > 12 | COL2 > 15 );
not_ = ~( COL2 > 7 );
datalines;
11.21 5.3
3.11 11.4
;
PROC PRINT DATA = MYDATA1;
RUN;ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ต่อไปนี้
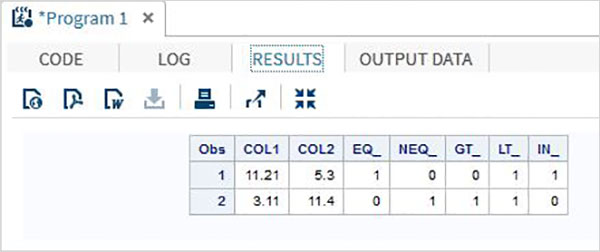
ตัวดำเนินการเปรียบเทียบ
ตารางด้านล่างอธิบายรายละเอียดของตัวดำเนินการเปรียบเทียบ ตัวดำเนินการเหล่านี้เปรียบเทียบค่าของตัวแปรและผลลัพธ์คือค่าความจริงที่นำเสนอโดย 1 สำหรับ TRUE และ 0 สำหรับ False สมมติตัวแปรข้อมูลสองตัวV1 และ V2ด้วยค่า 8 และ 4 ตามลำดับ
| ตัวดำเนินการ | คำอธิบาย | ตัวอย่าง |
|---|---|---|
| = | ตัวดำเนินการที่เท่าเทียมกัน หากค่าข้อมูลทั้งสองเท่ากันผลลัพธ์คือ 1 มิฉะนั้นจะเป็น 0 | (V1 = 8) ให้ 1. |
| ^ = | ตัวดำเนินการไม่เท่ากัน หากค่าข้อมูลทั้งสองไม่เท่ากันผลลัพธ์คือ 1 มิฉะนั้นจะเป็น 0 | (V1 ^ = V2) ให้ 1. |
| < | น้อยกว่าโอเปอเรเตอร์ | (V2 <V2) ให้ 1. |
| <= | น้อยกว่าหรือเท่ากับโอเปอเรเตอร์ | (V2 <= 4) ให้ 1. |
| > | ผู้ปฏิบัติงานที่ยิ่งใหญ่กว่า | (V2> V1) ให้ 1. |
| > = | ยิ่งใหญ่กว่าหรือเท่ากับ Operator | (V2> = V1) ให้ 0 |
| ใน | ตัวดำเนินการใน หากค่าของตัวแปรเท่ากับค่าใดค่าหนึ่งในรายการค่าที่กำหนดค่านั้นจะส่งกลับ 1 อย่างอื่นจะคืนค่าเป็น 0 | V1 ใน (5,7,9,8) ให้ 1. |
ตัวอย่าง
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1;
EQ_ = (COL1 = 11.21);
NEQ_= (COL1 ^= 11.21);
GT_ = (COL2 => 8);
LT_ = (COL2 <= 12);
IN_ = COL2 in( 6.2,5.3,12 );
datalines;
11.21 5.3
3.11 11.4
;
PROC PRINT DATA = MYDATA1;
RUN;ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ต่อไปนี้
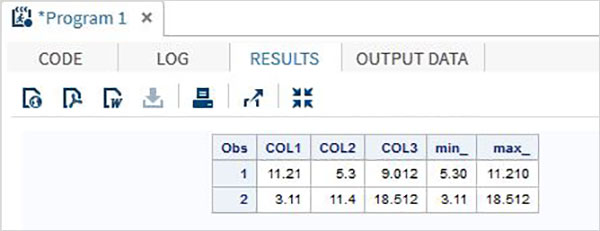
ตัวดำเนินการขั้นต่ำ / สูงสุด
ตารางด้านล่างอธิบายรายละเอียดของตัวดำเนินการขั้นต่ำ / สูงสุด ตัวดำเนินการเหล่านี้เปรียบเทียบค่าของตัวแปรในแถวและค่าต่ำสุดหรือสูงสุดจากรายการค่าในแถวจะถูกส่งกลับ
| ตัวดำเนินการ | คำอธิบาย | ตัวอย่าง |
|---|---|---|
| นาที | ตัวดำเนินการขั้นต่ำ ส่งคืนค่าต่ำสุดจากรายการค่าในแถว | MIN (45.2,11.6,15.41) ให้ 11.6 |
| MAX | ตัวดำเนินการ MAX ส่งคืนค่าสูงสุดจากรายการค่าในแถว | MAX (45.2,11.6,15.41) ให้ 45.2 |
ตัวอย่าง
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1 @12 COL3 6.3;
min_ = MIN(COL1 , COL2 , COL3);
max_ = MAX( COL1, COl2 , COL3);
datalines;
11.21 5.3 29.012
3.11 11.4 18.512
;
PROC PRINT DATA = MYDATA1;
RUN;ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ต่อไปนี้
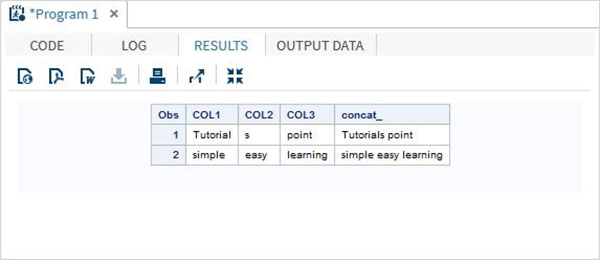
ตัวดำเนินการเชื่อมต่อ
ตารางด้านล่างอธิบายรายละเอียดของตัวดำเนินการเชื่อมต่อ ตัวดำเนินการนี้เชื่อมต่อค่าสตริงตั้งแต่สองค่าขึ้นไป ค่าอักขระเดียวจะถูกส่งกลับ
| ตัวดำเนินการ | คำอธิบาย | ตัวอย่าง |
|---|---|---|
| || | ตัวดำเนินการเชื่อมต่อ จะคืนค่าการเรียงต่อกันของค่าตั้งแต่สองค่าขึ้นไป | 'สวัสดี' || ' World 'ให้ Hello World |
ตัวอย่าง
DATA MYDATA1;
input COL1 $ COL2 $ COL3 $;
concat_ = (COL1 || COL2 || COL3);
datalines;
Tutorial s point
simple easy learning
;
PROC PRINT DATA = MYDATA1;
RUN;ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ต่อไปนี้
ลำดับความสำคัญของตัวดำเนินการ
ลำดับความสำคัญของตัวดำเนินการระบุลำดับของการประเมินตัวดำเนินการหลายตัวที่มีอยู่ในนิพจน์ที่ซับซ้อน ตารางด้านล่างอธิบายลำดับความสำคัญของตัวดำเนินการในกลุ่ม
| กลุ่ม | ใบสั่ง | สัญลักษณ์ |
|---|---|---|
| กลุ่ม I | จากขวาไปซ้าย | ** + - ไม่ต่ำสุด |
| กลุ่ม II | ซ้ายไปขวา | * / |
| กลุ่มที่สาม | ซ้ายไปขวา | + - |
| กลุ่ม IV | ซ้ายไปขวา | || |
| กลุ่ม V | ซ้ายไปขวา | <<= => => |
คุณอาจพบสถานการณ์เมื่อบล็อกโค้ดต้องดำเนินการหลาย ๆ ครั้ง โดยทั่วไปคำสั่งจะดำเนินการตามลำดับ - คำสั่งแรกในฟังก์ชันจะถูกเรียกใช้ก่อนตามด้วยคำสั่งที่สองและอื่น ๆ แต่เมื่อคุณต้องการให้ชุดคำสั่งเดิมดำเนินการซ้ำแล้วซ้ำเล่าเราต้องการความช่วยเหลือจากลูป
ในการวนซ้ำ SAS ทำได้โดยใช้คำสั่ง DO เรียกอีกอย่างว่าDO Loop. ด้านล่างเป็นรูปแบบทั่วไปของคำสั่ง DO loop ใน SAS
แผนภาพการไหล

ต่อไปนี้เป็นประเภทของ DO ลูปใน SAS
| ซีเนียร์ | ประเภทห่วงและคำอธิบาย |
|---|---|
| 1 | ทำดัชนี การวนซ้ำจะดำเนินต่อไปจากค่าเริ่มต้นจนถึงค่าหยุดของตัวแปรดัชนี |
| 2 | ทำในขณะที่ ลูปจะดำเนินต่อไปจนกว่าเงื่อนไข while จะกลายเป็นเท็จ |
| 3 | ดำเนินการจนถึง การวนซ้ำจะดำเนินต่อไปจนกว่าเงื่อนไข UNTIL จะกลายเป็น True |
โครงสร้างการตัดสินใจกำหนดให้โปรแกรมเมอร์ระบุเงื่อนไขอย่างน้อยหนึ่งเงื่อนไขที่จะประเมินหรือทดสอบโดยโปรแกรมพร้อมกับคำสั่งหรือคำสั่งที่จะดำเนินการหากเงื่อนไขถูกกำหนดให้เป็น trueและเป็นทางเลือกที่จะเรียกใช้คำสั่งอื่น ๆ หากเงื่อนไขถูกกำหนดให้เป็น false.
ต่อไปนี้เป็นรูปแบบทั่วไปของโครงสร้างการตัดสินใจทั่วไปที่พบในภาษาโปรแกรมส่วนใหญ่ -
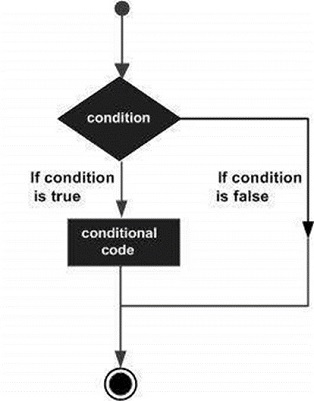
SAS จัดเตรียมประเภทของงบการตัดสินใจดังต่อไปนี้ คลิกลิงก์ต่อไปนี้เพื่อตรวจสอบรายละเอียด
| ซีเนียร์ | ประเภทงบและคำอธิบาย |
|---|---|
| 1 | คำสั่ง IF อัน if statementประกอบด้วยเงื่อนไข หากเงื่อนไขเป็นจริงระบบจะดึงข้อมูลเฉพาะ |
| 2 | คำสั่ง IF-THEN-ELSE อัน if statement ตามด้วยคำสั่ง else ซึ่งดำเนินการเมื่อเงื่อนไขบูลีนเป็นเท็จ |
| 3 | คำสั่ง IF-THEN-ELSE-IF อัน if statement ตามด้วยคำสั่งอื่นซึ่งตามด้วยคำสั่ง IF-THEN อีกคู่หนึ่ง |
| 4 | คำสั่ง IF-THEN-DELETE อัน if statement ประกอบด้วย acondition ซึ่งเมื่อ true ลบข้อมูลเฉพาะจากการสังเกต |
SAS มีฟังก์ชันในตัวที่หลากหลายซึ่งช่วยในการวิเคราะห์และประมวลผลข้อมูล ฟังก์ชันเหล่านี้ใช้เป็นส่วนหนึ่งของคำสั่ง DATA พวกเขารับตัวแปรข้อมูลเป็นอาร์กิวเมนต์และส่งคืนผลลัพธ์ที่เก็บไว้ในตัวแปรอื่น ขึ้นอยู่กับประเภทของฟังก์ชันจำนวนอาร์กิวเมนต์ที่ใช้อาจแตกต่างกันไป บางฟังก์ชันยอมรับอาร์กิวเมนต์เป็นศูนย์ในขณะที่บางฟังก์ชันยอมรับจำนวนตัวแปรคงที่ ด้านล่างนี้คือรายการประเภทของฟังก์ชันที่ SAS มีให้
ไวยากรณ์
ไวยากรณ์ทั่วไปสำหรับการใช้ฟังก์ชันใน SAS มีดังต่อไปนี้
FUNCTIONNAME(argument1, argument2...argumentn)ที่นี่อาร์กิวเมนต์อาจเป็นค่าคงที่ตัวแปรนิพจน์หรือฟังก์ชันอื่น
หมวดหมู่ฟังก์ชัน
ขึ้นอยู่กับการใช้งานฟังก์ชั่นใน SAS แบ่งออกเป็นด้านล่าง
- Mathematical
- วันและเวลา
- Character
- Truncation
- Miscellaneous
ฟังก์ชันทางคณิตศาสตร์
นี่คือฟังก์ชันที่ใช้ในการคำนวณทางคณิตศาสตร์กับค่าตัวแปร
ตัวอย่าง
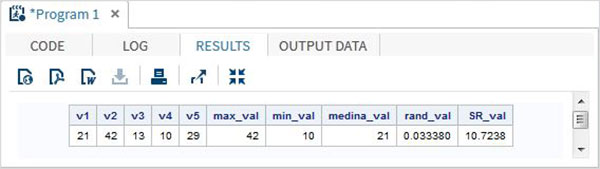
โปรแกรม SAS ด้านล่างนี้แสดงการใช้ฟังก์ชันทางคณิตศาสตร์ที่สำคัญบางอย่าง
data Math_functions;
v1=21; v2=42; v3=13; v4=10; v5=29;
/* Get Maximum value */
max_val = MAX(v1,v2,v3,v4,v5);
/* Get Minimum value */
min_val = MIN (v1,v2,v3,v4,v5);
/* Get Median value */
med_val = MEDIAN (v1,v2,v3,v4,v5);
/* Get a random number */
rand_val = RANUNI(0);
/* Get Square root of sum of the values */
SR_val= SQRT(sum(v1,v2,v3,v4,v5));
proc print data = Math_functions noobs;
run;เมื่อรันโค้ดด้านบนเราจะได้ผลลัพธ์ต่อไปนี้ -
ฟังก์ชันวันที่และเวลา
นี่คือฟังก์ชันที่ใช้ในการประมวลผลค่าวันที่และเวลา
ตัวอย่าง
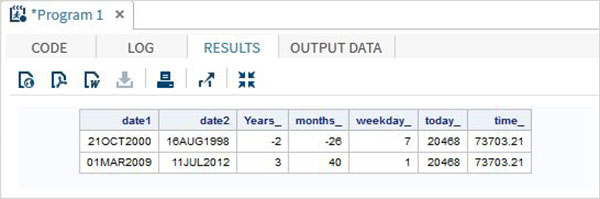
โปรแกรม SAS ด้านล่างแสดงการใช้ฟังก์ชันวันที่และเวลา
data date_functions;
INPUT @1 date1 date9. @11 date2 date9.;
format date1 date9. date2 date9.;
/* Get the interval between the dates in years*/
Years_ = INTCK('YEAR',date1,date2);
/* Get the interval between the dates in months*/
months_ = INTCK('MONTH',date1,date2);
/* Get the week day from the date*/
weekday_ = WEEKDAY(date1);
/* Get Today's date in SAS date format */
today_ = TODAY();
/* Get current time in SAS time format */
time_ = time();
DATALINES;
21OCT2000 16AUG1998
01MAR2009 11JUL2012
;
proc print data = date_functions noobs;
run;เมื่อรันโค้ดด้านบนเราจะได้ผลลัพธ์ต่อไปนี้ -
ฟังก์ชั่นตัวละคร
นี่คือฟังก์ชันที่ใช้ในการประมวลผลค่าอักขระหรือข้อความ
ตัวอย่าง
โปรแกรม SAS ด้านล่างนี้แสดงการใช้ฟังก์ชันอักขระ
data character_functions;
/* Convert the string into lower case */
lowcse_ = LOWCASE('HELLO');
/* Convert the string into upper case */
upcase_ = UPCASE('hello');
/* Reverse the string */
reverse_ = REVERSE('Hello');
/* Return the nth word */
nth_letter_ = SCAN('Learn SAS Now',2);
run;
proc print data = character_functions noobs;
run;เมื่อรันโค้ดด้านบนเราจะได้ผลลัพธ์ต่อไปนี้ -
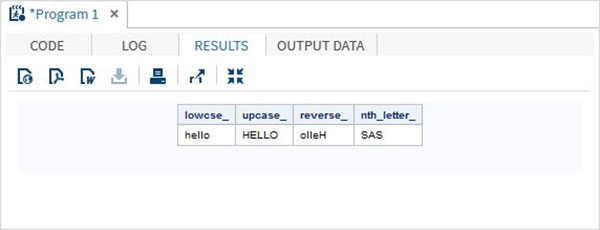
ฟังก์ชันการตัดทอน
นี่คือฟังก์ชันที่ใช้ในการตัดทอนค่าตัวเลข
ตัวอย่าง
โปรแกรม SAS ด้านล่างแสดงการใช้ฟังก์ชันการตัดทอน
data trunc_functions;
/* Nearest greatest integer */
ceil_ = CEIL(11.85);
/* Nearest greatest integer */
floor_ = FLOOR(11.85);
/* Integer portion of a number */
int_ = INT(32.41);
/* Round off to nearest value */
round_ = ROUND(5621.78);
run;
proc print data = trunc_functions noobs;
run;เมื่อรันโค้ดด้านบนเราจะได้ผลลัพธ์ต่อไปนี้ -

ฟังก์ชันเบ็ดเตล็ด
ตอนนี้ให้เราเข้าใจฟังก์ชั่นเบ็ดเตล็ดของ SAS พร้อมตัวอย่างบางส่วน
ตัวอย่าง
โปรแกรม SAS ด้านล่างแสดงการใช้ฟังก์ชันเบ็ดเตล็ด
data misc_functions;
/* Nearest greatest integer */
state2=zipstate('01040');
/* Amortization calculation */
payment = mort(50000, . , .10/12,30*12);
proc print data = misc_functions noobs;
run;เมื่อรันโค้ดด้านบนเราจะได้ผลลัพธ์ต่อไปนี้ -

วิธีการป้อนข้อมูลใช้เพื่ออ่านข้อมูลดิบ ข้อมูลดิบอาจมาจากแหล่งภายนอกหรือจากข้อมูลในสตรีม คำสั่งอินพุตจะสร้างตัวแปรที่มีชื่อที่คุณกำหนดให้กับแต่ละฟิลด์ ดังนั้นคุณต้องสร้างตัวแปรในคำสั่งอินพุต ตัวแปรเดียวกันจะแสดงในเอาต์พุตของ SAS Dataset ด้านล่างนี้คือวิธีการป้อนข้อมูลต่างๆที่มีอยู่ใน SAS
- วิธีการป้อนรายการ
- ชื่อวิธีการป้อนข้อมูล
- วิธีการป้อนข้อมูลคอลัมน์
- วิธีการป้อนข้อมูลที่จัดรูปแบบ
รายละเอียดของวิธีการป้อนข้อมูลแต่ละวิธีอธิบายไว้ดังต่อไปนี้
วิธีการป้อนรายการ
ในวิธีนี้ตัวแปรจะแสดงรายการด้วยชนิดข้อมูล ข้อมูลดิบจะได้รับการวิเคราะห์อย่างรอบคอบเพื่อให้ลำดับของตัวแปรที่ประกาศตรงกับข้อมูล ตัวคั่น (โดยปกติคือช่องว่าง) ควรมีความสม่ำเสมอระหว่างคู่ของคอลัมน์ที่อยู่ติดกัน ข้อมูลที่ขาดหายไปจะทำให้เกิดปัญหาในผลลัพธ์เนื่องจากผลลัพธ์จะไม่ถูกต้อง
ตัวอย่าง
รหัสต่อไปนี้และเอาต์พุตแสดงการใช้วิธีการป้อนรายการ
DATA TEMP;
INPUT EMPID ENAME $ DEPT $ ;
DATALINES;
1 Rick IT
2 Dan OPS
3 Tusar IT
4 Pranab OPS
5 Rasmi FIN
;
PROC PRINT DATA = TEMP;
RUN;ในการรันโค้ด bove เราจะได้ผลลัพธ์ต่อไปนี้
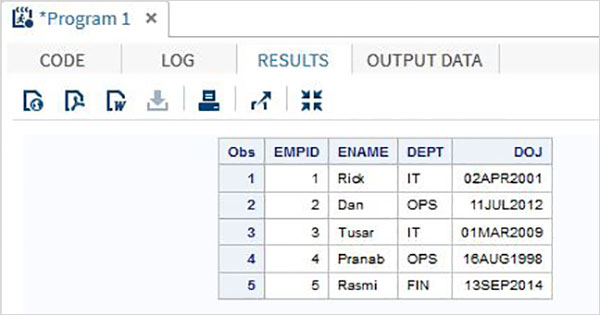
ชื่อวิธีการป้อนข้อมูล
ในวิธีนี้ตัวแปรจะแสดงรายการด้วยชนิดข้อมูล ข้อมูลดิบถูกแก้ไขให้มีการประกาศชื่อตัวแปรไว้ด้านหน้าข้อมูลที่ตรงกัน ตัวคั่น (โดยปกติคือช่องว่าง) ควรมีความสม่ำเสมอระหว่างคู่ของคอลัมน์ที่อยู่ติดกัน
ตัวอย่าง
โค้ดและเอาต์พุตต่อไปนี้แสดงการใช้ Named Input Method
DATA TEMP;
INPUT
EMPID= ENAME= $ DEPT= $ ;
DATALINES;
EMPID = 1 ENAME = Rick DEPT = IT
EMPID = 2 ENAME = Dan DEPT = OPS
EMPID = 3 ENAME = Tusar DEPT = IT
EMPID = 4 ENAME = Pranab DEPT = OPS
EMPID = 5 ENAME = Rasmi DEPT = FIN
;
PROC PRINT DATA = TEMP;
RUN;ในการรันโค้ด bove เราจะได้ผลลัพธ์ต่อไปนี้
วิธีการป้อนข้อมูลคอลัมน์
ในวิธีนี้ตัวแปรจะแสดงรายการด้วยชนิดข้อมูลและความกว้างของคอลัมน์ซึ่งระบุค่าของข้อมูลคอลัมน์เดียว ตัวอย่างเช่นถ้าชื่อพนักงานมีอักขระสูงสุด 9 ตัวและชื่อพนักงานแต่ละคนเริ่มต้นที่คอลัมน์ที่ 10 ความกว้างของคอลัมน์สำหรับตัวแปรชื่อพนักงานจะเป็น 10-19
ตัวอย่าง
โค้ดต่อไปนี้แสดงการใช้ Column Input Method
DATA TEMP;
INPUT EMPID 1-3 ENAME $ 4-12 DEPT $ 13-16;
DATALINES;
14 Rick IT
241Dan OPS
30 Sanvi IT
410Chanchal OPS
52 Piyu FIN
;
PROC PRINT DATA = TEMP;
RUN;เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
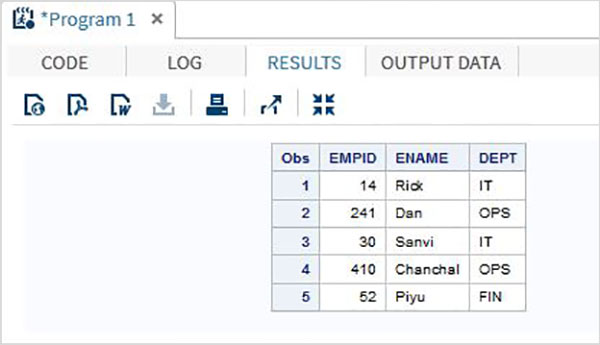
วิธีการป้อนข้อมูลที่จัดรูปแบบ
ในวิธีนี้ตัวแปรจะถูกอ่านจากจุดเริ่มต้นคงที่จนกว่าจะพบช่องว่าง เนื่องจากทุกตัวแปรมีจุดเริ่มต้นคงที่จำนวนคอลัมน์ระหว่างตัวแปรคู่ใด ๆ จึงกลายเป็นความกว้างของตัวแปรแรก อักขระ "@n" ใช้เพื่อระบุตำแหน่งคอลัมน์เริ่มต้นของตัวแปรเป็นคอลัมน์ที่ n
ตัวอย่าง
รหัสต่อไปนี้แสดงการใช้วิธีการป้อนข้อมูลที่จัดรูปแบบ
DATA TEMP;
INPUT @1 EMPID $ @4 ENAME $ @13 DEPT $ ;
DATALINES;
14 Rick IT
241 Dan OPS
30 Sanvi IT
410 Chanchal OPS
52 Piyu FIN
;
PROC PRINT DATA = TEMP;
RUN;เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังนี้ -
SAS มีคุณสมบัติการเขียนโปรแกรมที่มีประสิทธิภาพที่เรียกว่า Macrosซึ่งช่วยให้เราหลีกเลี่ยงส่วนซ้ำ ๆ ของโค้ดและใช้ซ้ำแล้วซ้ำอีกเมื่อจำเป็น นอกจากนี้ยังช่วยสร้างตัวแปรแบบไดนามิกภายในโค้ดที่สามารถรับค่าที่แตกต่างกันสำหรับอินสแตนซ์การรันที่แตกต่างกันของโค้ดเดียวกัน นอกจากนี้ยังสามารถประกาศมาโครสำหรับบล็อกโค้ดซึ่งจะถูกนำมาใช้ซ้ำหลายครั้งในลักษณะเดียวกันกับตัวแปรมาโคร เราจะเห็นทั้งสองอย่างนี้ในตัวอย่างด้านล่าง
ตัวแปรมาโคร
นี่คือตัวแปรที่เก็บค่าไว้เพื่อใช้ซ้ำแล้วซ้ำอีกโดยโปรแกรม SAS มีการประกาศเมื่อเริ่มต้นโปรแกรม SAS และจะถูกเรียกออกมาในภายหลังในเนื้อหาของโปรแกรม สามารถเป็น Global หรือ Local ในขอบเขตได้
ตัวแปร Global Macro
เรียกว่าตัวแปรมาโครส่วนกลางเนื่องจากสามารถเข้าถึงได้โดยโปรแกรม SAS ที่มีอยู่ในสภาพแวดล้อม SAS โดยทั่วไปเป็นตัวแปรที่ระบบกำหนดให้ซึ่งเข้าถึงได้โดยหลายโปรแกรม ตัวอย่างทั่วไปคือวันที่ของระบบ
ตัวอย่าง
ด้านล่างนี้เป็นตัวอย่างของตัวแปร SAS ที่เรียกว่า SYSDATE ซึ่งแสดงถึงวันที่ของระบบ พิจารณาสถานการณ์จำลองเพื่อพิมพ์วันที่ของระบบในชื่อของรายงาน SAS ทุกวันที่สร้างรายงาน ชื่อเรื่องจะแสดงวันที่และวันปัจจุบันโดยที่เราไม่ได้เข้ารหัสค่าใด ๆ ให้ เราใช้ชุดข้อมูล SAS ในตัวที่เรียกว่า CARS ที่มีอยู่ในไลบรารี SASHELP
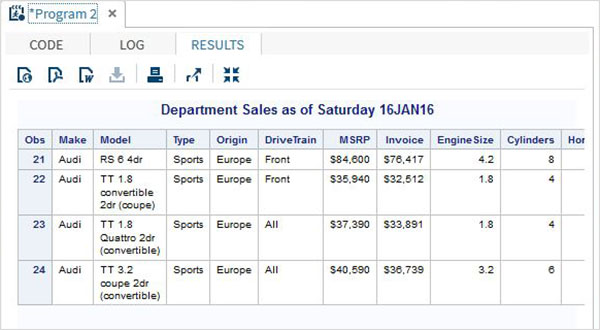
proc print data = sashelp.cars;
where make = 'Audi' and type = 'Sports' ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;เมื่อรันโค้ดด้านบนเราจะได้ผลลัพธ์ต่อไปนี้
ตัวแปร Local Macro
ตัวแปรเหล่านี้สามารถเข้าถึงได้โดยโปรแกรม SAS ซึ่งมีการประกาศให้เป็นส่วนหนึ่งของโปรแกรม โดยทั่วไปจะใช้เพื่อจัดหา varaibels ที่แตกต่างกันให้กับคำสั่ง SAS sl เดียวกันซึ่งสามารถประมวลผลการสังเกตที่แตกต่างกันของชุดข้อมูลได้
ไวยากรณ์
ตัวแปรโลคัลถูกทำลายด้วยไวยากรณ์ด้านล่าง
% LET (Macro Variable Name) = Value;ที่นี่ช่อง Value สามารถรับค่าตัวเลขข้อความหรือวันที่ตามที่โปรแกรมต้องการ ชื่อตัวแปรมาโครคือตัวแปร SAS ที่ถูกต้อง
ตัวอย่าง
ตัวแปรถูกใช้โดยคำสั่ง SAS โดยใช้ & อักขระต่อท้ายชื่อตัวแปร โปรแกรมด้านล่างนี้ทำให้เราทุกคนสังเกตเห็นรถยนต์ 'Audi' และประเภท 'Sports' ในกรณีที่เราต้องการผลลัพธ์ของdifferent makeเราจำเป็นต้องเปลี่ยนค่าของตัวแปร make_nameโดยไม่ต้องเปลี่ยนส่วนอื่น ๆ ของโปรแกรม ในกรณีของโปรแกรมนำตัวแปรนี้สามารถอ้างอิงซ้ำแล้วซ้ำอีกในคำสั่ง SAS ใด ๆ
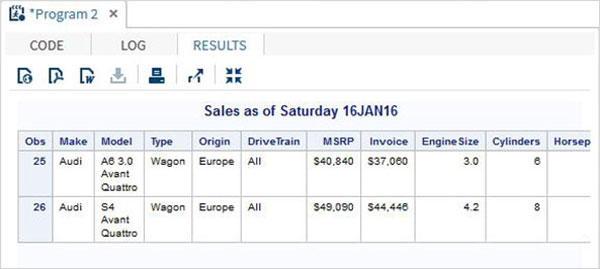
%LET make_name = 'Audi';
%LET type_name = 'Sports';
proc print data = sashelp.cars;
where make = &make_name and type = &type_name ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;เมื่อรันโค้ดด้านบนเราจะได้ผลลัพธ์เดียวกันกับโปรแกรมก่อนหน้า แต่เรามาเปลี่ยนไฟล์type name ถึง 'Wagon'และเรียกใช้โปรแกรมเดียวกัน เราจะได้ผลลัพธ์ด้านล่าง
โปรแกรมมาโคร
มาโครคือกลุ่มของคำสั่ง SAS ที่อ้างถึงด้วยชื่อและใช้ในโปรแกรมได้ทุกที่โดยใช้ชื่อนั้น เริ่มต้นด้วยคำสั่ง% MACRO และลงท้ายด้วยคำสั่ง% MEND
ไวยากรณ์
ตัวแปรท้องถิ่นถูกประกาศด้วยไวยากรณ์ด้านล่าง
# Creating a Macro program.
%MACRO <macro name>(Param1, Param2,….Paramn);
Macro Statements;
%MEND;
# Calling a Macro program.
%MacroName (Value1, Value2,…..Valuen);ตัวอย่าง
โปรแกรมด้านล่างนี้เป็นกลุ่มของ SAT staemnets ภายใต้มาโครที่ชื่อ 'show_result'; มาโครนี้ถูกเรียกโดยคำสั่ง SAS อื่น
%MACRO show_result(make_ , type_);
proc print data = sashelp.cars;
where make = "&make_" and type = "&type_" ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;
%MEND;
%show_result(BMW,SUV);เมื่อรันโค้ดด้านบนเราจะได้ผลลัพธ์ต่อไปนี้

มาโครที่ใช้กันทั่วไป
SAS มีคำสั่ง MACRO จำนวนมากซึ่งสร้างขึ้นในภาษาโปรแกรม SAS โปรแกรมเหล่านี้ถูกใช้โดยโปรแกรม SAS อื่น ๆ โดยไม่ได้ประกาศอย่างชัดเจนตัวอย่างทั่วไปคือ - การยุติโปรแกรมเมื่อตรงตามเงื่อนไขบางอย่างหรือจับค่ารันไทม์ของตัวแปรในบันทึกโปรแกรม ด้านล่างนี้คือตัวอย่างบางส่วน
มาโคร% PUT
คำสั่งแมโครนี้เขียนข้อความหรือข้อมูลตัวแปรแมโครไปยังบันทึก SAS ในตัวอย่างด้านล่างค่าของตัวแปร "today" จะถูกเขียนลงในบันทึกของโปรแกรม
data _null_;
CALL SYMPUT ('today',
TRIM(PUT("&sysdate"d,worddate22.)));
run;
%put &today;เมื่อรันโค้ดด้านบนเราจะได้ผลลัพธ์ต่อไปนี้

ผลตอบแทนมาโคร%
การดำเนินการของแมโครนี้ทำให้เกิดการยุติตามปกติของแมโครที่กำลังดำเนินการอยู่เมื่อเงื่อนไขบางอย่างประเมินว่าเป็นจริง ในตัวอย่างด้านล่างเมื่อค่าของตัวแปร"val" กลายเป็น 10 มาโครจะยุติมิฉะนั้นจะเกิดขึ้น
%macro check_condition(val);
%if &val = 10 %then %return;
data p;
x = 34.2;
run;
%mend check_condition;
%check_condition(11) ;เมื่อรันโค้ดด้านบนเราจะได้ผลลัพธ์ต่อไปนี้

มาโคร% END
นิยามมาโครนี้ประกอบด้วยไฟล์ %DO %WHILEลูปที่สิ้นสุดตามต้องการด้วยคำสั่ง% END ในตัวอย่างด้านล่างแมโครที่มีชื่อว่าการทดสอบรับอินพุตของผู้ใช้และรัน DO loop โดยใช้ค่าอินพุตนี้ การสิ้นสุดของลูป DO ทำได้โดยใช้คำสั่ง% end ในขณะที่การสิ้นสุดของมาโครทำได้โดยใช้คำสั่ง% mend
%macro test(finish);
%let i = 1;
%do %while (&i <&finish);
%put the value of i is &i;
%let i=%eval(&i+1);
%end;
%mend test;
%test(5)เมื่อรันโค้ดด้านบนเราจะได้ผลลัพธ์ต่อไปนี้

วันที่ใน SAS เป็นกรณีพิเศษของค่าตัวเลข แต่ละวันจะมีการกำหนดค่าตัวเลขเฉพาะโดยเริ่มตั้งแต่วันที่ 1 มกราคม 1960 วันที่นี้กำหนดค่าวันที่ 0 และวันที่ถัดไปมีค่าวันที่เป็น 1 เป็นต้นไป วันก่อนหน้าจนถึงวันนี้แสดงด้วย -1, -2 และอื่น ๆ ด้วยแนวทางนี้ SAS สามารถแสดงวันที่ในอนาคตและวันที่ใดก็ได้ในอดีต
เมื่อ SAS อ่านข้อมูลจากแหล่งข้อมูลจะแปลงข้อมูลที่อ่านเป็นรูปแบบวันที่เฉพาะตามที่ระบุรูปแบบวันที่ ตัวแปรในการจัดเก็บค่าวันที่ถูกประกาศด้วยข้อมูลที่เหมาะสมที่จำเป็น วันที่ส่งออกจะแสดงโดยใช้รูปแบบข้อมูลเอาต์พุต
SAS Date Informat
ข้อมูลแหล่งที่มาสามารถอ่านได้อย่างถูกต้องโดยใช้ข้อมูลวันที่ที่ระบุดังที่แสดงด้านล่าง ตัวเลขที่ส่วนท้ายของข้อมูลระบุความกว้างต่ำสุดของสตริงวันที่ที่จะอ่านอย่างสมบูรณ์โดยใช้ข้อมูล ความกว้างที่น้อยกว่าจะให้ผลลัพธ์ที่ไม่ถูกต้อง ด้วย SAS V9 จะมีรูปแบบวันที่ทั่วไปanydtdte15. ซึ่งสามารถประมวลผลการป้อนวันที่ใดก็ได้
| วันที่ป้อนข้อมูล | ความกว้างของวันที่ | Informat |
|---|---|---|
| 03/11/2014 | 10 | mmddyy 10. |
| 03/11/14 | 8 | mmddyy 8. |
| 11 ธันวาคม 2555 | 20 | worddate20. |
| 14 มี.ค. 2554 | 9 | วันที่ 9. |
| 14 มี.ค. 2554 | 11 | วันที่ 11. |
| 14 มี.ค. 2554 | 15 | anydtdte15. |
ตัวอย่าง
รหัสด้านล่างแสดงการอ่านรูปแบบวันที่ต่างๆ โปรดทราบว่าค่าผลลัพธ์ทั้งหมดเป็นเพียงตัวเลขเนื่องจากเราไม่ได้ใช้คำสั่งรูปแบบใด ๆ กับค่าผลลัพธ์
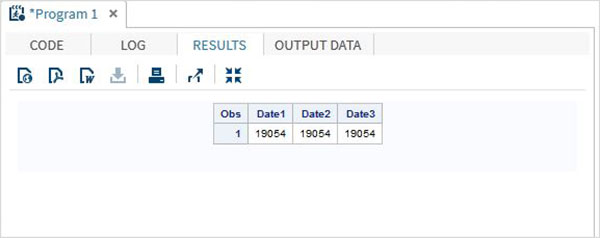
DATA TEMP;
INPUT @1 Date1 date11. @12 Date2 anydtdte15. @23 Date3 mmddyy10. ;
DATALINES;
02-mar-2012 3/02/2012 3/02/2012
;
PROC PRINT DATA = TEMP;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้
รูปแบบเอาต์พุตวันที่ SAS
วันที่หลังจากอ่านแล้วสามารถแปลงเป็นรูปแบบอื่นได้ตามที่ต้องการโดยการแสดงผล สิ่งนี้ทำได้โดยใช้คำสั่งรูปแบบสำหรับประเภทวันที่ พวกเขาใช้รูปแบบเดียวกับข้อมูล
ตัวอย่าง
ในตัวอย่างด้านล่างวันที่ถูกอ่านในรูปแบบเดียว แต่แสดงในรูปแบบอื่น
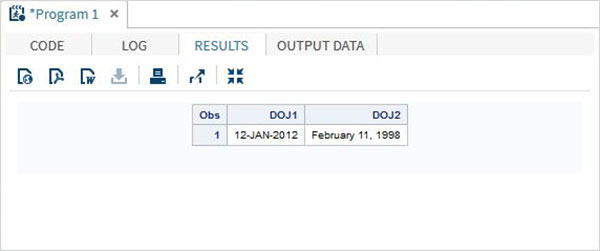
DATA TEMP;
INPUT @1 DOJ1 mmddyy10. @12 DOJ2 mmddyy10.;
format DOJ1 date11. DOJ2 worddate20. ;
DATALINES;
01/12/2012 02/11/1998
;
PROC PRINT DATA = TEMP;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้
SAS สามารถอ่านข้อมูลจากแหล่งต่างๆซึ่งรวมถึงไฟล์หลายรูปแบบ รูปแบบไฟล์ที่ใช้ในสภาพแวดล้อม SAS จะกล่าวถึงด้านล่าง
- ชุดข้อมูล ASCII (ข้อความ)
- ข้อมูลที่คั่น
- ข้อมูล Excel
- ข้อมูลตามลำดับชั้น
การอ่านชุดข้อมูล ASCII (ข้อความ)
นี่คือไฟล์ที่มีข้อมูลในรูปแบบข้อความ โดยปกติข้อมูลจะถูกคั่นด้วยช่องว่าง แต่อาจมีตัวคั่นประเภทต่างๆที่ SAS สามารถจัดการได้ ลองพิจารณาไฟล์ ASCII ที่มีข้อมูลพนักงาน เราอ่านไฟล์นี้โดยใช้ไฟล์Infile คำสั่งที่มีอยู่ใน SAS
ตัวอย่าง
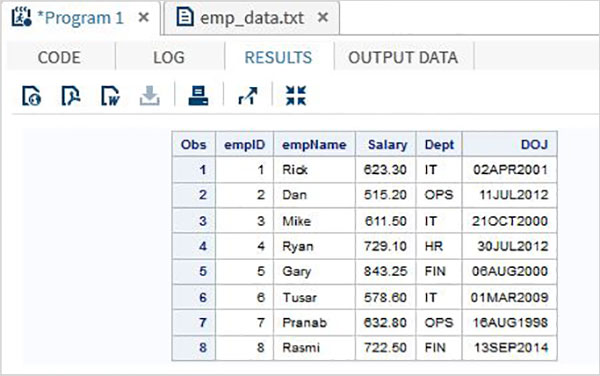
ในตัวอย่างด้านล่างเราอ่านไฟล์ข้อมูลที่ชื่อ emp_data.txt จากสภาพแวดล้อมในท้องถิ่น
data TEMP;
infile
'/folders/myfolders/sasuser.v94/TutorialsPoint/emp_data.txt';
input empID empName $ Salary Dept $ DOJ date9. ;
format DOJ date9.;
run;
PROC PRINT DATA = TEMP;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้
การอ่านข้อมูลที่คั่น
ไฟล์เหล่านี้คือไฟล์ข้อมูลที่ค่าคอลัมน์ถูกคั่นด้วยอักขระคั่นเช่นลูกน้ำหรือไปป์ไลน์เป็นต้นในกรณีนี้เราใช้ dlm ตัวเลือกใน infile คำให้การ.
ตัวอย่าง
ในตัวอย่างด้านล่างเราอ่านไฟล์ข้อมูลชื่อ emp.csv จากสภาพแวดล้อมภายในเครื่อง
data TEMP;
infile
'/folders/myfolders/sasuser.v94/TutorialsPoint/emp.csv' dlm=",";
input empID empName $ Salary Dept $ DOJ date9. ;
format DOJ date9.;
run;
PROC PRINT DATA = TEMP;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้
การอ่านข้อมูล Excel
SAS สามารถอ่านไฟล์ excel ได้โดยตรงโดยใช้สิ่งอำนวยความสะดวกในการนำเข้า ดังที่เห็นในบทชุดข้อมูล SAS สามารถจัดการไฟล์ได้หลากหลายประเภทรวมถึง MS excel สมมติว่าไฟล์ emp.xls พร้อมใช้งานในระบบ SAS
ตัวอย่าง
FILENAME REFFILE
"/folders/myfolders/TutorialsPoint/emp.xls"
TERMSTR = CR;
PROC IMPORT DATAFILE = REFFILE
DBMS = XLS
OUT = WORK.IMPORT;
GETNAMES = YES;
RUN;
PROC PRINT DATA = WORK.IMPORT RUN;โค้ดด้านบนอ่านข้อมูลจากไฟล์ excel และให้ผลลัพธ์เหมือนกับไฟล์สองประเภทข้างต้น
การอ่านไฟล์ลำดับชั้น
ในไฟล์เหล่านี้ข้อมูลจะอยู่ในรูปแบบลำดับชั้น สำหรับการสังเกตที่ระบุมีบันทึกส่วนหัวด้านล่างซึ่งมีการกล่าวถึงบันทึกรายละเอียดมากมาย จำนวนบันทึกรายละเอียดอาจแตกต่างกันไปในแต่ละข้อสังเกต ด้านล่างนี้คือภาพประกอบของไฟล์ลำดับชั้น
ในไฟล์ด้านล่างมีรายละเอียดของพนักงานแต่ละคนในแต่ละแผนก ระเบียนแรกคือระเบียนส่วนหัวที่กล่าวถึงแผนกและระเบียนถัดไปไม่กี่ระเบียนที่เริ่มต้นด้วย DTLS คือระเบียนรายละเอียด
DEPT:IT
DTLS:1:Rick:623
DTLS:3:Mike:611
DTLS:6:Tusar:578
DEPT:OPS
DTLS:7:Pranab:632
DTLS:2:Dan:452
DEPT:HR
DTLS:4:Ryan:487
DTLS:2:Siyona:452ตัวอย่าง
ในการอ่านไฟล์ลำดับชั้นเราใช้โค้ดด้านล่างซึ่งเราระบุเร็กคอร์ดส่วนหัวด้วยคำสั่ง IF และใช้ do loop เพื่อประมวลผลบันทึกรายละเอียด
data employees(drop = Type);
length Type $ 3 Department
empID $ 3 empName $ 10 Empsal 3 ;
retain Department;
infile
'/folders/myfolders/TutorialsPoint/empdtls.txt' dlm = ':';
input Type $ @; if Type = 'DEP' then input Department $;
else do;
input empID empName $ Empsal ;
output;
end;
run;
PROC PRINT DATA = employees;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้

เช่นเดียวกับการอ่านชุดข้อมูล SAS สามารถเขียนชุดข้อมูลในรูปแบบต่างๆ สามารถเขียนข้อมูลจากไฟล์ SAS ไปยังไฟล์ข้อความปกติไฟล์เหล่านี้สามารถอ่านได้โดยโปรแกรมซอฟต์แวร์อื่น ๆ SAS ใช้PROC EXPORT เพื่อเขียนชุดข้อมูล
กระบวนการส่งออก
เป็นโพรซีเดอร์ SAS inbuilt ที่ใช้ในการเอ็กซ์พอร์ตชุดข้อมูล SAS สำหรับการเขียนข้อมูลลงในไฟล์ในรูปแบบต่างๆ
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการเขียนโพรซีเดอร์ใน SAS คือ -
PROC EXPORT
DATA = libref.SAS data-set (SAS data-set-options)
OUTFILE = "filename"
DBMS = identifier LABEL(REPLACE);ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
SAS data-setคือชื่อชุดข้อมูลที่กำลังส่งออก SAS สามารถแชร์ชุดข้อมูลจากสภาพแวดล้อมกับแอปพลิเคชันอื่น ๆ โดยการสร้างไฟล์ที่ระบบปฏิบัติการต่างๆสามารถอ่านได้ ใช้ฟังก์ชัน EXPORT ในตัวเพื่อออกไฟล์ชุดข้อมูลในรูปแบบต่างๆ ในบทนี้เราจะเห็นการเขียนชุดข้อมูล SAS โดยใช้proc export พร้อมกับตัวเลือก dlm และ dbms.
SAS data-set-options ใช้เพื่อระบุชุดย่อยของคอลัมน์ที่จะส่งออก
filename คือชื่อของไฟล์ที่ข้อมูลถูกเขียนลงไป
identifier ใช้เพื่อกล่าวถึงตัวคั่นที่จะเขียนลงในไฟล์
LABEL ตัวเลือกใช้เพื่อระบุชื่อของตัวแปรที่เขียนลงในไฟล์
ตัวอย่าง
เราจะใช้ชุดข้อมูล SAS ที่มีชื่อรถยนต์ที่มีอยู่ในไลบรารี SASHELP เราส่งออกเป็นไฟล์ข้อความที่คั่นด้วยช่องว่างพร้อมรหัสดังที่แสดงในโปรแกรมต่อไปนี้
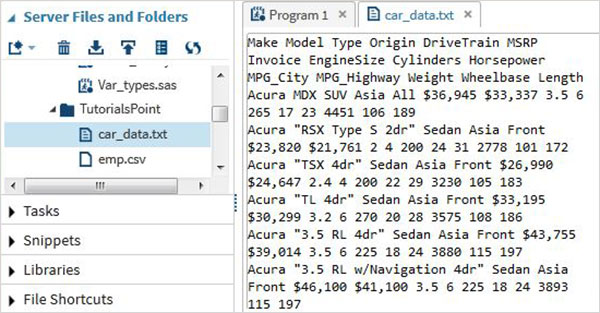
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_data.txt'
dbms = dlm;
delimiter = ' ';
run;ในการรันโค้ดด้านบนเราจะเห็นผลลัพธ์เป็นไฟล์ข้อความและคลิกขวาที่มันเพื่อดูเนื้อหาดังที่แสดงด้านล่าง
การเขียนไฟล์ CSV
ในการเขียนไฟล์ที่คั่นด้วยจุลภาคเราสามารถใช้ตัวเลือก dlm ที่มีค่า "csv" รหัสต่อไปนี้เขียนไฟล์ car_data.csv
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_data.csv'
dbms = csv;
run;ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ด้านล่าง

การเขียนไฟล์ที่คั่นด้วยแท็บ
ในการเขียนไฟล์ที่คั่นด้วยแท็บเราสามารถใช้ไฟล์ dlmตัวเลือกที่มีค่า "แท็บ" รหัสต่อไปนี้เขียนไฟล์car_tab.txt.
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_tab.txt'
dbms = csv;
run;ข้อมูลสามารถเขียนเป็นไฟล์ HTML ซึ่งเราจะเห็นภายใต้บทระบบการส่งออก
ชุดข้อมูล SAS หลายชุดสามารถเชื่อมต่อกันเพื่อให้ชุดข้อมูลเดียวโดยใช้ SETคำให้การ. จำนวนการสังเกตทั้งหมดในชุดข้อมูลที่ต่อกันคือผลรวมของจำนวนการสังเกตในชุดข้อมูลดั้งเดิม ลำดับของการสังเกตเป็นลำดับ การสังเกตทั้งหมดจากชุดข้อมูลแรกตามด้วยการสังเกตทั้งหมดจากชุดข้อมูลที่สองและอื่น ๆ
ตามหลักการแล้วชุดข้อมูลการรวมทั้งหมดมีตัวแปรเหมือนกัน แต่ในกรณีที่มีจำนวนตัวแปรต่างกันตัวแปรทั้งหมดจะปรากฏขึ้นพร้อมกับค่าที่ขาดหายไปสำหรับชุดข้อมูลที่เล็กกว่า
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับคำสั่ง SET ใน SAS คือ -
SET data-set 1 data-set 2 data-set 3.....;ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
data-set1,data-set2 คือชื่อชุดข้อมูลที่เขียนทีละชื่อ
ตัวอย่าง
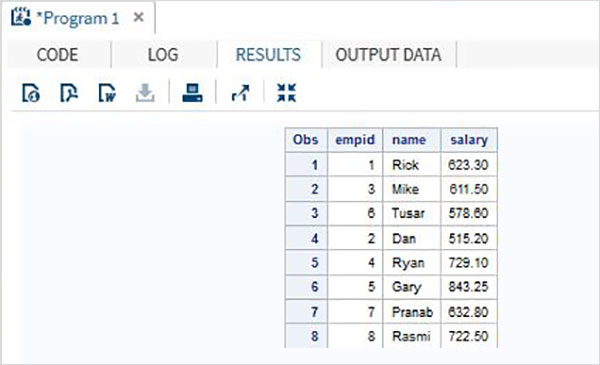
พิจารณาข้อมูลพนักงานขององค์กรซึ่งมีอยู่ในชุดข้อมูลที่แตกต่างกันสองชุดชุดหนึ่งสำหรับแผนกไอทีและอีกชุดหนึ่งสำหรับแผนกที่ไม่ใช่ไอที เพื่อให้ได้รายละเอียดที่สมบูรณ์ของพนักงานทั้งหมดเราเชื่อมต่อทั้งสองชุดข้อมูลโดยใช้คำสั่ง SET ที่แสดงไว้ด้านล่าง
DATA ITDEPT;
INPUT empid name $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้
สถานการณ์
เมื่อเรามีหลายรูปแบบในชุดข้อมูลสำหรับการเรียงต่อกันผลลัพธ์ของตัวแปรอาจแตกต่างกันได้ แต่จำนวนการสังเกตทั้งหมดในชุดข้อมูลที่เรียงต่อกันจะเป็นผลรวมของการสังเกตในแต่ละชุดข้อมูลเสมอ เราจะพิจารณาสถานการณ์ต่างๆด้านล่างเกี่ยวกับรูปแบบนี้
จำนวนตัวแปรที่แตกต่างกัน
หากชุดข้อมูลเดิมชุดหนึ่งมีจำนวนตัวแปรมากกว่าอีกชุดข้อมูลจะยังคงรวมกัน แต่ในชุดข้อมูลที่มีขนาดเล็กกว่าชุดข้อมูลเหล่านั้นจะปรากฏว่าขาดหายไป
ตัวอย่าง
ในตัวอย่างด้านล่างชุดข้อมูลแรกมีตัวแปรพิเศษชื่อ DOJ ในผลลัพธ์ค่า DOJ สำหรับชุดข้อมูลที่สองจะปรากฏว่าหายไป
DATA ITDEPT;
INPUT empid name $ salary DOJ date9. ;
DATALINES;
1 Rick 623.3 02APR2001
3 Mike 611.5 21OCT2000
6 Tusar 578.6 01MAR2009
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้

ชื่อตัวแปรที่แตกต่างกัน
ในสถานการณ์นี้ชุดข้อมูลมีจำนวนตัวแปรเท่ากัน แต่ชื่อตัวแปรแตกต่างกัน ในกรณีนั้นการเรียงต่อกันตามปกติจะสร้างตัวแปรทั้งหมดในชุดผลลัพธ์และให้ผลลัพธ์ที่ขาดหายไปสำหรับตัวแปรทั้งสองซึ่งแตกต่างกัน แม้ว่าเราจะไม่สามารถเปลี่ยนชื่อตัวแปรในชุดข้อมูลดั้งเดิมได้ แต่เราสามารถใช้ฟังก์ชัน RENAME ในชุดข้อมูลที่ต่อกันที่เราสร้างขึ้นได้ ซึ่งจะให้ผลลัพธ์เช่นเดียวกับการเรียงต่อกันตามปกติ แต่แน่นอนว่ามีชื่อตัวแปรใหม่แทนชื่อตัวแปรที่แตกต่างกันสองชื่อที่มีอยู่ในชุดข้อมูลเดิม
ตัวอย่าง
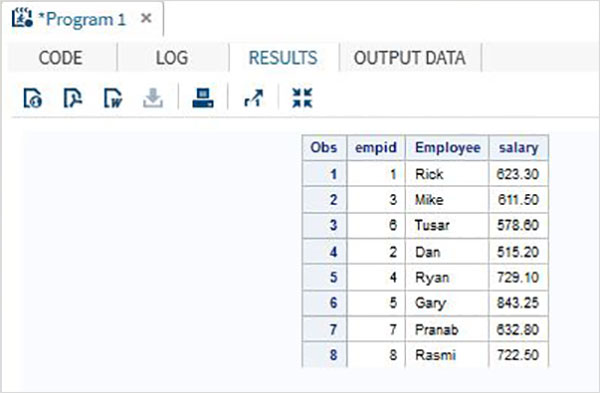
ในชุดข้อมูลตัวอย่างด้านล่าง ITDEPT มีชื่อตัวแปร ename ในขณะที่ชุดข้อมูล NON_ITDEPT มีชื่อตัวแปร empname.แต่ตัวแปรทั้งสองนี้แสดงถึงประเภทเดียวกัน (อักขระ) เราใช้RENAME ฟังก์ชันในคำสั่ง SET ดังแสดงด้านล่าง
DATA ITDEPT;
INPUT empid ename $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid empname $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT(RENAME =(ename = Employee) ) NON_ITDEPT(RENAME =(empname = Employee) );
RUN;
PROC PRINT DATA = All_Dept;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้
ความยาวตัวแปรต่างกัน
หากความยาวตัวแปรในชุดข้อมูลทั้งสองแตกต่างจากชุดข้อมูลที่ต่อกันจะมีค่าที่ข้อมูลบางส่วนถูกตัดทอนสำหรับตัวแปรที่มีความยาวน้อยกว่า จะเกิดขึ้นหากชุดข้อมูลแรกมีความยาวน้อยกว่า ในการแก้ปัญหานี้เราใช้ความยาวที่สูงขึ้นกับชุดข้อมูลทั้งสองดังที่แสดงด้านล่าง
ตัวอย่าง
ในตัวอย่างด้านล่างตัวแปร enameมีความยาว 5 ในชุดข้อมูลแรกและ 7 ในชุดที่สอง เมื่อเชื่อมต่อกันเราใช้คำสั่ง LENGTH ในชุดข้อมูลที่ต่อกันเพื่อตั้งค่าความยาวเคลือบเป็น 7
DATA ITDEPT;
INPUT empid 1-2 ename $ 3-7 salary 8-14 ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid 1-2 ename $ 3-9 salary 10-16 ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; LENGTH ename $ 7 ;
SET ITDEPT NON_ITDEPT ;
RUN;
PROC PRINT DATA = All_Dept;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้
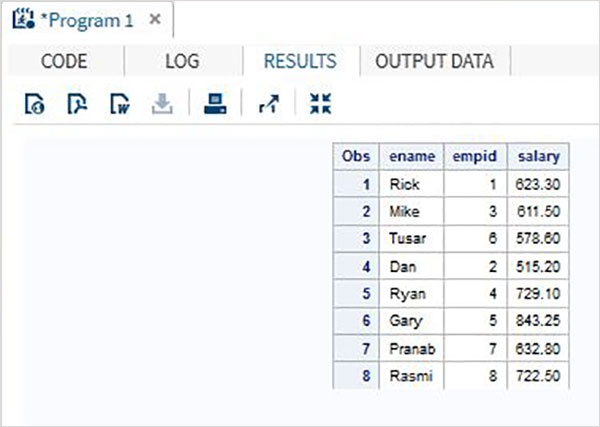
ชุดข้อมูล SAS หลายชุดสามารถรวมเข้าด้วยกันโดยยึดตามตัวแปรทั่วไปเฉพาะเพื่อให้เป็นชุดข้อมูลเดียว ซึ่งทำได้โดยใช้ไฟล์MERGE คำสั่งและ BYคำให้การ. จำนวนการสังเกตทั้งหมดในชุดข้อมูลที่ผสานมักจะน้อยกว่าผลรวมของจำนวนการสังเกตในชุดข้อมูลเดิม เป็นเพราะตัวแปรในรูปแบบข้อมูลทั้งสองชุดถูกรวมเป็นระเบียนเดียวตามเมื่อมีค่าของตัวแปรร่วมตรงกัน
มีข้อกำหนดเบื้องต้นสองประการสำหรับการรวมชุดข้อมูลที่ระบุด้านล่าง -
- ชุดข้อมูลอินพุตต้องมีตัวแปรร่วมอย่างน้อยหนึ่งตัวเพื่อรวมเข้าด้วยกัน
- ชุดข้อมูลอินพุตต้องเรียงตามตัวแปรทั่วไปที่จะใช้ในการผสาน
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับคำสั่ง MERGE และ BY ใน SAS คือ -
MERGE Data-Set 1 Data-Set 2
BY Common Variableต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
Data-set1,Data-set2 คือชื่อชุดข้อมูลที่เขียนทีละชื่อ
Common Variable คือตัวแปรตามค่าที่ตรงกันซึ่งชุดข้อมูลจะถูกรวมเข้าด้วยกัน
การรวมข้อมูล
ให้เราเข้าใจการรวมข้อมูลด้วยความช่วยเหลือของตัวอย่าง
ตัวอย่าง
พิจารณาชุดข้อมูล SAS สองชุดชุดหนึ่งมีรหัสพนักงานพร้อมชื่อและเงินเดือนและอีกชุดที่มีรหัสพนักงานพร้อมรหัสพนักงานและแผนก ในกรณีนี้เพื่อให้ได้ข้อมูลที่สมบูรณ์สำหรับพนักงานแต่ละคนเราสามารถรวมชุดข้อมูลทั้งสองนี้เข้าด้วยกัน ชุดข้อมูลสุดท้ายจะยังคงมีการสังเกตหนึ่งครั้งต่อพนักงาน แต่จะมีทั้งตัวแปรเงินเดือนและแผนก
# Data set 1
ID NAME SALARY
1 Rick 623.3
2 Dan 515.2
3 Mike 611.5
4 Ryan 729.1
5 Gary 843.25
6 Tusar 578.6
7 Pranab 632.8
8 Rasmi 722.5
# Data set 2
ID DEPT
1 IT
2 OPS
3 IT
4 HR
5 FIN
6 IT
7 OPS
8 FIN
# Merged data set
ID NAME SALARY DEPT
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FINผลลัพธ์ข้างต้นทำได้โดยใช้รหัสต่อไปนี้ซึ่งใช้ตัวแปรทั่วไป (ID) ในคำสั่ง BY โปรดทราบว่าการสังเกตในทั้งสองชุดข้อมูลได้รับการจัดเรียงในคอลัมน์ ID แล้ว
DATA SALARY;
INPUT empid name $ salary ; DATALINES; 1 Rick 623.3 2 Dan 515.2 3 Mike 611.5 4 Ryan 729.1 5 Gary 843.25 6 Tusar 578.6 7 Pranab 632.8 8 Rasmi 722.5 ; RUN; DATA DEPT; INPUT empid dEPT $ ;
DATALINES;
1 IT
2 OPS
3 IT
4 HR
5 FIN
6 IT
7 OPS
8 FIN
;
RUN;
DATA All_details;
MERGE SALARY DEPT;
BY (empid);
RUN;
PROC PRINT DATA = All_details;
RUN;ไม่มีค่าในคอลัมน์ที่ตรงกัน
อาจมีบางกรณีที่ค่าบางค่าของตัวแปรร่วมไม่ตรงกันระหว่างชุดข้อมูล ในกรณีเช่นนี้ชุดข้อมูลยังคงรวมเข้าด้วยกัน แต่ให้ค่าที่ขาดหายไปในผลลัพธ์
ตัวอย่าง
ID NAME SALARY DEPT
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 . . IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 .
7 Pranab 632.8 OPS
8 Rasmi 722.5 FINการรวมเฉพาะการจับคู่
เพื่อหลีกเลี่ยงค่าที่ขาดหายไปในผลลัพธ์เราสามารถพิจารณาเก็บเฉพาะการสังเกตที่มีค่าที่ตรงกันสำหรับตัวแปรทั่วไป ที่ทำได้โดยใช้INคำให้การ. คำสั่งผสานของโปรแกรม SAS จำเป็นต้องมีการเปลี่ยนแปลง
ตัวอย่าง
ในตัวอย่างด้านล่างไฟล์ IN= value เก็บเฉพาะการสังเกตโดยที่ค่าจากทั้งสองชุดข้อมูล SALARY และ DEPT การแข่งขัน.
DATA All_details;
MERGE SALARY(IN = a) DEPT(IN = b);
BY (empid);
IF a = 1 and b = 1;
RUN;
PROC PRINT DATA = All_details;
RUN;เมื่อดำเนินการโปรแกรม SAS ข้างต้นพร้อมกับส่วนที่เปลี่ยนแปลงข้างต้นเราจะได้ผลลัพธ์ดังต่อไปนี้
1 Rick 623.3 IT
2 Dan 515.2 OPS
4 Ryan 729.1 HR
5 Gary 843.25 FIN
7 Pranab 632.8 OPS
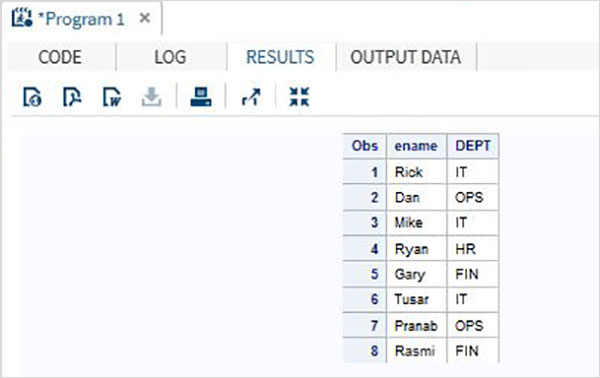
8 Rasmi 722.5 FINการย่อยชุดข้อมูล SAS หมายถึงการแยกส่วนของชุดข้อมูลโดยการเลือกตัวแปรจำนวนน้อยลงหรือจำนวนการสังเกตน้อยลงหรือทั้งสองอย่าง ในขณะที่การย่อยตัวแปรทำได้โดยใช้KEEP และ DROP คำสั่งการตั้งค่าย่อยของการสังเกตทำได้โดยใช้ DELETE คำให้การ.
นอกจากนี้ข้อมูลที่เป็นผลลัพธ์จากการดำเนินการย่อยจะถูกเก็บไว้ในชุดข้อมูลใหม่ซึ่งสามารถใช้สำหรับการวิเคราะห์เพิ่มเติมได้ การตั้งค่าย่อยส่วนใหญ่จะใช้เพื่อวัตถุประสงค์ในการวิเคราะห์ส่วนหนึ่งของชุดข้อมูลโดยไม่ใช้ตัวแปรหรือข้อสังเกตเหล่านั้นซึ่งอาจไม่เกี่ยวข้องกับการวิเคราะห์
ตัวแปรย่อย
ในวิธีนี้เราดึงตัวแปรเพียงไม่กี่ตัวจากชุดข้อมูลทั้งหมด
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับตัวแปรการตั้งค่าย่อยใน SAS คือ -
KEEP var1 var2 ... ;
DROP var1 var2 ... ;ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
var1 and var2 คือชื่อตัวแปรจากชุดข้อมูลที่ต้องเก็บไว้หรือทิ้ง
ตัวอย่าง
พิจารณาชุดข้อมูล SAS ด้านล่างที่มีรายละเอียดพนักงานขององค์กร หากเราสนใจเฉพาะการรับชื่อและค่าแผนกจากชุดข้อมูลเราสามารถใช้รหัสด้านล่างนี้ได้
DATA Employee;
INPUT empid ename $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
KEEP ename DEPT;
RUN;
PROC PRINT DATA = OnlyDept;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้
ผลลัพธ์เดียวกันสามารถหาได้จากการวางตัวแปรที่ไม่ต้องการ รหัสด้านล่างแสดงให้เห็นถึงสิ่งนี้
DATA Employee;
INPUT empid ename $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
DROP empid salary;
RUN;
PROC PRINT DATA = OnlyDept;
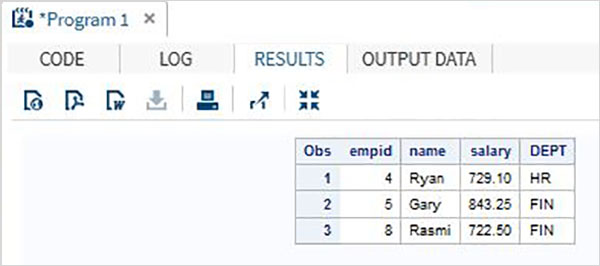
RUN;การตั้งค่าการสังเกต
ในวิธีนี้เราดึงการสังเกตเพียงเล็กน้อยจากชุดข้อมูลทั้งหมด
ไวยากรณ์
เราใช้ PROC FREQ ซึ่งติดตามการสังเกตที่เลือกสำหรับชุดข้อมูลใหม่
ไวยากรณ์สำหรับการสังเกตการตั้งค่าย่อยคือ -
IF Var Condition THEN DELETE ;ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
Var คือชื่อของตัวแปรตามค่าที่การสังเกตจะถูกลบโดยใช้เงื่อนไขที่ระบุ
ตัวอย่าง
พิจารณาชุดข้อมูล SAS ด้านล่างที่มีรายละเอียดพนักงานขององค์กร หากเราสนใจเฉพาะการรับข้อมูลสำหรับพนักงานที่มีเงินเดือนมากกว่า 700 ให้ใช้รหัสด้านล่าง
DATA Employee;
INPUT empid name $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
IF salary < 700 THEN DELETE;
RUN;
PROC PRINT DATA = OnlyDept;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้
บางครั้งเราต้องการแสดงข้อมูลที่วิเคราะห์ในรูปแบบที่แตกต่างจากรูปแบบที่มีอยู่แล้วในชุดข้อมูล ตัวอย่างเช่นเราต้องการเพิ่มเครื่องหมายดอลลาร์และทศนิยมสองตำแหน่งให้กับตัวแปรที่มีข้อมูลราคา หรือเราอาจต้องการแสดงตัวแปรข้อความทั้งหมดเป็นตัวพิมพ์ใหญ่ เราสามารถใช้FORMAT เพื่อใช้รูปแบบ SAS ที่สร้างขึ้นและ PROC FORMATคือการใช้รูปแบบที่ผู้ใช้กำหนด นอกจากนี้รูปแบบเดียวยังสามารถใช้กับตัวแปรหลายตัวได้
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการใช้รูปแบบ SAS ในตัวคือ -
format variable name format nameต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
variable name คือชื่อตัวแปรที่ใช้ในชุดข้อมูล
format name คือรูปแบบข้อมูลที่จะใช้กับตัวแปร
ตัวอย่าง
ลองพิจารณาชุดข้อมูล SAS ด้านล่างที่มีรายละเอียดพนักงานขององค์กร เราต้องการแสดงชื่อทั้งหมดเป็นตัวพิมพ์ใหญ่ formatstatement ถูกใช้เพื่อบรรลุเป้าหมายนี้
DATA Employee;
INPUT empid name $ salary DEPT $ ;
format name $upcase9. ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
PROC PRINT DATA = Employee;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้

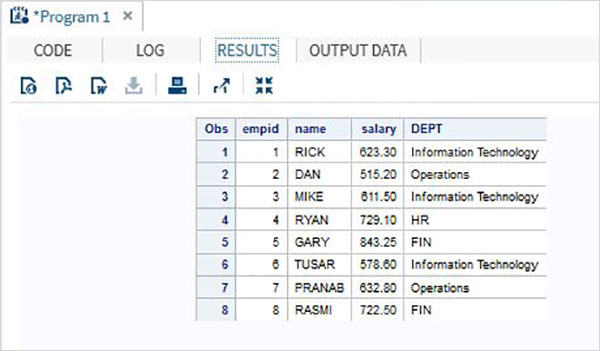
การใช้ PROC FORMAT
เรายังสามารถใช้ PROC FORMATเพื่อจัดรูปแบบข้อมูล ในตัวอย่างด้านล่างเรากำหนดค่าใหม่ให้กับตัวแปร DEPT ที่ขยายชื่อของแผนก
DATA Employee;
INPUT empid name $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; proc format; value $DEP 'IT' = 'Information Technology'
'OPS'= 'Operations' ;
RUN;
PROC PRINT DATA = Employee;
format name $upcase9. DEPT $DEP.;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้
SAS ให้การสนับสนุนอย่างกว้างขวางสำหรับฐานข้อมูลเชิงสัมพันธ์ยอดนิยมส่วนใหญ่โดยใช้แบบสอบถาม SQL ภายในโปรแกรม SAS ส่วนใหญ่ANSI SQLรองรับไวยากรณ์ ขั้นตอนPROC SQLใช้ในการประมวลผลคำสั่ง SQL โพรซีเดอร์นี้ไม่เพียง แต่ให้ผลลัพธ์ของคิวรี SQL เท่านั้น แต่ยังสามารถสร้างตารางและตัวแปร SAS ได้อีกด้วย ตัวอย่างของสถานการณ์ทั้งหมดเหล่านี้อธิบายไว้ด้านล่าง
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการใช้ PROC SQL ใน SAS คือ -
PROC SQL;
SELECT Columns
FROM TABLE
WHERE Columns
GROUP BY Columns
;
QUIT;ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
แบบสอบถาม SQL เขียนอยู่ใต้คำสั่ง PROC SQL ตามด้วยคำสั่ง QUIT
ด้านล่างเราจะดูว่าขั้นตอน SAS นี้สามารถใช้สำหรับไฟล์ CRUD (สร้างอ่านอัปเดตและลบ) การดำเนินการใน SQL
SQL สร้างการดำเนินการ
การใช้ SQL เราสามารถสร้างชุดข้อมูลใหม่ในรูปแบบข้อมูลดิบ ในตัวอย่างด้านล่างก่อนอื่นเราประกาศชุดข้อมูลชื่อ TEMP ที่มีข้อมูลดิบ จากนั้นเราเขียนแบบสอบถาม SQL เพื่อสร้างตารางจากตัวแปรของชุดข้อมูลนี้
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;
PROC SQL;
CREATE TABLE EMPLOYEES AS
SELECT * FROM TEMP;
QUIT;
PROC PRINT data = EMPLOYEES;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
การดำเนินการอ่าน SQL
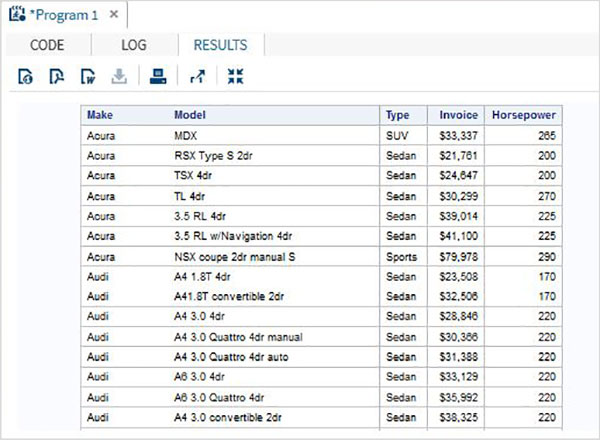
การดำเนินการอ่านใน SQL เกี่ยวข้องกับการเขียนแบบสอบถาม SQL SELECT เพื่ออ่านข้อมูลจากตาราง ในโปรแกรมด้านล่างจะค้นหาชุดข้อมูล SAS ชื่อ CARS ที่มีอยู่ในไลบรารี SASHELP แบบสอบถามดึงข้อมูลบางคอลัมน์ของชุดข้อมูล
PROC SQL;
SELECT make,model,type,invoice,horsepower
FROM
SASHELP.CARS
;
QUIT;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
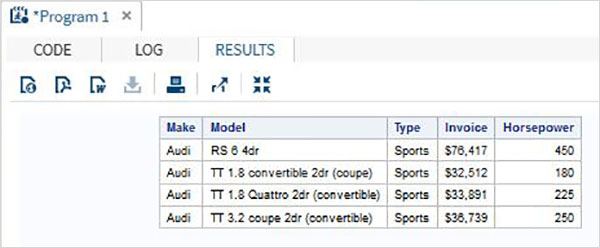
SQL SELECT พร้อม WHERE Clause
โปรแกรมด้านล่างจะค้นหาชุดข้อมูล CARS ด้วยไฟล์ whereอนุประโยค ผลลัพธ์ที่ได้เราได้รับเฉพาะการสังเกตที่ทำให้เป็น 'Audi' และพิมพ์เป็น 'Sports'
PROC SQL;
SELECT make,model,type,invoice,horsepower
FROM
SASHELP.CARS
Where make = 'Audi'
and Type = 'Sports'
;
QUIT;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
การทำงานของ SQL UPDATE
เราสามารถอัปเดตตาราง SAS โดยใช้คำสั่ง SQL Update ด้านล่างเราสร้างตารางใหม่ชื่อ EMPLOYEES2 ก่อนจากนั้นอัปเดตโดยใช้คำสั่ง SQL UPDATE
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;
PROC SQL;
CREATE TABLE EMPLOYEES2 AS
SELECT ID as EMPID,
Name as EMPNAME ,
SALARY as SALARY,
DEPARTMENT as DEPT,
SALARY*0.23 as COMMISION
FROM TEMP;
QUIT;
PROC SQL;
UPDATE EMPLOYEES2
SET SALARY = SALARY*1.25;
QUIT;
PROC PRINT data = EMPLOYEES2;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -

การดำเนินการลบ SQL
การดำเนินการลบใน SQL เกี่ยวข้องกับการลบค่าบางอย่างออกจากตารางโดยใช้คำสั่ง SQL DELETE เรายังคงใช้ข้อมูลจากตัวอย่างข้างต้นและลบแถวออกจากตารางที่เงินเดือนของพนักงานมากกว่า 900
PROC SQL;
DELETE FROM EMPLOYEES2
WHERE SALARY > 900;
QUIT;
PROC PRINT data = EMPLOYEES2;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -

ผลลัพธ์จากโปรแกรม SAS สามารถแปลงเป็นรูปแบบที่เป็นมิตรกับผู้ใช้มากขึ้นเช่น .html หรือ PDF. ซึ่งทำได้โดยใช้ไฟล์ ODSคำสั่งที่มีอยู่ใน SAS ODS ย่อมาจากoutput delivery system.ส่วนใหญ่จะใช้เพื่อจัดรูปแบบข้อมูลผลลัพธ์ของโปรแกรม SAS เป็นรายงานที่ดีซึ่งควรดูและทำความเข้าใจ นอกจากนี้ยังช่วยแบ่งปันผลผลิตกับแพลตฟอร์มอื่น ๆ และผลิตภัณฑ์ซอฟท์แวร์ นอกจากนี้ยังสามารถรวมผลลัพธ์จากคำสั่ง PROC หลายรายการในไฟล์เดียว
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการใช้คำสั่ง ODS ใน SAS คือ -
ODS outputtype
PATH path name
FILE = Filename and Path
STYLE = StyleName
;
PROC some proc
;
ODS outputtype CLOSE;ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
PATHแสดงถึงคำสั่งที่ใช้ในกรณีของเอาต์พุต HTML ในเอาต์พุตประเภทอื่น ๆ เรารวมพา ธ ไว้ในชื่อไฟล์
Style แสดงถึงหนึ่งในสไตล์ที่สร้างขึ้นที่มีอยู่ในสภาพแวดล้อม SAS
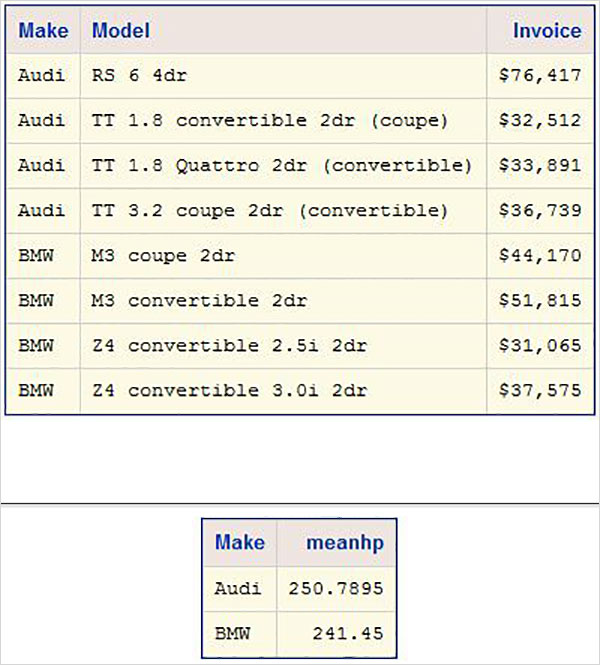
การสร้างเอาต์พุต HTML
เราสร้างเอาต์พุต HTML โดยใช้คำสั่ง ODS HTML ในตัวอย่างด้านล่างเราสร้างไฟล์ html ในเส้นทางที่เราต้องการ เราใช้สไตล์ที่มีอยู่ในไลบรารีสไตล์ เราสามารถเห็นไฟล์เอาต์พุตในพา ธ ที่กล่าวถึงและเราสามารถดาวน์โหลดเพื่อบันทึกในสภาพแวดล้อมที่แตกต่างจากสภาพแวดล้อม SAS โปรดทราบว่าเรามีคำสั่ง proc SQL สองคำสั่งและเอาต์พุตทั้งสองจะถูกบันทึกเป็นไฟล์เดียว
ODS HTML
PATH = '/folders/myfolders/sasuser.v94/TutorialsPoint/'
FILE = 'CARS2.html'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS HTML CLOSE;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
การสร้างเอาต์พุต PDF
ในตัวอย่างด้านล่างเราสร้างไฟล์ PDF ในเส้นทางที่เราต้องการ เราใช้สไตล์ที่มีอยู่ในไลบรารีสไตล์ เราสามารถเห็นไฟล์เอาต์พุตในพา ธ ที่กล่าวถึงและเราสามารถดาวน์โหลดเพื่อบันทึกในสภาพแวดล้อมที่แตกต่างจากสภาพแวดล้อม SAS โปรดทราบว่าเรามีคำสั่ง proc SQL สองคำสั่งและเอาต์พุตทั้งสองจะถูกบันทึกเป็นไฟล์เดียว
ODS PDF
FILE = '/folders/myfolders/sasuser.v94/TutorialsPoint/CARS2.pdf'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS PDF CLOSE;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
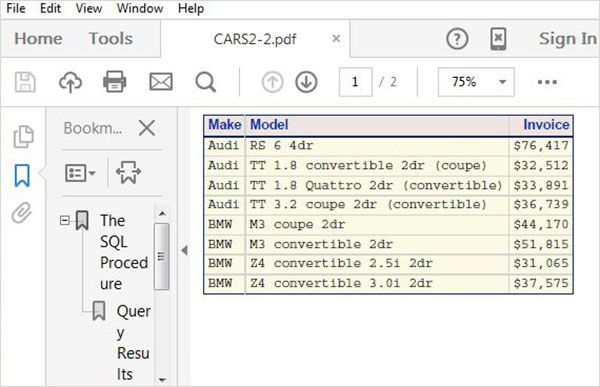
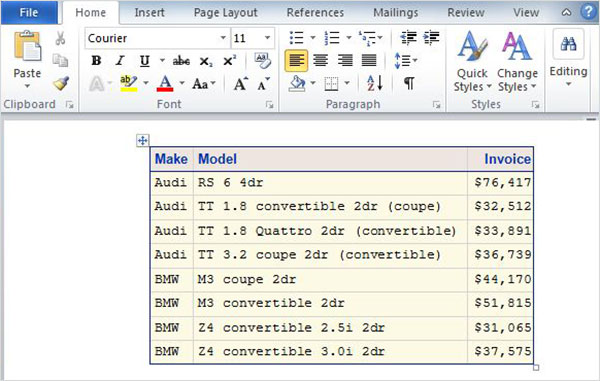
การสร้างผลลัพธ์ของ TRF (Word)
ในตัวอย่างด้านล่างเราสร้างไฟล์ RTF ในเส้นทางที่เราต้องการ เราใช้สไตล์ที่มีอยู่ในไลบรารีสไตล์ เราสามารถเห็นไฟล์เอาต์พุตในพา ธ ที่กล่าวถึงและเราสามารถดาวน์โหลดเพื่อบันทึกในสภาพแวดล้อมที่แตกต่างจากสภาพแวดล้อม SAS โปรดทราบว่าเรามีคำสั่ง proc SQL สองคำสั่งและเอาต์พุตทั้งสองจะถูกบันทึกเป็นไฟล์เดียว
ODS RTF
FILE = '/folders/myfolders/sasuser.v94/TutorialsPoint/CARS.rtf'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS rtf CLOSE;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
การจำลองเป็นเทคนิคการคำนวณที่ใช้การคำนวณซ้ำกับตัวอย่างสุ่มที่แตกต่างกันจำนวนมากเพื่อประมาณปริมาณทางสถิติ การใช้ SAS เราสามารถจำลองข้อมูลที่ซับซ้อนซึ่งมีคุณสมบัติทางสถิติที่ระบุไว้ในระบบจริง เราใช้ซอฟต์แวร์เพื่อสร้างแบบจำลองของระบบและสร้างข้อมูลที่เป็นตัวเลขซึ่งคุณสามารถใช้เพื่อความเข้าใจที่ดีขึ้นเกี่ยวกับพฤติกรรมของระบบในโลกแห่งความเป็นจริง ส่วนหนึ่งของศิลปะในการออกแบบโมเดลจำลองด้วยคอมพิวเตอร์คือการตัดสินใจว่าด้านใดของระบบในชีวิตจริงที่จำเป็นเพื่อรวมไว้ในแบบจำลองเพื่อให้ข้อมูลที่สร้างขึ้นโดยแบบจำลองสามารถใช้ในการตัดสินใจได้อย่างมีประสิทธิภาพ เนื่องจากความซับซ้อนนี้ SAS จึงมีส่วนประกอบซอฟต์แวร์เฉพาะสำหรับการจำลอง
ส่วนประกอบซอฟต์แวร์ SAS ที่ใช้ในการสร้างการจำลอง SAS เรียกว่า SAS Simulation Studio. อินเทอร์เฟซผู้ใช้แบบกราฟิกมีชุดเครื่องมือเต็มรูปแบบสำหรับการสร้างดำเนินการและวิเคราะห์ผลลัพธ์ของแบบจำลองเหตุการณ์แบบไม่ต่อเนื่อง
การแจกแจงทางสถิติประเภทต่างๆที่สามารถใช้การจำลอง SAS ได้แสดงอยู่ด้านล่าง
- จำลองข้อมูลจากการกระจายอย่างต่อเนื่อง
- จำลองข้อมูลจากการจัดจำหน่ายที่ไม่ถูกต้อง
- จำลองข้อมูลจากการผสมผสานของการจัดจำหน่าย
- จำลองข้อมูลจากการจัดจำหน่ายที่ซับซ้อน
- จำลองข้อมูลจากการกระจายข้อมูลที่หลากหลาย
- ประมาณการกระจายตัวอย่าง
- ประเมินการลงทะเบียนโดยประมาณ
ฮิสโตแกรมคือการแสดงข้อมูลแบบกราฟิกโดยใช้แถบที่มีความสูงต่างกัน เป็นการจัดกลุ่มตัวเลขต่างๆในชุดข้อมูลออกเป็นหลายช่วง นอกจากนี้ยังแสดงถึงการประมาณความน่าจะเป็นของการแจกแจงของตัวแปรต่อเนื่อง ใน SAS thePROC UNIVARIATE ใช้ในการสร้างฮิสโทแกรมด้วยตัวเลือกด้านล่าง
ไวยากรณ์
ไวยากรณ์พื้นฐานในการสร้างฮิสโตแกรมใน SAS คือ -
PROC UNIVARAITE DATA = DATASET;
HISTOGRAM variables;
RUN;DATASET คือชื่อของชุดข้อมูลที่ใช้
variables คือค่าที่ใช้ในการพล็อตฮิสโตแกรม
ฮิสโตแกรมอย่างง่าย
ฮิสโตแกรมอย่างง่ายถูกสร้างขึ้นโดยการระบุชื่อของตัวแปรและช่วงที่จะพิจารณาเพื่อจัดกลุ่มค่า
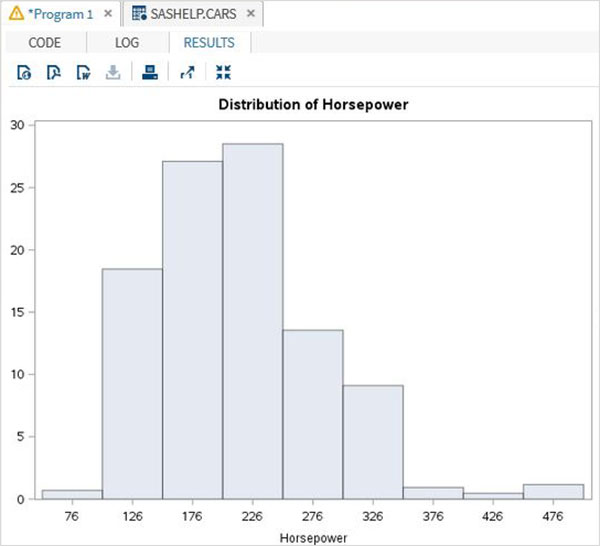
ตัวอย่าง
ในตัวอย่างด้านล่างเราพิจารณาค่าต่ำสุดและสูงสุดของแรงม้าตัวแปรและใช้ช่วง 50 ดังนั้นค่าจึงรวมกันเป็นกลุ่มในขั้นตอนที่ 50
proc univariate data = sashelp.cars;
histogram horsepower
/ midpoints = 176 to 350 by 50;
run;เมื่อเรารันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
ฮิสโตแกรมพร้อม Curve Fitting
เราสามารถใส่เส้นโค้งการกระจายบางส่วนลงในฮิสโตแกรมได้โดยใช้ตัวเลือกเพิ่มเติม
ตัวอย่าง
ในตัวอย่างด้านล่างเราพอดีกับเส้นโค้งการแจกแจงที่มีค่าเฉลี่ยและค่าเบี่ยงเบนมาตรฐานที่กล่าวถึงเป็น EST ตัวเลือกนี้ใช้และประมาณค่าพารามิเตอร์
proc univariate data = sashelp.cars noprint;
histogram horsepower
/
normal (
mu = est
sigma = est
color = blue
w = 2.5
)
barlabel = percent
midpoints = 70 to 550 by 50;
run;เมื่อเรารันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -

แผนภูมิแท่งแสดงข้อมูลเป็นแท่งสี่เหลี่ยมโดยมีความยาวของแท่งเป็นสัดส่วนกับค่าของตัวแปร SAS ใช้โพรซีเดอร์PROC SGPLOTเพื่อสร้างแผนภูมิแท่ง เราสามารถวาดแท่งทั้งแบบธรรมดาและแบบเรียงซ้อนในแผนภูมิแท่ง ในแผนภูมิแท่งแต่ละแท่งสามารถกำหนดสีที่แตกต่างกันได้
ไวยากรณ์
ไวยากรณ์พื้นฐานในการสร้างแผนภูมิแท่งใน SAS คือ -
PROC SGPLOT DATA = DATASET;
VBAR variables;
RUN;DATASET - คือชื่อของชุดข้อมูลที่ใช้
variables - คือค่าที่ใช้ในการพล็อตฮิสโตแกรม
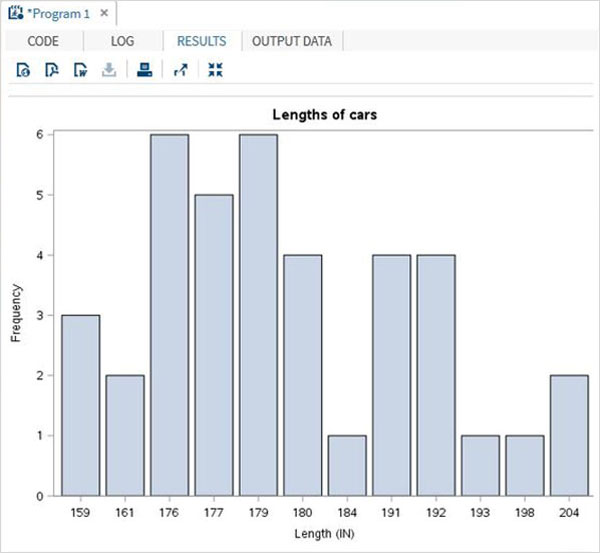
แผนภูมิแท่งอย่างง่าย
แผนภูมิแท่งอย่างง่ายคือแผนภูมิแท่งที่แสดงตัวแปรจากชุดข้อมูลเป็นแท่ง
ตัวอย่าง
สคริปต์ด้านล่างนี้จะสร้างแผนภูมิแท่งที่แสดงความยาวของรถยนต์เป็นแท่ง
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc SGPLOT data = work.cars1;
vbar length ;
title 'Lengths of cars';
run;
quit;เมื่อเรารันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
แผนภูมิแท่งแบบเรียงซ้อน
แผนภูมิแท่งแบบเรียงซ้อนคือแผนภูมิแท่งที่มีการคำนวณตัวแปรจากชุดข้อมูลเทียบกับตัวแปรอื่น
ตัวอย่าง
สคริปต์ด้านล่างนี้จะสร้างแผนภูมิแท่งแบบเรียงซ้อนซึ่งจะคำนวณความยาวของรถยนต์สำหรับรถแต่ละประเภท เราใช้ตัวเลือกกลุ่มเพื่อระบุตัวแปรที่สอง
proc SGPLOT data = work.cars1;
vbar length /group = type ;
title 'Lengths of Cars by Types';
run;
quit;เมื่อเรารันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
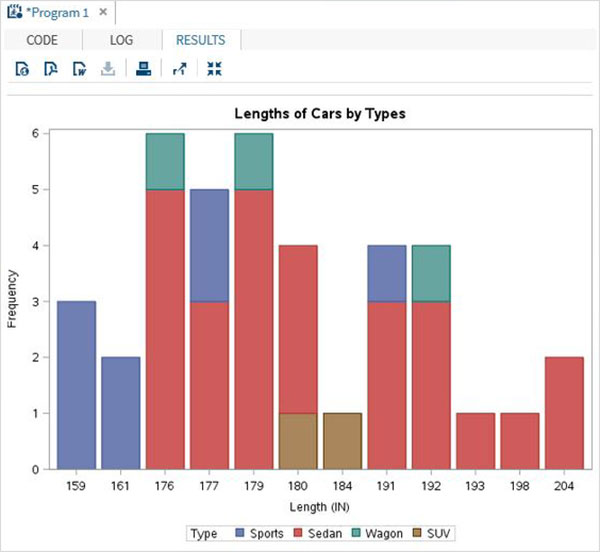
แผนภูมิแท่งแบบคลัสเตอร์
แผนภูมิแท่งแบบคลัสเตอร์ถูกสร้างขึ้นเพื่อแสดงให้เห็นว่าค่าของตัวแปรกระจายไปตามวัฒนธรรมอย่างไร
ตัวอย่าง
สคริปต์ด้านล่างนี้จะสร้างแผนภูมิแท่งแบบคลัสเตอร์ซึ่งความยาวของรถจะรวมกันเป็นกลุ่มรอบประเภทรถดังนั้นเราจึงเห็นแท่งสองแท่งที่อยู่ติดกันที่ความยาว 191 แท่งหนึ่งสำหรับรถประเภท 'Sedan' และอีกแท่งสำหรับรถประเภท 'Wagon' .
proc SGPLOT data = work.cars1;
vbar length /group = type GROUPDISPLAY = CLUSTER;
title 'Cluster of Cars by Types';
run;
quit;เมื่อเรารันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -

แผนภูมิวงกลมคือการแสดงค่าเป็นส่วนของวงกลมที่มีสีต่างกัน ชิ้นส่วนจะมีป้ายกำกับและตัวเลขที่ตรงกับแต่ละชิ้นจะแสดงในแผนภูมิด้วย
ใน SAS แผนภูมิวงกลมถูกสร้างขึ้นโดยใช้ PROC TEMPLATE ซึ่งใช้พารามิเตอร์เพื่อควบคุมเปอร์เซ็นต์ป้ายกำกับสีชื่อเรื่อง ฯลฯ
ไวยากรณ์
ไวยากรณ์พื้นฐานในการสร้างแผนภูมิวงกลมใน SAS คือ -
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = variable /
DATALABELLOCATION = OUTSIDE
CATEGORYDIRECTION = CLOCKWISE
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = ' ';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;variable คือค่าที่เราสร้างแผนภูมิวงกลม
แผนภูมิวงกลมอย่างง่าย
ในแผนภูมิวงกลมนี้เราใช้ตัวแปรเดียวในรูปแบบชุดข้อมูล แผนภูมิวงกลมถูกสร้างขึ้นด้วยค่าของชิ้นส่วนที่แสดงถึงเศษส่วนของจำนวนตัวแปรตามมูลค่ารวมของตัวแปร
ตัวอย่าง
ในตัวอย่างด้านล่างแต่ละชิ้นแสดงถึงเศษส่วนของประเภทรถยนต์จากจำนวนรถยนต์ทั้งหมด
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type /
DATALABELLOCATION = OUTSIDE
CATEGORYDIRECTION = CLOCKWISE
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;เมื่อเรารันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
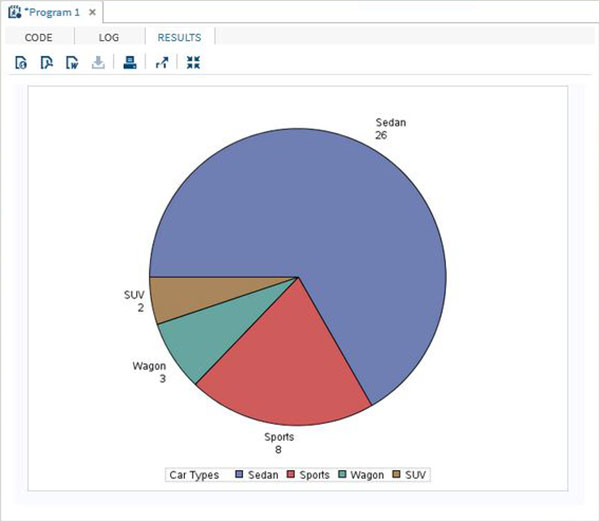
แผนภูมิวงกลมพร้อมป้ายกำกับข้อมูล
ในแผนภูมิวงกลมนี้เราแสดงทั้งค่าเศษส่วนและค่าเปอร์เซ็นต์สำหรับแต่ละชิ้น เรายังเปลี่ยนตำแหน่งของป้ายกำกับให้อยู่ในแผนภูมิ รูปแบบลักษณะที่ปรากฏของแผนภูมิถูกแก้ไขโดยใช้ตัวเลือก DATASKIN ใช้หนึ่งในสไตล์ที่สร้างขึ้นซึ่งมีอยู่ในสภาพแวดล้อม SAS
ตัวอย่าง
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type /
DATALABELLOCATION = INSIDE
DATALABELCONTENT = ALL
CATEGORYDIRECTION = CLOCKWISE
DATASKIN = SHEEN
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;เมื่อเรารันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
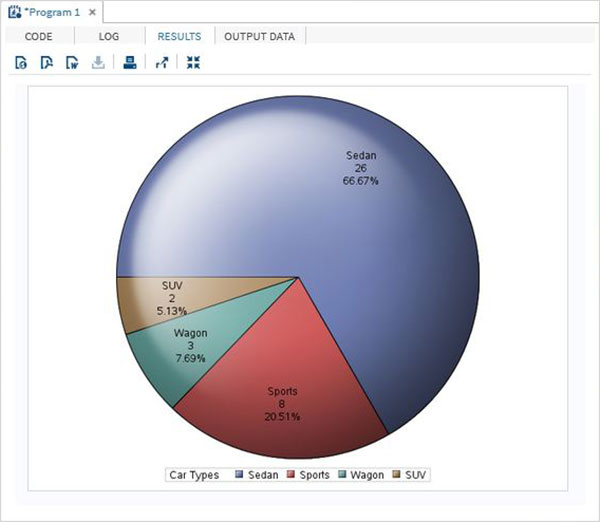
แผนภูมิวงกลมที่จัดกลุ่ม
ในแผนภูมิวงกลมนี้ค่าของตัวแปรที่แสดงในกราฟจะถูกจัดกลุ่มตามตัวแปรอื่นของชุดข้อมูลเดียวกัน แต่ละกลุ่มจะกลายเป็นหนึ่งวงกลมและแผนภูมิจะมีวงกลมศูนย์กลางมากเท่าจำนวนกลุ่มที่มี
ตัวอย่าง
ในตัวอย่างด้านล่างเราจัดกลุ่มแผนภูมิตามตัวแปรชื่อ "Make" เนื่องจากมีสองค่าให้เลือก ("Audi" และ "BMW") เราจึงได้วงกลมศูนย์กลางสองวงซึ่งแต่ละวงแสดงถึงประเภทรถในยี่ห้อของมันเอง
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type / Group = make
DATALABELLOCATION = INSIDE
DATALABELCONTENT = ALL
CATEGORYDIRECTION = CLOCKWISE
DATASKIN = SHEEN
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;เมื่อเรารันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
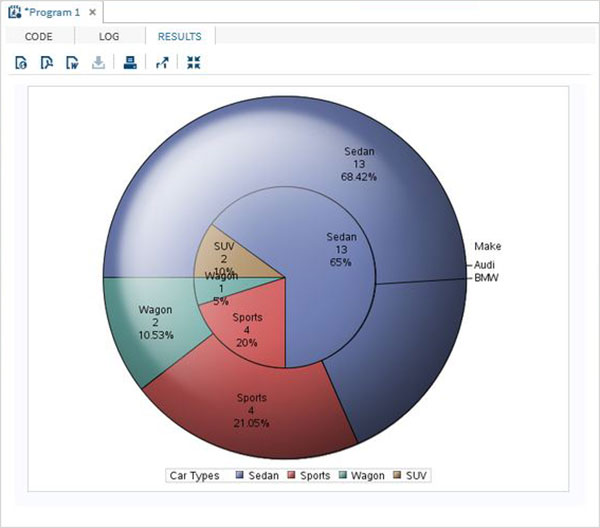
scatterplot คือกราฟประเภทหนึ่งที่ใช้ค่าจากสองตัวแปรที่ลงจุดในระนาบคาร์ทีเซียน โดยปกติจะใช้เพื่อหาความสัมพันธ์ระหว่างสองตัวแปร ใน SAS เราใช้PROC SGSCATTER เพื่อสร้าง scatterplots
โปรดทราบว่าเราสร้างชุดข้อมูลชื่อ CARS1 ในตัวอย่างแรกและใช้ชุดข้อมูลเดียวกันสำหรับชุดข้อมูลที่ตามมาทั้งหมด ชุดข้อมูลนี้ยังคงอยู่ในไลบรารีงานจนกระทั่งสิ้นสุดเซสชัน SAS
ไวยากรณ์
ไวยากรณ์พื้นฐานในการสร้าง scatter-plot ใน SAS คือ -
PROC sgscatter DATA = DATASET;
PLOT VARIABLE_1 * VARIABLE_2
/ datalabel = VARIABLE group = VARIABLE;
RUN;ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
DATASET คือชื่อของชุดข้อมูล
VARIABLE คือตัวแปรที่ใช้จากชุดข้อมูล
Scatterplot อย่างง่าย
ใน scatterplot อย่างง่ายเราเลือกตัวแปรสองตัวจากชุดข้อมูลและจัดกลุ่มตามตัวแปรที่สาม เรายังสามารถติดป้ายกำกับข้อมูล ผลลัพธ์แสดงให้เห็นว่าตัวแปรทั้งสองกระจัดกระจายอย่างไรในไฟล์Cartesian plane.
ตัวอย่าง
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
TITLE 'Scatterplot - Two Variables';
PROC sgscatter DATA = CARS1;
PLOT horsepower*Invoice
/ datalabel = make group = type grid;
title 'Horsepower vs. Invoice for car makers by types';
RUN;เมื่อเรารันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
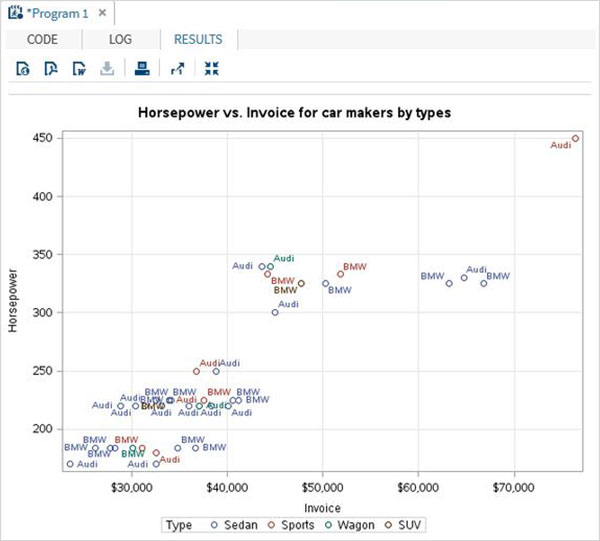
Scatterplot พร้อมการทำนาย
เราสามารถใช้พารามิเตอร์การประมาณเพื่อทำนายความแข็งแรงของความสัมพันธ์ระหว่างกันโดยการวาดวงรีรอบ ๆ ค่า เราใช้ตัวเลือกเพิ่มเติมในขั้นตอนเพื่อวาดวงรีดังที่แสดงด้านล่าง
ตัวอย่าง
proc sgscatter data = cars1;
compare y = Invoice x = (horsepower length)
/ group = type ellipse =(alpha = 0.05 type = predicted);
title
'Average Invoice vs. horsepower for cars by length';
title2
'-- with 95% prediction ellipse --'
;
format
Invoice dollar6.0;
run;เมื่อเรารันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -

กระจายเมทริกซ์
นอกจากนี้เรายังสามารถมี scatterplot ที่เกี่ยวข้องกับตัวแปรมากกว่าสองตัวแปรโดยการจัดกลุ่มให้เป็นคู่ ในตัวอย่างด้านล่างเราพิจารณาตัวแปรสามตัวและวาดเมทริกซ์พล็อตกระจาย เราได้เมทริกซ์ผลลัพธ์ 3 คู่
ตัวอย่าง
PROC sgscatter DATA = CARS1;
matrix horsepower invoice length
/ group = type;
title 'Horsepower vs. Invoice vs. Length for car makers by types';
RUN;เมื่อเรารันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
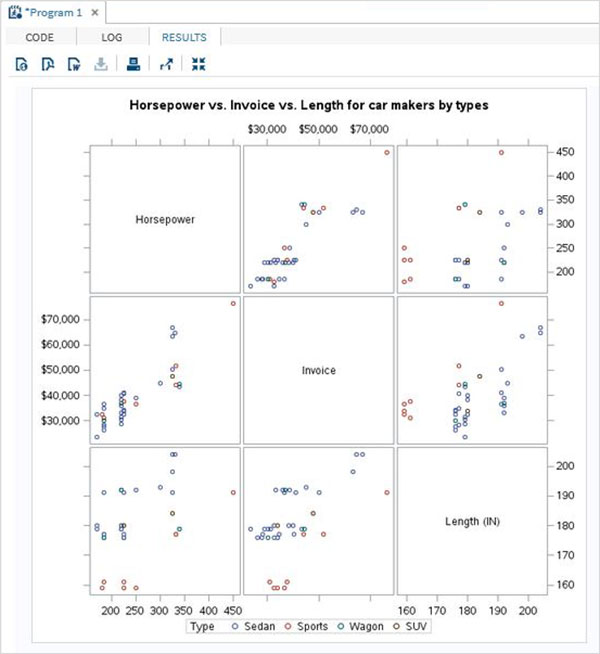
Boxplot คือการแสดงกลุ่มข้อมูลตัวเลขแบบกราฟิกผ่านควอไทล์ พล็อตกล่องอาจมีเส้นที่ยื่นออกมาในแนวตั้งจากกล่อง (หนวด) ซึ่งแสดงถึงความแปรปรวนภายนอกควอไทล์บนและล่าง ด้านล่างและด้านบนของกล่องจะเป็นควอร์ไทล์ที่หนึ่งและสามเสมอและวงดนตรีในกล่องจะเป็นควอไทล์ที่สองเสมอ (ค่ามัธยฐาน) ใน SAS จะมีการสร้าง Boxplot อย่างง่ายโดยใช้ไฟล์PROC SGPLOT และกล่องพล็อตแบบแผงถูกสร้างขึ้นโดยใช้ PROC SGPANEL.
โปรดทราบว่าเราสร้างชุดข้อมูลชื่อ CARS1 ในตัวอย่างแรกและใช้ชุดข้อมูลเดียวกันสำหรับชุดข้อมูลที่ตามมาทั้งหมด ชุดข้อมูลนี้ยังคงอยู่ในไลบรารีงานจนกระทั่งสิ้นสุดเซสชัน SAS
ไวยากรณ์
ไวยากรณ์พื้นฐานในการสร้าง boxplot ใน SAS คือ -
PROC SGPLOT DATA = DATASET;
VBOX VARIABLE / category = VARIABLE;
RUN;
PROC SGPANEL DATA = DATASET;;
PANELBY VARIABLE;
VBOX VARIABLE> / category = VARIABLE;
RUN;DATASET - คือชื่อของชุดข้อมูลที่ใช้
VARIABLE - คือค่าที่ใช้ในการพล็อต Boxplot
Boxplot ง่ายๆ
ใน Boxplot ธรรมดาเราเลือกตัวแปรหนึ่งตัวจากชุดข้อมูลและอีกตัวแปรหนึ่งเพื่อสร้างหมวดหมู่ ค่าของตัวแปรแรกจะถูกจัดประเภทเป็นกลุ่มจำนวนมากเท่ากับจำนวนค่าที่แตกต่างกันในตัวแปรที่สอง
ตัวอย่าง
ในตัวอย่างด้านล่างเราเลือกแรงม้าตัวแปรเป็นตัวแปรแรกและพิมพ์เป็นตัวแปรหมวดหมู่ ดังนั้นเราจึงได้บ็อกซ์พล็อตสำหรับการกระจายค่าแรงม้าสำหรับรถแต่ละประเภท
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
PROC SGPLOT DATA = CARS1;
VBOX horsepower
/ category = type;
title 'Horsepower of cars by types';
RUN;เมื่อเรารันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
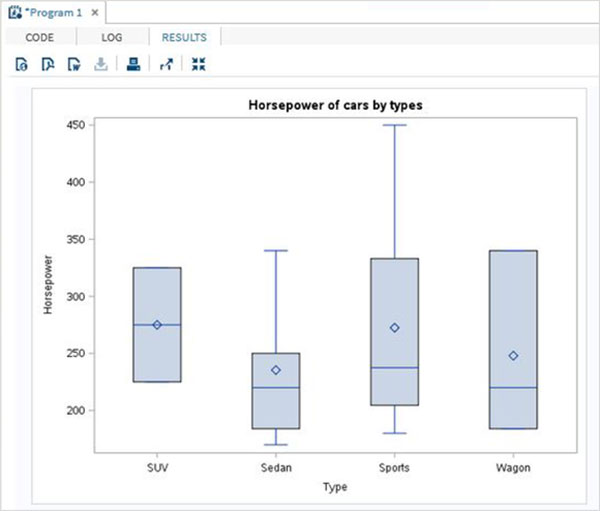
Boxplot ในแผงแนวตั้ง
เราสามารถแบ่ง Boxplots ของตัวแปรออกเป็นแผงแนวตั้ง (คอลัมน์) ได้มากมาย แต่ละแผงมีบ็อกซ์พล็อตสำหรับตัวแปรเชิงหมวดหมู่ทั้งหมด แต่บ็อกซ์พล็อตจะถูกจัดกลุ่มเพิ่มเติมโดยใช้ตัวแปรที่สามอีกตัวซึ่งแบ่งกราฟออกเป็นแผงต่างๆ
ตัวอย่าง
ในตัวอย่างด้านล่างเราได้จัดวางกราฟโดยใช้ตัวแปร 'make' เนื่องจากมีค่า 'make' สองค่าที่แตกต่างกันดังนั้นเราจึงได้แผงแนวตั้งสองแผง
PROC SGPANEL DATA = CARS1;
PANELBY MAKE;
VBOX horsepower / category = type;
title 'Horsepower of cars by types';
RUN;เมื่อเรารันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
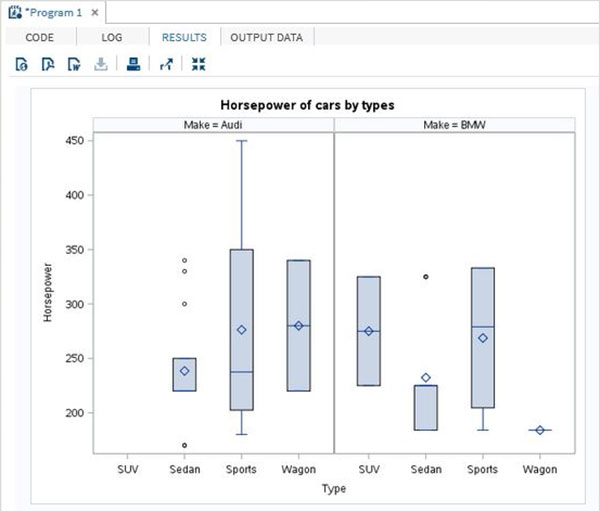
Boxplot ในแผงแนวนอน
เราสามารถแบ่ง Boxplots ของตัวแปรออกเป็นแผงแนวนอน (แถว) ได้มากมาย แต่ละแผงมีบ็อกซ์พล็อตสำหรับตัวแปรเชิงหมวดหมู่ทั้งหมด แต่บ็อกซ์พล็อตจะถูกจัดกลุ่มเพิ่มเติมโดยใช้ตัวแปรที่สามอีกตัวซึ่งแบ่งกราฟออกเป็นแผงต่างๆ ในตัวอย่างด้านล่างเราได้จัดวางกราฟโดยใช้ตัวแปร 'make' เนื่องจากมีค่า 'make' สองค่าที่แตกต่างกันดังนั้นเราจึงได้แผงแนวนอนสองแผง
PROC SGPANEL DATA = CARS1;
PANELBY MAKE / columns = 1 novarname;
VBOX horsepower / category = type;
title 'Horsepower of cars by types';
RUN;เมื่อเรารันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
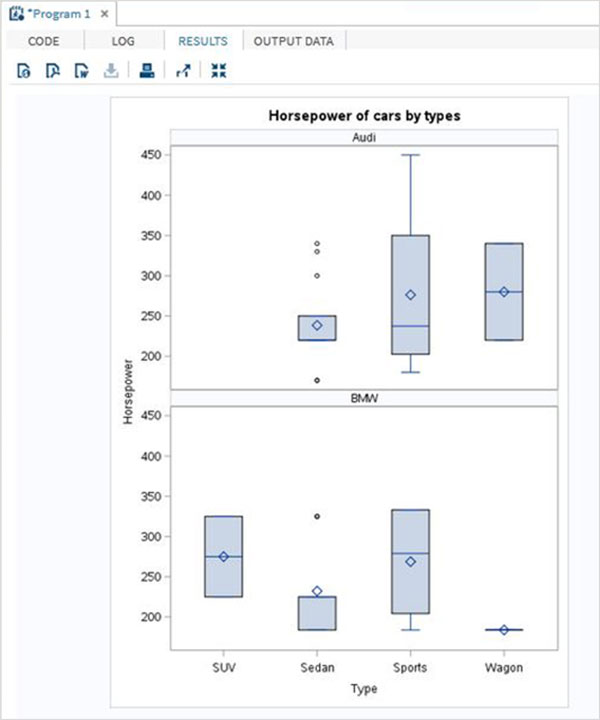
ค่าเฉลี่ยเลขคณิตคือค่าที่ได้จากการหาค่าผลรวมของตัวแปรตัวเลขแล้วหารผลรวมด้วยจำนวนตัวแปร เรียกอีกอย่างว่าค่าเฉลี่ย ใน SAS ค่าเฉลี่ยเลขคณิตคำนวณโดยใช้PROC MEANS. การใช้ขั้นตอน SAS นี้เราสามารถค้นหาค่าเฉลี่ยของตัวแปรทั้งหมดหรือตัวแปรบางตัวของชุดข้อมูล นอกจากนี้เรายังสามารถสร้างกลุ่มและค้นหาค่าเฉลี่ยของตัวแปรของค่าเฉพาะสำหรับกลุ่มนั้น ๆ
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการคำนวณค่าเฉลี่ยเลขคณิตใน SAS คือ -
PROC MEANS DATA = DATASET;
CLASS Variables ;
VAR Variables;ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
DATASET - คือชื่อของชุดข้อมูลที่ใช้
Variables - คือชื่อของตัวแปรจากชุดข้อมูล
ค่าเฉลี่ยของชุดข้อมูล
ค่าเฉลี่ยของตัวแปรตัวเลขแต่ละตัวในชุดข้อมูลคำนวณโดยใช้ PROC โดยระบุเฉพาะชื่อชุดข้อมูลโดยไม่มีตัวแปรใด ๆ
ตัวอย่าง
ในตัวอย่างด้านล่างเราพบค่าเฉลี่ยของตัวแปรตัวเลขทั้งหมดในชุดข้อมูล SAS ชื่อ CARS เราระบุตัวเลขสูงสุดหลังตำแหน่งทศนิยมเป็น 2 และหาผลรวมของตัวแปรเหล่านั้นด้วย
PROC MEANS DATA = sashelp.CARS Mean SUM MAXDEC=2;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ต่อไปนี้ -
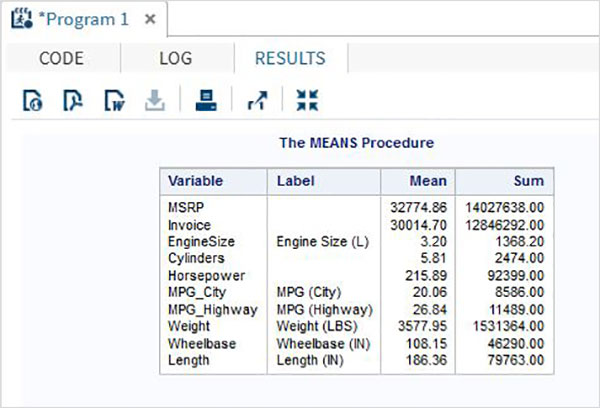
ค่าเฉลี่ยของตัวแปรที่เลือก
เราสามารถหาค่าเฉลี่ยของตัวแปรบางตัวได้โดยระบุชื่อในไฟล์ var ตัวเลือก
ตัวอย่าง
ด้านล่างเราคำนวณค่าเฉลี่ยของตัวแปรสามตัว
PROC MEANS DATA = sashelp.CARS mean SUM MAXDEC=2 ;
var horsepower invoice EngineSize;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ต่อไปนี้ -
ค่าเฉลี่ยตามชั้นเรียน
เราสามารถหาค่าเฉลี่ยของตัวแปรตัวเลขได้โดยจัดเป็นกลุ่มโดยใช้ตัวแปรอื่น ๆ
ตัวอย่าง
ในตัวอย่างด้านล่างเราจะพบค่าเฉลี่ยของแรงม้าที่แปรผันสำหรับแต่ละประเภทภายใต้ยี่ห้อรถแต่ละรุ่น
PROC MEANS DATA = sashelp.CARS mean SUM MAXDEC=2;
class make type;
var horsepower;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ต่อไปนี้ -
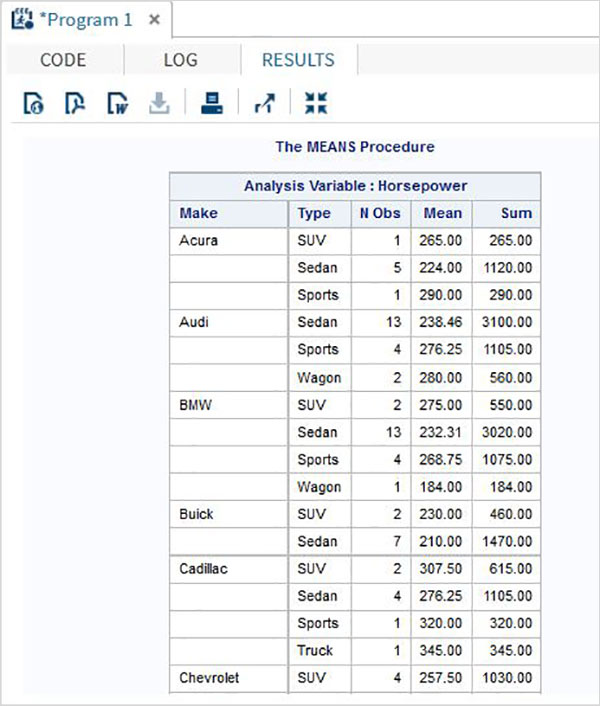
Standard Deviation (SD) คือการวัดความแตกต่างของข้อมูลในชุดข้อมูล ในทางคณิตศาสตร์จะวัดว่าค่าแต่ละค่าอยู่ห่างไกลหรือใกล้เพียงใดกับค่าเฉลี่ยของชุดข้อมูล ค่าเบี่ยงเบนมาตรฐานที่ใกล้ 0 แสดงว่าจุดข้อมูลมีแนวโน้มที่จะใกล้เคียงกับค่าเฉลี่ยของชุดข้อมูลมากและค่าเบี่ยงเบนมาตรฐานสูงบ่งชี้ว่าจุดข้อมูลกระจายออกไปในช่วงค่าที่กว้างขึ้น
ใน SAS ค่า SD จะถูกวัดโดยใช้ PROC MEAN และ PROC SURVEYMEANS
การใช้ PROC หมายถึง
ในการวัด SD โดยใช้ proc meansเราเลือกตัวเลือก STD ในขั้นตอน PROC จะนำเอาค่า SD สำหรับตัวแปรตัวเลขแต่ละตัวที่มีอยู่ในชุดข้อมูล
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการคำนวณค่าเบี่ยงเบนมาตรฐานใน SAS คือ -
PROC means DATA = dataset STD;ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
Dataset - คือชื่อของชุดข้อมูล
ตัวอย่าง
ในตัวอย่างด้านล่างเราสร้างชุดข้อมูล CARS1 จากชุดข้อมูล CARS ในไลบรารี SASHELP เราเลือกตัวเลือก STD ด้วยขั้นตอนวิธีการ PROC
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc means data = CARS1 STD;
run;เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังต่อไปนี้ -
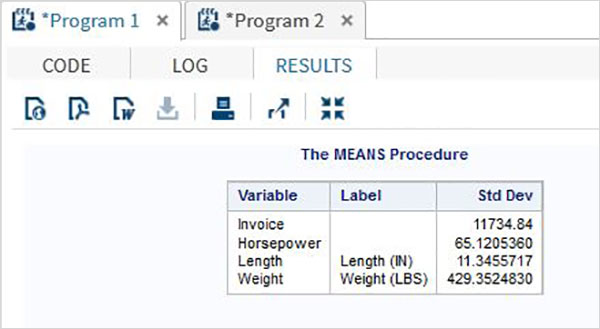
การใช้ PROC SURVEYMEANS
ขั้นตอนนี้ยังใช้สำหรับการวัด SD พร้อมกับคุณสมบัติขั้นสูงบางอย่างเช่นการวัด SD สำหรับตัวแปรตามหมวดหมู่รวมถึงการประมาณการความแปรปรวน
ไวยากรณ์
ไวยากรณ์สำหรับการใช้ PROC SURVEYMEANS คือ -
PROC SURVEYMEANS options statistic-keywords ;
BY variables ;
CLASS variables ;
VAR variables ;ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
BY - ระบุตัวแปรที่ใช้ในการสร้างกลุ่มการสังเกต
CLASS - ระบุตัวแปรที่ใช้สำหรับตัวแปรจัดหมวดหมู่
VAR - ระบุตัวแปรที่จะคำนวณ SD
ตัวอย่าง
ตัวอย่างด้านล่างอธิบายการใช้งาน class ตัวเลือกที่สร้างสถิติสำหรับแต่ละค่าในตัวแปรคลาส
proc surveymeans data = CARS1 STD;
class type;
var type horsepower;
ods output statistics = rectangle;
run;
proc print data = rectangle;
run;เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังต่อไปนี้ -
ใช้ตัวเลือก BY
โค้ดด้านล่างนี้เป็นตัวอย่างของตัวเลือก BY ผลลัพธ์จะถูกจัดกลุ่มสำหรับแต่ละค่าในตัวเลือก BY
ตัวอย่าง
proc surveymeans data = CARS1 STD;
var horsepower;
BY make;
ods output statistics = rectangle;
run;
proc print data = rectangle;
run;เมื่อเรารันโค้ดด้านบนจะให้ผลลัพธ์ดังต่อไปนี้ -
ผลลัพธ์ของ make = "Audi"

ผลลัพธ์ของ make = "BMW"
การแจกแจงความถี่คือตารางแสดงความถี่ของจุดข้อมูลในชุดข้อมูล แต่ละรายการในตารางประกอบด้วยความถี่หรือจำนวนการเกิดขึ้นของค่าภายในกลุ่มหรือช่วงเวลาหนึ่ง ๆ และด้วยวิธีนี้ตารางจะสรุปการกระจายของค่าในตัวอย่าง
SAS จัดเตรียมโพรซีเดอร์ที่เรียกว่า PROC FREQ เพื่อคำนวณการแจกแจงความถี่ของจุดข้อมูลในชุดข้อมูล
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการคำนวณการแจกแจงความถี่ใน SAS คือ -
PROC FREQ DATA = Dataset ;
TABLES Variable_1 ;
BY Variable_2 ;ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
Dataset คือชื่อของชุดข้อมูล
Variables_1 คือชื่อตัวแปรของชุดข้อมูลที่ต้องคำนวณการแจกแจงความถี่
Variables_2 คือตัวแปรที่แบ่งประเภทของผลการแจกแจงความถี่
การกระจายความถี่ตัวแปรเดียว
เราสามารถกำหนดการแจกแจงความถี่ของตัวแปรเดียวได้โดยใช้ PROC FREQ.ในกรณีนี้ผลลัพธ์จะแสดงความถี่ของแต่ละค่าของตัวแปร ผลลัพธ์ยังแสดงการแจกแจงเปอร์เซ็นต์ความถี่สะสมและเปอร์เซ็นต์สะสม
ตัวอย่าง
ในตัวอย่างด้านล่างเราพบการแจกแจงความถี่ของแรงม้าตัวแปรสำหรับชุดข้อมูลที่ชื่อ CARS1 ซึ่งสร้างขึ้นจากไลบรารี SASHELP.CARS.เราสามารถเห็นผลลัพธ์ที่แบ่งออกเป็นสองประเภทของผลลัพธ์ หนึ่งสำหรับแต่ละยี่ห้อของรถ
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1 ;
tables horsepower;
by make;
run;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -

การกระจายความถี่หลายตัวแปร
เราสามารถค้นหาการแจกแจงความถี่สำหรับตัวแปรหลายตัวซึ่งจัดกลุ่มให้เป็นชุดค่าผสมที่เป็นไปได้ทั้งหมด
ตัวอย่าง
ในตัวอย่างด้านล่างเราคำนวณการแจกแจงความถี่สำหรับยี่ห้อรถยนต์สำหรับ grouped by car type และการแจกแจงความถี่ของรถแต่ละประเภท grouped by each make.
proc FREQ data = CARS1 ;
tables make type;
run;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -
การแจกแจงความถี่ด้วยน้ำหนัก
ด้วยตัวเลือกน้ำหนักเราสามารถคำนวณการแจกแจงความถี่เอนเอียงกับน้ำหนักของตัวแปรได้ ที่นี่ค่าของตัวแปรจะถูกนำมาใช้เป็นจำนวนการสังเกตแทนการนับมูลค่า
ตัวอย่าง
ในตัวอย่างด้านล่างเราคำนวณการแจกแจงความถี่ของตัวแปรที่สร้างและพิมพ์ด้วยน้ำหนักที่กำหนดให้กับแรงม้า
proc FREQ data = CARS1 ;
tables make type;
weight horsepower;
run;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -
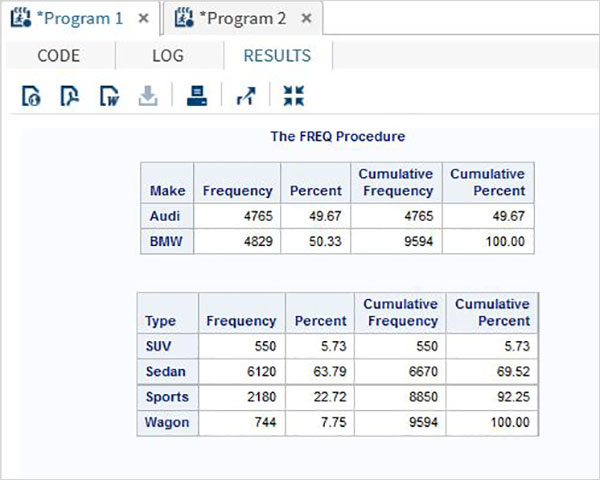
Cross tabulation เกี่ยวข้องกับการสร้างตารางไขว้หรือที่เรียกว่าตารางที่อาจเกิดขึ้นโดยใช้การผสมผสานที่เป็นไปได้ทั้งหมดของตัวแปรตั้งแต่สองตัวขึ้นไป ใน SAS จะถูกสร้างขึ้นโดยใช้ไฟล์PROC FREQ พร้อมกับ TABLESตัวเลือก ตัวอย่างเช่น - หากเราต้องการความถี่ของแต่ละรุ่นสำหรับแต่ละยี่ห้อในรถยนต์แต่ละประเภทเราจำเป็นต้องใช้ตัวเลือกตารางของ PROC FREQ
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการใช้ cross tabulation ใน SAS คือ -
PROC FREQ DATA = dataset;
TABLES variable_1*Variable_2;ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
Dataset คือชื่อของชุดข้อมูล
Variable_1 and Variable_2 คือชื่อตัวแปรของชุดข้อมูลที่ต้องคำนวณการแจกแจงความถี่
ตัวอย่าง
พิจารณากรณีการค้นหาประเภทรถที่มีอยู่ภายใต้รถยนต์แต่ละยี่ห้อจากชุดข้อมูล cars1 ซึ่งสร้างแบบฟอร์ม SASHELP.CARSดังแสดงด้านล่าง ในกรณีนี้เราต้องการค่าความถี่แต่ละค่าตลอดจนผลรวมของค่าความถี่ในแต่ละยี่ห้อและข้ามประเภท เราสามารถสังเกตได้ว่าผลลัพธ์แสดงค่าในแถวและคอลัมน์
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1;
tables make*type;
run;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -
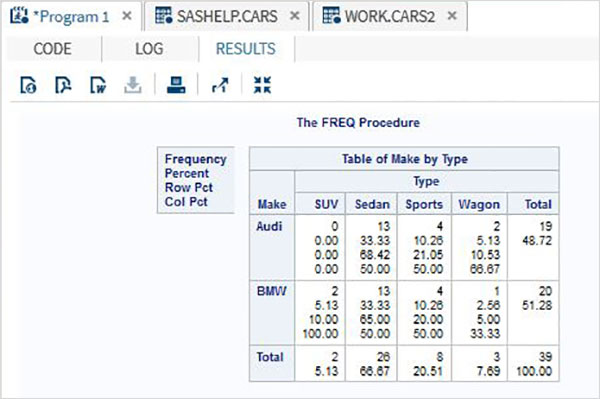
ตารางข้าม 3 ตัวแปร
เมื่อเรามีตัวแปรสามตัวเราสามารถจัดกลุ่ม 2 ตัวแปรและข้ามตารางแต่ละตัวแปรทั้งสองนี้ด้วยตัวแปรที่สาม ดังนั้นเราจึงมีตารางกากบาทสองตาราง
ตัวอย่าง
ในตัวอย่างด้านล่างเราจะพบความถี่ของรถยนต์แต่ละประเภทและรถยนต์แต่ละรุ่นที่เกี่ยวข้องกับยี่ห้อของรถ นอกจากนี้เรายังใช้ตัวเลือก nocol และ norow เพื่อหลีกเลี่ยงค่าผลรวมและเปอร์เซ็นต์
proc FREQ data = CARS2 ;
tables make * (type model) / nocol norow nopercent;
run;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -
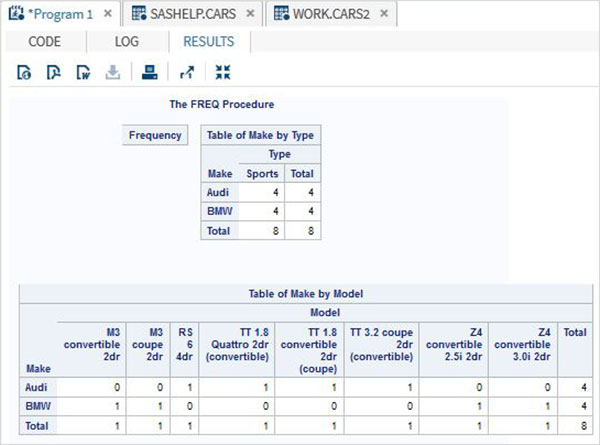
ตารางไขว้ของ 4 ตัวแปร
ด้วยตัวแปร 4 ตัวจำนวนชุดค่าผสมที่จับคู่จะเพิ่มขึ้นเป็น 4 ตัวแปรแต่ละตัวจากกลุ่ม 1 จะจับคู่กับตัวแปรแต่ละตัวของกลุ่ม 2
ตัวอย่าง
ในตัวอย่างด้านล่างเราจะพบความถี่ของความยาวของรถสำหรับแต่ละยี่ห้อและแต่ละรุ่น ในทำนองเดียวกันความถี่ของแรงม้าสำหรับแต่ละยี่ห้อและแต่ละรุ่น
proc FREQ data = CARS2 ;
tables (make model) * (length horsepower) / nocol norow nopercent;
run;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -
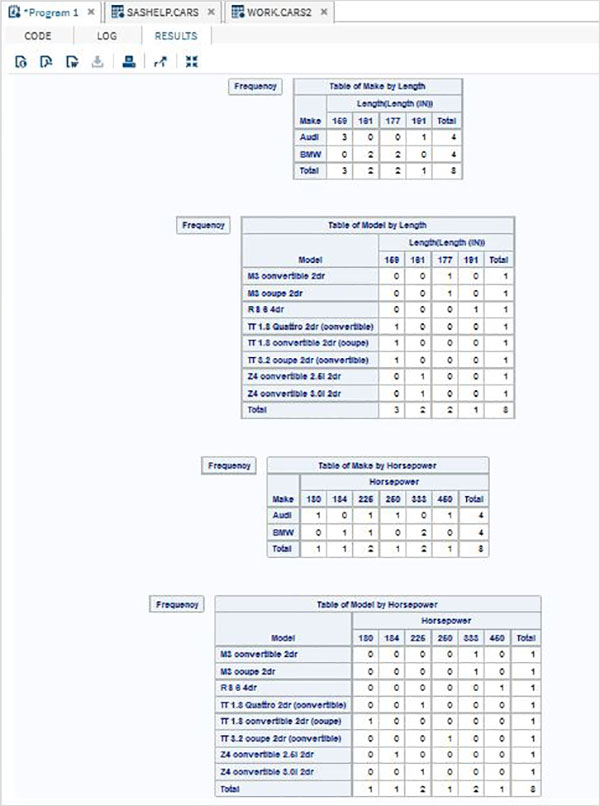
การทดสอบ T ดำเนินการเพื่อคำนวณขีดจำกัดความเชื่อมั่นสำหรับหนึ่งตัวอย่างหรือสองตัวอย่างอิสระโดยการเปรียบเทียบค่าเฉลี่ยและความแตกต่างของค่าเฉลี่ย ชื่อกระบวนงาน SASPROC TTEST ใช้เพื่อทำการทดสอบ t กับตัวแปรเดียวและตัวแปรคู่
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการใช้ PROC TTEST ใน SAS คือ -
PROC TTEST DATA = dataset;
VAR variable;
CLASS Variable;
PAIRED Variable_1 * Variable_2;ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
Dataset คือชื่อของชุดข้อมูล
Variable_1 and Variable_2 คือชื่อตัวแปรของชุดข้อมูลที่ใช้ในการทดสอบ t
ตัวอย่าง
ด้านล่างนี้เราจะเห็นการทดสอบตัวอย่างหนึ่งตัวอย่างซึ่งค้นหาการประมาณค่าการทดสอบ t สำหรับแรงม้าตัวแปรที่มีขีดจำกัดความมั่นใจ 95 เปอร์เซ็นต์
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc ttest data = cars1 alpha = 0.05 h0 = 0;
var horsepower;
run;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -
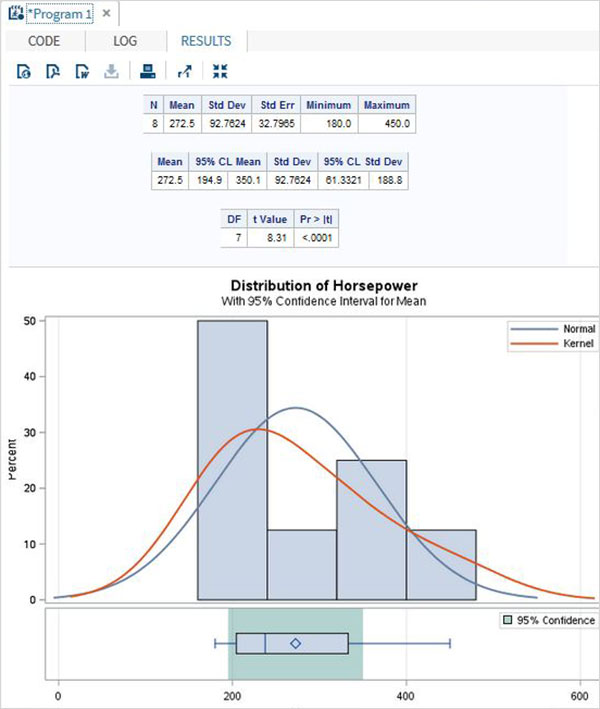
จับคู่ T-test
การทดสอบ T แบบจับคู่จะดำเนินการเพื่อทดสอบว่าตัวแปรตามสองตัวมีความแตกต่างกันทางสถิติหรือไม่
ตัวอย่าง
เนื่องจากความยาวและน้ำหนักของรถจะขึ้นอยู่กับแต่ละอื่น ๆ เราจึงใช้การทดสอบ T แบบจับคู่ตามที่แสดงด้านล่าง
proc ttest data = cars1 ;
paired weight*length;
run;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -
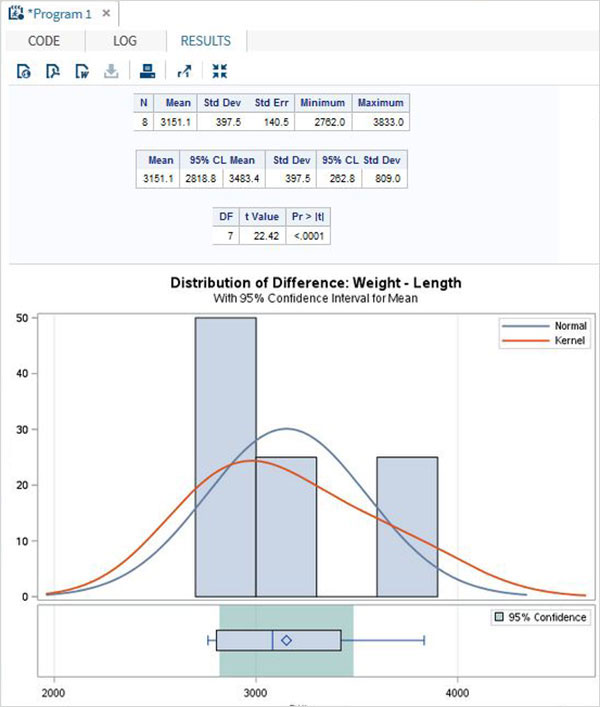
t-test สองตัวอย่าง
t-test นี้ออกแบบมาเพื่อเปรียบเทียบค่าตัวแปรเดียวกันระหว่างสองกลุ่ม
ตัวอย่าง
ในกรณีของเราเราเปรียบเทียบค่าเฉลี่ยของแรงม้าที่แปรผันระหว่างสองยี่ห้อที่แตกต่างกันของรถยนต์ ("Audi" และ "BMW")
proc ttest data = cars1 sides = 2 alpha = 0.05 h0 = 0;
title "Two sample t-test example";
class make;
var horsepower;
run;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -
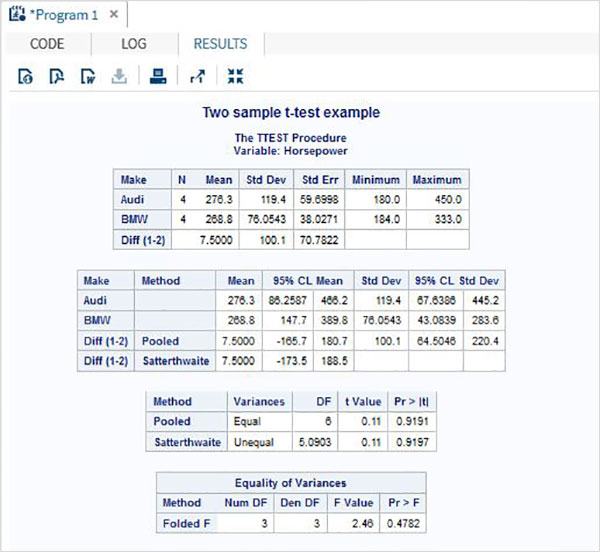
การวิเคราะห์สหสัมพันธ์เกี่ยวข้องกับความสัมพันธ์ระหว่างตัวแปร ค่าสัมประสิทธิ์สหสัมพันธ์เป็นการวัดความสัมพันธ์เชิงเส้นระหว่างสองตัวแปรค่าของสัมประสิทธิ์สหสัมพันธ์จะอยู่ระหว่าง -1 ถึง +1 เสมอ SAS จัดเตรียมขั้นตอนPROC CORR เพื่อหาค่าสัมประสิทธิ์สหสัมพันธ์ระหว่างตัวแปรคู่หนึ่งในชุดข้อมูล
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการใช้ PROC CORR ใน SAS คือ -
PROC CORR DATA = dataset options;
VAR variable;ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
Dataset คือชื่อของชุดข้อมูล
Options เป็นตัวเลือกเพิ่มเติมที่มีขั้นตอนเช่นการวางแผนเมทริกซ์เป็นต้น
Variable คือชื่อตัวแปรของชุดข้อมูลที่ใช้ในการค้นหาความสัมพันธ์
ตัวอย่าง
ค่าสัมประสิทธิ์สหสัมพันธ์ระหว่างคู่ของตัวแปรที่มีอยู่ในชุดข้อมูลสามารถหาได้โดยใช้ชื่อของพวกเขาในคำสั่ง VAR ในตัวอย่างด้านล่างเราใช้ชุดข้อมูล CARS1 และได้ผลลัพธ์ที่แสดงค่าสัมประสิทธิ์สหสัมพันธ์ระหว่างแรงม้าและน้ำหนัก
PROC SQL;
create table CARS1 as
SELECT invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc corr data = cars1 ;
VAR horsepower weight ;
BY make;
run;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -
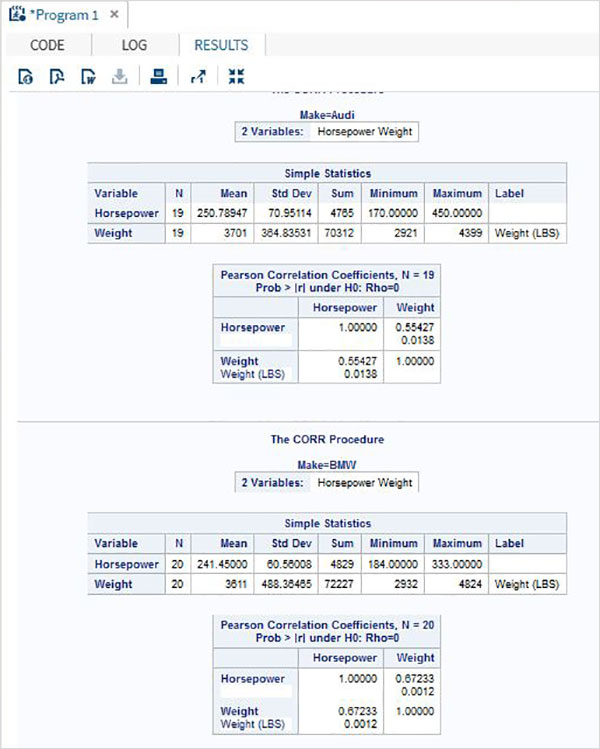
ความสัมพันธ์ระหว่างตัวแปรทั้งหมด
ค่าสัมประสิทธิ์สหสัมพันธ์ระหว่างตัวแปรทั้งหมดที่มีอยู่ในชุดข้อมูลสามารถหาได้โดยใช้ขั้นตอนกับชื่อชุดข้อมูล
ตัวอย่าง
ในตัวอย่างด้านล่างเราใช้ชุดข้อมูล CARS1 และได้ผลลัพธ์ที่แสดงค่าสัมประสิทธิ์สหสัมพันธ์ระหว่างตัวแปรแต่ละคู่
proc corr data = cars1 ;
run;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -
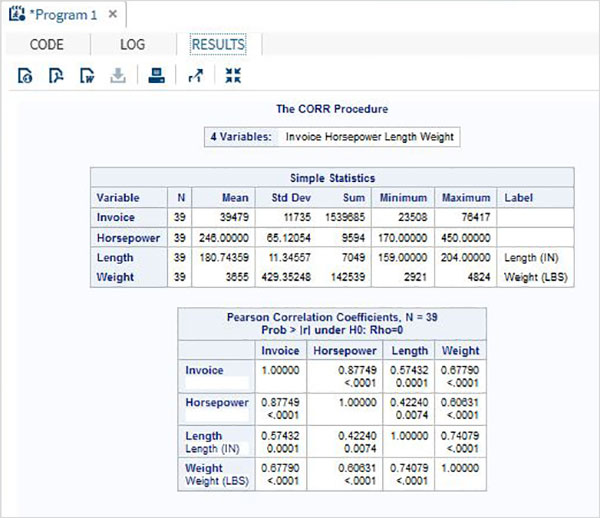
เมทริกซ์สหสัมพันธ์
เราสามารถรับเมทริกซ์ scatterplot ระหว่างตัวแปรได้โดยเลือกตัวเลือกเพื่อลงจุดเมทริกซ์ในไฟล์ PROC คำให้การ.
ตัวอย่าง
ในตัวอย่างด้านล่างเราจะได้เมทริกซ์ระหว่างแรงม้าและน้ำหนัก
proc corr data = cars1 plots = matrix ;
VAR horsepower weight ;
run;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -
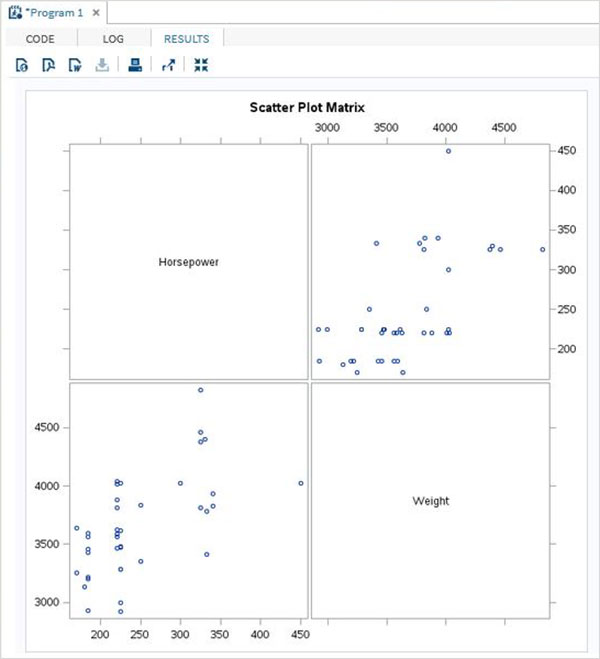
Linear Regression ใช้เพื่อระบุความสัมพันธ์ระหว่างตัวแปรตามและตัวแปรอิสระหนึ่งตัวหรือมากกว่า มีการเสนอแบบจำลองของความสัมพันธ์และใช้การประมาณค่าพารามิเตอร์เพื่อพัฒนาสมการการถดถอยโดยประมาณ
จากนั้นจะใช้การทดสอบต่างๆเพื่อพิจารณาว่าแบบจำลองนั้นน่าพอใจหรือไม่ หากเป็นเช่นนั้นสามารถใช้สมการการถดถอยโดยประมาณเพื่อทำนายค่าของตัวแปรตามค่าที่กำหนดสำหรับตัวแปรอิสระ ใน SAS ขั้นตอนPROC REG ใช้เพื่อค้นหาแบบจำลองการถดถอยเชิงเส้นระหว่างสองตัวแปร
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการใช้ PROC REG ใน SAS คือ -
PROC REG DATA = dataset;
MODEL variable_1 = variable_2;ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
Dataset คือชื่อของชุดข้อมูล
variable_1 and variable_2 คือชื่อตัวแปรของชุดข้อมูลที่ใช้ในการค้นหาความสัมพันธ์
ตัวอย่าง
ตัวอย่างด้านล่างแสดงขั้นตอนการค้นหาความสัมพันธ์ระหว่างสองตัวแปรแรงม้าและน้ำหนักของรถโดยใช้ PROC REG. ในผลลัพธ์เราจะเห็นค่าการสกัดกั้นซึ่งสามารถใช้ในการสร้างสมการการถดถอย
PROC SQL;
create table CARS1 as
SELECT invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc reg data = cars1;
model horsepower = weight ;
run;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -
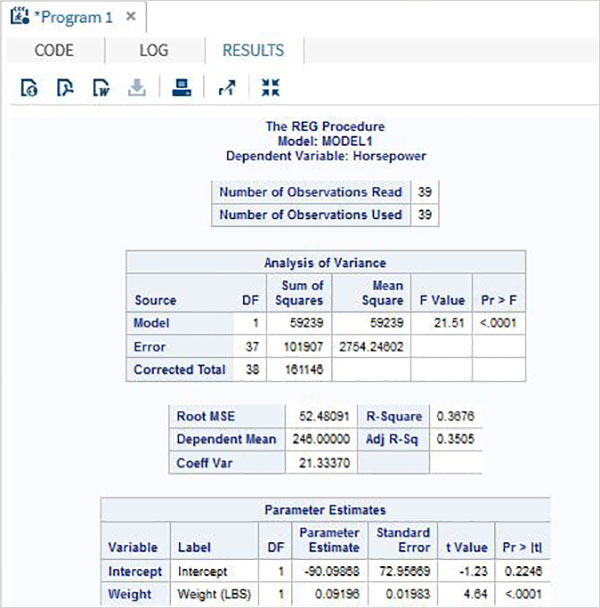
โค้ดด้านบนยังให้มุมมองแบบกราฟิกของค่าประมาณต่างๆของโมเดลดังที่แสดงด้านล่าง การเป็นโพรซีเดอร์ SAS ขั้นสูงมันไม่ได้หยุดอยู่แค่การให้ค่าการสกัดกั้นเป็นผลลัพธ์
การวิเคราะห์ Bland-Altman เป็นกระบวนการตรวจสอบขอบเขตของข้อตกลงหรือความขัดแย้งระหว่างสองวิธีที่ออกแบบมาเพื่อวัดพารามิเตอร์เดียวกัน ความสัมพันธ์ที่สูงระหว่างวิธีการบ่งชี้ว่ามีการเลือกตัวอย่างที่ดีเพียงพอในการวิเคราะห์ข้อมูล ใน SAS เราสร้างแผนภาพ Bland-Altman โดยคำนวณค่าเฉลี่ยขีด จำกัด บนและขีด จำกัด ล่างของค่าตัวแปร จากนั้นเราใช้ PROC SGPLOT เพื่อสร้างพล็อต Bland-Altman
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการใช้ PROC SGPLOT ใน SAS คือ -
PROC SGPLOT DATA = dataset;
SCATTER X = variable Y = Variable;
REFLINE value;ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
Dataset คือชื่อของชุดข้อมูล
SCATTER คำสั่งหยุดกราฟพล็อตการกระจายของค่าที่ให้มาในรูปแบบของ X และ Y
REFLINE สร้างเส้นอ้างอิงแนวนอนหรือแนวตั้ง
ตัวอย่าง
ในตัวอย่างด้านล่างเราได้ผลลัพธ์ของการทดลองสองครั้งที่สร้างขึ้นโดยสองวิธีที่ชื่อว่าใหม่และเก่า เราคำนวณความแตกต่างในค่าของตัวแปรและค่าเฉลี่ยของตัวแปรของการสังเกตเดียวกัน นอกจากนี้เรายังคำนวณค่าเบี่ยงเบนมาตรฐานที่จะใช้ในขีด จำกัด บนและล่างของการคำนวณ
ผลลัพธ์จะแสดงพล็อต Bland-Altman เป็นพล็อตกระจาย
data mydata;
input new old;
datalines;
31 45
27 12
11 37
36 25
14 8
27 15
3 11
62 42
38 35
20 9
35 54
62 67
48 25
77 64
45 53
32 42
16 19
15 27
22 9
8 38
24 16
59 25
;
data diffs ;
set mydata ;
/* calculate the difference */
diff = new-old ;
/* calculate the average */
mean = (new+old)/2 ;
run ;
proc print data = diffs;
run;
proc sql noprint ;
select mean(diff)-2*std(diff), mean(diff)+2*std(diff)
into :lower, :upper
from diffs ;
quit;
proc sgplot data = diffs ;
scatter x = mean y = diff;
refline 0 &upper &lower / LABEL = ("zero bias line" "95% upper limit" "95%
lower limit");
TITLE 'Bland-Altman Plot';
footnote 'Accurate prediction with 10% homogeneous error';
run ;
quit ;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -
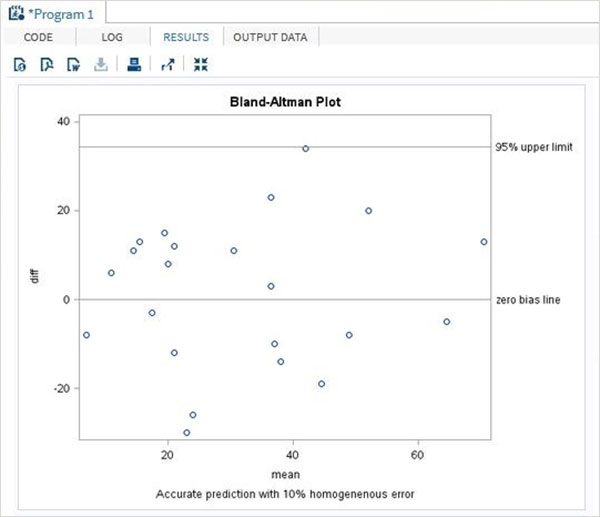
รุ่นปรับปรุง
ในแบบจำลองขั้นสูงของโปรแกรมข้างต้นเราได้รับการปรับเส้นโค้งระดับความมั่นใจ 95 เปอร์เซ็นต์
proc sgplot data = diffs ;
reg x = new y = diff/clm clmtransparency = .5;
needle x = new y = diff/baseline = 0;
refline 0 / LABEL = ('No diff line');
TITLE 'Enhanced Bland-Altman Plot';
footnote 'Accurate prediction with 10% homogeneous error';
run ;
quit ;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -
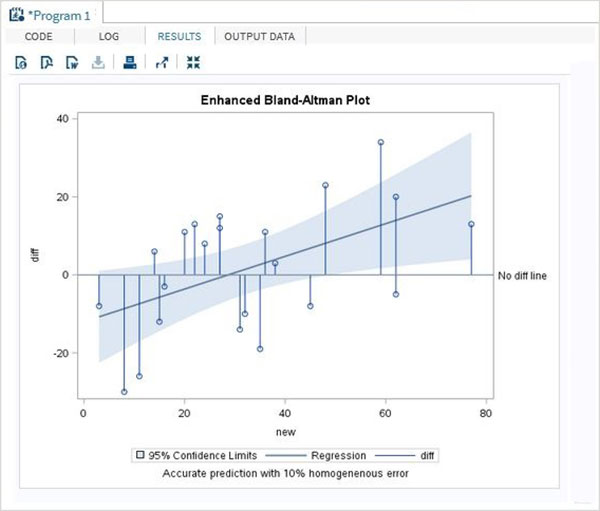
การทดสอบไคสแควร์ใช้เพื่อตรวจสอบความสัมพันธ์ระหว่างตัวแปรเชิงหมวดหมู่สองตัวแปร สามารถใช้เพื่อทดสอบทั้งขอบเขตของการพึ่งพาและขอบเขตของความเป็นอิสระระหว่างตัวแปร SAS ใช้PROC FREQ พร้อมกับตัวเลือก chisq เพื่อกำหนดผลการทดสอบ Chi-Square
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการใช้ PROC FREQ สำหรับการทดสอบ Chi-Square ใน SAS คือ -
PROC FREQ DATA = dataset;
TABLES variables
/CHISQ TESTP = (percentage values);ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
Dataset คือชื่อของชุดข้อมูล
Variables คือชื่อตัวแปรของชุดข้อมูลที่ใช้ในการทดสอบไคสแควร์
Percentage Values ในคำสั่ง TESTP แสดงเปอร์เซ็นต์ของระดับของตัวแปร
ตัวอย่าง
ในตัวอย่างด้านล่างเราจะพิจารณาการทดสอบไคสแควร์กับตัวแปรที่มีชื่อประเภทในชุดข้อมูล SASHELP.CARS. ตัวแปรนี้มีหกระดับและเรากำหนดเปอร์เซ็นต์ให้กับแต่ละระดับตามการออกแบบของการทดสอบ
proc freq data = sashelp.cars;
tables type
/chisq
testp = (0.20 0.12 0.18 0.10 0.25 0.15);
run;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -

นอกจากนี้เรายังได้รับแผนภูมิแท่งที่แสดงความเบี่ยงเบนของประเภทตัวแปรดังที่แสดงในภาพหน้าจอต่อไปนี้
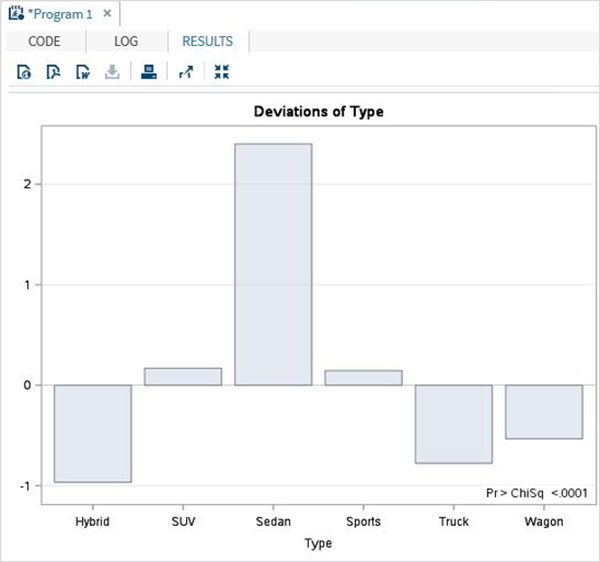
ไคสแควร์สองทาง
การทดสอบ Chi-Square สองทางใช้เมื่อเราใช้การทดสอบกับตัวแปรสองตัวของชุดข้อมูล
ตัวอย่าง
ในตัวอย่างด้านล่างเราใช้การทดสอบไคสแควร์กับตัวแปรสองตัวที่ชื่อว่า type and origin ผลลัพธ์จะแสดงรูปแบบตารางของชุดค่าผสมทั้งหมดของตัวแปรทั้งสองนี้
proc freq data = sashelp.cars;
tables type*origin
/chisq
;
run;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -
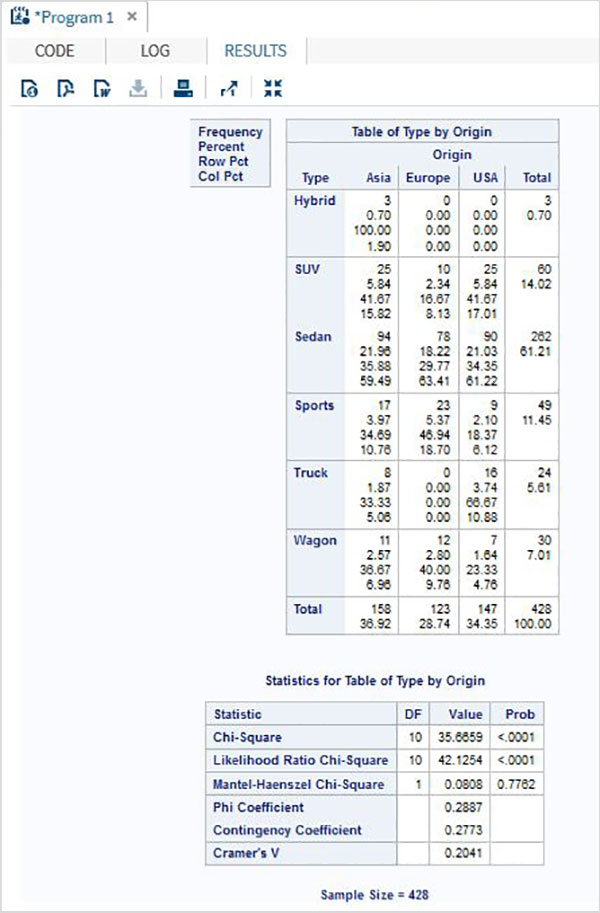
การทดสอบที่แน่นอนของฟิชเชอร์เป็นการทดสอบทางสถิติที่ใช้เพื่อตรวจสอบว่ามีการเชื่อมโยงที่ไม่ใช่เงื่อนไขระหว่างตัวแปรเชิงหมวดหมู่สองตัวแปรหรือไม่ใน SAS จะดำเนินการโดยใช้ PROC FREQ. เราใช้ตัวเลือกตารางเพื่อใช้ตัวแปรสองตัวที่อยู่ภายใต้การทดสอบของ Fisher Exact
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการใช้การทดสอบ Fisher Exact ใน SAS คือ -
PROC FREQ DATA = dataset ;
TABLES Variable_1*Variable_2 / fisher;ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
dataset คือชื่อของชุดข้อมูล
Variable_1*Variable_2 เป็นตัวแปรที่สร้างชุดข้อมูล
ใช้การทดสอบที่แน่นอนของฟิชเชอร์
ในการใช้การทดสอบที่แน่นอนของฟิชเชอร์เราเลือกตัวแปรเชิงหมวดหมู่ 2 ตัวแปรชื่อ Test1 และ Test2 และผลลัพธ์เราใช้ PROC FREQ เพื่อใช้การทดสอบที่แสดงด้านล่าง
ตัวอย่าง
data temp;
input Test1 Test2 Result @@;
datalines;
1 1 3 1 2 1 2 1 1 2 2 3
;
proc freq;
tables Test1*Test2 / fisher;
run;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -
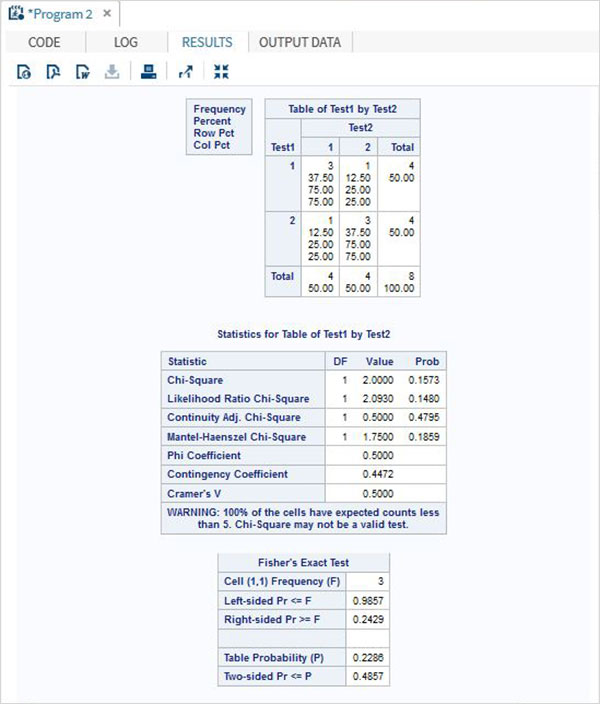
การวิเคราะห์การวัดซ้ำจะใช้เมื่อสมาชิกทั้งหมดของตัวอย่างสุ่มถูกวัดภายใต้เงื่อนไขที่แตกต่างกันหลายประการ เมื่อตัวอย่างสัมผัสกับแต่ละเงื่อนไขการวัดตัวแปรตามจะถูกทำซ้ำ การใช้ ANOVA มาตรฐานในกรณีนี้ไม่เหมาะสมเนื่องจากไม่สามารถสร้างแบบจำลองความสัมพันธ์ระหว่างการวัดซ้ำได้
ควรมีความชัดเจนเกี่ยวกับความแตกต่างระหว่างไฟล์ repeated measures design และก simple multivariate design. สำหรับทั้งสองตัวอย่างสมาชิกจะได้รับการวัดหลายครั้งหรือการทดลอง แต่ในการออกแบบการวัดซ้ำการทดลองแต่ละครั้งแสดงถึงการวัดลักษณะเดียวกันภายใต้เงื่อนไขที่แตกต่างกัน
ใน SAS PROC GLM ใช้ในการวิเคราะห์การวัดซ้ำ
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับ PROC GLM ใน SAS คือ -
PROC GLM DATA = dataset;
CLASS variable;
MODEL variables = group / NOUNI;
REPEATED TRIAL n;ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
dataset คือชื่อของชุดข้อมูล
CLASS ให้ตัวแปรเป็นตัวแปรที่ใช้เป็นตัวแปรจำแนก
MODEL กำหนดโมเดลให้เหมาะสมโดยใช้ตัวแปรบางตัวในรูปแบบชุดข้อมูล
REPEATED กำหนดจำนวนการวัดซ้ำของแต่ละกลุ่มเพื่อทดสอบสมมติฐาน
ตัวอย่าง
ลองพิจารณาตัวอย่างด้านล่างซึ่งเรามีกลุ่มคนสองกลุ่มที่ต้องผ่านการทดสอบฤทธิ์ของยา เวลาในการเกิดปฏิกิริยาของแต่ละคนจะถูกบันทึกไว้สำหรับยาแต่ละชนิดที่ทดสอบ ที่นี่มีการทดลอง 5 ครั้งเพื่อให้คนแต่ละกลุ่มได้เห็นความแข็งแกร่งของความสัมพันธ์ระหว่างผลของยาทั้งสี่ชนิด
DATA temp;
INPUT person group $ r1 r2 r3 r4;
CARDS;
1 A 2 1 6 5
2 A 5 4 11 9
3 A 6 14 12 10
4 A 2 4 5 8
5 A 0 5 10 9
6 B 9 11 16 13
7 B 12 4 13 14
8 B 15 9 13 8
9 B 6 8 12 5
10 B 5 7 11 9
;
RUN;
PROC PRINT DATA = temp ;
RUN;
PROC GLM DATA = temp;
CLASS group;
MODEL r1-r4 = group / NOUNI ;
REPEATED trial 5;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -
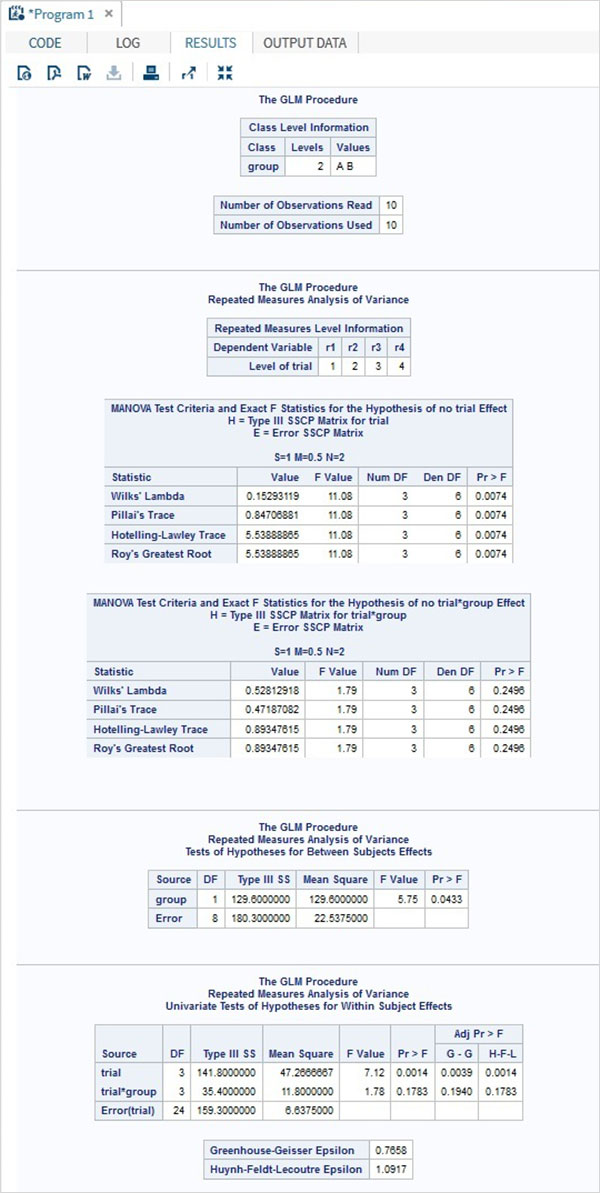
ANOVA ย่อมาจาก Analysis of Variance ใน SAS ทำได้โดยใช้ไฟล์PROC ANOVA. ทำการวิเคราะห์ข้อมูลจากการออกแบบการทดลองที่หลากหลาย ในกระบวนการนี้ตัวแปรตอบสนองต่อเนื่องที่เรียกว่าตัวแปรตามถูกวัดภายใต้เงื่อนไขการทดลองที่ระบุโดยตัวแปรการจำแนกซึ่งเรียกว่าตัวแปรอิสระ การเปลี่ยนแปลงในการตอบสนองจะถือว่าเกิดจากผลกระทบในการจำแนกประเภทโดยมีการบันทึกข้อผิดพลาดแบบสุ่มสำหรับรูปแบบที่เหลือ
ไวยากรณ์
ไวยากรณ์พื้นฐานสำหรับการใช้ PROC ANOVA ใน SAS คือ -
PROC ANOVA dataset ;
CLASS Variable;
MODEL Variable1 = variable2 ;
MEANS ;ต่อไปนี้เป็นคำอธิบายของพารามิเตอร์ที่ใช้ -
dataset คือชื่อของชุดข้อมูล
CLASS ให้ตัวแปรเป็นตัวแปรที่ใช้เป็นตัวแปรจำแนก
MODEL กำหนดโมเดลให้เหมาะสมโดยใช้ตัวแปรบางอย่างจากชุดข้อมูล
Variable_1 and Variable_2 คือชื่อตัวแปรของชุดข้อมูลที่ใช้ในการวิเคราะห์
MEANS กำหนดประเภทของการคำนวณและการเปรียบเทียบค่าเฉลี่ย
ใช้ ANOVA
ตอนนี้ให้เราเข้าใจแนวคิดของการใช้ ANOVA ใน SAS
ตัวอย่าง
ลองพิจารณาชุดข้อมูล SASHELP.CARS ที่นี่เราศึกษาการพึ่งพาระหว่างตัวแปรประเภทรถและแรงม้า เนื่องจากประเภทรถยนต์เป็นตัวแปรที่มีค่าตามหมวดหมู่เราจึงใช้เป็นตัวแปรคลาสและใช้ตัวแปรทั้งสองนี้ใน MODEL
PROC ANOVA DATA = SASHELPS.CARS;
CLASS type;
MODEL horsepower = type;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -

การใช้ ANOVA กับ MEANS
ตอนนี้ให้เราเข้าใจแนวคิดของการประยุกต์ใช้ ANOVA กับ MEANS ใน SAS
ตัวอย่าง
นอกจากนี้เรายังสามารถขยายโมเดลได้โดยใช้คำสั่ง MEANS ซึ่งเราใช้วิธี Studentized ของตุรกีเพื่อเปรียบเทียบค่าเฉลี่ยของรถประเภทต่างๆหมวดหมู่ของประเภทรถจะแสดงรายการด้วยค่าเฉลี่ยของแรงม้าในแต่ละประเภทพร้อมกับค่าเพิ่มเติมบางอย่างเช่น error mean square เป็นต้น
PROC ANOVA DATA = SASHELPS.CARS;
CLASS type;
MODEL horsepower = type;
MEANS type / tukey lines;
RUN;เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังนี้ -

การทดสอบสมมติฐานคือการใช้สถิติเพื่อกำหนดความน่าจะเป็นที่สมมติฐานที่กำหนดจะเป็นจริง ขั้นตอนปกติของการทดสอบสมมติฐานประกอบด้วยสี่ขั้นตอนดังที่แสดงด้านล่าง
ขั้นตอนที่ 1
กำหนดสมมติฐานว่าง H0 (โดยทั่วไปว่าการสังเกตเป็นผลมาจากโอกาสบริสุทธิ์) และสมมติฐานทางเลือก H1 (โดยทั่วไปการสังเกตจะแสดงผลที่แท้จริงรวมกับองค์ประกอบของการเปลี่ยนแปลงของโอกาส)
ขั้นตอนที่ 2
ระบุสถิติการทดสอบที่สามารถใช้เพื่อประเมินความจริงของสมมติฐานว่าง
ขั้นตอนที่ 3
คำนวณค่า P ซึ่งเป็นความน่าจะเป็นที่สถิติทดสอบอย่างน้อยมีนัยสำคัญเท่าที่สังเกตได้โดยสมมติว่าสมมติฐานว่างเป็นจริง ยิ่งค่า P น้อยเท่าใดหลักฐานก็จะยิ่งเทียบกับสมมติฐานว่างได้มากขึ้นเท่านั้น
ขั้นตอนที่ 4
เปรียบเทียบค่า p กับค่านัยสำคัญที่ยอมรับได้อัลฟ่า (บางครั้งเรียกว่าค่าอัลฟา) ถ้า p <= alpha แสดงว่าผลที่สังเกตได้มีนัยสำคัญทางสถิติสมมติฐานว่างจะถูกตัดออกและสมมติฐานทางเลือกนั้นใช้ได้
ภาษาโปรแกรม SAS มีคุณสมบัติในการทดสอบสมมติฐานประเภทต่างๆดังแสดงด้านล่าง
| ทดสอบ | คำอธิบาย | กระบวนการ SAS |
|---|---|---|
| T-Test | การทดสอบค่าทีใช้เพื่อทดสอบว่าค่าเฉลี่ยของตัวแปรหนึ่งตัวแตกต่างจากค่าสมมุติฐานอย่างมีนัยสำคัญหรือไม่นอกจากนี้เรายังพิจารณาด้วยว่าค่าความหมายสำหรับกลุ่มอิสระสองกลุ่มมีความแตกต่างกันอย่างมีนัยสำคัญหรือไม่และความหมายสำหรับกลุ่มที่ขึ้นกับหรือจับคู่มีความแตกต่างกัน | PROC TTEST |
| ANOVA | นอกจากนี้ยังใช้เพื่อเปรียบเทียบวิธีการเมื่อมีตัวแปรเชิงหมวดหมู่อิสระหนึ่งตัว เราต้องการใช้ความแปรปรวนทางเดียวเมื่อทดสอบเพื่อดูว่าค่าเฉลี่ยของตัวแปรตามช่วงเวลาแตกต่างกันหรือไม่ตามตัวแปรเชิงหมวดอิสระ | PROC ANOVA |
| Chi-Square | เราใช้ความดีของไคสแควร์เพื่อประเมินว่าความถี่ของตัวแปรเชิงหมวดหมู่มีแนวโน้มที่จะเกิดขึ้นเนื่องจากความบังเอิญหรือไม่ การใช้การทดสอบไคสแควร์จำเป็นหรือไม่ว่าสัดส่วนของตัวแปรเชิงหมวดหมู่เป็นค่าสมมุติฐานหรือไม่ | PROC FREQ |
| Linear Regression | การถดถอยเชิงเส้นอย่างง่ายใช้เมื่อต้องการทดสอบว่าตัวแปรทำนายตัวแปรอื่นได้ดีเพียงใด การย้อนกลับเชิงเส้นหลายตัวช่วยให้สามารถทดสอบว่าตัวแปรหลายตัวทำนายตัวแปรที่สนใจได้ดีเพียงใด เมื่อใช้การถดถอยเชิงเส้นพหุคูณเราจะถือว่าตัวแปรทำนายเป็นอิสระ | PROC REG |