Weka - การจัดกลุ่ม
อัลกอริทึมการทำคลัสเตอร์จะค้นหากลุ่มของอินสแตนซ์ที่คล้ายกันในชุดข้อมูลทั้งหมด WEKA สนับสนุนอัลกอริทึมการทำคลัสเตอร์หลายแบบเช่น EM, FilteredClusterer, HierarchicalClusterer, SimpleKMeans เป็นต้น คุณควรเข้าใจอัลกอริทึมเหล่านี้อย่างสมบูรณ์เพื่อใช้ประโยชน์จากความสามารถของ WEKA อย่างเต็มที่
เช่นเดียวกับในกรณีของการจำแนก WEKA ช่วยให้คุณเห็นภาพของคลัสเตอร์ที่ตรวจพบในรูปแบบกราฟิก เพื่อสาธิตการจัดกลุ่มเราจะใช้ฐานข้อมูลม่านตาที่ให้มา ชุดข้อมูลประกอบด้วยสามคลาสละ 50 อินสแตนซ์ แต่ละชั้นหมายถึงพืชไอริสชนิดหนึ่ง
กำลังโหลดข้อมูล
ใน WEKA explorer เลือกไฟล์ Preprocessแท็บ คลิกที่Open file ... และเลือก iris.arffไฟล์ในกล่องโต้ตอบการเลือกไฟล์ เมื่อคุณโหลดข้อมูลหน้าจอจะมีลักษณะดังที่แสดงด้านล่าง -
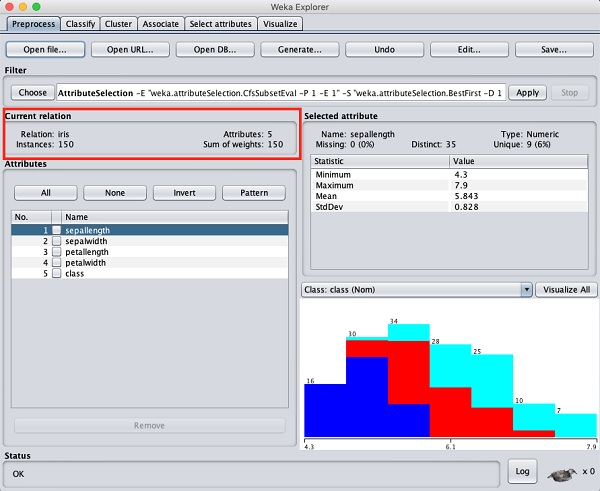
คุณสามารถสังเกตได้ว่ามี 150 อินสแตนซ์และ 5 แอตทริบิวต์ ชื่อของแอตทริบิวต์แสดงรายการเป็นsepallength, sepalwidth, petallength, petalwidth และ class. แอตทริบิวต์สี่รายการแรกเป็นประเภทตัวเลขในขณะที่คลาสเป็นประเภทระบุที่มีค่าต่างกัน 3 ค่า ตรวจสอบแอตทริบิวต์แต่ละรายการเพื่อทำความเข้าใจคุณลักษณะของฐานข้อมูล เราจะไม่ดำเนินการใด ๆ ล่วงหน้ากับข้อมูลนี้และดำเนินการสร้างแบบจำลองทันที
การทำคลัสเตอร์
คลิกที่ ClusterTAB เพื่อใช้อัลกอริทึมการทำคลัสเตอร์กับข้อมูลที่โหลดของเรา คลิกที่Chooseปุ่ม. คุณจะเห็นหน้าจอต่อไปนี้ -

ตอนนี้เลือก EMเป็นอัลกอริทึมการจัดกลุ่ม ในCluster mode หน้าต่างย่อยเลือกไฟล์ Classes to clusters evaluation ตามที่แสดงในภาพหน้าจอด้านล่าง -

คลิกที่ Startปุ่มเพื่อประมวลผลข้อมูล หลังจากนั้นสักครู่ผลลัพธ์จะถูกนำเสนอบนหน้าจอ
ต่อไปให้เราศึกษาผลลัพธ์
การตรวจสอบผลลัพธ์
ผลลัพธ์ของการประมวลผลข้อมูลจะแสดงในหน้าจอด้านล่าง -
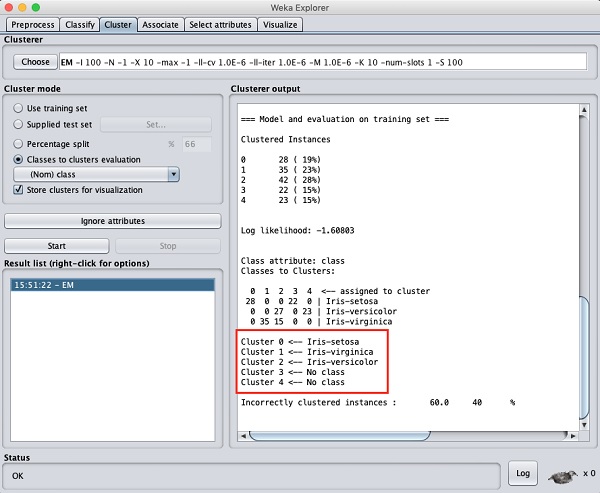
จากหน้าจอเอาต์พุตคุณสามารถสังเกตได้ว่า -
ตรวจพบอินสแตนซ์แบบคลัสเตอร์ 5 รายการในฐานข้อมูล
Cluster 0 เป็นตัวแทนของ setosa Cluster 1 แสดงถึง virginica Cluster 2 แสดงถึงความหลากหลายในขณะที่สองคลัสเตอร์สุดท้ายไม่มีคลาสใด ๆ ที่เกี่ยวข้อง
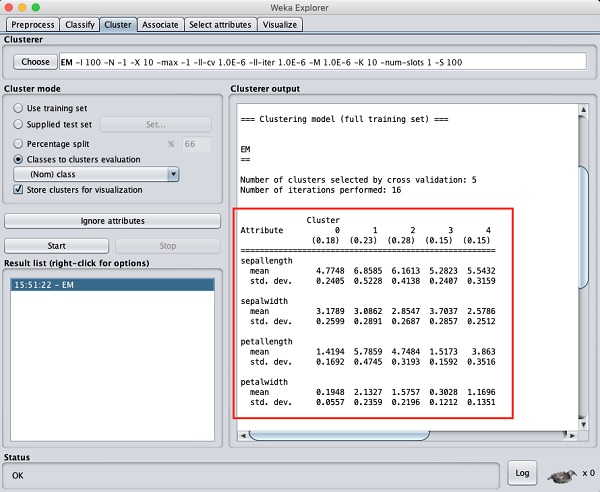
หากคุณเลื่อนหน้าต่างผลลัพธ์ขึ้นคุณจะเห็นสถิติบางอย่างที่ให้ค่าเฉลี่ยและค่าเบี่ยงเบนมาตรฐานสำหรับแต่ละแอตทริบิวต์ในคลัสเตอร์ต่างๆที่ตรวจพบ สิ่งนี้แสดงในภาพหน้าจอด้านล่าง -
ต่อไปเราจะดูการแสดงภาพของคลัสเตอร์
การแสดงภาพคลัสเตอร์
หากต้องการดูภาพของคลัสเตอร์ให้คลิกขวาที่ไฟล์ EM ส่งผลให้ไฟล์ Result list. คุณจะเห็นตัวเลือกต่อไปนี้ -
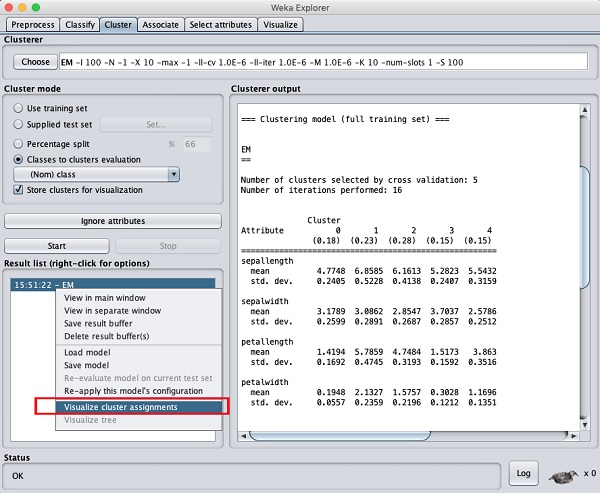
เลือก Visualize cluster assignments. คุณจะเห็นผลลัพธ์ต่อไปนี้ -
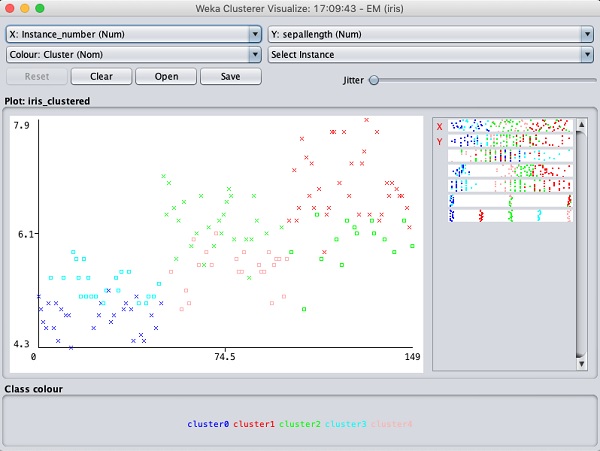
เช่นเดียวกับในกรณีของการจัดประเภทคุณจะสังเกตเห็นความแตกต่างระหว่างอินสแตนซ์ที่ระบุอย่างถูกต้องและไม่ถูกต้อง คุณสามารถเล่นได้โดยเปลี่ยนแกน X และ Y เพื่อวิเคราะห์ผลลัพธ์ คุณอาจใช้การกระวนกระวายใจเช่นเดียวกับในกรณีของการจัดประเภทเพื่อค้นหาความเข้มข้นของอินสแตนซ์ที่ระบุอย่างถูกต้อง การดำเนินการในพล็อตการแสดงภาพคล้ายกับที่คุณศึกษาในกรณีของการจำแนกประเภท
การใช้ Hierarchical Clusterer
เพื่อแสดงให้เห็นถึงพลังของ WEKA ตอนนี้ให้เราตรวจสอบการประยุกต์ใช้อัลกอริทึมการทำคลัสเตอร์อื่น ใน WEKA explorer เลือกไฟล์HierarchicalClusterer เป็นอัลกอริทึม ML ของคุณดังที่แสดงในภาพหน้าจอที่แสดงด้านล่าง -
เลือก Cluster mode เลือกเป็น Classes to cluster evaluationแล้วคลิกที่ไฟล์ Startปุ่ม. คุณจะเห็นผลลัพธ์ต่อไปนี้ -
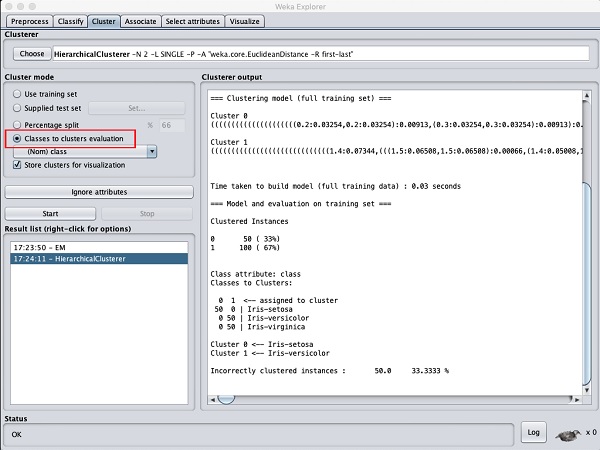
สังเกตว่าในไฟล์ Result listมีรายการผลลัพธ์สองรายการ: รายการแรกคือผลลัพธ์ EM และผลลัพธ์ที่สองคือลำดับชั้นปัจจุบัน ในทำนองเดียวกันคุณสามารถใช้อัลกอริทึม ML หลายชุดกับชุดข้อมูลเดียวกันและเปรียบเทียบผลลัพธ์ได้อย่างรวดเร็ว
หากคุณตรวจสอบต้นไม้ที่สร้างโดยอัลกอริทึมนี้คุณจะเห็นผลลัพธ์ต่อไปนี้ -
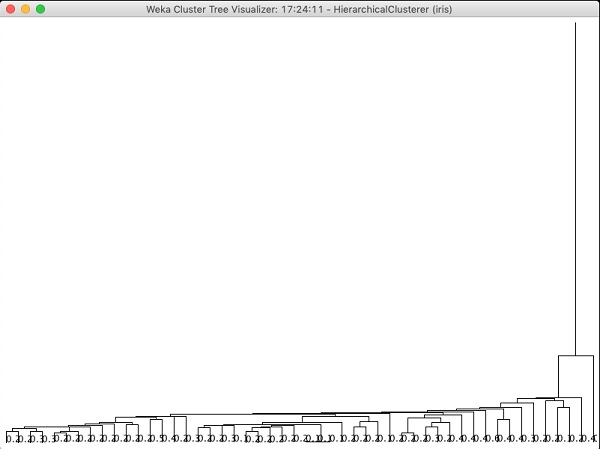
ในบทถัดไปคุณจะศึกษาไฟล์ Associate ประเภทของอัลกอริทึม ML