Weka - คู่มือฉบับย่อ
รากฐานของแอปพลิเคชัน Machine Learning คือข้อมูลไม่ใช่แค่ข้อมูลเล็กน้อย แต่เป็นข้อมูลขนาดใหญ่ที่เรียกว่า Big Data ในคำศัพท์ปัจจุบัน
ในการฝึกอบรมเครื่องเพื่อวิเคราะห์ข้อมูลขนาดใหญ่คุณต้องมีข้อพิจารณาหลายประการเกี่ยวกับข้อมูล -
- ข้อมูลต้องสะอาด
- ไม่ควรมีค่าว่าง
นอกจากนี้ไม่ใช่ทุกคอลัมน์ในตารางข้อมูลที่จะมีประโยชน์สำหรับประเภทของการวิเคราะห์ที่คุณพยายามบรรลุ คอลัมน์ข้อมูลที่ไม่เกี่ยวข้องหรือ 'คุณลักษณะ' ตามที่เรียกในคำศัพท์ของ Machine Learning จะต้องถูกลบออกก่อนที่ข้อมูลจะถูกป้อนเข้าในอัลกอริทึมการเรียนรู้ของเครื่อง
กล่าวโดยสรุปข้อมูลขนาดใหญ่ของคุณจำเป็นต้องมีการประมวลผลล่วงหน้าจำนวนมากก่อนจึงจะสามารถใช้กับ Machine Learning ได้ เมื่อข้อมูลพร้อมแล้วคุณจะใช้อัลกอริทึม Machine Learning ต่างๆเช่นการจัดหมวดหมู่การถดถอยการจัดกลุ่มและอื่น ๆ เพื่อแก้ปัญหาในตอนท้ายของคุณ
ประเภทของอัลกอริทึมที่คุณใช้นั้นขึ้นอยู่กับความรู้เกี่ยวกับโดเมนของคุณเป็นส่วนใหญ่ แม้จะอยู่ในประเภทเดียวกันตัวอย่างเช่นการจัดประเภทก็มีอัลกอริทึมหลายแบบ คุณอาจต้องการทดสอบอัลกอริทึมต่างๆภายใต้คลาสเดียวกันเพื่อสร้างโมเดลแมชชีนเลิร์นนิงที่มีประสิทธิภาพ ในขณะที่ทำเช่นนั้นคุณต้องการการแสดงภาพข้อมูลที่ประมวลผลดังนั้นคุณจึงต้องใช้เครื่องมือแสดงภาพด้วย
ในบทต่อ ๆ ไปคุณจะได้เรียนรู้เกี่ยวกับ Weka ซึ่งเป็นซอฟต์แวร์ที่ช่วยให้คุณทำงานกับข้อมูลขนาดใหญ่ได้อย่างสะดวกสบาย
WEKA - ซอฟต์แวร์โอเพนซอร์สมีเครื่องมือสำหรับการประมวลผลข้อมูลล่วงหน้าการใช้อัลกอริทึมการเรียนรู้ของเครื่องและเครื่องมือการแสดงภาพต่างๆเพื่อให้คุณสามารถพัฒนาเทคนิคการเรียนรู้ของเครื่องและนำไปใช้กับปัญหาการขุดข้อมูลในโลกแห่งความเป็นจริง สิ่งที่ WEKA นำเสนอมีสรุปไว้ในแผนภาพต่อไปนี้ -
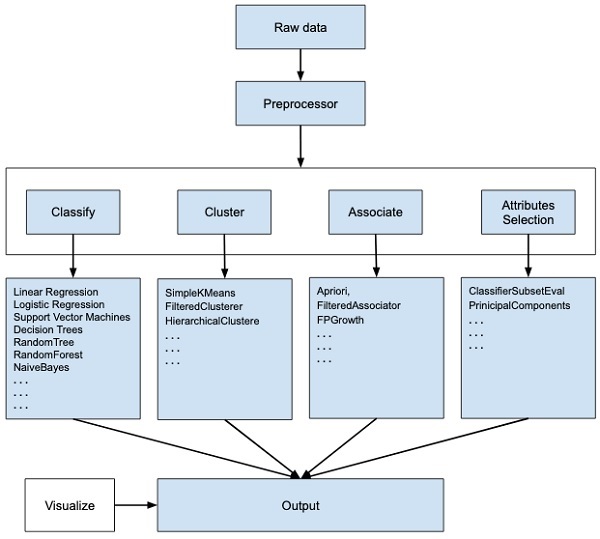
หากคุณสังเกตจุดเริ่มต้นของการไหลของภาพคุณจะเข้าใจว่ามีหลายขั้นตอนในการจัดการกับข้อมูลขนาดใหญ่เพื่อให้เหมาะสำหรับการเรียนรู้ของเครื่อง -
ขั้นแรกคุณจะเริ่มต้นด้วยข้อมูลดิบที่รวบรวมจากฟิลด์ ข้อมูลนี้อาจมีค่า null หลายค่าและฟิลด์ที่ไม่เกี่ยวข้อง คุณใช้เครื่องมือก่อนการประมวลผลข้อมูลที่มีให้ใน WEKA เพื่อล้างข้อมูล
จากนั้นคุณจะบันทึกข้อมูลที่ประมวลผลล่วงหน้าไว้ในที่จัดเก็บในตัวเครื่องของคุณเพื่อใช้อัลกอริทึม ML
ถัดไปขึ้นอยู่กับชนิดของรูปแบบ ML ที่คุณพยายามพัฒนาคุณจะเลือกหนึ่งในตัวเลือกเช่น Classify, Cluster, หรือ Associate. Attributes Selection อนุญาตให้เลือกคุณลักษณะโดยอัตโนมัติเพื่อสร้างชุดข้อมูลที่ลดลง
โปรดทราบว่าในแต่ละหมวดหมู่ WEKA มีการใช้งานอัลกอริทึมต่างๆ คุณจะต้องเลือกอัลกอริทึมที่คุณต้องการตั้งค่าพารามิเตอร์ที่ต้องการและเรียกใช้บนชุดข้อมูล
จากนั้น WEKA จะให้ผลลัพธ์ทางสถิติของการประมวลผลแบบจำลองแก่คุณ มีเครื่องมือแสดงภาพเพื่อตรวจสอบข้อมูล
สามารถใช้โมเดลต่างๆกับชุดข้อมูลเดียวกันได้ จากนั้นคุณสามารถเปรียบเทียบผลลัพธ์ของรุ่นต่างๆและเลือกสิ่งที่ดีที่สุดที่ตรงตามวัตถุประสงค์ของคุณ
ดังนั้นการใช้ WEKA จึงส่งผลให้เกิดการพัฒนาโมเดลแมชชีนเลิร์นนิงโดยรวมได้เร็วขึ้น
ตอนนี้เราได้เห็นแล้วว่า WEKA คืออะไรและทำหน้าที่อะไรในบทถัดไปให้เราเรียนรู้วิธีการติดตั้ง WEKA บนเครื่องคอมพิวเตอร์ของคุณ
ในการติดตั้ง WEKA บนเครื่องของคุณให้ไปที่เว็บไซต์อย่างเป็นทางการของ WEKAและดาวน์โหลดไฟล์การติดตั้ง WEKA รองรับการติดตั้งบน Windows, Mac OS X และ Linux คุณเพียงแค่ทำตามคำแนะนำในหน้านี้เพื่อติดตั้ง WEKA สำหรับระบบปฏิบัติการของคุณ
ขั้นตอนในการติดตั้งบน Mac มีดังต่อไปนี้ -
- ดาวน์โหลดไฟล์การติดตั้ง Mac
- ดับเบิลคลิกที่ไฟล์ weka-3-8-3-corretto-jvm.dmg file.
คุณจะเห็นหน้าจอต่อไปนี้เมื่อติดตั้งสำเร็จ
- คลิกที่ weak-3-8-3-corretto-jvm ไอคอนเพื่อเริ่ม Weka
- หรือคุณอาจเริ่มจากบรรทัดคำสั่ง -
java -jar weka.jarแอปพลิเคชัน WEKA GUI Chooser จะเริ่มทำงานและคุณจะเห็นหน้าจอต่อไปนี้ -
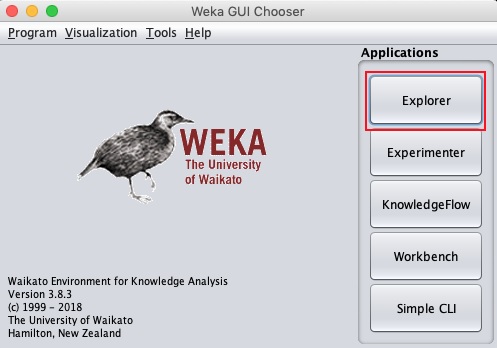
แอปพลิเคชัน GUI Chooser ช่วยให้คุณสามารถเรียกใช้แอปพลิเคชันได้ห้าประเภทตามที่ระบุไว้ที่นี่ -
- Explorer
- Experimenter
- KnowledgeFlow
- Workbench
- CLI ที่เรียบง่าย
เราจะใช้ Explorer ในบทช่วยสอนนี้
ในบทนี้ให้เราดูฟังก์ชันต่างๆที่นักสำรวจมีให้สำหรับการทำงานกับข้อมูลขนาดใหญ่
เมื่อคุณคลิกที่ไฟล์ Explorer ในปุ่ม Applications ตัวเลือกจะเปิดหน้าจอต่อไปนี้ -
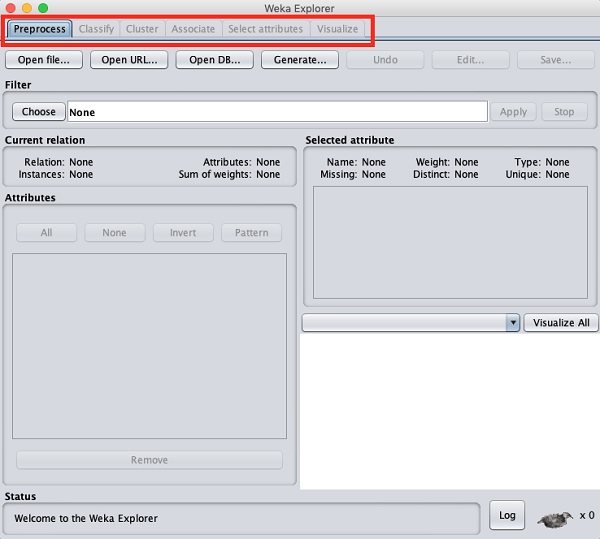
ด้านบนคุณจะเห็นแท็บต่างๆตามรายการที่นี่ -
- Preprocess
- Classify
- Cluster
- Associate
- เลือกแอตทริบิวต์
- Visualize
ภายใต้แท็บเหล่านี้มีอัลกอริธึมแมชชีนเลิร์นนิงที่ใช้งานล่วงหน้าหลายตัว ให้เราดูรายละเอียดแต่ละข้อในตอนนี้
แท็บ Preprocess
เริ่มแรกเมื่อคุณเปิด explorer เฉพาะไฟล์ Preprocessเปิดใช้งานแท็บ ขั้นตอนแรกในการเรียนรู้ของเครื่องคือการประมวลผลข้อมูลล่วงหน้า ดังนั้นในPreprocess คุณจะเลือกไฟล์ข้อมูลประมวลผลและทำให้เหมาะสมสำหรับการใช้อัลกอริทึมการเรียนรู้ของเครื่องต่างๆ
จำแนกแท็บ
Classifyแท็บมีอัลกอริทึมการเรียนรู้ของเครื่องหลายอย่างสำหรับการจัดหมวดหมู่ข้อมูลของคุณ หากต้องการแสดงรายการบางส่วนคุณอาจใช้อัลกอริทึมเช่น Linear Regression, Logistic Regression, Support Vector Machines, Decision Trees, RandomTree, RandomForest, NaiveBayes และอื่น ๆ รายการนี้มีข้อมูลครบถ้วนสมบูรณ์และมีทั้งอัลกอริธึมการเรียนรู้ของเครื่องที่อยู่ภายใต้การดูแลและไม่ได้รับการดูแล
แท็บคลัสเตอร์
ภายใต้ Cluster มีอัลกอริธึมการทำคลัสเตอร์หลายแบบเช่น SimpleKMeans, FilteredClusterer, HierarchicalClusterer และอื่น ๆ
เชื่อมโยงแท็บ
ภายใต้ Associate คุณจะพบ Apriori, FilteredAssociator และ FPGrowth
เลือกแท็บคุณสมบัติ
Select Attributes ช่วยให้คุณสามารถเลือกคุณลักษณะตามอัลกอริทึมต่างๆเช่น ClassifierSubsetEval, PrinicipalComponents เป็นต้น
แสดงภาพแท็บ
สุดท้าย Visualize ตัวเลือกช่วยให้คุณเห็นภาพข้อมูลที่ประมวลผลของคุณสำหรับการวิเคราะห์
อย่างที่คุณสังเกตเห็น WEKA มีอัลกอริทึมที่พร้อมใช้งานมากมายสำหรับการทดสอบและสร้างแอปพลิเคชันแมชชีนเลิร์นนิงของคุณ ในการใช้ WEKA อย่างมีประสิทธิภาพคุณต้องมีความรู้ที่ดีเกี่ยวกับอัลกอริทึมเหล่านี้วิธีการทำงานสิ่งที่จะเลือกภายใต้สถานการณ์ใดสิ่งที่ต้องค้นหาในผลลัพธ์ที่ประมวลผลและอื่น ๆ ในระยะสั้นคุณต้องมีพื้นฐานที่มั่นคงในการเรียนรู้ของเครื่องเพื่อใช้ WEKA อย่างมีประสิทธิภาพในการสร้างแอปของคุณ
ในบทต่อ ๆ ไปคุณจะได้ศึกษาแต่ละแท็บใน explorer ในเชิงลึก
ในบทนี้เราจะเริ่มต้นด้วยแท็บแรกที่คุณใช้เพื่อประมวลผลข้อมูลล่วงหน้า นี่เป็นเรื่องปกติสำหรับอัลกอริทึมทั้งหมดที่คุณจะนำไปใช้กับข้อมูลของคุณในการสร้างโมเดลและเป็นขั้นตอนทั่วไปสำหรับการดำเนินการที่ตามมาทั้งหมดใน WEKA
เพื่อให้อัลกอริทึมการเรียนรู้ของเครื่องให้ความแม่นยำที่ยอมรับได้สิ่งสำคัญคือคุณต้องล้างข้อมูลของคุณก่อน เนื่องจากข้อมูลดิบที่รวบรวมจากฟิลด์อาจมีค่า null คอลัมน์ที่ไม่เกี่ยวข้องเป็นต้น
ในบทนี้คุณจะได้เรียนรู้วิธีประมวลผลข้อมูลดิบล่วงหน้าและสร้างชุดข้อมูลที่สะอาดและมีความหมายสำหรับการใช้งานต่อไป
ขั้นแรกคุณจะได้เรียนรู้การโหลดไฟล์ข้อมูลลงใน WEKA explorer ข้อมูลสามารถโหลดได้จากแหล่งต่อไปนี้ -
- ระบบไฟล์ภายในเครื่อง
- Web
- Database
ในบทนี้เราจะเห็นตัวเลือกการโหลดข้อมูลทั้งหมดสามตัวเลือกโดยละเอียด
กำลังโหลดข้อมูลจาก Local File System
ใต้แท็บ Machine Learning ที่คุณศึกษาในบทเรียนก่อนหน้านี้คุณจะพบปุ่มสามปุ่มต่อไปนี้ -
- เปิดไฟล์ …
- เปิด URL ...
- เปิดฐานข้อมูล ...
คลิกที่ Open fileปุ่ม ... หน้าต่างไดเร็กทอรีเนวิเกเตอร์จะเปิดขึ้นดังที่แสดงในหน้าจอต่อไปนี้ -
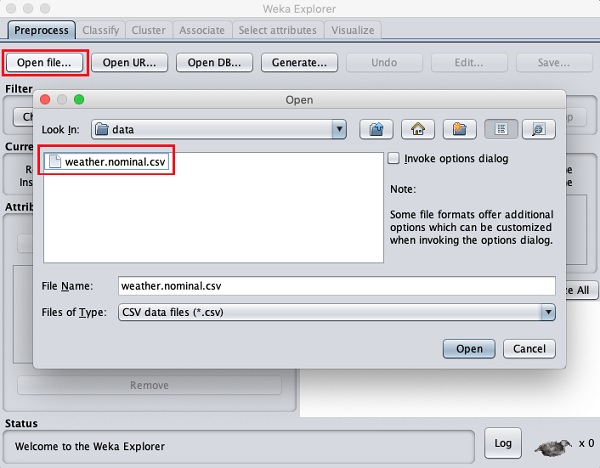
ตอนนี้ไปที่โฟลเดอร์ที่เก็บไฟล์ข้อมูลของคุณ การติดตั้ง WEKA มีฐานข้อมูลตัวอย่างมากมายให้คุณทดลอง สิ่งเหล่านี้มีอยู่ในไฟล์data โฟลเดอร์ของการติดตั้ง WEKA
เพื่อการเรียนรู้เลือกไฟล์ข้อมูลจากโฟลเดอร์นี้ เนื้อหาของไฟล์จะถูกโหลดในสภาพแวดล้อม WEKA เร็ว ๆ นี้เราจะเรียนรู้วิธีตรวจสอบและประมวลผลข้อมูลที่โหลดนี้ ก่อนหน้านั้นให้เราดูวิธีการโหลดไฟล์ข้อมูลจากเว็บ
กำลังโหลดข้อมูลจากเว็บ
เมื่อคุณคลิกที่ไฟล์ Open URL … คุณจะเห็นหน้าต่างดังต่อไปนี้ -
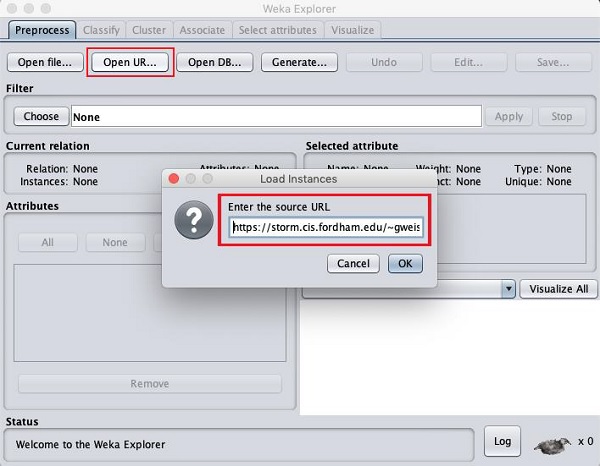
เราจะเปิดไฟล์จาก URL สาธารณะพิมพ์ URL ต่อไปนี้ในกล่องป๊อปอัป -
https://storm.cis.fordham.edu/~gweiss/data-mining/weka-data/weather.nominal.arff
คุณสามารถระบุ URL อื่นที่จัดเก็บข้อมูลของคุณ Explorer จะโหลดข้อมูลจากไซต์ระยะไกลเข้าสู่สภาพแวดล้อม
กำลังโหลดข้อมูลจาก DB
เมื่อคุณคลิกที่ไฟล์ Open DB ... คุณจะเห็นหน้าต่างดังต่อไปนี้ -
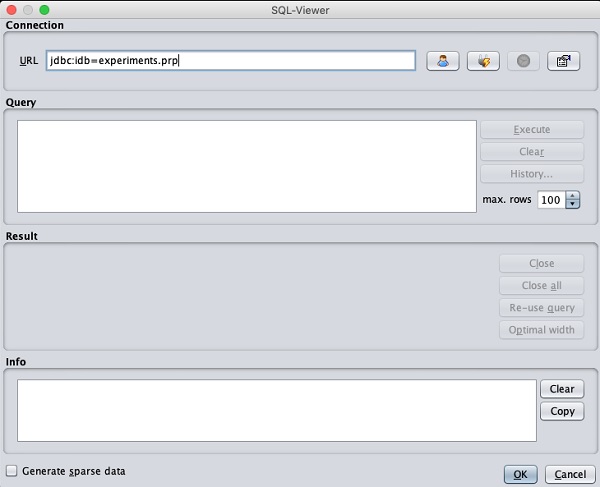
ตั้งค่าสตริงการเชื่อมต่อกับฐานข้อมูลของคุณตั้งค่าแบบสอบถามสำหรับการเลือกข้อมูลประมวลผลแบบสอบถามและโหลดระเบียนที่เลือกใน WEKA
WEKA รองรับรูปแบบไฟล์จำนวนมากสำหรับข้อมูล นี่คือรายการทั้งหมด -
- arff
- arff.gz
- bsi
- csv
- dat
- data
- json
- json.gz
- libsvm
- m
- names
- xrff
- xrff.gz
ประเภทของไฟล์ที่รองรับจะแสดงอยู่ในกล่องรายการแบบหล่นลงที่ด้านล่างของหน้าจอ สิ่งนี้แสดงในภาพหน้าจอด้านล่าง
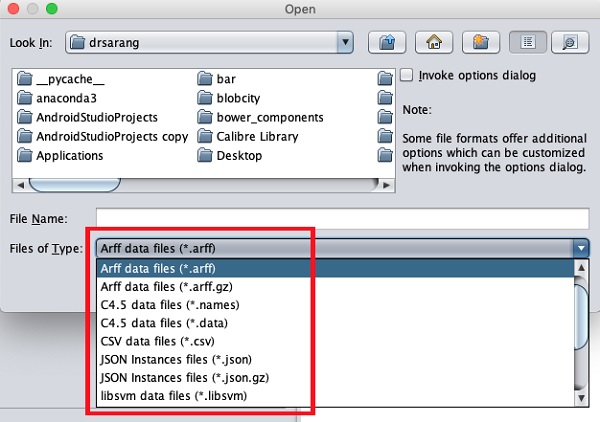
อย่างที่คุณสังเกตเห็นว่ารองรับหลายรูปแบบรวมถึง CSV และ JSON ประเภทไฟล์เริ่มต้นคือ Arff
รูปแบบ Arff
อัน Arff ไฟล์มีสองส่วน - ส่วนหัวและข้อมูล
- ส่วนหัวอธิบายประเภทแอตทริบิวต์
- ส่วนข้อมูลประกอบด้วยรายการข้อมูลที่คั่นด้วยจุลภาค
ดังตัวอย่างสำหรับรูปแบบ Arff ไฟล์ Weather ไฟล์ข้อมูลที่โหลดจากฐานข้อมูลตัวอย่าง WEKA แสดงอยู่ด้านล่าง -

จากภาพหน้าจอคุณสามารถสรุปประเด็นต่อไปนี้ -
แท็ก @relation กำหนดชื่อของฐานข้อมูล
แท็ก @attribute กำหนดแอตทริบิวต์
แท็ก @data เริ่มต้นรายการแถวข้อมูลแต่ละแถวมีฟิลด์ที่คั่นด้วยเครื่องหมายจุลภาค
แอตทริบิวต์สามารถรับค่าเล็กน้อยเช่นในกรณีของ Outlook ที่แสดงไว้ที่นี่ -
@attribute outlook (sunny, overcast, rainy)แอตทริบิวต์สามารถรับค่าจริงได้ในกรณีนี้ -
@attribute temperature realคุณยังสามารถตั้งค่า Target หรือตัวแปร Class ที่เรียกว่า play ดังที่แสดงไว้ที่นี่ -
@attribute play (yes, no)เป้าหมายจะถือว่าค่าเล็กน้อยสองค่าใช่หรือไม่ใช่
รูปแบบอื่น ๆ
Explorer สามารถโหลดข้อมูลในรูปแบบที่กล่าวถึงก่อนหน้านี้ เนื่องจาก arff เป็นรูปแบบที่ต้องการใน WEKA คุณสามารถโหลดข้อมูลจากรูปแบบใดก็ได้และบันทึกลงในรูปแบบ arff เพื่อใช้ในภายหลัง หลังจากประมวลผลข้อมูลล่วงหน้าแล้วเพียงแค่บันทึกลงในรูปแบบ arff เพื่อการวิเคราะห์เพิ่มเติม
ตอนนี้คุณได้เรียนรู้วิธีโหลดข้อมูลลงใน WEKA แล้วในบทถัดไปคุณจะได้เรียนรู้วิธีประมวลผลข้อมูลล่วงหน้า
ข้อมูลที่รวบรวมจากสนามประกอบด้วยสิ่งที่ไม่ต้องการมากมายที่นำไปสู่การวิเคราะห์ที่ผิดพลาด ตัวอย่างเช่นข้อมูลอาจมีช่องว่างอาจมีคอลัมน์ที่ไม่เกี่ยวข้องกับการวิเคราะห์ปัจจุบันเป็นต้น ดังนั้นข้อมูลจะต้องได้รับการประมวลผลล่วงหน้าเพื่อให้เป็นไปตามข้อกำหนดของประเภทการวิเคราะห์ที่คุณต้องการ นี่คือสิ่งที่เสร็จสิ้นในโมดูลก่อนการประมวลผล
เพื่อแสดงให้เห็นถึงคุณสมบัติที่มีอยู่ในการประมวลผลล่วงหน้าเราจะใช้ไฟล์ Weather ฐานข้อมูลที่มีให้ในการติดตั้ง
ใช้ Open file ... ตัวเลือกภายใต้ Preprocess เลือกแท็ก weather-nominal.arff ไฟล์.
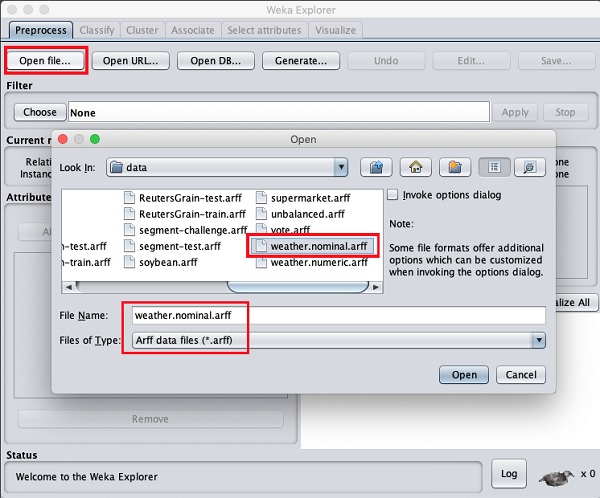
เมื่อคุณเปิดไฟล์หน้าจอของคุณจะมีลักษณะดังที่แสดงไว้ที่นี่ -
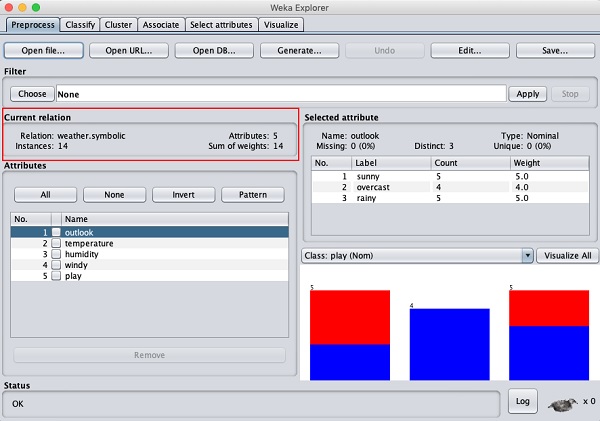
หน้าจอนี้จะบอกเราหลายอย่างเกี่ยวกับข้อมูลที่โหลดซึ่งจะกล่าวถึงเพิ่มเติมในบทนี้
การทำความเข้าใจข้อมูล
ก่อนอื่นให้เราดูที่ไฮไลต์ Current relationหน้าต่างย่อย จะแสดงชื่อของฐานข้อมูลที่โหลดอยู่ คุณสามารถสรุปได้สองจุดจากหน้าต่างย่อยนี้ -
มี 14 อินสแตนซ์ - จำนวนแถวในตาราง
ตารางประกอบด้วย 5 แอตทริบิวต์ - ฟิลด์ซึ่งจะกล่าวถึงในส่วนต่อไป
ทางด้านซ้ายให้สังเกต Attributes หน้าต่างย่อยที่แสดงฟิลด์ต่างๆในฐานข้อมูล
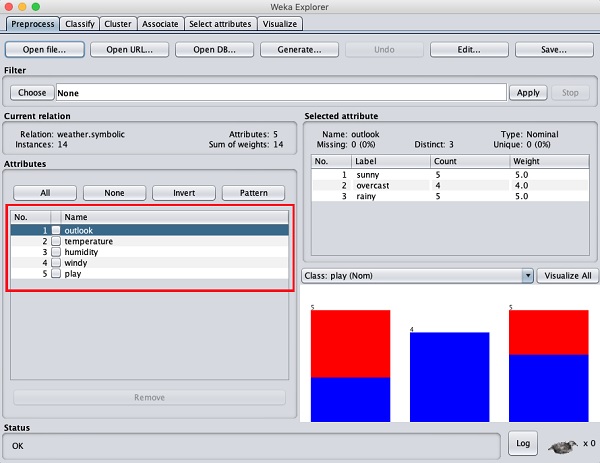
weatherฐานข้อมูลประกอบด้วยห้าฟิลด์ - แนวโน้มอุณหภูมิความชื้นลมแรงและการเล่น เมื่อคุณเลือกแอตทริบิวต์จากรายการนี้โดยคลิกที่รายละเอียดเพิ่มเติมเกี่ยวกับแอตทริบิวต์นั้นจะแสดงทางด้านขวามือ
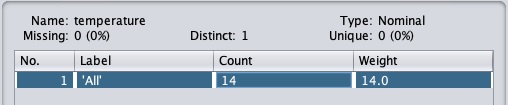
ให้เราเลือกแอตทริบิวต์อุณหภูมิก่อน เมื่อคุณคลิกที่มันคุณจะเห็นหน้าจอต่อไปนี้ -
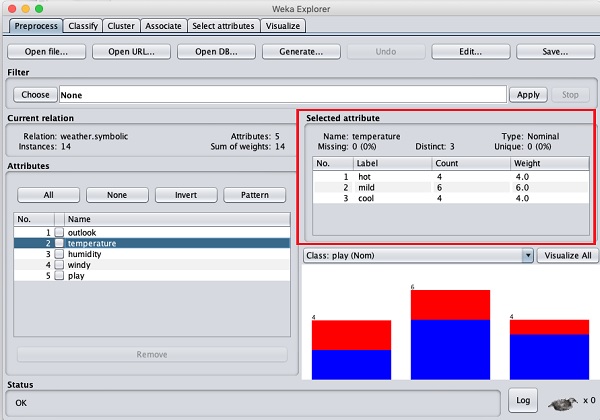
ใน Selected Attribute หน้าต่างย่อยคุณสามารถสังเกตสิ่งต่อไปนี้ -
ชื่อและประเภทของแอตทริบิวต์จะปรากฏขึ้น
ประเภทของไฟล์ temperature แอตทริบิวต์คือ Nominal.
จำนวน Missing ค่าเป็นศูนย์
มีค่าที่แตกต่างกันสามค่าโดยไม่มีค่าที่ไม่ซ้ำกัน
ตารางด้านล่างข้อมูลนี้แสดงค่าเล็กน้อยสำหรับฟิลด์นี้ว่าร้อนอ่อนและเย็น
นอกจากนี้ยังแสดงจำนวนและน้ำหนักในรูปของเปอร์เซ็นต์สำหรับแต่ละค่าเล็กน้อย
ที่ด้านล่างของหน้าต่างคุณจะเห็นการแสดงภาพของไฟล์ class ค่า
หากคุณคลิกที่ไฟล์ Visualize All คุณจะสามารถเห็นคุณสมบัติทั้งหมดในหน้าต่างเดียวดังที่แสดงไว้ที่นี่ -
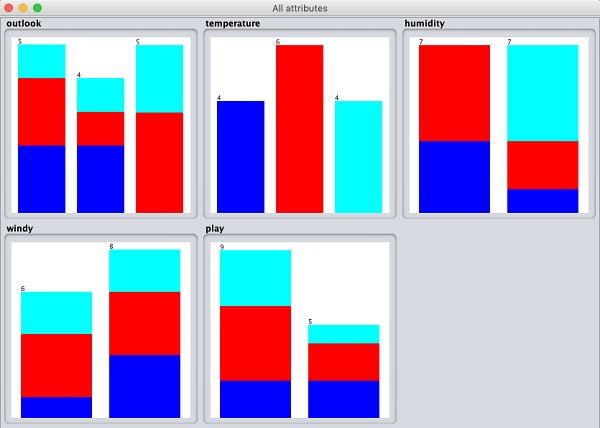
การลบแอตทริบิวต์
หลายครั้งข้อมูลที่คุณต้องการใช้สำหรับการสร้างแบบจำลองจะมาพร้อมกับฟิลด์ที่ไม่เกี่ยวข้องมากมาย ตัวอย่างเช่นฐานข้อมูลลูกค้าอาจมีหมายเลขโทรศัพท์มือถือของเขาซึ่งเกี่ยวข้องกับการวิเคราะห์อันดับเครดิตของเขา
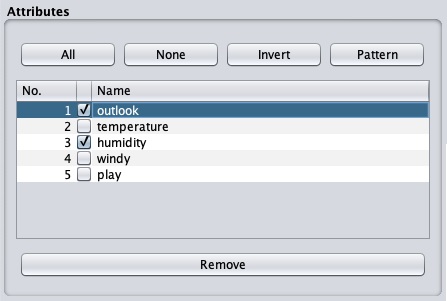
ในการลบ Attribute / s ให้เลือกและคลิกที่ไฟล์ Remove ปุ่มด้านล่าง
แอตทริบิวต์ที่เลือกจะถูกลบออกจากฐานข้อมูล หลังจากที่คุณประมวลผลข้อมูลล่วงหน้าอย่างสมบูรณ์แล้วคุณสามารถบันทึกไว้สำหรับการสร้างแบบจำลอง
จากนั้นคุณจะได้เรียนรู้การประมวลผลข้อมูลล่วงหน้าโดยใช้ตัวกรองกับข้อมูลนี้
การใช้ตัวกรอง
เทคนิคการเรียนรู้ของเครื่องบางอย่างเช่นการขุดกฎการเชื่อมโยงต้องใช้ข้อมูลที่เป็นหมวดหมู่ เพื่อแสดงให้เห็นถึงการใช้ฟิลเตอร์เราจะใช้weather-numeric.arff ฐานข้อมูลที่มีสอง numeric คุณลักษณะ - temperature และ humidity.
เราจะแปลงสิ่งเหล่านี้เป็น nominalโดยใช้ตัวกรองกับข้อมูลดิบของเรา คลิกที่Choose ในปุ่ม Filter หน้าต่างย่อยและเลือกตัวกรองต่อไปนี้ -
weka→filters→supervised→attribute→Discretize

คลิกที่ Apply และตรวจสอบไฟล์ temperature และ / หรือ humidityแอตทริบิวต์ คุณจะสังเกตเห็นว่าสิ่งเหล่านี้เปลี่ยนจากตัวเลขเป็นประเภทเล็กน้อย
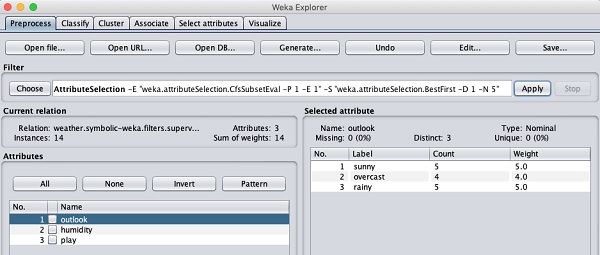
ให้เราดูตัวกรองอื่นในขณะนี้ สมมติว่าคุณต้องการเลือกแอตทริบิวต์ที่ดีที่สุดสำหรับการตัดสินใจplay. เลือกและใช้ตัวกรองต่อไปนี้ -
weka→filters→supervised→attribute→AttributeSelection
คุณจะสังเกตเห็นว่ามันลบแอตทริบิวต์อุณหภูมิและความชื้นออกจากฐานข้อมูล
หลังจากคุณพอใจกับการประมวลผลข้อมูลล่วงหน้าแล้วให้บันทึกข้อมูลโดยคลิกที่ไฟล์ Saveปุ่ม ... คุณจะใช้ไฟล์ที่บันทึกไว้นี้สำหรับการสร้างโมเดล
ในบทต่อไปเราจะสำรวจการสร้างแบบจำลองโดยใช้อัลกอริทึม ML ที่กำหนดไว้ล่วงหน้าหลายแบบ
แอปพลิเคชันการเรียนรู้ของเครื่องจำนวนมากเกี่ยวข้องกับการจำแนกประเภท ตัวอย่างเช่นคุณอาจต้องการจัดประเภทของเนื้องอกว่าเป็นมะเร็งหรือไม่ร้ายแรง คุณอาจต้องการตัดสินใจว่าจะเล่นเกมนอกบ้านขึ้นอยู่กับสภาพอากาศ โดยทั่วไปการตัดสินใจนี้ขึ้นอยู่กับคุณสมบัติ / เงื่อนไขหลายประการของสภาพอากาศ ดังนั้นคุณอาจต้องการใช้ลักษณนามต้นไม้ในการตัดสินใจว่าจะเล่นหรือไม่
ในบทนี้เราจะเรียนรู้วิธีสร้างตัวจำแนกต้นไม้ดังกล่าวบนข้อมูลสภาพอากาศเพื่อตัดสินใจเกี่ยวกับสภาพการเล่น
การตั้งค่าข้อมูลการทดสอบ
เราจะใช้ไฟล์ข้อมูลสภาพอากาศที่ประมวลผลล่วงหน้าจากบทเรียนที่แล้ว เปิดไฟล์ที่บันทึกไว้โดยใช้ไฟล์Open file ... ตัวเลือกภายใต้ Preprocess คลิกที่แท็บ Classify และคุณจะเห็นหน้าจอต่อไปนี้ -
ก่อนที่คุณจะเรียนรู้เกี่ยวกับตัวแยกประเภทที่มีให้เราตรวจสอบตัวเลือกการทดสอบ คุณจะสังเกตเห็นตัวเลือกการทดสอบสี่แบบตามรายการด้านล่าง -
- ชุดฝึก
- ชุดทดสอบที่ให้มา
- Cross-validation
- การแบ่งเปอร์เซ็นต์
เว้นแต่คุณจะมีชุดการฝึกอบรมของคุณเองหรือชุดทดสอบที่ลูกค้าจัดหาให้คุณจะใช้ตัวเลือกการตรวจสอบความถูกต้องข้ามหรือการแบ่งเปอร์เซ็นต์ ภายใต้การตรวจสอบความถูกต้องคุณสามารถกำหนดจำนวนพับที่ข้อมูลทั้งหมดจะถูกแบ่งและใช้ระหว่างการฝึกซ้ำแต่ละครั้ง ในการแบ่งเปอร์เซ็นต์คุณจะแบ่งข้อมูลระหว่างการฝึกและการทดสอบโดยใช้เปอร์เซ็นต์การแบ่งชุด
ตอนนี้ให้ใช้ค่าเริ่มต้น play ตัวเลือกสำหรับคลาสเอาต์พุต -
ถัดไปคุณจะเลือกลักษณนาม
การเลือกลักษณนาม
คลิกที่ปุ่มเลือกและเลือกลักษณนามต่อไปนี้ -
weka→classifiers>trees>J48
สิ่งนี้แสดงในภาพหน้าจอด้านล่าง -
คลิกที่ Startปุ่มเพื่อเริ่มกระบวนการจัดหมวดหมู่ หลังจากนั้นไม่นานผลการจัดประเภทจะปรากฏบนหน้าจอของคุณดังที่แสดงไว้ที่นี่ -
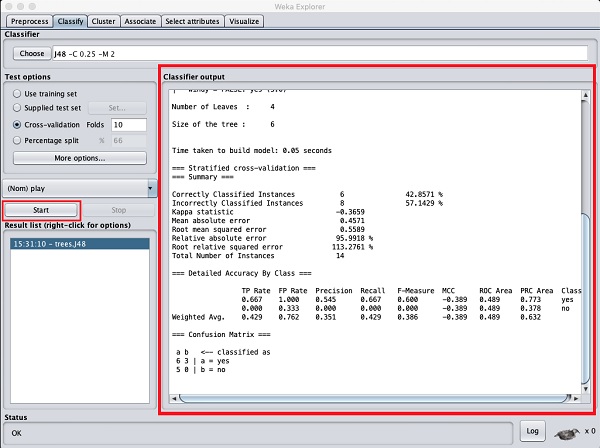
ให้เราตรวจสอบผลลัพธ์ที่แสดงทางด้านขวามือของหน้าจอ
มันบอกว่าขนาดของต้นไม้คือ 6 คุณจะเห็นภาพของต้นไม้ในไม่ช้า ในสรุประบุว่าอินสแตนซ์ที่จัดประเภทอย่างถูกต้องเป็น 2 และอินสแตนซ์ที่จัดประเภทไม่ถูกต้องเป็น 3 นอกจากนี้ยังระบุด้วยว่าข้อผิดพลาดสัมบูรณ์สัมพัทธ์คือ 110% นอกจากนี้ยังแสดงเมทริกซ์ความสับสน การวิเคราะห์ผลลัพธ์เหล่านี้อยู่นอกเหนือขอบเขตของบทช่วยสอนนี้ อย่างไรก็ตามคุณสามารถสรุปได้อย่างง่ายดายจากผลลัพธ์เหล่านี้ว่าการจัดประเภทไม่เป็นที่ยอมรับและคุณจะต้องมีข้อมูลเพิ่มเติมสำหรับการวิเคราะห์เพื่อปรับแต่งการเลือกคุณสมบัติของคุณสร้างโมเดลใหม่และอื่น ๆ จนกว่าคุณจะพอใจกับความแม่นยำของโมเดล อย่างไรก็ตามนั่นคือสิ่งที่ WEKA เป็นข้อมูลเกี่ยวกับ ช่วยให้คุณทดสอบความคิดของคุณได้อย่างรวดเร็ว
เห็นภาพผลลัพธ์
หากต้องการดูการแสดงภาพของผลลัพธ์ให้คลิกขวาที่ผลลัพธ์ในไฟล์ Result listกล่อง. ตัวเลือกต่างๆจะปรากฏขึ้นบนหน้าจอดังที่แสดงไว้ที่นี่ -
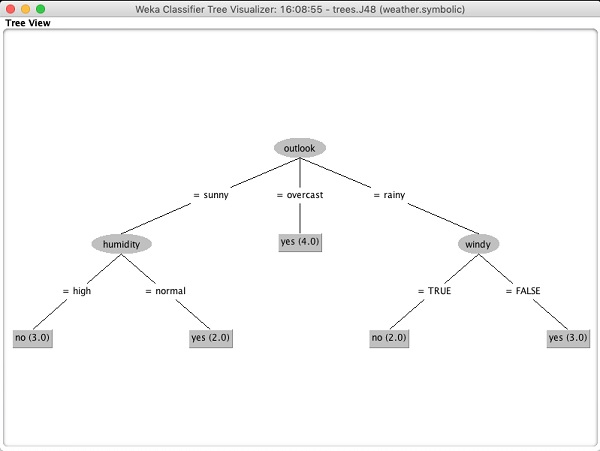
เลือก Visualize tree เพื่อให้เห็นภาพของต้นไม้ข้ามผ่านดังที่เห็นในภาพหน้าจอด้านล่าง -
กำลังเลือก Visualize classifier errors จะพล็อตผลลัพธ์ของการจำแนกตามที่แสดงไว้ที่นี่ -
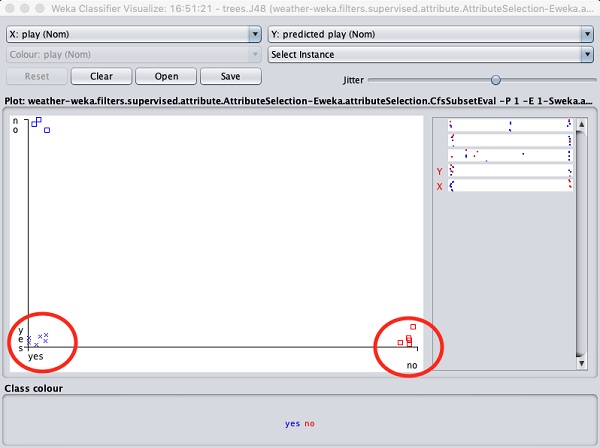
ก cross แสดงถึงอินสแตนซ์ที่จัดประเภทอย่างถูกต้องในขณะที่ squaresแสดงถึงอินสแตนซ์ที่จัดประเภทไม่ถูกต้อง ที่มุมล่างซ้ายของพล็อตคุณจะเห็นไฟล์cross ที่ระบุว่า outlook ตอนนั้นแดดจัด playเกม. นี่คืออินสแตนซ์ที่ถูกจัดประเภทอย่างถูกต้อง หากต้องการค้นหาอินสแตนซ์คุณสามารถแนะนำความกระวนกระวายใจได้โดยเลื่อนไฟล์jitter แถบเลื่อน
พล็อตปัจจุบันคือ outlook เทียบกับ play. ซึ่งจะระบุโดยกล่องรายการแบบเลื่อนลงสองช่องที่ด้านบนสุดของหน้าจอ
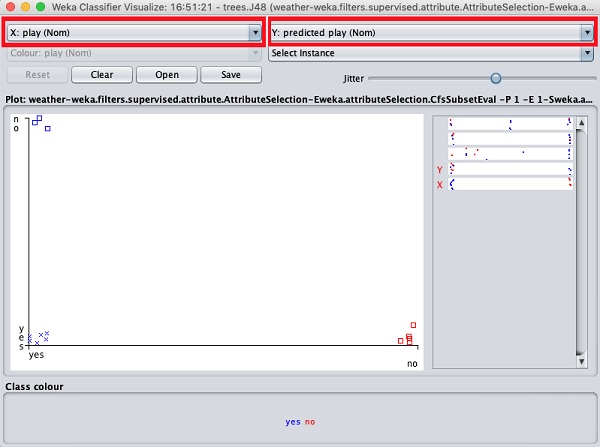
ตอนนี้ลองเลือกตัวเลือกอื่นในแต่ละกล่องเหล่านี้และสังเกตว่าแกน X & Y เปลี่ยนไปอย่างไร สามารถทำได้โดยใช้แถบแนวนอนทางด้านขวามือของพล็อต แต่ละแถบแสดงถึงคุณลักษณะ คลิกซ้ายที่แถบจะตั้งค่าแอตทริบิวต์ที่เลือกบนแกน X ในขณะที่การคลิกขวาจะตั้งค่าบนแกน Y
มีแผนการอื่น ๆ อีกมากมายสำหรับการวิเคราะห์เชิงลึกของคุณ ใช้พวกเขาอย่างรอบคอบเพื่อปรับแต่งโมเดลของคุณ หนึ่งในพล็อตดังกล่าวCost/Benefit analysis แสดงไว้ด้านล่างสำหรับการอ้างอิงอย่างรวดเร็วของคุณ
การอธิบายการวิเคราะห์ในแผนภูมิเหล่านี้อยู่นอกเหนือขอบเขตของบทช่วยสอนนี้ ขอแนะนำให้ผู้อ่านทำความเข้าใจเกี่ยวกับการวิเคราะห์อัลกอริทึมการเรียนรู้ของเครื่อง
ในบทถัดไปเราจะเรียนรู้ชุดถัดไปของอัลกอริทึมการเรียนรู้ของเครื่องนั่นคือการทำคลัสเตอร์
อัลกอริทึมการทำคลัสเตอร์จะค้นหากลุ่มของอินสแตนซ์ที่คล้ายกันในชุดข้อมูลทั้งหมด WEKA สนับสนุนอัลกอริทึมการทำคลัสเตอร์หลายแบบเช่น EM, FilteredClusterer, HierarchicalClusterer, SimpleKMeans เป็นต้น คุณควรเข้าใจอัลกอริทึมเหล่านี้อย่างสมบูรณ์เพื่อใช้ประโยชน์จากความสามารถของ WEKA อย่างเต็มที่
เช่นเดียวกับในกรณีของการจำแนก WEKA ช่วยให้คุณเห็นภาพของคลัสเตอร์ที่ตรวจพบในรูปแบบกราฟิก เพื่อสาธิตการจัดกลุ่มเราจะใช้ฐานข้อมูลม่านตาที่ให้มา ชุดข้อมูลประกอบด้วยสามคลาสละ 50 อินสแตนซ์ แต่ละชั้นหมายถึงพืชไอริสชนิดหนึ่ง
กำลังโหลดข้อมูล
ใน WEKA explorer เลือกไฟล์ Preprocessแท็บ คลิกที่Open file ... และเลือก iris.arffไฟล์ในกล่องโต้ตอบการเลือกไฟล์ เมื่อคุณโหลดข้อมูลหน้าจอจะมีลักษณะดังที่แสดงด้านล่าง -
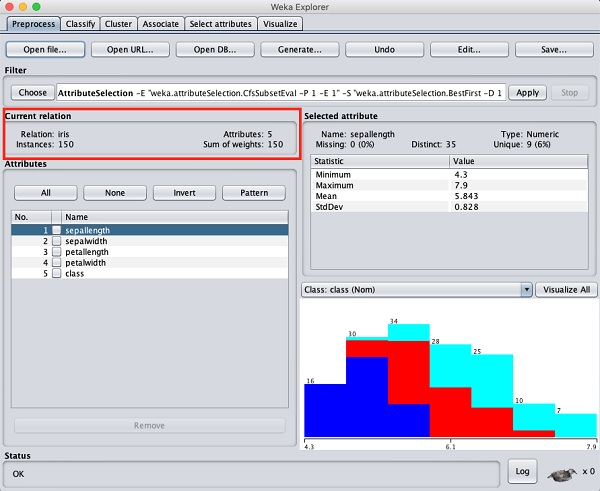
คุณสามารถสังเกตได้ว่ามี 150 อินสแตนซ์และ 5 แอตทริบิวต์ ชื่อของแอตทริบิวต์แสดงรายการเป็นsepallength, sepalwidth, petallength, petalwidth และ class. แอตทริบิวต์สี่รายการแรกเป็นประเภทตัวเลขในขณะที่คลาสเป็นประเภทระบุที่มีค่าต่างกัน 3 ค่า ตรวจสอบแอตทริบิวต์แต่ละรายการเพื่อทำความเข้าใจคุณลักษณะของฐานข้อมูล เราจะไม่ดำเนินการใด ๆ ล่วงหน้ากับข้อมูลนี้และดำเนินการสร้างแบบจำลองทันที
การทำคลัสเตอร์
คลิกที่ ClusterTAB เพื่อใช้อัลกอริทึมการทำคลัสเตอร์กับข้อมูลที่โหลดของเรา คลิกที่Chooseปุ่ม. คุณจะเห็นหน้าจอต่อไปนี้ -

ตอนนี้เลือก EMเป็นอัลกอริทึมการจัดกลุ่ม ในCluster mode หน้าต่างย่อยเลือกไฟล์ Classes to clusters evaluation ตามที่แสดงในภาพหน้าจอด้านล่าง -

คลิกที่ Startปุ่มเพื่อประมวลผลข้อมูล หลังจากนั้นสักครู่ผลลัพธ์จะถูกนำเสนอบนหน้าจอ
ต่อไปให้เราศึกษาผลลัพธ์
การตรวจสอบผลลัพธ์
ผลลัพธ์ของการประมวลผลข้อมูลจะแสดงในหน้าจอด้านล่าง -
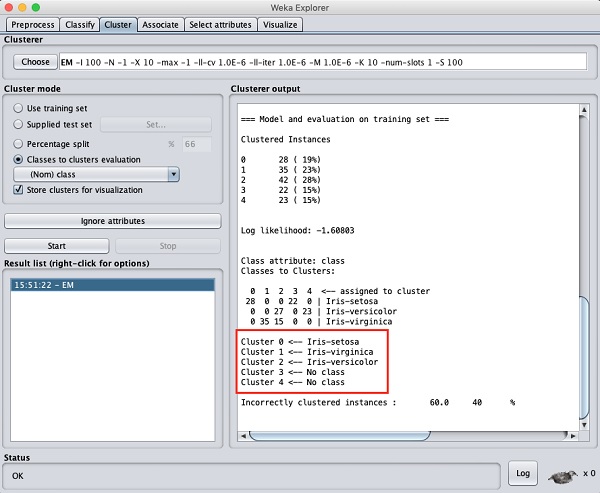
จากหน้าจอเอาต์พุตคุณสามารถสังเกตได้ว่า -
ตรวจพบอินสแตนซ์แบบคลัสเตอร์ 5 รายการในฐานข้อมูล
Cluster 0 เป็นตัวแทนของ setosa Cluster 1 แสดงถึง virginica Cluster 2 แสดงถึงความหลากหลายในขณะที่สองคลัสเตอร์สุดท้ายไม่มีคลาสใด ๆ ที่เกี่ยวข้อง
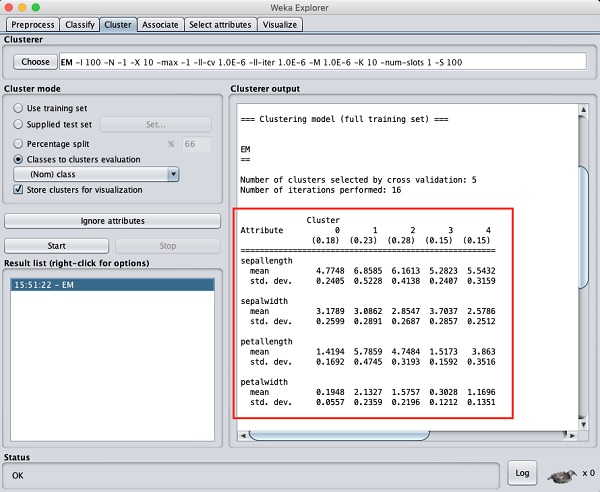
หากคุณเลื่อนหน้าต่างผลลัพธ์ขึ้นคุณจะเห็นสถิติบางอย่างที่ให้ค่าเฉลี่ยและค่าเบี่ยงเบนมาตรฐานสำหรับแต่ละแอตทริบิวต์ในคลัสเตอร์ต่างๆที่ตรวจพบ สิ่งนี้แสดงในภาพหน้าจอด้านล่าง -
ต่อไปเราจะดูการแสดงภาพของคลัสเตอร์
การแสดงภาพคลัสเตอร์
หากต้องการดูภาพของคลัสเตอร์ให้คลิกขวาที่ไฟล์ EM ส่งผลให้ไฟล์ Result list. คุณจะเห็นตัวเลือกต่อไปนี้ -
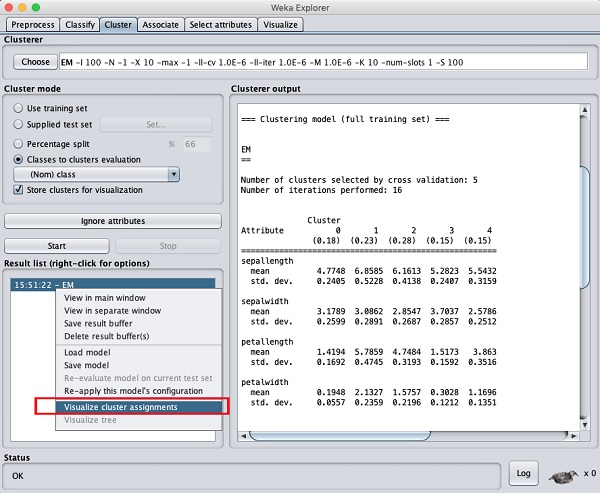
เลือก Visualize cluster assignments. คุณจะเห็นผลลัพธ์ต่อไปนี้ -
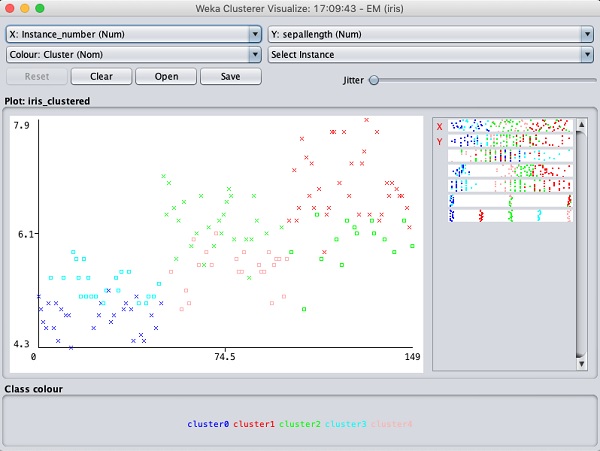
เช่นเดียวกับในกรณีของการจัดประเภทคุณจะสังเกตเห็นความแตกต่างระหว่างอินสแตนซ์ที่ระบุอย่างถูกต้องและไม่ถูกต้อง คุณสามารถเล่นได้โดยเปลี่ยนแกน X และ Y เพื่อวิเคราะห์ผลลัพธ์ คุณอาจใช้การกระวนกระวายใจเช่นเดียวกับในกรณีของการจัดประเภทเพื่อค้นหาความเข้มข้นของอินสแตนซ์ที่ระบุอย่างถูกต้อง การดำเนินการในพล็อตการแสดงภาพคล้ายกับที่คุณศึกษาในกรณีของการจำแนกประเภท
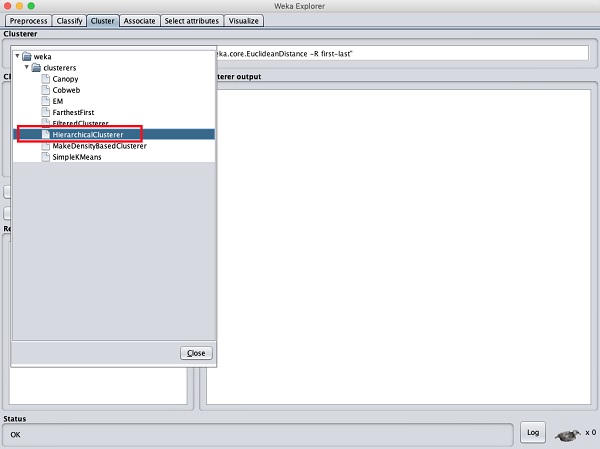
การใช้ Hierarchical Clusterer
เพื่อแสดงให้เห็นถึงพลังของ WEKA ตอนนี้ให้เราตรวจสอบการประยุกต์ใช้อัลกอริทึมการทำคลัสเตอร์อื่น ใน WEKA explorer เลือกไฟล์HierarchicalClusterer เป็นอัลกอริทึม ML ของคุณดังที่แสดงในภาพหน้าจอที่แสดงด้านล่าง -
เลือก Cluster mode เลือกเป็น Classes to cluster evaluationแล้วคลิกที่ไฟล์ Startปุ่ม. คุณจะเห็นผลลัพธ์ต่อไปนี้ -
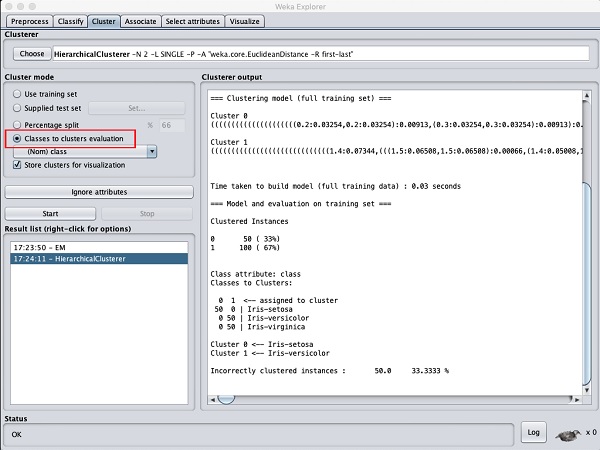
สังเกตว่าในไฟล์ Result listมีรายการผลลัพธ์สองรายการ: รายการแรกคือผลลัพธ์ EM และผลลัพธ์ที่สองคือลำดับชั้นปัจจุบัน ในทำนองเดียวกันคุณสามารถใช้อัลกอริทึม ML หลายชุดกับชุดข้อมูลเดียวกันและเปรียบเทียบผลลัพธ์ได้อย่างรวดเร็ว
หากคุณตรวจสอบต้นไม้ที่สร้างโดยอัลกอริทึมนี้คุณจะเห็นผลลัพธ์ต่อไปนี้ -
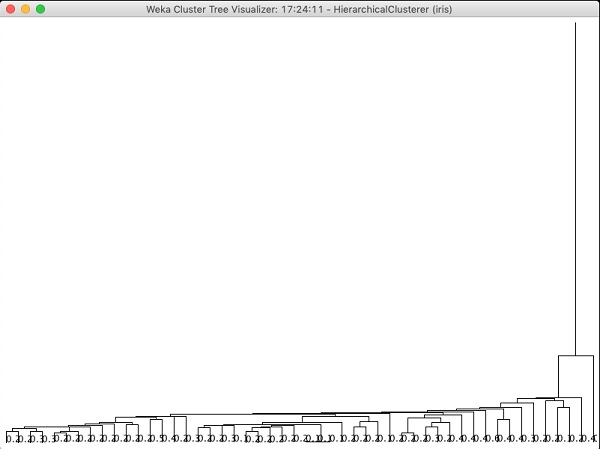
ในบทถัดไปคุณจะศึกษาไฟล์ Associate ประเภทของอัลกอริทึม ML
เป็นที่สังเกตว่าคนที่ซื้อเบียร์ก็ซื้อผ้าอ้อมพร้อมกัน นั่นคือมีสมาคมในการซื้อเบียร์และผ้าอ้อมด้วยกัน แม้ว่าสิ่งนี้จะดูไม่น่าเชื่อนัก แต่กฎของสมาคมนี้ถูกขุดขึ้นมาจากฐานข้อมูลขนาดใหญ่ของซูเปอร์มาร์เก็ต ในทำนองเดียวกันอาจพบความสัมพันธ์ระหว่างเนยถั่วกับขนมปัง
การค้นหาความสัมพันธ์ดังกล่าวมีความสำคัญสำหรับซูเปอร์มาร์เก็ตเนื่องจากพวกเขาจะเก็บผ้าอ้อมไว้ข้างๆเบียร์เพื่อให้ลูกค้าสามารถค้นหาทั้งสองรายการได้อย่างง่ายดายส่งผลให้มียอดขายเพิ่มขึ้นสำหรับซูเปอร์มาร์เก็ต
Aprioriอัลกอริทึมเป็นหนึ่งในอัลกอริทึมใน ML ที่ค้นหาการเชื่อมโยงที่เป็นไปได้และสร้างกฎการเชื่อมโยง WEKA ให้การใช้อัลกอริทึม Apriori คุณสามารถกำหนดการสนับสนุนขั้นต่ำและระดับความเชื่อมั่นที่ยอมรับได้ขณะคำนวณกฎเหล่านี้ คุณจะใช้Apriori อัลกอริทึมไปยังไฟล์ supermarket ข้อมูลที่ให้ไว้ในการติดตั้ง WEKA
กำลังโหลดข้อมูล
ใน WEKA explorer ให้เปิดไฟล์ Preprocess คลิกที่แท็บ Open file ... แล้วเลือก supermarket.arffฐานข้อมูลจากโฟลเดอร์การติดตั้ง หลังจากโหลดข้อมูลแล้วคุณจะเห็นหน้าจอต่อไปนี้ -
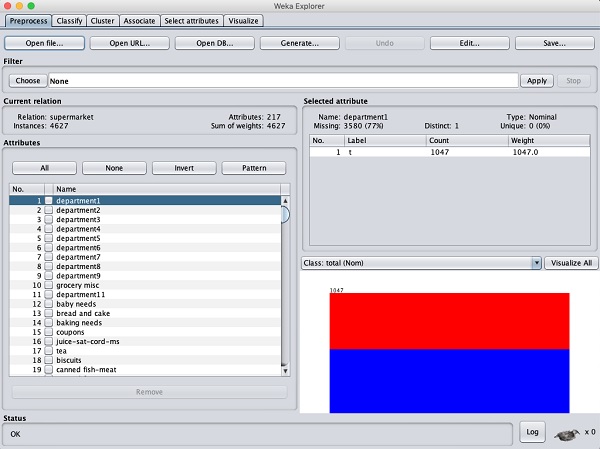
ฐานข้อมูลประกอบด้วยอินสแตนซ์ 4627 และแอ็ตทริบิวต์ 217 รายการ คุณสามารถเข้าใจได้อย่างง่ายดายว่าการตรวจจับความสัมพันธ์ระหว่างแอตทริบิวต์จำนวนมากนั้นยากเพียงใด โชคดีที่งานนี้เป็นไปโดยอัตโนมัติด้วยความช่วยเหลือของอัลกอริทึม Apriori
ผู้ร่วมงาน
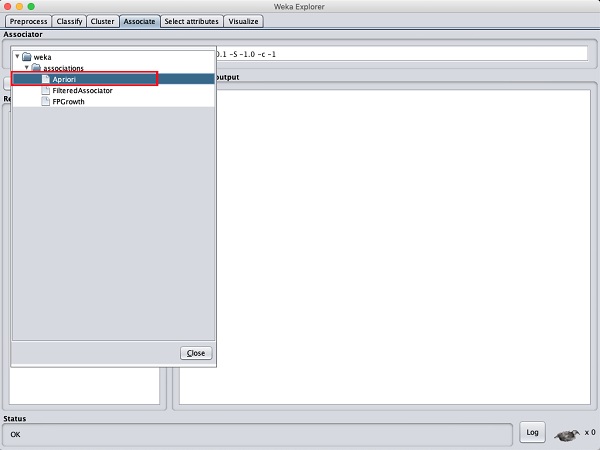
คลิกที่ Associate TAB และคลิกที่ไฟล์ Chooseปุ่ม. เลือกไฟล์Apriori การเชื่อมโยงตามที่แสดงในภาพหน้าจอ -
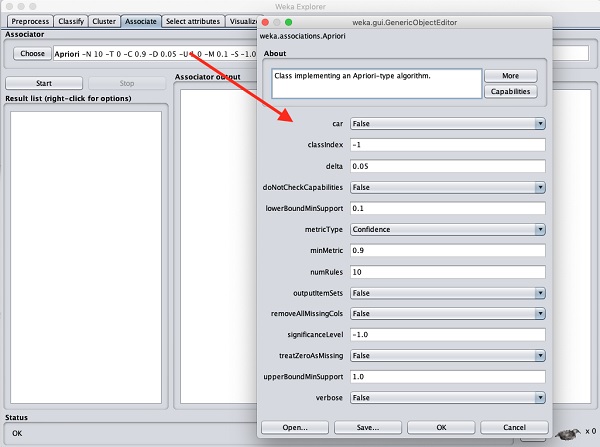
ในการตั้งค่าพารามิเตอร์สำหรับอัลกอริทึม Apriori ให้คลิกที่ชื่อหน้าต่างจะปรากฏขึ้นตามที่แสดงด้านล่างเพื่อให้คุณตั้งค่าพารามิเตอร์ -
หลังจากคุณตั้งค่าพารามิเตอร์แล้วให้คลิกไฟล์ Startปุ่ม. หลังจากนั้นไม่นานคุณจะเห็นผลลัพธ์ตามที่แสดงในภาพหน้าจอด้านล่าง -
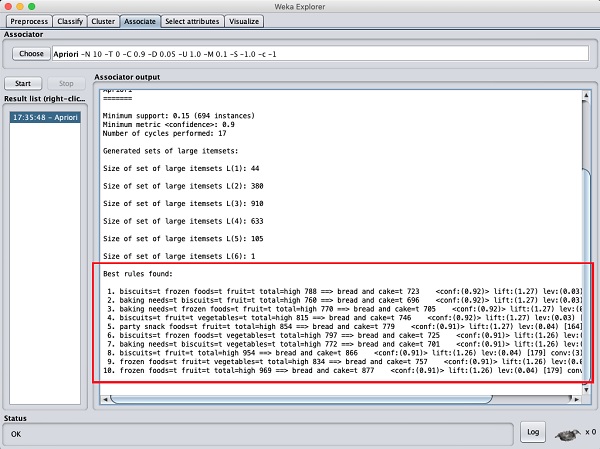
ที่ด้านล่างคุณจะพบกฎการเชื่อมโยงที่ดีที่สุดที่ตรวจพบ วิธีนี้จะช่วยซุปเปอร์มาร์เก็ตในการจัดเก็บสินค้าในชั้นวางที่เหมาะสม
เมื่อฐานข้อมูลมีแอตทริบิวต์จำนวนมากจะมีแอตทริบิวต์หลายรายการที่ไม่สำคัญในการวิเคราะห์ที่คุณกำลังค้นหา ดังนั้นการลบแอตทริบิวต์ที่ไม่ต้องการออกจากชุดข้อมูลจึงกลายเป็นงานสำคัญในการพัฒนารูปแบบการเรียนรู้ของเครื่องที่ดี
คุณสามารถตรวจสอบชุดข้อมูลทั้งหมดด้วยสายตาและตัดสินใจเกี่ยวกับแอตทริบิวต์ที่ไม่เกี่ยวข้อง นี่อาจเป็นงานใหญ่สำหรับฐานข้อมูลที่มีแอตทริบิวต์จำนวนมากเช่นกรณีซูเปอร์มาร์เก็ตที่คุณเห็นในบทเรียนก่อนหน้านี้ โชคดีที่ WEKA มีเครื่องมืออัตโนมัติสำหรับการเลือกคุณสมบัติ
บทนี้สาธิตคุณลักษณะนี้บนฐานข้อมูลที่มีแอตทริบิวต์จำนวนมาก
กำลังโหลดข้อมูล
ใน Preprocess แท็กของ WEKA explorer เลือกไฟล์ labor.arffไฟล์สำหรับโหลดเข้าสู่ระบบ เมื่อคุณโหลดข้อมูลคุณจะเห็นหน้าจอต่อไปนี้ -
สังเกตว่ามี 17 แอตทริบิวต์ งานของเราคือสร้างชุดข้อมูลที่ลดลงโดยการกำจัดคุณลักษณะบางอย่างที่ไม่เกี่ยวข้องกับการวิเคราะห์ของเรา
คุณสมบัติการสกัด
คลิกที่ Select attributesTAB คุณจะเห็นหน้าจอต่อไปนี้ -
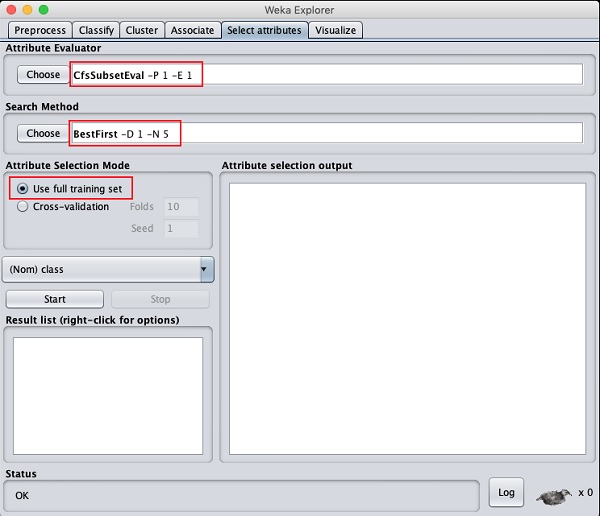
ภายใต้ Attribute Evaluator และ Search Methodคุณจะพบตัวเลือกมากมาย เราจะใช้ค่าเริ่มต้นที่นี่ ในAttribute Selection Modeใช้ตัวเลือกชุดการฝึกอบรมแบบเต็ม
คลิกที่ปุ่มเริ่มเพื่อประมวลผลชุดข้อมูล คุณจะเห็นผลลัพธ์ต่อไปนี้ -

ที่ด้านล่างของหน้าต่างผลลัพธ์คุณจะได้รับรายการ Selectedคุณลักษณะ. ในการรับการแสดงภาพให้คลิกขวาที่ผลลัพธ์ในไฟล์Result รายการ.
ผลลัพธ์จะแสดงในภาพหน้าจอต่อไปนี้ -
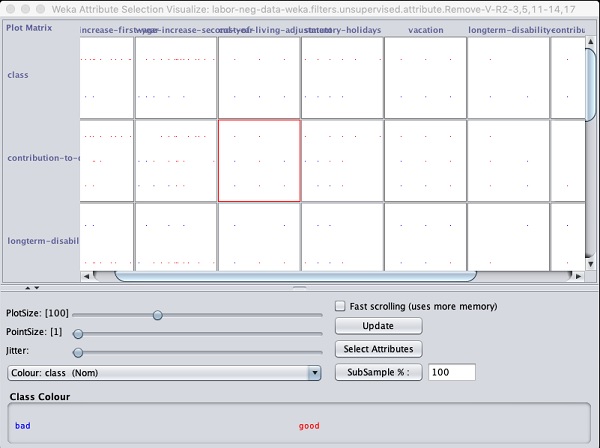
การคลิกที่สี่เหลี่ยมใด ๆ จะทำให้คุณได้พล็อตข้อมูลสำหรับการวิเคราะห์เพิ่มเติม พล็อตข้อมูลทั่วไปแสดงไว้ด้านล่าง -
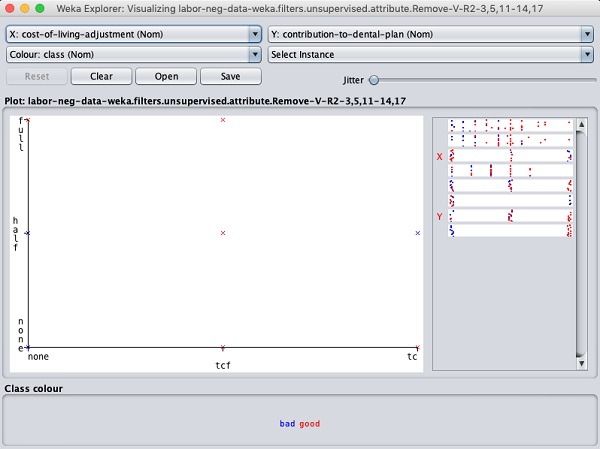
สิ่งนี้คล้ายกับที่เราเห็นในบทก่อนหน้านี้ ลองเล่นกับตัวเลือกต่างๆที่มีให้เพื่อวิเคราะห์ผลลัพธ์
อะไรต่อไป?
คุณได้เห็นถึงพลังของ WEKA ในการพัฒนาโมเดลแมชชีนเลิร์นนิงอย่างรวดเร็ว สิ่งที่เราใช้คือเครื่องมือกราฟิกที่เรียกว่าExplorerสำหรับการพัฒนาโมเดลเหล่านี้ WEKA ยังมีอินเทอร์เฟซบรรทัดคำสั่งที่ให้พลังมากกว่าที่มีให้ใน explorer
คลิกไฟล์ Simple CLI ในปุ่ม GUI Chooser แอปพลิเคชันเริ่มต้นอินเทอร์เฟซบรรทัดคำสั่งซึ่งแสดงในภาพหน้าจอด้านล่าง -
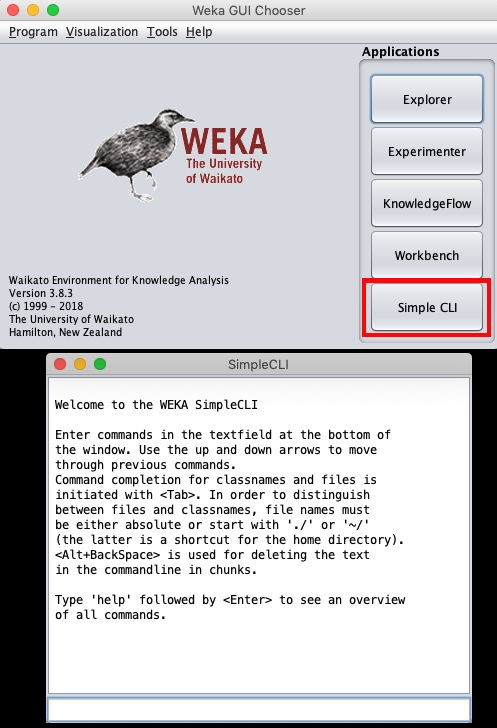
พิมพ์คำสั่งของคุณในช่องป้อนข้อมูลที่ด้านล่าง คุณจะสามารถทำทุกอย่างที่คุณเคยทำใน explorer และอื่น ๆ อีกมากมาย อ้างอิงเอกสาร WEKA (https://www.cs.waikato.ac.nz/ml/weka/documentation.html) สำหรับรายละเอียดเพิ่มเติม
สุดท้าย WEKA ได้รับการพัฒนาใน Java และมีอินเทอร์เฟซสำหรับ API ดังนั้นหากคุณเป็นนักพัฒนา Java และต้องการรวมการใช้งาน WEKA ML ในโปรเจ็กต์ Java ของคุณเองคุณสามารถทำได้อย่างง่ายดาย
สรุป
WEKA เป็นเครื่องมือที่มีประสิทธิภาพสำหรับการพัฒนาโมเดลแมชชีนเลิร์นนิง มีการใช้อัลกอริทึม ML ที่ใช้กันอย่างแพร่หลาย ก่อนที่อัลกอริทึมเหล่านี้จะถูกนำไปใช้กับชุดข้อมูลของคุณคุณสามารถประมวลผลข้อมูลล่วงหน้าได้ด้วย ประเภทของอัลกอริทึมที่ได้รับการสนับสนุนถูกจัดประเภทภายใต้แอตทริบิวต์ Classify, Cluster, Associate และ Select ผลลัพธ์ในขั้นตอนต่างๆของการประมวลผลสามารถมองเห็นได้ด้วยการแสดงภาพที่สวยงามและทรงพลัง สิ่งนี้ทำให้นักวิทยาศาสตร์ข้อมูลสามารถประยุกต์ใช้เทคนิคการเรียนรู้ของเครื่องต่างๆบนชุดข้อมูลของเขาได้ง่ายขึ้นอย่างรวดเร็วเปรียบเทียบผลลัพธ์และสร้างแบบจำลองที่ดีที่สุดสำหรับการใช้งานขั้นสุดท้าย