H2O - Kurulum
H2O, aşağıda listelendiği gibi beş farklı seçenekle yapılandırılabilir ve kullanılabilir -
Python'da yükle
R'ye yükle
Web tabanlı Flow GUI
Hadoop
Anaconda Bulut
Sonraki bölümlerimizde, mevcut seçeneklere göre H2O'nun kurulum talimatlarını göreceksiniz. Seçeneklerden birini kullanmanız muhtemeldir.
Python'da yükle
H2O'yu Python ile çalıştırmak için kurulum birkaç bağımlılık gerektirir. Öyleyse, H2O'yu çalıştırmak için minimum bağımlılık setini kurmaya başlayalım.
Bağımlılıkları Yükleme
Bir bağımlılık kurmak için aşağıdaki pip komutunu yürütün -
$ pip install requestsKonsol pencerenizi açın ve istek paketini yüklemek için yukarıdaki komutu yazın. Aşağıdaki ekran görüntüsü, yukarıdaki komutun Mac makinemizde yürütülmesini gösterir -
İstekleri yükledikten sonra, aşağıda gösterildiği gibi üç paket daha kurmanız gerekir -
$ pip install tabulate
$ pip install "colorama >= 0.3.8"
$ pip install futureEn güncel bağımlılık listesi H2O GitHub sayfasında mevcuttur. Bu yazının yazıldığı sırada aşağıdaki bağımlılıklar sayfada listelenmiştir.
python 2. H2O — Installation
pip >= 9.0.1
setuptools
colorama >= 0.3.7
future >= 0.15.2Eski Sürümleri Kaldırma
Yukarıdaki bağımlılıkları yükledikten sonra, mevcut H2O kurulumunu kaldırmanız gerekir. Bunu yapmak için aşağıdaki komutu çalıştırın -
$ pip uninstall h2oEn Son Sürümü Yükleme
Şimdi, aşağıdaki komutu kullanarak H2O'nun en son sürümünü kuralım -
$ pip install -f http://h2o-release.s3.amazonaws.com/h2o/latest_stable_Py.html h2oBaşarılı bir kurulumdan sonra, ekranda aşağıdaki mesajı görmelisiniz -
Installing collected packages: h2o
Successfully installed h2o-3.26.0.1Kurulumu Test Etme
Kurulumu test etmek için, H2O kurulumunda sağlanan örnek uygulamalardan birini çalıştıracağız. Önce aşağıdaki komutu yazarak Python istemini başlatın -
$ Python3Python yorumlayıcısı başladığında, Python komut istemine aşağıdaki Python ifadesini yazın -
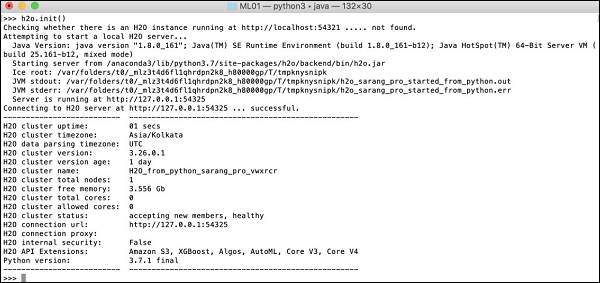
>>>import h2oYukarıdaki komut, H2O paketini programınıza aktarır. Ardından, aşağıdaki komutu kullanarak H2O sistemini başlatın -
>>>h2o.init()Ekranınız küme bilgilerini gösterecek ve bu aşamada aşağıdakilere bakmalıdır -
Artık örnek kodu çalıştırmaya hazırsınız. Python komut istemine aşağıdaki komutu yazın ve çalıştırın.
>>>h2o.demo("glm")Demo, bir dizi komut içeren bir Python not defterinden oluşur. Her bir komutu çalıştırdıktan sonra, çıktısı hemen ekranda gösterilir ve bir sonraki adıma geçmek için tuşuna basmanız istenir. Defterdeki son ifadenin yürütülmesine ilişkin kısmi ekran görüntüsü burada gösterilmektedir -
Bu aşamada Python kurulumunuz tamamlanmıştır ve kendi denemeniz için hazırsınız.
R'ye yükle
H2O for R geliştirme kurulumu, kurulum için R komut istemini kullanmanız dışında, Python için kurulumuna çok benzer.
R Konsolunu Başlatma
Makinenizdeki R uygulama simgesine tıklayarak R konsolunu başlatın. Konsol ekranı aşağıdaki ekran görüntüsünde gösterildiği gibi görünecektir -
H2O kurulumunuz yukarıdaki R komut isteminde yapılacaktır. RStudio kullanmayı tercih ediyorsanız, komutları R konsolu alt penceresine yazın.
Eski Sürümleri Kaldırma
Başlamak için, R komut isteminde aşağıdaki komutu kullanarak eski sürümleri kaldırın -
> if ("package:h2o" %in% search()) { detach("package:h2o", unload=TRUE) }
> if ("h2o" %in% rownames(installed.packages())) { remove.packages("h2o") }Bağımlılıkları İndirme
Aşağıdaki kodu kullanarak H2O için bağımlılıkları indirin -
> pkgs <- c("RCurl","jsonlite")
for (pkg in pkgs) {
if (! (pkg %in% rownames(installed.packages()))) { install.packages(pkg) }
}H2O kurulumu
R komut isteminde aşağıdaki komutu yazarak H2O'yu kurun -
> install.packages("h2o", type = "source", repos = (c("http://h2o-release.s3.amazonaws.com/h2o/latest_stable_R")))Aşağıdaki ekran görüntüsü beklenen çıktıyı göstermektedir -
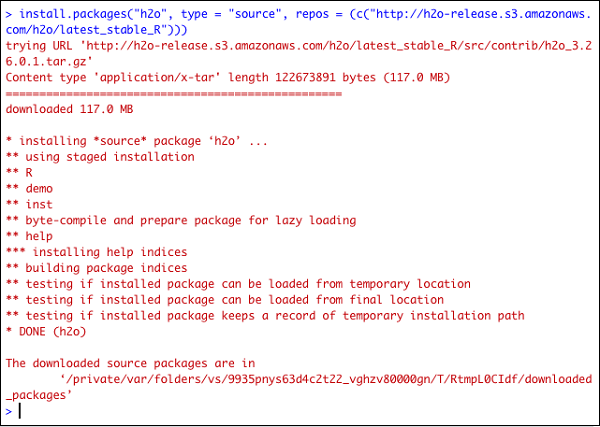
H2O'yu R'ye kurmanın başka bir yolu var.
CRAN'dan R'ye yükleyin
CRAN'dan R yüklemek için, R isteminde aşağıdaki komutu kullanın -
> install.packages("h2o")Aynayı seçmeniz istenecek -
--- Please select a CRAN mirror for use in this session ---
Ekranınızda yansıma sitelerinin listesini görüntüleyen bir iletişim kutusu gösterilir. En yakın konumu veya tercih ettiğiniz aynayı seçin.
Kurulum Testi
R isteminde, aşağıdaki kodu yazın ve çalıştırın -
> library(h2o)
> localH2O = h2o.init()
> demo(h2o.kmeans)Oluşturulan çıktı aşağıdaki ekran görüntüsünde gösterildiği gibi olacaktır -
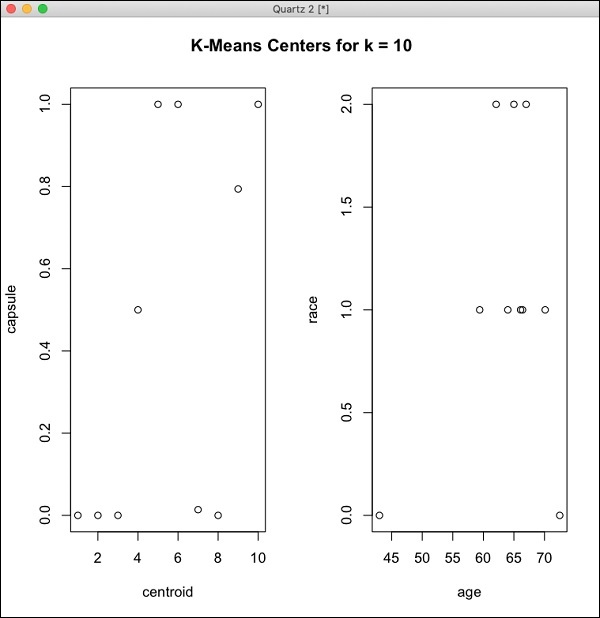
R'deki H2O kurulumunuz şimdi tamamlandı.
Web GUI Akışını Yükleme
GUI Flow'u yüklemek için kurulum dosyasını H20 sitesinden indirin. İndirdiğiniz dosyayı tercih ettiğiniz klasörde açın. Kurulumda h2o.jar dosyasının varlığına dikkat edin. Bu dosyayı aşağıdaki komutu kullanarak bir komut penceresinde çalıştırın -
$ java -jar h2o.jarBir süre sonra konsol pencerenizde aşağıdakiler görünecektir.
07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO: H2O started in 7725ms
07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO:
07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO: Open H2O Flow in your web browser: http://192.168.1.18:54321
07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO:Akışı başlatmak için verilen URL'yi açın http://localhost:54321tarayıcınızda. Aşağıdaki ekran görünecektir -
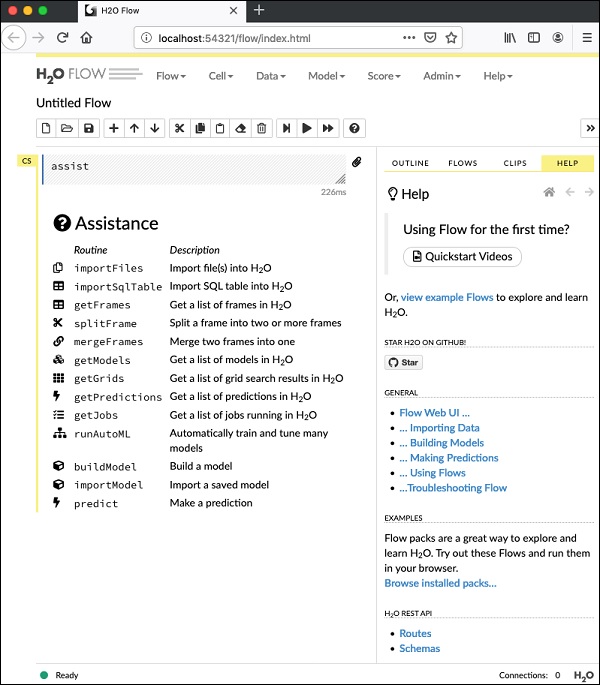
Bu aşamada Flow kurulumunuz tamamlanmıştır.
Hadoop / Anaconda Cloud'a yükleyin
Tecrübeli bir geliştirici değilseniz, H2O'yu Büyük Veri üzerinde kullanmayı düşünmezsiniz. Burada H2O modellerinin birkaç terabaytlık dev veri tabanlarında verimli bir şekilde çalıştığını söylemek yeterlidir. Verileriniz Hadoop kurulumunuzda veya Buluttaysa, ilgili veritabanınız için yüklemek için H2O sitesinde verilen adımları izleyin.
Artık H2O'yu makinenize başarıyla kurup test ettiğinize göre, gerçek geliştirmeye hazırsınız. İlk olarak, geliştirmeyi bir Komut isteminden göreceğiz. Sonraki derslerimizde, H2O Flow'da model testinin nasıl yapılacağını öğreneceğiz.
Komut İsteminde Geliştirme
Şimdi, Makine Öğrenimi uygulamaları geliştirmek için ücretsiz olarak temin edilebilen, iyi bilinen iris veri kümesinin bitkilerini sınıflandırmak için H2O kullanmayı düşünelim.
Python yorumlayıcısını kabuk pencerenize aşağıdaki komutu yazarak başlatın -
$ Python3Bu, Python yorumlayıcısını başlatır. Aşağıdaki komutu kullanarak h2o platformunu içe aktarın -
>>> import h2oSınıflandırma için Random Forest algoritmasını kullanacağız. Bu, H2ORandomForestEstimator paketinde sağlanır. Bu paketi aşağıdaki gibi import ifadesini kullanarak içe aktarıyoruz -
>>> from h2o.estimators import H2ORandomForestEstimatorH2o ortamını init yöntemini çağırarak başlatıyoruz.
>>> h2o.init()Başarılı bir başlatmada, küme bilgileriyle birlikte konsolda aşağıdaki mesajı görmelisiniz.
Checking whether there is an H2O instance running at http://localhost:54321 . connected.Şimdi, iris verilerini H2O'da import_file yöntemini kullanarak içe aktaracağız.
>>> data = h2o.import_file('iris.csv')İlerleme, aşağıdaki ekran görüntüsünde gösterildiği gibi görüntülenecektir -

Dosya belleğe yüklendikten sonra, yüklenen tablonun ilk 10 satırını görüntüleyerek bunu doğrulayabilirsiniz. Sen kullanhead bunu yapma yöntemi -
>>> data.head()Aşağıdaki çıktıyı tablo biçiminde göreceksiniz.
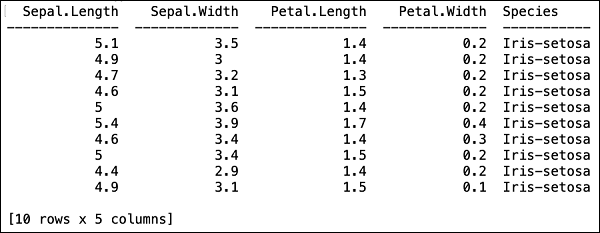
Tablo ayrıca sütun adlarını da görüntüler. İlk dört sütunu ML algoritmamızın özellikleri olarak ve son sütun sınıfını da tahmin edilen çıktı olarak kullanacağız. Bunu, önce aşağıdaki iki değişkeni oluşturarak ML algoritmamıza yapılan çağrıda belirtiyoruz.
>>> features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
>>> output = 'class'Daha sonra, split_frame yöntemini çağırarak verileri eğitim ve teste ayırıyoruz.
>>> train, test = data.split_frame(ratios = [0.8])Veriler 80:20 oranında bölünmüştür. Eğitim için% 80 ve test için% 20 veri kullanıyoruz.
Şimdi, yerleşik Random Forest modelini sisteme yüklüyoruz.
>>> model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)Yukarıdaki çağrıda, ağaç sayısını 50'ye, ağaç için maksimum derinliği 20'ye ve çapraz doğrulama için kat sayısını 10'a ayarladık. Şimdi modeli eğitmemiz gerekiyor. Bunu tren yöntemini aşağıdaki gibi çağırarak yapıyoruz -
>>> model.train(x = features, y = output, training_frame = train)Tren yöntemi, daha önce oluşturduğumuz özellikleri ve çıktıyı ilk iki parametre olarak alır. Eğitim veri kümesi, tam veri kümemizin% 80'i olan eğitime ayarlanmıştır. Eğitim sırasında ilerlemeyi burada gösterildiği gibi göreceksiniz -
Şimdi, model oluşturma süreci sona erdiğinde, modeli test etme zamanı. Bunu, eğitilmiş model nesnesi üzerinde model_performance yöntemini çağırarak yapıyoruz.
>>> performance = model.model_performance(test_data=test)Yukarıdaki yöntem çağrısında, parametremiz olarak test verilerini gönderdik.
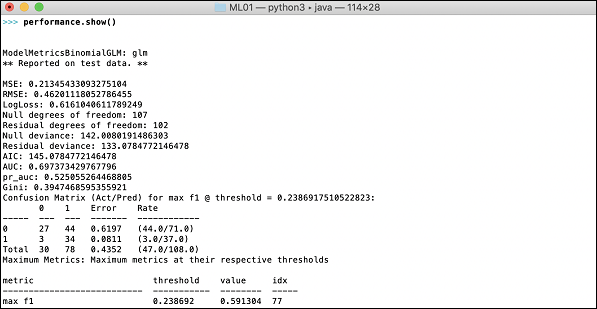
Şimdi modelimizin performansı olan çıktıyı görme zamanı. Bunu sadece performansı yazdırarak yaparsınız.
>>> print (performance)Bu size aşağıdaki çıktıyı verecektir -
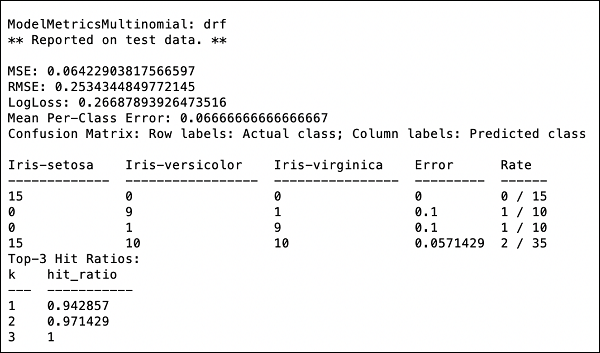
Çıktı, Ortalama Kare Hatasını (MSE), Ortalama Karekök Hatasını (RMSE), LogLoss'u ve hatta Karışıklık Matrisini gösterir.
Jupyter'de koşmak
Komuttan yürütmeyi gördük ve ayrıca her kod satırının amacını anladık. Tüm kodu bir Jupyter ortamında, satır satır veya tüm programı bir seferde çalıştırabilirsiniz. Tam liste burada verilmiştir -
import h2o
from h2o.estimators import H2ORandomForestEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios=[0.8])
model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data=test)
print (performance)Kodu çalıştırın ve çıktıyı gözlemleyin. Artık veri kümenizde bir Random Forest algoritması uygulamanın ve test etmenin ne kadar kolay olduğunu anlayabilirsiniz. H20'nin gücü bu yeteneğin çok ötesine geçiyor. Daha iyi performans elde edip edemeyeceğinizi görmek için aynı veri kümesinde başka bir model denemek isterseniz ne olur? Bu, sonraki bölümümüzde açıklanmaktadır.
Farklı Bir Algoritma Uygulama
Şimdi, nasıl performans gösterdiğini görmek için önceki veri kümemize bir Gradient Boosting algoritmasının nasıl uygulanacağını öğreneceğiz. Yukarıdaki tam listede, aşağıdaki kodda vurgulandığı gibi yalnızca iki küçük değişiklik yapmanız gerekecek -
import h2o
from h2o.estimators import H2OGradientBoostingEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios = [0.8])
model = H2OGradientBoostingEstimator
(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data = test)
print (performance)Kodu çalıştırın ve aşağıdaki çıktıyı alacaksınız -
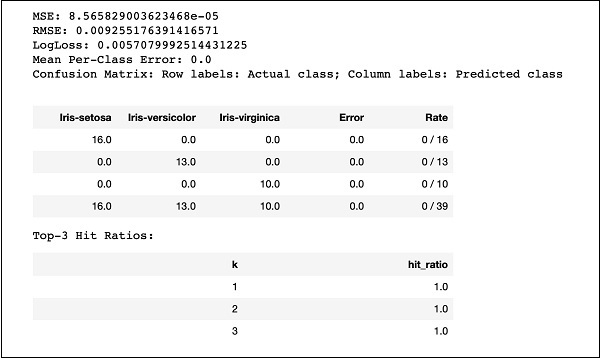
Sadece MSE, RMSE, Confusion Matrix, vb. Sonuçları önceki çıktıyla karşılaştırın ve üretim dağıtımı için hangisinin kullanılacağına karar verin. Aslında, amacınıza en uygun olanı seçmek için birkaç farklı algoritma uygulayabilirsiniz.