H2O - Örnek Uygulama Çalıştırma
Aşağıdaki ekran görüntüsünde gösterildiği gibi örnekler listesindeki Havayolları Gecikme Akışı bağlantısını tıklayın -
Onayladıktan sonra yeni not defteri yüklenecektir.
Tüm Çıktıların Silinmesi
Defterdeki kod ifadelerini açıklamadan önce, tüm çıktıları temizleyelim ve ardından dizüstü bilgisayarı kademeli olarak çalıştıralım. Tüm çıktıları temizlemek için aşağıdaki menü seçeneğini seçin -
Flow / Clear All Cell ContentsBu, aşağıdaki ekran görüntüsünde gösterilmektedir -
Tüm çıktılar silindiğinde, not defterindeki her bir hücreyi ayrı ayrı çalıştırıp çıktısını inceleyeceğiz.
İlk Hücreyi Çalıştırmak
İlk hücreyi tıklayın. Sol tarafta hücrenin seçildiğini gösteren kırmızı bir bayrak belirir. Bu, aşağıdaki ekran görüntüsünde gösterildiği gibidir -

Bu hücrenin içeriği yalnızca MarkDown (MD) dilinde yazılmış program açıklamasıdır. İçerik, yüklenen uygulamanın ne yaptığını açıklar. Hücreyi çalıştırmak için aşağıdaki ekran görüntüsünde gösterildiği gibi Çalıştır simgesine tıklayın -

Geçerli hücrede çalıştırılabilir kod olmadığı için hücrenin altında herhangi bir çıktı görmezsiniz. İmleç artık otomatik olarak bir sonraki hücreye hareket eder ve bu hücre çalışmaya hazırdır.
Verileri İçe Aktarma
Sonraki hücre aşağıdaki Python ifadesini içerir -
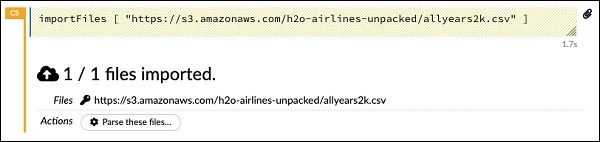
importFiles ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"]Açıklama, allyears2k.csv dosyasını Amazon AWS'den sisteme aktarır. Hücreyi çalıştırdığınızda, dosyayı içe aktarır ve size aşağıdaki çıktıyı verir.
Veri Ayrıştırıcıyı Kurma
Şimdi verileri ayrıştırmamız ve ML algoritmamıza uygun hale getirmemiz gerekiyor. Bu, aşağıdaki komut kullanılarak yapılır -
setupParse paths: [ "https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv" ]Yukarıdaki ifadenin yürütülmesi üzerine, bir kurulum konfigürasyonu diyaloğu belirir. İletişim kutusu, dosyayı ayrıştırmak için size birkaç ayar sağlar. Bu, aşağıdaki ekran görüntüsünde gösterildiği gibidir -
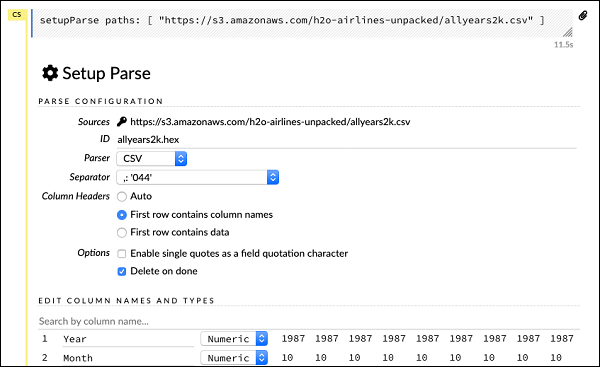
Bu iletişim kutusunda, verilen açılır listeden istenen ayrıştırıcıyı seçebilir ve alan ayırıcı gibi diğer parametreleri ayarlayabilirsiniz.
Verileri Ayrıştırma
Yukarıdaki yapılandırmayı kullanarak veri dosyasını gerçekten ayrıştıran sonraki ifade, uzun bir ifadedir ve burada gösterildiği gibidir -
parseFiles
paths: ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"]
destination_frame: "allyears2k.hex"
parse_type: "CSV"
separator: 44
number_columns: 31
single_quotes: false
column_names: ["Year","Month","DayofMonth","DayOfWeek","DepTime","CRSDepTime",
"ArrTime","CRSArrTime","UniqueCarrier","FlightNum","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"Origin","Dest","Distance","TaxiIn","TaxiOut","Cancelled","CancellationCode",
"Diverted","CarrierDelay","WeatherDelay","NASDelay","SecurityDelay",
"LateAircraftDelay","IsArrDelayed","IsDepDelayed"]
column_types: ["Enum","Enum","Enum","Enum","Numeric","Numeric","Numeric"
,"Numeric","Enum","Enum","Enum","Numeric","Numeric","Numeric","Numeric",
"Numeric","Enum","Enum","Numeric","Numeric","Numeric","Enum","Enum",
"Numeric","Numeric","Numeric","Numeric","Numeric","Numeric","Enum","Enum"]
delete_on_done: true
check_header: 1
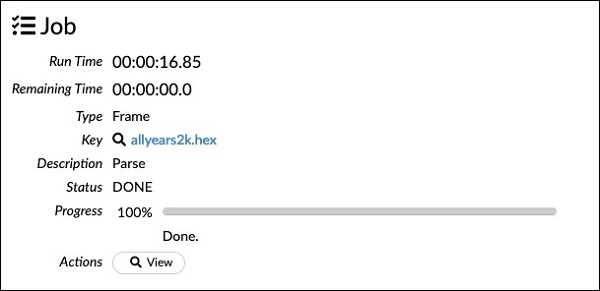
chunk_size: 4194304Yapılandırma kutusunda ayarladığınız parametrelerin yukarıdaki kodda listelendiğine dikkat edin. Şimdi bu hücreyi çalıştırın. Bir süre sonra ayrıştırma tamamlanır ve aşağıdaki çıktıyı görürsünüz -
Dataframe İnceleniyor
İşlemden sonra, aşağıdaki ifade kullanılarak incelenebilen bir veri çerçevesi oluşturur -
getFrameSummary "allyears2k.hex"Yukarıdaki ifadenin yürütülmesi üzerine, aşağıdaki çıktıyı göreceksiniz -
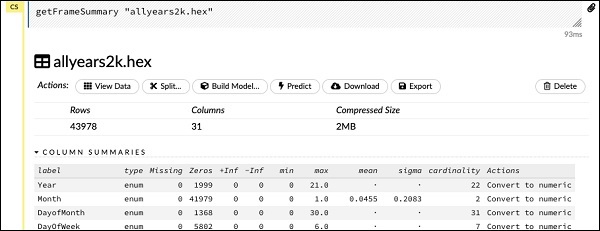
Artık verileriniz bir Makine Öğrenimi algoritmasına beslenmeye hazır.
Bir sonraki ifade, regresyon modelini kullanacağımızı söyleyen ve önceden ayarlanmış düzenlileştirmeyi ve lambda değerlerini belirten bir program açıklamasıdır.
Modeli Oluşturmak
Ardından en önemli ifade geliyor ve bu modelin kendisini inşa etmektir. Bu, aşağıdaki ifadede belirtilmiştir -
buildModel 'glm', {
"model_id":"glm_model","training_frame":"allyears2k.hex",
"ignored_columns":[
"DayofMonth","DepTime","CRSDepTime","ArrTime","CRSArrTime","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted","CarrierDelay",
"WeatherDelay","NASDelay","SecurityDelay","LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"response_column":"IsDepDelayed","family":"binomial",
"solver":"IRLSM","alpha":[0.5],"lambda":[0.00001],"lambda_search":false,
"standardize":true,"non_negative":false,"score_each_iteration":false,
"max_iterations":-1,"link":"family_default","intercept":true,
"objective_epsilon":0.00001,"beta_epsilon":0.0001,"gradient_epsilon":0.0001,
"prior":-1,"max_active_predictors":-1
}Aile tipi binom olarak ayarlanmış Genelleştirilmiş Doğrusal Model grubu olan glm kullanıyoruz. Bunları yukarıdaki açıklamada vurgulanmış olarak görebilirsiniz. Bizim durumumuzda, beklenen çıktı ikilidir ve bu yüzden binom tipini kullanıyoruz. Diğer parametreleri kendiniz inceleyebilirsiniz; örneğin, daha önce belirttiğimiz alfa ve lambda'ya bakın. Tüm parametrelerin açıklaması için GLM modeli belgelerine bakın.
Şimdi bu ifadeyi çalıştırın. Yürütme üzerine, aşağıdaki çıktı üretilecektir -

Elbette, makinenizde yürütme süresi farklı olacaktır. Şimdi, bu örnek kodun en ilginç kısmı geliyor.
Çıktının İncelenmesi
Aşağıdaki ifadeyi kullanarak oluşturduğumuz modeli basitçe çıkarıyoruz -
getModel "glm_model"Glm_model'in, önceki ifadede modeli oluştururken model_id parametresi olarak belirttiğimiz model kimliği olduğuna dikkat edin. Bu bize sonuçları çeşitli parametrelerle ayrıntılandıran büyük bir çıktı sağlar. Raporun kısmi bir çıktısı aşağıdaki ekran görüntüsünde gösterilmektedir -
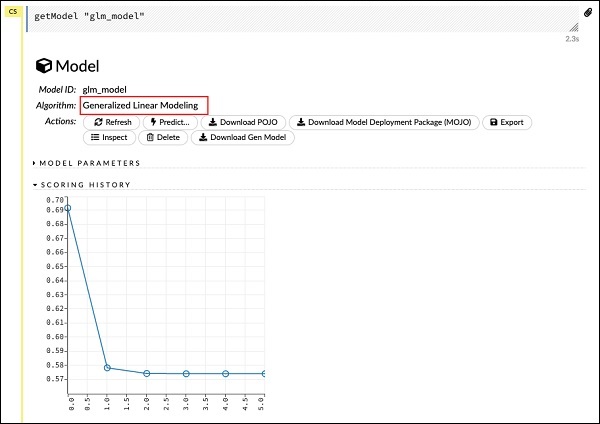
Çıktıda görebileceğiniz gibi, bunun veri kümenizde Genelleştirilmiş Doğrusal Modelleme algoritmasını çalıştırmanın bir sonucu olduğunu söylüyor.
PUANLAMA GEÇMİŞİ'nin hemen yukarısında, MODEL PARAMETRELERİ etiketini görürsünüz, genişletirsiniz ve modeli oluştururken kullanılan tüm parametrelerin listesini görürsünüz. Bu, aşağıdaki ekran görüntüsünde gösterilmektedir.
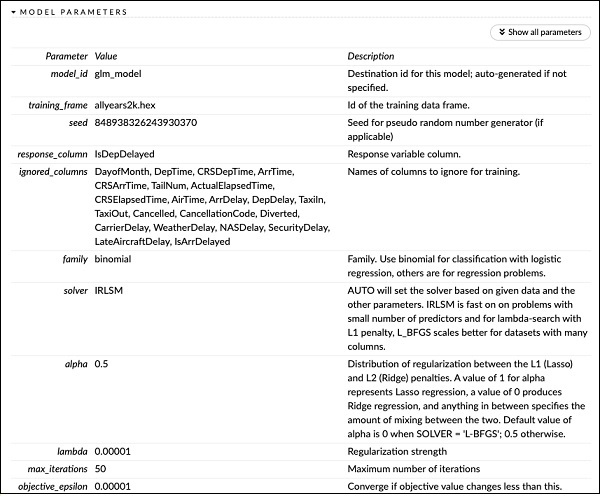
Benzer şekilde, her etiket belirli bir türün ayrıntılı bir çıktısını sağlar. Farklı türlerin çıktılarını incelemek için çeşitli etiketleri kendiniz genişletin.
Başka Bir Model Oluşturmak
Ardından, veri çerçevemizde bir Derin Öğrenme modeli oluşturacağız. Örnek koddaki sonraki ifade sadece bir program açıklamasıdır. Aşağıdaki ifade aslında bir model oluşturma komutudur. Burada gösterildiği gibidir -
buildModel 'deeplearning', {
"model_id":"deeplearning_model","training_frame":"allyear
s2k.hex","ignored_columns":[
"DepTime","CRSDepTime","ArrTime","CRSArrTime","FlightNum","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted",
"CarrierDelay","WeatherDelay","NASDelay","SecurityDelay",
"LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"res ponse_column":"IsDepDelayed",
"activation":"Rectifier","hidden":[200,200],"epochs":"100",
"variable_importances":false,"balance_classes":false,
"checkpoint":"","use_all_factor_levels":true,
"train_samples_per_iteration":-2,"adaptive_rate":true,
"input_dropout_ratio":0,"l1":0,"l2":0,"loss":"Automatic","score_interval":5,
"score_training_samples":10000,"score_duty_cycle":0.1,"autoencoder":false,
"overwrite_with_best_model":true,"target_ratio_comm_to_comp":0.02,
"seed":6765686131094811000,"rho":0.99,"epsilon":1e-8,"max_w2":"Infinity",
"initial_weight_distribution":"UniformAdaptive","classification_stop":0,
"diagnostics":true,"fast_mode":true,"force_load_balance":true,
"single_node_mode":false,"shuffle_training_data":false,"missing_values_handling":
"MeanImputation","quiet_mode":false,"sparse":false,"col_major":false,
"average_activation":0,"sparsity_beta":0,"max_categorical_features":2147483647,
"reproducible":false,"export_weights_and_biases":false
}Yukarıdaki kodda görebileceğiniz gibi, derin öğrenme modelinin belgelerinde belirtildiği gibi uygun değerlere ayarlanmış birkaç parametre ile modeli oluşturmak için derin öğrenme belirtiyoruz. Bu ifadeyi çalıştırdığınızda, GLM model oluşturmadan daha uzun zaman alacaktır. Farklı zamanlamalarla da olsa, model oluşturma tamamlandığında aşağıdaki çıktıyı göreceksiniz.

Derin Öğrenme Modeli Çıktısının İncelenmesi
Bu, önceki durumda olduğu gibi aşağıdaki ifade kullanılarak incelenebilen çıktı türünü üretir.
getModel "deeplearning_model"Hızlı referans için aşağıda gösterildiği gibi ROC eğrisi çıktısını dikkate alacağız.
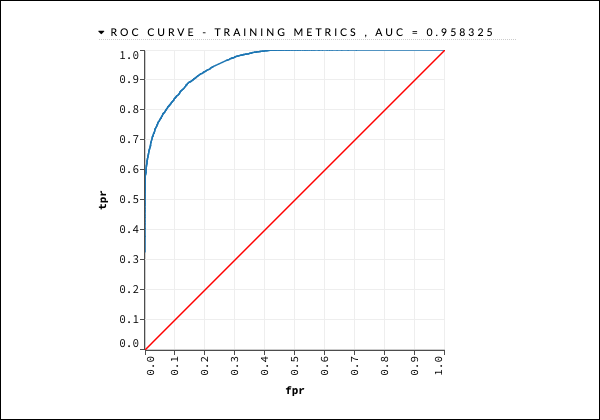
Önceki durumda olduğu gibi, çeşitli sekmeleri genişletin ve farklı çıktıları inceleyin.
Modeli Kaydetme
Farklı modellerin çıktılarını inceledikten sonra, üretim ortamınızdakilerden birini kullanmaya karar verirsiniz. H20, bu modeli bir POJO (Plain Old Java Object) olarak kaydetmenize izin verir.
Çıktıdaki son etiketi ÖNİZLEME POJO'yu genişletin ve ince ayarlı modeliniz için Java kodunu göreceksiniz. Bunu üretim ortamınızda kullanın.
Ardından, H2O'nun çok heyecan verici bir özelliğini öğreneceğiz. Performanslarına göre çeşitli algoritmaları test etmek ve sıralamak için AutoML'yi nasıl kullanacağımızı öğreneceğiz.