H2O - Hızlı Kılavuz
Hiç devasa bir veritabanı üzerinde bir Makine Öğrenimi modeli geliştirmeniz istendi mi? Tipik olarak, müşteri size veritabanını sağlar ve sizden potansiyel alıcıların kim olacağı gibi belirli tahminlerde bulunmanızı ister; dolandırıcılık vakalarının erken tespiti olabilir. Bu soruları yanıtlamak için göreviniz, müşterinin sorgusuna yanıt verecek bir Makine Öğrenimi algoritması geliştirmek olacaktır. Sıfırdan bir Makine Öğrenimi algoritması geliştirmek kolay bir iş değildir ve piyasada çok sayıda kullanıma hazır Makine Öğrenimi kitaplığı varken bunu neden yapmalısınız?
Bu günlerde, bu kitaplıkları kullanmayı, bu kitaplıklardan iyi test edilmiş bir algoritma uygulamayı ve performansına bakmayı tercih edersiniz. Performans kabul edilebilir sınırlar içinde değilse, mevcut algoritmada ince ayar yapmaya veya tamamen farklı bir algoritma denemeye çalışırdınız.
Aynı şekilde, aynı veri kümesinde birden çok algoritma deneyebilir ve ardından müşterinin gereksinimlerini tatmin edici bir şekilde karşılayan en iyi algoritmayı seçebilirsiniz. H2O'nun kurtarmaya geldiği yer burasıdır. Yaygın olarak kabul edilen çeşitli makine öğrenimi algoritmalarının tam olarak test edilmiş uygulamalarını içeren açık kaynaklı bir Makine Öğrenimi çerçevesidir. Algoritmayı devasa deposundan almanız ve veri kümenize uygulamanız yeterlidir. En yaygın kullanılan istatistiksel ve makine öğrenimi algoritmalarını içerir.
Burada birkaçından bahsetmek gerekirse, gradyan artırılmış makineler (GBM), genelleştirilmiş doğrusal model (GLM), derin öğrenme ve çok daha fazlasını içerir. Yalnızca veri kümenizdeki farklı algoritmaların performansını sıralayacak AutoML işlevini desteklemesi ve böylece en iyi performans gösteren modeli bulma çabalarınızı azaltması değil. H2O, dünya çapında 18000'den fazla kuruluş tarafından kullanılmaktadır ve geliştirme kolaylığınız için R ve Python ile iyi bir şekilde arayüz oluşturur. Üstün performans sağlayan bir bellek içi platformdur.
Bu eğitimde, ilk olarak H2O'yu hem Python hem de R seçenekleriyle makinenize kurmayı öğreneceksiniz. Bunu komut satırında nasıl kullanacağımızı anlayacağız, böylece çalışmasını satır bazında anlayacaksınız. Bir Python aşığıysanız, H2O uygulamaları geliştirmek için Jupyter veya seçtiğiniz başka bir IDE'yi kullanabilirsiniz. R'yi tercih ederseniz, geliştirme için RStudio'yu kullanabilirsiniz.
Bu eğitimde, H2O ile nasıl çalışılacağını anlamak için bir örnek ele alacağız. Ayrıca, program kodunuzdaki algoritmayı nasıl değiştireceğinizi öğrenecek ve performansını öncekiyle karşılaştıracağız. H2O ayrıca veri kümenizdeki farklı algoritmaları test etmek için web tabanlı bir araç sağlar. Buna Akış denir.
Eğitim, size Flow'un kullanımını tanıtacaktır. Bunun yanı sıra, veri kümenizde en iyi performans gösteren algoritmayı belirleyecek AutoML kullanımını tartışacağız. H2O öğrenmek için heyecanlı değil misiniz? Okumaya devam et!
H2O, aşağıda listelendiği gibi beş farklı seçenekle yapılandırılabilir ve kullanılabilir -
Python'da yükle
R'ye yükle
Web tabanlı Flow GUI
Hadoop
Anaconda Bulut
Sonraki bölümlerimizde, mevcut seçeneklere göre H2O'nun kurulum talimatlarını göreceksiniz. Seçeneklerden birini kullanmanız olasıdır.
Python'da yükle
H2O'yu Python ile çalıştırmak için kurulum birkaç bağımlılık gerektirir. Öyleyse, H2O'yu çalıştırmak için minimum bağımlılık setini kurmaya başlayalım.
Bağımlılıkları Yükleme
Bir bağımlılık kurmak için aşağıdaki pip komutunu yürütün -
$ pip install requestsKonsol pencerenizi açın ve istek paketini yüklemek için yukarıdaki komutu yazın. Aşağıdaki ekran görüntüsü, yukarıdaki komutun Mac makinemizde yürütülmesini gösterir -
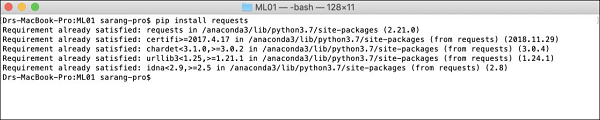
İstekleri yükledikten sonra, aşağıda gösterildiği gibi üç paket daha kurmanız gerekir -
$ pip install tabulate
$ pip install "colorama >= 0.3.8" $ pip install futureEn güncel bağımlılık listesi H2O GitHub sayfasında mevcuttur. Bu yazının yazıldığı sırada aşağıdaki bağımlılıklar sayfada listelenmiştir.
python 2. H2O — Installation
pip >= 9.0.1
setuptools
colorama >= 0.3.7
future >= 0.15.2Eski Sürümleri Kaldırma
Yukarıdaki bağımlılıkları kurduktan sonra, mevcut H2O kurulumunu kaldırmanız gerekir. Bunu yapmak için aşağıdaki komutu çalıştırın -
$ pip uninstall h2oEn Son Sürümü Yükleme
Şimdi, aşağıdaki komutu kullanarak H2O'nun en son sürümünü kuralım -
$ pip install -f http://h2o-release.s3.amazonaws.com/h2o/latest_stable_Py.html h2oBaşarılı bir kurulumdan sonra, ekranda aşağıdaki mesajı görmelisiniz -
Installing collected packages: h2o
Successfully installed h2o-3.26.0.1Kurulumu Test Etme
Kurulumu test etmek için, H2O kurulumunda sağlanan örnek uygulamalardan birini çalıştıracağız. Önce aşağıdaki komutu yazarak Python istemini başlatın -
$ Python3Python yorumlayıcısı başladığında, Python komut istemine aşağıdaki Python ifadesini yazın -
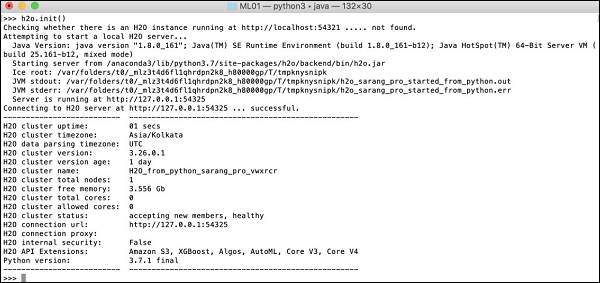
>>>import h2oYukarıdaki komut, H2O paketini programınıza aktarır. Ardından, aşağıdaki komutu kullanarak H2O sistemini başlatın -
>>>h2o.init()Ekranınız küme bilgilerini gösterecek ve bu aşamada aşağıdakilere bakmalıdır -
Artık örnek kodu çalıştırmaya hazırsınız. Python komut istemine aşağıdaki komutu yazın ve çalıştırın.
>>>h2o.demo("glm")Demo, bir dizi komut içeren bir Python not defterinden oluşur. Her bir komutu çalıştırdıktan sonra, çıktısı hemen ekranda gösterilir ve bir sonraki adıma geçmek için tuşuna basmanız istenir. Defterdeki son ifadenin yürütülmesine ilişkin kısmi ekran görüntüsü burada gösterilmektedir -
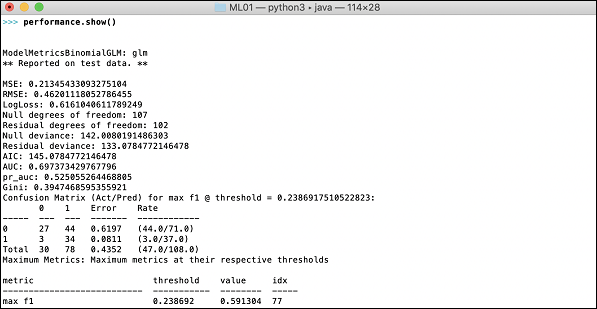
Bu aşamada Python kurulumunuz tamamlanmıştır ve kendi denemeniz için hazırsınız.
R'ye yükle
H2O for R geliştirme kurulumu, kurulum için R komut istemini kullanmanız dışında, Python için kurulumuna çok benzer.
R Konsolunu Başlatma
Makinenizdeki R uygulama simgesine tıklayarak R konsolunu başlatın. Konsol ekranı aşağıdaki ekran görüntüsünde gösterildiği gibi görünecektir -
H2O kurulumunuz yukarıdaki R komut isteminde yapılacaktır. RStudio kullanmayı tercih ediyorsanız, komutları R konsolu alt penceresine yazın.
Eski Sürümleri Kaldırma
Başlamak için, R komut isteminde aşağıdaki komutu kullanarak eski sürümleri kaldırın -
> if ("package:h2o" %in% search()) { detach("package:h2o", unload=TRUE) }
> if ("h2o" %in% rownames(installed.packages())) { remove.packages("h2o") }Bağımlılıkları İndirme
Aşağıdaki kodu kullanarak H2O için bağımlılıkları indirin -
> pkgs <- c("RCurl","jsonlite")
for (pkg in pkgs) {
if (! (pkg %in% rownames(installed.packages()))) { install.packages(pkg) }
}H2O kurulumu
R komut isteminde aşağıdaki komutu yazarak H2O'yu kurun -
> install.packages("h2o", type = "source", repos = (c("http://h2o-release.s3.amazonaws.com/h2o/latest_stable_R")))Aşağıdaki ekran görüntüsü beklenen çıktıyı göstermektedir -
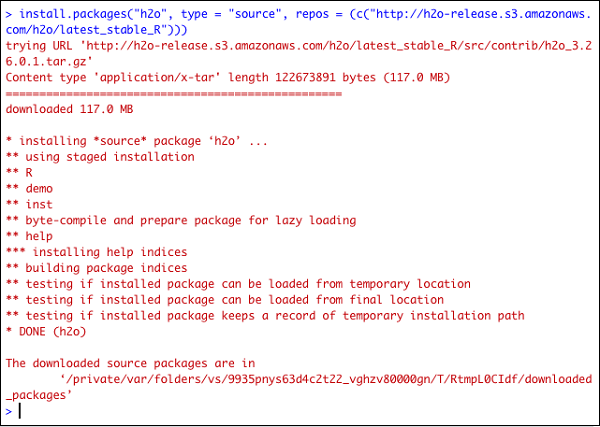
H2O'yu R'ye kurmanın başka bir yolu var.
CRAN'dan R'ye yükleyin
CRAN'dan R yüklemek için, R isteminde aşağıdaki komutu kullanın -
> install.packages("h2o")Aynayı seçmeniz istenecek -
--- Please select a CRAN mirror for use in this session ---
Ekranınızda yansıma sitelerinin listesini görüntüleyen bir iletişim kutusu gösterilir. En yakın konumu veya tercih ettiğiniz aynayı seçin.
Kurulum Testi
R isteminde aşağıdaki kodu yazın ve çalıştırın -
> library(h2o)
> localH2O = h2o.init()
> demo(h2o.kmeans)Oluşturulan çıktı aşağıdaki ekran görüntüsünde gösterildiği gibi olacaktır -
R'deki H2O kurulumunuz şimdi tamamlandı.
Web GUI Akışını Yükleme
GUI Flow'u yüklemek için kurulum dosyasını H20 sitesinden indirin. İndirdiğiniz dosyayı tercih ettiğiniz klasörde açın. Kurulumda h2o.jar dosyasının varlığına dikkat edin. Bu dosyayı aşağıdaki komutu kullanarak bir komut penceresinde çalıştırın -
$ java -jar h2o.jarBir süre sonra konsol pencerenizde aşağıdakiler görünecektir.
07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO: H2O started in 7725ms
07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO:
07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO: Open H2O Flow in your web browser: http://192.168.1.18:54321
07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO:Akışı başlatmak için verilen URL'yi açın http://localhost:54321tarayıcınızda. Aşağıdaki ekran görünecektir -
Bu aşamada Flow kurulumunuz tamamlanmıştır.
Hadoop / Anaconda Cloud'a yükleyin
Tecrübeli bir geliştirici değilseniz, H2O'yu Büyük Veri üzerinde kullanmayı düşünmezsiniz. Burada H2O modellerinin birkaç terabaytlık dev veri tabanlarında verimli bir şekilde çalıştığını söylemek yeterlidir. Verileriniz Hadoop kurulumunuzda veya Buluttaysa, ilgili veritabanınız için yüklemek için H2O sitesinde verilen adımları izleyin.
Artık H2O'yu makinenize başarıyla kurup test ettiğinize göre, gerçek geliştirmeye hazırsınız. İlk olarak, geliştirmeyi bir Komut isteminden göreceğiz. Sonraki derslerimizde, H2O Flow'da model testinin nasıl yapılacağını öğreneceğiz.
Komut İsteminde Geliştirme
Şimdi, Makine Öğrenimi uygulamaları geliştirmek için ücretsiz olarak kullanılabilen, iyi bilinen iris veri setinin bitkilerini sınıflandırmak için H2O'yu kullanmayı düşünelim.
Python yorumlayıcısını kabuk pencerenize aşağıdaki komutu yazarak başlatın -
$ Python3Bu, Python yorumlayıcısını başlatır. Aşağıdaki komutu kullanarak h2o platformunu içe aktarın -
>>> import h2oSınıflandırma için Random Forest algoritmasını kullanacağız. Bu, H2ORandomForestEstimator paketinde sağlanır. Bu paketi, aşağıdaki gibi import ifadesini kullanarak içe aktarıyoruz -
>>> from h2o.estimators import H2ORandomForestEstimatorH2o ortamını init yöntemini çağırarak başlatıyoruz.
>>> h2o.init()Başarılı bir şekilde başlatıldığında, konsolda küme bilgileriyle birlikte aşağıdaki iletiyi görmelisiniz.
Checking whether there is an H2O instance running at http://localhost:54321 . connected.Şimdi, iris verilerini H2O'da import_file yöntemini kullanarak içe aktaracağız.
>>> data = h2o.import_file('iris.csv')İlerleme, aşağıdaki ekran görüntüsünde gösterildiği gibi görüntülenecektir -

Dosya belleğe yüklendikten sonra, yüklenen tablonun ilk 10 satırını görüntüleyerek bunu doğrulayabilirsiniz. Sen kullanhead bunu yapma yöntemi -
>>> data.head()Aşağıdaki çıktıyı tablo biçiminde göreceksiniz.
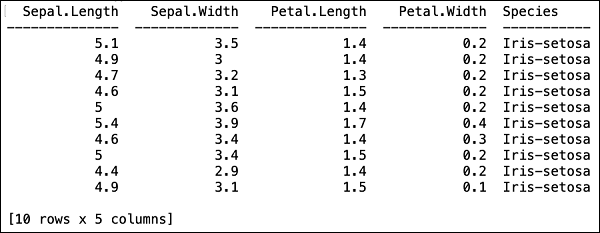
Tablo ayrıca sütun adlarını da görüntüler. İlk dört sütunu ML algoritmamızın özellikleri olarak ve son sütun sınıfını da tahmin edilen çıktı olarak kullanacağız. Bunu, önce aşağıdaki iki değişkeni oluşturarak ML algoritmamıza yapılan çağrıda belirtiyoruz.
>>> features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
>>> output = 'class'Daha sonra, split_frame yöntemini çağırarak verileri eğitim ve teste ayırıyoruz.
>>> train, test = data.split_frame(ratios = [0.8])Veriler 80:20 oranında bölünmüştür. Eğitim için% 80 ve test için% 20 veri kullanıyoruz.
Şimdi, yerleşik Random Forest modelini sisteme yüklüyoruz.
>>> model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)Yukarıdaki çağrıda, ağaç sayısını 50'ye, ağaç için maksimum derinliği 20'ye ve çapraz doğrulama için kat sayısını 10'a ayarladık. Şimdi modeli eğitmemiz gerekiyor. Bunu tren yöntemini aşağıdaki gibi çağırarak yapıyoruz -
>>> model.train(x = features, y = output, training_frame = train)Tren yöntemi, daha önce oluşturduğumuz özellikleri ve çıktıyı ilk iki parametre olarak alır. Eğitim veri kümesi, tam veri kümemizin% 80'i olan eğitime ayarlanmıştır. Eğitim sırasında ilerlemeyi burada gösterildiği gibi göreceksiniz -
Şimdi, model oluşturma süreci sona erdiği için modeli test etme zamanı. Bunu, eğitilmiş model nesnesi üzerinde model_performance yöntemini çağırarak yapıyoruz.
>>> performance = model.model_performance(test_data=test)Yukarıdaki yöntem çağrısında, parametremiz olarak test verilerini gönderdik.
Şimdi modelimizin performansı olan çıktıyı görme zamanı. Bunu sadece performansı yazdırarak yaparsınız.
>>> print (performance)Bu size aşağıdaki çıktıyı verecektir -
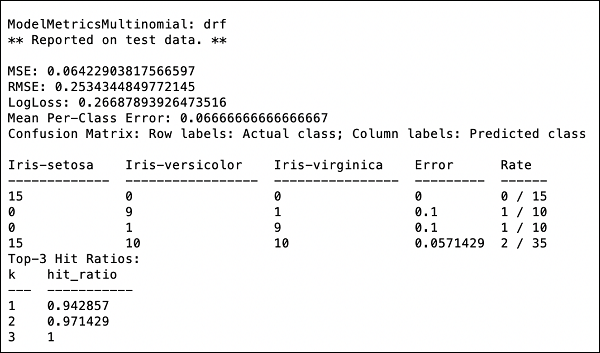
Çıktı, Ortalama Kare Hatasını (MSE), Ortalama Karekök Hatasını (RMSE), LogLoss'u ve hatta Karışıklık Matrisini gösterir.
Jupyter'de koşmak
Komuttan yürütmeyi gördük ve ayrıca her kod satırının amacını anladık. Tüm kodu bir Jupyter ortamında, satır satır veya tüm programı bir seferde çalıştırabilirsiniz. Tam liste burada verilmiştir -
import h2o
from h2o.estimators import H2ORandomForestEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios=[0.8])
model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data=test)
print (performance)Kodu çalıştırın ve çıktıyı gözlemleyin. Artık veri kümenizde bir Random Forest algoritması uygulamanın ve test etmenin ne kadar kolay olduğunu anlayabilirsiniz. H20'nin gücü bu yeteneğin çok ötesine geçiyor. Daha iyi performans elde edip edemeyeceğinizi görmek için aynı veri kümesinde başka bir model denemek isterseniz ne olur? Bu, sonraki bölümümüzde açıklanmaktadır.
Farklı Bir Algoritma Uygulama
Şimdi, nasıl performans gösterdiğini görmek için önceki veri kümemize bir Gradient Boosting algoritmasının nasıl uygulanacağını öğreneceğiz. Yukarıdaki tam listede, aşağıdaki kodda vurgulandığı gibi yalnızca iki küçük değişiklik yapmanız gerekecek -
import h2o
from h2o.estimators import H2OGradientBoostingEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios = [0.8])
model = H2OGradientBoostingEstimator
(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data = test)
print (performance)Kodu çalıştırın ve aşağıdaki çıktıyı alacaksınız -
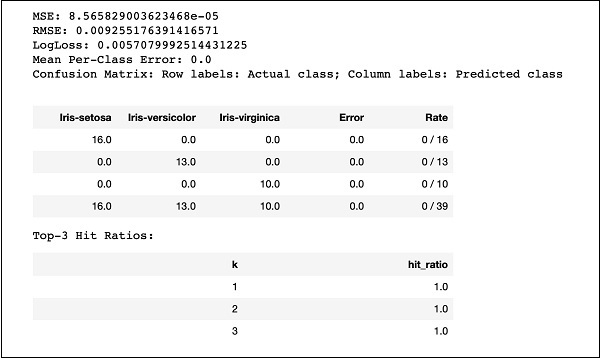
Sadece MSE, RMSE, Confusion Matrix, vb. Sonuçları önceki çıktıyla karşılaştırın ve üretim dağıtımı için hangisinin kullanılacağına karar verin. Aslında, amacınıza en uygun olanı seçmek için birkaç farklı algoritma uygulayabilirsiniz.
Son derste, komut satırı arayüzünü kullanarak H2O tabanlı makine öğrenimi modelleri oluşturmayı öğrendiniz. H2O Flow, web tabanlı bir arayüzle aynı amacı yerine getirir.
Aşağıdaki derslerde size H2O Flow'u nasıl başlatacağınızı ve örnek bir uygulamayı nasıl çalıştıracağınızı göstereceğim.
H2O Akışını Başlatma
Daha önce indirdiğiniz H2O kurulumu h2o.jar dosyasını içerir. H2O Flow'u başlatmak için önce bu kavanozu komut isteminden çalıştırın -
$ java -jar h2o.jarKavanoz başarılı bir şekilde çalıştığında, konsolda aşağıdaki mesajı alırsınız -
Open H2O Flow in your web browser: http://192.168.1.10:54321Şimdi, istediğiniz tarayıcıyı açın ve yukarıdaki URL'yi yazın. H2O web tabanlı masaüstünü burada gösterildiği gibi göreceksiniz -
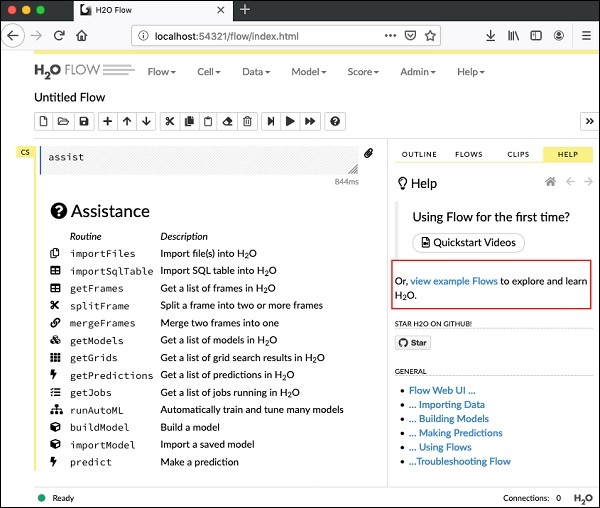
Bu temelde Colab veya Jupyter'e benzer bir not defteri. Flow'daki çeşitli özellikleri açıklarken size bu deftere örnek bir uygulamayı nasıl yükleyeceğinizi ve çalıştıracağınızı göstereceğim. Sağlanan örneklerin listesini görmek için yukarıdaki ekranda örnek Akışları görüntüle bağlantısını tıklayın.
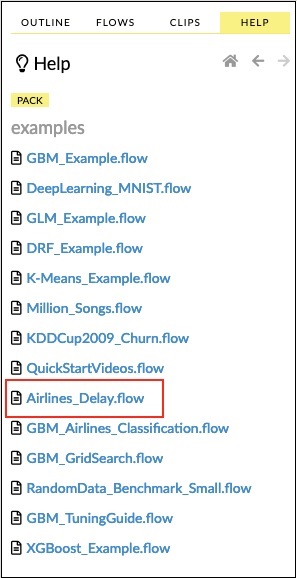
Örnekten Havayolları gecikme Akış örneğini açıklayacağım.
Aşağıdaki ekran görüntüsünde gösterildiği gibi örnekler listesindeki Havayolları Gecikme Akışı bağlantısını tıklayın -
Onayladıktan sonra yeni not defteri yüklenecektir.
Tüm Çıktıların Silinmesi
Defterdeki kod ifadelerini açıklamadan önce, tüm çıktıları temizleyelim ve ardından dizüstü bilgisayarı kademeli olarak çalıştıralım. Tüm çıktıları temizlemek için aşağıdaki menü seçeneğini seçin -
Flow / Clear All Cell ContentsBu, aşağıdaki ekran görüntüsünde gösterilmektedir -
Tüm çıktılar temizlendikten sonra, not defterindeki her bir hücreyi ayrı ayrı çalıştıracağız ve çıktılarını inceleyeceğiz.
İlk Hücreyi Çalıştırmak
İlk hücreyi tıklayın. Solda hücrenin seçildiğini gösteren kırmızı bir bayrak belirir. Bu, aşağıdaki ekran görüntüsünde gösterildiği gibidir -

Bu hücrenin içeriği yalnızca MarkDown (MD) dilinde yazılmış program açıklamasıdır. İçerik, yüklenen uygulamanın ne yaptığını açıklar. Hücreyi çalıştırmak için aşağıdaki ekran görüntüsünde gösterildiği gibi Çalıştır simgesine tıklayın -

Geçerli hücrede çalıştırılabilir kod olmadığı için hücrenin altında herhangi bir çıktı görmezsiniz. İmleç artık otomatik olarak bir sonraki hücreye hareket eder ve bu hücre çalışmaya hazırdır.
Verileri İçe Aktarma
Sonraki hücre aşağıdaki Python ifadesini içerir -
importFiles ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"]Açıklama, allyears2k.csv dosyasını Amazon AWS'den sisteme aktarır. Hücreyi çalıştırdığınızda, dosyayı içe aktarır ve size aşağıdaki çıktıyı verir.
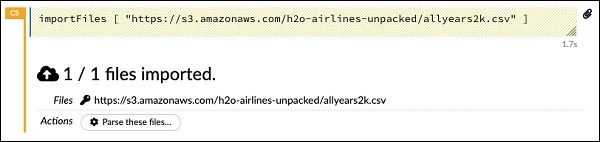
Veri Ayrıştırıcıyı Kurma
Şimdi verileri ayrıştırmamız ve ML algoritmamıza uygun hale getirmemiz gerekiyor. Bu, aşağıdaki komut kullanılarak yapılır -
setupParse paths: [ "https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv" ]Yukarıdaki ifadenin yürütülmesi üzerine, bir kurulum konfigürasyonu diyaloğu belirir. İletişim kutusu, dosyayı ayrıştırmak için size birkaç ayar sağlar. Bu, aşağıdaki ekran görüntüsünde gösterildiği gibidir -
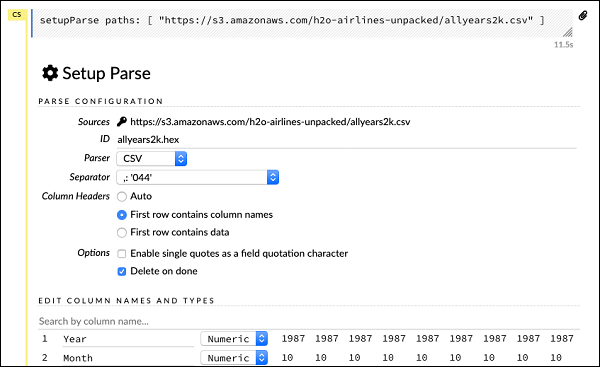
Bu iletişim kutusunda, verilen açılır listeden istenen ayrıştırıcıyı seçebilir ve alan ayırıcı gibi diğer parametreleri ayarlayabilirsiniz.
Verileri Ayrıştırma
Yukarıdaki yapılandırmayı kullanarak veri dosyasını gerçekten ayrıştıran sonraki ifade, uzun bir ifadedir ve burada gösterildiği gibidir -
parseFiles
paths: ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"]
destination_frame: "allyears2k.hex"
parse_type: "CSV"
separator: 44
number_columns: 31
single_quotes: false
column_names: ["Year","Month","DayofMonth","DayOfWeek","DepTime","CRSDepTime",
"ArrTime","CRSArrTime","UniqueCarrier","FlightNum","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"Origin","Dest","Distance","TaxiIn","TaxiOut","Cancelled","CancellationCode",
"Diverted","CarrierDelay","WeatherDelay","NASDelay","SecurityDelay",
"LateAircraftDelay","IsArrDelayed","IsDepDelayed"]
column_types: ["Enum","Enum","Enum","Enum","Numeric","Numeric","Numeric"
,"Numeric","Enum","Enum","Enum","Numeric","Numeric","Numeric","Numeric",
"Numeric","Enum","Enum","Numeric","Numeric","Numeric","Enum","Enum",
"Numeric","Numeric","Numeric","Numeric","Numeric","Numeric","Enum","Enum"]
delete_on_done: true
check_header: 1
chunk_size: 4194304Yapılandırma kutusunda ayarladığınız parametrelerin yukarıdaki kodda listelendiğine dikkat edin. Şimdi bu hücreyi çalıştırın. Bir süre sonra ayrıştırma tamamlanır ve aşağıdaki çıktıyı görürsünüz -
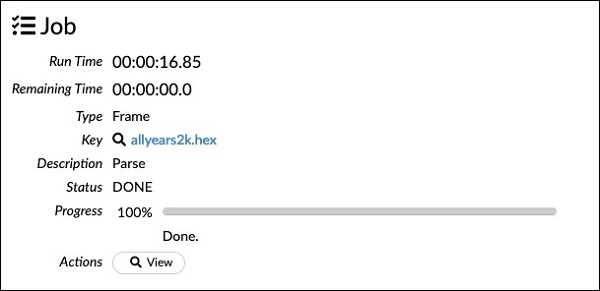
Dataframe İnceleniyor
İşlemden sonra, aşağıdaki ifade kullanılarak incelenebilen bir veri çerçevesi oluşturur -
getFrameSummary "allyears2k.hex"Yukarıdaki ifadenin yürütülmesi üzerine, aşağıdaki çıktıyı göreceksiniz -
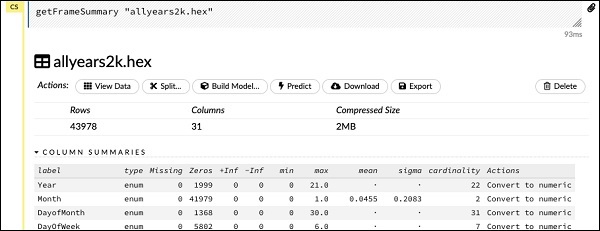
Artık verileriniz bir Makine Öğrenimi algoritmasına beslenmeye hazır.
Bir sonraki ifade, regresyon modelini kullanacağımızı söyleyen ve önceden ayarlanmış düzenlileştirmeyi ve lambda değerlerini belirten bir program açıklamasıdır.
Modeli Oluşturmak
Ardından en önemli ifade geliyor ve bu modelin kendisini inşa etmektir. Bu, aşağıdaki ifadede belirtilmiştir -
buildModel 'glm', {
"model_id":"glm_model","training_frame":"allyears2k.hex",
"ignored_columns":[
"DayofMonth","DepTime","CRSDepTime","ArrTime","CRSArrTime","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted","CarrierDelay",
"WeatherDelay","NASDelay","SecurityDelay","LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"response_column":"IsDepDelayed","family":"binomial",
"solver":"IRLSM","alpha":[0.5],"lambda":[0.00001],"lambda_search":false,
"standardize":true,"non_negative":false,"score_each_iteration":false,
"max_iterations":-1,"link":"family_default","intercept":true,
"objective_epsilon":0.00001,"beta_epsilon":0.0001,"gradient_epsilon":0.0001,
"prior":-1,"max_active_predictors":-1
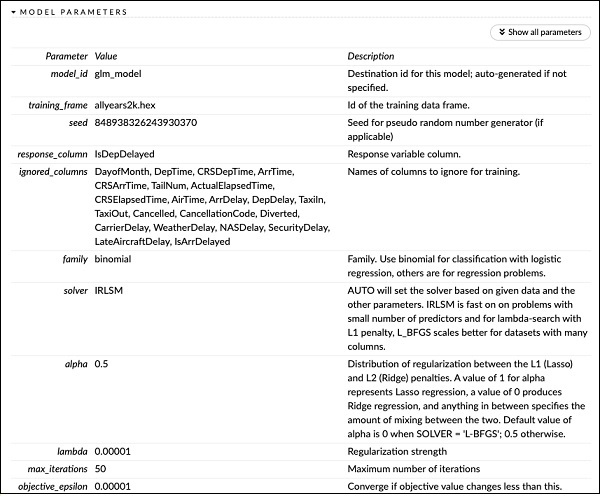
}Aile tipi binom olarak ayarlanmış Genelleştirilmiş Doğrusal Model grubu olan glm kullanıyoruz. Bunları yukarıdaki açıklamada vurgulanmış olarak görebilirsiniz. Bizim durumumuzda, beklenen çıktı ikilidir ve bu yüzden binom tipini kullanıyoruz. Diğer parametreleri kendiniz inceleyebilirsiniz; örneğin, daha önce belirttiğimiz alfa ve lambda'ya bakın. Tüm parametrelerin açıklaması için GLM modeli belgelerine bakın.
Şimdi bu ifadeyi çalıştırın. Yürütme üzerine, aşağıdaki çıktı üretilecektir -

Elbette, makinenizde yürütme süresi farklı olacaktır. Şimdi, bu örnek kodun en ilginç kısmı geliyor.
Çıktının İncelenmesi
Aşağıdaki ifadeyi kullanarak oluşturduğumuz modeli basitçe çıkarıyoruz -
getModel "glm_model"Glm_model'in, önceki ifadede modeli oluştururken model_id parametresi olarak belirttiğimiz model kimliği olduğuna dikkat edin. Bu bize sonuçları çeşitli parametrelerle ayrıntılandıran büyük bir çıktı sağlar. Raporun kısmi bir çıktısı aşağıdaki ekran görüntüsünde gösterilmektedir -
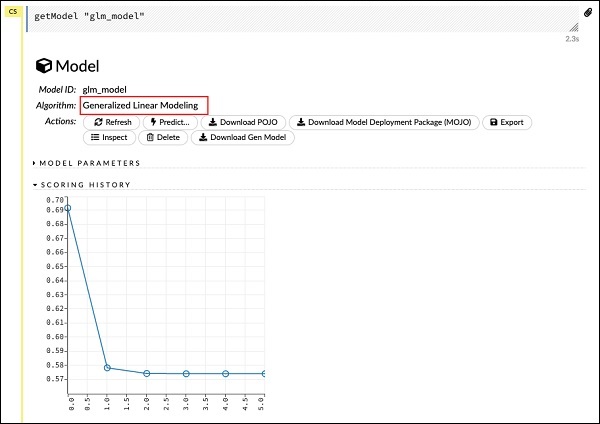
Çıktıda görebileceğiniz gibi, bunun veri kümenizde Genelleştirilmiş Doğrusal Modelleme algoritmasının çalıştırılmasının bir sonucu olduğunu söylüyor.
PUANLAMA GEÇMİŞİ'nin hemen yukarısında, MODEL PARAMETRELERİ etiketini görürsünüz, genişletirsiniz ve modeli oluştururken kullanılan tüm parametrelerin listesini görürsünüz. Bu, aşağıdaki ekran görüntüsünde gösterilmektedir.
Benzer şekilde, her etiket belirli bir türün ayrıntılı bir çıktısını sağlar. Farklı türlerin çıktılarını incelemek için çeşitli etiketleri kendiniz genişletin.
Başka Bir Model Oluşturmak
Ardından, veri çerçevemizde bir Derin Öğrenme modeli oluşturacağız. Örnek koddaki sonraki ifade sadece bir program açıklamasıdır. Aşağıdaki ifade aslında bir model oluşturma komutudur. Burada gösterildiği gibidir -
buildModel 'deeplearning', {
"model_id":"deeplearning_model","training_frame":"allyear
s2k.hex","ignored_columns":[
"DepTime","CRSDepTime","ArrTime","CRSArrTime","FlightNum","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted",
"CarrierDelay","WeatherDelay","NASDelay","SecurityDelay",
"LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"res ponse_column":"IsDepDelayed",
"activation":"Rectifier","hidden":[200,200],"epochs":"100",
"variable_importances":false,"balance_classes":false,
"checkpoint":"","use_all_factor_levels":true,
"train_samples_per_iteration":-2,"adaptive_rate":true,
"input_dropout_ratio":0,"l1":0,"l2":0,"loss":"Automatic","score_interval":5,
"score_training_samples":10000,"score_duty_cycle":0.1,"autoencoder":false,
"overwrite_with_best_model":true,"target_ratio_comm_to_comp":0.02,
"seed":6765686131094811000,"rho":0.99,"epsilon":1e-8,"max_w2":"Infinity",
"initial_weight_distribution":"UniformAdaptive","classification_stop":0,
"diagnostics":true,"fast_mode":true,"force_load_balance":true,
"single_node_mode":false,"shuffle_training_data":false,"missing_values_handling":
"MeanImputation","quiet_mode":false,"sparse":false,"col_major":false,
"average_activation":0,"sparsity_beta":0,"max_categorical_features":2147483647,
"reproducible":false,"export_weights_and_biases":false
}Yukarıdaki kodda görebileceğiniz gibi, derin öğrenme modelinin belgelerinde belirtildiği gibi uygun değerlere ayarlanmış birkaç parametre ile modeli oluşturmak için derin öğrenme belirtiyoruz. Bu ifadeyi çalıştırdığınızda, GLM model oluşturmadan daha uzun zaman alacaktır. Farklı zamanlamalarla da olsa, model oluşturma tamamlandığında aşağıdaki çıktıyı göreceksiniz.

Derin Öğrenme Modeli Çıktısının İncelenmesi
Bu, önceki durumda olduğu gibi aşağıdaki ifade kullanılarak incelenebilen çıktı türünü üretir.
getModel "deeplearning_model"Hızlı referans için aşağıda gösterildiği gibi ROC eğrisi çıktısını dikkate alacağız.
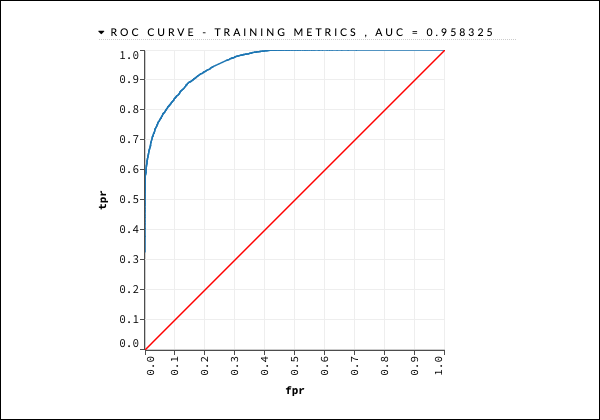
Önceki durumda olduğu gibi, çeşitli sekmeleri genişletin ve farklı çıktıları inceleyin.
Modeli Kaydetme
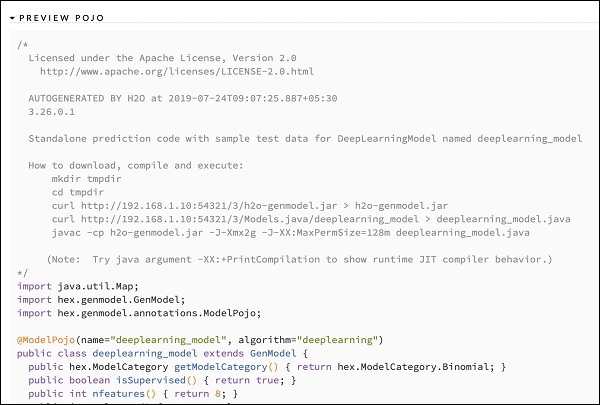
Farklı modellerin çıktılarını inceledikten sonra, üretim ortamınızdakilerden birini kullanmaya karar verirsiniz. H20, bu modeli bir POJO (Düz Eski Java Nesnesi) olarak kaydetmenize izin verir.
Çıktıdaki son etiketi ÖNİZLEME POJO'yu genişletin ve ince ayarlı modeliniz için Java kodunu göreceksiniz. Bunu üretim ortamınızda kullanın.
Ardından, H2O'nun çok heyecan verici bir özelliğini öğreneceğiz. Performanslarına göre çeşitli algoritmaları test etmek ve sıralamak için AutoML'yi nasıl kullanacağımızı öğreneceğiz.
AutoML'yi kullanmak için yeni bir Jupyter not defteri başlatın ve aşağıda gösterilen adımları izleyin.
AutoML'yi içe aktarma
Önce aşağıdaki iki ifadeyi kullanarak H2O ve AutoML paketini projeye içe aktarın -
import h2o
from h2o.automl import H2OAutoMLH2O'yu başlatın
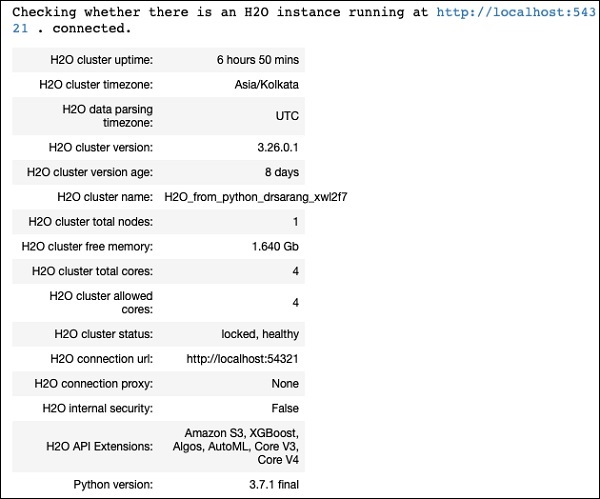
Aşağıdaki ifadeyi kullanarak h2o'yu başlatın -
h2o.init()Aşağıdaki ekran görüntüsünde gösterildiği gibi ekranda küme bilgilerini görmelisiniz -
Veri yükleniyor
Bu öğreticide daha önce kullandığınız iris.csv veri kümesinin aynısını kullanacağız. Aşağıdaki ifadeyi kullanarak verileri yükleyin -
data = h2o.import_file('iris.csv')Veri Kümesi Hazırlanıyor
Özelliklere ve tahmin sütunlarına karar vermemiz gerekiyor. Önceki durumumuzda olduğu gibi aynı özellikleri ve tahmin sütununu kullanıyoruz. Aşağıdaki iki ifadeyi kullanarak özellikleri ve çıktı sütununu ayarlayın -
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'Verileri eğitim ve test için 80:20 oranında bölün -
train, test = data.split_frame(ratios=[0.8])AutoML'yi uygulama
Artık hepimiz veri kümemize AutoML uygulamak için hazırız. AutoML, tarafımızdan belirlenen sabit bir süre boyunca çalışacak ve bize optimize edilmiş modeli verecektir. AutoML'yi aşağıdaki ifadeyi kullanarak kuruyoruz -
aml = H2OAutoML(max_models = 30, max_runtime_secs=300, seed = 1)İlk parametre, değerlendirmek ve karşılaştırmak istediğimiz modellerin sayısını belirtir.
İkinci parametre, algoritmanın çalıştığı zamanı belirtir.
Şimdi burada gösterildiği gibi AutoML nesnesinde tren yöntemini çağırıyoruz -
aml.train(x = features, y = output, training_frame = train)Daha önce oluşturduğumuz özellikler dizisi olarak x'i, tahmin edilen değeri belirtmek için çıktı değişkeni olarak ve veri çerçevesini şu şekilde belirtiyoruz: train veri kümesi.
Kodu çalıştırın, aşağıdaki çıktıyı elde edene kadar 5 dakika beklemeniz gerekecek (max_runtime_secs değerini 300 olarak ayarladık) -

Liderler Panosunu Yazdırma
AutoML işleme tamamlandığında, değerlendirdiği 30 algoritmanın tümünü sıralayan bir liderlik tablosu oluşturur. Skor tablosunun ilk 10 kaydını görmek için aşağıdaki kodu kullanın -
lb = aml.leaderboard
lb.head()Yürütme üzerine, yukarıdaki kod aşağıdaki çıktıyı üretecektir -
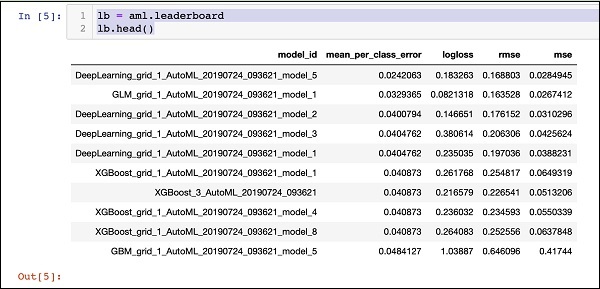
Açıkça, DeepLearning algoritması maksimum puana sahip.
Test Verilerini Tahmin Etme
Artık modelleri sıraladınız, en yüksek puan alan modelin performansını test verilerinizde görebilirsiniz. Bunu yapmak için aşağıdaki kod ifadesini çalıştırın -
preds = aml.predict(test)İşlem bir süre devam eder ve tamamlandığında aşağıdaki çıktıyı görürsünüz.

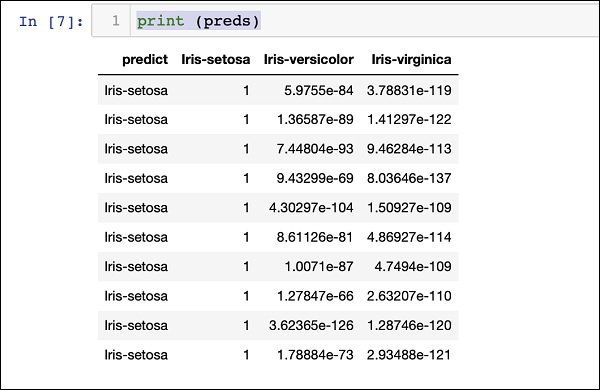
Baskı Sonucu
Aşağıdaki ifadeyi kullanarak tahmin edilen sonucu yazdırın -
print (preds)Yukarıdaki ifadenin yürütülmesi üzerine, aşağıdaki sonucu göreceksiniz -
Herkes İçin Sıralamayı Yazdırma
Test edilen tüm algoritmaların sıralarını görmek istiyorsanız, aşağıdaki kod ifadesini çalıştırın -
lb.head(rows = lb.nrows)Yukarıdaki ifadenin yürütülmesi üzerine, aşağıdaki çıktı üretilecektir (kısmen gösterilmektedir) -
Sonuç
H2O, belirli bir veri kümesinde farklı makine öğrenimi algoritmalarını uygulamak için kullanımı kolay bir açık kaynak platformu sağlar. Derin öğrenme dahil olmak üzere çeşitli istatistiksel ve makine öğrenimi algoritmaları sağlar. Test sırasında, parametreleri bu algoritmalara göre ince ayar yapabilirsiniz. Bunu komut satırını veya sağlanan Flow adlı web tabanlı arabirimi kullanarak yapabilirsiniz. H2O ayrıca, performanslarına göre çeşitli algoritmalar arasında sıralama sağlayan AutoML'yi de destekler. H2O, Büyük Veri üzerinde de iyi performans gösteriyor. Bu, Veri Bilimcilerinin veri kümelerine farklı Makine Öğrenimi modellerini uygulaması ve ihtiyaçlarını karşılayacak en iyisini seçmesi için kesinlikle bir nimettir.