Python Derin Öğrenme - Uygulamalar
Derin öğrenmenin bu uygulamasında, amacımız belirli bir banka için müşteri kayıplarını veya çalkalama verilerini tahmin etmektir - hangi müşterilerin bu banka hizmetinden çıkma olasılığı yüksektir. Kullanılan Veri Kümesi nispeten küçüktür ve 14 sütunlu 10000 satır içerir. Anaconda dağıtımını ve Theano, TensorFlow ve Keras gibi çerçeveleri kullanıyoruz. Keras, arka uçları olarak işlev gören Tensorflow ve Theano'nun üzerine inşa edilmiştir.
# Artificial Neural Network
# Installing Theano
pip install --upgrade theano
# Installing Tensorflow
pip install –upgrade tensorflow
# Installing Keras
pip install --upgrade keras1. Adım: Veri ön işleme
In[]:
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the database
dataset = pd.read_csv('Churn_Modelling.csv')Adım 2
Veri kümesinin özelliklerinin matrislerini ve sütun 14 olan hedef değişkeni "Çıkıldı" olarak etiketlendiriyoruz.
Verilerin ilk görünümü aşağıda gösterildiği gibidir -
In[]:
X = dataset.iloc[:, 3:13].values
Y = dataset.iloc[:, 13].values
XÇıktı
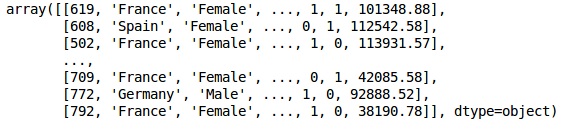
Aşama 3
YÇıktı
array([1, 0, 1, ..., 1, 1, 0], dtype = int64)4. adım
Dize değişkenlerini kodlayarak analizi daha basit hale getiriyoruz. Sütunlardaki farklı etiketleri 0 ila n_class-1 arasında otomatik olarak kodlamak için ScikitLearn 'LabelEncoder' fonksiyonunu kullanıyoruz.
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X_1 = LabelEncoder()
X[:,1] = labelencoder_X_1.fit_transform(X[:,1])
labelencoder_X_2 = LabelEncoder()
X[:, 2] = labelencoder_X_2.fit_transform(X[:, 2])
XÇıktı

Yukarıdaki çıktıda ülke adları 0, 1 ve 2 ile değiştirilmiştir; erkek ve dişi 0 ve 1 ile değiştirilir.
Adım 5
Labelling Encoded Data
Aynısını kullanıyoruz ScikitLearn kütüphane ve başka bir işlev adı verilen OneHotEncoder sadece bir kukla değişken oluşturarak sütun numarasını geçmek için.
onehotencoder = OneHotEncoder(categorical features = [1])
X = onehotencoder.fit_transform(X).toarray()
X = X[:, 1:]
XŞimdi, ilk 2 sütun ülkeyi temsil ediyor ve 4. sütun cinsiyeti temsil ediyor.
Çıktı
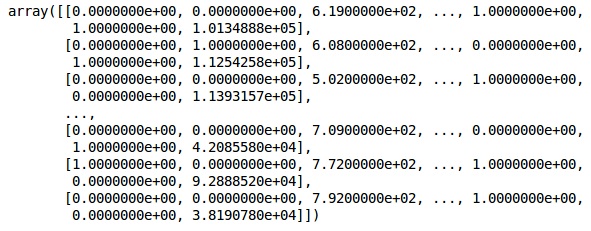
Verilerimizi her zaman eğitim ve test bölümüne ayırıyoruz; modelimizi eğitim verileri üzerine eğitiriz ve ardından modelin verimliliğini değerlendirmeye yardımcı olan test verileri üzerindeki bir modelin doğruluğunu kontrol ederiz.
6. Adım
ScikitLearn kullanıyoruz train_test_splitverilerimizi eğitim seti ve test setine bölme işlevi. Tren-test bölme oranını 80:20 olarak tutuyoruz.
#Splitting the dataset into the Training set and the Test Set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)Bazı değişkenler binlik değerlere sahipken, bazıları onlarca veya birde değerlere sahiptir. Verileri daha iyi temsil edecek şekilde ölçeklendiriyoruz.
7. Adım
Bu kodda, eğitim verilerini uyduruyor ve dönüştürüyoruz. StandardScalerişlevi. Test verilerini dönüştürmek / ölçeklendirmek için aynı uygun yöntemi kullanacak şekilde ölçeklendirmemizi standartlaştırıyoruz.
# Feature Scalingfromsklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)Çıktı
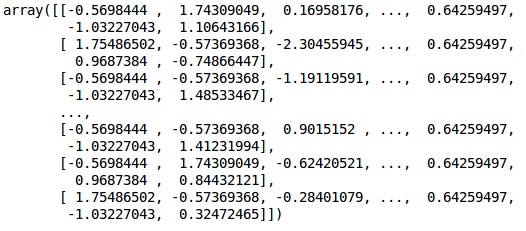
Veriler artık doğru şekilde ölçeklendi. Son olarak, veri ön işlemlerimizi tamamladık. Şimdi modelimizle başlayacağız.
8. Adım
Gerekli Modülleri buraya aktarıyoruz. Sinir ağını başlatmak için Sıralı modüle ve gizli katmanları eklemek için yoğun modüle ihtiyacımız var.
# Importing the Keras libraries and packages
import keras
from keras.models import Sequential
from keras.layers import Dense9. Adım
Amacımız müşteri kaybını sınıflandırmak olduğu için modeli Sınıflandırıcı olarak adlandıracağız. Ardından, başlatma için Sıralı modülü kullanıyoruz.
#Initializing Neural Network
classifier = Sequential()10. adım
Gizli katmanları yoğun işlevini kullanarak tek tek ekliyoruz. Aşağıdaki kodda birçok argüman göreceğiz.
İlk parametremiz output_dim. Bu katmana eklediğimiz düğüm sayısıdır.initStokastik Gradient Decent'in başlatılmasıdır. Bir Sinir Ağında her düğüme ağırlık atarız. Başlatma sırasında, ağırlıklar sıfıra yakın olmalıdır ve ağırlıkları tek tip işlevi kullanarak rastgele başlatırız. input_dimparametresi, model girdi değişkenlerimizin sayısını bilmediğinden, yalnızca ilk katman için gereklidir. Burada toplam girdi değişken sayısı 11'dir. İkinci katmanda, model ilk gizli katmandan girdi değişkenlerinin sayısını otomatik olarak bilir.
Giriş katmanını ve ilk gizli katmanı eklemek için aşağıdaki kod satırını yürütün -
classifier.add(Dense(units = 6, kernel_initializer = 'uniform',
activation = 'relu', input_dim = 11))İkinci gizli katmanı eklemek için aşağıdaki kod satırını yürütün -
classifier.add(Dense(units = 6, kernel_initializer = 'uniform',
activation = 'relu'))Çıktı katmanını eklemek için aşağıdaki kod satırını yürütün -
classifier.add(Dense(units = 1, kernel_initializer = 'uniform',
activation = 'sigmoid'))11. adım
Compiling the ANN
Şimdiye kadar sınıflandırıcımıza birden çok katman ekledik. Şimdi bunları kullanarak derleyeceğizcompileyöntem. Son derleme kontrolüne eklenen argümanlar sinir ağını tamamlıyor, bu yüzden bu adımda dikkatli olmamız gerekiyor.
İşte argümanların kısa bir açıklaması.
İlk argüman OptimizerBu, optimum ağırlık setini bulmak için kullanılan bir algoritmadır. Bu algoritmayaStochastic Gradient Descent (SGD). Burada, 'Adam optimizer' adı verilen birkaç türden birini kullanıyoruz. SGD kayba bağlıdır, dolayısıyla ikinci parametremiz kayıptır. Bağımlı değişkenimiz ikili ise, logaritmik kayıp fonksiyonunu kullanırız.‘binary_crossentropy’ve eğer bağımlı değişkenimizin çıktıda ikiden fazla kategorisi varsa, o zaman kullanırız ‘categorical_crossentropy’. Sinir ağımızın performansını aşağıdakilere dayanarak iyileştirmek istiyoruz:accuracyyani ekliyoruz metrics doğruluk olarak.
# Compiling Neural Network
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])Adım 1/2
Bu adımda bir dizi kodun yürütülmesi gerekir.
YSA'nın Eğitim Setine Takılması
Şimdi modelimizi eğitim verileri üzerinde eğitiyoruz. KullanıyoruzfitModelimize uyacak yöntem. Model verimliliğini artırmak için ağırlıkları da optimize ediyoruz. Bunun için ağırlıkları güncellememiz gerekiyor.Batch size ağırlıkları güncelledikten sonra gözlemlerin sayısıdır. Epochtoplam yineleme sayısıdır. Parti boyutu ve dönem değerleri, deneme yanılma yöntemi ile seçilir.
classifier.fit(X_train, y_train, batch_size = 10, epochs = 50)Tahmin yapmak ve modeli değerlendirmek
# Predicting the Test set results
y_pred = classifier.predict(X_test)
y_pred = (y_pred > 0.5)Tek bir yeni gözlemi tahmin etmek
# Predicting a single new observation
"""Our goal is to predict if the customer with the following data will leave the bank:
Geography: Spain
Credit Score: 500
Gender: Female
Age: 40
Tenure: 3
Balance: 50000
Number of Products: 2
Has Credit Card: Yes
Is Active Member: Yes13. adım
Predicting the test set result
Tahmin sonucu size müşterinin şirketten ayrılma olasılığını verecektir. Bu olasılığı ikili 0 ve 1'e çevireceğiz.
# Predicting the Test set results
y_pred = classifier.predict(X_test)
y_pred = (y_pred > 0.5)new_prediction = classifier.predict(sc.transform
(np.array([[0.0, 0, 500, 1, 40, 3, 50000, 2, 1, 1, 40000]])))
new_prediction = (new_prediction > 0.5)14. adım
Bu, model performansımızı değerlendirdiğimiz son adımdır. Zaten orijinal sonuçlarımız var ve bu nedenle modelimizin doğruluğunu kontrol etmek için kafa karışıklığı matrisi oluşturabiliriz.
Making the Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print (cm)Çıktı
loss: 0.3384 acc: 0.8605
[ [1541 54]
[230 175] ]Karışıklık matrisinden, modelimizin Doğruluğu şu şekilde hesaplanabilir:
Accuracy = 1541+175/2000=0.858We achieved 85.8% accuracy, hangisi iyi.
İleri Yayılma Algoritması
Bu bölümde, basit bir sinir ağı için ileriye doğru yayılma (tahmin) yapmak için kod yazmayı öğreneceğiz -
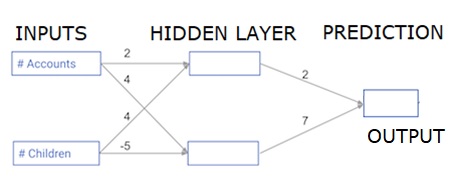
Her veri noktası bir müşteridir. İlk girdi, kaç hesaba sahip oldukları ve ikinci girdi, kaç çocuğa sahip olduklarıdır. Model, kullanıcının önümüzdeki yıl kaç işlem yapacağını tahmin edecek.
Giriş verileri, giriş verileri olarak önceden yüklenir ve ağırlıklar, ağırlıklar adı verilen bir sözlükte bulunur. Gizli katmandaki ilk düğüm için ağırlık dizisi ağırlıkları ['düğüm_0'] ve gizli katmandaki ikinci düğüm için ağırlıkları sırasıyla ['düğüm_1'] şeklindedir.
Çıkış düğümüne beslenen ağırlıklar ağırlık olarak mevcuttur.
Doğrultulmuş Doğrusal Aktivasyon Fonksiyonu
Bir "etkinleştirme işlevi", her düğümde çalışan bir işlevdir. Düğümün girişini bir çıkışa dönüştürür.
Düzeltilmiş doğrusal aktivasyon işlevi ( ReLU olarak adlandırılır ), çok yüksek performanslı ağlarda yaygın olarak kullanılmaktadır. Bu fonksiyon giriş olarak tek bir sayıyı alır, giriş negatifse 0 döndürür ve giriş pozitifse çıkış olarak girer.
İşte bazı örnekler -
- relu (4) = 4
- relu (-2) = 0
Relu () fonksiyonunun tanımını dolduruyoruz−
- Relu () çıktısının değerini hesaplamak için max () işlevini kullanırız.
- Node_0_output'u hesaplamak için relu () işlevini node_0_input'a uygularız.
- Node_1_output'u hesaplamak için relu () işlevini node_1_input'a uygularız.
import numpy as np
input_data = np.array([-1, 2])
weights = {
'node_0': np.array([3, 3]),
'node_1': np.array([1, 5]),
'output': np.array([2, -1])
}
node_0_input = (input_data * weights['node_0']).sum()
node_0_output = np.tanh(node_0_input)
node_1_input = (input_data * weights['node_1']).sum()
node_1_output = np.tanh(node_1_input)
hidden_layer_output = np.array(node_0_output, node_1_output)
output =(hidden_layer_output * weights['output']).sum()
print(output)
def relu(input):
'''Define your relu activation function here'''
# Calculate the value for the output of the relu function: output
output = max(input,0)
# Return the value just calculated
return(output)
# Calculate node 0 value: node_0_output
node_0_input = (input_data * weights['node_0']).sum()
node_0_output = relu(node_0_input)
# Calculate node 1 value: node_1_output
node_1_input = (input_data * weights['node_1']).sum()
node_1_output = relu(node_1_input)
# Put node values into array: hidden_layer_outputs
hidden_layer_outputs = np.array([node_0_output, node_1_output])
# Calculate model output (do not apply relu)
odel_output = (hidden_layer_outputs * weights['output']).sum()
print(model_output)# Print model outputÇıktı
0.9950547536867305
-3Ağı birçok Gözleme / veri satırına uygulama
Bu bölümde, tahmin_with_network () adlı bir işlevi nasıl tanımlayacağımızı öğreneceğiz. Bu işlev, yukarıda girdi_verisi olarak alınan ağdan alınan çoklu veri gözlemleri için tahminler üretecektir. Yukarıdaki ağda verilen ağırlıklar kullanılmaktadır. Relu () fonksiyon tanımı da kullanılmaktadır.
İki bağımsız değişkeni - input_data_row ve ağırlıklar - kabul eden ve çıktı olarak ağdan bir tahmin döndüren tahmin_with_network () adında bir işlev tanımlayalım.
Her düğüm için girdi ve çıktı değerlerini hesaplayarak bunları şu şekilde saklıyoruz: node_0_input, node_0_output, node_1_input ve node_1_output.
Bir düğümün girdi değerini hesaplamak için, ilgili dizileri birlikte çarpar ve toplamlarını hesaplarız.
Bir düğümün çıktı değerini hesaplamak için düğümün giriş değerine relu () işlevini uygularız. İnput_data üzerinde yinelemek için bir 'for döngüsü' kullanıyoruz -
Ayrıca, input_data - input_data_row'un her satırı için tahminler oluşturmak için predik_with_network () işlevimizi kullanırız. Ayrıca her tahmini sonuçlara ekliyoruz.
# Define predict_with_network()
def predict_with_network(input_data_row, weights):
# Calculate node 0 value
node_0_input = (input_data_row * weights['node_0']).sum()
node_0_output = relu(node_0_input)
# Calculate node 1 value
node_1_input = (input_data_row * weights['node_1']).sum()
node_1_output = relu(node_1_input)
# Put node values into array: hidden_layer_outputs
hidden_layer_outputs = np.array([node_0_output, node_1_output])
# Calculate model output
input_to_final_layer = (hidden_layer_outputs*weights['output']).sum()
model_output = relu(input_to_final_layer)
# Return model output
return(model_output)
# Create empty list to store prediction results
results = []
for input_data_row in input_data:
# Append prediction to results
results.append(predict_with_network(input_data_row, weights))
print(results)# Print resultsÇıktı
[0, 12]Burada relu (26) = 26 ve relu (-13) = 0 vb. Yerlerde relu fonksiyonunu kullandık.
Derin çok katmanlı sinir ağları
Burada, iki gizli katmana sahip bir sinir ağının ileriye doğru yayılması için kod yazıyoruz. Her gizli katmanın iki düğümü vardır. Giriş verileri şu şekilde önceden yüklenmiştir:input_data. İlk gizli katmandaki düğümlere düğüm_0_0 ve düğüm_0_1 adı verilir.
Ağırlıkları, sırasıyla ağırlıklar ['düğüm_0_0'] ve ağırlıklar ['düğüm_0_1'] olarak önceden yüklenmiştir.
İkinci gizli katmandaki düğümler denir node_1_0 and node_1_1. Ağırlıkları şu şekilde önceden yüklenmiştir:weights['node_1_0'] ve weights['node_1_1'] sırasıyla.
Ardından, önceden yüklenmiş ağırlıkları kullanarak gizli düğümlerden bir model çıktısı oluşturuyoruz. weights['output'].
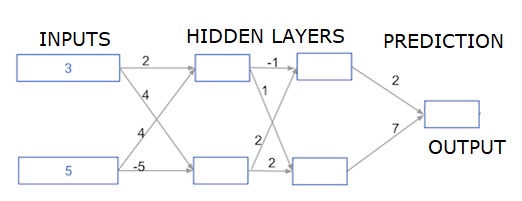
Node_0_0_input, ağırlık ağırlıklarını ['node_0_0'] ve verilen input_data'yı kullanarak hesaplıyoruz. Ardından node_0_0_output'u elde etmek için relu () işlevini uygulayın.
Node_0_1_input için node_0_1_output almak için yukarıdakiyle aynı şeyi yapıyoruz.
Node_1_0_input, ağırlık ağırlıklarını ['node_1_0'] ve ilk gizli katmandan - hidden_0_outputs - çıktıları kullanarak hesaplıyoruz. Daha sonra node_1_0_output'u elde etmek için relu () işlevini uygularız.
Node_1_1_output düğümünü almak için node_1_1_input için yukarıdakiyle aynı şeyi yapıyoruz.
Model_output'u ağırlıkları ['output'] ve ikinci gizli katmandan hidden_1_outputs dizisinden çıkan çıktıları kullanarak hesaplarız. Relu () fonksiyonunu bu çıktıya uygulamıyoruz.
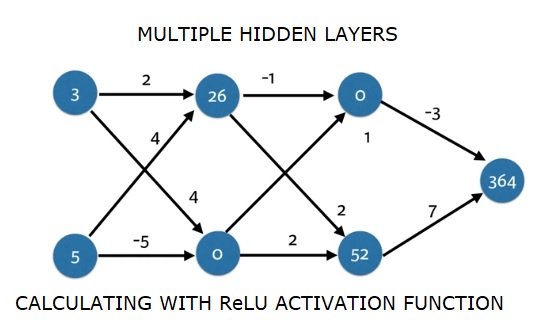
import numpy as np
input_data = np.array([3, 5])
weights = {
'node_0_0': np.array([2, 4]),
'node_0_1': np.array([4, -5]),
'node_1_0': np.array([-1, 1]),
'node_1_1': np.array([2, 2]),
'output': np.array([2, 7])
}
def predict_with_network(input_data):
# Calculate node 0 in the first hidden layer
node_0_0_input = (input_data * weights['node_0_0']).sum()
node_0_0_output = relu(node_0_0_input)
# Calculate node 1 in the first hidden layer
node_0_1_input = (input_data*weights['node_0_1']).sum()
node_0_1_output = relu(node_0_1_input)
# Put node values into array: hidden_0_outputs
hidden_0_outputs = np.array([node_0_0_output, node_0_1_output])
# Calculate node 0 in the second hidden layer
node_1_0_input = (hidden_0_outputs*weights['node_1_0']).sum()
node_1_0_output = relu(node_1_0_input)
# Calculate node 1 in the second hidden layer
node_1_1_input = (hidden_0_outputs*weights['node_1_1']).sum()
node_1_1_output = relu(node_1_1_input)
# Put node values into array: hidden_1_outputs
hidden_1_outputs = np.array([node_1_0_output, node_1_1_output])
# Calculate model output: model_output
model_output = (hidden_1_outputs*weights['output']).sum()
# Return model_output
return(model_output)
output = predict_with_network(input_data)
print(output)Çıktı
364