Python Derin Öğrenme - Hızlı Kılavuz
Derin yapılandırılmış öğrenme veya hiyerarşik öğrenme veya kısaca derin öğrenme, kendileri daha geniş Yapay Zeka alanının bir alt kümesi olan makine öğrenimi yöntemleri ailesinin bir parçasıdır.
Derin öğrenme, özellik çıkarma ve dönüştürme için doğrusal olmayan işlem birimlerinin birkaç katmanını kullanan bir makine öğrenimi algoritmaları sınıfıdır. Her ardışık katman, önceki katmandan gelen çıktıyı girdi olarak kullanır.
Derin sinir ağları, derin inanç ağları ve tekrarlayan sinir ağları, bilgisayarla görme, konuşma tanıma, doğal dil işleme, ses tanıma, sosyal ağ filtreleme, makine çevirisi ve biyoinformatik gibi alanlara uygulandı ve bazı durumlarda benzer sonuçlar ürettiler. insan uzmanlardan daha iyi.
Derin Öğrenme Algoritmaları ve Ağları -
çok seviyeli özelliklerin veya verilerin temsillerinin denetimsiz öğrenilmesine dayanır. Daha yüksek seviyeli özellikler, hiyerarşik bir temsil oluşturmak için daha düşük seviyeli özelliklerden türetilir.
eğitim için bir çeşit gradyan inişi kullanın.
Bu bölümde, Python Derin Öğrenme için ayarlanan ortamı öğreneceğiz. Derin öğrenme algoritmaları yapmak için aşağıdaki yazılımları kurmamız gerekiyor.
- Python 2.7+
- Numpy ile Scipy
- Matplotlib
- Theano
- Keras
- TensorFlow
Python, NumPy, SciPy ve Matplotlib'in Anaconda dağıtımı aracılığıyla yüklenmesi şiddetle önerilir. Tüm bu paketlerle birlikte geliyor.
Farklı yazılım türlerinin doğru şekilde kurulduğundan emin olmamız gerekir.
Komut satırı programımıza gidip aşağıdaki komutu yazalım -
$ python
Python 3.6.3 |Anaconda custom (32-bit)| (default, Oct 13 2017, 14:21:34)
[GCC 7.2.0] on linuxArdından, gerekli kitaplıkları içe aktarabilir ve sürümlerini yazdırabiliriz -
import numpy
print numpy.__version__Çıktı
1.14.2Theano, TensorFlow ve Keras kurulumu
Theano, TensorFlow ve Keras gibi paketlerin kurulumuna başlamadan önce, pipyüklendi. Anaconda'daki paket yönetim sistemine pip denir.
Pip kurulumunu onaylamak için komut satırına şunu yazın -
$ pipPip kurulumu onaylandıktan sonra, aşağıdaki komutu çalıştırarak TensorFlow ve Keras'ı kurabiliriz -
$pip install theano $pip install tensorflow
$pip install kerasAşağıdaki kod satırını yürüterek Theano kurulumunu onaylayın -
$python –c “import theano: print (theano.__version__)”Çıktı
1.0.1Aşağıdaki kod satırını çalıştırarak Tensorflow kurulumunu onaylayın -
$python –c “import tensorflow: print tensorflow.__version__”Çıktı
1.7.0Aşağıdaki kod satırını yürüterek Keras kurulumunu onaylayın -
$python –c “import keras: print keras.__version__”
Using TensorFlow backendÇıktı
2.1.5Yapay Zeka (AI), bir bilgisayarın insan bilişsel davranışını veya zekasını taklit etmesini sağlayan herhangi bir kod, algoritma veya tekniktir. Makine Öğrenimi (ML), makinelerin deneyimle öğrenmesini ve gelişmesini sağlamak için istatistiksel yöntemler kullanan bir AI alt kümesidir. Derin Öğrenme, çok katmanlı sinir ağlarının hesaplanmasını mümkün kılan Makine Öğreniminin bir alt kümesidir. Makine Öğrenimi sığ öğrenme olarak görülürken, Derin Öğrenme soyutlama ile hiyerarşik öğrenme olarak görülüyor.
Makine öğrenimi, çok çeşitli kavramlarla ilgilenir. Kavramlar aşağıda listelenmiştir -
- supervised
- unsupervised
- pekiştirmeli öğrenme
- doğrusal regresyon
- maliyet fonksiyonları
- overfitting
- under-fitting
- hiper parametre vb.
Denetimli öğrenmede, etiketli verilerden değerleri tahmin etmeyi öğreniriz. Burada yardımcı olan bir makine öğrenimi tekniği, hedef değerlerin ayrı değerler olduğu sınıflandırmadır; örneğin, kediler ve köpekler. Makine öğreniminde yardımcı olabilecek başka bir teknik de regresyondur. Regresyon, hedef değerler üzerinde çalışır. Hedef değerler sürekli değerlerdir; örneğin, borsa verileri Regresyon kullanılarak analiz edilebilir.
Denetimsiz öğrenmede, etiketlenmemiş veya yapılandırılmamış girdi verilerinden çıkarımlar yaparız. Bir milyon tıbbi kaydımız varsa ve bunu anlamamız, altta yatan yapıyı bulmamız, aykırı değerleri bulmamız veya anormallikleri tespit etmemiz gerekiyorsa, verileri geniş kümelere ayırmak için kümeleme tekniğini kullanırız.
Veri setleri eğitim setlerine, test setlerine, doğrulama setlerine vb. Ayrılmıştır.
2012'deki bir atılım, Derin Öğrenme kavramını öne çıkardı. Bir algoritma, 2 GPU ve Büyük Veri gibi en son teknolojileri kullanarak 1 milyon görüntüyü 1000 kategoride başarıyla sınıflandırdı.
Derin Öğrenme ile Geleneksel Makine Öğrenimini İlişkilendirme
Geleneksel makine öğrenimi modellerinde karşılaşılan en büyük zorluklardan biri, özellik çıkarma adı verilen bir süreçtir. Programcının spesifik olması ve bilgisayara aranacak özellikleri söylemesi gerekir. Bu özellikler karar vermede yardımcı olacaktır.
Algoritmaya ham verilerin girilmesi nadiren işe yaradığından özellik çıkarma, geleneksel makine öğrenimi iş akışının kritik bir parçasıdır.
Bu, programcıya büyük bir sorumluluk yükler ve algoritmanın verimliliği büyük ölçüde programcının ne kadar yaratıcı olduğuna bağlıdır. Nesne tanıma veya el yazısı tanıma gibi karmaşık sorunlar için bu çok büyük bir sorundur.
Birden çok temsil katmanını öğrenme yeteneği ile derin öğrenme, otomatik özellik çıkarmada bize yardımcı olan birkaç yöntemden biridir. Alt katmanların, programcıdan çok az rehberlik gerektiren veya hiç rehberlik gerektirmeyen otomatik öznitelik çıkarımı yaptığı varsayılabilir.
Yapay Sinir Ağı veya kısaca sinir ağı yeni bir fikir değil. Yaklaşık 80 yıldır ortalıkta.
Derin Sinir Ağlarının yeni teknikler, büyük veri kümesi kullanılabilirliği ve güçlü bilgisayarların kullanımıyla popüler hale geldiği 2011 yılına kadar değildi.
Bir sinir ağı, dendritlere, çekirdeğe, aksona ve terminal aksona sahip bir nöronu taklit eder.
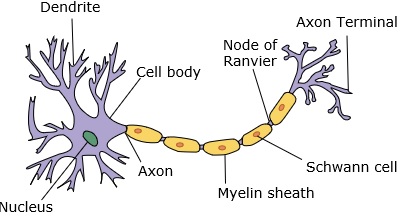
Bir ağ için iki nörona ihtiyacımız var. Bu nöronlar, birinin dendritleri ile diğerinin terminal aksonu arasındaki sinaps yoluyla bilgi aktarır.
Yapay bir nöronun olası bir modeli şuna benzer -
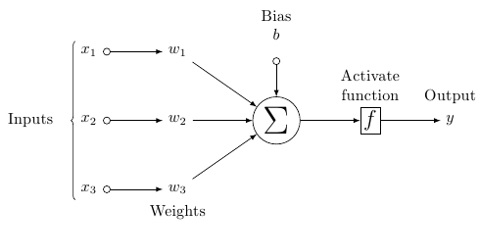
Bir sinir ağı aşağıda gösterildiği gibi görünecektir -
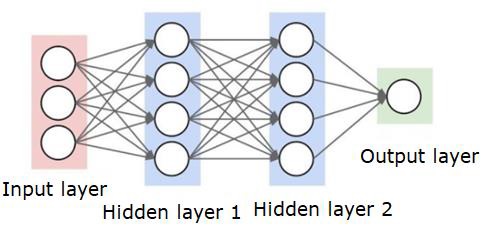
Daireler nöronlar veya düğümlerdir, veri üzerindeki işlevleri ve bunları birbirine bağlayan çizgiler / kenarlar, aktarılan ağırlıklar / bilgilerdir.
Her sütun bir katmandır. Verilerinizin ilk katmanı giriş katmanıdır. Ardından, giriş katmanı ile çıktı katmanı arasındaki tüm katmanlar gizli katmanlardır.
Bir veya birkaç gizli katmanınız varsa, sığ bir sinir ağınız vardır. Çok sayıda gizli katmanınız varsa, derin bir sinir ağınız var demektir.
Bu modelde, girdi verileriniz var, onu tartıyorsunuz ve nörondaki eşik işlevi veya aktivasyon işlevi adı verilen işlevden geçiriyorsunuz.
Temel olarak, tüm değerlerin belirli bir değerle karşılaştırıldıktan sonra toplamıdır. Bir sinyal ateşlerseniz, sonuç (1) dışarı çıkar veya hiçbir şey ateşlenmez, sonra (0). Bu daha sonra ağırlıklandırılır ve bir sonraki nörona aktarılır ve aynı tür işlev çalıştırılır.
Aktivasyon fonksiyonu olarak sigmoid (s-şekli) fonksiyonumuz olabilir.
Ağırlıklara gelince, bunlar sadece rastgele başlamaktadır ve düğüm / nöron girişine göre benzersizdirler.
Tipik bir "ileri beslemeli", en temel sinir ağı türü olarak, bilgilerinizin doğrudan oluşturduğunuz ağdan geçmesini sağlarsınız ve çıktıyı, çıktının örnek verilerinizi kullanmasını umduğunuzla karşılaştırırsınız.
Buradan, çıktınızı istediğiniz çıktıya uyacak şekilde elde etmenize yardımcı olacak ağırlıkları ayarlamanız gerekir.
Doğrudan bir sinir ağı üzerinden veri gönderme eylemine feed forward neural network.
Verilerimiz sırasıyla girdiden katmanlara, sonra çıktıya gider.
Geriye dönüp, kaybı / maliyeti en aza indirmek için ağırlıkları ayarlamaya başladığımızda buna back propagation.
Bu bir optimization problem. Sinir ağı ile gerçek pratikte yüz binlerce değişkenle veya milyonlarla veya daha fazlasıyla uğraşmak zorundayız.
İlk çözüm, optimizasyon yöntemi olarak stokastik gradyan inişini kullanmaktı. Şimdi AdaGrad, Adam Optimizer ve benzeri seçenekler var. Her iki durumda da, bu çok büyük bir hesaplama işlemidir. Bu nedenle Sinir Ağları çoğunlukla yarım yüzyıldan fazla rafta kaldı. Çok yakın bir zamanda makinelerimizde bu işlemleri yapmayı düşünecek güce ve mimariye ve buna uygun boyutta veri setlerine bile sahiptik.
Basit sınıflandırma görevleri için, sinir ağı performans açısından K Nearest Neighbors gibi diğer basit algoritmalara nispeten yakındır. Sinir ağlarının gerçek faydası, her ikisi de diğer makine öğrenimi modellerinden daha iyi performans gösteren çok daha büyük verilere ve çok daha karmaşık sorulara sahip olduğumuzda fark edilir.
Derin bir sinir ağı (DNN), giriş ve çıkış katmanları arasında çok sayıda gizli katman bulunan bir YSA'dır. Sığ YSA'lara benzer şekilde, DNN'ler karmaşık doğrusal olmayan ilişkileri modelleyebilir.
Bir sinir ağının temel amacı, bir dizi girdi almak, bunlar üzerinde aşamalı olarak karmaşık hesaplamalar yapmak ve sınıflandırma gibi gerçek dünya sorunlarını çözmek için çıktı vermektir. Sinir ağlarını ileri beslemek için kendimizi kısıtlıyoruz.
Derin bir ağda bir girdi, çıktı ve sıralı veri akışımız var.
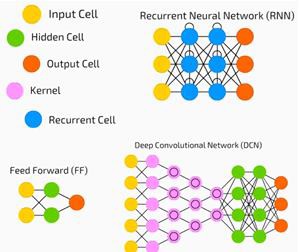
Sinir ağları, denetimli öğrenme ve pekiştirmeli öğrenme problemlerinde yaygın olarak kullanılmaktadır. Bu ağlar, birbirine bağlı bir dizi katmana dayanmaktadır.
Derin öğrenmede, çoğunlukla doğrusal olmayan gizli katmanların sayısı büyük olabilir; yaklaşık 1000 katman deyin.
DL modelleri, normal makine öğrenimi ağlarından çok daha iyi sonuçlar verir.
Ağı optimize etmek ve kayıp fonksiyonunu en aza indirmek için çoğunlukla gradyan iniş yöntemini kullanıyoruz.
Kullanabiliriz Imagenet, bir veri kümesini kediler ve köpekler gibi kategorilere ayırmak için milyonlarca dijital görüntüden oluşan bir havuz. DL ağları, statik ağlar dışında dinamik görüntüler için ve zaman serileri ve metin analizi için giderek daha fazla kullanılmaktadır.
Veri setlerinin eğitimi, Derin Öğrenme modellerinin önemli bir parçasını oluşturur. Ek olarak, Geri yayılım, DL modellerinin eğitiminde ana algoritmadır.
DL, karmaşık giriş çıkış dönüşümlerine sahip büyük sinir ağlarını eğitmekle ilgilenir.
DL'nin bir örneği, bir fotoğrafın sosyal ağlarda olduğu gibi fotoğraftaki kişi (ler) in adıyla eşleştirilmesidir ve bir resmi bir cümle ile açıklamak, DL'nin yeni bir başka uygulamasıdır.
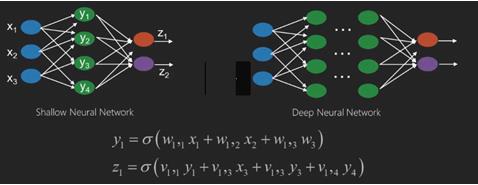
Sinir ağları, x1, x2, x3 gibi girdileri olan ve z1, z2, z3 ve benzeri çıktılara iki (sığ ağlar) veya katmanlar (derin ağlar) olarak da adlandırılan birkaç ara işlem halinde dönüştürülen işlevlerdir.
Ağırlıklar ve önyargılar katmandan katmana değişir. 'w' ve 'v', sinir ağlarının katmanlarının ağırlıkları veya sinapslarıdır.
Derin öğrenmenin en iyi kullanım durumu denetimli öğrenme problemidir.Burada, istenen çıktı setine sahip geniş veri girişleri setimiz var.
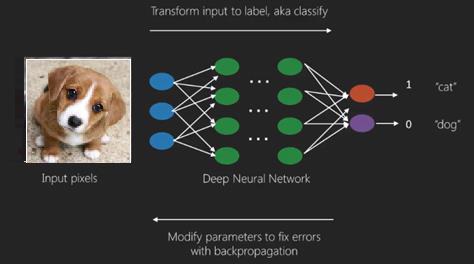
Burada doğru çıktı tahminini elde etmek için geri yayılma algoritması uyguluyoruz.
Derin öğrenmenin en temel veri seti, elle yazılmış rakamlardan oluşan bir veri kümesi olan MNIST'tir.
Bu veri setinden el yazısıyla yazılmış rakamların görüntülerini sınıflandırmak için Keras ile Evrişimli Sinir Ağı'nı derinlemesine eğitebiliriz.
Bir sinir ağı sınıflandırıcısının ateşlenmesi veya etkinleştirilmesi bir skor üretir. Örneğin hastaları hasta ve sağlıklı olarak sınıflandırmak için boy, kilo ve vücut ısısı, kan basıncı vb. Parametreleri dikkate alıyoruz.
Yüksek puan hastanın hasta olduğu ve düşük puan hastanın sağlıklı olduğu anlamına gelir.
Çıktı ve gizli katmanlardaki her düğümün kendi sınıflandırıcıları vardır. Giriş katmanı girdileri alır ve daha fazla aktivasyon için puanlarını bir sonraki gizli katmana aktarır ve bu, çıktıya ulaşılana kadar devam eder.
Bu ileriye doğru soldan sağa girdiden çıktıya doğru ilerleme denir forward propagation.
Bir sinir ağındaki kredi atama yolu (CAP), girişten çıkışa kadar uzanan bir dizi dönüşümdür. CAP'ler, girdi ve çıktı arasındaki olası nedensel bağlantıları ayrıntılandırır.
Belirli bir ileri beslemeli sinir ağı veya CAP derinliği için CAP derinliği, gizli katman sayısı artı çıktı katmanı dahil edildiğinde birdir. Bir sinyalin bir katmandan birkaç kez yayılabildiği tekrarlayan sinir ağları için, CAP derinliği potansiyel olarak sınırsız olabilir.
Derin Ağlar ve Sığ Ağlar
Sığ öğrenmeyi derin öğrenmeden ayıran net bir derinlik eşiği yoktur; ancak doğrusal olmayan çoklu katmanlara sahip derin öğrenme için CAP'nin ikiden büyük olması gerektiği konusunda çoğunlukla mutabık kalınmıştır.
Bir sinir ağındaki temel düğüm, biyolojik bir sinir ağındaki bir nöronu taklit eden bir algıdır. Sonra çok katmanlı Algı veya MLP'ye sahibiz. Her girdi kümesi, bir dizi ağırlık ve önyargı ile değiştirilir; her kenarın benzersiz bir ağırlığı ve her düğümün benzersiz bir eğilimi vardır.
Tahmini accuracy bir sinir ağının weights and biases.
Sinir ağının doğruluğunu geliştirme sürecine training. Bir ileri destek ağından elde edilen çıktı, doğru olduğu bilinen değerle karşılaştırılır.
cost function or the loss function üretilen çıktı ile gerçek çıktı arasındaki farktır.
Eğitimin amacı, eğitimin maliyetini milyonlarca eğitim örneğinde olabildiğince küçük yapmaktır.Bunu yapmak için ağ, tahmin doğru çıktıyla eşleşene kadar ağırlıkları ve önyargıları ayarlar.
İyi eğitildikten sonra, bir sinir ağı her seferinde doğru bir tahmin yapma potansiyeline sahiptir.
Kalıp karmaşıklaştığında ve bilgisayarınızın onları tanımasını istediğinizde, sinir ağlarına gitmeniz gerekir. Bu tür karmaşık model senaryolarında, sinir ağı diğer tüm rakip algoritmalardan daha iyi performans gösterir.
Artık onları her zamankinden daha hızlı eğitebilen GPU'lar var. Derin sinir ağları zaten AI alanında devrim yaratıyor
Bilgisayarların, tekrarlayan hesaplamaları gerçekleştirmede ve ayrıntılı talimatları takip etmede iyi olduğu kanıtlandı, ancak karmaşık kalıpları tanımada o kadar iyi olamadı.
Basit örüntülerin tanınması sorunu varsa, bir destek vektör makinesi (svm) veya bir lojistik regresyon sınıflandırıcı işi iyi yapabilir, ancak örüntü karmaşıklığı arttıkça, derin sinir ağlarına gitmekten başka yol yoktur.
Bu nedenle, insan yüzü gibi karmaşık modeller için, sığ sinir ağları başarısız olur ve daha fazla katmana sahip derin sinir ağlarına gitmekten başka alternatifleri yoktur. Derin ağlar, karmaşık kalıpları daha basit olanlara bölerek işlerini yapabilirler. Örneğin insan yüzü; adeep net dudaklar, burun, gözler, kulaklar vb. gibi parçaları tespit etmek için kenarları kullanır ve ardından bunları bir insan yüzü oluşturmak için yeniden birleştirir
Doğru tahminin doğruluğu o kadar doğru hale geldi ki, son zamanlarda bir Google Kalıp Tanıma Mücadelesinde, derin bir ağ insanı yendi.
Bu katmanlı algılayıcılar ağı fikri bir süredir ortalıkta dolaşıyor; bu alanda derin ağlar insan beynini taklit eder. Ancak bunun bir dezavantajı, eğitilmelerinin uzun sürmesi, bir donanım kısıtlaması
Bununla birlikte, yakın zamandaki yüksek performanslı GPU'lar bu kadar derin ağları bir haftadan kısa sürede eğitebildi; hızlı cpus'un aynısını yapması haftalar veya belki aylar sürebilirdi.
Derin Ağ Seçmek
Derin bir ağ nasıl seçilir? Bir sınıflandırıcı mı oluşturacağımıza yoksa verilerde kalıplar bulmaya mı çalışacağımıza ve denetimsiz öğrenmeyi kullanıp kullanmayacağımıza karar vermeliyiz. Bir dizi etiketsiz veriden desenleri çıkarmak için, Sınırlı Boltzman makinesi veya Otomatik kodlayıcı kullanıyoruz.
Derin bir ağ seçerken aşağıdaki noktaları göz önünde bulundurun -
Metin işleme, duygu analizi, ayrıştırma ve ad varlık tanıma için, tekrarlayan bir ağ veya özyinelemeli sinir tensör ağı veya RNTN kullanırız;
Karakter düzeyinde çalışan herhangi bir dil modeli için yinelenen ağı kullanıyoruz.
Görüntü tanıma için derin inanç ağı DBN veya evrişimli ağ kullanıyoruz.
Nesne tanıma için bir RNTN veya bir evrişimli ağ kullanıyoruz.
Konuşma tanıma için yinelenen net kullanıyoruz.
Genel olarak, derin inanç ağları ve düzeltilmiş doğrusal birimler veya RELU'lu çok katmanlı algılayıcılar, sınıflandırma için iyi seçeneklerdir.
Zaman serisi analizi için her zaman yinelenen ağ kullanılması önerilir.
Sinir ağları 50 yıldan fazladır etrafta; ama ancak şimdi öne çıktılar. Nedeni, eğitilmelerinin zor olmasıdır; onları geri yayılma adı verilen bir yöntemle eğitmeye çalıştığımızda, yok olma veya patlayan gradyanlar denen bir problemle karşılaşırız. Bu olduğunda, eğitim daha uzun sürer ve doğruluk arka planda kalır. Bir veri setini eğitirken, tahmin edilen çıktı ile etiketli eğitim verilerinin fiili çıktıları arasındaki fark olan maliyet fonksiyonunu sürekli olarak hesaplıyoruz. Daha sonra maliyet fonksiyonu, ağırlıkları ve önyargı değerlerini en düşük değere kadar ayarlayarak en aza indirilir. elde edildi. Eğitim süreci, ağırlık veya önyargı değerlerindeki değişime göre maliyetin değişeceği oran olan bir gradyan kullanır.
Kısıtlanmış Boltzman Ağları veya Otomatik Kodlayıcılar - RBN'ler
2006 yılında, yok olan eğim sorununu çözme konusunda bir atılım gerçekleştirildi. Geoff Hinton, yeni bir strateji geliştirdi.Restricted Boltzman Machine - RBM, sığ iki katmanlı bir ağ.
İlk katman, visible katman ve ikinci katman hiddenkatman. Görünür katmandaki her düğüm, gizli katmandaki her düğüme bağlıdır. Ağ, aynı katmandaki iki katmanın bir bağlantıyı paylaşmasına izin verilmediğinden, kısıtlı olarak bilinir.
Otomatik kodlayıcılar, giriş verilerini vektör olarak kodlayan ağlardır. Ham verilerin gizli veya sıkıştırılmış bir temsilini oluştururlar. Vektörler boyut azaltmada faydalıdır; vektör, ham verileri daha az sayıda temel boyutta sıkıştırır. Otomatik kodlayıcılar, giriş verilerinin gizli gösterimi temelinde yeniden yapılandırılmasına izin veren kod çözücülerle eşleştirilir.
RBM, iki yönlü bir çevirmenin matematiksel eşdeğeridir. İleri geçiş, girişleri alır ve bunları girişleri kodlayan bir sayı kümesine çevirir. Bu arada bir geri geçiş, bu sayı dizisini alır ve onları yeniden yapılandırılmış girdilere dönüştürür. İyi eğitilmiş bir ağ, yüksek derecede doğrulukla arka destek sağlar.
Her iki adımda da ağırlıklar ve önyargılar kritik bir role sahiptir; RBM'ye girdiler arasındaki karşılıklı ilişkilerin kodunu çözmede ve modelleri tespit etmede hangi girdilerin gerekli olduğuna karar vermede yardımcı olurlar. İleri ve geri geçişler yoluyla, RBM, girdi ve oradaki yapı mümkün olduğunca yakın olana kadar girdiyi farklı ağırlık ve önyargılarla yeniden inşa etmek için eğitilir. RBM'nin ilginç bir yönü, verilerin etiketlenmesine gerek olmamasıdır. Bu, tümü etiketsiz olma eğiliminde olan fotoğraflar, videolar, sesler ve sensör verileri gibi gerçek dünya veri kümeleri için çok önemli olduğu ortaya çıkıyor. Verileri insanlar tarafından manuel olarak etiketlemek yerine, RBM verileri otomatik olarak sıralar; Bir RBM, ağırlıkları ve önyargıları uygun şekilde ayarlayarak önemli özellikleri çıkarabilir ve girdiyi yeniden yapılandırabilir. RBM, verilerdeki doğal kalıpları tanımak için tasarlanmış özellik çıkarıcı sinir ağları ailesinin bir parçasıdır. Bunlara otomatik kodlayıcılar da denir çünkü kendi yapılarını kodlamaları gerekir.

Derin İnanç Ağları - DBN'ler
Derin inanç ağları (DBN'ler), RBM'leri birleştirerek ve akıllı bir eğitim yöntemi getirilerek oluşturulur. Sonunda kaybolan gradyan sorununu çözen yeni bir modelimiz var. Geoff Hinton geri yayılmaya alternatif olarak RBM'leri ve ayrıca Derin İnanç Ağlarını icat etti.
Bir DBN, yapı olarak bir MLP'ye (Çok katmanlı algılayıcı) benzer, ancak eğitim söz konusu olduğunda çok farklıdır. DBN'lerin sığ emsallerinden daha iyi performans göstermesini sağlayan eğitimdir
Bir DBN, bir RBM'nin gizli katmanının, üzerindeki RBM'nin görünür katmanı olduğu bir RBM yığını olarak görselleştirilebilir. İlk RBM, girdisini olabildiğince doğru bir şekilde yeniden yapılandırmak için eğitilmiştir.
İlk RBM'nin gizli katmanı, ikinci RBM'nin görünür katmanı olarak alınır ve ikinci RBM, birinci RBM'den gelen çıktılar kullanılarak eğitilir. Bu süreç, ağdaki her katman eğitilene kadar yinelenir.
Bir DBN'de, her bir RBM tüm girişi öğrenir. Bir DBN, bir görüntüyü yavaşça odaklayan bir kamera lensi gibi model yavaş yavaş gelişirken, tüm girdiyi art arda ince ayarlayarak küresel olarak çalışır. Çok katmanlı bir algılayıcı MLP, tek bir algılayıcıdan daha iyi performans gösterdiğinden, bir grup RBM tek bir RBM'den daha iyi performans gösterir.
Bu aşamada, RBM'ler verilerde herhangi bir isim veya etiket olmaksızın içsel kalıplar tespit etmişlerdir. DBN eğitimini bitirmek için, kalıplara etiketler eklememiz ve denetimli öğrenmeyle ağa ince ayar yapmalıyız.
Özelliklerin ve modellerin bir adla ilişkilendirilebilmesi için çok küçük bir etiketli örnek setine ihtiyacımız var. Bu küçük etiketli veri seti eğitim için kullanılır. Bu etiketlenmiş veri kümesi, orijinal veri kümesiyle karşılaştırıldığında çok küçük olabilir.
Ağırlıklar ve önyargılar hafifçe değiştirilerek ağın kalıpları algılamasında küçük bir değişikliğe ve genellikle toplam doğrulukta küçük bir artışa neden olur.
Sığ ağlara kıyasla çok doğru sonuçlar veren GPU'lar kullanılarak eğitim makul bir sürede tamamlanabilir ve kaybolan gradyan sorununa da bir çözüm görüyoruz.
Üretken Çekişmeli Ağlar - GAN'lar
Üretken düşmanlık ağları, iki ağdan oluşan derin sinir ağlarıdır, biri diğerine karşı çekiştirilmiştir, dolayısıyla “düşman” adıdır.
GAN'lar, 2014 yılında Montreal Üniversitesi'ndeki araştırmacılar tarafından yayınlanan bir makalede tanıtıldı. Facebook'un yapay zeka uzmanı Yann LeCun, GAN'lara atıfta bulunarak, “ML'de son 10 yılın en ilginç fikri” olarak nitelendirdi.
Ağ taraması herhangi bir veri dağılımını taklit etmeyi öğrendiğinden GAN'ların potansiyeli çok büyük. GAN'lara herhangi bir alanda bizimkine çarpıcı şekilde benzer paralel dünyalar yaratmaları öğretilebilir: resimler, müzik, konuşma, düzyazı. Bir bakıma robot sanatçılar ve çıktıları oldukça etkileyici.
Bir GAN'da, jeneratör olarak bilinen bir sinir ağı yeni veri örnekleri üretirken diğeri, ayırıcı, bunları özgünlük açısından değerlendirir.
MNIST veri setinde bulunanlar gibi gerçek dünyadan alınan elle yazılmış rakamlar üretmeye çalıştığımızı varsayalım. Ayrımcının işi, gerçek MNIST veri kümesinden bir örnek gösterildiğinde, onları gerçek olarak tanımaktır.
Şimdi GAN'ın aşağıdaki adımlarını düşünün -
Jeneratör ağı, rasgele sayılar biçiminde girdi alır ve bir görüntü döndürür.
Oluşturulan bu görüntü, gerçek veri setinden alınan bir görüntü akışı ile birlikte ayırıcı ağa girdi olarak verilir.
Ayırıcı, hem gerçek hem de sahte görüntüleri alır ve olasılıkları döndürür, 0 ile 1 arasında bir sayı, 1 orijinallik tahminini ve 0 ise sahteyi temsil eder.
Yani bir çift geri bildirim döngünüz var -
Ayırıcı, bildiğimiz görüntülerin temel gerçekliği ile bir geribildirim döngüsü içindedir.
Jeneratör, ayırıcı ile bir geri bildirim döngüsü içindedir.
Tekrarlayan Sinir Ağları - RNN'ler
RNNVerilerin herhangi bir yönde akabildiği sare sinir ağları. Bu ağlar, dil modelleme veya Doğal Dil İşleme (NLP) gibi uygulamalar için kullanılır.
RNN'lerin altında yatan temel kavram, sıralı bilgileri kullanmaktır. Normal bir sinir ağında, tüm giriş ve çıkışların birbirinden bağımsız olduğu varsayılır. Bir cümledeki sonraki kelimeyi tahmin etmek istiyorsak, ondan önce hangi kelimelerin geldiğini bilmemiz gerekir.
RNN'ler, bir dizinin her öğesi için aynı görevi tekrarladıkları için tekrarlayan olarak adlandırılır ve çıktı önceki hesaplamalara dayanır. Bu nedenle, RNN'lerin daha önce hesaplananlarla ilgili bilgileri yakalayan bir "hafızaya" sahip olduğu söylenebilir. Teorik olarak, RNN'ler bilgiyi çok uzun sıralarda kullanabilir, ancak gerçekte sadece birkaç adım geriye bakabilirler.
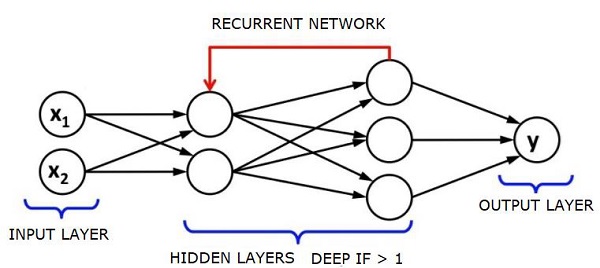
Uzun kısa süreli bellek ağları (LSTM'ler) en yaygın olarak kullanılan RNN'lerdir.
Evrişimli Sinir Ağları ile birlikte RNN'ler, etiketlenmemiş görüntüler için tanımlamalar üretmek için bir modelin parçası olarak kullanılmıştır. Bunun ne kadar iyi çalıştığı oldukça şaşırtıcı.
Evrişimli Derin Sinir Ağları - CNN'ler
Bir sinir ağındaki katman sayısını daha derin hale getirmek için arttırırsak, ağın karmaşıklığını artırır ve daha karmaşık işlevleri modellememize olanak tanır. Bununla birlikte, ağırlıkların ve önyargıların sayısı katlanarak artacaktır. Nitekim bu tür zor problemleri öğrenmek normal sinir ağları için imkansız hale gelebilir. Bu bir çözüme, evrişimli sinir ağlarına götürür.
CNN'ler bilgisayarla görmede yaygın olarak kullanılır; otomatik konuşma tanıma için akustik modellemede de uygulanmıştır.
Evrişimli sinir ağlarının arkasındaki fikir, görüntüden geçen "hareketli filtre" fikridir. Bu hareketli filtre veya evrişim, belirli bir düğüm mahalli için geçerlidir, örneğin pikseller olabilir, burada uygulanan filtre 0,5 x düğüm değeridir -
Tanınmış araştırmacı Yann LeCun, evrişimli sinir ağlarına öncülük etti. Yüz tanıma yazılımı olarak Facebook bu ağları kullanıyor. CNN, makine vizyonu projeleri için en uygun çözüm olmuştur. Evrişimli bir ağın birçok katmanı vardır. Imagenet yarışmasında, bir makine 2015 yılında nesne tanımada bir insanı yenmeyi başardı.
Özetle, Evrişimli Sinir Ağları (CNN'ler) çok katmanlı sinir ağlarıdır. Katmanlar bazen 17 veya daha fazla olabilir ve giriş verilerinin görüntü olduğunu varsayar.
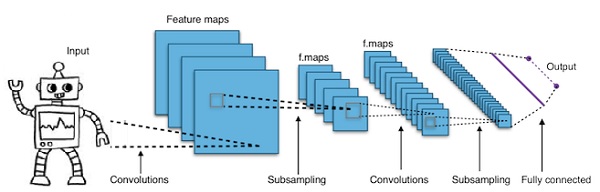
CNN'ler, ayarlanması gereken parametre sayısını önemli ölçüde azaltır. Böylece, CNN'ler ham görüntülerin yüksek boyutluluğunu verimli bir şekilde işler.
Bu bölümde, Python Derin Öğrenmenin temellerini inceleyeceğiz.
Derin öğrenme modelleri / algoritmaları
Şimdi farklı derin öğrenme modellerini / algoritmalarını öğrenelim.
Derin öğrenmedeki popüler modellerden bazıları aşağıdaki gibidir:
- Evrişimli sinir ağları
- Tekrarlayan sinir ağları
- Derin inanç ağları
- Üretken hasım ağları
- Otomatik kodlayıcılar vb.
Girişler ve çıkışlar vektörler veya tensörler olarak temsil edilir. Örneğin, bir sinir ağı, bir görüntüdeki ayrı piksel RGB değerlerinin vektörler olarak temsil edildiği girdilere sahip olabilir.
Giriş katmanı ile çıktı katmanı arasında yer alan nöron katmanlarına gizli katmanlar denir. Sinir ağı sorunları çözmeye çalıştığında işin çoğunun gerçekleştiği yer burasıdır. Gizli katmanlara daha yakından bakmak, ağın verilerden çıkarmayı öğrendiği özellikler hakkında çok şey ortaya çıkarabilir.
Bir sonraki katmandaki diğer nöronlara hangi nöronların bağlanacağı seçilerek farklı sinir ağları mimarileri oluşturulur.
Çıktıyı hesaplamak için sözde kod
Aşağıdakilerin çıktısını hesaplamak için sözde kod Forward-propagating Neural Network -
- # düğüm []: = topolojik olarak sıralanmış düğümler dizisi
- # A'dan b'ye bir kenar, a'nın b'nin solunda olduğu anlamına gelir
- # Sinir Ağında R girişleri ve S çıkışları varsa,
- # sonra ilk R düğümleri giriş düğümleridir ve son S düğümleri çıkış düğümleridir.
- # gelen [x]: = x düğümüne bağlı düğüm
- # ağırlık [x]: = x'e gelen kenarların ağırlıkları
Her x nöronu için, soldan sağa -
- eğer x <= R: hiçbir şey yapmayın # onun bir giriş düğümü
- girişler [x] = [gelen [x]] i için çıkış [i]
- weighted_sum = dot_product (ağırlıklar [x], girişler [x])
- çıktı [x] = Etkinleştirme_işlevi (ağırlıklı_toplam)
Şimdi bir sinir ağını nasıl eğiteceğimizi öğreneceğiz. Ayrıca geri yayılma algoritmasını ve Python Derin Öğrenmede geriye doğru geçişi öğreneceğiz.
İstenilen çıktıyı elde etmek için bir sinir ağının ağırlıklarının optimal değerlerini bulmalıyız. Bir sinir ağını eğitmek için yinelemeli gradyan iniş yöntemini kullanıyoruz. Başlangıçta ağırlıkların rastgele başlatılmasıyla başlıyoruz. Rastgele başlatmadan sonra, ileri yayılma süreciyle verilerin bazı alt kümeleri üzerinde tahminler yapar, karşılık gelen maliyet fonksiyonu C'yi hesaplar ve her ağırlık w'yi dC / dw ile orantılı bir miktarda güncelleriz, yani maliyet fonksiyonlarının türevi ağırlık. Orantılılık sabiti, öğrenme hızı olarak bilinir.
Gradyanlar, geri yayılma algoritması kullanılarak verimli bir şekilde hesaplanabilir. Geriye doğru yayılmanın veya geriye doğru yayılmanın temel gözlemi, farklılaşma zincir kuralı nedeniyle, sinir ağındaki her bir nörondaki gradyanın, nöronlardaki gradyan kullanılarak hesaplanabilmesidir. Bu nedenle, degradeleri geriye doğru hesaplıyoruz, yani önce çıktı katmanının gradyanlarını, ardından en üstteki gizli katmanı, ardından önceki gizli katmanı vb. Hesaplayarak girdi katmanında son buluyoruz.
Geri yayılma algoritması, çoğunlukla, her bir nöronun hesaplama grafiğindeki birçok düğüme genişletildiği ve toplama, çarpma gibi basit bir matematiksel işlem gerçekleştirdiği bir hesaplama grafiği fikri kullanılarak uygulanır. Hesaplama grafiğinin kenarlarında ağırlık yoktur; tüm ağırlıklar düğümlere atanır, böylece ağırlıklar kendi düğümleri olur. Geriye doğru yayılma algoritması daha sonra hesaplama grafiğinde çalıştırılır. Hesaplama tamamlandıktan sonra, güncelleme için yalnızca ağırlık düğümlerinin gradyanları gereklidir. Degradelerin geri kalanı atılabilir.
Gradyan İniş Optimizasyon Tekniği
Ağırlıkları neden oldukları hataya göre ayarlayan yaygın olarak kullanılan bir optimizasyon işlevine "gradyan inişi" denir.
Gradyan, eğimin başka bir adıdır ve bir xy grafiğindeki eğim, iki değişkenin birbiriyle nasıl ilişkili olduğunu temsil eder: yatay mesafeden yükselme, zamandaki değişime göre mesafedeki değişim, vb. Bu durumda, eğim şu şekildedir: ağ hatası ile tek bir ağırlık arasındaki oran; yani, ağırlık değiştikçe hata nasıl değişir?
Daha kesin bir ifadeyle, hangi ağırlığın en az hata verdiğini bulmak istiyoruz. Giriş verilerinde bulunan sinyalleri doğru şekilde temsil eden ve bunları doğru bir sınıflandırmaya çeviren ağırlığı bulmak istiyoruz.
Bir sinir ağı öğrendikçe, birçok ağırlığı yavaşça ayarlar, böylece sinyali doğru anlamla eşleştirebilirler. Ağ Hatası ile bu ağırlıkların her biri arasındaki oran bir türevdir, dE / dw, bir ağırlıktaki küçük bir değişikliğin hatada küçük bir değişikliğe neden olma derecesini hesaplar.
Her ağırlık, birçok dönüşümü içeren derin bir ağda yalnızca bir faktördür; ağırlığın sinyali birkaç katman üzerinden etkinleştirmelerden ve toplamlardan geçer, bu nedenle ağ etkinleştirmeleri ve çıktıları üzerinden geri çalışmak için kalkülüs zincir kuralını kullanırız.Bu bizi söz konusu ağırlığa ve bunun genel hata ile ilişkisine götürür.
İki değişken verildiğinde, hata ve ağırlık, üçüncü bir değişken tarafından aracılık edilir, activationağırlığın geçtiği yer. Önce aktivasyondaki bir değişikliğin Hatadaki bir değişikliği nasıl etkilediğini ve ağırlıktaki bir değişikliğin aktivasyondaki bir değişikliği nasıl etkilediğini hesaplayarak ağırlıktaki bir değişikliğin hatadaki bir değişikliği nasıl etkilediğini hesaplayabiliriz.
Derin öğrenmedeki temel fikir bundan başka bir şey değildir: Hatayı daha fazla azaltamayana kadar ürettiği hataya yanıt olarak modelin ağırlıklarını ayarlamak.
Derin ağ, gradyan değeri küçükse yavaş ve değer yüksekse hızlı eğitilir. Eğitimdeki herhangi bir yanlışlık, yanlış çıktılara yol açar. Ağları çıktıdan girdiye geri döndürme sürecine geri yayılma veya geri propagasyon denir. İleriye doğru yayılmanın girdiyle başladığını ve ileriye doğru işlediğini biliyoruz. Back prop, gradyanı sağdan sola hesaplayarak ters / tersi yapar.
Bir gradyanı her hesapladığımızda, o noktaya kadar önceki tüm gradyanları kullanırız.
Çıktı katmanındaki bir düğümden başlayalım. Kenar, bu düğümdeki gradyanı kullanır. Gizli katmanlara geri döndüğümüzde, daha karmaşık hale geliyor. 0 ile 1 arasındaki iki sayının çarpımı size daha küçük bir sayı verir. Gradyan değeri küçülmeye devam ediyor ve sonuç olarak arka pervanenin eğitilmesi çok zaman alıyor ve doğruluk zarar görüyor.
Derin Öğrenme Algoritmalarındaki Zorluklar
Hem sığ sinir ağları hem de derin sinir ağları için aşırı uyum ve hesaplama süresi gibi belirli zorluklar vardır. DNN'ler aşırı uyumdan etkilenir çünkü ek soyutlama katmanlarının kullanılması, eğitim verilerinde nadir görülen bağımlılıkları modellemelerine olanak tanır.
RegularizationAşırı uyumla mücadele etmek için eğitim sırasında okulu bırakma, erken durdurma, veri artırma, aktarım öğrenme gibi yöntemler uygulanır. Düzenlemeyi bırakma, eğitim sırasında birimleri gizli katmanlardan rastgele çıkararak nadir görülen bağımlılıklardan kaçınmaya yardımcı olur. DNN'ler boyut, yani katman sayısı ve katman başına birim sayısı, öğrenme hızı ve başlangıç ağırlıkları gibi çeşitli eğitim parametrelerini dikkate alır. En uygun parametreleri bulmak, yüksek zaman maliyeti ve hesaplama kaynakları nedeniyle her zaman pratik değildir. Gruplama gibi birkaç hack işlemi, hesaplamayı hızlandırabilir. GPU'ların büyük işlem gücü, gereken matris ve vektör hesaplamaları GPU'larda iyi uygulandığından eğitim sürecine önemli ölçüde yardımcı oldu.
Bırakmak
Bırakma, sinir ağları için popüler bir düzenleme tekniğidir. Derin sinir ağları özellikle aşırı uyuma eğilimlidir.
Şimdi bırakmanın ne olduğunu ve nasıl çalıştığını görelim.
Derin Öğrenmenin öncülerinden Geoffrey Hinton'un sözleriyle, 'Derin bir sinir ağınız varsa ve bu fazla uygun değilse, muhtemelen daha büyük bir tane kullanmalı ve bırakmayı kullanmalısınız'.
Bırakma, gradyan inişinin her yinelemesi sırasında rastgele seçilen bir dizi düğüm düşürdüğümüz bir tekniktir. Bu, bazı düğümleri yokmuş gibi rastgele görmezden geldiğimiz anlamına gelir.
Her nöron q olasılığı ile tutulur ve 1-q olasılığı ile rastgele düşer. Q değeri, sinir ağındaki her katman için farklı olabilir. Gizli katmanlar için 0,5 ve giriş katmanı için 0 değeri, çok çeşitli görevlerde iyi çalışır.
Değerlendirme ve tahmin sırasında, herhangi bir bırakma kullanılmaz. Her bir nöronun çıktısı q ile çarpılır, böylece bir sonraki katmana giriş aynı beklenen değere sahip olur.
Dropout'un arkasındaki fikir şu şekildedir: Bırakma düzenlemesi olmayan bir sinir ağında, nöronlar birbirleri arasında aşırı uyuma yol açan bir eş bağımlılık geliştirir.
Uygulama hilesi
TensorFlow ve Pytorch gibi kütüphanelerde rastgele seçilen nöronların çıktısını 0 olarak tutarak bırakma uygulanır. Yani nöron var olsa da çıktısının üzerine 0 yazılır.
Erken Durma
Gradyan iniş adı verilen yinelemeli bir algoritma kullanarak sinir ağlarını eğitiyoruz.
Erken durdurmanın arkasındaki fikir sezgiseldir; Hata artmaya başladığında eğitimi durdururuz. Burada, hata ile, hiper parametreleri ayarlamak için kullanılan eğitim verilerinin bir parçası olan doğrulama verilerinde ölçülen hatayı kastediyoruz. Bu durumda, hiper parametre durdurma ölçütüdür.
Veri Büyütme
Elimizdeki verinin kuantumunu arttırdığımız veya var olan verileri kullanarak ve üzerinde bazı dönüşümler uygulayarak onu büyüttüğümüz süreç. Kullanılan tam dönüşümler, başarmayı planladığımız göreve bağlıdır. Dahası, sinir ağına yardımcı olan dönüşümler mimarisine bağlıdır.
Örneğin, nesne sınıflandırması gibi birçok bilgisayar görüşü görevinde, etkili bir veri artırma tekniği, orijinal verilerin kırpılmış veya çevrilmiş sürümleri olan yeni veri noktaları eklemektir.
Bir bilgisayar bir görüntüyü girdi olarak kabul ettiğinde, bir dizi piksel değeri alır. Tüm görüntünün 15 piksel sola kaydırıldığını varsayalım. Farklı yönlerde birçok farklı kayma uygulayarak, orijinal veri kümesinin boyutunun birçok katı genişletilmiş bir veri kümesiyle sonuçlanır.
Transfer Öğrenimi
Önceden eğitilmiş bir model alma ve modele kendi veri setimizle "ince ayar yapma" sürecine aktarımla öğrenme denir. Bunu yapmanın birkaç yolu vardır: Aşağıda birkaç yol açıklanmıştır -
Önceden eğitilmiş modeli büyük bir veri kümesi üzerinde eğitiyoruz. Ardından, ağın son katmanını kaldırıp, rastgele ağırlıklara sahip yeni bir katmanla değiştiriyoruz.
Daha sonra diğer tüm katmanların ağırlıklarını donduruyoruz ve ağı normal şekilde eğitiyoruz. Burada katmanları dondurmak, gradyan inişi veya optimizasyonu sırasında ağırlıkları değiştirmez.
Bunun arkasındaki konsept, önceden eğitilmiş modelin bir özellik çıkarıcı olarak hareket etmesi ve sadece son katmanın mevcut görev için eğitilmesidir.
Geri yayılım, hesaplamalı grafikler kullanılarak Tensorflow, Torch, Theano vb. Gibi derin öğrenme çerçevelerinde uygulanır. Daha da önemlisi, hesaplama grafiklerinde geri yayılmayı anlamak, birkaç farklı algoritmayı ve zaman içinde geri dönüş ve paylaşılan ağırlıklarla geri dönüş gibi varyasyonlarını birleştirir. Her şey bir hesaplama grafiğine dönüştürüldüğünde, bunlar hala aynı algoritmadır - sadece hesaplama grafiklerinde geriye doğru yayılma.
Hesaplamalı Grafik nedir
Hesaplamalı grafik, düğümlerin matematiksel işlemlere karşılık geldiği yönlendirilmiş bir grafik olarak tanımlanır. Hesaplamalı grafikler, matematiksel bir ifadeyi ifade etmenin ve değerlendirmenin bir yoludur.
Örneğin, işte basit bir matematiksel denklem -
$$p = x+y$$
Yukarıdaki denklemin hesaplama grafiğini aşağıdaki gibi çizebiliriz.
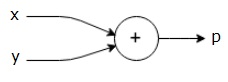
Yukarıdaki hesaplama grafiğinde, iki giriş değişkeni x ve y ve bir çıkış q olan bir toplama düğümü ("+" işaretli düğüm) vardır.
Biraz daha karmaşık başka bir örnek alalım. Aşağıdaki denkleme sahibiz.
$$g = \left (x+y \right ) \ast z $$
Yukarıdaki denklem aşağıdaki hesaplama grafiğiyle temsil edilmektedir.
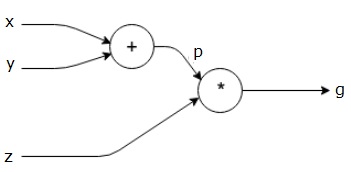
Hesaplamalı Grafikler ve Geri Yayımlama
Hesaplamalı grafikler ve geri yayılım, her ikisi de sinir ağlarını eğitmek için derin öğrenmede önemli temel kavramlardır.
Doğrudan geçiş
İleri geçiş, hesaplamalı grafiklerle temsil edilen matematiksel ifadenin değerini değerlendirme prosedürüdür. İleri geçiş yapmak, değeri değişkenlerden ileri yönde soldan (giriş) çıkışın olduğu sağa doğru geçirdiğimiz anlamına gelir.
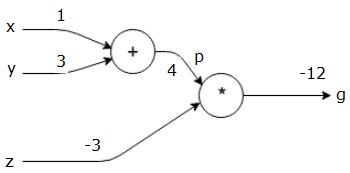
Tüm girdilere bir değer vererek bir örnek ele alalım. Aşağıdaki değerlerin tüm girişlere verildiğini varsayalım.
$$x=1, y=3, z=−3$$
Bu değerleri girişlere vererek, ileri geçiş gerçekleştirebilir ve her bir düğümdeki çıkışlar için aşağıdaki değerleri alabiliriz.
İlk olarak, p = 4 elde etmek için x = 1 ve y = 3 değerlerini kullanıyoruz.

Sonra g = -12 elde etmek için p = 4 ve z = -3'ü kullanırız. Soldan sağa doğru ilerliyoruz.
Geriye Pasın Amaçları
Geriye doğru geçişte, niyetimiz her girdi için gradyanları nihai çıktıya göre hesaplamaktır. Bu gradyanlar, gradyan inişini kullanarak sinir ağını eğitmek için gereklidir.
Örneğin, aşağıdaki gradyanları istiyoruz.
İstenilen gradyanlar
$$\frac{\partial x}{\partial f}, \frac{\partial y}{\partial f}, \frac{\partial z}{\partial f}$$
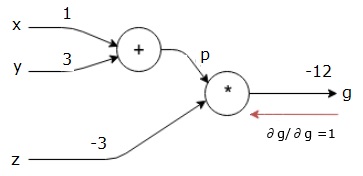
Geri geçiş (geri yayılım)
Geriye doğru geçişe, nihai çıktının (kendisi!) Nihai çıktıya göre türevini bularak başlıyoruz. Böylece, özdeşliğin türetilmesi ile sonuçlanacaktır ve değer bire eşittir.
$$\frac{\partial g}{\partial g} = 1$$
Hesaplama grafiğimiz artık aşağıda gösterildiği gibi görünüyor -
Daha sonra geriye doğru geçişi "*" işlemi ile yapacağız. Degradeleri p ve z'de hesaplayacağız. G = p * z olduğundan, bunu biliyoruz -
$$\frac{\partial g}{\partial z} = p$$
$$\frac{\partial g}{\partial p} = z$$
Z ve p'nin değerlerini ileri geçişten zaten biliyoruz. Bu nedenle, biz -
$$\frac{\partial g}{\partial z} = p = 4$$
ve
$$\frac{\partial g}{\partial p} = z = -3$$
X ve y'deki gradyanları hesaplamak istiyoruz -
$$\frac{\partial g}{\partial x}, \frac{\partial g}{\partial y}$$
Ancak, bunu verimli bir şekilde yapmak istiyoruz (x ve g bu grafikte sadece iki atlama uzaklıkta olmasına rağmen, birbirlerinden gerçekten uzak olduklarını hayal edin). Bu değerleri verimli bir şekilde hesaplamak için, farklılaşmanın zincir kuralını kullanacağız. Zincir kuralına göre, biz -
$$\frac{\partial g}{\partial x}=\frac{\partial g}{\partial p}\ast \frac{\partial p}{\partial x}$$
$$\frac{\partial g}{\partial y}=\frac{\partial g}{\partial p}\ast \frac{\partial p}{\partial y}$$
Ancak dg / dp = -3, dp / dx ve dp / dy'nin kolay olduğunu zaten biliyoruz çünkü p doğrudan x ve y'ye bağlıdır. Elimizde -
$$p=x+y\Rightarrow \frac{\partial x}{\partial p} = 1, \frac{\partial y}{\partial p} = 1$$
Bu nedenle, biz -
$$\frac{\partial g} {\partial f} = \frac{\partial g} {\partial p}\ast \frac{\partial p} {\partial x} = \left ( -3 \right ).1 = -3$$
Ek olarak, y - girişi için
$$\frac{\partial g} {\partial y} = \frac{\partial g} {\partial p}\ast \frac{\partial p} {\partial y} = \left ( -3 \right ).1 = -3$$
Bunu geriye doğru yapmamızın ana nedeni, x'teki gradyanı hesaplamamız gerektiğinde, yalnızca önceden hesaplanmış değerleri ve dq / dx'i (aynı düğümün girdisine göre düğüm çıktısının türevi) kullanmamızdır. Küresel bir değeri hesaplamak için yerel bilgileri kullandık.
Bir sinir ağını eğitmek için adımlar
Bir sinir ağını eğitmek için şu adımları izleyin -
Veri kümesindeki x veri noktası için, girdi olarak x ile ileriye doğru geçiyoruz ve çıktı olarak c maliyetini hesaplıyoruz.
C'den başlayarak geriye doğru geçiş yapıyoruz ve grafikteki tüm düğümler için gradyanları hesaplıyoruz. Bu, sinir ağı ağırlıklarını temsil eden düğümleri içerir.
Daha sonra ağırlıkları W = W - öğrenme oranı * gradyanları yaparak güncelliyoruz.
Durdurma kriterleri karşılanana kadar bu işlemi tekrar ederiz.
Derin öğrenme, bilgisayarla görme, dil çevirisi, resim yazısı oluşturma, ses transkripsiyonu, moleküler biyoloji, konuşma tanıma, doğal dil işleme, kendi kendine giden arabalar, beyin tümörü algılama, gerçek zamanlı konuşma çevirisi, müzik gibi birkaç uygulama için iyi sonuçlar üretti. kompozisyon, otomatik oyun oynama vb.
Derin öğrenme, daha gelişmiş bir uygulama ile makine öğreniminden sonraki büyük adımdır. Şu anda, ham yapılandırılmamış verilerle uğraşırken güçlü bir oyun değiştirici olma vaadi getiren bir endüstri standardı olma yolunda ilerliyor.
Derin öğrenme şu anda çok çeşitli gerçek dünya sorunları için en iyi çözüm sağlayıcılardan biridir. Geliştiriciler, önceden verilen kuralları kullanmak yerine karmaşık görevleri çözmek için örneklerden öğrenen AI programları geliştiriyorlar. Derin öğrenmenin birçok veri bilimcisi tarafından kullanılmasıyla, daha derin sinir ağları, her zamankinden daha doğru sonuçlar veriyor.
Buradaki fikir, her ağ için eğitim katmanlarının sayısını artırarak derin sinir ağları geliştirmektir; makine, olabildiğince doğru olana kadar veriler hakkında daha fazla bilgi edinir. Geliştiriciler, karmaşık makine öğrenimi görevlerini uygulamak için derin öğrenme tekniklerini kullanabilir ve yüksek düzeyde algısal tanımaya sahip olmak için yapay zeka ağlarını eğitebilir.
Derin öğrenme, popülerliğini Bilgisayar vizyonunda bulur. Burada elde edilen görevlerden biri, verilen girdi görüntülerinin kedi, köpek vb. Olarak veya görüntüyü en iyi tanımlayan bir sınıf veya etiket olarak sınıflandırıldığı görüntü sınıflandırmasıdır. İnsanlar olarak bizler bu görevi nasıl yapacağımızı hayatımızın çok erken dönemlerinde öğreniyoruz ve kalıpları hızlı bir şekilde tanıma, önceki bilgilerden genelleme ve farklı görüntü ortamlarına uyum sağlama becerilerine sahibiz.
Bu bölümde, derin öğrenmeyi farklı kütüphaneler ve çerçevelerle ilişkilendireceğiz.
Derin öğrenme ve Theano
Derin bir sinir ağını kodlamaya başlamak istiyorsak, Theano, TensorFlow, Keras, PyTorch vb. Gibi farklı çerçevelerin nasıl çalıştığına dair bir fikrimiz olması daha iyidir.
Theano, makinemizde hızlı bir şekilde eğitilen derin ağlar oluşturmak için bir dizi işlev sağlayan bir python kitaplığıdır.
Theano, derin bir ağ öncüsü olan Yoshua Bengio'nun önderliğinde Kanada, Montreal Üniversitesi'nde geliştirildi.
Theano, matematiksel ifadeleri dikdörtgen sayı dizileri olan vektörler ve matrislerle tanımlamamıza ve değerlendirmemize izin verir.
Teknik olarak konuşursak, hem sinir ağları hem de giriş verileri matrisler olarak temsil edilebilir ve tüm standart ağ işlemleri matris işlemleri olarak yeniden tanımlanabilir. Bilgisayarlar matris işlemlerini çok hızlı gerçekleştirebildikleri için bu önemlidir.
Birden fazla matris değerini paralel olarak işleyebiliriz ve bu temel yapı ile bir sinir ağı oluşturursak, makul bir zaman aralığında devasa ağları eğitmek için GPU'lu tek bir makine kullanabiliriz.
Ancak Theano kullanırsak, derin ağı sıfırdan inşa etmeliyiz. Kitaplık, belirli bir derin ağ türü oluşturmak için tam işlevsellik sağlamaz.
Bunun yerine, derin ağın model, katmanlar, aktivasyon, eğitim metodu ve aşırı uydurmayı durdurmak için özel yöntemler gibi her yönünü kodlamalıyız.
Bununla birlikte, iyi haber şu ki, Theano bizim uygulamamızı vektörize edilmiş fonksiyonların üstüne inşa etmemize izin vererek bize oldukça optimize edilmiş bir çözüm sunuyor.
Theano'nun işlevselliğini artıran birçok başka kütüphane vardır. TensorFlow ve Keras, Theano ile arka uç olarak kullanılabilir.
TensorFlow ile Derin Öğrenme
Googles TensorFlow bir python kitaplığıdır. Bu kütüphane, ticari düzeyde derin öğrenme uygulamaları oluşturmak için harika bir seçimdir.
TensorFlow, Google Brain Project'in bir parçası olan başka bir DistBelief V2 kitaplığından büyüdü. Bu kütüphane, makine öğreniminin taşınabilirliğini genişletmeyi amaçlamaktadır, böylece araştırma modelleri ticari düzeydeki uygulamalara uygulanabilir.
Theano kitaplığına çok benzer şekilde, TensorFlow, bir düğümün kalıcı verileri veya matematik işlemi temsil ettiği ve kenarların, çok boyutlu bir dizi veya tensör olan düğümler arasındaki veri akışını temsil ettiği hesaplama grafiklerine dayanır; dolayısıyla TensorFlow adı
Bir işlemden veya bir dizi işlemden elde edilen çıktı, bir sonrakine girdi olarak beslenir.
TensorFlow sinir ağları için tasarlanmış olsa da, hesaplamanın veri akış grafiği olarak modellenebileceği diğer ağlar için de iyi çalışıyor.
TensorFlow ayrıca, ortak ve alt ifade eleme, otomatik farklılaştırma, paylaşılan ve sembolik değişkenler gibi Theano'nun çeşitli özelliklerini kullanır.
Evrişimli ağlar, Otomatik kodlayıcılar, RNTN, RNN, RBM, DBM / MLP ve benzeri gibi TensorFlow kullanılarak farklı derin ağ türleri oluşturulabilir.
Ancak TensorFlow'da hiper parametre yapılandırması için destek yoktur.Bu işlevsellik için Keras kullanabiliriz.
Derin Öğrenme ve Keras
Keras, derin öğrenme modellerini geliştirmek ve değerlendirmek için güçlü, kullanımı kolay bir Python kitaplığıdır.
Katman katman net bir katman oluşturmamızı sağlayan minimalist bir tasarıma sahiptir; eğitin ve çalıştırın.
Verimli sayısal hesaplama kitaplıkları Theano ve TensorFlow'u sarar ve sinir ağı modellerini birkaç kısa kod satırında tanımlamamıza ve eğitmemize olanak tanır.
Derin öğrenme ve yapay zekadan geniş ölçüde yararlanmaya yardımcı olan üst düzey bir sinir ağı API'sidir. TensorFlow, Theano vb. Dahil olmak üzere bir dizi alt düzey kitaplığın üzerinde çalışır. Keras kodu taşınabilir; Theano veya TensorFlow kullanarak, kodda herhangi bir değişiklik yapmadan bir arka uç olarak Keras'ta bir sinir ağı uygulayabiliriz.
Derin öğrenmenin bu uygulamasında, amacımız belirli bir banka için müşteri kayıplarını veya çalkalama verilerini tahmin etmektir - hangi müşterilerin bu banka hizmetinden çıkma olasılığı yüksektir. Kullanılan Veri Kümesi nispeten küçüktür ve 14 sütunlu 10000 satır içerir. Anaconda dağıtımını ve Theano, TensorFlow ve Keras gibi çerçeveleri kullanıyoruz. Keras, arka uçları olarak işlev gören Tensorflow ve Theano'nun üzerine inşa edilmiştir.
# Artificial Neural Network
# Installing Theano
pip install --upgrade theano
# Installing Tensorflow
pip install –upgrade tensorflow
# Installing Keras
pip install --upgrade keras1. Adım: Veri ön işleme
In[]:
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the database
dataset = pd.read_csv('Churn_Modelling.csv')Adım 2
Veri setinin özelliklerinin matrislerini ve sütun 14 olan hedef değişkeni “Çıkıldı” olarak etiketlendiriyoruz.
Verilerin ilk görünümü aşağıda gösterildiği gibidir -
In[]:
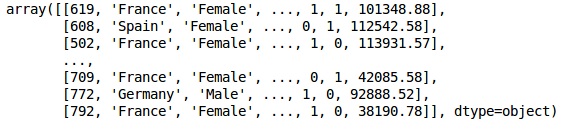
X = dataset.iloc[:, 3:13].values
Y = dataset.iloc[:, 13].values
XÇıktı
Aşama 3
YÇıktı
array([1, 0, 1, ..., 1, 1, 0], dtype = int64)4. adım
Dize değişkenlerini kodlayarak analizi daha basit hale getiriyoruz. Sütunlardaki farklı etiketleri 0 ila n_class-1 arasında otomatik olarak kodlamak için ScikitLearn 'LabelEncoder' fonksiyonunu kullanıyoruz.
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X_1 = LabelEncoder()
X[:,1] = labelencoder_X_1.fit_transform(X[:,1])
labelencoder_X_2 = LabelEncoder()
X[:, 2] = labelencoder_X_2.fit_transform(X[:, 2])
XÇıktı

Yukarıdaki çıktıda, ülke adları 0, 1 ve 2 ile değiştirilmiştir; erkek ve dişi 0 ve 1 ile değiştirilir.
Adım 5
Labelling Encoded Data
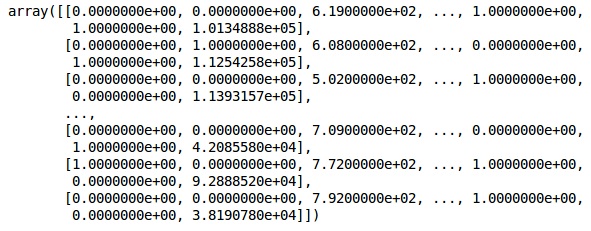
Aynısını kullanıyoruz ScikitLearn kütüphane ve başka bir işlev adı verilen OneHotEncoder sadece bir kukla değişken oluşturarak sütun numarasını geçmek için.
onehotencoder = OneHotEncoder(categorical features = [1])
X = onehotencoder.fit_transform(X).toarray()
X = X[:, 1:]
XŞimdi, ilk 2 sütun ülkeyi temsil ediyor ve 4. sütun cinsiyeti temsil ediyor.
Çıktı
Verilerimizi daima eğitim ve test bölümüne ayırırız; modelimizi eğitim verileri üzerine eğitiriz ve daha sonra modelin verimliliğini değerlendirmeye yardımcı olan test verileri üzerindeki bir modelin doğruluğunu kontrol ederiz.
6. Adım
ScikitLearn kullanıyoruz train_test_splitverilerimizi eğitim seti ve test setine ayırma işlevi. Tren-test bölme oranını 80:20 olarak tutuyoruz.
#Splitting the dataset into the Training set and the Test Set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)Bazı değişkenler binlik değerlere sahipken, bazıları onlarda veya birlerde değerlere sahiptir. Verileri daha iyi temsil edecek şekilde ölçeklendiriyoruz.
7. Adım
Bu kodda, eğitim verilerini uyduruyor ve dönüştürüyoruz. StandardScalerişlevi. Test verilerini dönüştürmek / ölçeklendirmek için aynı uygun yöntemi kullanacak şekilde ölçeklendirmemizi standartlaştırıyoruz.
# Feature Scalingfromsklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)Çıktı
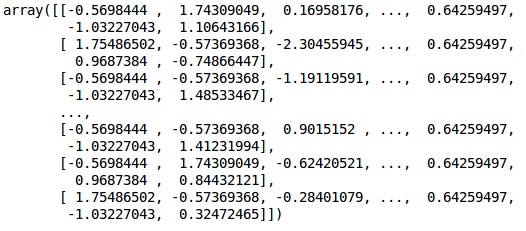
Veriler artık doğru şekilde ölçeklendi. Son olarak, veri ön işlemlerimizi tamamladık. Şimdi modelimizle başlayacağız.
8. Adım
Gerekli Modülleri buraya aktarıyoruz. Sinir ağını başlatmak için Sıralı modüle ve gizli katmanları eklemek için yoğun modüle ihtiyacımız var.
# Importing the Keras libraries and packages
import keras
from keras.models import Sequential
from keras.layers import Dense9. Adım
Amacımız müşteri kaybını sınıflandırmak olduğu için modeli Sınıflandırıcı olarak adlandıracağız. Ardından, başlatma için Sıralı modülü kullanıyoruz.
#Initializing Neural Network
classifier = Sequential()10. adım
Gizli katmanları yoğun işlevini kullanarak tek tek ekliyoruz. Aşağıdaki kodda birçok argüman göreceğiz.
İlk parametremiz output_dim. Bu katmana eklediğimiz düğüm sayısıdır.initStokastik Gradient Decent'in başlatılmasıdır. Bir Sinir Ağında her düğüme ağırlık atarız. Başlangıçta, ağırlıklar sıfıra yakın olmalı ve ağırlıkları tek tip fonksiyonu kullanarak rastgele başlatıyoruz. input_dimparametresi, model girdi değişkenlerimizin sayısını bilmediğinden, yalnızca ilk katman için gereklidir. Burada toplam girdi değişken sayısı 11'dir. İkinci katmanda, model ilk gizli katmandan girdi değişkenlerinin sayısını otomatik olarak bilir.
Giriş katmanını ve ilk gizli katmanı eklemek için aşağıdaki kod satırını yürütün -
classifier.add(Dense(units = 6, kernel_initializer = 'uniform',
activation = 'relu', input_dim = 11))İkinci gizli katmanı eklemek için aşağıdaki kod satırını yürütün -
classifier.add(Dense(units = 6, kernel_initializer = 'uniform',
activation = 'relu'))Çıktı katmanını eklemek için aşağıdaki kod satırını yürütün -
classifier.add(Dense(units = 1, kernel_initializer = 'uniform',
activation = 'sigmoid'))11. adım
Compiling the ANN
Şimdiye kadar sınıflandırıcımıza birden çok katman ekledik. Şimdi bunları kullanarak derleyeceğizcompileyöntem. Son derleme kontrolüne eklenen argümanlar sinir ağını tamamlıyor, bu yüzden bu adımda dikkatli olmamız gerekiyor.
İşte argümanların kısa bir açıklaması.
İlk argüman OptimizerBu, optimum ağırlık setini bulmak için kullanılan bir algoritmadır. Bu algoritmayaStochastic Gradient Descent (SGD). Burada, 'Adam optimizer' adı verilen birkaç türden birini kullanıyoruz. SGD kayba bağlıdır, dolayısıyla ikinci parametremiz kayıptır. Bağımlı değişkenimiz ikili ise, logaritmik kayıp fonksiyonunu kullanırız.‘binary_crossentropy’ve eğer bağımlı değişkenimizin çıktıda ikiden fazla kategorisi varsa, o zaman kullanırız ‘categorical_crossentropy’. Sinir ağımızın performansını aşağıdakilere dayalı olarak iyileştirmek istiyoruz:accuracyyani ekliyoruz metrics doğruluk olarak.
# Compiling Neural Network
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])Adım 1/2
Bu adımda bir dizi kodun yürütülmesi gerekir.
YSA'nın Eğitim Setine Takılması
Şimdi modelimizi eğitim verileri üzerinde eğitiyoruz. KullanıyoruzfitModelimize uyacak yöntem. Model verimliliğini artırmak için ağırlıkları da optimize ediyoruz. Bunun için ağırlıkları güncellememiz gerekiyor.Batch size ağırlıkları güncelledikten sonra gözlemlerin sayısıdır. Epochtoplam yineleme sayısıdır. Parti boyutu ve dönem değerleri, deneme yanılma yöntemi ile seçilir.
classifier.fit(X_train, y_train, batch_size = 10, epochs = 50)Tahmin yapmak ve modeli değerlendirmek
# Predicting the Test set results
y_pred = classifier.predict(X_test)
y_pred = (y_pred > 0.5)Tek bir yeni gözlemi tahmin etmek
# Predicting a single new observation
"""Our goal is to predict if the customer with the following data will leave the bank:
Geography: Spain
Credit Score: 500
Gender: Female
Age: 40
Tenure: 3
Balance: 50000
Number of Products: 2
Has Credit Card: Yes
Is Active Member: YesAdım 13
Predicting the test set result
Tahmin sonucu size müşterinin şirketten ayrılma olasılığını verecektir. Bu olasılığı ikili 0 ve 1'e çevireceğiz.
# Predicting the Test set results
y_pred = classifier.predict(X_test)
y_pred = (y_pred > 0.5)new_prediction = classifier.predict(sc.transform
(np.array([[0.0, 0, 500, 1, 40, 3, 50000, 2, 1, 1, 40000]])))
new_prediction = (new_prediction > 0.5)14. adım
Bu, model performansımızı değerlendirdiğimiz son adımdır. Zaten orijinal sonuçlarımız var ve bu nedenle modelimizin doğruluğunu kontrol etmek için kafa karışıklığı matrisi oluşturabiliriz.
Making the Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print (cm)Çıktı
loss: 0.3384 acc: 0.8605
[ [1541 54]
[230 175] ]Karışıklık matrisinden, modelimizin Doğruluğu şu şekilde hesaplanabilir:
Accuracy = 1541+175/2000=0.858We achieved 85.8% accuracy, hangisi iyi.
İleri Yayılma Algoritması
Bu bölümde, basit bir sinir ağı için ileriye doğru yayılma (tahmin) yapmak için kod yazmayı öğreneceğiz -
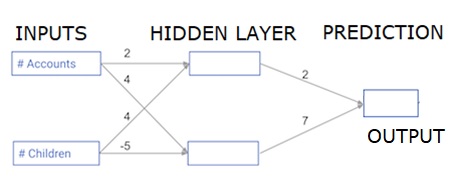
Her veri noktası bir müşteridir. İlk girdi, kaç hesaba sahip oldukları ve ikinci girdi, kaç çocuğa sahip olduklarıdır. Model, kullanıcının önümüzdeki yıl kaç işlem yapacağını tahmin edecek.
Giriş verileri, giriş verileri olarak önceden yüklenir ve ağırlıklar, ağırlıklar adı verilen bir sözlükte bulunur. Gizli katmandaki ilk düğüm için ağırlık dizisi ağırlıkları ['düğüm_0'] ve gizli katmandaki ikinci düğüm için ağırlıkları sırasıyla ['düğüm_1'] şeklindedir.
Çıkış düğümüne beslenen ağırlıklar ağırlık olarak mevcuttur.
Doğrultulmuş Doğrusal Aktivasyon Fonksiyonu
Bir "etkinleştirme işlevi", her düğümde çalışan bir işlevdir. Düğümün girişini bir çıkışa dönüştürür.
Düzeltilmiş doğrusal aktivasyon işlevi ( ReLU olarak adlandırılır ), çok yüksek performanslı ağlarda yaygın olarak kullanılmaktadır. Bu fonksiyon, giriş olarak tek bir sayıyı alır, giriş negatifse 0 döndürür ve giriş pozitifse çıkış olarak girer.
İşte bazı örnekler -
- relu (4) = 4
- relu (-2) = 0
Relu () fonksiyonunun tanımını dolduruyoruz−
- Relu () çıktısının değerini hesaplamak için max () işlevini kullanırız.
- Node_0_output'u hesaplamak için relu () işlevini node_0_input'a uygularız.
- Node_1_output'u hesaplamak için relu () fonksiyonunu node_1_input'a uygularız.
import numpy as np
input_data = np.array([-1, 2])
weights = {
'node_0': np.array([3, 3]),
'node_1': np.array([1, 5]),
'output': np.array([2, -1])
}
node_0_input = (input_data * weights['node_0']).sum()
node_0_output = np.tanh(node_0_input)
node_1_input = (input_data * weights['node_1']).sum()
node_1_output = np.tanh(node_1_input)
hidden_layer_output = np.array(node_0_output, node_1_output)
output =(hidden_layer_output * weights['output']).sum()
print(output)
def relu(input):
'''Define your relu activation function here'''
# Calculate the value for the output of the relu function: output
output = max(input,0)
# Return the value just calculated
return(output)
# Calculate node 0 value: node_0_output
node_0_input = (input_data * weights['node_0']).sum()
node_0_output = relu(node_0_input)
# Calculate node 1 value: node_1_output
node_1_input = (input_data * weights['node_1']).sum()
node_1_output = relu(node_1_input)
# Put node values into array: hidden_layer_outputs
hidden_layer_outputs = np.array([node_0_output, node_1_output])
# Calculate model output (do not apply relu)
odel_output = (hidden_layer_outputs * weights['output']).sum()
print(model_output)# Print model outputÇıktı
0.9950547536867305
-3Ağı birçok Gözlem / veri satırına uygulama
Bu bölümde, tahmin_with_network () adlı bir işlevi nasıl tanımlayacağımızı öğreneceğiz. Bu işlev, yukarıda girdi_verisi olarak alınan ağdan alınan çoklu veri gözlemleri için tahminler üretecektir. Yukarıdaki ağda verilen ağırlıklar kullanılmaktadır. Relu () fonksiyon tanımı da kullanılmaktadır.
İki bağımsız değişkeni - input_data_row ve ağırlıklar - kabul eden ve çıktı olarak ağdan bir tahmin döndüren tahmin_with_network () adında bir işlev tanımlayalım.
Her düğüm için girdi ve çıktı değerlerini hesaplayarak bunları şu şekilde saklıyoruz: node_0_input, node_0_output, node_1_input ve node_1_output.
Bir düğümün girdi değerini hesaplamak için, ilgili dizileri birlikte çarpıp toplamlarını hesaplıyoruz.
Bir düğümün çıktı değerini hesaplamak için düğümün giriş değerine relu () işlevini uygularız. İnput_data üzerinde yinelemek için 'for döngüsü' kullanıyoruz -
Ayrıca, input_data - input_data_row'un her satırı için tahminler oluşturmak için predik_with_network () işlevimizi kullanırız. Ayrıca her tahmini sonuçlara ekliyoruz.
# Define predict_with_network()
def predict_with_network(input_data_row, weights):
# Calculate node 0 value
node_0_input = (input_data_row * weights['node_0']).sum()
node_0_output = relu(node_0_input)
# Calculate node 1 value
node_1_input = (input_data_row * weights['node_1']).sum()
node_1_output = relu(node_1_input)
# Put node values into array: hidden_layer_outputs
hidden_layer_outputs = np.array([node_0_output, node_1_output])
# Calculate model output
input_to_final_layer = (hidden_layer_outputs*weights['output']).sum()
model_output = relu(input_to_final_layer)
# Return model output
return(model_output)
# Create empty list to store prediction results
results = []
for input_data_row in input_data:
# Append prediction to results
results.append(predict_with_network(input_data_row, weights))
print(results)# Print resultsÇıktı
[0, 12]Burada relu (26) = 26 ve relu (-13) = 0 vb. Yerlerde relu fonksiyonunu kullandık.
Derin çok katmanlı sinir ağları
Burada, iki gizli katmana sahip bir sinir ağının ileriye doğru yayılması için kod yazıyoruz. Her gizli katmanın iki düğümü vardır. Giriş verileri şu şekilde önceden yüklenmiştir:input_data. İlk gizli katmandaki düğümlere düğüm_0_0 ve düğüm_0_1 adı verilir.
Ağırlıkları sırasıyla ağırlıklar ['düğüm_0_0'] ve ağırlıklar ['düğüm_0_1'] olarak önceden yüklenmiştir.
İkinci gizli katmandaki düğümler denir node_1_0 and node_1_1. Ağırlıkları şu şekilde önceden yüklenmiştir:weights['node_1_0'] ve weights['node_1_1'] sırasıyla.
Daha sonra önceden yüklenmiş ağırlıkları kullanarak gizli düğümlerden bir model çıktısı oluşturuyoruz. weights['output'].
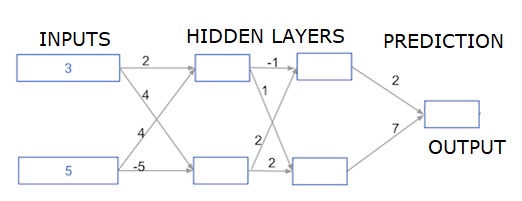
Node_0_0_input, ağırlık ağırlıklarını ['node_0_0'] ve verilen input_data kullanarak hesaplıyoruz. Ardından node_0_0_output'u elde etmek için relu () işlevini uygulayın.
Node_0_1_input için node_0_1_output almak için yukarıdakiyle aynı şeyi yapıyoruz.
Node_1_0_input, ağırlık ağırlıklarını ['node_1_0'] ve ilk gizli katmandan - hidden_0_outputs - çıktılarını kullanarak hesaplıyoruz. Daha sonra node_1_0_output'u elde etmek için relu () işlevini uygularız.
Node_1_1_output düğümünü almak için node_1_1_input için yukarıdakiyle aynı şeyi yapıyoruz.
Model_output'u ağırlıkları ['output'] ve ikinci gizli katmandan hidden_1_outputs dizisinden çıkan çıktıları kullanarak hesaplarız. Relu () fonksiyonunu bu çıktıya uygulamıyoruz.
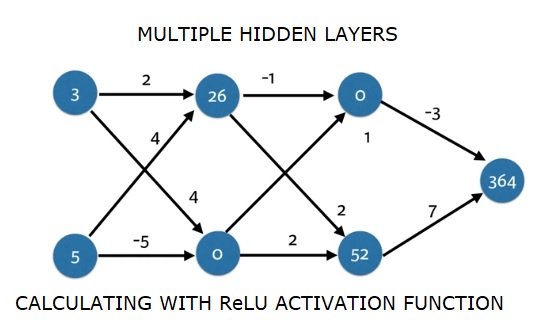
import numpy as np
input_data = np.array([3, 5])
weights = {
'node_0_0': np.array([2, 4]),
'node_0_1': np.array([4, -5]),
'node_1_0': np.array([-1, 1]),
'node_1_1': np.array([2, 2]),
'output': np.array([2, 7])
}
def predict_with_network(input_data):
# Calculate node 0 in the first hidden layer
node_0_0_input = (input_data * weights['node_0_0']).sum()
node_0_0_output = relu(node_0_0_input)
# Calculate node 1 in the first hidden layer
node_0_1_input = (input_data*weights['node_0_1']).sum()
node_0_1_output = relu(node_0_1_input)
# Put node values into array: hidden_0_outputs
hidden_0_outputs = np.array([node_0_0_output, node_0_1_output])
# Calculate node 0 in the second hidden layer
node_1_0_input = (hidden_0_outputs*weights['node_1_0']).sum()
node_1_0_output = relu(node_1_0_input)
# Calculate node 1 in the second hidden layer
node_1_1_input = (hidden_0_outputs*weights['node_1_1']).sum()
node_1_1_output = relu(node_1_1_input)
# Put node values into array: hidden_1_outputs
hidden_1_outputs = np.array([node_1_0_output, node_1_1_output])
# Calculate model output: model_output
model_output = (hidden_1_outputs*weights['output']).sum()
# Return model_output
return(model_output)
output = predict_with_network(input_data)
print(output)Çıktı
364