R - Hızlı Kılavuz
R, istatistiksel analiz, grafik gösterimi ve raporlama için bir programlama dili ve yazılım ortamıdır. R, Yeni Zelanda Auckland Üniversitesi'nde Ross Ihaka ve Robert Gentleman tarafından oluşturuldu ve şu anda R Geliştirme Çekirdek Ekibi tarafından geliştiriliyor.
R'nin özü, işlevler kullanarak modüler programlamanın yanı sıra dallanma ve döngüye izin veren yorumlanmış bir bilgisayar dilidir. R, verimlilik için C, C ++, .Net, Python veya FORTRAN dillerinde yazılmış prosedürlerle entegrasyon sağlar.
R, GNU Genel Kamu Lisansı altında ücretsiz olarak mevcuttur ve Linux, Windows ve Mac gibi çeşitli işletim sistemleri için önceden derlenmiş ikili sürümler sağlanır.
R, GNU tarzı bir kopya altında dağıtılan özgür bir yazılımdır ve GNU projesinin resmi bir parçasıdır. GNU S.
R Evrimi
R başlangıçta tarafından yazılmıştır Ross Ihaka ve Robert GentlemanAuckland, Yeni Zelanda'daki Auckland Üniversitesi İstatistik Bölümü'nde. R, 1993 yılında ilk kez ortaya çıktı.
Büyük bir grup insan, kod ve hata raporları göndererek R'ye katkıda bulundu.
1997 ortasından beri R kaynak kodu arşivini değiştirebilen bir çekirdek grup ("R Çekirdek Ekibi") var.
R'nin Özellikleri
Daha önce belirtildiği gibi, R istatistiksel analiz, grafik gösterimi ve raporlama için bir programlama dili ve yazılım ortamıdır. Aşağıdakiler R'nin önemli özellikleridir -
R, koşullu ifadeler, döngüler, kullanıcı tanımlı özyinelemeli işlevler ve giriş ve çıkış olanaklarını içeren iyi geliştirilmiş, basit ve etkili bir programlama dilidir.
R'nin etkili bir veri işleme ve depolama tesisi vardır,
R, diziler, listeler, vektörler ve matrisler üzerindeki hesaplamalar için bir operatör paketi sağlar.
R, veri analizi için geniş, tutarlı ve entegre bir araç koleksiyonu sağlar.
R, veri analizi ve doğrudan bilgisayarda veya kağıtlara yazdırılması için grafiksel olanaklar sağlar.
Sonuç olarak, R, dünyanın en yaygın kullanılan istatistik programlama dilidir. Bu, veri bilimcilerin 1 numaralı tercihidir ve canlı ve yetenekli bir katılımcı topluluğu tarafından desteklenir. R, üniversitelerde öğretilir ve kritik iş uygulamalarında konuşlandırılır. Bu eğitim, size R programlamayı basit ve kolay adımlarla uygun örneklerle birlikte öğretecektir.
Yerel Ortam Kurulumu
Yine de ortamınızı R için kurmaya istekli iseniz, aşağıda verilen adımları takip edebilirsiniz.
Windows Kurulumu
R'nin Windows yükleyici sürümünü Windows için R-3.2.2'den (32/64 bit) indirebilir ve yerel bir dizine kaydedebilirsiniz.
"R-version-win.exe" adlı bir Windows yükleyicisi (.exe) olduğundan. Varsayılan ayarları kabul ederek yükleyiciyi çift tıklayıp çalıştırabilirsiniz. Windows'un 32 bit sürümü varsa, 32 bit sürümü yükler. Ancak pencereleriniz 64 bit ise, hem 32 bit hem de 64 bit sürümleri yükler.
Kurulumdan sonra, Programı Windows Program Dosyaları altında "R \ R3.2.2 \ bin \ i386 \ Rgui.exe" dizin yapısında çalıştırmak için simgeyi bulabilirsiniz. Bu simgeye tıklamak, R Programlama yapmak için R konsolu olan R-GUI'yi getirir.
Linux Kurulumu
R, Linux'un birçok sürümü için R Binaries konumunda bir ikili dosya olarak mevcuttur .
Linux kurma talimatı çeşitten türe değişir. Bu adımlar, belirtilen bağlantıda her bir Linux sürümü türünün altında belirtilmiştir. Ancak aceleniz varsa kullanabilirsinizyum R'yi aşağıdaki gibi yükleme komutu -
$ yum install RYukarıdaki komut, standart paketlerle birlikte R programlamanın temel işlevlerini yükleyecektir, yine de ek pakete ihtiyacınız vardır, ardından aşağıdaki gibi R komut istemini başlatabilirsiniz -
$ R
R version 3.2.0 (2015-04-16) -- "Full of Ingredients"
Copyright (C) 2015 The R Foundation for Statistical Computing
Platform: x86_64-redhat-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
>Artık, gerekli paketi yüklemek için R isteminde install komutunu kullanabilirsiniz. Örneğin, aşağıdaki komut yüklenecektirplotrix 3B grafikler için gerekli olan paket.
> install.packages("plotrix")Bir kural olarak, bir "Merhaba, Dünya!" Yazarak R programlamayı öğrenmeye başlayacağız. programı. İhtiyaçlara bağlı olarak, programınızı yazmak için R komut isteminde programlayabilir veya bir R komut dosyası kullanabilirsiniz. İkisini de tek tek kontrol edelim.
R Komut İstemi
R ortamı kurulumuna sahip olduğunuzda, komut isteminize aşağıdaki komutu yazarak R komut isteminizi başlatmak kolaydır -
$ RBu, R yorumlayıcısını başlatacak ve aşağıdaki gibi programınızı yazmaya başlayabileceğiniz bir komut alacaksınız -
> myString <- "Hello, World!"
> print ( myString)
[1] "Hello, World!"Buradaki ilk ifade, myString bir dize değişkenini tanımlar, burada "Merhaba, Dünya!" ve daha sonra, myString değişkeninde depolanan değeri yazdırmak için bir sonraki ifade print () kullanılır.
R Komut Dosyası Dosyası
Genellikle programınızı programlarınızı komut dosyası dosyalarına yazarak yaparsınız ve daha sonra bu komut dosyalarını komut isteminizde adı verilen R yorumlayıcısı yardımıyla çalıştırırsınız. Rscript. Öyleyse aşağıdaki kodu test.R adlı bir metin dosyasına aşağıdaki gibi yazmaya başlayalım -
# My first program in R Programming
myString <- "Hello, World!"
print ( myString)Yukarıdaki kodu bir test.R dosyasına kaydedin ve aşağıda belirtildiği gibi Linux komut isteminde çalıştırın. Windows veya başka bir sistem kullanıyor olsanız bile, sözdizimi aynı kalacaktır.
$ Rscript test.RYukarıdaki programı çalıştırdığımızda aşağıdaki sonucu verir.
[1] "Hello, World!"Yorumlar
Yorumlar, R programınızdaki yardımcı metin gibidir ve gerçek programınızı çalıştırırken yorumlayıcı tarafından yok sayılır. Tek yorum, ifadenin başında # kullanılarak şu şekilde yazılır -
# My first program in R ProgrammingR, çok satırlı yorumları desteklemez ancak aşağıdaki gibi bir numara yapabilirsiniz -
if(FALSE) {
"This is a demo for multi-line comments and it should be put inside either a
single OR double quote"
}
myString <- "Hello, World!"
print ( myString)[1] "Hello, World!"Yukarıdaki yorumlar R yorumlayıcı tarafından yürütülecekse de, gerçek programınıza müdahale etmeyecektir. Bu tür yorumları tek veya çift tırnak içine koymalısınız.
Genel olarak, herhangi bir programlama dilinde programlama yaparken, çeşitli bilgileri depolamak için çeşitli değişkenler kullanmanız gerekir. Değişkenler, değerleri saklamak için ayrılmış bellek konumlarından başka bir şey değildir. Bu, bir değişken oluşturduğunuzda bellekte biraz yer ayırdığınız anlamına gelir.
Karakter, geniş karakter, tamsayı, kayan nokta, çift kayan nokta, Boole vb. Gibi çeşitli veri türlerinin bilgilerini depolamak isteyebilirsiniz. ayrılmış hafıza.
R'deki C ve java gibi diğer programlama dillerinin aksine, değişkenler bazı veri türleri olarak bildirilmez. Değişkenler R-Nesneleri ile atanır ve R-nesnesinin veri türü değişkenin veri türü olur. Pek çok R-nesnesi türü vardır. Sık kullanılanlar -
- Vectors
- Lists
- Matrices
- Arrays
- Factors
- Veri Çerçeveleri
Bu nesnelerin en basiti vector objectve altı vektör sınıfı olarak da adlandırılan bu atomik vektörlerin altı veri türü vardır. Diğer R-Nesneleri atomik vektörler üzerine inşa edilmiştir.
| Veri tipi | Misal | Doğrulayın |
|---|---|---|
| Mantıklı | DOĞRU YANLIŞ |
aşağıdaki sonucu verir - |
| Sayısal | 12,3, 5, 999 |
aşağıdaki sonucu verir - |
| Tamsayı | 2L, 34L, 0L |
aşağıdaki sonucu verir - |
| Karmaşık | 3 + 2i |
aşağıdaki sonucu verir - |
| Karakter | "a", "iyi", "DOĞRU", "23, 4" |
aşağıdaki sonucu verir - |
| Çiğ | "Merhaba" 48 65 6c 6c 6f olarak saklanır |
aşağıdaki sonucu verir - |
R programlamada, çok temel veri türleri adı verilen R nesneleridir. vectorsyukarıda gösterildiği gibi farklı sınıfların unsurlarını barındıran. Lütfen R'de sınıf sayısının yalnızca yukarıdaki altı türle sınırlı olmadığını unutmayın. Örneğin, birçok atomik vektör kullanabilir ve sınıfı dizi olacak bir dizi oluşturabiliriz.
Vektörler
Birden fazla elemanlı vektör oluşturmak istediğinizde, kullanmalısınız c() işlevi, öğeleri bir vektörde birleştirmek anlamına gelir.
# Create a vector.
apple <- c('red','green',"yellow")
print(apple)
# Get the class of the vector.
print(class(apple))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] "red" "green" "yellow"
[1] "character"Listeler
Bir liste, içinde vektörler, fonksiyonlar ve hatta içindeki başka bir liste gibi birçok farklı türde öğe içerebilen bir R-nesnesidir.
# Create a list.
list1 <- list(c(2,5,3),21.3,sin)
# Print the list.
print(list1)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[[1]]
[1] 2 5 3
[[2]]
[1] 21.3
[[3]]
function (x) .Primitive("sin")Matrisler
Bir matris, iki boyutlu dikdörtgen bir veri kümesidir. Matris işlevine bir vektör girdisi kullanılarak oluşturulabilir.
# Create a matrix.
M = matrix( c('a','a','b','c','b','a'), nrow = 2, ncol = 3, byrow = TRUE)
print(M)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[,1] [,2] [,3]
[1,] "a" "a" "b"
[2,] "c" "b" "a"Diziler
Matrisler iki boyutla sınırlıyken, diziler herhangi bir sayıda boyutta olabilir. Dizi işlevi, gerekli sayıda boyut oluşturan bir dim niteliği alır. Aşağıdaki örnekte, her biri 3x3 matris olan iki elemanlı bir dizi oluşturuyoruz.
# Create an array.
a <- array(c('green','yellow'),dim = c(3,3,2))
print(a)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
, , 1
[,1] [,2] [,3]
[1,] "green" "yellow" "green"
[2,] "yellow" "green" "yellow"
[3,] "green" "yellow" "green"
, , 2
[,1] [,2] [,3]
[1,] "yellow" "green" "yellow"
[2,] "green" "yellow" "green"
[3,] "yellow" "green" "yellow"Faktörler
Faktörler, bir vektör kullanılarak oluşturulan r nesneleridir. Vektörü, vektördeki öğelerin farklı değerleriyle birlikte etiketler olarak depolar. Giriş vektöründeki sayısal veya karakter veya Boole vb. Olmasına bakılmaksızın etiketler her zaman karakterdir. İstatistiksel modellemede faydalıdırlar.
Faktörler kullanılarak oluşturulur factor()işlevi. nlevels fonksiyonlar seviye sayısını verir.
# Create a vector.
apple_colors <- c('green','green','yellow','red','red','red','green')
# Create a factor object.
factor_apple <- factor(apple_colors)
# Print the factor.
print(factor_apple)
print(nlevels(factor_apple))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] green green yellow red red red green
Levels: green red yellow
[1] 3Veri Çerçeveleri
Veri çerçeveleri tablo veri nesneleridir. Veri çerçevesindeki bir matrisin aksine, her sütun farklı veri modları içerebilir. İlk sütun sayısal olabilirken, ikinci sütun karakter ve üçüncü sütun mantıksal olabilir. Eşit uzunluktaki vektörlerin bir listesidir.
Veri Çerçeveleri, data.frame() işlevi.
# Create the data frame.
BMI <- data.frame(
gender = c("Male", "Male","Female"),
height = c(152, 171.5, 165),
weight = c(81,93, 78),
Age = c(42,38,26)
)
print(BMI)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
gender height weight Age
1 Male 152.0 81 42
2 Male 171.5 93 38
3 Female 165.0 78 26Bir değişken, programlarımızın değiştirebileceği adlandırılmış depolama alanı sağlar. R'deki bir değişken, bir atomik vektörü, atomik vektörler grubunu veya birçok Robject'in bir kombinasyonunu depolayabilir. Geçerli bir değişken adı harflerden, sayılardan ve nokta veya altı çizili karakterlerden oluşur. Değişken adı bir harfle veya noktadan sonra bir sayı gelmeden başlar.
| Değişken ismi | Geçerlilik | Nedeni |
|---|---|---|
| var_name2. | geçerli | Harf, sayı, nokta ve alt çizgi içerir |
| var_name% | Geçersiz | '%' Karakterine sahiptir. Yalnızca nokta (.) Ve alt çizgiye izin verilir. |
| 2var_name | geçersiz | Bir sayı ile başlar |
.var_name, var.name |
geçerli | Bir nokta (.) İle başlayabilir ancak noktanın (.) Ardından bir sayı gelmemelidir. |
| .2var_name | geçersiz | Başlangıç noktasının ardından onu geçersiz kılan bir sayı gelir. |
| _var_name | geçersiz | Geçerli olmayan _ ile başlar |
Değişken Atama
Değişkenler, sola, sağa ve operatöre eşit kullanılarak değerler atanabilir. Değişkenlerin değerleri kullanılarak yazdırılabilirprint() veya cat()işlevi. cat() işlevi, birden çok öğeyi sürekli bir baskı çıktısında birleştirir.
# Assignment using equal operator.
var.1 = c(0,1,2,3)
# Assignment using leftward operator.
var.2 <- c("learn","R")
# Assignment using rightward operator.
c(TRUE,1) -> var.3
print(var.1)
cat ("var.1 is ", var.1 ,"\n")
cat ("var.2 is ", var.2 ,"\n")
cat ("var.3 is ", var.3 ,"\n")Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 0 1 2 3
var.1 is 0 1 2 3
var.2 is learn R
var.3 is 1 1Note- c (DOĞRU, 1) vektörü mantıksal ve sayısal sınıfın bir karışımına sahiptir. Dolayısıyla mantıksal sınıf, 1 olarak DOĞRU yapan sayısal sınıfa zorlanır.
Bir Değişkenin Veri Türü
R'de, bir değişkenin kendisi herhangi bir veri türünden bildirilmez, bunun yerine kendisine atanan R nesnesinin veri türünü alır. Dolayısıyla R'ye dinamik olarak yazılmış bir dil denir, bu da bir değişkenin aynı değişkenin veri türünü bir programda kullanırken tekrar tekrar değiştirebileceğimiz anlamına gelir.
var_x <- "Hello"
cat("The class of var_x is ",class(var_x),"\n")
var_x <- 34.5
cat(" Now the class of var_x is ",class(var_x),"\n")
var_x <- 27L
cat(" Next the class of var_x becomes ",class(var_x),"\n")Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
The class of var_x is character
Now the class of var_x is numeric
Next the class of var_x becomes integerDeğişkenleri Bulmak
Çalışma alanında şu anda mevcut olan tüm değişkenleri bilmek için ls()işlevi. Ayrıca ls () işlevi, değişken adlarını eşleştirmek için kalıpları kullanabilir.
print(ls())Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] "my var" "my_new_var" "my_var" "var.1"
[5] "var.2" "var.3" "var.name" "var_name2."
[9] "var_x" "varname"Note - Ortamınızda hangi değişkenlerin bildirildiğine bağlı olarak örnek bir çıktıdır.
Ls () işlevi, değişken adlarını eşleştirmek için kalıpları kullanabilir.
# List the variables starting with the pattern "var".
print(ls(pattern = "var"))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] "my var" "my_new_var" "my_var" "var.1"
[5] "var.2" "var.3" "var.name" "var_name2."
[9] "var_x" "varname"İle başlayan değişkenler dot(.) gizlidirler, ls () işlevinin "all.names = TRUE" argümanı kullanılarak listelenebilir.
print(ls(all.name = TRUE))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] ".cars" ".Random.seed" ".var_name" ".varname" ".varname2"
[6] "my var" "my_new_var" "my_var" "var.1" "var.2"
[11]"var.3" "var.name" "var_name2." "var_x"Değişkenleri Silme
Değişkenler kullanılarak silinebilir rm()işlevi. Aşağıda var.3 değişkenini siliyoruz. Baskı sırasında değişken hatanın değeri atılır.
rm(var.3)
print(var.3)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] "var.3"
Error in print(var.3) : object 'var.3' not foundTüm değişkenler kullanılarak silinebilir rm() ve ls() birlikte çalışır.
rm(list = ls())
print(ls())Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
character(0)Operatör, derleyiciye belirli matematiksel veya mantıksal işlemleri gerçekleştirmesini söyleyen bir semboldür. R dili yerleşik operatörler açısından zengindir ve aşağıdaki operatör türlerini sağlar.
Operatör Türleri
R programlamada aşağıdaki operatör türlerine sahibiz -
- Aritmetik operatörler
- İlişkisel Operatörler
- Mantıksal operatörler
- Atama Operatörleri
- Çeşitli Operatörler
Aritmetik operatörler
Aşağıdaki tablo, R dili tarafından desteklenen aritmetik operatörleri göstermektedir. Operatörler, vektörün her bir elemanı üzerinde hareket eder.
| Şebeke | Açıklama | Misal |
|---|---|---|
| + | İki vektör ekler |
aşağıdaki sonucu verir - |
| - | İlk vektörden ikinci vektörü çıkarır. |
aşağıdaki sonucu verir - |
| * | Her iki vektörü de çarpar |
aşağıdaki sonucu verir - |
| / | İlk vektörü ikinciye bölün |
Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir - |
| %% | İlk vektörün kalanını ikinciyle birlikte verin |
aşağıdaki sonucu verir - |
| % /% | Birinci vektörün ikinciye (bölüm) bölünmesinin sonucu |
aşağıdaki sonucu verir - |
| ^ | İkinci vektörün üssüne yükseltilen ilk vektör |
aşağıdaki sonucu verir - |
İlişkisel Operatörler
Aşağıdaki tablo, R dili tarafından desteklenen ilişkisel operatörleri göstermektedir. İlk vektörün her bir elemanı, ikinci vektörün karşılık gelen elemanıyla karşılaştırılır. Karşılaştırmanın sonucu bir Boole değeridir.
| Şebeke | Açıklama | Misal |
|---|---|---|
| > | İlk vektörün her bir öğesinin ikinci vektörün karşılık gelen öğesinden büyük olup olmadığını kontrol eder. |
aşağıdaki sonucu verir - |
| < | İlk vektörün her bir öğesinin, ikinci vektörün karşılık gelen öğesinden daha küçük olup olmadığını kontrol eder. |
aşağıdaki sonucu verir - |
| == | İlk vektörün her bir öğesinin, ikinci vektörün karşılık gelen öğesine eşit olup olmadığını kontrol eder. |
aşağıdaki sonucu verir - |
| <= | İlk vektörün her bir öğesinin, ikinci vektörün karşılık gelen öğesinden küçük veya ona eşit olup olmadığını kontrol eder. |
aşağıdaki sonucu verir - |
| > = | İlk vektörün her bir öğesinin, ikinci vektörün karşılık gelen öğesinden büyük veya ona eşit olup olmadığını kontrol eder. |
aşağıdaki sonucu verir - |
| ! = | İlk vektörün her bir elemanının, ikinci vektörün karşılık gelen elemanına eşit olup olmadığını kontrol eder. |
aşağıdaki sonucu verir - |
Mantıksal operatörler
Aşağıdaki tablo, R dili tarafından desteklenen mantıksal operatörleri göstermektedir. Yalnızca mantıksal, sayısal veya karmaşık tipteki vektörler için geçerlidir. 1'den büyük tüm sayılar, DOĞRU mantıksal değer olarak kabul edilir.
İlk vektörün her bir elemanı, ikinci vektörün karşılık gelen elemanıyla karşılaştırılır. Karşılaştırmanın sonucu bir Boole değeridir.
| Şebeke | Açıklama | Misal |
|---|---|---|
| & | Element-wise Logical AND operatörü olarak adlandırılır. İlk vektörün her bir elemanını ikinci vektörün karşılık gelen elemanıyla birleştirir ve her iki eleman da TRUE ise bir çıktı TRUE verir. |
aşağıdaki sonucu verir - |
| | | Element-wise Logical OR operatörü olarak adlandırılır. İlk vektörün her bir elemanını ikinci vektörün karşılık gelen elemanıyla birleştirir ve elemanlardan biri TRUE ise bir çıktı TRUE verir. |
aşağıdaki sonucu verir - |
| ! | Mantıksal DEĞİL operatörü olarak adlandırılır. Vektörün her bir öğesini alır ve zıt mantıksal değeri verir. |
aşağıdaki sonucu verir - |
Mantıksal operatör && ve || vektörlerin sadece ilk elemanını dikkate alır ve çıktı olarak tek elemandan oluşan bir vektör verir.
| Şebeke | Açıklama | Misal |
|---|---|---|
| && | Mantıksal AND operatörü çağrıldı. Her iki vektörün ilk elemanını alır ve sadece her ikisi de DOĞRU ise DOĞRU verir. |
aşağıdaki sonucu verir - |
| || | Mantıksal VEYA operatörü çağrıldı. Her iki vektörün de ilk elemanını alır ve bunlardan biri DOĞRU ise DOĞRU verir. |
aşağıdaki sonucu verir - |
Atama Operatörleri
Bu operatörler, vektörlere değer atamak için kullanılır.
| Şebeke | Açıklama | Misal |
|---|---|---|
| <- veya = veya << - |
Sol Atama olarak adlandırılan |
aşağıdaki sonucu verir - |
| -> veya - >> |
Sağ Atama Denir |
aşağıdaki sonucu verir - |
Çeşitli Operatörler
Bu operatörler, genel matematiksel veya mantıksal hesaplama için değil, belirli bir amaç için kullanılır.
| Şebeke | Açıklama | Misal |
|---|---|---|
| : | Kolon operatörü. Bir vektör için sırayla sayı serileri oluşturur. |
aşağıdaki sonucu verir - |
| %içinde% | Bu operatör, bir elemanın bir vektöre ait olup olmadığını belirlemek için kullanılır. |
aşağıdaki sonucu verir - |
| % *% | Bu operatör, bir matrisi transpoze ile çarpmak için kullanılır. |
aşağıdaki sonucu verir - |
Karar verme yapıları, programcının, program tarafından değerlendirilecek veya test edilecek bir veya daha fazla koşulu, koşulun geçerli olduğu belirlenirse yürütülecek bir ifade veya ifadeyle birlikte belirtmesini gerektirir. trueve isteğe bağlı olarak, koşul olarak belirlenirse yürütülecek diğer ifadeler false.
Aşağıda, programlama dillerinin çoğunda bulunan tipik bir karar verme yapısının genel biçimi verilmiştir -
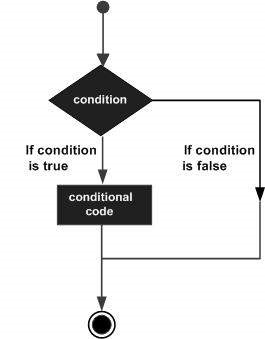
R, aşağıdaki türden karar verme beyanları sağlar. Ayrıntılarını kontrol etmek için aşağıdaki bağlantıları tıklayın.
| Sr.No. | Açıklama ve Açıklama |
|---|---|
| 1 | eğer ifadesi Bir if ifade, bir veya daha fazla ifadenin izlediği bir Boole ifadesinden oluşur. |
| 2 | if ... else ifadesi Bir if ifadenin ardından isteğe bağlı bir else Boolean ifadesi yanlış olduğunda yürütülen ifade. |
| 3 | anahtar deyimi Bir switch ifadesi, bir değişkenin bir değerler listesine karşı eşitlik açısından test edilmesine izin verir. |
Bir kod bloğunu birkaç kez çalıştırmanız gereken bir durum olabilir. Genelde ifadeler sırayla yürütülür. Bir fonksiyondaki ilk ifade önce çalıştırılır, ardından ikincisi yapılır ve bu böyle devam eder.
Programlama dilleri, daha karmaşık yürütme yollarına izin veren çeşitli kontrol yapıları sağlar.
Bir döngü deyimi, bir deyimi veya deyim grubunu birden çok kez yürütmemize izin verir ve aşağıdaki, programlama dillerinin çoğunda bir döngü ifadesinin genel biçimidir -
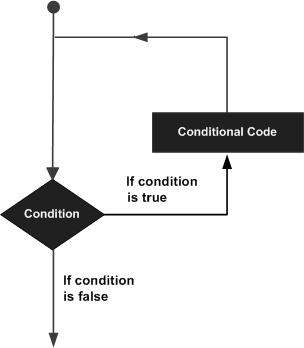
R programlama dili, döngü gereksinimlerini karşılamak için aşağıdaki döngü türlerini sağlar. Ayrıntılarını kontrol etmek için aşağıdaki bağlantıları tıklayın.
| Sr.No. | Döngü Tipi ve Açıklaması |
|---|---|
| 1 | döngüyü tekrarla Bir dizi ifadeyi birden çok kez yürütür ve döngü değişkenini yöneten kodu kısaltır. |
| 2 | döngü sırasında Belirli bir koşul doğruyken bir ifadeyi veya ifade grubunu tekrarlar. Döngü gövdesini çalıştırmadan önce koşulu test eder. |
| 3 | döngü için Döngü gövdesinin sonundaki koşulu test etmesi dışında bir while ifadesi gibi. |
Döngü Kontrol İfadeleri
Döngü kontrol ifadeleri, yürütmeyi normal sırasından değiştirir. Yürütme bir kapsam bıraktığında, bu kapsamda oluşturulan tüm otomatik nesneler yok edilir.
R, aşağıdaki kontrol ifadelerini destekler. Ayrıntılarını kontrol etmek için aşağıdaki bağlantıları tıklayın.
| Sr.No. | Kontrol İfadesi ve Açıklama |
|---|---|
| 1 | break ifadesi Sonlandırır loop deyimi ve yürütmeyi döngüden hemen sonra deyime aktarır. |
| 2 | Sonraki ifade next deyimi, R anahtarının davranışını simüle eder. |
Bir işlev, belirli bir görevi gerçekleştirmek için birlikte düzenlenen bir dizi ifadedir. R'nin çok sayıda yerleşik işlevi vardır ve kullanıcı kendi işlevlerini oluşturabilir.
R'de, bir işlev bir nesnedir, bu nedenle R yorumlayıcısı, işlevin eylemleri gerçekleştirmesi için gerekli olabilecek argümanlarla birlikte işlevi işleve geçirebilir.
İşlev sırayla görevini yerine getirir ve kontrolü yorumlayıcıya ve diğer nesnelerde saklanabilecek herhangi bir sonucu döndürür.
İşlev Tanımı
Anahtar sözcük kullanılarak bir R işlevi oluşturulur. function. Bir R işlevi tanımının temel sözdizimi aşağıdaki gibidir -
function_name <- function(arg_1, arg_2, ...) {
Function body
}Fonksiyon Bileşenleri
Bir işlevin farklı bölümleri şunlardır:
Function Name- Bu, işlevin gerçek adıdır. Bu isimde bir nesne olarak R ortamında depolanır.
Arguments- Bir argüman yer tutucudur. Bir işlev çağrıldığında, bağımsız değişkene bir değer iletirsiniz. Bağımsız değişkenler isteğe bağlıdır; yani, bir işlev bağımsız değişken içermeyebilir. Ayrıca argümanlar varsayılan değerlere sahip olabilir.
Function Body - İşlev gövdesi, işlevin ne yaptığını tanımlayan bir dizi deyim içerir.
Return Value - Bir işlevin dönüş değeri, değerlendirilecek işlev gövdesindeki son ifadedir.
R'nin birçok in-builtönce tanımlanmadan programda doğrudan çağrılabilen işlevler. Ayrıca kendi işlevlerimizi oluşturabilir ve kullanabiliriz:user defined fonksiyonlar.
Yerleşik İşlev
Yerleşik işlevlerin basit örnekleri seq(), mean(), max(), sum(x) ve paste(...)vb. Kullanıcı tarafından yazılan programlar tarafından doğrudan çağrılırlar. En yaygın kullanılan R işlevlerine başvurabilirsiniz .
# Create a sequence of numbers from 32 to 44.
print(seq(32,44))
# Find mean of numbers from 25 to 82.
print(mean(25:82))
# Find sum of numbers frm 41 to 68.
print(sum(41:68))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 32 33 34 35 36 37 38 39 40 41 42 43 44
[1] 53.5
[1] 1526Kullanıcı tanımlı İşlev
R'de kullanıcı tanımlı işlevler oluşturabiliriz. Bunlar bir kullanıcının ne istediğine özgüdür ve bir kez oluşturulduktan sonra yerleşik işlevler gibi kullanılabilirler. Aşağıda bir işlevin nasıl oluşturulup kullanıldığına dair bir örnek verilmiştir.
# Create a function to print squares of numbers in sequence.
new.function <- function(a) {
for(i in 1:a) {
b <- i^2
print(b)
}
}Bir Fonksiyon Çağırma
# Create a function to print squares of numbers in sequence.
new.function <- function(a) {
for(i in 1:a) {
b <- i^2
print(b)
}
}
# Call the function new.function supplying 6 as an argument.
new.function(6)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 1
[1] 4
[1] 9
[1] 16
[1] 25
[1] 36Bağımsız Değişken Olmadan Bir Fonksiyonu Çağırma
# Create a function without an argument.
new.function <- function() {
for(i in 1:5) {
print(i^2)
}
}
# Call the function without supplying an argument.
new.function()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 1
[1] 4
[1] 9
[1] 16
[1] 25Bağımsız Değişken Değerleri İçeren Bir Fonksiyonu Çağırma (konuma ve ada göre)
Bir işlev çağrısına yönelik argümanlar, işlevde tanımlananlarla aynı sırada sağlanabilir veya farklı bir sırayla sağlanabilir, ancak argümanların adlarına atanabilir.
# Create a function with arguments.
new.function <- function(a,b,c) {
result <- a * b + c
print(result)
}
# Call the function by position of arguments.
new.function(5,3,11)
# Call the function by names of the arguments.
new.function(a = 11, b = 5, c = 3)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 26
[1] 58Varsayılan Bağımsız Değişkenle Bir Fonksiyonu Çağırma
Fonksiyon tanımındaki argümanların değerini tanımlayabilir ve varsayılan sonucu almak için herhangi bir argüman sağlamadan fonksiyonu çağırabiliriz. Ancak argümanın yeni değerlerini sağlayarak bu tür işlevleri çağırabilir ve varsayılan olmayan bir sonuç elde edebiliriz.
# Create a function with arguments.
new.function <- function(a = 3, b = 6) {
result <- a * b
print(result)
}
# Call the function without giving any argument.
new.function()
# Call the function with giving new values of the argument.
new.function(9,5)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 18
[1] 45Fonksiyonun Tembel Değerlendirilmesi
İşlevlere yönelik argümanlar tembel olarak değerlendirilir, yani yalnızca işlev gövdesi tarafından ihtiyaç duyulduğunda değerlendirilir.
# Create a function with arguments.
new.function <- function(a, b) {
print(a^2)
print(a)
print(b)
}
# Evaluate the function without supplying one of the arguments.
new.function(6)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 36
[1] 6
Error in print(b) : argument "b" is missing, with no defaultBir çift tek tırnak veya çift tırnak içinde yazılan herhangi bir değer, bir dizge olarak kabul edilir. Dahili olarak R, tek tırnakla oluşturduğunuzda bile her dizeyi çift tırnak içinde saklar.
İp Yapımında Uygulanan Kurallar
Bir dizenin başındaki ve sonundaki tırnaklar hem çift tırnak hem de tek tırnak olmalıdır. Karıştırılamazlar.
Tek tırnakla başlayıp biten bir dizeye çift tırnak eklenebilir.
Çift tırnak ile başlayan ve biten bir dizeye tek tırnak eklenebilir.
Çift tırnak ile başlayan ve biten bir dizeye çift tırnak eklenemez.
Tek tırnak ile başlayan ve biten bir dizeye tek tırnak eklenemez.
Geçerli Dizelerin Örnekleri
Aşağıdaki örnekler, R'de bir dize oluşturmayla ilgili kuralları netleştirir.
a <- 'Start and end with single quote'
print(a)
b <- "Start and end with double quotes"
print(b)
c <- "single quote ' in between double quotes"
print(c)
d <- 'Double quotes " in between single quote'
print(d)Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz -
[1] "Start and end with single quote"
[1] "Start and end with double quotes"
[1] "single quote ' in between double quote"
[1] "Double quote \" in between single quote"Geçersiz Dizelerin Örnekleri
e <- 'Mixed quotes"
print(e)
f <- 'Single quote ' inside single quote'
print(f)
g <- "Double quotes " inside double quotes"
print(g)Komut dosyasını çalıştırdığımızda, aşağıdaki sonuçları vermede başarısız oluyor.
Error: unexpected symbol in:
"print(e)
f <- 'Single"
Execution haltedDize Manipülasyonu
Dizeleri Birleştirme - yapıştır () işlevi
R'deki birçok dize, paste()işlevi. Bir araya getirilmesi için herhangi bir sayıda argüman gerekebilir.
Sözdizimi
Yapıştırma işlevi için temel sözdizimi -
paste(..., sep = " ", collapse = NULL)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
... birleştirilecek herhangi bir sayıda argümanı temsil eder.
sepbağımsız değişkenler arasındaki herhangi bir ayırıcıyı temsil eder. İsteğe bağlıdır.
collapseiki dizge arasındaki boşluğu ortadan kaldırmak için kullanılır. Ancak bir dizenin iki kelimesi arasındaki boşluk değil.
Misal
a <- "Hello"
b <- 'How'
c <- "are you? "
print(paste(a,b,c))
print(paste(a,b,c, sep = "-"))
print(paste(a,b,c, sep = "", collapse = ""))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] "Hello How are you? "
[1] "Hello-How-are you? "
[1] "HelloHoware you? "Sayıları ve dizeleri biçimlendirme - format () işlevi
Sayılar ve dizeler kullanılarak belirli bir stile göre biçimlendirilebilir format() işlevi.
Sözdizimi
Biçim işlevinin temel sözdizimi -
format(x, digits, nsmall, scientific, width, justify = c("left", "right", "centre", "none"))Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
x vektör girdisidir.
digits görüntülenen toplam basamak sayısıdır.
nsmall ondalık ayırıcının sağındaki minimum basamak sayısıdır.
scientific bilimsel gösterimi görüntülemek için TRUE olarak ayarlanmıştır.
width başlangıçta boşlukları doldurarak görüntülenecek minimum genişliği belirtir.
justify dizenin sola, sağa veya ortadaki görüntüsüdür.
Misal
# Total number of digits displayed. Last digit rounded off.
result <- format(23.123456789, digits = 9)
print(result)
# Display numbers in scientific notation.
result <- format(c(6, 13.14521), scientific = TRUE)
print(result)
# The minimum number of digits to the right of the decimal point.
result <- format(23.47, nsmall = 5)
print(result)
# Format treats everything as a string.
result <- format(6)
print(result)
# Numbers are padded with blank in the beginning for width.
result <- format(13.7, width = 6)
print(result)
# Left justify strings.
result <- format("Hello", width = 8, justify = "l")
print(result)
# Justfy string with center.
result <- format("Hello", width = 8, justify = "c")
print(result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] "23.1234568"
[1] "6.000000e+00" "1.314521e+01"
[1] "23.47000"
[1] "6"
[1] " 13.7"
[1] "Hello "
[1] " Hello "Bir dizedeki karakter sayısını sayma - nchar () işlevi
Bu işlev, bir dizedeki boşluklar dahil olmak üzere karakterlerin sayısını sayar.
Sözdizimi
Nchar () işlevi için temel sözdizimi -
nchar(x)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
x vektör girdisidir.
Misal
result <- nchar("Count the number of characters")
print(result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 30Durum değiştirme - toupper () ve tolower () işlevleri
Bu işlevler, bir dizedeki karakterlerin durumunu değiştirir.
Sözdizimi
Toupper () & tolower () işlevinin temel sözdizimi -
toupper(x)
tolower(x)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
x vektör girdisidir.
Misal
# Changing to Upper case.
result <- toupper("Changing To Upper")
print(result)
# Changing to lower case.
result <- tolower("Changing To Lower")
print(result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] "CHANGING TO UPPER"
[1] "changing to lower"Bir dizenin parçalarını çıkarma - substring () işlevi
Bu işlev bir String'in parçalarını çıkarır.
Sözdizimi
Substring () işlevi için temel sözdizimi -
substring(x,first,last)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
x karakter vektör girdisidir.
first ayıklanacak ilk karakterin konumudur.
last ayıklanacak son karakterin konumudur.
Misal
# Extract characters from 5th to 7th position.
result <- substring("Extract", 5, 7)
print(result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] "act"Vektörler en temel R veri nesneleridir ve altı tür atomik vektör vardır. Mantıksal, tamsayı, çift, karmaşık, karakter ve ham.
Vektör Oluşturma
Tek Eleman Vektör
R'ye sadece bir değer yazdığınızda bile, 1 uzunluğunda bir vektör olur ve yukarıdaki vektör türlerinden birine aittir.
# Atomic vector of type character.
print("abc");
# Atomic vector of type double.
print(12.5)
# Atomic vector of type integer.
print(63L)
# Atomic vector of type logical.
print(TRUE)
# Atomic vector of type complex.
print(2+3i)
# Atomic vector of type raw.
print(charToRaw('hello'))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] "abc"
[1] 12.5
[1] 63
[1] TRUE
[1] 2+3i
[1] 68 65 6c 6c 6fBirden çok öğe Vektör
Using colon operator with numeric data
# Creating a sequence from 5 to 13.
v <- 5:13
print(v)
# Creating a sequence from 6.6 to 12.6.
v <- 6.6:12.6
print(v)
# If the final element specified does not belong to the sequence then it is discarded.
v <- 3.8:11.4
print(v)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 5 6 7 8 9 10 11 12 13
[1] 6.6 7.6 8.6 9.6 10.6 11.6 12.6
[1] 3.8 4.8 5.8 6.8 7.8 8.8 9.8 10.8Using sequence (Seq.) operator
# Create vector with elements from 5 to 9 incrementing by 0.4.
print(seq(5, 9, by = 0.4))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 5.0 5.4 5.8 6.2 6.6 7.0 7.4 7.8 8.2 8.6 9.0Using the c() function
Karakter olmayan değerler, öğelerden biri bir karakterse, karakter türüne zorlanır.
# The logical and numeric values are converted to characters.
s <- c('apple','red',5,TRUE)
print(s)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] "apple" "red" "5" "TRUE"Vektör Öğelerine Erişim
Bir Vector öğelerine indeksleme kullanılarak erişilir. [ ] bracketsindeksleme için kullanılır. İndeksleme, konum 1 ile başlar. İndekste negatif bir değer verilmesi, o öğeyi sonuçtan düşürür.TRUE, FALSE veya 0 ve 1 indeksleme için de kullanılabilir.
# Accessing vector elements using position.
t <- c("Sun","Mon","Tue","Wed","Thurs","Fri","Sat")
u <- t[c(2,3,6)]
print(u)
# Accessing vector elements using logical indexing.
v <- t[c(TRUE,FALSE,FALSE,FALSE,FALSE,TRUE,FALSE)]
print(v)
# Accessing vector elements using negative indexing.
x <- t[c(-2,-5)]
print(x)
# Accessing vector elements using 0/1 indexing.
y <- t[c(0,0,0,0,0,0,1)]
print(y)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] "Mon" "Tue" "Fri"
[1] "Sun" "Fri"
[1] "Sun" "Tue" "Wed" "Fri" "Sat"
[1] "Sun"Vektör Manipülasyonu
Vektör aritmetiği
Aynı uzunlukta iki vektör eklenebilir, çıkarılabilir, çarpılabilir veya bölünerek sonuç vektör çıktısı olarak alınabilir.
# Create two vectors.
v1 <- c(3,8,4,5,0,11)
v2 <- c(4,11,0,8,1,2)
# Vector addition.
add.result <- v1+v2
print(add.result)
# Vector subtraction.
sub.result <- v1-v2
print(sub.result)
# Vector multiplication.
multi.result <- v1*v2
print(multi.result)
# Vector division.
divi.result <- v1/v2
print(divi.result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 7 19 4 13 1 13
[1] -1 -3 4 -3 -1 9
[1] 12 88 0 40 0 22
[1] 0.7500000 0.7272727 Inf 0.6250000 0.0000000 5.5000000Vektör Öğesi Geri Dönüşümü
Eşit olmayan uzunluktaki iki vektöre aritmetik işlemler uygularsak, daha kısa vektörün elemanları işlemleri tamamlamak için geri dönüştürülür.
v1 <- c(3,8,4,5,0,11)
v2 <- c(4,11)
# V2 becomes c(4,11,4,11,4,11)
add.result <- v1+v2
print(add.result)
sub.result <- v1-v2
print(sub.result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 7 19 8 16 4 22
[1] -1 -3 0 -6 -4 0Vektör Eleman Sıralama
Bir vektördeki öğeler, sort() işlevi.
v <- c(3,8,4,5,0,11, -9, 304)
# Sort the elements of the vector.
sort.result <- sort(v)
print(sort.result)
# Sort the elements in the reverse order.
revsort.result <- sort(v, decreasing = TRUE)
print(revsort.result)
# Sorting character vectors.
v <- c("Red","Blue","yellow","violet")
sort.result <- sort(v)
print(sort.result)
# Sorting character vectors in reverse order.
revsort.result <- sort(v, decreasing = TRUE)
print(revsort.result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] -9 0 3 4 5 8 11 304
[1] 304 11 8 5 4 3 0 -9
[1] "Blue" "Red" "violet" "yellow"
[1] "yellow" "violet" "Red" "Blue"Listeler, sayılar, dizeler, vektörler ve içindeki başka bir liste gibi farklı türdeki öğeleri içeren R nesneleridir. Bir liste, öğeleri olarak bir matris veya bir işlev de içerebilir. Liste kullanılarak oluşturulurlist() işlevi.
Liste Oluşturmak
Aşağıda dizeler, sayılar, vektörler ve mantıksal değerler içeren bir liste oluşturmak için bir örnek verilmiştir.
# Create a list containing strings, numbers, vectors and a logical
# values.
list_data <- list("Red", "Green", c(21,32,11), TRUE, 51.23, 119.1)
print(list_data)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[[1]]
[1] "Red"
[[2]]
[1] "Green"
[[3]]
[1] 21 32 11
[[4]]
[1] TRUE
[[5]]
[1] 51.23
[[6]]
[1] 119.1Liste Öğelerini Adlandırma
Liste elemanlarına isim verilebilir ve bu isimler kullanılarak erişilebilirler.
# Create a list containing a vector, a matrix and a list.
list_data <- list(c("Jan","Feb","Mar"), matrix(c(3,9,5,1,-2,8), nrow = 2),
list("green",12.3))
# Give names to the elements in the list.
names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list")
# Show the list.
print(list_data)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
$`1st_Quarter` [1] "Jan" "Feb" "Mar" $A_Matrix
[,1] [,2] [,3]
[1,] 3 5 -2
[2,] 9 1 8
$A_Inner_list $A_Inner_list[[1]]
[1] "green"
$A_Inner_list[[2]]
[1] 12.3Liste Öğelerine Erişim
Listenin elemanlarına listedeki elemanın indeksi ile erişilebilir. İsimlendirilmiş listeler olması durumunda isimler kullanılarak da erişilebilir.
Yukarıdaki örnekteki listeyi kullanmaya devam ediyoruz -
# Create a list containing a vector, a matrix and a list.
list_data <- list(c("Jan","Feb","Mar"), matrix(c(3,9,5,1,-2,8), nrow = 2),
list("green",12.3))
# Give names to the elements in the list.
names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list")
# Access the first element of the list.
print(list_data[1])
# Access the thrid element. As it is also a list, all its elements will be printed.
print(list_data[3])
# Access the list element using the name of the element.
print(list_data$A_Matrix)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
$`1st_Quarter` [1] "Jan" "Feb" "Mar" $A_Inner_list
$A_Inner_list[[1]] [1] "green" $A_Inner_list[[2]]
[1] 12.3
[,1] [,2] [,3]
[1,] 3 5 -2
[2,] 9 1 8Liste Öğelerini Değiştirme
Liste öğelerini aşağıda gösterildiği gibi ekleyebilir, silebilir ve güncelleyebiliriz. Öğeleri yalnızca bir listenin sonuna ekleyebilir ve silebiliriz. Ancak herhangi bir öğeyi güncelleyebiliriz.
# Create a list containing a vector, a matrix and a list.
list_data <- list(c("Jan","Feb","Mar"), matrix(c(3,9,5,1,-2,8), nrow = 2),
list("green",12.3))
# Give names to the elements in the list.
names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list")
# Add element at the end of the list.
list_data[4] <- "New element"
print(list_data[4])
# Remove the last element.
list_data[4] <- NULL
# Print the 4th Element.
print(list_data[4])
# Update the 3rd Element.
list_data[3] <- "updated element"
print(list_data[3])Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[[1]]
[1] "New element"
$<NA> NULL $`A Inner list`
[1] "updated element"Listeleri Birleştirme
Tüm listeleri bir list () işlevi içine yerleştirerek birçok listeyi tek bir listede birleştirebilirsiniz.
# Create two lists.
list1 <- list(1,2,3)
list2 <- list("Sun","Mon","Tue")
# Merge the two lists.
merged.list <- c(list1,list2)
# Print the merged list.
print(merged.list)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[[1]]
[1] 1
[[2]]
[1] 2
[[3]]
[1] 3
[[4]]
[1] "Sun"
[[5]]
[1] "Mon"
[[6]]
[1] "Tue"Listeyi Vektöre Dönüştürme
Bir liste bir vektöre dönüştürülebilir, böylece vektörün öğeleri daha fazla manipülasyon için kullanılabilir. Liste vektöre dönüştürüldükten sonra vektörler üzerindeki tüm aritmetik işlemler uygulanabilir. Bu dönüşümü yapmak için,unlist()işlevi. Listeyi girdi olarak alır ve bir vektör üretir.
# Create lists.
list1 <- list(1:5)
print(list1)
list2 <-list(10:14)
print(list2)
# Convert the lists to vectors.
v1 <- unlist(list1)
v2 <- unlist(list2)
print(v1)
print(v2)
# Now add the vectors
result <- v1+v2
print(result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[[1]]
[1] 1 2 3 4 5
[[1]]
[1] 10 11 12 13 14
[1] 1 2 3 4 5
[1] 10 11 12 13 14
[1] 11 13 15 17 19Matrisler, elemanların iki boyutlu dikdörtgen bir düzende düzenlendiği R nesneleridir. Aynı atomik türden elementler içerirler. Yalnızca karakterler veya yalnızca mantıksal değerler içeren bir matris oluşturabilsek de, bunların pek bir faydası yoktur. Matematiksel hesaplamalarda kullanılacak sayısal öğeler içeren matrisler kullanıyoruz.
Bir Matrix, matrix() işlevi.
Sözdizimi
R'de bir matris oluşturmak için temel sözdizimi -
matrix(data, nrow, ncol, byrow, dimnames)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
data matrisin veri elemanları haline gelen girdi vektörüdür.
nrow oluşturulacak satır sayısıdır.
ncol oluşturulacak sütun sayısıdır.
byrowmantıklı bir ipucudur. TRUE ise, giriş vektör öğeleri satıra göre düzenlenir.
dimname satırlara ve sütunlara atanan adlardır.
Misal
Girdi olarak sayılardan oluşan bir vektör alarak bir matris oluşturun.
# Elements are arranged sequentially by row.
M <- matrix(c(3:14), nrow = 4, byrow = TRUE)
print(M)
# Elements are arranged sequentially by column.
N <- matrix(c(3:14), nrow = 4, byrow = FALSE)
print(N)
# Define the column and row names.
rownames = c("row1", "row2", "row3", "row4")
colnames = c("col1", "col2", "col3")
P <- matrix(c(3:14), nrow = 4, byrow = TRUE, dimnames = list(rownames, colnames))
print(P)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[,1] [,2] [,3]
[1,] 3 4 5
[2,] 6 7 8
[3,] 9 10 11
[4,] 12 13 14
[,1] [,2] [,3]
[1,] 3 7 11
[2,] 4 8 12
[3,] 5 9 13
[4,] 6 10 14
col1 col2 col3
row1 3 4 5
row2 6 7 8
row3 9 10 11
row4 12 13 14Bir Matrisin Elemanlarına Erişim
Bir matrisin elemanlarına, elemanın sütun ve satır indeksi kullanılarak erişilebilir. Aşağıdaki belirli öğeleri bulmak için yukarıdaki P matrisini ele alıyoruz.
# Define the column and row names.
rownames = c("row1", "row2", "row3", "row4")
colnames = c("col1", "col2", "col3")
# Create the matrix.
P <- matrix(c(3:14), nrow = 4, byrow = TRUE, dimnames = list(rownames, colnames))
# Access the element at 3rd column and 1st row.
print(P[1,3])
# Access the element at 2nd column and 4th row.
print(P[4,2])
# Access only the 2nd row.
print(P[2,])
# Access only the 3rd column.
print(P[,3])Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 5
[1] 13
col1 col2 col3
6 7 8
row1 row2 row3 row4
5 8 11 14Matris Hesaplamaları
R operatörleri kullanılarak matrisler üzerinde çeşitli matematiksel işlemler gerçekleştirilir. İşlemin sonucu da bir matristir.
İşlemde yer alan matrisler için boyutlar (satır ve sütun sayısı) aynı olmalıdır.
Matris Toplama ve Çıkarma
# Create two 2x3 matrices.
matrix1 <- matrix(c(3, 9, -1, 4, 2, 6), nrow = 2)
print(matrix1)
matrix2 <- matrix(c(5, 2, 0, 9, 3, 4), nrow = 2)
print(matrix2)
# Add the matrices.
result <- matrix1 + matrix2
cat("Result of addition","\n")
print(result)
# Subtract the matrices
result <- matrix1 - matrix2
cat("Result of subtraction","\n")
print(result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[,1] [,2] [,3]
[1,] 3 -1 2
[2,] 9 4 6
[,1] [,2] [,3]
[1,] 5 0 3
[2,] 2 9 4
Result of addition
[,1] [,2] [,3]
[1,] 8 -1 5
[2,] 11 13 10
Result of subtraction
[,1] [,2] [,3]
[1,] -2 -1 -1
[2,] 7 -5 2Matris Çarpma ve Bölme
# Create two 2x3 matrices.
matrix1 <- matrix(c(3, 9, -1, 4, 2, 6), nrow = 2)
print(matrix1)
matrix2 <- matrix(c(5, 2, 0, 9, 3, 4), nrow = 2)
print(matrix2)
# Multiply the matrices.
result <- matrix1 * matrix2
cat("Result of multiplication","\n")
print(result)
# Divide the matrices
result <- matrix1 / matrix2
cat("Result of division","\n")
print(result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[,1] [,2] [,3]
[1,] 3 -1 2
[2,] 9 4 6
[,1] [,2] [,3]
[1,] 5 0 3
[2,] 2 9 4
Result of multiplication
[,1] [,2] [,3]
[1,] 15 0 6
[2,] 18 36 24
Result of division
[,1] [,2] [,3]
[1,] 0.6 -Inf 0.6666667
[2,] 4.5 0.4444444 1.5000000Diziler, verileri ikiden fazla boyutta depolayabilen R veri nesneleridir. Örneğin - Bir boyut dizisi (2, 3, 4) oluşturursak, her biri 2 satır ve 3 sütun içeren 4 dikdörtgen matris oluşturur. Diziler yalnızca veri türünü depolayabilir.
Bir dizi, array()işlevi. Vektörleri girdi olarak alır ve içindeki değerleri kullanır.dim bir dizi oluşturmak için parametre.
Misal
Aşağıdaki örnek, her biri 3 satır ve 3 sütun içeren iki 3x3 matristen oluşan bir dizi oluşturur.
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
# Take these vectors as input to the array.
result <- array(c(vector1,vector2),dim = c(3,3,2))
print(result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
, , 1
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
, , 2
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15Sütunları ve Satırları Adlandırma
Dizideki satırlara, sütunlara ve matrislere isim verebiliriz. dimnames parametre.
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
column.names <- c("COL1","COL2","COL3")
row.names <- c("ROW1","ROW2","ROW3")
matrix.names <- c("Matrix1","Matrix2")
# Take these vectors as input to the array.
result <- array(c(vector1,vector2),dim = c(3,3,2),dimnames = list(row.names,column.names,
matrix.names))
print(result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
, , Matrix1
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15
, , Matrix2
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15Dizi Öğelerine Erişim
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
column.names <- c("COL1","COL2","COL3")
row.names <- c("ROW1","ROW2","ROW3")
matrix.names <- c("Matrix1","Matrix2")
# Take these vectors as input to the array.
result <- array(c(vector1,vector2),dim = c(3,3,2),dimnames = list(row.names,
column.names, matrix.names))
# Print the third row of the second matrix of the array.
print(result[3,,2])
# Print the element in the 1st row and 3rd column of the 1st matrix.
print(result[1,3,1])
# Print the 2nd Matrix.
print(result[,,2])Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
COL1 COL2 COL3
3 12 15
[1] 13
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15Dizi Öğelerini Düzenleme
Dizi çok boyutlu matrislerden oluştuğundan, dizinin elemanları üzerindeki işlemler matrislerin elemanlarına erişilerek gerçekleştirilir.
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
# Take these vectors as input to the array.
array1 <- array(c(vector1,vector2),dim = c(3,3,2))
# Create two vectors of different lengths.
vector3 <- c(9,1,0)
vector4 <- c(6,0,11,3,14,1,2,6,9)
array2 <- array(c(vector1,vector2),dim = c(3,3,2))
# create matrices from these arrays.
matrix1 <- array1[,,2]
matrix2 <- array2[,,2]
# Add the matrices.
result <- matrix1+matrix2
print(result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[,1] [,2] [,3]
[1,] 10 20 26
[2,] 18 22 28
[3,] 6 24 30Dizi Öğeleri Genelinde Hesaplamalar
Bir dizideki öğeler arasında hesaplamalar yapabiliriz. apply() işlevi.
Sözdizimi
apply(x, margin, fun)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
x bir dizidir.
margin kullanılan veri kümesinin adıdır.
fun dizinin elemanları arasında uygulanacak işlevdir.
Misal
Tüm matrisler boyunca bir dizinin satırlarında bulunan öğelerin toplamını hesaplamak için aşağıdaki apply () işlevini kullanıyoruz.
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
# Take these vectors as input to the array.
new.array <- array(c(vector1,vector2),dim = c(3,3,2))
print(new.array)
# Use apply to calculate the sum of the rows across all the matrices.
result <- apply(new.array, c(1), sum)
print(result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
, , 1
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
, , 2
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
[1] 56 68 60Faktörler, verileri kategorize etmek ve seviyeler halinde saklamak için kullanılan veri nesneleridir. Hem dizeleri hem de tam sayıları depolayabilirler. Sınırlı sayıda benzersiz değeri olan sütunlarda kullanışlıdırlar. "Erkek", "Kadın" ve Doğru, Yanlış vb. Gibi. İstatistiksel modelleme için veri analizinde faydalıdırlar.
Faktörler kullanılarak oluşturulur factor () girdi olarak bir vektör alarak fonksiyon.
Misal
# Create a vector as input.
data <- c("East","West","East","North","North","East","West","West","West","East","North")
print(data)
print(is.factor(data))
# Apply the factor function.
factor_data <- factor(data)
print(factor_data)
print(is.factor(factor_data))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] "East" "West" "East" "North" "North" "East" "West" "West" "West" "East" "North"
[1] FALSE
[1] East West East North North East West West West East North
Levels: East North West
[1] TRUEVeri Çerçevesindeki Faktörler
Bir metin verisi sütunuyla herhangi bir veri çerçevesi oluştururken, R, metin sütununu kategorik veriler olarak ele alır ve üzerinde faktörler oluşturur.
# Create the vectors for data frame.
height <- c(132,151,162,139,166,147,122)
weight <- c(48,49,66,53,67,52,40)
gender <- c("male","male","female","female","male","female","male")
# Create the data frame.
input_data <- data.frame(height,weight,gender)
print(input_data)
# Test if the gender column is a factor.
print(is.factor(input_data$gender)) # Print the gender column so see the levels. print(input_data$gender)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
height weight gender
1 132 48 male
2 151 49 male
3 162 66 female
4 139 53 female
5 166 67 male
6 147 52 female
7 122 40 male
[1] TRUE
[1] male male female female male female male
Levels: female maleSeviye Sırasını Değiştirme
Bir faktördeki seviyelerin sırası, seviyelerin yeni sırası ile tekrar faktör fonksiyonu uygulanarak değiştirilebilir.
data <- c("East","West","East","North","North","East","West",
"West","West","East","North")
# Create the factors
factor_data <- factor(data)
print(factor_data)
# Apply the factor function with required order of the level.
new_order_data <- factor(factor_data,levels = c("East","West","North"))
print(new_order_data)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] East West East North North East West West West East North
Levels: East North West
[1] East West East North North East West West West East North
Levels: East West NorthFaktör Seviyeleri Oluşturma
Faktör seviyelerini, gl()işlevi. Girdi olarak iki tamsayı alır, bu da her seviyede kaç seviye ve kaç kez olduğunu gösterir.
Sözdizimi
gl(n, k, labels)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
n düzey sayısını veren bir tam sayıdır.
k yineleme sayısını veren bir tam sayıdır.
labels ortaya çıkan faktör seviyeleri için bir etiket vektörüdür.
Misal
v <- gl(3, 4, labels = c("Tampa", "Seattle","Boston"))
print(v)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
Tampa Tampa Tampa Tampa Seattle Seattle Seattle Seattle Boston
[10] Boston Boston Boston
Levels: Tampa Seattle BostonVeri çerçevesi, her sütunun bir değişkenin değerlerini içerdiği ve her satırın her sütundan bir değer kümesi içerdiği bir tablo veya iki boyutlu dizi benzeri bir yapıdır.
Bir veri çerçevesinin özellikleri aşağıdadır.
- Sütun adları boş olmamalıdır.
- Satır adları benzersiz olmalıdır.
- Bir veri çerçevesinde saklanan veriler sayısal, faktör veya karakter tipinde olabilir.
- Her sütun aynı sayıda veri öğesi içermelidir.
Veri Çerçevesi Oluşturun
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Print the data frame.
print(emp.data)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
emp_id emp_name salary start_date
1 1 Rick 623.30 2012-01-01
2 2 Dan 515.20 2013-09-23
3 3 Michelle 611.00 2014-11-15
4 4 Ryan 729.00 2014-05-11
5 5 Gary 843.25 2015-03-27Veri Çerçevesinin Yapısını Alın
Veri çerçevesinin yapısı kullanılarak görülebilir str() işlevi.
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Get the structure of the data frame.
str(emp.data)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
'data.frame': 5 obs. of 4 variables:
$ emp_id : int 1 2 3 4 5 $ emp_name : chr "Rick" "Dan" "Michelle" "Ryan" ...
$ salary : num 623 515 611 729 843 $ start_date: Date, format: "2012-01-01" "2013-09-23" "2014-11-15" "2014-05-11" ...Veri Çerçevesindeki Verilerin Özeti
Verilerin istatistiksel özeti ve niteliği uygulama yapılarak elde edilebilir summary() işlevi.
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Print the summary.
print(summary(emp.data))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
emp_id emp_name salary start_date
Min. :1 Length:5 Min. :515.2 Min. :2012-01-01
1st Qu.:2 Class :character 1st Qu.:611.0 1st Qu.:2013-09-23
Median :3 Mode :character Median :623.3 Median :2014-05-11
Mean :3 Mean :664.4 Mean :2014-01-14
3rd Qu.:4 3rd Qu.:729.0 3rd Qu.:2014-11-15
Max. :5 Max. :843.2 Max. :2015-03-27Veri Çerçevesinden Veri Çıkarın
Sütun adını kullanarak bir veri çerçevesinden belirli bir sütunu çıkarın.
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01","2013-09-23","2014-11-15","2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Extract Specific columns.
result <- data.frame(emp.data$emp_name,emp.data$salary)
print(result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
emp.data.emp_name emp.data.salary
1 Rick 623.30
2 Dan 515.20
3 Michelle 611.00
4 Ryan 729.00
5 Gary 843.25İlk iki satırı ve ardından tüm sütunları çıkarın
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Extract first two rows.
result <- emp.data[1:2,]
print(result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
emp_id emp_name salary start_date
1 1 Rick 623.3 2012-01-01
2 2 Dan 515.2 2013-09-233 ekstrakte rd ve 5 inci 2'ye satır nd ve 4 inci kolon
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Extract 3rd and 5th row with 2nd and 4th column.
result <- emp.data[c(3,5),c(2,4)]
print(result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
emp_name start_date
3 Michelle 2014-11-15
5 Gary 2015-03-27Veri Çerçevesini Genişlet
Bir veri çerçevesi, sütunlar ve satırlar eklenerek genişletilebilir.
Sütun Ekle
Yeni bir sütun adı kullanarak sütun vektörünü eklemeniz yeterlidir.
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Add the "dept" coulmn.
emp.data$dept <- c("IT","Operations","IT","HR","Finance")
v <- emp.data
print(v)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
emp_id emp_name salary start_date dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 5 Gary 843.25 2015-03-27 FinanceSatır ekle
Mevcut bir veri çerçevesine kalıcı olarak daha fazla satır eklemek için, yeni satırları mevcut veri çerçevesiyle aynı yapıya getirmemiz ve rbind() işlevi.
Aşağıdaki örnekte, yeni satırlarla bir veri çerçevesi oluşturuyoruz ve son veri çerçevesini oluşturmak için bunu mevcut veri çerçevesiyle birleştiriyoruz.
# Create the first data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
dept = c("IT","Operations","IT","HR","Finance"),
stringsAsFactors = FALSE
)
# Create the second data frame
emp.newdata <- data.frame(
emp_id = c (6:8),
emp_name = c("Rasmi","Pranab","Tusar"),
salary = c(578.0,722.5,632.8),
start_date = as.Date(c("2013-05-21","2013-07-30","2014-06-17")),
dept = c("IT","Operations","Fianance"),
stringsAsFactors = FALSE
)
# Bind the two data frames.
emp.finaldata <- rbind(emp.data,emp.newdata)
print(emp.finaldata)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
emp_id emp_name salary start_date dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 5 Gary 843.25 2015-03-27 Finance
6 6 Rasmi 578.00 2013-05-21 IT
7 7 Pranab 722.50 2013-07-30 Operations
8 8 Tusar 632.80 2014-06-17 FiananceR paketleri, R işlevleri, uyumlu kod ve örnek verilerden oluşan bir koleksiyondur. Adlı bir dizinde saklanırlar"library"R ortamında. Varsayılan olarak, R, kurulum sırasında bir dizi paket kurar. Daha sonra, belirli bir amaç için ihtiyaç duyulduğunda daha fazla paket eklenir. R konsolunu başlattığımızda, varsayılan olarak yalnızca varsayılan paketler kullanılabilir. Halihazırda kurulu olan diğer paketlerin, onları kullanacak olan R programı tarafından kullanılmak üzere açıkça yüklenmesi gerekir.
R dilinde mevcut olan tüm paketler R Paketlerinde listelenmiştir .
Aşağıda, R paketlerini kontrol etmek, doğrulamak ve kullanmak için kullanılacak komutların bir listesi bulunmaktadır.
Mevcut R Paketlerini Kontrol Edin
R paketleri içeren kitaplık konumlarını alın
.libPaths()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir. Bilgisayarınızın yerel ayarlarına bağlı olarak değişebilir.
[2] "C:/Program Files/R/R-3.2.2/library"Yüklü tüm paketlerin listesini alın
library()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir. Bilgisayarınızın yerel ayarlarına bağlı olarak değişebilir.
Packages in library ‘C:/Program Files/R/R-3.2.2/library’:
base The R Base Package
boot Bootstrap Functions (Originally by Angelo Canty
for S)
class Functions for Classification
cluster "Finding Groups in Data": Cluster Analysis
Extended Rousseeuw et al.
codetools Code Analysis Tools for R
compiler The R Compiler Package
datasets The R Datasets Package
foreign Read Data Stored by 'Minitab', 'S', 'SAS',
'SPSS', 'Stata', 'Systat', 'Weka', 'dBase', ...
graphics The R Graphics Package
grDevices The R Graphics Devices and Support for Colours
and Fonts
grid The Grid Graphics Package
KernSmooth Functions for Kernel Smoothing Supporting Wand
& Jones (1995)
lattice Trellis Graphics for R
MASS Support Functions and Datasets for Venables and
Ripley's MASS
Matrix Sparse and Dense Matrix Classes and Methods
methods Formal Methods and Classes
mgcv Mixed GAM Computation Vehicle with GCV/AIC/REML
Smoothness Estimation
nlme Linear and Nonlinear Mixed Effects Models
nnet Feed-Forward Neural Networks and Multinomial
Log-Linear Models
parallel Support for Parallel computation in R
rpart Recursive Partitioning and Regression Trees
spatial Functions for Kriging and Point Pattern
Analysis
splines Regression Spline Functions and Classes
stats The R Stats Package
stats4 Statistical Functions using S4 Classes
survival Survival Analysis
tcltk Tcl/Tk Interface
tools Tools for Package Development
utils The R Utils PackageŞu anda R ortamında yüklü olan tüm paketleri alın
search()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir. Bilgisayarınızın yerel ayarlarına bağlı olarak değişebilir.
[1] ".GlobalEnv" "package:stats" "package:graphics"
[4] "package:grDevices" "package:utils" "package:datasets"
[7] "package:methods" "Autoloads" "package:base"Yeni Bir Paket Kurun
Yeni R paketleri eklemenin iki yolu vardır. Biri doğrudan CRAN dizininden yükleme, diğeri ise paketi yerel sisteminize indirip manuel olarak yüklemektir.
Doğrudan CRAN'dan yükleyin
Aşağıdaki komut paketleri doğrudan CRAN web sayfasından alır ve paketi R ortamına yükler. En yakın aynayı seçmeniz istenebilir. Bulunduğunuz yere uygun olanı seçin.
install.packages("Package Name")
# Install the package named "XML".
install.packages("XML")Paketi manuel olarak yükleyin
Gerekli paketi indirmek için R Paketleri bağlantısına gidin . Paketi bir.zip yerel sistemde uygun bir konumda dosya.
Şimdi bu paketi R ortamına kurmak için aşağıdaki komutu çalıştırabilirsiniz.
install.packages(file_name_with_path, repos = NULL, type = "source")
# Install the package named "XML"
install.packages("E:/XML_3.98-1.3.zip", repos = NULL, type = "source")Paketi Kitaplığa Yükle
Bir paket kodda kullanılmadan önce mevcut R ortamına yüklenmelidir. Ayrıca önceden yüklenmiş ancak mevcut ortamda bulunmayan bir paketi de yüklemeniz gerekir.
Aşağıdaki komut kullanılarak bir paket yüklenir -
library("package Name", lib.loc = "path to library")
# Load the package named "XML"
install.packages("E:/XML_3.98-1.3.zip", repos = NULL, type = "source")R'de Veri Yeniden Şekillendirme, verilerin satırlar ve sütunlar halinde düzenlenme şeklini değiştirmekle ilgilidir. R'deki çoğu zaman veri işleme, giriş verilerini bir veri çerçevesi olarak alarak yapılır. Bir veri çerçevesinin satırlarından ve sütunlarından veri çıkarmak kolaydır, ancak veri çerçevesine, onu aldığımız formattan farklı bir formatta ihtiyaç duyduğumuz durumlar vardır. R, bir veri çerçevesinde satırları bölmek, birleştirmek ve sütunlara dönüştürmek için birçok işleve sahiptir.
Veri Çerçevesindeki Sütunları ve Satırları Birleştirme
Bir veri çerçevesi oluşturmak için birden fazla vektörü birleştirebiliriz. cbind()işlevi. Ayrıca iki veri çerçevesini kullanarak birleştirebilirizrbind() işlevi.
# Create vector objects.
city <- c("Tampa","Seattle","Hartford","Denver")
state <- c("FL","WA","CT","CO")
zipcode <- c(33602,98104,06161,80294)
# Combine above three vectors into one data frame.
addresses <- cbind(city,state,zipcode)
# Print a header.
cat("# # # # The First data frame\n")
# Print the data frame.
print(addresses)
# Create another data frame with similar columns
new.address <- data.frame(
city = c("Lowry","Charlotte"),
state = c("CO","FL"),
zipcode = c("80230","33949"),
stringsAsFactors = FALSE
)
# Print a header.
cat("# # # The Second data frame\n")
# Print the data frame.
print(new.address)
# Combine rows form both the data frames.
all.addresses <- rbind(addresses,new.address)
# Print a header.
cat("# # # The combined data frame\n")
# Print the result.
print(all.addresses)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
# # # # The First data frame
city state zipcode
[1,] "Tampa" "FL" "33602"
[2,] "Seattle" "WA" "98104"
[3,] "Hartford" "CT" "6161"
[4,] "Denver" "CO" "80294"
# # # The Second data frame
city state zipcode
1 Lowry CO 80230
2 Charlotte FL 33949
# # # The combined data frame
city state zipcode
1 Tampa FL 33602
2 Seattle WA 98104
3 Hartford CT 6161
4 Denver CO 80294
5 Lowry CO 80230
6 Charlotte FL 33949Veri Çerçevelerini Birleştirme
Kullanarak iki veri çerçevesini birleştirebiliriz merge()işlevi. Veri çerçeveleri, birleştirmenin gerçekleştiği sütun adlarıyla aynı olmalıdır.
Aşağıdaki örnekte, "MASS" kitaplığında bulunan Pima Kızılderili Kadınlarında Diyabet hakkındaki veri setlerini ele alıyoruz. iki veri setini kan basıncı ("bp") ve vücut kitle indeksi ("bmi") değerlerine göre birleştiriyoruz. Birleştirme için bu iki sütunu seçerken, bu iki değişkenin değerlerinin her iki veri kümesinde eşleştiği kayıtlar tek bir veri çerçevesi oluşturmak için bir araya getirilir.
library(MASS)
merged.Pima <- merge(x = Pima.te, y = Pima.tr,
by.x = c("bp", "bmi"),
by.y = c("bp", "bmi")
)
print(merged.Pima)
nrow(merged.Pima)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
bp bmi npreg.x glu.x skin.x ped.x age.x type.x npreg.y glu.y skin.y ped.y
1 60 33.8 1 117 23 0.466 27 No 2 125 20 0.088
2 64 29.7 2 75 24 0.370 33 No 2 100 23 0.368
3 64 31.2 5 189 33 0.583 29 Yes 3 158 13 0.295
4 64 33.2 4 117 27 0.230 24 No 1 96 27 0.289
5 66 38.1 3 115 39 0.150 28 No 1 114 36 0.289
6 68 38.5 2 100 25 0.324 26 No 7 129 49 0.439
7 70 27.4 1 116 28 0.204 21 No 0 124 20 0.254
8 70 33.1 4 91 32 0.446 22 No 9 123 44 0.374
9 70 35.4 9 124 33 0.282 34 No 6 134 23 0.542
10 72 25.6 1 157 21 0.123 24 No 4 99 17 0.294
11 72 37.7 5 95 33 0.370 27 No 6 103 32 0.324
12 74 25.9 9 134 33 0.460 81 No 8 126 38 0.162
13 74 25.9 1 95 21 0.673 36 No 8 126 38 0.162
14 78 27.6 5 88 30 0.258 37 No 6 125 31 0.565
15 78 27.6 10 122 31 0.512 45 No 6 125 31 0.565
16 78 39.4 2 112 50 0.175 24 No 4 112 40 0.236
17 88 34.5 1 117 24 0.403 40 Yes 4 127 11 0.598
age.y type.y
1 31 No
2 21 No
3 24 No
4 21 No
5 21 No
6 43 Yes
7 36 Yes
8 40 No
9 29 Yes
10 28 No
11 55 No
12 39 No
13 39 No
14 49 Yes
15 49 Yes
16 38 No
17 28 No
[1] 17Eritme ve Döküm
R programlamanın en ilginç yönlerinden biri, istenen şekli elde etmek için verilerin şeklini birden çok adımda değiştirmektir. Bunu yapmak için kullanılan işlevleremelt() ve cast().
"MASS" adlı kütüphanede bulunan gemi adı verilen veri setini dikkate alıyoruz.
library(MASS)
print(ships)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
type year period service incidents
1 A 60 60 127 0
2 A 60 75 63 0
3 A 65 60 1095 3
4 A 65 75 1095 4
5 A 70 60 1512 6
.............
.............
8 A 75 75 2244 11
9 B 60 60 44882 39
10 B 60 75 17176 29
11 B 65 60 28609 58
............
............
17 C 60 60 1179 1
18 C 60 75 552 1
19 C 65 60 781 0
............
............Verileri Eritin
Şimdi verileri düzenlemek için eritiyoruz, tür ve yıl dışındaki tüm sütunları birden çok satıra dönüştürüyoruz.
molten.ships <- melt(ships, id = c("type","year"))
print(molten.ships)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
type year variable value
1 A 60 period 60
2 A 60 period 75
3 A 65 period 60
4 A 65 period 75
............
............
9 B 60 period 60
10 B 60 period 75
11 B 65 period 60
12 B 65 period 75
13 B 70 period 60
...........
...........
41 A 60 service 127
42 A 60 service 63
43 A 65 service 1095
...........
...........
70 D 70 service 1208
71 D 75 service 0
72 D 75 service 2051
73 E 60 service 45
74 E 60 service 0
75 E 65 service 789
...........
...........
101 C 70 incidents 6
102 C 70 incidents 2
103 C 75 incidents 0
104 C 75 incidents 1
105 D 60 incidents 0
106 D 60 incidents 0
...........
...........Erimiş Verileri Dökme
Erimiş verileri, her yıl için her gemi türünün toplamının oluşturulduğu yeni bir forma dönüştürebiliriz. Kullanılarak yapılırcast() işlevi.
recasted.ship <- cast(molten.ships, type+year~variable,sum)
print(recasted.ship)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
type year period service incidents
1 A 60 135 190 0
2 A 65 135 2190 7
3 A 70 135 4865 24
4 A 75 135 2244 11
5 B 60 135 62058 68
6 B 65 135 48979 111
7 B 70 135 20163 56
8 B 75 135 7117 18
9 C 60 135 1731 2
10 C 65 135 1457 1
11 C 70 135 2731 8
12 C 75 135 274 1
13 D 60 135 356 0
14 D 65 135 480 0
15 D 70 135 1557 13
16 D 75 135 2051 4
17 E 60 135 45 0
18 E 65 135 1226 14
19 E 70 135 3318 17
20 E 75 135 542 1R'de, R ortamı dışında depolanan dosyalardan verileri okuyabiliriz. Ayrıca, işletim sistemi tarafından saklanacak ve erişilecek dosyalara da veri yazabiliriz. R, csv, excel, xml vb. Gibi çeşitli dosya formatlarını okuyabilir ve yazabilir.
Bu bölümde bir csv dosyasından veri okumayı ve ardından bir csv dosyasına veri yazmayı öğreneceğiz. Dosya, R'nin okuyabilmesi için geçerli çalışma dizininde bulunmalıdır. Elbette kendi dizinimizi de ayarlayabilir ve oradan dosya okuyabiliriz.
Çalışma Dizinini Alma ve Ayarlama
R çalışma alanının hangi dizine işaret ettiğini kontrol edebilirsiniz. getwd()işlevi. Ayrıca yeni bir çalışma dizini de ayarlayabilirsiniz.setwd()işlevi.
# Get and print current working directory.
print(getwd())
# Set current working directory.
setwd("/web/com")
# Get and print current working directory.
print(getwd())Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] "/web/com/1441086124_2016"
[1] "/web/com"Bu sonuç, işletim sisteminize ve çalıştığınız mevcut dizininize bağlıdır.
CSV Dosyası olarak girin
Csv dosyası, sütunlardaki değerlerin virgülle ayrıldığı bir metin dosyasıdır. Adlı dosyada bulunan aşağıdaki verileri düşüneliminput.csv.
Bu dosyayı, bu verileri kopyalayıp yapıştırarak Windows not defteri kullanarak oluşturabilirsiniz. Dosyayı farklı kaydedininput.csv Not defterinde Tüm dosyalar olarak kaydet (*. *) seçeneğini kullanarak.
id,name,salary,start_date,dept
1,Rick,623.3,2012-01-01,IT
2,Dan,515.2,2013-09-23,Operations
3,Michelle,611,2014-11-15,IT
4,Ryan,729,2014-05-11,HR
5,Gary,843.25,2015-03-27,Finance
6,Nina,578,2013-05-21,IT
7,Simon,632.8,2013-07-30,Operations
8,Guru,722.5,2014-06-17,FinanceCSV Dosyasını Okumak
Aşağıdaki basit bir örnektir read.csv() mevcut çalışma dizininizde bulunan bir CSV dosyasını okuma işlevi -
data <- read.csv("input.csv")
print(data)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
id, name, salary, start_date, dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
6 6 Nina 578.00 2013-05-21 IT
7 7 Simon 632.80 2013-07-30 Operations
8 8 Guru 722.50 2014-06-17 FinanceCSV Dosyasını Analiz Etme
Varsayılan olarak read.csv()işlevi, çıktıyı bir veri çerçevesi olarak verir. Bu, aşağıdaki şekilde kolayca kontrol edilebilir. Ayrıca sütun ve satır sayısını da kontrol edebiliriz.
data <- read.csv("input.csv")
print(is.data.frame(data))
print(ncol(data))
print(nrow(data))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] TRUE
[1] 5
[1] 8Bir veri çerçevesindeki verileri okuduktan sonra, sonraki bölümde açıklandığı gibi veri çerçevelerine uygulanabilir tüm işlevleri uygulayabiliriz.
Maksimum maaşı alın
# Create a data frame.
data <- read.csv("input.csv")
# Get the max salary from data frame.
sal <- max(data$salary)
print(sal)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 843.25Maksimum maaşı olan kişinin detaylarını alın
SQL where cümlesine benzer belirli filtre kriterlerini karşılayan satırları getirebiliriz.
# Create a data frame.
data <- read.csv("input.csv")
# Get the max salary from data frame.
sal <- max(data$salary)
# Get the person detail having max salary.
retval <- subset(data, salary == max(salary))
print(retval)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
id name salary start_date dept
5 NA Gary 843.25 2015-03-27 FinanceBT departmanında çalışan tüm insanları toplayın
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset( data, dept == "IT")
print(retval)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
id name salary start_date dept
1 1 Rick 623.3 2012-01-01 IT
3 3 Michelle 611.0 2014-11-15 IT
6 6 Nina 578.0 2013-05-21 ITMaaşı 600'ün üzerinde olan kişileri bilgi işlem departmanına alın
# Create a data frame.
data <- read.csv("input.csv")
info <- subset(data, salary > 600 & dept == "IT")
print(info)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
id name salary start_date dept
1 1 Rick 623.3 2012-01-01 IT
3 3 Michelle 611.0 2014-11-15 IT2014'te veya sonrasında katılan kişileri alın
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01"))
print(retval)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
id name salary start_date dept
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
8 8 Guru 722.50 2014-06-17 FinanceCSV Dosyasına Yazmak
R, mevcut veri çerçevesinden csv dosyası oluşturabilir. write.csv()işlevi csv dosyasını oluşturmak için kullanılır. Bu dosya çalışma dizininde oluşturulur.
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01"))
# Write filtered data into a new file.
write.csv(retval,"output.csv")
newdata <- read.csv("output.csv")
print(newdata)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
X id name salary start_date dept
1 3 3 Michelle 611.00 2014-11-15 IT
2 4 4 Ryan 729.00 2014-05-11 HR
3 5 NA Gary 843.25 2015-03-27 Finance
4 8 8 Guru 722.50 2014-06-17 FinanceBurada X sütunu, yeni veri kümesinden gelir. Bu, dosya yazılırken ek parametreler kullanılarak bırakılabilir.
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01"))
# Write filtered data into a new file.
write.csv(retval,"output.csv", row.names = FALSE)
newdata <- read.csv("output.csv")
print(newdata)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
id name salary start_date dept
1 3 Michelle 611.00 2014-11-15 IT
2 4 Ryan 729.00 2014-05-11 HR
3 NA Gary 843.25 2015-03-27 Finance
4 8 Guru 722.50 2014-06-17 FinanceMicrosoft Excel, verileri .xls veya .xlsx biçiminde depolayan en yaygın kullanılan elektronik tablo programıdır. R, bazı excel paketlerini kullanarak doğrudan bu dosyalardan okuyabilir. Bu tür paketlerin birkaçı - XLConnect, xlsx, gdata vb. Xlsx paketi kullanacağız. R, bu paketi kullanarak excel dosyasına da yazabilir.
Xlsx Paketini Kurun
"Xlsx" paketini kurmak için R konsolunda aşağıdaki komutu kullanabilirsiniz. Bu paketin bağlı olduğu bazı ek paketlerin kurulmasını isteyebilir. Ek paketleri yüklemek için gerekli paket adıyla aynı komutu uygulayın.
install.packages("xlsx")"Xlsx" Paketini Doğrulayın ve Yükleyin
"Xlsx" paketini doğrulamak ve yüklemek için aşağıdaki komutu kullanın.
# Verify the package is installed.
any(grepl("xlsx",installed.packages()))
# Load the library into R workspace.
library("xlsx")Komut dosyası çalıştırıldığında aşağıdaki çıktıyı alıyoruz.
[1] TRUE
Loading required package: rJava
Loading required package: methods
Loading required package: xlsxjarsXlsx Dosyası olarak girin
Microsoft excel'i açın. Aşağıdaki verileri kopyalayıp sayfa1 adlı çalışma sayfasına yapıştırın.
id name salary start_date dept
1 Rick 623.3 1/1/2012 IT
2 Dan 515.2 9/23/2013 Operations
3 Michelle 611 11/15/2014 IT
4 Ryan 729 5/11/2014 HR
5 Gary 43.25 3/27/2015 Finance
6 Nina 578 5/21/2013 IT
7 Simon 632.8 7/30/2013 Operations
8 Guru 722.5 6/17/2014 FinanceAyrıca aşağıdaki verileri başka bir çalışma sayfasına kopyalayıp yapıştırın ve bu çalışma sayfasını "şehir" olarak yeniden adlandırın.
name city
Rick Seattle
Dan Tampa
Michelle Chicago
Ryan Seattle
Gary Houston
Nina Boston
Simon Mumbai
Guru DallasExcel dosyasını "input.xlsx" olarak kaydedin. Bunu R çalışma alanının mevcut çalışma dizinine kaydetmelisiniz.
Excel Dosyasını Okumak
İnput.xlsx, read.xlsx()aşağıda gösterildiği gibi işlev görür. Sonuç, R ortamında bir veri çerçevesi olarak saklanır.
# Read the first worksheet in the file input.xlsx.
data <- read.xlsx("input.xlsx", sheetIndex = 1)
print(data)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
id, name, salary, start_date, dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
6 6 Nina 578.00 2013-05-21 IT
7 7 Simon 632.80 2013-07-30 Operations
8 8 Guru 722.50 2014-06-17 Financeİkili dosya, yalnızca bit ve bayt biçiminde depolanan bilgileri içeren bir dosyadır. (0'lar ve 1'ler). İçerisindeki baytlar, yazdırılamayan diğer birçok karakter içeren karakterlere ve sembollere çevrildiğinden, bunlar insan tarafından okunamaz. Herhangi bir metin düzenleyici kullanarak ikili dosya okumaya çalışmak Ø ve ð gibi karakterleri gösterecektir.
İkili dosyanın kullanılabilir olması için belirli programlar tarafından okunması gerekir. Örneğin, bir Microsoft Word programının ikili dosyası, yalnızca Word programı tarafından okunabilir bir biçime okunabilir. Bu, insan tarafından okunabilir metnin yanı sıra, alfasayısal karakterlerle birlikte saklanan karakterlerin biçimlendirilmesi ve sayfa numaraları vb. Gibi çok daha fazla bilgi olduğunu gösterir. Ve son olarak bir ikili dosya sürekli bir bayt dizisidir. Bir metin dosyasında gördüğümüz satır sonu, ilk satırı bir sonrakine katan bir karakterdir.
Bazen, diğer programlar tarafından üretilen verilerin bir ikili dosya olarak R tarafından işlenmesi gerekir. Ayrıca diğer programlarla paylaşılabilen ikili dosyalar oluşturmak için R gereklidir.
R'nin iki işlevi vardır WriteBin() ve readBin() ikili dosyalar oluşturmak ve okumak için.
Sözdizimi
writeBin(object, con)
readBin(con, what, n )Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
con ikili dosyayı okumak veya yazmak için bağlantı nesnesidir.
object yazılacak ikili dosyadır.
what okunacak baytları temsil eden karakter, tamsayı vb. gibi moddur.
n ikili dosyadan okunacak bayt sayısıdır.
Misal
R dahili verilerini "mtcars" olarak kabul ediyoruz. İlk önce ondan bir csv dosyası oluşturup bunu ikili bir dosyaya dönüştürüp OS dosyası olarak saklıyoruz. Daha sonra, R'de oluşturulan bu ikili dosyayı okuyoruz.
İkili Dosyayı Yazmak
"Mtcars" veri çerçevesini bir csv dosyası olarak okuyoruz ve ardından işletim sistemine ikili dosya olarak yazıyoruz.
# Read the "mtcars" data frame as a csv file and store only the columns
"cyl", "am" and "gear".
write.table(mtcars, file = "mtcars.csv",row.names = FALSE, na = "",
col.names = TRUE, sep = ",")
# Store 5 records from the csv file as a new data frame.
new.mtcars <- read.table("mtcars.csv",sep = ",",header = TRUE,nrows = 5)
# Create a connection object to write the binary file using mode "wb".
write.filename = file("/web/com/binmtcars.dat", "wb")
# Write the column names of the data frame to the connection object.
writeBin(colnames(new.mtcars), write.filename)
# Write the records in each of the column to the file.
writeBin(c(new.mtcars$cyl,new.mtcars$am,new.mtcars$gear), write.filename)
# Close the file for writing so that it can be read by other program.
close(write.filename)İkili Dosyayı Okumak
Yukarıda oluşturulan ikili dosya, tüm verileri sürekli baytlar olarak depolar. Bu nedenle, sütun adlarının yanı sıra sütun değerlerinin de uygun değerlerini seçerek okuyacağız.
# Create a connection object to read the file in binary mode using "rb".
read.filename <- file("/web/com/binmtcars.dat", "rb")
# First read the column names. n = 3 as we have 3 columns.
column.names <- readBin(read.filename, character(), n = 3)
# Next read the column values. n = 18 as we have 3 column names and 15 values.
read.filename <- file("/web/com/binmtcars.dat", "rb")
bindata <- readBin(read.filename, integer(), n = 18)
# Print the data.
print(bindata)
# Read the values from 4th byte to 8th byte which represents "cyl".
cyldata = bindata[4:8]
print(cyldata)
# Read the values form 9th byte to 13th byte which represents "am".
amdata = bindata[9:13]
print(amdata)
# Read the values form 9th byte to 13th byte which represents "gear".
geardata = bindata[14:18]
print(geardata)
# Combine all the read values to a dat frame.
finaldata = cbind(cyldata, amdata, geardata)
colnames(finaldata) = column.names
print(finaldata)Yukarıdaki kodu çalıştırdığımızda, aşağıdaki sonucu ve grafiği üretir -
[1] 7108963 1728081249 7496037 6 6 4
[7] 6 8 1 1 1 0
[13] 0 4 4 4 3 3
[1] 6 6 4 6 8
[1] 1 1 1 0 0
[1] 4 4 4 3 3
cyl am gear
[1,] 6 1 4
[2,] 6 1 4
[3,] 4 1 4
[4,] 6 0 3
[5,] 8 0 3Gördüğümüz gibi, orijinal veriyi R'deki ikili dosyayı okuyarak geri aldık.
XML, hem dosya biçimini hem de World Wide Web, intranetler ve diğer yerlerdeki verileri standart ASCII metni kullanarak paylaşan bir dosya biçimidir. Genişletilebilir İşaretleme Dili (XML) anlamına gelir. HTML'ye benzer şekilde, işaretleme etiketleri içerir. Ancak, biçimlendirme etiketinin sayfanın yapısını tanımladığı HTML'den farklı olarak, xml'de biçimlendirme etiketleri, dosyasında bulunan verilerin anlamını açıklar.
"XML" paketini kullanarak R'deki bir xml dosyasını okuyabilirsiniz. Bu paket aşağıdaki komut kullanılarak kurulabilir.
install.packages("XML")Giriş Verileri
Aşağıdaki verileri not defteri gibi bir metin düzenleyiciye kopyalayarak bir XMl dosyası oluşturun. Dosyayı bir.xml uzantısı ve dosya türünü seçme all files(*.*).
<RECORDS>
<EMPLOYEE>
<ID>1</ID>
<NAME>Rick</NAME>
<SALARY>623.3</SALARY>
<STARTDATE>1/1/2012</STARTDATE>
<DEPT>IT</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>2</ID>
<NAME>Dan</NAME>
<SALARY>515.2</SALARY>
<STARTDATE>9/23/2013</STARTDATE>
<DEPT>Operations</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>3</ID>
<NAME>Michelle</NAME>
<SALARY>611</SALARY>
<STARTDATE>11/15/2014</STARTDATE>
<DEPT>IT</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>4</ID>
<NAME>Ryan</NAME>
<SALARY>729</SALARY>
<STARTDATE>5/11/2014</STARTDATE>
<DEPT>HR</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>5</ID>
<NAME>Gary</NAME>
<SALARY>843.25</SALARY>
<STARTDATE>3/27/2015</STARTDATE>
<DEPT>Finance</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>6</ID>
<NAME>Nina</NAME>
<SALARY>578</SALARY>
<STARTDATE>5/21/2013</STARTDATE>
<DEPT>IT</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>7</ID>
<NAME>Simon</NAME>
<SALARY>632.8</SALARY>
<STARTDATE>7/30/2013</STARTDATE>
<DEPT>Operations</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>8</ID>
<NAME>Guru</NAME>
<SALARY>722.5</SALARY>
<STARTDATE>6/17/2014</STARTDATE>
<DEPT>Finance</DEPT>
</EMPLOYEE>
</RECORDS>XML Dosyasını Okuma
Xml dosyası, işlev kullanılarak R tarafından okunur xmlParse(). R'de bir liste olarak saklanır.
# Load the package required to read XML files.
library("XML")
# Also load the other required package.
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Print the result.
print(result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
1
Rick
623.3
1/1/2012
IT
2
Dan
515.2
9/23/2013
Operations
3
Michelle
611
11/15/2014
IT
4
Ryan
729
5/11/2014
HR
5
Gary
843.25
3/27/2015
Finance
6
Nina
578
5/21/2013
IT
7
Simon
632.8
7/30/2013
Operations
8
Guru
722.5
6/17/2014
FinanceXML Dosyasında Bulunan Düğüm Sayısını Alın
# Load the packages required to read XML files.
library("XML")
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Exract the root node form the xml file.
rootnode <- xmlRoot(result)
# Find number of nodes in the root.
rootsize <- xmlSize(rootnode)
# Print the result.
print(rootsize)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
output
[1] 8İlk Düğümün Ayrıntıları
Ayrıştırılan dosyanın ilk kaydına bakalım. Bize en üst düzey düğümde bulunan çeşitli öğeler hakkında bir fikir verecektir.
# Load the packages required to read XML files.
library("XML")
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Exract the root node form the xml file.
rootnode <- xmlRoot(result)
# Print the result.
print(rootnode[1])Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
$EMPLOYEE
1
Rick
623.3
1/1/2012
IT
attr(,"class")
[1] "XMLInternalNodeList" "XMLNodeList"Bir Düğümün Farklı Öğelerini Alın
# Load the packages required to read XML files.
library("XML")
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Exract the root node form the xml file.
rootnode <- xmlRoot(result)
# Get the first element of the first node.
print(rootnode[[1]][[1]])
# Get the fifth element of the first node.
print(rootnode[[1]][[5]])
# Get the second element of the third node.
print(rootnode[[3]][[2]])Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
1
IT
MichelleVeri Çerçevesine XML
Verileri büyük dosyalarda etkin bir şekilde işlemek için xml dosyasındaki verileri bir veri çerçevesi olarak okuruz. Ardından veri analizi için veri çerçevesini işleyin.
# Load the packages required to read XML files.
library("XML")
library("methods")
# Convert the input xml file to a data frame.
xmldataframe <- xmlToDataFrame("input.xml")
print(xmldataframe)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
ID NAME SALARY STARTDATE DEPT
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
6 6 Nina 578.00 2013-05-21 IT
7 7 Simon 632.80 2013-07-30 Operations
8 8 Guru 722.50 2014-06-17 FinanceVeriler artık bir veri çerçevesi olarak mevcut olduğundan, dosyayı okumak ve işlemek için veri çerçevesiyle ilgili işlevi kullanabiliriz.
JSON dosyası, verileri insan tarafından okunabilir biçimde metin olarak depolar. Json, JavaScript Object Notation'ın kısaltmasıdır. R, rjson paketini kullanarak JSON dosyalarını okuyabilir.
Rjson Paketini Kurun
R konsolunda, rjson paketini kurmak için aşağıdaki komutu verebilirsiniz.
install.packages("rjson")Giriş Verileri
Aşağıdaki verileri not defteri gibi bir metin düzenleyiciye kopyalayarak bir JSON dosyası oluşturun. Dosyayı bir.json uzantısı ve dosya türünü seçme all files(*.*).
{
"ID":["1","2","3","4","5","6","7","8" ],
"Name":["Rick","Dan","Michelle","Ryan","Gary","Nina","Simon","Guru" ],
"Salary":["623.3","515.2","611","729","843.25","578","632.8","722.5" ],
"StartDate":[ "1/1/2012","9/23/2013","11/15/2014","5/11/2014","3/27/2015","5/21/2013",
"7/30/2013","6/17/2014"],
"Dept":[ "IT","Operations","IT","HR","Finance","IT","Operations","Finance"]
}JSON Dosyasını Okuyun
JSON dosyası, aşağıdaki işlev kullanılarak R tarafından okunur. JSON(). R'de bir liste olarak saklanır.
# Load the package required to read JSON files.
library("rjson")
# Give the input file name to the function.
result <- fromJSON(file = "input.json")
# Print the result.
print(result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
$ID
[1] "1" "2" "3" "4" "5" "6" "7" "8"
$Name [1] "Rick" "Dan" "Michelle" "Ryan" "Gary" "Nina" "Simon" "Guru" $Salary
[1] "623.3" "515.2" "611" "729" "843.25" "578" "632.8" "722.5"
$StartDate [1] "1/1/2012" "9/23/2013" "11/15/2014" "5/11/2014" "3/27/2015" "5/21/2013" "7/30/2013" "6/17/2014" $Dept
[1] "IT" "Operations" "IT" "HR" "Finance" "IT"
"Operations" "Finance"JSON'u Veri Çerçevesine dönüştürme
Yukarıdaki çıkarılan verileri daha fazla analiz için bir R veri çerçevesine dönüştürebiliriz. as.data.frame() işlevi.
# Load the package required to read JSON files.
library("rjson")
# Give the input file name to the function.
result <- fromJSON(file = "input.json")
# Convert JSON file to a data frame.
json_data_frame <- as.data.frame(result)
print(json_data_frame)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
id, name, salary, start_date, dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
6 6 Nina 578.00 2013-05-21 IT
7 7 Simon 632.80 2013-07-30 Operations
8 8 Guru 722.50 2014-06-17 FinanceBirçok web sitesi, kullanıcıları tarafından tüketilmesi için veri sağlar. Örneğin, Dünya Sağlık Örgütü (WHO) CSV, txt ve XML dosyaları biçiminde sağlık ve tıbbi bilgiler hakkında raporlar sağlar. R programlarını kullanarak, bu tür web sitelerinden programlı olarak belirli verileri çıkarabiliriz. Web'den verileri hurdaya çıkarmak için kullanılan bazı paketler - "RCurl", XML "ve" stringr "olup, URL'lere bağlanmak, dosyalar için gerekli bağlantıları belirlemek ve bunları yerel ortama indirmek için kullanılırlar.
R Paketlerini Yükleyin
Aşağıdaki paketler, URL'lerin ve dosyalara olan bağlantıların işlenmesi için gereklidir. R Ortamınızda bulunmuyorlarsa, aşağıdaki komutları kullanarak bunları kurabilirsiniz.
install.packages("RCurl")
install.packages("XML")
install.packages("stringr")
install.packages("plyr")Giriş Verileri
2015 yılı için URL hava durumu verilerini ziyaret edecek ve R kullanarak CSV dosyalarını indireceğiz.
Misal
İşlevi kullanacağız getHTMLLinks()dosyaların URL'lerini toplamak için. O zaman işlevi kullanacağızdownload.file()Dosyaları yerel sisteme kaydetmek için. Aynı kodu birden çok dosya için tekrar tekrar uygulayacağımızdan, birden çok kez çağrılacak bir işlev oluşturacağız. Dosya adları, bu işleve bir R listesi nesnesi biçiminde parametreler olarak aktarılır.
# Read the URL.
url <- "http://www.geos.ed.ac.uk/~weather/jcmb_ws/"
# Gather the html links present in the webpage.
links <- getHTMLLinks(url)
# Identify only the links which point to the JCMB 2015 files.
filenames <- links[str_detect(links, "JCMB_2015")]
# Store the file names as a list.
filenames_list <- as.list(filenames)
# Create a function to download the files by passing the URL and filename list.
downloadcsv <- function (mainurl,filename) {
filedetails <- str_c(mainurl,filename)
download.file(filedetails,filename)
}
# Now apply the l_ply function and save the files into the current R working directory.
l_ply(filenames,downloadcsv,mainurl = "http://www.geos.ed.ac.uk/~weather/jcmb_ws/")Dosya İndirmeyi Doğrulayın
Yukarıdaki kodu çalıştırdıktan sonra, aşağıdaki dosyaları geçerli R çalışma dizininde bulabilirsiniz.
"JCMB_2015.csv" "JCMB_2015_Apr.csv" "JCMB_2015_Feb.csv" "JCMB_2015_Jan.csv"
"JCMB_2015_Mar.csv"Veriler, İlişkisel veritabanı sistemleri normalleştirilmiş bir formatta saklanır. Dolayısıyla, istatistiksel hesaplama yapmak için çok gelişmiş ve karmaşık Sql sorgularına ihtiyacımız olacak. Ancak R, MySql, Oracle, Sql server vb. Birçok ilişkisel veritabanına kolayca bağlanabilir ve onlardan bir veri çerçevesi olarak kayıtları alabilir. Veriler R ortamında mevcut olduğunda, normal bir R veri seti haline gelir ve tüm güçlü paketler ve işlevler kullanılarak işlenebilir veya analiz edilebilir.
Bu eğitimde, R'ye bağlanmak için referans veritabanımız olarak MySql kullanacağız.
RMySQL Paketi
R, MySql veritabanı ile arasında yerel bağlantı sağlayan "RMySQL" adlı yerleşik bir pakete sahiptir. Bu paketi aşağıdaki komutu kullanarak R ortamına kurabilirsiniz.
install.packages("RMySQL")R'yi MySql'e bağlama
Paket kurulduktan sonra, veritabanına bağlanmak için R'de bir bağlantı nesnesi oluşturuyoruz. Giriş olarak kullanıcı adı, şifre, veritabanı adı ve ana bilgisayar adını alır.
# Create a connection Object to MySQL database.
# We will connect to the sampel database named "sakila" that comes with MySql installation.
mysqlconnection = dbConnect(MySQL(), user = 'root', password = '', dbname = 'sakila',
host = 'localhost')
# List the tables available in this database.
dbListTables(mysqlconnection)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] "actor" "actor_info"
[3] "address" "category"
[5] "city" "country"
[7] "customer" "customer_list"
[9] "film" "film_actor"
[11] "film_category" "film_list"
[13] "film_text" "inventory"
[15] "language" "nicer_but_slower_film_list"
[17] "payment" "rental"
[19] "sales_by_film_category" "sales_by_store"
[21] "staff" "staff_list"
[23] "store"Tabloları Sorgulama
MySql'deki veritabanı tablolarını fonksiyonu kullanarak sorgulayabiliriz dbSendQuery(). Sorgu MySql'de çalıştırılır ve sonuç kümesi R kullanılarak döndürülür.fetch()işlevi. Son olarak R'de bir veri çerçevesi olarak saklanır.
# Query the "actor" tables to get all the rows.
result = dbSendQuery(mysqlconnection, "select * from actor")
# Store the result in a R data frame object. n = 5 is used to fetch first 5 rows.
data.frame = fetch(result, n = 5)
print(data.fame)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
actor_id first_name last_name last_update
1 1 PENELOPE GUINESS 2006-02-15 04:34:33
2 2 NICK WAHLBERG 2006-02-15 04:34:33
3 3 ED CHASE 2006-02-15 04:34:33
4 4 JENNIFER DAVIS 2006-02-15 04:34:33
5 5 JOHNNY LOLLOBRIGIDA 2006-02-15 04:34:33Filtre Maddeli Sorgu
Sonucu almak için herhangi bir geçerli seçme sorgusunu geçebiliriz.
result = dbSendQuery(mysqlconnection, "select * from actor where last_name = 'TORN'")
# Fetch all the records(with n = -1) and store it as a data frame.
data.frame = fetch(result, n = -1)
print(data)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
actor_id first_name last_name last_update
1 18 DAN TORN 2006-02-15 04:34:33
2 94 KENNETH TORN 2006-02-15 04:34:33
3 102 WALTER TORN 2006-02-15 04:34:33Tablolardaki Satırları Güncelleme
Güncelleme sorgusunu dbSendQuery () işlevine ileterek bir Mysql tablosundaki satırları güncelleyebiliriz.
dbSendQuery(mysqlconnection, "update mtcars set disp = 168.5 where hp = 110")Yukarıdaki kodu çalıştırdıktan sonra MySql Ortamında tablonun güncellendiğini görebiliriz.
Tablolara Veri Ekleme
dbSendQuery(mysqlconnection,
"insert into mtcars(row_names, mpg, cyl, disp, hp, drat, wt, qsec, vs, am, gear, carb)
values('New Mazda RX4 Wag', 21, 6, 168.5, 110, 3.9, 2.875, 17.02, 0, 1, 4, 4)"
)Yukarıdaki kodu çalıştırdıktan sonra MySql Ortamında tabloya eklenen satırı görebiliriz.
MySql'de Tablo Oluşturma
MySql'de fonksiyonu kullanarak tablolar oluşturabiliriz dbWriteTable(). Zaten varsa tablonun üzerine yazar ve girdi olarak bir veri çerçevesi alır.
# Create the connection object to the database where we want to create the table.
mysqlconnection = dbConnect(MySQL(), user = 'root', password = '', dbname = 'sakila',
host = 'localhost')
# Use the R data frame "mtcars" to create the table in MySql.
# All the rows of mtcars are taken inot MySql.
dbWriteTable(mysqlconnection, "mtcars", mtcars[, ], overwrite = TRUE)Yukarıdaki kodu çalıştırdıktan sonra MySql Ortamında oluşturulan tabloyu görebiliriz.
MySql'de Tabloları Bırakma
Drop table deyimini dbSendQuery () 'ye ileterek MySql veritabanındaki tabloları tablolardan veri sorgulamak için kullandığımız gibi bırakabiliriz.
dbSendQuery(mysqlconnection, 'drop table if exists mtcars')Yukarıdaki kodu çalıştırdıktan sonra tablonun MySql Ortamına düştüğünü görebiliriz.
R Programlama dili, çizelgeler ve grafikler oluşturmak için çok sayıda kitaplığa sahiptir. Pasta grafik, farklı renklere sahip bir dairenin dilimleri olarak değerlerin temsilidir. Dilimler etiketlenir ve her dilime karşılık gelen sayılar da grafikte temsil edilir.
R'de pasta grafik, pie()vektör girdisi olarak pozitif sayılar alan fonksiyon. Ek parametreler etiketleri, rengi, başlığı vb. Kontrol etmek için kullanılır.
Sözdizimi
R kullanarak pasta grafik oluşturmak için temel sözdizimi -
pie(x, labels, radius, main, col, clockwise)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
x pasta grafiğinde kullanılan sayısal değerleri içeren bir vektördür.
labels dilimlere açıklama vermek için kullanılır.
radius pasta grafiğin dairesinin yarıçapını gösterir. (-1 ile +1 arasındaki değer).
main grafiğin başlığını gösterir.
col renk paletini gösterir.
clockwise dilimlerin saat yönünde mi yoksa saat yönünün tersine mi çizildiğini gösteren mantıksal bir değerdir.
Misal
Sadece giriş vektörü ve etiketleri kullanılarak çok basit bir pasta grafik oluşturulur. Aşağıdaki komut dosyası, pasta grafiği oluşturacak ve geçerli R çalışma dizinine kaydedecektir.
# Create data for the graph.
x <- c(21, 62, 10, 53)
labels <- c("London", "New York", "Singapore", "Mumbai")
# Give the chart file a name.
png(file = "city.png")
# Plot the chart.
pie(x,labels)
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
Pasta Grafik Başlığı ve Renkleri
İşleve daha fazla parametre ekleyerek grafiğin özelliklerini genişletebiliriz. Parametresini kullanacağızmain grafiğe bir başlık ve başka bir parametre eklemek için colBu, grafiği çizerken gökkuşağı renk paletinden yararlanacaktır. Paletin uzunluğu, tablo için sahip olduğumuz değerlerin sayısıyla aynı olmalıdır. Bu nedenle uzunluk (x) kullanıyoruz.
Misal
Aşağıdaki komut dosyası, pasta grafiği oluşturacak ve geçerli R çalışma dizinine kaydedecektir.
# Create data for the graph.
x <- c(21, 62, 10, 53)
labels <- c("London", "New York", "Singapore", "Mumbai")
# Give the chart file a name.
png(file = "city_title_colours.jpg")
# Plot the chart with title and rainbow color pallet.
pie(x, labels, main = "City pie chart", col = rainbow(length(x)))
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
Dilim Yüzdeleri ve Grafik Göstergesi
Ek grafik değişkenleri oluşturarak dilim yüzdesi ve bir grafik göstergesi ekleyebiliriz.
# Create data for the graph.
x <- c(21, 62, 10,53)
labels <- c("London","New York","Singapore","Mumbai")
piepercent<- round(100*x/sum(x), 1)
# Give the chart file a name.
png(file = "city_percentage_legends.jpg")
# Plot the chart.
pie(x, labels = piepercent, main = "City pie chart",col = rainbow(length(x)))
legend("topright", c("London","New York","Singapore","Mumbai"), cex = 0.8,
fill = rainbow(length(x)))
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
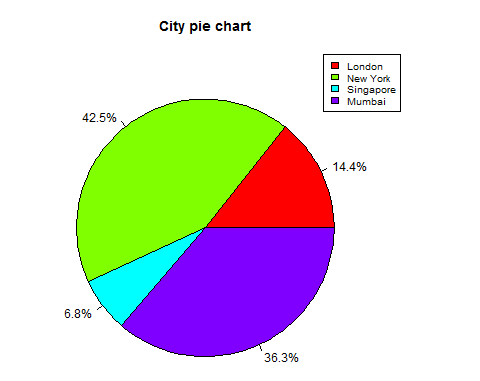
3D Pasta Grafiği
Ek paketler kullanılarak 3 boyutlu bir pasta grafik çizilebilir. Paketplotrix adlı bir işlevi vardır pie3D() bunun için kullanılır.
# Get the library.
library(plotrix)
# Create data for the graph.
x <- c(21, 62, 10,53)
lbl <- c("London","New York","Singapore","Mumbai")
# Give the chart file a name.
png(file = "3d_pie_chart.jpg")
# Plot the chart.
pie3D(x,labels = lbl,explode = 0.1, main = "Pie Chart of Countries ")
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
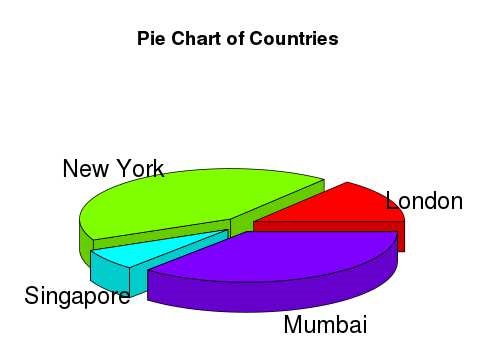
Çubuk grafik, değişkenin değeriyle orantılı çubuk uzunluğu ile dikdörtgen çubuklardaki verileri temsil eder. R işlevi kullanırbarplot()çubuk grafikler oluşturmak için. R, çubuk grafikte hem dikey hem de Yatay çubuklar çizebilir. Çubuk grafikte, çubukların her birine farklı renkler verilebilir.
Sözdizimi
R'de bir çubuk grafik oluşturmak için temel sözdizimi -
barplot(H,xlab,ylab,main, names.arg,col)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
- H çubuk grafikte kullanılan sayısal değerleri içeren bir vektör veya matristir.
- xlab x ekseni için etikettir.
- ylab y ekseni için etikettir.
- main çubuk grafiğin başlığıdır.
- names.arg her çubuğun altında görünen adların bir vektörüdür.
- col grafikteki çubuklara renk vermek için kullanılır.
Misal
Yalnızca giriş vektörü ve her çubuğun adı kullanılarak basit bir çubuk grafik oluşturulur.
Aşağıdaki komut dosyası, çubuk grafiği oluşturacak ve geçerli R çalışma dizininde kaydedecektir.
# Create the data for the chart
H <- c(7,12,28,3,41)
# Give the chart file a name
png(file = "barchart.png")
# Plot the bar chart
barplot(H)
# Save the file
dev.off()Yukarıdaki kodu çalıştırdığımızda, aşağıdaki sonucu verir -
Çubuk Grafik Etiketleri, Başlık ve Renkler
Çubuk grafiğin özellikleri, daha fazla parametre eklenerek genişletilebilir. main parametre eklemek için kullanılır title. colparametresi çubuklara renk eklemek için kullanılır. args.name her çubuğun anlamını açıklamak için giriş vektörüyle aynı sayıda değere sahip bir vektördür.
Misal
Aşağıdaki komut dosyası, çubuk grafiği oluşturacak ve geçerli R çalışma dizininde kaydedecektir.
# Create the data for the chart
H <- c(7,12,28,3,41)
M <- c("Mar","Apr","May","Jun","Jul")
# Give the chart file a name
png(file = "barchart_months_revenue.png")
# Plot the bar chart
barplot(H,names.arg=M,xlab="Month",ylab="Revenue",col="blue",
main="Revenue chart",border="red")
# Save the file
dev.off()Yukarıdaki kodu çalıştırdığımızda, aşağıdaki sonucu verir -
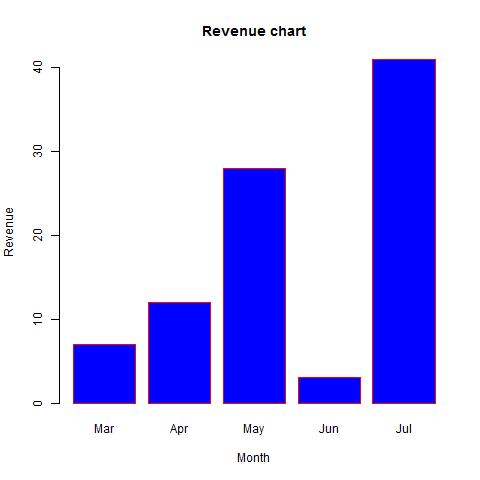
Grup Çubuk Grafik ve Yığılmış Çubuk Grafik
Giriş değerleri olarak bir matris kullanarak her çubukta çubuk grupları ve yığınları olan çubuk grafik oluşturabiliriz.
İkiden fazla değişken, grup çubuk grafiği ve yığınlı çubuk grafik oluşturmak için kullanılan bir matris olarak temsil edilir.
# Create the input vectors.
colors = c("green","orange","brown")
months <- c("Mar","Apr","May","Jun","Jul")
regions <- c("East","West","North")
# Create the matrix of the values.
Values <- matrix(c(2,9,3,11,9,4,8,7,3,12,5,2,8,10,11), nrow = 3, ncol = 5, byrow = TRUE)
# Give the chart file a name
png(file = "barchart_stacked.png")
# Create the bar chart
barplot(Values, main = "total revenue", names.arg = months, xlab = "month", ylab = "revenue", col = colors)
# Add the legend to the chart
legend("topleft", regions, cex = 1.3, fill = colors)
# Save the file
dev.off()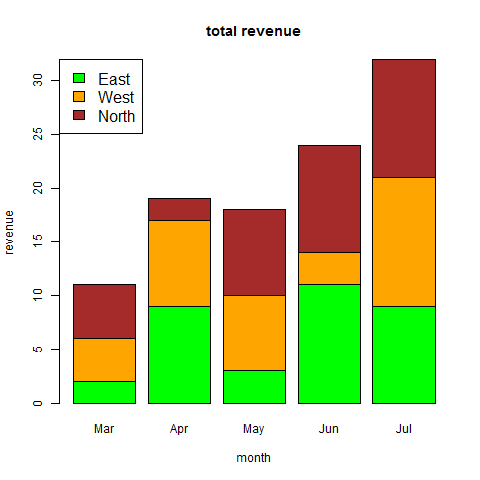
Kutu grafikleri, bir veri kümesindeki verilerin ne kadar iyi dağıtıldığının bir ölçüsüdür. Veri kümesini üç çeyreğe ayırır. Bu grafik, veri setindeki minimum, maksimum, medyan, ilk çeyrek ve üçüncü çeyrek temsil eder. Ayrıca, her biri için kutu grafikleri çizerek veri kümeleri arasında verilerin dağılımını karşılaştırmak için de yararlıdır.
Kutu grafikleri, R'de boxplot() işlevi.
Sözdizimi
R'de bir kutu grafiği oluşturmak için temel sözdizimi -
boxplot(x, data, notch, varwidth, names, main)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
x bir vektör veya formüldür.
data veri çerçevesidir.
notchmantıksal bir değerdir. Bir çentik çizmek için DOĞRU olarak ayarlayın.
varwidthmantıksal bir değerdir. Örnek boyutuyla orantılı olarak kutunun genişliğini çizmek için true olarak ayarlayın.
names her kutu grafiğinin altına basılacak grup etiketleridir.
main grafiğe bir başlık vermek için kullanılır.
Misal
Temel bir kutu grafiği oluşturmak için R ortamında bulunan "mtcars" veri setini kullanıyoruz. Mtcars'taki "mpg" ve "cyl" sütunlarına bakalım.
input <- mtcars[,c('mpg','cyl')]
print(head(input))Yukarıdaki kodu çalıştırdığımızda, aşağıdaki sonucu verir -
mpg cyl
Mazda RX4 21.0 6
Mazda RX4 Wag 21.0 6
Datsun 710 22.8 4
Hornet 4 Drive 21.4 6
Hornet Sportabout 18.7 8
Valiant 18.1 6Kutu Grafiğini Oluşturmak
Aşağıdaki komut dosyası, mpg (galon başına mil) ve cyl (silindir sayısı) arasındaki ilişki için bir kutu grafiği grafiği oluşturacaktır.
# Give the chart file a name.
png(file = "boxplot.png")
# Plot the chart.
boxplot(mpg ~ cyl, data = mtcars, xlab = "Number of Cylinders",
ylab = "Miles Per Gallon", main = "Mileage Data")
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
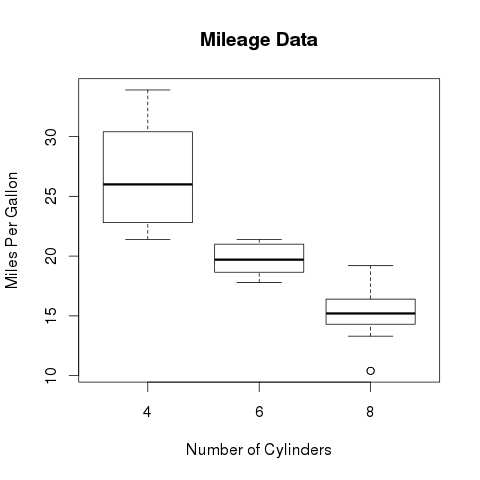
Notch ile Boxplot
Farklı veri gruplarının medyanlarının birbirleriyle nasıl eşleştiğini bulmak için çentikli kutu grafiği çizebiliriz.
Aşağıdaki komut dosyası, veri gruplarının her biri için çentikli bir kutu çizimi grafiği oluşturacaktır.
# Give the chart file a name.
png(file = "boxplot_with_notch.png")
# Plot the chart.
boxplot(mpg ~ cyl, data = mtcars,
xlab = "Number of Cylinders",
ylab = "Miles Per Gallon",
main = "Mileage Data",
notch = TRUE,
varwidth = TRUE,
col = c("green","yellow","purple"),
names = c("High","Medium","Low")
)
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
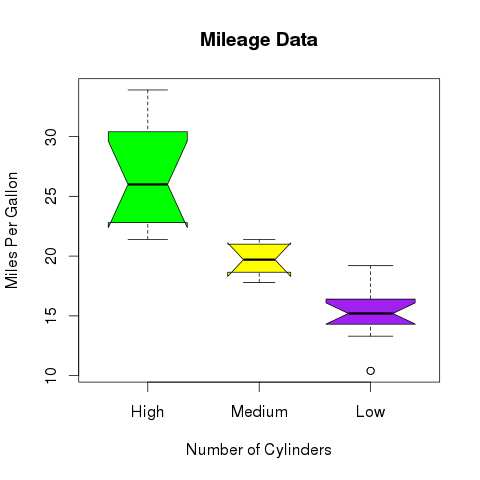
Histogram, aralıklar halinde paketlenmiş bir değişkenin değerlerinin frekanslarını temsil eder. Histogram, çubuk sohbetine benzer, ancak fark, değerleri sürekli aralıklar halinde gruplandırmasıdır. Histogramdaki her çubuk, o aralıkta bulunan değerlerin yüksekliğini temsil eder.
R kullanarak histogram oluşturur hist()işlevi. Bu işlev bir vektörü girdi olarak alır ve histogramları çizmek için daha fazla parametre kullanır.
Sözdizimi
R kullanarak bir histogram oluşturmak için temel sözdizimi -
hist(v,main,xlab,xlim,ylim,breaks,col,border)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
v histogramda kullanılan sayısal değerleri içeren bir vektördür.
main grafiğin başlığını gösterir.
col çubukların rengini ayarlamak için kullanılır.
border her çubuğun kenarlık rengini ayarlamak için kullanılır.
xlab x ekseninin tanımını vermek için kullanılır.
xlim x eksenindeki değer aralığını belirtmek için kullanılır.
ylim y eksenindeki değer aralığını belirtmek için kullanılır.
breaks her çubuğun genişliğini belirtmek için kullanılır.
Misal
Giriş vektörü, etiket, sütun ve sınır parametreleri kullanılarak basit bir histogram oluşturulur.
Aşağıda verilen komut dosyası histogramı oluşturacak ve mevcut R çalışma dizinine kaydedecektir.
# Create data for the graph.
v <- c(9,13,21,8,36,22,12,41,31,33,19)
# Give the chart file a name.
png(file = "histogram.png")
# Create the histogram.
hist(v,xlab = "Weight",col = "yellow",border = "blue")
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
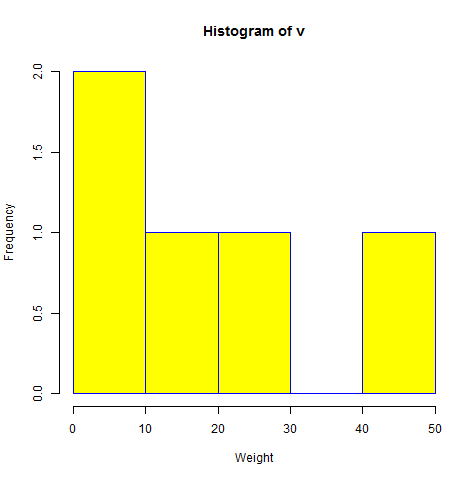
X ve Y değerleri aralığı
X ekseni ve Y ekseninde izin verilen değer aralığını belirtmek için xlim ve ylim parametrelerini kullanabiliriz.
Çubuğun her birinin genişliği, molalar kullanılarak belirlenebilir.
# Create data for the graph.
v <- c(9,13,21,8,36,22,12,41,31,33,19)
# Give the chart file a name.
png(file = "histogram_lim_breaks.png")
# Create the histogram.
hist(v,xlab = "Weight",col = "green",border = "red", xlim = c(0,40), ylim = c(0,5),
breaks = 5)
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
Çizgi grafik, aralarında çizgi parçaları çizerek bir dizi noktayı birbirine bağlayan bir grafiktir. Bu noktalar, koordinatlarından (genellikle x koordinatı) birinde sıralanır. Çizgi grafikler genellikle verilerdeki eğilimleri belirlemede kullanılır.
plot() R'deki fonksiyon çizgi grafiği oluşturmak için kullanılır.
Sözdizimi
R'de bir çizgi grafik oluşturmak için temel sözdizimi -
plot(v,type,col,xlab,ylab)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
v sayısal değerleri içeren bir vektördür.
type yalnızca noktaları çizmek için "p" değerini, yalnızca çizgileri çizmek için "l" ve hem noktaları hem de çizgileri çizmek için "o" değerini alır.
xlab x ekseni için etikettir.
ylab y ekseni için etikettir.
main grafiğin Başlığıdır.
col hem noktalara hem de çizgilere renk vermek için kullanılır.
Misal
Giriş vektörü ve "O" olarak tip parametresi kullanılarak basit bir çizgi grafiği oluşturulur. Aşağıdaki komut dosyası, geçerli R çalışma dizininde bir çizgi grafiği oluşturacak ve kaydedecektir.
# Create the data for the chart.
v <- c(7,12,28,3,41)
# Give the chart file a name.
png(file = "line_chart.jpg")
# Plot the bar chart.
plot(v,type = "o")
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
Çizgi Grafik Başlığı, Rengi ve Etiketler
Çizgi grafiğin özellikleri ek parametreler kullanılarak genişletilebilir. Noktalara ve çizgilere renk katıyoruz, grafiğe bir başlık veriyoruz ve eksenlere etiketler ekliyoruz.
Misal
# Create the data for the chart.
v <- c(7,12,28,3,41)
# Give the chart file a name.
png(file = "line_chart_label_colored.jpg")
# Plot the bar chart.
plot(v,type = "o", col = "red", xlab = "Month", ylab = "Rain fall",
main = "Rain fall chart")
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
Çizgi Grafikte Birden Çok Çizgi
Kullanılarak aynı grafik üzerinde birden fazla çizgi çizilebilir. lines()işlevi.
İlk çizgi çizildikten sonra, lines () fonksiyonu, grafikte ikinci çizgiyi çizmek için girdi olarak ek bir vektör kullanabilir,
# Create the data for the chart.
v <- c(7,12,28,3,41)
t <- c(14,7,6,19,3)
# Give the chart file a name.
png(file = "line_chart_2_lines.jpg")
# Plot the bar chart.
plot(v,type = "o",col = "red", xlab = "Month", ylab = "Rain fall",
main = "Rain fall chart")
lines(t, type = "o", col = "blue")
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
Dağılım grafikleri, Kartezyen düzlemde çizilen birçok noktayı gösterir. Her nokta, iki değişkenin değerlerini temsil eder. Bir değişken yatay eksende ve diğeri dikey eksende seçilir.
Basit dağılım grafiği, plot() işlevi.
Sözdizimi
R'de dağılım grafiği oluşturmak için temel sözdizimi -
plot(x, y, main, xlab, ylab, xlim, ylim, axes)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
x değerleri yatay koordinatlar olan veri kümesidir.
y değerleri dikey koordinatlar olan veri kümesidir.
main grafiğin döşemesidir.
xlab yatay eksendeki etikettir.
ylab dikey eksendeki etikettir.
xlim çizim için kullanılan x değerlerinin sınırlarıdır.
ylim çizim için kullanılan y değerlerinin sınırlarıdır.
axes her iki eksenin de çizim üzerinde çizilmesi gerekip gerekmediğini gösterir.
Misal
Veri setini kullanıyoruz "mtcars"R ortamında temel bir dağılım grafiği oluşturmak için kullanılabilir. Mtcarlarda "wt" ve "mpg" sütunlarını kullanalım.
input <- mtcars[,c('wt','mpg')]
print(head(input))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
wt mpg
Mazda RX4 2.620 21.0
Mazda RX4 Wag 2.875 21.0
Datsun 710 2.320 22.8
Hornet 4 Drive 3.215 21.4
Hornet Sportabout 3.440 18.7
Valiant 3.460 18.1Dağılım Grafiği Oluşturma
Aşağıdaki komut dosyası, wt (ağırlık) ve mpg (galon başına mil) arasındaki ilişki için bir dağılım grafiği grafiği oluşturacaktır.
# Get the input values.
input <- mtcars[,c('wt','mpg')]
# Give the chart file a name.
png(file = "scatterplot.png")
# Plot the chart for cars with weight between 2.5 to 5 and mileage between 15 and 30.
plot(x = input$wt,y = input$mpg,
xlab = "Weight",
ylab = "Milage",
xlim = c(2.5,5),
ylim = c(15,30),
main = "Weight vs Milage"
)
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
Dağılım grafiği Matrisleri
İkiden fazla değişkenimiz olduğunda ve bir değişkenle diğer değişkenler arasındaki korelasyonu bulmak istediğimizde dağılım grafiği matrisini kullanırız. Kullanırızpairs() dağılım grafiklerinin matrislerini oluşturma işlevi.
Sözdizimi
R'de dağılım grafiği matrisleri oluşturmak için temel sözdizimi -
pairs(formula, data)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
formula çiftler halinde kullanılan değişken serisini temsil eder.
data değişkenlerin alınacağı veri setini temsil eder.
Misal
Her değişken, kalan değişkenlerin her biriyle eşleştirilir. Her çift için bir dağılım grafiği çizilir.
# Give the chart file a name.
png(file = "scatterplot_matrices.png")
# Plot the matrices between 4 variables giving 12 plots.
# One variable with 3 others and total 4 variables.
pairs(~wt+mpg+disp+cyl,data = mtcars,
main = "Scatterplot Matrix")
# Save the file.
dev.off()Yukarıdaki kod çalıştırıldığında aşağıdaki çıktıyı alıyoruz.
R'deki istatistiksel analiz, birçok yerleşik işlev kullanılarak gerçekleştirilir. Bu işlevlerin çoğu R temel paketinin parçasıdır. Bu fonksiyonlar R vektörünü argümanlarla birlikte girdi olarak alır ve sonucu verir.
Bu bölümde tartıştığımız işlevler ortalama, medyan ve moddur.
Anlamına gelmek
Bir veri serisindeki değerlerin toplamı alınarak ve değerlerin sayısına bölünerek hesaplanır.
İşlev mean() bunu R'de hesaplamak için kullanılır.
Sözdizimi
R'deki ortalamayı hesaplamak için temel sözdizimi -
mean(x, trim = 0, na.rm = FALSE, ...)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
x girdi vektörüdür.
trim sıralanmış vektörün her iki ucundan bazı gözlemleri bırakmak için kullanılır.
na.rm eksik değerleri giriş vektöründen çıkarmak için kullanılır.
Misal
# Create a vector.
x <- c(12,7,3,4.2,18,2,54,-21,8,-5)
# Find Mean.
result.mean <- mean(x)
print(result.mean)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 8.22Kırpma Seçeneğini Uygulama
Kırpma parametresi sağlandığında, vektördeki değerler sıralanır ve ardından gerekli gözlem sayısı ortalamanın hesaplanmasından çıkarılır.
Trim = 0.3 olduğunda, ortalamayı bulmak için her uçtan 3 değer hesaplamalardan çıkarılacaktır.
Bu durumda sıralanmış vektör (−21, −5, 2, 3, 4.2, 7, 8, 12, 18, 54) ve ortalamanın hesaplanması için vektörden çıkarılan değerler (−21, −5,2) soldan ve (12,18,54) sağdan.
# Create a vector.
x <- c(12,7,3,4.2,18,2,54,-21,8,-5)
# Find Mean.
result.mean <- mean(x,trim = 0.3)
print(result.mean)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 5.55NA Seçeneğini Uygulama
Eksik değerler varsa, ortalama işlev NA değerini döndürür.
Eksik değerleri hesaplamadan çıkarmak için na.rm = TRUE kullanın. bu, NA değerlerini kaldırmak anlamına gelir.
# Create a vector.
x <- c(12,7,3,4.2,18,2,54,-21,8,-5,NA)
# Find mean.
result.mean <- mean(x)
print(result.mean)
# Find mean dropping NA values.
result.mean <- mean(x,na.rm = TRUE)
print(result.mean)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] NA
[1] 8.22Medyan
Bir veri serisindeki en ortadaki değere medyan denir. median() fonksiyonu R'de bu değeri hesaplamak için kullanılır.
Sözdizimi
R'de medyanı hesaplamak için temel sözdizimi -
median(x, na.rm = FALSE)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
x girdi vektörüdür.
na.rm eksik değerleri giriş vektöründen çıkarmak için kullanılır.
Misal
# Create the vector.
x <- c(12,7,3,4.2,18,2,54,-21,8,-5)
# Find the median.
median.result <- median(x)
print(median.result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 5.6Mod
Mod, bir veri kümesinde en yüksek tekrar sayısına sahip olan değerdir. Ortalama ve medyandan farklı olarak, mod hem sayısal hem de karakter verilerine sahip olabilir.
R, modu hesaplamak için standart yerleşik bir işleve sahip değildir. Bu nedenle, R'deki bir veri kümesinin modunu hesaplamak için bir kullanıcı işlevi oluştururuz. Bu işlev, vektörü girdi olarak alır ve mod değerini çıktı olarak verir.
Misal
# Create the function.
getmode <- function(v) {
uniqv <- unique(v)
uniqv[which.max(tabulate(match(v, uniqv)))]
}
# Create the vector with numbers.
v <- c(2,1,2,3,1,2,3,4,1,5,5,3,2,3)
# Calculate the mode using the user function.
result <- getmode(v)
print(result)
# Create the vector with characters.
charv <- c("o","it","the","it","it")
# Calculate the mode using the user function.
result <- getmode(charv)
print(result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 2
[1] "it"Regresyon analizi, iki değişken arasında bir ilişki modeli oluşturmak için çok yaygın olarak kullanılan bir istatistiksel araçtır. Bu değişkenlerden biri, değeri deneylerle elde edilen yordayıcı değişken olarak adlandırılır. Diğer değişken, değeri yordayıcı değişkenden türetilen yanıt değişkeni olarak adlandırılır.
Doğrusal Regresyonda bu iki değişken, her iki değişkenin üssünün (kuvvetinin) 1 olduğu bir denklem yoluyla ilişkilidir. Matematiksel olarak doğrusal bir ilişki, grafik olarak çizildiğinde düz bir çizgiyi temsil eder. Herhangi bir değişkenin üssünün 1'e eşit olmadığı doğrusal olmayan bir ilişki bir eğri oluşturur.
Doğrusal regresyon için genel matematiksel denklem -
y = ax + bAşağıda kullanılan parametrelerin açıklaması verilmiştir -
y yanıt değişkendir.
x yordayıcı değişkendir.
a ve b katsayılar olarak adlandırılan sabitlerdir.
Bir Regresyon Oluşturma Adımları
Basit bir regresyon örneği, boyu bilindiğinde bir kişinin kilosunu tahmin etmektir. Bunu yapmak için bir kişinin boyu ile kilosu arasındaki ilişkiye sahip olmamız gerekir.
İlişkiyi yaratmanın adımları -
Gözlenen boy ve buna karşılık gelen ağırlık değerlerinden bir örnek toplama deneyini gerçekleştirin.
Kullanarak bir ilişki modeli oluşturun lm() R'deki fonksiyonlar
Oluşturulan modelden katsayıları bulun ve bunları kullanarak matematiksel denklemi oluşturun
Tahmindeki ortalama hatayı bilmek için ilişki modelinin bir özetini alın. Olarak da adlandırılırresiduals.
Yeni kişilerin ağırlığını tahmin etmek için, predict() R'de işlev
Giriş Verileri
Gözlemleri temsil eden örnek veriler aşağıdadır -
# Values of height
151, 174, 138, 186, 128, 136, 179, 163, 152, 131
# Values of weight.
63, 81, 56, 91, 47, 57, 76, 72, 62, 48lm () İşlevi
Bu işlev, yordayıcı ve yanıt değişkeni arasındaki ilişki modelini oluşturur.
Sözdizimi
İçin temel sözdizimi lm() doğrusal regresyonda fonksiyon -
lm(formula,data)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
formula x ve y arasındaki ilişkiyi sunan bir semboldür.
data formülün uygulanacağı vektördür.
İlişki Modeli oluşturun ve Katsayıları alın
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)
y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)
# Apply the lm() function.
relation <- lm(y~x)
print(relation)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
Call:
lm(formula = y ~ x)
Coefficients:
(Intercept) x
-38.4551 0.6746İlişkinin Özetini Alın
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)
y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)
# Apply the lm() function.
relation <- lm(y~x)
print(summary(relation))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-6.3002 -1.6629 0.0412 1.8944 3.9775
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -38.45509 8.04901 -4.778 0.00139 **
x 0.67461 0.05191 12.997 1.16e-06 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.253 on 8 degrees of freedom
Multiple R-squared: 0.9548, Adjusted R-squared: 0.9491
F-statistic: 168.9 on 1 and 8 DF, p-value: 1.164e-06tahmin () İşlevi
Sözdizimi
Doğrusal regresyonda tahmin () için temel sözdizimi -
predict(object, newdata)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
object lm () işlevi kullanılarak önceden oluşturulmuş formüldür.
newdata yordayıcı değişken için yeni değeri içeren vektördür.
Yeni kişilerin ağırlığını tahmin edin
# The predictor vector.
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)
# The resposne vector.
y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)
# Apply the lm() function.
relation <- lm(y~x)
# Find weight of a person with height 170.
a <- data.frame(x = 170)
result <- predict(relation,a)
print(result)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
1
76.22869Regresyonu Grafik Olarak Görselleştirin
# Create the predictor and response variable.
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)
y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)
relation <- lm(y~x)
# Give the chart file a name.
png(file = "linearregression.png")
# Plot the chart.
plot(y,x,col = "blue",main = "Height & Weight Regression",
abline(lm(x~y)),cex = 1.3,pch = 16,xlab = "Weight in Kg",ylab = "Height in cm")
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
Çoklu regresyon, ikiden fazla değişken arasındaki ilişkiye doğrusal regresyonun bir uzantısıdır. Basit doğrusal ilişkide bir tahmin edicimiz ve bir yanıt değişkenimiz vardır, ancak çoklu regresyonda birden fazla tahmin değişkenimiz ve bir yanıt değişkenimiz vardır.
Çoklu regresyon için genel matematiksel denklem -
y = a + b1x1 + b2x2 +...bnxnAşağıda kullanılan parametrelerin açıklaması verilmiştir -
y yanıt değişkendir.
a, b1, b2...bn katsayılardır.
x1, x2, ...xn tahmin değişkenleridir.
Regresyon modelini kullanarak lm()R'deki fonksiyon. Model, giriş verilerini kullanarak katsayıların değerini belirler. Daha sonra, bu katsayıları kullanarak belirli bir yordayıcı değişken seti için yanıt değişkeninin değerini tahmin edebiliriz.
lm () İşlevi
Bu işlev, yordayıcı ve yanıt değişkeni arasındaki ilişki modelini oluşturur.
Sözdizimi
İçin temel sözdizimi lm() çoklu regresyondaki fonksiyon -
lm(y ~ x1+x2+x3...,data)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
formula yanıt değişkeni ile yordayıcı değişkenler arasındaki ilişkiyi sunan bir semboldür.
data formülün uygulanacağı vektördür.
Misal
Giriş Verileri
R ortamında bulunan "mtcars" veri setini düşünün. Galon başına kilometre (mpg), silindir deplasmanı ("disp"), beygir gücü ("hp"), arabanın ağırlığı ("wt") ve daha fazla parametre açısından farklı araba modelleri arasında bir karşılaştırma sağlar.
Modelin amacı, bir yanıt değişkeni olarak "mpg" ile tahmin değişkenleri olarak "disp", "hp" ve "wt" arasındaki ilişkiyi kurmaktır. Bu amaçla mtcars veri setinden bu değişkenlerin bir alt kümesini oluşturuyoruz.
input <- mtcars[,c("mpg","disp","hp","wt")]
print(head(input))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
mpg disp hp wt
Mazda RX4 21.0 160 110 2.620
Mazda RX4 Wag 21.0 160 110 2.875
Datsun 710 22.8 108 93 2.320
Hornet 4 Drive 21.4 258 110 3.215
Hornet Sportabout 18.7 360 175 3.440
Valiant 18.1 225 105 3.460İlişki Modeli oluşturun ve Katsayıları alın
input <- mtcars[,c("mpg","disp","hp","wt")]
# Create the relationship model.
model <- lm(mpg~disp+hp+wt, data = input)
# Show the model.
print(model)
# Get the Intercept and coefficients as vector elements.
cat("# # # # The Coefficient Values # # # ","\n")
a <- coef(model)[1]
print(a)
Xdisp <- coef(model)[2]
Xhp <- coef(model)[3]
Xwt <- coef(model)[4]
print(Xdisp)
print(Xhp)
print(Xwt)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
Call:
lm(formula = mpg ~ disp + hp + wt, data = input)
Coefficients:
(Intercept) disp hp wt
37.105505 -0.000937 -0.031157 -3.800891
# # # # The Coefficient Values # # #
(Intercept)
37.10551
disp
-0.0009370091
hp
-0.03115655
wt
-3.800891Regresyon Modeli için Denklem Oluşturun
Yukarıdaki kesişme ve katsayı değerlerine dayanarak matematiksel denklemi oluşturuyoruz.
Y = a+Xdisp.x1+Xhp.x2+Xwt.x3
or
Y = 37.15+(-0.000937)*x1+(-0.0311)*x2+(-3.8008)*x3Yeni Değerleri tahmin etmek için Denklem uygulayın
Yer değiştirme, beygir gücü ve ağırlık için yeni bir değerler kümesi sağlandığında kilometreyi tahmin etmek için yukarıda oluşturulan regresyon denklemini kullanabiliriz.
Disp = 221, hp = 102 ve wt = 2.91 olan bir otomobil için tahmini kilometre -
Y = 37.15+(-0.000937)*221+(-0.0311)*102+(-3.8008)*2.91 = 22.7104Lojistik Regresyon, yanıt değişkeninin (bağımlı değişken) Doğru / Yanlış veya 0/1 gibi kategorik değerlere sahip olduğu bir regresyon modelidir. Aslında, bir ikili cevabın olasılığını, tahmin değişkenleriyle ilişkilendiren matematiksel denkleme dayalı olarak yanıt değişkeninin değeri olarak ölçer.
Lojistik regresyon için genel matematiksel denklem -
y = 1/(1+e^-(a+b1x1+b2x2+b3x3+...))Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
y yanıt değişkendir.
x yordayıcı değişkendir.
a ve b sayısal sabitler olan katsayılardır.
Regresyon modelini oluşturmak için kullanılan işlev, glm() işlevi.
Sözdizimi
İçin temel sözdizimi glm() lojistik regresyondaki fonksiyon -
glm(formula,data,family)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
formula değişkenler arasındaki ilişkiyi gösteren semboldür.
data bu değişkenlerin değerlerini veren veri setidir.
familymodelin ayrıntılarını belirtmek için R nesnesidir. Lojistik regresyon için değeri iki terimli.
Misal
Dahili veri seti "mtcars", çeşitli motor özellikleriyle bir otomobilin farklı modellerini tanımlar. "Mtcars" veri setinde, iletim modu (otomatik veya manuel), ikili bir değer (0 veya 1) olan am sütunu ile tanımlanır. "Am" sütunları ile diğer 3 sütun - hp, wt ve cyl arasında lojistik regresyon modeli oluşturabiliriz.
# Select some columns form mtcars.
input <- mtcars[,c("am","cyl","hp","wt")]
print(head(input))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
am cyl hp wt
Mazda RX4 1 6 110 2.620
Mazda RX4 Wag 1 6 110 2.875
Datsun 710 1 4 93 2.320
Hornet 4 Drive 0 6 110 3.215
Hornet Sportabout 0 8 175 3.440
Valiant 0 6 105 3.460Regresyon Modeli Oluşturun
Kullanıyoruz glm() regresyon modelini oluşturma ve analiz için özetini alma işlevi.
input <- mtcars[,c("am","cyl","hp","wt")]
am.data = glm(formula = am ~ cyl + hp + wt, data = input, family = binomial)
print(summary(am.data))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
Call:
glm(formula = am ~ cyl + hp + wt, family = binomial, data = input)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.17272 -0.14907 -0.01464 0.14116 1.27641
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 19.70288 8.11637 2.428 0.0152 *
cyl 0.48760 1.07162 0.455 0.6491
hp 0.03259 0.01886 1.728 0.0840 .
wt -9.14947 4.15332 -2.203 0.0276 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 43.2297 on 31 degrees of freedom
Residual deviance: 9.8415 on 28 degrees of freedom
AIC: 17.841
Number of Fisher Scoring iterations: 8Sonuç
Özet olarak, son sütundaki p değeri, "cyl" ve "hp" değişkenleri için 0,05'ten fazla olduğundan, "am" değişkeninin değerine katkıda bulunmada bunların önemsiz olduğunu düşünüyoruz. Bu regresyon modelinde sadece ağırlık (wt) "am" değerini etkiler.
Bağımsız kaynaklardan rastgele bir veri toplanmasında, genellikle verilerin dağılımının normal olduğu gözlemlenir. Yani, yatay eksendeki değişkenin değeri ve dikey eksendeki değerlerin sayısı ile bir grafik çizerken bir çan şekli eğrisi elde ederiz. Eğrinin merkezi, veri kümesinin ortalamasını temsil eder. Grafikte, değerlerin yüzde ellisi ortalamanın solunda ve diğer yüzde ellisi grafiğin sağında yer alır. Bu istatistikte normal dağılım olarak adlandırılır.
R normal dağılım oluşturmak için dört yerleşik işleve sahiptir. Aşağıda açıklanmıştır.
dnorm(x, mean, sd)
pnorm(x, mean, sd)
qnorm(p, mean, sd)
rnorm(n, mean, sd)Aşağıdaki fonksiyonlarda kullanılan parametrelerin açıklaması aşağıdadır -
x sayıların bir vektörüdür.
p bir olasılık vektörüdür.
n gözlem sayısıdır (örneklem büyüklüğü).
meanörnek verilerin ortalama değeridir. Varsayılan değeri sıfırdır.
sdstandart sapmadır. Varsayılan değeri 1'dir.
dnorm ()
Bu fonksiyon, verilen bir ortalama ve standart sapma için her noktada olasılık dağılımının yüksekliğini verir.
# Create a sequence of numbers between -10 and 10 incrementing by 0.1.
x <- seq(-10, 10, by = .1)
# Choose the mean as 2.5 and standard deviation as 0.5.
y <- dnorm(x, mean = 2.5, sd = 0.5)
# Give the chart file a name.
png(file = "dnorm.png")
plot(x,y)
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
pnorm ()
Bu işlev, normal olarak dağıtılan rastgele bir sayının, belirli bir sayının değerinden daha az olma olasılığını verir. Aynı zamanda "Kümülatif Dağıtım Fonksiyonu" olarak da adlandırılır.
# Create a sequence of numbers between -10 and 10 incrementing by 0.2.
x <- seq(-10,10,by = .2)
# Choose the mean as 2.5 and standard deviation as 2.
y <- pnorm(x, mean = 2.5, sd = 2)
# Give the chart file a name.
png(file = "pnorm.png")
# Plot the graph.
plot(x,y)
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
qnorm ()
Bu fonksiyon, olasılık değerini alır ve kümülatif değeri olasılık değeriyle eşleşen bir sayı verir.
# Create a sequence of probability values incrementing by 0.02.
x <- seq(0, 1, by = 0.02)
# Choose the mean as 2 and standard deviation as 3.
y <- qnorm(x, mean = 2, sd = 1)
# Give the chart file a name.
png(file = "qnorm.png")
# Plot the graph.
plot(x,y)
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
rnorm ()
Bu işlev, dağılımı normal olan rastgele sayılar üretmek için kullanılır. Örnek boyutunu girdi olarak alır ve o kadar çok rastgele sayı üretir. Oluşturulan sayıların dağılımını göstermek için bir histogram çiziyoruz.
# Create a sample of 50 numbers which are normally distributed.
y <- rnorm(50)
# Give the chart file a name.
png(file = "rnorm.png")
# Plot the histogram for this sample.
hist(y, main = "Normal DIstribution")
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
Binom dağılım modeli, bir dizi deneyde yalnızca iki olası sonucu olan bir olayın başarı olasılığını bulmakla ilgilenir. Örneğin, yazı tura atmak her zaman bir kafa veya kuyruk verir. Bir jetonu 10 kez tekrar tekrar atarken tam olarak 3 tur bulma olasılığı binom dağılımı sırasında tahmin edilir.
R, iki terimli dağılım oluşturmak için dört yerleşik işleve sahiptir. Aşağıda açıklanmıştır.
dbinom(x, size, prob)
pbinom(x, size, prob)
qbinom(p, size, prob)
rbinom(n, size, prob)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
x sayıların bir vektörüdür.
p bir olasılık vektörüdür.
n gözlem sayısıdır.
size deneme sayısıdır.
prob her denemenin başarı olasılığıdır.
dbinom ()
Bu fonksiyon, her noktada olasılık yoğunluk dağılımını verir.
# Create a sample of 50 numbers which are incremented by 1.
x <- seq(0,50,by = 1)
# Create the binomial distribution.
y <- dbinom(x,50,0.5)
# Give the chart file a name.
png(file = "dbinom.png")
# Plot the graph for this sample.
plot(x,y)
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
pbinom ()
Bu işlev, bir olayın kümülatif olasılığını verir. Olasılığı temsil eden tek bir değerdir.
# Probability of getting 26 or less heads from a 51 tosses of a coin.
x <- pbinom(26,51,0.5)
print(x)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 0.610116qbinom ()
Bu fonksiyon, olasılık değerini alır ve kümülatif değeri olasılık değeriyle eşleşen bir sayı verir.
# How many heads will have a probability of 0.25 will come out when a coin
# is tossed 51 times.
x <- qbinom(0.25,51,1/2)
print(x)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 23rbinom ()
Bu işlev, belirli bir örnekten belirli olasılıkların gerekli sayıda rastgele değerini üretir.
# Find 8 random values from a sample of 150 with probability of 0.4.
x <- rbinom(8,150,.4)
print(x)Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 58 61 59 66 55 60 61 67Poisson Regresyon, yanıt değişkeninin kesirli sayılar değil sayılar biçiminde olduğu regresyon modellerini içerir. Örneğin, bir futbol maçı serisindeki doğum sayısı veya galibiyet sayısı. Ayrıca yanıt değişkenlerinin değerleri bir Poisson dağılımını izler.
Poisson regresyonunun genel matematiksel denklemi -
log(y) = a + b1x1 + b2x2 + bnxn.....Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
y yanıt değişkendir.
a ve b sayısal katsayılardır.
x yordayıcı değişkendir.
Poisson regresyon modelini oluşturmak için kullanılan işlev, glm() işlevi.
Sözdizimi
İçin temel sözdizimi glm() Poisson regresyonunda fonksiyon -
glm(formula,data,family)Aşağıdaki fonksiyonlarda kullanılan parametrelerin açıklaması aşağıdadır -
formula değişkenler arasındaki ilişkiyi gösteren semboldür.
data bu değişkenlerin değerlerini veren veri setidir.
familymodelin ayrıntılarını belirtmek için R nesnesidir. Lojistik Regresyon için değeri 'Poisson'dur.
Misal
Yün tipi (A veya B) ve gerginliğin (düşük, orta veya yüksek) dokuma tezgahı başına çözgü kopuşu sayısı üzerindeki etkisini tanımlayan dahili veri seti "çözgü kırılmaları" na sahibiz. "Kesmeleri", kırılma sayısı olan yanıt değişkeni olarak düşünelim. Yünün "tipi" ve "gerilimi" yordayıcı değişkenler olarak alınır.
Input Data
input <- warpbreaks
print(head(input))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
breaks wool tension
1 26 A L
2 30 A L
3 54 A L
4 25 A L
5 70 A L
6 52 A LRegresyon Modeli Oluşturun
output <-glm(formula = breaks ~ wool+tension, data = warpbreaks,
family = poisson)
print(summary(output))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
Call:
glm(formula = breaks ~ wool + tension, family = poisson, data = warpbreaks)
Deviance Residuals:
Min 1Q Median 3Q Max
-3.6871 -1.6503 -0.4269 1.1902 4.2616
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.69196 0.04541 81.302 < 2e-16 ***
woolB -0.20599 0.05157 -3.994 6.49e-05 ***
tensionM -0.32132 0.06027 -5.332 9.73e-08 ***
tensionH -0.51849 0.06396 -8.107 5.21e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 297.37 on 53 degrees of freedom
Residual deviance: 210.39 on 50 degrees of freedom
AIC: 493.06
Number of Fisher Scoring iterations: 4Özet olarak, tahmin değişkeninin yanıt değişkeni üzerindeki etkisini değerlendirmek için son sütundaki p değerinin 0,05'ten küçük olmasını arıyoruz. Görüldüğü gibi, M ve H gerilim tipine sahip yün tipi B, kırılmaların sayısı üzerinde etkiye sahiptir.
Yordayıcı değişkenlerdeki varyasyonun yanıt değişkeni üzerindeki etkisini tanımlayan modeller oluşturmak için Regresyon analizini kullanırız. Bazen, Evet / Hayır veya Erkek / Kadın gibi değerlere sahip kategorik bir değişkenimiz varsa. Basit regresyon analizi, kategorik değişkenin her bir değeri için birden fazla sonuç verir. Böyle bir senaryoda, kategorik değişkenin etkisini yordayıcı değişkenle birlikte kullanarak ve kategorik değişkenin her seviyesi için regresyon çizgilerini karşılaştırarak inceleyebiliriz. Böyle bir analiz şu şekilde adlandırılır:Analysis of Covariance olarak da adlandırılır ANCOVA.
Misal
R yerleşik veri seti mtcars'ı düşünün. İçinde "am" alanının aktarım türünü (otomatik veya manuel) temsil ettiğini gözlemliyoruz. 0 ve 1 değerlerine sahip kategorik bir değişkendir. Bir arabanın galon başına mil değeri (mpg), beygir gücünün ("hp") değerinin yanı sıra ona da bağlı olabilir.
"Am" değerinin "mpg" ve "hp" arasındaki regresyon üzerindeki etkisini inceliyoruz. Kullanılarak yapılıraov() işlevi ve ardından anova() çoklu regresyonları karşılaştırma işlevi.
Giriş Verileri
Mtcars veri setinden "mpg", "hp" ve "am" alanlarını içeren bir veri çerçevesi oluşturun. Burada yanıt değişkeni olarak "mpg" yi, tahmin değişkeni olarak "hp" yi ve kategorik değişken olarak "am" yı alıyoruz.
input <- mtcars[,c("am","mpg","hp")]
print(head(input))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
am mpg hp
Mazda RX4 1 21.0 110
Mazda RX4 Wag 1 21.0 110
Datsun 710 1 22.8 93
Hornet 4 Drive 0 21.4 110
Hornet Sportabout 0 18.7 175
Valiant 0 18.1 105ANCOVA Analizi
Öngörücü değişken olarak "hp" yi ve yanıt değişkeni olarak "mpg" yi "am" ve "hp" arasındaki etkileşimi hesaba katarak bir regresyon modeli oluşturuyoruz.
Kategorik değişken ve yordayıcı değişken arasındaki etkileşimli model
# Get the dataset.
input <- mtcars
# Create the regression model.
result <- aov(mpg~hp*am,data = input)
print(summary(result))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
Df Sum Sq Mean Sq F value Pr(>F)
hp 1 678.4 678.4 77.391 1.50e-09 ***
am 1 202.2 202.2 23.072 4.75e-05 ***
hp:am 1 0.0 0.0 0.001 0.981
Residuals 28 245.4 8.8
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Bu sonuç, her iki durumda da p değeri 0,05'ten az olduğundan, hem beygir gücü hem de şanzıman türünün galon başına mil üzerinde önemli etkiye sahip olduğunu göstermektedir. Ancak bu iki değişken arasındaki etkileşim, p değeri 0.05'ten fazla olduğu için anlamlı değildir.
Kategorik değişken ile yordayıcı değişken arasında etkileşim olmadan model
# Get the dataset.
input <- mtcars
# Create the regression model.
result <- aov(mpg~hp+am,data = input)
print(summary(result))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
Df Sum Sq Mean Sq F value Pr(>F)
hp 1 678.4 678.4 80.15 7.63e-10 ***
am 1 202.2 202.2 23.89 3.46e-05 ***
Residuals 29 245.4 8.5
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Bu sonuç, her iki durumda da p değeri 0,05'ten az olduğundan, hem beygir gücü hem de şanzıman türünün galon başına mil üzerinde önemli etkiye sahip olduğunu göstermektedir.
İki Modeli Karşılaştırmak
Şimdi, değişkenlerin etkileşiminin gerçekten anlamlı olup olmadığı sonucuna varmak için iki modeli karşılaştırabiliriz. Bunun için kullanıyoruzanova() işlevi.
# Get the dataset.
input <- mtcars
# Create the regression models.
result1 <- aov(mpg~hp*am,data = input)
result2 <- aov(mpg~hp+am,data = input)
# Compare the two models.
print(anova(result1,result2))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
Model 1: mpg ~ hp * am
Model 2: mpg ~ hp + am
Res.Df RSS Df Sum of Sq F Pr(>F)
1 28 245.43
2 29 245.44 -1 -0.0052515 6e-04 0.9806P değeri 0.05'ten büyük olduğu için, beygir gücü ile aktarım türü arasındaki etkileşimin önemli olmadığı sonucuna vardık. Bu nedenle, galon başına kilometre, hem otomatik hem de manuel şanzıman modunda otomobilin beygir gücüne benzer şekilde bağlı olacaktır.
Zaman serisi, her veri noktasının bir zaman damgasıyla ilişkilendirildiği bir dizi veri noktasıdır. Basit bir örnek, borsadaki bir hisse senedinin belirli bir günde farklı zaman noktalarında fiyatıdır. Bir başka örnek, bir bölgedeki yılın farklı aylarında yağış miktarıdır. R dili, zaman serisi verilerini oluşturmak, işlemek ve çizmek için birçok işlev kullanır. Zaman serileri için veriler, adı verilen bir R nesnesinde saklanırtime-series object. Aynı zamanda bir vektör veya veri çerçevesi gibi bir R veri nesnesidir.
Zaman serisi nesnesi, ts() işlevi.
Sözdizimi
İçin temel sözdizimi ts() zaman serisi analizinde fonksiyon -
timeseries.object.name <- ts(data, start, end, frequency)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
data zaman serilerinde kullanılan değerleri içeren bir vektör veya matristir.
start zaman serisindeki ilk gözlem için başlangıç zamanını belirtir.
end zaman serisindeki son gözlemin bitiş zamanını belirtir.
frequency birim zamandaki gözlem sayısını belirtir.
"Veri" parametresi dışında diğer tüm parametreler isteğe bağlıdır.
Misal
Ocak 2012'den itibaren bir yerde yıllık yağış ayrıntılarını düşünün. 12 aylık bir süre için bir R zaman serisi nesnesi oluşturup grafiğini çiziyoruz.
# Get the data points in form of a R vector.
rainfall <- c(799,1174.8,865.1,1334.6,635.4,918.5,685.5,998.6,784.2,985,882.8,1071)
# Convert it to a time series object.
rainfall.timeseries <- ts(rainfall,start = c(2012,1),frequency = 12)
# Print the timeseries data.
print(rainfall.timeseries)
# Give the chart file a name.
png(file = "rainfall.png")
# Plot a graph of the time series.
plot(rainfall.timeseries)
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda, aşağıdaki sonucu ve grafiği üretir -
Jan Feb Mar Apr May Jun Jul Aug Sep
2012 799.0 1174.8 865.1 1334.6 635.4 918.5 685.5 998.6 784.2
Oct Nov Dec
2012 985.0 882.8 1071.0Zaman serisi grafiği -
Farklı Zaman Aralıkları
Değeri frequencyts () fonksiyonundaki parametre, veri noktalarının ölçüldüğü zaman aralıklarına karar verir. 12 değeri, zaman serisinin 12 aylık olduğunu gösterir. Diğer değerler ve anlamları aşağıdaki gibidir -
frequency = 12 veri noktalarını yılın her ayı için sabitler.
frequency = 4 veri noktalarını yılın her çeyreği için sabitler.
frequency = 6 Veri noktalarını bir saatin her 10 dakikası için sabitler.
frequency = 24*6 veri noktalarını günün her 10 dakikası için sabitler.
Çoklu Zaman Serileri
Her iki seriyi bir matris halinde birleştirerek birden fazla zaman serisini tek bir grafikte çizebiliriz.
# Get the data points in form of a R vector.
rainfall1 <- c(799,1174.8,865.1,1334.6,635.4,918.5,685.5,998.6,784.2,985,882.8,1071)
rainfall2 <-
c(655,1306.9,1323.4,1172.2,562.2,824,822.4,1265.5,799.6,1105.6,1106.7,1337.8)
# Convert them to a matrix.
combined.rainfall <- matrix(c(rainfall1,rainfall2),nrow = 12)
# Convert it to a time series object.
rainfall.timeseries <- ts(combined.rainfall,start = c(2012,1),frequency = 12)
# Print the timeseries data.
print(rainfall.timeseries)
# Give the chart file a name.
png(file = "rainfall_combined.png")
# Plot a graph of the time series.
plot(rainfall.timeseries, main = "Multiple Time Series")
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda, aşağıdaki sonucu ve grafiği üretir -
Series 1 Series 2
Jan 2012 799.0 655.0
Feb 2012 1174.8 1306.9
Mar 2012 865.1 1323.4
Apr 2012 1334.6 1172.2
May 2012 635.4 562.2
Jun 2012 918.5 824.0
Jul 2012 685.5 822.4
Aug 2012 998.6 1265.5
Sep 2012 784.2 799.6
Oct 2012 985.0 1105.6
Nov 2012 882.8 1106.7
Dec 2012 1071.0 1337.8Çoklu Zaman serisi grafiği -
Regresyon analizi için gerçek dünya verilerini modellerken, nadiren modelin denkleminin doğrusal bir grafik veren doğrusal bir denklem olduğunu gözlemliyoruz. Çoğu zaman, gerçek dünya verileri modelinin denklemi, 3'ün üssü veya günah işlevi gibi daha yüksek dereceli matematiksel işlevleri içerir. Böyle bir senaryoda, modelin grafiği bir çizgi yerine bir eğri verir. Hem doğrusal hem de doğrusal olmayan regresyonun amacı, verilerinize en yakın çizgiyi veya eğriyi bulmak için modelin parametrelerinin değerlerini ayarlamaktır. Bu değerleri bulduktan sonra, yanıt değişkenini iyi bir doğrulukla tahmin edebileceğiz.
En Küçük Kareler regresyonunda, regresyon eğrisinden farklı noktaların dikey uzaklıklarının karelerinin toplamının minimize edildiği bir regresyon modeli oluşturuyoruz. Genel olarak tanımlanmış bir modelle başlar ve katsayılar için bazı değerler alırız. Daha sonra uygularıznls() Güven aralıkları ile birlikte daha doğru değerleri elde etmek için R'nin fonksiyonu.
Sözdizimi
R'de doğrusal olmayan bir en küçük kare testi oluşturmak için temel sözdizimi -
nls(formula, data, start)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
formula değişkenler ve parametreler içeren doğrusal olmayan bir model formülüdür.
data formüldeki değişkenleri değerlendirmek için kullanılan bir veri çerçevesidir.
start başlangıç tahminlerinin adlandırılmış bir listesi veya adlandırılmış sayısal vektörüdür.
Misal
Katsayılarının başlangıç değerlerinin varsayıldığı doğrusal olmayan bir modeli ele alacağız. Daha sonra, bu varsayılan değerlerin güven aralıklarının ne olduğunu göreceğiz, böylece bu değerlerin modele ne kadar iyi girdiğine karar verebiliriz.
Öyleyse bu amaç için aşağıdaki denklemi ele alalım -
a = b1*x^2+b2Başlangıç katsayılarının 1 ve 3 olduğunu varsayalım ve bu değerleri nls () fonksiyonuna sığdıralım.
xvalues <- c(1.6,2.1,2,2.23,3.71,3.25,3.4,3.86,1.19,2.21)
yvalues <- c(5.19,7.43,6.94,8.11,18.75,14.88,16.06,19.12,3.21,7.58)
# Give the chart file a name.
png(file = "nls.png")
# Plot these values.
plot(xvalues,yvalues)
# Take the assumed values and fit into the model.
model <- nls(yvalues ~ b1*xvalues^2+b2,start = list(b1 = 1,b2 = 3))
# Plot the chart with new data by fitting it to a prediction from 100 data points.
new.data <- data.frame(xvalues = seq(min(xvalues),max(xvalues),len = 100))
lines(new.data$xvalues,predict(model,newdata = new.data))
# Save the file.
dev.off()
# Get the sum of the squared residuals.
print(sum(resid(model)^2))
# Get the confidence intervals on the chosen values of the coefficients.
print(confint(model))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
[1] 1.081935
Waiting for profiling to be done...
2.5% 97.5%
b1 1.137708 1.253135
b2 1.497364 2.496484
B1'in değerinin 1'e, b2'nin değerinin 3'e değil 2'ye daha yakın olduğu sonucuna varabiliriz.
Karar ağacı, seçenekleri ve sonuçlarını bir ağaç şeklinde temsil eden bir grafiktir. Grafikteki düğümler bir olayı veya seçimi temsil eder ve grafiğin kenarları karar kurallarını veya koşullarını temsil eder. Çoğunlukla Makine Öğrenimi ve Veri Madenciliği uygulamalarında R kullanarak kullanılır.
Karar ağının kullanımına örnekler - bir e-postayı istenmeyen posta olarak veya istenmeyen posta olarak tahmin etmek, bir tümörün kanserli olduğunu tahmin etmek veya bunların her birindeki faktörlere dayalı olarak bir krediyi iyi veya kötü bir kredi riski olarak tahmin etmektir. Genel olarak, eğitim verileri olarak da adlandırılan gözlemlenen verilerle bir model oluşturulur. Ardından modeli doğrulamak ve iyileştirmek için bir dizi doğrulama verisi kullanılır. R, karar ağaçları oluşturmak ve görselleştirmek için kullanılan paketlere sahiptir. Yeni öngörücü değişken kümesi için, verilerin kategorisi (evet / Hayır, istenmeyen posta / istenmeyen posta değil) hakkında bir karara varmak için bu modeli kullanırız.
R paketi "party" karar ağaçları oluşturmak için kullanılır.
R Paketini Kurun
Paketi yüklemek için R konsolunda aşağıdaki komutu kullanın. Ayrıca varsa bağımlı paketleri de kurmanız gerekir.
install.packages("party")"Parti" paketinin işlevi vardır ctree() karar ağacı oluşturmak ve analiz etmek için kullanılır.
Sözdizimi
R'de bir karar ağacı oluşturmak için temel sözdizimi -
ctree(formula, data)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
formula yordayıcı ve yanıt değişkenlerini açıklayan bir formüldür.
data kullanılan veri kümesinin adıdır.
Giriş Verileri
Adlı yerleşik R veri kümesini kullanacağız readingSkillsbir karar ağacı oluşturmak için. "Yaş", "ayakkabı boyu", "puan" değişkenlerini ve kişinin anadili olup olmadığını bildiğimizde, kişinin okuma becerilerinin puanını açıklar.
İşte örnek veriler.
# Load the party package. It will automatically load other
# dependent packages.
library(party)
# Print some records from data set readingSkills.
print(head(readingSkills))Yukarıdaki kodu çalıştırdığımızda, aşağıdaki sonucu ve grafiği üretir -
nativeSpeaker age shoeSize score
1 yes 5 24.83189 32.29385
2 yes 6 25.95238 36.63105
3 no 11 30.42170 49.60593
4 yes 7 28.66450 40.28456
5 yes 11 31.88207 55.46085
6 yes 10 30.07843 52.83124
Loading required package: methods
Loading required package: grid
...............................
...............................Misal
Kullanacağız ctree() Karar ağacını oluşturmak ve grafiğini görmek için işlev.
# Load the party package. It will automatically load other
# dependent packages.
library(party)
# Create the input data frame.
input.dat <- readingSkills[c(1:105),]
# Give the chart file a name.
png(file = "decision_tree.png")
# Create the tree.
output.tree <- ctree(
nativeSpeaker ~ age + shoeSize + score,
data = input.dat)
# Plot the tree.
plot(output.tree)
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
null device
1
Loading required package: methods
Loading required package: grid
Loading required package: mvtnorm
Loading required package: modeltools
Loading required package: stats4
Loading required package: strucchange
Loading required package: zoo
Attaching package: ‘zoo’
The following objects are masked from ‘package:base’:
as.Date, as.Date.numeric
Loading required package: sandwich
Sonuç
Yukarıda gösterilen karar ağacından, okuma becerileri puanı 38,3'ün altında ve yaşı 6'dan büyük olanların anadil konuşmacı olmadığı sonucuna varabiliriz.
Rastgele orman yaklaşımında çok sayıda karar ağacı oluşturulur. Her gözlem, her karar ağacına beslenir. Her gözlem için en yaygın sonuç, nihai çıktı olarak kullanılır. Tüm ağaçlara yeni bir gözlem verilir ve her sınıflandırma modeli için çoğunluk oyu alınır.
Ağaç oluşturulurken kullanılmayan durumlar için hata tahmini yapılır. Buna birOOB (Out-of-bag) yüzde olarak belirtilen hata tahmini.
R paketi "randomForest" rastgele ormanlar oluşturmak için kullanılır.
R Paketini Kurun
Paketi yüklemek için R konsolunda aşağıdaki komutu kullanın. Ayrıca varsa bağımlı paketleri de kurmanız gerekir.
install.packages("randomForest)"RandomForest" paketi şu işleve sahiptir: randomForest() rastgele ormanlar oluşturmak ve analiz etmek için kullanılır.
Sözdizimi
R'de rastgele bir orman oluşturmak için temel sözdizimi şudur:
randomForest(formula, data)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
formula yordayıcı ve yanıt değişkenlerini açıklayan bir formüldür.
data kullanılan veri kümesinin adıdır.
Giriş Verileri
Bir karar ağacı oluşturmak için ReadingSkills adlı dahili R veri setini kullanacağız. "Yaş", "ayakkabı boyu", "puan" değişkenlerini ve kişinin anadili olup olmadığını bildiğimizde, kişinin okuma becerilerinin puanını açıklar.
İşte örnek veriler.
# Load the party package. It will automatically load other
# required packages.
library(party)
# Print some records from data set readingSkills.
print(head(readingSkills))Yukarıdaki kodu çalıştırdığımızda, aşağıdaki sonucu ve grafiği üretir -
nativeSpeaker age shoeSize score
1 yes 5 24.83189 32.29385
2 yes 6 25.95238 36.63105
3 no 11 30.42170 49.60593
4 yes 7 28.66450 40.28456
5 yes 11 31.88207 55.46085
6 yes 10 30.07843 52.83124
Loading required package: methods
Loading required package: grid
...............................
...............................Misal
Kullanacağız randomForest() Karar ağacını oluşturmak ve grafiğini görmek için işlev.
# Load the party package. It will automatically load other
# required packages.
library(party)
library(randomForest)
# Create the forest.
output.forest <- randomForest(nativeSpeaker ~ age + shoeSize + score,
data = readingSkills)
# View the forest results.
print(output.forest)
# Importance of each predictor.
print(importance(fit,type = 2))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
Call:
randomForest(formula = nativeSpeaker ~ age + shoeSize + score,
data = readingSkills)
Type of random forest: classification
Number of trees: 500
No. of variables tried at each split: 1
OOB estimate of error rate: 1%
Confusion matrix:
no yes class.error
no 99 1 0.01
yes 1 99 0.01
MeanDecreaseGini
age 13.95406
shoeSize 18.91006
score 56.73051Sonuç
Yukarıda gösterilen rastgele ormandan, ayakkabı boyutunun ve puanın, bir kişinin anadili olup olmadığına karar veren önemli faktörler olduğu sonucuna varabiliriz. Ayrıca modelde sadece% 1 hata var, bu da% 99 doğrulukla tahmin edebileceğimiz anlamına geliyor.
Hayatta kalma analizi, belirli bir olayın meydana geleceği zamanı tahmin etmekle ilgilenir. Aynı zamanda arıza zamanı analizi veya ölüme kadar geçen süre analizi olarak da bilinir. Örneğin kanserli bir kişinin hayatta kalacağı gün sayısını tahmin etmek veya mekanik bir sistemin ne zaman başarısız olacağını tahmin etmek.
R paketi adlı survivalhayatta kalma analizi yapmak için kullanılır. Bu paket şu işlevi içerir:Surv()Girdi verilerini bir R formülü olarak alan ve analiz için seçilen değişkenler arasında bir hayatta kalma nesnesi oluşturan. Sonra işlevi kullanırızsurvfit() analiz için bir arsa oluşturmak için.
Kurulum paketi
install.packages("survival")Sözdizimi
R'de hayatta kalma analizi oluşturmak için temel sözdizimi -
Surv(time,event)
survfit(formula)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
time olay meydana gelene kadar takip süresidir.
event beklenen olayın meydana gelme durumunu gösterir.
formula yordayıcı değişkenler arasındaki ilişkidir.
Misal
Yukarıda kurulu hayatta kalma paketlerinde bulunan "pbc" adlı veri setini dikkate alacağız. Karaciğerin birincil biliyer sirozundan (PBC) etkilenen kişilerle ilgili hayatta kalma veri noktalarını açıklar. Veri kümesinde bulunan birçok sütun arasında, öncelikle "zaman" ve "durum" alanlarıyla ilgileniyoruz. Zaman, hastanın kaydı ile hastanın karaciğer nakli yapılan ya da hastanın ölümü arasındaki olayın başlangıcı arasındaki günlerin sayısını temsil eder.
# Load the library.
library("survival")
# Print first few rows.
print(head(pbc))Yukarıdaki kodu çalıştırdığımızda, aşağıdaki sonucu ve grafiği üretir -
id time status trt age sex ascites hepato spiders edema bili chol
1 1 400 2 1 58.76523 f 1 1 1 1.0 14.5 261
2 2 4500 0 1 56.44627 f 0 1 1 0.0 1.1 302
3 3 1012 2 1 70.07255 m 0 0 0 0.5 1.4 176
4 4 1925 2 1 54.74059 f 0 1 1 0.5 1.8 244
5 5 1504 1 2 38.10541 f 0 1 1 0.0 3.4 279
6 6 2503 2 2 66.25873 f 0 1 0 0.0 0.8 248
albumin copper alk.phos ast trig platelet protime stage
1 2.60 156 1718.0 137.95 172 190 12.2 4
2 4.14 54 7394.8 113.52 88 221 10.6 3
3 3.48 210 516.0 96.10 55 151 12.0 4
4 2.54 64 6121.8 60.63 92 183 10.3 4
5 3.53 143 671.0 113.15 72 136 10.9 3
6 3.98 50 944.0 93.00 63 NA 11.0 3Yukarıdaki verilerden analizimiz için zaman ve durumu düşünüyoruz.
Surv () ve survfit () İşlevini Uygulama
Şimdi uygulamaya geçiyoruz Surv() Yukarıdaki veri setine işlev verin ve eğilimi gösterecek bir grafik oluşturun.
# Load the library.
library("survival")
# Create the survival object.
survfit(Surv(pbc$time,pbc$status == 2)~1) # Give the chart file a name. png(file = "survival.png") # Plot the graph. plot(survfit(Surv(pbc$time,pbc$status == 2)~1))
# Save the file.
dev.off()Yukarıdaki kodu çalıştırdığımızda, aşağıdaki sonucu ve grafiği üretir -
Call: survfit(formula = Surv(pbc$time, pbc$status == 2) ~ 1)
n events median 0.95LCL 0.95UCL
418 161 3395 3090 3853
Yukarıdaki grafikteki eğilim, belirli sayıda günün sonunda hayatta kalma olasılığını tahmin etmemize yardımcı olur.
Chi-Square testiki kategorik değişkenin aralarında anlamlı bir korelasyon olup olmadığını belirlemek için istatistiksel bir yöntemdir. Her iki değişken de aynı popülasyondan olmalı ve - Evet / Hayır, Erkek / Kadın, Kırmızı / Yeşil gibi kategorik olmalıdır.
Örneğin, insanların dondurma satın alma alışkanlıklarına ilişkin gözlemlerle bir veri kümesi oluşturabilir ve bir kişinin cinsiyeti ile tercih ettiği dondurmanın aromasını ilişkilendirmeye çalışabiliriz. Bir korelasyon bulunursa, ziyaret eden kişilerin cinsiyetini bilerek uygun tat stoğu planlayabiliriz.
Sözdizimi
Ki-Kare testi yapmak için kullanılan işlev chisq.test().
R'de ki-kare testi oluşturmak için temel sözdizimi -
chisq.test(data)Aşağıda kullanılan parametrelerin açıklaması verilmiştir -
data gözlemdeki değişkenlerin sayım değerini içeren bir tablo şeklindeki verilerdir.
Misal
Cars93 verilerini 1993 yılında farklı otomobil modellerinin satışını temsil eden "MASS" kütüphanesine alacağız.
library("MASS")
print(str(Cars93))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
'data.frame': 93 obs. of 27 variables:
$ Manufacturer : Factor w/ 32 levels "Acura","Audi",..: 1 1 2 2 3 4 4 4 4 5 ...
$ Model : Factor w/ 93 levels "100","190E","240",..: 49 56 9 1 6 24 54 74 73 35 ... $ Type : Factor w/ 6 levels "Compact","Large",..: 4 3 1 3 3 3 2 2 3 2 ...
$ Min.Price : num 12.9 29.2 25.9 30.8 23.7 14.2 19.9 22.6 26.3 33 ... $ Price : num 15.9 33.9 29.1 37.7 30 15.7 20.8 23.7 26.3 34.7 ...
$ Max.Price : num 18.8 38.7 32.3 44.6 36.2 17.3 21.7 24.9 26.3 36.3 ... $ MPG.city : int 25 18 20 19 22 22 19 16 19 16 ...
$ MPG.highway : int 31 25 26 26 30 31 28 25 27 25 ... $ AirBags : Factor w/ 3 levels "Driver & Passenger",..: 3 1 2 1 2 2 2 2 2 2 ...
$ DriveTrain : Factor w/ 3 levels "4WD","Front",..: 2 2 2 2 3 2 2 3 2 2 ... $ Cylinders : Factor w/ 6 levels "3","4","5","6",..: 2 4 4 4 2 2 4 4 4 5 ...
$ EngineSize : num 1.8 3.2 2.8 2.8 3.5 2.2 3.8 5.7 3.8 4.9 ... $ Horsepower : int 140 200 172 172 208 110 170 180 170 200 ...
$ RPM : int 6300 5500 5500 5500 5700 5200 4800 4000 4800 4100 ... $ Rev.per.mile : int 2890 2335 2280 2535 2545 2565 1570 1320 1690 1510 ...
$ Man.trans.avail : Factor w/ 2 levels "No","Yes": 2 2 2 2 2 1 1 1 1 1 ... $ Fuel.tank.capacity: num 13.2 18 16.9 21.1 21.1 16.4 18 23 18.8 18 ...
$ Passengers : int 5 5 5 6 4 6 6 6 5 6 ... $ Length : int 177 195 180 193 186 189 200 216 198 206 ...
$ Wheelbase : int 102 115 102 106 109 105 111 116 108 114 ... $ Width : int 68 71 67 70 69 69 74 78 73 73 ...
$ Turn.circle : int 37 38 37 37 39 41 42 45 41 43 ... $ Rear.seat.room : num 26.5 30 28 31 27 28 30.5 30.5 26.5 35 ...
$ Luggage.room : int 11 15 14 17 13 16 17 21 14 18 ... $ Weight : int 2705 3560 3375 3405 3640 2880 3470 4105 3495 3620 ...
$ Origin : Factor w/ 2 levels "USA","non-USA": 2 2 2 2 2 1 1 1 1 1 ... $ Make : Factor w/ 93 levels "Acura Integra",..: 1 2 4 3 5 6 7 9 8 10 ...Yukarıdaki sonuç, veri kümesinin kategorik değişkenler olarak kabul edilebilecek birçok faktör değişkenine sahip olduğunu göstermektedir. Modelimiz için "AirBags" ve "Type" değişkenlerini dikkate alacağız. Burada satılan araba türleri ile sahip olduğu Hava yastığı türleri arasındaki önemli bir ilişkiyi bulmayı hedefliyoruz. Korelasyon gözlemlenirse, hangi tür arabaların hangi hava yastıkları ile daha iyi satılabileceğini tahmin edebiliriz.
# Load the library.
library("MASS")
# Create a data frame from the main data set.
car.data <- data.frame(Cars93$AirBags, Cars93$Type)
# Create a table with the needed variables.
car.data = table(Cars93$AirBags, Cars93$Type)
print(car.data)
# Perform the Chi-Square test.
print(chisq.test(car.data))Yukarıdaki kodu çalıştırdığımızda aşağıdaki sonucu verir -
Compact Large Midsize Small Sporty Van
Driver & Passenger 2 4 7 0 3 0
Driver only 9 7 11 5 8 3
None 5 0 4 16 3 6
Pearson's Chi-squared test
data: car.data
X-squared = 33.001, df = 10, p-value = 0.0002723
Warning message:
In chisq.test(car.data) : Chi-squared approximation may be incorrectSonuç
Sonuç, bir dizi korelasyonunu gösteren 0,05'ten küçük p değerini gösterir.