Khoa học dữ liệu Agile - Xử lý dữ liệu trong Agile
Trong chương này, chúng ta sẽ tập trung vào sự khác biệt giữa dữ liệu có cấu trúc, bán cấu trúc và phi cấu trúc.
Dữ liệu có cấu trúc
Dữ liệu có cấu trúc liên quan đến dữ liệu được lưu trữ ở định dạng SQL trong bảng với các hàng và cột. Nó bao gồm một khóa quan hệ, được ánh xạ vào các trường được thiết kế trước. Dữ liệu có cấu trúc được sử dụng trên quy mô lớn hơn.
Dữ liệu có cấu trúc chỉ đại diện cho 5 đến 10 phần trăm của tất cả dữ liệu tin học.
Dữ liệu bán cấu trúc
Dữ liệu bán cấu trúc bao gồm dữ liệu không nằm trong cơ sở dữ liệu quan hệ. Chúng bao gồm một số thuộc tính của tổ chức giúp phân tích dễ dàng hơn. Nó bao gồm quá trình tương tự để lưu trữ chúng trong cơ sở dữ liệu quan hệ. Các ví dụ về cơ sở dữ liệu bán cấu trúc là tệp CSV, tài liệu XML và JSON. Cơ sở dữ liệu NoSQL được coi là có cấu trúc bán nguyệt.
Dữ liệu phi cấu trúc
Dữ liệu phi cấu trúc đại diện cho 80 phần trăm dữ liệu. Nó thường bao gồm văn bản và nội dung đa phương tiện. Các ví dụ tốt nhất về dữ liệu phi cấu trúc bao gồm tệp âm thanh, bản trình bày và trang web. Các ví dụ về dữ liệu phi cấu trúc do máy tạo ra là hình ảnh vệ tinh, dữ liệu khoa học, ảnh và video, dữ liệu radar và sóng siêu âm.
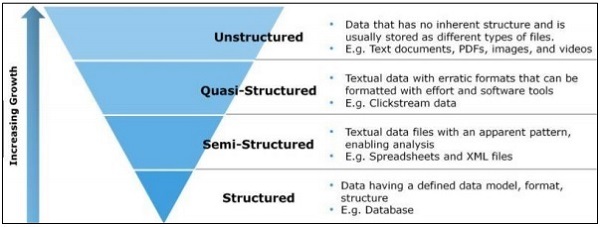
Cấu trúc kim tự tháp trên đặc biệt tập trung vào số lượng dữ liệu và tỷ lệ mà nó bị phân tán.
Dữ liệu chuẩn có cấu trúc xuất hiện dưới dạng loại giữa dữ liệu không có cấu trúc và bán cấu trúc. Trong hướng dẫn này, chúng tôi sẽ tập trung vào dữ liệu bán cấu trúc, có lợi cho phương pháp luận nhanh và nghiên cứu khoa học dữ liệu.
Dữ liệu bán cấu trúc không có mô hình dữ liệu chính thức nhưng có mô hình và cấu trúc rõ ràng, tự mô tả được phát triển bằng phân tích của nó.