Mạng thần kinh nhân tạo - Hướng dẫn nhanh
Mạng nơ-ron là các thiết bị tính toán song song, về cơ bản là một nỗ lực để tạo ra một mô hình máy tính của bộ não. Mục tiêu chính là phát triển một hệ thống để thực hiện các tác vụ tính toán khác nhau nhanh hơn các hệ thống truyền thống. Những tác vụ này bao gồm nhận dạng và phân loại mẫu, tính gần đúng, tối ưu hóa và phân cụm dữ liệu.
Mạng thần kinh nhân tạo là gì?
Mạng thần kinh nhân tạo (ANN) là một hệ thống tính toán hiệu quả có chủ đề trung tâm được mượn từ sự tương tự của mạng thần kinh sinh học. ANN cũng được đặt tên là “hệ thống thần kinh nhân tạo” hoặc “hệ thống xử lý phân tán song song” hoặc “hệ thống kết nối”. ANN có được một tập hợp lớn các đơn vị được kết nối với nhau theo một số kiểu để cho phép giao tiếp giữa các đơn vị. Những đơn vị này, còn được gọi là nút hoặc nơ-ron, là những bộ xử lý đơn giản hoạt động song song.
Mọi nơron đều được kết nối với nơron khác thông qua một liên kết kết nối. Mỗi liên kết kết nối được liên kết với một trọng số có thông tin về tín hiệu đầu vào. Đây là thông tin hữu ích nhất cho các tế bào thần kinh để giải quyết một vấn đề cụ thể vì trọng lượng thường kích thích hoặc ức chế tín hiệu được truyền đạt. Mỗi tế bào thần kinh có một trạng thái bên trong, trạng thái này được gọi là tín hiệu kích hoạt. Tín hiệu đầu ra, được tạo ra sau khi kết hợp các tín hiệu đầu vào và quy tắc kích hoạt, có thể được gửi đến các đơn vị khác.
Lược sử ANN
Lịch sử của ANN có thể được chia thành ba thời đại sau:
ANN trong những năm 1940 đến 1960
Một số phát triển chính của thời đại này như sau:
1943 - Người ta cho rằng khái niệm mạng nơron bắt đầu từ công trình của nhà sinh lý học, Warren McCulloch và nhà toán học, Walter Pitts, khi vào năm 1943, họ đã lập mô hình một mạng nơron đơn giản bằng cách sử dụng các mạch điện để mô tả cách các nơron trong não có thể hoạt động. .
1949- Cuốn sách của Donald Hebb, Tổ chức của Hành vi , đưa ra thực tế rằng việc kích hoạt lặp đi lặp lại một nơ-ron này sẽ làm tăng sức mạnh của nó mỗi khi chúng được sử dụng.
1956 - Một mạng bộ nhớ kết hợp đã được giới thiệu bởi Taylor.
1958 - Một phương pháp học tập cho mô hình nơ-ron McCulloch và Pitts tên là Perceptron được phát minh bởi Rosenblatt.
1960 - Bernard Widrow và Marcian Hoff đã phát triển các mô hình được gọi là "ADALINE" và "MADALINE."
ANN trong những năm 1960 đến 1980
Một số phát triển chính của thời đại này như sau:
1961 - Rosenblatt đã cố gắng không thành công nhưng đã đề xuất kế hoạch "nhân giống ngược" cho các mạng nhiều lớp.
1964 - Taylor đã xây dựng một mạch thắng-lấy-tất cả với sự ức chế giữa các đơn vị đầu ra.
1969 - Multilayer perceptron (MLP) được phát minh bởi Minsky và Papert.
1971 - Kohonen phát triển ký ức liên kết.
1976 - Stephen Grossberg và Gail Carpenter đã phát triển lý thuyết cộng hưởng thích ứng.
ANN từ những năm 1980 đến nay
Một số phát triển chính của thời đại này như sau:
1982 - Sự phát triển chính là phương pháp tiếp cận Năng lượng của Hopfield.
1985 - Máy Boltzmann được phát triển bởi Ackley, Hinton và Sejnowski.
1986 - Rumelhart, Hinton và Williams đã giới thiệu Quy tắc Delta Chung.
1988 - Kosko đã phát triển Bộ nhớ liên kết nhị phân (BAM) và cũng đưa ra khái niệm Logic mờ trong ANN.
Đánh giá lịch sử cho thấy rằng lĩnh vực này đã đạt được những tiến bộ đáng kể. Các chip dựa trên mạng thần kinh đang nổi lên và các ứng dụng cho các vấn đề phức tạp đang được phát triển. Chắc chắn, ngày nay là thời kỳ chuyển đổi của công nghệ mạng nơ-ron.
Neuron sinh học
Tế bào thần kinh (neuron) là một tế bào sinh học đặc biệt xử lý thông tin. Theo ước tính, có số lượng tế bào thần kinh khổng lồ, khoảng 10 11 với nhiều liên kết với nhau, khoảng 10 15 .
Sơ đồ
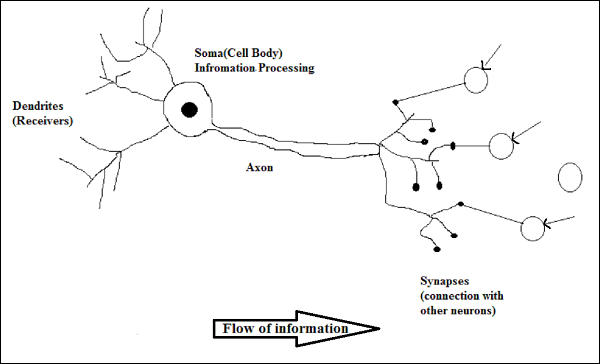
Hoạt động của một nơron sinh học
Như được minh họa trong sơ đồ trên, một nơ-ron điển hình bao gồm bốn phần sau với sự trợ giúp của chúng tôi có thể giải thích hoạt động của nó:
Dendrites- Chúng là những nhánh giống như cây, có nhiệm vụ nhận thông tin từ các tế bào thần kinh khác mà nó được kết nối. Theo nghĩa khác, chúng ta có thể nói rằng chúng giống như tai của nơ-ron.
Soma - Nó là thân tế bào của nơron và có nhiệm vụ xử lý thông tin, chúng nhận được từ đuôi gai.
Axon - Nó giống như một sợi cáp mà qua đó các tế bào thần kinh gửi thông tin.
Synapses - Là phần nối giữa sợi trục và các đuôi gai nơron khác.
ANN so với BNN
Trước khi xem xét sự khác biệt giữa Mạng thần kinh nhân tạo (ANN) và Mạng thần kinh sinh học (BNN), chúng ta hãy xem xét những điểm tương đồng dựa trên thuật ngữ giữa hai mạng này.
| Mạng thần kinh sinh học (BNN) | Mạng thần kinh nhân tạo (ANN) |
|---|---|
| Soma | Nút |
| Nhánh cây | Đầu vào |
| Synapse | Trọng lượng hoặc kết nối |
| Axon | Đầu ra |
Bảng sau đây cho thấy sự so sánh giữa ANN và BNN dựa trên một số tiêu chí đã đề cập.
| Tiêu chí | BNN | ANN |
|---|---|---|
| Processing | Song song ồ ạt, chậm nhưng vượt trội hơn ANN | Song song ồ ạt, nhanh nhưng kém hơn BNN |
| Size | 10 11 nơron và 10 15 kết nối | 10 2 đến 10 4 nút (chủ yếu phụ thuộc vào loại ứng dụng và nhà thiết kế mạng) |
| Learning | Họ có thể chịu đựng sự mơ hồ | Dữ liệu có cấu trúc và định dạng rất chính xác là bắt buộc để chống lại sự mơ hồ |
| Fault tolerance | Hiệu suất suy giảm với thậm chí hư hỏng một phần | Nó có khả năng hoạt động mạnh mẽ, do đó có khả năng chịu lỗi |
| Storage capacity | Lưu trữ thông tin trong khớp thần kinh | Lưu trữ thông tin trong các vị trí bộ nhớ liên tục |
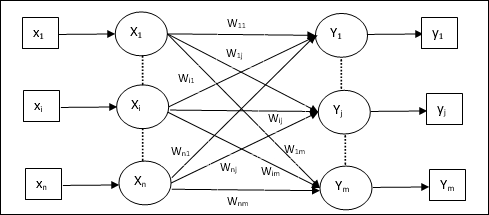
Mô hình mạng nơ ron nhân tạo
Sơ đồ sau đây đại diện cho mô hình chung của ANN theo sau là quá trình xử lý của nó.
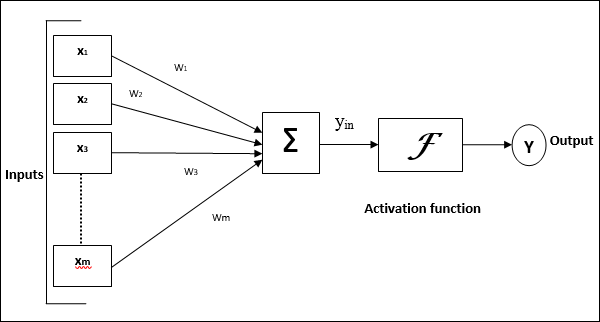
Đối với mô hình chung của mạng nơron nhân tạo ở trên, đầu vào ròng có thể được tính như sau:
$$ y_ {in} \: = \: x_ {1} .w_ {1} \: + \: x_ {2} .w_ {2} \: + \: x_ {3} .w_ {3} \: \ dotso \: x_ {m} .w_ {m} $$
tức là, giá trị nhập ròng $ y_ {in} \: = \: \ sum_i ^ m \: x_ {i} .w_ {i} $
Đầu ra có thể được tính toán bằng cách áp dụng chức năng kích hoạt trên đầu vào ròng.
$$ Y \: = \: F (y_ {in}) $$
Đầu ra = chức năng (đầu vào ròng được tính toán)
Việc xử lý ANN phụ thuộc vào ba khối xây dựng sau:
- Cấu trúc mạng
- Điều chỉnh trọng lượng hoặc học tập
- Chức năng kích hoạt
Trong chương này, chúng tôi sẽ thảo luận chi tiết về ba khối xây dựng này của ANN
Cấu trúc mạng
Cấu trúc liên kết mạng là sự sắp xếp của một mạng cùng với các nút và đường kết nối của nó. Theo cấu trúc liên kết, ANN có thể được phân loại thành các loại sau:
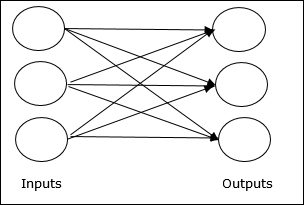
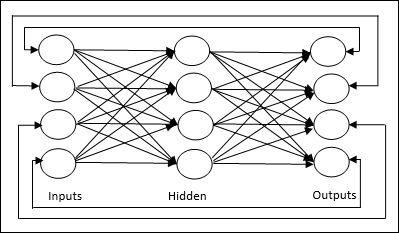
Mạng chuyển tiếp
Nó là một mạng không lặp lại có các đơn vị / nút xử lý trong các lớp và tất cả các nút trong một lớp được kết nối với các nút của các lớp trước đó. Kết nối có trọng lượng khác nhau đối với chúng. Không có vòng phản hồi có nghĩa là tín hiệu chỉ có thể truyền theo một hướng, từ đầu vào đến đầu ra. Nó có thể được chia thành hai loại sau:
Single layer feedforward network- Khái niệm về ANN truyền tiếp chỉ có một lớp trọng số. Nói cách khác, chúng ta có thể nói lớp đầu vào được kết nối hoàn toàn với lớp đầu ra.
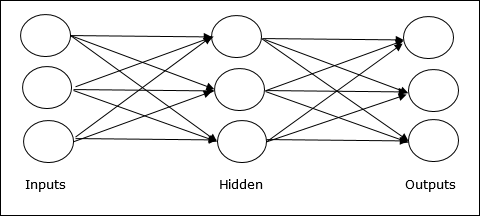
Multilayer feedforward network- Khái niệm ANN truyền thẳng có nhiều hơn một lớp có trọng số. Vì mạng này có một hoặc nhiều lớp giữa đầu vào và lớp đầu ra, nó được gọi là các lớp ẩn.
Mạng phản hồi
Như tên cho thấy, mạng phản hồi có các đường phản hồi, có nghĩa là tín hiệu có thể truyền theo cả hai hướng bằng cách sử dụng các vòng lặp. Điều này làm cho nó trở thành một hệ động lực phi tuyến tính, thay đổi liên tục cho đến khi nó đạt trạng thái cân bằng. Nó có thể được chia thành các loại sau:
Recurrent networks- Chúng là mạng phản hồi với các vòng khép kín. Sau đây là hai loại mạng lặp lại.
Fully recurrent network - Nó là kiến trúc mạng nơ ron đơn giản nhất vì tất cả các nút được kết nối với tất cả các nút khác và mỗi nút hoạt động như cả đầu vào và đầu ra.
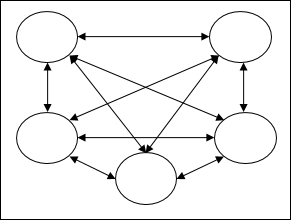
Jordan network - Là một mạng vòng kín, trong đó đầu ra sẽ chuyển đến đầu vào một lần nữa dưới dạng phản hồi như trong sơ đồ sau.
Điều chỉnh trọng lượng hoặc học tập
Học, trong mạng nơ-ron nhân tạo, là phương pháp điều chỉnh trọng số của các kết nối giữa các nơ-ron của một mạng cụ thể. Học trong ANN có thể được phân thành ba loại cụ thể là học có giám sát, học không giám sát và học tăng cường.
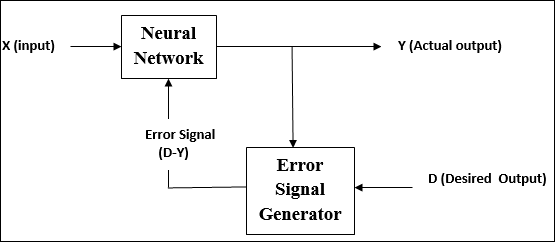
Học tập có giám sát
Như tên cho thấy, loại hình học tập này được thực hiện dưới sự giám sát của một giáo viên. Quá trình học tập này là phụ thuộc.
Trong quá trình đào tạo ANN theo phương pháp học có giám sát, vectơ đầu vào được trình bày cho mạng, vectơ này sẽ đưa ra một vectơ đầu ra. Vectơ đầu ra này được so sánh với vectơ đầu ra mong muốn. Một tín hiệu lỗi được tạo ra, nếu có sự khác biệt giữa đầu ra thực tế và vector đầu ra mong muốn. Trên cơ sở tín hiệu lỗi này, các trọng số được điều chỉnh cho đến khi kết quả đầu ra thực tế khớp với đầu ra mong muốn.
Học tập không giám sát
Như tên cho thấy, loại hình học tập này được thực hiện mà không có sự giám sát của giáo viên. Quá trình học tập này là độc lập.
Trong quá trình đào tạo ANN dưới sự học tập không giám sát, các vectơ đầu vào cùng loại được kết hợp để tạo thành các cụm. Khi một mẫu đầu vào mới được áp dụng, thì mạng nơ ron sẽ đưa ra phản hồi đầu ra cho biết lớp mà mẫu đầu vào thuộc về.
Không có phản hồi từ môi trường về những gì nên là đầu ra mong muốn và nếu nó là chính xác hoặc không chính xác. Do đó, trong kiểu học tập này, bản thân mạng phải khám phá ra các mẫu và tính năng từ dữ liệu đầu vào và mối quan hệ giữa dữ liệu đầu vào với đầu ra.
Học tăng cường
Như tên cho thấy, kiểu học này được sử dụng để củng cố hoặc tăng cường mạng lưới qua một số thông tin phê bình. Quá trình học tập này tương tự như học tập có giám sát, tuy nhiên chúng ta có thể có rất ít thông tin.
Trong quá trình đào tạo mạng theo học tăng cường, mạng nhận được một số phản hồi từ môi trường. Điều này làm cho nó tương tự như học có giám sát. Tuy nhiên, phản hồi thu được ở đây là đánh giá không mang tính hướng dẫn, có nghĩa là không có giáo viên như trong học tập có giám sát. Sau khi nhận được phản hồi, mạng thực hiện điều chỉnh trọng số để có được thông tin phê bình tốt hơn trong tương lai.
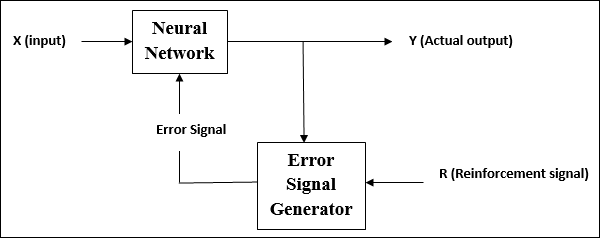
Chức năng kích hoạt
Nó có thể được định nghĩa là lực hoặc nỗ lực bổ sung tác dụng lên đầu vào để có được đầu ra chính xác. Trong ANN, chúng tôi cũng có thể áp dụng các hàm kích hoạt trên đầu vào để có được đầu ra chính xác. Tiếp theo là một số chức năng kích hoạt được quan tâm -
Chức năng kích hoạt tuyến tính
Nó còn được gọi là hàm nhận dạng vì nó không thực hiện chỉnh sửa đầu vào. Nó có thể được định nghĩa là -
$$ F (x) \: = \: x $$
Chức năng kích hoạt Sigmoid
Nó có hai loại như sau:
Binary sigmoidal function- Chức năng kích hoạt này thực hiện chỉnh sửa đầu vào từ 0 đến 1. Bản chất là tích cực. Nó luôn có giới hạn, có nghĩa là đầu ra của nó không được nhỏ hơn 0 và lớn hơn 1. Về bản chất, nó cũng đang tăng lên một cách nghiêm ngặt, có nghĩa là càng nhiều đầu vào cao hơn sẽ là đầu ra. Nó có thể được định nghĩa là
$$ F (x) \: = \: sigm (x) \: = \: \ frac {1} {1 \: + \: exp (-x)} $$
Bipolar sigmoidal function- Chức năng kích hoạt này thực hiện chỉnh sửa đầu vào giữa -1 và 1. Nó có thể là tích cực hoặc tiêu cực về bản chất. Nó luôn có giới hạn, có nghĩa là đầu ra của nó không thể nhỏ hơn -1 và nhiều hơn 1. Nó cũng đang tăng dần về bản chất giống như hàm sigmoid. Nó có thể được định nghĩa là
$$ F (x) \: = \: sigm (x) \: = \: \ frac {2} {1 \: + \: exp (-x)} \: - \: 1 \: = \: \ frac {1 \: - \: exp (x)} {1 \: + \: exp (x)} $$
Như đã nói trước đó, ANN hoàn toàn được lấy cảm hứng từ cách hệ thống thần kinh sinh học, tức là bộ não con người hoạt động. Đặc điểm ấn tượng nhất của bộ não con người là học hỏi, do đó ANN có được tính năng tương tự.
Học trong ANN là gì?
Về cơ bản, học tập có nghĩa là thực hiện và thích ứng với sự thay đổi của chính nó khi có sự thay đổi trong môi trường. ANN là một hệ thống phức tạp hay chính xác hơn chúng ta có thể nói rằng nó là một hệ thống thích ứng phức tạp, có thể thay đổi cấu trúc bên trong của nó dựa trên thông tin đi qua nó.
Tại sao nó lại quan trọng?
Là một hệ thống thích ứng phức tạp, học trong ANN ngụ ý rằng một đơn vị xử lý có khả năng thay đổi hành vi đầu vào / đầu ra của nó do sự thay đổi của môi trường. Tầm quan trọng của việc học trong ANN tăng lên do chức năng kích hoạt cố định cũng như vector đầu vào / đầu ra, khi một mạng cụ thể được xây dựng. Bây giờ để thay đổi hành vi đầu vào / đầu ra, chúng ta cần điều chỉnh trọng số.
Phân loại
Nó có thể được định nghĩa là quá trình học cách phân biệt dữ liệu của các mẫu thành các lớp khác nhau bằng cách tìm ra các đặc điểm chung giữa các mẫu của cùng các lớp. Ví dụ: để thực hiện đào tạo ANN, chúng tôi có một số mẫu đào tạo với các tính năng độc đáo và để thực hiện kiểm tra, chúng tôi có một số mẫu thử nghiệm với các tính năng độc đáo khác. Phân loại là một ví dụ về học có giám sát.
Quy tắc học tập mạng thần kinh
Chúng tôi biết rằng, trong quá trình học ANN, để thay đổi hành vi đầu vào / đầu ra, chúng tôi cần điều chỉnh trọng số. Do đó, cần có một phương pháp với sự trợ giúp của trọng số có thể được sửa đổi. Các phương pháp này được gọi là Học quy tắc, đơn giản là các thuật toán hoặc phương trình. Sau đây là một số quy tắc học tập cho mạng nơ-ron:
Quy tắc học tiếng Hebbian
Quy tắc này, một trong những quy tắc lâu đời nhất và đơn giản nhất, đã được Donald Hebb giới thiệu trong cuốn sách Tổ chức hành vi của ông vào năm 1949. Đây là một kiểu học tập tiến lên, không giám sát.
Basic Concept - Quy tắc này dựa trên một đề xuất do Hebb đưa ra, người đã viết -
“Khi một sợi trục của tế bào A ở gần đủ để kích thích tế bào B và liên tục hoặc liên tục tham gia vào quá trình kích hoạt nó, một số quá trình tăng trưởng hoặc thay đổi trao đổi chất diễn ra ở một hoặc cả hai tế bào sao cho hiệu quả của tế bào A, khi một trong các tế bào bắn ra B , được tăng lên. ”
Từ định đề trên, chúng ta có thể kết luận rằng các kết nối giữa hai tế bào thần kinh có thể được củng cố nếu các tế bào thần kinh hoạt động cùng một lúc và có thể yếu đi nếu chúng hoạt động vào những thời điểm khác nhau.
Mathematical Formulation - Theo quy tắc học Hebbian, sau đây là công thức để tăng trọng số của kết nối tại mỗi bước thời gian.
$$ \ Delta w_ {ji} (t) \: = \: \ alpha x_ {i} (t) .y_ {j} (t) $$
Ở đây, $ \ Delta w_ {ji} (t) $ = gia số theo đó trọng lượng của kết nối tăng lên tại bước thời gian t
$ \ alpha $ = tỷ lệ học tập tích cực và liên tục
$ x_ {i} (t) $ = giá trị đầu vào từ nơ-ron tiền synap ở bước thời gian t
$ y_ {i} (t) $ = đầu ra của nơ-ron tiền synap ở cùng một bước t
Quy tắc học tập Perceptron
Quy tắc này là một lỗi sửa chữa thuật toán học có giám sát của các mạng truyền thẳng lớp đơn với chức năng kích hoạt tuyến tính, được giới thiệu bởi Rosenblatt.
Basic Concept- Bản chất là được giám sát, để tính toán sai số, sẽ có sự so sánh giữa đầu ra mong muốn / mục tiêu và đầu ra thực tế. Nếu có bất kỳ sự khác biệt nào được tìm thấy, thì phải thực hiện thay đổi đối với trọng số của kết nối.
Mathematical Formulation - Để giải thích công thức toán học của nó, giả sử chúng ta có 'n' số vectơ đầu vào hữu hạn, x (n), cùng với vectơ đầu ra mong muốn / đích của nó t (n), trong đó n = 1 đến N.
Bây giờ đầu ra 'y' có thể được tính toán, như đã giải thích trước đó trên cơ sở đầu vào ròng và hàm kích hoạt đang được áp dụng trên đầu vào ròng đó có thể được biểu thị như sau:
$$ y \: = \: f (y_ {in}) \: = \: \ begin {case} 1, & y_ {in} \:> \: \ theta \\ 0, & y_ {in} \: \ leqslant \: \ theta \ end {case} $$
Ở đâu θ là ngưỡng.
Việc cập nhật trọng lượng có thể được thực hiện trong hai trường hợp sau:
Case I - khi nào t ≠ y, sau đó
$$ w (mới) \: = \: w (cũ) \: + \; tx $$
Case II - khi nào t = y, sau đó
Không thay đổi trọng lượng
Quy tắc học tập Delta (Quy tắc Widrow-Hoff)
Nó được giới thiệu bởi Bernard Widrow và Marcian Hoff, còn được gọi là phương pháp Least Mean Square (LMS), để giảm thiểu sai số trên tất cả các mẫu huấn luyện. Nó là một loại thuật toán học có giám sát với chức năng kích hoạt liên tục.
Basic Concept- Cơ sở của quy tắc này là phương pháp tiếp cận gradient-descent, tiếp cận mãi mãi. Quy tắc Delta cập nhật trọng số của khớp thần kinh để giảm thiểu đầu vào ròng cho đơn vị đầu ra và giá trị đích.
Mathematical Formulation - Để cập nhật trọng số synap, quy tắc delta được đưa ra bởi
$$ \ Delta w_ {i} \: = \: \ alpha \:. X_ {i} .e_ {j} $$
Đây $ \ Delta w_ {i} $ = thay đổi trọng lượng cho thứ pattern của tôi ;
$ \ alpha $ = tỷ lệ học tập tích cực và liên tục;
$ x_ {i} $ = giá trị đầu vào từ nơ-ron trước synap;
$ e_ {j} $ = $ (t \: - \: y_ {in}) $, sự khác biệt giữa đầu ra mong muốn / mục tiêu và đầu ra thực tế $ y_ {in} $
Quy tắc delta ở trên chỉ dành cho một đơn vị đầu ra duy nhất.
Việc cập nhật trọng lượng có thể được thực hiện trong hai trường hợp sau:
Case-I - khi nào t ≠ y, sau đó
$$ w (mới) \: = \: w (cũ) \: + \: \ Delta w $$
Case-II - khi nào t = y, sau đó
Không thay đổi trọng lượng
Quy tắc học tập cạnh tranh (Người thắng-giành-tất cả)
Nó liên quan đến việc đào tạo không có giám sát, trong đó các nút đầu ra cố gắng cạnh tranh với nhau để đại diện cho mẫu đầu vào. Để hiểu quy tắc học tập này, chúng ta phải hiểu mạng cạnh tranh được đưa ra như sau:
Basic Concept of Competitive Network- Mạng này giống như một mạng chuyển tiếp một lớp với kết nối phản hồi giữa các đầu ra. Các kết nối giữa các đầu ra là kiểu ức chế, được thể hiện bằng các đường chấm, có nghĩa là các đối thủ không bao giờ hỗ trợ mình.
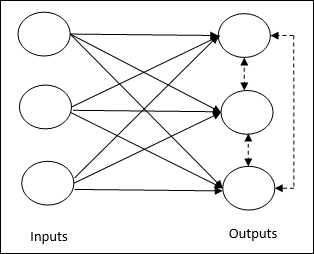
Basic Concept of Competitive Learning Rule- Như đã nói trước đó, sẽ có sự cạnh tranh giữa các nút đầu ra. Do đó, khái niệm chính là trong quá trình đào tạo, đơn vị đầu ra có kích hoạt cao nhất đối với một mẫu đầu vào nhất định, sẽ được tuyên bố là người chiến thắng. Quy tắc này còn được gọi là Winner-take-all vì chỉ có nơ-ron chiến thắng được cập nhật và các nơ-ron còn lại không thay đổi.
Mathematical formulation - Sau đây là ba yếu tố quan trọng để lập công thức toán học của quy tắc học tập này -
Condition to be a winner - Giả sử nếu một nơ-ron $ y_ {k} $ muốn trở thành người chiến thắng thì sẽ có điều kiện sau:
$$ y_ {k} \: = \: \ begin {case} 1 & if \: v_ {k} \:> \: v_ {j} \: cho \: tất cả \: j, \: j \: \ neq \: k \\ 0 và nếu không thì \ end {case} $$
Có nghĩa là nếu bất kỳ nơ-ron nào, chẳng hạn $ y_ {k} $ , muốn giành chiến thắng, thì trường cục bộ cảm ứng của nó (đầu ra của đơn vị tính tổng), ví dụ $ v_ {k} $, phải lớn nhất trong số tất cả các nơ-ron khác trong mạng.
Condition of sum total of weight - Một hạn chế khác đối với quy tắc học cạnh tranh là, tổng tổng trọng số của một nơ-ron đầu ra cụ thể sẽ là 1. Ví dụ, nếu chúng ta xem xét nơ-ron k sau đó -
$$ \ displaystyle \ sum \ limit_ {j} w_ {kj} \: = \: 1 \: \: \: \: \: \: \: \: \: \: cho \: tất cả \: k $$
Change of weight for winner- Nếu một tế bào thần kinh không đáp ứng với mẫu đầu vào, thì không có học tập nào diễn ra trong tế bào thần kinh đó. Tuy nhiên, nếu một nơron cụ thể thắng, thì trọng số tương ứng được điều chỉnh như sau
$$ \ Delta w_ {kj} \: = \: \ begin {case} - \ alpha (x_ {j} \: - \: w_ {kj}) và if \: neuron \: k \: win \\ 0, & if \: neuron \: k \: lỗ \ end {case} $$
Đây $ \ alpha $ là tỷ lệ học tập.
Điều này cho thấy rõ ràng rằng chúng ta đang ủng hộ nơ-ron chiến thắng bằng cách điều chỉnh trọng lượng của nó và nếu nơ-ron bị mất đi thì chúng ta không cần phải điều chỉnh lại trọng lượng của nó.
Quy tắc học tập Outstar
Quy tắc này, được giới thiệu bởi Grossberg, liên quan đến việc học có giám sát vì các đầu ra mong muốn đã được biết trước. Nó còn được gọi là học Grossberg.
Basic Concept- Quy tắc này được áp dụng trên các tế bào thần kinh được sắp xếp trong một lớp. Nó được thiết kế đặc biệt để tạo ra đầu ra mong muốnd của lớp p tế bào thần kinh.
Mathematical Formulation - Các điều chỉnh trọng lượng trong quy tắc này được tính như sau
$$ \ Delta w_ {j} \: = \: \ alpha \ :( d \: - \: w_ {j}) $$
Đây d là đầu ra nơ-ron mong muốn và $ \ alpha $ là tốc độ học.
Như tên cho thấy, supervised learningdiễn ra dưới sự giám sát của một giáo viên. Quá trình học tập này là phụ thuộc. Trong quá trình đào tạo ANN theo phương pháp học có giám sát, vectơ đầu vào được trình bày cho mạng, vectơ này sẽ tạo ra một vectơ đầu ra. Vectơ đầu ra này được so sánh với vectơ đầu ra mong muốn / mục tiêu. Tín hiệu lỗi được tạo ra nếu có sự khác biệt giữa đầu ra thực tế và vector đầu ra mong muốn / đích. Trên cơ sở của tín hiệu lỗi này, trọng số sẽ được điều chỉnh cho đến khi đầu ra thực tế khớp với đầu ra mong muốn.
Perceptron
Được phát triển bởi Frank Rosenblatt bằng cách sử dụng mô hình McCulloch và Pitts, perceptron là đơn vị hoạt động cơ bản của mạng nơ-ron nhân tạo. Nó sử dụng quy tắc học có giám sát và có thể phân loại dữ liệu thành hai lớp.
Đặc điểm hoạt động của tế bào cảm thụ: Nó bao gồm một tế bào thần kinh duy nhất với số lượng đầu vào tùy ý cùng với trọng lượng có thể điều chỉnh, nhưng đầu ra của tế bào thần kinh là 1 hoặc 0 tùy thuộc vào ngưỡng. Nó cũng bao gồm một sai lệch có trọng số luôn là 1. Hình dưới đây cho ta biểu diễn giản đồ của perceptron.
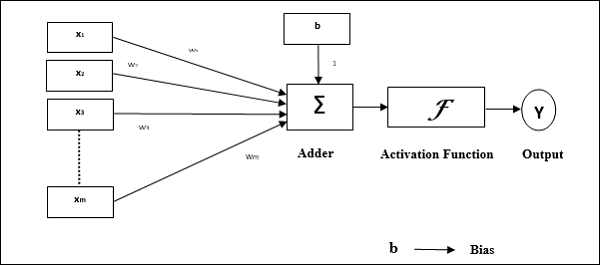
Do đó, Perceptron có ba phần tử cơ bản sau:
Links - Nó sẽ có một tập hợp các liên kết kết nối, mang trọng số bao gồm thiên vị luôn có trọng số 1.
Adder - Nó thêm đầu vào sau khi chúng được nhân với trọng số tương ứng của chúng.
Activation function- Nó giới hạn đầu ra của nơron. Chức năng kích hoạt cơ bản nhất là chức năng bước Heaviside có hai đầu ra có thể. Hàm này trả về 1, nếu đầu vào là dương và 0 đối với bất kỳ đầu vào âm nào.
Thuật toán đào tạo
Mạng Perceptron có thể được huấn luyện cho đơn vị đầu ra duy nhất cũng như nhiều đơn vị đầu ra.
Thuật toán đào tạo cho đơn vị đầu ra đơn
Step 1 - Khởi tạo phần sau để bắt đầu đào tạo -
- Weights
- Bias
- Tỷ lệ học tập $ \ alpha $
Để dễ tính toán và đơn giản, trọng số và độ lệch phải được đặt bằng 0 và tốc độ học tập phải được đặt bằng 1.
Step 2 - Tiếp tục bước 3-8 khi điều kiện dừng không đúng.
Step 3 - Tiếp tục bước 4-6 cho mọi vector đào tạo x.
Step 4 - Kích hoạt từng đơn vị đầu vào như sau -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: to \: n) $$
Step 5 - Bây giờ lấy đầu vào ròng với quan hệ sau:
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i}. \: w_ {i} $$
Đây ‘b’ là thiên vị và ‘n’ là tổng số nơ-ron đầu vào.
Step 6 - Áp dụng chức năng kích hoạt sau để có được kết quả cuối cùng.
$$ f (y_ {in}) \: = \: \ begin {case} 1 & if \: y_ {in} \:> \: \ theta \\ 0 & if \: - \ theta \: \ leqslant \ : y_ {in} \: \ leqslant \: \ theta \\ - 1 & if \: y_ {in} \: <\: - \ theta \ end {case} $$
Step 7 - Điều chỉnh trọng lượng và độ chệch như sau -
Case 1 - nếu y ≠ t sau đó,
$$ w_ {i} (mới) \: = \: w_ {i} (cũ) \: + \: \ alpha \: tx_ {i} $$
$$ b (mới) \: = \: b (cũ) \: + \: \ alpha t $$
Case 2 - nếu y = t sau đó,
$$ w_ {i} (mới) \: = \: w_ {i} (cũ) $$
$$ b (mới) \: = \: b (cũ) $$
Đây ‘y’ là sản lượng thực tế và ‘t’ là đầu ra mong muốn / mục tiêu.
Step 8 - Kiểm tra điều kiện dừng, sẽ xảy ra khi không có sự thay đổi về trọng lượng.
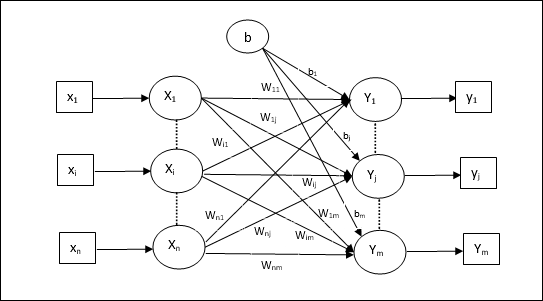
Thuật toán đào tạo cho nhiều đơn vị đầu ra
Sơ đồ sau là kiến trúc của perceptron cho nhiều lớp đầu ra.
Step 1 - Khởi tạo phần sau để bắt đầu đào tạo -
- Weights
- Bias
- Tỷ lệ học tập $ \ alpha $
Để dễ tính toán và đơn giản, trọng số và độ lệch phải được đặt bằng 0 và tốc độ học tập phải được đặt bằng 1.
Step 2 - Tiếp tục bước 3-8 khi điều kiện dừng không đúng.
Step 3 - Tiếp tục bước 4-6 cho mọi vector đào tạo x.
Step 4 - Kích hoạt từng đơn vị đầu vào như sau -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: to \: n) $$
Step 5 - Lấy đầu vào ròng với mối quan hệ sau:
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i} \: w_ {ij} $$
Đây ‘b’ là thiên vị và ‘n’ là tổng số nơ-ron đầu vào.
Step 6 - Áp dụng chức năng kích hoạt sau để có được đầu ra cuối cùng cho mỗi đơn vị đầu ra j = 1 to m -
$$ f (y_ {in}) \: = \: \ begin {case} 1 & if \: y_ {secure} \:> \: \ theta \\ 0 & if \: - \ theta \: \ leqslant \ : y_ {secure} \: \ leqslant \: \ theta \\ - 1 & if \: y_ {secure} \: <\: - \ theta \ end {case} $$
Step 7 - Điều chỉnh trọng lượng và thiên vị cho x = 1 to n và j = 1 to m như sau -
Case 1 - nếu yj ≠ tj sau đó,
$$ w_ {ij} (mới) \: = \: w_ {ij} (cũ) \: + \: \ alpha \: t_ {j} x_ {i} $$
$$ b_ {j} (mới) \: = \: b_ {j} (cũ) \: + \: \ alpha t_ {j} $$
Case 2 - nếu yj = tj sau đó,
$$ w_ {ij} (mới) \: = \: w_ {ij} (cũ) $$
$$ b_ {j} (mới) \: = \: b_ {j} (cũ) $$
Đây ‘y’ là sản lượng thực tế và ‘t’ là đầu ra mong muốn / mục tiêu.
Step 8 - Kiểm tra điều kiện dừng, sẽ xảy ra khi không có sự thay đổi về trọng lượng.
Neuron tuyến tính thích ứng (Adaline)
Adaline là viết tắt của Adaptive Linear Neuron, là một mạng có một đơn vị tuyến tính duy nhất. Nó được phát triển bởi Widrow và Hoff vào năm 1960. Một số điểm quan trọng về Adaline như sau:
Nó sử dụng chức năng kích hoạt lưỡng cực.
Nó sử dụng quy tắc delta để đào tạo nhằm giảm thiểu Sai số trung bình bình phương (MSE) giữa đầu ra thực tế và đầu ra mong muốn / mục tiêu.
Có thể điều chỉnh trọng lượng và độ lệch.
Ngành kiến trúc
Cấu trúc cơ bản của Adaline tương tự như perceptron có thêm một vòng phản hồi với sự trợ giúp của đầu ra thực tế được so sánh với đầu ra mong muốn / mục tiêu. Sau khi so sánh trên cơ sở thuật toán huấn luyện, trọng số và độ lệch sẽ được cập nhật.
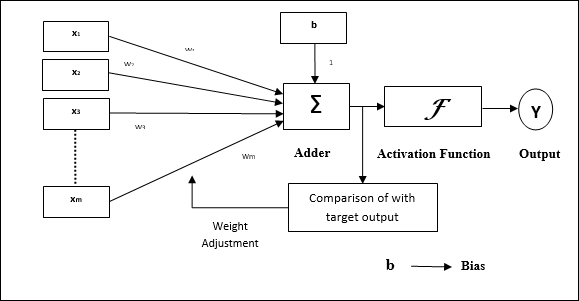
Thuật toán đào tạo
Step 1 - Khởi tạo phần sau để bắt đầu đào tạo -
- Weights
- Bias
- Tỷ lệ học tập $ \ alpha $
Để dễ tính toán và đơn giản, trọng số và độ lệch phải được đặt bằng 0 và tốc độ học tập phải được đặt bằng 1.
Step 2 - Tiếp tục bước 3-8 khi điều kiện dừng không đúng.
Step 3 - Tiếp tục bước 4-6 cho mỗi cặp huấn luyện lưỡng cực s:t.
Step 4 - Kích hoạt từng đơn vị đầu vào như sau -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: to \: n) $$
Step 5 - Lấy đầu vào ròng với mối quan hệ sau:
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i} \: w_ {i} $$
Đây ‘b’ là thiên vị và ‘n’ là tổng số nơ-ron đầu vào.
Step 6 - Áp dụng chức năng kích hoạt sau để có được kết quả cuối cùng -
$$ f (y_ {in}) \: = \: \ begin {case} 1 & if \: y_ {in} \: \ geqslant \: 0 \\ - 1 & if \: y_ {in} \: < \: 0 \ end {case} $$
Step 7 - Điều chỉnh trọng lượng và độ chệch như sau -
Case 1 - nếu y ≠ t sau đó,
$$ w_ {i} (mới) \: = \: w_ {i} (cũ) \: + \: \ alpha (t \: - \: y_ {in}) x_ {i} $$
$$ b (mới) \: = \: b (cũ) \: + \: \ alpha (t \: - \: y_ {in}) $$
Case 2 - nếu y = t sau đó,
$$ w_ {i} (mới) \: = \: w_ {i} (cũ) $$
$$ b (mới) \: = \: b (cũ) $$
Đây ‘y’ là sản lượng thực tế và ‘t’ là đầu ra mong muốn / mục tiêu.
$ (t \: - \; y_ {in}) $ là lỗi tính toán.
Step 8 - Kiểm tra điều kiện dừng, sẽ xảy ra khi không có sự thay đổi trọng lượng hoặc sự thay đổi trọng lượng cao nhất xảy ra trong quá trình tập luyện nhỏ hơn dung sai quy định.
Nhiều nơron tuyến tính thích ứng (Madaline)
Madaline là viết tắt của Multiple Adaptive Linear Neuron, là một mạng bao gồm nhiều Adaline song song. Nó sẽ có một đơn vị đầu ra duy nhất. Một số điểm quan trọng về Madaline như sau:
Nó giống như một perceptron nhiều lớp, nơi Adaline sẽ hoạt động như một đơn vị ẩn giữa đầu vào và lớp Madaline.
Trọng số và độ lệch giữa các lớp đầu vào và Adaline, như chúng ta thấy trong kiến trúc Adaline, có thể điều chỉnh được.
Các lớp Adaline và Madaline có trọng lượng cố định và độ lệch là 1.
Việc đào tạo có thể được thực hiện với sự trợ giúp của quy tắc Delta.
Ngành kiến trúc
Kiến trúc của Madaline bao gồm “n” tế bào thần kinh của lớp đầu vào, “m”tế bào thần kinh của lớp Adaline, và 1 tế bào thần kinh của lớp Madaline. Lớp Adaline có thể được coi là lớp ẩn vì nó nằm giữa lớp đầu vào và lớp đầu ra, tức là lớp Madaline.
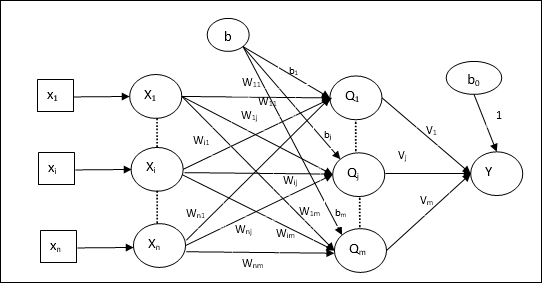
Thuật toán đào tạo
Bây giờ chúng ta biết rằng chỉ có trọng số và độ lệch giữa đầu vào và lớp Adaline mới được điều chỉnh, còn trọng số và độ lệch giữa Adaline và lớp Madaline được cố định.
Step 1 - Khởi tạo phần sau để bắt đầu đào tạo -
- Weights
- Bias
- Tỷ lệ học tập $ \ alpha $
Để dễ tính toán và đơn giản, trọng số và độ lệch phải được đặt bằng 0 và tốc độ học tập phải được đặt bằng 1.
Step 2 - Tiếp tục bước 3-8 khi điều kiện dừng không đúng.
Step 3 - Tiếp tục bước 4-6 cho mỗi cặp huấn luyện lưỡng cực s:t.
Step 4 - Kích hoạt từng đơn vị đầu vào như sau -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: to \: n) $$
Step 5 - Lấy đầu vào ròng tại mỗi lớp ẩn, tức là lớp Adaline với mối quan hệ sau:
$$ Q_ {secure} \: = \: b_ {j} \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i} \: w_ {ij} \: \: \: j \: = \: 1 \: tới \: m $$
Đây ‘b’ là thiên vị và ‘n’ là tổng số nơ-ron đầu vào.
Step 6 - Áp dụng chức năng kích hoạt sau để có được kết quả cuối cùng ở lớp Adaline và lớp Madaline -
$$ f (x) \: = \: \ begin {case} 1 & if \: x \: \ geqslant \: 0 \\ - 1 & if \: x \: <\: 0 \ end {case} $ $
Đầu ra ở đơn vị ẩn (Adaline)
$$ Q_ {j} \: = \: f (Q_ {cast}) $$
Đầu ra cuối cùng của mạng
$$ y \: = \: f (y_ {in}) $$
i.e. $ \: \: y_ {cast} \: = \: b_ {0} \: + \: \ sum_ {j = 1} ^ m \: Q_ {j} \: v_ {j} $
Step 7 - Tính sai số và điều chỉnh trọng số như sau -
Case 1 - nếu y ≠ t và t = 1 sau đó,
$$ w_ {ij} (mới) \: = \: w_ {ij} (cũ) \: + \: \ alpha (1 \: - \: Q_ {inv}) x_ {i} $$
$$ b_ {j} (mới) \: = \: b_ {j} (cũ) \: + \: \ alpha (1 \: - \: Q_ {tiêm}) $$
Trong trường hợp này, trọng số sẽ được cập nhật trên Qj trong đó đầu vào ròng gần bằng 0 vì t = 1.
Case 2 - nếu y ≠ t và t = -1 sau đó,
$$ w_ {ik} (mới) \: = \: w_ {ik} (cũ) \: + \: \ alpha (-1 \: - \: Q_ {ink}) x_ {i} $$
$$ b_ {k} (mới) \: = \: b_ {k} (cũ) \: + \: \ alpha (-1 \: - \: Q_ {ink}) $$
Trong trường hợp này, trọng số sẽ được cập nhật trên Qk trong đó đầu vào ròng là dương vì t = -1.
Đây ‘y’ là sản lượng thực tế và ‘t’ là đầu ra mong muốn / mục tiêu.
Case 3 - nếu y = t sau đó
Sẽ không có thay đổi về trọng lượng.
Step 8 - Kiểm tra điều kiện dừng, sẽ xảy ra khi không có sự thay đổi trọng lượng hoặc sự thay đổi trọng lượng cao nhất xảy ra trong quá trình tập luyện nhỏ hơn dung sai quy định.
Mạng thần kinh lan truyền trở lại
Mạng nơ ron truyền ngược (BPN) là một mạng nơ ron đa lớp bao gồm lớp đầu vào, ít nhất một lớp ẩn và lớp đầu ra. Như tên gọi của nó cho thấy, truyền ngược sẽ diễn ra trong mạng này. Lỗi được tính toán ở lớp đầu ra, bằng cách so sánh đầu ra mục tiêu và đầu ra thực tế, sẽ được truyền ngược trở lại lớp đầu vào.
Ngành kiến trúc
Như thể hiện trong sơ đồ, kiến trúc của BPN có ba lớp liên kết với nhau có trọng số trên chúng. Lớp ẩn cũng như lớp đầu ra cũng có độ lệch, có trọng số luôn là 1 trên chúng. Như đã thấy rõ từ sơ đồ, hoạt động của BPN gồm hai giai đoạn. Một pha gửi tín hiệu từ lớp đầu vào đến lớp đầu ra, và pha kia truyền lại lỗi từ lớp đầu ra đến lớp đầu vào.

Thuật toán đào tạo
Để đào tạo, BPN sẽ sử dụng chức năng kích hoạt sigmoid nhị phân. Việc đào tạo BPN sẽ có ba giai đoạn sau.
Phase 1 - Giai đoạn chuyển tiếp nguồn cấp dữ liệu
Phase 2 - Lùi lại lỗi lan truyền
Phase 3 - Cập nhật trọng lượng
Tất cả các bước này sẽ được kết luận trong thuật toán như sau
Step 1 - Khởi tạo phần sau để bắt đầu đào tạo -
- Weights
- Tỷ lệ học tập $ \ alpha $
Để dễ dàng tính toán và đơn giản, hãy lấy một số giá trị ngẫu nhiên nhỏ.
Step 2 - Tiếp tục bước 3-11 khi điều kiện dừng không đúng.
Step 3 - Tiếp tục bước 4-10 cho mỗi cặp huấn luyện.
Giai đoạn 1
Step 4 - Mỗi đơn vị đầu vào nhận tín hiệu đầu vào xi và gửi nó đến đơn vị ẩn cho tất cả i = 1 to n
Step 5 - Tính toán đầu vào ròng tại đơn vị ẩn theo quan hệ sau:
$$ Q_ {secure} \: = \: b_ {0j} \: + \: \ sum_ {i = 1} ^ n x_ {i} v_ {ij} \: \: \: \: \: j \: = \ : 1 \: đến \: p $$
Đây b0j là thiên vị về đơn vị ẩn, vij trọng lượng trên j đơn vị của lớp ẩn đến từ i đơn vị của lớp đầu vào.
Bây giờ hãy tính toán sản lượng ròng bằng cách áp dụng hàm kích hoạt sau
$$ Q_ {j} \: = \: f (Q_ {cast}) $$
Gửi các tín hiệu đầu ra này của các đơn vị lớp ẩn tới các đơn vị lớp đầu ra.
Step 6 - Tính toán đầu vào ròng tại đơn vị lớp đầu ra theo quan hệ sau:
$$ y_ {ink} \: = \: b_ {0k} \: + \: \ sum_ {j = 1} ^ p \: Q_ {j} \: w_ {jk} \: \: k \: = \ : 1 \: đến \: m $$
Đây b0k Là sai lệch về đơn vị đầu ra, wjk trọng lượng trên k đơn vị của lớp đầu ra đến từ j đơn vị của lớp ẩn.
Tính toán sản lượng ròng bằng cách áp dụng chức năng kích hoạt sau
$$ y_ {k} \: = \: f (y_ {ink}) $$
Giai đoạn 2
Step 7 - Tính toán thời hạn sửa lỗi, tương ứng với mẫu đích nhận được ở mỗi đơn vị đầu ra, như sau:
$$ \ delta_ {k} \: = \ :( t_ {k} \: - \: y_ {k}) f ^ {'} (y_ {ink}) $$
Trên cơ sở này, cập nhật trọng số và độ chệch như sau:
$$ \ Delta v_ {jk} \: = \: \ alpha \ delta_ {k} \: Q_ {ij} $$
$$ \ Delta b_ {0k} \: = \: \ alpha \ delta_ {k} $$
Sau đó, gửi $ \ delta_ {k} $ trở lại lớp ẩn.
Step 8 - Bây giờ mỗi đơn vị ẩn sẽ là tổng các đầu vào delta của nó từ các đơn vị đầu ra.
$$ \ delta_ {secure} \: = \: \ displaystyle \ sum \ limit_ {k = 1} ^ m \ delta_ {k} \: w_ {jk} $$
Thuật ngữ lỗi có thể được tính như sau:
$$ \ delta_ {j} \: = \: \ delta_ {casting} f ^ {'} (Q_ {inv}) $$
Trên cơ sở này, cập nhật trọng số và độ chệch như sau:
$$ \ Delta w_ {ij} \: = \: \ alpha \ delta_ {j} x_ {i} $$
$$ \ Delta b_ {0j} \: = \: \ alpha \ delta_ {j} $$
Giai đoạn 3
Step 9 - Mỗi đơn vị đầu ra (ykk = 1 to m) cập nhật trọng lượng và độ lệch như sau:
$$ v_ {jk} (mới) \: = \: v_ {jk} (cũ) \: + \: \ Delta v_ {jk} $$
$$ b_ {0k} (mới) \: = \: b_ {0k} (cũ) \: + \: \ Delta b_ {0k} $$
Step 10 - Mỗi đơn vị đầu ra (zjj = 1 to p) cập nhật trọng lượng và độ lệch như sau:
$$ w_ {ij} (mới) \: = \: w_ {ij} (cũ) \: + \: \ Delta w_ {ij} $$
$$ b_ {0j} (mới) \: = \: b_ {0j} (cũ) \: + \: \ Delta b_ {0j} $$
Step 11 - Kiểm tra điều kiện dừng, có thể là số kỷ nguyên đã đạt được hoặc đầu ra mục tiêu khớp với đầu ra thực tế.
Quy tắc học tập Delta tổng quát
Quy tắc Delta chỉ hoạt động cho lớp đầu ra. Mặt khác, quy tắc đồng bằng tổng quát, còn được gọi làback-propagation là một cách tạo ra các giá trị mong muốn của lớp ẩn.
Công thức toán học
Đối với chức năng kích hoạt $ y_ {k} \: = \: f (y_ {ink}) $, dẫn xuất của đầu vào ròng trên lớp Ẩn cũng như trên lớp đầu ra có thể được cung cấp bởi
$$ y_ {ink} \: = \: \ displaystyle \ sum \ limit_i \: z_ {i} w_ {jk} $$
Và $ \: \: y_ {inv} \: = \: \ sum_i x_ {i} v_ {ij} $
Bây giờ, lỗi phải được giảm thiểu là
$$ E \: = \: \ frac {1} {2} \ displaystyle \ sum \ limit_ {k} \: [t_ {k} \: - \: y_ {k}] ^ 2 $$
Bằng cách sử dụng quy tắc chuỗi, chúng tôi có
$$ \ frac {\ một phần E} {\ một phần w_ {jk}} \: = \: \ frac {\ một phần} {\ một phần w_ {jk}} (\ frac {1} {2} \ displaystyle \ sum \ giới hạn_ {k} \: [t_ {k} \: - \: y_ {k}] ^ 2) $$
$$ = \: \ frac {\ part} {\ một phần w_ {jk}} \ lgroup \ frac {1} {2} [t_ {k} \: - \: t (y_ {ink})] ^ 2 \ rgroup $$
$$ = \: - [t_ {k} \: - \: y_ {k}] \ frac {\ part} {\ một phần w_ {jk}} f (y_ {ink}) $$
$$ = \: - [t_ {k} \: - \: y_ {k}] f (y_ {ink}) \ frac {\ part} {\ part w_ {jk}} (y_ {ink}) $$
$$ = \: - [t_ {k} \: - \: y_ {k}] f ^ {'} (y_ {ink}) z_ {j} $$
Bây giờ chúng ta hãy nói $ \ delta_ {k} \: = \: - [t_ {k} \: - \: y_ {k}] f ^ {'} (y_ {ink}) $
Trọng lượng của các kết nối với thiết bị ẩn zj có thể được đưa ra bởi -
$$ \ frac {\ một phần E} {\ một phần v_ {ij}} \: = \: - \ displaystyle \ sum \ limit_ {k} \ delta_ {k} \ frac {\ một phần} {\ một phần v_ {ij} } \ :( y_ {ink}) $$
Đặt giá trị $ y_ {ink} $ chúng ta sẽ nhận được những điều sau
$$ \ delta_ {j} \: = \: - \ displaystyle \ sum \ limit_ {k} \ delta_ {k} w_ {jk} f ^ {'} (z_ {secure}) $$
Việc cập nhật trọng lượng có thể được thực hiện như sau:
Đối với đơn vị đầu ra -
$$ \ Delta w_ {jk} \: = \: - \ alpha \ frac {\ một phần E} {\ một phần w_ {jk}} $$
$$ = \: \ alpha \: \ delta_ {k} \: z_ {j} $$
Đối với đơn vị ẩn -
$$ \ Delta v_ {ij} \: = \: - \ alpha \ frac {\ một phần E} {\ một phần v_ {ij}} $$
$$ = \: \ alpha \: \ delta_ {j} \: x_ {i} $$
Như tên cho thấy, loại hình học tập này được thực hiện mà không có sự giám sát của giáo viên. Quá trình học tập này là độc lập. Trong quá trình đào tạo ANN dưới sự học tập không giám sát, các vectơ đầu vào cùng loại được kết hợp để tạo thành các cụm. Khi một mẫu đầu vào mới được áp dụng, thì mạng nơ ron sẽ đưa ra phản hồi đầu ra cho biết lớp mà mẫu đầu vào thuộc về. Trong điều này, sẽ không có phản hồi từ môi trường về những gì nên là đầu ra mong muốn và liệu nó đúng hay sai. Do đó, trong kiểu học này, bản thân mạng phải khám phá ra các mẫu, các tính năng từ dữ liệu đầu vào và mối quan hệ giữa dữ liệu đầu vào với đầu ra.
Người chiến thắng-giành-tất cả các mạng
Các loại mạng này dựa trên quy tắc học tập cạnh tranh và sẽ sử dụng chiến lược trong đó nó chọn nơ-ron có tổng đầu vào lớn nhất làm người chiến thắng. Các kết nối giữa các nơ-ron đầu ra cho thấy sự cạnh tranh giữa chúng và một trong số chúng sẽ là 'BẬT' có nghĩa là nó sẽ là người chiến thắng và những tế bào khác sẽ là 'TẮT'.
Sau đây là một số mạng dựa trên khái niệm đơn giản này bằng cách sử dụng phương pháp học không giám sát.
Mạng lưới Hamming
Trong hầu hết các mạng nơ-ron sử dụng phương pháp học không giám sát, điều cần thiết là phải tính khoảng cách và thực hiện so sánh. Loại mạng này là mạng Hamming, trong đó đối với mỗi vectơ đầu vào nhất định, nó sẽ được nhóm lại thành các nhóm khác nhau. Sau đây là một số tính năng quan trọng của Hamming Networks:
Lippmann bắt đầu làm việc trên mạng Hamming vào năm 1987.
Nó là một mạng một lớp.
Các đầu vào có thể là nhị phân {0, 1} của lưỡng cực {-1, 1}.
Trọng lượng của lưới được tính bằng các vectơ mẫu.
Nó là một mạng lưới trọng lượng cố định có nghĩa là trọng lượng sẽ không thay đổi ngay cả trong khi tập luyện.
Mạng tối đa
Đây cũng là một mạng trọng số cố định, đóng vai trò như một mạng con để chọn nút có đầu vào cao nhất. Tất cả các nút được kết nối hoàn toàn với nhau và tồn tại các trọng số đối xứng trong tất cả các kết nối có trọng số này.
Ngành kiến trúc
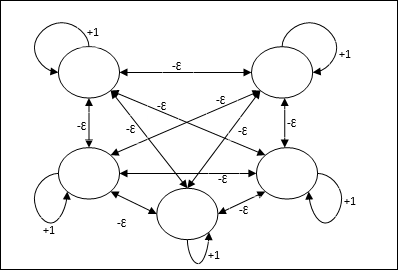
Nó sử dụng cơ chế là một quá trình lặp đi lặp lại và mỗi nút nhận đầu vào ức chế từ tất cả các nút khác thông qua các kết nối. Nút duy nhất có giá trị lớn nhất sẽ hoạt động hoặc chiến thắng và các kích hoạt của tất cả các nút khác sẽ không hoạt động. Max Net sử dụng chức năng kích hoạt danh tính với $$ f (x) \: = \: \ begin {case} x & if \: x> 0 \\ 0 & if \: x \ leq 0 \ end {case} $$
Nhiệm vụ của mạng này được thực hiện nhờ trọng lượng tự kích thích +1 và cường độ ức chế lẫn nhau, được đặt như [0 <ɛ <$ \ frac {1} {m} $] trong đó “m” là tổng số nút.
Học tập cạnh tranh trong ANN
Nó liên quan đến việc đào tạo không có giám sát, trong đó các nút đầu ra cố gắng cạnh tranh với nhau để đại diện cho mẫu đầu vào. Để hiểu quy tắc học tập này, chúng ta sẽ phải hiểu mạng lưới cạnh tranh được giải thích như sau:
Khái niệm cơ bản về mạng lưới cạnh tranh
Mạng này giống như một mạng chuyển tiếp cấp một lớp có kết nối phản hồi giữa các đầu ra. Các kết nối giữa các đầu ra là kiểu ức chế, được thể hiện bằng các đường chấm, có nghĩa là các đối thủ cạnh tranh không bao giờ hỗ trợ mình.
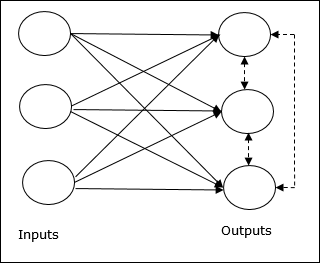
Khái niệm cơ bản về Quy tắc học tập cạnh tranh
Như đã nói trước đó, sẽ có sự cạnh tranh giữa các nút đầu ra vì vậy khái niệm chính là - trong quá trình đào tạo, đơn vị đầu ra có kích hoạt cao nhất đối với một mẫu đầu vào nhất định, sẽ được tuyên bố là người chiến thắng. Quy tắc này còn được gọi là Winner-take-all vì chỉ có nơ-ron chiến thắng được cập nhật và các nơ-ron còn lại không thay đổi.
Công thức toán học
Sau đây là ba yếu tố quan trọng để xây dựng công thức toán học của quy tắc học tập này:
Điều kiện để trở thành người chiến thắng
Giả sử nếu một tế bào thần kinh yk muốn trở thành người chiến thắng thì cần có điều kiện sau
$$ y_ {k} \: = \: \ begin {case} 1 & if \: v_ {k}> v_ {j} \: for \: all \: \: j, \: j \: \ neq \ : k \\ 0 và nếu không thì \ end {case} $$
Có nghĩa là nếu bất kỳ nơron nào, yk muốn giành chiến thắng, thì trường cục bộ gây ra của nó (đầu ra của đơn vị tổng hợp), nói vk, phải lớn nhất trong số tất cả các nơ-ron khác trong mạng.
Điều kiện của tổng trọng lượng
Một hạn chế khác đối với quy tắc học tập cạnh tranh là tổng trọng số của một nơ-ron đầu ra cụ thể sẽ là 1. Ví dụ, nếu chúng ta xem xét nơ-ron k sau đó
$$ \ displaystyle \ sum \ limit_ {k} w_ {kj} \: = \: 1 \: \: \: \: cho \: tất cả \: \: k $$
Thay đổi trọng lượng cho người chiến thắng
Nếu một tế bào thần kinh không đáp ứng với mẫu đầu vào, thì sẽ không có hoạt động học nào diễn ra trong tế bào thần kinh đó. Tuy nhiên, nếu một nơ-ron cụ thể thắng, thì trọng số tương ứng được điều chỉnh như sau:
$$ \ Delta w_ {kj} \: = \: \ begin {case} - \ alpha (x_ {j} \: - \: w_ {kj}) và if \: neuron \: k \: win \\ 0 & if \: neuron \: k \: lỗ \ end {case} $$
Đây $ \ alpha $ là tỷ lệ học tập.
Điều này cho thấy rõ ràng rằng chúng ta đang ủng hộ nơ-ron chiến thắng bằng cách điều chỉnh trọng lượng của nó và nếu một nơ-ron bị mất, chúng ta không cần phải điều chỉnh lại trọng lượng của nó.
K-means Clustering Algorithm
K-mean là một trong những thuật toán phân cụm phổ biến nhất mà chúng ta sử dụng khái niệm thủ tục phân vùng. Chúng tôi bắt đầu với một phân vùng ban đầu và liên tục di chuyển các mẫu từ cụm này sang cụm khác, cho đến khi chúng tôi nhận được kết quả ưng ý.
Thuật toán
Step 1 - Chọn kđiểm như là trung tâm ban đầu. Khởi tạok nguyên mẫu (w1,…,wk), ví dụ, chúng ta có thể xác định chúng bằng các vectơ đầu vào được chọn ngẫu nhiên -
$$ W_ {j} \: = \: i_ {p}, \: \: \: ở đâu \: j \: \ in \ lbrace1, ...., k \ rbrace \: và \: p \: \ trong \ lbrace1, ...., n \ rbrace $$
Từng cụm Cj được liên kết với nguyên mẫu wj.
Step 2 - Lặp lại bước 3-5 cho đến khi E không còn giảm nữa, hoặc thành viên của cụm không còn thay đổi.
Step 3 - Đối với mỗi vector đầu vào ip Ở đâu p ∈ {1,…,n}, đặt ip trong cụm Cj* với nguyên mẫu gần nhất wj* có mối quan hệ sau
$$ | i_ {p} \: - \: w_ {j *} | \: \ leq \: | i_ {p} \: - \: w_ {j} |, \: j \: \ in \ lbrace1, ...., k \ rbrace $$
Step 4 - Đối với từng cụm Cj, Ở đâu j ∈ { 1,…,k}, cập nhật nguyên mẫu wj trở thành trung tâm của tất cả các mẫu hiện tại Cj , vậy nên
$$ w_ {j} \: = \: \ sum_ {i_ {p} \ in C_ {j}} \ frac {i_ {p}} {| C_ {j} |} $$
Step 5 - Tính tổng sai số lượng tử hóa như sau:
$$ E \: = \: \ sum_ {j = 1} ^ k \ sum_ {i_ {p} \ in w_ {j}} | i_ {p} \: - \: w_ {j} | ^ 2 $$
Neocognitron
Nó là một mạng chuyển tiếp nhiều lớp, được phát triển bởi Fukushima vào năm 1980. Mô hình này dựa trên việc học có giám sát và được sử dụng để nhận dạng mẫu trực quan, chủ yếu là các ký tự viết tay. Về cơ bản nó là một phần mở rộng của mạng Cognitron, cũng được phát triển bởi Fukushima vào năm 1975.
Ngành kiến trúc
Nó là một mạng phân cấp, bao gồm nhiều lớp và có một kiểu kết nối cục bộ trong các lớp đó.
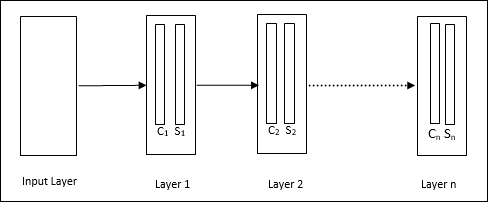
Như chúng ta đã thấy trong sơ đồ trên, neocognitron được chia thành các lớp kết nối khác nhau và mỗi lớp có hai ô. Giải thích về các ô này như sau:
S-Cell - Nó được gọi là một ô đơn giản, được huấn luyện để phản ứng với một mẫu hoặc một nhóm mẫu cụ thể.
C-Cell- Nó được gọi là ô phức hợp, kết hợp đầu ra từ ô S và đồng thời làm giảm số lượng đơn vị trong mỗi mảng. Theo một nghĩa khác, ô C thay thế kết quả của ô S.
Thuật toán đào tạo
Việc đào tạo neocognitron được phát hiện từng lớp một. Các trọng lượng từ lớp đầu vào đến lớp đầu tiên được đào tạo và đóng băng. Sau đó, các trọng lượng từ lớp đầu tiên đến lớp thứ hai được huấn luyện, v.v. Các tính toán nội bộ giữa S-cell và Ccell phụ thuộc vào trọng lượng đến từ các lớp trước đó. Do đó, chúng ta có thể nói rằng thuật toán huấn luyện phụ thuộc vào các phép tính trên ô S và ô C.
Tính toán trong ô S
Tế bào S sở hữu tín hiệu kích thích nhận được từ lớp trước và sở hữu các tín hiệu ức chế thu được trong cùng lớp.
$$ \ theta = \: \ sqrt {\ sum \ sum t_ {i} c_ {i} ^ 2} $$
Đây, ti là trọng lượng cố định và ci là đầu ra từ C-cell.
Đầu vào được chia tỷ lệ của ô S có thể được tính như sau:
$$ x \: = \: \ frac {1 \: + \: e} {1 \: + \: vw_ {0}} \: - \: 1 $$
Đây, $ e \: = \: \ sum_i c_ {i} w_ {i} $
wi là trọng lượng được điều chỉnh từ ô C sang ô S.
w0 là trọng lượng có thể điều chỉnh giữa đầu vào và ô S.
v là đầu vào kích thích từ C-cell.
Việc kích hoạt tín hiệu đầu ra là,
$$ s \: = \: \ begin {case} x, & if \: x \ geq 0 \\ 0 và if \: x <0 \ end {case} $$
Tính toán trong ô C
Đầu vào ròng của lớp C là
$$ C \: = \: \ displaystyle \ sum \ limit_i s_ {i} x_ {i} $$
Đây, si là đầu ra từ S-cell và xi là trọng lượng cố định từ ô S đến ô C.
Kết quả cuối cùng như sau:
$$ C_ {out} \: = \: \ begin {case} \ frac {C} {a + C} & if \: C> 0 \\ 0, & nếu không thì \ end {case} $$
Đây ‘a’ là tham số phụ thuộc vào hiệu suất của mạng.
Học lượng tử hóa vectơ (LVQ), khác với lượng tử hóa vectơ (VQ) và Bản đồ tự tổ chức Kohonen (KSOM), về cơ bản là một mạng cạnh tranh sử dụng học có giám sát. Chúng ta có thể định nghĩa nó như một quá trình phân loại các mẫu trong đó mỗi đơn vị đầu ra đại diện cho một lớp. Vì nó sử dụng phương pháp học có giám sát, mạng sẽ được cung cấp một tập hợp các mẫu đào tạo với phân loại đã biết cùng với phân phối ban đầu của lớp đầu ra. Sau khi hoàn thành quá trình huấn luyện, LVQ sẽ phân loại vector đầu vào bằng cách gán nó vào cùng lớp với của đơn vị đầu ra.
Ngành kiến trúc
Hình sau cho thấy kiến trúc của LVQ khá giống với kiến trúc của KSOM. Như chúng ta có thể thấy, có“n” số lượng đơn vị đầu vào và “m”số lượng đơn vị đầu ra. Các lớp được kết nối hoàn toàn với nhau với trọng lượng trên chúng.

Các thông số được sử dụng
Sau đây là các tham số được sử dụng trong quá trình đào tạo LVQ cũng như trong lưu đồ
x= vectơ huấn luyện (x 1 , ..., x i , ..., x n )
T = lớp đào tạo vector x
wj = vectơ trọng lượng cho jth Đơn vị đầu ra
Cj = lớp liên kết với jth Đơn vị đầu ra
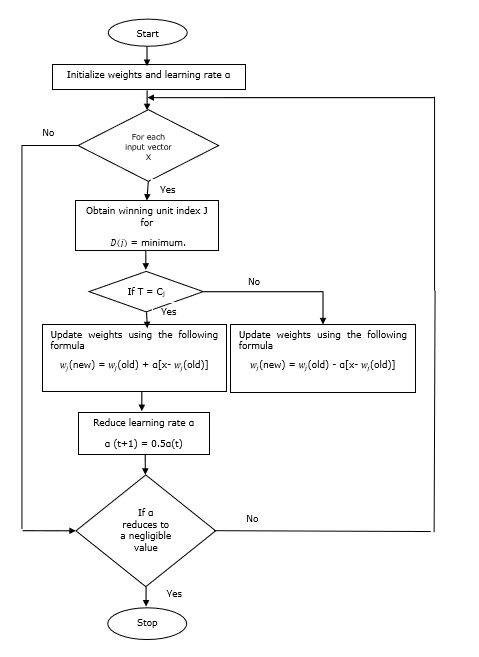
Thuật toán đào tạo
Step 1 - Khởi tạo vectơ tham chiếu, có thể được thực hiện như sau:
Step 1(a) - Từ tập các vectơ huấn luyện đã cho, lấy “m”(Số cụm) vectơ huấn luyện và sử dụng chúng làm vectơ trọng số. Các vectơ còn lại có thể được dùng để huấn luyện.
Step 1(b) - Ấn định trọng lượng ban đầu và phân loại ngẫu nhiên.
Step 1(c) - Áp dụng phương pháp phân cụm K-mean.
Step 2 - Khởi tạo vector tham chiếu $ \ alpha $
Step 3 - Tiếp tục với các bước 4-9, nếu điều kiện dừng thuật toán này không được đáp ứng.
Step 4 - Làm theo các bước 5-6 cho mọi vectơ đầu vào đào tạo x.
Step 5 - Tính Bình phương Khoảng cách Euclid cho j = 1 to m và i = 1 to n
$$ D (j) \: = \: \ displaystyle \ sum \ limit_ {i = 1} ^ n \ displaystyle \ sum \ limit_ {j = 1} ^ m (x_ {i} \: - \: w_ {ij }) ^ 2 $$
Step 6 - Lấy đơn vị chiến thắng J Ở đâu D(j) là tối thiểu.
Step 7 - Tính trọng lượng mới của đơn vị thắng cuộc theo quan hệ sau:
nếu T = Cj sau đó $ w_ {j} (mới) \: = \: w_ {j} (cũ) \: + \: \ alpha [x \: - \: w_ {j} (cũ)] $
nếu T ≠ Cj sau đó $ w_ {j} (mới) \: = \: w_ {j} (cũ) \: - \: \ alpha [x \: - \: w_ {j} (cũ)] $
Step 8 - Giảm tỷ lệ học tập $ \ alpha $.
Step 9- Kiểm tra điều kiện dừng. Nó có thể như sau:
- Đã đạt đến số kỷ nguyên tối đa.
- Tỷ lệ học tập giảm xuống một giá trị không đáng kể.
Sơ đồ
Các biến thể
Ba biến thể khác là LVQ2, LVQ2.1 và LVQ3 đã được phát triển bởi Kohonen. Sự phức tạp trong cả ba biến thể này, do khái niệm rằng người chiến thắng cũng như đơn vị á quân sẽ học được, nhiều hơn trong LVQ.
LVQ2
Như đã thảo luận, khái niệm về các biến thể khác của LVQ ở trên, điều kiện của LVQ2 được hình thành theo cửa sổ. Cửa sổ này sẽ dựa trên các thông số sau:
x - vectơ đầu vào hiện tại
yc - vectơ tham chiếu gần nhất với x
yr - vectơ tham chiếu khác, gần nhất với x
dc - khoảng cách từ x đến yc
dr - khoảng cách từ x đến yr
Vectơ đầu vào x rơi trong cửa sổ, nếu
$$ \ frac {d_ {c}} {d_ {r}} \:> \: 1 \: - \: \ theta \: \: và \: \: \ frac {d_ {r}} {d_ {c }} \:> \: 1 \: + \: \ theta $$
Ở đây, $ \ theta $ là số lượng mẫu đào tạo.
Việc cập nhật có thể được thực hiện theo công thức sau:
$ y_ {c} (t \: + \: 1) \: = \: y_ {c} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {c} (t)] $ (belongs to different class)
$ y_ {r} (t \: + \: 1) \: = \: y_ {r} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {r} (t)] $ (belongs to same class)
Đây $ \ alpha $ là tỷ lệ học tập.
LVQ2.1
Trong LVQ2.1, chúng tôi sẽ lấy hai vectơ gần nhất là yc1 và yc2 và điều kiện cho cửa sổ như sau:
$$ Min \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \:> \ :( 1 \ : - \: \ theta) $$
$$ Max \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \: <\ :( 1 \ : + \: \ theta) $$
Việc cập nhật có thể được thực hiện theo công thức sau:
$ y_ {c1} (t \: + \: 1) \: = \: y_ {c1} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {c1} (t)] $ (belongs to different class)
$ y_ {c2} (t \: + \: 1) \: = \: y_ {c2} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {c2} (t)] $ (belongs to same class)
Ở đây, $ \ alpha $ là tỷ lệ học tập.
LVQ3
Trong LVQ3, chúng tôi sẽ lấy hai vectơ gần nhất cụ thể là yc1 và yc2 và điều kiện cho cửa sổ như sau:
$$ Min \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \:> \ :( 1 \ : - \: \ theta) (1 \: + \: \ theta) $$
Đây $ \ theta \ khoảng 0,2 $
Việc cập nhật có thể được thực hiện theo công thức sau:
$ y_ {c1} (t \: + \: 1) \: = \: y_ {c1} (t) \: + \: \ beta (t) [x (t) \: - \: y_ {c1} (t)] $ (belongs to different class)
$ y_ {c2} (t \: + \: 1) \: = \: y_ {c2} (t) \: + \: \ beta (t) [x (t) \: - \: y_ {c2} (t)] $ (belongs to same class)
Đây $ \ beta $ là bội số của tỷ lệ học tập $ \ alpha $ và $\beta\:=\:m \alpha(t)$ Cho mọi 0.1 < m < 0.5
Mạng này được phát triển bởi Stephen Grossberg và Gail Carpenter vào năm 1987. Nó dựa trên sự cạnh tranh và sử dụng mô hình học tập không giám sát. Các mạng của Lý thuyết Cộng hưởng Thích ứng (ART), như tên gọi cho thấy, luôn mở ra cho việc học mới (thích ứng) mà không làm mất đi các mô hình cũ (cộng hưởng). Về cơ bản, mạng ART là một bộ phân loại vectơ chấp nhận một vectơ đầu vào và phân loại nó thành một trong các loại tùy thuộc vào mẫu được lưu trữ mà nó giống nhất.
Điều hành chính
Hoạt động chính của phân loại ART có thể được chia thành các giai đoạn sau:
Recognition phase- Vectơ đầu vào được so sánh với phân loại được trình bày ở mọi nút trong lớp đầu ra. Đầu ra của nơ-ron trở thành “1” nếu nó phù hợp nhất với phân loại được áp dụng, nếu không nó trở thành “0”.
Comparison phase- Trong pha này, việc so sánh vector đầu vào với vector lớp so sánh được thực hiện. Điều kiện để đặt lại là mức độ giống nhau sẽ nhỏ hơn tham số cảnh giác.
Search phase- Trong đợt này, nhà mạng sẽ tìm kiếm reset cũng như trận đấu đã thực hiện ở các đợt trên. Do đó, nếu không có thiết lập lại và trận đấu khá tốt, thì phân loại kết thúc. Nếu không, quá trình sẽ được lặp lại và mẫu đã lưu khác phải được gửi đi để tìm kết quả phù hợp.
ART1
Nó là một loại ART, được thiết kế để phân cụm các vectơ nhị phân. Chúng ta có thể hiểu về điều này với kiến trúc của nó.
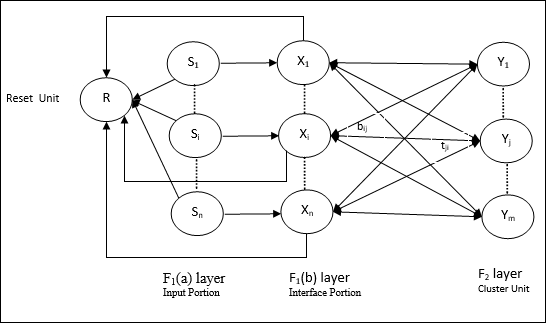
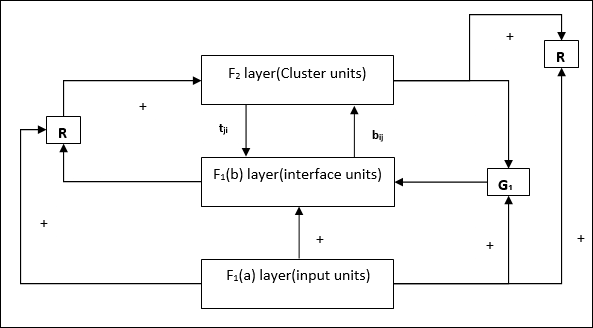
Kiến trúc của ART1
Nó bao gồm hai đơn vị sau:
Computational Unit - Nó được tạo thành từ những điều sau -
Input unit (F1 layer) - Nó còn có hai phần sau -
F1(a) layer (Input portion)- Trong ART1, sẽ không có xử lý trong phần này thay vì chỉ có các vectơ đầu vào. Nó được kết nối với lớp F 1 (b) (phần giao diện).
F1(b) layer (Interface portion)- Phần này kết hợp tín hiệu từ phần đầu vào với tín hiệu của lớp F 2 . Lớp F 1 (b) được kết nối với lớp F 2 thông qua các quả nặng từ dưới lênbijvà lớp F 2 được kết nối với lớp F 1 (b) thông qua các trọng lượng từ trên xuốngtji.
Cluster Unit (F2 layer)- Đây là tầng cạnh tranh. Đơn vị có đầu vào ròng lớn nhất được chọn để tìm hiểu kiểu đầu vào. Kích hoạt của tất cả các đơn vị cụm khác được đặt thành 0.
Reset Mechanism- Công việc của cơ chế này dựa trên sự giống nhau giữa trọng số từ trên xuống và vectơ đầu vào. Bây giờ, nếu mức độ tương tự này nhỏ hơn tham số cảnh giác, thì cụm không được phép tìm hiểu mẫu và phần còn lại sẽ xảy ra.
Supplement Unit - Thực ra vấn đề với cơ chế Reset là lớp F2phải bị ức chế trong những điều kiện nhất định và cũng phải sẵn sàng khi một số học tập xảy ra. Đó là lý do tại sao hai đơn vị bổ sung,G1 và G2 được thêm vào cùng với đơn vị đặt lại, R. Chúng được gọi làgain control units. Các đơn vị này nhận và gửi tín hiệu đến các đơn vị khác có trong mạng.‘+’ chỉ ra một tín hiệu kích thích, trong khi ‘−’ chỉ ra một tín hiệu ức chế.
Các thông số được sử dụng
Các thông số sau được sử dụng:
n - Số thành phần trong vector đầu vào
m - Số lượng cụm tối đa có thể được hình thành
bij- Trọng lượng từ lớp F 1 (b) đến lớp F 2 , tức là trọng lượng từ dưới lên
tji- Trọng lượng từ F 2 đến F 1 (b) lớp, tức là trọng lượng từ trên xuống
ρ - Tham số cảnh giác
||x|| - Định mức của vectơ x
Thuật toán
Step 1 - Khởi tạo tốc độ học, tham số cảnh giác và trọng số như sau:
$$ \ alpha \:> \: 1 \: \: và \: \: 0 \: <\ rho \: \ leq \: 1 $$
$$ 0 \: <\: b_ {ij} (0) \: <\: \ frac {\ alpha} {\ alpha \: - \: 1 \: + \: n} \: \: và \: \: t_ {ij} (0) \: = \: 1 $$
Step 2 - Tiếp tục bước 3-9, khi điều kiện dừng không đúng.
Step 3 - Tiếp tục bước 4-6 cho mọi đầu vào đào tạo.
Step 4- Đặt kích hoạt của tất cả các đơn vị F 1 (a) và F 1 như sau
F2 = 0 and F1(a) = input vectors
Step 5- Tín hiệu đầu vào từ lớp F 1 (a) đến lớp F 1 (b) phải được gửi như
$$ s_ {i} \: = \: x_ {i} $$
Step 6- Đối với mọi nút F 2 bị ức chế
$ y_ {j} \: = \: \ sum_i b_ {ij} x_ {i} $ điều kiện là yj ≠ -1
Step 7 - Thực hiện bước 8-10, khi thiết lập lại là đúng.
Step 8 - Tìm J cho yJ ≥ yj cho tất cả các nút j
Step 9- Một lần nữa tính toán kích hoạt trên F 1 (b) như sau
$$ x_ {i} \: = \: sitJi $$
Step 10 - Bây giờ, sau khi tính toán chuẩn của vector x và vector s, chúng ta cần kiểm tra điều kiện đặt lại như sau:
Nếu ||x||/ ||s|| <thông số cảnh giác ρ, Theninression node J và chuyển sang bước 7
Khác nếu ||x||/ ||s|| ≥ thông số cảnh giác ρ, sau đó tiến hành thêm.
Step 11 - Cập nhật trọng lượng cho nút J có thể được thực hiện như sau:
$$ b_ {ij} (mới) \: = \: \ frac {\ alpha x_ {i}} {\ alpha \: - \: 1 \: + \: || x ||} $$
$$ t_ {ij} (mới) \: = \: x_ {i} $$
Step 12 - Điều kiện dừng của thuật toán phải được kiểm tra và nó có thể như sau:
- Không có bất kỳ thay đổi nào về trọng lượng.
- Đặt lại không được thực hiện cho các đơn vị.
- Đã đạt đến số kỷ nguyên tối đa.
Giả sử chúng ta có một số mẫu có kích thước tùy ý, tuy nhiên, chúng ta cần chúng ở một chiều hoặc hai chiều. Sau đó, quá trình ánh xạ đối tượng sẽ rất hữu ích để chuyển đổi không gian mẫu rộng thành không gian đối tượng điển hình. Bây giờ, câu hỏi đặt ra là tại sao chúng ta yêu cầu bản đồ đối tượng tự tổ chức? Lý do là, cùng với khả năng chuyển đổi các kích thước tùy ý thành 1-D hoặc 2-D, nó cũng phải có khả năng duy trì cấu trúc liên kết lân cận.
Cấu trúc liên kết láng giềng ở Kohonen SOM
Có thể có nhiều cấu trúc liên kết khác nhau, tuy nhiên hai cấu trúc liên kết sau được sử dụng nhiều nhất:
Cấu trúc liên kết lưới hình chữ nhật
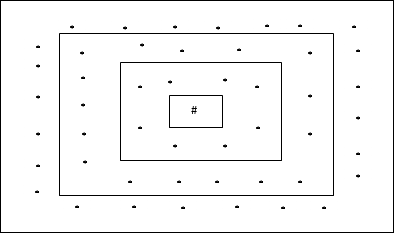
Cấu trúc liên kết này có 24 nút trong lưới khoảng cách-2, 16 nút trong lưới khoảng cách-1 và 8 nút trong lưới khoảng cách-0, có nghĩa là sự khác biệt giữa mỗi lưới hình chữ nhật là 8 nút. Đơn vị chiến thắng được biểu thị bằng #.
Cấu trúc liên kết lưới lục giác
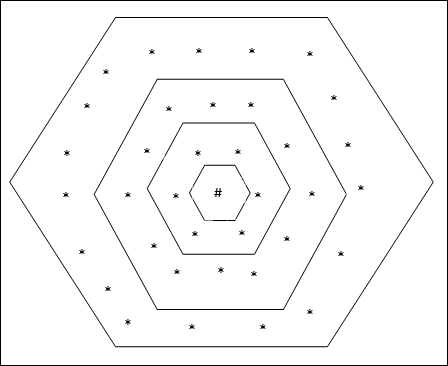
Cấu trúc liên kết này có 18 nút trong lưới khoảng cách-2, 12 nút trong lưới khoảng cách-1 và 6 nút trong lưới khoảng cách-0, có nghĩa là sự khác biệt giữa mỗi lưới hình chữ nhật là 6 nút. Đơn vị chiến thắng được biểu thị bằng #.
Ngành kiến trúc
Kiến trúc của KSOM tương tự như kiến trúc của mạng cạnh tranh. Với sự trợ giúp của các sơ đồ lân cận, đã thảo luận trước đó, việc đào tạo có thể diễn ra trên vùng mở rộng của mạng.
Thuật toán đào tạo
Step 1 - Khởi tạo trọng số, tỷ lệ học α và sơ đồ tôpô lân cận.
Step 2 - Tiếp tục bước 3-9, khi điều kiện dừng không đúng.
Step 3 - Tiếp tục bước 4-6 cho mọi vectơ đầu vào x.
Step 4 - Tính Bình phương Khoảng cách Euclid cho j = 1 to m
$$ D (j) \: = \: \ displaystyle \ sum \ limit_ {i = 1} ^ n \ displaystyle \ sum \ limit_ {j = 1} ^ m (x_ {i} \: - \: w_ {ij }) ^ 2 $$
Step 5 - Lấy đơn vị chiến thắng J Ở đâu D(j) là tối thiểu.
Step 6 - Tính trọng lượng mới của đơn vị thắng cuộc theo quan hệ sau:
$$ w_ {ij} (mới) \: = \: w_ {ij} (cũ) \: + \: \ alpha [x_ {i} \: - \: w_ {ij} (cũ)] $$
Step 7 - Cập nhật tỷ lệ học tập α theo quan hệ sau -
$$ \ alpha (t \: + \: 1) \: = \: 0,5 \ alpha t $$
Step 8 - Giảm bán kính của lược đồ tôpô.
Step 9 - Kiểm tra tình trạng dừng của mạng.
Các loại mạng nơ-ron này hoạt động trên cơ sở liên kết mẫu, có nghĩa là chúng có thể lưu trữ các mẫu khác nhau và tại thời điểm đưa ra đầu ra, chúng có thể tạo ra một trong các mẫu được lưu trữ bằng cách khớp chúng với mẫu đầu vào đã cho. Những loại ký ức này còn được gọi làContent-Addressable Memory(CAM). Bộ nhớ liên kết thực hiện tìm kiếm song song với các mẫu được lưu trữ dưới dạng tệp dữ liệu.
Sau đây là hai loại ký ức liên kết mà chúng ta có thể quan sát:
- Bộ nhớ liên kết tự động
- Hetero Associative memory
Bộ nhớ liên kết tự động
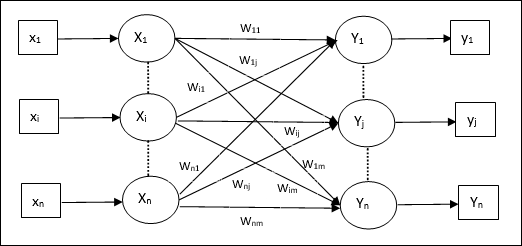
Đây là mạng nơ-ron một lớp trong đó vectơ huấn luyện đầu vào và vectơ mục tiêu đầu ra giống nhau. Các trọng số được xác định để mạng lưu trữ một tập hợp các mẫu.
Ngành kiến trúc
Như thể hiện trong hình sau, kiến trúc của mạng bộ nhớ Auto Associative có ‘n’ số vectơ đào tạo đầu vào và tương tự ‘n’ số vectơ mục tiêu đầu ra.
Thuật toán đào tạo
Để đào tạo, mạng này đang sử dụng quy tắc học tập Hebb hoặc Delta.
Step 1 - Khởi tạo tất cả các trọng số bằng 0 như wij = 0 (i = 1 to n, j = 1 to n)
Step 2 - Thực hiện các bước 3-4 cho mỗi vector đầu vào.
Step 3 - Kích hoạt từng đơn vị đầu vào như sau -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: to \: n) $$
Step 4 - Kích hoạt từng đơn vị đầu ra như sau -
$$ y_ {j} \: = \: s_ {j} \ :( j \: = \: 1 \: to \: n) $$
Step 5 - Điều chỉnh trọng lượng như sau -
$$ w_ {ij} (mới) \: = \: w_ {ij} (cũ) \: + \: x_ {i} y_ {j} $$
Thuật toán kiểm tra
Step 1 - Đặt trọng lượng thu được trong quá trình luyện tập cho quy tắc của Hebb.
Step 2 - Thực hiện các bước 3-5 cho mỗi vector đầu vào.
Step 3 - Đặt kích hoạt của các đơn vị đầu vào bằng với kích hoạt của vector đầu vào.
Step 4 - Tính toán đầu vào ròng cho mỗi đơn vị đầu ra j = 1 to n
$$ y_ {secure} \: = \: \ displaystyle \ sum \ limit_ {i = 1} ^ n x_ {i} w_ {ij} $$
Step 5 - Áp dụng chức năng kích hoạt sau để tính toán đầu ra
$$ y_ {j} \: = \: f (y_ {inv}) \: = \: \ begin {case} +1 & nếu \: y_ {inv} \:> \: 0 \\ - 1 & nếu \: y_ {secure} \: \ leqslant \: 0 \ end {case} $$
Hetero Associative memory
Tương tự như mạng Bộ nhớ tự động liên kết, đây cũng là mạng nơ-ron một lớp. Tuy nhiên, trong mạng này, vectơ huấn luyện đầu vào và vectơ đích đầu ra không giống nhau. Các trọng số được xác định để mạng lưu trữ một tập hợp các mẫu. Mạng liên kết Hetero có bản chất là tĩnh, do đó, sẽ không có các hoạt động phi tuyến tính và trễ.
Ngành kiến trúc
Như thể hiện trong hình sau, kiến trúc của mạng Bộ nhớ liên kết Hetero có ‘n’ số lượng vectơ đào tạo đầu vào và ‘m’ số vectơ mục tiêu đầu ra.
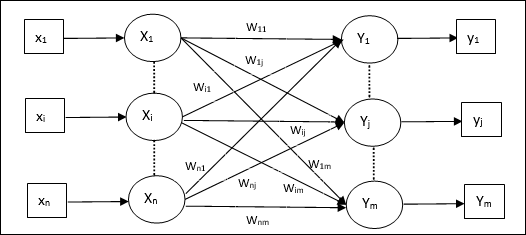
Thuật toán đào tạo
Để đào tạo, mạng này đang sử dụng quy tắc học tập Hebb hoặc Delta.
Step 1 - Khởi tạo tất cả các trọng số bằng 0 như wij = 0 (i = 1 to n, j = 1 to m)
Step 2 - Thực hiện các bước 3-4 cho mỗi vector đầu vào.
Step 3 - Kích hoạt từng đơn vị đầu vào như sau -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: to \: n) $$
Step 4 - Kích hoạt từng đơn vị đầu ra như sau -
$$ y_ {j} \: = \: s_ {j} \ :( j \: = \: 1 \: to \: m) $$
Step 5 - Điều chỉnh trọng lượng như sau -
$$ w_ {ij} (mới) \: = \: w_ {ij} (cũ) \: + \: x_ {i} y_ {j} $$
Thuật toán kiểm tra
Step 1 - Đặt trọng lượng thu được trong quá trình luyện tập cho quy tắc của Hebb.
Step 2 - Thực hiện các bước 3-5 cho mỗi vector đầu vào.
Step 3 - Đặt kích hoạt của các đơn vị đầu vào bằng với kích hoạt của vector đầu vào.
Step 4 - Tính toán đầu vào ròng cho mỗi đơn vị đầu ra j = 1 to m;
$$ y_ {secure} \: = \: \ displaystyle \ sum \ limit_ {i = 1} ^ n x_ {i} w_ {ij} $$
Step 5 - Áp dụng chức năng kích hoạt sau để tính toán đầu ra
$$ y_ {j} \: = \: f (y_ {inv}) \: = \: \ begin {case} +1 & if \: y_ {inv} \:> \: 0 \\ 0 & if \ : y_ {secure} \: = \: 0 \\ - 1 & if \: y_ {secure} \: <\: 0 \ end {case} $$
Mạng nơ-ron Hopfield được phát minh bởi Tiến sĩ John J. Hopfield vào năm 1982. Nó bao gồm một lớp duy nhất chứa một hoặc nhiều nơ-ron lặp lại được kết nối đầy đủ. Mạng Hopfield thường được sử dụng cho các nhiệm vụ tự động liên kết và tối ưu hóa.
Mạng Hopfield rời rạc
Một mạng Hopfield hoạt động theo kiểu đường rời rạc hay nói cách khác, có thể nói các mẫu đầu vào và đầu ra là vector rời rạc, có thể có bản chất là nhị phân (0,1) hoặc lưỡng cực (+1, -1). Mạng có trọng số đối xứng không có tự kết nối, tức làwij = wji và wii = 0.
Ngành kiến trúc
Sau đây là một số điểm quan trọng cần ghi nhớ về mạng Hopfield rời rạc:
Mô hình này bao gồm các tế bào thần kinh với một đầu ra đảo ngược và một đầu ra không đảo ngược.
Đầu ra của mỗi tế bào thần kinh phải là đầu vào của các tế bào thần kinh khác nhưng không phải là đầu vào của bản thân.
Trọng lượng / cường độ kết nối được biểu thị bằng wij.
Kết nối có thể kích thích cũng như ức chế. Sẽ rất kích thích nếu đầu ra của nơron giống với đầu vào, ngược lại là ức chế.
Trọng lượng phải đối xứng, tức là wij = wji
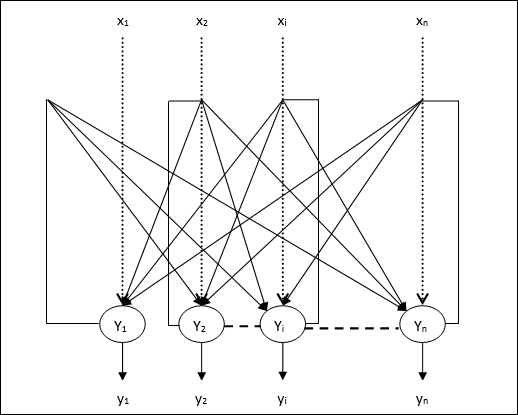
Đầu ra từ Y1 sẽ Y2, Yi và Yn có trọng lượng w12, w1i và w1ntương ứng. Tương tự, các cung khác có trọng lượng trên chúng.
Thuật toán đào tạo
Trong quá trình huấn luyện mạng Hopfield rời rạc, các trọng số sẽ được cập nhật. Như chúng ta biết rằng chúng ta có thể có các vectơ đầu vào nhị phân cũng như các vectơ đầu vào lưỡng cực. Do đó, trong cả hai trường hợp, cập nhật trọng lượng có thể được thực hiện với mối quan hệ sau
Case 1 - Mẫu đầu vào nhị phân
Đối với một tập hợp các mẫu nhị phân s(p), p = 1 to P
Đây, s(p) = s1(p), s2(p),..., si(p),..., sn(p)
Ma trận trọng lượng được đưa ra bởi
$$ w_ {ij} \: = \: \ sum_ {p = 1} ^ P [2s_ {i} (p) - \: 1] [2s_ {j} (p) - \: 1] \: \: \: \: \: cho \: i \: \ neq \: j $$
Case 2 - Mẫu đầu vào lưỡng cực
Đối với một tập hợp các mẫu nhị phân s(p), p = 1 to P
Đây, s(p) = s1(p), s2(p),..., si(p),..., sn(p)
Ma trận trọng lượng được đưa ra bởi
$$ w_ {ij} \: = \: \ sum_ {p = 1} ^ P [s_ {i} (p)] [s_ {j} (p)] \: \: \: \: \: cho \ : i \: \ neq \: j $$
Thuật toán kiểm tra
Step 1 - Khởi tạo các trọng số thu được từ thuật toán huấn luyện bằng cách sử dụng nguyên tắc Hebbian.
Step 2 - Thực hiện các bước 3-9, nếu các kích hoạt của mạng không được hợp nhất.
Step 3 - Đối với mỗi vector đầu vào X, thực hiện các bước 4-8.
Step 4 - Thực hiện kích hoạt ban đầu của mạng bằng vectơ đầu vào bên ngoài X như sau -
$$ y_ {i} \: = \: x_ {i} \: \: \: cho \: i \: = \: 1 \: tới \: n $$
Step 5 - Đối với từng đơn vị Yi, thực hiện các bước 6-9.
Step 6 - Tính toán đầu vào thực của mạng như sau -
$$ y_ {ini} \: = \: x_ {i} \: + \: \ displaystyle \ sum \ limit_ {j} y_ {j} w_ {ji} $$
Step 7 - Áp dụng kích hoạt như sau trên đầu vào ròng để tính toán đầu ra -
$$ y_ {i} \: = \ begin {case} 1 & if \: y_ {ini} \:> \: \ theta_ {i} \\ y_ {i} & if \: y_ {ini} \: = \: \ theta_ {i} \\ 0 & if \: y_ {ini} \: <\: \ theta_ {i} \ end {case} $$
Đây $ \ theta_ {i} $ là ngưỡng.
Step 8 - Phát đầu ra này yi cho tất cả các đơn vị khác.
Step 9 - Kiểm tra mạng để kết hợp.
Đánh giá chức năng năng lượng
Một chức năng năng lượng được định nghĩa là một chức năng được liên kết và chức năng không tăng của trạng thái của hệ thống.
Chức năng năng lượng Ef, cũng được gọi là Lyapunov function xác định tính ổn định của mạng Hopfield rời rạc và được đặc trưng như sau:
$$ E_ {f} \: = \: - \ frac {1} {2} \ displaystyle \ sum \ limit_ {i = 1} ^ n \ displaystyle \ sum \ limit_ {j = 1} ^ n y_ {i} y_ {j} w_ {ij} \: - \: \ displaystyle \ sum \ limit_ {i = 1} ^ n x_ {i} y_ {i} \: + \: \ displaystyle \ sum \ limit_ {i = 1} ^ n \ theta_ {i} y_ {i} $$
Condition - Trong mạng ổn định, bất cứ khi nào trạng thái của nút thay đổi, cơ năng trên sẽ giảm.
Giả sử khi nút i đã thay đổi trạng thái từ $ y_i ^ {(k)} $ thành $ y_i ^ {(k \: + \: 1)} $ vậy thì sự thay đổi Năng lượng $ \ Delta E_ {f} $ được cho bởi quan hệ sau
$$ \ Delta E_ {f} \: = \: E_ {f} (y_i ^ {(k + 1)}) \: - \: E_ {f} (y_i ^ {(k)}) $$
$$ = \: - \ left (\ begin {array} {c} \ displaystyle \ sum \ limit_ {j = 1} ^ n w_ {ij} y_i ^ {(k)} \: + \: x_ {i} \: - \: \ theta_ {i} \ end {array} \ right) (y_i ^ {(k + 1)} \: - \: y_i ^ {(k)}) $$
$$ = \: - \ :( net_ {i}) \ Delta y_ {i} $$
Đây $ \ Delta y_ {i} \: = \: y_i ^ {(k \: + \: 1)} \: - \: y_i ^ {(k)} $
Sự thay đổi năng lượng phụ thuộc vào thực tế là chỉ một đơn vị có thể cập nhật kích hoạt của nó tại một thời điểm.
Mạng Hopfield liên tục
So với mạng Hopfield rời rạc, mạng liên tục có thời gian là một biến liên tục. Nó cũng được sử dụng trong các vấn đề liên kết và tối ưu hóa ô tô như vấn đề nhân viên bán hàng đi du lịch.
Model - Mô hình hoặc kiến trúc có thể được xây dựng bằng cách thêm các thành phần điện như bộ khuếch đại có thể ánh xạ điện áp đầu vào với điện áp đầu ra qua một chức năng kích hoạt sigmoid.
Đánh giá chức năng năng lượng
$$ E_f = \ frac {1} {2} \ displaystyle \ sum \ limit_ {i = 1} ^ n \ sum _ {\ substack {j = 1 \\ j \ ne i}} ^ n y_i y_j w_ {ij} - \ displaystyle \ sum \ limit_ {i = 1} ^ n x_i y_i + \ frac {1} {\ lambda} \ displaystyle \ sum \ limit_ {i = 1} ^ n \ sum _ {\ substack {j = 1 \\ j \ ne i}} ^ n w_ {ij} g_ {ri} \ int_ {0} ^ {y_i} a ^ {- 1} (y) dy $$
Đây λ là tham số khuếch đại và gri độ dẫn đầu vào.
Đây là các quy trình học ngẫu nhiên có cấu trúc lặp lại và là cơ sở của các kỹ thuật tối ưu hóa ban đầu được sử dụng trong ANN. Boltzmann Machine được Geoffrey Hinton và Terry Sejnowski phát minh vào năm 1985. Có thể thấy rõ hơn qua những lời của Hinton về Boltzmann Machine.
“Một tính năng đáng ngạc nhiên của mạng này là nó chỉ sử dụng thông tin có sẵn tại địa phương. Sự thay đổi của trọng lượng chỉ phụ thuộc vào hành vi của hai đơn vị nó kết nối, mặc dù sự thay đổi đó tối ưu hóa một thước đo toàn cầu ”- Ackley, Hinton 1985.
Một số điểm quan trọng về Boltzmann Machine -
Chúng sử dụng cấu trúc lặp lại.
Chúng bao gồm các tế bào thần kinh ngẫu nhiên, có một trong hai trạng thái có thể có, 1 hoặc 0.
Một số tế bào thần kinh trong số này là thích nghi (trạng thái tự do) và một số bị kẹp (trạng thái đông lạnh).
Nếu chúng ta áp dụng phương pháp ủ mô phỏng trên mạng Hopfield rời rạc, thì nó sẽ trở thành Máy Boltzmann.
Mục tiêu của Máy Boltzmann
Mục đích chính của Boltzmann Machine là tối ưu hóa giải pháp của một vấn đề. Công việc của Boltzmann Machine là tối ưu hóa trọng lượng và số lượng liên quan đến vấn đề cụ thể đó.
Ngành kiến trúc
Sơ đồ sau đây cho thấy kiến trúc của máy Boltzmann. Rõ ràng từ sơ đồ, rằng nó là một mảng đơn vị hai chiều. Ở đây, trọng số về kết nối giữa các đơn vị là–p Ở đâu p > 0. Trọng lượng của các kết nối tự được đưa ra bởib Ở đâu b > 0.
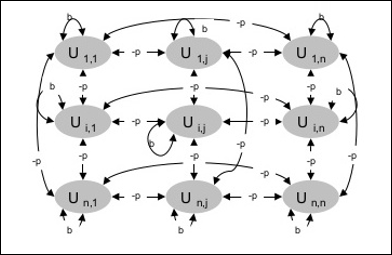
Thuật toán đào tạo
Như chúng ta biết rằng máy Boltzmann có trọng số cố định, do đó sẽ không có thuật toán huấn luyện vì chúng ta không cần cập nhật trọng số trong mạng. Tuy nhiên, để kiểm tra mạng, chúng ta phải thiết lập các trọng số cũng như tìm hàm đồng thuận (CF).
Máy Boltzmann có một tập hợp các đơn vị Ui và Uj và có kết nối hai chiều trên chúng.
Chúng tôi đang xem xét trọng lượng cố định nói wij.
wij ≠ 0 nếu Ui và Uj được kết nối.
Cũng tồn tại một sự đối xứng trong liên kết có trọng số, tức là wij = wji.
wii cũng tồn tại, tức là sẽ có sự tự kết nối giữa các đơn vị.
Đối với bất kỳ đơn vị nào Ui, trạng thái của nó ui sẽ là 1 hoặc 0.
Mục tiêu chính của Boltzmann Machine là tối đa hóa Hàm đồng thuận (CF) có thể được đưa ra bởi quan hệ sau
$$ CF \: = \: \ displaystyle \ sum \ limit_ {i} \ displaystyle \ sum \ limit_ {j \ leqslant i} w_ {ij} u_ {i} u_ {j} $$
Bây giờ, khi trạng thái thay đổi từ 1 thành 0 hoặc từ 0 thành 1, thì sự thay đổi về sự đồng thuận có thể được đưa ra bởi quan hệ sau:
$$ \ Delta CF \: = \ :( 1 \: - \: 2u_ {i}) (w_ {ij} \: + \: \ displaystyle \ sum \ limit_ {j \ neq i} u_ {i} w_ { ij}) $$
Đây ui là trạng thái hiện tại của Ui.
Sự thay đổi trong hệ số (1 - 2ui) được cho bởi quan hệ sau:
$$ (1 \: - \: 2u_ {i}) \: = \: \ begin {case} +1, & U_ {i} \: is \: current \: off \\ - 1, & U_ {i } \: is \: current \: on \ end {case} $$
Nói chung, đơn vị Uikhông thay đổi trạng thái của nó, nhưng nếu có thì thông tin sẽ được cư trú cục bộ cho đơn vị. Với sự thay đổi đó, cũng sẽ tăng sự đồng thuận của mạng lưới.
Xác suất mạng chấp nhận sự thay đổi trạng thái của thiết bị được cho bởi quan hệ sau:
$$ AF (i, T) \: = \: \ frac {1} {1 \: + \: exp [- \ frac {\ Delta CF (i)} {T}]} $$
Đây, Tlà tham số điều khiển. Nó sẽ giảm khi CF đạt giá trị lớn nhất.
Thuật toán kiểm tra
Step 1 - Khởi tạo phần sau để bắt đầu đào tạo -
- Trọng số đại diện cho hạn chế của vấn đề
- Thông số điều khiển T
Step 2 - Tiếp tục bước 3-8, khi điều kiện dừng không đúng.
Step 3 - Thực hiện các bước 4-7.
Step 4 - Giả sử rằng một trong các trạng thái đã thay đổi trọng số và chọn số nguyên I, J như các giá trị ngẫu nhiên giữa 1 và n.
Step 5 - Tính toán sự thay đổi trong sự đồng thuận như sau -
$$ \ Delta CF \: = \ :( 1 \: - \: 2u_ {i}) (w_ {ij} \: + \: \ displaystyle \ sum \ limit_ {j \ neq i} u_ {i} w_ { ij}) $$
Step 6 - Tính xác suất để mạng này chấp nhận sự thay đổi trạng thái
$$ AF (i, T) \: = \: \ frac {1} {1 \: + \: exp [- \ frac {\ Delta CF (i)} {T}]} $$
Step 7 - Chấp nhận hoặc từ chối thay đổi này như sau -
Case I - nếu R < AF, chấp nhận sự thay đổi.
Case II - nếu R ≥ AF, từ chối thay đổi.
Đây, R là số ngẫu nhiên từ 0 đến 1.
Step 8 - Giảm thông số điều khiển (nhiệt độ) như sau -
T(new) = 0.95T(old)
Step 9 - Kiểm tra các điều kiện dừng có thể như sau:
- Nhiệt độ đạt đến một giá trị xác định
- Không có thay đổi về trạng thái đối với một số lần lặp được chỉ định
Mạng nơ-ron Brain-State-in-a-Box (BSB) là một mạng nơ-ron tự động liên kết phi tuyến và có thể được mở rộng thành liên kết khác nhau với hai hoặc nhiều lớp. Nó cũng tương tự như mạng Hopfield. Nó được đề xuất bởi JA Anderson, JW Silverstein, SA Ritz và RS Jones vào năm 1977.
Một số điểm quan trọng cần nhớ về BSB Network -
Nó là một mạng được kết nối đầy đủ với số lượng nút tối đa tùy thuộc vào kích thước n của không gian đầu vào.
Tất cả các tế bào thần kinh được cập nhật đồng thời.
Tế bào thần kinh nhận giá trị từ -1 đến +1.
Công thức toán học
Hàm nút được sử dụng trong mạng BSB là một hàm dốc, có thể được định nghĩa như sau:
$$ f (net) \: = \: min (1, \: max (-1, \: net)) $$
Hàm đường nối này được giới hạn và liên tục.
Như chúng ta biết rằng mỗi nút sẽ thay đổi trạng thái của nó, nó có thể được thực hiện với sự trợ giúp của quan hệ toán học sau:
$$ x_ {t} (t \: + \: 1) \: = \: f \ left (\ begin {array} {c} \ displaystyle \ sum \ limit_ {j = 1} ^ n w_ {i, j } x_ {j} (t) \ end {array} \ right) $$
Đây, xi(t) là trạng thái của ith nút tại thời điểm t.
Trọng lượng từ ith nút tới jth nút có thể được đo bằng quan hệ sau:
$$ w_ {ij} \: = \: \ frac {1} {P} \ displaystyle \ sum \ limit_ {p = 1} ^ P (v_ {p, i} \: v_ {p, j}) $$
Đây, P là số lượng các mẫu đào tạo, có tính lưỡng cực.
Tối ưu hóa là một hành động làm cho một cái gì đó như thiết kế, tình huống, tài nguyên và hệ thống trở nên hiệu quả nhất có thể. Sử dụng sự tương đồng giữa hàm chi phí và hàm năng lượng, chúng ta có thể sử dụng các nơ-ron có tính liên kết cao để giải quyết các vấn đề tối ưu hóa. Một loại mạng nơ-ron như vậy là mạng Hopfield, bao gồm một lớp đơn chứa một hoặc nhiều nơ-ron lặp lại được kết nối đầy đủ. Điều này có thể được sử dụng để tối ưu hóa.
Những điểm cần nhớ khi sử dụng mạng Hopfield để tối ưu hóa -
Hàm năng lượng phải nhỏ nhất của mạng.
Nó sẽ tìm ra giải pháp thỏa đáng hơn là chọn một trong số các mẫu được lưu trữ.
Chất lượng của giải pháp được tìm thấy bởi mạng Hopfield phụ thuộc đáng kể vào trạng thái ban đầu của mạng.
Vấn đề nhân viên bán hàng đi du lịch
Tìm tuyến đường ngắn nhất mà nhân viên bán hàng đi là một trong những bài toán tính toán, có thể được tối ưu hóa bằng cách sử dụng mạng nơ-ron Hopfield.
Khái niệm cơ bản về TSP
Bài toán người bán hàng đi du lịch (TSP) là một bài toán tối ưu hóa cổ điển trong đó người bán hàng phải đi du lịch ncác thành phố được kết nối với nhau, giữ cho chi phí cũng như khoảng cách di chuyển ở mức tối thiểu. Ví dụ: nhân viên bán hàng phải đi du lịch một nhóm 4 thành phố A, B, C, D và mục tiêu là tìm chuyến tham quan vòng tròn ngắn nhất, ABC – D, để giảm thiểu chi phí, cũng bao gồm chi phí đi từ thành phố D cuối cùng đến thành phố A đầu tiên.
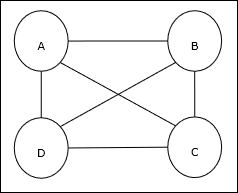
Biểu diễn ma trận
Trên thực tế, mỗi chuyến tham quan TSP n-city có thể được thể hiện như n × n ma trận có ith hàng mô tả ithvị trí của thành phố. Ma trận này,M, đối với 4 thành phố A, B, C, D có thể được biểu thị như sau:
$$ M = \ begin {bmatrix} A: & 1 & 0 & 0 & 0 \\ B: & 0 & 1 & 0 & 0 \\ C: & 0 & 0 & 1 & 0 \\ D: & 0 & 0 & 0 & 1 \ end {bmatrix} $$
Giải pháp của Hopfield Network
Trong khi xem xét giải pháp của mạng TSP bởi Hopfield này, mọi nút trong mạng tương ứng với một phần tử trong ma trận.
Tính toán hàm năng lượng
Để trở thành giải pháp tối ưu hóa, hàm năng lượng phải ở mức tối thiểu. Trên cơ sở các ràng buộc sau, chúng ta có thể tính hàm năng lượng như sau:
Ràng buộc-I
Ràng buộc đầu tiên, trên cơ sở đó chúng ta sẽ tính toán hàm năng lượng, là một phần tử phải bằng 1 trong mỗi hàng của ma trận M và các phần tử khác trong mỗi hàng phải bằng 0bởi vì mỗi thành phố chỉ có thể xảy ra ở một vị trí trong chuyến tham quan TSP. Ràng buộc này có thể được viết về mặt toán học như sau:
$$ \ displaystyle \ sum \ limit_ {j = 1} ^ n M_ {x, j} \: = \: 1 \: for \: x \: \ in \: \ lbrace1, ..., n \ rbrace $ $
Bây giờ hàm năng lượng được tối thiểu hóa, dựa trên ràng buộc ở trên, sẽ chứa một số hạng tỷ lệ với -
$$ \ displaystyle \ sum \ limit_ {x = 1} ^ n \ left (\ begin {array} {c} 1 \: - \: \ displaystyle \ sum \ limit_ {j = 1} ^ n M_ {x, j } \ end {array} \ right) ^ 2 $$
Constraint-II
Như chúng ta đã biết, trong TSP, một thành phố có thể xuất hiện ở bất kỳ vị trí nào trong chuyến tham quan do đó trong mỗi cột ma trận M, một phần tử phải bằng 1 và các phần tử khác phải bằng 0. Ràng buộc này có thể được viết về mặt toán học như sau:
$$ \ displaystyle \ sum \ limit_ {x = 1} ^ n M_ {x, j} \: = \: 1 \: for \: j \: \ in \: \ lbrace1, ..., n \ rbrace $ $
Bây giờ hàm năng lượng được tối thiểu hóa, dựa trên ràng buộc ở trên, sẽ chứa một số hạng tỷ lệ với -
$$ \ displaystyle \ sum \ limit_ {j = 1} ^ n \ left (\ begin {array} {c} 1 \: - \: \ displaystyle \ sum \ limit_ {x = 1} ^ n M_ {x, j } \ end {array} \ right) ^ 2 $$
Tính toán hàm chi phí
Giả sử một ma trận vuông của (n × n) đóng góp bởi C biểu thị ma trận chi phí của TSP cho n thành phố nơi n > 0. Sau đây là một số tham số trong khi tính toán hàm chi phí:
Cx, y - Yếu tố của ma trận chi phí biểu thị chi phí đi từ thành phố x đến y.
Sự liền kề của các phần tử của A và B có thể được thể hiện bằng quan hệ sau:
$$ M_ {x, i} \: = \: 1 \: \: và \: \: M_ {y, i \ pm 1} \: = \: 1 $$
Như chúng ta đã biết, trong Ma trận giá trị đầu ra của mỗi nút có thể là 0 hoặc 1, do đó đối với mỗi cặp thành phố A, B, chúng ta có thể thêm các số hạng sau vào hàm năng lượng:
$$ \ displaystyle \ sum \ limit_ {i = 1} ^ n C_ {x, y} M_ {x, i} (M_ {y, i + 1} \: + \: M_ {y, i-1}) $$
Trên cơ sở của hàm chi phí và giá trị ràng buộc ở trên, hàm năng lượng cuối cùng E có thể được đưa ra như sau:
$$ E \: = \: \ frac {1} {2} \ displaystyle \ sum \ limit_ {i = 1} ^ n \ displaystyle \ sum \ limit_ {x} \ displaystyle \ sum \ limit_ {y \ neq x} C_ {x, y} M_ {x, i} (M_ {y, i + 1} \: + \: M_ {y, i-1}) \: + $$
$$ \: \ begin {bmatrix} \ gamma_ {1} \ displaystyle \ sum \ limit_ {x} \ left (\ begin {array} {c} 1 \: - \: \ displaystyle \ sum \ limit_ {i} M_ {x, i} \ end {array} \ right) ^ 2 \: + \: \ gamma_ {2} \ displaystyle \ sum \ limit_ {i} \ left (\ begin {array} {c} 1 \: - \ : \ displaystyle \ sum \ limit_ {x} M_ {x, i} \ end {array} \ right) ^ 2 \ end {bmatrix} $$
Đây, γ1 và γ2 là hai hằng số cân.
Kỹ thuật Gradient Descent được lặp lại
Gradient descent, còn được gọi là dốc xuống dốc nhất, là một thuật toán tối ưu hóa lặp đi lặp lại để tìm điểm tối thiểu cục bộ của một hàm. Trong khi giảm thiểu chức năng, chúng tôi quan tâm đến chi phí hoặc lỗi cần được giảm thiểu (Hãy nhớ vấn đề người bán hàng đi du lịch). Nó được sử dụng rộng rãi trong học sâu, rất hữu ích trong nhiều tình huống khác nhau. Điểm cần lưu ý ở đây là chúng tôi quan tâm đến tối ưu hóa cục bộ chứ không phải tối ưu hóa toàn cầu.
Ý tưởng làm việc chính
Chúng ta có thể hiểu ý tưởng hoạt động chính của gradient descent với sự trợ giúp của các bước sau:
Đầu tiên, hãy bắt đầu với phỏng đoán ban đầu về giải pháp.
Sau đó, lấy gradient của hàm tại điểm đó.
Sau đó, lặp lại quy trình bằng cách hướng dung dịch theo hướng âm của gradient.
Bằng cách làm theo các bước trên, thuật toán cuối cùng sẽ hội tụ ở nơi gradient bằng không.
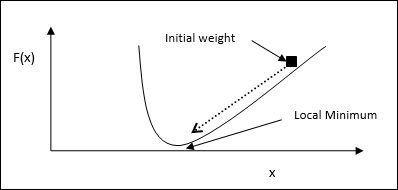
Khái niệm toán học
Giả sử chúng ta có một hàm f(x)và chúng tôi đang cố gắng tìm mức tối thiểu của hàm này. Sau đây là các bước để tìm mức tối thiểu củaf(x).
Đầu tiên, hãy cung cấp một số giá trị ban đầu $ x_ {0} \: cho \: x $
Bây giờ lấy hàm gradient $ \ nabla f $ of, với trực giác rằng gradient sẽ cho độ dốc của đường cong tại đó x và hướng của nó sẽ chỉ đến sự gia tăng của chức năng, để tìm ra hướng tốt nhất để giảm thiểu nó.
Bây giờ thay đổi x như sau:
$$ x_ {n \: + \: 1} \: = \: x_ {n} \: - \: \ theta \ nabla f (x_ {n}) $$
Đây, θ > 0 là tốc độ đào tạo (kích thước bước) buộc thuật toán thực hiện các bước nhảy nhỏ.
Ước tính kích thước bước
Trên thực tế, kích thước bước sai θcó thể không đạt đến sự hội tụ, do đó, việc lựa chọn cẩn thận giống nhau là rất quan trọng. Các điểm sau phải được ghi nhớ khi chọn kích thước bước
Không nên chọn kích thước bước quá lớn, nếu không sẽ có tác động tiêu cực, tức là nó sẽ phân kỳ chứ không hội tụ.
Không nên chọn kích thước bước quá nhỏ, nếu không sẽ mất nhiều thời gian để hội tụ.
Một số tùy chọn liên quan đến việc chọn kích thước bước -
Một tùy chọn là chọn kích thước bước cố định.
Một tùy chọn khác là chọn kích thước bước khác nhau cho mỗi lần lặp.
Ủ mô phỏng
Khái niệm cơ bản về ủ mô phỏng (SA) được thúc đẩy bởi quá trình ủ trong chất rắn. Trong quá trình ủ, nếu chúng ta nung một kim loại trên nhiệt độ nóng chảy của nó và làm nguội nó thì các đặc tính cấu trúc sẽ phụ thuộc vào tốc độ làm nguội. Chúng ta cũng có thể nói rằng SA mô phỏng quá trình luyện kim của quá trình ủ.
Sử dụng trong ANN
SA là một phương pháp tính toán ngẫu nhiên, lấy cảm hứng từ phép loại suy Annealing, để ước tính tối ưu hóa toàn cục của một hàm nhất định. Chúng ta có thể sử dụng SA để đào tạo mạng nơ-ron chuyển tiếp.
Thuật toán
Step 1 - Tạo một giải pháp ngẫu nhiên.
Step 2 - Tính giá thành của nó bằng cách sử dụng một số hàm chi phí.
Step 3 - Tạo một giải pháp lân cận ngẫu nhiên.
Step 4 - Tính toán chi phí giải pháp mới theo cùng một hàm chi phí.
Step 5 - So sánh chi phí của một giải pháp mới với một giải pháp cũ như sau:
Nếu CostNew Solution < CostOld Solution sau đó chuyển sang giải pháp mới.
Step 6 - Kiểm tra điều kiện dừng, có thể là số lần lặp tối đa đạt được hoặc có được giải pháp chấp nhận được.
Thiên nhiên luôn là nguồn cảm hứng dồi dào cho cả nhân loại. Thuật toán di truyền (GA) là thuật toán tìm kiếm dựa trên các khái niệm về chọn lọc tự nhiên và di truyền. GA là một tập con của một nhánh tính toán lớn hơn nhiều, được gọi làEvolutionary Computation.
GAs được phát triển bởi John Holland cùng các sinh viên và đồng nghiệp của ông tại Đại học Michigan, nổi bật nhất là David E. Goldberg và kể từ đó đã được thử nghiệm trên các vấn đề tối ưu hóa khác nhau với mức độ thành công cao.
Trong GAs, chúng tôi có một nhóm hoặc một tập hợp các giải pháp khả thi cho vấn đề đã cho. Các giải pháp này sau đó trải qua quá trình tái tổ hợp và đột biến (giống như trong di truyền tự nhiên), tạo ra những đứa trẻ mới và quá trình này được lặp lại qua nhiều thế hệ khác nhau. Mỗi cá thể (hoặc giải pháp ứng cử viên) được chỉ định một giá trị phù hợp (dựa trên giá trị hàm mục tiêu của nó) và các cá thể phù hợp có cơ hội giao phối cao hơn và mang lại nhiều cá thể “hợp lứa” hơn. Điều này phù hợp với Lý thuyết của Darwin về “Sự sống sót của những người khỏe mạnh nhất”.
Bằng cách này, chúng tôi tiếp tục “phát triển” các cá nhân hoặc giải pháp tốt hơn qua nhiều thế hệ, cho đến khi chúng tôi đạt được tiêu chí dừng.
Các thuật toán di truyền về bản chất là đủ ngẫu nhiên, tuy nhiên chúng hoạt động tốt hơn nhiều so với tìm kiếm cục bộ ngẫu nhiên (trong đó chúng tôi chỉ thử các giải pháp ngẫu nhiên khác nhau, theo dõi các giải pháp tốt nhất cho đến nay), vì chúng cũng khai thác thông tin lịch sử.
Ưu điểm của GAs
GA có nhiều lợi thế khác nhau đã làm cho chúng trở nên vô cùng phổ biến. Chúng bao gồm -
Không yêu cầu bất kỳ thông tin phái sinh nào (có thể không có sẵn cho nhiều vấn đề trong thế giới thực).
Nhanh hơn và hiệu quả hơn so với các phương pháp truyền thống.
Có khả năng song song rất tốt.
Tối ưu hóa cả các chức năng liên tục và rời rạc cũng như các bài toán đa mục tiêu.
Cung cấp danh sách các giải pháp “tốt” chứ không chỉ là một giải pháp duy nhất.
Luôn nhận được câu trả lời cho vấn đề, vấn đề này sẽ tốt hơn theo thời gian.
Hữu ích khi không gian tìm kiếm rất lớn và có nhiều tham số liên quan.
Hạn chế của GAs
Giống như bất kỳ kỹ thuật nào, GAs cũng gặp phải một số hạn chế. Chúng bao gồm -
GAs không phù hợp cho tất cả các vấn đề, đặc biệt là các vấn đề đơn giản và có sẵn thông tin phái sinh.
Giá trị thể chất được tính toán nhiều lần, có thể tốn kém về mặt tính toán đối với một số vấn đề.
Là ngẫu nhiên, không có gì đảm bảo về tính tối ưu hoặc chất lượng của giải pháp.
Nếu không được triển khai đúng cách, GA có thể không hội tụ thành giải pháp tối ưu.
GA - Động lực
Thuật toán di truyền có khả năng cung cấp một giải pháp “đủ tốt” “đủ nhanh”. Điều này làm cho Gas trở nên hấp dẫn để sử dụng trong việc giải quyết các vấn đề tối ưu hóa. Các lý do tại sao GAs là cần thiết như sau:
Giải quyết các vấn đề khó khăn
Trong khoa học máy tính, có một loạt các vấn đề, đó là NP-Hard. Điều này về cơ bản có nghĩa là, ngay cả những hệ thống máy tính mạnh nhất cũng phải mất một thời gian rất dài (thậm chí hàng năm!) Để giải quyết vấn đề đó. Trong trường hợp như vậy, GAs chứng tỏ là một công cụ hiệu quả để cung cấpusable near-optimal solutions trong một khoảng thời gian ngắn.
Thất bại của các phương pháp dựa trên Gradient
Các phương pháp dựa trên giải tích truyền thống hoạt động bằng cách bắt đầu tại một điểm ngẫu nhiên và bằng cách di chuyển theo hướng của gradient, cho đến khi chúng ta lên đến đỉnh đồi. Kỹ thuật này hiệu quả và hoạt động rất tốt cho các hàm mục tiêu một đỉnh như hàm chi phí trong hồi quy tuyến tính. Tuy nhiên, trong hầu hết các tình huống thực tế, chúng ta gặp một vấn đề rất phức tạp được gọi là cảnh quan, được tạo bởi nhiều đỉnh và nhiều thung lũng, khiến các phương pháp này không thành công, vì chúng có xu hướng cố hữu là bị mắc kẹt tại optima cục bộ như được hiển thị trong hình sau.
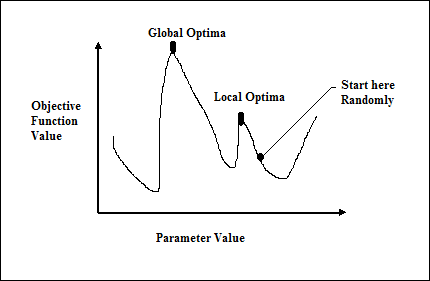
Nhận giải pháp tốt nhanh chóng
Một số bài toán khó như Bài toán Người bán hàng Đi du lịch (TSP), có các ứng dụng trong thế giới thực như tìm đường và Thiết kế VLSI. Bây giờ, hãy tưởng tượng rằng bạn đang sử dụng hệ thống Định vị GPS của mình và mất vài phút (hoặc thậm chí vài giờ) để tính toán đường đi “tối ưu” từ nguồn đến đích. Sự chậm trễ trong các ứng dụng trong thế giới thực như vậy là không thể chấp nhận được và do đó, một giải pháp “đủ tốt”, được cung cấp “nhanh chóng” là điều cần thiết.
Cách sử dụng GA cho các vấn đề về tối ưu hóa?
Chúng ta đã biết rằng tối ưu hóa là một hành động làm cho một cái gì đó như thiết kế, tình huống, tài nguyên và hệ thống hiệu quả nhất có thể. Quá trình tối ưu hóa được hiển thị trong sơ đồ sau.

Các giai đoạn của Cơ chế GA cho quá trình tối ưu hóa
Tiếp theo là các giai đoạn của cơ chế GA khi được sử dụng để tối ưu hóa các vấn đề.
Tạo quần thể ban đầu một cách ngẫu nhiên.
Chọn giải pháp ban đầu với các giá trị phù hợp nhất.
Kết hợp lại các giải pháp đã chọn bằng cách sử dụng các toán tử đột biến và chéo.
Đưa con lai vào quần thể.
Bây giờ nếu điều kiện dừng được đáp ứng, sau đó trả lại giải pháp với giá trị thể lực tốt nhất của họ. Nếu không, hãy chuyển sang bước 2.
Trước khi nghiên cứu các lĩnh vực mà ANN đã được sử dụng rộng rãi, chúng ta cần hiểu tại sao ANN lại là lựa chọn ứng dụng ưu tiên.
Tại sao lại sử dụng mạng thần kinh nhân tạo?
Chúng ta cần hiểu câu trả lời cho câu hỏi trên bằng một ví dụ về một con người. Khi còn nhỏ, chúng ta thường học những điều với sự giúp đỡ của người lớn tuổi, bao gồm cả cha mẹ hoặc giáo viên của chúng ta. Sau đó bằng cách tự học hoặc thực hành chúng ta tiếp tục học trong suốt cuộc đời. Các nhà khoa học và nhà nghiên cứu cũng đang làm cho cỗ máy trở nên thông minh giống như con người và ANN cũng đóng một vai trò rất quan trọng do những lý do sau:
Với sự trợ giúp của mạng nơ-ron, chúng ta có thể tìm ra lời giải cho những vấn đề như vậy mà phương pháp thuật toán nào đắt tiền hoặc không tồn tại.
Mạng nơ-ron có thể học theo ví dụ, do đó chúng ta không cần phải lập trình nó nhiều.
Mạng nơron có độ chính xác và tốc độ nhanh hơn đáng kể so với tốc độ thông thường.
Lĩnh vực ứng dụng
Tiếp theo là một số lĩnh vực mà ANN đang được sử dụng. Nó gợi ý rằng ANN có một cách tiếp cận liên ngành trong quá trình phát triển và ứng dụng của nó.
Nhận dạng giọng nói
Lời nói chiếm một vai trò nổi bật trong tương tác giữa con người với con người. Do đó, mọi người mong đợi giao diện giọng nói với máy tính là điều tự nhiên. Trong thời đại hiện nay, để giao tiếp với máy móc, con người vẫn cần những ngôn ngữ phức tạp, khó học và khó sử dụng. Để giảm bớt rào cản giao tiếp này, một giải pháp đơn giản có thể là giao tiếp bằng ngôn ngữ nói mà máy móc có thể hiểu được.
Tuy nhiên, lĩnh vực này đã đạt được nhiều tiến bộ vượt bậc, tuy nhiên, những hệ thống kiểu như vậy vẫn đang phải đối mặt với vấn đề hạn chế về từ vựng hoặc ngữ pháp cùng với vấn đề đào tạo lại hệ thống cho những người nói khác nhau trong những điều kiện khác nhau. ANN đang đóng một vai trò quan trọng trong lĩnh vực này. Các ANN sau đã được sử dụng để nhận dạng giọng nói -
Mạng nhiều lớp
Mạng nhiều lớp có kết nối lặp lại
Bản đồ tính năng tự tổ chức của Kohonen
Mạng hữu ích nhất cho việc này là bản đồ tính năng Tự tổ chức của Kohonen, có đầu vào là các đoạn ngắn của dạng sóng giọng nói. Nó sẽ ánh xạ cùng một loại âm vị với mảng đầu ra, được gọi là kỹ thuật trích xuất đặc trưng. Sau khi trích xuất các tính năng, với sự trợ giúp của một số mô hình âm thanh như xử lý back-end, nó sẽ nhận ra lời nói.
Nhận dạng ký tự
Đây là một vấn đề thú vị thuộc lĩnh vực chung của Nhận dạng mẫu. Nhiều mạng nơ-ron đã được phát triển để tự động nhận dạng các ký tự viết tay, cả chữ cái hoặc chữ số. Sau đây là một số ANN đã được sử dụng để nhận dạng ký tự -
- Mạng nơ-ron đa lớp chẳng hạn như mạng nơ-ron lan truyền ngược.
- Neocognitron
Mặc dù mạng nơ-ron lan truyền ngược có một số lớp ẩn, nhưng mô hình kết nối từ lớp này sang lớp tiếp theo được bản địa hóa. Tương tự, neocognitron cũng có một số lớp ẩn và quá trình đào tạo của nó được thực hiện từng lớp cho các loại ứng dụng như vậy.
Ứng dụng Xác minh Chữ ký
Chữ ký là một trong những cách hữu ích nhất để ủy quyền và xác thực một người trong các giao dịch hợp pháp. Kỹ thuật xác minh chữ ký là một kỹ thuật không dựa trên thị lực.
Đối với ứng dụng này, cách tiếp cận đầu tiên là trích xuất đối tượng địa lý hay đúng hơn là tập hợp đặc điểm hình học đại diện cho chữ ký. Với các bộ tính năng này, chúng ta phải đào tạo mạng nơ-ron bằng cách sử dụng một thuật toán mạng nơ-ron hiệu quả. Mạng nơ-ron được đào tạo này sẽ phân loại chữ ký là thật hay giả mạo trong giai đoạn xác minh.
Nhận dạng khuôn mặt người
Nó là một trong những phương pháp sinh trắc học để xác định khuôn mặt đã cho. Đây là một nhiệm vụ điển hình vì đặc điểm của hình ảnh "không có khuôn mặt". Tuy nhiên, nếu một mạng nơron được đào tạo tốt, thì nó có thể được chia thành hai lớp: hình ảnh có khuôn mặt và hình ảnh không có khuôn mặt.
Đầu tiên, tất cả các hình ảnh đầu vào phải được xử lý trước. Sau đó, kích thước của hình ảnh đó phải được giảm bớt. Và, cuối cùng nó phải được phân loại bằng cách sử dụng thuật toán huấn luyện mạng nơ-ron. Các mạng nơron sau được sử dụng cho mục đích đào tạo với hình ảnh được xử lý trước -
Được đào tạo mạng nơ-ron truyền tới nhiều lớp được kết nối đầy đủ với sự trợ giúp của thuật toán lan truyền ngược.
Để giảm kích thước, phân tích thành phần chính (PCA) được sử dụng.