Caffe2 - Hướng dẫn nhanh
Vài năm gần đây, Học sâu đã trở thành một xu hướng lớn trong Học máy. Nó đã được áp dụng thành công để giải quyết các vấn đề nan giải trước đây trong Vision, Speech Recognition and Natural Language Processing(NLP). Có rất nhiều lĩnh vực khác mà Deep Learning đang được áp dụng và đã cho thấy tính hữu ích của nó.
Caffe (Convolutional Architecture for Fast Feature Embedding) là một khung học tập sâu được phát triển tại Berkeley Vision and Learning Center (BVLC). Dự án Caffe được tạo ra bởi Yangqing Jia trong thời gian tiến sĩ của ông. tại Đại học California - Berkeley. Caffe cung cấp một cách dễ dàng để thử nghiệm học sâu. Nó được viết bằng C ++ và cung cấp các ràng buộc choPython và Matlab.
Nó hỗ trợ nhiều loại kiến trúc học sâu khác nhau như CNN (Mạng nơron hợp pháp), LSTM(Bộ nhớ ngắn hạn dài hạn) và FC (Kết nối đầy đủ). Nó hỗ trợ GPU và do đó, lý tưởng cho các môi trường sản xuất liên quan đến mạng thần kinh sâu. Nó cũng hỗ trợ các thư viện hạt nhân dựa trên CPU nhưNVIDIA, Thư viện Mạng thần kinh sâu CUDA (cuDNN) và Thư viện Hạt nhân Toán học Intel (Intel MKL).
Vào tháng 4 năm 2017, công ty cung cấp dịch vụ mạng xã hội Facebook có trụ sở tại Hoa Kỳ đã công bố Caffe2, hiện bao gồm RNN (Mạng thần kinh tái tạo) và vào tháng 3 năm 2018, Caffe2 được sáp nhập vào PyTorch. Những người sáng tạo Caffe2 và các thành viên cộng đồng đã tạo ra các mô hình giải quyết các vấn đề khác nhau. Những người mẫu này có sẵn cho công chúng như những người mẫu được đào tạo trước. Caffe2 giúp người sáng tạo sử dụng các mô hình này và tạo mạng của riêng mình để đưa ra dự đoán trên tập dữ liệu.
Trước khi đi vào chi tiết của Caffe2, chúng ta hãy hiểu sự khác biệt giữa machine learning và deep learning. Điều này là cần thiết để hiểu cách các mô hình được tạo ra và sử dụng trong Caffe2.
Học máy v / s Học sâu
Trong bất kỳ thuật toán học máy nào, dù là thuật toán truyền thống hay học sâu, việc lựa chọn các tính năng trong tập dữ liệu đóng một vai trò cực kỳ quan trọng để có được độ chính xác dự đoán mong muốn. Trong các kỹ thuật học máy truyền thống,feature selectionđược thực hiện hầu hết bằng sự kiểm tra, phán đoán của con người và kiến thức miền sâu. Đôi khi, bạn có thể tìm kiếm sự trợ giúp từ một số thuật toán đã được thử nghiệm để lựa chọn tính năng.
Luồng học máy truyền thống được mô tả trong hình bên dưới -

Trong học sâu, việc lựa chọn tính năng là tự động và là một phần của chính thuật toán học sâu. Điều này được thể hiện trong hình bên dưới -

Trong thuật toán học sâu, feature engineeringđược thực hiện tự động. Nói chung, kỹ thuật tính năng tốn nhiều thời gian và đòi hỏi chuyên môn giỏi về miền. Để thực hiện trích xuất tính năng tự động, các thuật toán học sâu thường yêu cầu lượng dữ liệu khổng lồ, vì vậy nếu bạn chỉ có hàng nghìn và hàng chục nghìn điểm dữ liệu, kỹ thuật học sâu có thể không mang lại cho bạn kết quả như ý.
Với dữ liệu lớn hơn, các thuật toán học sâu tạo ra kết quả tốt hơn so với các thuật toán ML truyền thống với lợi thế bổ sung là ít hoặc không có kỹ thuật tính năng.
Bây giờ, khi bạn đã có một số hiểu biết về học sâu, hãy để chúng tôi tìm hiểu tổng quan về Caffe là gì.
Đào tạo CNN
Hãy cùng chúng tôi tìm hiểu quy trình đào tạo CNN để phân loại hình ảnh. Quy trình bao gồm các bước sau:
Data Preparation- Trong bước này, chúng tôi cắt giữa các hình ảnh và thay đổi kích thước của chúng để tất cả các hình ảnh để đào tạo và thử nghiệm sẽ có cùng kích thước. Điều này thường được thực hiện bằng cách chạy một tập lệnh Python nhỏ trên dữ liệu hình ảnh.
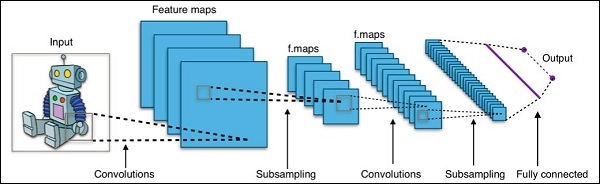
Model Definition- Trong bước này, chúng tôi xác định một kiến trúc CNN. Cấu hình được lưu trữ trong.pb (protobuf)tập tin. Một kiến trúc CNN điển hình được thể hiện trong hình bên dưới.
Solver Definition- Chúng tôi xác định tệp cấu hình bộ giải. Solver thực hiện tối ưu hóa mô hình.
Model Training- Chúng tôi sử dụng tiện ích Caffe có sẵn để huấn luyện người mẫu. Việc đào tạo có thể mất một lượng thời gian và mức sử dụng CPU đáng kể. Sau khi hoàn thành khóa đào tạo, Caffe lưu trữ mô hình trong một tệp, tệp này sau này có thể được sử dụng trên dữ liệu thử nghiệm và triển khai cuối cùng cho các dự đoán.
Có gì mới trong Caffe2
Trong Caffe2, bạn sẽ tìm thấy nhiều mô hình được đào tạo trước sẵn sàng sử dụng và cũng thường xuyên tận dụng sự đóng góp của cộng đồng cho các mô hình và thuật toán mới. Các mô hình mà bạn tạo có thể dễ dàng mở rộng quy mô bằng cách sử dụng sức mạnh GPU trong đám mây và cũng có thể được đưa xuống sử dụng hàng loạt trên thiết bị di động với các thư viện đa nền tảng của nó.
Những cải tiến được thực hiện trong Caffe2 so với Caffe có thể được tóm tắt như sau:
- Triển khai di động
- Hỗ trợ phần cứng mới
- Hỗ trợ đào tạo phân tán quy mô lớn
- Tính toán lượng tử hóa
- Stress test trên Facebook
Demo mô hình tiền chế
Trang web Trung tâm Học tập và Tầm nhìn Berkeley (BVLC) cung cấp các bản demo về mạng lưới được đào tạo trước của họ. Một mạng như vậy để phân loại hình ảnh có sẵn trên liên kết được nêu trong đâyhttps://caffe2.ai/docs/learn-more#null__caffe-neural-network-for-image-classification và được mô tả trong ảnh chụp màn hình bên dưới.
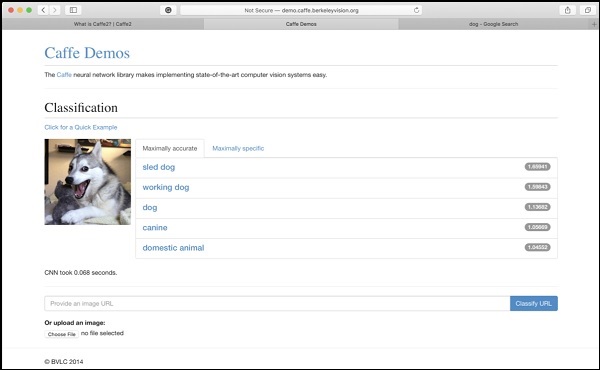
Trong ảnh chụp màn hình, hình ảnh một con chó được phân loại và gắn nhãn với độ chính xác dự đoán của nó. Nó cũng nói rằng nó chỉ mất0.068 secondsđể phân loại hình ảnh. Bạn có thể thử một hình ảnh do chính mình lựa chọn bằng cách chỉ định URL của hình ảnh hoặc tải lên chính hình ảnh đó trong các tùy chọn được đưa ra ở cuối màn hình.
Bây giờ, bạn đã có đủ hiểu biết về các khả năng của Caffe2, đã đến lúc tự mình thử nghiệm Caffe2. Để sử dụng các mô hình được đào tạo trước hoặc để phát triển các mô hình của bạn bằng mã Python của riêng bạn, trước tiên bạn phải cài đặt Caffe2 trên máy của mình.
Trên trang cài đặt của trang Caffe2 có tại liên kết https://caffe2.ai/docs/getting-started.html bạn sẽ thấy phần sau để chọn nền tảng và loại cài đặt của mình.

Như bạn có thể thấy trong ảnh chụp màn hình ở trên, Caffe2 hỗ trợ một số nền tảng phổ biến bao gồm cả nền tảng di động.
Bây giờ, chúng ta sẽ hiểu các bước để MacOS installation mà tất cả các dự án trong hướng dẫn này đều được thử nghiệm.
Cài đặt MacOS
Việc cài đặt có thể có bốn kiểu như được đưa ra dưới đây:
- Binaries dựng sẵn
- Xây dựng từ nguồn
- Hình ảnh Docker
- Cloud
Tùy thuộc vào sở thích của bạn, hãy chọn bất kỳ tùy chọn nào ở trên làm kiểu cài đặt của bạn. Các hướng dẫn được đưa ra ở đây theo trang web cài đặt Caffe2 chopre-built binaries. Nó sử dụng Anaconda choJupyter environment. Thực thi lệnh sau trên dấu nhắc bảng điều khiển của bạn
pip install torch_nightly -f
https://download.pytorch.org/whl/nightly/cpu/torch_nightly.htmlNgoài những thứ trên, bạn sẽ cần một vài thư viện của bên thứ ba, được cài đặt bằng các lệnh sau:
conda install -c anaconda setuptools
conda install -c conda-forge graphviz
conda install -c conda-forge hypothesis
conda install -c conda-forge ipython
conda install -c conda-forge jupyter
conda install -c conda-forge matplotlib
conda install -c anaconda notebook
conda install -c anaconda pydot
conda install -c conda-forge python-nvd3
conda install -c anaconda pyyaml
conda install -c anaconda requests
conda install -c anaconda scikit-image
conda install -c anaconda scipyMột số hướng dẫn trong trang web Caffe2 cũng yêu cầu cài đặt zeromq, được cài đặt bằng lệnh sau:
conda install -c anaconda zeromqCài đặt Windows / Linux
Thực thi lệnh sau trên dấu nhắc bảng điều khiển của bạn:
conda install -c pytorch pytorch-nightly-cpuNhư bạn đã nhận thấy, bạn sẽ cần Anaconda để sử dụng cài đặt trên. Bạn sẽ cần cài đặt các gói bổ sung như được chỉ định trongMacOS installation.
Thử nghiệm cài đặt
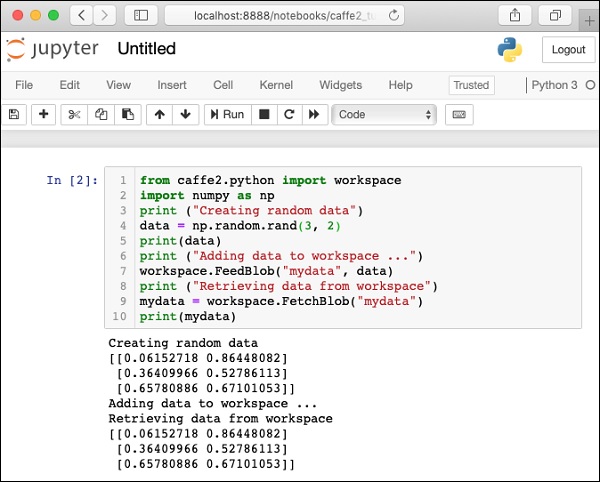
Để kiểm tra cài đặt của bạn, một tập lệnh Python nhỏ được đưa ra bên dưới, bạn có thể cắt và dán vào dự án Juypter của mình và thực thi.
from caffe2.python import workspace
import numpy as np
print ("Creating random data")
data = np.random.rand(3, 2)
print(data)
print ("Adding data to workspace ...")
workspace.FeedBlob("mydata", data)
print ("Retrieving data from workspace")
mydata = workspace.FetchBlob("mydata")
print(mydata)Khi bạn thực thi đoạn mã trên, bạn sẽ thấy kết quả sau:
Creating random data
[[0.06152718 0.86448082]
[0.36409966 0.52786113]
[0.65780886 0.67101053]]
Adding data to workspace ...
Retrieving data from workspace
[[0.06152718 0.86448082]
[0.36409966 0.52786113]
[0.65780886 0.67101053]]Ảnh chụp màn hình của trang kiểm tra cài đặt được hiển thị ở đây để bạn tham khảo nhanh -
Bây giờ, bạn đã cài đặt Caffe2 trên máy của mình, hãy tiến hành cài đặt các ứng dụng hướng dẫn.
Hướng dẫn cài đặt
Tải xuống nguồn hướng dẫn bằng lệnh sau trên bảng điều khiển của bạn -
git clone --recursive https://github.com/caffe2/tutorials caffe2_tutorialsSau khi tải xuống hoàn tất, bạn sẽ tìm thấy một số dự án Python trong caffe2_tutorialsthư mục trong thư mục cài đặt của bạn. Ảnh chụp màn hình của thư mục này được đưa ra để bạn xem nhanh.
/Users/yourusername/caffe2_tutorials
Bạn có thể mở một số hướng dẫn này để xem Caffe2 codegiống như. Hai dự án tiếp theo được mô tả trong hướng dẫn này phần lớn dựa trên các mẫu được hiển thị ở trên.
Bây giờ là lúc để thực hiện một số mã hóa Python của riêng chúng ta. Hãy để chúng tôi hiểu, cách sử dụng mô hình được đào tạo trước từ Caffe2. Sau đó, bạn sẽ học cách tạo mạng thần kinh nhỏ của riêng mình để đào tạo về tập dữ liệu của riêng bạn.
Trước khi bạn học cách sử dụng một mô hình được đào tạo trước trong ứng dụng Python của mình, trước tiên hãy để chúng tôi xác minh rằng các mô hình đó đã được cài đặt trên máy của bạn và có thể truy cập được thông qua mã Python.
Khi bạn cài đặt Caffe2, các mô hình được đào tạo trước sẽ được sao chép vào thư mục cài đặt. Trên máy có cài đặt Anaconda, các mô hình này có sẵn trong thư mục sau.
anaconda3/lib/python3.7/site-packages/caffe2/python/modelsKiểm tra thư mục cài đặt trên máy của bạn để biết sự hiện diện của các mô hình này. Bạn có thể thử tải các mô hình này từ thư mục cài đặt bằng tập lệnh Python ngắn sau:
CAFFE_MODELS = os.path.expanduser("/anaconda3/lib/python3.7/site-packages/caffe2/python/models")
INIT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'init_net.pb')
PREDICT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'predict_net.pb')
print(INIT_NET)
print(PREDICT_NET)Khi tập lệnh chạy thành công, bạn sẽ thấy kết quả sau:
/anaconda3/lib/python3.7/site-packages/caffe2/python/models/squeezenet/init_net.pb
/anaconda3/lib/python3.7/site-packages/caffe2/python/models/squeezenet/predict_net.pbĐiều này xác nhận rằng squeezenet mô-đun được cài đặt trên máy của bạn và có thể truy cập vào mã của bạn.
Bây giờ, bạn đã sẵn sàng viết mã Python của riêng mình để phân loại hình ảnh bằng Caffe2 squeezenet đào tạo trước học phần.
Trong bài học này, bạn sẽ học cách sử dụng một mô hình được đào tạo trước để phát hiện các đối tượng trong một hình ảnh nhất định. Bạn sẽ sử dụngsqueezenet mô-đun được đào tạo trước giúp phát hiện và phân loại các đối tượng trong một hình ảnh nhất định với độ chính xác cao.
Mở một cái mới Juypter notebook và làm theo các bước để phát triển ứng dụng phân loại ảnh này.
Nhập thư viện
Đầu tiên, chúng tôi nhập các gói được yêu cầu bằng mã bên dưới -
from caffe2.proto import caffe2_pb2
from caffe2.python import core, workspace, models
import numpy as np
import skimage.io
import skimage.transform
from matplotlib import pyplot
import os
import urllib.request as urllib2
import operatorTiếp theo, chúng tôi thiết lập một số variables -
INPUT_IMAGE_SIZE = 227
mean = 128Các hình ảnh được sử dụng để đào tạo rõ ràng sẽ có kích thước khác nhau. Tất cả những hình ảnh này phải được chuyển đổi thành một kích thước cố định để đào tạo chính xác. Tương tự như vậy, hình ảnh thử nghiệm và hình ảnh mà bạn muốn dự đoán trong môi trường sản xuất cũng phải được chuyển đổi thành kích thước, giống như hình ảnh được sử dụng trong quá trình đào tạo. Do đó, chúng tôi tạo một biến ở trên được gọi làINPUT_IMAGE_SIZE có giá trị 227. Do đó, chúng tôi sẽ chuyển đổi tất cả hình ảnh của mình sang kích thước227x227 trước khi sử dụng nó trong bộ phân loại của chúng tôi.
Chúng tôi cũng khai báo một biến được gọi là mean có giá trị 128, được sử dụng sau này để cải thiện kết quả phân loại.
Tiếp theo, chúng tôi sẽ phát triển hai chức năng để xử lý hình ảnh.
Đang xử lý hình ảnh
Quá trình xử lý hình ảnh bao gồm hai bước. Đầu tiên là thay đổi kích thước hình ảnh, và thứ hai là cắt hình ảnh một cách trung tâm. Đối với hai bước này, chúng ta sẽ viết hai hàm thay đổi kích thước và cắt xén.
Thay đổi kích thước hình ảnh
Đầu tiên, chúng ta sẽ viết một hàm để thay đổi kích thước hình ảnh. Như đã nói trước đó, chúng tôi sẽ thay đổi kích thước hình ảnh thành227x227. Vì vậy, chúng ta hãy xác định hàmresize như sau -
def resize(img, input_height, input_width):Chúng tôi thu được tỷ lệ khung hình của hình ảnh bằng cách chia chiều rộng cho chiều cao.
original_aspect = img.shape[1]/float(img.shape[0])Nếu tỷ lệ khung hình lớn hơn 1, nó chỉ ra rằng hình ảnh rộng, có nghĩa là nó đang ở chế độ ngang. Bây giờ chúng tôi điều chỉnh chiều cao hình ảnh và trả lại hình ảnh đã thay đổi kích thước bằng cách sử dụng mã sau:
if(original_aspect>1):
new_height = int(original_aspect * input_height)
return skimage.transform.resize(img, (input_width,
new_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)Nếu tỷ lệ khung hình là less than 1, nó chỉ ra portrait mode. Bây giờ chúng tôi điều chỉnh chiều rộng bằng cách sử dụng mã sau:
if(original_aspect<1):
new_width = int(input_width/original_aspect)
return skimage.transform.resize(img, (new_width,
input_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)Nếu tỷ lệ khung hình bằng 1, chúng tôi không thực hiện bất kỳ điều chỉnh chiều cao / chiều rộng nào.
if(original_aspect == 1):
return skimage.transform.resize(img, (input_width,
input_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)Mã chức năng đầy đủ được cung cấp bên dưới để bạn tham khảo nhanh -
def resize(img, input_height, input_width):
original_aspect = img.shape[1]/float(img.shape[0])
if(original_aspect>1):
new_height = int(original_aspect * input_height)
return skimage.transform.resize(img, (input_width,
new_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)
if(original_aspect<1):
new_width = int(input_width/original_aspect)
return skimage.transform.resize(img, (new_width,
input_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)
if(original_aspect == 1):
return skimage.transform.resize(img, (input_width,
input_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)Bây giờ chúng ta sẽ viết một hàm để cắt hình ảnh xung quanh tâm của nó.
Cắt hình ảnh
Chúng tôi tuyên bố crop_image chức năng như sau -
def crop_image(img,cropx,cropy):Chúng tôi trích xuất các kích thước của hình ảnh bằng cách sử dụng câu lệnh sau:
y,x,c = img.shapeChúng tôi tạo điểm bắt đầu mới cho hình ảnh bằng hai dòng mã sau:
startx = x//2-(cropx//2)
starty = y//2-(cropy//2)Cuối cùng, chúng tôi trả lại hình ảnh đã cắt bằng cách tạo một đối tượng hình ảnh với kích thước mới -
return img[starty:starty+cropy,startx:startx+cropx]Toàn bộ mã chức năng được cung cấp bên dưới để bạn tham khảo nhanh -
def crop_image(img,cropx,cropy):
y,x,c = img.shape
startx = x//2-(cropx//2)
starty = y//2-(cropy//2)
return img[starty:starty+cropy,startx:startx+cropx]Bây giờ, chúng ta sẽ viết mã để kiểm tra các chức năng này.
Xử lý hình ảnh
Đầu tiên, sao chép một tệp hình ảnh vào images thư mục con trong thư mục dự án của bạn. tree.jpgtệp được sao chép trong dự án. Đoạn mã Python sau tải hình ảnh và hiển thị trên bảng điều khiển:
img = skimage.img_as_float(skimage.io.imread("images/tree.jpg")).astype(np.float32)
print("Original Image Shape: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Original image')Kết quả như sau:
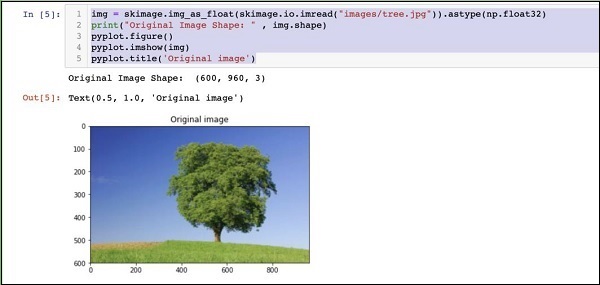
Lưu ý rằng kích thước của hình ảnh gốc là 600 x 960. Chúng tôi cần thay đổi kích thước này thành đặc điểm kỹ thuật của chúng tôi227 x 227. Gọi điện được xác định trước đó của chúng tôiresizechức năng thực hiện công việc này.
img = resize(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print("Image Shape after resizing: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Resized image')Đầu ra như dưới đây:
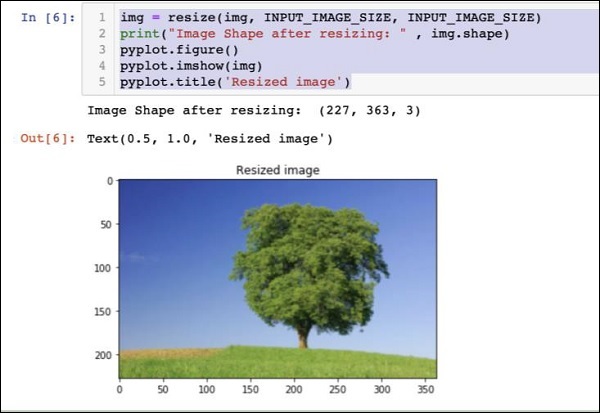
Lưu ý rằng bây giờ kích thước hình ảnh là 227 x 363. Chúng ta cần cắt nó để227 x 227cho nguồn cấp dữ liệu cuối cùng cho thuật toán của chúng tôi. Chúng tôi gọi hàm crop được xác định trước đó cho mục đích này.
img = crop_image(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print("Image Shape after cropping: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Center Cropped')Dưới đây được đề cập là đầu ra của mã -
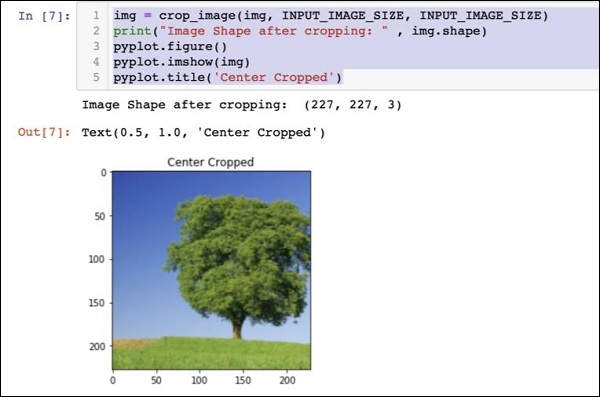
Tại thời điểm này, hình ảnh có kích thước 227 x 227và sẵn sàng để xử lý thêm. Bây giờ chúng ta hoán đổi các trục hình ảnh để trích xuất ba màu thành ba vùng khác nhau.
img = img.swapaxes(1, 2).swapaxes(0, 1)
print("CHW Image Shape: " , img.shape)Dưới đây là kết quả -
CHW Image Shape: (3, 227, 227)Lưu ý rằng trục cuối cùng bây giờ đã trở thành kích thước đầu tiên trong mảng. Bây giờ chúng ta sẽ vẽ sơ đồ ba kênh bằng đoạn mã sau:
pyplot.figure()
for i in range(3):
pyplot.subplot(1, 3, i+1)
pyplot.imshow(img[i])
pyplot.axis('off')
pyplot.title('RGB channel %d' % (i+1))Đầu ra được nêu dưới đây -

Cuối cùng, chúng tôi thực hiện một số xử lý bổ sung trên hình ảnh, chẳng hạn như chuyển đổi Red Green Blue đến Blue Green Red (RGB to BGR), loại bỏ giá trị trung bình để có kết quả tốt hơn và thêm trục kích thước lô bằng cách sử dụng ba dòng mã sau:
# convert RGB --> BGR
img = img[(2, 1, 0), :, :]
# remove mean
img = img * 255 - mean
# add batch size axis
img = img[np.newaxis, :, :, :].astype(np.float32)Tại thời điểm này, hình ảnh của bạn đang ở NCHW formatvà đã sẵn sàng để đưa vào mạng của chúng tôi. Tiếp theo, chúng tôi sẽ tải các tệp mô hình được đào tạo trước của mình và nạp hình ảnh trên vào đó để dự đoán.
Dự đoán các đối tượng trong hình ảnh đã xử lý
Đầu tiên, chúng tôi thiết lập các đường dẫn cho init và predict mạng được xác định trong các mô hình Caffe được đào tạo trước.
Đặt đường dẫn tệp mô hình
Hãy nhớ từ cuộc thảo luận trước đó của chúng tôi, tất cả các mô hình được đào tạo trước đều được cài đặt trong modelsthư mục. Chúng tôi thiết lập đường dẫn đến thư mục này như sau:
CAFFE_MODELS = os.path.expanduser("/anaconda3/lib/python3.7/site-packages/caffe2/python/models")Chúng tôi thiết lập đường dẫn đến init_net tệp protobuf của squeezenet mô hình như sau -
INIT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'init_net.pb')Tương tự như vậy, chúng tôi thiết lập đường dẫn đến predict_net protobuf như sau -
PREDICT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'predict_net.pb')Chúng tôi in hai đường dẫn cho mục đích chẩn đoán -
print(INIT_NET)
print(PREDICT_NET)Đoạn mã trên cùng với đầu ra được đưa ra ở đây để bạn tham khảo nhanh -
CAFFE_MODELS = os.path.expanduser("/anaconda3/lib/python3.7/site-packages/caffe2/python/models")
INIT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'init_net.pb')
PREDICT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'predict_net.pb')
print(INIT_NET)
print(PREDICT_NET)Đầu ra được đề cập bên dưới -
/anaconda3/lib/python3.7/site-packages/caffe2/python/models/squeezenet/init_net.pb
/anaconda3/lib/python3.7/site-packages/caffe2/python/models/squeezenet/predict_net.pbTiếp theo, chúng tôi sẽ tạo một công cụ dự đoán.
Tạo dự đoán
Chúng tôi đọc các tệp mô hình bằng hai câu lệnh sau:
with open(INIT_NET, "rb") as f:
init_net = f.read()
with open(PREDICT_NET, "rb") as f:
predict_net = f.read()Dự đoán được tạo bằng cách chuyển con trỏ đến hai tệp dưới dạng tham số cho Predictor chức năng.
p = workspace.Predictor(init_net, predict_net)Các pđối tượng là dự đoán, được sử dụng để dự đoán các đối tượng trong bất kỳ hình ảnh nhất định nào. Lưu ý rằng mỗi hình ảnh đầu vào phải ở định dạng NCHW như những gì chúng tôi đã làm trước đó vớitree.jpg tập tin.
Dự đoán đối tượng
Để dự đoán các đối tượng trong một hình ảnh nhất định là điều tầm thường - chỉ cần thực hiện một dòng lệnh duy nhất. Chúng tôi gọirun phương pháp trên predictor đối tượng để phát hiện đối tượng trong một hình ảnh nhất định.
results = p.run({'data': img})Kết quả dự đoán hiện đã có trong results đối tượng mà chúng tôi chuyển đổi thành một mảng để chúng tôi dễ đọc.
results = np.asarray(results)In các kích thước của mảng để bạn hiểu bằng cách sử dụng câu lệnh sau:
print("results shape: ", results.shape)Đầu ra như hình dưới đây -
results shape: (1, 1, 1000, 1, 1)Bây giờ chúng ta sẽ loại bỏ trục không cần thiết -
preds = np.squeeze(results)Dự đoán trên cùng hiện có thể được truy xuất bằng cách lấy max giá trị trong preds mảng.
curr_pred, curr_conf = max(enumerate(preds), key=operator.itemgetter(1))
print("Prediction: ", curr_pred)
print("Confidence: ", curr_conf)Kết quả như sau:
Prediction: 984
Confidence: 0.89235985Như bạn thấy, mô hình đã dự đoán một đối tượng có giá trị chỉ mục 984 với 89%sự tự tin. Chỉ số 984 không có nhiều ý nghĩa đối với chúng tôi trong việc hiểu loại đối tượng nào được phát hiện. Chúng ta cần lấy tên được xâu chuỗi cho đối tượng bằng giá trị chỉ mục của nó. Loại đối tượng mà mô hình nhận dạng cùng với các giá trị chỉ mục tương ứng của chúng có sẵn trên kho lưu trữ github.
Bây giờ, chúng ta sẽ xem cách lấy tên cho đối tượng của chúng ta có giá trị chỉ mục là 984.
Chuỗi kết quả
Chúng tôi tạo một đối tượng URL cho kho lưu trữ github như sau:
codes = "https://gist.githubusercontent.com/aaronmarkham/cd3a6b6ac0
71eca6f7b4a6e40e6038aa/raw/9edb4038a37da6b5a44c3b5bc52e448ff09bfe5b/alexnet_codes"Chúng tôi đọc nội dung của URL -
response = urllib2.urlopen(codes)Phản hồi sẽ chứa danh sách tất cả các mã và mô tả của nó. Dưới đây là một vài dòng phản hồi để bạn hiểu về những gì nó chứa -
5: 'electric ray, crampfish, numbfish, torpedo',
6: 'stingray',
7: 'cock',
8: 'hen',
9: 'ostrich, Struthio camelus',
10: 'brambling, Fringilla montifringilla',Bây giờ chúng tôi lặp lại toàn bộ mảng để xác định mã 984 mong muốn của chúng tôi bằng cách sử dụng for vòng lặp như sau -
for line in response:
mystring = line.decode('ascii')
code, result = mystring.partition(":")[::2]
code = code.strip()
result = result.replace("'", "")
if (code == str(curr_pred)):
name = result.split(",")[0][1:]
print("Model predicts", name, "with", curr_conf, "confidence")Khi bạn chạy mã, bạn sẽ thấy kết quả sau:
Model predicts rapeseed with 0.89235985 confidenceBây giờ bạn có thể thử mô hình trên một hình ảnh khác.
Dự đoán một hình ảnh khác
Để dự đoán một hình ảnh khác, chỉ cần sao chép tệp hình ảnh vào imagesthư mục của thư mục dự án của bạn. Đây là thư mục mà trước đó của chúng tôitree.jpgtệp được lưu trữ. Thay đổi tên của tệp hình ảnh trong mã. Chỉ cần một thay đổi như hình bên dưới
img = skimage.img_as_float(skimage.io.imread("images/pretzel.jpg")).astype(np.float32)Hình ảnh ban đầu và kết quả dự đoán được hiển thị bên dưới -

Đầu ra được đề cập bên dưới -
Model predicts pretzel with 0.99999976 confidenceNhư bạn thấy, mô hình được đào tạo trước có thể phát hiện các đối tượng trong một hình ảnh nhất định với độ chính xác cao.
Nguồn đầy đủ
Nguồn đầy đủ cho đoạn mã trên sử dụng mô hình được đào tạo trước để phát hiện đối tượng trong một hình ảnh nhất định được đề cập ở đây để bạn tham khảo nhanh -
def crop_image(img,cropx,cropy):
y,x,c = img.shape
startx = x//2-(cropx//2)
starty = y//2-(cropy//2)
return img[starty:starty+cropy,startx:startx+cropx]
img = skimage.img_as_float(skimage.io.imread("images/pretzel.jpg")).astype(np.float32)
print("Original Image Shape: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Original image')
img = resize(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print("Image Shape after resizing: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Resized image')
img = crop_image(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print("Image Shape after cropping: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Center Cropped')
img = img.swapaxes(1, 2).swapaxes(0, 1)
print("CHW Image Shape: " , img.shape)
pyplot.figure()
for i in range(3):
pyplot.subplot(1, 3, i+1)
pyplot.imshow(img[i])
pyplot.axis('off')
pyplot.title('RGB channel %d' % (i+1))
# convert RGB --> BGR
img = img[(2, 1, 0), :, :]
# remove mean
img = img * 255 - mean
# add batch size axis
img = img[np.newaxis, :, :, :].astype(np.float32)
CAFFE_MODELS = os.path.expanduser("/anaconda3/lib/python3.7/site-packages/caffe2/python/models")
INIT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'init_net.pb')
PREDICT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'predict_net.pb')
print(INIT_NET)
print(PREDICT_NET)
with open(INIT_NET, "rb") as f:
init_net = f.read()
with open(PREDICT_NET, "rb") as f:
predict_net = f.read()
p = workspace.Predictor(init_net, predict_net)
results = p.run({'data': img})
results = np.asarray(results)
print("results shape: ", results.shape)
preds = np.squeeze(results)
curr_pred, curr_conf = max(enumerate(preds), key=operator.itemgetter(1))
print("Prediction: ", curr_pred)
print("Confidence: ", curr_conf)
codes = "https://gist.githubusercontent.com/aaronmarkham/cd3a6b6ac071eca6f7b4a6e40e6038aa/raw/9edb4038a37da6b5a44c3b5bc52e448ff09bfe5b/alexnet_codes"
response = urllib2.urlopen(codes)
for line in response:
mystring = line.decode('ascii')
code, result = mystring.partition(":")[::2]
code = code.strip()
result = result.replace("'", "")
if (code == str(curr_pred)):
name = result.split(",")[0][1:]
print("Model predicts", name, "with", curr_conf, "confidence")Đến lúc này, bạn biết cách sử dụng mô hình được đào tạo trước để thực hiện các dự đoán trên tập dữ liệu của mình.
Điều tiếp theo là tìm hiểu cách xác định neural network (NN) kiến trúc trong Caffe2và đào tạo họ trên tập dữ liệu của bạn. Bây giờ chúng ta sẽ học cách tạo một NN đơn lớp tầm thường.
Trong bài học này, bạn sẽ học cách xác định single layer neural network (NN)trong Caffe2 và chạy nó trên tập dữ liệu được tạo ngẫu nhiên. Chúng tôi sẽ viết mã để mô tả bằng đồ thị kiến trúc mạng, in các giá trị đầu vào, đầu ra, trọng số và độ lệch. Để hiểu bài học này, bạn phải làm quen vớineural network architectures, nó là terms và mathematics được sử dụng trong chúng.
Kiến trúc mạng
Chúng ta hãy xem xét rằng chúng ta muốn xây dựng một lớp NN đơn lẻ như trong hình bên dưới -

Về mặt toán học, mạng này được biểu diễn bằng mã Python sau:
Y = X * W^T + bỞ đâu X, W, b là căng thẳng và Ylà đầu ra. Chúng tôi sẽ điền vào tất cả ba tensor bằng một số dữ liệu ngẫu nhiên, chạy mạng và kiểm traYđầu ra. Để xác định mạng và bộ căng, Caffe2 cung cấp một sốOperator chức năng.
Nhà điều hành Caffe2
Trong Caffe2, Operatorlà đơn vị cơ bản của tính toán. The Caffe2Operator được biểu diễn như sau.
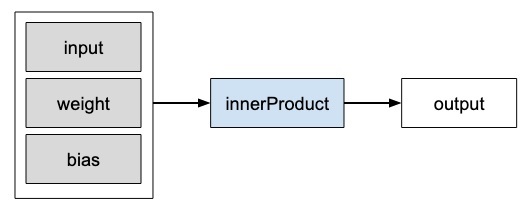
Caffe2 cung cấp một danh sách đầy đủ các nhà khai thác. Đối với mạng mà chúng tôi đang thiết kế hiện tại, chúng tôi sẽ sử dụng toán tử có tên FC, toán tử này tính toán kết quả của việc truyền một vectơ đầu vàoX thành một mạng được kết nối đầy đủ với ma trận trọng số hai chiều W và một vectơ thiên vị một chiều b. Nói cách khác, nó tính toán phương trình toán học sau
Y = X * W^T + bỞ đâu X có kích thước (M x k), W có kích thước (n x k) và b Là (1 x n). Đầu raY sẽ có kích thước (M x n), Ở đâu M là kích thước lô.
Đối với các vectơ X và W, chúng tôi sẽ sử dụng GaussianFilltoán tử để tạo một số dữ liệu ngẫu nhiên. Để tạo giá trị thiên vịb, chúng tôi sẽ sử dụng ConstantFill nhà điều hành.
Bây giờ chúng ta sẽ tiến hành xác định mạng của chúng ta.
Tạo mạng
Trước hết, hãy nhập các gói được yêu cầu -
from caffe2.python import core, workspaceTiếp theo, xác định mạng bằng cách gọi core.Net như sau -
net = core.Net("SingleLayerFC")Tên của mạng được chỉ định là SingleLayerFC. Tại thời điểm này, đối tượng mạng được gọi là net được tạo ra. Nó không chứa bất kỳ lớp nào cho đến nay.
Tạo độ căng
Bây giờ chúng ta sẽ tạo ba vectơ mà mạng của chúng ta yêu cầu. Đầu tiên, chúng ta sẽ tạo tensor X bằng cách gọiGaussianFill toán tử như sau -
X = net.GaussianFill([], ["X"], mean=0.0, std=1.0, shape=[2, 3], run_once=0)Các X vector có kích thước 2 x 3 với giá trị dữ liệu trung bình là 0,0 và độ lệch chuẩn là 1.0.
Tương tự như vậy, chúng tôi tạo W tensor như sau -
W = net.GaussianFill([], ["W"], mean=0.0, std=1.0, shape=[5, 3], run_once=0)Các W vectơ có kích thước 5 x 3.
Cuối cùng, chúng tôi tạo ra sự thiên vị b ma trận có kích thước 5.
b = net.ConstantFill([], ["b"], shape=[5,], value=1.0, run_once=0)Bây giờ, đến phần quan trọng nhất của mã và đó là xác định chính mạng.
Xác định mạng
Chúng tôi xác định mạng trong câu lệnh Python sau:
Y = X.FC([W, b], ["Y"])Chúng tôi gọi FC toán tử trên dữ liệu đầu vào X. Các trọng lượng được chỉ định trongWvà thiên vị trong b. Đầu ra làY. Ngoài ra, bạn có thể tạo mạng bằng cách sử dụng câu lệnh Python sau, câu này dài dòng hơn.
Y = net.FC([X, W, b], ["Y"])Tại thời điểm này, mạng được tạo đơn giản. Cho đến khi chúng tôi chạy mạng ít nhất một lần, nó sẽ không chứa bất kỳ dữ liệu nào. Trước khi chạy mạng, chúng tôi sẽ kiểm tra kiến trúc của nó.
Kiến trúc mạng in
Caffe2 xác định kiến trúc mạng trong tệp JSON, có thể được kiểm tra bằng cách gọi phương thức Proto trên tệp đã tạo net vật.
print (net.Proto())Điều này tạo ra kết quả sau:
name: "SingleLayerFC"
op {
output: "X"
name: ""
type: "GaussianFill"
arg {
name: "mean"
f: 0.0
}
arg {
name: "std"
f: 1.0
}
arg {
name: "shape"
ints: 2
ints: 3
}
arg {
name: "run_once"
i: 0
}
}
op {
output: "W"
name: ""
type: "GaussianFill"
arg {
name: "mean"
f: 0.0
}
arg {
name: "std"
f: 1.0
}
arg {
name: "shape"
ints: 5
ints: 3
}
arg {
name: "run_once"
i: 0
}
}
op {
output: "b"
name: ""
type: "ConstantFill"
arg {
name: "shape"
ints: 5
}
arg {
name: "value"
f: 1.0
}
arg {
name: "run_once"
i: 0
}
}
op {
input: "X"
input: "W"
input: "b"
output: "Y"
name: ""
type: "FC"
}Như bạn có thể thấy trong danh sách trên, trước tiên nó xác định các toán tử X, W và b. Hãy để chúng tôi xem xét định nghĩa củaWnhư một ví dụ. LoạiW được chỉ định là GausianFill. Cácmean được định nghĩa là float 0.0, độ lệch chuẩn được định nghĩa là float 1.0, và shape Là 5 x 3.
op {
output: "W"
name: "" type: "GaussianFill"
arg {
name: "mean"
f: 0.0
}
arg {
name: "std"
f: 1.0
}
arg {
name: "shape"
ints: 5
ints: 3
}
...
}Kiểm tra các định nghĩa của X và bcho sự hiểu biết của riêng bạn. Cuối cùng, chúng ta hãy xem định nghĩa của mạng lớp đơn của chúng tôi, được tái tạo ở đây
op {
input: "X"
input: "W"
input: "b"
output: "Y"
name: ""
type: "FC"
}Đây, loại mạng là FC (Kết nối đầy đủ) với X, W, b làm đầu vào và Ylà đầu ra. Định nghĩa mạng này quá dài dòng và đối với các mạng lớn, việc kiểm tra nội dung của nó sẽ trở nên tẻ nhạt. May mắn thay, Caffe2 cung cấp một biểu diễn đồ họa cho các mạng đã tạo.
Biểu diễn đồ họa mạng
Để có được biểu diễn đồ họa của mạng, hãy chạy đoạn mã sau, về cơ bản chỉ là hai dòng mã Python.
from caffe2.python import net_drawer
from IPython import display
graph = net_drawer.GetPydotGraph(net, rankdir="LR")
display.Image(graph.create_png(), width=800)Khi bạn chạy mã, bạn sẽ thấy kết quả sau:
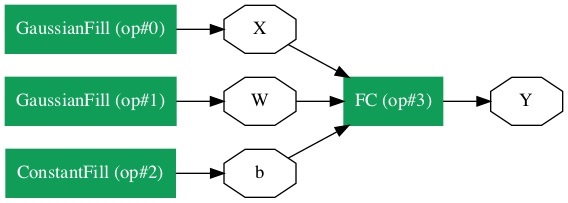
Đối với các mạng lớn, biểu diễn đồ họa trở nên cực kỳ hữu ích trong việc trực quan hóa và gỡ lỗi định nghĩa mạng.
Cuối cùng, bây giờ là lúc để chạy mạng.
Mạng đang chạy
Bạn chạy mạng bằng cách gọi RunNetOnce phương pháp trên workspace đối tượng -
workspace.RunNetOnce(net)Sau khi mạng được chạy một lần, tất cả dữ liệu của chúng tôi được tạo ngẫu nhiên sẽ được tạo, đưa vào mạng và đầu ra sẽ được tạo. Các tenxơ được tạo ra sau khi chạy mạng được gọi làblobstrong Caffe2. Không gian làm việc bao gồmblobsbạn tạo và lưu trữ trong bộ nhớ. Điều này khá giống với Matlab.
Sau khi chạy mạng, bạn có thể kiểm tra blobs mà không gian làm việc chứa bằng cách sử dụng print chỉ huy
print("Blobs in the workspace: {}".format(workspace.Blobs()))Bạn sẽ thấy kết quả sau:
Blobs in the workspace: ['W', 'X', 'Y', 'b']Lưu ý rằng không gian làm việc bao gồm ba đốm màu đầu vào - X, W và b. Nó cũng chứa blob đầu ra được gọi làY. Bây giờ chúng ta hãy xem xét nội dung của những đốm màu này.
for name in workspace.Blobs():
print("{}:\n{}".format(name, workspace.FetchBlob(name)))Bạn sẽ thấy kết quả sau:
W:
[[ 1.0426593 0.15479846 0.25635982]
[-2.2461145 1.4581774 0.16827184]
[-0.12009818 0.30771437 0.00791338]
[ 1.2274994 -0.903331 -0.68799865]
[ 0.30834186 -0.53060573 0.88776857]]
X:
[[ 1.6588869e+00 1.5279824e+00 1.1889904e+00]
[ 6.7048723e-01 -9.7490678e-04 2.5114202e-01]]
Y:
[[ 3.2709925 -0.297907 1.2803618 0.837985 1.7562964]
[ 1.7633215 -0.4651525 0.9211631 1.6511179 1.4302125]]
b:
[1. 1. 1. 1. 1.]Lưu ý rằng dữ liệu trên máy của bạn hoặc thực tế là trên mỗi lần chạy mạng sẽ khác nhau vì tất cả các đầu vào được tạo ngẫu nhiên. Bây giờ bạn đã xác định thành công một mạng và chạy nó trên máy tính của mình.
Trong bài học trước, bạn đã học cách tạo một mạng tầm thường và học cách thực thi nó cũng như kiểm tra đầu ra của nó. Quy trình tạo mạng phức tạp tương tự như quy trình được mô tả ở trên. Caffe2 cung cấp một tập hợp các toán tử khổng lồ để tạo ra các kiến trúc phức tạp. Bạn được khuyến khích xem tài liệu Caffe2 để biết danh sách các nhà khai thác. Sau khi nghiên cứu mục đích của các nhà khai thác khác nhau, bạn sẽ có thể tạo ra các mạng phức tạp và đào tạo chúng. Để đào tạo mạng, Caffe2 cung cấp một sốpredefined computation units- đó là các toán tử. Bạn sẽ cần chọn các nhà khai thác thích hợp để đào tạo mạng của bạn cho loại sự cố mà bạn đang cố gắng giải quyết.
Sau khi mạng được đào tạo để bạn hài lòng, bạn có thể lưu trữ nó trong một tệp mô hình tương tự như các tệp mô hình được đào tạo trước mà bạn đã sử dụng trước đó. Những mô hình được đào tạo này có thể được đóng góp vào kho Caffe2 vì lợi ích của những người dùng khác. Hoặc bạn có thể chỉ cần đặt mô hình được đào tạo để sử dụng cho sản xuất tư nhân của riêng bạn.
Tóm lược
Caffe2, là một khuôn khổ học tập sâu cho phép bạn thử nghiệm với một số loại mạng thần kinh để dự đoán dữ liệu của bạn. Trang Caffe2 cung cấp nhiều mô hình được đào tạo trước. Bạn đã học cách sử dụng một trong những mô hình được đào tạo trước để phân loại các đối tượng trong một hình ảnh nhất định. Bạn cũng đã học cách xác định kiến trúc mạng thần kinh mà bạn chọn. Các mạng tùy chỉnh như vậy có thể được đào tạo bằng cách sử dụng nhiều toán tử được xác định trước trong Caffe. Một mô hình đã đào tạo được lưu trữ trong một tệp có thể được đưa vào môi trường sản xuất.