Trượt web Python - Xử lý văn bản
Trong chương trước, chúng ta đã biết cách xử lý video và hình ảnh mà chúng ta thu được dưới dạng một phần của nội dung tìm kiếm trên web. Trong chương này, chúng ta sẽ giải quyết phân tích văn bản bằng cách sử dụng thư viện Python và sẽ tìm hiểu chi tiết về điều này.
Giới thiệu
Bạn có thể thực hiện phân tích văn bản bằng cách sử dụng thư viện Python có tên là Bộ công cụ ngôn ngữ tự nhiên (NLTK). Trước khi đi vào các khái niệm về NLTK, chúng ta hãy hiểu mối quan hệ giữa phân tích văn bản và tìm kiếm trang web.
Phân tích các từ trong văn bản có thể dẫn chúng ta biết về những từ nào là quan trọng, những từ nào là bất thường, cách các từ được nhóm lại. Phân tích này giúp giảm bớt nhiệm vụ tìm kiếm web.
Bắt đầu với NLTK
Bộ công cụ ngôn ngữ tự nhiên (NLTK) là tập hợp các thư viện Python được thiết kế đặc biệt để xác định và gắn thẻ các phần của giọng nói được tìm thấy trong văn bản của ngôn ngữ tự nhiên như tiếng Anh.
Cài đặt NLTK
Bạn có thể sử dụng lệnh sau để cài đặt NLTK bằng Python:
pip install nltkNếu bạn đang sử dụng Anaconda, thì một gói conda cho NLTK có thể được tạo bằng cách sử dụng lệnh sau:
conda install -c anaconda nltkTải xuống dữ liệu của NLTK
Sau khi cài đặt NLTK, chúng ta phải tải về các kho văn bản cài sẵn. Nhưng trước khi tải xuống kho lưu trữ đặt trước văn bản, chúng ta cần nhập NLTK với sự trợ giúp củaimport lệnh như sau:
mport nltkBây giờ, với sự trợ giúp của lệnh sau, dữ liệu NLTK có thể được tải xuống -
nltk.download()Việc cài đặt tất cả các gói có sẵn của NLTK sẽ mất một khoảng thời gian, nhưng bạn nên cài đặt tất cả các gói.
Cài đặt các gói cần thiết khác
Chúng tôi cũng cần một số gói Python khác như gensim và pattern để thực hiện phân tích văn bản cũng như xây dựng các ứng dụng xử lý ngôn ngữ tự nhiên bằng cách sử dụng NLTK.
gensim- Một thư viện mô hình ngữ nghĩa mạnh mẽ, hữu ích cho nhiều ứng dụng. Nó có thể được cài đặt bằng lệnh sau:
pip install gensimpattern - Dùng để chế tạo gensimgói hoạt động đúng cách. Nó có thể được cài đặt bằng lệnh sau:
pip install patternMã hóa
Quá trình chia nhỏ văn bản đã cho, thành các đơn vị nhỏ hơn được gọi là mã thông báo, được gọi là mã hóa. Các mã thông báo này có thể là các từ, số hoặc dấu chấm câu. Nó còn được gọi làword segmentation.
Thí dụ

Mô-đun NLTK cung cấp các gói khác nhau để mã hóa. Chúng tôi có thể sử dụng các gói này theo yêu cầu của chúng tôi. Một số gói được mô tả ở đây -
sent_tokenize package- Gói này sẽ chia văn bản đầu vào thành các câu. Bạn có thể sử dụng lệnh sau để nhập gói này:
from nltk.tokenize import sent_tokenizeword_tokenize package- Gói này sẽ chia văn bản đầu vào thành các từ. Bạn có thể sử dụng lệnh sau để nhập gói này:
from nltk.tokenize import word_tokenizeWordPunctTokenizer package- Gói này sẽ chia văn bản đầu vào cũng như các dấu câu thành các từ. Bạn có thể sử dụng lệnh sau để nhập gói này:
from nltk.tokenize import WordPuncttokenizerGốc
Trong bất kỳ ngôn ngữ nào, có các dạng khác nhau của một từ. Một ngôn ngữ bao gồm rất nhiều biến thể do các lý do ngữ pháp. Ví dụ, hãy xem xét các từdemocracy, democraticvà democratization. Đối với máy học cũng như các dự án duyệt web, điều quan trọng là máy móc phải hiểu rằng những từ khác nhau này có cùng một dạng cơ sở. Do đó, chúng ta có thể nói rằng có thể hữu ích khi trích xuất các dạng cơ bản của từ trong khi phân tích văn bản.
Điều này có thể đạt được bằng cách tách gốc, có thể được định nghĩa là quá trình tự khám phá để trích xuất các dạng cơ sở của từ bằng cách cắt bỏ các đầu của từ.
Mô-đun NLTK cung cấp các gói khác nhau để tạo gốc. Chúng tôi có thể sử dụng các gói này theo yêu cầu của chúng tôi. Một số gói này được mô tả ở đây -
PorterStemmer package- Thuật toán của Porter được gói gốc Python này sử dụng để trích xuất biểu mẫu cơ sở. Bạn có thể sử dụng lệnh sau để nhập gói này:
from nltk.stem.porter import PorterStemmerVí dụ, sau khi đưa ra từ ‘writing’ là đầu vào cho trình gốc này, đầu ra sẽ là từ ‘write’ sau khi chiết cành.
LancasterStemmer package- Thuật toán Lancaster được gói gốc Python này sử dụng để trích xuất dạng cơ sở. Bạn có thể sử dụng lệnh sau để nhập gói này:
from nltk.stem.lancaster import LancasterStemmerVí dụ, sau khi đưa ra từ ‘writing’ là đầu vào cho trình gốc này thì đầu ra sẽ là từ ‘writ’ sau khi chiết cành.
SnowballStemmer package- Thuật toán của Snowball được gói gốc Python này sử dụng để trích xuất dạng cơ sở. Bạn có thể sử dụng lệnh sau để nhập gói này:
from nltk.stem.snowball import SnowballStemmerVí dụ: sau khi đưa từ 'viết' làm đầu vào cho trình tạo gốc này thì đầu ra sẽ là từ 'viết' sau khi nhập gốc.
Bổ sung
Một cách khác để trích xuất dạng cơ sở của từ là bằng cách bổ sung, thông thường nhằm mục đích loại bỏ các kết thúc vô hướng bằng cách sử dụng từ vựng và phân tích hình thái. Dạng cơ sở của bất kỳ từ nào sau khi bổ đề được gọi là bổ đề.
Mô-đun NLTK cung cấp các gói sau để lemmatization -
WordNetLemmatizer package- Nó sẽ trích xuất dạng cơ sở của từ tùy thuộc vào việc nó có được sử dụng như danh từ như một động từ hay không. Bạn có thể sử dụng lệnh sau để nhập gói này:
from nltk.stem import WordNetLemmatizerChunking
Chunking, có nghĩa là chia dữ liệu thành các phần nhỏ, là một trong những quá trình quan trọng trong xử lý ngôn ngữ tự nhiên để xác định các phần của lời nói và các cụm từ ngắn như cụm danh từ. Chunking là thực hiện việc ghi nhãn các mã thông báo. Chúng ta có thể có được cấu trúc của câu với sự trợ giúp của quá trình phân khúc.
Thí dụ
Trong ví dụ này, chúng ta sẽ triển khai phân đoạn Danh từ-Cụm từ bằng cách sử dụng mô-đun Python NLTK. NP chunking là một thể loại phân đoạn sẽ tìm các cụm danh từ trong câu.
Các bước để thực hiện tách cụm danh từ
Chúng ta cần làm theo các bước dưới đây để thực hiện phân tách cụm danh từ -
Bước 1 - Định nghĩa ngữ pháp khối
Trong bước đầu tiên, chúng tôi sẽ xác định ngữ pháp cho phân khúc. Nó sẽ bao gồm các quy tắc mà chúng ta cần tuân theo.
Bước 2 - Tạo trình phân tích cú pháp Chunk
Bây giờ, chúng ta sẽ tạo một trình phân tích cú pháp chunk. Nó sẽ phân tích ngữ pháp và đưa ra kết quả.
Bước 3 - Đầu ra
Trong bước cuối cùng này, đầu ra sẽ được tạo ở định dạng cây.
Đầu tiên, chúng ta cần nhập gói NLTK như sau:
import nltkTiếp theo, chúng ta cần xác định câu. Ở đây DT: định thức, VBP: động từ, JJ: tính từ, IN: giới từ và NN: danh từ.
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]Tiếp theo, chúng tôi đưa ra ngữ pháp ở dạng biểu thức chính quy.
grammar = "NP:{<DT>?<JJ>*<NN>}"Bây giờ, dòng mã tiếp theo sẽ xác định một trình phân tích cú pháp để phân tích ngữ pháp.
parser_chunking = nltk.RegexpParser(grammar)Bây giờ, trình phân tích cú pháp sẽ phân tích cú pháp câu.
parser_chunking.parse(sentence)Tiếp theo, chúng tôi đưa ra đầu ra của chúng tôi trong biến.
Output = parser_chunking.parse(sentence)Với sự trợ giúp của đoạn mã sau, chúng ta có thể vẽ đầu ra của mình dưới dạng cây như hình dưới đây.
output.draw()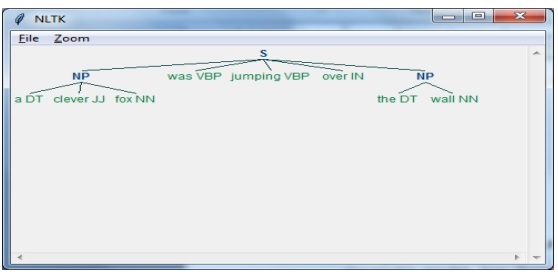
Mô hình Bag of Word (BoW) Trích xuất và chuyển đổi văn bản thành dạng số
Bag of Word (BoW), một mô hình hữu ích trong xử lý ngôn ngữ tự nhiên, về cơ bản được sử dụng để trích xuất các tính năng từ văn bản. Sau khi trích xuất các tính năng từ văn bản, nó có thể được sử dụng trong mô hình hóa trong các thuật toán học máy vì dữ liệu thô không thể được sử dụng trong các ứng dụng ML.
Hoạt động của Mô hình BoW
Ban đầu, mô hình trích xuất một từ vựng từ tất cả các từ trong tài liệu. Sau đó, sử dụng ma trận thuật ngữ tài liệu, nó sẽ xây dựng một mô hình. Theo cách này, mô hình BoW đại diện cho tài liệu chỉ như một túi từ và thứ tự hoặc cấu trúc bị loại bỏ.
Thí dụ
Giả sử chúng ta có hai câu sau:
Sentence1 - Đây là một ví dụ về mô hình Bag of Words.
Sentence2 - Chúng tôi có thể trích xuất các tính năng bằng cách sử dụng mô hình Bag of Words.
Bây giờ, bằng cách xem xét hai câu này, chúng ta có 14 từ khác biệt sau:
- This
- is
- an
- example
- bag
- of
- words
- model
- we
- can
- extract
- features
- by
- using
Xây dựng Mô hình Túi từ trong NLTK
Hãy để chúng tôi xem xét tập lệnh Python sau đây sẽ xây dựng mô hình BoW trong NLTK.
Đầu tiên, nhập gói sau:
from sklearn.feature_extraction.text import CountVectorizerTiếp theo, xác định tập hợp các câu -
Sentences=['This is an example of Bag of Words model.', ' We can extract
features by using Bag of Words model.']
vector_count = CountVectorizer()
features_text = vector_count.fit_transform(Sentences).todense()
print(vector_count.vocabulary_)Đầu ra
Nó cho thấy rằng chúng ta có 14 từ khác biệt trong hai câu trên -
{
'this': 10, 'is': 7, 'an': 0, 'example': 4, 'of': 9,
'bag': 1, 'words': 13, 'model': 8, 'we': 12, 'can': 3,
'extract': 5, 'features': 6, 'by': 2, 'using':11
}Mô hình chủ đề: Xác định các mẫu trong dữ liệu văn bản
Nói chung, các tài liệu được nhóm thành các chủ đề và mô hình chủ đề là một kỹ thuật để xác định các mẫu trong văn bản tương ứng với một chủ đề cụ thể. Nói cách khác, mô hình hóa chủ đề được sử dụng để khám phá các chủ đề trừu tượng hoặc cấu trúc ẩn trong một bộ tài liệu nhất định.
Bạn có thể sử dụng mô hình chủ đề trong các tình huống sau:
Phân loại văn bản
Việc phân loại có thể được cải thiện bằng cách lập mô hình chủ đề vì nó nhóm các từ tương tự lại với nhau thay vì sử dụng từng từ riêng biệt như một đặc điểm.
Hệ thống đề xuất
Chúng ta có thể xây dựng hệ thống khuyến nghị bằng cách sử dụng các biện pháp tương tự.
Các thuật toán lập mô hình chủ đề
Chúng tôi có thể triển khai mô hình chủ đề bằng cách sử dụng các thuật toán sau:
Latent Dirichlet Allocation(LDA) - Đây là một trong những thuật toán phổ biến nhất sử dụng các mô hình đồ họa xác suất để thực hiện mô hình hóa chủ đề.
Latent Semantic Analysis(LDA) or Latent Semantic Indexing(LSI) - Nó dựa trên Đại số tuyến tính và sử dụng khái niệm SVD (Phân hủy giá trị số ít) trên ma trận thuật ngữ tài liệu.
Non-Negative Matrix Factorization (NMF) - Nó cũng dựa trên Đại số tuyến tính như LDA.
Các thuật toán được đề cập ở trên sẽ có các yếu tố sau:
- Số lượng chủ đề: Tham số
- Ma trận Tài liệu-Từ: Đầu vào
- WTM (Ma trận chủ đề Word) & TDM (Ma trận tài liệu chủ đề): Đầu ra