Trau tin web Python - Hướng dẫn nhanh
Lướt web là một quá trình tự động trích xuất thông tin từ web. Chương này sẽ cung cấp cho bạn ý tưởng chuyên sâu về việc thu thập thông tin trên web, sự so sánh của nó với việc thu thập thông tin trên web và tại sao bạn nên chọn quét web. Bạn cũng sẽ tìm hiểu về các thành phần và hoạt động của một trình duyệt web.
Web Scraping là gì?
Nghĩa từ điển của từ 'Scrapping' có nghĩa là lấy thứ gì đó từ web. Ở đây nảy sinh hai câu hỏi: Chúng ta có thể lấy gì từ web và Làm thế nào để có được điều đó.
Câu trả lời cho câu hỏi đầu tiên là ‘data’. Dữ liệu là thứ không thể thiếu đối với bất kỳ lập trình viên nào và yêu cầu cơ bản của mọi dự án lập trình là lượng lớn dữ liệu hữu ích.
Câu trả lời cho câu hỏi thứ hai là một chút phức tạp, bởi vì có rất nhiều cách để lấy dữ liệu. Nói chung, chúng tôi có thể lấy dữ liệu từ cơ sở dữ liệu hoặc tệp dữ liệu và các nguồn khác. Nhưng nếu chúng ta cần một lượng lớn dữ liệu có sẵn trên mạng thì sao? Một cách để có được loại dữ liệu như vậy là tìm kiếm theo cách thủ công (nhấp vào trong trình duyệt web) và lưu (sao chép-dán vào bảng tính hoặc tệp) dữ liệu cần thiết. Phương pháp này khá tẻ nhạt và tốn thời gian. Một cách khác để lấy dữ liệu đó là sử dụngweb scraping.
Web scraping, còn được gọi là web data mining hoặc là web harvesting, là quá trình xây dựng một tác nhân có thể trích xuất, phân tích cú pháp, tải xuống và sắp xếp thông tin hữu ích từ web một cách tự động. Nói cách khác, chúng ta có thể nói rằng thay vì lưu dữ liệu từ các trang web theo cách thủ công, phần mềm quét web sẽ tự động tải và trích xuất dữ liệu từ nhiều trang web theo yêu cầu của chúng tôi.
Nguồn gốc của Web Scraping
Nguồn gốc của quét web là quét màn hình, được sử dụng để tích hợp các ứng dụng không dựa trên web hoặc các ứng dụng windows gốc. Ban đầu việc cạo màn hình đã được sử dụng trước khi World Wide Web (WWW) được sử dụng rộng rãi, nhưng nó không thể mở rộng quy mô WWW được mở rộng. Điều này khiến nó cần thiết phải tự động hóa phương pháp cạo màn hình và kỹ thuật được gọi là‘Web Scraping’ thừa hưởng sự tồn tại.
Thu thập thông tin web v / s Web Scraping
Các thuật ngữ Web Crawling và Scraping thường được sử dụng thay thế cho nhau vì khái niệm cơ bản của chúng là trích xuất dữ liệu. Tuy nhiên, chúng khác xa nhau. Chúng ta có thể hiểu sự khác biệt cơ bản từ các định nghĩa của chúng.
Thu thập thông tin web về cơ bản được sử dụng để lập chỉ mục thông tin trên trang bằng cách sử dụng bot hay còn gọi là trình thu thập thông tin. Nó còn được gọi làindexing. Mặt khác, trích xuất trang web là một cách tự động trích xuất thông tin bằng cách sử dụng bot hay còn gọi là công cụ nạo. Nó còn được gọi làdata extraction.
Để hiểu sự khác biệt giữa hai thuật ngữ này, chúng ta hãy xem xét bảng so sánh được đưa ra dưới đây:
| Thu thập thông tin web | Rút trích nội dung trang web |
|---|---|
| Đề cập đến việc tải xuống và lưu trữ nội dung của một số lượng lớn các trang web. | Đề cập đến việc trích xuất các phần tử dữ liệu riêng lẻ từ trang web bằng cách sử dụng cấu trúc dành riêng cho trang web. |
| Chủ yếu được thực hiện trên quy mô lớn. | Có thể thực hiện ở mọi quy mô. |
| Mang lại thông tin chung. | Mang lại thông tin cụ thể. |
| Được sử dụng bởi các công cụ tìm kiếm lớn như Google, Bing, Yahoo. Googlebot là một ví dụ về trình thu thập thông tin web. | Thông tin được trích xuất bằng cách sử dụng công cụ quét web có thể được sử dụng để sao chép trong một số trang web khác hoặc có thể được sử dụng để thực hiện phân tích dữ liệu. Ví dụ, các phần tử dữ liệu có thể là tên, địa chỉ, giá, v.v. |
Sử dụng Web Scraping
Việc sử dụng và lý do sử dụng web cạo cũng vô tận như việc sử dụng World Wide Web. Người quét web có thể làm bất cứ điều gì như đặt thức ăn trực tuyến, quét trang web mua sắm trực tuyến cho bạn và mua vé của một trận đấu ngay khi họ có mặt, v.v. giống như con người có thể làm. Một số ứng dụng quan trọng của việc nạo web được thảo luận ở đây -
E-commerce Websites - Người tìm kiếm trên web có thể thu thập dữ liệu liên quan đặc biệt đến giá của một sản phẩm cụ thể từ các trang web thương mại điện tử khác nhau để so sánh.
Content Aggregators - Việc thu thập dữ liệu web được sử dụng rộng rãi bởi các công ty tổng hợp nội dung như trình tổng hợp tin tức và trình tổng hợp việc làm để cung cấp dữ liệu cập nhật cho người dùng của họ.
Marketing and Sales Campaigns - Có thể sử dụng công cụ quét web để lấy dữ liệu như email, số điện thoại, v.v. cho các chiến dịch bán hàng và tiếp thị.
Search Engine Optimization (SEO) - Web cạo được sử dụng rộng rãi bởi các công cụ SEO như SEMRush, Majestic, v.v. để cho doanh nghiệp biết cách họ xếp hạng cho các từ khóa tìm kiếm quan trọng đối với họ.
Data for Machine Learning Projects - Việc truy xuất dữ liệu cho các dự án máy học phụ thuộc vào việc quét web.
Data for Research - Các nhà nghiên cứu có thể thu thập dữ liệu hữu ích cho mục đích công việc nghiên cứu của họ bằng cách tiết kiệm thời gian của họ bằng quy trình tự động này.
Các thành phần của Web Scraper
Trình duyệt web bao gồm các thành phần sau:
Mô-đun trình thu thập thông tin web
Một thành phần rất cần thiết của trình quét web, mô-đun trình thu thập thông tin web, được sử dụng để điều hướng trang web mục tiêu bằng cách thực hiện yêu cầu HTTP hoặc HTTPS đến các URL. Trình thu thập thông tin tải xuống dữ liệu phi cấu trúc (nội dung HTML) và chuyển nó đến trình trích xuất, mô-đun tiếp theo.
Vắt
Trình trích xuất xử lý nội dung HTML đã tìm nạp và trích xuất dữ liệu sang định dạng bán cấu trúc. Đây cũng được gọi là mô-đun phân tích cú pháp và sử dụng các kỹ thuật phân tích cú pháp khác nhau như Biểu thức chính quy, Phân tích cú pháp HTML, Phân tích cú pháp DOM hoặc Trí tuệ nhân tạo để hoạt động.
Chuyển đổi dữ liệu và làm sạch mô-đun
Dữ liệu trích xuất ở trên không phù hợp để sử dụng sẵn sàng. Nó phải đi qua một số mô-đun làm sạch để chúng tôi có thể sử dụng nó. Các phương thức như thao tác chuỗi hoặc biểu thức chính quy có thể được sử dụng cho mục đích này. Lưu ý rằng việc trích xuất và biến đổi cũng có thể được thực hiện trong một bước duy nhất.
Mô-đun lưu trữ
Sau khi giải nén dữ liệu, chúng tôi cần lưu trữ nó theo yêu cầu của chúng tôi. Mô-đun lưu trữ sẽ xuất dữ liệu ở định dạng chuẩn có thể được lưu trữ trong cơ sở dữ liệu hoặc định dạng JSON hoặc CSV.
Làm việc của một Web Scraper
Trình quét web có thể được định nghĩa là một phần mềm hoặc tập lệnh được sử dụng để tải xuống nội dung của nhiều trang web và trích xuất dữ liệu từ đó.
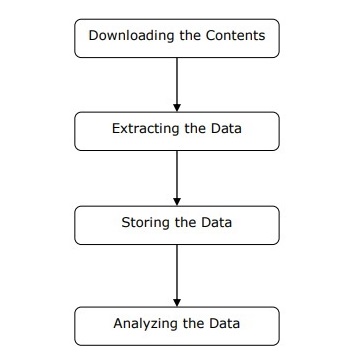
Chúng ta có thể hiểu hoạt động của một trình duyệt web theo các bước đơn giản như được hiển thị trong sơ đồ ở trên.
Bước 1: Tải xuống nội dung từ các trang web
Trong bước này, trình duyệt web sẽ tải xuống nội dung được yêu cầu từ nhiều trang web.
Bước 2: Trích xuất dữ liệu
Dữ liệu trên các trang web là HTML và hầu hết là không có cấu trúc. Do đó, trong bước này, trình duyệt web sẽ phân tích cú pháp và trích xuất dữ liệu có cấu trúc từ nội dung đã tải xuống.
Bước 3: Lưu trữ dữ liệu
Tại đây, một trình duyệt web sẽ lưu trữ và lưu dữ liệu được trích xuất ở bất kỳ định dạng nào như CSV, JSON hoặc trong cơ sở dữ liệu.
Bước 4: Phân tích dữ liệu
Sau khi tất cả các bước này được thực hiện thành công, trình duyệt web sẽ phân tích dữ liệu thu được.
Trong chương đầu tiên, chúng ta đã tìm hiểu về việc nạo web là gì. Trong chương này, chúng ta hãy xem cách triển khai tính năng quét web bằng Python.
Tại sao sử dụng Python cho Web Scraping?
Python là một công cụ phổ biến để thực hiện việc tìm kiếm web. Ngôn ngữ lập trình Python cũng được sử dụng cho các dự án hữu ích khác liên quan đến an ninh mạng, thử nghiệm thâm nhập cũng như các ứng dụng pháp y kỹ thuật số. Bằng cách sử dụng lập trình cơ sở của Python, có thể thực hiện quét web mà không cần sử dụng bất kỳ công cụ bên thứ ba nào khác.
Ngôn ngữ lập trình Python đang trở nên phổ biến rộng rãi và những lý do khiến Python trở thành một lựa chọn phù hợp cho các dự án duyệt web như sau:
Sự đơn giản về cú pháp
Python có cấu trúc đơn giản nhất khi so sánh với các ngôn ngữ lập trình khác. Tính năng này của Python giúp việc kiểm tra dễ dàng hơn và nhà phát triển có thể tập trung hơn vào lập trình.
Mô-đun có sẵn
Một lý do khác để sử dụng Python để tìm kiếm web là các thư viện hữu ích bên ngoài cũng như sẵn có mà nó sở hữu. Chúng tôi có thể thực hiện nhiều triển khai liên quan đến việc quét web bằng cách sử dụng Python làm nền tảng để lập trình.
Ngôn ngữ lập trình nguồn mở
Python nhận được sự ủng hộ rất lớn từ cộng đồng vì nó là một ngôn ngữ lập trình mã nguồn mở.
Ứng dụng rộng rãi
Python có thể được sử dụng cho các tác vụ lập trình khác nhau, từ các tập lệnh shell nhỏ đến các ứng dụng web doanh nghiệp.
Cài đặt Python
Bản phân phối Python có sẵn cho các nền tảng như Windows, MAC và Unix / Linux. Chúng tôi chỉ cần tải xuống mã nhị phân áp dụng cho nền tảng của chúng tôi để cài đặt Python. Nhưng trong trường hợp nếu mã nhị phân cho nền tảng của chúng tôi không có sẵn, chúng tôi phải có trình biên dịch C để mã nguồn có thể được biên dịch theo cách thủ công.
Chúng tôi có thể cài đặt Python trên các nền tảng khác nhau như sau:
Cài đặt Python trên Unix và Linux
Bạn cần làm theo các bước dưới đây để cài đặt Python trên máy Unix / Linux -
Step 1 - Vào liên kết https://www.python.org/downloads/
Step 2 - Tải xuống mã nguồn nén sẵn có cho Unix / Linux ở liên kết trên.
Step 3 - Giải nén các tập tin vào máy tính của bạn.
Step 4 - Sử dụng các lệnh sau để hoàn tất cài đặt -
run ./configure script
make
make installBạn có thể tìm thấy Python đã cài đặt tại vị trí tiêu chuẩn /usr/local/bin và các thư viện của nó tại /usr/local/lib/pythonXX, trong đó XX là phiên bản của Python.
Cài đặt Python trên Windows
Bạn cần làm theo các bước dưới đây để cài đặt Python trên máy Windows -
Step 1 - Vào liên kết https://www.python.org/downloads/
Step 2 - Tải xuống trình cài đặt Windows python-XYZ.msi , trong đó XYZ là phiên bản chúng ta cần cài đặt.
Step 3 - Bây giờ, lưu tệp trình cài đặt vào máy cục bộ của bạn và chạy tệp MSI.
Step 4 - Cuối cùng, chạy tệp đã tải xuống để hiển thị trình hướng dẫn cài đặt Python.
Cài đặt Python trên Macintosh
Chúng ta phải sử dụng Homebrew để cài đặt Python 3 trên Mac OS X. Homebrew dễ cài đặt và là một trình cài đặt gói tuyệt vời.
Homebrew cũng có thể được cài đặt bằng cách sử dụng lệnh sau:
$ ruby -e "$(curl -fsSL
https://raw.githubusercontent.com/Homebrew/install/master/install)"Để cập nhật trình quản lý gói, chúng ta có thể sử dụng lệnh sau:
$ brew updateVới sự trợ giúp của lệnh sau, chúng ta có thể cài đặt Python3 trên máy MAC của mình -
$ brew install python3Thiết lập PATH
Bạn có thể sử dụng các hướng dẫn sau để thiết lập đường dẫn trên các môi trường khác nhau -
Thiết lập đường dẫn trên Unix / Linux
Sử dụng các lệnh sau để thiết lập đường dẫn bằng các trình bao lệnh khác nhau:
Đối với shell csh
setenv PATH "$PATH:/usr/local/bin/python".Đối với bash shell (Linux)
ATH="$PATH:/usr/local/bin/python".Đối với vỏ sh hoặc ksh
PATH="$PATH:/usr/local/bin/python".Thiết lập đường dẫn trên Windows
Để thiết lập đường dẫn trên Windows, chúng ta có thể sử dụng đường dẫn %path%;C:\Python tại dấu nhắc lệnh và sau đó nhấn Enter.
Chạy Python
Chúng ta có thể bắt đầu Python bằng bất kỳ cách nào trong ba cách sau:
Phiên dịch tương tác
Hệ điều hành như UNIX và DOS cung cấp trình thông dịch dòng lệnh hoặc trình bao có thể được sử dụng để khởi động Python.
Chúng ta có thể bắt đầu viết mã trong trình thông dịch tương tác như sau:
Step 1 - Nhập python tại dòng lệnh.
Step 2 - Sau đó, chúng ta có thể bắt đầu viết mã ngay trong trình thông dịch tương tác.
$python # Unix/Linux
or
python% # Unix/Linux
or
C:> python # Windows/DOSTập lệnh từ dòng lệnh
Chúng ta có thể thực thi một tập lệnh Python tại dòng lệnh bằng cách gọi trình thông dịch. Nó có thể được hiểu như sau:
$python script.py # Unix/Linux
or
python% script.py # Unix/Linux
or
C: >python script.py # Windows/DOSMôi trường phát triển tích hợp
Chúng tôi cũng có thể chạy Python từ môi trường GUI nếu hệ thống đang có ứng dụng GUI hỗ trợ Python. Dưới đây là một số IDE hỗ trợ Python trên các nền tảng khác nhau:
IDE for UNIX - UNIX, dành cho Python, có IDLE IDE.
IDE for Windows - Windows có PythonWin IDE cũng có GUI.
IDE for Macintosh - Macintosh có IDLE IDE có thể tải xuống dưới dạng tệp MacBinary hoặc BinHex'd từ trang web chính.
Trong chương này, chúng ta hãy tìm hiểu các mô-đun Python khác nhau mà chúng ta có thể sử dụng để tìm kiếm web.
Môi trường phát triển Python sử dụng virtualenv
Virtualenv là một công cụ để tạo môi trường Python cô lập. Với sự trợ giúp của virtualenv, chúng tôi có thể tạo một thư mục chứa tất cả các tệp thực thi cần thiết để sử dụng các gói mà dự án Python của chúng tôi yêu cầu. Nó cũng cho phép chúng tôi thêm và sửa đổi các mô-đun Python mà không cần quyền truy cập vào cài đặt toàn cầu.
Bạn có thể sử dụng lệnh sau để cài đặt virtualenv -
(base) D:\ProgramData>pip install virtualenv
Collecting virtualenv
Downloading
https://files.pythonhosted.org/packages/b6/30/96a02b2287098b23b875bc8c2f58071c3
5d2efe84f747b64d523721dc2b5/virtualenv-16.0.0-py2.py3-none-any.whl
(1.9MB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 1.9MB 86kB/s
Installing collected packages: virtualenv
Successfully installed virtualenv-16.0.0Bây giờ, chúng ta cần tạo một thư mục đại diện cho dự án với sự trợ giúp của lệnh sau:
(base) D:\ProgramData>mkdir webscrapBây giờ, hãy nhập vào thư mục đó với sự trợ giúp của lệnh sau:
(base) D:\ProgramData>cd webscrapBây giờ, chúng ta cần khởi tạo thư mục môi trường ảo mà chúng ta chọn như sau:
(base) D:\ProgramData\webscrap>virtualenv websc
Using base prefix 'd:\\programdata'
New python executable in D:\ProgramData\webscrap\websc\Scripts\python.exe
Installing setuptools, pip, wheel...done.Bây giờ, kích hoạt môi trường ảo bằng lệnh dưới đây. Sau khi kích hoạt thành công, bạn sẽ thấy tên của nó ở bên tay trái trong ngoặc.
(base) D:\ProgramData\webscrap>websc\scripts\activateChúng tôi có thể cài đặt bất kỳ mô-đun nào trong môi trường này như sau:
(websc) (base) D:\ProgramData\webscrap>pip install requests
Collecting requests
Downloading
https://files.pythonhosted.org/packages/65/47/7e02164a2a3db50ed6d8a6ab1d6d60b69
c4c3fdf57a284257925dfc12bda/requests-2.19.1-py2.py3-none-any.whl (9
1kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 148kB/s
Collecting chardet<3.1.0,>=3.0.2 (from requests)
Downloading
https://files.pythonhosted.org/packages/bc/a9/01ffebfb562e4274b6487b4bb1ddec7ca
55ec7510b22e4c51f14098443b8/chardet-3.0.4-py2.py3-none-any.whl (133
kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 143kB 369kB/s
Collecting certifi>=2017.4.17 (from requests)
Downloading
https://files.pythonhosted.org/packages/df/f7/04fee6ac349e915b82171f8e23cee6364
4d83663b34c539f7a09aed18f9e/certifi-2018.8.24-py2.py3-none-any.whl
(147kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 153kB 527kB/s
Collecting urllib3<1.24,>=1.21.1 (from requests)
Downloading
https://files.pythonhosted.org/packages/bd/c9/6fdd990019071a4a32a5e7cb78a1d92c5
3851ef4f56f62a3486e6a7d8ffb/urllib3-1.23-py2.py3-none-any.whl (133k
B)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 143kB 517kB/s
Collecting idna<2.8,>=2.5 (from requests)
Downloading
https://files.pythonhosted.org/packages/4b/2a/0276479a4b3caeb8a8c1af2f8e4355746
a97fab05a372e4a2c6a6b876165/idna-2.7-py2.py3-none-any.whl (58kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 61kB 339kB/s
Installing collected packages: chardet, certifi, urllib3, idna, requests
Successfully installed certifi-2018.8.24 chardet-3.0.4 idna-2.7 requests-2.19.1
urllib3-1.23Để hủy kích hoạt môi trường ảo, chúng ta có thể sử dụng lệnh sau:
(websc) (base) D:\ProgramData\webscrap>deactivate
(base) D:\ProgramData\webscrap>Bạn có thể thấy rằng (websc) đã bị vô hiệu hóa.
Mô-đun Python cho Web Scraping
Lướt web là quá trình xây dựng một tác nhân có thể trích xuất, phân tích cú pháp, tải xuống và sắp xếp thông tin hữu ích từ web một cách tự động. Nói cách khác, thay vì lưu dữ liệu từ các trang web theo cách thủ công, phần mềm quét web sẽ tự động tải và trích xuất dữ liệu từ nhiều trang web theo yêu cầu của chúng tôi.
Trong phần này, chúng ta sẽ thảo luận về các thư viện Python hữu ích cho việc tìm kiếm web.
Yêu cầu
Nó là một thư viện tìm kiếm web python đơn giản. Nó là một thư viện HTTP hiệu quả được sử dụng để truy cập các trang web. Với sự giúp đỡ củaRequests, chúng ta có thể lấy HTML thô của các trang web sau đó có thể được phân tích cú pháp để truy xuất dữ liệu. Trước khi sử dụngrequests, hãy cho chúng tôi hiểu cài đặt của nó.
Yêu cầu cài đặt
Chúng tôi có thể cài đặt nó trong môi trường ảo của chúng tôi hoặc trên cài đặt toàn cầu. Với sự giúp đỡ củapip , chúng ta có thể dễ dàng cài đặt nó như sau:
(base) D:\ProgramData> pip install requests
Collecting requests
Using cached
https://files.pythonhosted.org/packages/65/47/7e02164a2a3db50ed6d8a6ab1d6d60b69
c4c3fdf57a284257925dfc12bda/requests-2.19.1-py2.py3-none-any.whl
Requirement already satisfied: idna<2.8,>=2.5 in d:\programdata\lib\sitepackages
(from requests) (2.6)
Requirement already satisfied: urllib3<1.24,>=1.21.1 in
d:\programdata\lib\site-packages (from requests) (1.22)
Requirement already satisfied: certifi>=2017.4.17 in d:\programdata\lib\sitepackages
(from requests) (2018.1.18)
Requirement already satisfied: chardet<3.1.0,>=3.0.2 in
d:\programdata\lib\site-packages (from requests) (3.0.4)
Installing collected packages: requests
Successfully installed requests-2.19.1Thí dụ
Trong ví dụ này, chúng tôi đang thực hiện một yêu cầu GET HTTP cho một trang web. Đối với điều này, trước tiên chúng ta cần nhập thư viện yêu cầu như sau:
In [1]: import requestsTrong dòng mã sau đây, chúng tôi sử dụng các yêu cầu để thực hiện yêu cầu GET HTTP cho url: https://authoraditiagarwal.com/ bằng cách đưa ra yêu cầu GET.
In [2]: r = requests.get('https://authoraditiagarwal.com/')Bây giờ chúng ta có thể truy xuất nội dung bằng cách sử dụng .text tài sản như sau -
In [5]: r.text[:200]Quan sát rằng trong đầu ra sau đây, chúng tôi có 200 ký tự đầu tiên.
Out[5]: '<!DOCTYPE html>\n<html lang="en-US"\n\titemscope
\n\titemtype="http://schema.org/WebSite" \n\tprefix="og: http://ogp.me/ns#"
>\n<head>\n\t<meta charset
="UTF-8" />\n\t<meta http-equiv="X-UA-Compatible" content="IE'Urllib3
Nó là một thư viện Python khác có thể được sử dụng để truy xuất dữ liệu từ các URL tương tự như requeststhư viện. Bạn có thể đọc thêm về điều này tại tài liệu kỹ thuật của nó tạihttps://urllib3.readthedocs.io/en/latest/.
Cài đặt Urllib3
Sử dụng pip lệnh, chúng ta có thể cài đặt urllib3 trong môi trường ảo của chúng tôi hoặc trong cài đặt toàn cầu.
(base) D:\ProgramData>pip install urllib3
Collecting urllib3
Using cached
https://files.pythonhosted.org/packages/bd/c9/6fdd990019071a4a32a5e7cb78a1d92c5
3851ef4f56f62a3486e6a7d8ffb/urllib3-1.23-py2.py3-none-any.whl
Installing collected packages: urllib3
Successfully installed urllib3-1.23Ví dụ: Scraping bằng Urllib3 và BeautifulSoup
Trong ví dụ sau, chúng tôi đang tìm kiếm trang web bằng cách sử dụng Urllib3 và BeautifulSoup. Chúng tôi đang sử dụngUrllib3tại vị trí của thư viện yêu cầu để lấy dữ liệu thô (HTML) từ trang web. Sau đó, chúng tôi đang sử dụngBeautifulSoup để phân tích cú pháp dữ liệu HTML đó.
import urllib3
from bs4 import BeautifulSoup
http = urllib3.PoolManager()
r = http.request('GET', 'https://authoraditiagarwal.com')
soup = BeautifulSoup(r.data, 'lxml')
print (soup.title)
print (soup.title.text)Đây là đầu ra bạn sẽ quan sát được khi chạy mã này -
<title>Learn and Grow with Aditi Agarwal</title>
Learn and Grow with Aditi AgarwalSelen
Nó là một bộ kiểm tra tự động mã nguồn mở cho các ứng dụng web trên các trình duyệt và nền tảng khác nhau. Nó không phải là một công cụ đơn lẻ mà là một bộ phần mềm. Chúng tôi có các liên kết selen cho Python, Java, C #, Ruby và JavaScript. Ở đây, chúng ta sẽ thực hiện thao tác quét web bằng cách sử dụng selen và các liên kết Python của nó. Bạn có thể tìm hiểu thêm về Selenium với Java trên liên kết Selenium .
Các liên kết Selenium Python cung cấp một API thuận tiện để truy cập Selenium WebDrivers như Firefox, IE, Chrome, Remote, v.v. Các phiên bản Python được hỗ trợ hiện tại là 2.7, 3.5 trở lên.
Cài đặt Selenium
Sử dụng pip lệnh, chúng ta có thể cài đặt urllib3 trong môi trường ảo của chúng tôi hoặc trong cài đặt toàn cầu.
pip install seleniumVì selen yêu cầu trình điều khiển để giao diện với trình duyệt đã chọn, chúng tôi cần tải xuống. Bảng sau đây cho thấy các trình duyệt khác nhau và các liên kết tải xuống giống nhau của chúng.
Chrome |
https://sites.google.com/a/chromium.org/ |
Edge |
https://developer.microsoft.com/ |
Firefox |
https://github.com/ |
Safari |
https://webkit.org/ |
Thí dụ
Ví dụ này cho thấy việc tìm kiếm trên web bằng cách sử dụng selen. Nó cũng có thể được sử dụng để thử nghiệm được gọi là thử nghiệm selen.
Sau khi tải xuống trình điều khiển cụ thể cho phiên bản trình duyệt được chỉ định, chúng ta cần lập trình bằng Python.
Đầu tiên, cần nhập webdriver từ selen như sau -
from selenium import webdriverBây giờ, cung cấp đường dẫn của trình điều khiển web mà chúng tôi đã tải xuống theo yêu cầu của chúng tôi -
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
browser = webdriver.Chrome(executable_path = path)Bây giờ, hãy cung cấp url mà chúng tôi muốn mở trong trình duyệt web đó hiện được điều khiển bởi tập lệnh Python của chúng tôi.
browser.get('https://authoraditiagarwal.com/leadershipmanagement')Chúng tôi cũng có thể loại bỏ một phần tử cụ thể bằng cách cung cấp xpath như được cung cấp trong lxml.
browser.find_element_by_xpath('/html/body').click()Bạn có thể kiểm tra trình duyệt, được điều khiển bởi tập lệnh Python, để biết đầu ra.
Trị liệu
Scrapy là một khung thu thập dữ liệu web mã nguồn mở, nhanh chóng được viết bằng Python, được sử dụng để trích xuất dữ liệu từ trang web với sự trợ giúp của các bộ chọn dựa trên XPath. Scrapy được phát hành lần đầu tiên vào ngày 26 tháng 6 năm 2008 được cấp phép theo BSD, với mốc 1.0 phát hành vào tháng 6 năm 2015. Nó cung cấp cho chúng tôi tất cả các công cụ cần thiết để trích xuất, xử lý và cấu trúc dữ liệu từ các trang web.
Cài đặt Scrapy
Sử dụng pip lệnh, chúng ta có thể cài đặt urllib3 trong môi trường ảo của chúng tôi hoặc trong cài đặt toàn cầu.
pip install scrapyĐể biết thêm chi tiết về Scrapy, bạn có thể vào liên kết Scrapy
Với Python, chúng ta có thể loại bỏ bất kỳ trang web nào hoặc các phần tử cụ thể của một trang web nhưng bạn có biết liệu nó có hợp pháp hay không? Trước khi cạo bất kỳ trang web nào, chúng ta phải biết về tính hợp pháp của việc cạo trang web. Chương này sẽ giải thích các khái niệm liên quan đến tính hợp pháp của việc quét web.
Giới thiệu
Nói chung, nếu bạn định sử dụng dữ liệu cóp nhặt cho mục đích cá nhân thì có thể không có vấn đề gì. Nhưng nếu bạn định xuất bản lại dữ liệu đó, thì trước khi thực hiện điều tương tự, bạn nên gửi yêu cầu tải xuống cho chủ sở hữu hoặc thực hiện một số nghiên cứu cơ bản về các chính sách cũng như về dữ liệu bạn sẽ thu thập.
Nghiên cứu cần thiết trước khi làm phế liệu
Nếu bạn đang nhắm mục tiêu một trang web để thu thập dữ liệu từ nó, chúng tôi cần hiểu quy mô và cấu trúc của nó. Sau đây là một số tệp mà chúng tôi cần phân tích trước khi bắt đầu quét web.
Phân tích robots.txt
Trên thực tế, hầu hết các nhà xuất bản đều cho phép lập trình viên thu thập dữ liệu trang web của họ ở một mức độ nào đó. Theo cách khác, nhà xuất bản muốn thu thập thông tin các phần cụ thể của trang web. Để xác định điều này, các trang web phải đặt một số quy tắc để nêu rõ phần nào có thể được thu thập thông tin và phần nào không thể được. Các quy tắc như vậy được xác định trong một tệp có tênrobots.txt.
robots.txtlà tệp có thể đọc được của con người được sử dụng để xác định các phần của trang web mà trình thu thập thông tin được phép cũng như không được phép cạo. Không có định dạng chuẩn của tệp robots.txt và nhà xuất bản trang web có thể thực hiện các sửa đổi theo nhu cầu của họ. Chúng tôi có thể kiểm tra tệp robots.txt cho một trang web cụ thể bằng cách cung cấp dấu gạch chéo và robots.txt sau url của trang web đó. Ví dụ: nếu chúng ta muốn kiểm tra nó cho Google.com, thì chúng ta cần nhậphttps://www.google.com/robots.txt và chúng ta sẽ nhận được một cái gì đó như sau:
User-agent: *
Disallow: /search
Allow: /search/about
Allow: /search/static
Allow: /search/howsearchworks
Disallow: /sdch
Disallow: /groups
Disallow: /index.html?
Disallow: /?
Allow: /?hl=
Disallow: /?hl=*&
Allow: /?hl=*&gws_rd=ssl$
and so on……..Một số quy tắc phổ biến nhất được xác định trong tệp robots.txt của trang web như sau:
User-agent: BadCrawler
Disallow: /Quy tắc trên có nghĩa là tệp robots.txt yêu cầu trình thu thập thông tin BadCrawler tác nhân người dùng không thu thập dữ liệu trang web của họ.
User-agent: *
Crawl-delay: 5
Disallow: /trapQuy tắc trên có nghĩa là tệp robots.txt trì hoãn trình thu thập thông tin trong 5 giây giữa các yêu cầu tải xuống cho tất cả tác nhân người dùng để tránh máy chủ quá tải. Các/trapliên kết sẽ cố gắng chặn các trình thu thập dữ liệu độc hại đi theo các liên kết không được phép. Có nhiều quy tắc khác có thể được xác định bởi nhà xuất bản của trang web theo yêu cầu của họ. Một số trong số chúng được thảo luận ở đây -
Phân tích tệp Sơ đồ trang web
Bạn phải làm gì nếu muốn thu thập thông tin một trang web để biết thông tin cập nhật? Bạn sẽ thu thập dữ liệu mọi trang web để nhận thông tin cập nhật đó, nhưng điều này sẽ làm tăng lưu lượng truy cập máy chủ của trang web cụ thể đó. Đó là lý do tại sao các trang web cung cấp tệp sơ đồ trang web để giúp trình thu thập thông tin xác định nội dung cập nhật mà không cần thu thập dữ liệu mọi trang web. Tiêu chuẩn sơ đồ trang web được xác định tạihttp://www.sitemaps.org/protocol.html.
Nội dung của tệp Sơ đồ trang web
Sau đây là nội dung của tệp sơ đồ trang web của https://www.microsoft.com/robots.txt được phát hiện trong tệp robot.txt -
Sitemap: https://www.microsoft.com/en-us/explore/msft_sitemap_index.xml
Sitemap: https://www.microsoft.com/learning/sitemap.xml
Sitemap: https://www.microsoft.com/en-us/licensing/sitemap.xml
Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml
Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8
Sitemap: https://www.microsoft.com/store/collections.xml
Sitemap: https://www.microsoft.com/store/productdetailpages.index.xml
Sitemap: https://www.microsoft.com/en-us/store/locations/store-locationssitemap.xmlNội dung trên cho thấy rằng sơ đồ trang web liệt kê các URL trên trang web và hơn nữa cho phép quản trị viên web chỉ định một số thông tin bổ sung như ngày cập nhật lần cuối, nội dung thay đổi, tầm quan trọng của URL với các URL khác, v.v. về mỗi URL.
Kích thước của trang web là gì?
Kích thước của một trang web, tức là số lượng các trang của một trang web có ảnh hưởng đến cách chúng ta thu thập dữ liệu không? Chắc chắn có. Bởi vì nếu chúng ta có ít trang web hơn để thu thập thông tin, thì hiệu quả sẽ không phải là vấn đề nghiêm trọng, nhưng giả sử nếu trang web của chúng ta có hàng triệu trang web, ví dụ như Microsoft.com, thì việc tải xuống từng trang một cách tuần tự sẽ mất vài tháng và thì hiệu quả sẽ là một mối quan tâm nghiêm túc.
Kiểm tra kích thước trang web
Bằng cách kiểm tra kích thước kết quả của trình thu thập thông tin của Google, chúng tôi có thể ước tính kích thước của một trang web. Kết quả của chúng tôi có thể được lọc bằng cách sử dụng từ khóasitetrong khi thực hiện tìm kiếm trên Google. Ví dụ: ước tính kích thước củahttps://authoraditiagarwal.com/ được đưa ra dưới đây -
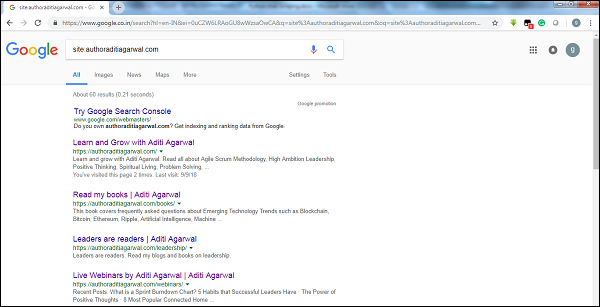
Bạn có thể thấy có khoảng 60 kết quả có nghĩa là nó không phải là một trang web lớn và việc thu thập thông tin sẽ không dẫn đến vấn đề hiệu quả.
Trang web sử dụng công nghệ nào?
Một câu hỏi quan trọng khác là liệu công nghệ mà trang web sử dụng có ảnh hưởng đến cách chúng ta thu thập dữ liệu hay không? Có, nó ảnh hưởng. Nhưng làm thế nào chúng ta có thể kiểm tra về công nghệ được sử dụng bởi một trang web? Có một thư viện Python có tênbuiltwith với sự trợ giúp của chúng tôi có thể tìm hiểu về công nghệ được sử dụng bởi một trang web.
Thí dụ
Trong ví dụ này, chúng tôi sẽ kiểm tra công nghệ được sử dụng bởi trang web https://authoraditiagarwal.com với sự trợ giúp của thư viện Python builtwith. Nhưng trước khi sử dụng thư viện này, chúng ta cần cài đặt nó như sau:
(base) D:\ProgramData>pip install builtwith
Collecting builtwith
Downloading
https://files.pythonhosted.org/packages/9b/b8/4a320be83bb3c9c1b3ac3f9469a5d66e0
2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz
Requirement already satisfied: six in d:\programdata\lib\site-packages (from
builtwith) (1.10.0)
Building wheels for collected packages: builtwith
Running setup.py bdist_wheel for builtwith ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b
f926764a924873e0304f10b2524
Successfully built builtwith
Installing collected packages: builtwith
Successfully installed builtwith-1.3.3Giờ đây, với sự trợ giúp của dòng mã đơn giản sau, chúng tôi có thể kiểm tra công nghệ được sử dụng bởi một trang web cụ thể -
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}Chủ sở hữu của trang web là ai?
Chủ sở hữu của trang web cũng quan trọng vì nếu chủ sở hữu được biết đến là người đã chặn các trình thu thập thông tin, thì các trình thu thập thông tin phải cẩn thận trong khi thu thập dữ liệu từ trang web. Có một giao thức có tênWhois với sự trợ giúp của chúng tôi có thể tìm hiểu về chủ sở hữu của trang web.
Thí dụ
Trong ví dụ này, chúng tôi sẽ kiểm tra chủ sở hữu của trang web nói rằng microsoft.com với sự trợ giúp của Whois. Nhưng trước khi sử dụng thư viện này, chúng ta cần cài đặt nó như sau:
(base) D:\ProgramData>pip install python-whois
Collecting python-whois
Downloading
https://files.pythonhosted.org/packages/63/8a/8ed58b8b28b6200ce1cdfe4e4f3bbc8b8
5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s
Requirement already satisfied: future in d:\programdata\lib\site-packages (from
python-whois) (0.16.0)
Building wheels for collected packages: python-whois
Running setup.py bdist_wheel for python-whois ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b
4dcc81ab212a3d5e52ab32dc531
Successfully built python-whois
Installing collected packages: python-whois
Successfully installed python-whois-0.7.0Giờ đây, với sự trợ giúp của dòng mã đơn giản sau, chúng tôi có thể kiểm tra công nghệ được sử dụng bởi một trang web cụ thể -
In [1]: import whois
In [2]: print (whois.whois('microsoft.com'))
{
"domain_name": [
"MICROSOFT.COM",
"microsoft.com"
],
-------
"name_servers": [
"NS1.MSFT.NET",
"NS2.MSFT.NET",
"NS3.MSFT.NET",
"NS4.MSFT.NET",
"ns3.msft.net",
"ns1.msft.net",
"ns4.msft.net",
"ns2.msft.net"
],
"emails": [
"[email protected]",
"[email protected]",
"[email protected]",
"[email protected]"
],
}Phân tích một trang web có nghĩa là hiểu cấu trúc của nó. Bây giờ, câu hỏi được đặt ra là tại sao nó lại quan trọng đối với việc quét web? Trong chương này, chúng ta hãy hiểu chi tiết điều này.
Phân tích trang web
Phân tích trang web rất quan trọng bởi vì nếu không phân tích, chúng ta không thể biết chúng ta sẽ nhận dữ liệu từ dạng nào (có cấu trúc hoặc không có cấu trúc) trang web đó sau khi trích xuất. Chúng tôi có thể phân tích trang web theo những cách sau:
Xem nguồn trang
Đây là một cách để hiểu cách một trang web được cấu trúc bằng cách kiểm tra mã nguồn của nó. Để thực hiện điều này, chúng ta cần nhấp chuột phải vào trang và sau đó phải chọnView page sourceLựa chọn. Sau đó, chúng tôi sẽ lấy dữ liệu mà chúng tôi quan tâm từ trang web đó dưới dạng HTML. Nhưng mối quan tâm chính là về khoảng trắng và định dạng mà chúng tôi khó định dạng.
Kiểm tra nguồn trang bằng cách nhấp vào tùy chọn kiểm tra phần tử
Đây là một cách khác để phân tích trang web. Nhưng sự khác biệt là nó sẽ giải quyết vấn đề định dạng và khoảng trắng trong mã nguồn của trang web. Bạn có thể thực hiện điều này bằng cách nhấp chuột phải và sau đó chọnInspect hoặc là Inspect elementtùy chọn từ menu. Nó sẽ cung cấp thông tin về khu vực hoặc phần tử cụ thể của trang web đó.
Các cách khác nhau để trích xuất dữ liệu từ trang web
Các phương pháp sau chủ yếu được sử dụng để trích xuất dữ liệu từ một trang web:
Biểu hiện thông thường
Chúng là ngôn ngữ lập trình chuyên biệt cao được nhúng trong Python. Chúng ta có thể sử dụng nó thông quaremô-đun của Python. Nó còn được gọi là RE hoặc regexes hoặc các mẫu regex. Với sự trợ giúp của các biểu thức chính quy, chúng ta có thể chỉ định một số quy tắc cho tập hợp các chuỗi có thể có mà chúng ta muốn đối sánh từ dữ liệu.
Nếu bạn muốn tìm hiểu thêm về biểu thức chính quy nói chung, hãy truy cập liên kết https://www.tutorialspoint.com/automata_theory/regular_expressions.htmvà nếu bạn muốn biết thêm về mô-đun re hoặc biểu thức chính quy trong Python, bạn có thể theo liên kết https://www.tutorialspoint.com/python/python_reg_expressions.htm .
Thí dụ
Trong ví dụ sau, chúng tôi sẽ thu thập dữ liệu về Ấn Độ từ http://example.webscraping.com sau khi khớp nội dung của <td> với sự trợ giúp của biểu thức chính quy.
import re
import urllib.request
response =
urllib.request.urlopen('http://example.webscraping.com/places/default/view/India-102')
html = response.read()
text = html.decode()
re.findall('<td class="w2p_fw">(.*?)</td>',text)Đầu ra
Đầu ra tương ứng sẽ được hiển thị ở đây -
[
'<img src="/places/static/images/flags/in.png" />',
'3,287,590 square kilometres',
'1,173,108,018',
'IN',
'India',
'New Delhi',
'<a href="/places/default/continent/AS">AS</a>',
'.in',
'INR',
'Rupee',
'91',
'######',
'^(\\d{6})$',
'enIN,hi,bn,te,mr,ta,ur,gu,kn,ml,or,pa,as,bh,sat,ks,ne,sd,kok,doi,mni,sit,sa,fr,lus,inc',
'<div>
<a href="/places/default/iso/CN">CN </a>
<a href="/places/default/iso/NP">NP </a>
<a href="/places/default/iso/MM">MM </a>
<a href="/places/default/iso/BT">BT </a>
<a href="/places/default/iso/PK">PK </a>
<a href="/places/default/iso/BD">BD </a>
</div>'
]Quan sát rằng trong đầu ra ở trên, bạn có thể xem chi tiết về đất nước Ấn Độ bằng cách sử dụng biểu thức chính quy.
Súp đẹp
Giả sử chúng ta muốn thu thập tất cả các siêu liên kết từ một trang web, thì chúng ta có thể sử dụng một trình phân tích cú pháp có tên là BeautifulSoup, có thể biết chi tiết hơn tại https://www.crummy.com/software/BeautifulSoup/bs4/doc/.Nói một cách dễ hiểu, BeautifulSoup là một thư viện Python để kéo dữ liệu ra khỏi các tệp HTML và XML. Nó có thể được sử dụng với các yêu cầu, vì nó cần một đầu vào (tài liệu hoặc url) để tạo một đối tượng súp vì nó không thể tự tìm nạp một trang web. Bạn có thể sử dụng tập lệnh Python sau để thu thập tiêu đề của trang web và các siêu liên kết.
Cài đặt Beautiful Soup
Sử dụng pip lệnh, chúng ta có thể cài đặt beautifulsoup trong môi trường ảo của chúng tôi hoặc trong cài đặt toàn cầu.
(base) D:\ProgramData>pip install bs4
Collecting bs4
Downloading
https://files.pythonhosted.org/packages/10/ed/7e8b97591f6f456174139ec089c769f89
a94a1a4025fe967691de971f314/bs4-0.0.1.tar.gz
Requirement already satisfied: beautifulsoup4 in d:\programdata\lib\sitepackages
(from bs4) (4.6.0)
Building wheels for collected packages: bs4
Running setup.py bdist_wheel for bs4 ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\a0\b0\b2\4f80b9456b87abedbc0bf2d
52235414c3467d8889be38dd472
Successfully built bs4
Installing collected packages: bs4
Successfully installed bs4-0.0.1Thí dụ
Lưu ý rằng trong ví dụ này, chúng tôi đang mở rộng ví dụ trên được triển khai với mô-đun python yêu cầu. chúng tôi đang sử dụngr.text để tạo một đối tượng súp sẽ tiếp tục được sử dụng để tìm nạp các chi tiết như tiêu đề của trang web.
Đầu tiên, chúng ta cần nhập các mô-đun Python cần thiết -
import requests
from bs4 import BeautifulSoupTrong dòng mã sau, chúng tôi sử dụng các yêu cầu để thực hiện một yêu cầu GET HTTP cho url: https://authoraditiagarwal.com/ bằng cách đưa ra yêu cầu GET.
r = requests.get('https://authoraditiagarwal.com/')Bây giờ chúng ta cần tạo một đối tượng Soup như sau:
soup = BeautifulSoup(r.text, 'lxml')
print (soup.title)
print (soup.title.text)Đầu ra
Đầu ra tương ứng sẽ được hiển thị ở đây -
<title>Learn and Grow with Aditi Agarwal</title>
Learn and Grow with Aditi AgarwalLxml
Một thư viện Python khác mà chúng ta sẽ thảo luận để tìm kiếm web là lxml. Nó là một thư viện phân tích cú pháp HTML và XML hiệu suất cao. Nó tương đối nhanh và đơn giản. Bạn có thể đọc thêm về nó trênhttps://lxml.de/.
Cài đặt lxml
Sử dụng lệnh pip, chúng ta có thể cài đặt lxml trong môi trường ảo của chúng tôi hoặc trong cài đặt toàn cầu.
(base) D:\ProgramData>pip install lxml
Collecting lxml
Downloading
https://files.pythonhosted.org/packages/b9/55/bcc78c70e8ba30f51b5495eb0e
3e949aa06e4a2de55b3de53dc9fa9653fa/lxml-4.2.5-cp36-cp36m-win_amd64.whl
(3.
6MB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 3.6MB 64kB/s
Installing collected packages: lxml
Successfully installed lxml-4.2.5Ví dụ: Trích xuất dữ liệu bằng lxml và các yêu cầu
Trong ví dụ sau, chúng tôi đang loại bỏ một phần tử cụ thể của trang web từ authoraditiagarwal.com bằng cách sử dụng lxml và các yêu cầu -
Đầu tiên, chúng ta cần nhập các yêu cầu và html từ thư viện lxml như sau:
import requests
from lxml import htmlBây giờ chúng ta cần cung cấp url của trang web để tìm kiếm
url = 'https://authoraditiagarwal.com/leadershipmanagement/'Bây giờ chúng ta cần cung cấp đường dẫn (Xpath) thành phần cụ thể của trang web đó -
path = '//*[@id="panel-836-0-0-1"]/div/div/p[1]'
response = requests.get(url)
byte_string = response.content
source_code = html.fromstring(byte_string)
tree = source_code.xpath(path)
print(tree[0].text_content())Đầu ra
Đầu ra tương ứng sẽ được hiển thị ở đây -
The Sprint Burndown or the Iteration Burndown chart is a powerful tool to communicate
daily progress to the stakeholders. It tracks the completion of work for a given sprint
or an iteration. The horizontal axis represents the days within a Sprint. The vertical
axis represents the hours remaining to complete the committed work.Trong các chương trước, chúng ta đã tìm hiểu về cách trích xuất dữ liệu từ các trang web hoặc quét web bằng các mô-đun Python khác nhau. Trong chương này, chúng ta hãy xem xét các kỹ thuật khác nhau để xử lý dữ liệu đã được loại bỏ.
Giới thiệu
Để xử lý dữ liệu đã được cạo, chúng ta phải lưu trữ dữ liệu trên máy cục bộ của mình ở một định dạng cụ thể như bảng tính (CSV), JSON hoặc đôi khi trong cơ sở dữ liệu như MySQL.
Xử lý dữ liệu CSV và JSON
Đầu tiên, chúng tôi sẽ viết thông tin, sau khi lấy từ trang web, vào tệp CSV hoặc bảng tính. Trước tiên hãy để chúng tôi hiểu thông qua một ví dụ đơn giản, trong đó chúng tôi sẽ lấy thông tin đầu tiên bằng cách sử dụngBeautifulSoup mô-đun, như đã làm trước đó, và sau đó bằng cách sử dụng mô-đun CSV của Python, chúng tôi sẽ ghi thông tin dạng văn bản đó vào tệp CSV.
Đầu tiên, chúng ta cần nhập các thư viện Python cần thiết như sau:
import requests
from bs4 import BeautifulSoup
import csvTrong dòng mã sau đây, chúng tôi sử dụng các yêu cầu để thực hiện yêu cầu GET HTTP cho url: https://authoraditiagarwal.com/ bằng cách đưa ra yêu cầu GET.
r = requests.get('https://authoraditiagarwal.com/')Bây giờ, chúng ta cần tạo một đối tượng Soup như sau:
soup = BeautifulSoup(r.text, 'lxml')Bây giờ, với sự trợ giúp của các dòng mã tiếp theo, chúng ta sẽ ghi dữ liệu đã lấy vào một tệp CSV có tên dataprocessing.csv.
f = csv.writer(open(' dataprocessing.csv ','w'))
f.writerow(['Title'])
f.writerow([soup.title.text])Sau khi chạy tập lệnh này, thông tin văn bản hoặc tiêu đề của trang web sẽ được lưu trong tệp CSV được đề cập ở trên trên máy cục bộ của bạn.
Tương tự, chúng ta có thể lưu thông tin thu thập được trong một tệp JSON. Sau đây là một tập lệnh Python dễ hiểu để thực hiện tương tự trong đó chúng ta đang lấy thông tin giống như chúng ta đã làm trong tập lệnh Python trước, nhưng lần này thông tin lấy được được lưu trong JSONfile.txt bằng cách sử dụng mô-đun JSON Python.
import requests
from bs4 import BeautifulSoup
import csv
import json
r = requests.get('https://authoraditiagarwal.com/')
soup = BeautifulSoup(r.text, 'lxml')
y = json.dumps(soup.title.text)
with open('JSONFile.txt', 'wt') as outfile:
json.dump(y, outfile)Sau khi chạy tập lệnh này, thông tin nắm được tức là tiêu đề của trang web sẽ được lưu trong tệp văn bản được đề cập ở trên trên máy cục bộ của bạn.
Xử lý dữ liệu bằng AWS S3
Đôi khi, chúng tôi có thể muốn lưu dữ liệu cóp nhặt trong bộ nhớ cục bộ của mình cho mục đích lưu trữ. Nhưng nếu chúng ta cần lưu trữ và phân tích dữ liệu này ở quy mô lớn thì sao? Câu trả lời là dịch vụ lưu trữ đám mây có tên Amazon S3 hoặc AWS S3 (Simple Storage Service). Về cơ bản AWS S3 là một bộ lưu trữ đối tượng được xây dựng để lưu trữ và truy xuất bất kỳ lượng dữ liệu nào từ bất kỳ đâu.
Chúng ta có thể làm theo các bước sau để lưu trữ dữ liệu trong AWS S3 -
Step 1- Trước tiên, chúng tôi cần một tài khoản AWS sẽ cung cấp cho chúng tôi các khóa bí mật để sử dụng trong tập lệnh Python của chúng tôi trong khi lưu trữ dữ liệu. Nó sẽ tạo một thùng S3 để chúng ta có thể lưu trữ dữ liệu của mình.
Step 2 - Tiếp theo, chúng ta cần cài đặt boto3Thư viện Python để truy cập thùng S3. Nó có thể được cài đặt với sự trợ giúp của lệnh sau:
pip install boto3Step 3 - Tiếp theo, chúng ta có thể sử dụng tập lệnh Python sau để thu thập dữ liệu từ trang web và lưu nó vào nhóm AWS S3.
Đầu tiên, chúng tôi cần nhập các thư viện Python để cạo, ở đây chúng tôi đang làm việc với requestsvà boto3 lưu dữ liệu vào nhóm S3.
import requests
import boto3Bây giờ chúng ta có thể lấy dữ liệu từ URL của mình.
data = requests.get("Enter the URL").textBây giờ để lưu trữ dữ liệu vào thùng S3, chúng ta cần tạo ứng dụng khách S3 như sau:
s3 = boto3.client('s3')
bucket_name = "our-content"Dòng mã tiếp theo sẽ tạo nhóm S3 như sau:
s3.create_bucket(Bucket = bucket_name, ACL = 'public-read')
s3.put_object(Bucket = bucket_name, Key = '', Body = data, ACL = "public-read")Bây giờ bạn có thể kiểm tra nhóm với tên nội dung của chúng tôi từ tài khoản AWS của bạn.
Xử lý dữ liệu bằng MySQL
Hãy để chúng tôi tìm hiểu cách xử lý dữ liệu bằng MySQL. Nếu bạn muốn tìm hiểu về MySQL, thì bạn có thể theo liên kếthttps://www.tutorialspoint.com/mysql/.
Với sự trợ giúp của các bước sau, chúng tôi có thể thu thập và xử lý dữ liệu vào bảng MySQL -
Step 1- Đầu tiên, bằng cách sử dụng MySQL, chúng ta cần tạo một cơ sở dữ liệu và bảng mà chúng ta muốn lưu dữ liệu đã cạo của mình. Ví dụ: chúng tôi đang tạo bảng với truy vấn sau:
CREATE TABLE Scrap_pages (id BIGINT(7) NOT NULL AUTO_INCREMENT,
title VARCHAR(200), content VARCHAR(10000),PRIMARY KEY(id));Step 2- Tiếp theo, chúng ta cần xử lý Unicode. Lưu ý rằng MySQL không xử lý Unicode theo mặc định. Chúng ta cần bật tính năng này với sự trợ giúp của các lệnh sau sẽ thay đổi bộ ký tự mặc định cho cơ sở dữ liệu, cho bảng và cho cả hai cột -
ALTER DATABASE scrap CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
ALTER TABLE Scrap_pages CONVERT TO CHARACTER SET utf8mb4 COLLATE
utf8mb4_unicode_ci;
ALTER TABLE Scrap_pages CHANGE title title VARCHAR(200) CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;
ALTER TABLE pages CHANGE content content VARCHAR(10000) CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;Step 3- Bây giờ, tích hợp MySQL với Python. Đối với điều này, chúng tôi sẽ cần PyMySQL có thể được cài đặt với sự trợ giúp của lệnh sau
pip install PyMySQLStep 4- Bây giờ, cơ sở dữ liệu của chúng tôi có tên là Scrap, đã được tạo trước đó, đã sẵn sàng để lưu dữ liệu, sau khi được quét từ web, vào bảng có tên Scrap_pages. Ở đây trong ví dụ của chúng tôi, chúng tôi sẽ lấy dữ liệu từ Wikipedia và nó sẽ được lưu vào cơ sở dữ liệu của chúng tôi.
Đầu tiên, chúng ta cần nhập các mô-đun Python được yêu cầu.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import pymysql
import reBây giờ, hãy tạo một kết nối, đó là tích hợp điều này với Python.
conn = pymysql.connect(host='127.0.0.1',user='root', passwd = None, db = 'mysql',
charset = 'utf8')
cur = conn.cursor()
cur.execute("USE scrap")
random.seed(datetime.datetime.now())
def store(title, content):
cur.execute('INSERT INTO scrap_pages (title, content) VALUES ''("%s","%s")', (title, content))
cur.connection.commit()Bây giờ, hãy kết nối với Wikipedia và lấy dữ liệu từ nó.
def getLinks(articleUrl):
html = urlopen('http://en.wikipedia.org'+articleUrl)
bs = BeautifulSoup(html, 'html.parser')
title = bs.find('h1').get_text()
content = bs.find('div', {'id':'mw-content-text'}).find('p').get_text()
store(title, content)
return bs.find('div', {'id':'bodyContent'}).findAll('a',href=re.compile('^(/wiki/)((?!:).)*$'))
links = getLinks('/wiki/Kevin_Bacon')
try:
while len(links) > 0:
newArticle = links[random.randint(0, len(links)-1)].attrs['href']
print(newArticle)
links = getLinks(newArticle)Cuối cùng, chúng ta cần đóng cả con trỏ và kết nối.
finally:
cur.close()
conn.close()Thao tác này sẽ lưu dữ liệu thu thập từ Wikipedia vào bảng có tên là scrap_pages. Nếu bạn đã quen với MySQL và tìm kiếm web, thì đoạn mã trên sẽ không khó hiểu.
Xử lý dữ liệu bằng PostgreSQL
PostgreSQL, được phát triển bởi một nhóm tình nguyện viên trên toàn thế giới, là một hệ thống quản lý cơ sở dữ liệu quan hệ mã nguồn mở (RDMS). Quá trình xử lý dữ liệu đã được cạo bằng PostgreSQL tương tự như quá trình của MySQL. Sẽ có hai thay đổi: Thứ nhất, các lệnh sẽ khác với MySQL và thứ hai, ở đây chúng ta sẽ sử dụngpsycopg2 Thư viện Python để thực hiện tích hợp với Python.
Nếu bạn chưa quen với PostgreSQL thì bạn có thể tìm hiểu nó tại https://www.tutorialspoint.com/postgresql/. Và với sự trợ giúp của lệnh sau, chúng ta có thể cài đặt thư viện Python psycopg2 -
pip install psycopg2Việc tìm kiếm trên web thường bao gồm tải xuống, lưu trữ và xử lý nội dung phương tiện web. Trong chương này, chúng ta hãy hiểu cách xử lý nội dung được tải xuống từ web.
Giới thiệu
Nội dung phương tiện web mà chúng tôi thu được trong quá trình cạo có thể là hình ảnh, tệp âm thanh và video, ở dạng không phải trang web cũng như tệp dữ liệu. Tuy nhiên, liệu chúng ta có thể tin tưởng vào dữ liệu đã tải xuống, đặc biệt là trên phần mở rộng của dữ liệu mà chúng ta sẽ tải xuống và lưu trữ trong bộ nhớ máy tính của mình không? Điều này làm cho nó trở nên cần thiết để biết về loại dữ liệu mà chúng tôi sẽ lưu trữ cục bộ.
Lấy nội dung đa phương tiện từ trang web
Trong phần này, chúng ta sẽ tìm hiểu cách chúng ta có thể tải xuống nội dung phương tiện thể hiện chính xác loại phương tiện dựa trên thông tin từ máy chủ web. Chúng tôi có thể làm điều đó với sự trợ giúp của Pythonrequests như chúng ta đã làm trong chương trước.
Đầu tiên, chúng ta cần nhập các mô-đun Python cần thiết như sau:
import requestsBây giờ, hãy cung cấp URL của nội dung phương tiện mà chúng tôi muốn tải xuống và lưu trữ cục bộ.
url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg"Sử dụng mã sau để tạo đối tượng phản hồi HTTP.
r = requests.get(url)Với sự trợ giúp của dòng mã sau, chúng tôi có thể lưu nội dung nhận được dưới dạng tệp .png.
with open("ThinkBig.png",'wb') as f:
f.write(r.content)Sau khi chạy tập lệnh Python ở trên, chúng ta sẽ nhận được một tệp có tên ThinkBig.png, tệp này sẽ có hình ảnh được tải xuống.
Trích xuất tên tệp từ URL
Sau khi tải xuống nội dung từ trang web, chúng tôi cũng muốn lưu nó vào một tệp có tên tệp được tìm thấy trong URL. Nhưng chúng tôi cũng có thể kiểm tra xem có số lượng đoạn bổ sung tồn tại trong URL hay không. Đối với điều này, chúng tôi cần tìm tên tệp thực tế từ URL.
Với sự trợ giúp của tập lệnh Python sau đây, sử dụng urlparse, chúng tôi có thể trích xuất tên tệp từ URL -
import urllib3
import os
url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg"
a = urlparse(url)
a.pathBạn có thể quan sát đầu ra như hình dưới đây:
'/wp-content/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg'
os.path.basename(a.path)Bạn có thể quan sát đầu ra như hình dưới đây:
'MetaSlider_ThinkBig-1080x180.jpg'Khi bạn chạy tập lệnh trên, chúng tôi sẽ nhận được tên tệp từ URL.
Thông tin về Loại nội dung từ URL
Trong khi trích xuất nội dung từ máy chủ web, theo yêu cầu GET, chúng tôi cũng có thể kiểm tra thông tin của nó do máy chủ web cung cấp. Với sự trợ giúp của tập lệnh Python sau, chúng tôi có thể xác định máy chủ web có ý nghĩa gì với loại nội dung -
Đầu tiên, chúng ta cần nhập các mô-đun Python cần thiết như sau:
import requestsBây giờ, chúng tôi cần cung cấp URL của nội dung phương tiện mà chúng tôi muốn tải xuống và lưu trữ cục bộ.
url = "https://authoraditiagarwal.com/wpcontent/uploads/2018/05/MetaSlider_ThinkBig-1080x180.jpg"Dòng mã sau sẽ tạo đối tượng phản hồi HTTP.
r = requests.get(url, allow_redirects=True)Bây giờ, chúng tôi có thể nhận được loại thông tin về nội dung có thể được cung cấp bởi máy chủ web.
for headers in r.headers: print(headers)Bạn có thể quan sát đầu ra như hình dưới đây:
Date
Server
Upgrade
Connection
Last-Modified
Accept-Ranges
Content-Length
Keep-Alive
Content-TypeVới sự trợ giúp của dòng mã sau, chúng tôi có thể nhận được thông tin cụ thể về loại nội dung, chẳng hạn như loại nội dung -
print (r.headers.get('content-type'))Bạn có thể quan sát đầu ra như hình dưới đây:
image/jpegVới sự trợ giúp của dòng mã sau, chúng tôi có thể nhận được thông tin cụ thể về loại nội dung, chẳng hạn như EType -
print (r.headers.get('ETag'))Bạn có thể quan sát đầu ra như hình dưới đây:
NoneTuân theo lệnh sau -
print (r.headers.get('content-length'))Bạn có thể quan sát đầu ra như hình dưới đây:
12636Với sự trợ giúp của dòng mã sau, chúng tôi có thể nhận được thông tin cụ thể về loại nội dung, chẳng hạn như Máy chủ -
print (r.headers.get('Server'))Bạn có thể quan sát đầu ra như hình dưới đây:
ApacheTạo hình thu nhỏ cho hình ảnh
Hình thu nhỏ là một mô tả hoặc đại diện rất nhỏ. Người dùng có thể muốn chỉ lưu hình thu nhỏ của một hình ảnh lớn hoặc lưu cả hình ảnh cũng như hình thu nhỏ. Trong phần này, chúng ta sẽ tạo một hình thu nhỏ của hình ảnh có tênThinkBig.png đã tải xuống trong phần trước “Lấy nội dung đa phương tiện từ trang web”.
Đối với tập lệnh Python này, chúng ta cần cài đặt thư viện Python có tên là Pillow, một nhánh của thư viện Python Image có các chức năng hữu ích để xử lý hình ảnh. Nó có thể được cài đặt với sự trợ giúp của lệnh sau:
pip install pillowTập lệnh Python sau sẽ tạo một hình thu nhỏ của hình ảnh và sẽ lưu nó vào thư mục hiện tại bằng cách đặt tiền tố tệp hình thu nhỏ với Th_
import glob
from PIL import Image
for infile in glob.glob("ThinkBig.png"):
img = Image.open(infile)
img.thumbnail((128, 128), Image.ANTIALIAS)
if infile[0:2] != "Th_":
img.save("Th_" + infile, "png")Đoạn mã trên rất dễ hiểu và bạn có thể kiểm tra tệp hình thu nhỏ trong thư mục hiện tại.
Ảnh chụp màn hình từ Trang web
Trong thao tác tìm kiếm trên web, một nhiệm vụ rất phổ biến là chụp ảnh màn hình của một trang web. Để thực hiện điều này, chúng tôi sẽ sử dụng selen và webdriver. Tập lệnh Python sau sẽ chụp ảnh màn hình từ trang web và sẽ lưu nó vào thư mục hiện tại.
From selenium import webdriver
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
browser = webdriver.Chrome(executable_path = path)
browser.get('https://tutorialspoint.com/')
screenshot = browser.save_screenshot('screenshot.png')
browser.quitBạn có thể quan sát đầu ra như hình dưới đây:
DevTools listening on ws://127.0.0.1:1456/devtools/browser/488ed704-9f1b-44f0-
a571-892dc4c90eb7
<bound method WebDriver.quit of <selenium.webdriver.chrome.webdriver.WebDriver
(session="37e8e440e2f7807ef41ca7aa20ce7c97")>>Sau khi chạy tập lệnh, bạn có thể kiểm tra thư mục hiện tại của mình cho screenshot.png tập tin.
Tạo hình thu nhỏ cho video
Giả sử chúng tôi đã tải xuống video từ trang web và muốn tạo hình thu nhỏ cho chúng để có thể nhấp vào một video cụ thể, dựa trên hình thu nhỏ của nó. Để tạo hình thu nhỏ cho video, chúng tôi cần một công cụ đơn giản có tên làffmpeg có thể tải xuống từ www.ffmpeg.org. Sau khi tải xuống, chúng tôi cần cài đặt nó theo thông số kỹ thuật của hệ điều hành của chúng tôi.
Tập lệnh Python sau sẽ tạo hình thu nhỏ của video và sẽ lưu nó vào thư mục cục bộ của chúng tôi -
import subprocess
video_MP4_file = “C:\Users\gaurav\desktop\solar.mp4
thumbnail_image_file = 'thumbnail_solar_video.jpg'
subprocess.call(['ffmpeg', '-i', video_MP4_file, '-ss', '00:00:20.000', '-
vframes', '1', thumbnail_image_file, "-y"])Sau khi chạy tập lệnh trên, chúng ta sẽ nhận được hình thu nhỏ có tên thumbnail_solar_video.jpg được lưu trong thư mục cục bộ của chúng tôi.
Ripping video MP4 thành MP3
Giả sử bạn đã tải xuống một số tệp video từ một trang web, nhưng bạn chỉ cần âm thanh từ tệp đó để phục vụ mục đích của mình, thì nó có thể được thực hiện bằng Python với sự trợ giúp của thư viện Python được gọi là moviepy có thể được cài đặt với sự trợ giúp của lệnh sau:
pip install moviepyBây giờ, sau khi cài đặt thành công phimepy với sự trợ giúp của tập lệnh sau, chúng ta có thể chuyển đổi MP4 sang MP3.
import moviepy.editor as mp
clip = mp.VideoFileClip(r"C:\Users\gaurav\Desktop\1234.mp4")
clip.audio.write_audiofile("movie_audio.mp3")Bạn có thể quan sát đầu ra như hình dưới đây:
[MoviePy] Writing audio in movie_audio.mp3
100%|¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦
¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 674/674 [00:01<00:00,
476.30it/s]
[MoviePy] Done.Tập lệnh trên sẽ lưu tệp MP3 âm thanh trong thư mục cục bộ.
Trong chương trước, chúng ta đã biết cách xử lý video và hình ảnh mà chúng ta thu được dưới dạng một phần của nội dung tìm kiếm trên web. Trong chương này, chúng ta sẽ giải quyết phân tích văn bản bằng cách sử dụng thư viện Python và sẽ tìm hiểu chi tiết về điều này.
Giới thiệu
Bạn có thể thực hiện phân tích văn bản bằng cách sử dụng thư viện Python có tên là Bộ công cụ ngôn ngữ tự nhiên (NLTK). Trước khi đi vào các khái niệm về NLTK, chúng ta hãy hiểu mối quan hệ giữa phân tích văn bản và tìm kiếm trang web.
Phân tích các từ trong văn bản có thể giúp chúng ta biết những từ nào là quan trọng, những từ nào là bất thường, cách các từ được nhóm lại. Phân tích này giúp giảm bớt nhiệm vụ tìm kiếm web.
Bắt đầu với NLTK
Bộ công cụ ngôn ngữ tự nhiên (NLTK) là tập hợp các thư viện Python được thiết kế đặc biệt để xác định và gắn thẻ các phần của giọng nói được tìm thấy trong văn bản của ngôn ngữ tự nhiên như tiếng Anh.
Cài đặt NLTK
Bạn có thể sử dụng lệnh sau để cài đặt NLTK bằng Python:
pip install nltkNếu bạn đang sử dụng Anaconda, thì một gói chung cư cho NLTK có thể được tạo bằng cách sử dụng lệnh sau:
conda install -c anaconda nltkTải xuống dữ liệu của NLTK
Sau khi cài đặt NLTK, chúng ta phải tải về các kho văn bản cài sẵn. Nhưng trước khi tải xuống kho lưu trữ đặt trước văn bản, chúng ta cần nhập NLTK với sự trợ giúp củaimport lệnh như sau:
mport nltkBây giờ, với sự trợ giúp của lệnh sau, dữ liệu NLTK có thể được tải xuống -
nltk.download()Việc cài đặt tất cả các gói có sẵn của NLTK sẽ mất một khoảng thời gian, nhưng bạn nên cài đặt tất cả các gói.
Cài đặt các gói cần thiết khác
Chúng tôi cũng cần một số gói Python khác như gensim và pattern để thực hiện phân tích văn bản cũng như xây dựng các ứng dụng xử lý ngôn ngữ tự nhiên bằng cách sử dụng NLTK.
gensim- Một thư viện mô hình ngữ nghĩa mạnh mẽ, hữu ích cho nhiều ứng dụng. Nó có thể được cài đặt bằng lệnh sau:
pip install gensimpattern - Dùng để chế tạo gensimgói hoạt động đúng cách. Nó có thể được cài đặt bằng lệnh sau:
pip install patternMã hóa
Quá trình chia nhỏ văn bản đã cho, thành các đơn vị nhỏ hơn được gọi là mã thông báo, được gọi là mã hóa. Các mã thông báo này có thể là các từ, số hoặc dấu chấm câu. Nó còn được gọi làword segmentation.
Thí dụ

Mô-đun NLTK cung cấp các gói khác nhau để mã hóa. Chúng tôi có thể sử dụng các gói này theo yêu cầu của chúng tôi. Một số gói được mô tả ở đây -
sent_tokenize package- Gói này sẽ chia văn bản đầu vào thành các câu. Bạn có thể sử dụng lệnh sau để nhập gói này:
from nltk.tokenize import sent_tokenizeword_tokenize package- Gói này sẽ chia văn bản đầu vào thành các từ. Bạn có thể sử dụng lệnh sau để nhập gói này:
from nltk.tokenize import word_tokenizeWordPunctTokenizer package- Gói này sẽ chia văn bản đầu vào cũng như các dấu câu thành các từ. Bạn có thể sử dụng lệnh sau để nhập gói này:
from nltk.tokenize import WordPuncttokenizerGốc
Trong bất kỳ ngôn ngữ nào, có các dạng khác nhau của một từ. Một ngôn ngữ bao gồm rất nhiều biến thể do các lý do ngữ pháp. Ví dụ, hãy xem xét các từdemocracy, democraticvà democratization. Đối với học máy cũng như đối với các dự án duyệt web, điều quan trọng là máy móc phải hiểu rằng những từ khác nhau này có cùng một dạng cơ sở. Do đó, chúng ta có thể nói rằng việc trích xuất các dạng cơ bản của từ trong khi phân tích văn bản có thể hữu ích.
Điều này có thể đạt được bằng cách tách gốc, có thể được định nghĩa là quá trình tự khám phá để rút ra các dạng cơ sở của từ bằng cách cắt bỏ các phần cuối của từ.
Mô-đun NLTK cung cấp các gói khác nhau để tạo gốc. Chúng tôi có thể sử dụng các gói này theo yêu cầu của chúng tôi. Một số gói này được mô tả ở đây -
PorterStemmer package- Thuật toán của Porter được gói gốc Python này sử dụng để trích xuất biểu mẫu cơ sở. Bạn có thể sử dụng lệnh sau để nhập gói này:
from nltk.stem.porter import PorterStemmerVí dụ, sau khi đưa ra từ ‘writing’ là đầu vào cho trình gốc này, đầu ra sẽ là từ ‘write’ sau khi chiết cành.
LancasterStemmer package- Thuật toán Lancaster được sử dụng bởi gói gốc Python này để trích xuất dạng cơ sở. Bạn có thể sử dụng lệnh sau để nhập gói này:
from nltk.stem.lancaster import LancasterStemmerVí dụ, sau khi đưa ra từ ‘writing’ là đầu vào cho trình gốc này thì đầu ra sẽ là từ ‘writ’ sau khi chiết cành.
SnowballStemmer package- Thuật toán của Snowball được gói gốc Python này sử dụng để trích xuất dạng cơ sở. Bạn có thể sử dụng lệnh sau để nhập gói này:
from nltk.stem.snowball import SnowballStemmerVí dụ: sau khi đưa từ 'viết' làm đầu vào cho trình tạo gốc này thì đầu ra sẽ là từ 'viết' sau khi nhập gốc.
Bổ sung
Một cách khác để trích xuất dạng cơ sở của từ là bằng cách bổ sung, thông thường nhằm loại bỏ các kết thúc không theo chiều hướng bằng cách sử dụng phân tích từ vựng và hình thái học. Dạng cơ sở của bất kỳ từ nào sau khi bổ đề được gọi là bổ đề.
Mô-đun NLTK cung cấp các gói sau để lemmatization -
WordNetLemmatizer package- Nó sẽ chiết xuất dạng cơ sở của từ tùy thuộc vào việc nó có được sử dụng như danh từ như một động từ hay không. Bạn có thể sử dụng lệnh sau để nhập gói này:
from nltk.stem import WordNetLemmatizerChunking
Chunking, có nghĩa là chia dữ liệu thành nhiều phần nhỏ, là một trong những quá trình quan trọng trong xử lý ngôn ngữ tự nhiên để xác định các phần của lời nói và các cụm từ ngắn như cụm danh từ. Chunking là thực hiện việc ghi nhãn các mã thông báo. Chúng ta có thể có được cấu trúc của câu với sự trợ giúp của quá trình phân khúc.
Thí dụ
Trong ví dụ này, chúng ta sẽ triển khai phân đoạn Danh từ-Cụm từ bằng cách sử dụng mô-đun Python NLTK. NP chunking là một thể loại phân khúc sẽ tìm các cụm danh từ trong câu.
Các bước để thực hiện tách cụm danh từ
Chúng ta cần làm theo các bước dưới đây để thực hiện phân tách cụm danh từ -
Bước 1 - Định nghĩa ngữ pháp khối
Trong bước đầu tiên, chúng tôi sẽ xác định ngữ pháp cho phân khúc. Nó sẽ bao gồm các quy tắc mà chúng ta cần tuân theo.
Bước 2 - Tạo trình phân tích cú pháp Chunk
Bây giờ, chúng ta sẽ tạo một trình phân tích cú pháp chunk. Nó sẽ phân tích ngữ pháp và đưa ra kết quả.
Bước 3 - Đầu ra
Trong bước cuối cùng này, đầu ra sẽ được tạo ở định dạng cây.
Đầu tiên, chúng ta cần nhập gói NLTK như sau:
import nltkTiếp theo, chúng ta cần xác định câu. Ở đây DT: định thức, VBP: động từ, JJ: tính từ, IN: giới từ và NN: danh từ.
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]Tiếp theo, chúng tôi đưa ra ngữ pháp ở dạng biểu thức chính quy.
grammar = "NP:{<DT>?<JJ>*<NN>}"Bây giờ, dòng mã tiếp theo sẽ xác định một trình phân tích cú pháp để phân tích ngữ pháp.
parser_chunking = nltk.RegexpParser(grammar)Bây giờ, trình phân tích cú pháp sẽ phân tích cú pháp câu.
parser_chunking.parse(sentence)Tiếp theo, chúng tôi đưa ra đầu ra của chúng tôi trong biến.
Output = parser_chunking.parse(sentence)Với sự trợ giúp của đoạn mã sau, chúng ta có thể vẽ đầu ra của mình ở dạng cây như hình dưới đây.
output.draw()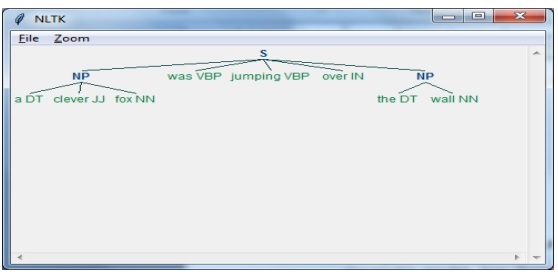
Mô hình Bag of Word (BoW) Trích xuất và chuyển đổi văn bản thành dạng số
Bag of Word (BoW), một mô hình hữu ích trong xử lý ngôn ngữ tự nhiên, về cơ bản được sử dụng để trích xuất các tính năng từ văn bản. Sau khi trích xuất các tính năng từ văn bản, nó có thể được sử dụng trong mô hình hóa trong các thuật toán học máy vì dữ liệu thô không thể được sử dụng trong các ứng dụng ML.
Hoạt động của Mô hình BoW
Ban đầu, mô hình trích xuất một từ vựng từ tất cả các từ trong tài liệu. Sau đó, sử dụng ma trận thuật ngữ tài liệu, nó sẽ xây dựng một mô hình. Theo cách này, mô hình BoW đại diện cho tài liệu chỉ như một túi từ và thứ tự hoặc cấu trúc bị loại bỏ.
Thí dụ
Giả sử chúng ta có hai câu sau:
Sentence1 - Đây là một ví dụ về mô hình Bag of Words.
Sentence2 - Chúng tôi có thể trích xuất các tính năng bằng cách sử dụng mô hình Bag of Words.
Bây giờ, bằng cách xem xét hai câu này, chúng ta có 14 từ khác biệt sau đây:
- This
- is
- an
- example
- bag
- of
- words
- model
- we
- can
- extract
- features
- by
- using
Xây dựng Mô hình Túi từ trong NLTK
Hãy để chúng tôi xem xét tập lệnh Python sau đây sẽ xây dựng mô hình BoW trong NLTK.
Đầu tiên, nhập gói sau:
from sklearn.feature_extraction.text import CountVectorizerTiếp theo, xác định tập hợp các câu -
Sentences=['This is an example of Bag of Words model.', ' We can extract
features by using Bag of Words model.']
vector_count = CountVectorizer()
features_text = vector_count.fit_transform(Sentences).todense()
print(vector_count.vocabulary_)Đầu ra
Nó cho thấy rằng chúng ta có 14 từ khác biệt trong hai câu trên -
{
'this': 10, 'is': 7, 'an': 0, 'example': 4, 'of': 9,
'bag': 1, 'words': 13, 'model': 8, 'we': 12, 'can': 3,
'extract': 5, 'features': 6, 'by': 2, 'using':11
}Lập mô hình chủ đề: Xác định các mẫu trong dữ liệu văn bản
Nói chung, các tài liệu được nhóm thành các chủ đề và mô hình chủ đề là một kỹ thuật để xác định các mẫu trong một văn bản tương ứng với một chủ đề cụ thể. Nói cách khác, mô hình hóa chủ đề được sử dụng để khám phá các chủ đề trừu tượng hoặc cấu trúc ẩn trong một bộ tài liệu nhất định.
Bạn có thể sử dụng mô hình chủ đề trong các tình huống sau:
Phân loại văn bản
Việc phân loại có thể được cải thiện bằng cách lập mô hình chủ đề vì nó nhóm các từ tương tự lại với nhau thay vì sử dụng từng từ riêng biệt làm đặc điểm.
Hệ thống đề xuất
Chúng ta có thể xây dựng hệ thống khuyến nghị bằng cách sử dụng các biện pháp tương tự.
Các thuật toán lập mô hình chủ đề
Chúng tôi có thể triển khai mô hình chủ đề bằng cách sử dụng các thuật toán sau:
Latent Dirichlet Allocation(LDA) - Đây là một trong những thuật toán phổ biến nhất sử dụng các mô hình đồ họa xác suất để thực hiện mô hình hóa chủ đề.
Latent Semantic Analysis(LDA) or Latent Semantic Indexing(LSI) - Nó dựa trên Đại số tuyến tính và sử dụng khái niệm SVD (Phân hủy giá trị số ít) trên ma trận thuật ngữ tài liệu.
Non-Negative Matrix Factorization (NMF) - Nó cũng dựa trên Đại số tuyến tính như LDA.
Các thuật toán được đề cập ở trên sẽ có các yếu tố sau:
- Số lượng chủ đề: Tham số
- Ma trận Tài liệu-Từ: Đầu vào
- WTM (Ma trận chủ đề Word) & TDM (Ma trận tài liệu chủ đề): Đầu ra
Giới thiệu
Gỡ bỏ trang web là một công việc phức tạp và độ phức tạp còn nhân lên nếu trang web là động. Theo Kiểm toán Toàn cầu về Khả năng Tiếp cận Web của Liên hợp quốc, hơn 70% các trang web có bản chất động và chúng dựa vào JavaScript cho các chức năng của chúng.
Ví dụ về trang web động
Hãy để chúng tôi xem xét một ví dụ về một trang web động và biết về lý do tại sao nó rất khó để loại bỏ. Ở đây chúng ta sẽ lấy ví dụ về việc tìm kiếm từ một trang web có tênhttp://example.webscraping.com/places/default/search.Nhưng làm thế nào chúng ta có thể nói rằng trang web này có tính chất động? Nó có thể được đánh giá từ đầu ra của tập lệnh Python sau đây sẽ cố gắng lấy dữ liệu từ trang web được đề cập ở trên -
import re
import urllib.request
response = urllib.request.urlopen('http://example.webscraping.com/places/default/search')
html = response.read()
text = html.decode()
re.findall('(.*?)',text)Đầu ra
[ ]Kết quả ở trên cho thấy rằng trình quét ví dụ không thể trích xuất thông tin vì phần tử <div> mà chúng tôi đang cố gắng tìm trống.
Các phương pháp tiếp cận để thu thập dữ liệu từ các trang web động
Chúng tôi đã thấy rằng trình quét không thể thu thập thông tin từ một trang web động vì dữ liệu được tải động bằng JavaScript. Trong những trường hợp như vậy, chúng tôi có thể sử dụng hai kỹ thuật sau để thu thập dữ liệu từ các trang web phụ thuộc JavaScript động:
- JavaScript Kỹ thuật Đảo ngược
- Hiển thị JavaScript
JavaScript Kỹ thuật Đảo ngược
Quá trình được gọi là kỹ thuật đảo ngược sẽ hữu ích và cho phép chúng tôi hiểu cách dữ liệu được tải động bởi các trang web.
Để thực hiện việc này, chúng ta cần nhấp vào inspect elementcho một URL được chỉ định. Tiếp theo, chúng tôi sẽ nhấp vàoNETWORK để tìm tất cả các yêu cầu được thực hiện cho trang web đó bao gồm cả search.json với đường dẫn là /ajax. Thay vì truy cập dữ liệu AJAX từ trình duyệt hoặc qua tab NETWORK, chúng tôi cũng có thể thực hiện việc đó với sự trợ giúp của tập lệnh Python sau:
import requests
url=requests.get('http://example.webscraping.com/ajax/search.json?page=0&page_size=10&search_term=a')
url.json()Thí dụ
Tập lệnh trên cho phép chúng tôi truy cập phản hồi JSON bằng cách sử dụng phương thức Python json. Tương tự, chúng ta có thể tải xuống phản hồi chuỗi thô và bằng cách sử dụng phương thức json.loads của python, chúng ta cũng có thể tải nó. Chúng tôi đang làm điều này với sự trợ giúp của tập lệnh Python sau. Về cơ bản, nó sẽ loại bỏ tất cả các quốc gia bằng cách tìm kiếm chữ cái trong bảng chữ cái 'a' và sau đó lặp lại các trang kết quả của các câu trả lời JSON.
import requests
import string
PAGE_SIZE = 15
url = 'http://example.webscraping.com/ajax/' + 'search.json?page={}&page_size={}&search_term=a'
countries = set()
for letter in string.ascii_lowercase:
print('Searching with %s' % letter)
page = 0
while True:
response = requests.get(url.format(page, PAGE_SIZE, letter))
data = response.json()
print('adding %d records from the page %d' %(len(data.get('records')),page))
for record in data.get('records'):countries.add(record['country'])
page += 1
if page >= data['num_pages']:
break
with open('countries.txt', 'w') as countries_file:
countries_file.write('n'.join(sorted(countries)))Sau khi chạy tập lệnh trên, chúng ta sẽ nhận được kết quả sau và các bản ghi sẽ được lưu trong tệp có tên là country.txt.
Đầu ra
Searching with a
adding 15 records from the page 0
adding 15 records from the page 1
...Hiển thị JavaScript
Trong phần trước, chúng tôi đã thiết kế ngược trên trang web về cách API hoạt động và cách chúng tôi có thể sử dụng nó để truy xuất kết quả trong một yêu cầu duy nhất. Tuy nhiên, chúng ta có thể gặp phải những khó khăn sau khi thực hiện thiết kế ngược -
Đôi khi các trang web có thể rất khó. Ví dụ: nếu trang web được tạo bằng công cụ trình duyệt nâng cao như Bộ công cụ Web của Google (GWT), thì mã JS tạo ra sẽ được tạo bằng máy và khó hiểu và khó hiểu và phải được thiết kế ngược.
Một số khung cấp cao hơn như React.js có thể gây khó khăn cho kỹ thuật đảo ngược bằng cách trừu tượng hóa logic JavaScript vốn đã phức tạp.
Giải pháp cho những khó khăn trên là sử dụng công cụ kết xuất trình duyệt phân tích cú pháp HTML, áp dụng định dạng CSS và thực thi JavaScript để hiển thị một trang web.
Thí dụ
Trong ví dụ này, để hiển thị Java Script, chúng ta sẽ sử dụng một mô-đun Python quen thuộc Selenium. Đoạn mã Python sau sẽ hiển thị một trang web với sự trợ giúp của Selenium:
Đầu tiên, chúng ta cần nhập webdriver từ selen như sau:
from selenium import webdriverBây giờ, cung cấp đường dẫn của trình điều khiển web mà chúng tôi đã tải xuống theo yêu cầu của chúng tôi -
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
driver = webdriver.Chrome(executable_path = path)Bây giờ, hãy cung cấp url mà chúng tôi muốn mở trong trình duyệt web đó hiện được điều khiển bởi tập lệnh Python của chúng tôi.
driver.get('http://example.webscraping.com/search')Bây giờ, chúng ta có thể sử dụng ID của hộp công cụ tìm kiếm để thiết lập phần tử cần chọn.
driver.find_element_by_id('search_term').send_keys('.')Tiếp theo, chúng ta có thể sử dụng java script để thiết lập nội dung hộp chọn như sau:
js = "document.getElementById('page_size').options[1].text = '100';"
driver.execute_script(js)Dòng mã sau cho thấy rằng tìm kiếm đã sẵn sàng để được nhấp vào trang web -
driver.find_element_by_id('search').click()Dòng mã tiếp theo cho thấy rằng nó sẽ đợi trong 45 giây để hoàn thành yêu cầu AJAX.
driver.implicitly_wait(45)Bây giờ, để chọn liên kết quốc gia, chúng ta có thể sử dụng công cụ chọn CSS như sau:
links = driver.find_elements_by_css_selector('#results a')Giờ đây, văn bản của mỗi liên kết có thể được trích xuất để tạo danh sách các quốc gia -
countries = [link.text for link in links]
print(countries)
driver.close()Trong chương trước, chúng ta đã thấy các trang web động. Trong chương này, chúng ta hãy hiểu việc loại bỏ các trang web hoạt động dựa trên đầu vào của người dùng, đó là các trang web dựa trên biểu mẫu.
Giới thiệu
Ngày nay WWW (World Wide Web) đang hướng tới phương tiện truyền thông xã hội cũng như nội dung do người dùng tạo. Vì vậy, câu hỏi đặt ra làm thế nào chúng ta có thể truy cập loại thông tin ngoài màn hình đăng nhập? Đối với điều này, chúng ta cần xử lý các biểu mẫu và thông tin đăng nhập.
Trong các chương trước, chúng ta đã làm việc với phương thức HTTP GET để yêu cầu thông tin nhưng trong chương này, chúng ta sẽ làm việc với phương thức HTTP POST để đẩy thông tin đến máy chủ web để lưu trữ và phân tích.
Tương tác với các biểu mẫu Đăng nhập
Khi làm việc trên Internet, chắc hẳn bạn đã nhiều lần tiếp xúc với các biểu mẫu đăng nhập. Chúng có thể rất đơn giản như chỉ bao gồm một vài trường HTML, nút gửi và trang hành động hoặc chúng có thể phức tạp và có một số trường bổ sung như email, để lại tin nhắn cùng với hình ảnh xác thực vì lý do bảo mật.
Trong phần này, chúng ta sẽ giải quyết một biểu mẫu gửi đơn giản với sự trợ giúp của thư viện yêu cầu Python.
Đầu tiên, chúng ta cần nhập thư viện yêu cầu như sau:
import requestsBây giờ, chúng ta cần cung cấp thông tin cho các trường của biểu mẫu đăng nhập.
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}Trong dòng mã tiếp theo, chúng tôi cần cung cấp URL mà hành động của biểu mẫu sẽ xảy ra.
r = requests.post(“enter the URL”, data = parameters)
print(r.text)Sau khi chạy script, nó sẽ trả về nội dung của trang nơi hành động đã xảy ra.
Giả sử nếu bạn muốn gửi bất kỳ hình ảnh nào với biểu mẫu, thì nó rất dễ dàng với request.post (). Bạn có thể hiểu nó với sự trợ giúp của tập lệnh Python sau:
import requests
file = {‘Uploadfile’: open(’C:\Usres\desktop\123.png’,‘rb’)}
r = requests.post(“enter the URL”, files = file)
print(r.text)Tải Cookie từ Máy chủ Web
Cookie, đôi khi được gọi là cookie web hoặc cookie internet, là một phần nhỏ dữ liệu được gửi từ một trang web và máy tính của chúng tôi lưu trữ nó trong một tệp nằm bên trong trình duyệt web của chúng tôi.
Trong bối cảnh giao dịch với các biểu mẫu đăng nhập, cookie có thể có hai loại. Một, chúng tôi đã đề cập ở phần trước, cho phép chúng tôi gửi thông tin đến một trang web và thứ hai cho phép chúng tôi duy trì trạng thái “đã đăng nhập” vĩnh viễn trong suốt chuyến thăm của chúng tôi vào trang web. Đối với loại biểu mẫu thứ hai, các trang web sử dụng cookie để theo dõi ai đã đăng nhập và ai chưa đăng nhập.
Cookies làm gì?
Ngày nay, hầu hết các trang web đang sử dụng cookie để theo dõi. Chúng tôi có thể hiểu hoạt động của cookie với sự trợ giúp của các bước sau:
Step 1- Đầu tiên, trang web sẽ xác thực thông tin đăng nhập của chúng tôi và lưu trữ nó trong cookie của trình duyệt của chúng tôi. Cookie này thường chứa thông tin cập nhật, thời gian chờ và theo dõi do máy chủ tạo.
Step 2- Tiếp theo, trang web sẽ sử dụng cookie như một bằng chứng xác thực. Xác thực này luôn được hiển thị bất cứ khi nào chúng tôi truy cập trang web.
Cookie rất có vấn đề đối với người tìm kiếm trên web bởi vì nếu người duyệt web không theo dõi cookie, biểu mẫu đã gửi sẽ bị gửi lại và ở trang tiếp theo có vẻ như họ chưa bao giờ đăng nhập. Rất dễ dàng theo dõi cookie với sự trợ giúp Python requests thư viện, như hình dưới đây -
import requests
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}
r = requests.post(“enter the URL”, data = parameters)Trong dòng mã trên, URL sẽ là trang sẽ hoạt động như bộ xử lý cho biểu mẫu đăng nhập.
print(‘The cookie is:’)
print(r.cookies.get_dict())
print(r.text)Sau khi chạy tập lệnh trên, chúng tôi sẽ truy xuất cookie từ kết quả của yêu cầu cuối cùng.
Có một vấn đề khác với cookie mà đôi khi các trang web thường xuyên sửa đổi cookie mà không có cảnh báo. Loại tình huống như vậy có thể được giải quyếtrequests.Session() như sau -
import requests
session = requests.Session()
parameters = {‘Name’:’Enter your name’, ‘Email-id’:’Your Emailid’,’Message’:’Type your message here’}
r = session.post(“enter the URL”, data = parameters)Trong dòng mã trên, URL sẽ là trang sẽ hoạt động như bộ xử lý cho biểu mẫu đăng nhập.
print(‘The cookie is:’)
print(r.cookies.get_dict())
print(r.text)Quan sát rằng bạn có thể dễ dàng hiểu sự khác biệt giữa tập lệnh có phiên và không có phiên.
Tự động hóa biểu mẫu với Python
Trong phần này, chúng ta sẽ giải quyết một mô-đun Python có tên là Mechanize sẽ giảm bớt công việc của chúng ta và tự động hóa quá trình điền vào các biểu mẫu.
Cơ giới hóa mô-đun
Mô-đun cơ học cung cấp cho chúng ta một giao diện cấp cao để tương tác với các biểu mẫu. Trước khi bắt đầu sử dụng, chúng ta cần cài đặt nó bằng lệnh sau:
pip install mechanizeLưu ý rằng nó sẽ chỉ hoạt động trong Python 2.x.
Thí dụ
Trong ví dụ này, chúng tôi sẽ tự động hóa quá trình điền vào biểu mẫu đăng nhập có hai trường là email và mật khẩu -
import mechanize
brwsr = mechanize.Browser()
brwsr.open(Enter the URL of login)
brwsr.select_form(nr = 0)
brwsr['email'] = ‘Enter email’
brwsr['password'] = ‘Enter password’
response = brwsr.submit()
brwsr.submit()Đoạn mã trên rất dễ hiểu. Đầu tiên, chúng tôi nhập mô-đun cơ giới hóa. Sau đó, một đối tượng trình duyệt Cơ học đã được tạo. Sau đó, chúng tôi điều hướng đến URL đăng nhập và chọn biểu mẫu. Sau đó, tên và giá trị được chuyển trực tiếp đến đối tượng trình duyệt.
Trong chương này, hãy để chúng tôi hiểu cách thực hiện quét web và xử lý CAPTCHA được sử dụng để kiểm tra người dùng cho con người hoặc rô bốt.
CAPTCHA là gì?
Hình thức đầy đủ của CAPTCHA là Completely Automated Public Turing test to tell Computers and Humans Apart, điều này cho thấy rõ ràng rằng đó là một bài kiểm tra để xác định xem người dùng có phải là con người hay không.
CAPTCHA là một hình ảnh bị bóp méo thường không dễ phát hiện bằng chương trình máy tính nhưng con người bằng cách nào đó có thể hiểu được nó. Hầu hết các trang web sử dụng CAPTCHA để ngăn không cho các bot tương tác.
Tải CAPTCHA bằng Python
Giả sử chúng ta muốn đăng ký trên một trang web và có biểu mẫu với CAPTCHA, thì trước khi tải ảnh CAPTCHA, chúng ta cần biết về thông tin cụ thể mà biểu mẫu yêu cầu. Với sự trợ giúp của tập lệnh Python tiếp theo, chúng tôi có thể hiểu các yêu cầu biểu mẫu của biểu mẫu đăng ký trên trang web có tênhttp://example.webscrapping.com.
import lxml.html
import urllib.request as urllib2
import pprint
import http.cookiejar as cookielib
def form_parsing(html):
tree = lxml.html.fromstring(html)
data = {}
for e in tree.cssselect('form input'):
if e.get('name'):
data[e.get('name')] = e.get('value')
return data
REGISTER_URL = '<a target="_blank" rel="nofollow"
href="http://example.webscraping.com/user/register">http://example.webscraping.com/user/register'</a>
ckj = cookielib.CookieJar()
browser = urllib2.build_opener(urllib2.HTTPCookieProcessor(ckj))
html = browser.open(
'<a target="_blank" rel="nofollow"
href="http://example.webscraping.com/places/default/user/register?_next">
http://example.webscraping.com/places/default/user/register?_next</a> = /places/default/index'
).read()
form = form_parsing(html)
pprint.pprint(form)Trong tập lệnh Python ở trên, trước tiên chúng ta đã xác định một hàm sẽ phân tích cú pháp biểu mẫu bằng cách sử dụng mô-đun python lxml và sau đó nó sẽ in các yêu cầu biểu mẫu như sau:
{
'_formkey': '5e306d73-5774-4146-a94e-3541f22c95ab',
'_formname': 'register',
'_next': '/places/default/index',
'email': '',
'first_name': '',
'last_name': '',
'password': '',
'password_two': '',
'recaptcha_response_field': None
}Bạn có thể kiểm tra từ đầu ra ở trên rằng tất cả các thông tin ngoại trừ recpatcha_response_fielddễ hiểu và đơn giản. Bây giờ câu hỏi đặt ra là làm thế nào chúng ta có thể xử lý thông tin phức tạp này và tải xuống CAPTCHA. Nó có thể được thực hiện với sự trợ giúp của thư viện Python gối như sau;
Gối Trăn gói
Pillow là một nhánh của thư viện Python Image có các chức năng hữu ích để xử lý hình ảnh. Nó có thể được cài đặt với sự trợ giúp của lệnh sau:
pip install pillowTrong ví dụ tiếp theo, chúng tôi sẽ sử dụng nó để tải CAPTCHA -
from io import BytesIO
import lxml.html
from PIL import Image
def load_captcha(html):
tree = lxml.html.fromstring(html)
img_data = tree.cssselect('div#recaptcha img')[0].get('src')
img_data = img_data.partition(',')[-1]
binary_img_data = img_data.decode('base64')
file_like = BytesIO(binary_img_data)
img = Image.open(file_like)
return imgTập lệnh python ở trên đang sử dụng pillowgói python và xác định một chức năng để tải hình ảnh CAPTCHA. Nó phải được sử dụng với chức năng có tênform_parser()được xác định trong tập lệnh trước để lấy thông tin về biểu mẫu đăng ký. Tập lệnh này sẽ lưu hình ảnh CAPTCHA ở định dạng hữu ích mà có thể được trích xuất dưới dạng chuỗi.
OCR: Trích xuất văn bản từ hình ảnh bằng Python
Sau khi tải CAPTCHA ở định dạng hữu ích, chúng tôi có thể giải nén nó với sự trợ giúp của Nhận dạng ký tự quang học (OCR), một quá trình trích xuất văn bản từ hình ảnh. Với mục đích này, chúng tôi sẽ sử dụng công cụ Tesseract OCR mã nguồn mở. Nó có thể được cài đặt với sự trợ giúp của lệnh sau:
pip install pytesseractThí dụ
Ở đây chúng tôi sẽ mở rộng tập lệnh Python ở trên, đã tải CAPTCHA bằng cách sử dụng Gói Python Pillow, như sau:
import pytesseract
img = get_captcha(html)
img.save('captcha_original.png')
gray = img.convert('L')
gray.save('captcha_gray.png')
bw = gray.point(lambda x: 0 if x < 1 else 255, '1')
bw.save('captcha_thresholded.png')Tập lệnh Python ở trên sẽ đọc CAPTCHA ở chế độ đen trắng sẽ rõ ràng và dễ chuyển tới tesseract như sau:
pytesseract.image_to_string(bw)Sau khi chạy tập lệnh trên, chúng ta sẽ nhận được CAPTCHA của biểu mẫu đăng ký làm đầu ra.
Chương này giải thích cách thực hiện kiểm tra bằng cách sử dụng công cụ quét web trong Python.
Giới thiệu
Trong các dự án web lớn, kiểm tra tự động phần phụ trợ của trang web được thực hiện thường xuyên nhưng kiểm tra giao diện người dùng thường bị bỏ qua. Lý do chính đằng sau điều này là việc lập trình các trang web giống như một mạng lưới các ngôn ngữ lập trình và đánh dấu khác nhau. Chúng ta có thể viết bài kiểm tra đơn vị cho một ngôn ngữ nhưng sẽ trở nên khó khăn nếu tương tác được thực hiện bằng ngôn ngữ khác. Đó là lý do tại sao chúng tôi phải có bộ kiểm tra để đảm bảo rằng mã của chúng tôi đang hoạt động như mong đợi của chúng tôi.
Thử nghiệm bằng Python
Khi chúng ta đang nói về thử nghiệm, nó có nghĩa là thử nghiệm đơn vị. Trước khi đi sâu vào thử nghiệm với Python, chúng ta phải biết về kiểm thử đơn vị. Sau đây là một số đặc điểm của kiểm thử đơn vị -
Ít nhất một khía cạnh của chức năng của một thành phần sẽ được kiểm tra trong mỗi bài kiểm tra đơn vị.
Mỗi bài kiểm tra đơn vị là độc lập và cũng có thể chạy độc lập.
Bài kiểm tra đơn vị không ảnh hưởng đến sự thành công hay thất bại của bất kỳ bài kiểm tra nào khác.
Các bài kiểm tra đơn vị có thể chạy theo bất kỳ thứ tự nào và phải chứa ít nhất một khẳng định.
Unittest - Mô-đun Python
Mô-đun Python có tên Unittest để kiểm tra đơn vị đi kèm với tất cả cài đặt Python tiêu chuẩn. Chúng ta chỉ cần nhập nó và phần còn lại là nhiệm vụ của lớp unittest.TestCase sẽ thực hiện những việc sau:
Các hàm SetUp và dropsDown được cung cấp bởi lớp unittest.TestCase. Các chức năng này có thể chạy trước và sau mỗi bài kiểm tra đơn vị.
Nó cũng cung cấp các câu lệnh khẳng định để cho phép các bài kiểm tra đạt hoặc không đạt.
Nó chạy tất cả các chức năng bắt đầu bằng test_ dưới dạng bài kiểm tra đơn vị.
Thí dụ
Trong ví dụ này, chúng tôi sẽ kết hợp việc tìm kiếm trên web với unittest. Chúng tôi sẽ kiểm tra trang Wikipedia để tìm kiếm chuỗi 'Python'. Về cơ bản, nó sẽ thực hiện hai bài kiểm tra, đầu tiên xem trang tiêu đề có giống với chuỗi tìm kiếm tức là 'Python' hay không và bài kiểm tra thứ hai đảm bảo rằng trang có div nội dung.
Đầu tiên, chúng tôi sẽ nhập các mô-đun Python được yêu cầu. Chúng tôi đang sử dụng BeautifulSoup để tìm kiếm web và tất nhiên là đơn nhất để thử nghiệm.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import unittestBây giờ chúng ta cần xác định một lớp sẽ mở rộng đơn nhất.TestCase. Đối tượng toàn cầu bs sẽ được chia sẻ giữa tất cả các xét nghiệm. Một hàm setUpClass được chỉ định độc nhất sẽ hoàn thành nó. Ở đây chúng tôi sẽ xác định hai chức năng, một để kiểm tra trang tiêu đề và một để kiểm tra nội dung trang.
class Test(unittest.TestCase):
bs = None
def setUpClass():
url = '<a target="_blank" rel="nofollow" href="https://en.wikipedia.org/wiki/Python">https://en.wikipedia.org/wiki/Python'</a>
Test.bs = BeautifulSoup(urlopen(url), 'html.parser')
def test_titleText(self):
pageTitle = Test.bs.find('h1').get_text()
self.assertEqual('Python', pageTitle);
def test_contentExists(self):
content = Test.bs.find('div',{'id':'mw-content-text'})
self.assertIsNotNone(content)
if __name__ == '__main__':
unittest.main()Sau khi chạy tập lệnh trên, chúng ta sẽ nhận được kết quả sau:
----------------------------------------------------------------------
Ran 2 tests in 2.773s
OK
An exception has occurred, use %tb to see the full traceback.
SystemExit: False
D:\ProgramData\lib\site-packages\IPython\core\interactiveshell.py:2870:
UserWarning: To exit: use 'exit', 'quit', or Ctrl-D.
warn("To exit: use 'exit', 'quit', or Ctrl-D.", stacklevel=1)Thử nghiệm với Selenium
Hãy để chúng tôi thảo luận về cách sử dụng Python Selenium để thử nghiệm. Nó còn được gọi là thử nghiệm Selenium. Cả Pythonunittest và Seleniumkhông có nhiều điểm chung. Chúng tôi biết rằng Selenium gửi các lệnh Python tiêu chuẩn đến các trình duyệt khác nhau, mặc dù có sự thay đổi trong thiết kế trình duyệt của chúng. Nhớ lại rằng chúng ta đã cài đặt và làm việc với Selenium trong các chương trước. Ở đây chúng tôi sẽ tạo các kịch bản thử nghiệm trong Selenium và sử dụng nó để tự động hóa.
Thí dụ
Với sự trợ giúp của tập lệnh Python tiếp theo, chúng tôi đang tạo tập lệnh thử nghiệm để tự động hóa trang Đăng nhập Facebook. Bạn có thể sửa đổi ví dụ để tự động hóa các biểu mẫu và thông tin đăng nhập khác mà bạn chọn, tuy nhiên khái niệm sẽ giống nhau.
Đầu tiên để kết nối với trình duyệt web, chúng tôi sẽ nhập webdriver từ mô-đun selen -
from selenium import webdriverBây giờ, chúng ta cần nhập các Khóa từ mô-đun selen.
from selenium.webdriver.common.keys import KeysTiếp theo, chúng ta cần cung cấp tên người dùng và mật khẩu để đăng nhập vào tài khoản facebook của mình
user = "[email protected]"
pwd = ""Tiếp theo, cung cấp đường dẫn đến trình điều khiển web cho Chrome.
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
driver = webdriver.Chrome(executable_path=path)
driver.get("http://www.facebook.com")Bây giờ chúng tôi sẽ xác minh các điều kiện bằng cách sử dụng từ khóa khẳng định.
assert "Facebook" in driver.titleVới sự trợ giúp của dòng mã sau đây, chúng tôi sẽ gửi các giá trị đến phần email. Ở đây chúng tôi đang tìm kiếm nó theo id của nó nhưng chúng tôi có thể làm điều đó bằng cách tìm kiếm nó theo tên nhưdriver.find_element_by_name("email").
element = driver.find_element_by_id("email")
element.send_keys(user)Với sự trợ giúp của dòng mã sau, chúng tôi sẽ gửi các giá trị đến phần mật khẩu. Ở đây chúng tôi đang tìm kiếm nó theo id của nó nhưng chúng tôi có thể làm điều đó bằng cách tìm kiếm nó theo tên nhưdriver.find_element_by_name("pass").
element = driver.find_element_by_id("pass")
element.send_keys(pwd)Dòng mã tiếp theo được sử dụng để nhấn enter / đăng nhập sau khi chèn các giá trị trong trường email và mật khẩu.
element.send_keys(Keys.RETURN)Bây giờ chúng ta sẽ đóng trình duyệt.
driver.close()Sau khi chạy đoạn mã trên, trình duyệt web Chrome sẽ được mở và bạn có thể thấy email và mật khẩu đang được chèn và nhấp vào nút đăng nhập.
So sánh: đơn nhất hoặc Selenium
Việc so sánh đơn nhất và selen là rất khó vì nếu bạn muốn làm việc với các bộ thử nghiệm lớn, thì cần phải có độ cứng cú pháp của các hợp nhất. Mặt khác, nếu bạn định kiểm tra tính linh hoạt của trang web thì thử nghiệm Selenium sẽ là lựa chọn đầu tiên của chúng tôi. Nhưng điều gì sẽ xảy ra nếu chúng ta có thể kết hợp cả hai. Chúng tôi có thể nhập selen vào Python mới nhất và tận dụng tốt nhất cả hai. Selenium có thể được sử dụng để lấy thông tin về một trang web và đơn nhất có thể đánh giá xem thông tin đó có đáp ứng các tiêu chí để vượt qua bài kiểm tra hay không.
Ví dụ: chúng tôi đang viết lại tập lệnh Python ở trên để tự động hóa đăng nhập Facebook bằng cách kết hợp cả hai như sau:
import unittest
from selenium import webdriver
class InputFormsCheck(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome(r'C:\Users\gaurav\Desktop\chromedriver')
def test_singleInputField(self):
user = "[email protected]"
pwd = ""
pageUrl = "http://www.facebook.com"
driver=self.driver
driver.maximize_window()
driver.get(pageUrl)
assert "Facebook" in driver.title
elem = driver.find_element_by_id("email")
elem.send_keys(user)
elem = driver.find_element_by_id("pass")
elem.send_keys(pwd)
elem.send_keys(Keys.RETURN)
def tearDown(self):
self.driver.close()
if __name__ == "__main__":
unittest.main()