Scraping Python Web - Giới thiệu
Lướt web là một quá trình tự động trích xuất thông tin từ web. Chương này sẽ cung cấp cho bạn ý tưởng chuyên sâu về việc thu thập dữ liệu web, sự so sánh của nó với việc thu thập dữ liệu web và lý do tại sao bạn nên chọn quét web. Bạn cũng sẽ tìm hiểu về các thành phần và hoạt động của một trình duyệt web.
Web Scraping là gì?
Nghĩa từ điển của từ 'Scrapping' có nghĩa là lấy thứ gì đó từ web. Ở đây nảy sinh hai câu hỏi: Chúng ta có thể lấy gì từ web và Làm thế nào để có được điều đó.
Câu trả lời cho câu hỏi đầu tiên là ‘data’. Dữ liệu là thứ không thể thiếu đối với bất kỳ lập trình viên nào và yêu cầu cơ bản của mọi dự án lập trình là số lượng lớn dữ liệu hữu ích.
Câu trả lời cho câu hỏi thứ hai là một chút phức tạp, bởi vì có rất nhiều cách để lấy dữ liệu. Nói chung, chúng tôi có thể lấy dữ liệu từ cơ sở dữ liệu hoặc tệp dữ liệu và các nguồn khác. Nhưng điều gì sẽ xảy ra nếu chúng ta cần một lượng lớn dữ liệu có sẵn trực tuyến? Một cách để có được loại dữ liệu như vậy là tìm kiếm theo cách thủ công (nhấp vào trong trình duyệt web) và lưu (sao chép-dán vào bảng tính hoặc tệp) dữ liệu cần thiết. Phương pháp này khá tẻ nhạt và tốn thời gian. Một cách khác để lấy dữ liệu đó là sử dụngweb scraping.
Web scraping, còn được gọi là web data mining hoặc là web harvesting, là quá trình xây dựng một tác nhân có thể trích xuất, phân tích cú pháp, tải xuống và sắp xếp thông tin hữu ích từ web một cách tự động. Nói cách khác, chúng ta có thể nói rằng thay vì lưu dữ liệu từ các trang web theo cách thủ công, phần mềm quét web sẽ tự động tải và trích xuất dữ liệu từ nhiều trang web theo yêu cầu của chúng tôi.
Nguồn gốc của Web Scraping
Nguồn gốc của quét web là quét màn hình, được sử dụng để tích hợp các ứng dụng không dựa trên web hoặc các ứng dụng windows gốc. Ban đầu việc cạo màn hình đã được sử dụng trước khi World Wide Web (WWW) được sử dụng rộng rãi, nhưng nó không thể mở rộng quy mô WWW mở rộng. Điều này khiến nó cần thiết phải tự động hóa phương pháp cạo màn hình và kỹ thuật được gọi là‘Web Scraping’ thừa hưởng sự tồn tại.
Thu thập thông tin web v / s Web Scraping
Các thuật ngữ Web Crawling và Scraping thường được sử dụng thay thế cho nhau vì khái niệm cơ bản của chúng là trích xuất dữ liệu. Tuy nhiên, chúng khác xa nhau. Chúng ta có thể hiểu sự khác biệt cơ bản từ các định nghĩa của họ.
Thu thập thông tin web về cơ bản được sử dụng để lập chỉ mục thông tin trên trang bằng cách sử dụng bot hay còn gọi là trình thu thập thông tin. Nó còn được gọi làindexing. Mặt khác, trích xuất trang web là một cách tự động trích xuất thông tin bằng cách sử dụng bot hay còn gọi là công cụ nạo. Nó còn được gọi làdata extraction.
Để hiểu sự khác biệt giữa hai thuật ngữ này, chúng ta hãy xem xét bảng so sánh được đưa ra dưới đây:
| Thu thập thông tin web | Rút trích nội dung trang web |
|---|---|
| Đề cập đến việc tải xuống và lưu trữ nội dung của một số lượng lớn các trang web. | Đề cập đến việc trích xuất các phần tử dữ liệu riêng lẻ từ trang web bằng cách sử dụng cấu trúc dành riêng cho trang web. |
| Chủ yếu được thực hiện trên quy mô lớn. | Có thể thực hiện ở mọi quy mô. |
| Mang lại thông tin chung. | Mang lại thông tin cụ thể. |
| Được sử dụng bởi các công cụ tìm kiếm lớn như Google, Bing, Yahoo. Googlebot là một ví dụ về trình thu thập thông tin web. | Thông tin được trích xuất bằng cách sử dụng công cụ quét web có thể được sử dụng để sao chép trong một số trang web khác hoặc có thể được sử dụng để thực hiện phân tích dữ liệu. Ví dụ, các phần tử dữ liệu có thể là tên, địa chỉ, giá, v.v. |
Sử dụng Web Scraping
Việc sử dụng và lý do sử dụng web cạo cũng vô tận như việc sử dụng World Wide Web. Người quét web có thể làm bất cứ điều gì như đặt thức ăn trực tuyến, quét trang web mua sắm trực tuyến cho bạn và mua vé của một trận đấu ngay khi họ có mặt, v.v. giống như con người có thể làm. Một số ứng dụng quan trọng của việc nạo web được thảo luận ở đây -
E-commerce Websites - Người nhặt web có thể thu thập dữ liệu liên quan đặc biệt đến giá của một sản phẩm cụ thể từ các trang web thương mại điện tử khác nhau để so sánh.
Content Aggregators - Web nháp được sử dụng rộng rãi bởi các công ty tổng hợp nội dung như trình tổng hợp tin tức và công việc tổng hợp để cung cấp dữ liệu cập nhật cho người dùng của họ.
Marketing and Sales Campaigns - Có thể sử dụng công cụ quét web để lấy dữ liệu như email, số điện thoại, v.v. cho các chiến dịch bán hàng và tiếp thị.
Search Engine Optimization (SEO) - Web cạo được sử dụng rộng rãi bởi các công cụ SEO như SEMRush, Majestic, v.v. để cho doanh nghiệp biết cách họ xếp hạng cho các từ khóa tìm kiếm quan trọng với họ.
Data for Machine Learning Projects - Việc truy xuất dữ liệu cho các dự án máy học phụ thuộc vào việc quét web.
Data for Research - Các nhà nghiên cứu có thể thu thập dữ liệu hữu ích cho mục đích công việc nghiên cứu của họ bằng cách tiết kiệm thời gian của họ bằng quy trình tự động này.
Các thành phần của Web Scraper
Trình duyệt web bao gồm các thành phần sau:
Mô-đun trình thu thập thông tin web
Một thành phần rất cần thiết của trình quét web, mô-đun trình thu thập thông tin web, được sử dụng để điều hướng trang web mục tiêu bằng cách thực hiện yêu cầu HTTP hoặc HTTPS đến các URL. Trình thu thập thông tin tải xuống dữ liệu phi cấu trúc (nội dung HTML) và chuyển nó đến trình trích xuất, mô-đun tiếp theo.
Vắt
Bộ giải nén xử lý nội dung HTML đã tìm nạp và trích xuất dữ liệu sang định dạng bán cấu trúc. Đây cũng được gọi là mô-đun phân tích cú pháp và sử dụng các kỹ thuật phân tích cú pháp khác nhau như Biểu thức chính quy, Phân tích cú pháp HTML, Phân tích cú pháp DOM hoặc Trí tuệ nhân tạo để hoạt động.
Chuyển đổi dữ liệu và làm sạch mô-đun
Dữ liệu trích xuất ở trên không thích hợp để sử dụng sẵn sàng. Nó phải đi qua một số mô-đun làm sạch để chúng tôi có thể sử dụng nó. Các phương thức như thao tác chuỗi hoặc biểu thức chính quy có thể được sử dụng cho mục đích này. Lưu ý rằng việc trích xuất và biến đổi cũng có thể được thực hiện trong một bước duy nhất.
Mô-đun lưu trữ
Sau khi giải nén dữ liệu, chúng tôi cần lưu trữ nó theo yêu cầu của chúng tôi. Mô-đun lưu trữ sẽ xuất dữ liệu ở định dạng chuẩn có thể được lưu trữ trong cơ sở dữ liệu hoặc định dạng JSON hoặc CSV.
Làm việc của một Web Scraper
Trình quét web có thể được định nghĩa là một phần mềm hoặc tập lệnh được sử dụng để tải xuống nội dung của nhiều trang web và trích xuất dữ liệu từ đó.
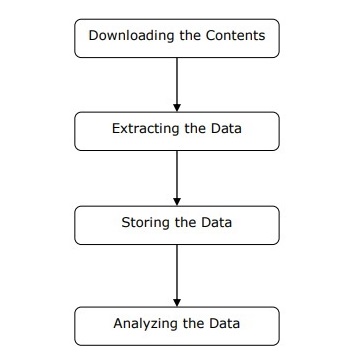
Chúng ta có thể hiểu hoạt động của một trình duyệt web theo các bước đơn giản như được hiển thị trong sơ đồ ở trên.
Bước 1: Tải xuống nội dung từ các trang web
Trong bước này, trình duyệt web sẽ tải xuống nội dung được yêu cầu từ nhiều trang web.
Bước 2: Trích xuất dữ liệu
Dữ liệu trên các trang web là HTML và hầu hết là không có cấu trúc. Do đó, trong bước này, trình duyệt web sẽ phân tích cú pháp và trích xuất dữ liệu có cấu trúc từ nội dung đã tải xuống.
Bước 3: Lưu trữ dữ liệu
Tại đây, một trình quét web sẽ lưu trữ và lưu dữ liệu được trích xuất ở bất kỳ định dạng nào như CSV, JSON hoặc trong cơ sở dữ liệu.
Bước 4: Phân tích dữ liệu
Sau khi tất cả các bước này được thực hiện thành công, trình duyệt web sẽ phân tích dữ liệu thu được.