Kibana - Aggregation und Metriken
Die beiden Begriffe, auf die Sie beim Erlernen von Kibana häufig stoßen, sind Bucket- und Metrics-Aggregation. In diesem Kapitel wird erläutert, welche Rolle sie in Kibana spielen, und weitere Einzelheiten dazu.
Was ist Kibana-Aggregation?
Aggregation bezieht sich auf die Sammlung von Dokumenten oder eine Reihe von Dokumenten, die aus einer bestimmten Suchabfrage oder einem bestimmten Filter stammen. Aggregation bildet das Hauptkonzept, um die gewünschte Visualisierung in Kibana zu erstellen.
Wann immer Sie eine Visualisierung durchführen, müssen Sie die Kriterien festlegen. Dies bedeutet, auf welche Weise Sie die Daten gruppieren möchten, um die Metrik darauf auszuführen.
In diesem Abschnitt werden zwei Arten der Aggregation erläutert:
- Bucket Aggregation
- Metrische Aggregation
Bucket Aggregation
Ein Eimer besteht hauptsächlich aus einem Schlüssel und einem Dokument. Wenn die Aggregation ausgeführt wird, werden die Dokumente in den jeweiligen Bucket gelegt. Am Ende sollten Sie also eine Liste von Eimern mit jeweils einer Liste von Dokumenten haben. Die Liste der Bucket Aggregation, die Sie beim Erstellen der Visualisierung in Kibana sehen, wird unten angezeigt -
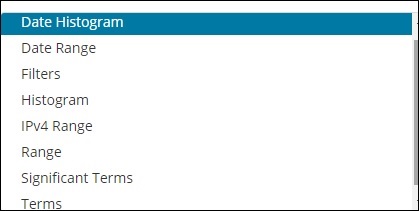
Bucket Aggregation hat die folgende Liste -
- Datumshistogramm
- Datumsbereich
- Filters
- Histogram
- IPv4-Bereich
- Range
- Wichtige Begriffe
- Terms
Während der Erstellung müssen Sie eine davon für die Bucket-Aggregation auswählen, dh um die Dokumente in den Buckets zu gruppieren.
Betrachten Sie zur Analyse beispielsweise die Länderdaten, die wir zu Beginn dieses Tutorials hochgeladen haben. Die im Länderindex verfügbaren Felder sind Ländername, Gebiet, Bevölkerung, Region. In den Länderdaten haben wir den Namen des Landes zusammen mit seiner Bevölkerung, Region und dem Gebiet.
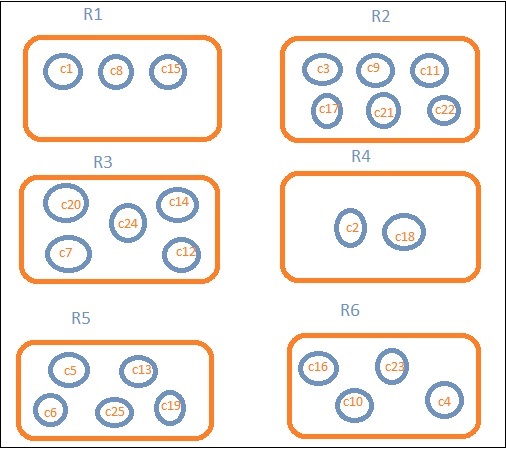
Nehmen wir an, wir wollen regionale Daten. Dann werden die in jeder Region verfügbaren Länder zu unserer Suchanfrage. In diesem Fall bildet die Region unsere Buckets. Das folgende Blockdiagramm zeigt, dass R1, R2, R3, R4, R5 und R6 die Buckets sind, die wir erhalten haben, und c1, c2 ..c25 die Liste der Dokumente sind, die Teil der Buckets R1 bis R6 sind.
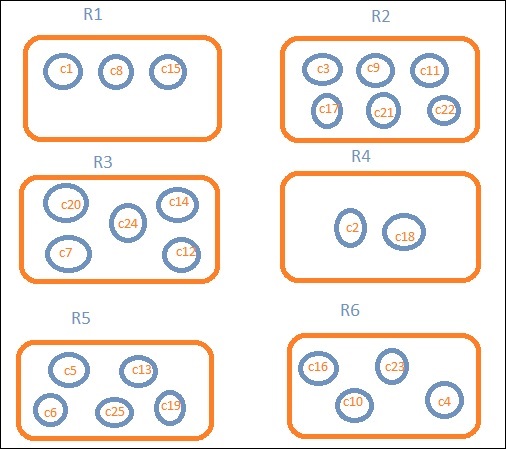
Wir können sehen, dass sich in jedem Eimer einige Kreise befinden. Sie bestehen aus Dokumenten, die auf den Suchkriterien basieren und in jeden Eimer fallen. Im Bucket R1 befinden sich die Dokumente c1, c8 und c15. Diese Dokumente sind die Länder, die in diese Region fallen, genau wie andere. Wenn wir also die Länder in Bucket R1 zählen, sind es 3, 6 für R2, 6 für R3, 2 für R4, 5 für R5 und 4 für R6.
Durch die Bucket-Aggregation können wir das Dokument in Buckets aggregieren und eine Liste der Dokumente in diesen Buckets erstellen, wie oben gezeigt.
Die Liste der Bucket Aggregation, die wir bisher haben, ist -
- Datumshistogramm
- Datumsbereich
- Filters
- Histogram
- IPv4-Bereich
- Range
- Wichtige Begriffe
- Terms
Lassen Sie uns nun im Detail diskutieren, wie diese Eimer einzeln geformt werden.
Datumshistogramm
Die Aggregation des Datumshistogramms wird für ein Datumsfeld verwendet. Der Index, den Sie zur Visualisierung verwenden, wenn Sie also ein Datumsfeld in diesem Index haben, kann nur dieser Aggregationstyp verwendet werden. Dies ist eine Aggregation mit mehreren Buckets. Dies bedeutet, dass Sie einige der Dokumente als Teil von mehr als einem Bucket haben können. Für diese Aggregation muss ein Intervall verwendet werden. Die Details sind wie folgt:
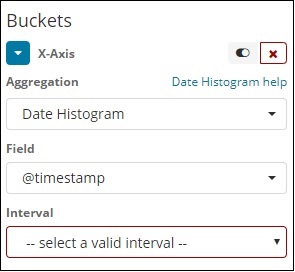
Wenn Sie Buckets Aggregation als Datumshistogramm auswählen, wird die Option Feld angezeigt, die nur die datumsbezogenen Felder enthält. Sobald Sie Ihr Feld ausgewählt haben, müssen Sie das Intervall auswählen, das die folgenden Details enthält:
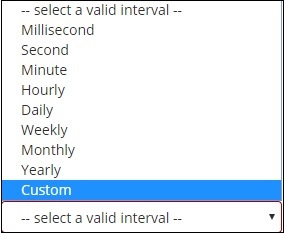
Die Dokumente aus dem ausgewählten Index und basierend auf dem ausgewählten Feld und Intervall kategorisieren die Dokumente in Buckets. Wenn Sie beispielsweise das Intervall als monatlich ausgewählt haben, werden die Dokumente basierend auf dem Datum in Buckets konvertiert und basierend auf dem Monat, dh von Januar bis Dezember, werden die Dokumente in die Buckets gestellt. Hier werden Jan, Feb, .. Dez die Eimer sein.
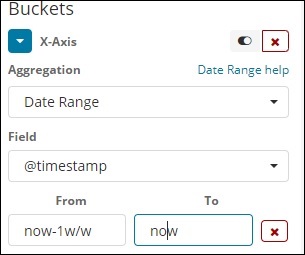
Datumsbereich
Sie benötigen ein Datumsfeld, um diesen Aggregationstyp zu verwenden. Hier haben wir einen Datumsbereich, der von Datum bis Datum angegeben werden soll. Die Dokumente der Eimer basieren auf dem angegebenen Formular und Datum.
Filter
Bei der Aggregation vom Filtertyp werden die Buckets basierend auf dem Filter gebildet. Hier erhalten Sie einen Multi-Bucket, der auf den Filterkriterien basiert, die ein Dokument in einem oder mehreren Buckets haben kann.
Mithilfe von Filtern können Benutzer ihre Abfragen wie unten gezeigt in die Filteroption schreiben.
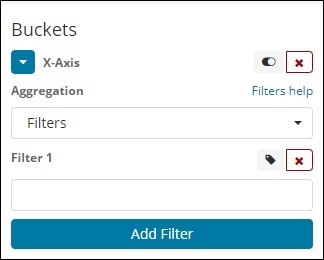
Sie können mehrere Filter Ihrer Wahl hinzufügen, indem Sie die Schaltfläche Filter hinzufügen verwenden.
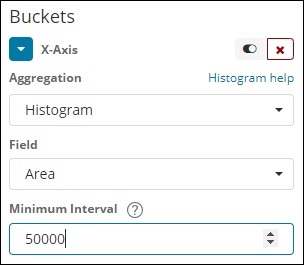
Histogramm
Diese Art der Aggregation wird auf ein Zahlenfeld angewendet und gruppiert die Dokumente basierend auf dem angewendeten Intervall in einem Bucket. Zum Beispiel 0-50,50-100,100-150 usw.
IPv4-Bereich
Diese Art der Aggregation wird hauptsächlich für IP-Adressen verwendet.
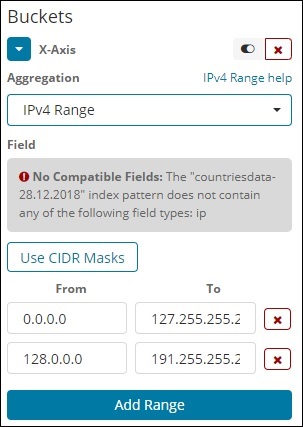
Der Index, den wir haben, ist contriesdata-28.12.2018, hat kein Feld vom Typ IP, daher wird eine Meldung wie oben gezeigt angezeigt. Wenn Sie zufällig das IP-Feld haben, können Sie die Werte Von und Bis wie oben gezeigt angeben.
Angebot
Für diese Art der Aggregation müssen Felder vom Typ Nummer sein. Sie müssen den Bereich angeben, und die Dokumente werden in den Eimern aufgelistet, die in den Bereich fallen.
Sie können bei Bedarf weitere Bereiche hinzufügen, indem Sie auf die Schaltfläche Bereich hinzufügen klicken.
Wichtige Begriffe
Diese Art der Aggregation wird hauptsächlich für die Zeichenfolgenfelder verwendet.
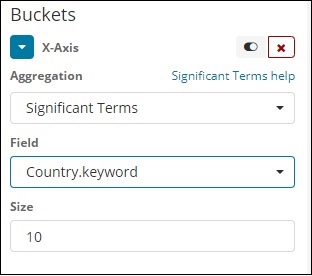
Bedingungen
Diese Art der Aggregation wird für alle verfügbaren Felder verwendet, nämlich Nummer, Zeichenfolge, Datum, Boolescher Wert, IP-Adresse, Zeitstempel usw. Beachten Sie, dass dies die Aggregation ist, die wir in all unseren Visualisierungen verwenden werden, an denen wir in diesem Bereich arbeiten werden Lernprogramm.
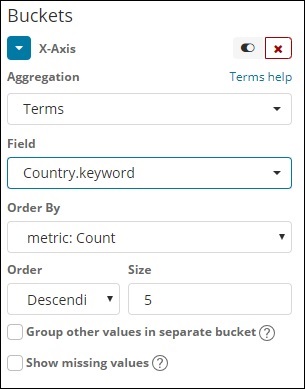
Wir haben eine Optionsreihenfolge, nach der wir die Daten basierend auf der von uns ausgewählten Metrik gruppieren. Die Größe bezieht sich auf die Anzahl der Buckets, die Sie in der Visualisierung anzeigen möchten.
Lassen Sie uns als nächstes über die metrische Aggregation sprechen.
Metrische Aggregation
Die metrische Aggregation bezieht sich hauptsächlich auf die mathematische Berechnung, die für die im Bucket vorhandenen Dokumente durchgeführt wird. Wenn Sie beispielsweise ein Zahlenfeld auswählen, können Sie die Metrik berechnen: COUNT, SUM, MIN, MAX, AVERAGE usw.
Eine Liste der Metrikaggregation, die wir diskutieren werden, finden Sie hier -
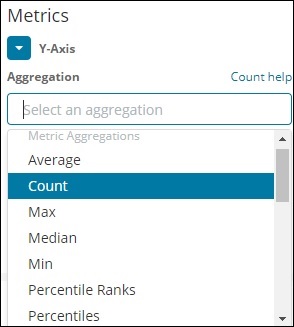
Lassen Sie uns in diesem Abschnitt die wichtigen diskutieren, die wir häufig verwenden werden -
- Average
- Count
- Max
- Min
- Sum
Die Metrik wird auf die einzelne Bucket-Aggregation angewendet, die wir oben bereits besprochen haben.
Lassen Sie uns als Nächstes die Liste der Metrikaggregation hier diskutieren -
Durchschnittlich
Dies gibt den Durchschnitt für die Werte der in den Buckets vorhandenen Dokumente an. Zum Beispiel -
R1 bis R6 sind die Eimer. In R1 haben wir c1, c8 und c15. Angenommen, der Wert von c1 ist 300, c8 ist 500 und c15 ist 700. Nun erhalten Sie den Durchschnittswert des R1-Buckets
R1 = Wert von c1 + Wert von c8 + Wert von c15 / 3 = 300 + 500 + 700/3 = 500.
Der Durchschnitt liegt bei 500 für Eimer R1. Hier könnte der Wert des Dokuments ungefähr so sein, wenn Sie die Länderdaten berücksichtigen, dass es sich um das Gebiet des Landes in dieser Region handelt.
Anzahl
Dies gibt die Anzahl der im Bucket vorhandenen Dokumente an. Angenommen, Sie möchten die Anzahl der in der Region vorhandenen Länder angeben, dann handelt es sich um die Gesamtzahl der in den Eimern vorhandenen Dokumente. Zum Beispiel ist R1 3, R2 = 6, R3 = 5, R4 = 2, R5 = 5 und R6 = 4.
Max
Dies gibt den Maximalwert des im Bucket vorhandenen Dokuments an. Betrachten Sie das obige Beispiel, wenn wir flächenbezogene Länderdaten im Regionsbereich haben. Das Maximum für jede Region ist das Land mit der maximalen Fläche. Es wird also ein Land aus jeder Region geben, dh R1 bis R6.
im
Dies gibt den Mindestwert des im Bucket vorhandenen Dokuments an. Betrachtet man das obige Beispiel, wenn wir flächenbezogene Länderdaten im Regionsbereich haben. Die Mindestanzahl für jede Region ist das Land mit der Mindestfläche. Es wird also ein Land aus jeder Region geben, dh R1 bis R6.
Summe
Dies ergibt die Summe der Werte des im Bucket vorhandenen Dokuments. Wenn Sie beispielsweise das obige Beispiel betrachten, wenn wir die Gesamtfläche oder die Länder in der Region möchten, ist dies die Summe der in der Region vorhandenen Dokumente.
Um beispielsweise die Gesamtzahl der Länder in der Region R1 zu kennen, ist dies 3, R2 = 6, R3 = 5, R4 = 2, R5 = 5 und R6 = 4.
Wenn wir Dokumente mit einem Gebiet in der Region als R1 bis R6 haben, wird das länderspezifische Gebiet für die Region zusammengefasst.