Kibana - Einführung in Elk Stack
Kibana ist ein Open-Source-Visualisierungstool, das hauptsächlich zur Analyse einer großen Anzahl von Protokollen in Form von Liniendiagrammen, Balkendiagrammen, Kreisdiagrammen, Heatmaps usw. verwendet wird. Kibana arbeitet synchron mit Elasticsearch und Logstash, die zusammen das sogenannte Protokoll bilden ELK Stapel.
ELK steht für Elasticsearch, Logstash und Kibana. ELK ist eine der beliebtesten Protokollverwaltungsplattformen, die weltweit für die Protokollanalyse verwendet wird.
Im ELK-Stapel -
Logstashextrahiert die Protokolldaten oder andere Ereignisse aus verschiedenen Eingabequellen. Es verarbeitet die Ereignisse und speichert sie später in Elasticsearch.
Kibana ist ein Visualisierungstool, das über Elasticsearch auf die Protokolle zugreift und dem Benutzer in Form von Liniendiagrammen, Balkendiagrammen, Kreisdiagrammen usw. angezeigt werden kann.
In diesem Tutorial werden wir eng mit Kibana und Elasticsearch zusammenarbeiten und die Daten in verschiedenen Formen visualisieren.
Lassen Sie uns in diesem Kapitel verstehen, wie Sie mit ELK Stack zusammenarbeiten. Außerdem werden Sie sehen, wie man -
- Laden Sie CSV-Daten von Logstash in Elasticsearch.
- Verwenden Sie Indizes von Elasticsearch in Kibana.
Laden Sie CSV-Daten von Logstash in Elasticsearch
Wir werden CSV-Daten verwenden, um Daten mit Logstash in Elasticsearch hochzuladen. Um an der Datenanalyse zu arbeiten, können wir Daten von der Website kaggle.com abrufen. Auf der Kaggle.com-Website werden alle Arten von Daten hochgeladen, und Benutzer können damit an der Datenanalyse arbeiten.
Wir haben die Länder.csv-Daten von hier genommen: https://www.kaggle.com/fernandol/countries-of-the-world. Sie können die CSV-Datei herunterladen und verwenden.
Die CSV-Datei, die wir verwenden werden, enthält die folgenden Details.
Dateiname - countrydata.csv
Spalten - "Land", "Region", "Bevölkerung", "Gebiet"
Sie können auch eine Dummy-CSV-Datei erstellen und verwenden. Wir werden mit logstash werden diese Daten - Dump von countriesdata.csv zu Elasticsearch.
Starten Sie die Elasticsearch und Kibana in Ihrem Terminal und lassen Sie es laufen. Wir müssen die Konfigurationsdatei für logstash erstellen, die Details zu den Spalten der CSV-Datei sowie andere Details enthält, wie in der unten angegebenen logstash-config-Datei gezeigt.
input {
file {
path => "C:/kibanaproject/countriesdata.csv"
start_position => "beginning"
sincedb_path => "NUL"
}
}
filter {
csv {
separator => ","
columns => ["Country","Region","Population","Area"]
}
mutate {convert => ["Population", "integer"]}
mutate {convert => ["Area", "integer"]}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
=> "countriesdata-%{+dd.MM.YYYY}"
}
stdout {codec => json_lines }
}In der Konfigurationsdatei haben wir 3 Komponenten erstellt -
Eingang
Wir müssen den Pfad der Eingabedatei angeben, die in unserem Fall eine CSV-Datei ist. Der Pfad, in dem die CSV-Datei gespeichert ist, wird dem Pfadfeld zugewiesen.
Filter
Wird die CSV-Komponente mit Trennzeichen verwendet, die in unserem Fall Komma ist, und auch die Spalten, die für unsere CSV-Datei verfügbar sind. Da logstash alle eingehenden Daten als Zeichenfolge betrachtet, muss float für den Fall, dass eine Spalte als Ganzzahl verwendet werden soll, mithilfe von mutate wie oben gezeigt angegeben werden.
Ausgabe
Für die Ausgabe müssen wir angeben, wo wir die Daten ablegen müssen. In unserem Fall verwenden wir hier die Elasticsearch. Die Daten, die für die Elasticsearch benötigt werden, sind die Hosts, auf denen sie ausgeführt wird. Wir haben sie als localhost bezeichnet. Das nächste Feld in ist der Index, den wir als Länder- aktuelles Datum angegeben haben. Wir müssen denselben Index in Kibana verwenden, sobald die Daten in Elasticsearch aktualisiert wurden.
Speichern Sie die obige Konfigurationsdatei als logstash_countries.config . Beachten Sie, dass wir im nächsten Schritt den Pfad dieser Konfiguration zum Befehl logstash angeben müssen.
Um die Daten aus der CSV-Datei in Elasticsearch zu laden, müssen wir den Elasticsearch-Server starten.
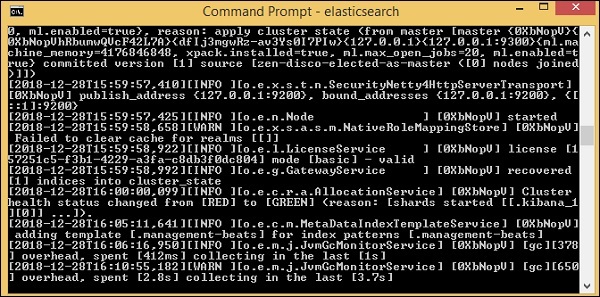
Jetzt renn http://localhost:9200 im Browser, um zu bestätigen, ob elasticsearch erfolgreich ausgeführt wird.
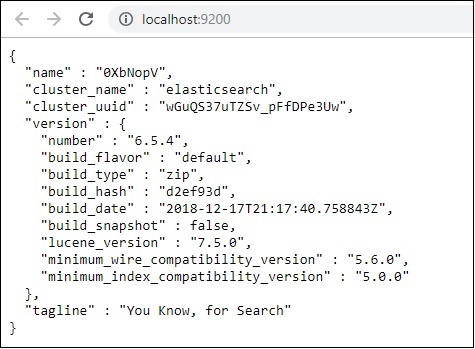
Wir haben Elasticsearch ausgeführt. Gehen Sie nun zu dem Pfad, in dem logstash installiert ist, und führen Sie den folgenden Befehl aus, um die Daten in elasticsearch hochzuladen.
> logstash -f logstash_countries.conf
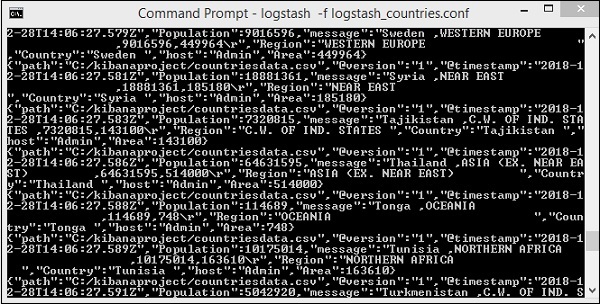
Der obige Bildschirm zeigt das Laden von Daten aus der CSV-Datei in Elasticsearch. Um zu wissen, ob der Index in Elasticsearch erstellt wurde, können Sie Folgendes überprüfen:
Wir können den Länderdaten-28.12.2018 Index sehen, der wie oben gezeigt erstellt wurde.

Die Details des Index - Länder-28.12.2018 sind wie folgt -
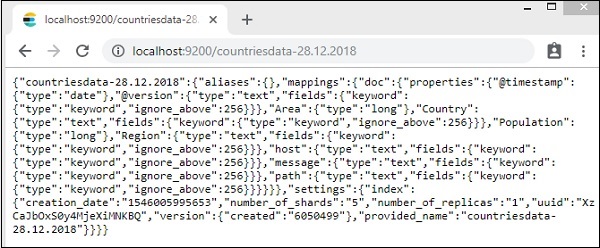
Beachten Sie, dass die Zuordnungsdetails mit Eigenschaften erstellt werden, wenn Daten von logstash zu elasticsearch hochgeladen werden.
Verwenden Sie Daten von Elasticsearch in Kibana
Derzeit läuft Kibana auf localhost, Port 5601 - http://localhost:5601. Die Benutzeroberfläche von Kibana wird hier angezeigt -
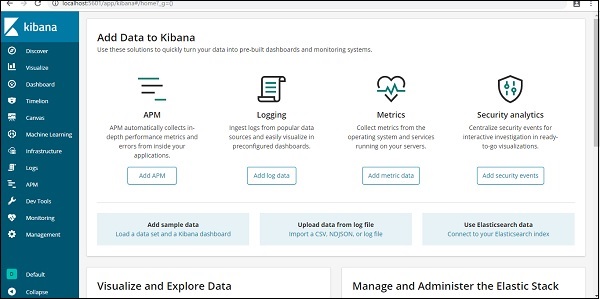
Beachten Sie, dass Kibana bereits mit Elasticsearch verbunden ist und wir sehen können sollten index :countries-28.12.2018 in Kibana.
Klicken Sie in der Kibana-Benutzeroberfläche auf der linken Seite auf die Option Verwaltungsmenü.
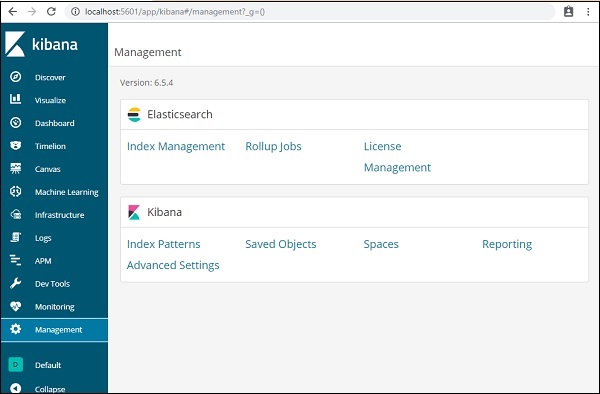
Klicken Sie nun auf Indexverwaltung -
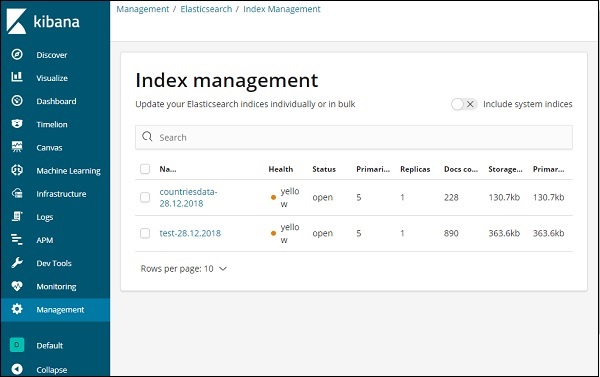
Die in Elasticsearch vorhandenen Indizes werden in der Indexverwaltung angezeigt. Der Index, den wir in Kibana verwenden werden, lautet countrydata-28.12.2018.
Da wir bereits den Elasticsearch-Index in Kibana haben, werden wir als nächstes verstehen, wie der Index in Kibana verwendet wird, um Daten in Form von Kreisdiagrammen, Balkendiagrammen, Liniendiagrammen usw. zu visualisieren.