Kibana - Laden von Beispieldaten
Wir haben gesehen, wie Daten aus logstash in elasticsearch hochgeladen werden. Wir werden hier Daten mit Logstash und Elasticsearch hochladen. Über die Daten mit Datums-, Längen- und Breitengradfeldern, die wir verwenden müssen, werden wir in den nächsten Kapiteln erfahren. Wir werden auch sehen, wie Daten direkt in Kibana hochgeladen werden, wenn wir keine CSV-Datei haben.
In diesem Kapitel werden wir folgende Themen behandeln:
- Verwenden von Logstash-Upload-Daten mit Datums-, Längen- und Breitengraden in Elasticsearch
- Verwenden von Dev-Tools zum Hochladen von Massendaten
Verwenden des Logstash-Uploads für Daten mit Feldern in Elasticsearch
Wir werden Daten in Form eines CSV-Formats verwenden. Das gleiche stammt von Kaggle.com, das sich mit Daten befasst, die Sie für eine Analyse verwenden können.
Die hier zu verwendenden medizinischen Hausbesuche werden von der Website Kaggle.com abgeholt.
Die folgenden Felder sind für die CSV-Datei verfügbar:
["Visit_Status","Time_Delay","City","City_id","Patient_Age","Zipcode","Latitude","Longitude",
"Pathology","Visiting_Date","Id_type","Id_personal","Number_Home_Visits","Is_Patient_Minor","Geo_point"]Die Home_visits.csv lautet wie folgt:
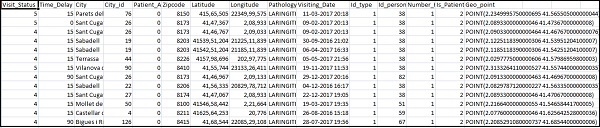
Das Folgende ist die conf-Datei, die mit logstash verwendet werden soll -
input {
file {
path => "C:/kibanaproject/home_visits.csv"
start_position => "beginning"
sincedb_path => "NUL"
}
}
filter {
csv {
separator => ","
columns =>
["Visit_Status","Time_Delay","City","City_id","Patient_Age",
"Zipcode","Latitude","Longitude","Pathology","Visiting_Date",
"Id_type","Id_personal","Number_Home_Visits","Is_Patient_Minor","Geo_point"]
}
date {
match => ["Visiting_Date","dd-MM-YYYY HH:mm"]
target => "Visiting_Date"
}
mutate {convert => ["Number_Home_Visits", "integer"]}
mutate {convert => ["City_id", "integer"]}
mutate {convert => ["Id_personal", "integer"]}
mutate {convert => ["Id_type", "integer"]}
mutate {convert => ["Zipcode", "integer"]}
mutate {convert => ["Patient_Age", "integer"]}
mutate {
convert => { "Longitude" => "float" }
convert => { "Latitude" => "float" }
}
mutate {
rename => {
"Longitude" => "[location][lon]"
"Latitude" => "[location][lat]"
}
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "medicalvisits-%{+dd.MM.YYYY}"
}
stdout {codec => json_lines }
}Standardmäßig betrachtet logstash alles, was in elasticsearch hochgeladen wird, als Zeichenfolge. Wenn Ihre CSV-Datei ein Datumsfeld enthält, müssen Sie Folgendes tun, um das Datumsformat zu erhalten.
For date field −
date {
match => ["Visiting_Date","dd-MM-YYYY HH:mm"]
target => "Visiting_Date"
}Im Falle einer geografischen Position versteht elasticsearch dasselbe wie -
"location": {
"lat":41.565505000000044,
"lon": 2.2349995750000695
}Wir müssen also sicherstellen, dass wir Längen- und Breitengrade in dem Format haben, das elasticsearch benötigt. Zuerst müssen wir Längen- und Breitengrad in Float umwandeln und später umbenennen, damit er als Teil von verfügbar istlocation json Objekt mit lat und lon. Der Code dafür wird hier angezeigt -
mutate {
convert => { "Longitude" => "float" }
convert => { "Latitude" => "float" }
}
mutate {
rename => {
"Longitude" => "[location][lon]"
"Latitude" => "[location][lat]"
}
}Verwenden Sie zum Konvertieren von Feldern in Ganzzahlen den folgenden Code:
mutate {convert => ["Number_Home_Visits", "integer"]}
mutate {convert => ["City_id", "integer"]}
mutate {convert => ["Id_personal", "integer"]}
mutate {convert => ["Id_type", "integer"]}
mutate {convert => ["Zipcode", "integer"]}
mutate {convert => ["Patient_Age", "integer"]}Führen Sie nach der Pflege der Felder den folgenden Befehl aus, um die Daten in elasticsearch hochzuladen:
- Gehen Sie in das Verzeichnis Logstash bin und führen Sie den folgenden Befehl aus.
logstash -f logstash_homevisists.conf- Sobald Sie fertig sind, sollten Sie den in der Datei logstash conf genannten Index in elasticsearch wie unten gezeigt sehen -
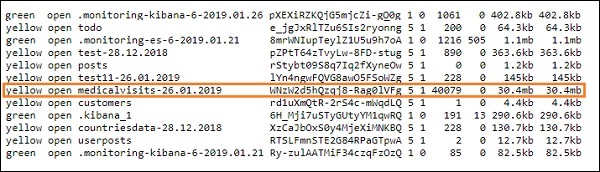
Wir können jetzt ein Indexmuster für den oben hochgeladenen Index erstellen und es für die Erstellung der Visualisierung weiter verwenden.
Verwenden von Dev Tools zum Hochladen von Massendaten
Wir werden Dev Tools von Kibana UI verwenden. Dev Tools ist hilfreich, um Daten in Elasticsearch hochzuladen, ohne Logstash zu verwenden. Wir können die gewünschten Daten in Kibana mit Dev Tools veröffentlichen, ablegen, löschen und durchsuchen.
In diesem Abschnitt werden wir versuchen, Beispieldaten in Kibana selbst zu laden. Wir können es verwenden, um mit den Beispieldaten zu üben und mit Kibana-Funktionen herumzuspielen, um ein gutes Verständnis von Kibana zu erhalten.
Nehmen wir die JSON-Daten aus der folgenden URL und laden Sie sie in Kibana hoch. Ebenso können Sie versuchen, beliebige JSON-Beispieldaten in Kibana zu laden.
Bevor wir mit dem Hochladen der Beispieldaten beginnen, müssen wir die JSON-Daten mit Indizes haben, die in der Elasticsearch verwendet werden sollen. Wenn wir es mit logstash hochladen, sorgt logstash dafür, dass die Indizes hinzugefügt werden, und der Benutzer muss sich nicht um die Indizes kümmern, die für elasticsearch erforderlich sind.
Normale Json-Daten
[
{"type":"act","line_id":1,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"ACT I"},
{"type":"scene","line_id":2,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"SCENE I.London. The palace."},
{"type":"line","line_id":3,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":
"Enter KING HENRY, LORD JOHN OF LANCASTER, the
EARL of WESTMORELAND, SIR WALTER BLUNT, and others"}
]Der mit Kibana zu verwendende JSON-Code muss wie folgt indiziert sein:
{"index":{"_index":"shakespeare","_id":0}}
{"type":"act","line_id":1,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"ACT I"}
{"index":{"_index":"shakespeare","_id":1}}
{"type":"scene","line_id":2,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"",
"text_entry":"SCENE I. London. The palace."}
{"index":{"_index":"shakespeare","_id":2}}
{"type":"line","line_id":3,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":
"Enter KING HENRY, LORD JOHN OF LANCASTER, the EARL
of WESTMORELAND, SIR WALTER BLUNT, and others"}Beachten Sie, dass die json-Datei zusätzliche Daten enthält -{"index":{"_index":"nameofindex","_id":key}}.
Um eine mit elasticsearch kompatible Json-Beispieldatei zu konvertieren, haben wir hier einen kleinen Code in PHP, der die Json-Datei in dem von Elasticsearch gewünschten Format ausgibt.
PHP-Code
<?php
$myfile = fopen("todo.json", "r") or die("Unable to open file!"); // your json
file here
$alldata = fread($myfile,filesize("todo.json"));
fclose($myfile);
$farray = json_decode($alldata);
$afinalarray = [];
$index_name = "todo";
$i=0;
$myfile1 = fopen("todonewfile.json", "w") or die("Unable to open file!"); //
writes a new file to be used in kibana dev tool
foreach ($farray as $a => $value) {
$_index = json_decode('{"index": {"_index": "'.$index_name.'", "_id": "'.$i.'"}}');
fwrite($myfile1, json_encode($_index));
fwrite($myfile1, "\n");
fwrite($myfile1, json_encode($value));
fwrite($myfile1, "\n");
$i++;
}
?>Wir haben die todo json Datei von genommen https://jsonplaceholder.typicode.com/todos und verwenden Sie PHP-Code, um in das Format zu konvertieren, das wir in Kibana hochladen müssen.
Öffnen Sie zum Laden der Beispieldaten die Registerkarte dev tools wie unten gezeigt -
Wir werden jetzt die Konsole wie oben gezeigt verwenden. Wir werden die JSON-Daten nehmen, die wir erhalten haben, nachdem wir sie durch PHP-Code ausgeführt haben.
Der Befehl, der in Entwicklertools zum Hochladen der JSON-Daten verwendet werden soll, lautet:
POST _bulkBeachten Sie, dass der Name des Index, den wir erstellen, todo lautet .
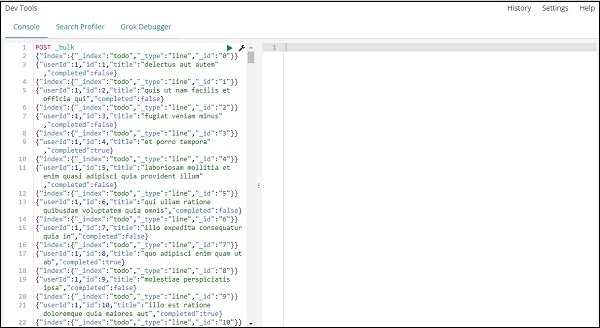

Sobald Sie auf die grüne Schaltfläche klicken, werden die Daten hochgeladen. Sie können wie folgt überprüfen, ob der Index in elasticsearch erstellt wurde oder nicht:

Sie können dasselbe in den Entwicklungstools selbst wie folgt überprüfen:
Command −
GET /_cat/indices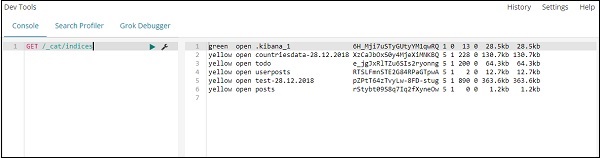
Wenn Sie etwas in Ihrem Index suchen möchten: todo, können Sie dies wie unten gezeigt tun -
Command in dev tool
GET /todo/_search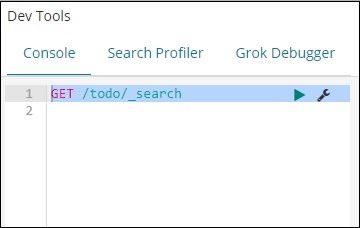
Die Ausgabe der obigen Suche ist wie folgt:

Es gibt alle im todoindex vorhandenen Datensätze an. Die Gesamtzahl der Rekorde, die wir erhalten, beträgt 200.
Suchen Sie nach einem Datensatz im Aufgabenindex
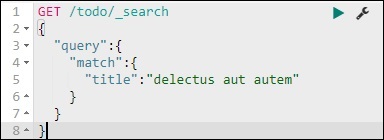
Wir können das mit dem folgenden Befehl tun -
GET /todo/_search
{
"query":{
"match":{
"title":"delectusautautem"
}
}
}

Wir können die Datensätze abrufen, die mit dem von uns angegebenen Titel übereinstimmen.