Kibana - Kurzanleitung
Kibana ist ein browserbasiertes Open-Source-Visualisierungstool, das hauptsächlich zur Analyse großer Protokollmengen in Form von Liniendiagrammen, Balkendiagrammen, Kreisdiagrammen, Wärmekarten, Regionskarten, Koordinatenkarten, Messgeräten, Zielen, Zeitpunkten usw. verwendet wird. Die Visualisierung macht es einfach Kibana arbeitet synchron mit Elasticsearch und Logstash, die zusammen das sogenannte bilden ELK Stapel.
Was ist ELK Stack?
ELK steht für Elasticsearch, Logstash und Kibana. ELKist eine der beliebtesten Protokollverwaltungsplattformen, die weltweit für die Protokollanalyse verwendet wird. Im ELK-Stapel extrahiert Logstash die Protokolldaten oder andere Ereignisse aus verschiedenen Eingabequellen. Es verarbeitet die Ereignisse und speichert sie später in Elasticsearch.
Kibana ist ein Visualisierungstool, das über Elasticsearch auf die Protokolle zugreift und dem Benutzer in Form von Liniendiagrammen, Balkendiagrammen, Kreisdiagrammen usw. angezeigt werden kann.
Der grundlegende Ablauf von ELK Stack ist im Bild hier dargestellt -
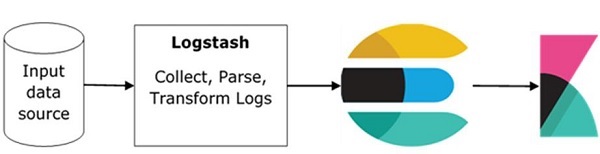
Logstash ist dafür verantwortlich, die Daten von allen Remote-Quellen zu sammeln, in denen die Protokolle abgelegt sind, und leitet sie an Elasticsearch weiter.
Elasticsearch fungiert als Datenbank, in der die Daten gesammelt werden, und Kibana verwendet die Daten von Elasticsearch, um die Daten für den Benutzer in Form von Balkendiagrammen, Kreisdiagrammen und Heatmaps darzustellen (siehe unten).
Es zeigt dem Benutzer die Daten in Echtzeit, beispielsweise tages- oder stündlich. Die Kibana-Benutzeroberfläche ist benutzerfreundlich und für Anfänger sehr leicht zu verstehen.
Eigenschaften von Kibana
Kibana bietet seinen Benutzern die folgenden Funktionen:
Visualisierung
Kibana bietet viele Möglichkeiten, Daten auf einfache Weise zu visualisieren. Einige der üblicherweise verwendeten sind vertikale Balkendiagramme, horizontale Balkendiagramme, Kreisdiagramme, Liniendiagramme, Wärmekarten usw.
Instrumententafel
Wenn wir die Visualisierungen fertig haben, können sie alle auf einer Tafel platziert werden - dem Dashboard. Wenn Sie verschiedene Abschnitte zusammen betrachten, erhalten Sie eine klare Vorstellung davon, was genau passiert.
Entwicklungswerkzeuge
Sie können mit Ihren Indizes mithilfe von Entwicklertools arbeiten. Anfänger können Dummy-Indizes aus Entwicklertools hinzufügen sowie Daten hinzufügen, aktualisieren, löschen und die Indizes zum Erstellen von Visualisierungen verwenden.
Berichte
Alle Daten in Form von Visualisierung und Dashboard können in Berichte (CSV-Format) konvertiert, in den Code eingebettet oder in Form von URLs für andere freigegeben werden.
Filter und Suchabfrage
Sie können Filter und Suchanfragen verwenden, um die erforderlichen Details für eine bestimmte Eingabe von einem Dashboard oder Visualisierungstool abzurufen.
Plugins
Sie können Plugins von Drittanbietern hinzufügen, um eine neue Visualisierung oder eine andere Benutzeroberfläche in Kibana hinzuzufügen.
Koordinaten- und Regionskarten
Eine Koordinaten- und Regionskarte in Kibana hilft dabei, die Visualisierung auf der geografischen Karte anzuzeigen und eine realistische Ansicht der Daten zu erhalten.
Timelion
Timelion, auch genannt als timelineist ein weiteres Visualisierungstool, das hauptsächlich für die zeitbasierte Datenanalyse verwendet wird. Um mit der Zeitachse arbeiten zu können, müssen wir eine einfache Ausdruckssprache verwenden, die uns hilft, eine Verbindung zum Index herzustellen und Berechnungen für die Daten durchzuführen, um die gewünschten Ergebnisse zu erhalten. Es hilft mehr beim Vergleich von Daten mit dem vorherigen Zyklus in Bezug auf Woche, Monat usw.
Segeltuch
Canvas ist ein weiteres mächtiges Feature in Kibana. Mithilfe der Canvas-Visualisierung können Sie Ihre Daten in verschiedenen Farbkombinationen, Formen, Texten und mehreren Seiten darstellen, die im Wesentlichen als Workpad bezeichnet werden.
Vorteile von Kibana
Kibana bietet seinen Nutzern folgende Vorteile:
Enthält ein auf Open Source-Browsern basierendes Visualisierungstool, das hauptsächlich zum Analysieren großer Protokollmengen in Form von Liniendiagrammen, Balkendiagrammen, Kreisdiagrammen, Heatmaps usw. verwendet wird.
Einfach und leicht für Anfänger zu verstehen.
Einfache Konvertierung von Visualisierung und Dashboard in Berichte.
Mithilfe der Canvas-Visualisierung können komplexe Daten auf einfache Weise analysiert werden.
Die Timelion-Visualisierung in Kibana hilft dabei, Daten rückwärts zu vergleichen, um die Leistung besser zu verstehen.
Nachteile von Kibana
Das Hinzufügen von Plugins zu Kibana kann sehr mühsam sein, wenn die Version nicht übereinstimmt.
Wenn Sie von einer älteren Version auf eine neue aktualisieren möchten, treten häufig Probleme auf.
Um mit Kibana arbeiten zu können, müssen wir Logstash, Elasticsearch und Kibana installieren. In diesem Kapitel werden wir versuchen, die Installation des ELK-Stacks hier zu verstehen.
Wir würden die folgenden Installationen hier diskutieren -
- Elasticsearch-Installation
- Logstash-Installation
- Kibana Installation
Elasticsearch-Installation
Eine ausführliche Dokumentation zu Elasticsearch finden Sie in unserer Bibliothek. Hier können Sie nach der Installation von elasticsearch suchen . Sie müssen die im Tutorial genannten Schritte ausführen, um Elasticsearch zu installieren.
Starten Sie nach Abschluss der Installation den Elasticsearch-Server wie folgt:
Schritt 1
For Windows
> cd kibanaproject/elasticsearch-6.5.4/elasticsearch-6.5.4/bin
> elasticsearchBitte beachten Sie, dass für Windows-Benutzer die Variable JAVA_HOME auf den Java-JDK-Pfad gesetzt werden muss.
For Linux
$ cd kibanaproject/elasticsearch-6.5.4/elasticsearch-6.5.4/bin $ elasticsearch
Der Standardport für Elasticsearch ist 9200. Anschließend können Sie die Elasticsearch an Port 9200 auf localhost überprüfen http://localhost:9200/as unten gezeigt -
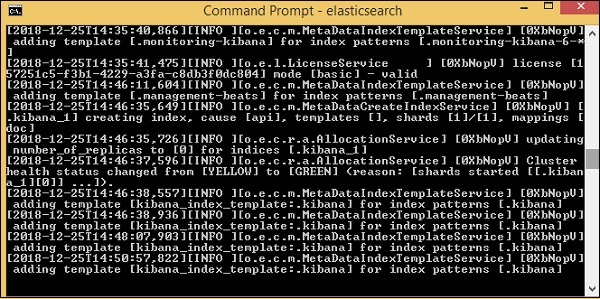
Logstash-Installation
Für Logstash Installation, folgen Sie dieser Elasticsearch Installation , die in unserer Bibliothek ist bereits vorhanden.
Kibana Installation
Gehen Sie zur offiziellen Kibana-Website -https://www.elastic.co/products/kibana

Klicken Sie oben rechts auf den Download- Link. Der Bildschirm wird wie folgt angezeigt:
Klicken Sie auf die Schaltfläche Herunterladen für Kibana. Bitte beachten Sie, dass wir für die Arbeit mit Kibana eine 64-Bit-Maschine benötigen und diese nicht mit 32-Bit funktioniert.
In diesem Tutorial verwenden wir Kibana Version 6. Die Download-Option ist für Windows, Mac und Linux verfügbar. Sie können nach Ihrer Wahl herunterladen.
Erstellen Sie einen Ordner und entpacken Sie die Tar / Zip-Downloads für Kibana. Wir werden mit Beispieldaten arbeiten, die in elasticsearch hochgeladen wurden. Lassen Sie uns nun sehen, wie Sie mit Elasticsearch und Kibana beginnen können. Gehen Sie dazu in den Ordner, in den Kibana entpackt ist.
For Windows
> cd kibanaproject/kibana-6.5.4/kibana-6.5.4/bin
> kibanaFor Linux
$ cd kibanaproject/kibana-6.5.4/kibana-6.5.4/bin $ kibanaSobald Kibana gestartet ist, kann der Benutzer den folgenden Bildschirm sehen:
Sobald Sie das Bereitschaftssignal in der Konsole sehen, können Sie Kibana im Browser mit öffnen http://localhost:5601/Der Standardport, an dem Kibana verfügbar ist, ist 5601.
Die Benutzeroberfläche von Kibana ist wie hier gezeigt -
In unserem nächsten Kapitel lernen wir, wie man die Benutzeroberfläche von Kibana verwendet. Um die Kibana-Version auf der Kibana-Benutzeroberfläche zu erfahren, gehen Sie auf die Registerkarte Verwaltung auf der linken Seite. Daraufhin wird die derzeit verwendete Kibana-Version angezeigt.
Kibana ist ein Open-Source-Visualisierungstool, das hauptsächlich zur Analyse einer großen Anzahl von Protokollen in Form von Liniendiagrammen, Balkendiagrammen, Kreisdiagrammen, Heatmaps usw. verwendet wird. Kibana arbeitet synchron mit Elasticsearch und Logstash, die zusammen das sogenannte Protokoll bilden ELK Stapel.
ELK steht für Elasticsearch, Logstash und Kibana. ELK ist eine der beliebtesten Protokollverwaltungsplattformen, die weltweit für die Protokollanalyse verwendet wird.
Im ELK-Stapel -
Logstashextrahiert die Protokolldaten oder andere Ereignisse aus verschiedenen Eingabequellen. Es verarbeitet die Ereignisse und speichert sie später in Elasticsearch.
Kibana ist ein Visualisierungstool, das über Elasticsearch auf die Protokolle zugreift und dem Benutzer in Form von Liniendiagrammen, Balkendiagrammen, Kreisdiagrammen usw. angezeigt werden kann.
In diesem Tutorial werden wir eng mit Kibana und Elasticsearch zusammenarbeiten und die Daten in verschiedenen Formen visualisieren.
Lassen Sie uns in diesem Kapitel verstehen, wie Sie mit ELK Stack zusammenarbeiten. Außerdem werden Sie auch sehen, wie man -
- Laden Sie CSV-Daten von Logstash in Elasticsearch.
- Verwenden Sie Indizes von Elasticsearch in Kibana.
Laden Sie CSV-Daten von Logstash in Elasticsearch
Wir werden CSV-Daten verwenden, um Daten mit Logstash zu Elasticsearch hochzuladen. Um an der Datenanalyse zu arbeiten, können wir Daten von der Website kaggle.com abrufen. Auf der Kaggle.com-Website werden alle Arten von Daten hochgeladen, und Benutzer können damit an der Datenanalyse arbeiten.
Wir haben die Länder.csv-Daten von hier genommen: https://www.kaggle.com/fernandol/countries-of-the-world. Sie können die CSV-Datei herunterladen und verwenden.
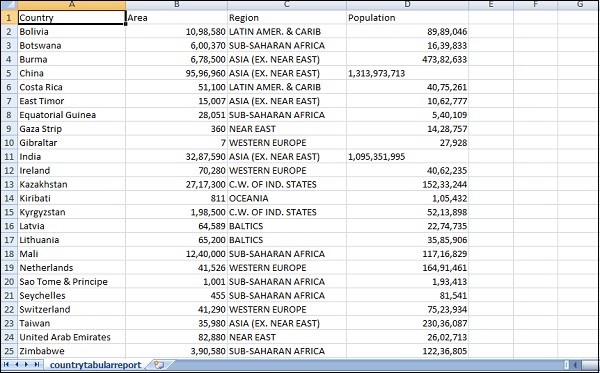
Die CSV-Datei, die wir verwenden werden, enthält die folgenden Details.
Dateiname - countrydata.csv
Spalten - "Land", "Region", "Bevölkerung", "Gebiet"
Sie können auch eine Dummy-CSV-Datei erstellen und verwenden. Wir werden mit logstash werden diese Daten - Dump von countriesdata.csv zu Elasticsearch.
Starten Sie die Elasticsearch und Kibana in Ihrem Terminal und lassen Sie es laufen. Wir müssen die Konfigurationsdatei für logstash erstellen, die Details zu den Spalten der CSV-Datei sowie andere Details enthält, wie in der unten angegebenen logstash-config-Datei gezeigt.
input {
file {
path => "C:/kibanaproject/countriesdata.csv"
start_position => "beginning"
sincedb_path => "NUL"
}
}
filter {
csv {
separator => ","
columns => ["Country","Region","Population","Area"]
}
mutate {convert => ["Population", "integer"]}
mutate {convert => ["Area", "integer"]}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
=> "countriesdata-%{+dd.MM.YYYY}"
}
stdout {codec => json_lines }
}In der Konfigurationsdatei haben wir 3 Komponenten erstellt -
Eingang
Wir müssen den Pfad der Eingabedatei angeben, die in unserem Fall eine CSV-Datei ist. Der Pfad, in dem die CSV-Datei gespeichert ist, wird dem Pfadfeld zugewiesen.
Filter
Wird die CSV-Komponente mit Trennzeichen verwendet, die in unserem Fall Komma ist, und auch die Spalten, die für unsere CSV-Datei verfügbar sind. Da logstash alle eingehenden Daten als Zeichenfolge betrachtet, muss float für den Fall, dass eine Spalte als Ganzzahl verwendet werden soll, mithilfe von mutate wie oben gezeigt angegeben werden.
Ausgabe
Für die Ausgabe müssen wir angeben, wo wir die Daten ablegen müssen. In unserem Fall verwenden wir hier die Elasticsearch. Die Daten, die für die Elasticsearch angegeben werden müssen, sind die Hosts, auf denen sie ausgeführt wird. Wir haben sie als localhost bezeichnet. Das nächste Feld in ist der Index, den wir als Länder- aktuelles Datum angegeben haben. Wir müssen denselben Index in Kibana verwenden, sobald die Daten in Elasticsearch aktualisiert wurden.
Speichern Sie die obige Konfigurationsdatei als logstash_countries.config . Beachten Sie, dass wir im nächsten Schritt den Pfad dieser Konfiguration zum Befehl logstash angeben müssen.
Um die Daten aus der CSV-Datei in Elasticsearch zu laden, müssen wir den Elasticsearch-Server starten.
Jetzt renn http://localhost:9200 im Browser, um zu bestätigen, ob elasticsearch erfolgreich ausgeführt wird.
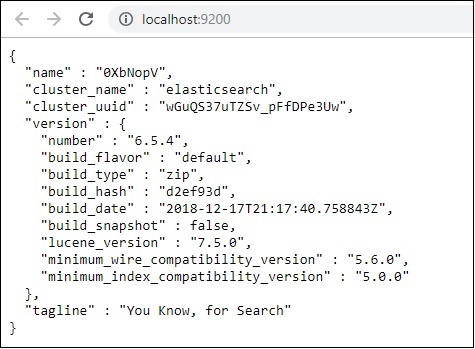
Wir haben Elasticsearch ausgeführt. Gehen Sie nun zu dem Pfad, in dem logstash installiert ist, und führen Sie den folgenden Befehl aus, um die Daten in elasticsearch hochzuladen.
> logstash -f logstash_countries.conf
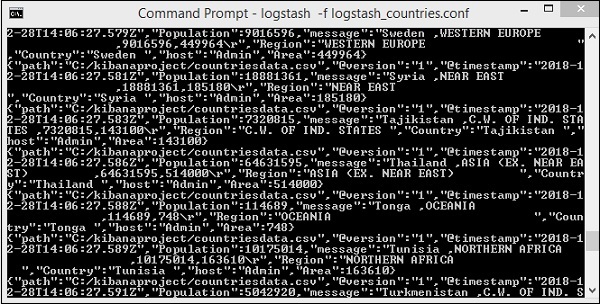
Der obige Bildschirm zeigt das Laden von Daten aus der CSV-Datei in Elasticsearch. Um zu wissen, ob der Index in Elasticsearch erstellt wurde, können Sie Folgendes überprüfen:
Wir können den Länderdaten-28.12.2018 Index sehen, der wie oben gezeigt erstellt wurde.

Die Details des Index - Länder-28.12.2018 sind wie folgt -
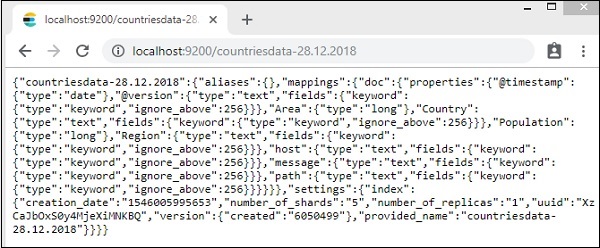
Beachten Sie, dass die Zuordnungsdetails mit Eigenschaften erstellt werden, wenn Daten von logstash zu elasticsearch hochgeladen werden.
Verwenden Sie Daten von Elasticsearch in Kibana
Derzeit läuft Kibana auf localhost, Port 5601 - http://localhost:5601. Die Benutzeroberfläche von Kibana wird hier angezeigt -
Beachten Sie, dass Kibana bereits mit Elasticsearch verbunden ist und wir sehen können sollten index :countries-28.12.2018 in Kibana.
Klicken Sie in der Kibana-Benutzeroberfläche auf der linken Seite auf die Option Verwaltungsmenü.
Klicken Sie nun auf Indexverwaltung -
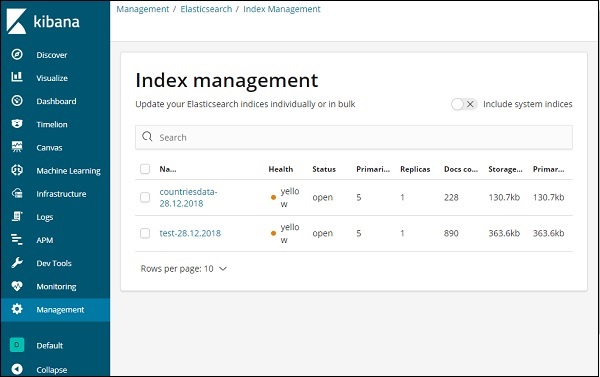
Die in Elasticsearch vorhandenen Indizes werden in der Indexverwaltung angezeigt. Der Index, den wir in Kibana verwenden werden, lautet countrydata-28.12.2018.
Da wir bereits über den Elasticsearch-Index in Kibana verfügen, wird als Nächstes erläutert, wie der Index in Kibana zur Visualisierung von Daten in Form von Kreisdiagrammen, Balkendiagrammen, Liniendiagrammen usw. verwendet wird.
Wir haben gesehen, wie Daten aus logstash in elasticsearch hochgeladen werden. Wir werden hier Daten mit logstash und elasticsearch hochladen. Über die Daten mit Datums-, Längen- und Breitengradfeldern, die wir verwenden müssen, werden wir in den nächsten Kapiteln erfahren. Wir werden auch sehen, wie Daten direkt in Kibana hochgeladen werden, wenn wir keine CSV-Datei haben.
In diesem Kapitel werden wir folgende Themen behandeln:
- Verwenden von Logstash-Upload-Daten mit Datums-, Längen- und Breitengraden in Elasticsearch
- Verwenden von Dev-Tools zum Hochladen von Massendaten
Verwenden des Logstash-Uploads für Daten mit Feldern in Elasticsearch
Wir werden Daten in Form eines CSV-Formats verwenden. Das gleiche stammt von Kaggle.com, das sich mit Daten befasst, die Sie für eine Analyse verwenden können.
Die hier zu verwendenden medizinischen Hausbesuche werden von der Website Kaggle.com abgeholt.
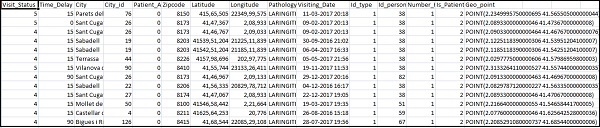
Die folgenden Felder sind für die CSV-Datei verfügbar:
["Visit_Status","Time_Delay","City","City_id","Patient_Age","Zipcode","Latitude","Longitude",
"Pathology","Visiting_Date","Id_type","Id_personal","Number_Home_Visits","Is_Patient_Minor","Geo_point"]Die Home_visits.csv lautet wie folgt:
Das Folgende ist die conf-Datei, die mit logstash verwendet werden soll -
input {
file {
path => "C:/kibanaproject/home_visits.csv"
start_position => "beginning"
sincedb_path => "NUL"
}
}
filter {
csv {
separator => ","
columns =>
["Visit_Status","Time_Delay","City","City_id","Patient_Age",
"Zipcode","Latitude","Longitude","Pathology","Visiting_Date",
"Id_type","Id_personal","Number_Home_Visits","Is_Patient_Minor","Geo_point"]
}
date {
match => ["Visiting_Date","dd-MM-YYYY HH:mm"]
target => "Visiting_Date"
}
mutate {convert => ["Number_Home_Visits", "integer"]}
mutate {convert => ["City_id", "integer"]}
mutate {convert => ["Id_personal", "integer"]}
mutate {convert => ["Id_type", "integer"]}
mutate {convert => ["Zipcode", "integer"]}
mutate {convert => ["Patient_Age", "integer"]}
mutate {
convert => { "Longitude" => "float" }
convert => { "Latitude" => "float" }
}
mutate {
rename => {
"Longitude" => "[location][lon]"
"Latitude" => "[location][lat]"
}
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "medicalvisits-%{+dd.MM.YYYY}"
}
stdout {codec => json_lines }
}Standardmäßig betrachtet logstash alles, was in elasticsearch hochgeladen wird, als Zeichenfolge. Wenn Ihre CSV-Datei ein Datumsfeld enthält, müssen Sie Folgendes tun, um das Datumsformat zu erhalten.
For date field −
date {
match => ["Visiting_Date","dd-MM-YYYY HH:mm"]
target => "Visiting_Date"
}Im Falle einer geografischen Position versteht elasticsearch dasselbe wie -
"location": {
"lat":41.565505000000044,
"lon": 2.2349995750000695
}Wir müssen also sicherstellen, dass wir Längen- und Breitengrade in dem Format haben, das elasticsearch benötigt. Zuerst müssen wir Längen- und Breitengrad in Float umwandeln und später umbenennen, damit er als Teil von verfügbar istlocation json Objekt mit lat und lon. Der Code dafür wird hier angezeigt -
mutate {
convert => { "Longitude" => "float" }
convert => { "Latitude" => "float" }
}
mutate {
rename => {
"Longitude" => "[location][lon]"
"Latitude" => "[location][lat]"
}
}Verwenden Sie zum Konvertieren von Feldern in Ganzzahlen den folgenden Code:
mutate {convert => ["Number_Home_Visits", "integer"]}
mutate {convert => ["City_id", "integer"]}
mutate {convert => ["Id_personal", "integer"]}
mutate {convert => ["Id_type", "integer"]}
mutate {convert => ["Zipcode", "integer"]}
mutate {convert => ["Patient_Age", "integer"]}Führen Sie nach der Pflege der Felder den folgenden Befehl aus, um die Daten in elasticsearch hochzuladen:
- Gehen Sie in das Verzeichnis Logstash bin und führen Sie den folgenden Befehl aus.
logstash -f logstash_homevisists.conf- Sobald Sie fertig sind, sollten Sie den in der Datei logstash conf genannten Index in elasticsearch sehen, wie unten gezeigt -
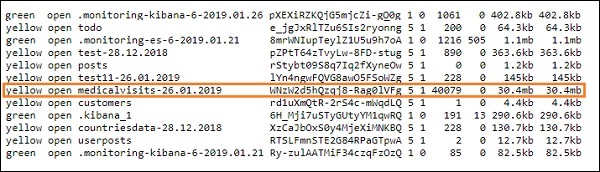
Wir können jetzt ein Indexmuster für den oben hochgeladenen Index erstellen und es für die Erstellung der Visualisierung weiter verwenden.
Verwenden von Dev Tools zum Hochladen von Massendaten
Wir werden Dev Tools von Kibana UI verwenden. Dev Tools ist hilfreich, um Daten in Elasticsearch hochzuladen, ohne Logstash zu verwenden. Wir können die gewünschten Daten in Kibana mit Dev Tools veröffentlichen, ablegen, löschen und durchsuchen.
In diesem Abschnitt werden wir versuchen, Beispieldaten in Kibana selbst zu laden. Wir können es verwenden, um mit den Beispieldaten zu üben und mit Kibana-Funktionen herumzuspielen, um ein gutes Verständnis von Kibana zu erhalten.
Nehmen wir die JSON-Daten aus der folgenden URL und laden Sie sie in Kibana hoch. Ebenso können Sie versuchen, beliebige JSON-Beispieldaten in Kibana zu laden.
Bevor wir mit dem Hochladen der Beispieldaten beginnen, müssen wir die JSON-Daten mit Indizes haben, die in der Elasticsearch verwendet werden sollen. Wenn wir es mit logstash hochladen, achtet logstash darauf, die Indizes hinzuzufügen, und der Benutzer muss sich nicht um die Indizes kümmern, die für elasticsearch erforderlich sind.
Normale Json-Daten
[
{"type":"act","line_id":1,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"ACT I"},
{"type":"scene","line_id":2,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"SCENE I.London. The palace."},
{"type":"line","line_id":3,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":
"Enter KING HENRY, LORD JOHN OF LANCASTER, the
EARL of WESTMORELAND, SIR WALTER BLUNT, and others"}
]Der mit Kibana zu verwendende JSON-Code muss wie folgt indiziert sein:
{"index":{"_index":"shakespeare","_id":0}}
{"type":"act","line_id":1,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"ACT I"}
{"index":{"_index":"shakespeare","_id":1}}
{"type":"scene","line_id":2,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"",
"text_entry":"SCENE I. London. The palace."}
{"index":{"_index":"shakespeare","_id":2}}
{"type":"line","line_id":3,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":
"Enter KING HENRY, LORD JOHN OF LANCASTER, the EARL
of WESTMORELAND, SIR WALTER BLUNT, and others"}Beachten Sie, dass die json-Datei zusätzliche Daten enthält -{"index":{"_index":"nameofindex","_id":key}}.
Um eine mit elasticsearch kompatible json-Beispieldatei zu konvertieren, haben wir hier einen kleinen Code in PHP, der die json-Datei in dem von elasticsearch gewünschten Format ausgibt -
PHP-Code
<?php
$myfile = fopen("todo.json", "r") or die("Unable to open file!"); // your json file here $alldata = fread($myfile,filesize("todo.json")); fclose($myfile);
$farray = json_decode($alldata);
$afinalarray = []; $index_name = "todo";
$i=0; $myfile1 = fopen("todonewfile.json", "w") or die("Unable to open file!"); //
writes a new file to be used in kibana dev tool
foreach ($farray as $a => $value) { $_index = json_decode('{"index": {"_index": "'.$index_name.'", "_id": "'.$i.'"}}');
fwrite($myfile1, json_encode($_index));
fwrite($myfile1, "\n"); fwrite($myfile1, json_encode($value)); fwrite($myfile1, "\n");
$i++;
}
?>Wir haben die todo json Datei von genommen https://jsonplaceholder.typicode.com/todos und verwenden Sie PHP-Code, um in das Format zu konvertieren, das wir in Kibana hochladen müssen.
Öffnen Sie zum Laden der Beispieldaten die Registerkarte dev tools wie unten gezeigt -
Wir werden jetzt die Konsole wie oben gezeigt verwenden. Wir werden die JSON-Daten nehmen, die wir erhalten haben, nachdem wir sie durch PHP-Code ausgeführt haben.
Der Befehl, der in Entwicklertools zum Hochladen der JSON-Daten verwendet werden soll, lautet:
POST _bulkBeachten Sie, dass der Name des Index, den wir erstellen, todo lautet .
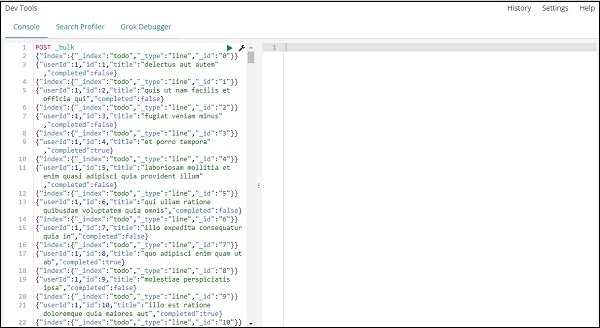

Sobald Sie auf die grüne Schaltfläche klicken, werden die Daten hochgeladen. Sie können wie folgt überprüfen, ob der Index in elasticsearch erstellt wurde oder nicht:

Sie können dasselbe in den Entwicklungstools selbst wie folgt überprüfen:
Command −
GET /_cat/indices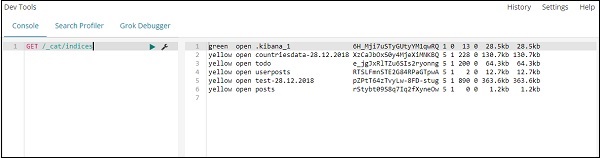
Wenn Sie etwas in Ihrem Index suchen möchten: todo, können Sie dies wie unten gezeigt tun -
Command in dev tool
GET /todo/_search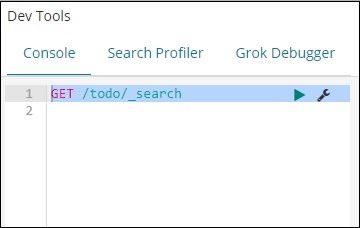
Die Ausgabe der obigen Suche ist wie folgt:

Es gibt alle im todoindex vorhandenen Datensätze an. Die Gesamtzahl der Rekorde, die wir erhalten, beträgt 200.
Suchen Sie nach einem Datensatz im Aufgabenindex
Wir können das mit dem folgenden Befehl tun -
GET /todo/_search
{
"query":{
"match":{
"title":"delectusautautem"
}
}
}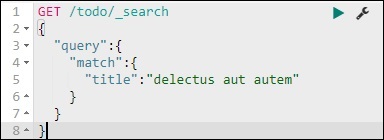

Wir können die Datensätze abrufen, die mit dem von uns angegebenen Titel übereinstimmen.
Der Abschnitt Verwaltung in Kibana wird zum Verwalten der Indexmuster verwendet. In diesem Kapitel werden wir Folgendes diskutieren:
- Indexmuster ohne Zeitfilterfeld erstellen
- Indexmuster mit Zeitfilterfeld erstellen
Feld Indexmuster ohne Zeitfilter erstellen
Gehen Sie dazu zur Kibana-Benutzeroberfläche und klicken Sie auf Verwaltung -
Um mit Kibana arbeiten zu können, müssen wir zuerst einen Index erstellen, der aus elasticsearch ausgefüllt wird. Sie können alle verfügbaren Indizes unter Elasticsearch → Index Management wie gezeigt abrufen -
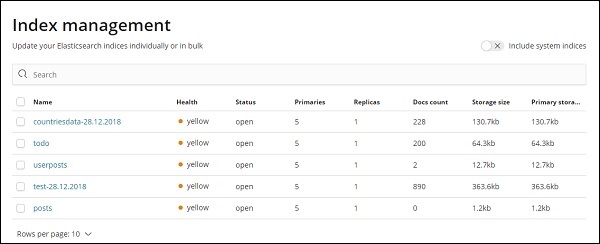
Derzeit hat elasticsearch die oben genannten Indizes. Die Anzahl der Dokumente gibt an, wie viele Datensätze in den einzelnen Indizes verfügbar sind. Wenn ein Index aktualisiert wird, ändert sich die Anzahl der Dokumente ständig. Der Primärspeicher gibt die Größe jedes hochgeladenen Index an.
Um einen neuen Index in Kibana zu erstellen, müssen wir wie unten gezeigt auf Indexmuster klicken.

Sobald Sie auf Indexmuster klicken, wird der folgende Bildschirm angezeigt:
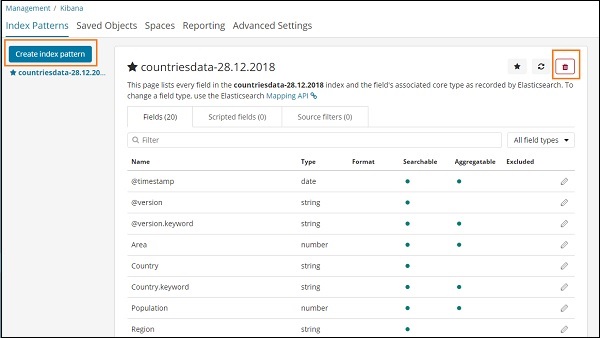
Beachten Sie, dass die Schaltfläche Indexmuster erstellen zum Erstellen eines neuen Index verwendet wird. Denken Sie daran, dass wir bereits zu Beginn des Tutorials die Länderdaten 28.12.2018 erstellt haben.
Indexmuster mit Zeitfilterfeld erstellen
Klicken Sie auf Indexmuster erstellen, um einen neuen Index zu erstellen.
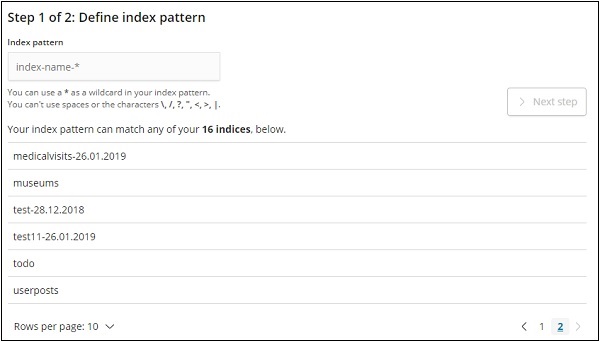
Die Indizes von elasticsearch werden angezeigt. Wählen Sie einen aus, um einen neuen Index zu erstellen.
Klicken Sie nun auf Nächster Schritt .
Der nächste Schritt besteht darin, die Einstellung zu konfigurieren, in der Sie Folgendes eingeben müssen:
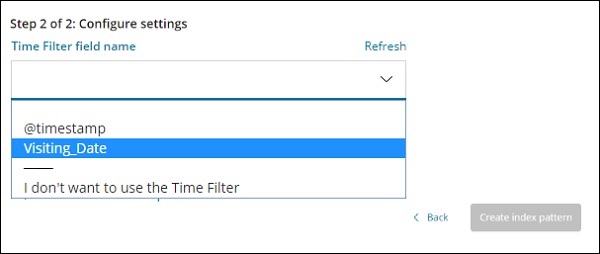
Der Name des Zeitfilterfelds wird verwendet, um Daten basierend auf der Zeit zu filtern. In der Dropdown-Liste werden alle zeit- und datumsbezogenen Felder aus dem Index angezeigt.
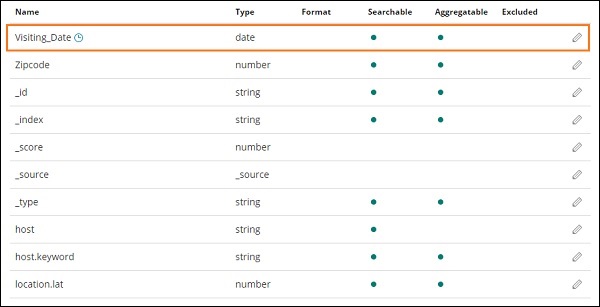
In der Abbildung unten haben wir Visiting_Date als Datumsfeld. Wählen Sie Visiting_Date als Feldnamen für den Zeitfilter.
Klicken Create index patternSchaltfläche zum Erstellen des Index. Sobald dies erledigt ist, werden alle Felder in Ihrem Index angezeigt. Medicalvisits-26.01.2019 wie unten gezeigt -
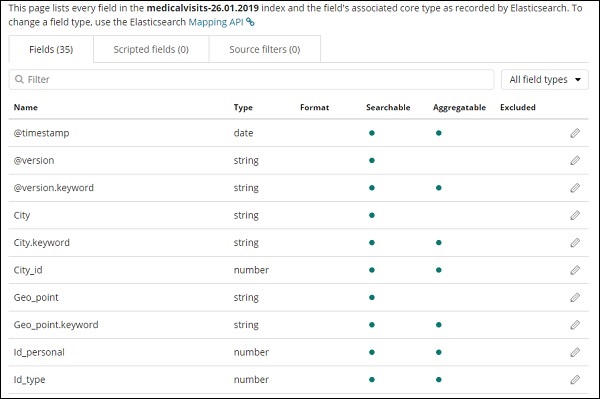
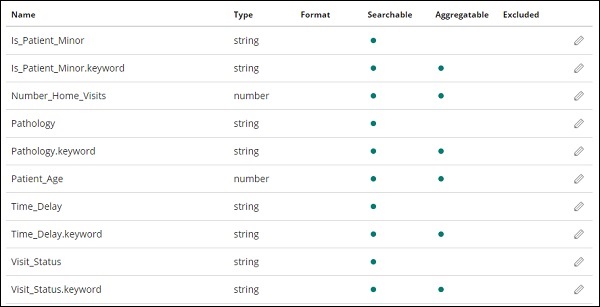
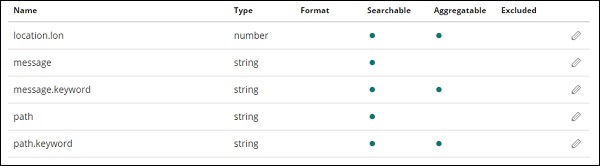
Wir haben folgende Felder im Index medicalvisits-26.01.2019 -
["Visit_Status","Time_Delay","City","City_id","Patient_Age","Zipcode","Latitude
","Longitude","Pathology","Visiting_Date","Id_type","Id_personal","Number_Home_
Visits","Is_Patient_Minor","Geo_point"].Der Index enthält alle Daten für Hausarztbesuche. Es gibt einige zusätzliche Felder, die von elasticsearch hinzugefügt werden, wenn sie aus logstash eingefügt werden.
In diesem Kapitel wird die Registerkarte "Entdecken" in der Kibana-Benutzeroberfläche erläutert. Wir werden im Detail über die folgenden Konzepte lernen -
- Index ohne Datumsfeld
- Index mit Datumsfeld
Index ohne Datumsfeld
Wählen Sie im Menü auf der linken Seite die Option Entdecken (siehe unten).
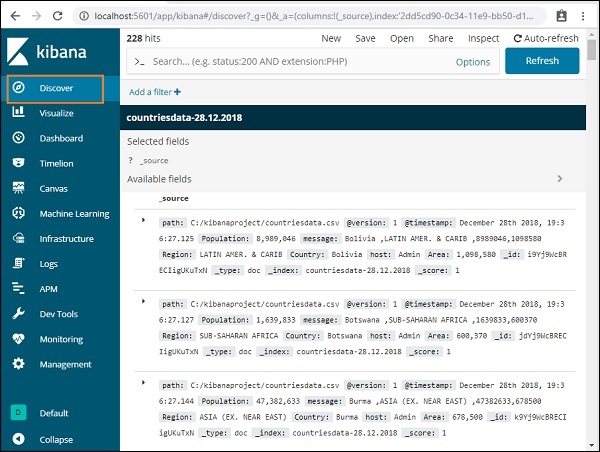
Auf der rechten Seite werden die Details der verfügbaren Daten angezeigt countriesdata- 28.12.2018 Index, den wir im vorherigen Kapitel erstellt haben.
In der oberen linken Ecke wird die Gesamtzahl der verfügbaren Datensätze angezeigt.

Wir können die Details der Daten innerhalb des Index erhalten (countriesdata-28.12.2018)in dieser Registerkarte. In der oberen linken Ecke des oben gezeigten Bildschirms sehen Sie Schaltflächen wie Neu, Speichern, Öffnen, Freigeben, Prüfen und Automatische Aktualisierung.
Wenn Sie auf Automatische Aktualisierung klicken, wird der folgende Bildschirm angezeigt:
Sie können das Intervall für die automatische Aktualisierung festlegen, indem Sie auf die Sekunden, Minuten oder Stunden von oben klicken. Kibana aktualisiert den Bildschirm automatisch und erhält nach jedem von Ihnen eingestellten Intervall-Timer neue Daten.
Die Daten von index:countriesdata-28.12.2018 wird wie folgt angezeigt -
Alle Felder zusammen mit den Daten werden zeilenweise angezeigt. Klicken Sie auf den Pfeil, um die Zeile zu erweitern. Daraufhin werden Details im Tabellen- oder JSON-Format angezeigt

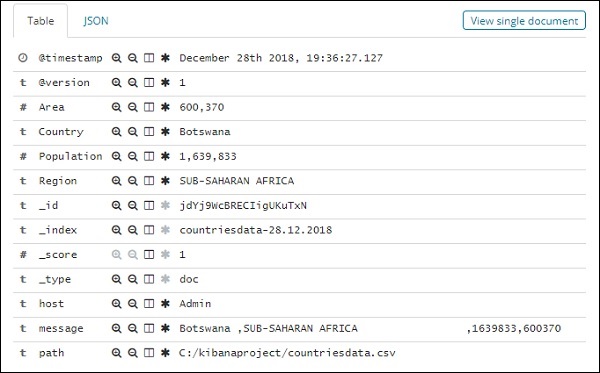
JSON-Format
Auf der linken Seite befindet sich eine Schaltfläche mit der Bezeichnung Einzeldokument anzeigen.
Wenn Sie darauf klicken, werden die Zeile oder die Daten in der Zeile auf der Seite angezeigt (siehe unten).
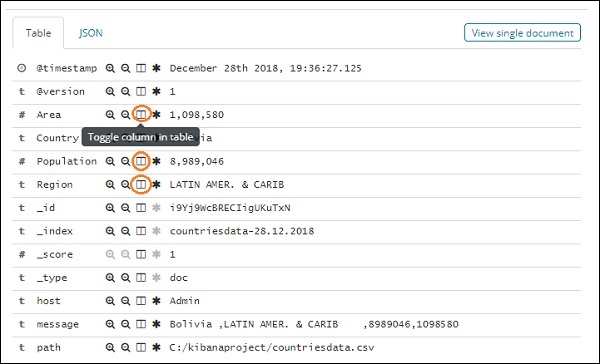
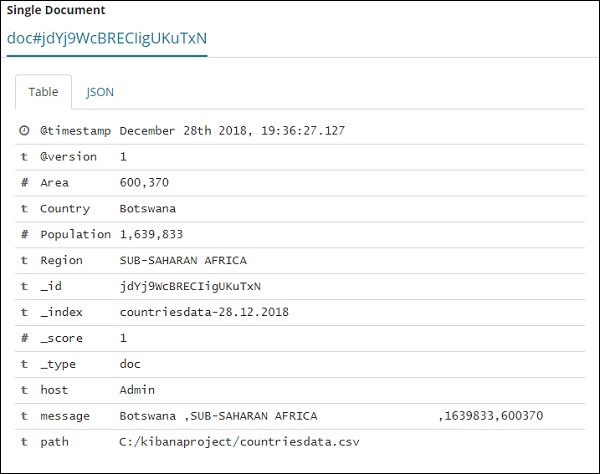
Obwohl wir hier alle Datendetails erhalten, ist es schwierig, sie alle durchzugehen.
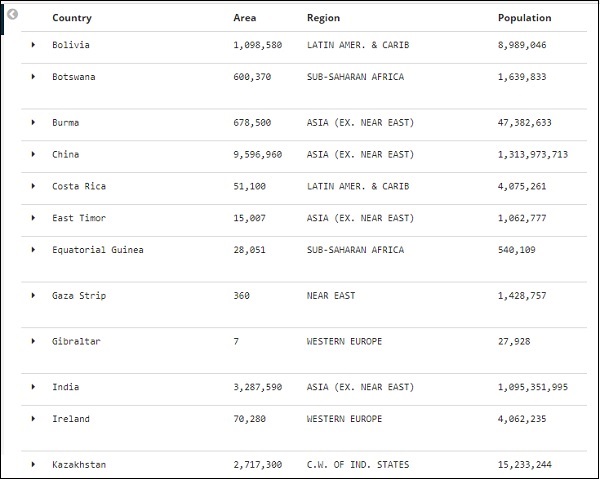
Versuchen wir nun, die Daten in Tabellenform abzurufen. Eine Möglichkeit, eine der Zeilen zu erweitern und auf die in jedem Feld verfügbare Option zum Umschalten der Spalte zu klicken, ist unten dargestellt.
Klicken Sie auf die Option Spalte in Tabelle umschalten, die jeweils verfügbar ist, und Sie werden feststellen, dass die Daten im Tabellenformat angezeigt werden.

Hier haben wir die Felder Land, Gebiet, Region und Bevölkerung ausgewählt. Wenn Sie die erweiterte Zeile reduzieren, sollten Sie jetzt alle Daten in Tabellenform sehen.
Die von uns ausgewählten Felder werden wie unten gezeigt auf der linken Seite des Bildschirms angezeigt.
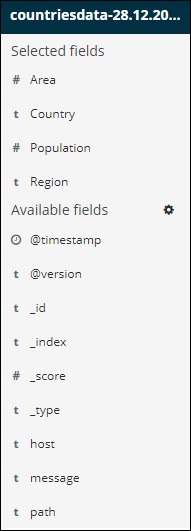
Beachten Sie, dass es zwei Optionen gibt - Ausgewählte Felder und Verfügbare Felder . Die Felder, die wir ausgewählt haben, um sie in Tabellenform anzuzeigen, sind Teil ausgewählter Felder. Wenn Sie ein Feld entfernen möchten, können Sie dies tun, indem Sie auf die Schaltfläche Entfernen klicken, die in der ausgewählten Feldoption über dem Feldnamen angezeigt wird.
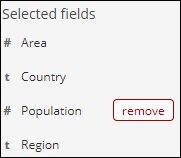
Nach dem Entfernen ist das Feld in den verfügbaren Feldern verfügbar, in denen Sie es wieder hinzufügen können, indem Sie auf die Schaltfläche Hinzufügen klicken, die über dem gewünschten Feld angezeigt wird. Sie können diese Methode auch verwenden, um Ihre Daten in Tabellenform abzurufen, indem Sie die erforderlichen Felder unter Verfügbare Felder auswählen .
In Discover steht eine Suchoption zur Verfügung, mit der wir nach Daten im Index suchen können. Lassen Sie uns hier Beispiele für Suchoptionen ausprobieren -
Angenommen, Sie möchten nach dem Land Indien suchen, können Sie Folgendes tun:
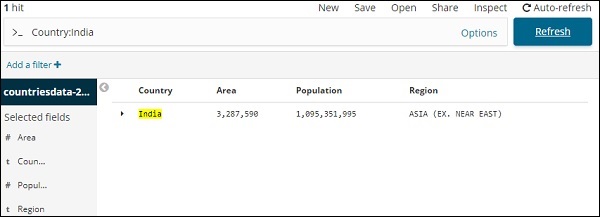
Sie können Ihre Suchdetails eingeben und auf die Schaltfläche Aktualisieren klicken. Wenn Sie nach Ländern suchen möchten, die mit Aus beginnen, können Sie dies wie folgt tun:

Klicken Sie auf Aktualisieren, um die Ergebnisse anzuzeigen
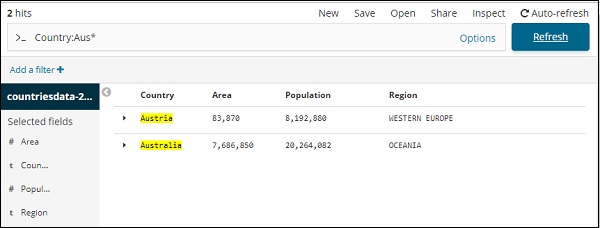
Hier haben wir zwei Länder, die mit Aus * beginnen. Das Suchfeld verfügt über eine Schaltfläche Optionen (siehe oben). Wenn ein Benutzer darauf klickt, wird eine Umschalttaste angezeigt, die beim Einschalten beim Schreiben der Suchabfrage hilft.
Aktivieren Sie die Abfragefunktionen und geben Sie den Feldnamen bei der Suche ein. Daraufhin werden die für dieses Feld verfügbaren Optionen angezeigt.
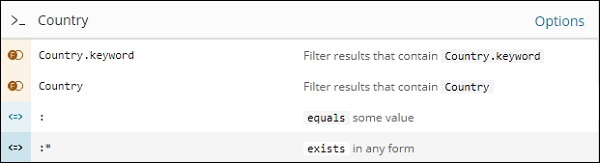
Das Feld "Land" ist beispielsweise eine Zeichenfolge und zeigt die folgenden Optionen für das Zeichenfolgenfeld an:
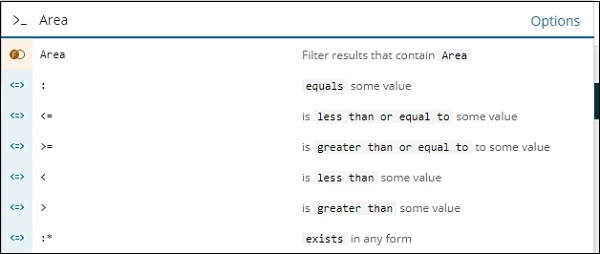
In ähnlicher Weise ist Bereich ein Zahlenfeld und zeigt die folgenden Optionen für das Zahlenfeld an:
Sie können verschiedene Kombinationen ausprobieren und die Daten nach Ihren Wünschen im Feld "Erkennen" filtern. Die Daten auf der Registerkarte "Erkennen" können über die Schaltfläche "Speichern" gespeichert werden, damit Sie sie für zukünftige Zwecke verwenden können.
Um die Daten in Discovery zu speichern, klicken Sie auf die Schaltfläche Speichern in der oberen rechten Ecke, wie unten gezeigt -
Geben Sie Ihrer Suche einen Titel und klicken Sie auf Speichern bestätigen, um sie zu speichern. Nach dem Speichern können Sie beim nächsten Besuch der Registerkarte "Entdecken" oben rechts auf die Schaltfläche "Öffnen" klicken, um die gespeicherten Titel wie unten gezeigt abzurufen.
Sie können die Daten auch mit anderen teilen, indem Sie auf die Schaltfläche Teilen in der oberen rechten Ecke klicken. Wenn Sie darauf klicken, finden Sie Freigabeoptionen wie unten gezeigt -
Sie können es mithilfe von CSV-Berichten oder in Form von Permalinks freigeben.
Die Option, die beim Klicken auf CSV-Berichte verfügbar ist, ist:
Klicken Sie auf CSV generieren, um den Bericht für andere freizugeben.
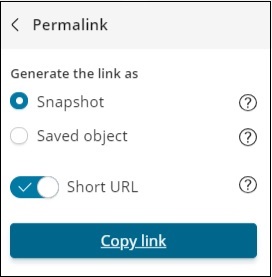
Die auf Klick auf Permalinks verfügbare Option lautet wie folgt:

Die Option Snapshot gibt einen Kibana-Link an, über den die derzeit in der Suche verfügbaren Daten angezeigt werden.
Mit der Option Gespeichertes Objekt wird ein Kibana-Link angezeigt, über den die zuletzt bei Ihrer Suche verfügbaren Daten angezeigt werden.
Schnappschuss - http://localhost:5601/goto/309a983483fccd423950cfb708fabfa5 Gespeichertes Objekt: http: // localhost: 5601 / app / kibana # / remove / 40bd89d0-10b1-11e9-9876-4f3d759b471e? _G = ()
Sie können mit der Registerkarte "Entdecken" und den verfügbaren Suchoptionen arbeiten und das erhaltene Ergebnis kann gespeichert und mit anderen geteilt werden.
Index mit Datumsfeld
Gehen Sie zur Registerkarte Entdecken und wählen Sie Index:medicalvisits-26.01.2019
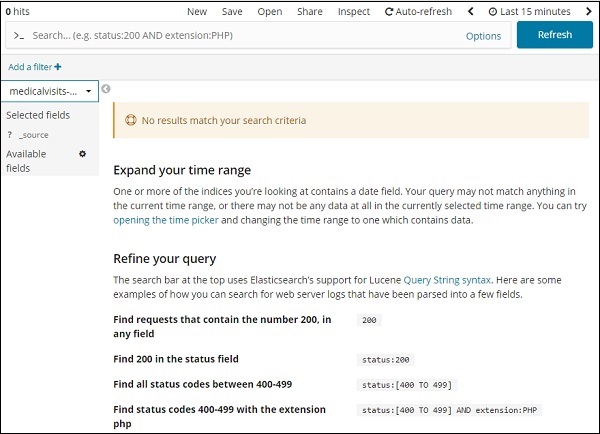
In den letzten 15 Minuten des von uns ausgewählten Index wurde die Meldung "Keine Ergebnisse entsprechen Ihren Suchkriterien" angezeigt. Der Index enthält Daten für die Jahre 2015, 2016, 2017 und 2018.
Ändern Sie den Zeitbereich wie unten gezeigt -
Klicken Sie auf die Registerkarte Absolut.
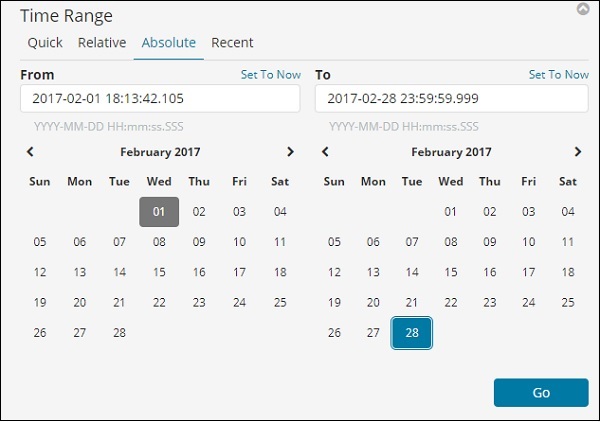
Wählen Sie das Datum vom 1. Januar 2017 bis zum 31. Dezember 2017 aus, da wir die Daten für das Jahr 2017 analysieren werden.
Klicken Sie auf die Schaltfläche Los, um den Zeitbereich hinzuzufügen. Es zeigt Ihnen die Daten und das Balkendiagramm wie folgt an:
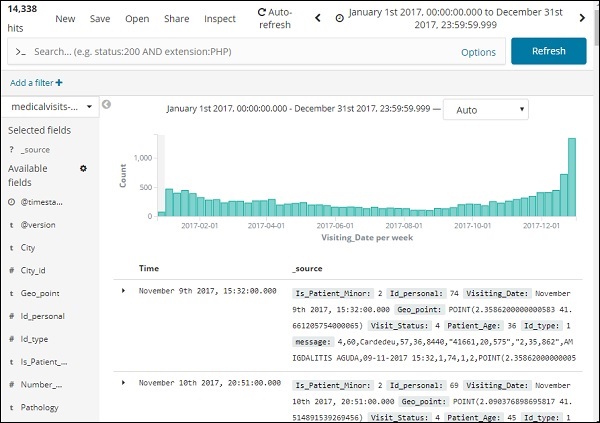
Dies sind die monatlichen Daten für das Jahr 2017 -
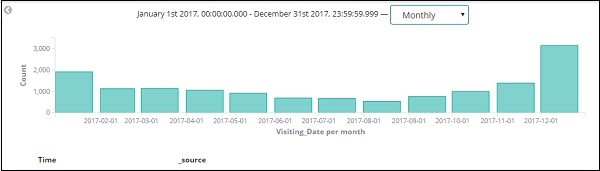
Da wir auch die Uhrzeit zusammen mit dem Datum gespeichert haben, können wir die Daten auch nach Stunden und Minuten filtern.
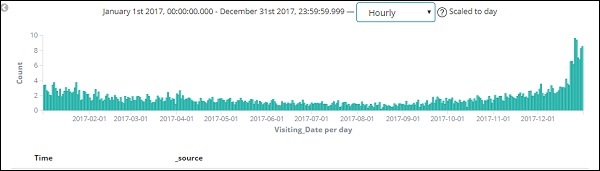
Die oben gezeigte Abbildung zeigt die Stundendaten für das Jahr 2017.
Hier werden die Felder aus dem Index angezeigt - medicalvisits-26.01.2019

Wir haben die verfügbaren Felder auf der linken Seite wie unten gezeigt -
Sie können die Felder aus den verfügbaren Feldern auswählen und die Daten wie unten gezeigt in ein Tabellenformat konvertieren. Hier haben wir folgende Felder ausgewählt -
Die tabellarischen Daten für die obigen Felder werden hier angezeigt -
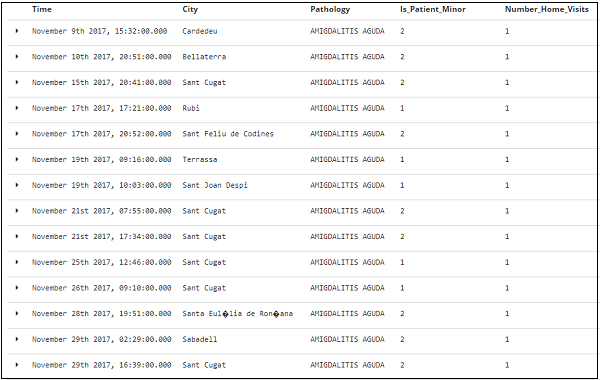
Die beiden Begriffe, auf die Sie beim Erlernen von Kibana häufig stoßen, sind Bucket- und Metrics-Aggregation. In diesem Kapitel wird erläutert, welche Rolle sie in Kibana spielen, und weitere Einzelheiten dazu.
Was ist Kibana-Aggregation?
Aggregation bezieht sich auf die Sammlung von Dokumenten oder eine Reihe von Dokumenten, die aus einer bestimmten Suchabfrage oder einem bestimmten Filter stammen. Aggregation bildet das Hauptkonzept, um die gewünschte Visualisierung in Kibana zu erstellen.
Wann immer Sie eine Visualisierung durchführen, müssen Sie die Kriterien festlegen. Dies bedeutet, auf welche Weise Sie die Daten gruppieren möchten, um die Metrik darauf auszuführen.
In diesem Abschnitt werden zwei Arten der Aggregation erläutert:
- Bucket Aggregation
- Metrische Aggregation
Bucket Aggregation
Ein Eimer besteht hauptsächlich aus einem Schlüssel und einem Dokument. Wenn die Aggregation ausgeführt wird, werden die Dokumente in den jeweiligen Bucket gelegt. Am Ende sollten Sie also eine Liste von Eimern mit jeweils einer Liste von Dokumenten haben. Die Liste der Bucket Aggregation, die Sie beim Erstellen der Visualisierung in Kibana sehen, wird unten angezeigt.
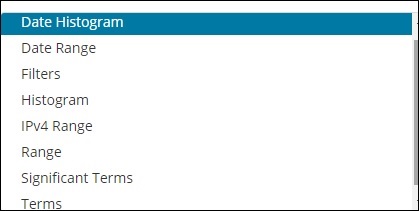
Bucket Aggregation hat die folgende Liste -
- Datumshistogramm
- Datumsbereich
- Filters
- Histogram
- IPv4-Bereich
- Range
- Wichtige Begriffe
- Terms
Während der Erstellung müssen Sie eine davon für die Bucket-Aggregation auswählen, dh um die Dokumente in den Buckets zu gruppieren.
Betrachten Sie zur Analyse beispielsweise die Länderdaten, die wir zu Beginn dieses Tutorials hochgeladen haben. Die im Länderindex verfügbaren Felder sind Ländername, Gebiet, Bevölkerung, Region. In den Länderdaten haben wir den Namen des Landes zusammen mit seiner Bevölkerung, Region und dem Gebiet.
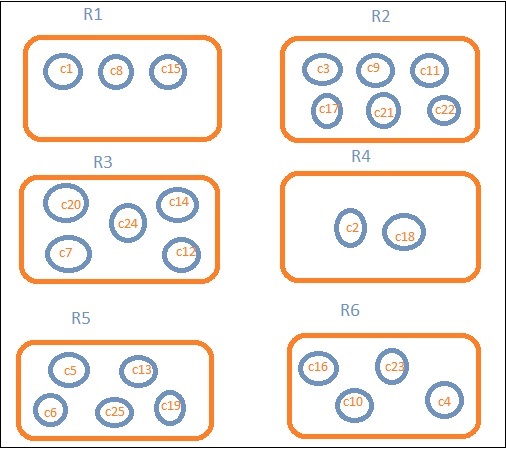
Nehmen wir an, wir wollen regionale Daten. Dann werden die in jeder Region verfügbaren Länder zu unserer Suchanfrage. In diesem Fall bildet die Region unsere Buckets. Das folgende Blockdiagramm zeigt, dass R1, R2, R3, R4, R5 und R6 die Buckets sind, die wir erhalten haben, und c1, c2 ..c25 die Liste der Dokumente sind, die Teil der Buckets R1 bis R6 sind.
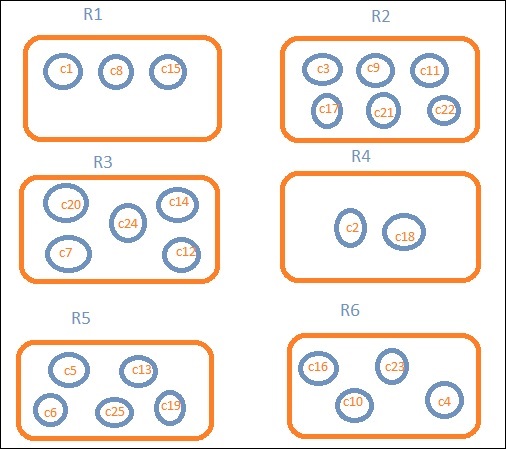
Wir können sehen, dass sich in jedem Eimer einige Kreise befinden. Sie bestehen aus Dokumenten, die auf den Suchkriterien basieren und in jeden Eimer fallen. Im Bucket R1 befinden sich die Dokumente c1, c8 und c15. Diese Dokumente sind die Länder, die in diese Region fallen, genau wie andere. Wenn wir also die Länder in Bucket R1 zählen, sind es 3, 6 für R2, 6 für R3, 2 für R4, 5 für R5 und 4 für R6.
Durch die Bucket-Aggregation können wir das Dokument in Buckets aggregieren und eine Liste der Dokumente in diesen Buckets erstellen, wie oben gezeigt.
Die Liste der Bucket Aggregation, die wir bisher haben, ist -
- Datumshistogramm
- Datumsbereich
- Filters
- Histogram
- IPv4-Bereich
- Range
- Wichtige Begriffe
- Terms
Lassen Sie uns nun im Detail diskutieren, wie diese Eimer einzeln geformt werden.
Datumshistogramm
Die Aggregation des Datumshistogramms wird für ein Datumsfeld verwendet. Wenn Sie also ein Datumsfeld in diesem Index haben, kann nur der Index verwendet werden, den Sie zur Visualisierung verwenden. Es kann nur dieser Aggregationstyp verwendet werden. Dies ist eine Aggregation mit mehreren Buckets. Dies bedeutet, dass Sie einige der Dokumente als Teil von mehr als einem Bucket haben können. Für diese Aggregation muss ein Intervall verwendet werden. Die Details sind wie folgt:
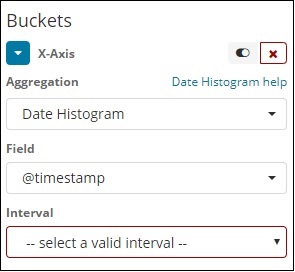
Wenn Sie Buckets Aggregation als Datumshistogramm auswählen, wird die Option Feld angezeigt, die nur die datumsbezogenen Felder enthält. Sobald Sie Ihr Feld ausgewählt haben, müssen Sie das Intervall auswählen, das die folgenden Details enthält:
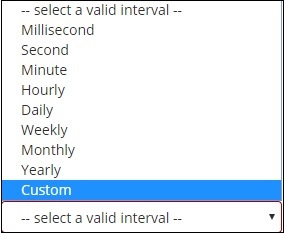
Die Dokumente aus dem ausgewählten Index und basierend auf dem ausgewählten Feld und Intervall kategorisieren die Dokumente in Buckets. Wenn Sie beispielsweise das Intervall als monatlich ausgewählt haben, werden die Dokumente basierend auf dem Datum in Buckets konvertiert und basierend auf dem Monat, dh von Januar bis Dezember, werden die Dokumente in die Buckets gestellt. Hier werden Jan, Feb, .. Dez die Eimer sein.
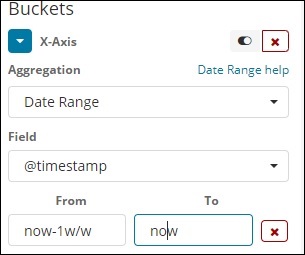
Datumsbereich
Sie benötigen ein Datumsfeld, um diesen Aggregationstyp zu verwenden. Hier haben wir einen Datumsbereich, der von Datum bis Datum angegeben werden soll. Die Dokumente der Eimer basieren auf dem Formular und dem angegebenen Datum.
Filter
Bei der Filtertypaggregation werden die Buckets basierend auf dem Filter gebildet. Hier erhalten Sie einen Multi-Bucket, der auf den Filterkriterien basiert, die ein Dokument in einem oder mehreren Buckets haben kann.
Mithilfe von Filtern können Benutzer ihre Abfragen wie unten gezeigt in die Filteroption schreiben.
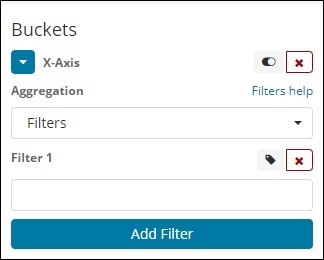
Sie können mehrere Filter Ihrer Wahl hinzufügen, indem Sie die Schaltfläche Filter hinzufügen verwenden.
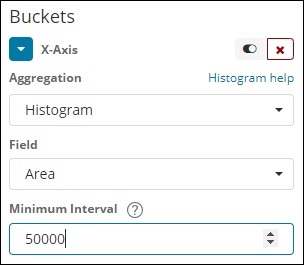
Histogramm
Diese Art der Aggregation wird auf ein Zahlenfeld angewendet und gruppiert die Dokumente basierend auf dem angewendeten Intervall in einem Bucket. Zum Beispiel 0-50,50-100,100-150 usw.
IPv4-Bereich
Diese Art der Aggregation wird hauptsächlich für IP-Adressen verwendet.
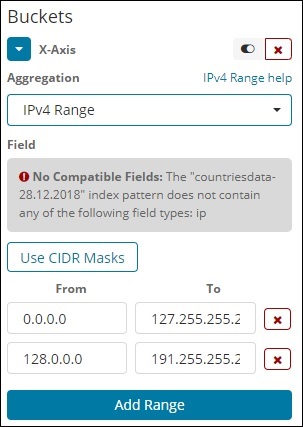
Der Index, den wir haben, ist contriesdata-28.12.2018, hat kein Feld vom Typ IP, daher wird eine Meldung wie oben gezeigt angezeigt. Wenn Sie zufällig das IP-Feld haben, können Sie die Werte Von und Bis wie oben gezeigt angeben.
Angebot
Für diese Art der Aggregation müssen Felder vom Typ Nummer sein. Sie müssen den Bereich angeben, und die Dokumente werden in den Eimern aufgelistet, die in den Bereich fallen.
Sie können bei Bedarf weitere Bereiche hinzufügen, indem Sie auf die Schaltfläche Bereich hinzufügen klicken.
Wichtige Begriffe
Diese Art der Aggregation wird hauptsächlich für die Zeichenfolgenfelder verwendet.
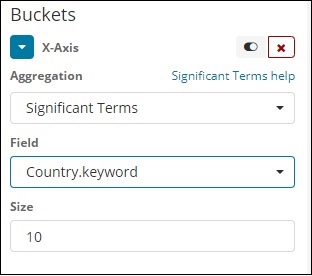
Bedingungen
Diese Art der Aggregation wird für alle verfügbaren Felder verwendet, nämlich Nummer, Zeichenfolge, Datum, Boolescher Wert, IP-Adresse, Zeitstempel usw. Beachten Sie, dass dies die Aggregation ist, die wir in all unseren Visualisierungen verwenden werden, an denen wir in diesem Bereich arbeiten werden Lernprogramm.
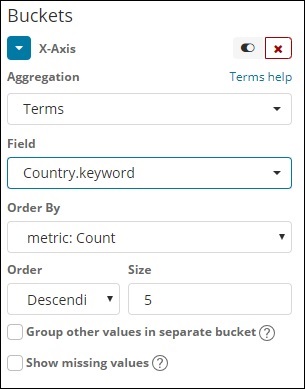
Wir haben eine Optionsreihenfolge, nach der wir die Daten basierend auf der von uns ausgewählten Metrik gruppieren. Die Größe bezieht sich auf die Anzahl der Buckets, die Sie in der Visualisierung anzeigen möchten.
Lassen Sie uns als nächstes über die metrische Aggregation sprechen.
Metrische Aggregation
Die metrische Aggregation bezieht sich hauptsächlich auf die mathematische Berechnung der im Bucket vorhandenen Dokumente. Wenn Sie beispielsweise ein Zahlenfeld auswählen, können Sie die Metrik berechnen: COUNT, SUM, MIN, MAX, AVERAGE usw.
Eine Liste der Metrikaggregation, die wir diskutieren werden, finden Sie hier -
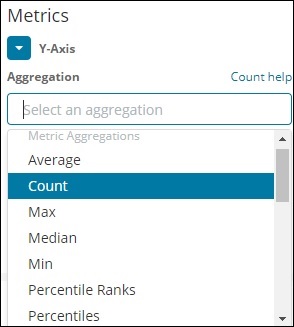
Lassen Sie uns in diesem Abschnitt die wichtigen diskutieren, die wir häufig verwenden werden -
- Average
- Count
- Max
- Min
- Sum
Die Metrik wird auf die einzelne Bucket-Aggregation angewendet, die wir oben bereits besprochen haben.
Lassen Sie uns als Nächstes die Liste der Metrikaggregation hier diskutieren -
Durchschnittlich
Dies gibt den Durchschnitt für die Werte der in den Buckets vorhandenen Dokumente an. Zum Beispiel -
R1 bis R6 sind die Eimer. In R1 haben wir c1, c8 und c15. Angenommen, der Wert von c1 ist 300, c8 ist 500 und c15 ist 700. Nun erhalten Sie den Durchschnittswert des R1-Buckets
R1 = Wert von c1 + Wert von c8 + Wert von c15 / 3 = 300 + 500 + 700/3 = 500.
Der Durchschnitt liegt bei 500 für Eimer R1. Hier könnte der Wert des Dokuments ungefähr so sein, wenn Sie die Länderdaten berücksichtigen, dass es sich um das Gebiet des Landes in dieser Region handelt.
Anzahl
Dies gibt die Anzahl der im Bucket vorhandenen Dokumente an. Angenommen, Sie möchten die Anzahl der in der Region vorhandenen Länder angeben, dann handelt es sich um die Gesamtzahl der in den Eimern vorhandenen Dokumente. Zum Beispiel ist R1 3, R2 = 6, R3 = 5, R4 = 2, R5 = 5 und R6 = 4.
Max
Dies gibt den Maximalwert des im Bucket vorhandenen Dokuments an. Betrachten Sie das obige Beispiel, wenn wir flächenbezogene Länderdaten im Regionsbereich haben. Das Maximum für jede Region ist das Land mit der maximalen Fläche. Es wird also ein Land aus jeder Region geben, dh R1 bis R6.
im
Dies gibt den Mindestwert des im Bucket vorhandenen Dokuments an. Betrachtet man das obige Beispiel, wenn wir flächenbezogene Länderdaten im Regionsbereich haben. Die Mindestanzahl für jede Region ist das Land mit der Mindestfläche. Es wird also ein Land aus jeder Region geben, dh R1 bis R6.
Summe
Dies ergibt die Summe der Werte des im Bucket vorhandenen Dokuments. Wenn Sie beispielsweise das obige Beispiel betrachten, wenn wir die Gesamtfläche oder die Länder in der Region möchten, ist dies die Summe der in der Region vorhandenen Dokumente.
Um beispielsweise die Gesamtzahl der Länder in der Region R1 zu kennen, ist dies 3, R2 = 6, R3 = 5, R4 = 2, R5 = 5 und R6 = 4.
Wenn wir Dokumente mit einem Gebiet in der Region als R1 bis R6 haben, wird das länderspezifische Gebiet für die Region zusammengefasst.
Wir können die vorhandenen Daten in Form von Balkendiagrammen, Liniendiagrammen, Kreisdiagrammen usw. visualisieren. In diesem Kapitel erfahren Sie, wie Sie eine Visualisierung erstellen.
Visualisierung erstellen
Gehen Sie wie unten gezeigt zur Kibana-Visualisierung -

Wir haben keine Visualisierung erstellt, daher wird sie leer angezeigt und es gibt eine Schaltfläche zum Erstellen einer.
Drück den Knopf Create a visualization wie im obigen Bildschirm gezeigt und es bringt Sie zum Bildschirm wie unten gezeigt -
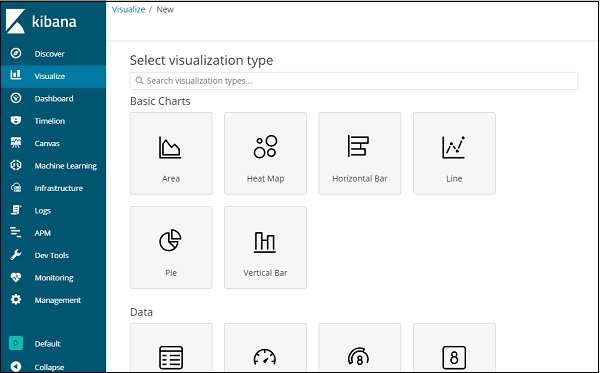
Hier können Sie die Option auswählen, die Sie zur Visualisierung Ihrer Daten benötigen. Wir werden jeden von ihnen in den kommenden Kapiteln im Detail verstehen. Wählen Sie jetzt zunächst ein Kreisdiagramm aus.
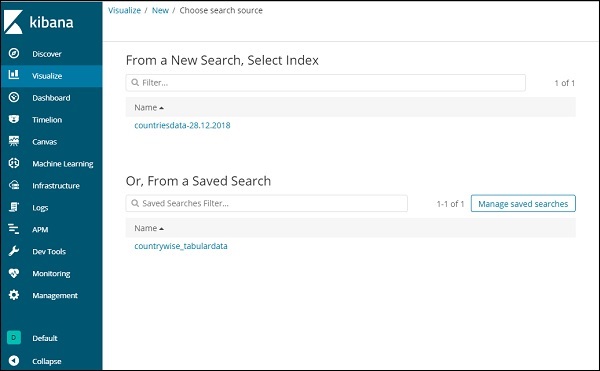
Nachdem Sie den Visualisierungstyp ausgewählt haben, müssen Sie nun den Index auswählen, an dem Sie arbeiten möchten. Daraufhin wird der folgende Bildschirm angezeigt:

Jetzt haben wir ein Standard-Kreisdiagramm. Wir werden die Länderdaten vom 28.12.2018 verwenden, um die Anzahl der in den Länderdaten verfügbaren Regionen im Kreisdiagrammformat zu ermitteln.
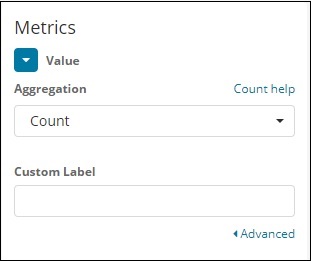
Bucket- und metrische Aggregation
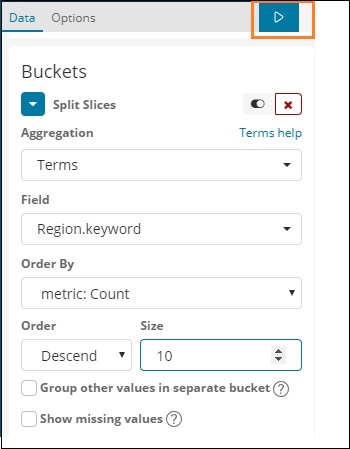
Die linke Seite enthält Metriken, die wir als Anzahl auswählen. In Buckets gibt es zwei Optionen: Slices teilen und Diagramm teilen. Wir werden die Option Slits teilen verwenden.
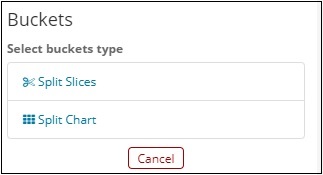
Wählen Sie nun Split Slices und es werden folgende Optionen angezeigt:
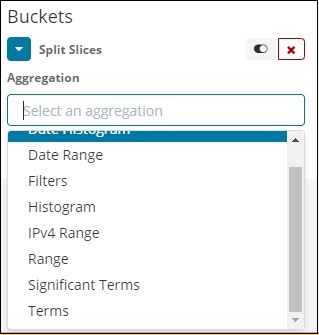
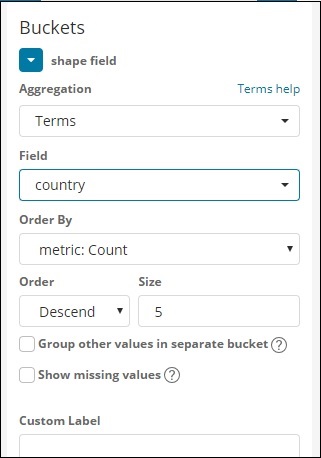
Wählen Sie nun die Aggregation als Begriffe aus und es werden weitere Optionen angezeigt, die wie folgt eingegeben werden können:

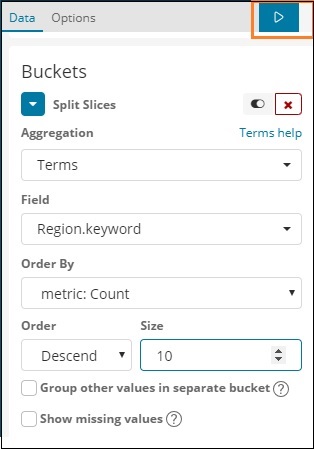
In der Dropdown-Liste Felder wird das gesamte Feld aus dem Index angezeigt: Länderdaten ausgewählt. Wir haben das Feld Region und Order By ausgewählt. Beachten Sie, dass wir die Metrik Count for Order By ausgewählt haben. Wir werden es absteigend bestellen und die Größe, die wir angenommen haben, als 10 annehmen. Dies bedeutet, dass wir hier die Top-10-Regionen aus dem Länderindex erhalten.
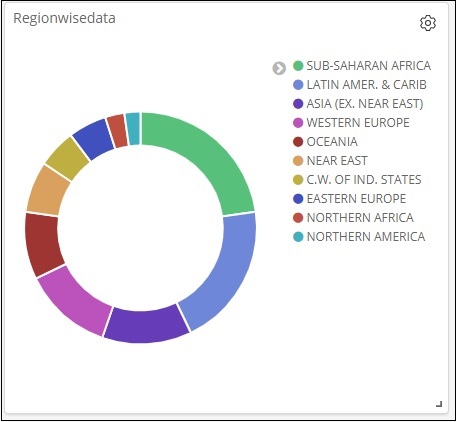
Klicken Sie nun wie unten hervorgehoben auf die Schaltfläche Analysieren. Das Kreisdiagramm sollte auf der rechten Seite aktualisiert werden.
Kreisdiagrammanzeige
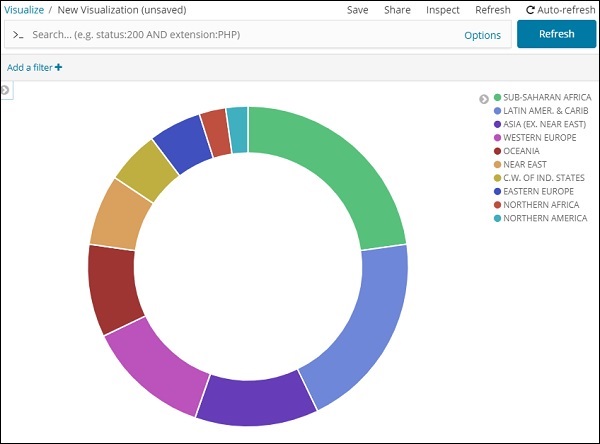
Alle Regionen werden in der rechten oberen Ecke mit Farben aufgelistet und die gleiche Farbe wird im Kreisdiagramm angezeigt. Wenn Sie mit der Maus über das Kreisdiagramm fahren, wird die Anzahl der Regionen sowie der Name der Region angezeigt (siehe unten).
Aus den von uns hochgeladenen Länderdaten geht hervor, dass 22,77% der Region von Subsahara-Afrikanern besetzt sind.
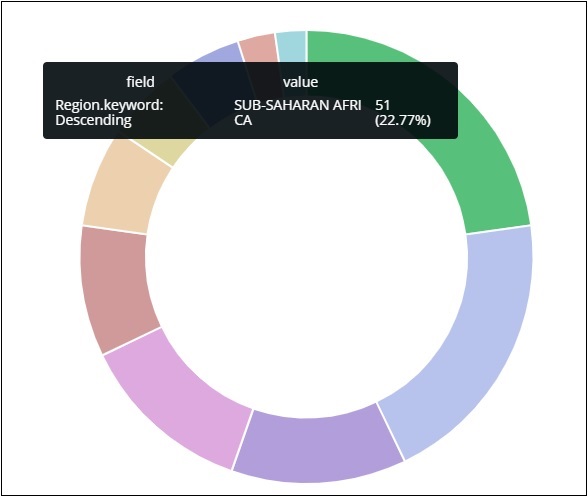

Die Region Asien umfasst 12,5% und 28.
Jetzt können wir die Visualisierung speichern, indem wir oben rechts auf die Schaltfläche Speichern klicken (siehe unten).

Speichern Sie nun die Visualisierung, damit sie später verwendet werden kann.
Wir können die Daten auch nach Belieben abrufen, indem wir die unten gezeigte Suchoption verwenden.
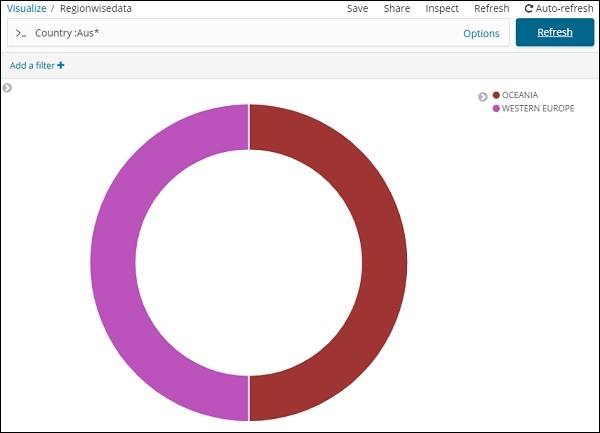
Wir haben Daten für Länder gefiltert, die mit Aus * beginnen. In den kommenden Kapiteln werden wir mehr über Kreisdiagramme und andere Visualisierungen erfahren.
Lassen Sie uns die am häufigsten verwendeten Diagramme in der Visualisierung untersuchen und verstehen.
- Horizontales Balkendiagramm
- Vertikales Balkendiagramm
- Kuchendiagramm
Im Folgenden sind die Schritte aufgeführt, die zum Erstellen der obigen Visualisierung ausgeführt werden müssen. Beginnen wir mit der horizontalen Leiste.
Horizontales Balkendiagramm
Öffnen Sie Kibana und klicken Sie auf die Registerkarte Visualisieren auf der linken Seite, wie unten gezeigt -
Klicken Sie auf die Schaltfläche +, um eine neue Visualisierung zu erstellen.
Klicken Sie auf die oben aufgeführte horizontale Leiste. Sie müssen eine Auswahl des Index treffen, den Sie visualisieren möchten.
Wähle aus countriesdata-28.12.2018Index wie oben gezeigt. Bei Auswahl des Index wird ein Bildschirm angezeigt, wie unten gezeigt -
Es wird eine Standardanzahl angezeigt. Lassen Sie uns nun ein horizontales Diagramm zeichnen, in dem wir die Daten der 10 besten Länderpopulationen sehen können.
Zu diesem Zweck müssen wir auswählen, was wir auf der Y- und X-Achse wollen. Wählen Sie daher den Bucket und die metrische Aggregation aus.
Wenn Sie nun auf die Y-Achse klicken, wird der folgende Bildschirm angezeigt:
Wählen Sie nun die gewünschte Aggregation aus den hier gezeigten Optionen aus -
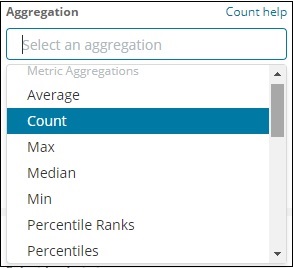
Beachten Sie, dass wir hier die maximale Aggregation auswählen, da wir Daten gemäß der maximal verfügbaren Population anzeigen möchten.
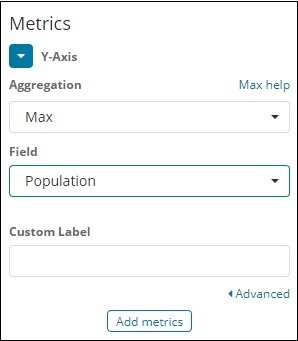
Als nächstes müssen wir das Feld auswählen, dessen Maximalwert erforderlich ist. In den Index -Länderdaten vom 28.12.2018 haben wir nur 2 Zahlenfelder - Fläche und Bevölkerung.
Da wir die maximale Bevölkerung wollen, wählen wir das Feld Bevölkerung wie unten gezeigt aus -
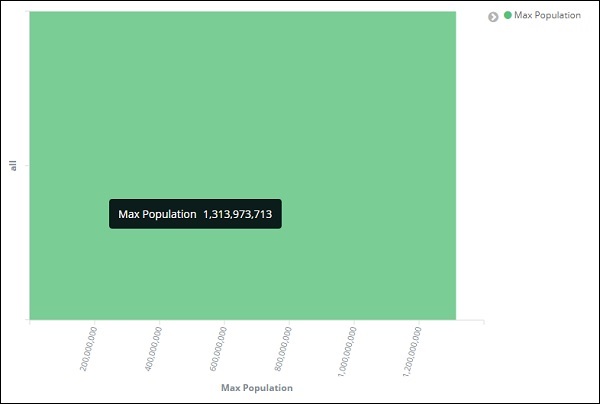
Damit sind wir mit der Y-Achse fertig. Die Ausgabe, die wir für die Y-Achse erhalten, ist wie folgt:
Wählen wir nun die X-Achse wie unten gezeigt aus -
Wenn Sie X-Achse auswählen, erhalten Sie die folgende Ausgabe:
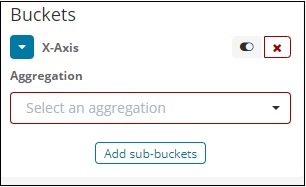
Wählen Sie Aggregation als Begriffe.
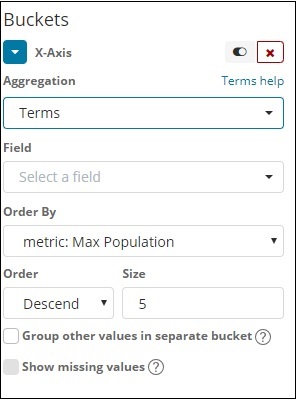
Wählen Sie das Feld aus der Dropdown-Liste. Wir wollen eine länderspezifische Bevölkerung, also wählen Sie ein Länderfeld aus. Bestellung von wir haben folgende Möglichkeiten -
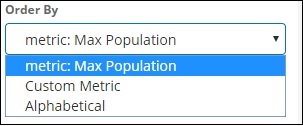
Wir werden die Reihenfolge nach Max. Bevölkerung auswählen, da das Land mit der höchsten Bevölkerung zuerst angezeigt werden soll und so weiter. Sobald die gewünschten Daten hinzugefügt wurden, klicken Sie oben auf den Metrikdaten auf die Schaltfläche Änderungen übernehmen (siehe unten).

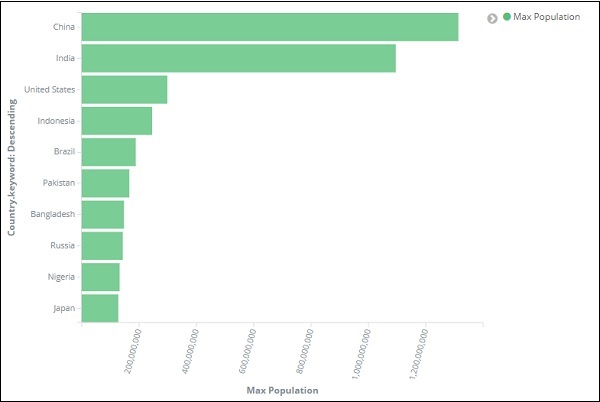
Sobald Sie auf Änderungen übernehmen klicken, haben wir das horizontale Diagramm, in dem wir sehen können, dass China das Land mit der höchsten Bevölkerungszahl ist, gefolgt von Indien, den Vereinigten Staaten usw.
Ebenso können Sie verschiedene Diagramme zeichnen, indem Sie das gewünschte Feld auswählen. Als Nächstes speichern wir diese Visualisierung als max_population, um sie später für die Dashboard-Erstellung zu verwenden.
Im nächsten Abschnitt erstellen wir ein vertikales Balkendiagramm.
Vertikales Balkendiagramm
Klicken Sie auf die Registerkarte Visualisieren und erstellen Sie eine neue Visualisierung mit vertikaler Leiste und Index als countriesdata-28.12.2018.
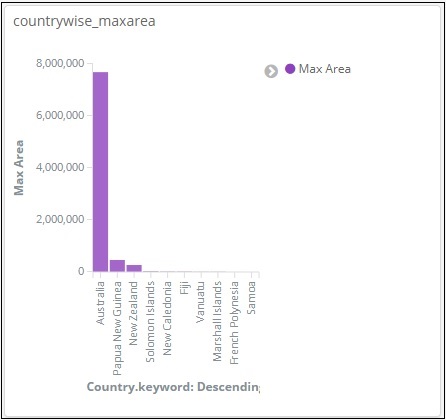
In dieser vertikalen Balkenvisualisierung erstellen wir ein Balkendiagramm mit länderbezogenem Bereich, dh Länder werden mit dem höchsten Bereich angezeigt.
Wählen wir also die Y- und X-Achse wie unten gezeigt aus -
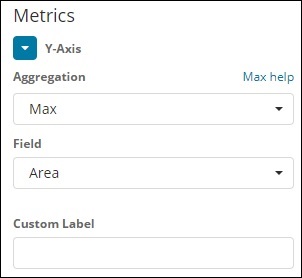
Y-Achse
X-Achse
Wenn wir die Änderungen hier anwenden, können wir die Ausgabe wie unten gezeigt sehen -

Aus der Grafik können wir ersehen, dass Russland die höchste Fläche hat, gefolgt von Kanada und den Vereinigten Staaten. Bitte beachten Sie, dass diese Daten aus den Index-Länderdaten und ihren Dummy-Daten ausgewählt werden, sodass die Zahlen bei Live-Daten möglicherweise nicht korrekt sind.
Speichern wir diese Visualisierung als countrywise_maxarea , um sie später mit dem Dashboard zu verwenden.
Als nächstes arbeiten wir am Kreisdiagramm.
Kuchendiagramm
Erstellen Sie also zuerst eine Visualisierung und wählen Sie das Kreisdiagramm mit dem Index als Länderdaten aus. Wir werden die Anzahl der in den Länderdaten verfügbaren Regionen im Kreisdiagrammformat anzeigen.
Die linke Seite enthält Metriken, die die Anzahl angeben. In Buckets gibt es zwei Optionen: Split Slices und Split Chart. Jetzt verwenden wir die Option Slices teilen.
Wenn Sie nun Slits teilen auswählen, werden die folgenden Optionen angezeigt:

Wählen Sie die Aggregation als Begriffe aus und es werden weitere Optionen angezeigt, die wie folgt eingegeben werden können:
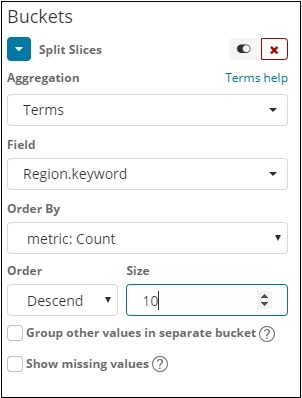
In der Dropdown-Liste Felder werden alle Felder aus dem ausgewählten Index angezeigt. Wir haben das Feld Region und die Reihenfolge Nach ausgewählt, die wir als Anzahl ausgewählt haben. Wir werden es absteigend bestellen und die Größe wird 10 annehmen. Hier erhalten wir also die Anzahl der 10 Regionen aus dem Länderindex.
Klicken Sie nun auf die Wiedergabetaste, wie unten hervorgehoben, und das Kreisdiagramm sollte auf der rechten Seite aktualisiert werden.
Kreisdiagrammanzeige

Alle Regionen werden in der rechten oberen Ecke mit Farben aufgelistet und die gleiche Farbe wird im Kreisdiagramm angezeigt. Wenn Sie mit der Maus über das Kreisdiagramm fahren, wird die Anzahl der Regionen sowie der Name der Region angezeigt (siehe unten).
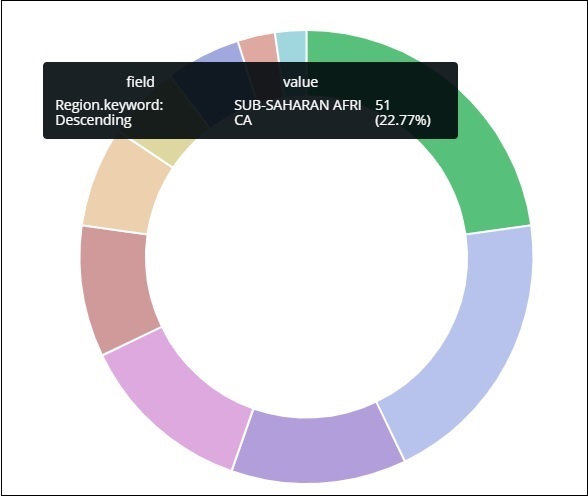

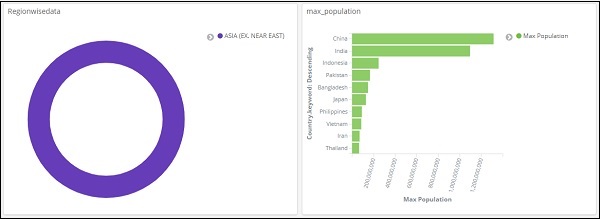
Dies zeigt uns, dass 22,77% der Region in den von uns hochgeladenen Länderdaten von Afrikanern südlich der Sahara besetzt sind.
Beachten Sie anhand des Kreisdiagramms, dass die Region Asien 12,5% abdeckt und die Zahl 28 beträgt.
Jetzt können wir die Visualisierung speichern, indem wir auf die Schaltfläche Speichern in der oberen rechten Ecke klicken, wie unten gezeigt -

Speichern Sie nun die Visualisierung, damit sie später im Dashboard verwendet werden kann.
In diesem Kapitel werden die beiden in der Visualisierung verwendeten Diagrammtypen erläutert.
- Liniendiagramm
- Area
Liniendiagramm
Lassen Sie uns zunächst eine Visualisierung erstellen und ein Liniendiagramm auswählen, um die Daten anzuzeigen und Kontradaten als Index zu verwenden. Wir müssen die Y-Achse und die X-Achse erstellen und die Details dafür sind unten gezeigt -
Für die Y-Achse
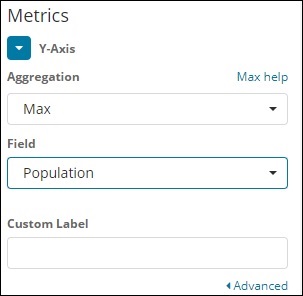
Beachten Sie, dass wir Max als Aggregation genommen haben. Hier zeigen wir die Datenpräsentation in einem Liniendiagramm. Jetzt werden wir ein Diagramm zeichnen, das die maximale Bevölkerungszahl in Bezug auf das Land zeigt. Das Feld, das wir genommen haben, ist Bevölkerung, da wir in Bezug auf das Land eine maximale Bevölkerung benötigen.
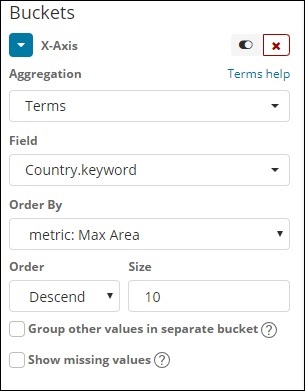
Für die X-Achse
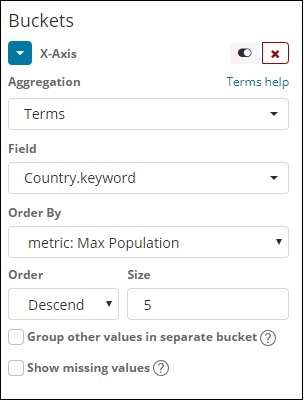
Auf der x-Achse haben wir Begriffe als Aggregation, Country.keyword als Feld und Metrik verwendet: Maximale Bevölkerungszahl für Bestellung nach und Bestellgröße ist 5. Es werden also die 5 Top-Länder mit maximaler Bevölkerungszahl dargestellt. Nachdem Sie die Änderungen übernommen haben, sehen Sie das Liniendiagramm wie folgt:
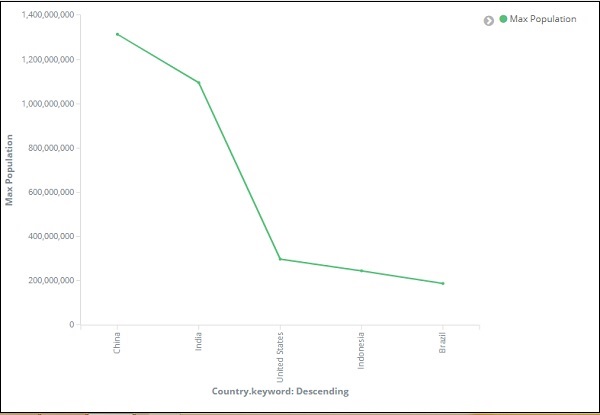
Wir haben also eine maximale Bevölkerungszahl in China, gefolgt von Indien, den Vereinigten Staaten, Indonesien und Brasilien als den fünf Ländern mit der höchsten Bevölkerungszahl.
Speichern wir nun dieses Liniendiagramm, damit wir es später im Dashboard verwenden können.
Klicken Sie auf Speichern bestätigen, und Sie können die Visualisierung speichern.
Flächendiagramm
Gehen Sie zur Visualisierung und wählen Sie einen Bereich mit Index als Länderdaten. Wir müssen die Y-Achse und die X-Achse auswählen. Wir werden ein Flächendiagramm für die maximale Fläche für das Land zeichnen.
Hier sind also die X-Achse und die Y-Achse wie unten gezeigt -
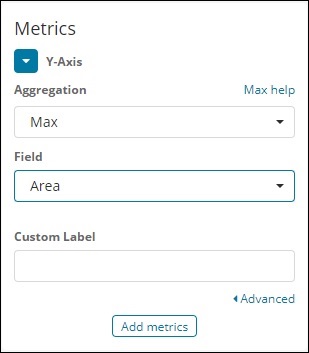

Nachdem Sie auf die Schaltfläche Änderungen übernehmen geklickt haben, wird die folgende Ausgabe angezeigt:
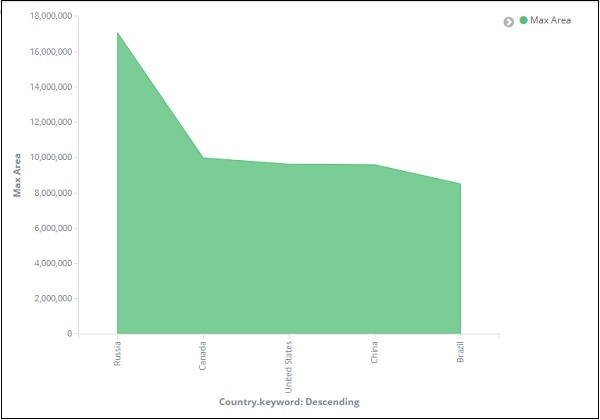
Aus der Grafik können wir ersehen, dass Russland die höchste Fläche hat, gefolgt von Kanada, den Vereinigten Staaten, China und Brasilien. Speichern Sie die Visualisierung, um sie später zu verwenden.
In diesem Kapitel erfahren Sie, wie Sie mit Heatmaps arbeiten. Die Wärmekarte zeigt die Datenpräsentation in verschiedenen Farben für den in den Datenmetriken ausgewählten Bereich.
Erste Schritte mit Heat Map
Zunächst müssen wir eine Visualisierung erstellen, indem wir auf die Registerkarte Visualisierung auf der linken Seite klicken, wie unten gezeigt -

Wählen Sie den Visualisierungstyp wie oben gezeigt als Heatmap aus. Sie werden aufgefordert, den Index wie unten gezeigt auszuwählen.
Wählen Sie die Index -Länderdaten-28.12.2018 wie oben gezeigt aus. Sobald der Index ausgewählt ist, müssen die Daten wie unten gezeigt ausgewählt werden -
Wählen Sie die Metriken wie unten gezeigt aus -

Wählen Sie die maximale Aggregation aus der Dropdown-Liste aus (siehe unten).
Wir haben Max ausgewählt, da wir Max Area länderspezifisch darstellen möchten.
Wählen Sie nun die Werte für Buckets wie unten gezeigt aus -
Lassen Sie uns nun die X-Achse wie unten gezeigt auswählen -
Wir haben Aggregation als Begriffe, Feld als Land und Reihenfolge nach maximaler Fläche verwendet. Klicken Sie wie unten gezeigt auf Änderungen übernehmen -
Wenn Sie auf Änderungen übernehmen klicken, sieht die Heatmap wie folgt aus:
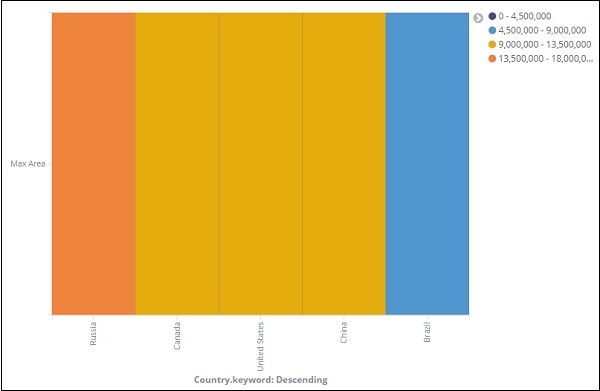
Die Wärmekarte wird in verschiedenen Farben angezeigt und der Bereich der Bereiche wird auf der rechten Seite angezeigt. Sie können die Farbe ändern, indem Sie auf die kleinen Kreise neben dem Bereichsbereich klicken, wie unten gezeigt -

Koordinatenkarten in Kibana zeigen Ihnen das geografische Gebiet und markieren das Gebiet mit Kreisen basierend auf der von Ihnen angegebenen Aggregation.
Index für Koordinatenkarte erstellen
Die für die Koordinatenkarte verwendete Bucket-Aggregation ist die Geohash-Aggregation. Für diese Art der Aggregation sollte Ihr Index, den Sie verwenden möchten, ein Feld vom Typ Geopunkt haben. Der Geopunkt ist eine Kombination aus Breiten- und Längengrad.
Wir werden einen Index mit Kibana-Entwicklungstools erstellen und Massendaten hinzufügen. Wir werden Mapping hinzufügen und den geo_point-Typ hinzufügen, den wir benötigen.
Die Daten, die wir verwenden werden, werden hier angezeigt -
{"index":{"_id":1}}
{"location": "2.089330000000046,41.47367000000008", "city": "SantCugat"}
{"index":{"_id":2}}
{"location": "2.2947825000000677,41.601800991000076", "city": "Granollers"}
{"index":{"_id":3}}
{"location": "2.1105957495300474,41.5496295760424", "city": "Sabadell"}
{"index":{"_id":4}}
{"location": "2.132605678083895,41.5370461908878", "city": "Barbera"}
{"index":{"_id":5}}
{"location": "2.151270020052683,41.497779918345415", "city": "Cerdanyola"}
{"index":{"_id":6}}
{"location": "2.1364609496220606,41.371303520399344", "city": "Barcelona"}
{"index":{"_id":7}}
{"location": "2.0819450306711165,41.385491966414705", "city": "Sant Just Desvern"}
{"index":{"_id":8}}
{"location": "2.00532082278266,41.542294286427385", "city": "Rubi"}
{"index":{"_id":9}}
{"location": "1.9560805366930398,41.56142635214226", "city": "Viladecavalls"}
{"index":{"_id":10}}
{"location": "2.09205348251486,41.39327140161001", "city": "Esplugas de Llobregat"}Führen Sie nun die folgenden Befehle in Kibana Dev Tools aus, wie unten gezeigt:
PUT /cities
{
"mappings": {
"_doc": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
}
POST /cities/_city/_bulk?refresh
{"index":{"_id":1}}
{"location": "2.089330000000046,41.47367000000008", "city": "SantCugat"}
{"index":{"_id":2}}
{"location": "2.2947825000000677,41.601800991000076", "city": "Granollers"}
{"index":{"_id":3}}
{"location": "2.1105957495300474,41.5496295760424", "city": "Sabadell"}
{"index":{"_id":4}}
{"location": "2.132605678083895,41.5370461908878", "city": "Barbera"}
{"index":{"_id":5}}
{"location": "2.151270020052683,41.497779918345415", "city": "Cerdanyola"}
{"index":{"_id":6}}
{"location": "2.1364609496220606,41.371303520399344", "city": "Barcelona"}
{"index":{"_id":7}}
{"location": "2.0819450306711165,41.385491966414705", "city": "Sant Just Desvern"}
{"index":{"_id":8}}
{"location": "2.00532082278266,41.542294286427385", "city": "Rubi"}
{"index":{"_id":9}}
{"location": "1.9560805366930398,41.56142635214226", "city": "Viladecavalls"}
{"index":{"_id":10}}
{"location": "2.09205348251486,41.3s9327140161001", "city": "Esplugas de Llobregat"}Führen Sie nun die obigen Befehle in den Kibana-Entwicklungstools aus -
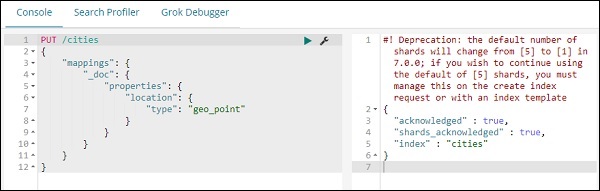
Mit dem obigen Befehl werden Städte mit Indexnamen vom Typ _doc erstellt, und die Feldposition ist vom Typ geo_point.
Fügen wir nun dem Index Daten hinzu: Städte -

Wir sind damit fertig, Indexnamen mit Daten zu erstellen. Lassen Sie uns nun auf der Registerkarte Verwaltung ein Indexmuster für Städte erstellen.
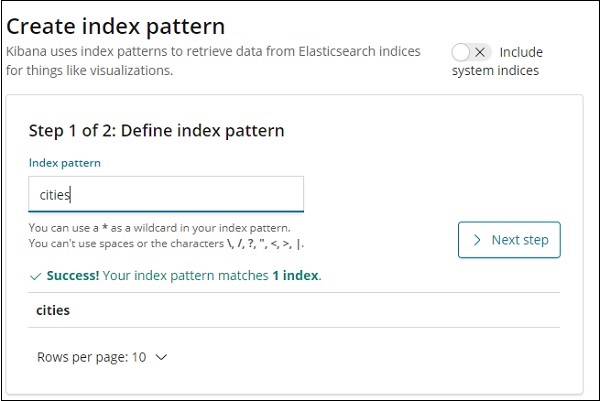
Die Details der Felder im Städteindex werden hier angezeigt -

Wir können sehen, dass der Ort vom Typ geo_point ist. Wir können es jetzt verwenden, um Visualisierung zu erstellen.
Erste Schritte mit Koordinatenkarten
Gehen Sie zu Visualisierung und wählen Sie Koordinatenkarten aus.
Wählen Sie die Städte mit dem Indexmuster aus und konfigurieren Sie die Aggregationsmetrik und den Bucket wie unten gezeigt -

Wenn Sie auf die Schaltfläche Analysieren klicken, wird der folgende Bildschirm angezeigt:
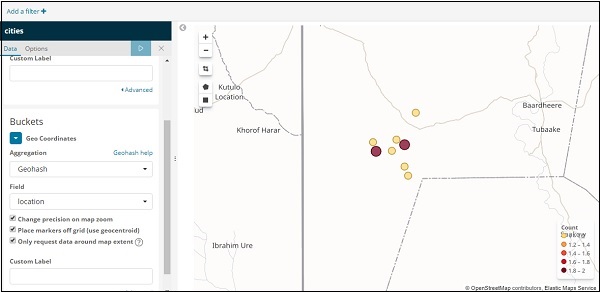
Basierend auf dem Längen- und Breitengrad werden die Kreise wie oben gezeigt auf der Karte dargestellt.
Mit dieser Visualisierung sehen Sie die auf der geografischen Weltkarte dargestellten Daten. Lassen Sie uns dies in diesem Kapitel im Detail sehen.
Index für Regionskarte erstellen
Wir werden einen neuen Index erstellen, um mit der Visualisierung von Regionskarten zu arbeiten. Die Daten, die wir hochladen werden, werden hier angezeigt -
{"index":{"_id":1}}
{"country": "China", "population": "1313973713"}
{"index":{"_id":2}}
{"country": "India", "population": "1095351995"}
{"index":{"_id":3}}
{"country": "United States", "population": "298444215"}
{"index":{"_id":4}}
{"country": "Indonesia", "population": "245452739"}
{"index":{"_id":5}}
{"country": "Brazil", "population": "188078227"}
{"index":{"_id":6}}
{"country": "Pakistan", "population": "165803560"}
{"index":{"_id":7}}
{"country": "Bangladesh", "population": "147365352"}
{"index":{"_id":8}}
{"country": "Russia", "population": "142893540"}
{"index":{"_id":9}}
{"country": "Nigeria", "population": "131859731"}
{"index":{"_id":10}}
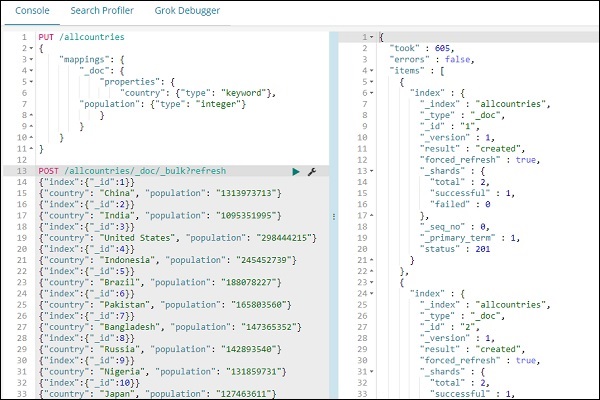
{"country": "Japan", "population": "127463611"}Beachten Sie, dass wir _bulk upload in dev tools verwenden, um die Daten hochzuladen.
Gehen Sie jetzt zu Kibana Dev Tools und führen Sie die folgenden Abfragen aus:
PUT /allcountries
{
"mappings": {
"_doc": {
"properties": {
"country": {"type": "keyword"},
"population": {"type": "integer"}
}
}
}
}
POST /allcountries/_doc/_bulk?refresh
{"index":{"_id":1}}
{"country": "China", "population": "1313973713"}
{"index":{"_id":2}}
{"country": "India", "population": "1095351995"}
{"index":{"_id":3}}
{"country": "United States", "population": "298444215"}
{"index":{"_id":4}}
{"country": "Indonesia", "population": "245452739"}
{"index":{"_id":5}}
{"country": "Brazil", "population": "188078227"}
{"index":{"_id":6}}
{"country": "Pakistan", "population": "165803560"}
{"index":{"_id":7}}
{"country": "Bangladesh", "population": "147365352"}
{"index":{"_id":8}}
{"country": "Russia", "population": "142893540"}
{"index":{"_id":9}}
{"country": "Nigeria", "population": "131859731"}
{"index":{"_id":10}}
{"country": "Japan", "population": "127463611"}Als nächstes erstellen wir Index-Länder. Wir haben den Länderfeldtyp als angegebenkeyword - -
PUT /allcountries
{
"mappings": {
"_doc": {
"properties": {
"country": {"type": "keyword"},
"population": {"type": "integer"}
}
}
}
}Note - Um mit Regionskarten arbeiten zu können, müssen Sie den Feldtyp angeben, der mit der Aggregation als Typ als Schlüsselwort verwendet werden soll.
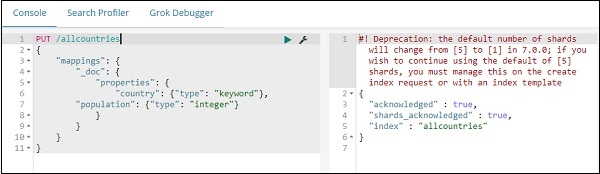
Laden Sie anschließend die Daten mit dem Befehl _bulk hoch.
Wir werden nun ein Indexmuster erstellen. Gehen Sie zur Registerkarte Kibana Management und wählen Sie Indexmuster erstellen.

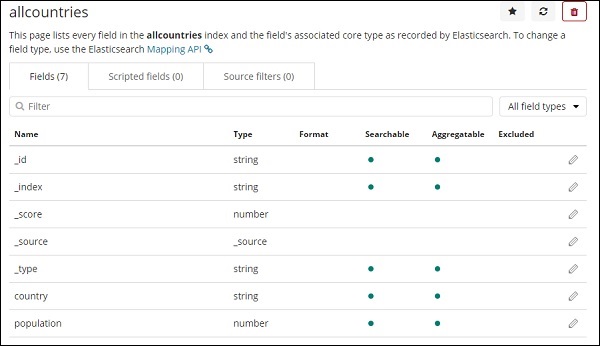
Hier sind die Felder, die im Index aller Länder angezeigt werden.
Erste Schritte mit Regionskarten
Wir werden nun die Visualisierung mit Region Maps erstellen. Gehen Sie zu Visualisierung und wählen Sie Regionskarten.
Wenn Sie fertig sind, wählen Sie den Index als alle Länder aus und fahren Sie fort.
Wählen Sie Aggregationsmetriken und Bucket-Metriken wie unten gezeigt aus -
Hier haben wir Feld als Land ausgewählt, da ich dasselbe auf der Weltkarte anzeigen möchte.
Vektorkarte und Join-Feld für Regionskarte
Für Regionskarten müssen wir auch Optionsregisterkarten auswählen, wie unten gezeigt -

Die Registerkarte Optionen verfügt über die Konfiguration der Ebeneneinstellungen, die zum Zeichnen der Daten auf der Weltkarte erforderlich sind.
Eine Vektorkarte bietet folgende Optionen:
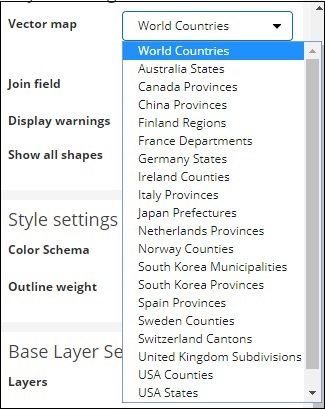
Hier werden wir Weltländer auswählen, da ich Länderdaten habe.
Das Join-Feld enthält folgende Details:
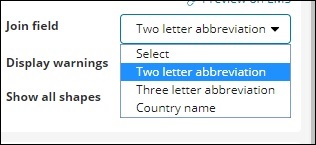
In unserem Index haben wir den Ländernamen, also wählen wir den Ländernamen aus.
In den Stileinstellungen können Sie die Farbe auswählen, die für die Länder angezeigt werden soll.
Wir werden Rot wählen. Wir werden den Rest der Details nicht berühren.
Klicken Sie nun auf die Schaltfläche Analysieren, um die Details der Länder anzuzeigen, die auf der Weltkarte dargestellt sind (siehe unten).
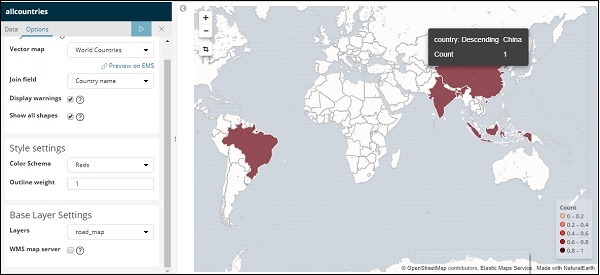
Selbst gehostete Vektorkarte und Join-Feld in Kibana
Sie können auch Ihre eigenen Kibana-Einstellungen für die Vektorkarte und das Verknüpfungsfeld hinzufügen. Gehen Sie dazu im Ordner kibana config zu kibana.yml und fügen Sie die folgenden Details hinzu:
regionmap:
includeElasticMapsService: false
layers:
- name: "Countries Data"
url: "http://localhost/kibana/worldcountries.geojson"
attribution: "INRAP"
fields:
- name: "Country"
description: "country names"Auf der Vektorkarte auf der Registerkarte "Optionen" werden die oben genannten Daten anstelle der Standarddaten ausgefüllt. Bitte beachten Sie, dass die angegebene URL CORS-fähig sein muss, damit Kibana dieselbe herunterladen kann. Die verwendete JSON-Datei sollte so sein, dass die Koordinaten fortgesetzt werden. Zum Beispiel -
https://vector.maps.elastic.co/blob/5659313586569216?elastic_tile_service_tos=agreeDie Registerkarte "Optionen", wenn Details der Region-Map-Vektorkarte selbst gehostet werden, wird unten angezeigt:
Eine Messgerätvisualisierung zeigt an, wie Ihre in den Daten berücksichtigte Metrik in den vordefinierten Bereich fällt.
Eine Zielvisualisierung gibt Auskunft über Ihr Ziel und darüber, wie sich Ihre Metrik für Ihre Daten zum Ziel hin entwickelt.
Arbeiten mit Messgerät
Um Gauge zu verwenden, gehen Sie zur Visualisierung und wählen Sie auf der Kibana-Benutzeroberfläche die Registerkarte Visualisieren.
Klicken Sie auf Messgerät und wählen Sie den Index aus, den Sie verwenden möchten.
Wir werden am Index für medizinische Besuche am 26.01.2019 arbeiten .
Wählen Sie den Zeitraum von Februar 2017
Jetzt können Sie die Metrik und die Bucket-Aggregation auswählen.
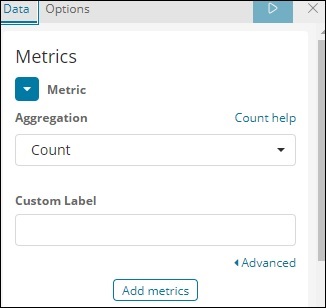
Wir haben die Metrikaggregation als Anzahl ausgewählt.
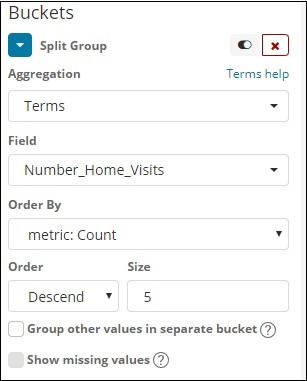
Die Bucket-Aggregation, die wir ausgewählt haben, und das ausgewählte Feld ist Number_Home_Visits.
Auf der Registerkarte Datenoptionen werden die ausgewählten Optionen unten angezeigt:

Der Messgerätetyp kann in Form eines Kreises oder eines Bogens vorliegen. Wir haben als Bogen ausgewählt und alle anderen als Standardwerte festgelegt.
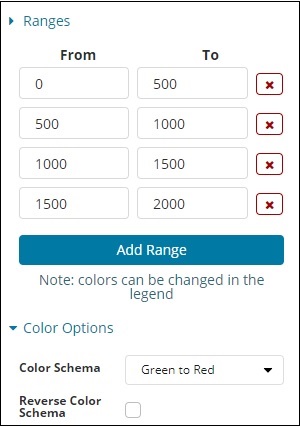
Der vordefinierte Bereich, den wir hinzugefügt haben, wird hier angezeigt -
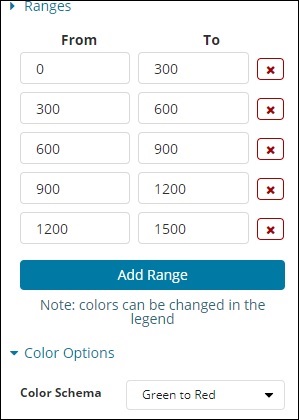
Die ausgewählte Farbe ist Grün bis Rot.
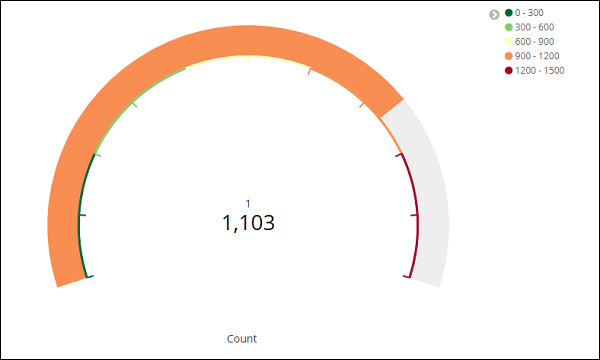
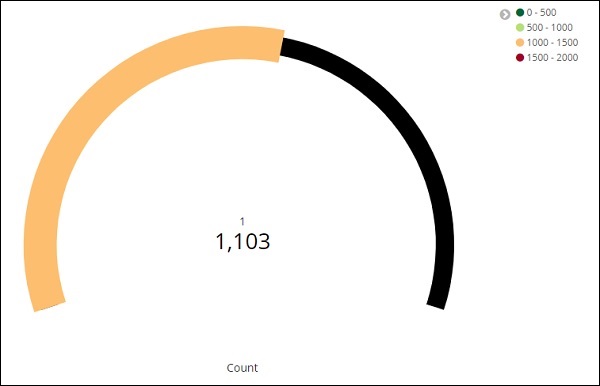
Klicken Sie nun auf die Schaltfläche Analysieren, um die Visualisierung in Form eines Messgeräts wie unten gezeigt anzuzeigen.
Mit Ziel arbeiten
Gehen Sie zur Registerkarte Visualisieren und wählen Sie Ziel wie unten gezeigt -
Wählen Sie Ziel und wählen Sie den Index.
Verwenden Sie medicalvisits-26.01.2019 als Index.
Wählen Sie die Metrikaggregation und die Bucket-Aggregation aus.
Metrische Aggregation

Wir haben Count als Metrikaggregation ausgewählt.
Bucket Aggregation
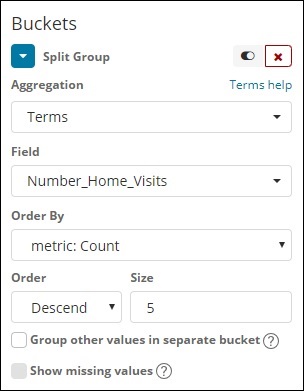
Wir haben Begriffe als Bucket-Aggregation ausgewählt und das Feld lautet Number_Home_Visits.
Folgende Optionen werden ausgewählt:
Der ausgewählte Bereich ist wie folgt:
Klicken Sie auf Analysieren und Sie sehen das Ziel wie folgt angezeigt:
Canvas ist ein weiteres mächtiges Feature in Kibana. Mithilfe der Leinwandvisualisierung können Sie Ihre Daten in verschiedenen Farbkombinationen, Formen, Texten, mehrseitigen Einstellungen usw. darstellen.
Wir brauchen Daten, um sie auf der Leinwand anzuzeigen. Laden wir nun einige Beispieldaten, die bereits in Kibana verfügbar sind.
Laden von Beispieldaten für die Canvas-Erstellung
Um die Beispieldaten zu erhalten, gehen Sie zur Kibana-Homepage und klicken Sie wie unten gezeigt auf Beispieldaten hinzufügen -

Klicken Sie auf Datensatz und Kibana-Dashboard laden. Sie gelangen wie unten gezeigt zum Bildschirm -
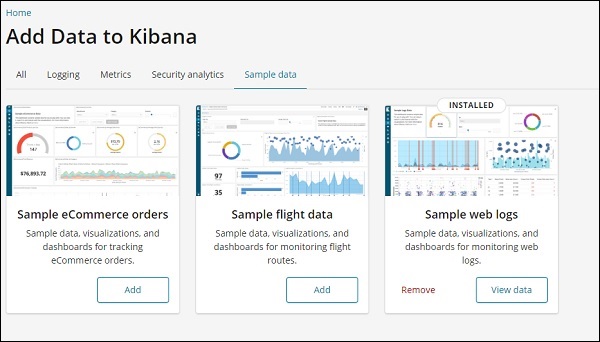
Klicken Sie auf die Schaltfläche Hinzufügen, um Beispiel-E-Commerce-Bestellungen anzuzeigen. Das Laden der Beispieldaten dauert einige Zeit. Sobald Sie fertig sind, erhalten Sie eine Warnmeldung mit dem Titel "Beispiel-E-Commerce-Daten geladen".
Erste Schritte mit der Canvas-Visualisierung
Gehen Sie nun wie unten gezeigt zur Canvas-Visualisierung -
Klicken Sie auf Leinwand und es wird der Bildschirm wie unten gezeigt angezeigt -
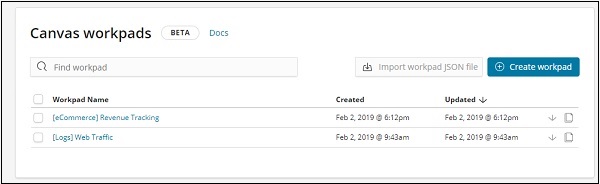
Wir haben Beispieldaten für E-Commerce und Web Traffic hinzugefügt. Wir können ein neues Workpad erstellen oder das vorhandene verwenden.
Hier wählen wir die vorhandene aus. Wählen Sie den Namen des E-Commerce-Umsatzverfolgungs-Workpads aus. Der folgende Bildschirm wird angezeigt:
Klonen eines vorhandenen Workpads in Canvas
Wir werden das Workpad klonen, damit wir Änderungen daran vornehmen können. Um ein vorhandenes Workpad zu klonen, klicken Sie auf den Namen des unten links angezeigten Workpads.
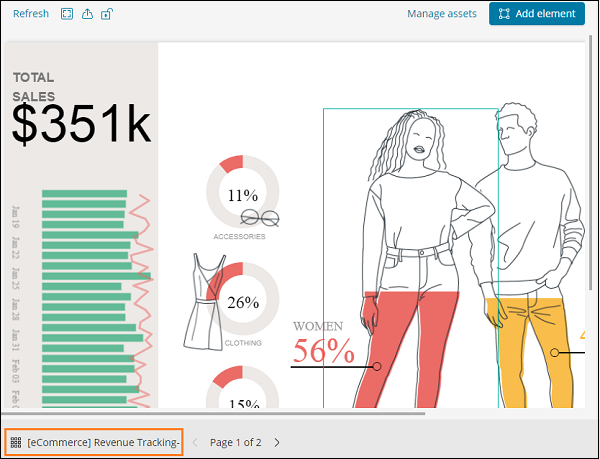
Klicken Sie auf den Namen und wählen Sie die Klonoption wie unten gezeigt -
Klicken Sie auf die Schaltfläche Klonen, um eine Kopie des E-Commerce-Umsatzverfolgungs-Workpads zu erstellen. Sie finden es wie unten gezeigt -
Lassen Sie uns in diesem Abschnitt die Verwendung des Workpads verstehen. Wenn Sie oben Workpad sehen, gibt es 2 Seiten dafür. Auf Leinwand können wir die Daten also auf mehreren Seiten darstellen.
Die Anzeige auf Seite 2 ist wie folgt:

Wählen Sie Seite 1 aus und klicken Sie auf den links angezeigten Gesamtumsatz (siehe unten).
Auf der rechten Seite erhalten Sie die dazugehörigen Daten -
Derzeit wird standardmäßig die grüne Farbe verwendet. Wir können hier die Farbe ändern und deren Anzeige überprüfen.
Wir haben auch die Schriftart und Größe für die Texteinstellungen wie unten gezeigt geändert -
Hinzufügen einer neuen Seite zum Workpad in Canvas
Gehen Sie wie folgt vor, um dem Workpad eine neue Seite hinzuzufügen:
Sobald die Seite wie unten gezeigt erstellt wurde -
Klicken Sie auf Element hinzufügen und es werden alle möglichen Visualisierungen angezeigt, wie unten gezeigt -
Wir haben zwei Elemente hinzugefügt: Datentabelle und Flächendiagramm, wie unten gezeigt
Sie können derselben Seite weitere Datenelemente hinzufügen oder auch weitere Seiten hinzufügen.
In unseren vorherigen Kapiteln haben wir gesehen, wie Visualisierungen in Form von vertikalen Balken, horizontalen Balken, Kreisdiagrammen usw. erstellt werden. In diesem Kapitel erfahren Sie, wie Sie sie in Form eines Dashboards miteinander kombinieren. Ein Dashboard ist eine Sammlung Ihrer erstellten Visualisierungen, sodass Sie alles gleichzeitig betrachten können.
Erste Schritte mit Dashboard
Um ein Dashboard in Kibana zu erstellen, klicken Sie auf die verfügbare Dashboard-Option (siehe unten).

Klicken Sie nun wie oben gezeigt auf die Schaltfläche Neues Dashboard erstellen. Es bringt uns zum Bildschirm wie unten gezeigt -

Beachten Sie, dass bisher noch kein Dashboard erstellt wurde. Oben finden Sie Optionen, mit denen Sie speichern, abbrechen, hinzufügen, Optionen, freigeben, automatisch aktualisieren und die Zeit ändern können, um die Daten in unser Dashboard zu übertragen. Wir erstellen ein neues Dashboard, indem wir auf die oben gezeigte Schaltfläche Hinzufügen klicken.
Visualisierung zum Dashboard hinzufügen
Wenn wir auf die Schaltfläche Hinzufügen (obere linke Ecke) klicken, wird die von uns erstellte Visualisierung wie unten gezeigt angezeigt.

Wählen Sie die Visualisierung aus, die Sie Ihrem Dashboard hinzufügen möchten. Wir werden die ersten drei Visualisierungen wie unten gezeigt auswählen -
So wird es gemeinsam auf dem Bildschirm angezeigt -

Auf diese Weise können Sie als Benutzer die allgemeinen Details zu den von uns hochgeladenen Daten abrufen - länderspezifisch mit den Feldern Ländername, Regionsname, Gebiet und Bevölkerung.
Jetzt kennen wir alle verfügbaren Regionen, die maximale Bevölkerungszahl in absteigender Reihenfolge, die maximale Fläche usw.
Dies ist nur die Beispieldatenvisualisierung, die wir hochgeladen haben. In der Praxis ist es jedoch sehr einfach, die Details Ihres Unternehmens zu verfolgen, z. B. wenn Sie eine Website haben, die monatlich oder täglich Millionen von Treffern erzielt. Sie möchten den Umsatz verfolgen Dies geschieht jeden Tag, jede Stunde, jede Minute und jede Sekunde. Wenn Sie Ihren ELK-Stapel installiert haben, kann Kibana Ihnen Ihre Verkaufsvisualisierung jede Stunde, Minute und Sekunde direkt vor Ihren Augen zeigen, wie Sie sehen möchten. Es zeigt die Echtzeitdaten an, wie sie in der realen Welt geschehen.
Insgesamt spielt Kibana eine sehr wichtige Rolle bei der Ermittlung der genauen Details Ihrer Geschäftstransaktion tages-, stündlich oder jede Minute, damit das Unternehmen weiß, wie der Fortschritt verläuft.
Dashboard speichern
Sie können Ihr Dashboard über die Schaltfläche Speichern oben speichern.

Es gibt einen Titel und eine Beschreibung, in die Sie den Namen des Dashboards eingeben können, sowie eine kurze Beschreibung, in der angegeben ist, was das Dashboard tut. Klicken Sie nun auf Speichern bestätigen, um das Dashboard zu speichern.
Ändern des Zeitbereichs für das Dashboard
Derzeit können Sie sehen, dass die angezeigten Daten die letzten 15 Minuten sind. Bitte beachten Sie, dass dies statische Daten ohne Zeitfeld sind, damit sich die angezeigten Daten nicht ändern. Wenn Sie die Daten mit dem Echtzeitsystem verbunden haben und die Zeit ändern, werden auch die Daten angezeigt.
Standardmäßig sehen Sie die letzten 15 Minuten wie unten gezeigt -
Klicken Sie auf die letzten 15 Minuten und es wird Ihnen der Zeitbereich angezeigt, den Sie nach Ihrer Wahl auswählen können.
Beachten Sie, dass es die Optionen Schnell, Relativ, Absolut und Zuletzt verwendet. Der folgende Screenshot zeigt die Details für die Option Schnell -
Klicken Sie nun auf Relativ, um die verfügbare Option anzuzeigen.
Hier können Sie das Von- und Bis-Datum in Minuten, Stunden, Sekunden, Monaten und Jahren angeben.
Die Option Absolut enthält die folgenden Details:
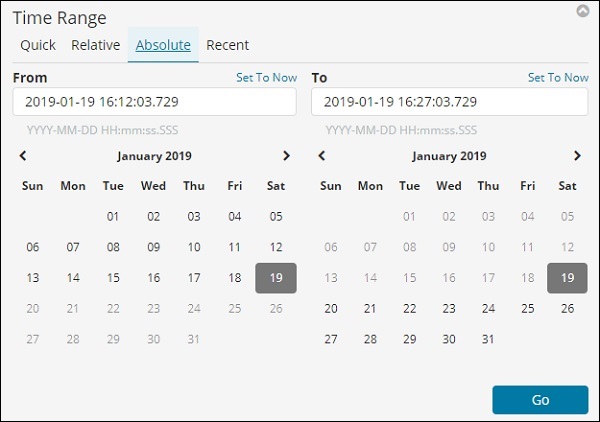
Sie können die Kalenderoption sehen und einen Datumsbereich auswählen.
Die Option "Zuletzt verwendet" gibt die Option "Letzte 15 Minuten" sowie eine andere Option zurück, die Sie kürzlich ausgewählt haben. Durch Auswahl des Zeitbereichs werden die Daten aktualisiert, die innerhalb dieses Zeitbereichs liegen.
Verwenden von Suchen und Filtern im Dashboard
Wir können auch das Suchen und Filtern im Dashboard verwenden. Angenommen, wir möchten eine Suche wie unten gezeigt hinzufügen, wenn wir die Details einer bestimmten Region abrufen möchten.

Bei der obigen Suche haben wir das Feld Region verwendet und möchten die Details der Region anzeigen: OCEANIA.
Wir erhalten folgende Ergebnisse -
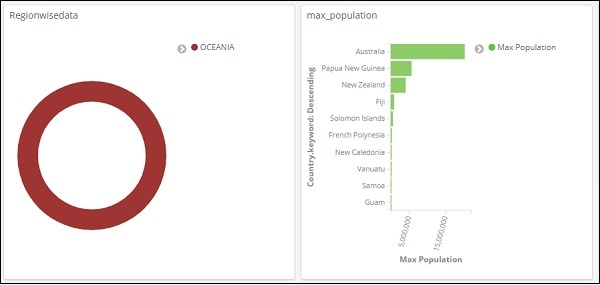
Wenn wir uns die obigen Daten ansehen, können wir sagen, dass Australien in der Region OCEANIA die maximale Bevölkerung und Fläche hat.
Ebenso können wir einen Filter wie unten gezeigt hinzufügen -
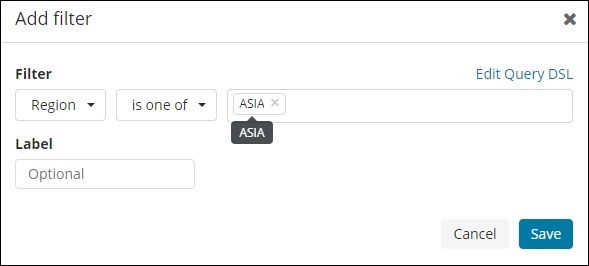
Klicken Sie anschließend auf die Schaltfläche Filter hinzufügen. Daraufhin werden die Details des in Ihrem Index verfügbaren Felds angezeigt (siehe unten).
Wählen Sie das Feld aus, nach dem Sie filtern möchten. Ich werde das Feld Region verwenden, um die Details der ASIA-Region zu erhalten, wie unten gezeigt -
Speichern Sie den Filter und Sie sollten den Filter wie folgt sehen -
Die Daten werden nun gemäß dem hinzugefügten Filter angezeigt -
Sie können auch weitere Filter hinzufügen, wie unten gezeigt -
Sie können den Filter deaktivieren, indem Sie wie unten gezeigt auf das Kontrollkästchen Deaktivieren klicken.

Sie können den Filter aktivieren, indem Sie auf dasselbe Kontrollkästchen klicken, um ihn zu aktivieren. Beachten Sie, dass es eine Schaltfläche zum Löschen gibt, um den Filter zu löschen. Schaltfläche Bearbeiten, um den Filter zu bearbeiten oder die Filteroptionen zu ändern.
Für die angezeigte Visualisierung sehen Sie drei Punkte, wie unten gezeigt -
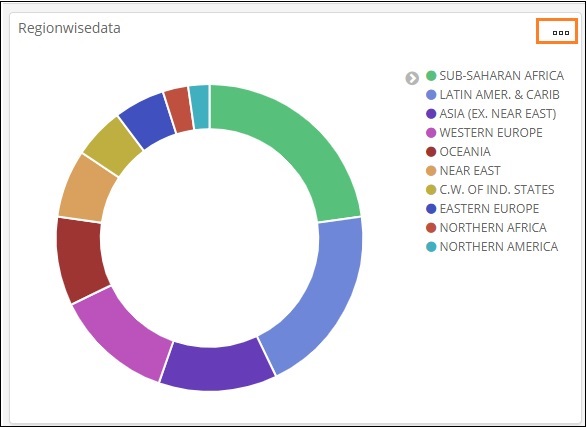
Klicken Sie darauf und es werden die folgenden Optionen angezeigt -
Inspizieren und Vollbild
Klicken Sie auf Inspizieren und es werden die Details der Region in tabellarischer Form angezeigt (siehe unten).
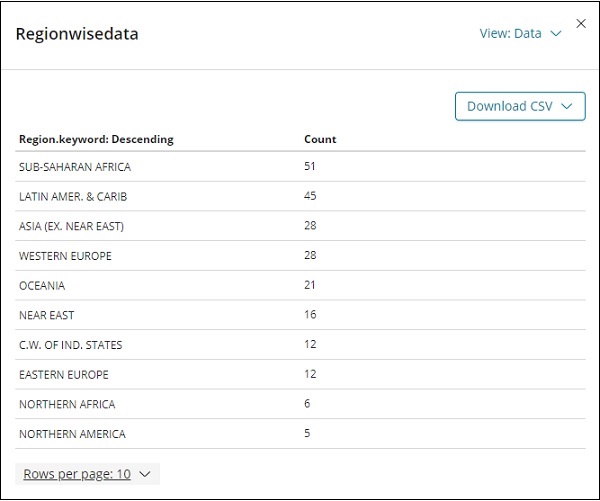
Es besteht die Möglichkeit, die Visualisierung im CSV-Format herunterzuladen, falls Sie sie in einem Excel-Blatt anzeigen möchten.
Die nächste Option Vollbild erhält die Visualisierung in einem Vollbildmodus wie unten gezeigt -

Sie können dieselbe Schaltfläche verwenden, um den Vollbildmodus zu verlassen.
Dashboard freigeben
Wir können das Dashboard über die Schaltfläche "Teilen" freigeben. Wenn Sie auf die Schaltfläche "Teilen" klicken, wird Folgendes angezeigt:
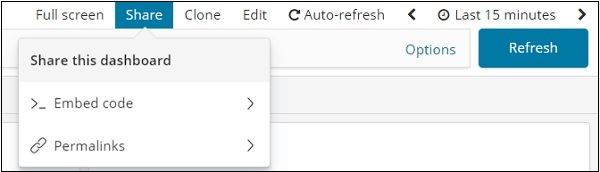
Sie können auch Einbettungscode verwenden, um das Dashboard auf Ihrer Website anzuzeigen, oder Permalinks verwenden, die ein Link sind, den Sie mit anderen teilen können.
Die URL lautet wie folgt:
http://localhost:5601/goto/519c1a088d5d0f8703937d754923b84bTimelion, auch als Timeline bezeichnet, ist ein weiteres Visualisierungswerkzeug, das hauptsächlich für die zeitbasierte Datenanalyse verwendet wird. Um mit der Zeitachse arbeiten zu können, müssen wir eine einfache Ausdruckssprache verwenden, die uns hilft, eine Verbindung zum Index herzustellen und Berechnungen für die Daten durchzuführen, um die gewünschten Ergebnisse zu erhalten.
Wo können wir Timelion verwenden?
Timelion wird verwendet, wenn Sie zeitbezogene Daten vergleichen möchten. Sie haben beispielsweise eine Website und erhalten täglich Ihre Ansichten. Sie möchten die Daten analysieren, bei denen Sie die aktuellen Wochendaten mit denen der Vorwoche vergleichen möchten, dh Montag-Montag, Dienstag-Dienstag usw., wie sich die Ansichten und auch der Datenverkehr unterscheiden.
Erste Schritte mit Timelion
Um mit Timelion zu arbeiten, klicken Sie wie unten gezeigt auf Timelion -

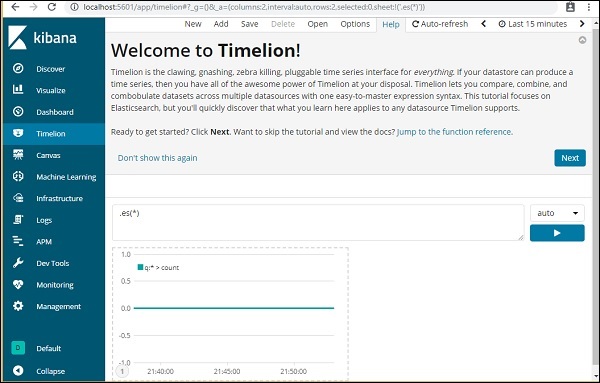
Timelion zeigt standardmäßig die Timeline aller Indizes wie unten gezeigt an -
Timelion arbeitet mit Ausdruckssyntax.
Note - es (*) => bedeutet alle Indizes.
Um die Details der Funktion zu erhalten, die für die Verwendung mit Timelion verfügbar ist, klicken Sie einfach auf den Textbereich wie unten gezeigt -

Sie erhalten eine Liste der Funktionen, die mit der Ausdruckssyntax verwendet werden sollen.
Sobald Sie mit Timelion beginnen, wird eine Willkommensnachricht angezeigt, wie unten gezeigt. Der hervorgehobene Abschnitt, dh Zur Funktionsreferenz springen, enthält die Details aller Funktionen, die für die Verwendung mit timelion verfügbar sind.
Timelion Willkommensnachricht
Die Begrüßungsnachricht von Timelion lautet wie folgt:
Klicken Sie auf die Schaltfläche Weiter und Sie werden durch die grundlegenden Funktionen und die Verwendung geführt. Wenn Sie jetzt auf Weiter klicken, sehen Sie die folgenden Details:
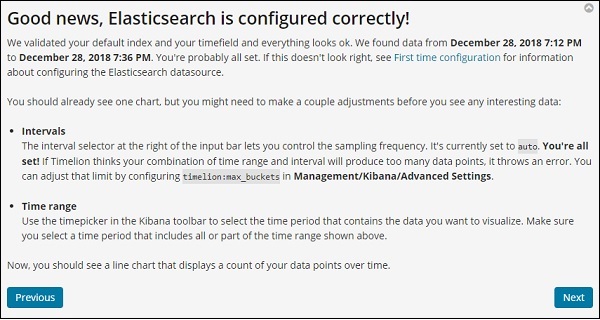

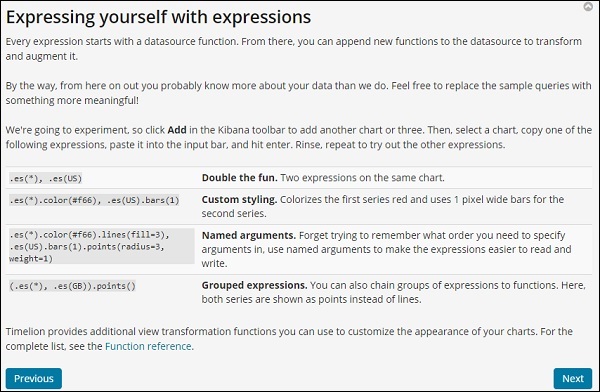
Timelion-Funktionsreferenz
Klicken Sie auf die Schaltfläche Hilfe, um die Details der für Timelion verfügbaren Funktionsreferenz abzurufen.
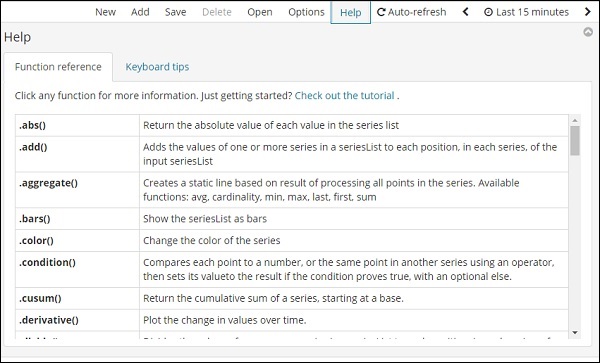
Timelion-Konfiguration
Die Einstellungen für timelion werden unter Kibana Management → Erweiterte Einstellungen vorgenommen.
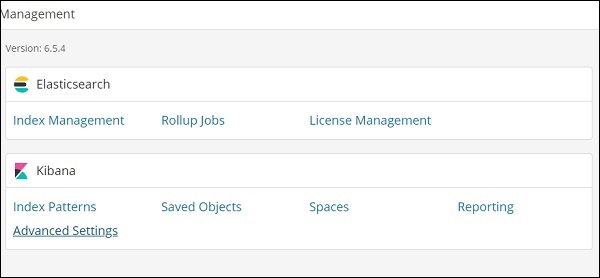
Klicken Sie auf Erweiterte Einstellungen und wählen Sie Timelion aus der Kategorie
Sobald Timelion ausgewählt ist, werden alle für die Timelion-Konfiguration erforderlichen Felder angezeigt.
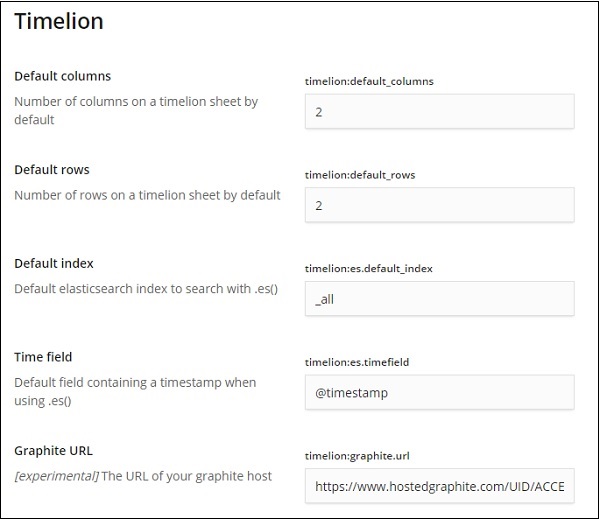
In den folgenden Feldern können Sie den Standardindex und das für den Index zu verwendende Zeitfeld ändern:
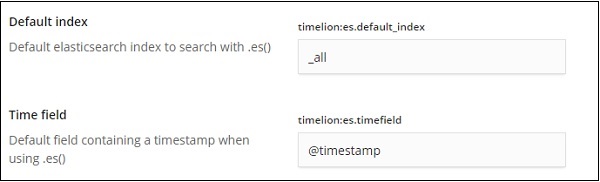
Der Standardwert ist _all und das Zeitfeld ist @timestamp. Wir würden es so lassen wie es ist und den Index und das Zeitfeld im Timelion selbst ändern.
Verwenden von Timelion zum Visualisieren von Daten
Wir werden den Index verwenden: medicalvisits-26.01.2019 . Die folgenden Daten werden vom Timelion für den 1. Januar 2017 bis zum 31. Dezember 2017 angezeigt -
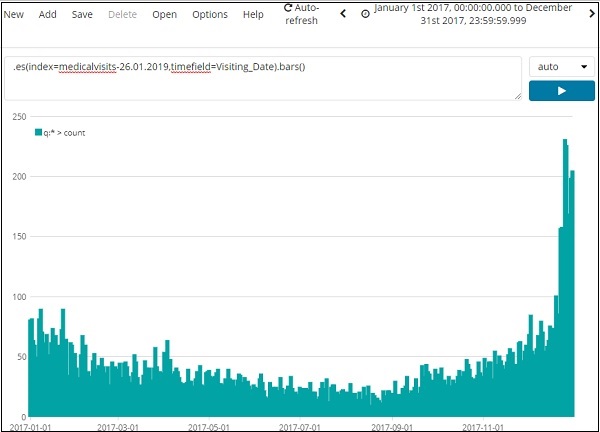
Der für die obige Visualisierung verwendete Ausdruck lautet wie folgt:
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date).bars()Wir haben den Index medicalvisits-26.01.2019 verwendet und das Zeitfeld für diesen Index ist Visiting_Date und hat die Balkenfunktion verwendet.
Im Folgenden haben wir 2 Städte für den Monat Januar 2017 tagesweise analysiert.
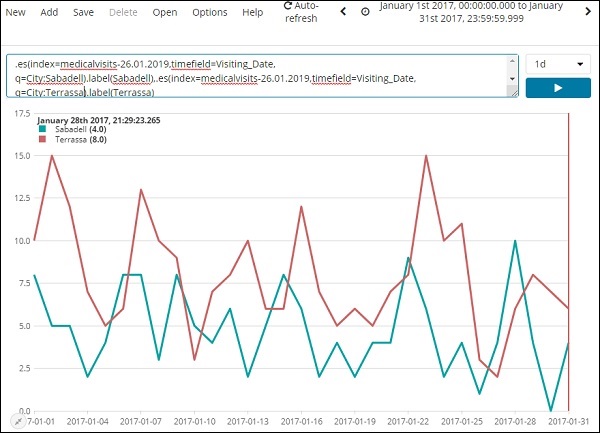
Der verwendete Ausdruck ist -
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date,
q=City:Sabadell).label(Sabadell),.es(index=medicalvisits-26.01.2019,
timefield=Visiting_Date, q=City:Terrassa).label(Terrassa)Der Zeitleistenvergleich für 2 Tage wird hier angezeigt -
Ausdruck
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date).label("August 2nd 2018"),
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date,offset=-1d).label("August 1st 2018")Hier haben wir Offset verwendet und eine Differenz von 1 Tag angegeben. Wir haben das aktuelle Datum als 2. August 2018 ausgewählt. Es gibt also Datenunterschiede für den 2. August 2018 und den 1. August 2018.
Die Liste der Top 5 Städte Daten für den Monat Januar 2017 ist unten gezeigt. Der Ausdruck, den wir hier verwendet haben, ist unten angegeben -
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date,split=City.keyword:5)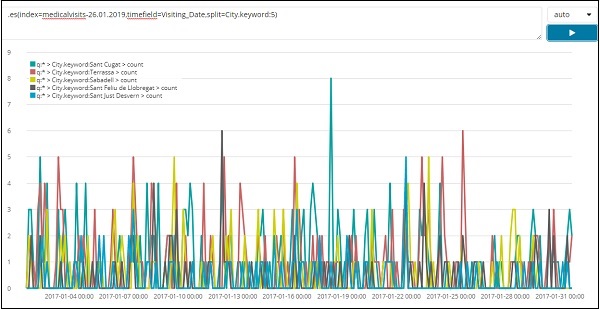
Wir haben split verwendet und den Feldnamen als Stadt angegeben. Da wir die fünf besten Städte aus dem Index benötigen, haben wir ihn als split = City.keyword: 5 angegeben
Es gibt die Anzahl der einzelnen Städte an und listet ihre Namen auf, wie in der grafischen Darstellung dargestellt.
Wir können Dev Tools verwenden, um Daten in Elasticsearch hochzuladen, ohne Logstash zu verwenden. Wir können die gewünschten Daten in Kibana mit Dev Tools veröffentlichen, ablegen, löschen und durchsuchen.
Um einen neuen Index in Kibana zu erstellen, können wir den folgenden Befehl in den Entwicklertools verwenden:
Erstellen Sie einen Index mit PUT
Der Befehl zum Erstellen eines Index lautet wie folgt:
PUT /usersdata?prettySobald Sie dies ausführen, werden leere Indexbenutzerdaten erstellt.
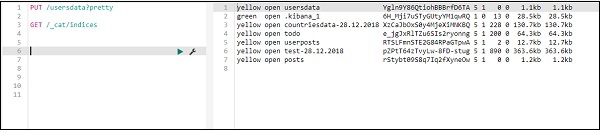
Wir sind mit der Indexerstellung fertig. Jetzt werden die Daten in den Index aufgenommen -
Hinzufügen von Daten zum Index mithilfe von PUT
Sie können einem Index Daten wie folgt hinzufügen:

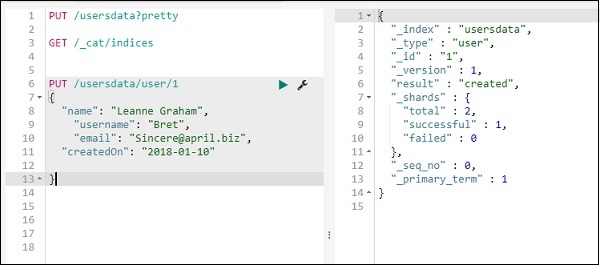
Wir werden einen weiteren Datensatz in den Benutzerdatenindex aufnehmen -
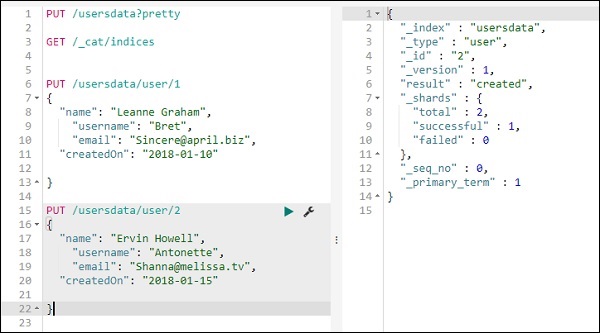
Wir haben also 2 Datensätze im Benutzerdatenindex.
Daten mit GET aus dem Index abrufen
Wir können die Details von Datensatz 1 wie folgt erhalten -

Sie können alle Datensätze wie folgt erhalten -
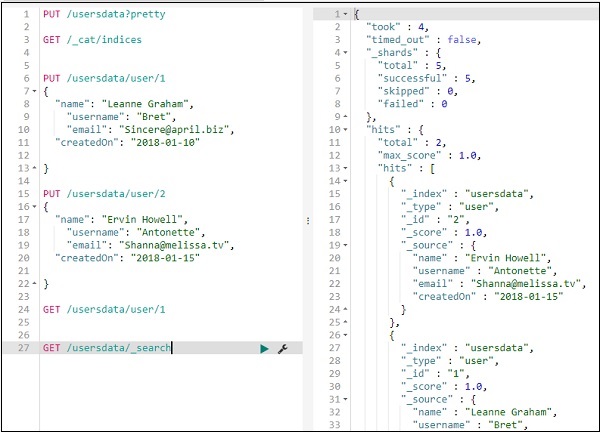
Auf diese Weise können wir alle Datensätze wie oben gezeigt aus Benutzerdaten abrufen.
Aktualisieren Sie die Daten im Index mit PUT
Um den Datensatz zu aktualisieren, können Sie wie folgt vorgehen:
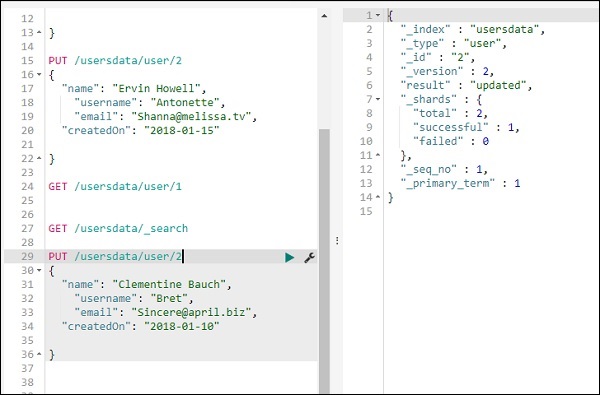
Wir haben den Namen von "Ervin Howell" in "Clementine Bauch" geändert. Jetzt können wir alle Datensätze aus dem Index abrufen und den aktualisierten Datensatz wie folgt anzeigen:
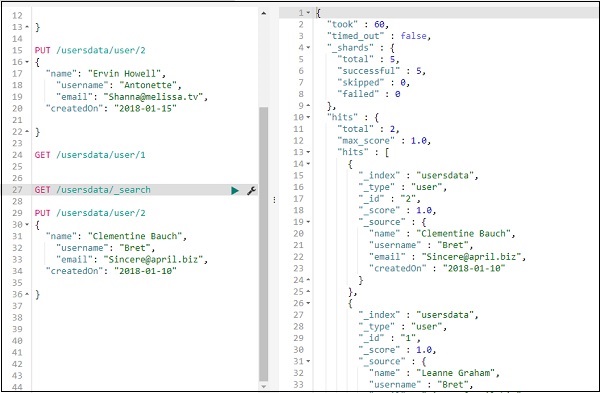
Löschen Sie Daten aus dem Index mit DELETE
Sie können den Datensatz wie hier gezeigt löschen -
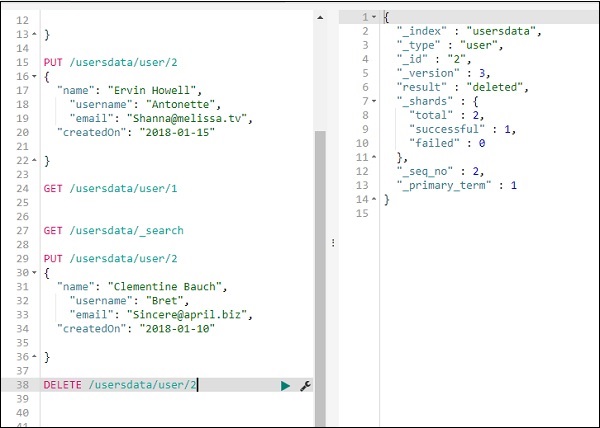
Wenn Sie nun die Gesamtzahl der Datensätze sehen, haben wir nur einen Datensatz -
Wir können den wie folgt erstellten Index löschen:

Wenn Sie nun die verfügbaren Indizes überprüfen, wird kein Benutzerdatenindex angezeigt, da der Index gelöscht wurde.
Kibana Monitoring enthält Details zur Leistung des ELK-Stacks. Wir können die Details des verwendeten Speichers, der Antwortzeit usw. abrufen.
Überwachungsdetails
Um Überwachungsdetails in Kibana zu erhalten, klicken Sie wie unten gezeigt auf die Registerkarte Überwachung.
Da wir die Überwachung zum ersten Mal verwenden, müssen wir sie eingeschaltet lassen. Klicken Sie dazu auf die SchaltflächeTurn on monitoringwie oben gezeigt. Hier sind die Details für Elasticsearch angezeigt -
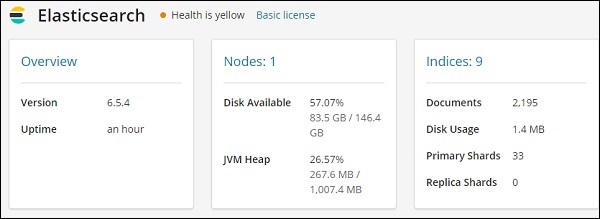
Es gibt die Version von Elasticsearch, die verfügbare Festplatte, die zur Elasticsearch hinzugefügten Indizes, die Festplattennutzung usw. an.
Die Überwachungsdetails für Kibana werden hier angezeigt -
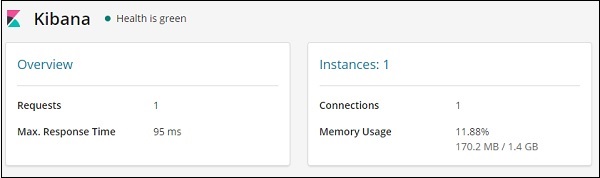
Es gibt die Anforderungen und die maximale Antwortzeit für die Anforderung sowie die laufenden Instanzen und die Speichernutzung an.
Berichte können einfach über die in der Kibana-Benutzeroberfläche verfügbare Schaltfläche "Teilen" erstellt werden.
Berichte in Kibana sind in den folgenden zwei Formen verfügbar:
- Permalinks
- CSV-Bericht
Als Permalinks melden
Bei der Durchführung der Visualisierung können Sie Folgendes wie folgt freigeben:
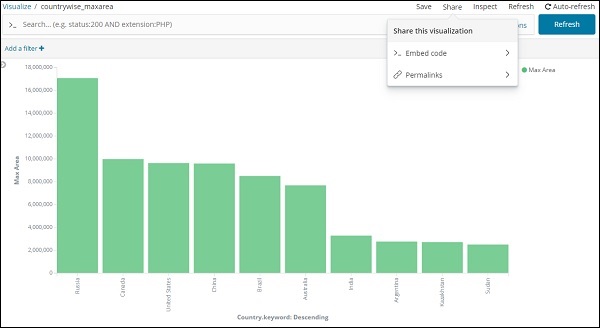
Verwenden Sie die Schaltfläche "Teilen", um die Visualisierung als Code einbetten oder Permalinks für andere freizugeben.
Beim Einbetten von Code erhalten Sie folgende Optionen:
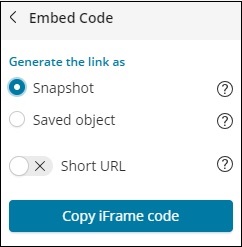
Sie können den Iframe-Code als kurze oder lange URL für den Schnappschuss oder das gespeicherte Objekt generieren. Snapshot gibt nicht die letzten Daten an und der Benutzer kann die Daten sehen, die gespeichert wurden, als der Link freigegeben wurde. Später vorgenommene Änderungen werden nicht berücksichtigt.
Im Falle eines gespeicherten Objekts erhalten Sie die letzten Änderungen an dieser Visualisierung.
Snapshot IFrame Code für lange URL -
<iframe src="http://localhost:5601/app/kibana#/visualize/edit/87af
cb60-165f-11e9-aaf1-3524d1f04792?embed=true&_g=()&_a=(filters:!(),linked:!f,query:(language:lucene,query:''),
uiState:(),vis:(aggs:!((enabled:!t,id:'1',params:(field:Area),schema:metric,type:max),(enabled:!t,id:'2',p
arams:(field:Country.keyword,missingBucket:!f,missingBucketLabel:Missing,order:desc,orderBy:'1',otherBucket:!
f,otherBucketLabel:Other,size:10),schema:segment,type:terms)),params:(addLegend:!t,addTimeMarker:!f,addToo
ltip:!t,categoryAxes:!((id:CategoryAxis-1,labels:(show:!t,truncate:100),position:bottom,scale:(type:linear),
show:!t,style:(),title:(),type:category)),grid:(categoryLines:!f,style:(color:%23eee)),legendPosition:right,
seriesParams:!((data:(id:'1',label:'Max+Area'),drawLi
nesBetweenPoints:!t,mode:stacked,show:true,showCircles:!t,type:histogram,valueAxis:ValueAxis-1)),times:!(),
type:histogram,valueAxes:!((id:ValueAxis-1,labels:(filter:!f,rotate:0,show:!t,truncate:100),name:LeftAxis-1,
position:left,scale:(mode:normal,type:linear),show:!t,style:(),title:(text:'Max+Area'),type:value))),title:
'countrywise_maxarea+',type:histogram))" height="600" width="800"></iframe>Snapshot Iframe Code für kurze URL -
<iframe src="http://localhost:5601/goto/f0a6c852daedcb6b4fa74cce8c2ff6c4?embed=true" height="600" width="800"><iframe>Als Schnappschuss und Schuss URL.
Mit kurzer URL -
http://localhost:5601/goto/f0a6c852daedcb6b4fa74cce8c2ff6c4Bei deaktivierter kurzer URL sieht der Link wie folgt aus:
http://localhost:5601/app/kibana#/visualize/edit/87afcb60-165f-11e9-aaf1-3524d1f04792?_g=()&_a=(filters:!(
),linked:!f,query:(language:lucene,query:''),uiState:(),vis:(aggs:!((enabled:!t,id:'1',params:(field:Area),
schema:metric,type:max),(enabled:!t,id:'2',params:(field:Country.keyword,missingBucket:!f,missingBucketLabel:
Missing,order:desc,orderBy:'1',otherBucket:!f,otherBucketLabel:Other,size:10),schema:segment,type:terms)),
params:(addLegend:!t,addTimeMarker:!f,addTooltip:!t,categoryAxes:!((id:CategoryAxis-1,labels:(show:!t,trun
cate:100),position:bottom,scale:(type:linear),show:!t,style:(),title:(),type:category)),grid:(categoryLine
s:!f,style:(color:%23eee)),legendPosition:right,seriesParams:!((data:(id:'1',label:'Max%20Area'),drawLines
BetweenPoints:!t,mode:stacked,show:true,showCircles:!t,type:histogram,valueAxis:ValueAxis-1)),times:!(),
type:histogram,valueAxes:!((id:ValueAxis-1,labels:(filter:!f,rotate:0,show:!t,truncate:100),name:LeftAxis-1,
position:left,scale:(mode:normal,type:linear),show:!t,style:(),title:(text:'Max%20Area'),type:value))),title:'countrywise_maxarea%20',type:histogram))Wenn Sie im Browser auf den obigen Link klicken, erhalten Sie dieselbe Visualisierung wie oben gezeigt. Die oben genannten Links werden lokal gehostet, sodass sie außerhalb der lokalen Umgebung nicht funktionieren.
CSV-Bericht
Sie können den CSV-Bericht in Kibana abrufen, wo sich Daten befinden, die sich hauptsächlich auf der Registerkarte Entdecken befinden.
Gehen Sie zur Registerkarte "Erkennen" und nehmen Sie einen beliebigen Index, für den Sie die Daten möchten. Hier haben wir den Index genommen: Länderdaten-26.12.2018 . Hier werden die Daten aus dem Index angezeigt -

Sie können tabellarische Daten aus den obigen Daten erstellen, wie unten gezeigt -

Wir haben die Felder unter Verfügbare Felder ausgewählt und die zuvor angezeigten Daten werden in ein Tabellenformat konvertiert.
Sie können die obigen Daten im CSV-Bericht wie unten gezeigt abrufen -

Die Schaltfläche "Teilen" bietet Optionen für CSV-Berichte und Permalinks. Sie können auf CSV-Bericht klicken und diesen herunterladen.
Bitte beachten Sie, dass Sie die CSV-Berichte erhalten, die Sie zum Speichern Ihrer Daten benötigen.

Bestätigen Sie Speichern und klicken Sie auf die Schaltfläche Freigeben und CSV-Berichte. Sie erhalten folgende Anzeige -
Klicken Sie auf CSV generieren, um Ihren Bericht zu erhalten. Sobald Sie fertig sind, werden Sie aufgefordert, die Registerkarte Verwaltung aufzurufen.
Gehen Sie zur Registerkarte Verwaltung → Berichterstellung

Es zeigt den Berichtsnamen, erstellt am, den Status und die Aktionen an. Sie können auf den Download-Button klicken, wie oben hervorgehoben, und Ihren CSV-Bericht erhalten.
Die CSV-Datei, die wir gerade heruntergeladen haben, ist wie hier gezeigt -